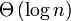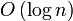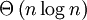Куча (память)
Ку́ча (англ. heap ) в информатике и программировании — название структуры данных, с помощью которой реализована динамически распределяемая память приложения, а также объём памяти, зарезервированный под эту структуру.
Организация
Куча использует память, выделяемую динамически или запрошенную статически у операционной системы. Эта память используется для размещения объектов, динамически созданных программой.
В любой момент времени существования кучи вся память, на которой работает куча, разделена на занятую и свободную. Занятая память использована под размещение объектов, уже созданных и ещё не освобождённых к этому моменту времени. Из объёма свободной памяти примитивы работы с кучей могут выделять память под новые объекты.
Для хранения данных о принадлежности памяти к занятой или свободной обычно используется дополнительная область памяти.
Принцип работы
Для размещения и удаления динамических объектов используются примитивы «создать объект» (например, malloc) и «удалить объект» (например, free). Кроме того, перед началом работы программы выполняется инициализация кучи, в ходе которой вся изначально выделенная под кучу память отмечается как свободная.
При размещении объекта реализация примитива «создать объект» просматривает доступную куче свободную память в поисках возможности разместить в ней объект требуемого размера. Многие реализации примитивов кучи могут в случае нехватки собственной свободной памяти запросить дополнительную память у операционной системы. В случае, если по тем или иным причинам разместить объект невозможно, примитив «создать объект» сообщает об ошибке (например, malloc возвращает NULL). Выбранная область памяти отмечается как занятая. Примитив возвращает адрес начала выделенной области.
При удалении объекта реализация примитива «удалить объект» отмечает, что область, ранее использованная удаляемым объектом, теперь свободна.
В промежутках между вызовами примитивов «создать объект» и «удалить объект» выделенная под объект область памяти не может быть отдана ни под какой другой объект. Поэтому приложение может свободно пользоваться выделенной ему областью памяти. В то же время, после вызова примитива «удалить объект» освобождённая область может быть использована повторно или отдана операционной системе, поэтому использование указателя, полученного ранее от примитива «создать объект», будет приводить к сбоям или непредсказуемой работе программы.
Вызовы функций библиотек обычно происходят быстрее и требуют меньше ресурсов на исполнение, чем вызовы системных прерываний или системных API-функций.
Алгоритмы кучи и производительность
Куча — длинный отрезок адресов памяти, поделенный на подряд идущие блоки различных размеров.
Блоки бывают свободные и занятые. Для возможности выделения памяти путем повторного использования свободного блока (без дорогостоящего увеличения кучи в целом — требует системного вызова) в том или ином виде нужен список свободных блоков.
Для сокращения списка свободных блоков с целью уменьшения времени его обхода всегда имеет смысл сливать 2 или 3 подряд идущих свободных блока в один. Если свободен последующий блок, то его легко найти, отступив вперед на размер освобождаемого блока. С предыдущим блоком все сложнее, и потому имеет смысл хранить размер предыдущего блока (для его поиска) в заголовке любого блока.
Список свободных блоков может быть организован по-разному, и от его организации прямо зависит производительность кучи. Дело в том, что главное время в операции выделения тратится именно на поиск в этом списке.
Очень хорошей реализацией является несколько списков, каждый для своего размера. Это позволяет быстро проигнорировать заведомо слишком маленькие свободные блоки целыми списками, без проверки каждого персонально.
Основные принципы программирования: стек и куча
Мы используем всё более продвинутые языки программирования, которые позволяют нам писать меньше кода и получать отличные результаты. За это приходится платить. Поскольку мы всё реже занимаемся низкоуровневыми вещами, нормальным становится то, что многие из нас не вполне понимают, что такое стек и куча, как на самом деле происходит компиляция, в чём разница между статической и динамической типизацией, и т.д. Я не говорю, что все программисты не знают об этих понятиях — я лишь считаю, что порой стоит возвращаться к таким олдскульным вещам.
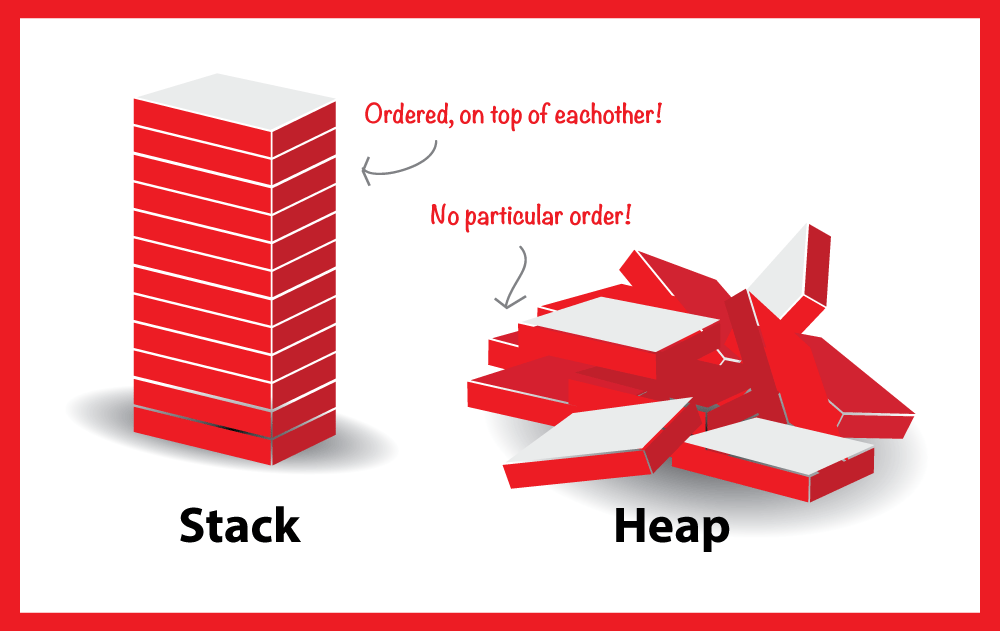
Сегодня мы поговорим лишь об одной теме: стек и куча. И стек, и куча относятся к различным местоположениям, где происходит управление памятью, но стратегия этого управления кардинально отличается.
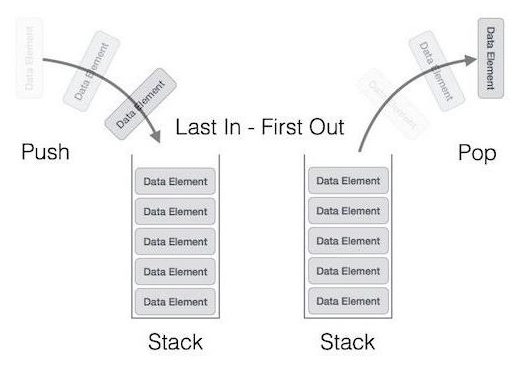
Стек
Стек — это область оперативной памяти, которая создаётся для каждого потока. Он работает в порядке LIFO (Last In, First Out), то есть последний добавленный в стек кусок памяти будет первым в очереди на вывод из стека. Каждый раз, когда функция объявляет новую переменную, она добавляется в стек, а когда эта переменная пропадает из области видимости (например, когда функция заканчивается), она автоматически удаляется из стека. Когда стековая переменная освобождается, эта область памяти становится доступной для других стековых переменных.
Имидж в IT: как junior-программисту заявить о себе
Из-за такой природы стека управление памятью оказывается весьма логичным и простым для выполнения на ЦП; это приводит к высокой скорости, в особенности потому, что время цикла обновления байта стека очень мало, т.е. этот байт скорее всего привязан к кэшу процессора. Тем не менее, у такой строгой формы управления есть и недостатки. Размер стека — это фиксированная величина, и превышение лимита выделенной на стеке памяти приведёт к переполнению стека. Размер задаётся при создании потока, и у каждой переменной есть максимальный размер, зависящий от типа данных. Это позволяет ограничивать размер некоторых переменных (например, целочисленных), и вынуждает заранее объявлять размер более сложных типов данных (например, массивов), поскольку стек не позволит им изменить его. Кроме того, переменные, расположенные на стеке, всегда являются локальными.
В итоге стек позволяет управлять памятью наиболее эффективным образом — но если вам нужно использовать динамические структуры данных или глобальные переменные, то стоит обратить внимание на кучу.
Куча
Куча — это хранилище памяти, также расположенное в ОЗУ, которое допускает динамическое выделение памяти и не работает по принципу стека: это просто склад для ваших переменных. Когда вы выделяете в куче участок памяти для хранения переменной, к ней можно обратиться не только в потоке, но и во всем приложении. Именно так определяются глобальные переменные. По завершении приложения все выделенные участки памяти освобождаются. Размер кучи задаётся при запуске приложения, но, в отличие от стека, он ограничен лишь физически, и это позволяет создавать динамические переменные.
Вы взаимодействуете с кучей посредством ссылок, обычно называемых указателями — это переменные, чьи значения являются адресами других переменных. Создавая указатель, вы указываете на местоположение памяти в куче, что задаёт начальное значение переменной и говорит программе, где получить доступ к этому значению. Из-за динамической природы кучи ЦП не принимает участия в контроле над ней; в языках без сборщика мусора (C, C++) разработчику нужно вручную освобождать участки памяти, которые больше не нужны. Если этого не делать, могут возникнуть утечки и фрагментация памяти, что существенно замедлит работу кучи.
Разработка на C++ с нуля в 2022 году: дорожная карта
В сравнении со стеком, куча работает медленнее, поскольку переменные разбросаны по памяти, а не сидят на верхушке стека. Некорректное управление памятью в куче приводит к замедлению её работы; тем не менее, это не уменьшает её важности — если вам нужно работать с динамическими или глобальными переменными, пользуйтесь кучей.
Заключение
Вот вы и познакомились с понятиями стека и кучи. Вкратце, стек — это очень быстрое хранилище памяти, работающее по принципу LIFO и управляемое процессором. Но эти преимущества приводят к ограниченному размеру стека и специальному способу получения значений. Для того, чтобы избежать этих ограничений, можно пользоваться кучей — она позволяет создавать динамические и глобальные переменные — но управлять памятью должен либо сборщик мусора, либо сам программист, да и работает куча медленнее.
Куча (программирование)
Сортирующее дерево (куча, пирамида) — такое двоичное дерево, для которого выполнены два условия:
- Каждый лист имеет глубину либо d либо d-1
- Значение в любой вершине больше (меньше), чем значения ее потомков.
структура данных для хранения сортирующего дерева
Удобная структура данных для сортирующего дерева — такой массив Array, что Array[1] — элемент в корне, а потомки элемента Array[i] — Array[2i] и Array[2i+1].