Борьба за ресурсы, часть 1: Основы Cgroups
Компьютеры – это «железо». И сегодня мы вернулись в исходную точку, в том смысле, что сейчас редко найдешь физический хост, на котором выполняется одна единственная задача. Даже если на сервере крутится только одно приложение, оно, скорее всего, состоит из нескольких процессов, контейнеров или даже виртуальных машин (ВМ), и все они работают на одном сервере. Red Hat Enterprise Linux 7 неплохо справляется с распределением системных ресурсов в таких ситуациях, но по умолчанию ведет себя как добрая бабушка, угощающая внуков домашним пирогом и приговаривающая: «Всем поровну, всем поровну».

В теории принцип «всем поровну», конечно, прекрасен, но на практике некоторые процессы, контейнеры или ВМ оказываются важнее других, и, следовательно, должны получать больше.
В Linux уже давно есть средства управления использованием ресурсов (nice, ulimit и прочее), однако с появлением Red Hat Enterprise Linux 7 и systemd у нас наконец-то появился мощный набор таких инструментов, встроенный в саму ОС. Дело в том, что ключевой компонент systemd – это уже готовый, настроенный набор cgroups, который в полной мере задействуется на уровне ОС.
Хорошо, а что это вообще за cgroups, и причем здесь управление ресурсами или производительностью?
Контроль на уровне ядра
Начиная с вышедшей в январе 2008 года версии 2.6.24, в ядре Linux появилось то, что изначально было придумано и создано в Google под именем «process containers», а в Linux стало называться «control groups», сокращенно cgroups. Вкратце, cgroups – это механизм ядра, позволяющий ограничивать использование, вести учет и изолировать потребление системных ресурсов (ЦП, память, дисковый ввод/вывод, сеть и т. п.) на уровне коллекций процессов. Cgroups также могут замораживать процессы для проверки и перезапуска. Контроллеры cgroups впервые появились в 6-й версии Red Hat Enterprise Linux, но там их надо было настраивать вручную. А вот с приходом Red Hat Enterprise Linux 7 и systemd преднастроенный набор cgroups идет уже в комплекте с ОС.
Все это работает на уровне ядра ОС и поэтому гарантирует строгий контроль над каждым процессом. Так что теперь какому-нибудь зловреду крайне сложно нагрузить систему так, чтобы она перестала реагировать и зависла. Хотя, конечно, багованный код с прямым доступом к «железу» (например, драйверы), все еще на такое способен. При этом, Red Hat Enterprise Linux 7 предоставляет интерфейс для взаимодействия с cgroups, и вся работа с ними в основном ведется через команду systemd.
Свой кусок пирога
На диаграмме ниже, напоминающей нарезанный пирог, представлены три cgroups, которые по умолчанию есть на сервере Red Hat Enterprise Linux 7 – System, User и Machine. Каждая из этих групп называется «слайс» (slice – сектор). Как видно на рисунке, каждый слайс может иметь дочерние секторы-слайсы. И, как и в случае с тортом, в сумме все слайсы дают 100% соответствующего ресурса.

Теперь рассмотрим несколько концепций cgroups на примере процессорных ресурсов.
На рисунке выше видно, что процессорное время поровну делится между тремя слайсами верхнего уровня (System, User и Machine). Но так происходит только под нагрузкой. Если же какой-то процесс из слайса User попросит 100% процессорных ресурсов, и никому больше эти ресурсы в данный момент не нужны, то он получит все 100% процессорного времени.
Каждый из трех слайсов верхнего уровня предназначен для своего типа рабочих нагрузок, которым нарезаются дочерние сектора в рамках родительского слайса:
- System – демоны и сервисы.
- User – пользовательские сеансы. Каждый пользователь получает свой дочерний слайс, причем все сеансы с одинаковым UID «живут» в одном и том же слайсе, чтобы особо ушлые умники не могли получить ресурсов больше положенного.
- Machine – виртуальные машины, типа KVM-гостей.
- System — 1024
- httpd — 1024
- sshd — 1024
- crond — 1024
- gdm — 1024
- bash (mrichter) — 1024
- bash (dorf) — 1024
- testvm — 1024
- Слайс System получает 33,333% процессорного времени и поровну делит его между четырьмя демонами, что дает каждому из них по 8,25% ресурсов ЦП.
- Слайс User получает 33,333% процессорного времени и делит его между двумя пользователями, каждый из которых имеет по 16,5% ресурсов ЦП. Если пользователь mrichter выйдет из системы или остановит все свои запущенные процессы, то пользователю dorf станет доступно 33% ресурсов ЦП.
- Слайс Machine получает 33,333% процессорного времени. Если выключить ВМ или перевести ее в холостой режим, то слайсы System и User будут получать примерно по 50 % ресурсов ЦП, которые затем поделятся между их дочерними слайсами.
Выкручиваем на полную!
Как можно поменять настройки слайсов?
Для этого у каждого слайса есть настраиваемые свойства. И поскольку это Linux, мы можем вручную прописывать настройки в файлах конфигураций или же задавать из командной строки.
Во втором случае используется команда systemctl set-property. Вот что будет на экране, если набрать эту команду, добавить в конце имя слайса (в нашем случае User) и затем нажать клавишу Tab для отображения опций:

Не все свойства на этом скриншоте являются настройками cgroup. Нас в основном интересуют те, что начинаются на Block, CPU и Memory.
Если вы предпочитаете не командную строку, а config-файлы (например, для автоматизированного развертывания на нескольких хостах), то тогда придется заняться файлами в папке /etc/systemd/system. Эти файлы автоматически создаются при установке свойств с помощью команды systemctl, но их также можно создавать в текстовом редакторе, штамповать через Puppet или даже генерировать скриптами на лету.
Итак, с базовыми понятиями cgroups все должно быть ясно. В следующий раз пройдем по некоторым сценариям и посмотрим, как изменения тех или иных свойств влияют на производительность.
А буквально завтра приглашаем всех на Red Hat Forum Russia 2018 – будет возможность задать вопросы напрямую инженерам Red Hat.
Другие посты по cgroups из нашей серии «Борьба за ресурсы» доступны по ссылкам:
- Часть 2 – habr.com/company/redhatrussia/blog/424367
- Часть 3 – habr.com/company/redhatrussia/blog/425803
- Часть 4 – habr.com/company/redhatrussia/blog/427413
- Часть 5 – habr.com/company/redhatrussia/blog/429064
- Часть 6 – habr.com/company/redhatrussia/blog/430748
Механизмы контейнеризации: cgroups
Продолжаем цикл статей о механизмах контейнеризации. В прошлый раз мы говорили об изоляции процессов с помощью механизма «пространств имён» (namespaces). Но для контейнеризации одной лишь изоляции ресурсов недостаточно. Если мы запускаем какое-либо приложение в изолированном окружении, мы должны быть уверены в том, что этому приложению выделено достаточно ресурсов и что оно не будет потреблять лишние ресурсы, нарушая тем самым работу остальной системы. Для решения этой задачи в ядре […]

Продолжаем цикл статей о механизмах контейнеризации. В прошлый раз мы говорили об изоляции процессов с помощью механизма «пространств имён» (namespaces). Но для контейнеризации одной лишь изоляции ресурсов недостаточно. Если мы запускаем какое-либо приложение в изолированном окружении, мы должны быть уверены в том, что этому приложению выделено достаточно ресурсов и что оно не будет потреблять лишние ресурсы, нарушая тем самым работу остальной системы. Для решения этой задачи в ядре Linux имеется специальный механизм — cgroups (сокращение от control groups, контрольные группы). О нём мы расскажем в сегодняшней статье.
Тема cgroups сегодня особенно актуальна: в ядро версии 4.5, вышедшей в свет в январе текущего года, была официально добавлена новая версия этого механизма — group v2 .
В ходе работы над ней cgroups был по сути переписан заново.Почему потребовались столь радикальные изменения? Чтобы ответить на этот вопрос, рассмотрим в деталях, как была реализована первая версия cgroups.
Cgroups: краткая история
Разработка cgroups была начата в 2006 году сотрудниками Google Полом Менеджем и Рохитом Сетом. Термин «контрольная группа» тогда ещё не использовался, а вместо него употреблялся термин « контейнеры процессов » (process containers). Собственно, сначала они и не ставили перед собой цели создать cgroups в современном понимании. Изначальный замысел был гораздо скромнее: усовершенствовать механизм cpuset , предназначенный для распределения процессорного времени и памяти между задачами. Но со временем всё переросло в более масштабный проект.
