Что такое параллелизм в программировании
Функциональная модель параллельных вычислений и язык программирования «Пифагор»
© 2002-2003 А.И. Легалов, Ф.А. Казаков, Д.А. Кузьмин, Д.В. Привалихин
Введение
История языков параллельного программирования насчитывает не один десяток лет. За это время были придуманы и апробированы разнообразные методы написания программ и способы их отображения на архитектуры параллельных вычислительных систем (ПВС). Существуют различные варианты классификации решений, полученных в этой области, одним из простых среди которых является выделение трех различных способов задания параллелизма [Алгоритмы, Хоар, Легалов-1994]:
- Использование последовательного программирования с дальнейшим автоматическим распараллеливанием разработанных программ.
- Применение языка программирования, обеспечивающего явное формирование потоков параллельного управления. Такой язык по существу является расширением традиционных последовательных языков за счет добавления операторов распараллеливания. При этом уровень параллелизма, достигаемый при программировании, полностью контролируется разработчиком и может меняться в зависимости от конкретных условий.
- Опора на язык, описывающий максимальный параллелизм, что обеспечивается заданием только информационных связей. Предполагается, что программа будет выполняться на ВС с бесконечными ресурсами, а выполнение операторов будет происходить немедленно по готовности данных. Адаптация программы к архитектуре конкретной ПВС осуществляется автоматически путем сжатия параллелизма в соответствии с ресурсными ограничениями.
Каждый из перечисленных подходов обладает своими достоинствами и недостатками.
Параллелизм и последовательное программирование
Последовательное программирование выглядит весьма привлекательным, так как, на первый взгляд, позволяет:
- применять опыт, накопленный в течение многолетней эксплуатации вычислительных машин с традиционной архитектурой;
- разрабатывать программы, совершенно не зависящие от особенностей параллельной вычислительной системы;
- использовать продукты, накопленные за многие годы создания программного обеспечения.
- не заботиться о параллельной организации программы, полагаясь в дальнейшем на то, что система автоматического распараллеливания решит все вопросы по эффективному переносу программ на любую параллельную систему [Вальковский].
В свое время этот подход достаточно широко и разносторонне исследовался. Однако многие из возлагаемых надежд не оправдались. В настоящее время он практически не используется в промышленном программировании, так как обладает следующими недостатками:
- распараллеливание последовательных программ очень редко обеспечивает достижение приемлемого уровня параллелизма из-за ограничений вычислительного метода, выбранного программистом, что часто обуславливается стереотипами последовательного мышления;
- в реальной ситуации учесть особенности различных параллельных систем оказалось гораздо труднее, чем это изначально предполагалось.
Архитектурно-зависимые языки параллельного программирования
Практически во все времена наиболее популярным являлся подход, учитывающий архитектуру системы. Его несомненным достоинством является максимальное использование возможностей предоставляемых технических средств. В частности, программист, опираясь на знание архитектуры системы, может весьма эффективно распределять задачу по конкретным вычислительным ресурсам. Явно указывая потоки управления, он может ограничить или расширить параллелизм задачи с учетом пропускной способности и производительности различных узлов ПВС.
Следует также отметить, что в ряде задач каждому процессу ставится в соответствие некоторый ресурс, а взаимодействие описывается на уровне их взаимодействия. Эти ресурсы могут создаваться и уничтожаться в ходе вычислений, взаимодействовать между собой как по информационным, так и по управляющим каналам. К таким задачам можно отнести моделирование параллельных систем, управление в реальном масштабе времени и другие. В этом случае использование языков программирования с явно задаваемыми потоками управления, возможностями объектного программирования и непосредственного управления ресурсами является предпочтительным.
Языки параллельного программирования, использующие явное управление, позволяют описать максимальный параллелизм задачи, но обеспечивают это не самым удобным способом, так как:
- программист сам должен формировать все параллельные фрагменты и следить за корректной синхронизацией данных;
- использование в языках такого типа «ручного» управления памятью может привести к конфликтам между процессами в борьбе за общий ресурс (программисту самому приходится тщательно следить за распределением памяти или явно соблюдать принцип единственного присваивания);
- при явном распараллеливании в ходе программирования не всегда адекватно можно отразить в создаваемой программе параллелизм данных, присущий задаче, что, в свою очередь может привести к дальнейшим искажениям при переносе написанной программы на другую архитектуру.
Функциональные и потоковые языки
Вместе с тем, создание прикладных параллельных программ, ориентированных на обработку информационных потоков, удобнее осуществлять с применением функциональных языков параллельного программирования, в которых выполнение каждого оператора осуществляется по готовности его данных. Они не требуют явного описания параллелизма задачи, который в этом случае определяется в соответствии с информационными связями. Использование такого языка позволяет:
- создавать мобильные программы с параллелизмом на уровне операторов, ограниченным лишь методом решения задачи;
- обеспечивать перенос программы на конкретную архитектуру, не распараллеливая программу, а сжимая ее максимальный параллелизм;
- проводить оптимизацию программы по множеству параметров с учетом специфики архитектуры ВС, для которой осуществляется трансляция без учета управляющих связей программы.
