Введение в OverlayFS
Псевдофайловая система OverlayFS была впервые включена в версию ядра Linux 3.18: она позволяет нам объединять два дерева каталогов или файловые системы («верхнюю» и «нижнюю») таким образом, чтобы это было полностью прозрачно для пользователя, что иметь доступ к файлам и каталогам на «объединённом» уровне так же, как он это делал бы в стандартной файловой системе.
В этом уроке мы изучаем основные концепции OverlayFS и видим демонстрацию его использования.
В этом уроке вы узнаете:
- Основные понятия OverlayFS
- Как объединить две файловые системы с помощью OverlayFS

Введение
Мы все должны быть знакомы со стандартным поведением ядра Linux при монтировании файловой системы: файлы и каталоги, существующие в каталоге, используемом в качестве точки монтирования, маскируются и становятся недоступными для пользователя, в то время как файлы и каталоги, существующие в смонтированной файловой системе, отображаются. Доступ к исходным файлам можно получить снова только после размонтирования файловой системы. Это также происходит, когда мы монтируем несколько файловых систем в один и тот же каталог. Вместо этого при использовании псевдофайловой системы OverlayFS файлы, существующие на разных уровнях, объединяются, и полученная файловая система может быть смонтирована сама.
OverlayFS обычно используется в системах, работающих на встраиваемых устройствах, таких как OpenWRT, где полезно сохранить базовый набор конфигураций и в то же время позволить пользователю вносить изменения. OverlayFS также лежит в основе драйверов хранилища Docker «overlay» и «overlay2». Давайте посмотрим, какая основная логика стоит за этим.
OverlayFS: основные понятия
В работе OverlayFS участвуют два уровня: нижний и верхний. Нижний уровень обычно монтируется в режиме только для чтения. При использовании этой настройки, поскольку прямое изменение файлов и каталогов, размещенных на ней, невозможно, ее можно использовать в качестве безопасного запасного варианта. Вместо этого верхний уровень может быть установлен в режиме чтения/записи. Файл, существующий на двух слоях, объединяется и становится доступным в так называемом «объединенном» слое, который можно смонтировать как стандартную файловую систему.
Как мы можем видеть на рисунке ниже, файл, существующий в нижнем слое, «скрыт» или «маскирован» файлом с таким же именем, существующим в верхнем. Когда пользователь изменяет файл, принадлежащий первому, его копия создается во втором, доступном для записи слое (эта стратегия называется «копирование»): этот файл маскирует исходный файл в прозрачном процессе. пользователю. То же самое происходит и с каталогами, которые объединены:

Что произойдет, если удалить файл или каталог? Если удаляемый нами файл принадлежит верхнему слою, он удаляется на месте; если он принадлежит нижнему уровню, вместо этого удаление моделируется с использованием белого файла (или непрозрачного каталога – каталога с расширенным атрибутом trusted.overlay.opaque ). ), который создается в записываемом слое и скрывает исходный элемент.
OverlayFS является основой драйверов Docker overlay и overlay2. В такой реализации нижний уровень, доступный только для чтения, представлен изображениями; вместо этого доступный для записи верхний уровень представлен основанными на них контейнерами . Образы неизменяемы: все изменения происходят внутри контейнеров и теряются при удалении контейнеров (поэтому для сохранения используются тома):

Использование OverlayFS
Давайте посмотрим, как использовать OverlayFS. В этом примере я предполагаю, что мы хотим объединить две файловые системы: нижнюю, существующую в разделе /dev/sda1 , и ту, которая будет использоваться в режиме чтения-записи и находиться на Раздел /dev/sda2 . Первое, что нам нужно сделать, это создать каталоги, которые мы будем использовать в качестве точек монтирования:
$ sudo mkdir /lower /overlay
Теперь давайте смонтируем файловую систему /dev/sda1 в каталог /lower в режиме только для чтения:
$ sudo mount -o ro /dev/sda1 /lower
Команда ls показывает, что файловая система содержит только один файл:
$ ls -l /lower total 20 -rw-r--r--. 1 root root 23 Sep 1 10:43 file1.txt drwx------. 2 root root 16384 Sep 1 10:40 lost+foun
Файлы содержат всего одну строку:
$ cat /lower/file1.txt this is the first line
Теперь продолжим. Следующим шагом мы смонтируем файловую систему /dev/sda2 в каталог /overlay :
$ sudo mount /dev/sda2 /overlay
После того, как файловая система смонтирована, мы создаем в ней два каталога: upper и work . Первый будет содержать файлы, являющиеся частью верхнего уровня, второй будет использоваться для внутренней подготовки файлов при их переключении с одного уровня на другой: он должен быть пустым и находиться в той же файловой системе, что и верхний уровень. :
$ sudo mkdir /overlay/
Теперь мы можем «собрать» и смонтировать накладку. Для выполнения задачи воспользуемся следующей командой:
$ sudo mount overlay -t overlay -o lowerdir=/lower,upperdir=/overlay/upper,workdir=/overlay/work /media
Мы вызвали mount , передав «overlay» в качестве аргумента опции -t (сокращение от —types ), тем самым указав тип файловой системы, которую мы хотите смонтировать (в данном случае псевдофайловую систему), то мы использовали флаг -o для вывода списка параметров монтирования: в данном случае «lowerdir», «upperdir» и «workdir» для указания: каталога на которой смонтирована файловая система, доступная только для чтения, каталог, в котором размещены файлы верхнего, доступного для записи слоя, и расположение «рабочего» каталога соответственно. Наконец, мы указали точку монтирования «объединенной» файловой системы: в данном случае /media .
