Управление памятью
В языке Go управление памятью осуществляется автоматически с помощью сборки мусора (garbage collection), что освобождает разработчика от ручного управления памятью. Вот некоторые ключевые аспекты управления памятью в Go:
Автоматическая сборка мусора
Go использует алгоритм сборки мусора с маркировкой и освобождением (mark-and-sweep). Во время выполнения программы, сборщик мусора анализирует и маркирует все объекты, которые по-прежнему используются, а затем освобождает память, занимаемую неиспользуемыми объектами.
Указатели и выделение памяти
В Go есть возможность работы с указателями, но прямое выделение и освобождение памяти с помощью указателей не поддерживается. Выделение памяти происходит автоматически при создании объектов и освобождение памяти происходит автоматически при сборке мусора.
Устранение утечек памяти
При правильном использовании Go управляет памятью и автоматически освобождает неиспользуемую память. Однако, неправильное использование конструкций, таких как циклы ссылок или долгоживущие объекты, может привести к утечкам памяти. Поэтому важно следить за правильным использованием ресурсов и избегать утечек памяти.
Слайсы (slices)
В Go часто используются слайсы, которые представляют собой динамически изменяемые массивы. Слайсы обеспечивают автоматическую расширяемость и управление памятью. При добавлении элементов в слайс или изменении его размера, Go автоматически управляет памятью, выделяя новый участок памяти и копируя данные при необходимости.
Стек и куча
В языке Go существуют две области памяти, известные как «стек» (stack) и «куча» (heap), которые используются для размещения данных и объектов во время выполнения программы. Вот более подробное описание каждой области:
Стек (Stack):
Стек представляет собой участок памяти, который используется для хранения локальных переменных и контекста вызова функций. Каждый поток выполнения программы имеет свой собственный стек. Когда функция вызывается, данные, такие как аргументы функции, локальные переменные и адрес возврата, сохраняются на вершине стека. Когда функция завершается, эти данные удаляются из стека. Операции в стеке очень быстрые и эффективные. Размер стека ограничен и задается на этапе компиляции.
Куча (Heap):
Куча представляет собой область памяти, которая используется для динамического выделения памяти под объекты и данные, которые не ограничены временем жизни функции. Объекты в куче могут быть доступны из разных частей программы и иметь долгоживущий жизненный цикл. Например, это могут быть структуры данных, объекты классов или слайсы. Управление памятью в куче осуществляется сборщиком мусора, который автоматически определяет, какая память больше не используется и освобождает ее. Куча имеет больший размер, чем стек, и обычно является общей памятью для всей программы.
В целом, Go предоставляет разработчику простой и эффективный механизм управления памятью, освобождая его от выделениея и освобождения памяти вручную, как в низкоуровневых языках программирования. Вместо этого, Go автоматически управляет памятью через сборку мусора и предоставляет высокоуровневые конструкции, такие как слайсы и указатели, для работы с данными. Это позволяет разработчику сосредоточиться на бизнес-логике приложения, а не на управлении памятью.
Escape analysis (эскейп анализ)
Escape analysis (Escape analysis) в языке Go является одной из оптимизаций компилятора, которая позволяет определить, будет ли объект или переменная «выброшена» из локальной области и будет ли использоваться вне нее. Этот анализ позволяет определить, следует ли выделить память для объекта на куче или же можно использовать стек для его хранения. Вот некоторые особенности анализа эскейпа в Go:
Стековое распределение (Stack Allocation)
Escape analysis пытается найти переменные, которые могут быть безопасно распределены на стеке вместо кучи. Это происходит, когда переменная не будет использоваться после выхода из локальной области, например, когда она не передается в другие функции или не сохраняется для использования после возврата из текущей функции.
Кучевое распределение (Heap Allocation)
Если Escape analysis обнаруживает, что переменная будет использоваться за пределами локальной области, то объект или переменная будет выделена на куче. Например, когда переменная передается по указателю или сохраняется в глобальной области, она считается «выброшенной» из локальной области и требует распределения памяти на куче.
Оптимизации аллокаций
Escape analysis позволяет компилятору Go оптимизировать аллокации памяти. Если компилятор обнаруживает, что объект может быть безопасно распределен на стеке, это может привести к повышению производительности, так как стековые аллокации более эффективны и быстрые, чем кучевые аллокации.
Escape analysis в Go выполняется компилятором во время компиляции программы. Разработчику не требуется явно указывать, где распределять объекты на стеке или куче — это определяется автоматически на основе анализа кода и его использования переменных и объектов.Оптимизации, которые происходят благодаря анализу эскейпа, позволяют Go достигать высокой производительности и эффективного использования памяти, освобождая разработчика от необходимости явно управлять памятью.
Go’s Garbage Collection: как работает и почему это важно знать
Привет! Меня зовут Дмитрий Королёв, я бэкенд-разработчик в Авито. Я хочу рассказать, как устроен сборщик мусора в Golang и как он работает, чтобы вы могли писать более производительные приложения и лучше понимать внутреннее устройство языка.
За последние 10 лет сборщик мусора в golang ускорился более чем в 400 раз. И это не предел. Расскажу, как разработчики этого добились, — от базовой имплементации до нетривиальных оптимизаций.

Mark and Sweep Garbage Collector — кто такой?
Mark and Sweep — популярный алгоритм для сборщиков мусора. Он или его модификации много лет работают сейчас или работали ранее в Java, Python, Lua и других языках. Его работа состоит из 2 фаз:
- Mark: находим и отмечаем все достижимые объекты из набора (например, в куче).
- Sweep: проходим по всем объектам в куче, затираем недостижимые и возвращаем их в пул свободной памяти.
Если вы не знакомы с тем, как выделяется память в Golang, то рекомендую эту статью.
Набор объектов в наборе можно представить в виде графа, а работа алгоритма похожа на обход в ширину. Рассмотрим на примере:
До начала разметки есть граф неразмеченных объектов произвольного размера:

Разметка — шаг 1. Покрасили объект 1. Пул объектов, которые связаны с объектом 1 — 3 и 4:

Разметка — шаг 2. Покрасили объекты 3 и 4. Пул объектов, связанных с окрашенной частью графа — 6:

Разметка — шаг 3. Покрасили объект 6. Объектов, связанных с окрашенной частью графа, не осталось. Пришло время чистить мусор:

Объекты 2 и 7 недостижимы, их можно переработать:

Память недостижимых объектов отмечается доступной для перезаписи или сразу возвращается системе.
В Golang память отмечается доступной для перезаписи, запускается горутина, которая постепенно возвращает её системе. За этот процесс отвечает Scavenger. Все достижимые объекты продолжают жить нетронутыми:

Чтобы операция прошла корректно, программа должна быть приостановлена во время стадии разметки (Mark). Такая пауза в выполнении называется Stop The World (STW).
STW — очевидное зло с точки зрения перфоманса приложений. Любой язык с механизмом сборки мусора стремится сократить его влияние до минимума.
Алгоритмы для уменьшения STW в Golang
Популярное решение для уменьшения STW — имплементация алгоритма трёхцветной маркировки (Three-color Marker Algorithm). Этот подход работает и в Golang: все объекты в стадии разметки красятся в чёрный, серый или белый цвет:
- белый — потенциальный мусор, ещё не затронутые алгоритмом объекты;
- серый — объекты «на рассмотрении»;
- чёрный — активные объекты.
Изначально все объекты в куче и на стеке окрашены в белый.
В целом, алгоритм можно представить циклом из нескольких шагов:
- Покрасить все корневые объекты (стек и глобальные переменные) в серый.
- Выбрать серый объект из набора серых объектов и пометить его как чёрный.
- Все объекты, на которые указывает чёрный объект, пометить серым. Это гарантирует, что сам объект и объекты, на которые он ссылается, не будут выброшены в мусор.
- Если в графе остались серые объекты, вернуться к шагу 2.




Шаг 5 (уже повторяем с шага 2):


Серые объекты кончились, но белые остались. Вот мы и нашли мусор! Теперь эти участки при необходимости могут быть перезаписаны.
Но есть проблема. Чтобы сборщик мусора работал, мы обязаны делать STW и за один заход проходиться сразу по всем объектам в памяти программы. А вот что будет, если попробовать красить итерационно.
Сейчас граф объектов окрашен таким образом:

Представим, что в процессе окраски мы создали связь между белым объектом и уже окрашенным в чёрный. При этом у белого объекта больше нет связей. Тогда алгоритм покраски его не затронет и в итоге он будет отмечен как мусор. Это фатальная ошибка для любого приложения.