В качестве одного из вариантов решения предлагается функциональный язык параллельного программирования (ФЯПП) «Пифагор», обладающий следующими характеристиками:
- параллелизм на уровне операций;
- архитектурная независимость, достигаемая за счёт описания в программе только информационных связей;
- асинхронный параллелизм, поддерживаемый выполнением операций по готовности данных;
- отсутствие переменных, что позволяет избежать конфликтов, связанных с совместным использованием памяти параллельными процессами;
- отсутствие операторов цикла, что позволяет избежать конфликтов при использовании различными данными одних и тех же фрагментов параллельной программы.
Фундамент работы
Нельзя сказать, что работа проводилась без учета знаний, накопленных в данной предметной области. Издавна существует ряд функциональных и потоковых моделей параллельных вычислений и языков программирования, построенных на их основе. К ним можно отнести схемы потока данных Денниса [Dennis, Деннис], функциональный язык программирования FP Бэкуса [Backus], язык LAU [Gelly] и другие [Arvind, Dennis, Алгоритмы, Хендерсон]. В каждый из этих языков и его модель заложены определенные методы порождения и синхронизации параллельных процессов, не позволяющие, в то же время, обеспечить максимальный параллелизм ряда задач из-за присущих ограничений механизма описания параллельных процессов.
Одним из факторов, ограничивающих параллелизм, является наличие в модели вычислений (МВ) языка элементов управления, тем или иным образом приводящих к разделению процессами общих вычислительных ресурсов. В частности, в схемах потока данных (СПД) Денниса таким ресурсом является узел слияния потоков данных. При одновременной обработке нескольких независимых потоков, поступающих на вход такой СПД, происходит задержка вновь поступающих данных на узлах слияния перед входом в разделяемый ресурс, например циклический фрагмент программы. Проблема решается введением специальных ресурсно-независимых моделей, в которых предполагается, что для каждого вновь формируемого процесса выделяется свой ресурс, а их максимальное число неограниченно. На уровне языковых и модельных средств описание неограниченности задается отказом от конвейерного параллелизма за счет предоставления своих программных и аппаратных ресурсов каждому новому набору данных, использованием рекурсии вместо циклов или описание циклических процессов с применением механизма раскраски, как это сделано в МВ Арвинда-Гостелоу [Арвинд].
Другой причиной, ограничивающей параллелизм функциональных языков является их набор функций и программно-формирующих операций, специально ориентированный на последовательные вычисления или ограниченный параллелизм. В частности, в ЛИСП операторы для работы с данными обеспечивают выборку только одной компоненты. FP [Backus] не предусматривает распараллеливание на уровне независимых операторов. Для того чтобы язык программирования мог поддерживать параллелизм любого типа, он должен содержать операторы размножения информационных потоков, их группирования в списки данных различного уровня вложенности, одновременного выделения из списков нескольких независимых и разнородных по составу групп. Обычно такие возможности заложены в потоковые МВ и построенные на их основе языки.
Немаловажным является и то, что ограничение параллелизма зависит от текстового представления конструкций языка. В большинстве функциональных языков просто отсутствует возможность описать параллелизм задачи из-за ограничений, присущих синтаксису. Несмотря на то, что потоковые языки обеспечивают представление параллелизма в текстовом виде, имеется ряд проблем, связанных с удобством восприятия этой записи. Эти проблемы вытекают из того, что функционально-потоковая параллельная программа является графом, в котором множество вершин операторов связаны между собой информационными связями. Разнообразие этих связей и их неструктурированность в традиционных потоковых моделях трудно поддается линейному представлению в виде текста. Возможно, что для параллельных программ более наглядным было бы графическое двумерное представление. Однако в настоящее время такое описание практически не распространено ни в параллельном, ни в последовательном программировании, несмотря на повсеместное использование экранных интерфейсов и визуального программирования.
В связи с выше сказанным можно отметить, что поиск моделей параллельных вычислений и форм представления функционально-потоковых программ в виде удобочитаемого текста в настоящее время не потеряли своей актуальности.
Цели и задачи работы
Цель работы
Создание средств, обеспечивающих инструментальную поддержку процессов написания, отладки и выполнения программ на функциональном языке параллельного программирования.
- Разработка и исследование функциональной модели параллельных вычислений.
- Разработка функционального языка параллельного программирования, обеспечивающего описание решаемой задачи путем задания только ее информационного графа.
- Разработка транслятора с функционального языка параллельного программирования.
- Разработка интерпретирующей системы, позволяющей выполнять написанные функциональные параллельные программы в последовательном режиме (на однопроцессорных системах).
- Апробация ФЯПП, заключающаяся в написании тестовых программ и проведении экспериментов с языковыми конструкциями.
Конкурентность: Параллелизм
В этой статье мне хотелось бы задокументировать всё, что я знаю о том, какие средства можно использовать для эффективного использования вычислительных ресурсов систем и/или удобства разработки.
