Tx\Rx bandwidth limit на 2950-той Сиське «( . )( . )» ?
Прошу прощения) за нескромный вопрос)) но мне раньше не доводилось иметь длительные отношения с коммутаторами от Cisco =)) Как настроить ограничение пропускной способности (bandwidth limit) на конкретный порт ? К примеру порт Fa0/24 (Rx 128 kbps)(Tx 512 kbps)

Architector120
18.01.16 16:41:16 MSK
conf t int fa0/24 traffic-shape # хз не помню rate-limit # аналогично end redixin ★★★★
( 18.01.16 16:43:38 MSK )
Ответ на: комментарий от redixin 18.01.16 16:43:38 MSK
Хотя такое может не прокатить на 2950
redixin ★★★★
( 18.01.16 16:46:10 MSK )
хмм.. вот список всех доступных команд на порт Fa0/24
cisco(config)#interface fastEthernet 0/24 cisco(config-if)#? Interface configuration commands: arp Set arp type (arpa, probe, snap) or timeout auto Configure Automation bandwidth Set bandwidth informational parameter carrier-delay Specify delay for interface transitions cdp CDP interface subcommands channel-group Etherchannel/port bundling configuration channel-protocol Select the channel protocol (LACP, PAgP) default Set a command to its defaults delay Specify interface throughput delay description Interface specific description dot1x Interface Config Commands for 802.1x duplex Configure duplex operation. exit Exit from interface configuration mode fair-queue Enable Fair Queuing on an Interface help Description of the interactive help system hold-queue Set hold queue depth ip Interface Internet Protocol config commands keepalive Enable keepalive lacp LACP interface subcommands load-interval Specify interval for load calculation for an interface logging Configure logging for interface mac MAC interface commands mac-address Manually set interface MAC address mls mls interface commands mvr MVR per port configuration no Negate a command or set its defaults pagp PAgP interface subcommands random-detect Enable Weighted Random Early Detection (WRED) on an Interface rmon Configure Remote Monitoring on an interface service-policy Configure QoS Service Policy shutdown Shutdown the selected interface snmp Modify SNMP interface parameters spanning-tree Spanning Tree Subsystem speed Configure speed operation. storm-control storm configuration switchport Set switching mode characteristics timeout Define timeout values for this interface transmit-interface Assign a transmit interface to a receive-only interface tx-ring-limit Configure PA level transmit ring limit udld Configure UDLD enabled or disabled and ignore global UDLD setting Architector120
( 18.01.16 17:11:43 MSK ) автор топика
Ответ на: комментарий от Architector120 18.01.16 17:11:43 MSK
Ну да, это походу из тех свичей что так совсем не умеют. Могу ошибаться
redixin ★★★★
( 18.01.16 17:15:05 MSK )
Ответ на: комментарий от redixin 18.01.16 17:15:05 MSK
На некоторых ресурсах пишут что нужно править системный конфиг, но подробного описания процедуры нет
Architector120
( 18.01.16 17:20:25 MSK ) автор топика
Ответ на: комментарий от Architector120 18.01.16 17:11:43 MSK
bandwidth Set bandwidth informational parameter Этот параметр отвечает за пропускную способность интерфейса читай мануал по этому параметру.
Impact of Transmit Ring Size (tx-ring-limit)
Technology Resources » QoS Mechanisms » Impact of Transmit Ring Size (tx-ring-limit) Output interface queues in most software switching platforms contain a software-only component and a FIFO queue shared between the CPU and the outgoing interface. That FIFO queue is usually organized as a ring structure, and its maximum size can be controlled with the tx-ring-limit parameter in Cisco IOS. The impact of that parameter should be obvious: larger tx-ring-limit values cause more delay and jitter, resulting in reduced quality-of-service of time-critical applications (like voice-over-IP) over low-speed interfaces. A series of tests performed in a small tightly controlled test-bed quantifies the actual impact.
Overview
The default value of tx-ring-limit is a good compromise between the latency/jitter requirements of medium speed links and increased CPU utilization due to I/O interrupts caused by low tx-ring-limit values. On low-speed links (128 kbps and below), the tx-ring-limit should be decreased to 1.
Test Bed
Two 2800-series routers were connected with a back-to-back serial link, one of them generating the clock. PPP encapsulation was used on the serial link. A traffic-generating node was connected to the Ethernet port of one of the routers to generate the background load. IP SLA using ICMP echo packets was started on the same router to measure response time and jitter of a simple request-response application (ICMP ping).
Router Configurations
Minimum router configurations were used with no dynamic routing. The relevant parts of router configurations are displayed below:
Configuration of the IP SLA originating router
hostname a1 ! ip cef ! class-map match-all Echo match protocol icmp ! policy-map EchoPriority class Echo priority 64 class class-default fair-queue ! interface FastEthernet0/0 ip address 10.0.0.5 255.255.255.0 ! interface Serial0/1/0 bandwidth 512 ip address 172.16.1.129 255.255.255.252 encapsulation ppp load-interval 30 service-policy output EchoPriority ! end The second router has an almost identical configuration (with different IP addresses).
Load Generation
UDP flooding implemented in PERL was used to generate the background load and saturate the WAN interface. Two sets of measurements were performed. In the first test, a continuous flood of constantly-spaced fixed-size packets sent to a single UDP port was generated (similar to constant bit rate traffic). This traffic stream generated a single conversation in the fair queuing model used on the WAN interface.
Cisco IOS uses fair queuing as soon as a service policy including a queuing action is configured on an interface.
The second test flooded the WAN link with variable-sized packets sent at a fixed interval to random destination UDP ports. The generated bandwidth varied widely due to random packet sizes and the traffic stream generated hundreds of conversations in the fair queuing structure. In both cases, the CPU utilization was measured on a1 and a2 to verify that the CPU load does not increase 50% (high CPU load could impact the jitter measurements).
a1#show proc cpu | inc CPU CPU utilization for five seconds: 8%/6%; one minute: 8%; five minutes: 5% a2#sh proc cpu | inc CPU CPU utilization for five seconds: 20%/10%; one minute: 12%; five minutes: 8% Response Time and Jitter Measurement
An IP SLA probe was configured on one of the routers generating small ICMP ECHO packets that were sent over the WAN link. The ICMP traffic is classified as priority traffic in the service policy attached to the WAN interface ensuring that the ICMP packets enter the hardware queue prior to any packets generated by the UDP flood. The measured delay and jitter is thus solely the result of the hardware queue between the software fair queuing structures and the interface hardware.
