Как обойти бинарное дерево
Существует достаточно много алгоритмов работы с древовидными структурами, в которых часто встречается понятие обхода (traversing) дерева или «прохода» по дереву. При таком методе исследования дерева каждый узел посещается только один раз, а полный обход задает линейное упорядочивание узлов, что позволяет упростить алгоритм, так как при этом можно использовать понятие «следующий» узел. т.е. узел стоящий после данного при выбранном порядке обхода.
Существует несколько принципиально разных способов обхода дерева:
Обход в прямом порядке
Каждый узел посещается до того, как посещены его потомки.
Для корня дерева рекурсивно вызывается следующая процедура:
Посетить узел Обойти левое поддерево Обойти правое поддерево
Примеры использования обхода:
- решение задачи методом деления на части
- разузлование сверху
- стратегия «разделяй и властвуй» (Сортировка Фон Hеймана, быстрая сортировка, одновременное нахождение максимума и минимума последовательности чисел, умножение длинных чисел).
Симметричный обход
Посещаем сначало левое поддерево, затем узел, затем — правое поддерево.
Для корня дерева рекурсивно вызывается следующая процедура:
Обойти левое поддерево Посетить узел Обойти правое поддерево
Обход в обратном порядке
Узлы посещаются ‘снизу вверх’.
Для корня дерева рекурсивно вызывается следующая процедура:
Обойти левое поддерево Обойти правое поддерево Посетить узел
Примеры использования обхода:
- анализ игр с полной информацией
- разузлование снизу
- динамическое программирование
Обход в ширину
При обходе в ширину узлы посещаются уровень за уровнем(N-й уровень дерева — множество узлов с высотой N). Каждый уровень обходится слева направо.
Для реализации используется структура queue — очередь с методами
- enqueue — поставить в очередь
- dequeue — взять из очереди
- empty — возвращает TRUE, если очередь пуста, иначе — FALSE
q.enqueue(root); // корень в очередь while (! q.empty) < x = q.dequeue(); visit x; // посетить x if (! x.left.empty) // x.left - левое поддерево q.enqueue(x.left); if (! x.right.empty) // x.right - правое поддерево q.enqueue(x.right); >
Рекурсивные обходы можно, очевидно, организовать и с помощью стека, ‘развернув’ рекурсию.
Обход двоичного дерева
Теги: Обход двоичного дерева, прямой обход, обратный обход, симметричный обход, поперечный обход, сортировка дерева, удаление дерева, стек, очередь, итеративный обход дерева, рекурсивный обход дерева, поиск в глубину, поиск в ширину, обход бесконечных деревьев.
Обход дерева в глубину
В отличие от линейных структур типа односвязного списка и массива, у которых есть каноничный, прямой способ обхода, деревья можно обходить несколькими способами, в зависимости от поставленной задачи. Начиная с корня, можно применять необходимое действия (именуемое в дальнейшем «визит») как к самому узлу, так и к его левой или правой ветви. Порядок, в котором операции применяются, и будет определять способ обхода.
Наиболее простыми и понятными являются рекурсивные алгоритмы. При сведении к итеративному алгоритму, так как дерево предполагает несколько путей обхода, часть узлов придётся «откладывать» для дальнейшей обработки, для чего будут использоваться стек или очередь.
Существует три основных способа обхода в глубину.
-
Прямой (pre-order)
Посетить корень
Обойти левое поддерево
Обойти правое поддерево
Прямой обход двоичного дерева
Симметричный обход двоичного дерева
Обратный обход двоичного дерева
Рекурсивное решение полностью соответствует описанию алгоритма
void preOrderTravers(Node* root) < if (root) < printf("%d ", root->data); preOrderTravers(root->left); preOrderTravers(root->right); > > void inOrderTravers(Node* root) < if (root) < inOrderTravers(root->left); printf("%d ", root->data); inOrderTravers(root->right); > > void postOrderTravers(Node* root) < if (root) < postOrderTravers(root->left); postOrderTravers(root->right); printf("%d ", root->data); > >
Переделаем функции, чтобы они могли работать с узлами. Для этого понадобится передавать функцию, которая могла бы работать с узлом и получать дополнительные параметры. Эти параметры будут передаваться указателем типа void. Если нам понадобится передать параметры, всегда можно будет их передать указателем на структуру.