В текущей реализации стадия покраски требует STW. Этот период в ранних версиях Go достигал сотен миллисекунд, а это довольно значительное время. От этого как-то хочется избавиться.
Что такое Write Barrier и зачем они нам
Кажется, что стоит научиться собирать мусор пошагово, по маленьким кусочкам, то есть амортизировать алгоритм. Тогда не придётся не останавливать выполнение программы на длительный период времени. Сборщик мусора с таким алгоритмом называется Incremental Garbage Collector.
Для пошаговой сборки мусора нужны гарантии, что если во время покраски добавить или удалить связи между объектами, графы останутся правильно окрашенными.
Write Barrier — это фрагмент кода, который выполняется при работе с памятью. Нам он нужен для поддержки инвариантов, которые гарантируют правильное пошаговое выполнение алгоритма. Звучит сложно, но на примерах станет понятнее.
Проведу небольшой экскурс в историю Go, чтобы понять, почему он устроен так, как устроен.
До версии Go 1.8 использовали Dijkstra insertion write barrier. Работал он так:
func writePointer(slot, ptr): shade(ptr) *slot = ptr slot — это место назначения (например, переменная) в коде Go.
ptr — это значение, которое помещается в слот в коде Go.
shade — превращает белые объекты в серые, серые и чёрные оставляет нетронутыми.
insertion в названии говорит о том, что триггером для его вызова служит создание связи между объектами.
Таким образом, если мы пишем x = y, то y всегда после этого будет серым:


Теперь мы стабильно поддерживаем такой инвариант: чёрные объекты указывают только на серые или другие чёрные объекты, а на белые — не указывают:

Это выглядит просто, работает корректно — что ещё нам надо? Есть подвох. Для объектов на стеке вместо включения Write Barrier был выбран другой подход. Их просто автоматом считали серыми, чтобы не нести потери в перформансе приложений. Но без Write Barrier нет гарантии, что мы не прикрепим белый объект к чёрному на стеке.
Чтобы этого избежать, на каждом шаге покраски стек заново покрасится в серый после выполнения программы. По всем объектам заново пройдётся сборщик мусора. Если обнаружится новая связь с белым объектом, он также будет перекрашен в серый.
Для приложений с большим количеством горутин этот период может достигать до 100 мс. Но считается, что этот подход оптимальнее использования Write Barrier на стеке.
Начиная с Go 1.8 придумали совместить Dijkstra insertion write barrier и Yuasa deletion write barrier. Deletion в названии означает, что триггером для вызова служит удаление связи между объектами.
Псевдокод для описания его работы:
func writePointer(slot, ptr) shade(slot) slot = ptrРассмотрим тот же пример, который приводился перед вводом write barriers:

Создание связи между объектами не триггерит Yuassa write barrier:

А вот удаление связей триггерит:

Таким образом мы не теряем белые объекты. Yuasa write barrier даёт такой инвариант: у любого белого объекта, на который указывает чёрный объект, должен быть достижимый путь до серого объекта.
Из этих двух Write barrier получается Hybrid Write Barrier:
func writePointer(slot, ptr): shade(*slot) if current stack is grey: shade(ptr) *slot = ptr Этот Write Barrier затеняет объект, на который перезаписывается ссылка. Если стек текущей горутины ещё не просканирован, то он затеняет и устанавливаемый объект
С гибридным барьером не нужно повторное сканирование стека. После того, как он был отсканирован и затемнён, он остаётся чёрным.
Этот Write Barrier гарантирует выполнение условий:
- чёрные объекты не указывают на белые объекты, только на серые или другие черные объекты (dijkstra write barrier);
- любой белый объект, на который указывает черный объект, должен иметь достижимый путь до серого объекта (yuasa write barrier)
А эти условия гарантируют корректность пошаговой покраски графа. Больше информации и доказательство корректности можно найти здесь. Все новые объекты, создаваемые в процессе работы алгоритма сразу помечаются чёрными, чтобы точно их не потерять.
Это может быть проблемой для некоторых приложений. Если создать очень много короткоживущих объектов, то все они точно доживут до следующей итерации GC.
Теперь мы знаем, как Golang избавился от долгих пауз в выполнении программы — Garbage Collector стал Incremental. Но стала ощутимее другая проблема: время работы сборщика мусора стало больше. Вот как выглядит процесс его работы:

Немного о Concurrent garbage collector
Очевидный вариант оптимизации — использовать все имеющиеся процессоры. Это кратно ускорит время работы GC:


Тут есть блок, в котором сборщик работает везде и одновременно. Это не случайно, некоторая часть его работы требует STW. Полностью от него избавиться не выйдет.
Стадии работы GC
Текущая стадия работы сборщика мусора хранится в глобальной переменной gcphase.
1. Sweep Termination. Останавливаем мир
A Guide to the Go Garbage Collector
This guide is intended to aid advanced Go users in better understanding their application costs by providing insights into the Go garbage collector. It also provides guidance on how Go users may use these insights to improve their applications’ resource utilization. It does not assume any knowledge of garbage collection, but does assume familiarity with the Go programming language.
The Go language takes responsibility for arranging the storage of Go values; in most cases, a Go developer need not care about where these values are stored, or why, if at all. In practice, however, these values often need to be stored in computer physical memory and physical memory is a finite resource. Because it is finite, memory must be managed carefully and recycled in order to avoid running out of it while executing a Go program. It’s the job of a Go implementation to allocate and recycle memory as needed.
Another term for automatically recycling memory is garbage collection. At a high level, a garbage collector (or GC, for short) is a system that recycles memory on behalf of the application by identifying which parts of memory are no longer needed. The Go standard toolchain provides a runtime library that ships with every application, and this runtime library includes a garbage collector.
Note that the existence of a garbage collector as described by this guide is not guaranteed by the Go specification, only that the underlying storage for Go values is managed by the language itself. This omission is intentional and enables the use of radically different memory management techniques.
Therefore, this guide is about a specific implementation of the Go programming language and may not apply to other implementations. Specifically, this following guide applies to the standard toolchain (the gc Go compiler and tools). Gccgo and Gollvm both use a very similar GC implementation so many of the same concepts apply, but details may vary.
Furthermore, this is a living document and will change over time to best reflect the latest release of Go. This document currently describes the garbage collector as of Go 1.19.
Where Go Values Live
Before we dive into the GC, let’s first discuss the memory that doesn’t need to be managed by the GC.
For instance, non-pointer Go values stored in local variables will likely not be managed by the Go GC at all, and Go will instead arrange for memory to be allocated that’s tied to the lexical scope in which it’s created. In general, this is more efficient than relying on the GC, because the Go compiler is able to predetermine when that memory may be freed and emit machine instructions that clean up. Typically, we refer to allocating memory for Go values this way as «stack allocation,» because the space is stored on the goroutine stack.
Go values whose memory cannot be allocated this way, because the Go compiler cannot determine its lifetime, are said to escape to the heap. «The heap» can be thought of as a catch-all for memory allocation, for when Go values need to be placed somewhere. The act of allocating memory on the heap is typically referred to as «dynamic memory allocation» because both the compiler and the runtime can make very few assumptions as to how this memory is used and when it can be cleaned up. That’s where a GC comes in: it’s a system that specifically identifies and cleans up dynamic memory allocations.
There are many reasons why a Go value might need to escape to the heap. One reason could be that its size is dynamically determined. Consider for instance the backing array of a slice whose initial size is determined by a variable, rather than a constant. Note that escaping to the heap must also be transitive: if a reference to a Go value is written into another Go value that has already been determined to escape, that value must also escape.
Whether a Go value escapes or not is a function of the context in which it is used and the Go compiler’s escape analysis algorithm. It would be fragile and difficult to try to enumerate precisely when values escape: the algorithm itself is fairly sophisticated and changes between Go releases. For more details on how to identify which values escape and which do not, see the section on eliminating heap allocations.
Tracing Garbage Collection
Garbage collection may refer to many different methods of automatically recycling memory; for example, reference counting. In the context of this document, garbage collection refers to tracing garbage collection, which identifies in-use, so-called live, objects by following pointers transitively.
Let’s define these terms more rigorously.
- Object—An object is a dynamically allocated piece of memory that contains one or more Go values.
- Pointer—A memory address that references any value within an object. This naturally includes Go values of the form *T , but also includes parts of built-in Go values. Strings, slices, channels, maps, and interface values all contain memory addresses that the GC must trace.
Together, objects and pointers to other objects form the object graph. To identify live memory, the GC walks the object graph starting at the program’s roots, pointers that identify objects that are definitely in-use by the program. Two examples of roots are local variables and global variables. The process of walking the object graph is referred to as scanning.
This basic algorithm is common to all tracing GCs. Where tracing GCs differ is what they do once they discover memory is live. Go’s GC uses the mark-sweep technique, which means that in order to keep track of its progress, the GC also marks the values it encounters as live. Once tracing is complete, the GC then walks over all memory in the heap and makes all memory that is not marked available for allocation. This process is called sweeping.
One alternative technique you may be familiar with is to actually move the objects to a new part of memory and leave behind a forwarding pointer that is later used to update all the application’s pointers. We call a GC that moves objects in this way a moving GC; Go has a non-moving GC.
The GC cycle
Because the Go GC is a mark-sweep GC, it broadly operates in two phases: the mark phase, and the sweep phase. While this statement might seem tautological, it contains an important insight: it’s not possible to release memory back to be allocated until all memory has been traced, because there may still be an un-scanned pointer keeping an object alive. As a result, the act of sweeping must be entirely separated from the act of marking. Furthermore, the GC may also not be active at all, when there’s no GC-related work to do. The GC continuously rotates through these three phases of sweeping, off, and marking in what’s known as the GC cycle. For the purposes of this document, consider the GC cycle starting with sweeping, turning off, then marking.
The next few sections will focus on building intuition for the costs of the GC to aid users in tweaking GC parameters for their own benefit.
Understanding costs
The GC is inherently a complex piece of software built on even more complex systems. It’s easy to become mired in detail when trying to understand the GC and tweak its behavior. This section is intended to provide a framework for reasoning about the cost of the Go GC and tuning parameters.
To begin with, consider this model of GC cost based on three simple axioms.
- The GC involves only two resources: CPU time, and physical memory.
- The GC’s memory costs consist of live heap memory, new heap memory allocated before the mark phase, and space for metadata that, even if proportional to the previous costs, are small in comparison. Note: live heap memory is memory that was determined to be live by the previous GC cycle, while new heap memory is any memory allocated in the current cycle, which may or may not be live by the end.
- The GC’s CPU costs are modeled as a fixed cost per cycle, and a marginal cost that scales proportionally with the size of the live heap. Note: Asymptotically speaking, sweeping scales worse than marking and scanning, as it must perform work proportional to the size of the whole heap, including memory that is determined to be not live (i.e. «dead»). However, in the current implementation sweeping is so much faster than marking and scanning that its associated costs can be ignored in this discussion.
This model is simple but effective: it accurately categorizes the dominant costs of the GC. However, this model says nothing about the magnitude of these costs, nor how they interact. To model that, consider the following situation, referred to from here on as the steady-state.
- The rate at which the application allocates new memory (in bytes per second) is constant. Note: it’s important to understand that this allocation rate is completely separate from whether or not this new memory is live. None of it could be live, all of it could be live, or some of it could be live. (On top of this, some old heap memory could also die, so it’s not necessarily the case that if that memory is live, the live heap size grows.)To put this more concretely, consider a web service that allocates 2 MiB of total heap memory for each request that it handles. During the request, at most 512 KiB of that 2 MiB stays live while the request is in flight, and when the service is finished handling the request, all that memory dies. Now, for the sake of simplicity suppose each request takes about 1 second to handle end-to-end. Then, a steady stream of requests, say 100 requests per second, results in an allocation rate of 200 MiB/s and a 50 MiB peak live heap.
- The application’s object graph looks roughly the same each time (objects are similarly sized, there’s a roughly constant number of pointers, the maximum depth of the graph is roughly constant). Another way to think about this is that the marginal costs of GC are constant.
Note: the steady-state may seem contrived, but it’s representative of the behavior of an application under some constant workload. Naturally, workloads can change even while an application is executing, but typically application behavior looks like a bunch of these steady-states strung together with some transient behavior in between.
Note: the steady-state makes no assumptions about the live heap. It may be growing with each subsequent GC cycle, it may shrink, or it may stay the same. However, trying to encompass all of these situations in the explanations to follow is tedious and not very illustrative, so the guide will focus on examples where the live heap remains constant. The GOGC section explores the non-constant live heap scenario in some more detail.
In the steady-state while the live heap size is constant, every GC cycle is going to look identical in the cost model as long as the GC executes after the same amount of time has passed. That’s because in that fixed amount of time, with a fixed rate of allocation by the application, a fixed amount of new heap memory will be allocated. So with the live heap size constant, and that new heap memory constant, memory use is always going to be the same. And because the live heap is the same size, the marginal GC CPU costs will be the same, and the fixed costs will be incurred at some regular interval.
Now consider if the GC were to shift the point at which it runs later in time. Then, more memory would be allocated but each GC cycle would still incur the same CPU cost. However over some other fixed window of time fewer GC cycles would finish, resulting in a lower overall CPU cost. The opposite would be true if the GC decided to start earlier in time: less memory would be allocated and CPU costs would be incurred more often.
This situation represents the fundamental trade-off between CPU time and memory that a GC can make, controlled by how often the GC actually executes. In other words, the trade-off is entirely defined by GC frequency.
One more detail remains to be defined, and that’s when the GC should decide to start. Note that this directly sets the GC frequency in any particular steady-state, defining the trade-off. In Go, deciding when the GC should start is the main parameter which the user has control over.
GOGC
At a high level, GOGC determines the trade-off between GC CPU and memory.
It works by determining the target heap size after each GC cycle, a target value for the total heap size in the next cycle. The GC’s goal is to finish a collection cycle before the total heap size exceeds the target heap size. Total heap size is defined as the live heap size at the end of the previous cycle, plus any new heap memory allocated by the application since the previous cycle. Meanwhile, target heap memory is defined as:
Target heap memory = Live heap + (Live heap + GC roots) * GOGC / 100
As an example, consider a Go program with a live heap size of 8 MiB, 1 MiB of goroutine stacks, and 1 MiB of pointers in global variables. Then, with a GOGC value of 100, the amount of new memory that will be allocated before the next GC runs will be 10 MiB, or 100% of the 10 MiB of work, for a total heap footprint of 18 MiB. With a GOGC value of 50, then it’ll be 50%, or 5 MiB. With a GOGC value of 200, it’ll be 200%, or 20 MiB.
Note: GOGC includes the root set only as of Go 1.18. Previously, it would only count the live heap. Often, the amount of memory in goroutine stacks is quite small and the live heap size dominates all other sources of GC work, but in cases where programs had hundreds of thousands of goroutines, the GC was making poor judgements.
The heap target controls GC frequency: the bigger the target, the longer the GC can wait to start another mark phase and vice versa. While the precise formula is useful for making estimates, it’s best to think of GOGC in terms of its fundamental purpose: a parameter that picks a point in the GC CPU and memory trade-off. The key takeaway is that doubling GOGC will double heap memory overheads and roughly halve GC CPU cost, and vice versa. (To see a full explanation as to why, see the appendix.)
Note: the target heap size is just a target, and there are several reasons why the GC cycle might not finish right at that target. For one, a large enough heap allocation can simply exceed the target. However, other reasons appear in GC implementations that go beyond the GC model this guide has been using thus far. For some more detail, see the latency section, but the complete details may be found in the additional resources.
GOGC may be configured through either the GOGC environment variable (which all Go programs recognize), or through the SetGCPercent API in the runtime/debug package.
Note that GOGC may also be used to turn off the GC entirely (provided the memory limit does not apply) by setting GOGC=off or calling SetGCPercent(-1) . Conceptually, this setting is equivalent to setting GOGC to a value of infinity, as the amount of new memory before a GC is triggered is unbounded.
To better understand everything we’ve discussed so far, try out the interactive visualization below that is built on the GC cost model discussed earlier. This visualization depicts the execution of some program whose non-GC work takes 10 seconds of CPU time to complete. In the first second it performs some initialization step (growing its live heap) before settling into a steady-state. The application allocates 200 MiB in total, with 20 MiB live at a time. It assumes that the only relevant GC work to complete comes from the live heap, and that (unrealistically) the application uses no additional memory.
Use the slider to adjust the value of GOGC to see how the application responds in terms of total duration and GC overhead. Each GC cycle ends while the new heap drops to zero. The time taken while the new heap drops to zero is the combined time for the mark phase for cycle N, and the sweep phase for the cycle N+1. Note that this visualization (and all the visualizations in this guide) assume the application is paused while the GC executes, so GC CPU costs are fully represented by the time it takes for new heap memory to drop to zero. This is only to make visualization simpler; the same intuition still applies. The X axis shifts to always show the full CPU-time duration of the program. Notice that additional CPU time used by the GC increases the overall duration.