И, надеюсь, кому-нибудь это может оказаться полезно, ибо кто-нибудь может чего-нибудь не знать, или, наоборот, окажется полезно мне, если кто-нибудь покажет что-нибудь ещё/укажет на изъяны в моих знаниях.
-
Параллелизм (часть 1, текущая)
- Потоки: scheduling, сон
- Синхронизация: Spinlock, семафоры, барьеры памяти
- Атомарность: TAS, CAS
Параллелизм
Когда-то процессоры были одноядерные (до 2001 года), а в системах был только один процессор (до 1966 года). А затем инструкции стали выполняться одновременно в рамках одной системы.
Потоки
Потоки — абстракция операционной системы, позволяющая выполнять некие куски кода параллельно. Каждый поток имеет «контекст», в который входит кусок памяти под стек и копию регистров процессора. Очевидно, что потоков в системе может быть запущено куда больше, чем у нас имеется процессоров и ядер, поэтому операционная система занимается тем, что schedule’ит (занимается диспетчеризацией, планированием) выполнение процессов, восстанавливая регистры в ядрах процессора для работы некоторого потока некоторое время, затем сохраняет обратно и даёт выполняться следующему.
Планирование должно быть хорошим, чтобы каждый поток работал примерно одинаковое время (но при этом достаточно малое, т.е. нас не удовлетворит, если каждый поток будет работать по несколько секунд), а так же само планирование занимало как можно меньше времени. Тут мы, традиционно, приходим к балансу latency/throughput: если давать потокам работать очень маленькие промежутки времени — задержки будут минимальны, но отношение времени полезной работы к времени на переключение контекстов уменьшится, и в итоге полезной работы будет выполнено меньше, а если слишком много — задержки станут заметны, что может проявиться на пользовательском интерфейсе/IO.
Тут же хотелось бы отметить довольно важную вещь, к которой будем отсылаться позже. Потоки можно погружать в сон. Мы можем попросить операционную систему усыпить поток на некоторое время. Тогда она может учитывать это при планировании, исключив этот поток из очереди на получение процессорного времени, что даст больше ресурсов другим потокам, либо снизит энергопотребление. Кроме того, в теории можно настраивать приоритеты, чтобы некоторые потоки работали дольше, либо чаще, чем другие.
Синхронизация
Ядер у нас стало много, а память как была одна сплошная, так и осталась (хотя в современной организации памяти можно ногу сломать, там и физическая, и виртуальная, и страницы туда-сюда ходят, что-то где-то кешируется, проверяется на ошибки, странно, что всё это до сих пор работает вообще).
И когда мы из нескольких потоков начинаем менять одну и ту же память — всё может пойти совершенно не так, как мы этого хотели. Могут возникать «гонки», когда в зависимости от того, в каком порядке выполнятся операции, вас ожидает разный результат, что может приводить к потере данных. И, что ещё хуже — данные могут совсем портиться в некоторых случаях. К примеру, если мы записываем некоторое значение на невыровненный адрес памяти, нам нужно записать в две ячейки памяти, и может получиться так, что один поток запишет в одну ячейку, а другой в другую. И если вы записывали указатель, или индекс массива — то скорее всего вы получите падение программы через какое-то время, когда попытаетесь обратиться к чужой памяти.
Чтобы этого не происходило, нужно использовать примитивы синхронизации, чтобы получать гарантии того, что некоторые блоки кода будут выполняться в строгом порядке относительно каких-то других блоков кода.
Spinlock
Самый простой примитив: у нас есть boolean’овая переменная, если true — значит блокировка кем-то была получена, false — свободна. И два метода: Lock, Unlock. Unlock устанавливает значение в false. Lock в цикле делает либо TAS, либо CAS (об этом будет далее), чтобы атомарно сменить false на true, и пытаться до тех пор, пока не получится.
Имея такую штуку мы можем делать блоки кода, которые будут выполняться эксклюзивно (т.е. пока один выполняется, другой стартовать не может). В начале блока он выполняет метод Lock, в конце Unlock. Важно, чтобы он не попытался сделать Lock второй раз, иначе некому будет сделать Unlock и получится deadlock.
Возможно навешивание плюшек. Например, сохранение идентификатора потока, кто захватил блокировку, чтобы никто кроме захватившего потока, не мог сделать Unlock, и если мы сделали Lock второй раз — он не зациклился, такая реализация это называется «мьютексом». А если вместо boolean’а у нас беззнаковое число, а Lock ждёт числа больше нуля, уменьшая его на единицу, получается «семафор», позволяющий работать некоторому заданному числу блоков одновременно, но не более.
Поскольку блокировка работает в бесконечном цикле она просто «жгёт» ресурсы, не делая ничего полезного. Существуют реализации, которые при неудачах говорят планировщику «я всё, передай остаток моего времени другим потокам». Или, например, есть «адаптивные мьютексы», которые при попытке получить блокировку, которую удерживает поток, который в данный момент выполняется — использует spinlock, а если не выполняется — передаёт выполнение другим потокам. Это логично, т.к. если поток, который может освободить ресурс сейчас работает, то у нас есть шансы, что он вот-вот освободится. А если он не выполняется — есть смысл подождать чуть больше и передать выполнение другому потоку, возможно даже тому, кого мы ждём.
