Работа с PDF-файлами в Python: чтение и разбор
Сегодня формат переносимых документов (PDF) относится к наиболее часто используемым форматам данных. В 1990 году структура документа PDF была определена Adobe. Идея, лежащая в основе формата PDF, заключается в том, что передаваемые данные / документы выглядят одинаково для обеих сторон, участвующих в процессе коммуникации — для создателя, автора или отправителя и получателя. PDF является преемником формата PostScript и стандартизирован как ISO 32000-2: 2017 .
Обработка PDF документов
Для Linux существуют мощные инструменты командной строки, такие как pdftk и pdfgrep. Как разработчик, вы с огромным энтузиазмом создаете свое собственное программное обеспечение, основанное на Python и использующее свободно доступные библиотеки PDF.
Эта статья — начало небольшой серии, в которой будут рассмотрены эти полезные библиотеки Python. В первой части мы сосредоточимся на манипулировании существующими PDF-файлами. Вы узнаете, как читать и извлекать содержимое (как текст, так и изображения), вращать отдельные страницы и разбивать документы на отдельные страницы. Вторая часть будет посвящена добавлению водяных знаков на основе наложений. Третья часть будет посвящена исключительно написанию / созданию PDF-файлов, а также удалению и повторному объединению отдельных страниц в новый документ.
Инструменты и библиотеки
Спектр доступных решений для связанных с Python инструментов, модулей и библиотек PDF немного сбивает с толку, и требуется время, чтобы понять, что к чему и какие проекты поддерживаются постоянно. На основании нашего исследования это те кандидаты, которые соответствуют современным требованиям:
PyPDF2 : библиотека Python для извлечения информации и содержимого документов, постраничного разделения документов, объединения документов, обрезки страниц и добавления водяных знаков. PyPDF2 поддерживает как незашифрованные, так и зашифрованные документы.
PDFMiner : полностью написан на Python и хорошо работает для Python 2.4. Для Python 3 используйте клонированный пакет PDFMiner.six . Оба пакета позволяют анализировать и преобразовывать PDF-документы. Это включает в себя поддержку PDF 1.7, а также языков CJK (китайский, японский и корейский) и различные типы шрифтов (Type1, TrueType, Type3 и CID).
PDFQuery : он описывает себя как «быструю и удобную библиотеку очистки PDF», которая реализована как оболочка для PDFMiner, lxml и pyquery . Его цель состоит в том, чтобы «надежно извлекать данные из наборов PDF-файлов, используя как можно меньше кода».
tabula-py : Это простая оболочка Python для tabula-java , которая может читать таблицы из PDF-файлов и преобразовывать их в Pandas DataFrames. Это также позволяет вам конвертировать файл PDF в файл CSV / TSV / JSON.
pdflib для Python: расширение библиотеки Poppler, которое предлагает для него привязки Python. Это позволяет вам анализировать и конвертировать PDF документы. Не следует путать его коммерческий клон с таким же именем.
PyFPDF : библиотека для создания документов PDF под Python. Портировано из библиотеки FPDF PHP, известной замены PDFlib-расширения со множеством примеров, сценариев и производных.
PDFTables : коммерческий сервис, предлагающий извлечение из таблиц в виде документа PDF. Предлагает API, позволяющий использовать PDFTables в качестве SAAS.
PyX — графический пакет Python: PyX — это пакет Python для создания файлов PostScript, PDF и SVG. Он сочетает в себе абстракцию модели чертежа PostScript с интерфейсом TeX / LaTeX. Сложные задачи, такие как создание 2D и 3D графиков в готовом для публикации качестве, построены из этих примитивов.
ReportLab : амбициозная промышленная библиотека, в основном ориентированная на точное создание PDF-документов. Доступна свободно как версия с открытым исходным кодом, так и коммерческая улучшенная версия с именем ReportLab PLUS.
