Моки и стабы
Существует категория классов, которые тестировать весьма просто. Если класс зависит только от примитивных типов данных и не имеет никаких связей с другими бизнес-сущностями, то достаточно создать экземпляр этого класса, «пнуть» его некоторым образом путем изменения свойства или вызова метода и проверить ожидаемое состояние.
Это самый простой и эффективный способ тестирования, и любой толковый дизайн отталкивается от подобных классов, которые являются «строительными блоками» нижнего уровня, на основе которых затем уже строятся более сложные абстракции. Но количество классов, которые живут в такой «изоляции» не много по своей природе. Даже если мы по нормальному выделили всю логику по работе с базой данных (или сервисом) в отдельный класс (или набор классов), то рано или поздно появится кто-то, кто эти классы будет использовать для получения более высокоуровневого поведения и этого «кого-то» тоже нужно будет тестировать.
Но для начала давайте рассмотрим более типичный случай, когда логика по работе с базой данных или внешним сервисом, а также логика обработки этих данных сосредоточена в одном месте.
// Модель представления, предназначенная для управления входом // пользователя в систему public class LoginViewModel < public LoginViewModel() < // Читаем имя последнего пользователя UserName = ReadLastUserName(); >// Имя пользователя; может быть изменено пользователем public string UserName < get; set; >// Логиним пользователя UserName public void Login() < // Не обращаем внимание на дополнительную логику, которая должна быть // выполнена. Считаем что нам достаточно просто сохранить имя текущего // пользователя SaveLastUserName(UserName); >// Читаем имя последнего залогиненного пользователя private string ReadLastUserName() < // Не важно, как она на самом деле реализована . // Просто возвращаем что-нибудь, чтобы компилятор не возражал return "Jonh Doe"; >// Сохраняем имя последнего пользователя private void SaveLastUserName(string lastUserName) < // Опять таки, нам не интересно, как она реализована >> Когда речь заходит о тестировании подобных классов, то обычно эта вью-модель помещается на форму, которая затем тестируется руками Если вместо вью-модели подобное смешивание логики происходит при реализации серверных компонент, то они тестируются путем создания простого консольного приложения, которое будет вызывать необходимые высокоуровневые функции, тестируя, таким образом, весь модуль целиком. В обоих случаях такой вариант тестирования нельзя назвать очень уж автоматическим.
ПРИМЕЧАНИЕ
Не нужно бросать в меня камнями с криками «Да кто сегодня вообще такую хрень написать можно? Ведь уже столько всего написано о вреде такого подхода, да и вообще, у нас есть юнити-шмунити и другие полезности, так что это нереальный баян двадцатилетней давности!». Кстати, да, это баян, но, во-первых, речь не юнитях и других контейнерах, а о базовых принципах, а во-вторых, подобное «интеграционное» тестирование все еще невероятно популярно, во всяком случае, среди многих моих «зарубежных» коллег.
Создания «швов» для тестирования приложения
Даже если не задумываться о том, какое количество новомодных принципов проектирования нарушает наша вью-модель, четко видно, что ее дизайн несколько … убог. Ведь даже если проектировать старым дедовским бучевским методом, то становится понятно, что всю работу по сохранению имени последнего пользователя, логику по работе с базой данных (или другим внешним источником данных) нужно спрятать подальше с глаз долой и сделать это «проблемой» кого-то другого и использовать уже этого «кого-то» в качестве «строительного блока» для получения более высокоуровневого поведения:
internal class LastUsernameProvider < // Читаем имя последнего пользователя из некоторого источника данных public string ReadLastUserName() < return "Jonh Doe"; >// Сохраняем это имя, откуда его можно будет впоследствии прочитать public void SaveLastUserName(string userName) < >> public class LoginViewModel < // Добавляем поле для получения и сохранения имени последнего пользователя private readonly LastUsernameProvider _provider = new LastUsernameProvider(); public LoginViewModel() < // Теперь просто вызываем функцию нового вспомогательного класса UserName = _provider.ReadLastUserName(); >public string UserName < get; set; >public void Login() < // Все действия по сохранению имени последнего пользователя также // делегируем новому классу _provider.SaveLastUserName(UserName); >> Пока что написание модульного теста все еще остается затруднительным, но становится понятным, как можно достаточно просто «подделать» реальную реализацию класса LastUsernameProvider и сымитировать нужное для нас поведение. Достаточно выделить методы этого класса в отдельный интерфейс или просто сделать их виртуальными и переопределить в наследнике. После чего останется лишь «прикрутить» нужный нам объект в нашу вью-модель.