void preOrderTravers(Node* root, void (*visit)(Node*, void*), void *params) < if (root) < visit(root, params); preOrderTravers(root->left, visit, params); preOrderTravers(root->right, visit, params); > > void inOrderTravers(Node* root, void (*visit)(Node*, void*), void *params) < if (root) < inOrderTravers(root->left, visit, params); visit(root, params); inOrderTravers(root->right, visit, params); > > void postOrderTravers(Node* root, void (*visit)(Node*, void*), void *params) < if (root) < postOrderTravers(root->left, visit, params); postOrderTravers(root->right, visit, params); visit(root, params); > >
В качестве функции visit можно передавать, например, такую функцию
void printNode(Node *current, void *args) < printf("%d ", current->data); >
inOrderTravers(root, printNode, NULL);
Рассмотрим теперь результат каждого из обходов.
inOrderTraversal выводит сначала самый левый узел, потом средний, потом правый. Если слева находилось дерево, то алгоритм применяется к нему рекурсивно. Если мы обрабатываем двоичное дерево поиска, то самым левым будет самый маленький элемент, самым правым и самым последним при обработке будет самый большой элемент. Симметричный обход выведет дерево в отсортированном по возрастанию виде. Для того, чтобы отсортировать дерево в обратном порядке, нужно сначала обработать правую ветвь, то есть функция
void inOrderTraversRL(Node* root) < if (root) < inOrderTraversRL(root->right); printf("%d ", root->data); inOrderTraversRL(root->left); > >
выведет дерево в обратном порядке.
postOrderTraversal выводит узлы слева направо, снизу вверх. Это имеет ряд применений, сейчас рассмотрим только одно – удаление дерева. Обход дерева начинается снизу, с узлов, у которых нет родителей. Их можно безболезненно удалять, так как обращение root->left и root->right происходят до удаления объекта.
void deleteTree(Node **root) < if (*root) < deleteTree(&((*root)->left)); deleteTree(&((*root)->right)); free(*root); > >
Напомню, что если мы хотим изменить указатель, то нужно передавать указатель на указатель.
Итеративная реализация обхода в глубину требует использования стека. Он нужен для того, чтобы «откладывать» на потом обработку некоторых узлов (например тех, у кого есть необработанные наследники, или всех левых улов и т.д.).
Реализовывать стек будем с помощью массива, который при переполнении будет изменять свой размер. Напомню, что реализация стека требует двух функций — push, которая кладёт значение на вершину стека и pop, которая снимает значение с вершины стека и возвращает его. Кроме того, будем использовать функцию peek, которая возвращает значение с вершины, но не удаляет его.
#define STACK_INIT_SIZE 100 typedef struct Stack < size_t size; size_t limit; Node **data; >Stack; Stack* createStack() < Stack *tmp = (Stack*) malloc(sizeof(Stack)); tmp->limit = STACK_INIT_SIZE; tmp->size = 0; tmp->data = (Node**) malloc(tmp->limit * sizeof(Node*)); return tmp; > void freeStack(Stack **s) < free((*s)->data); free(*s); *s = NULL; > void push(Stack *s, Node *item) < if (s->size >= s->limit) < s->limit *= 2; s->data = (Node**) realloc(s->data, s->limit * sizeof(Node*)); > s->data[s->size++] = item; > Node* pop(Stack *s) < if (s->size == 0) < exit(7); >s->size--; return s->data[s->size]; > Node* peek(Stack *s) < return s->data[s->size-1]; >
После того, как у нас готова реализация стека, напишем обходы.