В конце 2007 года название process containers было заменено на control groups. Это было сделано, чтобы избежать разночтений в толковании термина «контейнер» (в то время уже активно развивался проект OpenVZ, и слово «контейнер» стало употребляться в новом, современном значении).
В 2008 году механизм cgroups был официально добавлен в ядро Linux (версия 2.6.24). Что нового появилось в этой версии ядра по сравнению с предыдущими?
Ни одного системного вызова, предназначенного специально для работы с cgroups, добавлено не было. В числе главных изменений следует назвать файловую систему cgroups, известную также под названием cgroupfs.
В init/main.c были были добавлены отсылки к функциям для активации cgoups во время загрузки: cgroup_init и cgroup_init_early. Были незначительно изменены функции, используемые для порождения и завершения процесса — fork() и exit().
В виртуальной файловой системе /proc появились новые директории: /proc//сgroup (для каждого процесса) и /proc/cgroups (для системы в целом).
Архитектура
Механизм cgroups состоит из двух составных частей: ядра ( cgroup core ) и так называемых подсистем. В ядре версии 4.4.0.21 таких подсистем 12:
Имя Модуль ядра Функция blkio block/blkcroup.c Устанавливает лимиты на чтение и запись с блочных устройств cpuacct kernel/sched/cpuacct.c Предназначен для генерации отчётов об использовании ресурсов процессора cpu kernel/sched/core.c Обеспечивает доступ процессов в рамках контрольной группы к CPU cpuset kernel/cpuset.c Распределяет задачи в рамках контрольной группы между процессорными ядрами devices security/device_cgroup.c Разрешает или блокирует доступ к устройствам freezer kernel/cgroup_freezer.c Приостанавливает и возобновляет выполнение задач в рамках контрольной группы hugetlb mm/hugetlb_cgroup.c Активирует поддержку больших страниц памяти для контрольных групп memory mm/memcontrol.c Управляет выделением памяти для групп процессов net_cls net/core/netclassid_cgroup.c Помечает сетевые пакеты специальным тэгом, что позволяет идентифицировать пакеты, порождаемые определённой задачей в рамках контрольной группы net_prio net/core/netprio_cgroup.c Используется для динамической установки приоритетов по трафику perf_event evens/kernel.c Обеспечивает доступ контрольных групп к perf_events pids kernel/cgroup_pids.c Используется для ограничения количества процессов в рамках контрольной группы Вывести список подсистем на консоль можно с помощью команды:
$ ls /sys/fs/cgroup/ blkio cpu,cpuacct freezer net_cls perf_event cpu cpuset hugetlb net_cls,net_prio pids cpuacct devices memory net_prio systemdКаждая подсистема представляет собой директорию с управляющими файлами, в которых прописываются все настройки. В каждой из этих директорий имеются следующие управляющие файлы:
- cgroup.clone_children — позволяет передавать дочерним контрольным группам свойства родительских;
- tasks — содержит список PID всех процессов, включённых в контрольные группы;
cgroup.procs — содержит список TGID групп процессов, включённых в контрольные группы; - cgroup.event_control — позволяет отправлять уведомления в случае изменения статуса контрольной группы;
- release_agent — содержится команда, которая будет выполнена, если включена опция notify_on_release. Может использоваться, например, для автоматического удаления пустых контрольных групп;
- notify_on_release — содержит булеву переменную (0 или 1), включающую (или наоборот отключающую), выполнение команду, указанной в release_agent.
У каждой подсистемы имеются также собственные управляющие файлы. О некоторых из них мы расскажем ниже.
Чтобы создать контрольную группу, достаточно создать вложенную директорию в любой из подсистем. В эту вложенную директорию будут автоматически добавлены управляющие файлы (ниже мы расскажем об этом более подробно). Добавить процессы в группу очень просто: нужно просто записать их PID в управляющий файл tasks.
Совокупность контрольных групп, встроенных в подсистему, называется иерархией.Попробуем разобрать принципы функционирования cgroups на простых практических примерах.
Иерархия cgroups: практическое знакомство
Пример 1: управление процессорными ресурсами
$ mkdir /sys/fs/cgroup/cpuset/group0С помощью этой команды мы создали контрольную группу, в которой содержатся следующие управляющие файлы:
$ ls /sys/fs/cgroup/cpuset/group0 group.clone_children cpuset.memory_pressure cgroup.procs cpuset.memory_spread_page cpuset.cpu_exclusive cpuset.memory_spread_slab cpuset.cpus cpuset.mems cpuset.effective_cpus cpuset.sched_load_balance cpuset.effective_mems cpuset.sched_relax_domain_level cpuset.mem_exclusive notify_on_release cpuset.mem_hardwall tasks cpuset.memory_migrateПока что в нашей группе никаких процессов нет. Чтобы добавить процесс, нужно записать его PID в файл tasks, например:
$ echo $$ > /sys/fs/cgroup/cpuset/group0/tasksCимволами $$ обозначается PID процесса, выполняемого текущей командной оболочкой.
Этот процесс не закреплён ни за одним ядром CPU, что подтверждает следующая команда:
$ cat /proc/$$/status |grep '_allowed' Cpus_allowed: 2 Cpus_allowed_list: 0-1 Mems_allowed: 00000000,00000001 Mems_allowed_list: 0Вывод этой команды показывает, что для интересующего нас процесса доступны 2 ядра CPU с номерами 0 и 1.
Попробуем «привязать» этот процесс к ядру с номером 0:
$ echo 0 >/sys/fs/cgroup/cpuset/group0/cpuset.cpusПроверим, что получилось:
$ cat /proc/$$/status |grep '_allowed' Cpus_allowed: 1 Cpus_allowed_list: 0 Mems_allowed: 00000000,00000001 Mems_allowed_list: 0Пример 2: управление памятью
Встроим созданную в предыдущем примере группу ещё в одну подсистему:
$ mkdir /sys/fs/cgroup/memory/group0$ echo $$ > /sys/fs/cgroup/memory/group0/tasksПопробуем ограничить для контрольной группы group0 потребление памяти. Для этого нам понадобится прописать соответствующий лимит в файле memory.limit_in_bytes:
$ echo 40M > /sys/fs/cgroup/memory/group0/memory.limit_in_bytesМеханизм cgroups предоставляет очень обширные возможности управления памятью. Например, с его помощью мы можем оградить критически важные процессы от попадания под горячую руку OOM-killer’a:
$ echo 1 > /sys/fs/cgroup/memory/group0/memory.oom_control $ cat /sys/fs/cgroup/memory/group0/memory.oom_control oom_kill_disable 1 under_oom 0Если мы поместим в отдельную контрольную группу, например, ssh-демон и отключим для этой группы OOM-killer, то мы можем быть уверены в том, что он не будет «убит» при преувеличении потребления памяти.
Пример 3: управление устройствами
Добавим нашу контрольную группу ещё в одну иерархию:
$ mkdir /sys/fs/cgroup/devices/group0По умолчанию у группы нет никаких ограничений доступа к устройствам:
$ cat /sys/fs/cgroup/devices/group0/devices.list a *:* rwmПопробуем выставить ограничения:
$ echo 'c 1:3 rmw' > /sys/fs/cgroup/devices/group0/devices.denyЭта команда включит устройство /dev/null в список запрещённых для нашей контрольной группы. Мы записали в управляющий файл строку вида ‘c 1:3 rmw’. Сначала мы указываем тип устройства — в нашем случае это символьное устройство, обозначаемое буквой с (сокращение от character device). Два других типа устройств — это блочные (b) и все возможные устройства (а). Далее следуют мажорный и минорный номера устройства. Узнать номера можно с помощью команды вида:
$ ls -l /dev/nullВместо /dev/null, естественно, можно указать любой другой путь. Вывод этой команды выглядит так:
crw-rw-rw- 1 root root 1, 3 May 30 10:49 /dev/nullПервая цифра в выводе — это мажорный, а вторая — минорный номер.
Три последние буквы означают права доступа: r — разрешение читать файлы с указанного устройства, w — разрешение записывать на указанное устройство, m — разрешение создавать новые файлы устройств.
$ echo $$ > /sys/fs/cgroup/devices/group0/tasks $ echo "test" > /dev/nullПри выполнении последней команды система выдаст сообщение об ошибке:
-bash: /dev/null: Operation not permittedС устройством /dev/null мы никак взаимодействовать не можем, потому что доступ закрыт.