Честно говоря, я не большой фанат изменений в дизайне только ради «тестируемости» кода. Как показывает практика, нормальный ОО дизайн либо уже является достаточно «тестируемым» или же требует лишь минимальных телодвижений, чтобы сделать его таковым. Некоторые дополнительные мысли по этому поводу можно найти в заметке «Идеальная архитектура» .
Даже не прибегая ни к каким сторонним библиотекам для «инджекта» зависимостей мы можем сделать это самостоятельно несколько простыми способами. Нужную зависимость можно передать через дополнительный конструктор, через свойство или создать фабричный метод, который будет возвращать интерфейс ILastUsernmameProvider.
Давайте рассмотрим вариант с конструктором, который является довольно простым и популярным (при небольшом количестве внешних зависимостей он работает просто прекрасно).
// Выделяем методы в интерфейс internal interface ILastUsernameProvider < string ReadLastUserName(); void SaveLastUserName(string userName); >internal class LastUsernameProvider : ILastUsernameProvider < // Читаем имя последнего пользователя из некоторого источника данных public string ReadLastUserName() < return "Jonh Doe"; >// Сохраняем это имя, откуда его можно будет впоследствии прочитать public void SaveLastUserName(string userName) < >> public class LoginViewModel < private readonly ILastUsernameProvider _provider; // Единственный открытый конструктор создает реальный провайдер public LoginViewModel() : this(new LastUsernameProvider()) <>// "Внутренний" предназначен только для тестирования и может принимать "фейк" internal LoginViewModel(ILastUsernameProvider provider) < _provider = provider; UserName = _provider.ReadLastUserName(); >public string UserName < get; set; >public void Login() < _provider.SaveLastUserName(UserName); >> Поскольку дополнительный конструктор является внутренним (internal), то он доступен только внутри этой сборке, а также «дружеской» сборке юнит-тестов. Конечно, если тестируемые классы являются внутренними не будет не какой, но поскольку все «клиенты» внутреннего класса находятся в одной сборке, то и контролировать их проще. Подобный подход, основанный на добавлении внутреннего метода для установки «фальшивого» поведения является разумным компромиссом упрощения тестирования кода, не налагая ограничения на использования более сложных механизмов управления зависимостями, типа IoC контейнеров.
ПРИМЕЧАНИЕ
Одним из недостатков при работе с интерфейсами является падение читабельности, поскольку не понятно, сколько реализаций интерфейса существует и где находится реализация того или иного метода интерфейса. Такие инструменты, как Решарпер существенно смягчают эту проблему, поскольку поддерживают не только навигацию к объявлению метода (Go To Declaration), но также и навигацию к реализации метода (Go To Implementation):
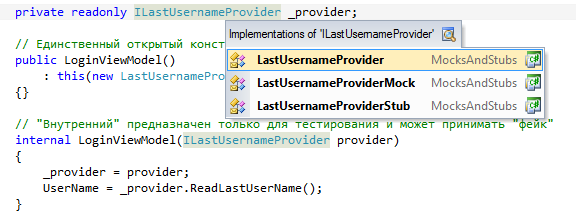
Проверка состояния vs проверка поведения
Теперь давайте попробуем написать юнит-тест вначале для конструктора класса LoginViewModel, который получает имя последнего залогиненного пользователя, а потом юнит-тест для метода Login, после выполнения которого, имя последнего пользователя должно быть сохранено.
Для нормальной реализации этих тестов нам нужна «фейковая» реализация интерфейса, при этом в первом случае, нам нужно вернуть произвольное имя последнего пользователя в методе ReadLastUserName, а во втором случае – удостовериться, что вызван метод SaveLastUserName.
Именно в этом и отличаются два типа «фейковых» классов: стабы предназначены для получения нужного состояния тестируемого объекта, а моки применяются для проверки ожидаемого поведения тестируемого объекта.
Стабы никогда не применяются в утверждениях, они простые «слуги», которые лишь моделируют внешнее окружение тестового класса; при этом в утверждениях проверяется состояние именно тестового класса, которое зависит от установленного состояния стаба.