PyMuPDF (он же «fitz»): привязки Python для MuPDF, который является облегченным средством просмотра PDF и XPS. Библиотека может получать доступ к файлам в форматах PDF, XPS, OpenXPS, epub, комиксах и художественных книгах, а также известна своей высокой производительностью и высоким качеством рендеринга.
pdfrw : чистый анализатор PDF на основе Python для чтения и записи PDF. Он точно воспроизводит векторные форматы без растеризации. Вместе с ReportLab он помогает повторно использовать части существующих PDF-файлов в новых PDF-файлах, созданных с помощью ReportLab.
| Библиотека | Используется для |
|---|---|
| PyPDF2 | чтение |
| PyMuPDF | чтение |
| PDFlib | чтение |
| PDFTables | чтение |
| Табула-ру | чтение |
| PDFMiner.six | чтение |
| PDFQuery | чтение |
| pdfrw | Чтение, Запись / Создание |
| ReportLab | Запись / Создание |
| дарохранительница | Запись / Создание |
| PyFPDF | Запись / Создание |
Ниже мы сосредоточимся на PyPDF2 и PyMuPDF и объясним, как извлечь текст и изображения самым простым способом. Чтобы понять использование PyPDF2, помогло сочетание официальной документации и множества примеров, доступных на других ресурсах. Напротив, официальная документация PyMuPDF намного понятнее и значительно быстрее при использовании библиотеки.
Извлечение текста с помощью PyPDF2
PyPDF2 может быть установлен как обычный программный пакет, так и с использованием pip3 (для Python3). Тесты здесь основаны на пакете для предстоящего выпуска Debian GNU / Linux 10 «Buster». Имя пакета Debian является python3-pypdf2 .
В листинге 1 PdfFileReader сначала импортируется класс. Затем, используя этот класс, он открывает документ и извлекает информацию о документе, используя метод getDocumentInfo() , количество используемых страниц getDocumentInfo() и содержимое первой страницы.
Обратите внимание, что PyPDF2 начинает считать страницы с 0, и поэтому вызов pdf.getPage(0) извлекает первую страницу документа. В конце концов, извлеченная информация печатается в stdout .
Листинг 1: Извлечение информации и содержимого документа.
#!/usr/bin/python from PyPDF2 import PdfFileReader pdf_document = "example.pdf" with open(pdf_document, "rb") as filehandle: pdf = PdfFileReader(filehandle) info = pdf.getDocumentInfo() pages = pdf.getNumPages() print (info) print ("number of pages: %i" % pages) page1 = pdf.getPage(0) print(page1) print(page1.extractText())
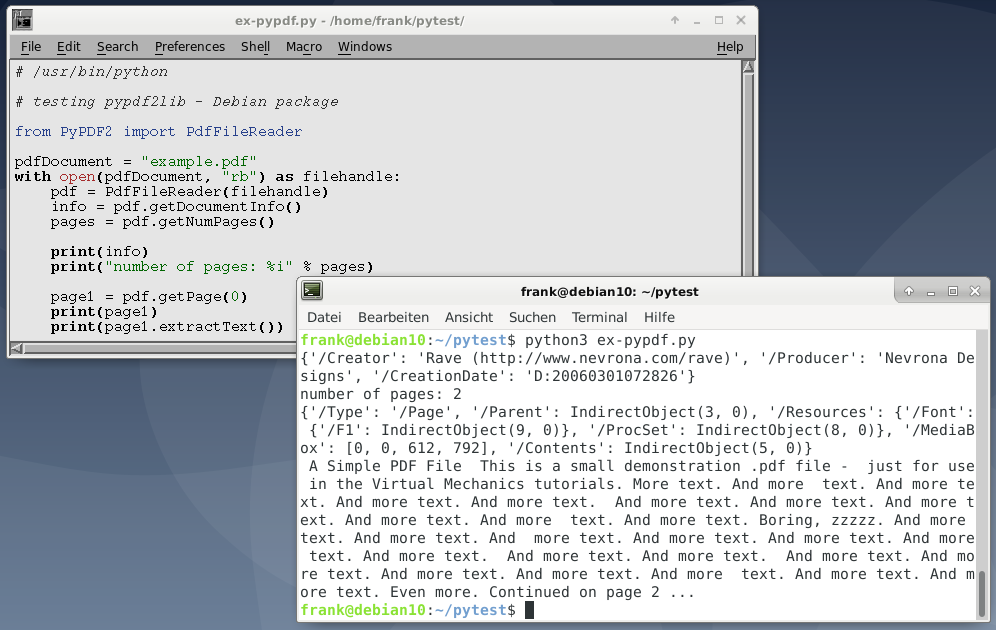
Как показано на рисунке 1 выше, извлеченный текст печатается на постоянной основе. Здесь нет ни абзацев, ни разделений предложений. Как указано в документации по PyPDF2, все текстовые данные возвращаются в том порядке, в котором они представлены в потоке содержимого страницы, и их использование может привести к неожиданностям. Это в основном зависит от внутренней структуры документа PDF и от того, как поток инструкций PDF был создан процессом записи PDF.