$ echo a > /sys/fs/cgroup/devices/group0/devices.allowВ результате выполнения этой команды в файл /sys/fs/cgroup/devices/group0/devices.allow будет добавлена запись a *:* rwm, и все ограничения будут сняты.
Cgroups и контейнеры
Из приведённых примеров понятно, в чём заключается принцип работы cgroups: мы помещаем определённые процессы в группу, которую затем «встраиваем» в подсистемы. Разберём теперь более сложные примеры и рассмотрим, как cgroups используются в современных инструментах контейнеризации на примере LXC.
Установим LXC и создадим контейнер:
$ sudo apt-get install lxc debootstrap bridge-utils $ sudo lxc-create -n ubuntu -t ubuntu -f /usr/share/doc/lxc/examples/lxc-veth.conf $ lxc-start -d -n ubuntuПосмотрим, что изменилось в директории cgroups после создания и запуска контейнера:
$ ls /sys/fs/cgroup/memory cgroup.clone_children memory.limit_in_bytes memory.swappiness cgroup.event_control memory.max_usage_in_bytes memory.usage_in_bytes cgroup.procs memory.move_charge_at_immigrate memory.use_hierarchy cgroup.sane_behavior memory.numa_stat notify_on_release lxc memory.oom_control release_agent memory.failcnt memory.pressure_level tasks memory.force_empty memory.soft_limit_in_bytesКак видим, в каждой иерархии появилась директория lxc, которая в свою очередь содержит поддиректорию Ubuntu. Для каждого нового контейнера в директории lxc будет создаваться отдельная поддиректория. PID всех запускаемых в этом контейнере процессов будут записываться в файл /sys/fs/cgroup/cpu/lxc/[имя контейнера]/tasks
Выделять ресурсы для контейнеров можно как с помощью управляющих файлов cgroups, так и с помощью специальных команд lxc, например:
$ lxc-cgroup -n [имя контейнера] memory.limit_in_bytes 400Аналогичным образом дело обстоит с контейнерами Docker, systemd-nspawn и другими.
Недостатки cgroups
На протяжении почти 10 лет существования механизм cgroups неоднократно подвергался критике. Как отметил автор одной статьи на LWN.net , разработчики ядра cgroups активно не любят. Причины такой нелюбви можно понять даже из приведённых в этой статье примеров, хоть мы и старались подавать их максимально нейтрально, без эмоций: встраивать контрольную группу в каждую подсистему по отдельности очень неудобно. Присмотревшись повнимательней, мы увидим, что такой подход отличается крайней непоследовательностью.
Если мы, например, создаём вложенную контрольную группу, то в некоторых подсистемах настройки родительской группы наследуются, а в некоторых — нет.
В подсистеме cpuset любое изменение в родительской контрольной группе автоматически передаётся вложенным группам, а в других подсистемах такого нет и нужно активировать параметр clone.children.Об устранении этих и других недостатков cgroups разговоры в сообществе разработчиков ядра шли очень давно: один из первых текстов на эту тему датируется началом 2012 года.
Автор этого текста, инженер Facebook Течжен Хе, прямо указал, что главная проблема cgroups заключается в неправильной организации, при которой подсистемы подключаются к многочисленным иерархиям контрольных групп. Он предложил использовать одну и только одну иерархию, а подсистемы добавлять для каждой группы отдельно. Такой подход повлёк за собой серьёзные изменения вплоть до смены названия: механизм изоляции ресурсов теперь называется cgroup (в единственном числе), а не cgroups.
Разберёмся более подробно в сути реализованных нововведений.Cgroup v2: что нового
Как уже было отмечено выше, сgroup v2 был включён в ядро Linux начиная с версии ядра 4.5. При этом старая версия поддерживается тоже. Для версии 4.6 уже существует патч, с помощью которого можно отключить поддержку первой версии при загрузке ядра.
На текущий момент в cgroup v2 можно работать только с тремя подсистемами: blkio, memory и PID. Уже появились (пока что в тестовом варианте) патчи, позволяющие управлять ресурсами CPU.
Cgroup v2 монтируется при помощи следующей команды:
$ mount -t cgroup2 none [точка монтирования]Предположим, мы смонтировали cgroup 2 в директорию /cgroup2. В этой директории будут автоматически созданы следующие управляющие файлы:
- cgroup.controllers — содержит список поддерживаемых подсистем;
- cgroup.procs — по завершении монтирования содержит список всех выполняемых процессов в системе, включая процессы-зомби. Если мы создадим группу, то для неё тоже будет создан такой файл; он будет пустым, пока в группу не добавлены процессы;
- cgroup.subtree_control — содержит список подсистем, активированных для данной контрольной группы; по умолчанию пуст.
Эти же самые файлы создаются в каждой новой контрольной группе. Также в группу добавляется файл cgroup.events, который в корневой директории отсутствует.
Новая группа создаётся так:
$ mkdir /cgroup2/group1Чтобы добавить для группы подсистему, нужно записать имя этой подсистемы в файл cgroup.subtree_control:
$ echo "+pid" > /cgroup2/group1/cgroup.subtree_controlДля удаления подсистемы используется аналогичная команда, только на место плюса ставится минус:
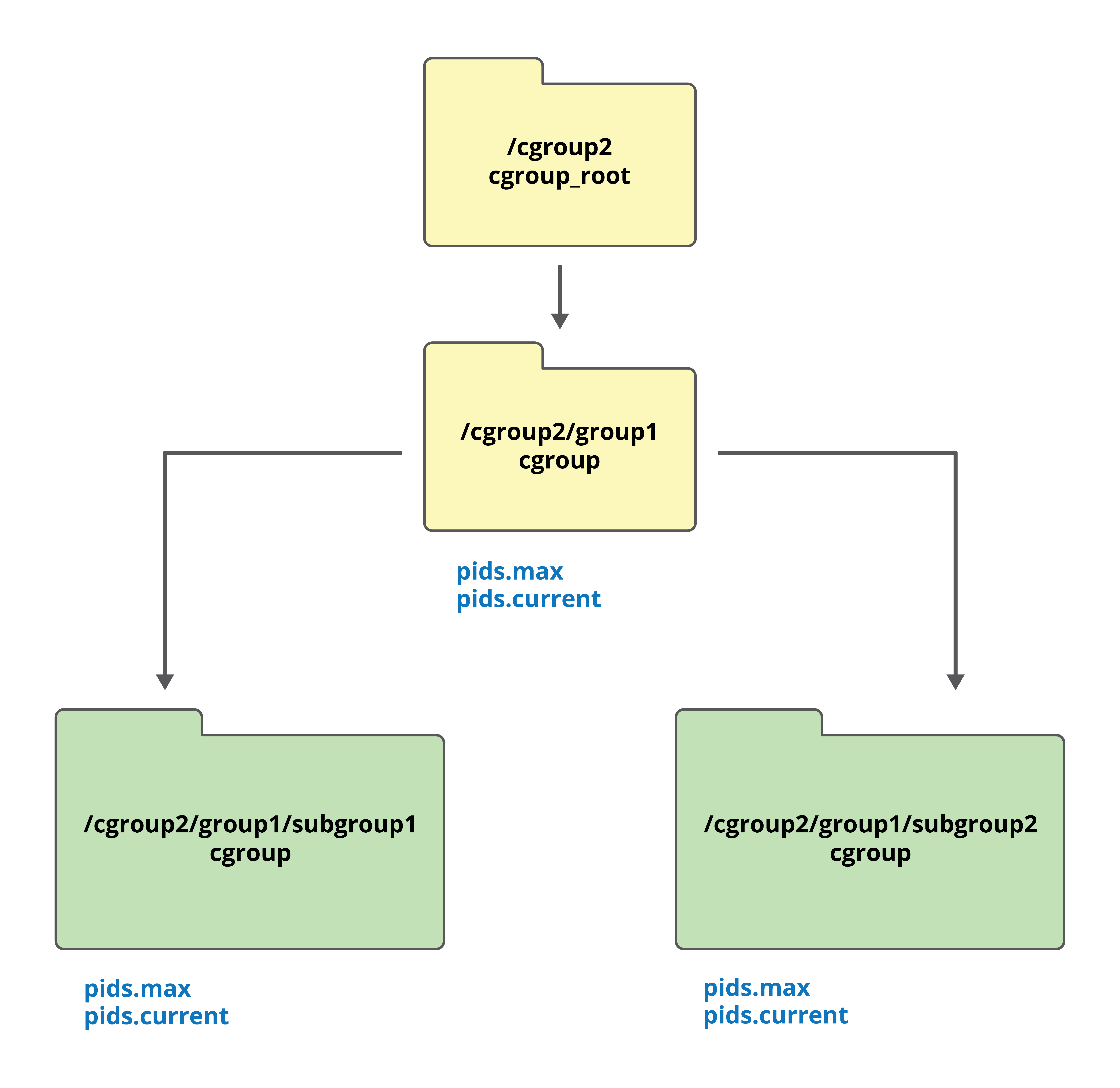
$ echo "-pid" > /cgroup2/group1/cgroup.subtree_controlКогда для группы активируется подсистема, в ней создаются дополнительные управляющие файлы. Например, после активации подсистемы PID в директории появятся файлы pids.max и pids.current. Первый из этих файлов используется для ограничения числа процессов в группе, а второй — содержит информацию о числе процессов, включённых в группу на текущий момент.
