Порядок вычислений выражений
Есть такая штука, как [порядок выполнения операторов]. Он никогда не меняется и, если в нем разобраться, пару раз поможет распутать баги.
8 апр 2014 в 8:41
Сомнения основаны на теме связанной с С++ на msdn social.msdn.microsoft.com/Forums/ru-RU/… «Т.е. никто и никогда не даст вам 100% гарантию того, что первым будет вычислен первый аргумент – i++, а вторым – i + 2. Т.е. результат может быть как: -2, так и 1. Это относится к C# в том числе.» Или это касается исключительно аргументов функций?
8 апр 2014 в 11:52
мы изначально говорили о немного разных вещах. Поправил ответ
8 апр 2014 в 12:41
8 апр 2014 в 15:16
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Порядок вычисления аргументов методов определен в пункте 7.5.1.2 стандарта:
7.5.1.2 Run-time evaluation of argument lists During the run-time processing of a function member invocation (§7.5.4), the expressions or variable references of an argument list are evaluated in order, from left to right
То есть параметры вычисляются слева направо. Получается, что либо ошибается стандарт, либо тот человек, с форума msdn, на чьи слова вы ссылались.
Однако существует такое понятие, как побочные эффекты функций. Так вот помимо вышесказанного необходимо, чтобы функции (а с ними и их побочные эффекты) выполнялись в той очередности, в которой объявлены, а параметры передавались слева направо в соответствии с сигнатурой. Например:
public static void Write(int i, int b) < Console.WriteLine("", i, b); > public static int First(ref int i) < Console.WriteLine("first"); return ++i; >public static int Second(ref int i) < Console.WriteLine("second"); i += 2; return i; >int i = 5; i = 5; /* тут все логично, выведет строки first second 6 8 потому что сначала First вернет ++i (то есть 6) а затем Second вернет i + 2 (то есть 8) */ Write(First(ref i), Second(ref i)); i = 5; /* а вот тут выведет first second 8 6 и результат может быть неожиданным, потому что компилятор сначала выполняет первую функцию, занося ее результат во второй параметр, а затем вторую, занося ее результат в первый параметр */ Write(b: First(ref i), i: Second(ref i)); Что касается операторов: у каждого оператора в C# (как и в других языках) есть свой приоритет и ассоциативность (он же порядок выполнения). Кроме того, C# в отличие от С++ лишен всяческих источников головной боли, связанных с UB, а потому всегда можно предсказать порядок выполнения и резуьтат выражения (хотя для человека это подчас нетривиальная и запутанная задача). Большая часть операторов в C# левоассоциативны (то есть выполняются слева направо). Однако не все (например, оператор присваивания выполняется справа налево). Подробнее о приоритете и ассоциативности можно почитать тут
Напоследок стоит заметить, что усложнять себе жизнь таким кодом, как вы привели выше, не стоит — компилятор способен разобрать это без труда, а вот человеку гораздо сложнее. Думаю, выпадать в осадок после часовой отладки багов, связанных с неверно рассчитанным приоритетом операций и побочными действиями функций (а в вашем коде есть и такое, что в общем-то тоже не приветствуется) — это далеко не предел мечтаний в работе программиста. Поэтому в подобных ситуациях лучше не жалеть скобочек для группировки операций — компилятор сожрёт, а человеку читать будет легче. Ну или даже разбивать операции на отдельные выражения
Арифметические операции — Основы PHP
На базовом уровне компьютеры оперируют только числами. Для сложения двух чисел в математике мы пишем, например, 3 + 4 . В программировании — то же самое. В этом уроке разберем, как проводить арифметические операции в коде.
Арифметика в программировании
Рассмотрим пример программы, которая складывает два числа:
// Не забываем точку с запятой в конце, так как каждая строчка в коде — инструкция 3 + 4; Арифметика в программировании практически не отличается от школьной. Инструкция 3 + 4; заставит интерпретатор сложить числа и узнать результат. Эта программа будет работать, но в ней нет смысла, потому что по сути мы не даем команду интерпретатору, мы просто говорим ему «смотри, сумма трех и четырех».
В реальной работе недостаточно сообщать интерпретатору о математическом выражении. Например, при создании интернет-магазина недостаточно просить интерпретатор посчитать стоимость товаров в корзине. В этом случае нужно просить посчитать стоимость и показать цену покупателю.
Нам нужно попросить интерпретатор сложить 3 + 4 и дать команду сделать что-то с результатом. Например, вывести его на экран:
// Снова не забываем точку с запятой в конце строчки print_r(3 + 4); // => 7 Кроме сложения доступны следующие операции:
- * — умножение
- / — деление
- — — вычитание
- % — остаток от деления
- ** — возведение в степень
Эти знаки операций называют операторами. Поговорим о них подробнее.
Операторы
Знак операции, например, + , называют оператором. Операторы обычно представлены одним или несколькими символами, реже — словом. Обычно они соответствуют математическим операциям.
Операторы выполняют операции над определенными значениями, которые называются операндами.
print_r(8 + 2); Здесь + — это оператор, а числа 8 и 2 — это операнды.
Операции, которые требуют наличия двух операндов, называются бинарными. В случае сложения у нас есть два операнда: один слева от знака + , другой — справа. Если пропустить хотя бы один операнд, например, 3 + ; , то программа завершится с синтаксической ошибкой.