iterativePreorder(node) parentStack = empty stack while (not parentStack.isEmpty() or node ≠ null) if (node ≠ null) visit(node) parentStack.push(node) node = node.left else node = parentStack.pop() node = node.right
void iterPreorder(Node *root) < Stack *ps = createStack(); while (ps->size != 0 || root != NULL) < if (root != NULL) < printf("visited %d\n", root->data); if (root->right) < push(ps, root->right); > root = root->left; > else < root = pop(ps); >> freeStack(&ps); >
iterativeInorder(node) parentStack = empty stack while (not parentStack.isEmpty() or node ≠ null) if (node ≠ null) parentStack.push(node) node = node.left else node = parentStack.pop() visit(node) node = node.right
void iterInorder(Node *root) < Stack *ps = createStack(); while (ps->size != 0 || root != NULL) < if (root != NULL) < push(ps, root); root = root->left; > else < root = pop(ps); printf("visited %d\n", root->data); root = root->right; > > freeStack(&ps); >
iterativePostorder(node) parentStack = empty stack lastnodevisited = null while (not parentStack.isEmpty() or node ≠ null) if (node ≠ null) parentStack.push(node) node = node->left else peeknode = parentStack.peek() if (peeknode->right ≠ null and lastnodevisited ≠ peeknode->right) /* if traversing node from left child AND right child exists, move right */ node = peeknode->right else parentStack.pop() visit(peeknode) lastnodevisited = peeknode
void iterPostorder(Node *root) < Stack *ps = createStack(); Node *lnp = NULL; Node *peekn = NULL; while (!ps->size == 0 || root != NULL) < if (root) < push(ps, root); root = root->left; > else < peekn = peek(ps); if (peekn->right && lnp != peekn->right) < root = peekn->right; > else < pop(ps); printf("visited %d\n", peekn->data); lnp = peekn; > > > freeStack(&ps); >
Обход в ширину
О бход в ширину подразумевает, что сначала мы посещаем корень, затем, слева направо, все ветви первого уровня, затем все ветви второго уровня и т.д.
Обход двоичного дерева в ширину
Пусть мы находимся в корне дерева. Далее необходимо посетить всех наследников корня. Таким образом, нужно засунуть в контейнер сначала узел, затем его наследников, при этом узел далее должен быть обработан первым. То есть, элемент, который вошёл первым должен быть обработан первым. Это очередь, и в этом примере мы будем использовать готовую реализацию очереди с помощью двусвязного списка.
breadthFirst(root) q = empty queue q.enqueue(root) while not q.empty do node := q.dequeue() visit(node) if node.left ≠ null then q.enqueue(node.left) if node.right ≠ null then q.enqueue(node.right)
Реализация на си
void breadthFirst(Node* root) < DblLinkedList *q = createDblLinkedList(); //Для начала поместим в очередь корень pushBack(q, root); while (q->size != 0) < Node *tmp = (Node*) popFront(q); printf("%d ", tmp->data); //Если есть левый наследник, то помещаем его в очередь для дальнейшей обработки if (tmp->left) < pushBack(q, tmp->left); > //Если есть правый наследник, то помещаем его в очередь для дальнейшей обработки if (tmp->right) < pushBack(q, tmp->right); > > deleteDblLinkedList(&q); >
Заменим очередь на стек
void breadthFirstWakaWaka(Node* root) < DblLinkedList *q = createDblLinkedList(); pushFront(q, root); while (q->size != 0) < Node *tmp = (Node*) popFront(q); printf("%d ", tmp->data); if (tmp->left) < pushFront(q, tmp->left); > if (tmp->right) < pushFront(q, tmp->right); > > deleteDblLinkedList(&q); >
Теперь функция обходит узлы как Post-Order, только задом наперёд.
Обход бесконечных деревьев
Б ывают ситуации, когда необходимо обработать бесконечное дерево. Дерево может генерироваться, когда мы обращаемся к нему (например, мы обходим сайт, страницы которого генерируются сервером во время обращения), либо его размер просто не известен (и возможно велик).
Если дерево растёт бесконечно в глубину, то его можно обрабатывать, используя проход в ширину. То есть, известно, что если спускаться вниз по ветви, то до конца мы не дойдём, но на данном уровне дерево имеет конечный размер.
Если дерево растёт бесконечно в ширину, но при этом имеет конечную глубину (то есть, у узла не два наследника, а из бесконечно много), то можно использовать поиск в глубину.
Обработку бесконечного дерева можно заканчивать например, когда обработано достаточно большое количество узлов или их значения достигли какой-то величины.