Внутри уже имеющихся групп можно создавать подгруппы:
$ mkdir /cgroup2/group1/subgroup1 $ mkdir /cgroup2/group1/subgroup2 $ echo "+memory" > /cgroup2/group1/cgroup.subtree_control,Все подгруппы наследуют характеристики родительской группы. В только что приведённом примере подсистема PID будет активирована как для группы group1, так и для обеих вложенных в неё подгрупп; в них также будут добавлены файлы pids.max и pids.current. Сказанное можно проиллюстрировать с помощью схемы:
Чтобы избежать недоразумений с вложенными группами (см. выше), в cgroup v2 действует следующее правило: нельзя добавить процесс во вложенную группу, если в ней уже активирована какая-либо подсистема:
В первой версии cgroups процесс мог входить в несколько подгрупп одновременно, если эти подгруппы входили в разные иерархии, встроенные в разные подсистемы. Во второй версии один процесс может принадлежать только к одной подгруппе, что позволяет избежать путаницы.
Заключение
В этой статье мы рассказали, как устроен механизм cgroups и какие изменения были внесены в его новую версию. Если у вас есть вопросы и дополнения — добро пожаловать в комментарии.
Для всех, кто хочет глубже погрузиться в тему, приводим список ссылок на интересные материалы:
- https://www.kernel.org/doc/Documentation/cgroup-v1/cgroups.txt — документация первой версии cgroups;
- https://www.kernel.org/doc/Documentation/cgroup-v2.txt — документация cgroup v2;
- https://www.youtube.com/watch?v=PzpG40WiEfM — лекция Течжена Хе о нововведениях cgroup v2;
- https://events.linuxfoundation.org/sites/events/files/slides/2014-KLF.pdf — презентация доклада о cgroup v2 с подробными разъяснениями всех нововведений и изменений.
Настольная книга по Linux/Cgroups
Управлять рядом ограничений для выбранных множеств процессов в системах на основе ядра Linux можно используя средства Cgroups — групп управления (англ. control groups .) В данном разделе мы рассмотрим примеры команд, позволяющих осуществить такое управление.
Подключение управляющего интерфейса [ править ]
Для управления Cgroups используется «виртуальная» файловая система (ФС) с идентификатором типа cgroup , подключаемая, как правило, [1] к директориям иерархии /sys/fs/cgroup . Каждое такое подключение соответствует отдельной и независимой иерархии групп управления.
Проверить наличие активных иерархий можно следующей командой:
$ grep -E -- \\\ < /proc/mounts cgroup /sys/fs/cgroup tmpfs rw,relatime 0 0 rg42 /sys/fs/cgroup/rg42 cgroup rw,relatime,memory 0 0 $
В данном примере, в системе активна единственная иерархия, управляемая через файлы директории /sys/fs/cgroup/rg42 , и позволяющая ограничивать использование памяти процессами, — на что указывает параметр memory . [2]
Создать такую иерархию можно командами mkdir и mount , подобно:
# mkdir -- /sys/fs/cgroup/rg42 # mount -t cgroup -o memory -- rg42 /sys/fs/cgroup/rg42 #
(При необходимости управлять или учитывать использование также и других ресурсов в рамках данной иерархии, после -o следует перечислить все соответствующие подсистемы, например: -o blkio,cpuacct,memory .)
Перед этим, однако, следует удостовериться в наличии директории /sys/fs/cgroup и, при необходимости, создать ее, подобно:
# mount -t tmpfs -o size=64M -- cgroup /sys/fs/cgroup #
Отметим, что использование Cgroups для ограничения используемой памяти предполагает некоторые накладные расходы независимо от фактического использования данной функции. Чтобы их избежать, поддержка подсистемы memory по-умолчанию отключена; ее включение требует явного указания параметра cgroup_enable=memory в командной строке ядра. (Для изменения последней, в свою очередь, необходима перезагрузка системы.)
Информацию о поддерживаемых используемой сборкой ядра и доступных непосредственно в текущий момент параметрах Cgroups можно найти в файле /proc/cgroups . Для решаемой задачи, в поле enabled для подсистемы memory должно присутствовать ненулевое значение.
Напомним также, что копия действующей командной строки ядра отражается в файл /proc/cmdline (должен присутствовать параметр cgroup_enable=memory ); поддерживаемые типы ФС перечислены в файле /proc/filesystems (должен присутствовать тип cgroup .)
Перемещение процессов между группами [ править ]
«Корень» созданной иерархии /sys/fs/cgroup/rg42 включает все процессы системы. Для того, чтобы установить ограничения только для конкретных процессов, следует создать для них отдельную группу в иерархии, подобно:
# mkdir -- /sys/fs/cgroup/rg42/lim1 #
Перенести выбранные процессы в эту группу можно просто записав их идентификаторы (pid) в файл tasks созданной директории:
# printf %s\\n 4919 8192 > /sys/fs/cgroup/rg42/lim1/tasks #
«Возвращение» процессов в «корневую» группу (и, тем самым, — снятие ограничений) выполняется совершенно аналогично:
# printf %s\\n 8192 9320 > /sys/fs/cgroup/rg42/tasks #
Список групп, к которым отнесен данный процесс в настоящий момент (каждая иерархия позволяет отнести процесс к одной и только одной группе), можно найти в файле cgroup директории процесса:
$ cat < /proc/4919/cgroup 1:rg42:/lim1 $
Ограничение памяти [ править ]
Ограничения памяти для группы определяются содержимым файлов limit_in_bytes и soft_limit_in_bytes — для оперативной памяти, и memory.memsw.limit_in_bytes — для полного объема виртуальной памяти. Получить эти ограничения можно подобно:
$ head -- /sys/fs/cgroup/rg42/lim1/memory.*limit*
Установить (условное ограничение — 1 GiB; жесткое — 1.5 GiB):
# printf %s\\n $((1024 * 1024 * 1024)) \ > /sys/fs/cgroup/rg42/lim1/soft_limit_in_bytes # printf %s\\n $((1536 * 1024 * 1024)) \ > /sys/fs/cgroup/rg42/lim1/limit_in_bytes #
См. также [ править ]
- Раздел Процессы.
- Resource Management Guide (англ.) Fedora 17Проверено 2015-05-22 г.
- Страницы руководства:
Примечания [ править ]
- ↑Cgroups (англ.) Linux Kernel DocumentationПроверено 2014-09-13 г.
- ↑Memory Resource Controller (англ.) Linux Kernel DocumentationПроверено 2014-09-13 г.
История контейнеризации

Контейнер — это изолированная рабочая среда, содержащая все зависимости, конфигурационные и исполняемые файлы необходимые для работы программы или пользователя, находящегося в контейнере. Для работы контейнера ОС выделяет пул изолированных ресурсов: ядра ЦП, оперативная память, диск и сеть. Важно понять, что контейнер работает на ядре хостовой ОС и изолируется средствами операционной системы, а не возможностями железа, как виртуальная машина. Пока в Linux существуют всего несколько инструментов ядра, которыми можно изолировать процессы и ограничить доступ к ресурсам. С помощью Namespaces (неймспейсы) процессы можно объединить в группы и изолировать, а с помощью Cgroups можно задать лимиты по ресурсам. Namespaces и Cgroups мы разберём чуть позже, а пока взглянем на функцию изоляции процессов на уровне ядра ОС, которой пользовались задолго до появления Namespaces и Cgroups — chroot.