По возможности стоит избегать использования спинлоков, их можно использовать только если блоки кода, которые они защищают, выполняются невероятно быстро, что шансы коллизии крайне малы. Иначе мы можем затратить довольно большое количество ресурсов просто на обогрев комнаты.
Лучшая альтернатива блокировкам — усыпление потока, чтобы планировщик исключил его из претендентов на процессорное время, а затем просьба из другого потока разбудить первый поток обратно, чтобы он обработал новые данные, которые уже на месте. Но это справедливо только для очень длительных ожиданий, если же скорости освобождения блокировок соразмерны с одним «тактом» выполнения потока — производительнее использовать спинлоки.
Барьер памяти
В погоне за скоростью работы, архитекторы процессоров создали очень много тёмной магии, которая пытается предсказывать будущее и может переставлять процессорные инструкции местами, если они не зависят друг от друга. Если у вас каждый процессор работает только со своей памятью — вы никогда не заметите, что инструкции a = 5 и b = 8 выполнились в другом порядке, не так, как вы написали в коде.
Но при параллельном исполнении это может привести к интересным случаям. Пример из википедии:
// Processor #1: while (f == 0); // Memory fence required here print(x);// Processor #2: x = 42; // Memory fence required here f = 1;Казалось бы, что здесь может пойти не так? Цикл завершится, когда f будет присвоена единица, на момент чего переменная x вроде как уже будет равна 42. Но нет, процессор может произвольно менять местами такие инструкции и в итоге сначала может выполниться f = 1 , а затем x = 42 и может вывестись не 42, а что-нибудь другое. И даже более того. Если с порядком записи всё нормально, может быть изменён порядок чтения, где значение x прочитается перед тем, как мы войдём в цикл.
Для противодействия этому используются барьеры памяти, специальные инструкции, которые препятствуют тому, чтобы инструкции были перемещены сквозь них. На хабре есть отличный перевод на эту тему.
Атомарность
Поскольку некоторые операции с памятью могут быть потоконебезопасны (например, прибавить к числу другое число и сохранить его обратно), существуют операции для проведения атомарных операций, для которых есть специальные процессорные инструкции.
Наиболее часто используемые:
- Test-and-Set — записывает значение, возвращает предыдущее.
- Compare-and-Swap — записывает значение только в том случае, если текущее значение переменной совпадает с неким ожидаемым, возвращает успех записи.
Возвращаясь к нашему спинлоку, операция получения блокировки может быть реализована как при помощи TAS:
void lock() < // Мы будем записывать 1 до тех пор, пока между нашими выполнениям кто-то не запишет в неё 0 while (test_and_set(&isLocked, 1) == 0); >Так и при помощи CAS:
void lock() < // Пытаемся записать 1, ожидая 0 while (!compare_and_swap(&isLocked, 0, 1)) >… как я сказал, мне бы хотелось задокументировать всё, но… получилось довольно много, поэтому я разобью это дело на три статьи. Stay tuned.
Параллелизм (информатика) — Concurrency (computer science)

Возможность выполнения различных частей или единиц программы, алгоритма или задачи вне очереди или в частичный порядок, не влияющий на конечный результат «Обеденные философы», классическая проблема, связанная с параллелизмом и общими ресурсами
В информатике, параллелизм — это способность различных частей или единиц программы, алгоритма или задачи выполняться вне очереди или в частичном порядке, не влияя на конечный результат. Это позволяет выполнять параллельное выполнение параллельных модулей, что может значительно повысить общую скорость выполнения в многопроцессорных и многоядерных системах. В более технических терминах параллелизм относится к свойству декомпозиции программы, алгоритма или проблемы на независимые от порядка или частично упорядоченные компоненты или единицы.
- 1 История
- 2 Проблемы
- 3 Теория
- 3.1 Модели
- 3.2 Логика
История
Как отмечает Лесли Лэмпорт (2015), «в то время как параллельное выполнение программы рассматривалось в течение многих лет, информатика параллелизма началось с основополагающей статьи Эдсгера Дейкстры 1965 года, в которой была представлена проблема взаимного исключения. В последующие десятилетия наблюдался огромный рост интереса к параллелизму, особенно в distri бутилированные системы. Оглядываясь на истоки этой области, можно выделить фундаментальную роль, которую играет Эдсгер Дейкстра ».
Проблемы
Поскольку вычисления в параллельной системе могут взаимодействовать друг с другом во время выполнения, количество возможных путей выполнения в системе может быть чрезвычайно большим, а результирующий результат может быть неопределенным. Одновременное использование общих ресурсов может быть источником неопределенности, приводящей к таким проблемам, как взаимоблокировки и нехватка ресурсов.