Notice that the GC always incurs some CPU and peak memory overhead. As GOGC increases, CPU overhead decreases, but peak memory increases proportionally to the live heap size. As GOGC decreases, the peak memory requirement decreases at the expense of additional CPU overhead.
Note: the graph displays CPU time, not wall-clock time to complete the program. If the program runs on 1 CPU and fully utilizes its resources, then these are equivalent. A real-world program likely runs on a multi-core system and does not 100% utilize the CPUs at all times. In these cases the wall-time impact of the GC will be lower.
Note: the Go GC has a minimum total heap size of 4 MiB, so if the GOGC-set target is ever below that, it gets rounded up. The visualization reflects this detail.
Here’s another example that’s a little bit more dynamic and realistic. Once again, the application takes 10 CPU-seconds to complete without the GC, but the steady-state allocation rate increases dramatically half-way through, and the live heap size shifts around a bit in the first phase. This example demonstrates how the steady-state might look when the live heap size is actually changing, and how a higher allocation rate leads to more frequent GC cycles.
Memory limit
Until Go 1.19, GOGC was the sole parameter that could be used to modify the GC’s behavior. While it works great as a way to set a trade-off, it doesn’t take into account that available memory is finite. Consider what happens when there’s a transient spike in the live heap size: because the GC will pick a total heap size proportional to that live heap size, GOGC must be configured such for the peak live heap size, even if in the usual case a higher GOGC value provides a better trade-off.
The visualization below demonstrates this transient heap spike situation.
If the example workload is running in a container with a bit over 60 MiB of memory available, then GOGC can’t be increased beyond 100, even though the rest of the GC cycles have the available memory to make use of that extra memory. Furthermore, in some applications, these transient peaks can be rare and hard to predict, leading to occasional, unavoidable, and potentially costly out-of-memory conditions.
That’s why in the 1.19 release, Go added support for setting a runtime memory limit. The memory limit may be configured either via the GOMEMLIMIT environment variable which all Go programs recognize, or through the SetMemoryLimit function available in the runtime/debug package.
This memory limit sets a maximum on the total amount of memory that the Go runtime can use. The specific set of memory included is defined in terms of runtime.MemStats as the expression
or equivalently in terms of the runtime/metrics package,
Because the Go GC has explicit control over how much heap memory it uses, it sets the total heap size based on this memory limit and how much other memory the Go runtime uses.
The visualization below depicts the same single-phase steady-state workload from the GOGC section, but this time with an extra 10 MiB of overhead from the Go runtime and with an adjustable memory limit. Try shifting around both GOGC and the memory limit and see what happens.
Memory Limit
Notice that when the memory limit is lowered below the peak memory that’s determined by GOGC (42 MiB for a GOGC of 100), the GC runs more frequently to keep the peak memory within the limit.
Returning to our previous example of the transient heap spike, by setting a memory limit and turning up GOGC, we can get the best of both worlds: no memory limit breach, and better resource economy. Try out the interactive visualization below.
Memory Limit
Notice that with some values of GOGC and the memory limit, peak memory use stops at whatever the memory limit is, but that the rest of the program’s execution still obeys the total heap size rule set by GOGC.
This observation leads to another interesting detail: even when GOGC is set to off, the memory limit is still respected! In fact, this particular configuration represents a maximization of resource economy because it sets the minimum GC frequency required to maintain some memory limit. In this case, all of the program’s execution has the heap size rise to meet the memory limit.
Now, while the memory limit is clearly a powerful tool, the use of a memory limit does not come without a cost, and certainly doesn’t invalidate the utility of GOGC.
Consider what happens when the live heap grows large enough to bring total memory use close to the memory limit. In the steady-state visualization above, try turning GOGC off and then slowly lowering the memory limit further and further to see what happens. Notice that the total time the application takes will start to grow in an unbounded manner as the GC is constantly executing to maintain an impossible memory limit.
This situation, where the program fails to make reasonable progress due to constant GC cycles, is called thrashing. It’s particularly dangerous because it effectively stalls the program. Even worse, it can happen for exactly the same situation we were trying to avoid with GOGC: a large enough transient heap spike can cause a program to stall indefinitely! Try reducing the memory limit (around 30 MiB or lower) in the transient heap spike visualization and notice how the worst behavior specifically starts with the heap spike.
In many cases, an indefinite stall is worse than an out-of-memory condition, which tends to result in a much faster failure.
For this reason, the memory limit is defined to be soft. The Go runtime makes no guarantees that it will maintain this memory limit under all circumstances; it only promises some reasonable amount of effort. This relaxation of the memory limit is critical to avoiding thrashing behavior, because it gives the GC a way out: let memory use surpass the limit to avoid spending too much time in the GC.
How this works internally is the GC sets an upper limit on the amount of CPU time it can use over some time window (with some hysteresis for very short transient spikes in CPU use). This limit is currently set at roughly 50%, with a 2 * GOMAXPROCS CPU-second window. The consequence of limiting GC CPU time is that the GC’s work is delayed, meanwhile the Go program may continue allocating new heap memory, even beyond the memory limit.
The intuition behind the 50% GC CPU limit is based on the worst-case impact on a program with ample available memory. In the case of a misconfiguration of the memory limit, where it is set too low mistakenly, the program will slow down at most by 2x, because the GC can’t take more than 50% of its CPU time away.
Note: the visualizations on this page do not simulate the GC CPU limit.
Suggested uses
While the memory limit is a powerful tool, and the Go runtime takes steps to mitigate the worst behaviors from misuse, it’s still important to use it thoughtfully. Below is a collection of tidbits of advice about where the memory limit is most useful and applicable, and where it might cause more harm than good.
- Do take advantage of the memory limit when the execution environment of your Go program is entirely within your control, and the Go program is the only program with access to some set of resources (i.e. some kind of memory reservation, like a container memory limit). A good example is the deployment of a web service into containers with a fixed amount of available memory. In this case, a good rule of thumb is to leave an additional 5-10% of headroom to account for memory sources the Go runtime is unaware of.
- Do feel free to adjust the memory limit in real time to adapt to changing conditions. A good example is a cgo program where C libraries temporarily need to use substantially more memory.
- Don’t set GOGC to off with a memory limit if the Go program might share some of its limited memory with other programs, and those programs are generally decoupled from the Go program. Instead, keep the memory limit since it may help to curb undesirable transient behavior, but set GOGC to some smaller, reasonable value for the average case. While it may be tempting to try and «reserve» memory for co-tenant programs, unless the programs are fully synchronized (e.g. the Go program calls some subprocess and blocks while its callee executes), the result will be less reliable as inevitably both programs will need more memory. Letting the Go program use less memory when it doesn’t need it will generate a more reliable result overall. This advice also applies to overcommit situations, where the sum of memory limits of containers running on one machine may exceed the actual physical memory available to the machine.
- Don’t use the memory limit when deploying to an execution environment you don’t control, especially when your program’s memory use is proportional to its inputs. A good example is a CLI tool or a desktop application. Baking a memory limit into the program when it’s unclear what kind of inputs it might be fed, or how much memory might be available on the system can lead to confusing crashes and poor performance. Plus, an advanced end-user can always set a memory limit if they wish.
- Don’t set a memory limit to avoid out-of-memory conditions when a program is already close to its environment’s memory limits. This effectively replaces an out-of-memory risk with a risk of severe application slowdown, which is often not a favorable trade, even with the efforts Go makes to mitigate thrashing. In such a case, it would be much more effective to either increase the environment’s memory limits (and then potentially set a memory limit) or decrease GOGC (which provides a much cleaner trade-off than thrashing-mitigation does).
Latency
The visualizations in this document have modeled the application as paused while the GC is executing. GC implementations do exist that behave this way, and they’re referred to as «stop-the-world» GCs.
The Go GC, however, is not fully stop-the-world and does most of its work concurrently with the application. This is primarily to reduce application latencies. Specifically, the end-to-end duration of a single unit of computation (e.g. a web request). Thus far, this document mainly considered application throughput (e.g. web requests handled per second). Note that each example in the GC cycle section focused on the total CPU duration of an executing program. However, such a duration is far less meaningful for say, a web service. While throughput is still important for a web service (i.e. queries per second), often the latency of each individual request matters even more.
In terms of latency, a stop-the-world GC may require a considerable length of time to execute both its mark and sweep phases, during which the application, and in the context of a web service, any in-flight request, is unable to make further progress. Instead, the Go GC avoids making the length of any global application pauses proportional to the size of the heap, and that the core tracing algorithm is performed while the application is actively executing. (The pauses are more strongly proportional to GOMAXPROCS algorithmically, but most commonly are dominated by the time it takes to stop running goroutines.) Collecting concurrently is not without cost: in practice it often leads to a design with lower throughput than an equivalent stop-the-world garbage collector. However, it’s important to note that lower latency does not inherently mean lower throughput, and the performance of the Go garbage collector has steadily improved over time, in both latency and throughput.
The concurrent nature of Go’s current GC does not invalidate anything discussed in this document so far: none of the statements relied on this design choice. GC frequency is still the primary way the GC trades off between CPU time and memory for throughput, and in fact, it also takes on this role for latency. This is because most of the costs for the GC are incurred while the mark phase is active.
The key takeaway then, is that reducing GC frequency may also lead to latency improvements. This applies not only to reductions in GC frequency from modifying tuning parameters, like increasing GOGC and/or the memory limit, but also applies to the optimizations described in the optimization guide.
However, latency is often more complex to understand than throughput, because it is a product of the moment-to-moment execution of the program and not just an aggregation of costs. As a result, the connection between latency and GC frequency is less direct. Below is a list of possible sources of latency for those inclined to dig deeper.
- Brief stop-the-world pauses when the GC transitions between the mark and sweep phases,
- Scheduling delays because the GC takes 25% of CPU resources when in the mark phase,
- User goroutines assisting the GC in response to a high allocation rate,
- Pointer writes requiring additional work while the GC is in the mark phase, and
- Running goroutines must be suspended for their roots to be scanned.
These latency sources are visible in execution traces, except for pointer writes requiring additional work.
Additional resources
While the information presented above is accurate, it lacks the detail to fully understand costs and trade-offs in the Go GC’s design. For more information, see the following additional resources.
- The GC Handbook—An excellent general resource and reference on garbage collector design.
- TCMalloc—Design document for the C/C++ memory allocator TCMalloc, which the Go memory allocator is based on.
- Go 1.5 GC announcement—The blog post announcing the Go 1.5 concurrent GC, which describes the algorithm in more detail.
- Getting to Go—An in-depth presentation about the evolution of Go’s GC design up to 2018.
- Go 1.5 concurrent GC pacing—Design document for determining when to start a concurrent mark phase.
- Smarter scavenging—Design document for revising the way the Go runtime returns memory to the operating system.
- Scalable page allocator—Design document for revising the way the Go runtime manages memory it gets from the operating system.
- GC pacer redesign (Go 1.18)—Design document for revising the algorithm to determine when to start a concurrent mark phase.
- Soft memory limit (Go 1.19)—Design document for the soft memory limit.
A note about virtual memory
This guide has largely focused on the physical memory use of the GC, but a question that comes up regularly is what exactly that means and how it compares to virtual memory (typically presented in programs like top as «VSS»).
Physical memory is memory housed in the actual physical RAM chip in most computers. Virtual memory is an abstraction over physical memory provided by the operating system to isolate programs from one another. It’s also typically acceptable for programs to reserve virtual address space that doesn’t map to any physical addresses at all.
Because virtual memory is just a mapping maintained by the operating system, it is typically very cheap to make large virtual memory reservations that don’t map to physical memory.
The Go runtime generally relies upon this view of the cost of virtual memory in a few ways:
- The Go runtime never deletes virtual memory that it maps. Instead, it uses special operations that most operating systems provide to explicitly release any physical memory resources associated with some virtual memory range. This technique is used explicitly to manage the memory limit and return memory to the operating system that the Go runtime no longer needs. The Go runtime also releases memory it no longer needs continuously in the background. See the additional resources for more information.
- On 32-bit platforms, the Go runtime reserves between 128 MiB and 512 MiB of address space up-front for the heap to limit fragmentation issues.
- The Go runtime uses large virtual memory address space reservations in the implementation of several internal data structures. On 64-bit platforms, these typically have a minimum virtual memory footprint of about 700 MiB. On 32-bit platforms, their footprint is negligible.
As a result, virtual memory metrics such as «VSS» in top are typically not very useful in understanding a Go program’s memory footprint. Instead, focus on «RSS» and similar measurements, which more directly reflect physical memory usage.
Optimization guide
Identifying costs
Before trying to optimize how your Go application interacts with the GC, it’s important to first identify that the GC is a major cost in the first place.