Мы можем просмотреть сводную информацию о настройке наложения с помощью команды mount :
$ mount | grep -i overlay overlay on /media type overlay (rw,relatime,seclabel,lowerdir=/lower,upperdir=/overlay/upper,workdir=/overlay/work)
Если мы перечислим файлы в каталоге /media , мы увидим, что существует только file1.txt , который, как мы знаем, принадлежит нижнему уровню:
$ ls -l /media total 20 -rw-r--r--. 1 root root 23 Sep 1 10:43 file1.txt drwx------. 2 root root 16384 Sep 1 10:40 lost+found
Теперь попробуем добавить строку в файл и посмотрим, что получится:
$ echo "this is the second line" | sudo tee -a /media/file1.txt
Если мы проверим содержимое файла, мы увидим, что строка была успешно добавлена:
$ cat /media/file1.txt this is the first line this is the second line
Однако исходный файл file1.txt не был изменен:
$ cat /lower/file1.txt this is the first line
Вместо этого в верхний слой был добавлен файл с таким же именем:
$ ls -l /overlay/upper -rw-r--r--. 1 root root 47 Sep 1 14:36 file1.txt
Теперь, если мы удалим файл /media/file1.txt , /overlay/upper/file1.txt станет белым файлом:
$ sudo rm /media/file1.txt $ ls -l /overlay/upper c---------. 2 root root 0, 0 Sep 1 14:45 file1.txt
Как указано в официальной документации, файл whiteout представляет собой символьное устройство (это отражается в выводе команды ls – см. выделенную начальную букву «c») с номером устройства 0/0.
Выводы
В этом уроке мы говорили о OverlayFS: мы изучили основные концепции его использования и увидели, как его можно использовать для объединения двух файловых систем или деревьев каталогов, а также каковы некоторые из возможных вариантов его использования. Наконец, мы увидели, как на самом деле создать настройку OverlayFS в Linux.
Все права защищены. © Linux-Console.net • 2019-2024
Overlay filesystem (Русский)
Состояние перевода: На этой странице представлен перевод статьи Overlay filesystem. Дата последней синхронизации: 27 мая 2020. Вы можете помочь синхронизировать перевод, если в английской версии произошли изменения.
Overlayfs позволяет накладывать одно дерево каталогов (обычно доступное в режиме «чтение-запись») на другое, но с доступом только для чтения. Все изменения переходят на верхний слой с возможностью записи. Данная схема чаще всего используется с Live CD, но существует и множество других применений. Данная реализация отличается от других каскадно-объединённых файловых систем тем, что после открытия файла все операции направляются непосредственно в базовую, «нижнюю» или «верхнюю» файловую систему, что упрощает реализацию и не ухудшает производительность в данных случаях.
Overlayfs доступен в ядре Linux с версии 3.18.
Установка
Overlayfs включён в ядре по умолчанию, а модуль overlay автоматически подгружается после ввода команды монтирования.
Использование
Используйте следующие аргументы mount для монтирования overlay:
# mount -t overlay overlay -o lowerdir=/lower,upperdir=/upper,workdir=/work /merged
Примечание: Рабочий каталог ( workdir ) должен быть пустым и находиться в той же точке монтирования файловой системы, что и верхний каталог.
Нижняя директория может быть списком каталогов, разделённых : , все изменения в каталоге merged по-прежнему будут отражаться в upper .
# mount -t overlay overlay -o lowerdir=/lower1:/lower2:/lower3,upperdir=/upper,workdir=/work /merged
Примечание: Порядок монтирования папок lowerdir : слева-направо/сверху-вниз. То есть крайняя левая папка из списка будет смонтирована как самый верхний слой из lowerdir , а крайняя правая папка, соответственно, как самый нижний слой.
Таким образом порядок слоёв из вышеупомянутого примера будет следующим:
/upper /lower1 /lower2 /lower3
Используйте следующий формат, чтобы добавить запись overlayfs в /etc/fstab :
/etc/fstab
overlay /merged overlay noauto,x-systemd.automount,lowerdir=/lower,upperdir=/upper,workdir=/work 0 0
Параметры монтирования noauto и x-systemd.automount необходимы для предотвращения зависания systemd при загрузке, например, из-за ошибки монтирования overlay. Также overlay теперь будет монтироваться при первом обращении, а запросы будут буферизироваться до готовности самого overlay. Для получения дополнительной информации смотрите раздел Fstab (Русский)#Автоматическое монтирование с systemd.
Overlay только для чтения
Иногда необходимо создать представление из комбинации двух или более каталогов, доступное только для чтения. В этом случае его можно создать более простым способом, так как каталоги upper и work не обязательны:
# mount -t overlay overlay -o lowerdir=/lower1:/lower2 /merged
Когда upperdir не указан, overlay автоматически монтируется только для чтения.
