Создаем кэшируемую пагинацию, которая не боится неожиданного добавления данных в БД
Если на вашем сайте присутствует большое количество контента, то для отображения пользователю его приходится так или иначе делить.
Все известные мне способы имеют недостатки и я попытался создать систему, которая сможет решить некоторые из них и при этом не будет слишком сложна для реализации.
Существующие методы
1. Пагинация (разделение на отдельные страницы)

Пагинация или разделение на отдельные страницы — достаточно старый способ разделения контента, который, в том числе используется на Хабре. Основным преимуществом является его универсальность и простота реализации как со стороны сервера так и клиентской части.
Код запроса данных из бд чаще всего ограничивается парой строк.
Тут и далее примеры на языке arangodb aql, я скрыл код сервера т.к там пока ничего интересного.
// Возврат по 20 элементов для каждой страницы. LET count = 20 LET offset = count * $ FOR post IN posts SORT post.date DESC // сортируем от новых к старым LIMIT offset, count RETURN postНа стороне клиента мы запрашиваем и выводим получившийся результат, я использую vuejs с nuxtjs для примера, но то же самое можно проделать на любом другом стеке, все специфичные для vue моменты я буду подписывать.
# https://example.com/posts?page=3 main.vue > Теперь у нас выводятся все посты на странице, но погодите, как пользователи будут переключаться между страницами? Добавим пару кнопок для перелистывания страниц.
> Минусы данного способа
- При достижении конца страницы пользователю нужно переключаться на следующую страницу вручную.
- Не получится кешировать результаты, т.к посты находящиеся на странице 2, при добавлении новых, непременно сместятся на страницу 3, 4 и так далее, т.е одна и та же операция GET возвращает разные результаты в зависимости от количества постов.
- Если в момент перелистывания добавятся новые посты, то мы повторно увидим просмотренные элементы на следующей странице и напротив, пропустим если будем листать в обратную сторону.
2. Бесконечный скроллинг
Этот способ решает первую проблему, теперь пользователю не нужно вручную переключаться между страницами.
Основная идея заключается в том, что мы получаем следующую страницу при достижении конца прошлой и добавляем новые элементы к существующим.
При таком подходе проблема №3 проявляются еще более явно, если раньше мы не могли увидеть 2 похожих элемента рядом, то теперь это станет обычной ситуацией, конечно можно воспользоваться грязным трюком и отфильтровывать элементы с совпадающим id прямо на клиенте, но что если добавится 40 новых элементов за раз? Мы потратим 3 запроса к серверу, чтобы достичь новых результатов, т.к прошлые сместятся на 2 страницы (при условии что на одной странице 20 элементов). Это не мой подход!
Как решают эту проблему люди из интернета:
- Используют описанный мной выше подход, я не искал подтверждение, но я практически уверен в этом, т.к это самое простое решение которое может прийти на ум, его можно использовать для быстрого прототипирования или создания mvp.
- Создают уникальный идентификатор при первом запросе, и сохраняют результаты запроса на сервере, а затем выдают порционно. Тут сразу напрашивается 2 минуса. Во-первых, это использование лишней памяти сервера для хранения результатов всех пользователей. Во-вторых, более сложная реализация, требующая и логики хранения результатов для каждого пользователя, и логики удаления устаревших запросов. Я уверен, что такие реализации существуют и возможно некоторым удалось решить проблему излишней памяти, но проще система от этого не стала, да и проблему кеширования это не решает, а лишь усугубляет ситуацию.
- Возможны и другие более или менее изобретательные решения, но то что я хочу вам предложить я пока не встречал. В свое время мне бы очень помогла подобная статья, поэтому я и решил её создать. Думаю что людям с похожей задачей она окажется полезной!
Моя реализация
Основная идея в том, что нам придется немного изменить логику запроса к базе, при этом не потребуется добавлять новые сущности или добавлять новые параметры в запрос.
Обновляем код на сервере
Для начала решим проблему кеширования, для этого просто всё перевернем.
Теперь последняя страница станет страницей номер 0, а предпоследняя страница номером 1, слово страница (page) сюда уже не вписывается, т.к мы с детства привыкли что в книжках страницы идут с начала, поэтому используем более нейтральное слово offset (смещение).
LET count = 20 LET offset = $ FOR post IN posts SORT post.date ASC // для этого отсортируем всё в обратном порядке LIMIT offset, count RETURN postТеперь сколько постов мы бы ни добавили, GET «/?offset=0» всегда будет возвращать один и тот же результат.