The Go ecosystem provides a number of tools for identifying costs and optimizing Go applications. For a brief overview of these tools, see the guide on diagnostics. Here, we’ll focus on a subset of these tools and a reasonable order to apply them in in order to understand GC impact and behavior.
- CPU profiles A good place to start is with CPU profiling. CPU profiling provides an overview of where CPU time is spent, though to the untrained eye it may be difficult to identify the magnitude of the role the GC plays in a particular application. Luckily, understanding how the GC fits in mostly boils down to knowing what different functions in the `runtime` package mean. Below is a useful subset of these functions for interpreting CPU profiles. Note: the functions listed below are not leaf functions, so they may not show up in the default the pprof tool provides with the top command. Instead, use the top -cum command or use the list command on these functions directly and focus on the cumulative percent column.
- runtime.gcBgMarkWorker : Entrypoint to the background mark worker goroutines. Time spent here scales with GC frequency and the complexity and size of the object graph. It represents a baseline for how much time the application spends marking and scanning. Note: Within these goroutines, you will find calls to runtime.gcDrainMarkWorkerDedicated , runtime.gcDrainMarkWorkerFractional , and runtime.gcDrainMarkWorkerIdle , which indicate worker type. In a largely idle Go application, the Go GC is going to use up additional (idle) CPU resources to get its job done faster, which is indicated with the runtime.gcDrainMarkWorkerIdle symbol. As a result, time here may represent a large fraction of CPU samples, which the Go GC believes are free. If the application becomes more active, CPU time in idle workers will drop. One common reason this can happen is if an application runs entirely in one goroutine but GOMAXPROCS is >1.
- runtime.mallocgc : Entrypoint to the memory allocator for heap memory. A large amount of cumulative time spent here (>15%) typically indicates a lot of memory being allocated.
- runtime.gcAssistAlloc : Function goroutines enter to yield some of their time to assist the GC with scanning and marking. A large amount of cumulative time spent here (>5%) indicates that the application is likely out-pacing the GC with respect to how fast it’s allocating. It indicates a particularly high degree of impact from the GC, and also represents time the application spend marking and scanning. Note that this is included in the runtime.mallocgc call tree, so it will inflate that as well.
- Execution traces While CPU profiles are great for identifying where time is spent in aggregate, they’re less useful for indicating performance costs that are more subtle, rare, or related to latency specifically. Execution traces on the other hand provide a rich and deep view into a short window of a Go program’s execution. They contain a variety of events related to the Go GC and specific execution paths can be directly observed, along with how the application might interact with the Go GC. All the GC events tracked are conveniently labeled as such in the trace viewer. See the documentation for the runtime/trace package for how to get started with execution traces.
- GC traces When all else fails, the Go GC provides a few different specific traces that provide much deeper insights into GC behavior. These traces are always printed directly to STDERR, one line per GC cycle, and are configured through the GODEBUG environment variable that all Go programs recognize. They’re mostly useful for debugging the Go GC itself since they require some familiarity with the specifics of the GC’s implementation, but nonetheless can occasionally be useful to gain a better understanding of GC behavior. The core GC trace is enabled by setting GODEBUG=gctrace=1 . The output produced by this trace is documented in the environment variables section in the documentation for the runtime package. A supplementary GC trace called the «pacer trace» provides even deeper insights and is enabled by setting GODEBUG=gcpacertrace=1 . Interpreting this output requires an understanding of the GC’s «pacer» (see additional resources), which is outside the scope of this guide.
Eliminating heap allocations
One way to reduce costs from the GC is to have the GC manage fewer values to begin with. The techniques described below can produce some of the largest improvements in performance, because as the GOGC section demonstrated, the allocation rate of a Go program is a major factor in GC frequency, the key cost metric used by this guide.
Heap profiling
After identifying that the GC is a source of significant costs, the next step in eliminating heap allocations is to find out where most of them are coming from. For this purpose, memory profiles (really, heap memory profiles) are very useful. Check out the documentation for how to get started with them.
Memory profiles describe where in the program heap allocations come from, identifying them by the stack trace at the point they were allocated. Each memory profile can break down memory in four ways.
- inuse_objects —Breaks down the number of objects that are live.
- inuse_space —Breaks down live objects by how much memory they use in bytes.
- alloc_objects —Breaks down the number of objects that have been allocated since the Go program began executing.
- alloc_space —Breaks down the total amount of memory allocated since the Go program began executing.
Switching between these different views of heap memory may be done with either the -sample_index flag to the pprof tool, or via the sample_index option when the tool is used interactively.
Note: memory profiles by default only sample a subset of heap objects so they will not contain information about every single heap allocation. However, this is sufficient to find hot-spots. To change the sampling rate, see runtime.MemProfileRate .
For the purposes of reducing GC costs, alloc_space is typically the most useful view as it directly corresponds to the allocation rate. This view will indicate allocation hot spots that would provide the most benefit.
Escape analysis
Once candidate heap allocation sites have been identified with the help of heap profiles, how can they be eliminated? The key is to leverage the Go compiler’s escape analysis to have the Go compiler find alternative, and more efficient storage for this memory, for example in the goroutine stack. Luckily, the Go compiler has the ability to describe why it decides to escape a Go value to the heap. With that knowledge, it becomes a matter of reorganizing your source code to change the outcome of the analysis (which is often the hardest part, but outside the scope of this guide).
As for how to access the information from the Go compiler’s escape analysis, the simplest way is through a debug flag supported by the Go compiler that describes all optimizations it applied or did not apply to some package in a text format. This includes whether or not values escape. Try the following command, where [package] is some Go package path.
$ go build -gcflags=-m=3 [package]
This information can also be visualized as an overlay in VS Code. This overlay is configured and enabled in the VS Code Go plugin settings.
- Set the ui.codelenses setting to include gc_details .
- Enable the overlay for escape analysis by setting ui.diagnostic.annotations to include escape .
Finally, the Go compiler provides this information in a machine-readable (JSON) format that may be used to build additional custom tooling. For more information on that, see the documentation in the source Go code.
Implementation-specific optimizations
The Go GC is sensitive to the demographics of live memory, because a complex graph of objects and pointers both limits parallelism and generates more work for the GC. As a result, the GC contains a few optimizations for specific common structures. The most directly useful ones for performance optimization are listed below.
Note: Applying the optimizations below may reduce the readability of your code by obscuring intent, and may fail to hold up across Go releases. Prefer to apply these optimizations only in the places they matter most. Such places may be identified by using the tools listed in the section on identifying costs.
- Pointer-free values are segregated from other values. As a result, it may be advantageous to eliminate pointers from data structures that do not strictly need them, as this reduces the cache pressure the GC exerts on the program. As a result, data structures that rely on indices over pointer values, while less well-typed, may perform better. This is only worth doing if it’s clear that the object graph is complex and the GC is spending a lot of time marking and scanning.
- The GC will stop scanning values at the last pointer in the value. As a result, it may be advantageous to group pointer fields in struct-typed values at the beginning of the value. This is only worth doing if it’s clear the application spends a lot of its time marking and scanning. (In theory the compiler can do this automatically, but it is not yet implemented, and struct fields are arranged as written in the source code.)
Furthermore, the GC must interact with nearly every pointer it sees, so using indices into an slice, for example, instead of pointers, can aid in reducing GC costs.
Linux transparent huge pages (THP)
When a program accesses memory, the CPU needs to translate the virtual memory addresses it uses into physical memory addresses that refer to the data it was trying to access. To do this, the CPU consults the «page table,» a data structure that represents the mapping from virtual to physical memory, managed by the operating system. Each entry in the page table represents an indivisible block of physical memory called a page, hence the name.
Transparent huge pages (THP) is a Linux feature that transparently replaces pages of physical memory backing contiguous virtual memory regions with bigger blocks of memory called huge pages. By using bigger blocks, fewer page table entries are needed to represent the same memory region, improving page table lookup times. However, bigger blocks mean more waste if only a small part of the huge page is used by the system.
When running Go programs in production, enabling transparent huge pages on Linux can improve throughput and latency at the cost of additional memory use. Applications with small heaps tend not to benefit from THP and may end up using a substantial amount of additional memory (as high as 50%). However, applications with big heaps (1 GiB or more) tend to benefit quite a bit (up to 10% throughput) without very much additional memory overhead (1-2% or less). Being aware of your THP settings in either case can be helpful, and experimentation is always recommended.
One can enable or disable transparent huge pages in a Linux environment by modifying /sys/kernel/mm/transparent_hugepage/enabled . See the official Linux admin guide for more details. If you choose to have your Linux production environment enable transparent huge pages, we recommend the following additional settings for Go programs.
-
Set /sys/kernel/mm/transparent_hugepage/defrag to defer or defer+madvise .
Appendix
Additional notes on GOGC
The GOGC section claimed that doubling GOGC doubles heap memory overheads and halves GC CPU costs. To see why, let’s break it down mathematically.
Firstly, the heap target sets a target for the total heap size. This target, however, mainly influences the new heap memory, because the live heap is fundamental to the application.
Target heap memory = Live heap + (Live heap + GC roots) * GOGC / 100
Total heap memory = Live heap + New heap memory
New heap memory = (Live heap + GC roots) * GOGC / 100
From this we can see that doubling GOGC would also double the amount of new heap memory that application will allocate each cycle, which captures heap memory overheads. Note that Live heap + GC roots is an approximation of the amount of memory the GC needs to scan.
Next, let’s look at GC CPU cost. Total cost can be broken down as the cost per cycle, times GC frequency over some time period T.
Total GC CPU cost = (GC CPU cost per cycle) * (GC frequency) * T
GC CPU cost per cycle can be derived from the GC model:
GC CPU cost per cycle = (Live heap + GC roots) * (Cost per byte) + Fixed cost
Note that sweep phase costs are ignored here as mark and scan costs dominate.
The steady-state is defined by a constant allocation rate and a constant cost per byte, so in the steady-state we can derive a GC frequency from this new heap memory:
GC frequency = (Allocation rate) / (New heap memory) = (Allocation rate) / ((Live heap + GC roots) * GOGC / 100)
Putting this together, we get the full equation for the total cost:
Total GC CPU cost = (Allocation rate) / ((Live heap + GC roots) * GOGC / 100) * ((Live heap + GC roots) * (Cost per byte) + Fixed cost) * T
For a sufficiently large heap (which represents most cases), the marginal costs of a GC cycle dominate the fixed costs. This allows for a significant simplification of the total GC CPU cost formula.
Total GC CPU cost = (Allocation rate) / (GOGC / 100) * (Cost per byte) * T
From this simplified formula, we can see that if we double GOGC, we halve total GC CPU cost. (Note that the visualizations in this guide do simulate fixed costs, so the GC CPU overheads reported by them will not exactly halve when GOGC doubles.) Furthermore, GC CPU costs are largely determined by allocation rate and the cost per byte to scan memory. For more information on how to reduce these costs specifically, see the optimization guide.
Note: there exists a discrepancy between the size of the live heap, and the amount of that memory the GC actually needs to scan: the same size live heap but with a different structure will result in a different CPU cost, but the same memory cost, resulting a different trade-off. This is why the structure of the heap is part of the definition of the steady-state. The heap target should arguably only include the scannable live heap as a closer approximation of memory the GC needs to scan, but this leads to degenerate behavior when there’s a very small amount of scannable live heap but the live heap is otherwise large.
Оптимизация памяти и управление сборщиком мусора в Go: GOGC и GOMEMLIMIT
Всем привет, меня зовут Нина Пакшина, я работаю Golang разработчиком в Лента Онлайн.
В данной статье я расскажу о том, как управлять сборщиком мусора в Go, как оптимизировать потребление памяти приложением и защититься от ошибки out-of-memory.
Стек и куча в Go
Я не буду подробно рассказывать о том, как работает сборщик мусора, поскольку на эту тему уже существует много статей и есть подробная официальная документация (это и это). Но я хочу упомянуть базовые понятия, которые помогут разобраться в теме моей статьи.
Вероятно, вы уже знаете, что в Go данные могут быть сохранены в двух основных хранилищах памяти: стеке (stack) и куче (heap).
Обычно в стеке хранятся данные, размер и время использования которых компилятор Go может предсказать: это локальные переменные функции, аргументы, передаваемые в функцию, возвращаемые значения и т. д.
Стек управляется автоматически и работает по принципу LIFO (последний вошел — первый вышел). При вызове функции все данные, связанные с ней, помещаются в вершину стека, а при завершении функции эти данные удаляются из стека.
Стек не требует сложного механизма сборки мусора и несет минимальные накладные расходы на управление памятью. Получение и сохранение данных в стеке происходит очень быстро.
Но не все данные программы могут быть сохранены в стеке. Данные, которые изменяются динамически в процессе выполнения или требуют доступа за пределами области видимости функции, не могут быть помещены в стек, так как компилятор не может предсказать их использование.
Такие данные сохраняются в куче.
В отличие от стека, получение данных из кучи и управление ею являются более затратными процессами.
Что идет в стек, а что в кучу?
Как я уже упоминала, в стек помещаются значения, у которых размер и время жизни могут быть предсказаны. Но на деле компилятор Go принимает во внимание множество нюансов при принятии решения о размещении данных в стеке или куче. Например, преаллоцированные срезы размером до 64 КБ будут храниться в стеке, а срезы размером больше 64 КБ — в куче. То же самое относится и к массивам: если массив превышает 10 МБ, то он будет сохранен в куче.