Еще операции бывают унарными — с одним операндом, и тернарными — с тремя операндами. Причем операторы могут выглядеть одинаково, но обозначать разные операции.
Символы + и — используются не только как операторы. Когда речь идет про отрицательные числа, то знак минуса становится частью числа:
print_r(-3); // => -3 Выше пример применения унарной операции к числу 3 . Оператор — перед тройкой говорит интерпретатору взять число 3 и найти противоположное, то есть -3 . Это может сбить с толку, потому что -3 — это одновременно и число, и оператор с операндом. Но у языков программирования такая структура:
// То же самое, что и 4 - 3 print_r(4 + -3); // => 1 То же самое касается и плюса:
print_r(+3); // => 3 print_r(1 + +3); // => 4 Коммутативная операция
В программировании используется базовый закон арифметики: от перемены мест слагаемых сумма не меняется. Он называется коммутативным законом. Если поменять местами операнды в бинарной операции, и получится тот же результат, такая операция будет коммутативной. Получается, что сложение — коммутативная операция: 3 + 2 = 2 + 3 .
Вычитание не будет являться коммутативной операцией: 2 — 3 ≠ 3 — 2 . В программировании этот закон тоже работает. Большинство операций, с которыми мы будем сталкиваться в реальной жизни, не являются коммутативными. Поэтому всегда нужно обращать внимание на порядок того, с чем работаем.
Композиция операций
Разберем пример композиции операций:
print_r(2 * 4 * 5 * 10); // 2 * 4 * 5 * 10 = 8 * 5 * 10 = 40 * 10 => 400 Операции можно соединять друг с другом. Это дает возможность вычислять более сложные составные выражения. Такое свойство операций называется композицией.
Композиция арифметических операций в программировании аналогична композиции из школьной программы. Она распространяется на все операции, а не только на арифметические.
Чтобы представить, как происходят вычисления внутри интерпретатора, разберем пример: 2 * 4 * 5 * 10 .
- Сначала вычисляется 2 * 4 и получается выражение 8 * 5 * 10
- Затем 8 * 5 . В итоге имеем 40 * 10
- В конце происходит последнее умножение, и получается результат 400
Приоритет операций
В школьной математике есть понятие «приоритет операции». Приоритет определяет, в какой последовательности должны выполняться операции.
Допустим, нам нужно вычислить такое выражение: 2 + 2 * 2 :
print_r(2 + 2 * 2); // => 6 Интерпретатор производит арифметические вычисления в правильном порядке: сначала деление и умножение, потом сложение и вычитание, а приоритет возведения в степень выше всех остальных арифметических операций: 2 ** 3 * 2 вычислится в 16 .
Иногда вычисления должны происходить в другом порядке. В этом случае приоритет задают круглыми скобками, например: (2 + 2) * 2 . Скобки можно ставить вокруг любой операции. Они могут вкладываться друг в друга сколько угодно раз. Вот пара примеров:
print_r(3 ** (4 - 2)); // => 9 print_r(7 * 3 + (4 / 2) - (8 + (2 - 1))); // => 14 В этом случае главное закрывать скобки в правильном порядке. Это часто становится причиной ошибок не только у новичков, но и у опытных программистов. Для удобства можно сразу ставить открывающую и закрывающую скобки, а потом писать внутреннюю часть.
Сейчас большинство редакторов кода делают это автоматически. Например, мы ставим открывающую скобку, а он автоматически ставит закрывающую. Это касается и других парных символов, например, кавычек. О них — в будущих уроках.
Иногда выражение сложно воспринимать визуально. Тогда можно расставить скобки, не повлияв на приоритет. Код пишется для людей, а машины будут только исполнять его. Для машин код — или корректный, или не корректный. Для них нет «более» понятного или «менее» понятного кода. Явная расстановка приоритетов упрощает чтение кода другими разработчиками.
Дополнительные материалы
![]()
Остались вопросы? Задайте их в разделе «Обсуждение»
Вам ответят команда поддержки Хекслета или другие студенты
Порядок выполнения арифметических операций
Как правильно вычислить \(\frac<48>(9+3)\) ? Один получает в ответе \(288\) , второй \(2\) . В таких случаях стоит помнить, что первое действие выполняется в скобках, и здесь важно знать порядок арифметических операций.
Порядок арифметических операций — это порядок, в котором все алгебраические выражения должны быть выполнены. Зачастую значение выражения меняется в зависимости от порядка его вычисления. Порядок выполнения арифметических операций:
- действия в скобках
- радикалы, то есть корни
- умножение и деление
- сложение и вычитание
Круглые скобки — это изогнутые символы \(()\) , которые помещаются вокруг части выражения, чтобы показать, что выражения внутри них должны быть вычислены в первую очередь. В круглых скобках следует соблюдать тот же порядок операций. Сначала вычисляются выражения в скобках, затем корни, то есть радикалы, умножение и деление и в конце сложение и вычитание. Если есть несколько одинаковых арифметических операций, то действия выполняются в порядке слева направо.
Пример 1. Вычислить:
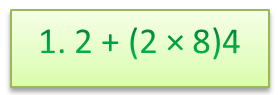
Сначала выполняем умножение в скобках \(2*8=16\) , потом деление \(16:4=4\) и затем сложение \(4+1,2=5,2\) . В результате выражения получаем \(5,2.\)
Пример 2. Вычислить:

Сначала обратим внимание, что нет скобок и корней, поэтому мы сразу переходим к умножению и делению \(3*3=9\) , затем переходим к сложению и вычитанию, работая слева направо \(9-5=4\) и \(4+2=6\) . В результате выражения получаем \(6.\)
Логическое обоснование порядка арифметических операций, помимо скобок, которые, очевидно, являются первыми, заключается в том, что умножение — это повторное сложение, а возведение в степень — это повторное умножение. Кроме того, деление обратно умножению.
Например, выражение:

должно быть решено в следующем порядке: вычисляем выражение в скобках \(6+7=13\) , потом выполняем умножение \(2*13=26\) и затем отнимаем от получившегося значения \(82\) и получаем \(-56\) . Это и есть наш окончательный результат -56.
Если бы желаемый порядок решения выражения был бы другим, на основе исходной задачи, то скобки были бы расположены по-другому. Порядок операций очень важен, поэтому вы должны понимать порядок арифметических операций на хорошем уровне.
Больше уроков и заданий по всем школьным предметам в онлайн-школе «Альфа». Запишитесь на пробное занятие прямо сейчас!
Арифметические операции: сложение, вычитание, умножение и деление
После изучения базовых типов данных, переменных и функций ввода/вывода пришло время познакомиться с арифметическими операциями языка Си. Начнем с самых очевидных:
Все эти операции можно использовать как бинарные, то есть, слева и справа от них записываются выражения, над которыми выполняется соответствующая операция:
Здесь левые и правые операнды могут быть любыми выражениями, над которыми можно выполнять соответствующую арифметическую операцию. В самом простом случае – это переменные и числовые литералы.
Обратите внимание, все рассматриваемые арифметические операции являются именно операциями, а не операторами. Это значит, они вычисляют значение и возвращают его. Именно поэтому мы можем совершенно свободно присвоить вычисленный результат какой-либо переменной следующим образом:
int result = 10 + 5;
int result; result = 10 - 5;
Здесь точка с запятой в конце превращает арифметическую операцию в завершенный оператор. В частности, это означает, что арифметические операции можно продолжать, пока не встретится символ точка с запятой:
int result = 10 + 5 - 7 * 3;
Но обо всем по порядку. Давайте непосредственно в программе посмотрим на работу операций сложения, вычитания и умножения:
#include int main(void) { short a = -5; int b = 10; float c = 5.4f; double d = -6.5; int res_1 = a + b; short res_2 = 100 - b; float res_3 = 5.4 - c; double res_4 = d * 4; return 0; }
Вначале идет объявление четырех переменных разных типов с определенными начальными значениями. Затем, эти переменные используются в арифметических операциях наряду с числовыми литералами. Наверное, первое, что бросается в глаза, возможность использования смешанных типов данных при арифметических вычислениях. Да, язык Си нас в этом не ограничивает, в отличие от некоторых других языков высокого уровня, где смешение типов не допускается. Но возникает вопрос, как это в деталях работает? Начнем с первой операции сложения двух целочисленных переменных a и b. Они имеют разные типы: short и int. Так вот, компилятор языка Си целочисленные значения по умолчанию приводит к единому типу int и только потом выполняет их сложение. То есть, переменная a будет приведена к типу int и мы получаем сложение двух значений одного типа.
Я думаю, вы понимаете, почему переменная a приводится именно к типу int? Как мы с вами уже говорили, тип int может превышать по размеру тип short, то есть, он является более общим и наиболее употребительным для представления целых числовых значений. Когда меньший тип приводится к большему, такая операция называется повышением типа.
Конечно, в общем случае, типа int может быть недостаточно, например, когда используются очень большие числовые значения. В этом случае компилятор повышает тип до long или long long так, чтобы не происходило потери данных при их представлении.
В следующей строчке программы записана операция вычитания:
short res_2 = 100 - b;