Первый механизм изоляции процессов — chroot
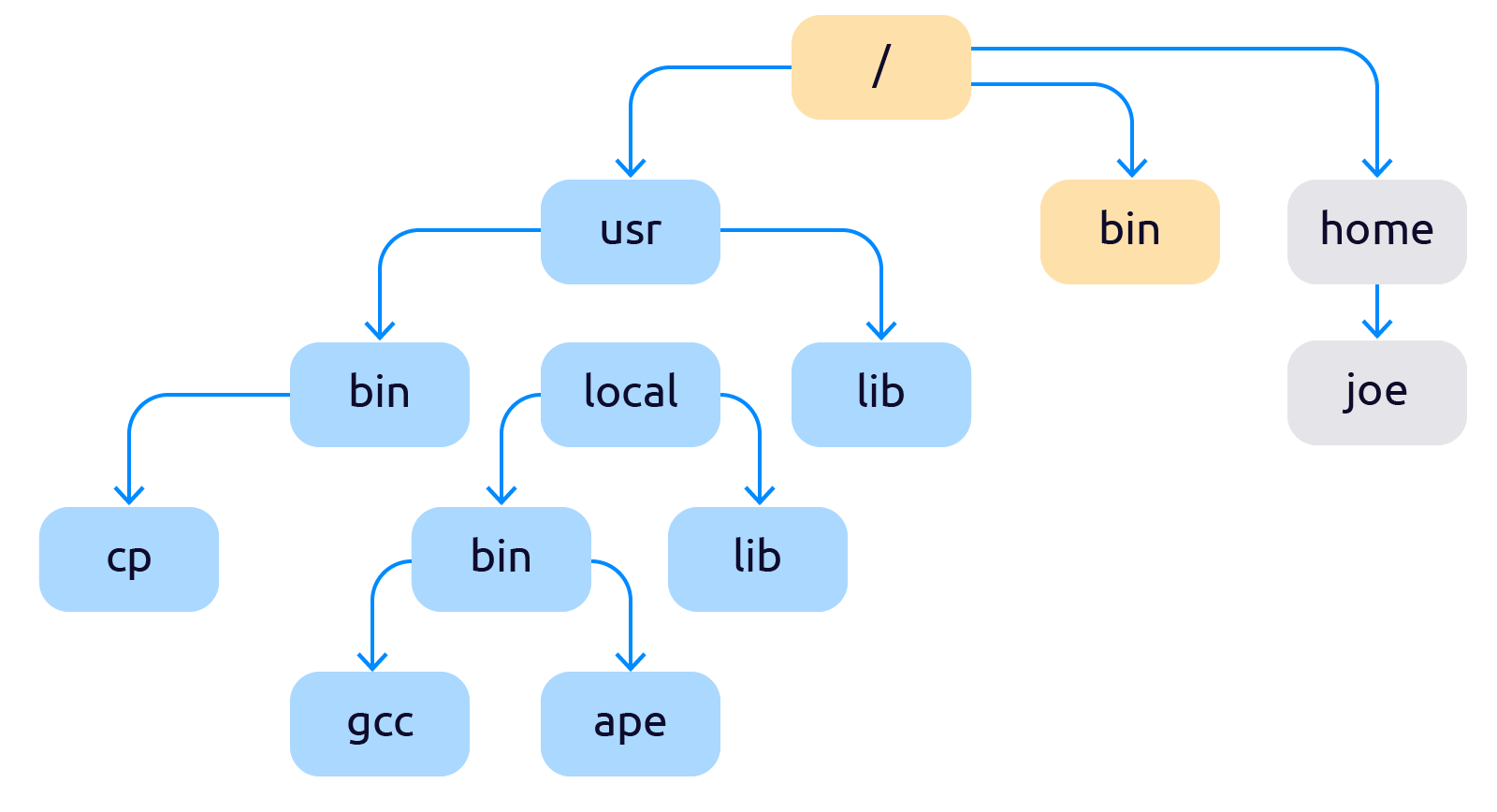 Про механизмы разделения процессов на изолированные окружения начали думать ещё в конце 70-х. Первым механизмом управления изоляцией процессов стал — chroot (чрут). Chroot — это подмена корня файловой системы для группы процессов или временная смена корня и контекста для запуска выбранных процессов. Точнее сказать так: chroot добавляет в систему второй корневой каталог «/», который с точки зрения пользователя ничем не будет отличаться от первого. После применения чрута файловая система начинает выглядеть как-то так:
Про механизмы разделения процессов на изолированные окружения начали думать ещё в конце 70-х. Первым механизмом управления изоляцией процессов стал — chroot (чрут). Chroot — это подмена корня файловой системы для группы процессов или временная смена корня и контекста для запуска выбранных процессов. Точнее сказать так: chroot добавляет в систему второй корневой каталог «/», который с точки зрения пользователя ничем не будет отличаться от первого. После применения чрута файловая система начинает выглядеть как-то так: 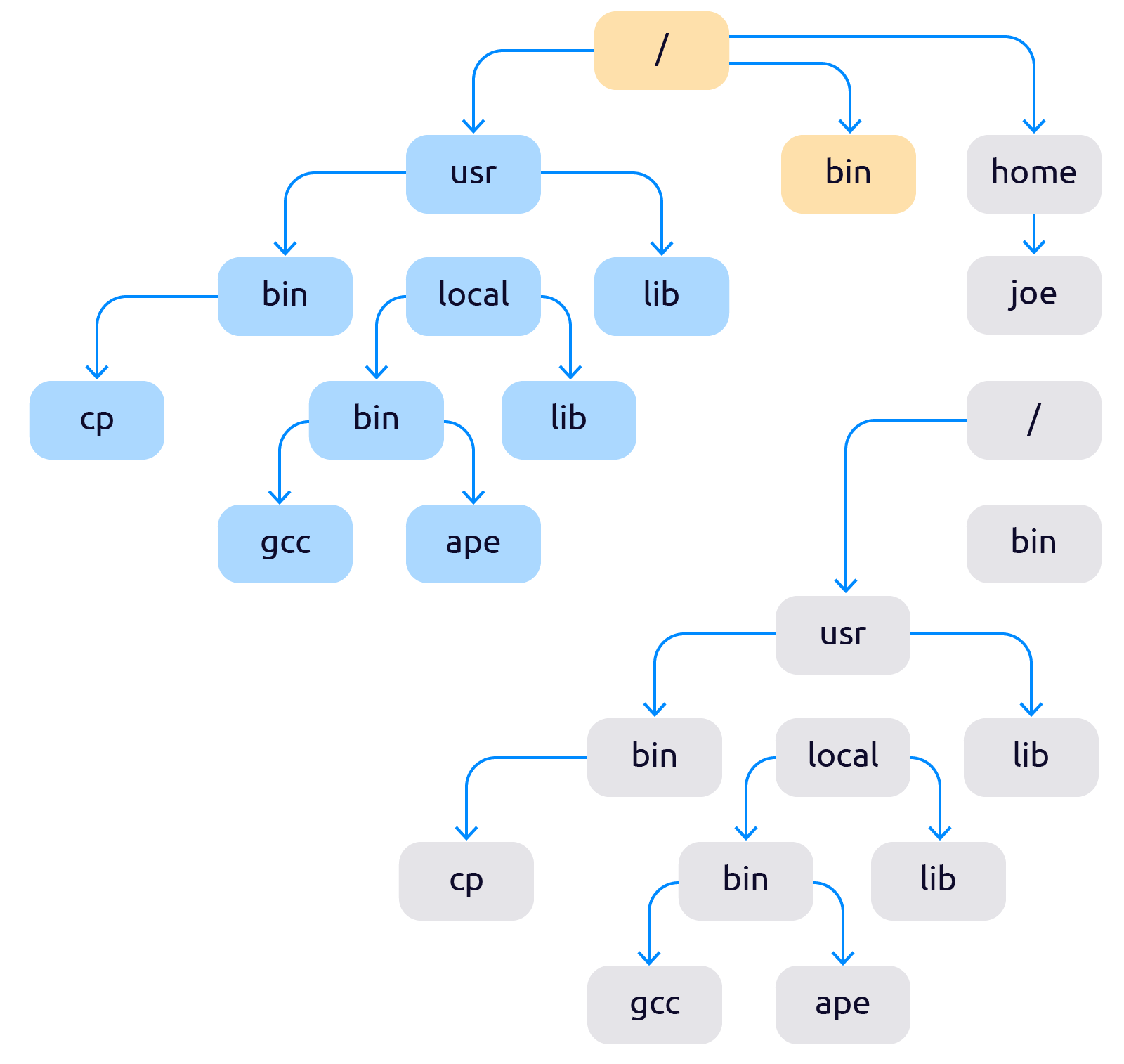 Теперь файловая система разделена на две не влияющие друг на друга части. Сейчас chroot стандартная функция любой *nix-ОС. Появившись впервые в 1982, в BSD 4.2, он почти не изменился, отсюда такое обилие недостатков:
Теперь файловая система разделена на две не влияющие друг на друга части. Сейчас chroot стандартная функция любой *nix-ОС. Появившись впервые в 1982, в BSD 4.2, он почти не изменился, отсюда такое обилие недостатков: - Общие пространство процессов — процесс запущенный в chroot видит все остальные процессы.