Извлечение текста с помощью PyMuPDF
PyMuPDF доступен на веб-сайте PyPi, и вы устанавливаете пакет с помощью следующей команды в терминале:
$ pip3 install PyMuPDF
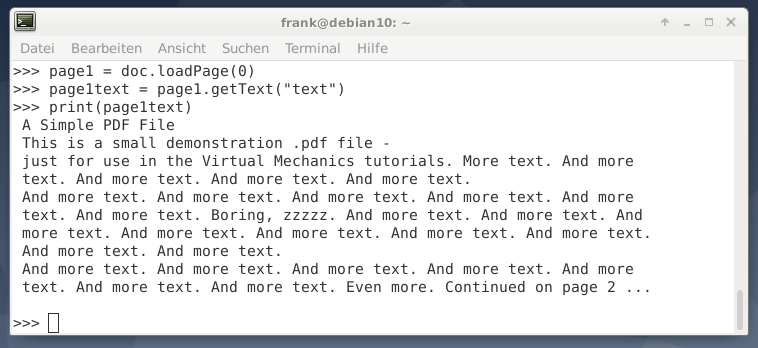
Отображение информации о документе, печать количества страниц и извлечение текста из документа PDF выполняется аналогично PyPDF2 (см. Листинг 2 ). Импортируемый модуль имеет имя fitz и возвращается к предыдущему имени PyMuPDF.
Листинг 2: Извлечение содержимого из документа PDF с использованием PyMuPDF.
#!/usr/bin/python import fitz pdf_document = "example.pdf" doc = fitz.open(pdf_document): print ("number of pages: %i" % doc.pageCount) print(doc.metadata)page1 = doc.loadPage(0) page1text = page1.getText("text") print(page1text)
Приятной особенностью PyMuPDF является то, что он сохраняет исходную структуру документа без изменений — целые абзацы с разрывами строк сохраняются такими же, как в PDF-документе (см. Рисунок 2 ).