Дизайн параллельных систем часто влечет за собой поиск надежных методов для координации их выполнения, обмена данными, выделения памяти и планирования выполнения для минимизации время отклика и максимизация пропускной способности.
Теория
Теория параллелизма была активной областью исследований в теоретической информатике. Одно из первых предложений было Основополагающая работа Карла Адама Петри о сетях Петри в начале 1960-х годов. Поэтому было разработано множество формализмов для моделирования и рассуждений о параллелизме.
Модели
Был разработан ряд формализмов для моделирования и понимания параллельных систем, в том числе:
- параллельная машина с произвольным доступом
- модель актора
- Вычислительные мостовые модели, такие как массовая синхронная параллельная (BSP) модель
- Сети Петри
- Технологические вычисления
- Расчет взаимодействующих систем (CCS)
- Последовательное взаимодействие процессы (CSP) модель
- π-исчисление
Некоторые из этих моделей параллелизма в первую очередь предназначены для поддержки рассуждений и спецификации, в то время как другие могут использоваться на протяжении всего цикла разработки, включая проектирование, реализацию, проверку, тестирование и моделирование параллельных систем. Некоторые из них основаны на передаче сообщений, в то время как другие имеют другие механизмы для параллелизма.
Распространение различных моделей параллелизма побудило некоторых исследователей разработать способы объединения этих различных теоретических моделей. Например, Ли и Сангиованни-Винсентелли продемонстрировали, что так называемая модель «помеченного сигнала» может использоваться для обеспечения общей структуры для определения денотационной семантики множества различных моделей параллелизма, в то время как Нильсен, Сассон и Винскель продемонстрировали, что теорию категорий можно использовать для обеспечения аналогичного единого понимания различных моделей.
Теорема представления параллелизма в модели акторов обеспечивает довольно общий способ представляют собой параллельные системы, которые закрыты в том смысле, что они не получают сообщений извне. (Другие системы параллелизма, например, вычисление процессов могут быть смоделированы в модели актора с использованием протокола двухфазной фиксации.) Математическое обозначение, обозначаемое закрытой системой S, строится все лучше приближения из начального поведения, называемого ⊥S, с использованием функции аппроксимации поведения прогрессия Sдля построения обозначения (значения) для S следующим образом:
Обозначить S≡ ⊔ i∈ω прогрессия S(⊥S)
Таким образом, S можно математически охарактеризовать в терминах всех его возможных вариантов поведения.
Логика
Различные типы временной логики могут использоваться, чтобы помочь рассуждать о параллельных системах. Некоторые из этих логик, например линейная темпоральная логика и логика дерева вычислений, позволяют делать утверждения о последовательностях состояний, через которые может проходить параллельная система. Другие, такие как логика Хеннесси-Милнера и логика действий Лэмпорта, строят свои утверждения из последовательностей действий (изменений состояния). Основное применение этой логики — написание спецификаций для параллельных систем.
Практика
Параллельное программирование охватывает языки программирования и алгоритмы, используемые для реализации параллельных систем. Параллельное программирование обычно считается более общим, чем параллельное программирование, потому что оно может включать произвольные и динамические шаблоны взаимодействия и взаимодействия, тогда как параллельные системы обычно имеют заранее определенный и хорошо структурированный шаблон взаимодействия. Основные цели параллельного программирования включают правильность, производительность и надежность. Параллельные системы, такие как Операционные системы и Системы управления базами данных, как правило, предназначены для работы в течение неограниченного времени, включая автоматическое восстановление после сбоя, и не прекращают работу неожиданно (см. Управление параллелизмом ). Некоторые параллельные системы реализуют форму прозрачного параллелизма, при которой параллельные вычислительные объекты могут конкурировать за один ресурс и совместно использовать его, но сложность этой конкуренции и совместного использования скрыта от программиста.
Поскольку они используют общие ресурсы, параллельные системы обычно требуют включения какого-то типа арбитра где-нибудь в своей реализации (часто в базовом оборудовании) для управления доступом к этим ресурсам. Использование арбитров вводит возможность неопределенности в параллельных вычислениях, что имеет серьезные последствия для практики, включая правильность и производительность. Например, арбитраж вводит неограниченный недетерминизм, который вызывает проблемы с проверкой модели, потому что он вызывает взрыв в пространстве состояний и может даже привести к тому, что модели будут иметь бесконечное количество состояний.
Некоторые модели параллельного программирования включают сопроцессы и детерминированный параллелизм. В этих моделях потоки управления явно передают свои временные интервалы либо системе, либо другому процессу.
См. Также
- Chu space
- Клиент – сервер сетевые узлы
- Clojure
- Кластер узлы
- Управление параллелизмом
- Параллельные вычисления
- Параллельные объектно-ориентированное программирование
- Шаблон параллелизма
- D (язык программирования)
- Распределенные системные узлы
- Elixir (язык программирования)
- Erlang (язык программирования)
- Go (язык программирования)
- Gordon Паск
- Международная конференция по теории параллелизма (CONCUR)
- OpenMP
- Параллельные вычисления
- Разделенное глобальное адресное пространство
- Процессы
- Проект Птолемея
- Rust (язык программирования)
- Сноп (математика)
- Потоки
- X10 (язык программирования)
Ссылки
Дополнительная литература
- Линч, Нэнси А. (1996). Распределенные алгоритмы. Морган Кауфманн. ISBN 978-1-55860-348-6 .