- Сеть общая — невозможно запустить изолированные серверы в разных чрутах.
- Нельзя назначить лимиты по ресурсам — в любой момент процесс из чрута может так же, как и любой другой процесс в системе аллоцировать все ресурсы.
В каких задачах chroot применяется до сих пор:
- ограничение прав анонимных пользователей, подключившихся по ftp-протоколу
- управление правами пользователей, подключившихся по ssh-протоколу.
Chroot служит для изоляции процессов. Например, bind во многих дистрибутивах Linux запускается в chroot, многие демоны перед понижением привилегий делают chroot в пустую директорию. Также chroot может изолировать пользователей — демоны ftp и ssh через chroot ограничивают права анонимных пользователей.
Если вам хочется попробовать chroot на практике и поупражняться в Linux-администрировании. Рекомендуем прочесть эту статью.
Chroot был самым простым и единственным способом изоляции процессов в течение 15 лет, пока не появился jail.
Первый контейнер — технология jail в FreeBSD 4.0
Jail появился в 1999-2000 годах, в FreeBSD 4.0. По факту jail — это тот же chroot только посложнее. В jail появилась изоляция сети. Однако во FreeBSD, это изоляция была половинчатой — сетевые интерфейсы были видны в любом окружении, но в зависимости от окружения были видны только определённые IP-адреса, которые были присвоены определенным интерфейсам. При этом loopback был общим.
Jail был уже намного продвинутее чрута, и на нём даже строили хостинги, однако ограничения ресурсов в нём по-прежнему не было. Назначать лимиты на ресурсы стало возможно лишь в FreeBSD версии 9.0, с появлением механизма управления ресурсами RCTL. Эта система позволяет ограничивать ресурсы как отдельным пользователям и процессам, так и целым jail.
Интересный факт
В мире кроме всем нам хорошо известных Linux и Windows есть много самописных ОС, которые, конечно, в качестве основы брали уже что-то готовое от других ОС, но при этом приносили и что-то неожиданное и оригинальное.
Такой ОС непохожей на все остальные была Plan9. Это ОС разработана в Bell labs. Её исходники опубликованы на рубеже 00-х.
Фишка Plan9 в отношении к идеологии *NIX. Постулат *NIX — «всё есть файл».

Однако сокеты в *NIX-системах не вписываются в эту абстракцию, а вот в Plan9, сокет — это тоже файл.
Разработчики Plan9 возвели идеологию *NIX-систем в абсолют. В будущем Plan9 вдохновит немало других ОС, таких, как Harvey OS и Jehanne OS.
Примерно в то же время, в начале 2000 на свет появилась Virtuozzo в качестве коммерческой контейнеризации и openvz. Однако неудачные попытки коммерциализации продукта сильно затормозили приход новой системы контейнеризации в массы.
Немного о свободном ПО и коммерциализации
Если бы Parallels, Inc последовали бы сразу заветам Ричарда Столлмана, о коммерциализации open source-проектов, исходя из его заветов: зарабатывать open source может только на платном суппорте и платной доработке фич, возможно, судьба Virtuozzo сложилась бы по другому.
Кстати, Столлман ещё тот олдфаг. На своих выступлениях и лекциях он часто призывает отказаться от сотовых телефонов и передачи своих личных данных третьим сторонам.

Вообще мировоззрения Ричарда сегодня могут многим показаться устаревшими и недееспособными, однако на фоне этого, все же невозможно отрицать его огромный вклад в развитие свободного ПО.
Ознакомиться с биографией Ричарда Мэттью Столмана можно в Википедии.
К тому же, в те же годы к разработчикам стало приходить понимание, что все существующие инструменты изоляции — это костыли и палки проросшие глубоко в ядро ОС, и нужно радикально менять подход.
Для более глубокого погружения в jail рекомендуем прочесть вот эту статью на Хабре. Внутри много кода и подробная инструкция по настройке jail.
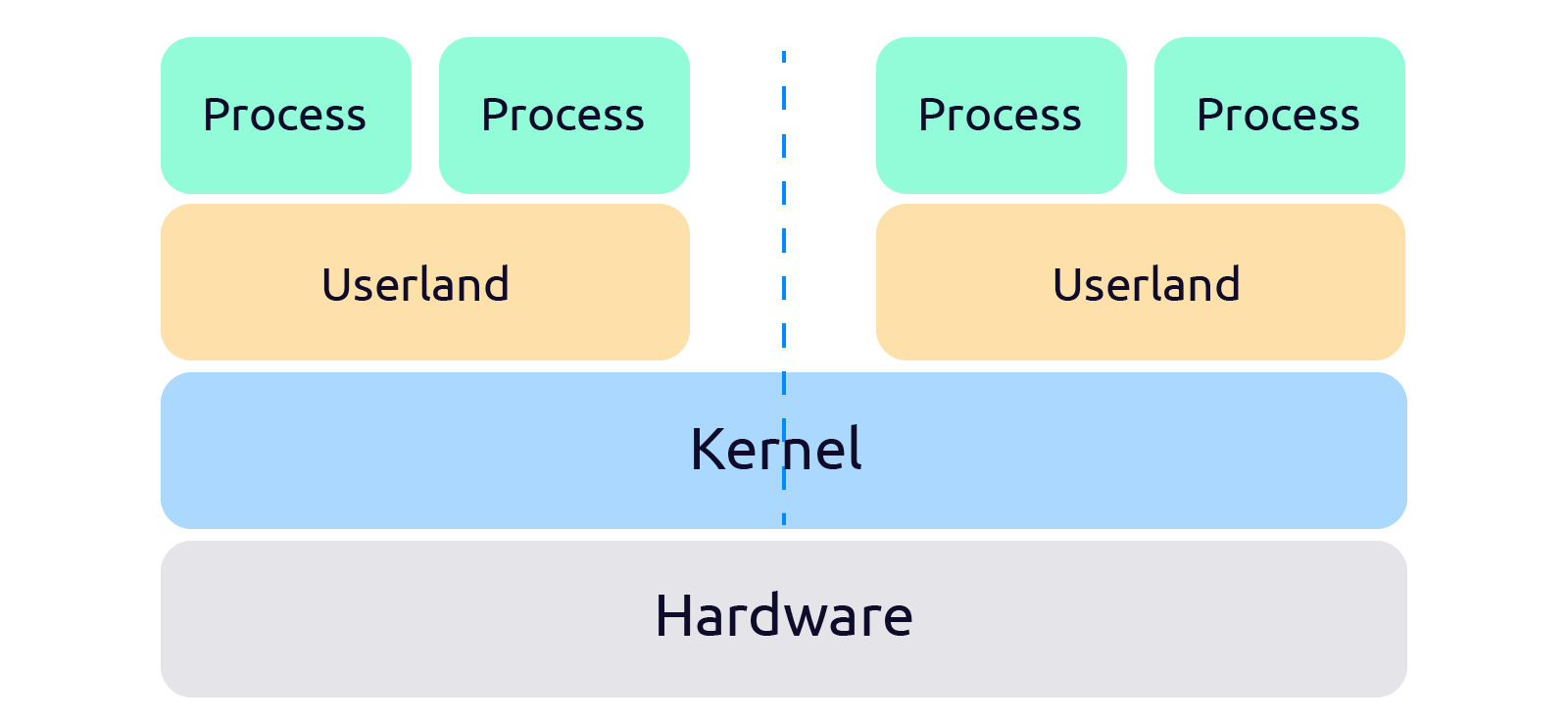
Переломный момент — появление Namespaces
Свежим глотком воздуха стало появление в 2002 году, в ядре Linux версии 2.4.19 нового API для создания абстракции контроля над общими ресурсами — Namespaces API.
Namespaces (пространства имен) — это абстракция (программная прослойка) над физическими ресурсами. Если раньше процессы обращались напрямую к ресурсам, то с появлением namespaces, все запросы проходят через этот дополнительный слой абстракции.
С появлением namespace в ядро было добавлено 3 новых функции, которые отвечают за управление атрибутами namespace:
- clone() — аналог fork() с возможностью выделения частей общих ресурсов в отдельные namespaces.