Смотрите также
- Документация файловой системы Overlay
- Обзор OverlayFS — что она делает и как работает
- Wikipedia:OverlayFS
Виртуальные файловые системы в Linux: зачем они нужны и как они работают? Часть 2
Всем привет, делимся с вами второй частью публикации «Виртуальные файловые системы в Linux: зачем они нужны и как они работают?» Первую часть можно прочитать тут. Напомним, данная серия публикаций приурочена к запуску нового потока по курсу «Администратор Linux», который стартует уже совсем скоро.
Как наблюдать за VFS с помощью инструментов eBPF и bcc
Самый простой способ понять, как ядро оперирует файлами sysfs – это посмотреть за этим на практике, а самый простой способ понаблюдать за ARM64 – это использовать eBPF. eBPF (сокращение от Berkeley Packet Filter) состоит из виртуальной машины, запущенной в ядре, которую привилегированные пользователи могут запрашивать ( query ) из командной строки. Исходники ядра сообщают читателю, что может сделать ядро; запуск инструментов eBPF в загруженной системе показывает, что на самом деле делает ядро.

К счастью, начать использовать eBPF достаточно легко с помощью инструментов bcc, которые доступны в качестве пакетов из общего дистрибутива Linux и подробно задокументированы Бернардом Греггом. Инструменты bcc – это скрипты на Python с маленькими вставками кода на С, это означает, что каждый, кто знаком с обоими языками может с легкостью их модифицировать. В bcc/tools есть 80 Python скриптов, а это значит, что скорее всего разработчик или системный администратор сможет подобрать себе что-нибудь подходящее для решения задачи.
Чтобы получить хотя бы поверхностное представление о том, какую работу выполняют VFS в запущенной системе, попробуйте vfscount или vfsstat . Это покажет, допустим, что десятки вызовов vfs_open() и «его друзей» происходят буквально каждую секунду.
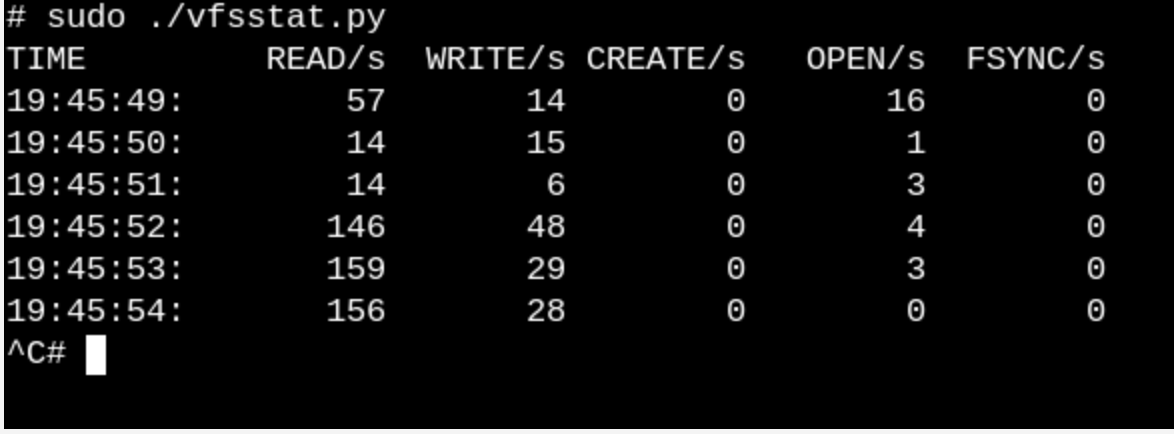
vfsstat.py – это скрипт на Python, со вставками С кода, который просто считает вызовы функций VFS.
Приведем более тривиальный пример и посмотрим, что бывает, когда мы вставляем USB-флеш накопитель в компьютер и его обнаруживает система.