- Tanenbaum, Andrew S.; Ван Стин, Маартен (2002). Распределенные системы: принципы и парадигмы. Прентис Холл. ISBN 978-0-13-088893-8 .
- Курки-Суонио, Рейно (2005). Практическая теория реактивных систем. Springer. ISBN 978-3-540-23342-8 .
- Гарг, Виджай К. (2002). Элементы распределенных вычислений. Wiley-IEEE Press. ISBN 978-0-471-03600-5 .
- Маги, Джефф; Крамер, Джефф (2006). Параллелизм: модели состояний и программирование на Java. Вайли. ISBN 978-0-470-09355-9 .
- Дистефано, С., и Брунео, Д. (2015). Количественные оценки распределенных систем: методологии и техники (1-е изд.). Сомерсет: John Wiley Sons Inc. ISBN 9781119131144
- Бхаттачарья, С.С. (2013; 2014;). Справочник по системам обработки сигналов (Вторая; 2; 2-я 2013; ред.). Нью-Йорк, штат Нью-Йорк: Springer, 10.1007 / 978-1-4614-6859-2 ISBN 9781461468592
- Уолтер, К. (2012; 2014;). Оценка устойчивости и оценка вычислительных систем (1. Aufl.; 1; ed.). Лондон; Берлин ;: Springer. ISBN 9783642290329
Внешние ссылки
- Параллельные системы в Виртуальная библиотека WWW
- Представление шаблонов параллелизма на scaleconf
Введение в параллелизм
Сейчас почти невозможно найти современную компьютерную систему без многоядерного процессора. Даже недорогие мобильные телефоны предлагают пару ядер под капотом. Идея многоядерных систем проста: это относительно эффективная технология для масштабирования потенциальной производительности процессора. Эта технология стала широкодоступной около двадцати лет назад, и теперь каждый современный разработчик способен создать приложение с параллельным выполнением для использования такой системы. На наш взгляд, сложность параллельного программирования часто недооценивается.
В этой статье мы попробуем разработать простейшее приложение, использующее для распараллеливания средства C++ и сравнить его с версией, использующей Intel oneTBB.
Операционные системы и язык C++ предоставляют интерфейсы для создания потоков, которые потенциально могут выполнять один и тот же или различные наборы инструкций одновременно.
Основными источниками проблем многопоточного выполнения являются data races (гонки данных) и race conditions (состояние гонки). Простыми словами, C++ определяет data race как одновременные и несинхронизированные доступы к одной и той же ячейке памяти, при этом один из доступов модифицирует данные. В то время как race conditions является более общим термином, описывающим ситуацию, когда результат выполнения программы зависит от последовательности или времени выполнения потоков.
Основная проблема race conditions заключается в том, что они могут быть незаметны во время разработки программного обеспечения и могут исчезнуть во время отладки. Такое поведение часто приводит к ситуации, когда приложение считается законченным и корректным, но у конечного пользователя периодически возникают проблемы, часто неясного характера. Для решения проблемы data race, C++ предоставляет набор интерфейсов, таких как атомарные операции и примитивы для создания критических секций (мьютексы).
Атомарные операции — это мощный инструмент, который позволяет избежать data races и создавать эффективные алгоритмы синхронизации. Однако, это создает замысловатую модель памяти C++, которая представляет собой еще один уровень сложности.
Использование мьютекса зачастую намного проще, чем использование атомарных операций. Он позволяет создать критическую секцию, которая может быть выполнена не более чем одним потоком в любой данный момент времени. Кроме того, продвинутые мьютексы, такие как shared_lock , в некоторых случаях могут повысить эффективность, позволяя группе потоков исполнять критическую секцию, если мьютекс не захвачен в эксклюзивное использование.
Давайте попытаемся распараллелить простую задачу вычисления суммы элементов массива. Решение этой проблемы в однопоточной программе может выглядеть следующим образом:
int summarize(const std::vector& vec)
Выполнение алгоритма в однопоточной программе:
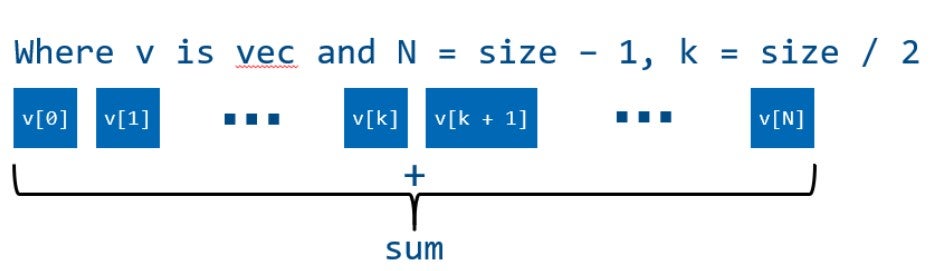
Для того чтобы исполнить алгоритм параллельно, нам нужно разделить его на независимые части, которые могут обрабатываться независимо друг от друга. Самый простой подход состоит в том, чтобы разделить обрабатываемые элементы на несколько частей и обработать каждую часть в своем собственном потоке.