Извлечение изображений из PDF с помощью PyMuPDF
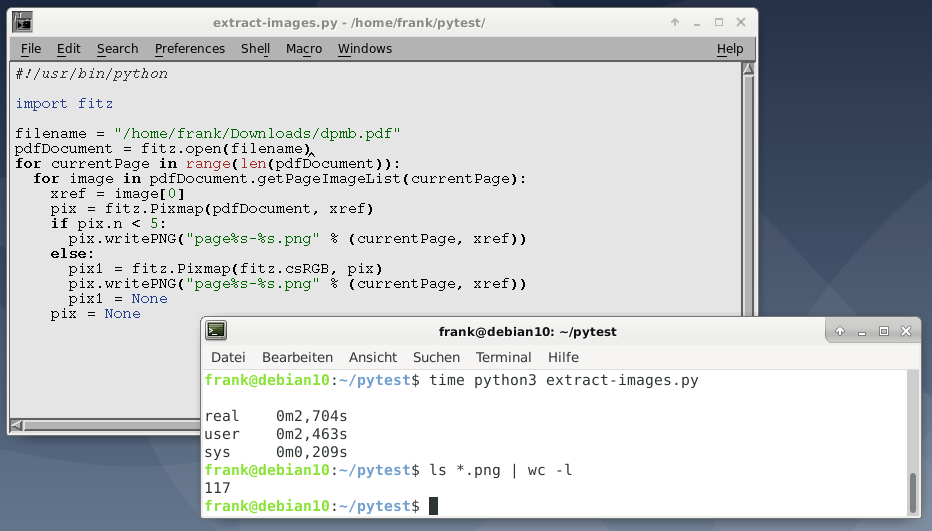
PyMuPDF упрощает извлечение изображений из документов PDF с использованием метода getPageImageList() . Листинг 3 основан на примере из вики-страницы PyMuPDF и извлекает и сохраняет все изображения из PDF в формате PNG постранично. Если изображение имеет цветовое пространство CMYK, оно будет сначала преобразовано в RGB.
Листинг 3: Извлечение изображений.
#!/usr/bin/python import fitz pdf_document = fitz.open("file.pdf") for current_page in range(len(pdf_document)): for image in pdf_document.getPageImageList(current_page): xref = image[0] pix = fitz.Pixmap(pdf_document, xref) if pix.n < 5: # this is GRAY or RGB pix.writePNG("page%s-%s.png" % (current_page, xref)) else: # CMYK: convert to RGB first pix1 = fitz.Pixmap(fitz.csRGB, pix) pix1.writePNG("page%s-%s.png" % (current_page, xref)) pix1 = None pix = None
Запустив этот скрипт Python на 400-страничном PDF, он извлек 117 изображений менее чем за 3 секунды, что удивительно. Отдельные изображения хранятся в формате PNG. Чтобы сохранить исходный формат и размер изображения вместо преобразования в PNG, взгляните на расширенные версии сценариев в вики PyMuPDF .
Разделение PDF-файлов на страницы с помощью PyPDF2
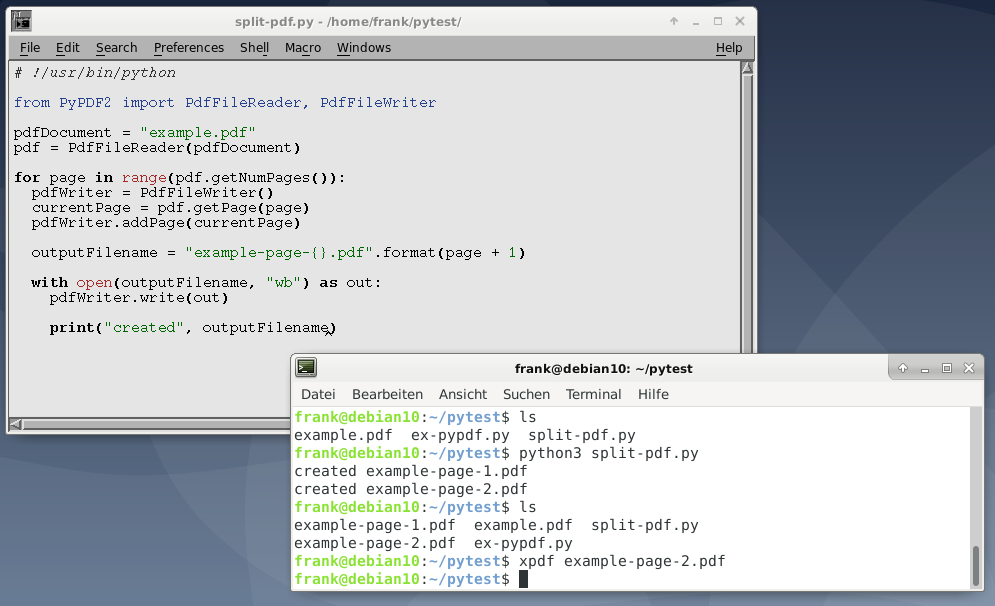
Для этого примера, в первую очередь необходимо импортировать классы PdfFileReader и PdfFileWriter . Затем мы открываем файл PDF, создаем объект для чтения и перебираем все страницы, используя метод объекта для чтения getNumPages .