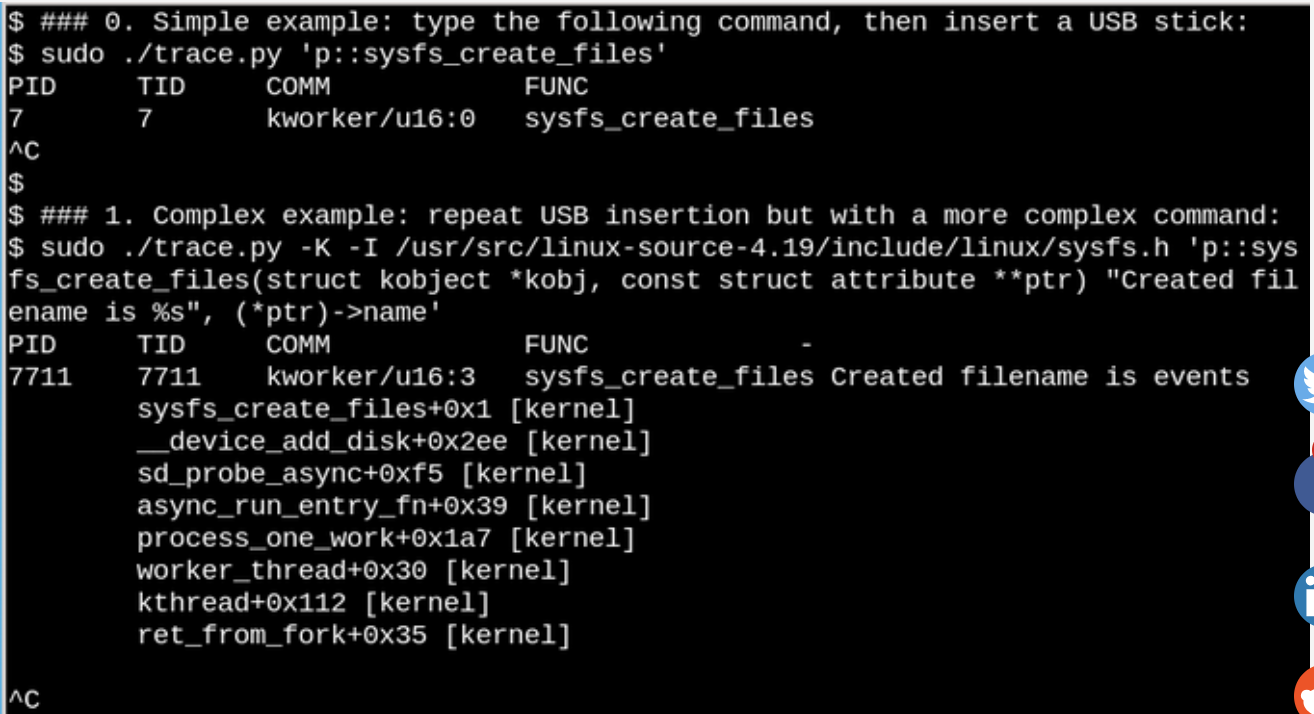
С помощью eBPF можно посмотреть, что происходит в /sys , когда вставлен USB-флеш накопитель. Здесь показан простой и сложный пример.
В примере, показанном сверху, bcc инструмент trace.py выводит сообщение, когда запускается команда sysfs_create_files() . Мы видим, что sysfs_create_files() был запущен с помощью kworker потока в ответ на то, что флешка была вставлена, но какой файл при этом создался? Второй пример показывает всю мощь eBPF. Здесь trace.py выводит обратную трассировку ядра (kernel backtrace) (опция -K) и имя файла, который был создан sysfs_create_files() . Вставка в одиночных высказываниях – это код на С, включающий легко распознаваемую строку формата, обеспечиваемую Python скриптом, который запускает LLVM just-in-time компилятор. Эту строку он компилирует и выполняет в виртуальной машине внутри ядра. Полная сигнатура функции sysfs_create_files () должна быть воспроизведена во второй команде, чтобы строка формата могла ссылаться на один из параметров. Ошибки в этом фрагменте кода на С приводят к распознаваемым ошибкам C-компилятора. Например, если пропущен параметр -l, то вы увидите «Failed to compile BPF text.» Разработчики, которые хорошо знакомы с С и Python, найдут инструменты bcc простыми для расширения и изменения.
Когда USB-накопитель вставлен, обратная трассировка ядра покажет, что PID 7711 – это поток kworker , который создал файл «events» в sysfs . Соответственно, вызов с sysfs_remove_files() покажет, что удаление накопителя привело к удалению файла events , что соответствует общей концепции подсчета ссылок. При этом, просмотр sysfs_create_link () с eBPF во время вставки USB-накопителя покажет, что создано не менее 48 символьных ссылок.
Так в чем же смысл файла events? Использование cscope для поиска __device_add_disk(), показывает, что она вызывает disk_add_events () , и либо «media_change» , либо «eject_request» могут быть записаны в файл событий. Здесь блочный слой ядра информирует userspace о появлении и извлечении «диска». Обратите внимание, насколько информативен этот метод исследования на примере вставки USB-накопителя по сравнению с попытками выяснить, как все работает, исключительно из исходников.
Корневые файловые системы только для чтения делают возможными встроенные устройства
Конечно, никто не выключает сервер или свой компьютер, вытаскивая вилку из розетки. Но почему? А все потому что смонтированные файловые системы на физических устройствах хранения могут иметь отложенные записи, а структуры данных, записывающие их состояние, могут не синхронизироваться с записями в хранилище. Когда это случается, владельцам системы приходится ждать следующей загрузки для запуска утилиты fsck filesystem-recovery и, в худшем случае, потерять данные.
Тем не менее, все мы знаем, что многие IoT устройства, а также маршрутизаторы, термостаты и автомобили теперь работают под управлением Linux. Многие из этих устройств практически не имеют пользовательского интерфейса, и нет никакого способа выключить их «чисто». Представьте себе запуск автомобиля с разряженной батареей, когда питание управляющего устройства на Linux постоянно скачет вверх-вниз. Как получается, что система загружается без длинного fsck , когда двигатель наконец начинает работать? А ответ прост. Встроенные устройства полагаются на корневую файловую систему только для чтения (сокращенно ro-rootfs (read-only root fileystem)).
ro-rootfs предлагают множество преимуществ, которые менее очевидны, чем неподдельность. Одно из преимуществ заключается в том, что вредоносное ПО не может писать в /usr или /lib , если ни один процесс Linux не может туда писать. Другое заключается в том, что в значительной степени неизменяемая файловая система имеет решающее значение для полевой поддержки удаленных устройств, поскольку вспомогательный персонал пользуется локальными системами, которые номинально идентичны системам на местах. Возможно, самым важным (но и самым коварным) преимуществом является то, что ro-rootfs заставляет разработчиков решать, какие системные объекты будут неизменными, еще на этапе проектирования системы. Работа с ro-rootfs может быть неудобной и болезненной, как это часто бывает с переменными const в языках программирования, но их преимущества легко окупают дополнительные накладные расходы.