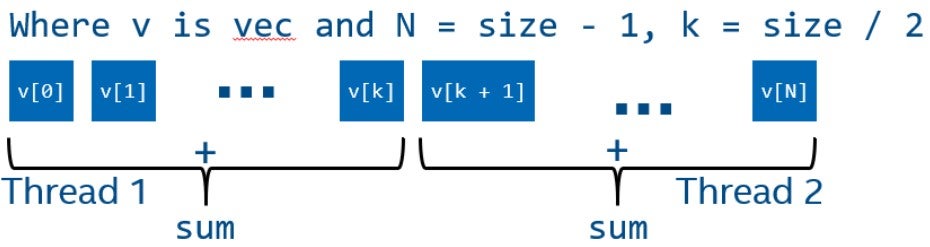
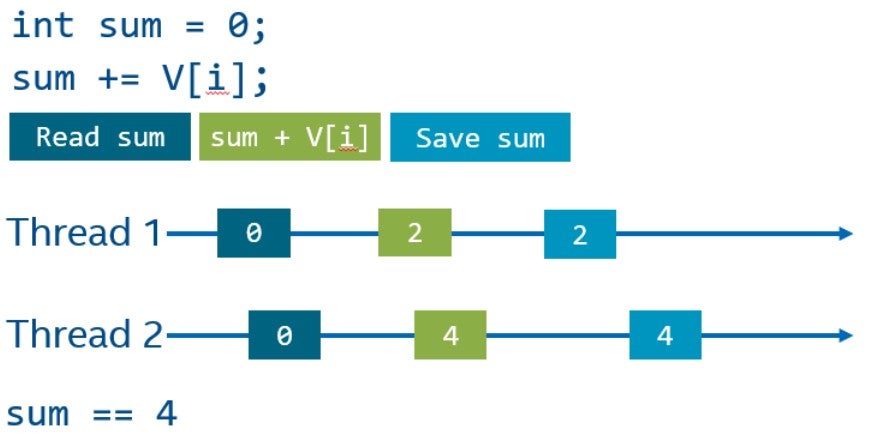
Однако в этом коде есть сложность, которая не позволяет нам просто разделить массив на две равные части и обрабатывать его параллельно. Все элементы суммируются в одну переменную, доступ к которой приведёт к data race, потому что один из потоков может записывать эту переменную одновременно с другим потоком, считывающим или записывающим в данную переменную.
Составной оператор (оператор +=), по сути, состоит из трех операций: чтение из памяти, операция сложения и сохранение результата в памяти. Эти операции могут выполняться параллельно разными потоками, что может привести к неожиданным результатам. На следующем рисунке показан возможный порядок операций на временной шкале двух потоков. Основная сложность заключается в том, что оба потока могут не получить результат операций другого потока и перезаписать данные. C++ трактует такие ситуации как data race, и поведение программы, в таких случаях, не определено. Например, в результате мы можем получить четыре, ожидая шесть (как показано на рисунке). В худшем случае данные могут быть в непредсказуемом состоянии.
Существует много способов борьбы с data race, давайте рассмотрим самый простой из них — мьютекс.
Мьютекс имеет два основных интерфейса: блокировка (lock) и разблокировка (unclock). Блокировка переводит мьютекс в эксклюзивное владение, а разблокировка освобождает его, делая доступным для других потоков. Поток, который не может заблокировать мьютекс, будет остановлен, ожидая, пока другой поток освободит данный мьютекс.
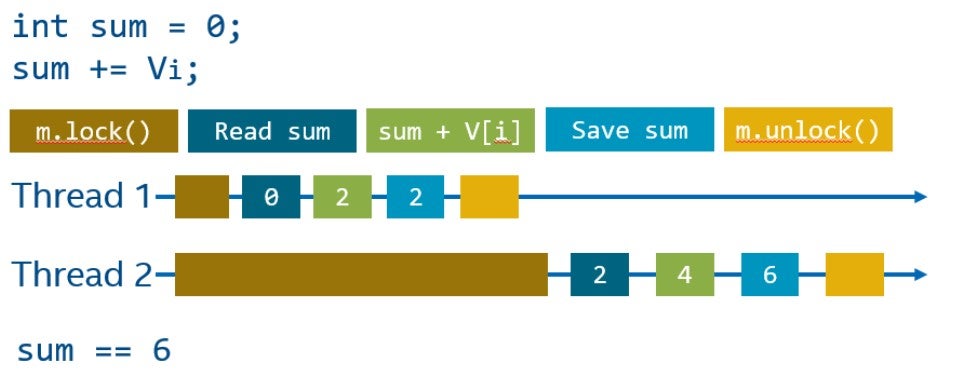
Код, защищенный мьютексом, также называется критической секцией. Важное наблюдение состоит в том, что второй поток, который не смог заблокировать мьютекс, не будет делать ничего полезного, во время того, пока первый поток находится в критической секции. Таким образом, размер критической секции может значительно повлиять на общую производительность системы.