Вы можете использовать escape-анализ для определения, где будет храниться определенная переменная. Например, вы можете проанализировать ваше приложение, запустив его из командной строки с флагом -gcflags=-m :
go build -gcflags=-m main.go
Hidden text
Например, если мы скомпилируем данное приложение main.go с флагом -m
package main func main()
То результатом будет:
# command-line-arguments ./main.go:3:6: can inline main ./main.go:7:6: moved to heap: arrayAfter10Mb ./main.go:10:23: make([]int, 8192) does not escape ./main.go:11:21: make([]int, 8193) escapes to heapМы видим, что массив arrayAfter10Mb был перенесен в кучу, так как его размер превышает 10 МБ, в то время как arrayBefore10Mb остался в стеке (для int переменной 10 МБ это 10 * 1024 * 1024 / 8 = 1310720 элементов).
Также срез sliceBefore64 не был отправлен в кучу, поскольку его размер меньше 64 КБ, в то время как sliceOver64 был сохранен в куче (для int переменной 64 КБ это 64 * 1024 / 8 = 8192 элементов).
Подробнее о том, где и что аллоцируется в куче, можно изучить здесь.
Таким образом, один из способов борьбы с кучей — избегать ее! Но что делать, если данные уже попали в кучу?
В отличие от стека, размер кучи неограничен и постоянно растет. В куче размещаются динамически создаваемые объекты, такие как структуры, срезы и карты, а также большие блоки памяти, которые не могут быть размещены в стеке из-за его ограничений.
Инструмент, позволяющий переиспользовать память в куче и предотвращать ее полную блокировку, это сборщик мусора.
Немного о работе сборщика мусора
Сборщик мусора, он же GC (Garbage Collector) — это система, специально предназначенная для определения и освобождения динамически выделенной памяти. В Go используется алгоритм сборки мусора на основе трассировки и алгоритма пометок Mark and Sweep.
На этапе маркировки (mark) сборщик мусора помечает данные, которые активно используются приложением, в качестве живых (live heap). Затем на этапе очистки (sweep) GC проходит по всей памяти, которая не была помечена как живая, и переиспользует ее.
Работа сборщика мусора не является бесплатной, поскольку он потребляет два важных ресурса системы: процессорное время и физическую память.
Память в сборщике мусора содержит в себе живую память кучи (память, которая была помечена как живая в предыдущем цикле сборки мусора), новую память кучи (память кучи, которая еще не была проанализирована сборщиком мусора), а также память, используемую для хранения некоторых метаданных, которая обычно незначительна по сравнению с первыми двумя сущностями.
Потребление процессорного времени сборщиком мусора связано с его спецификой работы. Существуют реализации сборщика мусора, называемые «stop-the-world», которые полностью останавливают выполнение программы на время сборки мусора, что приводит к тому, что в какой-то момент все процессорное время расходуется не на полезную работу.
В случае Go сборщик мусора не является полностью «stop-the-world» и выполняет большую часть своей работы, например, такую как разметка кучи (время выполнения которой пропорционально размеру кучи) параллельно с выполнением приложения.
Однако, в Go сборщик мусора все равно работает с некоторыми ограничениями, и несколько раз за цикл сборки мусора он полностью останавливает выполнение рабочего кода. Подробнее об этом можно узнать здесь.