Внутри цикла for мы создаем новый экземпляр PdfFileWriter , который еще не содержит страниц. Затем мы добавляем текущую страницу к нашему объекту записи, используя метод pdfWriter.addPage() . Этот метод принимает объект страницы, который мы получаем, используя метод PdfFileReader.getPage() .
Следующим шагом является создание уникального имени файла, что мы делаем, используя исходное имя файла плюс слово «page» плюс номер страницы. Мы добавляем 1 к текущему номеру страницы, потому что PyPDF2 считает номера страниц, начиная с нуля.
Наконец, мы открываем новое имя файла в режиме (режиме wb ) записи двоичного файла и используем метод write() класса pdfWriter для сохранения извлеченной страницы на диск.
Листинг 4: Разделение PDF на отдельные страницы.
#!/usr/bin/python from PyPDF2 import PdfFileReader, PdfFileWriter pdf_document = "example.pdf" pdf = PdfFileReader(pdf_document) for page in range(pdf.getNumPages()): pdf_writer = PdfFileWriter current_page = pdf.getPage(page) pdf_writer.addPage(current_page) outputFilename = "example-page-<>.pdf".format(page + 1) with open(outputFilename, "wb") as out: pdf_writer.write(out) print("created", outputFilename)
Найти все страницы, содержащие текст
Этот вариант использования довольно практичен и работает аналогично pdfgrep . Используя PyMuPDF, скрипт возвращает все номера страниц, которые содержат данную строку поиска. Страницы загружаются одна за другой, и с помощью метода searchFor() обнаруживаются все вхождения строки поиска. В случае совпадения соответствующее сообщение печатается на stdout .
Листинг 5: Поиск заданного текста.
#!/usr/bin/python import fitz filename = "example.pdf" search_term = "invoice" pdf_document = fitz.open(filename): for current_page in range(len(pdf_document)): page = pdf_document.loadPage(current_page) if page.searchFor(search_term): print("%s found on page %i" % (search_term, current_page))
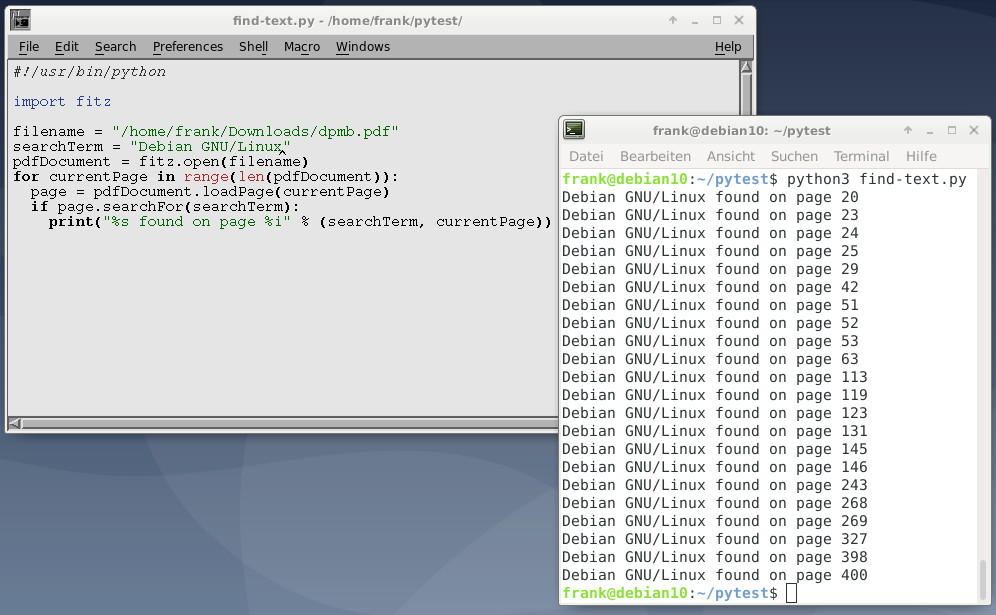
На рисунке 5 ниже показан результат поиска для термина «Debian GNU / Linux» в книге на 400 страниц.