ip sla 50000 icmp-jitter 172.16.1.130 timeout 1000 threshold 500 frequency 2 history hours-of-statistics-kept 1 history distributions-of-statistics-kept 2 The IP SLA probe was started after the test load has reached a steady state (saturated WAN interface) and the aggregated SLA statistics were inspected while the load was still present. The show ip sla statistics aggregated command was used to inspect the statistics and the RTT and source-to-destination jitter values were collected
a1#show ip sla statistics aggregated Round Trip Time (RTT) for Index 50000 Start Time Index: 13:15:22.851 UTC Fri Apr 18 2008 Type of operation: icmpJitter RTT Values: Number Of RTT: 387 RTT Min/Avg/Max: 6/15/31 Latency one-way time: Number of Latency one-way Samples: 0 Source to Destination Latency one way Min/Avg/Max: 0/0/0 Destination to Source Latency one way Min/Avg/Max: 0/0/0 Jitter Time: Number of Jitter Samples: 334 Source to Destination Jitter Min/Avg/Max: 1/6/23 Destination to Source Jitter Min/Avg/Max: 1/1/1 Test Results
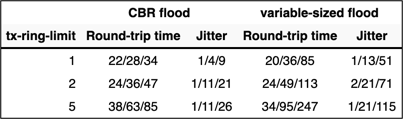
The tests were performed at line speeds of 128 and 512 kbps with different tx-ring-limit settings. The tx-ring-limit values were changed at both ends of the WAN link. The test result values are triplets: minimum, average and maximum measured value as reported by IP SLA. 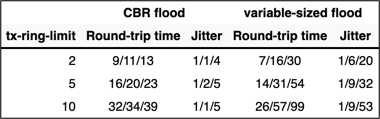
This article written by Ivan Pepelnjak in early 2000s was originally published on CT3 wiki which became unreachable in 2019. The text was retrieved from an Internet Archive snapshot, updated, and republished on ipSpace.net.
Understanding and Tuning the tx-ring-limit Value
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
Contents
Introduction
This document discusses the function of a hardware transmit ring and the purpose of the tx-ring-limit command on ATM router interface hardware that supports per-virtual circuit (VC) queueing. Cisco router interfaces configured with service policies store packets for an ATM VC in one of two sets of queues depending on the congestion level of the VC:
| Queue | Location | Queueing Methods | Service Policies Apply | Command to Tune |
|---|---|---|---|---|
| Hardware queue or transmit ring | Port adapter or network module | FIFO only | No | tx-ring-limit |
| Layer-3 queue | Layer-3 processor system or interface buffers | N/A | Yes | Varies with queueing method: — vc-hold-queue — queue-limit |
Prerequisites
Requirements
There are no specific requirements for this document.
Components Used
This document is not restricted to specific software and hardware versions.
Conventions
Refer to Cisco Technical Tips Conventions for more information on document conventions.
Understanding Particles
Before discussing the transmit ring, we first need to understand what a particle is. A particle forms the basic building block of packet buffering on many platforms, including the Cisco 7200 router series and the versatile interface processor (VIP) on the Cisco 7500 router series. Depending on the packet length, Cisco IOS® software uses one or more particles to store a packet. Let’s look at an example. When receiving a 1200-byte packet, IOS retrieves the next free particle and copies the packet data into the particle. When the first particle is filled, IOS moves to the next free particle, links it to the first particle, and continues copying the data into this second particle. Upon completion, the 1200 bytes of the packet are stored in three discontiguous pieces of memory that IOS logically makes a part of a single packet buffers. IOS particle size varies from platform to platform. All particles within a given pool are the same size. This uniformity simplifies the particle management algorithms and helps contribute to efficient memory use.
Understanding Buffer Rings
Along with public and private interface pools, Cisco IOS creates special buffer control structures called rings. Cisco IOS and interface controllers use these rings to control which buffers are used to receive and transmit packets to the media. The rings themselves consist of media-controller-specific elements that point to individual packet buffers elsewhere in I/O memory. Each interface has a pair of rings — a receive ring for receiving packets and a transmit ring for transmitting packets. The size of the rings can vary with the interface controller. In general, the size of the transmit ring is based on bandwidth of the interface or VC and is a power of two (Cisco Bug ID CSCdk17210).
| Interface | Rings | |||||
|---|---|---|---|---|---|---|
| Line Rate(Mb/s) | 2 | 10 | 20 | 30 | 40 | . |
| txcount | 2 | 4 | 8 | 16 | 32 | 64 |
Note: On the 7200 series platform, the transmit ring packet buffers come from the receive ring of the originating interface for a switched packet or from a public pool if the packet was originated by IOS. They are deallocated from the transmit ring and returned to their original pool after the payload data is transmitted.
PA-A3 Architecture Overview
To ensure high forwarding performance, the PA-A3 port adapter uses separate receive and transmit segmentation and reassembly (SAR) chips. Each SAR is supported by its own subsystem of onboard memory to store packets as well as key data structures like the VC table. This memory specifically includes 4 MB of SDRAM, which is chunked into particles. The following table illustrates the number and size of particles on the receive and transmit paths on the PA-A3.
| Ring | Particle Size | Number of Particles |
|---|---|---|
| Receive Ring | 288 bytes | n/a |
| Transmit Ring | 576* bytes | 6000 (144 particles are reserved) |
* The transmit ring’s particle size also is described as being 580 bytes. This value includes the 4-byte ATM core header that travels with the packet inside the router. The sizes in the above table were selected because they are divisible by 48 (the size of a cell’s payload field) and by the cache line size (32 bytes) for maximum performance. They are designed to prevent the SAR from introducing inter-buffer delay when a packet requires multiple buffers. The transmit particle size of 576 bytes also was selected to cover about 90 percent of Internet packets.
Transmit Ring Allocation Scheme on the PA-A3
The PA-A3 driver assigns a default transmit-ring value to each VC. This value varies with the ATM service category assigned to the VC. The following table lists the default values.
| VC Service Category | PA-A3-OC3, T3, E3 Default Transmit Ring Value | PA-A3-IMA Default Transmit Ring Value | PA-A3-OC12 Default Transmit Ring Value | Time of Enforcement |
|---|---|---|---|---|
| VBR-nrt | Based on formula**: (48 x SCR) / (Particle_size x 5) Minimum value is 40, and overrides any calculated value less than 40 with a very low SCR. Note: SCR is the cell rate with ATM overhead included. | Based on formula: (48 x SCR) / (Particle_size x 5) Minimum value is 40, and overrides any calculated value less than 40 with a very low SCR. Note: SCR is the cell rate with ATM overhead included. | Based on the following formula: Average rate (SCR) * 2 * TOTAL_CREDITS / VISIBLE_BANDWIDTH TOTAL_CREDITS = 8192 VISIBLE_BANDWIDTH = 599040 Note: If this formula calculates a value which is less than the default of 128, then the VC’s transmit ring limit is set to 128. | Always |
| ABR | 128 | 128 | N/A | Always* |
| UBR | 40 | 128 | 128 | Only when total credit utilization exceeds 75 percent or the tx_threshold value, as shown in show controller atm. |
* Originally, the PA-A3-OC12 did not implement always-active limiting of VBR-nrt PVCs to the current transmit ring value. Bug ID CSCdx11084 resolves this issue. . ** SCR should be expressed in cells/sec.