- setns() — подключает указанный процесс к заданному namespace.
- unshare() — изменение контекста текущего процесса.
В результате вызовов перечисленных функций ядра, namespaces становятся новыми атрибутами процессов. Это позволяет разным процессам иметь разное представление о тех глобальных ресурсах, которыми они распоряжаются.
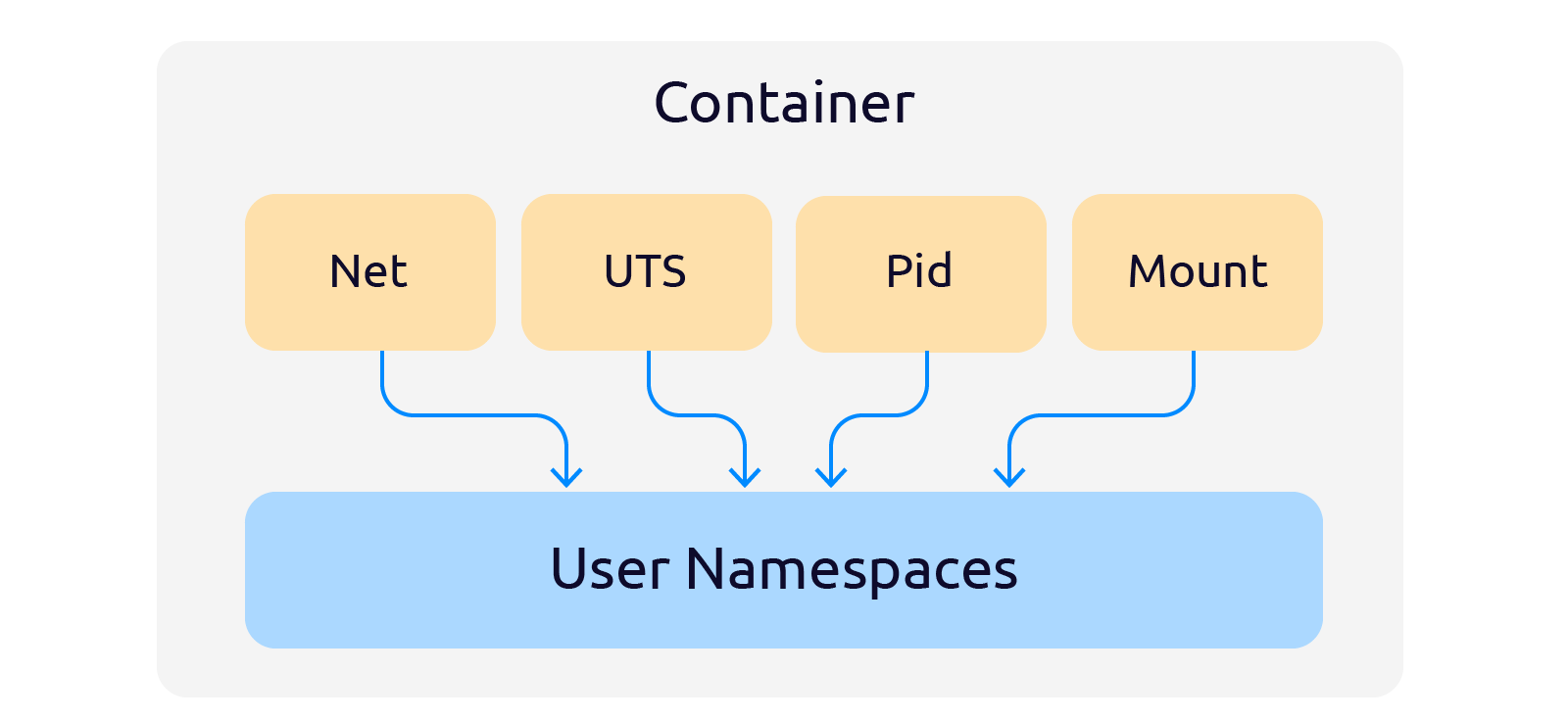
Существуют следующие пространства имён:
- Mount — абстракция над пространством имен для файловых систем. Mount позволяет сразу монтировать новое устройство в несколько пространств имён файловой системы, вместо монтирования в каждом отдельном пространстве.
- Network — абстракция над сетью: интерфейсы, таблицы маршрутизации и т.д. Пространство имен Network по сути выполняет роль туннеля между разными пространствами имён сети.
- IPC — абстракция над межпроцессным взаимодействием. Процесс в пространстве имен IPC не может писать или читать IPC ресурсы, принадлежащие другому пространству имен. Так процессы в одном контейнере не могут вмешиваться в другие контейнеры.
- PID — абстракция над пространством номеров процессов. PID изолирует пространство ID процессов. Процессы в различных пространствах могут иметь одинаковые ID.
- User — абстракция над пространством пользователей. User изолирует ID пользователей и групп, корневой каталог, ключи и capabilities.
- UTS (Unix Time Sharing) — абстракция над пространством hostname и NIS. UTS позволяет контейнерам иметь собственные доменные имена NIS domainname и имена контейнеров nodename.
- Cgroup — используется как атрибут, корневой узел дерева cgroup.
Перечисленные неймспейсы появлялись постепенно, по-мере необходимости решения определенных технических задач. Контейнер, по сути можно назвать квинтэссенцией неймспейсов. Вообще, тема неймспейсов очень обширна. Если вы хотите разобраться в ней лучше — почитайте этот отличный цикл статей на Хабре.
Неймспейсы решили вопросы изоляции, однако вопрос ограничения ресурсов для изолированных процессов оставался открытым. Решение этого вопроса появилось с выходом ядра версии 2.6.20 в 2008 году — в нём появился механизм Cgroups.
Ограничение ресурсов — Cgroups
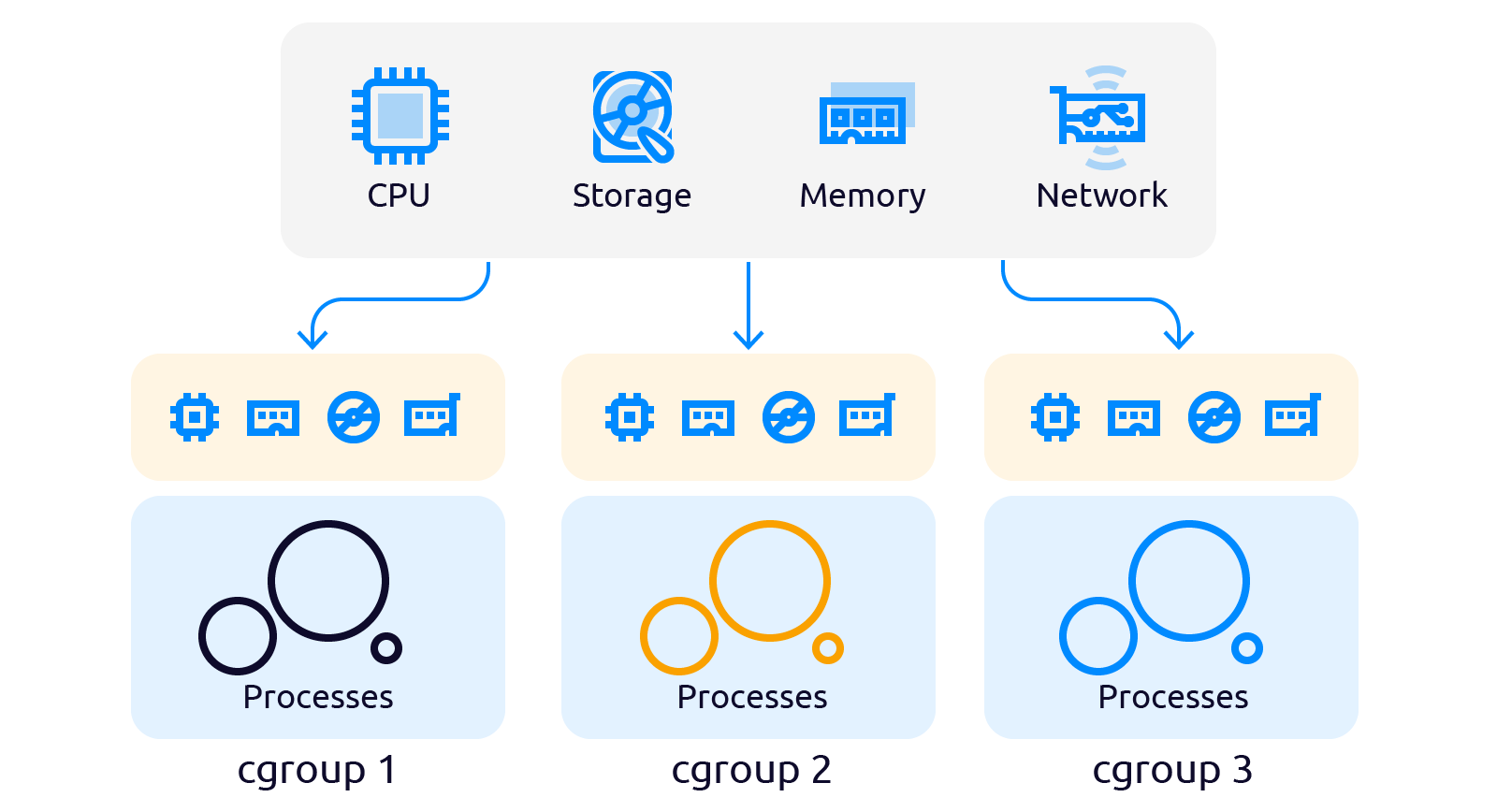
Cgroups (control group) — группа процессов Linux, на которые наложена изоляция и установлены ограничения на вычислительные ресурсы (процессорные, сетевые, ресурсы памяти, ресурсы ввода-вывода) со стороны ядра Linux.