Получать первую страницу стало немного сложнее, поэтому совместим оба выше приведенных способа, для этого перейдем с уровня запроса к базе на уровень сервера (язык nodejs):
async getPosts() < const isOffset = offset !== undefined if (isOffset && isNaN(+offset)) throw new BadRequestException() const count = 20 // Смещение должно быть кратно количеству элементов, чтобы результаты не пересекались if (offset % count !== 0) throw new BadRequestException() const sort = isOffset ? ` SORT post.date DESC LIMIT $, $ ` : ` SORT post.date ASC LIMIT 0, $ // Возвращаем больше чем нужно если это первая страница* ` const q = < query: ` FOR post IN posts $RETURN post `, bindVars: <> > // получаем результат запроса вместе с общим количеством найденных элементов const cursor = await this.db.query(q, ) const fullCount = cursor.extra.stats.fullCount /* *Если общее число элементов в базе не кратно count то в начальном запросе приходит 2 страницы [21-39] элементов В таком случае вторую страницу нужно пропустить т.к она уже входит в первую Если общее число делится на 20 то в первом запросе приходит 1-я страница c count элементов */ let data; if (isOffset) < // отсекаем попытку получить вторую страницу если она встроена в первую const allow = offset else < const all = await cursor.all() if (fullCount % count === 0) < // отрезаем лишние 20 элементов, это можно сделать как тут, так и в запросе к бд, вопрос лишь в оптимизации data = all.slice(0, count) >else < /* Тут посложней, если ранее мы могли иметь на последней странице 0-20 элементов, то теперь там нам всегда возвращается 20 элементов и недостачу нужно компенсировать, для этого на первую страницу добавляются дополнительные 0-20 элементов к имеющимся, в запросе к бд для первой страницы мы возвращаем с запасом 40 элементов и затем здесь отрезаем лишние */ const pagesCountUp = Math.ceil(fullCount / count) const resultCount = fullCount - pagesCountUp * count + count * 2 data = all.slice(0, resultCount) >> if (!data.length) throw new NotFoundException() return < fullCount, count: data.length, data >>Чего мы этим добились:
- Теперь перекрытия id после добавления новых элементов стали невозможны.
- Запросы теперь статичны и легко поддаются кешированию, единственным плавающим по количеству элементов и их id остался запрос без параметра offset.
- Наш код на клиенте теперь не работает(
Минусы моего способа:
- Вопрос что делать при удалении все ещё открыт, это не частая операция, поэтому можно каждый раз полностью сбрасывать кэш, либо возвращать null вместо отсутствующего элемента, это неплохое решение, т.к. зачастую реального удаления с сервера не происходит, элемент лишь помечается как удаленный, если таких «null-зомби» станет много, то можно удалить все null-зомби из выдачи и сбросить кэш для всех запросов.
- Если новый элемент оказывается не в начале после сортировки по выбранному полю (например по названию), то данный алгоритм не сработает. Поэтому подходит только сортировка по возрастающим или убывающим полям (например по дате или по id).
Обновляем код на клиенте
Заодно я покажу как сделать бесконечную прокрутку из пункта №2.
> Теперь у нас есть полностью лишенная обозначенных недостатков реализация. Несомненно присутствуют моменты которые можно сделать лучше, я хотел показать сам подход, реализация может быть у каждого разной.
Бонус: Добавляем гибкую систему перехода по страницам
В данный момент мы можем перемещаться лишь на 1 страницу вперед или назад, добавим возможность перейти на любую страницу, элемент управления может выглядеть примерно так (в квадратных скобках текущая страница):
Основа метода для генерации пагинации взята из этого обсуждения: https://gist.github.com/kottenator/9d936eb3e4e3c3e02598#gistcomment-3238804 и скрещена с моим решением.