Displaying the Current Transmit Ring Values
Originally, the value of the transmit ring was only visible via a hidden command. The show atm vc command now displays the current value. You also can use the debug atm events command to view the VC setup messages between the PA-A3 driver and the host CPU. The following sets of output were captured on a PA-A3 in a 7200 series router. The transmit ring value is displayed as the tx_limit value, which implements the particle buffer quota allocated for a specific VC in the transmit direction. PVC 1/100 is configured as VBR-nrt. Based on an SCR of 3500 kbps, the PA-A3 assigns a tx_limit of 137. To see how this calculation is made, we need to convert an SCR of 3500 kbps to cells/sec. Notice that (3,500,000 bits /sec) * (1 byte / 8 bits) * (1 cell / 53 byes ) = (3, 500, 000 cells) / (8 * 53 sec) = 8254 cells / sec. Once we have the SCR value in cells / sec, we can apply the formula above to ger tx_limit = 137.
7200-17(config)#interface atm 4/0 7200-17(config-if)#pvc 1/100 7200-17(config-if-atm-vc)#vbr-nrt 4000 3500 94 7200-17(config-if-atm-vc)# *Oct 14 17:56:06.886: Reserved bw for 1/100 Available bw = 141500 7200-17(config-if-atm-vc)#exit 7200-17(config-if)#logging *Oct 14 17:56:16.370: atmdx_setup_vc(ATM4/0): vc:6 vpi:1 vci:100 state:2 config_status:0 *Oct 14 17:56:16.370: atmdx_setup_cos(ATM4/0): vc:6 wred_name:- max_q:0 *Oct 14 17:56:16.370: atmdx_pas_vc_setup(ATM4/0): vcd 6, atm hdr 0x00100640, mtu 4482 *Oct 14 17:56:16.370: VBR: pcr 9433, scr 8254, mbs 94 *Oct 14 17:56:16.370: vc tx_limit=137, rx_limit=47 *Oct 14 17:56:16.374: Created 64-bit VC count
PVC 1/101 is configured as ABR. The PA-A3 assigns the default ABR tx_limit value of 128. (See the table above.)
7200-17(config-if)#pvc 1/102 7200-17(config-if-atm-vc)#abr ? Peak Cell Rate(PCR) in Kbps rate-factors Specify rate increase and rate decrease factors (inverse) 7200-17(config-if-atm-vc)#abr 4000 1000 7200-17(config-if-atm-vc)# *Oct 14 17:57:45.066: Reserved bw for 1/102 Available bw = 140500 *Oct 14 18:00:11.662: atmdx_setup_vc(ATM4/0): vc:8 vpi:1 vci:102 state:2 config_status:0 *Oct 14 18:00:11.662: atmdx_setup_cos(ATM4/0): vc:8 wred_name:- max_q:0 *Oct 14 18:00:11.662: atmdx_pas_vc_setup(ATM4/0): vcd 8, atm hdr 0x00100660, mtu 4482 *Oct 14 18:00:11.662: ABR: pcr 9433, mcr 2358, icr 9433 *Oct 14 18:00:11.662: vc tx_limit=128, rx_limit=47 *Oct 14 18:00:11.666: Created 64-bit VC counters
PVC 1/102 is configured as UBR. The PA-A3 assigns the default UBR tx_limit value of 40. (See the table above.)
7200-17(config-if)#pvc 1/101 7200-17(config-if-atm-vc)#ubr 10000 7200-17(config-if-atm-vc)# *Oct 14 17:56:49.466: Reserved bw for 1/101 Available bw = 141500 *Oct 14 17:57:03.734: atmdx_setup_vc(ATM4/0): vc:7 vpi:1 vci:101 state:2 config_status:0 *Oct 14 17:57:03.734: atmdx_setup_cos(ATM4/0): vc:7 wred_name:- max_q:0 *Oct 14 17:57:03.734: atmdx_pas_vc_setup(ATM4/0): vcd 7, atm hdr 0x00100650, mtu 4482 *Oct 14 17:57:03.734: UBR: pcr 23584 *Oct 14 17:57:03.734: vc tx_limit=40, rx_limit=117 *Oct 14 17:57:03.738: Created 64-bit VC counters
- Individual quota on each VBR-nrt and ABR VC — Compares each VC’s tx_count and tx_limit values. It discards subsequent packets when the tx_count is greater than the tx_limit on any one VC. It is important to note that a burst of packets can exceed the transmit ring of a VBR-nrt VC at an instant in time and lead to output drops.
- Overall quota — Considers the tx_threshold value. The PA-A3 allows for larger bursts on UBR VCs by enforcing traffic policing on such VCs only when the total packet buffer usage on the PA-A3 reaches this preset threshold.
Note: If a packet requires multiple particles and the transmit ring is full, the PA-A3 allows a VC to exceed its quota if particles are available. This scheme is designed to accommodate a small burst of packets without output drops.
The show controller atm command displays several counters relevant to transmit credits.
7200-17#show controller atm 4/0 Interface ATM4/0 is up Hardware is ENHANCED ATM PA - OC3 (155000Kbps) Framer is PMC PM5346 S/UNI-155-LITE, SAR is LSI ATMIZER II Firmware rev: G125, Framer rev: 0, ATMIZER II rev: 3 idb=0x622105EC, ds=0x62217DE0, vc=0x62246A00 slot 4, unit 9, subunit 0, fci_type 0x0059, ticks 190386 1200 rx buffers: size=512, encap=64, trailer=28, magic=4 Curr Stats: VCC count: current=7, peak=7 SAR crashes: Rx SAR=0, Tx SAR=0 rx_cell_lost=0, rx_no_buffer=0, rx_crc_10=0 rx_cell_len=0, rx_no_vcd=0, rx_cell_throttle=0, tx_aci_err=0 Rx Free Ring status: base=0x3E26E040, size=2048, write=176 Rx Compl Ring status: base=0x7B162E60, size=2048, read=1200 Tx Ring status: base=0x3E713540, size=8192, write=2157 Tx Compl Ring status: base=0x4B166EA0, size=4096, read=1078 BFD Cache status: base=0x62240980, size=6144, read=6142 Rx Cache status: base=0x62237E80, size=16, write=0 Tx Shadow status: base=0x62238900, size=8192, read=2143, write=2157 Control data: rx_max_spins=3, max_tx_count=17, tx_count=14 rx_threshold=800, rx_count=0, tx_threshold=4608 tx bfd write indx=0x4, rx_pool_info=0x62237F20
The following table describes the values used by the PA-A3 to enforce the overall transmit credit scheme:
| Value | Description |
|---|---|
| max_tx_count | Histogram of the maximum number of transmit particles ever held by the PA-A3 microcode. |
| tx_count | Total number of transmit particles currently being held by the PA-A3 microcode. |
Note: The PA-A3 microcode also tracks the tx_count of each VC. When a particle is sent to the PA-A3 microcode from the PA-A3 driver, the tx_count increments by one.