Здесь все работает аналогичным образом. Литерал 100 по умолчанию представляется типом int, переменная b также имеет тип int и результат тоже сохраняется в памяти как число типа int. А далее, полученное значение типа int присваивается переменной res_2 типа short. Перед присваиванием также происходит приведение типов, в данном случае значение int к типу short, т.к. тип переменной res_2 компилятор поменять самовольно не может. В результате получаем операцию понижения типа, которая может привести к потере данных, если присваиваемое значение не укладывается в меньший по размеру тип short. Вот на это всегда следует обращать внимание, при реализации арифметических операций. Как только встречается понижение типа данных, потенциально возможна потеря данных.
В следующей строчке:
float res_3 = 5.4 - c;
мы тоже видим понижение типа от double к float. Как мы помним, числовой литерал вещественного числа представляется типом double. Переменная c также приводится к типу double и результат вычитания сохраняется на уровне этого типа данных. После этого, значение double присваивается переменной res_3 меньшего типа float. Снова имеем понижение типов и потенциальную возможность потери данных. Поэтому, чаще всего на практике вещественные числа описываются типом double, чтобы избежать подобных преобразований.
Наконец, последняя строчка:
double res_4 = d * 4;
Здесь вещественное число d типа double умножается на целочисленное значение 4. Строго говоря, компьютер не умеет выполнять арифметические операции с вещественными и целыми числами. В нем реализована арифметика либо над целыми, либо над вещественными числами, не смешивая их. Поэтому здесь число 4 сначала будет приведено к более общему типу double, и только потом выполнена операция умножения над вещественными числами.
И у нас остается еще одна операция деления. Я думаю, вы теперь легко поймете принцип ее работы. Запишем ее в нескольких вариациях:
#include int main(void) { short a = -5; int b = 10; float c = 5.4f; double d = -6.5; int res_1 = 7 / 2; /* 3 */ double res_2 = -9 / 2; /* -4 */ float res_3 = a / c; /* -0.9259. */ double res_4 = d / b; /* -0.65 */ return 0; }
Смотрите, когда происходит деление двух целочисленных значений, то результат также получается целочисленным. Причем, в соответствии со стандартом C99, дробная часть просто отбрасывается. Именно так образуются целые значения. То есть, здесь нет округления по правилам математики, а просто отбрасывание дробной части, какой бы она ни была. Это следует запомнить. Если же один из операндов является вещественным значением, то все числа приводятся к типу double и после этого выполняется операция деления. Поэтому переменные res_3 и res_4 принимают дробные значения.
Операция приведения типов
Вот такой нюанс есть у операции деления в языке Си и начинающие программисты здесь очень часто совершают ошибки, когда делят два целых числа, ожидая получить вещественное значение. В действительности же происходит обычное целочисленное деление. И здесь может возникнуть вопрос: а как нам разделить две целочисленные переменные, чтобы получилось вещественное число? То есть, ситуация выглядит следующим образом:
#include int main(void) { short a = -5; int b = 10; double res_1 = a / b; /* 0 */ return 0; }
Для этого необходимо одну, а лучше обе переменные привести к вещественному типу double, используя операцию приведения типов:
double res_1 = (double)a / (double)b; /* -0.5 */
То есть, перед выражением (в данном случае переменной) в круглых скобках указывается тип, к которому должны быть приведены данные. В нашем примере значения переменных a и b сначала приводятся к типу double, а затем, выполняется операция деления над вещественными числами. Как результат получаем вещественное значение -0,5.
Если же мы оперируем конкретными числовыми значениями, например:
double res_2 = 7 / 2;
то для получения вещественного значения их удобнее записать в виде вещественных чисел:
double res_2 = 7.0 / 2.0;
вместо того, чтобы приводить целые числа к вещественному типу.
Унарные операции — и +