Показать продолжение бонуса
В начале вам нужно добавить этот вспомогательный метод внутрь тега
const getRange = (start, end) => Array(end - start + 1).fill().map((v, i) => i + start) const pagination = (currentPage, pagesCount, count = 4) => < const isFirst = currentPage === 1 const isLast = currentPage === pagesCount let delta if (pagesCount else < // delta === 2: [1 . 4 5 6 . 10] // delta === 4: [1 2 3 4 5 . 10] delta = currentPage >count + 1 && currentPage < pagesCount - (count - 1) ? 2 : 4 delta += count delta -= (!isFirst + !isLast) >const range = < start: Math.round(currentPage - delta / 2), end: Math.round(currentPage + delta / 2) >if (range.start - 1 === 1 || range.end + 1 === pagesCount) < range.start += 1 range.end += 1 >let pages = currentPage > delta ? getRange(Math.min(range.start, pagesCount - delta), Math.min(range.end, pagesCount)) : getRange(1, Math.min(pagesCount, delta + 1)) const withDots = (value, pair) => (pages.length + 1 !== pagesCount ? pair : [value]) if (pages[0] !== 1) < pages = withDots(1, [1, '. ']).concat(pages) >if (pages[pages.length - 1] < pagesCount) < pages = pages.concat(withDots(pagesCount, ['. ', pagesCount])) >if (!isFirst) pages.unshift('<') if (!isLast) pages.push('>') return pages >Добавляем недостающие методы
> Теперь, при необходимости, можно перейти на нужную страницу.
Пагинация¶
В Интернете под пагинацией понимают показ ограниченной части информации на одной веб-странице (например, 10 результатов поиска или 20 форумных трэдов). Она повсеместно используется в веб-приложениях для разбиения большого массива данных на страницы и включает в себя навигационный блок для перехода на другие страницы.
Paginate¶
- webhelpers.paginate
- https://github.com/Pylons/paginate
- https://v4-alpha.getbootstrap.com/components/pagination/
Модуль paginate делит список статей на страницы. Номер страницы передается методом GET , в параметре page . По умолчанию берется первая страница.
p = paginate.Page( items, page=1, items_per_page=42 )
Пример Mako шаблона, использующего Bootstrap4 для пагинации.
inherit file="base.mako"/> block name="content"> h2>$tag.title()>h2> br/> div class="row"> %for item in p: div class="col"> div class="row"> a href="$_static_prefix>/item/$item.id>.html"> �� a> div> br/> div class="row"> pre id='id-$item.id>' width=100%> $item.text> pre> div> div> %endfor div> # https://v4-alpha.getbootstrap.com/components/pagination/ div class="row"> nav aria-label="Page navigation example"> ul class="pagination"> $, link_tag=lambda page: 'li class="page-item <> <>">a class="page-link" href="<>"><>a>li>'.format( 'active' if page['type'] == 'current_page' else '', 'disabled' if not len(page['href'].strip()) else '', page['href'], page['value'] ) )> ul> nav> div> block>