Пусть робот «шмугл» индексирует страницы на сайте. Количество ссылок на странице конечно. (т.к. страница конечна). То есть можно рассматривать страницы как узел, ссылки с которой ведут к другим узлам. Конечно, есть ссылки, которые ведут на предыдущие страницы, есть кросс-ссылки между страницами на одном уровне вложенности и т.д., сейчас всех тонкостей рассматривать не будем. То есть, есть дерево, у каждого узла которого конечное число наследников. В лучшем случае количество ссылок конечно и охватывает весь сайт. Однако, может попасться страница, на которой есть календарь, ссылки с которого генерируются автоматически. Программист забыл, что ссылки в будущее надо запретить, поэтому в глубину мы получаем бесконечно дерево, каждый новый узел которого генерируется автоматически. Обход этого дерева закончится, например, когда будет забит канал или превышен лимит по ссылкам.
ru-Cyrl 18- tutorial Sypachev S.S. 1989-04-14 sypachev_s_s@mail.ru Stepan Sypachev students

Всё ещё не понятно? – пиши вопросы на ящик
Алгоритмы. Обход дерева
Давно я не писал, как то все времени не находилось. Мы говорили про деревья, давайте теперь поговорим про обход деревьев. Обходы деревьев нужны собственно для того чтоб оптимально быстрой найти необходимый элемент в дереве.
Собственно обход дерева, как и все обходы графов ( а дерево это обычный неориентированный граф ) делается двумя методами: в глубину (Depth-first) и в ширину (Breadth-first).
Какой из методов использовать?
На самом деле споров достаточно много, и если зайти на различные форумы — то вы получите огромное количество ответов, каждый из которых не факт что будет полезен для вас. Потому, для себя я решил таким образом( взято кстати с треда на stackoverflow):
- если вы знаете что решение где-то не далеко от вашей ноды — то лучше использовать обход в ширь, чтоб не закапываться глубоко в дерево
- если дерево очень глубокое, а решение редки — то лучше все таки попробовать поиск в ширь
- если дерево очень широкое, то можно попробовать поиск в глубь, потому как поиск в ширь может забрать слишком много времени.
Собственно, как я уже и писал, правильного ответа нет — потому надо пробовать разные варианты:) Эксперементировать всегда весело!
Так как мы будем пробовать на созданном бинарном дереве все алгоритмы, они редко бывают широкими, потому обсудим в начале поиск в глубь.
DFS. Алгоритмы в глубь имеют три типа обходов:
Pre-order стоит использовать именно тогда, когда вы знаете что вам нужно проверить руты перед тем как проверять их листья.
В результате Pre-order обхода мы получим такой порядок :
function preOrder(node) if (node == null) return;
console.log(node.value);
preOrder(node.left);
preOrder(node.right);
>
In-order обход используется как раз когда нам надо проверять в начале детей и только потом подыматься к родительским узлам.
В таком случае мы получаем просто: A,B,C,D,E,F,G,H,I
function inOrder(node) if (node == null) return;
inOrder(node.left);
console.log(node.value);
inOrder(node.right);
>
Post-order самый забавный случай — это случай когда нам нужно начать-так сказать с листов и завершить главным узлом — тоесть разложить дерево на то, как оно строилось.
В таком случае мы полчаем: A, C, E, D, B, H, I, G,F
function postOrder(node) if (node == null) return;
postOrder(node.left);
postOrder(node.right);
console.log(node.value);
>
Как видим — код очень похож:) просто разный порядок вызовов.
BFS точно такой же как и в графах. Все достаточно просто — мы бегаем в начале по рут ноде, потом по всем ее детям, потом по всем детям детей, и так далее.
function bfs(node) var queue = [];
var values = [];
queue.push(node); while(queue.length > 0) var tempNode = queue.shift();
values.push(tempNode.value);
if (tempNode.left) queue.push(tempNode.left);
> if (tempNode.right) queue.push(tempNode.right);
>
> return values;
>
Собственно на этом пока все:)
Как обычно: исходники примеров вы можете найти тут.