Далее, операции + и — можно использовать не только как бинарные, но и как унарные, то есть, перед выражением ставить знаки минус и плюс следующим образом:
#include int main(void) { short a = -5; // -5 int b = -a; // 5 int d = -(7 + a); // -(7 + -5) = -2 return 0; }
В первом случае знак минус стоит перед числовым литералом 5 и определяет его как отрицательное число, которое, затем, присваивается переменной a. В следующей строчке минус указан перед переменной и инвертирует знак числового значения, которое присваивается переменной b. При этом значение в переменной a не меняется. Наконец, в третьей строчке унарный минус поставлен перед выражением (7 + a). Соответственно, сначала вычисляется операция внутри скобок, а затем, выполняется инвертирование знака.
По аналогии можно использовать и унарный плюс, хотя, на практике он почти никогда не используется, т.к. по умолчанию значения определяются как положительные и лишний раз подчеркивать этот факт не имеет особого смысла.
Приоритеты арифметических операций
Важно знать, что приоритет любой унарной операции в языке Си выше, чем бинарной. Например, в следующей строчке:
int res = -10 + 7;
сначала будет выполнен унарный минус и только после этого бинарная операция сложения. Или так:
int res = -10 * 7;
Здесь также сначала унарный минус будет применен к числу 10 и только после этого выполнится бинарная операция умножения.
Если рассматривать бинарные арифметические операции, то сначала выполняются умножение и деление, а затем, сложение и вычитание. То есть, приоритет операций умножения и деления выше, чем у сложения и вычитания. Здесь все ровно так, как нас учат в школе на уроках математики. Например:
short a = -5, b = 7, c = 4; double D = b * b - 4 * a * c;
Сначала вычисляются умножения, а затем, бинарная операция вычитания. Причем, обратите внимание, порядок вычисления первого умножения b * b и второго 4 * a * c стандартом языка Си не определен. Разработчики компиляторов могут делать это в произвольном порядке с целью повышения скорости работы программы. Поэтому нет гарантии, что сначала вычислится b * b и только потом 4 * a * c. Порядок может быть другим. Это очень важный момент. А вот порядок вычисления подряд идущих арифметических операций с одинаковым приоритетом всегда выполняется слева-направо. То есть в выражении 4 * a * c сначала будет выполнено первое умножение и только потом – второе. В этом мы можем быть уверены. Поэтому запись вида:
double res = 5 / 3 * 2;
означает, что сначала 5 делится на 3 и результат умножается на 2. Это эквивалентно выражению (5 / 3) * 2. Иногда путаются и считают, что оно соответствует выражению 5 / (3 * 2). Но это неверно из-за строго порядка вычислений слева-направо.
Если нужно изменить порядок вычислений, то есть, приоритеты, то для этого используются круглые скобки, например, следующим образом:
int perimetr = 2 * (b + c);
Сначала будет вычислено выражение внутри скобок и только потом умножение на два.
В заключение этого занятия приведу простой пример программы, которая запрашивает два числа и на их основе вычисляет площадь треугольника:
#include int main(void) { double height, a; printf("Enter the height and length of the triangle's base: "); int res = scanf("%lf %lf", &height, &a); if(res != 2) { // проверка, что res не равна двум printf("Data entry error\n"); return 0; // завершение функции main и программы } double sq = height * a / 2.0; printf("The square of the triangle is: %.2f", sq); return 0; }
Вначале с помощью функции scanf() осуществляется ввод высоты и основания треугольника, затем, проверка, что данные были прочитаны корректно. Для этого, забегая вперед, я воспользовался условным оператором if, в котором проверяю, что переменная res не равна двум. Если это так, значит, произошла ошибка ввода значений. В этом случае выводится сообщение об ошибке в консоль и программа завершается. Если же данные введены верно, то вычисляется площадь треугольника и это значение выводится в консоль. Как видите, все достаточно просто.
На следующем занятии мы продолжим эту тему и рассмотрим следующую (заключительную) группу арифметических операций, а также особенности их работы.
Видео по теме