Как управлять сборщиком мусора?
Существует параметр, который позволяет управлять сборщиком мусора в Go — это переменная окружения GOGC или ее функциональный аналог SetGCPercent из пакета runtime/debug .
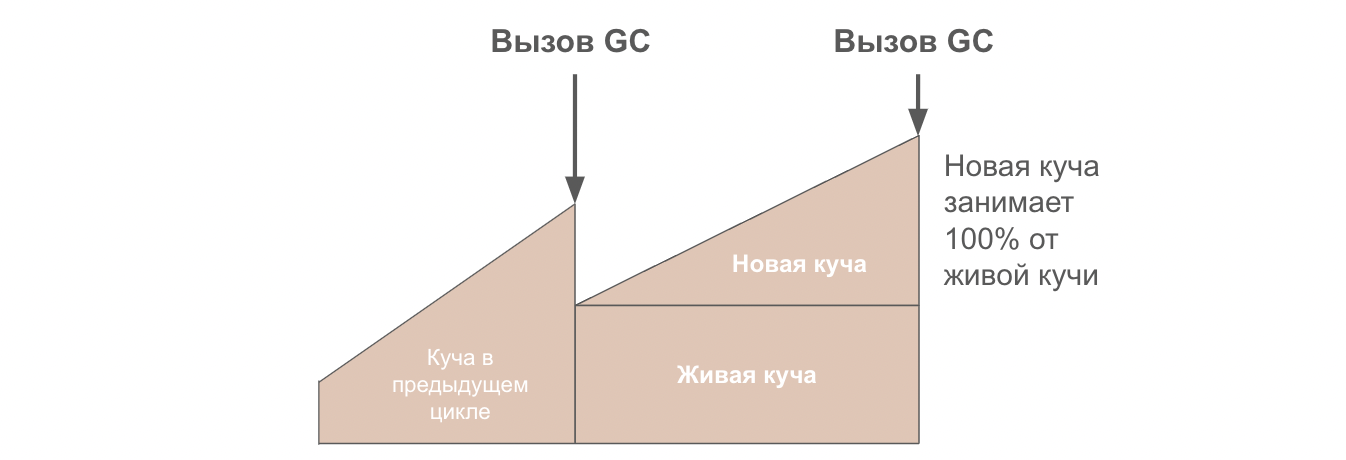
Параметр GOGC определяет процент новой необработанной памяти кучи от живой памяти, при достижении которого будет запущена сборка мусора. Значение GOGC по умолчанию равно 100, что означает, что сборка мусора будет запущена, когда объем новой памяти достигнет 100% от объема живой памяти кучи.
Давайте рассмотрим пример программы и отследим изменение размера кучи с помощью инструмента go tool trace . Для запуска программы используем версию Go 1.20.1.
В данном примере, функция performMemoryIntensiveTask использует большое количество памяти размещаемой в куче. Данная функция запускает обработчик с размером очереди NumWorker и количество задач равное NumTasks .
package main import ( "fmt" "os" "runtime/debug" "runtime/trace" "sync" "time" ) const ( NumWorkers = 4 // Количество воркеров. NumTasks = 500 // Количество задач. MemoryIntense = 10000 // Размер память затратной задачи (число элементов). ) func main() < // Запись в trace файл. f, _ := os.Create("trace.out") trace.Start(f) defer trace.Stop() // Установка целевого процента сборщика мусора. По умолчанию 100%. debug.SetGCPercent(100) // Очередь задач и очередь результата. taskQueue := make(chan int, NumTasks) resultQueue := make(chan int, NumTasks) // Запуск воркеров. var wg sync.WaitGroup wg.Add(NumWorkers) for i := 0; i < NumWorkers; i++ < go worker(taskQueue, resultQueue, &wg) >// Отправка задач в очередь. for i := 0; i < NumTasks; i++ < taskQueue close(taskQueue) // Получение результатов из очереди. go func() < wg.Wait() close(resultQueue) >() // Обработка результатов. for result := range resultQueue < fmt.Println("Результат:", result) >fmt.Println("Готово!") > // Функция воркера. func worker(tasks > // performMemoryIntensiveTask функция требующая много памяти. func performMemoryIntensiveTask(task int) int < // Создание среза большого размера. data := make([]int, MemoryIntense) for i := 0; i < MemoryIntense; i++ < data[i] = i + task >// Имитация временной задержки time.Sleep(10 * time.Millisecond) // Вычисление результата. result := 0 for _, value := range data < result += value >return result >Для трассировки работы программы результат записывается в файл trace.out :
// Запись в trace файл. f, _ := os.Create("trace.out") trace.Start(f) defer trace.Stop()
Используя инструмент go tool trace , мы можем наблюдать за изменениями размера кучи и анализировать поведение сборщика мусора в вашей программе.
Обратите внимание, что точные детали и возможности инструмента go tool trace могут варьироваться в разных версиях Go, поэтому рекомендуется обратиться к официальной документации для получения более подробной информации о его использовании в вашей конкретной версии Go.
GOGC по умолчанию
Параметр GOGC можно установить с помощью функции debug.SetGCPercent(100) из пакета runtime/debug . По умолчанию GOGC равно 100 (процентам).
Давайте запустим выполнение нашей программы с помощью команды:
go run main.goПо завершению выполнения программы будет создан файл trace.out , который мы сможем проанализировать с помощью утилиты go tool . Для этого выполним команду:
go tool trace trace.outЗатем мы можем перейти в веб-версию трассировщика, открыв веб-браузер и перейдя по адресу http://127.0.0.1:54784/trace
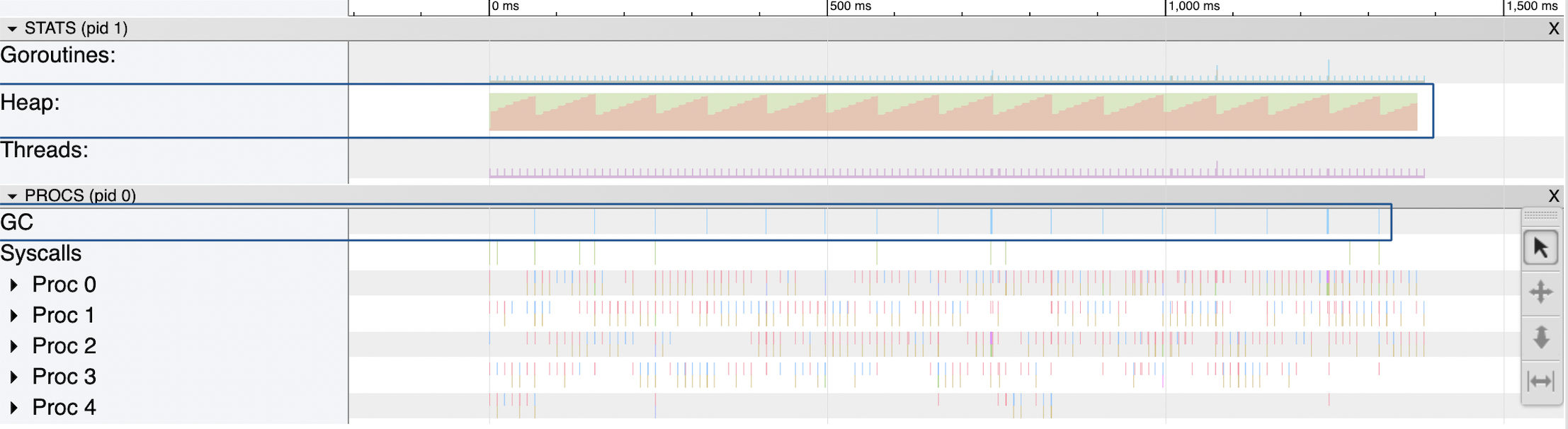
Во вкладке STATS мы видим поле «Heap» (куча), которое отображает, как менялся размер кучи при исполнении приложения. Красная область на графике представляет занятую кучей память.
Во вкладке PROCS в поле «GC» (сборщик мусора) отображаются столбцы голубого цвета, которые показывают моменты запуска сборщика мусора.
Как только размер новой кучи достигает 100% от размера живой кучи, запускается сборка мусора. Например, если размер живой кучи составляет 10 Мб, то сборщик мусора запустится, когда размер новой кучи достигнет 10 Мб (а общая память в GC = 20 Мб).
Если в поле GC выделить все вызовы сборщика мусора, можно узнать суммарное время, в течение которого работал сборщик мусора.

