Архитектура хранилищ данных: традиционная и облачная
Привет, Хабр! На тему архитектуры хранилищ данных написано немало, но так лаконично и емко как в статье, на которую я случайно натолкнулся, еще не встречал.
Предлагаю и вам познакомиться с данной статьей в моем переводе. Комментарии и дополнения только приветствуются!
Введение
Итак, архитектура хранилищ данных меняется. В этой статье рассмотрим сравнение традиционных корпоративных хранилищ данных и облачных решений с более низкой первоначальной стоимостью, улучшенной масштабируемостью и производительностью.
Хранилище данных – это система, в которой собраны данные из различных источников внутри компании и эти данные используются для поддержки принятия управленческих решений.
Компании все чаще переходят на облачные хранилища данных вместо традиционных локальных систем. Облачные хранилища данных имеют ряд отличий от традиционных хранилищ:
- Нет необходимости покупать физическое оборудование;
- Облачные хранилища данных быстрее и дешевле настроить и масштабировать;
- Облачные хранилища данных обычно могут выполнять сложные аналитические запросы гораздо быстрее, потому что они используют массовую параллельную обработку.
Традиционная архитектура хранилища данных
Следующие концепции освещают некоторые из устоявшихся идей и принципов проектирования, используемых для создания традиционных хранилищ данных.
Трехуровневая архитектура
Довольно часто традиционная архитектура хранилища данных имеет трехуровневую структуру, состоящую из следующих уровней:
- Нижний уровень: этот уровень содержит сервер базы данных, используемый для извлечения данных из множества различных источников, например, из транзакционных баз данных, используемых для интерфейсных приложений.
- Средний уровень: средний уровень содержит сервер OLAP, который преобразует данные в структуру, лучше подходящую для анализа и сложных запросов. Сервер OLAP может работать двумя способами: либо в качестве расширенной системы управления реляционными базами данных, которая отображает операции над многомерными данными в стандартные реляционные операции (Relational OLAP), либо с использованием многомерной модели OLAP, которая непосредственно реализует многомерные данные и операции.
- Верхний уровень: верхний уровень — это уровень клиента. Этот уровень содержит инструменты, используемые для высокоуровневого анализа данных, создания отчетов и анализа данных.

Kimball vs. Inmon
Два пионера хранилищ данных: Билл Инмон и Ральф Кимбалл предлагают разные подходы к проектированию.
Подход Ральфа Кимбалла основывается на важности витрин данных, которые являются хранилищами данных, принадлежащих конкретным направлениям бизнеса. Хранилище данных — это просто сочетание различных витрин данных, которые облегчают отчетность и анализ. Проект хранилища данных по принципу Кимбалла использует подход «снизу вверх».
Подход Билла Инмона основывается на том, что хранилище данных является централизованным хранилищем всех корпоративных данных. При таком подходе организация сначала создает нормализованную модель хранилища данных. Затем создаются витрины размерных данных на основе модели хранилища. Это известно как нисходящий подход к хранилищу данных.
Модели хранилищ данных
В традиционной архитектуре существует три общих модели хранилищ данных: виртуальное хранилище, витрина данных и корпоративное хранилище данных:
- Виртуальное хранилище данных — это набор отдельных баз данных, которые можно использовать совместно, чтобы пользователь мог эффективно получать доступ ко всем данным, как если бы они хранились в одном хранилище данных;
- Модель витрины данных используется для отчетности и анализа конкретных бизнес-линий. В этой модели хранилища – агрегированные данные из ряда исходных систем, относящихся к конкретной бизнес-сфере, такой как продажи или финансы;
- Модель корпоративного хранилища данных предполагает хранение агрегированных данных, охватывающих всю организацию. Эта модель рассматривает хранилище данных как сердце информационной системы предприятия с интегрированными данными всех бизнес-единиц
Звезда vs. Снежинка
Схемы «звезда» и «снежинка» — это два способа структурировать хранилище данных.
Схема типа «звезда» имеет централизованное хранилище данных, которое хранится в таблице фактов. Схема разбивает таблицу фактов на ряд денормализованных таблиц измерений. Таблица фактов содержит агрегированные данные, которые будут использоваться для составления отчетов, а таблица измерений описывает хранимые данные.
Денормализованные проекты менее сложны, потому что данные сгруппированы. Таблица фактов использует только одну ссылку для присоединения к каждой таблице измерений. Более простая конструкция звездообразной схемы значительно упрощает написание сложных запросов.
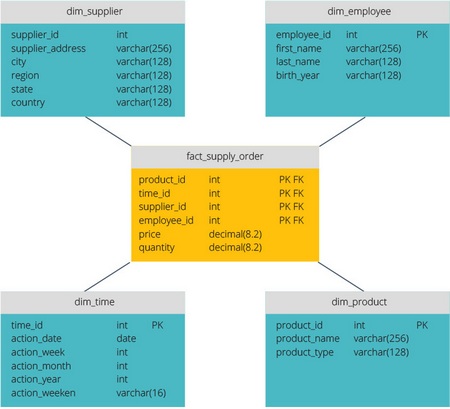
Схема типа «снежинка» отличается тем, что использует нормализованные данные. Нормализация означает эффективную организацию данных так, чтобы все зависимости данных были определены, и каждая таблица содержала минимум избыточности. Таким образом, отдельные таблицы измерений разветвляются на отдельные таблицы измерений.
Схема «снежинки» использует меньше дискового пространства и лучше сохраняет целостность данных. Основным недостатком является сложность запросов, необходимых для доступа к данным — каждый запрос должен пройти несколько соединений таблиц, чтобы получить соответствующие данные.
ETL vs. ELT
ETL и ELT — два разных способа загрузки данных в хранилище.
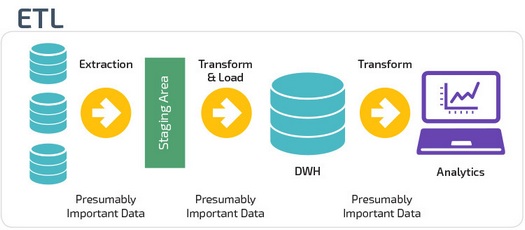
ETL (Extract, Transform, Load) сначала извлекают данные из пула источников данных. Данные хранятся во временной промежуточной базе данных. Затем выполняются операции преобразования, чтобы структурировать и преобразовать данные в подходящую форму для целевой системы хранилища данных. Затем структурированные данные загружаются в хранилище и готовы к анализу.
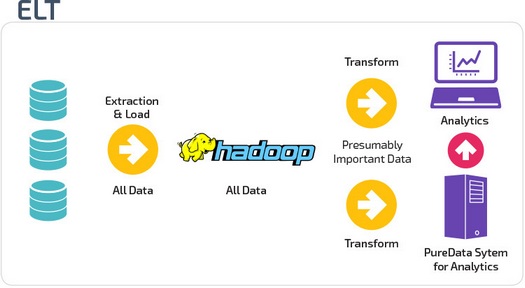
В случае ELT (Extract, Load, Transform) данные сразу же загружаются после извлечения из исходных пулов данных. Промежуточная база данных отсутствует, что означает, что данные немедленно загружаются в единый централизованный репозиторий.
Данные преобразуются в системе хранилища данных для использования с инструментами бизнес-аналитики и аналитики.
Организационная зрелость
Структура хранилища данных организации также зависит от его текущей ситуации и потребностей.
Базовая структура позволяет конечным пользователям хранилища напрямую получать доступ к сводным данным, полученным из исходных систем, создавать отчеты и анализировать эти данные. Эта структура полезна для случаев, когда источники данных происходят из одних и тех же типов систем баз данных.
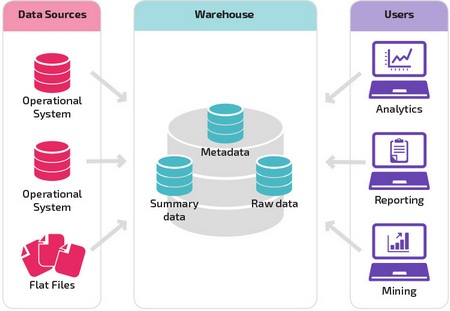
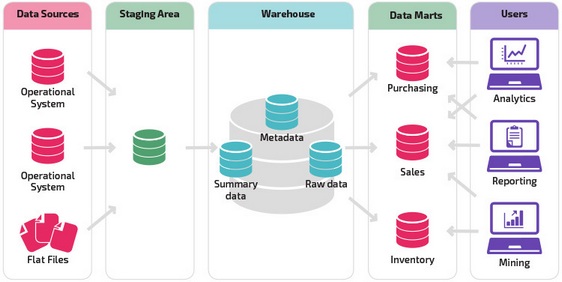
Хранилище с промежуточной областью является следующим логическим шагом в организации с разнородными источниками данных с множеством различных типов и форматов данных. Промежуточная область преобразует данные в обобщенный структурированный формат, который проще запрашивать с помощью инструментов анализа и отчетности.

Одной из разновидностей промежуточной структуры является добавление витрин данных в хранилище данных. В витринах данных хранятся сводные данные по конкретной сфере деятельности, что делает эти данные легко доступными для конкретных форм анализа.
Например, добавление витрин данных может позволить финансовому аналитику легче выполнять подробные запросы к данным о продажах, прогнозировать поведение клиентов. Витрины данных облегчают анализ, адаптируя данные специально для удовлетворения потребностей конечного пользователя.
Новые архитектуры хранилищ данных
В последние годы хранилища данных переходят в облако. Новые облачные хранилища данных не придерживаются традиционной архитектуры и каждое из них предлагает свою уникальную архитектуру.
В этом разделе кратко описываются архитектуры, используемые двумя наиболее популярными облачными хранилищами: Amazon Redshift и Google BigQuery.
Amazon Redshift
Amazon Redshift — это облачное представление традиционного хранилища данных.
Redshift требует, чтобы вычислительные ресурсы были подготовлены и настроены в виде кластеров, которые содержат набор из одного или нескольких узлов. Каждый узел имеет свой собственный процессор, память и оперативную память. Leader Node компилирует запросы и передает их вычислительным узлам, которые выполняют запросы.
На каждом узле данные хранятся в блоках, называемых срезами. Redshift использует колоночное хранение, то есть каждый блок данных содержит значения из одного столбца в нескольких строках, а не из одной строки со значениями из нескольких столбцов.
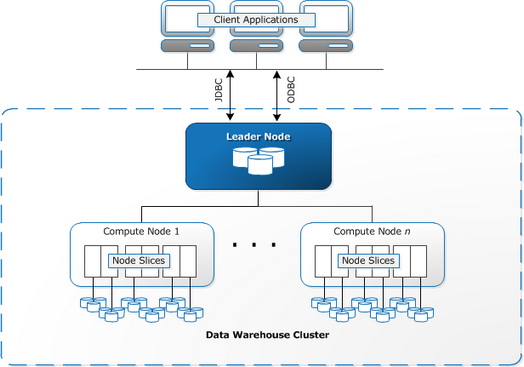
Redshift использует архитектуру MPP (Massively Parallel Processing), разбивая большие наборы данных на куски, которые назначаются слайсам в каждом узле. Запросы выполняются быстрее, потому что вычислительные узлы обрабатывают запросы в каждом слайсе одновременно. Узел Leader Node объединяет результаты и возвращает их клиентскому приложению.
Клиентские приложения, такие как BI и аналитические инструменты, могут напрямую подключаться к Redshift с использованием драйверов PostgreSQL JDBC и ODBC с открытым исходным кодом. Таким образом, аналитики могут выполнять свои задачи непосредственно на данных Redshift.
Redshift может загружать только структурированные данные. Можно загружать данные в Redshift с использованием предварительно интегрированных систем, включая Amazon S3 и DynamoDB, путем передачи данных с любого локального хоста с подключением SSH или путем интеграции других источников данных с помощью API Redshift.
Google BigQuery
Архитектура BigQuery не требует сервера, а это означает, что Google динамически управляет распределением ресурсов компьютера. Поэтому все решения по управлению ресурсами скрыты от пользователя.
BigQuery позволяет клиентам загружать данные из Google Cloud Storage и других читаемых источников данных. Альтернативным вариантом является потоковая передача данных, что позволяет разработчикам добавлять данные в хранилище данных в режиме реального времени, строка за строкой, когда они становятся доступными.
BigQuery использует механизм выполнения запросов под названием Dremel, который может сканировать миллиарды строк данных всего за несколько секунд. Dremel использует массивно параллельные запросы для сканирования данных в базовой системе управления файлами Colossus. Colossus распределяет файлы на куски по 64 мегабайта среди множества вычислительных ресурсов, называемых узлами, которые сгруппированы в кластеры.
Dremel использует колоночную структуру данных, аналогичную Redshift. Древовидная архитектура отправляет запросы тысячам машин за считанные секунды.
Для выполнения запросов к данным используются простые команды SQL.

Panoply
Panoply обеспечивает комплексное управление данными как услуга. Его уникальная самооптимизирующаяся архитектура использует машинное обучение и обработку естественного языка (NLP) для моделирования и рационализации передачи данных от источника к анализу, сокращая время от данных до значения как можно ближе к нулю.
Интеллектуальная инфраструктура данных Panoply включает в себя следующие функции:
- Анализ запросов и данных — определение наилучшей конфигурации для каждого варианта использования, корректировка ее с течением времени и создание индексов, сортировочных ключей, дисковых ключей, типов данных, вакуумирование и разбиение.
- Идентификация запросов, которые не следуют передовым методам — например, те, которые включают вложенные циклы или неявное приведение — и переписывает их в эквивалентный запрос, требующий доли времени выполнения или ресурсов.
- Оптимизация конфигурации сервера с течением времени на основе шаблонов запросов и изучения того, какая настройка сервера работает лучше всего. Платформа плавно переключает типы серверов и измеряет итоговую производительность.

По ту сторону облачных хранилищ данных
Облачные хранилища данных — это большой шаг вперед по сравнению с традиционными подходами к архитектуре. Однако пользователи по-прежнему сталкиваются с рядом проблем при их настройке:
- Загрузка данных в облачные хранилища данных нетривиальна, а для крупномасштабных конвейеров данных требуется настройка, тестирование и поддержка процесса ETL. Эта часть процесса обычно выполняется сторонними инструментами;
- Обновления, вставки и удаления могут быть сложными и должны выполняться осторожно, чтобы не допустить снижения производительности запросов;
- С полуструктурированными данными трудно иметь дело — их необходимо нормализовать в формате реляционной базы данных, что требует автоматизации больших потоков данных;
- Вложенные структуры обычно не поддерживаются в облачных хранилищах данных. Вам необходимо преобразовать вложенные таблицы в форматы, понятные хранилищу данных;
- Оптимизация кластера. Существуют различные варианты настройки кластера Redshift для запуска ваших рабочих нагрузок. Различные рабочие нагрузки, наборы данных или даже различные типы запросов могут потребовать иной настройки. Для достижения оптимальной работы, необходимо постоянно пересматривать и при необходимости дополнительно настраивать конфигурацию;
- Оптимизация запросов — пользовательские запросы могут не соответствовать передовым методам и, следовательно, будут выполняться намного дольше. Вы можете работать с пользователями или автоматизированными клиентскими приложениями для оптимизации запросов, чтобы хранилище данных могло работать так, как ожидалось
- Резервное копирование и восстановление — несмотря на то, что поставщики хранилищ данных предоставляют множество возможностей для резервного копирования ваших данных, их нетривиально настроить и они требуют мониторинга и пристального внимания
- sql
- хранилище данных
- архитектура
- cloud
- облачные технологии
- datawarehouse
- google cloud
- amazon web services
- Анализ и проектирование систем
- SQL
- Amazon Web Services
- Хранилища данных
- Облачные сервисы
Построение корпоративного хранилища данных (DWH)
ФТО занимается построением и поддержкой DWH на базе MS SQL Server и его инструментов.
Мы предлагаем услуги:
— построение DWH c нуля,
— поддержка, развитие и оптимизация существующего хранилища,
— перенос DWH на новую платформу (перевнедрение).
Что такое корпоративное хранилище?
Корпоративное хранилище данных (КХД, DWH) — неотъемлемый атрибут крупной компании, владеющей большими массивами данных, полученных из нескольких источников. Корпоративная база данных разрабатывается с учетом особенностей организации и предназначается для подготовки отчётов и бизнес-анализа.
На основе обработанных данных, как правило, принимаются важные управленческие решения в организации. Особенно актуален вопрос построения хранилищ данных при использовании инструментов класса BI.
Причины для разработки корпоративного хранилища данных
Разработка КХД – дорогой и непростой проект. Трудозатраты, в зависимости от сложности, могут варьироваться в широком диапазоне (300 – 1000 человеко-часов работы подрядчика в среднем на 1 проект).
Несмотря на сложность и капиталоемкость, разработка хранилища окупается минимизацией рисков потери данных. Поэтому в первую очередь о такой разработке необходимо задуматься в следующих случаях:
1) Если вы используете внешние источники данных
Вы можете покупать сеты данных у поставщика или собирать данные из внешних источников. Например, средние цены на вашем сегменте рынка. Рано или поздно поставщик может перестать вас устраивать, поменяет условия сотрудничества или перестанет существовать. В этом случае вы потеряете всю свою аналитику. Аналогичная ситуация если вы собираете данные самостоятельно из открытых источников. Например, с сайтов конкурентов или проводите опросы экспертов. База показателей (папка с файлами, Google-таблица или что-то подобное) могут быть повреждены или утеряны безвозвратно.
2) Если количество источников данных превышает 3-4
Почему именно это число? Фактически – это норма управляемости. Из нашей практики, при превышении такого количества источников данных, начинаются трудности с поддержанием целостности справочных/ мастер – данных, в то время, как загрузочный слой хранилища значительно снижает проблемы сопоставления.
3) Есть несколько потребителей одних и тех же данных
Хранилище может являться источником информации для неограниченного круга потребителей – BI система, алгоритмы предиктивной аналитики, специалисты, которым необходимо получать сеты данных в Excel (маркетологи, аналитики, экономисты). В этой ситуации хранилище выполняет еще одну роль – по разграничению прав доступа к определенным уровням данных. Например, аналитик в центральном офисе сможет загрузить историю по продажам для всех филиалов за всю историю, тогда как специалист по ценообразованию – только историю цен и только для определенного региона.
4) Объем данных превышает определенные ограничения или лимиты
Например, один из лидеров бизнес-аналитики, Power BI, для подписки уровня Premium ограничивает проект объемом 100 Гб данных, а общий объем хранения – 100 Тб. Похожие ограничения есть и у других BI-систем.
Зачем нужно строить хранилище?
Конечной целью является подготовка корпоративных отчетов. Но их можно формировать и без КХД. Разберем ключевые преимущества архитектуры хранилища, которые определяют их полезность:

Скорость извлечения необходимых данных
Когда все необходимые данные находятся в единой базе данных, структурированы и имеют корректные связи таблиц, то их обработка и извлечение для выгрузки в отчет происходят гораздо быстрее, чем в случае работы с многочисленными и разрозненными базами данных из разных корпоративных систем.

Неизбыточность данных
При проектировании хранилища архитектор должен понимать, каким целям и для каких отчетов хранилище будет использоваться. Это обуславливает хранение только нужных атрибутов и выборку только необходимых массивов данных с помощью фильтров при загрузке из конечного источника. Таким образом, в корпоративном хранилище данных есть все необходимые данные, но нет лишних.

Непротиворечивость данных
КХД использует данные из различных источников. Но прежде чем их использовать и объединять на уровне таблиц, они должны быть очищены и нормализованы. Мастер-данные импортируются централизовано, либо справочники ведутся на уровне инструментов DWH. Мы имеем таблицы без дублей и противоречий, а значит отчетность, которую строим на базе этих таблиц, покажет данные достоверно и не вызовет вопросов у заказчиков.
Какие услуги предлагает ФТО?
- Построение DWH с нуля – если вы пришли к пониманию, что вам нужно создание хранилища, которое отсутствует в принципе, мы вам поможем.
- Поддержка, развитие и оптимизация DWH – если у вас уже есть хранилище, требующее поддержки и доработки или оптимизации, и вы готовы рассматривать нас в качестве нового подрядчика.
- Перенос DWH на новую платформу – если версия платформы хранилища либо платформа в целом больше не соответствует целям по развитию данного инструмента и вы не готовы мириться с данным ограничением, есть смысл перейти на более оптимальную платформу, мы можем помочь вам выбрать ее и осуществить проект по переходу на новую платформу (перевнедрение).
С какими продуктами и технологиями мы работаем?
Преимущественно мы строим и поддерживаем хранилища на базе MS SQL Server и его инструментов, полный перечень технологий, с которыми мы работаем, приведен ниже.
- СУБД Microsoft SQL Server,
- Oracle,
- Teradata,
- Apache Cassandra,
- Microsoft Access ETL,
- Microsoft SSIS,
- IBM Node-RED,
- Informatica.

Необходима консультация по вопросам DWH?
Напишите на ml@fto.com.ru или оставьте заявку, и наш специалист свяжется с вами в ближайшее время.
Я даю свое согласие на обработку моих персональных данных на условиях, определенных Политикой Конфиденциальности. Оставить заявку Ничего не работает —>
Спасибо за заявку! Мы перезвоним вам в ближайшее время. Подписывайтесь на нас в соцсетях
- О компании
- Контакты
- Блог
- Проекты
- Карьера в ФТО
- Вакансии
- Прайс лист 1С
- ISO 9001:2015
- Карта сайта
- Наши услуги
- Внедрение решений на 1С
- Поддержка пользователей 1С
- 1С:Документооборот
- Ускорение производительности 1С
- Системы для бизнес-анализа (BI)
- Аналитика SimpleHR
- Комплексное обслуживание 1С
- Доработка конфигураций 1С
- Переход с 1С:УПП на 1С:ERP
- Переход на новый 1C:ЗУП 3.1
Как с нами связаться?
- 1С:Центр ERP
- 1С:Франчайзинг
- 1С:Центр реальной автоматизации
- ISO 9001:2015
- Qlik Partner
- DATAREON Partner
Мы используем данные файлы cookie, данные об IP-адресе и местоположении, разработанные третьими лицами для анализа событий на нашем сайте. Продолжая просмотр страниц сайта, вы принимаете условия его использования. Более подробные сведения можно посмотреть в Политике конфиденциальности.
Вы пользуетесь устаревшей версией браузера. Данная версия браузера не поддерживает многие современные технологии, из-за чего многие страницы отображаются некорректно, а главное — на сайтах могут работать не все функции.
Инструменты для создания Хранилищ данных
В 90-е годы западными корпорациями накоплен значительный опыт создания и внедрения Хранилищ данных (DWH). В последние 2-3 года большое количество информационных систем, которые с уверенностью можно отнести к категории DWH, создано и в России.
Этот опыт показал, что в случае успешного внедрения, проекты, связанные с DWH окупаются и приносят прибыль. Однако процент неудачных проектов очень велик. По некоторым оценкам он составляет 60-80 процентов. При внедрении Хранилищ возникает множество организационных, методических и технических трудностей, преодоление которых часто занимает месяцы, а иногда и годы. В результате превышается бюджет, иссякает терпение персонала и руководства.
Одна из причин неудач состоит в том, что Хранилище данных, также как в семидесятые годы БД, рассматривалось как готовый продукт, а не как средство разработки. Поэтому не принималось в расчет, что для проектирования и разработки Хранилища — БД, запросов, интерфейсов, правил извлечения, очистки и загрузки данных — с использованием универсальных инструментов необходимо десятки человеко-лет труда профессиональных проектировщиков и программистов. Вторая причина — каждая организация, внедряющая DWH, становилась первопроходцем в создании DWH в своей отрасли, и методом проб и ошибок искала верные методические решения.
На эти трудности рынок ответил появлением систем, предназначенных для ускорения разработки и внедрения Хранилищ и повышения вероятности успешного результата.
Универсальные инструменты для разработки DWH
Хранилища данных строятся на одной из трех платформ, или их совокупности:
- Реляционные СУБД (DB2, MS SQL, Oracle и т.д.),
- Специальные платформы (Sybase IQ, RedBrick, Teradata и т.д.),
- OLAP-серверы (Hyperion Essbase, IBM OLAP Server, MS Analysis Services, Oracle Express и т.д.).
Классическая архитектура DWH состоит из следующих элементов: реляционная, многомерная, или гибридная БД, средства извлечения, очистки и загрузки данных, средства визуализации данных и генерации отчетов (OLAP-клиенты). Реляционная БД строится по архитектуре «звезда», в которой с одной таблицей фактов связаны несколько таблиц измерений (справочников), или снежинка, отличающаяся наличием иерархических справочников. Это делается для оптимизации скорости выполнения объемных запросов (в последнее время появилось много статей, критикующих этот подход за его упрощенность и невозможность решения исключительно в рамках «звезды» всего многообразия задач DWH). В многомерной БД строятся «кубы» — специфические структуры, аналогичные по смыслу реляционным «снежинкам», но хранящие вычисленные агрегаты на всех пересечениях измерений.
- CASE-системы, предназначенные для проектирования специфических реляционных схем DWH — «звезда» и «снежинка».
- Системы для управления метаданными.
- Системы для извлечения, очистки и загрузки данных.
- Системы для выполнения запросов, визуализации данных и генерации отчетов.
Так продукт компании Sybase «Warehouse Studio» состоит из CASE-инструмента для проектирования реляционной или многомерной базы данных Хранилища WarehouseArchitect, системы управления метаданными Warehouse Control Center, системы импорта, очистки и загрузки данных PowerStage, системы визуализации данных и генерации отчетов InfoMaker. При этом для хранения метаданных предлагается СУБД Sybase Adaptive Server Enterprise/Anywhere, а для хранения данных — произвольная РСУБД или специальная СУБД для Хранилищ данных Sybase IQ, особенностью которой является одновременное компактное хранение как атомарных, так и агрегированных данных.
Рис. 1 Интерфейс проектирования структуры DWH системы Sybase Warehouse Architect
Платформа для создания Хранилищ данных Data Warehouse Framework от корпорации Microsoft включает в себя MS SQL Server для реляционной составляющей и хранения метаданных в специальном репозитории, MS Analysis Servises/MS OLAP Server для хранения агрегированных данных, MS Data Transformation Services для извлечения и загрузки данных, MS Pivot Table для визуализации данных.
Компания из Сантк-Петербурга Digital Design разработала свой набор инструментов Data Vision, интегрирующий платформу MS Data Warehouse Framework и предоставляющую единый интерфейс для проектирования, администрирования и эксплуатации гибридных Хранилищ данных.
Система Warehouse Builder корпорации Oracle представляет собой интегрированную среду для проектирования БД, хранения метаданных, маппинга источников и приемников данных, описания правил преобразования данных при загрузке. В сочетании с СУБД Oracle 8i, OLAP-клиентом Oracle Discoverer эта система позволяет построить законченное Хранилище данных на основе продуктов Oracle.
Универсальные инструменты существенно сокращают время разработки, снижают количество ошибок и, таким образом, уменьшают расходы и риски при создании Хранилища данных предприятия. Однако все эти продукты являются средствами разработки, а не конечными приложениями. От их приобретения до начала эксплуатации DWH должны быть пройдены все этапы создания ПО: анализ предметной области, проектирование бизнес-процессов, БД и интерфейсов, разработка, тестирование, документирование. Для реализации проекта предприятие должно обладать штатом квалифицированных разработчиков или заказать уникальную систему профессиональным софтверным компаниям.
Поэтому появились еще более высокоуровневые продукты, которые предлагают при создании Хранилищ данных предприятия использовать накопленный опыт в подобной области знаний или отрасли.
Специализированные Хранилища данных
При всем многообразии задач, решаемых Хранилищами данных, эти задачи поддаются классификации и обобщению. От этого постулата отталкиваются софтверные компании, создающие специализированные Хранилища данных. Специализированные DWH включают в свой состав готовые схемы данных, бизнес-объекты, интерфейсы, процедуры сбора данных, которые требуют только настройки на специфику предприятия, или предоставляют интерфейсы уровня конструкторов для создания новых объектов хранения из «заготовок». В этом случае от начала настройки до эксплуатации системы может пройти от нескольких дней, до нескольких месяцев, включая первоначальную загрузку архивных данных. Как правило, при этом получается система, похожая на ранее внедренные, что существенно снижает риск неудачи проекта. Кроме того, часто поставляются готовые управленческие и аналитические приложения, реализующие отлаженные методики.
Корпорация SAS предлагает свою систему CFO Vision, которая позиционируется как система финансовой консолидации данных и выпуска отчетов. Система основана на использовании технологий финансового хранилища данных и OLAP. В качестве платформы используется OLAP-сервер SAS, или СУБД третьих фирм. Как и в универсальных системах в состав CFO Vision входят инструменты сбора, очистки и загрузки данных, управления метаданными, многомерная БД. Отличие состоит в том, что в системе заранее реализованы стандартные для финансовых систем измерения такие как «Организация», «Валюта», «Счет», «Рынок», «Продукция», «Время». Кроме этого в интерфейсах, без программирования могут быть созданы дополнительные измерения. В систему встроены алгоритмы, реализующие основные финансовые законы и правила консолидации. Для внедрения финансового Хранилища данных требуется описать бизнес-модель предприятия, настроить процедуры импорта данных, правила консолидации и отчеты. Кроме сбора финансовых данных из подразделений и выпуска корпоративной отчетности система позволяет выполнять финансовое планирование, управление расходами и различные виды анализа: анализ продаж, анализ клиентской базы и т.д.
Sybase предлагает продукт Industry Warehouse Studio — интегрированный набор приложений, моделей данных и инструменты для быстрого создания Хранилища данных предприятия на основе модели подобного предприятия. Так же как и SAS, Sybase поставляет весь набор инструментов, необходимых для настройки и эксплуатации Хранилища данных. Особенностью является то, что в комплект входит библиотека готовых моделей данных, методологий и законченных приложений, построенных по технологии Хранилищ данных для различных отраслей. Комплект включает следующие приложения:
- Анализ проведения кампаний.
- Анализ покупательского профиля.
- Анализ лояльности.
- Анализ продаж.
- Анализ поддержки клиентов.
- Анализ производственной деятельности.
- Анализ прибыльности.
Для внедрения DWH требуется выбрать подходящие модели приложений и настроить их на специфику предприятия.
Российская компания Intersoft Lab (www.iso.ru) поставляет систему Контур Корпорация — студию для создания финансовых Хранилищ данных.
Контур Корпорация — специализированная студия для построения финансовых DWH
Система позволяет построить Хранилище данных на платформе MS SQL Server в ROLAP- или HOLAP-архитектуре. Система предоставляет технологию быстрого создания корпоративного Хранилища данных и управленческих приложений, использующих эти данные. Она обеспечивает консолидацию финансовых и других деловых данных, вычисления производных финансовых показателей, предоставляет инструменты выпуска отчетов и «заготовки» для создания системы бюджетирования многофилиальной организации или банка.
Также как и в SAS CFO Vision в системе заранее реализованы основные бизнес-объекты, которые, как правило, создаются в финансовых Хранилищах данных, но их перечень и структура несколько отличаются. В системе существуют «банки данных», однотипные объекты, которые одновременно играют роль специализированных информационно-поисковых систем и измерений для фактов — счетов, финансовых и количественных показателей, документов. В рамках каждого банка данных можно настроить множество типов объектов и их реквизиты. Это Субъект (Клиент, Контрагент, Конкурент, Сотрудник и т.д.), Организационно-штатная структура (Филиал, Отдел, Должность и т.д.), Бизнес-Операция (Направление деятельности, Продукт, Операция), Финансовый инструмент (Валюта, Ценная бумага и т.д.), Форма документа. Для описания модели финансового учета может быть создано неограниченное количество Планов счетов, показателей, бюджетов.
Уникальной особенностью системы является технология быстрой настройки Хранилища данных, которая позволяет описать его структуру в интерфейсе, без программирования, в терминах предметной области. При этом автоматически генерируются таблицы БД, процедуры манипуляции с данными, индексы для быстрого получения данных, XML-форматы обмена данными, настраиваются пользовательские интерфейсы, отчеты и процедуры загрузки данных. После настройки Хранилища система полностью готова к сбору данных из внешних систем, программирование на встроенном языке требуется только для описания тонких бизнес-правил.
Все настройки хранятся в виде метаданных. Существует инструмент навигации по метаданным Хранилища. Метаданные могут выгружаться в XML-формат и загружаться из XML-формата. Совокупность настроек Хранилища, сделанных для решения конкретной задачи, в терминах системы называется «приложением». Метаданные, описывающие эти настройки, и выгруженные в XML-файл становятся дистрибутивом приложения. Метаданные, описывающие избранные объекты системы, например, определенные типы документов, могут выгружаться для обмена с другими копиями системы, или с другими системами.
Для автоматизации сбора и контроля данных в систему встроены специфические финансовые механизмы. Например, проводка — для пакетного вычисления оборотов и остатков счетов в момент загрузки данных филиалов. Этот механизм выполняет вычисления по правилам двойной записи и нарастающих итогов, реализует специфические для России проводки задним числом, заключительные обороты. Он позволяет повторять бухучет в филиалах и ежедневно сравнивать полученные остатки с остатками в учетных системах для оперативного выявления ошибок и нарушений во всех подразделениях многофилиальной организации. Встроенные алгоритмы агрегации и консолидации данных во времени, по иерархии счетов и показателей, по организационной иерархии позволяют быстро получать отчеты за периоды и консолидированные отчеты.
Как и в системе SAS CFO Vision работа данными Хранилища во встроенных интерфейсах системы выполняется методом углубления (drill-down), что позволяет в процессе анализа спуститься от обобщенных финансовых показателей корпорации до аналитических счетов и проводок любого филиала.
Для выпуска отчетов и анализа данных Контур Корпорация оснащена встроенными специализированными интерфейсами, генераторами отчетов, интегрирована с приложениями MS Office и OLAP-клиентом Контур Стандарт, предоставляет API для других систем класса front-end и OLAP-сервер.
Система имеет объектную оболочку, которая реализована на языке Python. Каждому объекту Хранилища данных соответствует объект библиотеки, а каждому объекту библиотеки — XML-документ для обмена данными, метаданными и удаленного выполнения операций над данными. В сочетании с OLE DB и COM-интерфейсами это позволяет быстро создавать динамические страницы на корпоративном сайте с доступом к Хранилищу данных для поиска информации, выпуска отчетов и анализа.
Рис. 4 Работа с метаданными в системе Контур Корпорация
Кроме финансовых данных система позволяет собирать и предоставлять менеджерам и другую информацию, необходимую для управления территориально распределенной многофилиальной организацией: послужные списки сотрудников, данные о клиентах, произвольные документы (договоры, счета-фактуры, платежные документы, организационные документы), курсы валют и котировки акций, сведения о конкурентах и потенциальных клиентах.Также как и в Sybase Industry Warehouse Studio, для Контур Корпорации поставляются готовые приложения. Сегодня это два приложения для коммерческих банков: «Управление филиалами» и «Бюджет». Учитывая высокую степень готовности этих приложений к эксплуатации в банках, можно говорить о тиражном Хранилище данных. Опыт показывает, что внедрение системы в эксплуатацию со стандартными приложениями занимает от 1 до 6 месяцев в зависимости от количества индивидуальных настроек и доработок приложений.
Автор: В.Некрасов
Источник: «RM-Magazin», 2002, №1
Business DWH (DataWareHouse): аналитическое хранилище данных
Построение хранилища данных (например на базе HP Vertica, MS SQL, Exasol) — проект, требующий серьезной проработки и усилий со стороны бизнеса и поставщика информационных технологий. Наиболее эффективным подходом здесь будет совместный проект предприятия и компании, специализирующейся в этой области. Общемировая практика показывает, что хранилища данных создаются под конкретного заказчика. Серьезным преимуществом является наличие квалифицированного персонала, типовых Витрин Данных, а также отраслевой модели данных.
Хранилище может содержать:
— Учетную информацию о клиентах (персональные данные, адреса, телефоны)
— Информацию о банковских продуктах и услугах (кредиты, депозиты, пластиковые карточки, мобильный банк и т.д. )
— Данные об операциях (включая карточные) в минимальной детализации за последние 3 года
— Сведения о счетах, остатках на них и т.д.Чтобы спроектировать хранилище данных (DWH, DataWareHouse),
нужно ответить на вопросы о требованиях к хранилищу в целом:
Нужно определиться с назначением этого хранилища:- оно строится для BI системы;
- для сотрудников для формирования своих отчетов;
- общее решение для двух вариантов.
Во всех трех случаях, первым делом важно выявить целевых пользователей. Какие отчеты они используют в своей работе (важны запросы этих отчетов), что им не хватает.
Далее отталкиваться от этого и проектировать систему. Делать сразу для всех не получится: отчеты будут работать правильно и приемлемо (по времени), если хранилище заточено на работу с ними. В случае с BI, в некоторых системах мы можем переложить часть ETL (процесс Extract-Transform-Loading) на сторону BI, но это зависит от выбранной системы, например, у Qlik свой мощный ETL, а Tableau не умеет делать сложных преобразований.
В случае, если это только для BI, то нужно учитывать выбранную систему. Как писали выше, некоторые BI системы имеют свой мощный ETL и при этом это технология in-memory, что в разы сокращает время преобразования данных (чеки, остатки – большой поток данных, даже с учетом инкрементальной загрузки). Речь не о полном переносе трансформации в BI, а о совмещении инструментов.
В случае, если это для отчетов пользователей – то нужно понимать, какие запросы будут чаще всего делаться к хранилищу и затачивать его на эти конкретные запросы (80% всех запросов должны отрабатываться оптимально, 20% — нет, но они должны быть редкими)
В случае, если для обоих вариантов – все рассчитывается на уровне хранилища. BI – это просто инструмент визуализации (но вопрос зачем двойная отчетность).
После того, как появится понимание цели хранилища и примерных аналитик, которые в нем будут, нужно понять в каком виде нужно хранить эти данные.
Например: количество чеков может быть аддитивным и неаддитивным; остатки – нужны движения или предрассчитанные остатки, какой период нужен, частота обновления и т.д.
После этого шага можно будет спроектировать модель, реализовать в рамках пилотного проекта один из его блоков. Реализация позволит правильно оценить размеры хранилища (на n-ый период времени с учетом прироста).
Построение хранилища данных:
- Разработка Устава Проекта;
- Создание на корпоративном web-портале (или иной web-системе) узла Проекта и формирование структуры web-узла:
- библиотека бизнес-требований и методик;
- раздел Протоколов рабочих совещаний, текущих задач;
- подраздел обсуждений рабочих вопросов (возможно, в виде форума, трекинга);
- разделы документации по хранилищу данных, витринам, OLAP-кубам;
- система знаний (wiki);
- библиотека регламентов;
- раздел обучения, web-касты;
- и другие разделы».
- Сбор фрагментарных знаний о бизнес-процессах (БП) компании и метриках посредством проведения серий интервью с ключевыми бизнес-сотрудниками, экспертами. Формализация БП в виде укрупненных графических схем (например, BPMN-нотация);
- Получение доступов к учетным системам (желательно к копиям; доступ как на чтение данных на уровне СУБД, так и просмотру данных через графический интерфейс пользователя);
- Сбор и обсуждение методик, реализованных в существующих регламентных/управленческих отчетах;
- Формулирование требований/ обсуждение методологий для новых/желаемых регламентных/управленческих отчетов;
- Систематизация бизнес-требований (по результатам п.п 3, 5, 6) к составу атрибутов данных, которые должны быть отражены в хранилище данных;
- Построение/актуализация и описание логических моделей учетных систем — источников данных для DWH. (возможно, модели уже имеются, хотя чаще нет);
- Описание/актуализация физических моделей (построение ER-диаграмм) учетных систем — источников данных для DWH. (возможно, модели уже имеются, хотя чаще нет);
- Анализ и формализация бизнес-требований к составу атрибутов данных (по п.п. 7, 8, 9), которые должны быть отражены в хранилище данных;
- Подготовка технологической площадки для BI: сервер разработки, тестирования, производственного; установка серверного и прикладного программного обеспечения;
- Разработка (возможно реинжиниринг существующих) процедур по извлечению необходимых данных (п. 10) из учетных систем в буферные таблицы (stage area); наполнение буферных таблиц;
- Профилирование данных (по п.12), извлекаемых из учетных систем; систематизация статистики по метаданным и данным учетных систем;
- Разработка логической модели хранилища данных;
- Разработка структуры физической модели хранилища данных;
- Разработка концептуальной схемы, подходов ETL-процессов по загрузке данных из учетных систем в хранилище данных;
- Разработка карты мэппингов (поля source —> поля target);
- Технологическая реализация (программная разработка) ETL/ELT -процессов по перегрузке данных справочников из учетных систем в таблицы измерений (dimensions) хранилища. (Выполняется поэтапно по предметным областям бизнеса);
- Разработка процедур первичной/критической очистки/дедубликации данных справочников (совместно с п.18) [Проект НСИ (MDM) выполняется отдельным проектом/ подпроектом];
- Технологическая реализация (программная разработка) ETL/ELT -процессов по перегрузке данных из учетных систем в таблицы фактов (fact table, factless table) хранилища. (Выполняется поэтапно по предметным областям бизнеса);
- Тестирование:
- контроль сходимости итогов по данным в учетной системе с итогами по данным таблиц хранилища;
- скорости исполнения полного ETL-цикла»;
- Доработка п.п. 18, 19, 20 по выявленным ошибкам, замечаниям по результатам работ п. 21;
- Разработка структур витрин данных (агрегатных денормализованных таблиц/представлений). Выполняется поэтапно по предметным областям бизнеса;
- Разработка ETL/ELT-процедур по обновлению витрин данных, расчету производных показателей (обогащение витрин данными);
- Тестирование:
- контроль сходимости итогов по данным витрин с итогами по данным учетных систем и итогами по данным таблиц хранилища;
- скорости исполнения цикла обновления витрин данных»;
- Разработка документации по хранилищу данных;
- Разработка документации по витринам данных;
- Выработка и согласование требований к аналитическим OLAP кубам (перечень измерений, метрик, доп. действий, разграничение прав доступа);
- Разработка структур аналитических OLAP кубов, процедур обновления данных в кубах. Выполняется поэтапно по предметным областям бизнеса;
- Тестирование аналитических кубов;
- Подготовка, развёртывание инфраструктуры для публикации отчётов (репортинг, ad-hoc отчеты, OLAP) на web-портале (например, MS Sharepoint 2010 EE 64x + MS Reporting Services, возможно Gognos 10.х);
- Разработка документации по аналитическим кубам, публикация документации на web-портале в системе знаний;
- Разработка регламентных/управленческих отчётов (по п.п. 5, 6);
- Публикация и систематизация регламентных/управленческих отчётов на корпоративном web-портале;
- Обучение бизнес-пользователей интерактивному пользованию OLAP-кубами; выявление/формирование проактивных пользователей (power users);
- Бизнес-пользователи (по возможности) самостоятельно формируют отчеты (по результатам п. 35); приемка и публикация отчетов осуществляется по согласованию с IT-аналитическим подразделением (возможно на первых порах).