Давайте попробуем сделать наш последовательный пример параллельным. Для создания потоков используем библиотеку из стандартной библиотеки C++.
int summarize(const std::vector& vec)
int num_threads = 2;
auto thread_func = [&sum, &vec, &m] (int thread_id)
// Делим итерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
for (int i = start_index; i < end_index; ++i)
// Используем lock_guard, имплементирующий RAII идиому:
// — мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// — мьютекс освобождается в деструкторе (т.е. вызван mutex.unlock())
// Запускаем поток со стартовой функцией `thread_func`
// и аргументом функции ` thread_id`
threads[thread_id] = std::thread(thread_func, thread_id);
// Нам нужно дождаться всех потоков
// до разрушения std::vector
Запустив нашу программу, мы, вероятно, увидим неверный результат. Причина в том, что с помощью мьютекса мы защитили себя от data race при вычислении суммы, но основной поток может считывать переменную sum, в то время как другие потоки изменяют ее. Даже если мы защитим чтение с помощью мьютекса, это приведет к другой неочевидной сложности, называемой race condition: чтение, защищённое с помощью мьютекса, не гарантирует логическую корректность алгоритма. В нашем случае мы не дожидаемся полного завершения вычислений. Чтобы решить эту проблему, мы должны дождаться завершения потоков, прежде чем считывать результат. Однако, в данном случае мьютекс не требуется для чтения общей суммы , потому что синхронизация вычислений выполняется во время ожидания потоков (с помощью функции join).
int summarize(const std::vector& vec)
int num_threads = 2;
auto thread_func = [&sum, &vec, &m] (int thread_id)
// Делим итерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
for (int i = start_index; i < end_index; ++i)
// Используем lock_guard, имплементирующий RAII идиому:
// — мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// — мьютекс освобождается в деструкторе
// (т.е. вызван mutex.unlock())
// Запускаем поток со стартовой функцией `thread_func`
// и аргументом функции ` thread_id`
threads[thread_id] = std::thread(thread_func, thread_id);
// Нам нужно дождатьсявсех потоков до
Этот подход к распараллеливанию, очевидно, будет работать медленнее, чем последовательная версия, потому что для каждого sum += vec[i] мы берем мьютекс std:: lock_guard lock (m) . Таким образом, мы полностью упорядочиваем вычисления, т. е. разрешаем работать только одному потоку в любой момент времени. Чтобы избежать этого, мы можем сначала выполнить локальное суммирование в каждом потоке, а в конце вычислений добавить результат к глобальной сумме.
auto thread_func = [&sum, &vec, &m] (int thread_id)
// Делим origin rangeитерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
int local_sum = 0;
for (int i = start_index; i < end_index; ++i)
// Используем lock_guard, имплементирующий RAII идиому:
// — мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// — мьютекс освобождается в деструкторе
// (т.е. вызван mutex.unlock())
Этот простой пример демонстрирует, что параллельное программирование приводит к ряду проблем, которые невозможно наблюдать в последовательной программе. Более того, эти проблемы не всегда легко обнаружить, и они не всегда очевидны. Библиотеки, такие как oneTBB, упрощают параллельное программирование во многих аспектах. Для наглядности наш пример можно переписать с помощью parallel_reduce , который не требует каких-либо специальных синхронизаций и механизмов, чтобы избежать race conditions:
int summarize(const std::vector& vec)
int sum = tbb::parallel_reduce(tbb::blocked_range, 0,
[&vec] (const auto& r, int init)
for (auto i = r.begin(); i != r.end(); ++i)
Хотя этот пример относительно небольшой, он показывает набор значительных упрощений, которые предоставляет oneTBB. Например, oneTBB автоматически создаст набор потоков, которые будут повторно использоваться между несколькими вызовами параллельных алгоритмов. Кроме того, parallel_reduce реализует все необходимые синхронизации, а пользователю достаточно описать требуемую операцию свертки, например, std::plus .
oneTBB использует подход, основанный на work stealing алгоритме распределения задач, предоставляя обобщенные параллельные алгоритмы, применимые для широкого спектра приложений. Основное преимущество подхода oneTBB заключается в том, что он позволяет легко создавать параллелизм в различных независимых компонентах приложения.
В нашей серии статей мы продемонстрируем, как oneTBB можно использовать для динамической балансировки нагрузки и распараллеливания графов. Помимо параллелизма задач на процессоре, мы покажем, как oneTBB можно использовать в качестве уровня абстракции для балансировки вычислений между несколькими разнородными устройствами, такими как GPU.
- Блог компании Intel
- Высокая производительность
- Программирование
- C++
- Параллельное программирование