Блог¶
Данные¶
Для начала наполним блог случайными статьями при помощи функции generate_lorem_ipsum из пакета jinja2.utils .
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
from jinja2.utils import generate_lorem_ipsum ARTICLES = [] for id, article in enumerate(range(100), start=1): title = generate_lorem_ipsum( n=1, # Одно предложение html=False, # В виде обычного текста min=2, # Минимум 2 слова max=5 # Максимум 5 ) content = generate_lorem_ipsum() ARTICLES.append( 'id': id, 'title': title, 'content': content> )
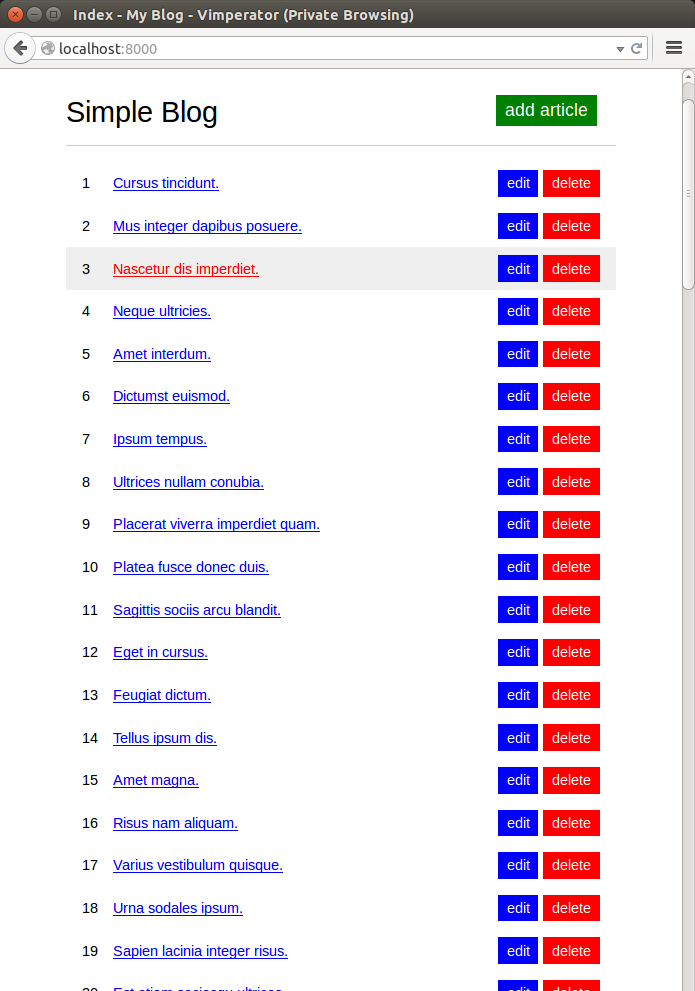
Много статей не помещаются на экран
Paginate¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
class BlogIndex(BaseBlog): def __iter__(self): self.start('200 OK', [('Content-Type', 'text/html')]) # Get page number from urllib.parse import parse_qs values = parse_qs(self.environ['QUERY_STRING']) # Wrap articles to paginated list from paginate import Page page = values.get('page', ['1', ]).pop() paged_articles = Page( ARTICLES, page=page, items_per_page=8, ) yield str.encode( env.get_template('index.html').render( articles=paged_articles ) )
templates/index.html ¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
extends "base.html" %> block title %>Index endblock %> block content %> div class="blog__title">Simple Blogdiv> a href="/article/add" class="blog__button">add articlea> div class="blog-list"> for article in articles %> div class="blog-list__item"> div class="blog-list__item-id"> <article.id >>div> a href="/article/ <article.id >>" class="blog-list__item-link"> <article.title >>a> div class="blog-list__item-action"> a href="/article/ <article.id >>/edit" class="blog-list__item-edit">edita> a href="/article/ <article.id >>/delete" onclick="return confirm_delete();" class="blog-list__item-delete">deletea> div> div> endfor %> div> div class="paginator"> <articles.pager(url="?page=$page") >> div> endblock %>
В результате на каждой странице отображаются только 8 статей.
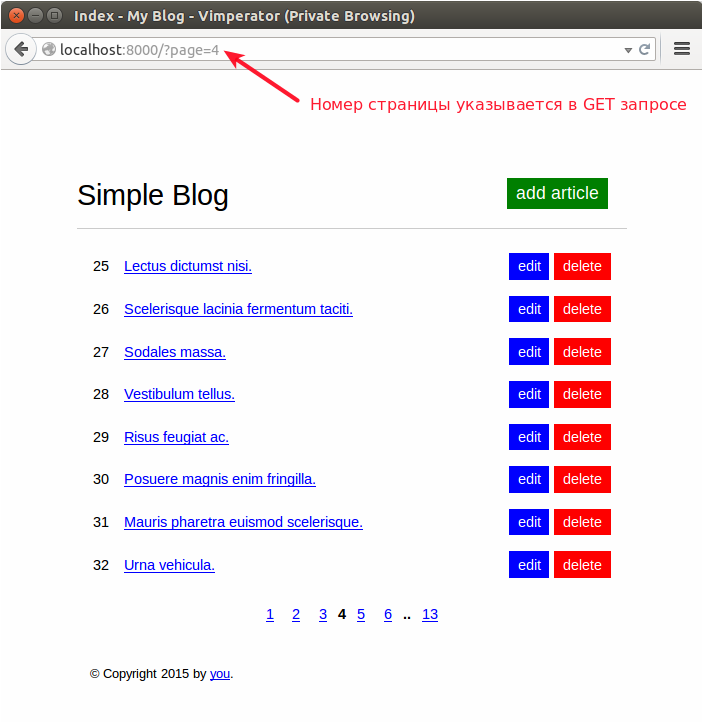
Блог со страницами
Previous: Статика Next: WebOb
© Copyright 2020, Кафедра Интеллектуальных Информационных Технологий ИнФО УрФУ. Created using Sphinx 1.7.6.
Пагинация страниц и способы её реализации на сайте

Сканируйте сайт на наличие технических ошибок и получите список задач с подробными инструкциями по их устранению.
Что такое пагинация?