Заключение
Методы, показанные здесь, довольно мощные. Сравнительно небольшое количество строк кода позволяет легко получить результат. Другие варианты использования рассматриваются во второй части (скоро!), Посвященной добавлению водяного знака в PDF.
PS Программа просмотра файлов для Python
Просматривайте документы PS в браузере без использования Adobe Acrobat или автоматизации с помощью Python.
Как просмотреть файлы PS с помощью библиотеки Python for .NET
Для просмотра файла PS мы будем использовать API Aspose.PDF for .NET, который представляет собой многофункциональный, мощный и простой в использовании API для работы с документами для платформы python-net. Откройте менеджер пакетов NuGet, найдите Aspose.pdf и установите. Вы также можете использовать следующую команду из консоли Package Manager.
Python Package Manager Console
pip install aspose-pdfПросмотр файлов PS с помощью Python
Вам нужен Aspose.PDF for .NET, чтобы опробовать код в своей среде.
- Загрузите PS с экземпляром документа.
- Просмотреть результирующий файл.
Системные требования
Просто убедитесь, что у вас есть следующие предварительные условия.
- Microsoft Windows или совместимая ОС с платформой .NET Framework, .NET Core и PHP, VBScript, C++ через COM Interop.
- Среда разработки, такая как Microsoft Visual Studio.
- Aspose.PDF для DLL .NET, на которую ссылается ваш проект.
Python — пример кода для просмотра файла PS.
# load PS with an instance of Document document = Document("template.ps", PsLoadOptions()) # save document in HTML format document.Save("output.html", Aspose.Pdf.SaveFormat.Html) О Aspose.PDF для API Python
Ознакомьтесь с нашими демонстрациями в реальном времени по адресу Просмотреть PDF со следующими преимуществами.
Subscribe to Aspose Product Updates.
Get monthly newsletters & offers directly delivered to your mailbox.
Шаблонизация PDF

Хабрахабр, уважаемые коллеги!
Проблема впечатывания данных в PDF документ не нова, не я первый и не я последний кто с ней сталкивается, поэтому решил поделиться опытом решения и заодно представить вашему вниманию небольшое веб приложение по этой теме.
1. PDF формат хорош тем, что он не редактируемый. Во всяком случае рядовой пользователь вряд-ли будет заниматься внесением правок в документ PDF. И значит формат PDF хорошо подходит для обмена важными документами.
2. PDF формат плох тем, что он нередактируемый ) Т.к. шаблонизация, заполнение набором данных бланка документа PDF в автоматическом режиме затруднена, а в ручном режиме требуется установка платных, тяжеловесных приложений.
Меня, как программиста, беспокоит прежде всего 2-й пункт. Как в программном приложении впечатать необходимый набор данных в документ PDF?
Область применения (постановка задачи)
Сразу хочу обозначить область применения, рамки поставленной задачи, чтобы исключить недоразумения в комментариях:
1. У вас есть веб API приложение на python с множеством функционала.
2. Есть бланк документа в формате pdf, в лучшем случае исходный docx файл из которого сделан этот pdf.
3. Есть требование от бизнес-заказчиков заполнить указанный pdf бланк данными клиента и в формате pdf выдать в браузер (или отправить на почту) клиенту.
Очередное гугление на эту тему не принесло результатов.