Бинарное дерево. Способы обхода и удаления вершин
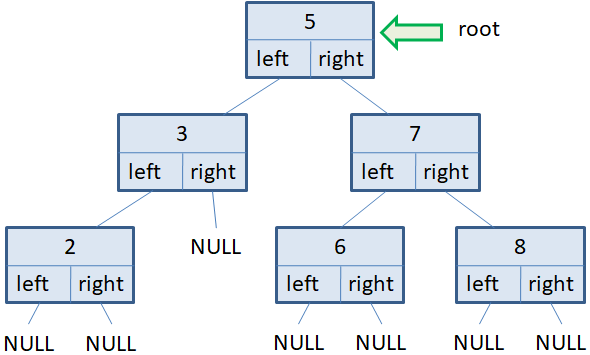
Давайте представим, что у нас имеется следующее двухуровневое бинарное дерево: На корневую вершину ведет указатель root. Создадим еще один вспомогательный указатель p на эту же вершину:
p = root
и список из вершин текущего уровня в порядке слева-направо:
v = [p]
Изначально в списке только одна корневая вершина. Сформируем два цикла: первый будет работать, пока список вершин не пуст, то есть, пока в дереве имеются узлы текущего уровня; а второй будет перебирать вершины текущего уровня, выводить информацию на экран и формировать список следующего уровня:
while v: vn = [] for x in v: print(x.data) if x.left: vn += [x.left] if x.right: vn += [x.right] v = vn
В результате, сначала будет выведено значение 7 корневого узла. Затем, сформирован список vn из двух узлов следующего уровня в порядке слева-направо. После этого списку v присваивается новый сформированный список vn следующего уровня и на следующей итерации цикла while во вложенном цикле for будут перебираться уже вершины первого уровня. На экран выведутся значения 2 и 5. Снова сформируется список vn из вершин следующего второго уровня. И на следующей итерации цикла while будут выведены значения 3, 4 и 6. После этого список vn окажется пустым, следовательно, список v также будет пустой и цикл while завершит свою работу. Вот пример реализации алгоритма перебора вершин бинарного дерева в ширину в самом простом варианте. При этом мы обходим по всем узлам дерева ровно один раз.
Алгоритм обхода в глубину
Следующий тип алгоритмов – это обход дерева в глубину. Здесь мы проходим по определенной ветви до листовой вершины. Лучше всего показать этот ход на конкретном примере. Пусть у нас то же самое бинарное дерево. Начальная вершина, как всегда, корневая (root). Затем, мы должны для себя решить, по какой из двух ветвей идти в первую очередь, а по какой – во вторую. Я решил обойти дерево сначала по левой ветви, а затем, с возвратами проходить правые ветви. Это можно реализовать следующей рекурсивной функцией:
def show_tree(self, node): if node is None: return self.show_tree(node.left) print(node.data) self.show_tree(node.right)
С начальным вызовом от корневой вершины:
show_tree(root)
Как она работает? Мы начинаем двигаться от корневого узла. Если он существует, то вызывается та же самая функция для левого узла. В результате, мы как бы попадаем в ту же самую функцию, только параметр node теперь является ссылкой на узел со значением 3. Здесь выполняется та же самая проверка: если узел существует, то по рекурсии мы снова переходим к следующему левому узлу. Это узел со значением 2. Снова делается проверка на его существование и, так как он существует, переходим к следующему левому узлу. Теперь параметр node принимает значение None (на рисунке NULL), рекурсия завершается и мы возвращаемся к прежнему вызову с параметром node узла 2. Это значение отображается на экране и делается попытка пройти по правой ветви. Так как справа объектов нет, то вызов текущей функции завершается и мы попадаем в функцию уровнем выше с параметром node на узел 3. Это значение 3 выводится на экран и делается попытка пройти по правой ветви. Ее нет, поэтому мы возвращаемся на уровень выше, то есть, к корневому узлу со значением 5. Это значение выводится на экран и далее мы переходим к правой вершине 7. Снова вызывается рекурсивная функция с параметром node на узел 7 и делается попытка пройти по левой ветви. Там имеется вершина со значение 6. Она выводится на экран с возвратом к функции узла 7. Затем, отображаем эту семерку на экран и переходит к левому узлу со значением 8. Это значение также отображается, после чего все вызовы рекурсивных функций завершаются. В результате мы на экране увидим следующие значения, записанные в вершинах бинарного дерева: 2, 3, 5, 6, 7, 8 Вы можете подумать, что такой возрастающий порядок значений получился чисто случайно. Однако нет. Если у нас имеется бинарное дерево сформированное по правилу добавления меньших значений в левую ветвь, а больших – в правую, то при обходе дерева в глубину в порядке: левое поддерево (L); промежуточная вершина (N); правое поддерево (R) всегда будет образовываться возрастающая последовательность чисел. Сокращенно такой алгоритм в глубину получил название LNR и относится к симметричному типу обхода. А если пройти сначала по правой ветви, затем вывести значение промежуточной вершины, а после пройти по левой ветви, то получим убывающую последовательность значений в бинарном дереве: 8, 7, 6, 5, 3, 2 Такой алгоритм сокращенно называется RNL и также является одним из видов симметричного обхода. Комбинируя различные варианты обхода и отображения значений вершин можно получать самые разнообразные вариации алгоритмов обхода в глубину.