When Should the Transmit Ring Be Tuned?
The transmit ring serves as a staging area for packets in line to be transmitted. The router needs to enqueue a sufficient number of packets on the transmit ring and ensure that the interface driver has packets with which to fill available cell timeslots.
Originally, the PA-A3 driver did not adjust the transmit ring size when a service policy with low latency queueing (LLQ) was applied. With current images, the PA-A3 tunes down the value from the above defaults (Cisco Bug ID CSCds63407) to minimize queueing-related delay.
The primary reason to tune the transmit ring is to reduce latency caused by queueing. When tuning the transmit ring, consider the following:
- On any network interface, queueing forces a choice between latency and the amount of burst that the interface can sustain. Larger queue sizes sustain longer bursts while increasing delay. Tune the size of a queue when you feel the VC’s traffic is experiencing unnecessary delay.
- Consider the packet size. Configure a tx-ring-limit value that accommodates four packets. For example, if your packets are 1500 bytes, set a tx-ring-limit value of 16 = (4 packets) * (4 particles).
- Ensure the transmit credit is large enough to support one MTU-sized packet and/or the number of cells equal to the maximum burst size (MBS) for a VBR-nrt PVC.
- Configure a low value with low-bandwidth VCs, such as a 128 kbps SCR. For example, on a low-speed VC with an SCR of 160 kbps, a tx-ring-limit of ten is relatively high and can lead to significant latency (for example, hundreds of milliseconds) in the driver-level queue. Tune the tx-ring-limit down to its minimum value in this configuration.
- Configure higher values for high-speed VCs. Selecting a value of less than four may inhibit the VC from transmitting at its configured rate if the PA-A3 implements back pressure too aggressively and the transmit ring does not have a ready supply of packets waiting to be transmitted. Ensure that a low value does not affect VC throughput. (See Cisco Bug ID CSCdk17210.)
In other words, the size of the transmit ring needs to be small enough to avoid introducing latency due to queueing, and it needs to be large enough to avoid drops and a resulting impact to TCP-based flows.
An interface first removes the packets from the layer-3 queueing system and then queues them on the transmit ring. Service policies apply only to packets in the layer-3 queues and are transparent to the transmit ring.
Queueing on the transmit ring introduces a serialization delay that is directly proportional to the depth of the ring. An excessive serialization delay can impact latency budgets for delay-sensitive applications such as voice. Thus, Cisco recommends reducing the size of the transmit ring for VCs carrying voice. Select a value based on the amount of amount of serialization delay, expressed in seconds, introduced by the transmit ring. Use the following formula:
((P*8)*D)/S P = Packet size in bytes. Multiply by eight to convert to bits. D = Transmit-ring depth. S = Speed of the VC in bps.
Note: IP packets on the Internet are typically one of three sizes: 64 bytes (for example, control messages), 1500 bytes (for example, file transfers), or 256 bytes (all other traffic). These values produce a typical overall Internet packet size of 250 bytes.
Note: The following table summarizes the advantages and disadvantages of larger or smaller transmit ring sizes:
| Size of Transmit Ring | Advantage | Disadvantage |
|---|---|---|
| High Value | Recommended for data VCs to accommodate bursts. | Not recommended for voice VCs. Can introduce increased latency and jitter. |
| Low Value | Recommended for voice VCs to reduce delay due to queueing and jitter. | Not recommended for relatively high-speed VCs. Can introduce reduced throughput if tuned to such a low value that no packets are ready to be sent once the wire is free. |
Use the tx-ring-limit command in VC configuration mode to tune the size of the transmit ring.
7200-1(config-subif)#pvc 2/2 7200-1(config-if-atm-vc)#? ATM virtual circuit configuration commands: abr Enter Available Bit Rate (pcr)(mcr) broadcast Pseudo-broadcast class-vc Configure default vc-class name default Set a command to its defaults encapsulation Select ATM Encapsulation for VC exit-vc Exit from ATM VC configuration mode ilmi Configure ILMI management inarp Change the inverse arp timer on the PVC no Negate a command or set its defaults oam Configure oam parameters oam-pvc Send oam cells on this pvc protocol Map an upper layer protocol to this connection. random-detect Configure WRED service-policy Attach a policy-map to a VC transmit-priority set the transmit priority for this VC tx-ring-limit Configure PA level transmit ring limit ubr Enter Unspecified Peak Cell Rate (pcr) in Kbps. vbr-nrt Enter Variable Bit Rate (pcr)(scr)(bcs) 7200-1(config-if-atm-vc)#tx-ring-limit ? 3-6000> Number (ring limit)
Use the show atm vc command to display the currently configured value.
7200-1#show atm vc VC 3 doesn't exist on interface ATM3/0 ATM5/0.2: VCD: 3, VPI: 2, VCI: 2 VBR-NRT, PeakRate: 30000, Average Rate: 20000, Burst Cells: 94 AAL5-LLC/SNAP, etype:0x0, Flags: 0x20, VCmode: 0x0 OAM frequency: 0 second(s) PA TxRingLimit: 10 InARP frequency: 15 minutes(s) Transmit priority 2 InPkts: 0, OutPkts: 0, InBytes: 0, OutBytes: 0 InPRoc: 0, OutPRoc: 0 InFast: 0, OutFast: 0, InAS: 0, OutAS: 0 InPktDrops: 0, OutPktDrops: 0 CrcErrors: 0, SarTimeOuts: 0, OverSizedSDUs: 0 OAM cells received: 0 OAM cells sent: 0 Status: UP
In addition, use the show atm pvc vpi/vci command to view both the current transmit and receive ring limits. The following output was captured on a 7200 Series router running Cisco IOS Software Release 12.2(10).
viking#show atm pvc 1/101 ATM6/0: VCD: 2, VPI: 1, VCI: 101 UBR, PeakRate: 149760 AAL5-LLC/SNAP, etype:0x0, Flags: 0xC20, VCmode: 0x0 OAM frequency: 0 second(s), OAM retry frequency: 1 second(s), OAM retry frequency: 1 second(s) OAM up retry count: 3, OAM down retry count: 5 OAM Loopback status: OAM Disabled OAM VC state: Not Managed ILMI VC state: Not Managed VC TxRingLimit: 40 particles VC Rx Limit: 800 particles
Impact of Very Small tx-ring-limit Values
On the transmit path, the host CPU transfers the payload from the host buffers to the local particle buffers on the PA-A3. The firmware running on the PA-A3 caches several buffer descriptors and frees them in a group. During the caching period, the PA-A3 does not accept new packets even though the contents of the local memory have been transmitted on the physical wire. The purpose of this scheme is to optimize overall performance. Thus, when configuring a non-default tx-ring-limit value, consider the buffer descriptor return delay.