Пагинация (Pagination) – это порядковая нумерация страниц, которая в основном размещается вверху либо внизу страниц сайта.
Преимущественно пагинацию используют на основных страницах либо разделах. Всё это выглядит вот так:

Попробуем разобрать самые актуальные трудности, которые возникают при внедрении пагинации:
Лимит посещаемости вашего сайта поисковой системой
Когда поисковые краулеры проводят сканирование вашего веб-сайта, структура и число страниц, которые ними проверяются, будут различаться зависимо от доверия к сайту, скорости обновления контента и других параметров. И, если вы располагаете огромным числом страниц для пагинации, то возможность прохождения поисковиками всех таких страниц значительно сокращается. Как следствие, появляется малая вероятность индексирования конкретных страниц. Лимит поисковых пауков будет попросту расходован на пагинацию, а не верификацию актуальных страниц сайта.
Проблема дублирования
Структура пагинации страниц вашего сайта может также вызвать эффект дублирования, вследствие чего на некоторых страницах сайта появится дублированное (идентичное) содержание. Кроме того, вы увидите, что на сайте присутствуют повторяющиеся мета-теги title и description. В такой ситуации дубли контента усложнят индексирование вашего сайта поисковыми системами. Они не смогут определять наиболее релевантный контент по текущим поисковым запросам.
Решить эту проблему можно 4 основными способами.
Особенности настройки пагинации WordPress
На самом деле, нумерация страниц является частью основных функций WordPress. Как известно, WordPress автоматически добавляет «Next Post» или «Previous Post» внизу каждой страницы, поэтому читатели могут легко переходить от одной к другой. В этом посте мы рассмотрим несколько плагинов WordPress для нумерации страниц и постов.
Когда вы добавляете нумерацию страниц, читателям не нужно искать среди тонны контента. Вместо этого они могут щелкнуть непосредственно на нужной странице.
Почему вы должны использовать плагины WordPress Pagination
Существует несколько причин, по которым вы должны добавить нумерацию страниц на свои блоговые страницы:
- Это делает ваш блог удобным для пользователя, помогая читателям легко находить страницы.
- Все ваши страницы могут не загружаться одновременно, что делает ваш сайт чуть быстрее.
- Вы также можете использовать нумерацию страниц, чтобы разбить длинный пост на несколько частей.
- Многие темы WordPress также включают функцию разбиения на страницы. Но если вы хотите контролировать нумерацию своих постов, стилизовать нумерацию без использования кода, плагины для WordPress могут быть лучшим вариантом.
Решение 1. Удаление страницы пагинации из индекса с помощью noindex
В основном такой способ будет самым быстрым и простым в реализации. Здесь главное – убрать из индекса поисковиков все страницы пагинации, за исключением первой.
Это делается следующим способом:
добавляется в раздел HEAD на всех страницах, за исключением первой. Благодаря этому мы сможем исключить полный набор страниц пагинации из индекса, кроме главного раздела каталога, а также обеспечим индексирование полного списка элементов / страниц, которые относятся к указанной директории. Также стоит отметить некоторые нюансы:
- Если вы будете вставлять описание для главной страницы каталога, то также очень важно установить его лишь на первой странице.
- Проверьте не присутствуют ли дубли с URL адресами основной страницы. Например, когда разбивка делается таким образом:
site.com/catalog?page=2
site.com/catalog?page=3
…
site.com/catalog?page=N
Стоит добавить ссылку на первую страницу, если вы находитесь за ее пределами
а с этой страницы
должны быть проставлены 301 редиректы на site.com/catalog.
Плюсы
- подходит для Яндекса;
- самый простой из всех возможных вариантов;
- очень эффективный способ исключения из индекса всех блоков пагинации, если не обязательно приобщать их к индексу.
Минусы
- хотя потенциальные сложности пагинации решаются, но вместе с этим из индекса исключается и содержимое контента остальных страниц пагинации;
- если имеется множество продуктов и вы не прибегаете к использованию карты сайта XML, то на индексацию элементов, расположенных в глубокой структуре каталога, понадобится очень много времени.
Решение 2. “Смотреть все” и rel=”canonical”
Такой способ требует использования Google, чтобы создать отдельную директорию «Просмотреть все», где будут располагаться ссылки на все продукты / страницы из этого каталога. А на любой из страниц пагинации мы проставляем rel=”canonical” на страницу «Просмотреть все».