// Стаб возвращающее указанное имя последнего пользователя internal class LastUsernameProviderStub : ILastUsernameProvider < // Добавляем публичное поле, для простоты тестирования и // возможности повторного использования этого класса public string UserName; // Реализация метода очень простая - просто возвращаем UserName public string ReadLastUserName() < return UserName; >// Этот метод в данном случае вообще не интересен public void SaveLastUserName(string userName) < >> [TestFixture] public class LoginViewModelTests < // Тестовый метод для проверки правильной реализации конструктора вью-модели [Test] public void TestViewModelConstructor() < var stub = new LastUsernameProviderStub(); // "моделируем" внешнее окружение stub.UserName = "Jon Skeet"; // Ух-ты!! var vm = new LoginViewModel(stub); // Проверяем состояние тестируемого класса Assert.That(vm.UserName, Is.EqualTo(stub.UserName)); >> У моков же другая роль. Моки «подсовываются» тестируемому объекту, но не для того, чтобы создать требуемое окружение (хотя они могут выполнять и эту роль), а прежде всего для того, чтобы потом можно было проверить, что тестируемый объект выполнил требуемые действия. (Именно поэтому такой вид тестирования называется behaviortesting, в отличие от стабов, которые применяются для state—basedtesting).
// Мок позволяет проверить, что метод SaveLastUserName был вызван // с определенными параметрами internal class LastUsernameProviderMock : ILastUsernameProvider < // Теперь в этом поле будет сохранятся имя последнего сохраненного пользователя public string SavedUserName; // Нам все еще нужно вернуть правильное значение из этого метода, // так что наш "мок" также является и "стабом" public string ReadLastUserName() < return "Jonh Skeet";>// А вот в этом методе мы сохраним параметр в SavedUserName для public void SaveLastUserName(string userName) < SavedUserName = userName; >> // Проверяем, что при вызове метода Login будет сохранено имя последнего пользователя [Test] public void TestLogin() < var mock = new LastUsernameProviderMock(); var vm = new LoginViewModel(mock); // Изменяем состояние вью-модели путем изменения ее свойства vm.UserName = "Bob Martin"; // А затем вызываем метод Login vm.Login(); // Теперь мы проверяем, что был вызван метод SaveLastUserName Assert.That(mock.SavedUserName, Is.EqualTo(vm.UserName)); >А зачем мне знать об этих отличиях?
Действительно, разница в понятиях может показаться незначительной, особенно если вы реализуете подобные «фейки» руками. В этом случае знание этих паттернов лишь позволит говорить с другими разработчиками на одном языке и упростит наименование фейковых классов.
Однако рано или поздно вам может надоесть это чудесное занятие по ручной реализации интерфейсов и вы обратите свое внимание на один из Isolation фреймворков, таких как Rhino Mocks, Moq или Microsoft Moles. Там эти термины встретятся обязательно и понимание отличий между этими типами фейков вам очень пригодится.
Я осознанно не касался ни одного из этих фреймворков, поскольку каждый из них заслуживает отдельной статьи и ИМО лишь усложнит понимание этих понятий. Но если вам все же интересно посмотреть на некоторые из этих фреймворков более подробно, то об одном из них я писал более подробно: “Microsoft Moles”.
Что такое криптор и стаб ?
Криптор (aka cryptor) — это тулза, которая предназначена для скрытия троянов, ботов и прочей нечисти от детектирования антивирусами.

Хорошие крипторы работают очень просто, быстро и надёжно, хоть и не безглючно. Они дописывают свой код (в контексте таких крипторов этот код называется стабом) в криптуемую программу и шифруют код самой программы. При запуске первым стартует стаб, он восстанавливает оригинальный код и программа начинает работать. Если криптор свежий (или просто хороший, об этом ниже), то закриптованная программа не будет детектироваться антивирусами.
Чаще всего такие крипторы полиморфны — т.е. код криптора в криптуемой программе каждый раз уникален, заполнен случайными инструкциями и бессмысленными вызовами функций API. Такие крипторы достаточно долго остаются недетектируемыми в силу уникальности каждого закриптованного файла. Такие крипторы тоже со временем детектируются, и если автор не чистит свой продукт, то криптор перестает быть уникальным.
Суть работы плохих крипторов вот в чем — есть стаб. Стаб в этом случае — это отдельная программа, к которой цепляется криптуемый файл. При запуске файл извлекается, расшифровывается и запускается.