In addition, if you configure a tx-ring-limit value of one with given a particle size of 576 bytes, a 1500-byte packet is removed from the queue as follows:
- The PA-A3 driver queues the first particle in the transmit ring, and remembers that this packet is stored in two other memory particles.
- During the next time that the transmit ring is empty, the second particle of the packet is put in the transmit ring.
- During the next time that the transmit ring is empty again, the third particle is put in the transmit ring.
Even though the transmit ring consists of only one 576 byte particle, MTU/port-speed is still the worst-case latency through the transmit ring.
Known Issues
When the tx-ring-limit command is applied to a VC through a vc-class statement, the PA-A3 does not apply the configured value. Confirm this result by displaying the current value in the show atm vc detail command. Tuning the transmit ring using a vc-class was implemented in Cisco IOS Software Release 12.1 (Cisco Bug ID CSCdm93064). CSCdv59010 resolves a problem with the tx-ring-limit in certain versions of Cisco IOS Software Release 12.2. When you apply the tx-ring-limit command through the vc-class statement to an ATM PVC, the transmit ring size is not modified. Confirm this result using the show atm vc detail command, after applying the command through the vc-class and class-vc command pairs.
When added to a PVC on a PA-A3 in a Cisco 7200 series router running Cisco IOS Software Release 12.2(1), the tx-ring-limit command is duplicated, as shown below (Cisco Bug ID CSCdu19350).
interface ATM1/0.1 point-to-point description dlci-101, cr3640 ip unnumbered Loopback0 pvc 0/101 tx-ring-limit 3 tx-ring-limit 3
The condition is harmless and does not affect the operation of the router.
Cisco bug ID CSCdv71623 resolves a problem with output drops on a multilink PPP bundle interface when the traffic rate is well below the line rate. This problem was seen in CSCdv89201 on an ATM interface with a tx-ring-limit value greater than five. The problem becomes particularly apparent when fragmentation is disabled or when the link weights (fragment size limits) are large — common on higher speed links like T1s or E1s — and the data traffic consists of a mix of small and large packets. Enabling fragmentation and using a small fragment size (set by the interface configuration command ppp multilink fragment delay) improves operation significantly. However, you should verify that your router has sufficient processing capacity to support these high levels of fragmentation without overloading the system CPU, before using this as a workaround.
Cisco bug ID CSCdw29890 resolves a problem with the tx-ring-limit command being accepted by the CLI for ATM PVC bundles, but not taking effect. However, you do not normally need to change the tx-ring-limit on ATM PVC bundles. The reason is that, reducing the ring size effectively moves all the transmit buffering to a QoS-controlled queue, so an arriving priority packet is transmitted immediately to minimize delay on low-speed interfaces. With ATM PVC bundles, cells from packets of all the member VCs are always sent simultaneously (and interleaved), so the delay is minimized automatically.
Tuning the tx-ring-limit on 3600 and 2600 Routers
Current Cisco IOS software images support tuning the transmit ring on the ATM network modules for Cisco 2600 and 3600 series routers (Cisco Bug ID CSCdt73385). The current value appears in the show atm vc output.
Related Information
- More ATM Information
- Tools and Resources — Cisco Systems
- Technical Support & Documentation — Cisco Systems
QoS в Cisco
[править] Утилиты для классификации и маркировки
[править] Class-Based Marking (CB Marking)
Особенности логики и настройки CB Marking:
- Для CB Marking нужно включать CEF, иначе соответствующую service-policy нельзя будет применить на интерфейсе.
- CB Marking включается для пакетов входящих или выходящих из интерфейса.
- Могут быть настроены несколько команд set для маркировки трафика в нескольких полях.
- Пакеты, которые не совпали с явно настроенными class, совпадают со специальным class, который называется class-default.
- Если для class не задана команда set, то трафик, который совпадает с ним, не маркируется.
[править] Настройка CB Marking
Маркировка трафика, который совпадает с параметрами class-map определенным значением поля IP Precedence:
router(config-pmap-c)# set [ip] precedence
Для этой и следующей команды, если указан параметр ip, то значение поля устанавливается только для пакетов IPv4. Если параметр опущен, то значения IPP и DSCP устанавливаются для пакетов IPv4 и IPv6.
Маркировка трафика определенным значением поля DSCP:
router(config-pmap-c)# set [ip] dscp
Маркировка трафика определенным значением поля CoS:
router(config-pmap-c)# set cos
Указание идентификатора группы для QoS group:
router(config-pmap-c)# set qos-group
Установка в ячейке ATM бита CLP:
router(config-pmap-c)# set atm-clp
Установка в кадре Frame Relay бита DE:
router(config-pmap-c)# set fr-de
[править] QoS Pre-Classification
Устройство, на котором выполняется маркировка трафика, может терминировать VPN-туннель. В этом случае в туннельные заголовки (IPsec или GRE) копируется значение поля ToS. Но такие функции как NBAR не могут работать с трафиком, который инкапсулирован в туннельный заголовок.
В IOS существует функция, которая помогает решить этот вопрос — QoS Pre-Classification.
QoS pre-classification «помнит» исходный, не зашифрованный трафик, до тех пор пока не будут выполнены действия QoS в исходящем направлении.
Эта функция может быть включена командой qos pre-classify в таких режимах:
- interface tunnel (для GRE и IPIP)
- interface virtual-template (для L2F и L2TP)
- crypto map (для IPsec)
[править] Просмотр информации
Для того чтобы регулировать частоту с которой проверяется статистика на интерфейсах (packet rate, bit rate) используется команда load-interval. Интервал указывается в секундах, по умолчанию 5 минут:
dyn5(config-if)# load-interval
[править] Управление перегрузками и избежание перегрузок
Управление перегрузками (congestion management) или queuing — каким образом маршрутизатор или коммутатор управляет пакетами или кадрами, пока они ожидают своей очереди для выхода из устройства.
Для маршрутизаторов характерно output queuing, а для коммутаторов input и output queuing.