Удаление вершин бинарного дерева
Теперь, когда мы с вами подробно разобрались в способах формирования бинарного дерева и алгоритмами обхода его вершин, остался один важный вопрос, связанный с удалением его узлов. Здесь возможны несколько типовых исходов.
Удаление листовых вершин
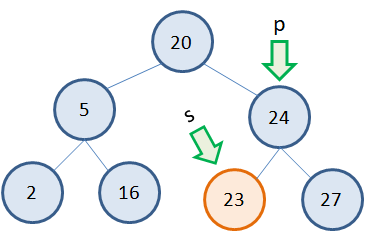
Самый простой случай, когда удаляется листовой узел дерева. Предположим, что это узел 23: Тогда, нам достаточно получить указатель p на родительский узел и указатель s на удаляемый узел. Сделать это очень просто, запоминая при обходе дерева предыдущую (родительскую) вершину и текущую. После этого ссылку, ведущую на удаляемый узел следует приравнять NULL и освободить память из под узла s:
p.left = NULL delete s
Все, листовой узел удален. Как видите, все достаточно просто.
Удаление узла с одним потомком
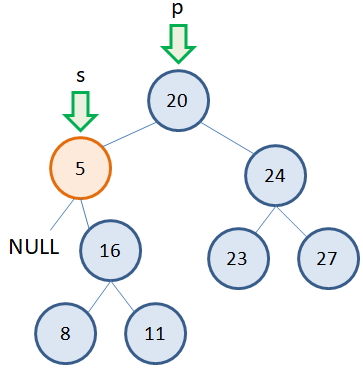
Также относительно просто обстоит ситуация, когда у удаляемого узла имеется один потомок (слева или справа). Например, нам нужно удалить узел 5, у которого один потомок справа: Здесь мы также должны иметь два указателя: p – на родительскую вершину; s – на удаляемую вершину. Затем, исключаем из дерева удаляемую вершину 5, меняя связь от родительской вершины 20 к вершине 16 (которая идет после удаляемой):
p.left = s.right delete s
Причем, ситуация принципиально не меняется, если у удаляемой вершины один правый или левый потомок. Алгоритм удаления таких вершин работает похожим образом.