Внедрение такого способа: после создания страницы «Просмотреть все» (например, это site.com/catalog/view-all.html), разметите на всех страницах пагинации в секции HEAD следующий код:
Так мы продемонстрируем поисковым системам, что каждая страница разбивки принадлежит к странице «Просмотреть все». Согласно рекомендациям Google:
- это самая подходящая для них методика;
- посетители сайта любят пролистывать сразу все содержимое категории в одном разделе (хотя этот нюанс считается довольно противоречивым, и во многом определяется ситуацией).
Нюансы
У страницы «Просмотреть все» должны быть высокие характеристики скорости, загрузка должна происходить в пределах 3 секунд. Такой способ оптимальный для категории, которая включает несколько страниц, с разбивкой от пяти до двадцати, но не вписывается в расклад для директорий с сотнями страниц пагинации.
Преимущества
- рекомендуемый метод Google;
- весь контент страницы пагинации будет размещен в индексе поиска благодаря странице «Просмотреть все».
Недостатки
- не подходит, если есть много страниц и качественных картинок для продуктов/статей;
- предполагает довольно сложную реализацию в ряде стандартных CMS.
Решение 3. Rel=”prev”/”next”
Последний предложенный вариант решения проблемы может показаться наиболее запутанным. Но он является самой универсальной методикой для Google (Yandex не принимает во внимание эти инструкции). В силу сложности реализации техники, нужно проявить максимальную осторожность при внедрении текущего метода. Давайте разберемся, как это работает.
Например, в вашем каталоге имеется четыре страницы. Применяя атрибуты rel=”prev”/”next”, вы сможете создать цепочку, связывающую все составляющие директории. Такая цепочка берет начало на первой странице. Для этого вставьте в секцию HEAD такой код:
Для первой страницы он должен быть единственным атрибутом. А для каждой последующей страницы следует указывать как предыдущую и следующую с помощью кода. Так делаем для второй страницы:
Для третьей страницы используем тот же алгоритм:
А в случае, если мы на 4-й странице, которая является последней, то указывается лишь предыдущая в последовательности:
Google использует атрибуты rel=”prev”/”next”, чтобы объединить страницы цепочки в одно целое в своем индексе. В основном репрезентативной становится первая страничка последовательности, поскольку она подходит больше всего.
Нюансы
- Google воспринимает rel=”prev” и rel=”next” как вспомогательные атрибуты, а не инструкции к выполнению;
- Значениями основных тегов могут выступать абсолютные и относительные URL-адреса;
- При использовании относительной ссылки, любые пути будут определяться в зависимости от базового урла;
- Если Google найдет неточности в разметке на сайте (к примеру, нужные значения атрибутов rel=”prev” или rel=”next” упущены) то в дальнейшем для распознавания контента и индексации страницы будет применяться эвристический алгоритм поисковика;
- Обязательно нужно проверить нет ли дубликатов у первой страницы цепочки.
Преимущества
- этот метод помогает решить проблему с пагинацией без дополнительного внедрения страницы «Смотреть все»;
- его внедрение предполагает лишь незначительные правки в HTML.
Недостатки
- эти атрибуты не принимаются во внимание Яндексом;
- реализация метода может потребовать комплексных мер;
- при вставке ссылок в цепочке нужно быть крайне внимательным.
Решение №4. AJAX и прокрутка Javascript
Возможно, вы уже сталкивались с бесконечной прокруткой (Ajax или JS пагинация ) товаров в интернет-магазинах, где постоянно появляются новые элементы внизу экрана при прокрутке. Несомненно, такой метод является хорошей возможностью оптимизировать юзабилити, но важно его правильно применять.
Эксперты считают, что новые элементы не должны загружаться в автоматическом режиме. В этом контексте подойдет кнопка «Показать больше».
Правильное использование параметров
В случае применения атрибутов rel=”prev”/”next”, пагинация может включать параметры, которые не меняют контент:
- сессионные переменные;
- сортировки;
- изменение количества элементов на странице.
В этом случае мы получим дублированный контент. Для исправления ситуации следует комбинировать rel=”prev”/”next” и rel=”canonical”. Чтобы сделать это, сперва следует убедиться, что все страницы страниц с rel=”prev”/”next” пользуются одинаковым параметром. Во-вторых, для каждого URL с параметром следует зафиксировать отдельную каноническую страницу без этого параметра.