Избежание перегрузок (congestion avoidance) — логика, которую использует устройство, когда решает отбрасывать ли пакет и когда его отбрасывать, если система очередей становится более загруженной.
[править] Программные и аппаратные очереди
- Программная очередь (software queue) — очереди, которые реализованы в программном обеспечении и которыми можно управлять с помощью различных утилит.
- Аппаратная очередь (hardware queue) — после того как пакет покидает программную очередь, он попадает в небольшую аппаратную FIFO очередь. В Cisco эта очередь ещё называется transmit queue (TX queue) или transmit ring (TX ring).
Свойства аппаратных очередей:
- после окончания отправки интерфейсом одного пакета, следующий пакет из аппаратной очереди может быть отправлен через интерфейс без вмешательства со стороны программного обеспечения,
- всегда используют логику FIFO,
- не могут быть изменены утилитами IOS,
- IOS автоматически уменьшает размер аппаратной очереди по сравнению с её размером по умолчанию, если настроена какая-то утилита управления очередями,
- Если длина аппаратной очереди меньше, то повышается вероятность, что передача данных будет контролироваться в программной очереди.
Посмотреть текущий размер аппаратной очереди (для этого маршрутизатора по умолчанию размер очереди 256):
dyn5# sh controllers fa0/0 . tx_limited=0(256) .
Изменение размера очереди:
dyn5(config)# int fa0/0 dyn5(config-if)# tx-ring-limit 3
После изменения размер аппаратной очереди:
dyn5# sh controllers fa0/0 . tx_limited=0(3) .
[править] Утилиты управления очередями
- Priority queuing (PQ)
- Custom queuing (CQ)
- Class-based weighted fair queuing (CBWFQ)
- Low-latency queuing (LLQ)
Классы определенные в policy-map соответствуют очередям. Поэтому термины очередь (queue) и класс (class) взаимозаменяемы в контексте обсуждения LLQ и CBWFQ.
LLQ и CBWFQ поддерживают 64 очереди. Кроме того, существует одна специальная очередь по умолчанию class-default queue. В эту очередь попадают пакеты, которые НЕ совпали с критериями явно настроенных классов.
[править] CBWFQ
Принципы работы CBWFQ:
- Классификация — выполняется на основании любых критериев, которые доступны в MQC с помощью команды match,
- Политика отбрасывания пакетов — tail drop или WRED, настраивается для каждой очереди,
- Количество очередей — 64,
- Максимальная длина очереди — зависит от модели маршрутизатора,
- Обслуживание в пределах одной очереди — FIFO в 63 очередях, FIFO или WFQ в class-default queue,
- Обслуживание между очередями — на основании выделенной пропускной способности для каждой очереди.
[править] Проверка количества выделенной пропускной способности
Когда policy-map применяется к интерфейсу (команда service-policy output), IOS выполняет проверку не выделяет ли эта policy map слишком много пропускной способности для конкретного интерфейса. Если policy map не проходит проверку, то она не применяется к интерфейсу.
Проверка выполняется на основании двух команд указанных в режиме настройки интерфейса:
IOS позволяет policy map выделять пропускную способность величиной (сумма всех значений bandwidth) не более чем произведение значений bandwidth и max-reserved-bandwidth (по умолчанию 75 процентов).
Пример задания величин на интерфейсе (bandwidth задается в килобитах, а max-reserved-bandwidth а процентах):
dyn5(config)# int fa0/0 dyn5(config-if)# bandwidth 10000 dyn5(config-if)# max-reserved-bandwidth 70
После задания таких параметров, если на интерфейс fa0/0 применяется policy-map, то пропускная способность, которая выделена в ней не должна быть более чем 7000.
dyn5(config)# policy-map test-bw dyn5(config-pmap)# class class1 dyn5(config-pmap-c)# bandwidth 4000 dyn5(config-pmap)# class class2 dyn5(config-pmap-c)# bandwidth 5000
Применение policy-map на интерфейсе:
dyn5(config-if)# service-policy output test-bw I/f FastEthernet0/0 class class2 requested bandwidth 5000 (kbps), available only 3000 (kbps)
Policy-map не была применена так как максимальное значение пропускной способности которое может быть для неё выделено 7000. Первый класс забрал 4000, а оставшихся 3000 не хватает для второго класса. Поэтому и появляется ошибка, что доступно только 3000, а класс запросил 5000.
Существует другой вариант выделения пропускной способности для policy-map. При выделении пропускной способности для класса используются команды:
- bandwidth percent — процент пропускной способности выделенной для класса, процент считается от всей пропускной способности интерфейса. Сумма пропускной способности выделенной для классов в policy-map не должна превышать max-reserved-bandwidth настроенной на соответствующем интерфейсе.
- bandwidth remaining percent — процент пропускной способности выделенной для класса, процент считается от значения произведения bandwidth и max-reserved-bandwidth интерфейса. Сумма пропускной способности выделенной для классов в policy-map соответственно может быть 100 процентов.
dyn5(config)# policy-map test-bw dyn5(config-pmap)# class class1 dyn5(config-pmap-c)# bandwidth percent 20
В одной policy-map может использоваться только один из трёх вариантов выделения пропускной способности для класса (bandwidth, bandwidth percent или bandwidth remaining percent).
[править] Размер очереди для CBWFQ
Пример задания размера очереди для класса (диапазон от 1 до 4096 пакетов):
dyn5(config)# policy-map test-bw dyn5(config-pmap)# class class1 dyn5(config-pmap-c)# queue-limit 500
[править] Включение WFQ для класса по умолчанию
Для класса по умолчанию можно включить WFQ (и только для него):
dyn5(config)# policy-map test-bw dyn5(config-pmap)# class class-default dyn5(config-pmap-c)# fair-queue
[править] congestive-discard-threshold
fair-queue [congestive-discard-threshold]
[править] LLQ
Синтаксис команды для настройки LLQ:
dyn5(config-pmap-c)# priority > [burst-size]
Команда priority для класса:
- включает LLQ,
- резервирует пропускную способность,
- включает функцию policing,
- (опционально) указывает размер burst для policer (по умолчанию 20 процентов).
Пропускная способность может быть задана конкретным значением или процентами от пропускной способности интерфейса. В одной и той же policy-map могут использоваться различные способы указания пропускной способности priority или priority percent.
Суммарная пропускная способность выделенная в policy-map командами priority и bandwidth не должна превышать значение произведения bandwidth и max-reserved-bandwidth.
Фактически LLQ будет использоваться только когда аппаратная очередь заполнена.
Параметр bandwidth указывает максимальное значение пропускной способности, которое выделяется пакетам, которые принадлежат классу в котором указана команда priority. Этот параметр с одной стороны гарантирует указанную пропускную способность классу, с другой — сдерживает поток пакетов приоритетного класса.