Т.е. надеюсь поняли отличия в первом случае шифруется код программы, и стаб расшифровывает уже команды программы, а во втором случае шифруется сам файл программы и расшифровывается тоже сам файл, ну и понятно, что второй тип криптора это не что иное как ерунда, т.к. практически любой антивирусник спалит вирус при расшифровке ! 😉
Некоторые крипторы напрямую файл на диск не пишут, а запускают его из памяти, но это их не оправдывает, т.к. продвинутый антивирус словит это при запуске.
В таких крипторах уникальность каждого закриптованного файла достигается разными стабами. Но такой подход весьма ограничен — в хороших криптах это всего-лишь код, и его можно сгенерировать, а со стабами в плохих крипторах уже сложнее, поэтому авторы чаще всего создают под каждого клиента отдельный стаб. Подход глуп до безобразия, ведь ежели спалится антивирусами один закриптованный файл — за ним полетят и все остальные.
По хардкору: дублеры, моки, стабы
Сегодня о тестах. Пост для тех, кто знаком с RSpec, но не понимает, что такое «мокать» и «застабить». Коротко, по делу и с примерами.
Дублер (test double)
Объект-каскадер, подменяющий реальный объект системы во время тестов:
describe NotificationsController do # NotificationsController загружает последние уведомления # со стороннего сервиса по HTTP # с помощью NotificationsDatasource. let(:datasource) do double(:datasource, as_json: notifications: [] >) end before do # Подменяем реальный NotificationsDatasource дублером, # чтобы не зависеть от внешнего сервиса в тестах: allow(NotificationsDatasource) .to receive(:new) .and_return(datasource) end describe "#index" do it "wraps notifications in 'data' key" do get :index, format: :json expect(json_response["data"].keys) .to have_key "notifications" end end end Стаб (stub)
Заглушка для метода или объекта, возвращающая заданное значение:
context "when attachment file is too large to email" do let(:max_file_size) Attachment::MAX_FILE_SIZE > before do allow(attachment) .to receive(:file_size) .and_return(max_file_size + 1) end it "raises 'file is too large' error" do # . end end Внимательный читатель со звездочкой уже заметил, что и в предыдущем примере с NotificationsController был стаб. Все верно: стаб — это дублер с зашитыми ответами.
Мок (mock)
Стаб с ожиданиями, которые RSpec проверит в конце теста:
context "when cloning process cannot be performed" do before do allow(doctor).to receive(:clone) raise "can't clone" > # стаб end it "notifies airbrake" do expect(Airbrake).to receive(:notify) # мок # Rspec застабит `Airbrake.notify` # и в конце этого `it do. end` блока # проверит, был ли он вызван. # Если вызова не было — ошибка и красный тест. # # Когда на собеседовании спросят, чем # отличается мок от стаба, отвечайте: # «Только мок может завалить тест». clone_poor_dolly end end Моки меняют порядок фаз в тесте. Вместо «Подготовка — Испытание — Проверка» получается «Проверка+Подготовка — Испытание». Если вам, как и мне, тяжело такое читать, используйте стаб с проверкой:
# мок it "notifies airbrake" do expect(Airbrake).to receive(:notify) # проверка + настройка clone_poor_dolly # испытание end # стаб + проверка it "notifies airbrake" do allow(Airbrake).to receive(:notify) # настройка clone_poor_dolly # испытание expect(Airbrake).to have_received(:notify) # проверка end Дублеры, моки и стабы привязывают тесты к интерфейсу используемого объекта, а реальные объекты — к их реализации. Чтобы узнать об этой дилемме больше и понять, стоит ли вам мокать-стабить все подряд, почитайте:
- Mocks Aren’t Stubs;
- Thoughts on Mocking, Part 2;
- Thoughts on Mocking.
P. S. Ещё больше постов о программировании, тестах и культуре разработки у меня в Телеграме.
⊙ 30 апреля 2016
Поделиться
Поделиться
- Стоп-комментарии
- ← →
- По хардкору: instance_double, verify_partial_doubles

Тестовый курс
Практический курс о тестировании в Ruby и Rails. С наставником, теорией, домашкой и дополнительными материалами: статьями, советами, видео.
Для разработчиков знакомых с Ruby и RSpec, но не до конца понимающих что и как тестировать. Для тех, кто прочитал RSpec Book, но не может написать тест с нуля. Для тех, кто исправляет баг за 5 минут, а потом 2 часа пишет тест.
Популярное
- Stylus → PostCSS
- Анти-паттерны в тестах
- По хардкору: что писать в комментарии к коммиту
- Ищу стажеров (уже нашел)
- По хардкору: describe и context
- Три правила ревью
- CSS инбоксы
- Дезодоранты и полезные комментарии
- Подростковое тестирование. Подборка
Из старого
- 3д-печать и ФФФ
- Баготерапия
- Дефолтные стили браузеров
- Просто не делай херни
- Датчик есть, но его как бы нет
- Большая маленькая ложь
- Карма тестировщика
- irb: echo on assignment
- Как тестировать код, завязанный на рандом
- Лайфхак: процедура завершения работы
- RSpec: to be_within().of()
- SPA на Реакте без Вебпака
- RSpec: skip и pending
- SSRF
- Range в ActiveRecord
- Не надо везде лепить восклицательные знаки!
- Планирование преемственности
- yakuake в iTerm
- Мониторинг ключевых метрик приложения на Рельсах в Графане
- Лайфхак: буферы для совещаний
- Проблема в занятости, а не в лени
- before + after → around
- Лайфхак: талоны за дипворк
- inbox.txt
- RSpec & Rails: как проверить deliver_later(wait_until: . )
- Стабы и моки юникс-сокетов
- А у нас Faker
- Фейковые данные в тестах
- Как тестировать код, работающий с внешним АПИ. Заглушка на Синатре
- На каких задачах сфокусироваться
- Тормоза mc на m1, zsh и nvm
- Как читать больше в эпоху цифрового максимализма
- Менеджерский лайфхак: 1:1 в Телеграме
- Задавать вопросы, а не перебирать варианты
- Ищу толкового стажера на Рельсах
- Достроить, чтобы обойти
- Заглушка из Rack-приложения в одну строчку
- Лайфхак: поработать в машине
- Линтим Руби в Виме
- Курс о профессиональном росте. Как расти самому, как растить команду
- Сервисы головного мозга
- «Что» и «Чтобы что» в пулреквестах
- Где проходит грань в изолированности объекта тестирования?
- Только то, что важно для проверки
- Меньше — лучше
- Пора валить?
- Когда использовать double, а не instance_double?
- RSpec: before и after хуки
- Как застабить переменные окружения в RSpec
- Что не нужно писать в it
- RuboCop, RSpec и стайлгад
- Как протестировать конфиг whenever
- Один тест — одна логическая проверка
- Обратная связь в тестах, guard и vim-test
- Не проверяйте отдельно ключи
- Не тестируйте attr_reader/_writer/_accessor
- Ищу сообразительного стажёра
- Только то, что влияет на проверку
- Какой тест упадет, если удалим этот кусок кода?
- Как отлаживать странное: в браузере на реальном Айфоне через Скайп, Зум или Хэнгаут
- let и before
- Впихнуть все в expect
- Сэнди Метц
- Конспект POODR. Reducing Costs with Duck Typing
- Конспект POODR. Creating Flexible Interfaces
- Конспект POODR. Managing Dependencies
- Конспект POODR. Designing Classes with a Single Responsibility
- Конспект POODR. Object-Oriented Design
- Ищу толкового стажёра
- Что почитать начинающему тимлиду
- Советы
- Сравнение CI-сервисов
- Как тестировать коллбэки ActiveRecord моделей
- Гигиена в тестах
- Проблемы с subject
- Стоит почитать
- По хардкору: instance_double, verify_partial_doubles
- Стоп-комментарии
- Сегодня я узнал
- Управление временем
- Хороший доклад
- К Оптимусу Прайму. Группировка CSS свойств
- Объясни это
- К Оптимусу Прайму. Сортировка CSS свойств по алфавиту
- Два способа признаться в ненависти к человечеству
- Реквием по ИЕ
- Былинное программирование
- Иисус и псевдоэлементы
- Удаленные мудаки
- Пусть страдают роботы
- Как пользоваться успехом у женщин с помощью CSS
- Воинствующие шаблонисты
- Нет, это дизайнерский таск
- Синдром бойлерной
- Рабочие столы
- Союз скобок
Чудес не бывает или я ошибаюсь?
Когда мы начали изучать модульное тестирование, то одними из первых терминов, с которыми пришлось познакомиться, стали Mock и Stub.
Ниже попробуем порассуждать в чем их сходство и различие, как и для чего они применяются.
Проверять работоспособность тестируемого объекта (system under test — SUT) можно двумя способами: оценивая состояние объекта или его поведение.
В первом случае проверка правильности работы метода SUT заключается в оценке состояния самого SUT, а также взаимодействующих объектов, после вызова этого метода.
Во-втором, мы проверяем набор и порядок действий (вызовов методов взаимодействующих объектов, других методов SUT), которое должен совершить метод SUT.
Собственно, если коротко, то в одном случае используется Stub, а в другом Mock. Это объекты, которые создаются и используются взамен реальных объектов, с которым взаимодействует SUT в процессе своей работы.
Gerard Meszaros использует термин Test Double (дублер), как обозначение для объекта, который заменяет реальный объект, от которого зависит SUT, в тестовых целях.
- Низкая скорость выполнения тестов с реальными объектами (если это, например, работа с базой, файлами, почтовым сервером и т.п.)
- Когда есть необходимость запуска тестов независимо от окружения (например, на машине у любого разработчика)
- Система, в которой работает код, не дает возможности (или дает, но это сложно делать) запустить код с определенным входным набором данных.
- Нет возможности проверить, что SUT отработал правильно, например, он меняет не свое состояние, а состояние внешней системы. И там эту проверку сделать сложно.
Fake — это объекты, которые имеют внутреннюю реализацию, но обычно она сильно урезанная и их нельзя использовать в готовом коде.
Stubs — обеспечивают жестко зашитый ответ на вызовы во время тестирования. Применяются для замены тех объектов, которые обеспечивают SUT входными данными. Также они могут сохранять в себе информацию о вызове (например параметры или количество этих вызовов) — такие иногда называют своим термином Test Spy. Такая «запись» позволяет оценить работу SUT, если состояние самого SUT не меняется.
Mocks — объекты, которые настраиваются (например, специфично каждому тесту) и позволяют задать ожидания в виде своего рода спецификации вызовов, которые мы планируем получить. Проверки соответствия ожиданиям проводятся через вызовы к Mock-объекту.
Из всех этих doubles только Mock’и работают на верификацию поведения. Остальные, как правило, используются для проверки состояния. В момент выполнения метода SUT использование doubles не отличается. Но Mock’и и некоторые Stub’ы требуют настроек перед запуском и позволяют оценить процесс выполнения.
Итого: если проверка результатов выполнения осуществляется через вызовы к double, то это Mock, если в ассертах мы анализируем состояние SUT, то это, скорее всего, Stub.
В классическом варианте модульного тестирования реальные объекты используются везде, где это возможно (за исключением случаев описанных выше). В мокирующем (mockist) варианте — мокируется все, кроме того объекта, который тестируем (SUT).
Какой использовать?
Плюсы и минусы есть у обоих. Остановимся на минусах.
При использовании классического подхода, когда все в тестах — это реальные объекты, в случае ошибки в одном из методов реального объекта, «красными» станут все тесты, в которых этот метод используется (независимо от того, тестируется он в них или просто используется другим объектом). Локализация проблемы может стать трудной задачей, если при написании тестов, вы не задумывались над гранулярностью теста: его минимально необходимыми зависимостями.
В обратную сторону, при мокировании всего и вся может возникнуть другая проблема: поведенческие тесты жестко фиксируют внутреннюю реализацию SUT. Что и как вызывается, с какими аргументами, какое API используется и тп. Все это создает трудности при рефакторинге и возможных изменениях в SUT, фактически «цементируя» код и вместе с изменением кода все тесты придется писать заново.
Что проще, выбирать вам. Из своего опыта скажу, что классика мне ближе и понятней (радует, что и Martin Fowler того же мнения). А вот с мокированием как-то не срослось.
И, пожалуйста, не мокируйте ничего в приемочных тестах — там все должно быть в живую, иначе тесты вас обманут. Неоднократно убеждался в этом на личном опыте. Хотя, если у вас в тестах идут запросы к API внешнего сервиса типа Facebook, то тут есть над чем подумать и скорее всего их имеет смысл замокировать в части тестов.
Источники:
Mocks Aren’t Stubs (Martin Fowler)
Test Double (Gerard Meszaros)
Некоторые фреймворки для мокирования (update 2020: список очень давно не обновлялся):
- Java: mockito, jMock
- .Net Rhino Mocks, moq
- C++ googlemock
- Python pyDoubles, mockito-python
«Software-Engineering Myth Busters (покрытие кода тестами, TDD, организация и распределенные команды)»
Забавные факты:
Что вы знаете о моках? Оказывается, есть целые mock-города для тестирования автономных автомобилей. Вот про один из них.