Правильное использование фильтров и rel=”prev”/”next”
Теперь давайте разберем случай, где используются переменные, по которым мы собираемся выдавать уникальный контент, и для нас существенно сберечь такие страницы после фильтрации среди проиндексированных. К примеру, у нас имеется категория кроссовок, и желание сгенерировать посадочные страницы для поисковых рассылок с разными брендами, используя эти параметры в урле.
В таком случае
- не стоит использовать rel=”canonical” для основной категории, если здесь имеется уникальное содержимое;
- создайте для каждой отдельной торговой марки свои уникальные цепочки, используя атрибут rel=”prev”/”next”;
- создайте уникальные мета-теги (заголовки, дескрипшены) для каждого фильтра.
Заключение
Подведем итог, что пагинация это способ нумерации страниц, которая решает ряд проблем связанных с дублированием контента на сайте. В заключение приведем несколько рекомендаций, которые должны помочь с решением проблем пагинации:
- Если у вас есть техническая возможность создать страницу «Просмотреть все» ( и такая страницы не имеет большого размера, загружаются легко), то советуем воспользоваться ею. Ведь Google считает такой вариант хорошим, а Яндекс воспринимает инструкцию rel=”canonical”;
- Но в большинстве ситуаций оптимальным вариантом станет объединение атрибута rel=”next page/prev page” (который воспринимается поисковой системой Google) и мета-тегом robots с атрибутами “noindex” и “follow”, который приемлемый и для Google, и для Яндекса.
Наталия — SEO-эксперт Sitechecker. Она отвечает за блог. Не может жить без создания ценного контента о SEO и диджитал маркетинге.
Проверьте ваш сайт на ошибки
Пагинация: как сделать правильно, инструкция по настройке
Как сделать постраничную пагинацию, оставлять ли страницы пагинации в индексе или закрывать их от индексации страницы пагинации, требования к страницам пагинации поисковых роботов Яндекс и Google.
Примет пагинации на листинге товаров/услуг
Всем привет. Меня зовут Толстенко Александр. Я частный специалист по продвижению сайтов в Яндекс/Google.
Работаю в сфере создания и продвижения сайтов с 2009 года (уже более 13 лет).
Кейсы продвижения и другие статьи, подтверждающие экспертизу, можно посмотреть на сайте marketing-digital.ru или в профиле на vc.ru.
Провожу 10 бесплатных консультаций длительностью 10-15 минут в месяц. Если актуально, пишите в личные сообщения и бронируйте место, контакты в конце.
Что такое пагинация?
Пагинация – это процесс разделения одного большого документа на отдельные динамические страницы с порядковым номером в url которого чаще всего будет get параметр, а иногда и чпу ссылки (примеры ниже).
Употребляя слово: Пагинация, всегда подразумевают страницы листингов товаров или услуг. Т.е. те страницы, где очень много карточек.
- https://site.ru/noutbuki/?page=2 — с гет параметром, вариант 1
- https://site.ru/category/cat1/?PAGEN_1=2 — с гет параметром, вариант 2
- https://site.ru/noutbuki/page=2 — с ЧПУ урлом, вариант 1
- https://site.ru/blog/page/2 — с ЧПУ урлом, вариант 2
�� Варианты исполнения могут быть разные, зависит от реализации программиста, суть от этого не меняется. Будет страница пагинации с ЧПУ или нет — для робота не важно.
Для чего делается показ контента по частям
С помощью страниц пагинация, можно снизить нагрузку на сервер, увеличить скорость загрузки страницы, сделать просмотр больших листингов товаров/услуг более комфортным. По словам Гугл — это позволит повысить позиции оптимизированного сайта в результатах поиска.
Какой способ реализации лучше выбрать
Ниже опишу различные способы реализации, которые рекомендуют поисковые роботы.
Какой конкретно выбрать, каждый решает сам. При продвижении клиентских проектов, я использую классический метод реализации. Из опыта, могу сказать, что если настраивать rel=canonical на страницу категории, ничего критичного не происходит, сайты хорошо чувствуют себя в обоих Яндекс и Google.
Как сделать пагинацию в html
Существует несколько методов реализации
1) Схема rel=prev и rel=next + canonical (Универсальный способ для Яндекс/Google)
Это классическая схема реализации. Правда rel=prev и rel=next сейчас игнорируются Google (Яндекс — никогда, не поддерживал).