Когда устройство не перегружено, то приоритетному классу разрешено превышать указанную пропускную способность. Если устройство перегружено, то трафик приоритетного класса, который превышает указанную пропускную способность, будет отброшен.
Пример policy-map в которой для class1 настроено LLQ:
dyn5(config)# policy-map test-bw dyn5(config-pmap)# class llq-class dyn5(config-pmap-c)# priority percent 30
dyn5# sh policy-map test-bw Policy Map test-bw Class llq-class Strict Priority Bandwidth 30 (%)
Просмотр статистики по конкретному классу:
dyn5# sh policy-map interface fa0/0 output class llq-class FastEthernet0/0 Service-policy output: test-bw Class-map: llq-class (match-all) 0 packets, 0 bytes 5 minute offered rate 0 bps, drop rate 0 bps Match: none Queueing Strict Priority Output Queue: Conversation 264 Bandwidth 30 (%) Bandwidth 30000 (kbps) Burst 750000 (Bytes) (pkts matched/bytes matched) 0/0 (total drops/bytes drops) 0/0
[править] Weighted Round Robin Queuing
Weighted Round Robin (WRR)
sw(config-if)# wrr-queue cos-map queue-id threshold-id cos-1. cos-n
wrr-queue priority-queue
sw(config-if)# wrr-queue bandwidth
[править] Weighted Random Early Detection (WRED)
Tail drop — когда очередь заполнена, IOS начинает отбрасывать новые пакеты.
Weighted Random Early Detection (WRED) — отслеживает длину очереди и отбрасывает некоторый процент пакетов в очереди для улучшения производительности сети.
WRED отбрасывает пакеты до тех пор как очередь заполнится.
Для того чтобы определить достаточно ли полна очередь для того чтобы отбрасывать пакеты WRED измеряет среднюю глубину очереди (average queue depth). Затем, значение average depth сравнивается с minimum threshold и maximum threshold. В зависимости от результата сравнения выполняются различные действия.
| Значение average depth относительно threshold | Действие | Название действия в WRED |
|---|---|---|
| average < min threshold | Пакеты не отбрасываются | No drop |
| min threshold < average < max threshold | Процент пакетов отбрасывается. Процент пакетов, которые отбрасываются возрастает от 0 до максимального процента по мере приближения значения average к max threshold | Random drop |
| average > max threshold | Все новые пакеты отбрасываются | Full drop |
Mark probability denominator (MPD) — на основании этого значения вычисляется процент пакетов, которые будут отброшены.
WRED дает больший приоритет пакетам с определенными значениями IPP и DSCP. Для того чтобы сделать это WRED использует разные профили трафика (traffic profile) для пакетов с разными значениями IPP и DSCP.
WRED traffic profile состоит из настроек для трёх переменных:
Профили WRED заданные по умолчанию для DSCP-based WRED:
| DSCP | Min threshold | Max threshold | MPD | 1/MPD |
|---|---|---|---|---|
| AFx1 | 33 | 40 | 10 | 10% |
| AFx2 | 28 | 40 | 10 | 10% |
| AFx3 | 24 | 40 | 10 | 10% |
| EF | 37 | 40 | 10 | 10% |
Exponential weighting constant контролирует насколько быстро меняется средняя глубина очереди. Если значение константы меньше, то средняя глубина очереди меняется быстрее; если константа больше, то — медленнее. По умолчанию используется значение 9.
[править] Настройка WRED
WRED может быть настроен на:
- физическом интерфейсе (с FIFO очередью),
- для класса (класс должен быть не LLQ) внутри CBWFQ policy-map,
- для ATM VC.
Для использования WRED на физическом интерфейсе, IOS отключает остальные механизмы управления очередями и создает одну очередь FIFO.
Команды по настройке WRED аналогичны на интерфейсе и для класса внутри policy-map.
Включение WRED (по умолчанию включается WRED с использованием IPP):
dyn5(config-if)# random-detect
Включение WRED с использованием DSCP для определения профиля трафика:
dyn5(config-if)# random-detect dscp-based
Изменение настроек по умолчанию WRED для конкретного значения IPP:
dyn5(config-if)# random-detect precedence
Изменение настроек по умолчанию WRED для конкретного значения DSCP:
dyn5(config-if)# random-detect dscp
Exponential weighting constant:
dyn5(config-if)# random-detect exponential-weighting-constant
[править] Просмотр настроек
dyn5# sh queueing [interface | custom | fair | priority | random-detect]
Пример вывода настроек:
dyn5# sh queueing Current fair queue configuration: Current DLCI priority queue configuration: Current priority queue configuration: Current custom queue configuration: Current random-detect configuration: FastEthernet0/0 Queueing strategy: random early detection (WRED) Random-detect not active on the dialer Exp-weight-constant: 9 (1/512) Mean queue depth: 0 class Random drop Tail drop Minimum Maximum Mark pkts/bytes pkts/bytes thresh thresh prob 0 0/0 0/0 20 40 1/10 1 0/0 0/0 22 40 1/10 2 0/0 0/0 24 40 1/10 3 0/0 0/0 26 40 1/10 4 0/0 0/0 28 40 1/10 5 0/0 0/0 31 40 1/10 6 0/0 0/0 33 40 1/10 7 0/0 0/0 35 40 1/10 rsvp 0/0 0/0 37 40 1/10 Current per-SID queue configuration:
[править] Modified Deficit Round-Robin (MDRR)
Утилита MDRR реализована только для маршрутизаторов Cisco 12000, так как они не поддерживают CBWFQ и LLQ.
MDRR позволяет классифицировать трафик на семь round-robin очередей (0-6), с одной дополнительной приоритетной очередью.
Если в приоритетной очереди нет пакетов, то WDRR обслуживает очереди по принципу round-robin. Если в приоритетной очереди есть пакеты, то WDRR может обрабатывать пакеты одним из вариантов:
- Strict priority mode — приоритетная очередь обслуживается сразу, как только там появляются пакеты;
- Alternate mode — приоритетная очередь обслуживается после каждой не приоритетной очереди.
MDRR поддерживает два типа scheduling.
- Quantum value (QV) — количество байтов. WDRR удаляет пакеты из очереди до тех пор пока QV для этой очереди будет удалено.
- Deficit — количество байт которые были обработаны сверх нормы (более чем QV). При следующем прохождении цикла с очереди в которой было взято больше байт, будет взято на эту же величину меньше.
[править] Управление перегрузками и избежание перегрузок на коммутаторах
Коммутаторы 3550 и 3560 выполняют входящее и исходящее управление очередями. У 3550 одна входящая очередь работающая по принципу FIFO. У 3560 две входящих очереди, одна из которых может быть настроена как приоритетная очередь.