Создание rootfs только для чтения требует некоторых дополнительных усилий для разработчиков встраиваемых систем, и именно здесь на сцену выходит VFS. Linux требует, чтобы файлы в /var были доступны для записи, и, кроме того, многие популярные приложения, которые запускают встроенные системы, будут пытаться создать конфигурационные dot-files в $HOME . Одним из решений для конфигурационных файлов в домашнем каталоге обычно является их предварительная генерация и сборка в rootfs . Для /var один из возможных подходов — это смонтировать его в отдельный раздел, доступный для записи, в то время как сам / монтируется только для чтения. Другой популярной альтернативой является использование связываемых или накладываемых маунтов (bind or overlay mounts).
Связываемые и накладываемые маунты, использование их контейнерами
Выполнение команды man mount – лучший способ узнать про связываемые и накладываемые маунты, которые дают разработчикам и системным администраторам возможность создавать файловую систему по одному пути, а затем предоставлять ее приложениям в другом. Для встроенных систем это означает возможность хранить файлы в /var на флеш-накопителе, доступном только для чтения, но накладываемое или связываемое монтирование пути из tmpfs в /var при загрузке позволит приложениям записывать туда заметки (scrawl). При следующем включении изменения в /var будут утеряны. Накладываемое монтирование создает объединение между tmpfs и нижележащей файловой системой и позволяет делать якобы изменения существующих файлов в ro-tootf тогда как связываемое монтирование может сделать новые пустые tmpfs папки видимыми как доступные для записи в ro-rootfs путях. В то время как overlayfs это правильный ( proper ) тип файловой системы, связываемое монтирование реализовано в пространстве имен VFS.
Основываясь на описании накладываемого и связываемого монтирования, никто не удивляется что Linux контейнеры активно их используют. Давайте понаблюдаем, что происходит, когда мы используем systemd-nspawn для запуска контейнера, используя инструмент mountsnoop от bcc .

Вызов system-nspawn запускает контейнер во время работы mountsnoop.py .
Посмотрим, что получилось:
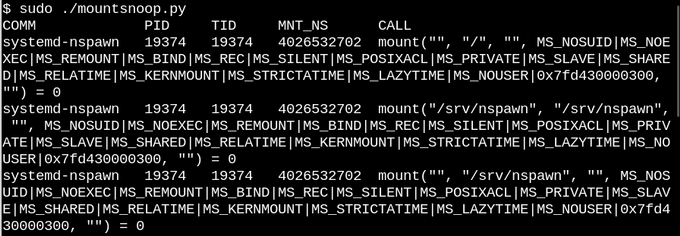
Запуск mountsnoop во время «загрузки» контейнера показывает, что среда выполнения контейнера сильно зависит от связываемого монтирования (Отображается только начало длинного вывода).
Здесь systemd-nspawn предоставляет выбранные файлы в procfs и sysfs хоста в контейнер как пути в его rootfs . Кроме MS_BIND флага, который устанавливает связывающее монтирование, некоторые другие флаги в монтируемой системе определяют взаимосвязь между изменениями в пространстве имен хоста и контейнера. Например, связываемое монтирование может либо пропускать изменения в /proc и /sys в контейнер, либо скрывать их в зависимости от вызова.
Понимание внутреннего устройства Linux может казаться невыполнимой задачей, так как само ядро содержит гигантское количество кода, оставляя в стороне приложения пользовательского пространства Linux и интерфейсы системных вызовов в библиотеках на языке C, таких как glibc . Один из способов добиться прогресса — прочитать исходный код одной подсистемы ядра с акцентом на понимание системных вызовов и заголовков, обращенных к пространству пользователя, а также основных внутренних интерфейсов ядра, к примеру, таблица file_operations . Файловые операции обеспечивают принцип «все является файлом», поэтому управление ими особенно приятно. Исходные файлы ядра на языке C в каталоге верхнего уровня fs/ представляют реализацию виртуальных файловых систем, которые являются слоем оболочки, обеспечивающим широкую и относительно простую совместимость популярных файловых систем и устройств хранения. Монтирование со связыванием и накладыванием через пространства имен Linux — это волшебство VFS, которое делает возможным создание контейнеров и корневых файловых систем только для чтения. В сочетании с изучением исходного кода, средство ядра eBPF и его интерфейс bcc
делают исследование ядра проще, чем когда-либо.
Друзья, напишите была ли эта статья полезной для вас? Возможно у вас есть какие-то комментарии или замечания? А тех, кому интересен курс «Администратор Linux», приглашаем на день открытых дверей, который пройдёт 18 апреля.
- Блог компании OTUS
- Настройка Linux
Описание файловой системы OverlayFS
Не закончен, так как не хватает знаний. По мере изучения, постараюсь дополнить.