Удалось нагуглить только, что с впечатыванием всё плохо (Почему так сложно извлекать текст из PDF?, PDF с точки зрения программиста) и есть вариант шаблонизировать сначала docx файл, это сделать не сложно (Заполняем документы в Microsoft Word. ), а затем преобразовать в консольном libreoffice (librewrite) docx-файл в PDF. Это всё можно сделать автоматически, из приложения.
Но во-первых, такое решение означает, что проект будет иметь тяжёлую зависимость от libreoffice.
А во-вторых, при преобразовании docx в PDF в libreoffice вид документа получается немного не таким, как он смотрится в word, и/или PDF сгенерированном в word из docx файла.
Перейдём наконец к сути рассматриваемого решения. Конечно «шаблонизация» в данном случае слово громкое, но предлагаемое решение вполне годное и полезное.
На python (и на php) есть несколько библиотек (не сложно загуглить), которые позволяют впечатывать строки и картинки в PDF-файлы, мы используем pdfrw + reportlab.Canvas. Т.е., в принципе впечатать данные нет проблем, проблема у этих библиотек в том, что для каждого поля нужно задать свои точные координаты в документе, а это значит, что
1. Нужен какой-то унифицированный функционал, который хранил бы координаты полей не внутри исходного кода, а в отдельном файле. Сразу уточню, что по опыту рекомендую хранить эти координаты в файлах и под контролем версий, т.е. коммитить координаты вместе с соответствующими PDF-бланками и методами, генерирующими тот или иной комплект документов. И не засовывать эти координаты в базу данных, т.к. это затруднит откат к предыдущим версиям (координатам) документов, если возникнет такая необходимость. Тут вроде бы всё понятно.
2. Эти координаты надо как-то вычислить, а это грустное занятие, если делать это вручную.
Тут основная идея заключается в том, чтобы в браузере создать перемещаемые div элементы, с помощью мышки настроить их положение в нужное место документа и получившиеся в браузере координаты элементов сохранить в файл на бэкенде. Собственно эти два пункта и реализованы в приложении
Способ применения
Похоже, что получилось небольшое веб приложение с фронтэндом и бэкендом, т.е. оформить его в качестве python пакета, пожалуй не получится.
1. Скачиваем с гита исходники
2. Устанавливаем зависимости
3. Читаем README.md (устанавливаем и настраиваем nginx для статических файлов)
4. В папке documents создаём подпапку с именем документа, который нужно генерировать и внутри этой подпапки создаём два файла и (если необходимо) одну дирректорию с картинками:
— form.pdf # бланк документа в который надо впечатывать данные
— fields.json # параметры полей, которые необходимо впечатывать
— images # не обязательно, набор картинок, которые необходимо впечатать
Рекомендую также сохранить исходный docx-файл (если имеется), который не участвует в генерации документа, но пригодится при необходимости внести изменения и перегенерировать бланк документа PDF
— form.docx # не обязательно, имя любое
Файл fields.json имеет следующую структуру, например:
Добавление/удаление строк в этот файл добавляет/удаляет поля, впечатываемые в бланк
5. Открываем страницу для настроек полей (http://127.0.0.1/tpdf/positioning?pdf_name=ZayavlenieNaZagranpasport&page_num=1)
6. Настраиваем положение полей с помощью мышки в браузере и сохраняем это положение
7. Мышкой не всегда точно удаётся установить нужное положение полей, чтобы подровнять положение полей можно открыть файл fieldd.json и поправить координаты вручную. Данные в файле упорядочены по координате Y и каждое поле хранится в своей строке файла. Т.е. файл с координатами полей отформатирован аккуратно, что позволяет вручную, легко вносить необходимые корректировки.
8. Создаём ещё один метод для печати данного типа документа (если нужно как-то подготовить исходные данные и/или взять их не из фронта, а из бэкэнда).