Нужно ли использовать атрибуты и в html коде? — В справке Google, написано, что можно, т.к. могут использоваться другими поисковыми роботами.
Требования к настройке для программистов
1.1.) У каждой страницы должен быть уникальный URL. Пример: ?page=n
1.2.) Страницы пагинации НЕ закрыты от индексации в robots.txt или мета-тегом robots
1.3.) С первой страницы пагинации, в .htaccess желательно настроить 301 редирект на основную категорию (Рекомендуется, но обычно не парюсь по этому пункту)
Пример редиректа в .htaccess:
301 https://site.ru/catalog/category?page=1 -> https://site.ru/catalog/category
1.4.) Со второй, третьей и т.д. страниц, настраивается тег каноникал на категорию
Пример атрибута canonical в head на странице пагинации:
1.5.) Если на странице категории размещен текст, он не должен быть на других страницах пагинации
1.6.) title, description и h1 на страницах пагинации оставляем такой же как на главной, чтобы страницы пагинации никак не мешали первой странице категории
1.7.) Не используем идентификаторы фрагментов URL (символ #) для нумерации страниц пагинации с результатами поиска. Поисковые роботы могут не сканировать пагинацию.
2) Пагинация с AJAX подгрузкой контента при нажатии на кнопку «Показать еще»
Для того чтобы увидеть больше результатов, пользователю понадобится нажать кнопку: Показать ещё
У данного способа есть технические нюансы внедрения.
Google бот при первом посещении сайта просканирует его без включенного js, т.е. он не увидит кнопку и ссылку на следующую страницу пагинации. У Яндекса нет таких мощностей, отрендирить страницу.
Если вы хотите избавиться от страниц пагинаций на сайте, реализуйте работу кнопку на js.
Если есть нужно «скормить» роботу ссылку на следующую страницу пагинацию в кнопке: «Показать еще», разместите ссылку на следующую страницу пагинации в теге , зашив ее физически в html.
Т.е. если, открыть сайт в браузере без отключенного js, в html коде должна быть ссылка на следующую страницу пагинации.
Требования к настройке, при данном способе реализации, такие же как в п.1
3) Бесконечная загрузка контента при прокручивании списка (ленивая загрузка)
У данного способа, с технической точки зрения еще больше нюансов в реализации. Описывать все не буду, не обзорная статья, кому интересно — погуглите справку. В справке гугла, подробно об этом написано.
Отличие от п.2 — при прокрутке контента, автоматически подгружается следующая часть результатов, до тех пор, пока результаты не закончится. Ссылки на пагинацию, не выводятся.
4) rel=prev и rel=next + canonical + кнопка «Показать еще», с AJAX подгрузкой контента
На данный момент, самый распространенный способ реализации, который используют маркетплейсы и многие современные интернет магазины.
При нажатии по кнопки: «Показать еще» — без перезагрузки страницы показывают результаты следующей страницы пагинации, без изменения адреса в url
При нажатии на цифрах пагинации — работает классическая схема реализации из п.1
Часто задаваемые вопросы
1) Использовать ли ЧПУ-адреса для пагинации?
Нет, это не обязательно. Робот найдет ссылку и просканирует страницу
2) Что делать со страницами пагинации и сортировки товаров?
Если на такие страницы нет трафика из поисковых систем и их контент во многом идентичен, рекомендуется настраивать атрибут rel=»canonical» тега
3) Что делать, если один товар находится в нескольких категориях с разным url?
Настроить атрибут rel=»canonical», указав какой именно товар оставить в результатах поиска поисковой машине (посмотрите перед этим популярность категории и на какую страницу идет больше трафика в Яндекс.метрике).
4) Как можно закрыть от индексации страницы пагинации?
Страницы пагинации можно закрыть через:
1) robots.txt (низкий приоритет),
2) meta robots (чуть по выше),
3) canonical (рекомендуемый для склеивания страниц)
4) X-Robots-Tag HTTP header (при обращении к url пагинации, робот не будет запрашивать ее содержимое, он получит данные из заголовка от сервера и пропустит ее. Данный метот сложный в реализации, но позволяет не сжирать краулинговый бюджет сайта.)
5) Нужно ли закрывать от индексации страницы пагинации?
Нет. В этом нет необходимости, если настроен атрибут rel=»canonical» в теге
На этом все, спасибо за внимание.
✌ Нужна консультация?
�� Пишите в личные сообщения кодовое слово: «ПагинацияVc»