Данная файловая системы используется, например, в Docker. Часто её можно наблюдать на роутерах или других подобных устройствах, где оперативная запись информации ведётся во временную наложенную ФС, доступную до момента выключения устройства.
С помощью OverlayFS я объединяю домашние фото и видео каталоги для удобного просмотра. Так как архивы исходных фотографий доступны только для чтения, наложением рабочей папки, для сохранения временных или промежуточных файлов обработки, я добиваюсь удобства в обработке фоток.
Перед пониманием темы Overlay Filesystem, мне необходимо провентилировать Linux Virtual File System.
Overlay Filesystem
Этот документ описывает прототип нового подхода к обеспечению функциональности overlay filesystem (наложенная файловая система) в Линукс (некоторые предпочитают называть union-filesystems объединённая файловая система). Overlay filesystem пытается показать файловую систему так, как результат наложения одной ФС поверх другой ФС.
Overlay объекты
Метод наложения файловой системы является смешанным, так как объекты, которые видны в этой ФС не всегда ей принадлежат. Во многих случаях, доступ к объекту в объединении будет неразличимым от доступа к соответствующему объекту из обычной файловой системы. Это наиболее очевидно из поля ‘st_dev’ возвращаемого системным вызовом stat ( man 2 stat ).
Почитав stat(2), я выяснил, что поле ‘st_dev’ описывает устройство на котором находится файл. ‘st_ino’ — номер inode.
В то время как директории будут сообщать ‘st_dev’ из наложенной файловой системы, объекты, не являющиеся каталогами, могут сообщать ‘st_dev’ из нижней или верхней файловой системы, которая предоставляет объект. Аналогично ‘st_ino’ будет уникальным только в сочетании с ‘st_dev’, и оба они могут изменяться в течение всего времени жизни объекта не-каталога. Многие приложения и инструменты игнорируют эти значения.
В особом случае, когда все наложенные слои принадлежат одной подлежащей файловой системе, то все объекты будут сообщать ‘st_dev’ из наложенной файловой системы, а ‘st_ino’ из подлежащей файловой системы. Это делает монтирование наложения более совместимым со сканерами файловой системы, и оверлей-объекты будут отличаться от соответствующих объектов в оригинальной файловой системе.
On 64bit systems, even if all overlay layers are not on the same underlying filesystem, the same compliant behavior could be achieved with the “xino” feature. The “xino” feature composes a unique object identifier from the real object st_ino and an underlying fsid index. If all underlying filesystems support NFS file handles and export file handles with 32bit inode number encoding (e.g. ext4), overlay filesystem will use the high inode number bits for fsid. Even when the underlying filesystem uses 64bit inode numbers, users can still enable the “xino” feature with the “-o xino=on” overlay mount option. That is useful for the case of underlying filesystems like xfs and tmpfs, which use 64bit inode numbers, but are very unlikely to use the high inode number bit.
Верхний и нижний слои
Наложенная файловая система комбинируется из двух ФС — верхней и нижней. Когда имя объекта существует в обеих ФС, тогда объект из верхней ФС виден, а объект из нижней ФС скрыт. В случае с совпадением имён каталогов, их содержимое будет объединено.
Было бы правильней употреблять термин верхнее и нижнее дерево каталогов вместо термина файловая система, поскольку вполне возможно, что оба дерева каталогов могут находиться в одной и той же файловой системе, и здесь не требуется указывать корень файловой системы для верхней или нижней файловой системы.
Нижняя файловая система может быть любой файловой системой, поддерживаемой Linux, и для неё не требуется прав на запись. Нижняя файловая система может быть даже другим оверлеем. Верхняя файловая система обычно доступна для записи, и в таком случае она должна поддерживать создание расширенных атрибутов “trusted.*”, и также должна предоставлять допустимый ’d_type’ в ‘readdir’ ответах, так что NFS не подходит.
readdir — чтение директории описание поля “d_type”…
«d_type» Это поле содержит значение, обозначающее тип файла, что позволяет избежать затрат на вызов lstat(2), если дальнейшие действия зависят от типа файла.
When a suitable feature test macro is defined (_DEFAULT_SOURCE on glibc versions since 2.19, or _BSD_SOURCE on glibc versions 2.19 and earlier), glibc defines the following macro constants for the value returned in d_type: DT_BLK This is a block device. DT_CHR This is a character device. DT_DIR This is a directory. DT_FIFO This is a named pipe (FIFO). DT_LNK This is a symbolic link. DT_REG This is a regular file. DT_SOCK This is a UNIX domain socket. DT_UNKNOWN The file type could not be determined.
На данный момент только некоторые файловые системы (среди них, такие как: Btrfs, ext2, ext3, and ext4) умеют возвращать правильное значение типа файла в поде “d_type”. Все приложения обязаны должным образом обрабатывать возвращаемое значение DT_UNKNOWN.
Только в варианте, когда наложенная ФС имеет атрибут “только для чтения” и составлена из двух “только для чтения” файловых систем, могут использоваться любые типы ФС.
Каталоги
В оверлее, в основном, участвуют каталоги. Если имя объекта ссылается не на каталог, и объект проявляется как в верхней, так и в нижней файловых системах, то нижний объект скрыт и имя относится только к верхнему объекту.
Если верхний и нижний объекты являются каталогами, то формируется объединенный каталог.
В момент монтирования две директории, указанные в опциях как “upperdir” и “lowerdir”, соединяются в одну объединённую директорию:
# mount -t overlay overlay -olowerdir=/lower,upperdir=/upper,workdir=/work /merged Опция “workdir” должна указывать на пустой каталог в той же файловой системе, где находится “upperdir”.
dentry — объект VFS, содержащий информацию о директориях ФС и существующий только в памяти файловой системы и не хранится на диске. Если я правильно понял, то предназначен для уменьшения обращений к ФС при перечитывании содержимого каталогов.
Тогда всякий раз, когда поиск запрашивается в такой объединенной директории, просмотр выполняется в каждой фактической директории и объединенный результат кэшируется в dentry, принадлежащем наложенной файловой системе. Если оба актуальных поиска находят каталоги, оба сохраняются и создается объединенный каталог, в противном случае сохраняется только один: верхний, если он существует, иначе нижний.
Объединяются только списки имён из директорий. Другое содержимое, такое как метаданные и расширенные атрибуты, отображается только для директорий из верхней ФС. Эти атрибуты для директории из нижней ФС скрыты.
“Выбеленные” и “непрозрачные” каталоги
Не уверен, что подобрал правильный перевод для “whiteouts and opaque directories”.
Чтобы выполнять rm и rmdir без изменения нижней файловой системы, наложенная файловая система должна записать в верхнюю файловую систему информацию о том, что файлы были удалены. Это делается с помощью “выбеленных” и “непрозрачных” каталогов (объекты не-каталоги всегда непрозрачны).
“Выбеленная” директория создаётся как символьное устройство с номером устройства 0/0. Когда в верхнем слое объединенного каталога обнаруживается “выбеленная” директория, любое совпадающее имя на нижнем уровне игнорируется, и сама “выбеленная” директория также скрывается.
Каталог объявляется “непрозрачным” установкой расширенного атрибута “trust.overlay.opaque” в значение “y”. Если верхний слой содержит “непрозрачный” каталог с именем совпадающим с именем каталога из нижнего слоя, тогда соответствующий каталог в нижнем слое игнорируется.
Системный запрос readdir (Чтение каталога)
Когда readdir запрашивается в объединенном каталоге, то каждый верхний и нижний каталог читается, а списки имён объединяются очевидным образом (сначала читается верхний, затем нижний, уже существующие имена не добавляются повторно). Этот объединенный список имён кэшируется в ‘struct file’ и таким остаётся так долго, пока файл остаётся открытым. Если директория открыта и одновременно читается двумя процессами, то каждый из них будет иметь отдельный кэш. A seekdir to the start of the directory (offset 0) followed by a readdir will cause the cache to be discarded and rebuilt.
Это означает, что изменения в объединённой директории не проявятся пока каталог читается. Вряд ли это будет замечено каким-либо программами.
seek offsets are assigned sequentially when the directories are read. Thus if
- read part of a directory
- remember an offset, and close the directory
- re-open the directory some time later
- seek to the remembered offset
there may be little correlation between the old and new locations in the list of filenames, particularly if anything has changed in the directory.
Readdir on directories that are not merged is simply handled by the underlying directory (upper or lower).
Переименование каталога
Когда переименовывается каталог, который является нижним или объединённым (то есть этот каталог не был создан на верхнем слое до начала операции), overlayfs может обработать его двумя различными способами:
- возврат EXDEV ошибки: эта ошибка возвращается вызовом rename , когда при попытке перемещения файла или директории нарушаются границы файловой системы. Приложение обычно готово обработать эту ошибку ( mv , для примера, рекурсивно копирует дерево директорий). Это поведение по умолчанию.
- Если свойство “redirect_dir” включено, тогда директория будет скопирована (без своего содержимого). Потом будет установлен расширенный атрибут “trusted.overlay.redirect” на путь оригинального местоположения от корня наложения. В заключении директория перемещается в новое место.
Есть несколько способов настроить “redirect_dir” свойство.
Kernel config options:
- OVERLAY_FS_REDIRECT_DIR:
- If this is enabled, then redirect_dir is turned on by default.
- If this is enabled, then redirects are always followed by default. Enabling this results in a less secure configuration. Enable this option only when worried about backward compatibility with kernels that have the redirect_dir feature and follow redirects even if turned off.
Module options (can also be changed through /sys/module/overlay/parameters/* ) :
- “redirect_dir=BOOL”:
- See OVERLAY_FS_REDIRECT_DIR kernel config option above.
- See OVERLAY_FS_REDIRECT_ALWAYS_FOLLOW kernel config option above.
- The maximum number of bytes in an absolute redirect (default is 256)
- “redirect_dir=on”: Redirects are enabled.
- “redirect_dir=follow”: Redirects are not created, but followed.
- “redirect_dir=off”: Redirects are not created and only followed if “redirect_always_follow” feature is enabled in the kernel/module config.
- “redirect_dir=nofollow”: Redirects are not created and not followed (equivalent to “redirect_dir=off” if “redirect_always_follow” feature is not enabled).