9. Если всё в порядке, то коммитим получившийся набор данных fields.json и файлы (только не ко мне на гит, а в свой локальный гит, хотя, если документ может кому-то ещё пригодиться, то можно и публичный банк документов собрать, это идея).
Полученный файл с координатами можно использовать в другом проекте, на другом языке программирования, например php, ведь координаты в файле записаны в единицах измерения (поинты) которые используются в PDF-файлах.
Если у вас проект на python, то исходники данного приложения можно просто внедрить в проект и через использование основного класса Tpdf генерировать PDF в любом удобном месте кода.
Часто нужно сгенерировать не просто один документ из нескольких страниц, а собрать в один PDF-файл несколько документов, каждый из которых должен быть напечатан в нужном порядке и некоторые из них более одного раза. В основном классе данного приложения имеется для этих нужд специальный метод, который генерирует комплект документов, смотрите обработку метод /tpdf/example/.
Данные в основной класс нужно передавать при его инстансцинировании. Основной класс можно расширять свойствами (@property), которые будут вычисляться на основе входных данных и вставляться в PDF по имени свойства = имени поля. Так в примере выводится поле fio, а данные передаются last_name, first_name, middle_name
Можно развернуть это небольшое приложение в качестве самостоятельного сервиса, а все остальные приложения окружения будут к нему обращаться за нужным документом по сети, но тогда появятся расходы времени передачи по сети, файлы PDF не слишком «лёгкие», сама генерация документов происходит быстро.
Вместо сотни слов, иногда лучше посмотреть видео инструкцию (звук не записывал).
Опыт реализации (грабли).
- Сначала я реализовал это небольшое приложение на библиотеке PyPDF2, но комплект документов из 28 страниц генерировался 3 секунды, как-то долго. Тогда, чтобы ускорить генерацию документов, я решил попробовать мультипоточность, выделив генерацию каждой страницы в отдельный поток, однако это усложнило код но, на удивление, не дало выигрыша производительности, плюс возникли дополнительные ошибки видимо из-за конфликтов процессов. Тогда я попробовал многопроцессность, однако результат оказался тот же — производительность не выросла а в некоторых конфигурациях кода даже ухудшалась. Наконец я решил проверить быстродействие другой, аналогичной библиотеки pdfrw под которую, оказалось, почти не пришлось переписывать код и она заработала почти на порядок быстрее без всякой мультипоточности и мультипроцессности. Т.е. комплект документов из 28 страниц сгенерировался за 0.3 секунды. Не зависимо от библиотеки код изначально оптимизировал с точки зрения повторной генерации страниц: каждая страница заполняется данными один раз и хранится в памяти, и если она должна быть напечатана несколько раз, то первый раз она генерируется, а последующие разы берётся готовая из памяти.
- Листание страниц лучше делать не на ajax, так как, чтобы подтянулись новые поля всё равно нужно перезагружать всю страницу.
- Было много возни с преобразованием координат с пикселей фронта в поинты PDF. В итоге, опытным путём и путём гугления выяснилось, что отношение фронтовые координаты нужно умножать на 3/4, чтобы получить координаты документа PDF. Обратное преобразование, соответственно, наоборот.
Нужно сделать (TODO)
-
Добавление и удаление новых полей с фронта.
- заполнение форм
- заполнить и распечатать бланки
- шаблонизация
python code
При выборе региона может измениться язык и рекламный контент, отображаемый на веб-сайте Adobe Stock.
Северная Америка
- Canada - English
- Canada - Français
- El Salvador
- México
- República Dominicana
- United States
Южная Америка
Европа, Ближний Восток и Африка
- Israel - English
- Italia
- Jordan - English
- Казахстан
- Kenya - English
- Kuwait - English
- Киргизия
- Latvija
- Lebanon - English
- Lietuva
- Luxembourg - Deutsch
- Luxembourg - English
- Luxembourg - Français
- Mauritius - English
- Moldova - English
- Hungary - English
- Malta - English
- Morocco - English
- Nederland
- Nigeria
- Norge
- Oman - English