Язык Си. Рождение легенды

#1. Этапы трансляции программы в машинный код. Стандарты

#2. Установка компилятора gcc и Visual Studio Code на ОС Windows

#3. Структура и понимание работы программы «Hello, World!»

#4. Двоичная, шестнадцатеричная и восьмеричная системы счисления

#5. Переменные и их базовые типы. Модификаторы unsigned и signed

#6. Операция присваивания. Числовые и символьные литералы. Операция sizeof

#7. Стандартные потоки ввода/вывода. Функции putchar() и getchar()

#8. Функция printf() для форматированного вывода

#9. Функция scanf() для форматированного ввода

#10. Арифметические операции: сложение, вычитание, умножение и деление

#11. Арифметические операции деления по модулю, инкремента и декремента

#12. Арифметические операции +=, -=, *=, /=, %=

#13. Булевый тип. Операции сравнения. Логические И, ИЛИ, НЕ

#14. Условный оператор if. Конструкция if-else

#15. Условное тернарное выражение

#16. Оператор switch множественного выбора. Ключевое слово break

#17. Битовые операции И, ИЛИ, НЕ, XOR. Сдвиговые операции

#18. Генерация псевдослучайных чисел. Функции математической библиотеки

#19. Директивы макропроцессора #define и #undef

#20. Директива #define для определения макросов-функций. Операции # и ##

#21. Директивы #include и условной компиляции

#22. Оператор цикла while

#23. Оператор цикла for

#24. Цикл do-while с постусловием. Вложенные циклы

#25. Операторы break, continue и goto

#26. Указатели. Проще простого

#27. Указатели. Приведение типов. Константа NULL

#28. Долгожданная адресная арифметика

#29. Введение в массивы

#30. Вычисление размера массива. Инициализация массивов

#31. Указатели на массивы

#32. Ключевое слово const с указателями и переменными

#33. Операции с массивами копирование, вставка, удаление и сортировка

#34. Двумерные и многомерные массивы. Указатели на двумерные массивы

#35. Строки. Способы объявления, escape-последовательности

#36. Ввод/вывод строк в стандартные потоки

#37. Строковые функции strlen(), strcpy(), strncpy(), strcat(), strncat()

#38. Строковые функции сравнения, поиска символов и фрагментов

#39. Строковые функции sprintf(), atoi(), atol(), atoll() и atof()

#40. Объявление и вызов функций

#41. Оператор return. Вызов функций в аргументах

#42. Прототипы функций

#43. Указатели как параметры. Передача массивов в функции

#44. Указатели на функцию. Функция как параметр (callback)

#45. Стековый фрейм. Автоматические переменные

#46. Рекурсивные функции

#47. Функции с произвольным числом параметров

#48. Локальные и глобальные переменные

#49. Локальные во вложенных блоках

#50. Ключевые слова static и extern

#51. Функции malloc(), free(), calloc(), realloc(), memcpy() и memmove()

#52. Перечисления (enum). Директива typedef

#53. Структуры. Вложенные структуры

#54. Указатели на структуры. Передача структур в функции

#55. Реализация стека (пример использования структур)

#56. Объединения (union). Битовые поля

#57. Файловые функции: fopen(), fclose(), fgetc(), fputc()

#58. Функции perror(), fseek() и ftell()

#59. Функции fputs(), fgets() и fprintf(), fscanf()

#60. Функции feof(), fflush(), setvbuf()

#61. Бинарный режим доступа. Функции fwrite() и fread()


#1. Первая программа на С++

#2. Ввод-вывод с помощью объектов cin и cout

#3. Пространства имен (namespace)

#4. Оператор using

#5. Новые типы данных. Приведение типов указателей

#6. Инициализация переменных. Ключевые слова auto и decltype

#7. Ссылки. Константные ссылки

#8. Объект-строка string. Операции с объектами класса string

#9. Файловые потоки. Открытие и закрытие файлов. Режимы доступа

#10. Чтение и запись данных в файл в текстовом режиме

#11. Чтение и запись данных в файл в бинарном режиме

#12. Перегрузка функций. Директива extern C

#13. Значения параметров функции по умолчанию


#15. Лямбда-выражения. Объявление и вызов

#16. Захват внешних значений в лямбда выражениях

#17. Структуры в С++, как обновленный тип данных

#18. Структуры. Режимы доступа. Сеттеры и геттеры

#19. Структуры. Конструкторы и деструкторы

#20. Операторы new / delete и new [] / delete []
© 2024 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта