Big O
Примечание. Сокращенный перевод, скорее пересказ своими словами.
UPD: как отметили в комментариях, примеры не идеальны. Автор не ищет лучшее решение задачи, его цель объяснить сложность алгоритмов «на пальцах».
Big O нотация нужна для описания сложности алгоритмов. Для этого используется понятие времени. Тема для многих пугающая, программисты избегающие разговоров о «времени порядка N» обычное дело.
Если вы способны оценить код в терминах Big O, скорее всего вас считают «умным парнем». И скорее всего вы пройдете ваше следующее собеседование. Вас не остановит вопрос можно ли уменьшить сложность какого-нибудь куска кода до n log n против n^2.
Структуры данных
Выбор структуры данных зависит от конкретной задачи: от вида данных и алгоритма их обработки. Разнообразные структуры данных (в .NET или Java или Elixir) создавались под определенные типы алгоритмов.
Часто, выбирая ту или иную структуру, мы просто копируем общепринятое решение. В большинстве случаев этого достаточно. Но на самом деле, не разобравшись в сложности алгоритмов, мы не можем сделать осознанный выбор. К теме структур данных можно переходить только после сложности алгоритмов.
Здесь мы будем использовать только массивы чисел (прямо как на собеседовании). Примеры на JavaScript.
Начнем с самого простого: O(1)
Возьмем массив из 5 чисел:
const nums = [1,2,3,4,5];Допустим надо получить первый элемент. Используем для это индекс:
const nums = [1,2,3,4,5]; const firstNumber = nums[0];Насколько это сложный алгоритм? Можно сказать: «совсем не сложный — просто берем первый элемент массива». Это верно, но корректнее описывать сложность через количество операций, выполняемых для достижения результата, в зависимости от ввода (операций на ввод).
Другими словами: насколько возрастет кол-во операций при увеличении кол-ва входных параметров.
В нашем примере входных параметров 5, потому что в массиве 5 элементов. Для получения результата нужно выполнить одну операцию (взять элемент по индексу). Сколько операций потребуется если элементов массива будет 100? Или 1000? Или 100 000? Все равно нужна только одна операция.
Т.е.: «одна операция для всех возможных входных данных» — O(1).
O(1) можно прочитать как «сложность порядка 1» (order 1), или «алгоритм выполняется за постоянное/константное время» (constant time).
Вы уже догадались что O(1) алгоритмы самые эффективные.
Итерации и «время порядка n»: O(n)
Теперь давайте найдем сумму элементов массива:
const nums = [1,2,3,4,5]; let sum = 0; for(let num of nums)
Опять зададимся вопросом: сколько операций на ввод нам потребуется? Здесь нужно перебрать все элементы, т.е. операция на каждый элемент. Чем больше массив, тем больше операций.
Используя Big O нотацию: O(n), или «сложность порядка n (order n)». Так же такой тип алгоритмов называют «линейными» или что алгоритм «линейно масштабируется».
Анализ
Можем ли мы сделать суммирование более эффективным? В общем случае нет. А если мы знаем, что массив гарантированно начинается с 1, отсортирован и не имеет пропусков? Тогда можно применить формулу S = n(n+1)/2 (где n последний элемент массива):
const sumContiguousArray = function(ary) < //get the last item const lastItem = ary[ary.length - 1]; //Gauss's trick return lastItem * (lastItem + 1) / 2; >const nums = [1,2,3,4,5]; const sumOfArray = sumContiguousArray(nums);Такой алгоритм гораздо эффективнее O(n), более того он выполняется за «постоянное/константное время», т.е. это O(1).
Фактически операций не одна: нужно получить длину массива, получить последний элемент, выполнить умножение и деление. Разве это не O(3) или что-нибудь такое? В Big O нотации фактическое кол-во шагов не важно, важно что алгоритм выполняется за константное время.
Алгоритмы с константным временем это всегда O(1). Тоже и с линейными алгоритмами, фактически операций может быть O(n+5), в Big O нотации это O(n).
Не самые лучшие решения: O(n^2)
Давайте напишем функцию которая проверяет массив на наличие дублей. Решение с вложенным циклом:
const hasDuplicates = function (num) < //loop the list, our O(n) op for (let i = 0; i < nums.length; i++) < const thisNum = nums[i]; //loop the list again, the O(n^2) op for (let j = 0; j < nums.length; j++) < //make sure we're not checking same number if (j !== i) < const otherNum = nums[j]; //if there's an equal value, return if (otherNum === thisNum) return true; >> > //if we're here, no dups return false; > const nums = [1, 2, 3, 4, 5, 5]; hasDuplicates(nums);//trueМы уже знаем что итерирование массива это O(n). У нас есть вложенный цикл, для каждого элемента мы еще раз итерируем — т.е. O(n^2) или «сложность порядка n квадрат».
Алгоритмы с вложенными циклами по той же коллекции всегда O(n^2).
«Сложность порядка log n»: O(log n)
В примере выше, вложенный цикл, сам по себе (если не учитывать что он вложенный) имеет сложность O(n), т.к. это перебор элементов массива. Этот цикл заканчивается как только будет найден нужный элемент, т.е. фактически не обязательно будут перебраны все элементы. Но в Big O нотации всегда рассматривается худший вариант — искомый элемент может быть самым последним.
Здесь вложенный цикл используется для поиска заданного элемента в массиве. Поиск элемента в массиве, при определенных условиях, можно оптимизировать — сделать лучше чем линейная O(n).
Пускай массив будет отсортирован. Тогда мы сможем использовать алгоритм «бинарный поиск»: делим массив на две половины, отбрасываем не нужную, оставшуюся опять делим на две части и так пока не найдем нужное значение. Такой тип алгоритмов называется «разделяй и влавствуй» Divide and Conquer.
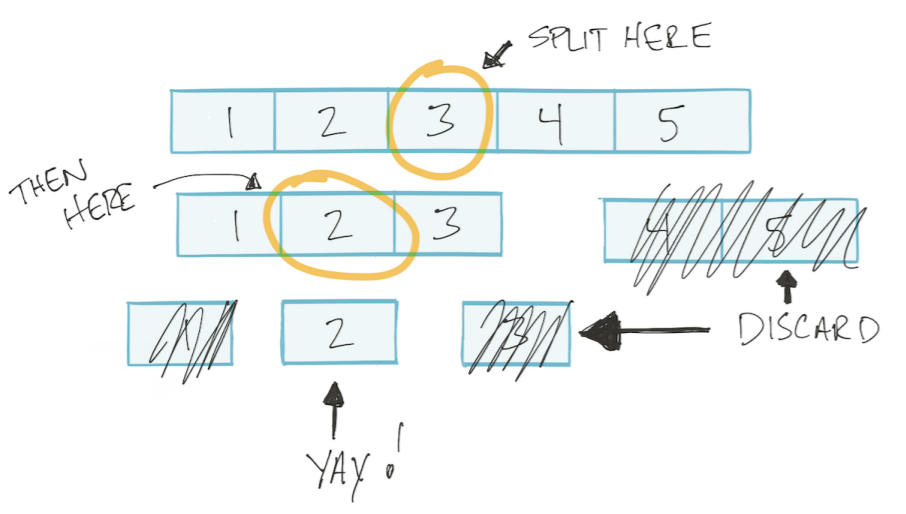
Этот алгоритм основан на логарифме.
Быстрый обзор логарифмов
Рассмотрим пример, чему будет равен x?
Нужно взять кубический корень от 8 — это будет 2. Теперь посложнее
С использованием логарифма задачу можно записать так
«логарифм по основанию 2 от 512 равен x». Обратите внимание «основание 2», т.е. мы мыслим двойками — сколько раз нужно перемножить 2 что бы получить 512.
В алгоритме «бинарный поиск» на каждом шаге мы делим массив на две части.
Мое дополнение. Т.е. в худшем случае делаем столько операций, сколько раз можем разделить массив на две части. Например, сколько раз мы можем разделить на две части массив из 4 элементов? 2 раза. А массив из 8 элементов? 3 раза. Т.е. кол-во делений/операций = log2(n) (где n кол-во элементов массива).
Получается, что зависимость кол-ва операций от кол-ва элементов ввода описывается как log2(n)
Таким образом, используя нотацию Big O, алгоритм «бинарный поиск» имеет сложность O(log n).
Улучшим O(n^2) до O(n log n)
Вернемся к задачке проверки массива на дубли. Мы перебирали все элементы массива и для каждого элемента еще раз делали перебор. Делали O(n) внутри O(n), т.е. O(n*n) или O(n^2).
Мы можем заменить вложенный цикл на бинарный поиск*. Т.е. у нас остается перебор всех элементов O(n), внутри делаем O(log n). Получается O(n * log n), или O(n log n).
const nums = [1, 2, 3, 4, 5]; const searchFor = function (items, num) < //use binary search! //if found, return the number. Otherwise. //return null. We'll do this in a later chapter. >const hasDuplicates = function (nums) < for (let num of nums) < //let's go through the list again and have a look //at all the other numbers so we can compare if (searchFor(nums, num)) < return true; >> //only arrive here if there are no dups return false; >* ВНИМАНИЕ, во избежание Импринтинга. Использовать бинарный поиск для проверки массива на дубли — плохое решение. Здесь лишь показывается как в терминах Big O оценить сложность алгоритма показанного в листинге кода выше. Хороший алгоритм или плохой — для данной заметки не важно, важна наглядность.
Мышление в терминах Big O
- Получение элемента коллекции это O(1). Будь то получение по индексу в массиве, или по ключу в словаре в нотации Big O это будет O(1)
- Перебор коллекции это O(n)
- Вложенные циклы по той же коллекции это O(n^2)
- Разделяй и властвуй (Divide and Conquer) всегда O(log n)
- Итерации которые используют Divide and Conquer это O(n log n)
- big-o notation
- алгоритмы
- javascript
- структуры данных
- сложность алгоритма
- сложность
- бинарный поиск
- JavaScript
- Программирование
- Алгоритмы
Временная сложность алгоритма
В информатике, теория сложности вычислений является разделом теории вычислений, изучающим стоимость работы, требуемой для решения вычислительной проблемы. Стоимость обычно измеряется абстрактными понятиями времени и пространства, называемыми вычислительными ресурсами. Время определяется количеством тривиальных шагов, необходимых для решения проблемы, тогда как пространство определяется объёмом памяти или места на носителе данных. Таким образом, в этой области предпринимается попытка ответить на центральный вопрос разработки алгоритмов: «как изменится время исполнения и объём занятой памяти в зависимости от размера входа и выхода?». Здесь под размером входа понимается длина описания данных задачи в битах (например, в задаче коммивояжера длина входа пропорциональна количеству городов и дорог между ними), а под размером выхода — длина описания решения задачи (оптимального маршрута в задаче коммивояжера).
В частности, теория сложности вычислений определяет NP-полные задачи, которые недетерминированная машина Тьюринга может решить за полиномиальное время, тогда как для детерминированной машины Тьюринга полиномиальный алгоритм неизвестен. Обычно это сложные проблемы оптимизации, например, задача коммивояжера.
Временная и пространственная сложности
Теория сложности вычислений возникла из потребности сравнивать быстродействие алгоритмов, чётко описывать их поведение (время исполнения и объём необходимой памяти) в зависимости от размера входа и выхода.
Количество элементарных операций, затраченных алгоритмом для решения конкретного экземпляра задачи, зависит не только от размера входных данных, но и от самих данных. Например, количество операций алгоритма сортировки вставками значительно меньше в случае, если входные данные уже отсортированы. Чтобы избежать подобных трудностей, рассматривают понятие временной сложности алгоритма в худшем случае.
Временная сложность алгоритма (в худшем случае) — это функция размера входных и выходных данных, равная максимальному количеству элементарных операций, проделываемых алгоритмом для решения экземпляра задачи указанного размера. Во многих задачах размер выхода не превосходит или пропорционален размеру входа — в этом случае можно рассматривать временную сложность как функцию размера только входных данных.
Аналогично понятию временной сложности в худшем случае определяется понятие временная сложность алгоритма в наилучшем случае. Также рассматривают понятие среднее время работы алгоритма, то есть математическое ожидание времени работы алгоритма. Иногда говорят просто: «Временная сложность алгоритма» или «Время работы алгоритма», имея в виду временную сложность алгоритма в худшем, наилучшем или среднем случае (в зависимости от контекста).
По аналогии с временной сложностью, определяют пространственную сложность алгоритма, только здесь говорят не о количестве элементарных операций, а о количестве затраченной памяти.
Асимптотическая сложность
Несмотря на то, что функция временной сложности алгоритма в некоторых случаях может быть определена точно, в большинстве случаев искать точное её значение бессмысленно. Дело в том, что во-первых, точное значение временной сложности зависит от определения элементарных операций (например, сложность можно измерять в количестве арифметических операций или операций на машине Тьюринга), а во-вторых, при увеличении размера входных данных вклад постоянных множителей и слагаемых низших порядков, фигурирующие в выражении для точного времени работы, становится крайне незначительным. Рассмотрение входных данных большого размера и оценка порядка роста времени работы алгоритма, приводит к понятию асимптотической сложности алгоритмов. Обычно алгоритм с меньшей асимптотической сложностью является более эффективным для всех входных данных, за исключением лишь, возможно, данных малого размера. Для записи асимптотической сложности алгоритмов используются асимптотические обозначения:
| Обозначение | Интуитивное объяснение | Определение |
|---|---|---|
 |
f ограничена сверху функцией g (с точностью до постоянного множителя) асимптотически | 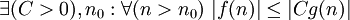 или или 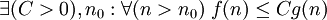 |
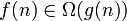 |
f ограничена снизу функцией g (с точностью до постоянного множителя) асимптотически | 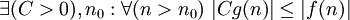 |
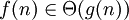 |
f ограничена снизу и сверху функцией g асимптотически | 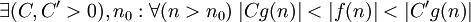 |
 |
g доминирует над f асимптотически | 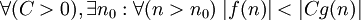 |
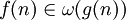 |
f доминирует над g асимптотически | 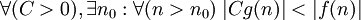 |
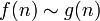 |
f эквивалентна g асимптотически | 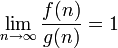 раз (открываний книги). При увеличении объема страниц до ста тысяч, проблема все еще решается за раз (открываний книги). При увеличении объема страниц до ста тысяч, проблема все еще решается за 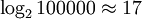 заходов. (См. Двоичный поиск.) заходов. (См. Двоичный поиск.)
ЗамечанияНеобходимо подчеркнуть, что степень роста наихудшего времени выполнения — не единственный или самый важный критерий оценки алгоритмов и программ. Приведем несколько соображений, позволяющих посмотреть на критерий времени выполнения с других точек зрения:
Если решение некоторой задачи для n-вершинного графа при одном алгоритме занимает время (число шагов) порядка n C , а при другом — порядка n+n!/C, где C — постоянное число, то согласно «полиномиальной идеологии» первый алгоритм практически эффективен, а второй — нет, хотя, например, при С=10 (10 10 ) дело обстоит как раз наоборот.
Классы сложностиОсновная статья: Класс сложности Класс сложности — это множество задач распознавания, для решения которых существуют алгоритмы, схожие по вычислительной сложности. Два важных представителя: Класс PОсновная статья: Класс P Класс P вмещает все те проблемы, решение которых считается «быстрым», то есть полиномиально зависящим от размера входа. Сюда относится сортировка, поиск во множестве, выяснение связности графов и многие другие. Класс NPОсновная статья: класс NP Класс NP содержит задачи, которые недетерминированная машина Тьюринга в состоянии решить за полиномиальное количество времени. Следует заметить, что недерминированная машина Тьюринга машина является лишь абстрактной моделью, в то время как современные компьютеры соответствуют детерминированной машине Тьюринга с ограниченной памятью. Таким образом, класс NP включает в себя класс P, а также некоторые проблемы, для решения которых известны лишь алгоритмы, экспоненциально зависящие от размера входа (т.е. неэффективные для больших входов). В класс NP входят многие знаменитые проблемы, такие как задача коммивояжёра, задача выполнимости булевых формул, факторизация и др. Проблема равенства классов P и NPОсновная статья: Равенство классов P и NP Вопрос о равенстве этих двух классов считается одной из самых сложных открытых проблем в области теоретической информатики. Математический институт Клэя включил эту проблему в список проблем тысячелетия, предложив награду размером в один миллион долларов США за её решение. Знаменитые ученые
См. также
Ссылки
Wikimedia Foundation . 2010 . Сколько стоят операции над list, set и dict в Python? Разбираемся с временной сложностьюВременная сложность алгоритма часто обозначается нотацией «О» большое. Разбираемся, что это и какова сложность операций над коллекциями в Python. Автор перевода Иван Капцов Программисту, работающему с данными, крайне важно выбирать правильные структуры данных для решения поставленной задачи, ведь выбор неправильного типа данных плохо влияет на производительность приложения. В этой статье объясняется нотация «О» большое и сложность ключевых операций структур данных в CPython. Что означает нотация «O» большое?В алгоритме выполняется ряд операций. Эти операции могут включать в себя итерацию по коллекции, копирование элемента или всей коллекции, добавление элемента в коллекцию, вставку элемента в начало или конец коллекции, удаление элемента или обновление элемента в коллекции. «O» большое служит обозначением временной сложности операций алгоритма. Она показывает, сколько времени потребуется алгоритму для вычисления требуемой операции. Можно также измерить пространственную сложность (сколько места занимает алгоритм), но в этой статье мы сосредоточимся на временной. Проще говоря, нотация «O» большое — это способ измерения производительности операции на основе размера ввода, известного как n. Значения нотации «О» большоеНа письме временная сложность алгоритма обозначается как O(n), где n — размер входной коллекции. O(1)Обозначение константной временной сложности. Независимо от размера коллекции, время, необходимое для выполнения операции, константно. Это обозначение константной временной сложности. Эти операции выполняются настолько быстро, насколько возможно. Например, операции, которые проверяют, есть ли внутри коллекции элементы, имеют сложность O(1). O(log n)Обозначение логарифмической временной сложности. В этом случае когда размер коллекции увеличивается, время, необходимое для выполнения операции, логарифмически увеличивается. Эту сложность имеют потенциально оптимизированные алгоритмы поиска. O(n)Обозначение линейной временной сложности. Время, необходимое для выполнения операции, прямо и линейно пропорционально количеству элементов в коллекции. Это обозначение линейной временной сложности. Это что-то среднее с точки зрения производительности. Например, если мы хотим суммировать все элементы в коллекции, нужно будет выполнить итерацию по коллекции. Следовательно, итерация коллекции является операцией O(n). O(n log n)Обозначение квазилинейной временной сложности. Скорость выполнения операции является квазилинейной функцией числа элементов в коллекции. Временная сложность оптимизированного алгоритма сортировки обычно равна O(n log n). O(n^2)Обозначение квадратичной временной сложности. Время, необходимое для выполнения операции, пропорционально квадрату элементов в коллекции. O(n!)Обозначение факториальной временной сложности. Каждая операция требует вычисления всех перестановок коллекции, следовательно требуемое время выполнения операции является факториалом размера входной коллекции. Это очень медленно. Нотация «O» большое относительна. Она не зависит от машины, игнорирует константы и понятна широкой аудитории, включая математиков, технологов, специалистов по данным и т. д. Благоприятные, средние и худшие случаиПри вычислении временной сложности операции можно получить сложность на основе благоприятного, среднего или худшего случая. Благоприятный случай. Как следует из названия, это сценарий, когда структуры данных и элементы в коллекции вместе с параметрами находятся в оптимальном состоянии. Например, мы хотим найти элемент в коллекции. Если этот элемент оказывается первым элементом коллекции, то это лучший сценарий для операции. Средний случай. Определяем сложность на основе распределения значений входных данных. Худший случай. Структуры данных и элементы в коллекции вместе с параметрами находятся в наиболее неоптимальном состоянии. Например, худший случай для операции, которой требуется найти элемент в большой коллекции в виде списка — когда искомый элемент находится в самом конце, а алгоритм перебирает коллекцию с самого начала. Коллекции Python и их временная сложностьСписок (list)Список является одной из самых важных структур данных в Python. Можно использовать списки для создания стека или очереди. Списки — это упорядоченные и изменяемые коллекции, которые можно обновлять по желанию. Операции списка и их временная сложностьВставка: O(n). Множество (set)Множества также являются одними из наиболее используемых типов данных в Python. Множество представляет собой неупорядоченную коллекцию. Множество не допускает дублирования, и, следовательно, каждый элемент в множестве уникален. Множество поддерживает множество математических операций, таких как объединение, разность, пересечение и так далее. Операции с множествами и их временная сложностьПроверить наличие элемента в множестве: O(1). Словарь (dict)Словарь — это коллекция пар ключ-значение. Ключи в словаре уникальны, чтобы предотвратить коллизию элементов. Это чрезвычайно полезная структура данных. Словари индексируются по ключам, которые могут быть строками, числами или даже кортежами со строками, числами или кортежами. Над словарём можно выполнить ряд операций, таких как сохранение значения для ключа, извлечение элемента на основе ключа, или итерация по элементам и так далее. Операции со словарями и их временная сложностьЗдесь мы считаем, что ключ используется для получения, установки или удаления элемента. Получение элемента: O(1). Вычислительная сложность машинного обучения. Базовые принципыЧуть ранее, в статье временная сложность алгоритмов машинного обучения, я разбирал временную сложность некоторых алгоритмов из библиотеки scykit-learn. Настало время немного подробнее остановиться на том, как в принципе считается вычислительная сложность data science. Вычислительная сложность (или асимптотическая сложность или производительность) — это свойство алгоритма. Она определяется функцией, которая показывает насколько ухудшается работа алгоритма с усложнением поставленной задачи. Вот пять основных правил расчета вычислительной сложности:
Нотация «O» большое всего лишь указывает на то, что мы рассматриваем ситуацию, когда алгоритму для завершения необходимо потребить максимальное возможное количество (худший случай). В предыдущей статье рассматривался частный случай, входящий в обобщенное понятие вычислительной сложности — временная сложность алгоритмов МО. Грубо говоря, объем задачи алгоритма всегда связан с вычислительными ресурсами — временем (или количеством шагов) вычислений и пространством (или объемом памяти), необходимыми для завершения задачи. Поэтому в различной специальной литературе по машинному обучению, где рассматриваются частные случаи алгоритмов, можно встретить отсылки как к вычислительной сложности в целом так и к сложности по времени или по памятми. На практике чаще всего встречаются следующие сложности:
Задачи со сложностью до \(O(N*\log(N))\) включительно решаемы. При грамотном управлении количеством входных данных решаемы и задачи со степенной сложностью. Экспоненциальные и факториальные сложности, в виду в целом большого входного объема данных, в МО неприменимы. Ключевым вопросом в оценке сложности алгоритмов МО является их класс, определяющий требования ко времени и ресурсам памяти, применительно к некой абстрактной машине (часто рассматривается детерминированная машина, в частности, машина Тьюринга). Для детерминированных машин определены следующие классы:
Для недетерминированных машин:
Аналогичным образом задачи делятся в зависимости от потребляемого объема памяти. Не вдаваясь в подроности, в общем случае \(P \subseteq NP\), экспоненциальные задачи, по сути, не считаемые, а задачей построения алгоритмов МО, в том числе, является их сведение к менее затратному классу. Задачи, которые входят в класс NP и к которым можно свести любые другие задачи этого класса за полиномиальное время называются NP-полными. NP-сложные задачи необязательно относятся к классу NP. Время обучения для алгоритмов МОФактическое время работы алгоритма МО зависит от конкретной машины, на которой алгоритм реализован. В общем случае алгоритм обучения с учителем имеет доступ к множеству примеров, классу гипотез, функции потерь и обучающему набору, взятому из множества примеров. Четкого понятия размера входных данных для такого алгоритма не существует, т.к. если мы предъявляем алгоритму избыточное количество обучающих примеров, он может игнорировать лишние. Поэтому увеличение размера обучающего набора не ведет к тому, что проблема обучения становится более трудной. кроме того, алгоритм обучения может передавать часть вычислений выходной гипотезе, в случае, когда такая гипотеза определена как функция, сохраняющая обучающий набор. Для этого вводятся понятия времени обучения и времени предсказания. Будем рассматривать алгоритмы, чье время предсказания не превышает время обучения. Вычислительная сложность алгоритма обучения определяется в два этапа:
В таком случае можно сказать, что алгоритм \(A\) эффективен на последовательности \((>, >, >)\), если его время работы равно \(O(p(n, 1/\epsilon, 1/\delta))\) для некоторого полинома p. Очевидно, что вопрос об эффективном решении проблемы обучения зависит от того, как именно задача обучения представлена в виде последовательности конкретных проблем. Более подробную информацию на эту тему можно найти в учебнике «Understanding Machine Learning», изданном в Cambridge University Press в 2014-ом году.
Особенности препроцессинга данных в scikit-learn В статье кратко раскрываются некоторые вопросы подготовки данных с помощью scikit-learn. Замена пропусков Scikit-learn не поддерживает замену пропусков с разными. Подготовка данных: кодирование категориальных признаков В статье «[особенности препроцессинга данных в scikit-learn](>)» разбирались особенности кодирования признаков с помощью библиотеки scikit-learn. К сожалению. Этот проект поддерживается KonstantinKlepikov |