В нашем случае сборщик мусора вызывался 16 раз с общим временем выполнения 14 мс.
Вызываем GC чаще
Если мы запустим код, предварительно установив debug.SetGCPercent(10) на 10%, то мы увидим, что частота вызова сборщика мусора увеличится: теперь сборщик мусора будет вызываться, когда размер текущей кучи составляет 10% от размера живой кучи.
Другими словами, если размер живой кучи составляет 10 Мб, то сборщик мусора будет запускаться, когда текущая куча достигнет размера 1 Мб (а общий размер = 11 Мб).

В данном случае сборщик мусора вызывался 38 раз, а общее время вызова сборщика мусора составило 28 мс.

Мы видим, что установка GOGC в значение меньше 100% может увеличить частоту сборки мусора, что может привести к увеличенному использованию процессорного времени и снижению производительности программы.
Вызываем GC реже
Если мы вызовем ту же программу, но с настройкой debug.SetGCPercent(1000) в 1000%, то получим следующий результат:
Мы видим, что текущая куча растет до тех пор, пока не достигнет размера, равного 1000% от размера живой кучи. Другими словами, если размер живой кучи составляет 10 Мб, то сборщик мусора будет запущен, когда текущий размер кучи достигнет 100 Мб (общий объем кучи = 110 Мб).

В текущем случае сборщик мусора был вызван 1 раз и выполнялся в течение 2 мс.
Отключаем GC
Мы можем также отключить сборщик мусора, установив GOGC=off или используя debug.SetGCPercent(-1) .
Так ведет себя куча при отключенном сборщике мусора без использования GOMEMLIMIT:

Сколько памяти занимает куча?
В реальности выделение памяти для живой кучи обычно не происходит так периодично и предсказуемо, как мы видим на предыдущих графиках.
Размер живой кучи может динамически изменяться с каждым циклом сборки мусора, и в определенных условиях могут возникать резкие скачки ее абсолютного значения.
Например, если при выполнении нескольких параллельных задач размер живой кучи может достигать 800 Мб, то сборщик мусора будет запущен только тогда, когда текущий размер кучи достигнет 1,6 Гб.
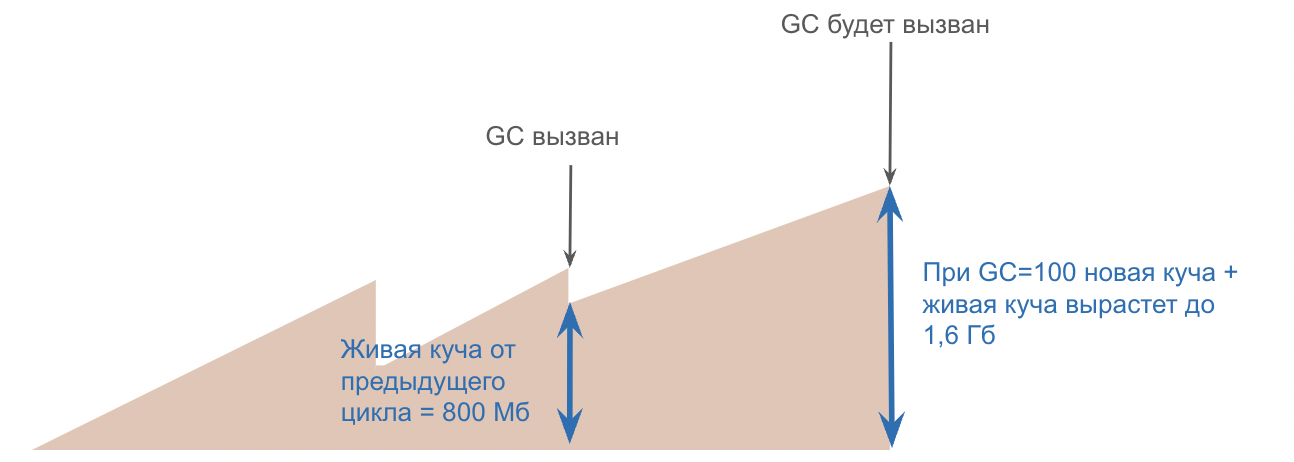
В современной разработке большую часть приложений мы запускаем в контейнерах, которые имеют ограничения по использованию памяти. Таким образом, если нашему контейнеру был установлен лимит памяти в 1 Гб, а общий размер кучи в какой-то момент увеличился до 1.6 Гб, то контейнер выйдет из строя из-за ошибки OOM (out-of-memory).
Давайте смоделируем эту ситуацию. Например запустим нашу программу в контейнере с ограничением по памяти 10 Мб (такое значение нереалистично, мы его используем исключительно для тестовых целей):
Описание Dockerfile для контейнера, исполняющего программу на Go:
FROM golang:latest as builder WORKDIR /src COPY . . RUN go env -w GO111MODULE=on RUN go mod vendor RUN CGO_ENABLED=0 GOOS=linux go build -mod=vendor -a -installsuffix cgo -o app ./cmd/ FROM golang:latest WORKDIR /root/ COPY --from=builder /src/app . EXPOSE 8080 CMD ["./app"]version: '3' services: my-app: build: context: . dockerfile: Dockerfile ports: - 8080:8080 deploy: resources: limits: memory: 10MДавайте воспользуемся предыдущим вариантом кода, в котором мы установили значение GOGC равным 1000%.
docker-compose build docker-compose up Через пару секунд наш контейнер упадет с ошибкой, которая соответствует ошибки OOM (out-of-memory):
exited with code 137Возникает очень неприятная ситуация: получается, параметр GOGC управляет только относительным значением новой кучи, в то время как контейнер имеет абсолютное ограничение по использованию памяти. Это значит, что в любой момент наше приложение может превысить доступный в среде исполнения лимит и упасть.

Как избежать OOM?
Начиная с версии 1.19 в Golang вводится так называемое мягкое управление памятью с помощью переменной окружения GOMEMLIMIT или аналогичной функции из пакета runtime/debug SetMemoryLimit (здесь можно прочитать некоторые интересные детали проектирования данного механизма).
Переменная окружения GOMEMLIMIT устанавливает общий объем памяти, которым может пользоваться среда выполнения Go (Go runtime), например:
GOMEMLIMIT = 8MiBДля установки значения памяти используется суффикс размерности, например MiB — это Мб.
Запустим контейнер с установленной переменной окружения GOMEMLIMIT = 8MiB . Для этого пропишем в docker-compose переменную окружения enviroment:
version: '3' services: my-app: environment: GOMEMLIMIT: "8MiB" build: context: . dockerfile: Dockerfile ports: - 8080:8080 deploy: resources: limits: memory: 10MТеперь, при запуске контейнера, программа выполняется полностью без ошибки OOM.
Это происходит потому, что после включения GOMEMLIMIT = 8MiB сборщик мусора вызывается всякий раз, когда общая память приближается к лимиту, и поддерживает размер кучи в заданных GOMEMLIMIT пределах. Это приводит к более частым вызовам сборщика мусора.
Именно для решения этой проблемы был придуман механизм GOMEMLIMIT .

Спираль смерти
GOMEMLIMIT является мощным и полезным инструментом, который также может выстрелить в ногу. Пример опасного поведения виден на предыдущем графике.
Когда размер общей памяти, вызванный ростом живой кучи или постоянными утечками горутин, приближается к GOMEMLIMIT , сборщик мусора начинает вызываться часто, чтобы уменьшить потребляемую память.
Из-за повторных вызовов сборщика мусора время работы приложения теоретически может неограниченно возрастать, забирая процессорное время у самого приложения. Такое поведение называется спиралью смерти. Это может привести к полной деградации работы приложения, и такое поведение, в отличие от ошибки OOM, очень сложно отследить.
Именно поэтому механизм GOMEMLIMIT работает как мягкое ограничение.
Go не предоставляет 100% гарантий соблюдения ограничения памяти GOMEMLIMIT . Это позволяет избежать ситуации частого вызова сборщика мусора, так как позволяет использовать память сверх лимита.
Для этого установлен предел использования процессорного времени. В настоящее время этот предел установлен на 50% с окном CPU в 2 * GOMAXPROCS секунды.
Также это значит в случае утечек памяти, что мы полностью не сможем избежать ошибки OOM, она просто произойдет значительно позже.
Как применять GOGC и GOMEMLIMIT
Механизм мягкого управления памятью с помощью GOMEMLIMIT и изменение настроек сборщика мусора GOGC может защитить нас от неприятных ситуаций и улучшить эффективность работы приложения.
Приведем примеры случаев, когда использование GOMEMLIMIT и GOGC может быть полезным:
- Приложение, запущенное в контейнере с ограниченным объемом памяти. Хорошей практикой будет настроить GOMEMLIMIT так, чтобы оставалось 5-10% от доступной в контейнере памяти.
- При запуске библиотеки или кода, требующего значительных ресурсов. Здесь можно динамически управлять GOMEMLIMIT для оптимальной работы.
- При запуске приложения в контейнере в качестве скрипта, где приложение выполняет определенную задачу в течение некоторого времени и затем завершается. Для повышения производительности можно отключить сборщик мусора GOGC=off , но установить GOMEMLIMIT , чтобы не превысить доступные ресурсы контейнера по памяти.
Существуют и случаи, когда лучше избегать использования GOMEMLIMIT :
- Не устанавливайте ограничение памяти, если программа уже близка к предельному значению памяти своей среды.
- Не используйте ограничение памяти при развертывании в исполнительной среде, которой вы не управляете, особенно если использование памяти вашей программой пропорционально входным данным. Например, это может быть CLI-инструмент или настольное приложение.