Cgroups — было отличное самодостаточное решение, которое сильно продвинуло технологии контейнеризации вперед. Первой попыткой создания подобного механизма лимитирования ресурсов для изолированных процессов был process accounting, появившийся в 1999 году.
Опять же не обошлось без Google
Google — компания, которая умеет идти своей дорогой, даже там, где дороги вроде бы и нет.
В 2006 году Google взялась за разработку собственного механизма управления ресурсами контейнеров — process containers. Разрабатывали механизм Пол Менедж и Рохит Сет.
Замысел был скромен — усовершенствовать механизм cpuset, предназначенный для распределения процессорного времени и памяти между задачами. Но обыкновенная палка в руках опытных разработчиков выстрелила!
В итоге в конце 2007 года название process containers было заменено на control groups, а в 2008 году cgroups был официально добавлен в ядро Linux (версия 2.6.24).
Разработанные в Google и, включенные в ядро в 2008 году Cgroup стали новой абстракцией над управлением ресурсами. Cgroups состоит из двух частей: cgroup core (ядро cgroup) и подсистем (директории с управляющими файлами).
Количество подсистем может отличаться в зависимости от версии ядра. Так в ядре версии 4.4.0.21 таких подсистем 12, в ядре версии 5.10.16.3, которое содержится в Ubuntu 20 TLS, подсистем уже 13:
- blkio — управляет лимитами чтения и записи на блочных устройствах;
- cpu — управляет доступом к ресурсам процессора;
- cpuset — выделяет отдельных процессоров группе;
- cpuacct — управляет ресурсами cpu (работает совместно с cpu);
- devices — ограничивает доступ к устройствам;
- hugetlb — управляет работой групп с большими страницами памяти (huge pages);
- net_cls — размечает спец. тегами сетевые пакеты, что позволяет процессам генерирующим их определять какие процессы их сгенерировали;
- perf_event rdma — предоставляет интерфейс для инструмента анализа производительности в Linux (perf);
- freezer — управляет приостановкой и возобновлением процессов выполнения задач внутри контрольной группы;
- memory — управляет выделением памяти для групп процессов;
- net_prio — управляет динамическим назначением приоритета трафика;
- pids — ограничивает количество процессов в рамках контрольной группы;
- unified — автоматически монтирует файловую систему в каталог /sys/fs/cgroup/unified при запуске системы.
Вывести список подсистем в вашей версии ядра можно следующей командой:
$ ls /sys/fs/cgroup/
blkio cpuacct devices hugetlb net_cls perf_event rdma cpu cpuset freezer memory net_prio pids unifiedПосмотреть к каким контрольным группам принадлежит процесс можно так:
- вызовите утилиту htop
- найдите нужный вам PID процесса
- перейдите в каталог /proc и найдите там директорию с нужным вам PID
- вызовите команду cat и передайте ей cgroup
Как работать с Cgroups
Работать с cgroups можно двумя способами:
- Стандартным способ — работать с cgroups как с файлами. Вносить записи групп с помощью echo в нужный контроллер.
- С помощью cgroup-tools — работать с cgroups через набор утилит, которые облегчают взаимодействие с cgroups.
Первый способ более предпочтительный, но более трудозатратный для пользователей, имеющих не богатый опыт администрирования Linux, поэтому мы пойдем вторым путем — будем использовать cgroup-tools.
Поместить процесс в контрольную группу просто. Достаточно выполнить команду cgcreate, передать ей следующие параметры:
- -t uid:gid — пользователи, получающие права на перемещение заданий в (из) группы.
- -a uid:gid — пользователи, получающие права на управление параметрами группы (опциональный параметр).
- -g список подсистем:путь.
Пример создания контрольной группы по памяти и процессору:
$ sudo cgcreate -t root:root -g memory,cpu:/mycgroup
Теперь в нашу вновь созданную группу нужно переместить процессы. Для этого есть команда cgclassify, в которую с помощью ключа g передается группа, её название и пиды процессов:
$ sudo cgclassify -g cpu:/mycgroup 7
Убедится, что процесс попал в новую группу можно с помощью команды cat:
Удалить процесс из группы можно также одной командой:
$ sudo cgdelete -g memory,cpu:/mycgroup
До этого мы умели лишь создавать группы и помещать в них процессы. Теперь научимся задавать ограничение ресурсов. Делается это командой cgset с параметром -r:
$ cgset -r cpu.shares=1 /mycgroup
Мы рассмотрели несколько основных инструментов управления контрольными группами из пакета cgroups-tools. Их там конечно же куда больше. Полное описание всех утилит пакета можно посмотреть тут.
Кстати, есть и альтернативный способ управления и настройки cgroups, о нём можно узнать из этой статьи:

Итак, мы кратко рассмотрели историю контейнеризации до этапа появления namespaces и cgroups, рассмотрели эти механизмы и теперь можно подвести итог.
Что же такое контейнер в итоге?

По сути контейнер — это определенные пространства имён (Namespaces) и наборы контрольных групп (Control groups), удобно управляемые с помощью сторонних утилит. Например, с помощью Docker.
Namespace — механизм изоляции процессов. Мы можем создавать пространства имён процессов (группы процессов) помещать туда нужные нам процессы по их идентификаторам — пидам (PID) и эти процессы не могут обращаться к процессам вне своего пространства имён.
Control groups — механизм определения количества выдаваемых ресурсов процессам.
Контейнеры обладают следующими важными преимуществами:
- Они легковесные и быстро выполняются, так как содержат только всё необходимое для работы контейнера: исполняемые и конфигурационные файлы, прочие зависимости.
- Хостовая ОС может смотреть внутрь контейнера и видеть дерево процессов. Когда мы смотрим на процесс виртуальной машины с хоста, мы видим один процесс.
- Появляется возможность использовать микросервисную архитектуру. Каждый сервис можно поместить в свой контейнер, назначить ему ресурсы, запускать и останавливать их независимо друг от друга.
- Можно быстрее развертывать приложения, легче масштабировать их горизонтально, проще находить в них ошибки.
- Выход из строя одного контейнера не влияет на дальнейшую работу других контейнеров.
Контейнеры нужны там, где требуется скорость разворачивания приложений и низкий уровень потребления системы виртуализации. Контейнеры подходят:
- для упрощения процесса развертывания приложений;
- для тестирования или отладки кода;
- для запуска приложений, требующих другого дистрибутива ОС (системные контейнеры);
- для микросервисов, которые можно разрабатывать и обновлять независимо;
- для горизонтально масштабируемых приложений — когда запускается несколько одинаковых контейнеров на текущих ресурсах без увеличения стоимости этих ресурсов;
- для модернизации и миграции существующих приложений в более современные среды.
Контейнеризация не подходит, если для работы приложения требуется другая ОС, а не та, что установлена на сервере.
И в конце, мы хотим оставить ссылку на интервью, того, без кого не было бы ни контейнеров, ни Линукса, ни системы контроля версий GIT, да и вообще, не было бы того технологического мира, в котором мы все с вами живём:
В следующих публикациях мы погрузимся в Docker и посмотрим на Docker-контейнеры через уже полученные знания о контейнеризации.