Удаление узла с двумя потомками
Несколько сложнее обстоит дело, когда у удаляемой вершины два потомка. Общая идея здесь такая. Сам узел не удаляется, меняется только его значение на новое. А новое берется как наименьшее из правой ветви. Например, если мы хотим удалить узел 5, то следует взять наименьшее значение 16 из правого поддерева. Записать его вместо 5, а листовой узел 16 просто удалить: 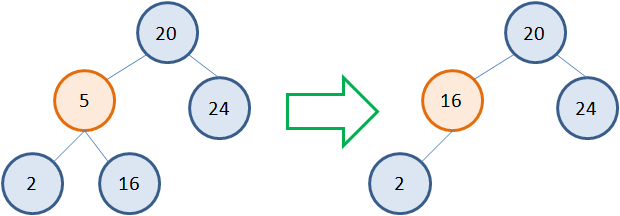 Но это если справа расположен листовой узел. А что если справа имеется полноценное поддерево с множеством вершин? Как быть в такой ситуации? По сути, также. Идея алгоритма остается прежней. Выбираем узел с наименьшим значением 11 в правом поддереве, заменяем 5 на 11 и удаляем листовой узел 11:
Но это если справа расположен листовой узел. А что если справа имеется полноценное поддерево с множеством вершин? Как быть в такой ситуации? По сути, также. Идея алгоритма остается прежней. Выбираем узел с наименьшим значением 11 в правом поддереве, заменяем 5 на 11 и удаляем листовой узел 11: 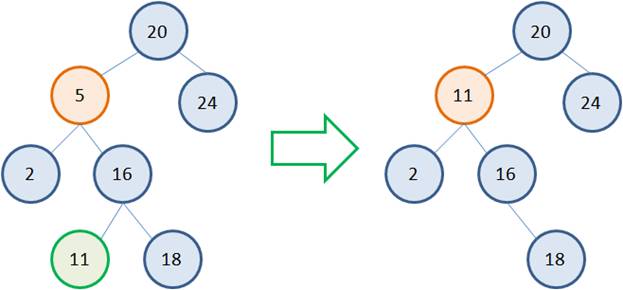 Но вершина с наименьшим значением в правом поддереве не всегда является листовой. Возможны и такие ситуации:
Но вершина с наименьшим значением в правом поддереве не всегда является листовой. Возможны и такие ситуации: 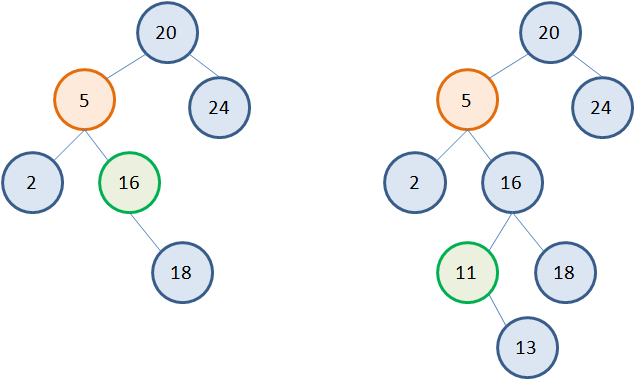 Однако можно заметить, что у узла с наименьшим значением может быть только один потомок справа. А значит, его удаление будет выполняться по алгоритму удаления вершин с одним потомком. Например, рассмотрим второе дерево. Нам потребуется три указателя: t – на удаляемую вершину (то есть, вершину, у которой будет меняться значение); s – на вершину с наименьшим значением в правом поддереве; p – на родительскую вершину для вершины s:
Однако можно заметить, что у узла с наименьшим значением может быть только один потомок справа. А значит, его удаление будет выполняться по алгоритму удаления вершин с одним потомком. Например, рассмотрим второе дерево. Нам потребуется три указателя: t – на удаляемую вершину (то есть, вершину, у которой будет меняться значение); s – на вершину с наименьшим значением в правом поддереве; p – на родительскую вершину для вершины s: 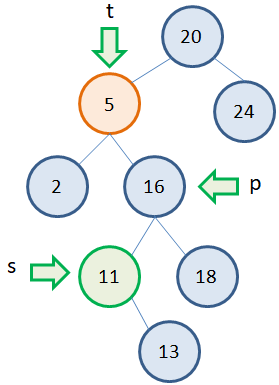 Затем, мы меняем значение вершины 5 на 11:
Затем, мы меняем значение вершины 5 на 11:
t.data = s.data
и производим удаление вершины 11 согласно алгоритму удаления вершин с одним потомком:
p.left = s.right delete s
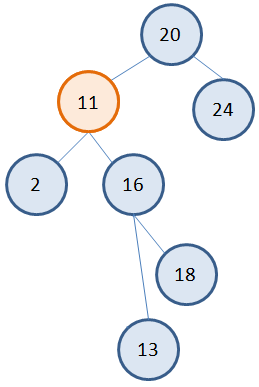
В результате получаем дерево: Вот основные типовые варианты удаления вершин в бинарном дереве:
- удаление листового узла;
- удаление узла с одним потомком (правым или левым);
- удаление узла с двумя потомками.
На следующем занятии, в качестве примера, реализуем бинарное дерево на языке Python, чтобы вы во всех деталях понимали принцип его работы. Курс по структурам данных: https://stepik.org/a/134212