When the NFS export feature is enabled, every copied up directory is indexed by the file handle of the lower inode and a file handle of the upper directory is stored in a “trusted.overlay.upper” extended attribute on the index entry. On lookup of a merged directory, if the upper directory does not match the file handle stores in the index, that is an indication that multiple upper directories may be redirected to the same lower directory. In that case, lookup returns an error and warns about a possible inconsistency.
Because lower layer redirects cannot be verified with the index, enabling NFS export support on an overlay filesystem with no upper layer requires turning off redirect follow (e.g. “redirect_dir=nofollow”).
Прочие объекты не-Каталоги
Объекты, не являющиеся каталогами (файлы, симлинки, device-special files, и т.д.), представлены в объединённой ФС из верхней, либо из нижней файловой системы, по обстоятельствам. Когда требуется доступ на запись к файлу, представленному в нижней файловой системе, то сначала файл копируется из нижней ФС в верхнюю (copy_up). Обратите внимание, что создание жёсткой ссылки также требует copy_up, тогда как создание симлинка такой операции конечно не требует.
Если файл, открытый на запись, не был изменён, то операция copy_up выполнена не будет.
Процесс copy_up начинается с проверки наличия в верхней ФС соответствующих каталогов, которые создаются при необходимости. После чего в существующий или созданный каталог копируется объект с такими же метаданными (owner, mode, mtime, symlink-target etc.). Далее, в случае если объект это файл, то копируется содержимое нижнего файла в только что созданный файл в верхней ФС. В заключении копируются расширенные атрибуты.
После завершения процесса copy_up, overlay ФС предоставит прямой доступ к только что созданному файлу из верхней файловой системы. Последующие операции над файлом будут едва заметны для overlay ФС (тогда как операции над именем файла, вроде переименования или unlink, конечно будут замечены и обработаны).
Множество нижних слоёв
Множество нижних слоёв можно задать с помощью символа двоеточие («:»), используя его как разделитель между именами каталогово. Для примера:
mount -t overlay overlay -olowerdir=/lower1:/lower2:/lower3 /mergedКак видно в примере, опции “upperdir=” и “workdir=” могут не указываться. И в этом случае наложение будет доступно только для чтения.
Указанные нижние каталоги будут стекированы справа налево, то есть lower1 будет на самом верху, lower2 посередине, а lower3 на нижнем уровне.
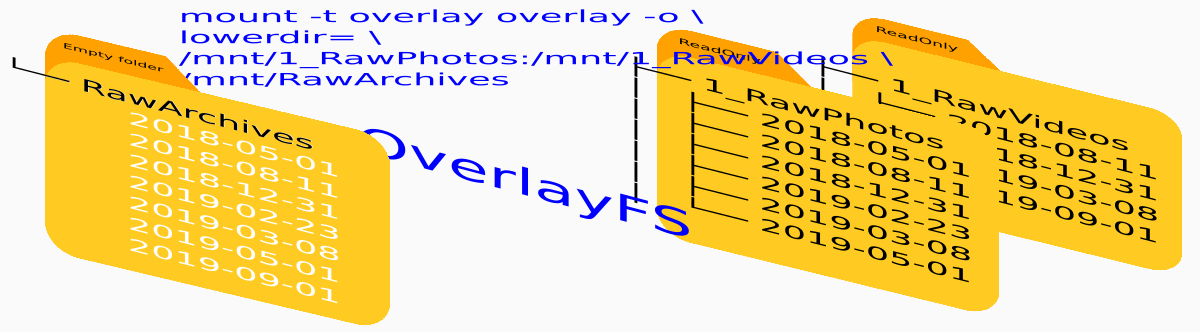
В пустом каталоге RawArchive , после монтирования доступном только для чтения, мы увидим объединённое отображение двух папок c исходниками фото- и видеоматериалов. Все каталоги, задействованные в этой схеме, могут находиться, как на одном носителе, так и на разных (даже сетевых?).
Копирование только метаданных
Когда включена опция копирования только метаданных, overlayfs скопирует только метаданные (в отличие от всего файла), в том случае когда выполняется определённая операция, типа chown/chmod . Полностью файл будет скопирован после того, как файл будет открыт для записи.
Другими словами, это операция с задержкой копирования данных. Данные будут скопированы в том случае, если понадобится их изменение.
Есть несколько способов включения/отключния этой опции. Опция CONFIG_OVERLAY_FS_METACOPY может быть установлена/снята для включения/отключения этой функции по умолчанию. Или можно включить/отключить эту опцию во время загрузки модуля с параметром metacopy=on/off. И наконец, использовать опцию metacopy=on/off во время монтирования.
Не стоит использовать metacopy=on с ненадёжными верхним/нижним каталогом. Otherwise it is possible that an attacker can create a handcrafted file with appropriate REDIRECT and METACOPY xattrs, and gain access to file on lower pointed by REDIRECT. This should not be possible on local system as setting “trusted.” xattrs will require CAP_SYS_ADMIN. But it should be possible for untrusted layers like from a pen drive.
Note: redirect_dir=
(*) redirect_dir=follow only conflicts with metacopy=on if upperdir=… is given.
Расшаривание и копирование слоёв
Нижние слои могут совместно использоваться при монтировании нескольких разных overlay-стеков, и это обычная практика. При монтировании какой-нибудь Overlay может использовать тот же путь до каталога нижнего слоя, что и другой overlay mount.