В 3560 packet scheduler использует метод shared round-robin (SRR) для того чтобы контролировать отправку пакетов. На входящих очередях SRR разделяет пропускную способность между очередями, в соответствии с настроенными весами. Вес выполняет роль относительной, а не абсолютной величины.
Пол умолчанию, трафик промаркированный значением COS 5 попадает во вторую очередь, остальной в первую. Можно настроить назначение трафика в очередь по значению DSCP.
switch# show mls qos maps cos-input-q
switch# show mls qos maps dscp-input-q
Настройка коэффициентов для очередей (по умолчанию 90 процентов в очередь 1 и 10 процентов в очередь 2):
switch(config)# mls qos srr-queue input buffers
Настройка процентов для пропускной способности, которые устанавливают частоту с которой scheduler берет пакеты из двух буферов (по умолчанию оба значения 4):
switch(config)# mls qos srr-queue input bandwidth
Две указанные команды вместе определяют какое количество данных коммутатор может
Настройка приоритетной очереди:
switch(config)# mls qos srr-queue input priority-queue bandwidth
Коммутатор будет обслуживать приоритетную очередь до тех пор, пока пропускная способность не достигнет настроенного значения weight. После этого остальная пропускная способность разделяется между очередями.
[править] Shaping и Policing
[править] Терминология
- Tc — временной интервал, измеряемый в секундах, в течение которого может быть отправлен commited burst (Bc). Для многих shaping утилит Tc=Bc/CIR.
- Bc — commited burst rate, измеряется в битах. Количество трафика которое будет отправлено в течение Tc интервала.
- CIR — commited information rate, в битах в секунду, определяет rate VC в соответствии с контрактом.
- Shaped rate — rate, в битах за секунду, до которого конкретная настройка делает shape трафику. Может быть установлен или нет в значение равное CIR.
- Be — excess burst size, в битах. Количество битов, которое может быть отправлено сверх указанного Bc после периода неактивности.
[править] Shaping в сетях Frame-Relay
Minimum information rate (MIR) или mincir.
Уменьшает rate шейпер в том случае, если обнаруживает перегрузку с помощью одного из двух методов:
- получает кадр с установленным битом BECN (Backward Explicit Congestion Notification),
- получает проприетарное сообщение о перегрузке (congestion message) Cisco ForeSight.
При получении BECN или ForeSight сообщения, шейпер снижает rate на 25 процентов от максимального rate. Фактически уменьшается Bc и Be на 25 процентов, а Tc остается неизменным. Если опять приходит сообщение BECN или ForeSight, то происходит уменьшение ещё на 25 процентов. Так происходит то тех пор пока не будет достигнут mincir.
После получения 16 сообщений без BECN или ForeSight, rate снова возрастает.
[править] Class-based shaping
CB shaping может быть настроен только для исходящих пакетов и может быть применен к физическому интерфейсу или подынтерфейсу.
dyn5(config-pmap-c)# shape [average | peak] [[burst-size][exceed-burst-size]]
Должен быть указан shaping rate. Bc и Be могут быть опущены, а Tc не может быть задан напрямую. Соответственно CB shaping высчитывает неуказанные значения. Значения высчитываются по-разному в зависимости от того чему равен shaping rate.
| Переменная | Rate | Rate > 320 kbps |
|---|---|---|
| Bc | 8000 bits | Bc = shaping rate * Tc |
| Be | Be = Bc = 8000 | Be = Bc |
| Tc | Tc = Bc / shaping rate | 25ms |
[править] CB shaping peak rate
Если CB shaping настроен командой shape peak, то:
- значения Bc, Be, Tc высчитываются как и для команды shape average,
- токены Bc и Be (а не только Bc) пополняются каждый временной интервал.
Shaping rate = configured rate (1 + Be/Bc)
[править] Generic Traffic Shaping
[править] Frame-Relay traffic shaping
Frame-Relay traffic shaping (FRTS):
- FRTS может использоваться только на frame-relay интерфейсах, а CB shaping может использоваться для любого протокола канального уровня.
- Как и CB shaping, FRTS позволяет использовать утилиты для управления очередями вместо одной очереди FIFO.
- В отличие от CB shaping, FRTS не позволяет включать дополнительные утилиты управления очередями на физическом интерфейсе одновременно с FRTS.
- FRTS всегда шейпит трафик в каждой VC отдельно.
- FRTS не может классифицировать трафик для того чтобы шейпить часть трафика конкретной VC.
- В отличие от CB shaping, FRTS может динамически получать значение CIR, Bc и Be, настроенные на FR-коммутаторе, используя Enhanced Local Management Interface (ELMI).
dyn5(config)# map-class frame-relay testFR dyn5(config-map-class)# frame-relay traffic-rate [peak]
Пример явного указания параметров:
dyn5(config)# map-class frame-relay testFR dyn5(config-map-class)# frame-relay cir 64000 dyn5(config-map-class)# frame-relay bc 640
Настройка динамического реагирования маршрутизатора на основании BECN:
dyn5(config-map-class)# frame-relay adaptive-shaping
[править] CB policing
CB policing разделяет пакеты на две или три категории, в зависимости от вида policing, а затем применяет к каждой категории соответствующее действие.
- conforming
- exceeding
- violating
[править] Single-rate, two-color policing (one bucket)
Policer использует две категории:
CB Policer заполняет bucket не на основании временных интервалов, а на основании пакетов.
Количество токенов высчитывается по формуле:
((current_packet_arrival_time - Previous_packet_arrival_time) * Police_rate) / 8
Так как токен представляет право на передачу одного байта, то результат разделен на 8, чтобы перевести его из битов в байты.
Когда приходит новый пакет, policer должен определить превышает или нет этот пакет установленный контракт.
Policer сравнивает количество байт в пакете (Xp) с количеством токенов в token bucket (Xb).
| Категория | Требования | Токены, которые забраны из bucket |
|---|---|---|
| Conform | Если Xp | Xp токенов |
| Exceed | Если Xp > Xb | не забираются |
[править] Single-rate, three-color policing (two buckets)
Policer использует три категории:
Xbc — количество токенов в Bc bucket, Xbe — количество токенов в Be bucket.
| Категория | Требования | Токены, которые забраны из bucket |
|---|---|---|
| Conform | Если Xp | Xp токенов из Bc bucket |
| Exceed | Если Xp > Xbc и Xp | Xp токенов из Be bucket |
| Violate | Если Xp > Xbc и Xp > Xbe | не забираются |
[править] Two-rate, three-color policing (two buckets)
- Commited information rate (CIR)
- Peak information rate (PIR)
Policer использует три категории:
- conform — пакеты передающиеся до CIR,
- exceed — пакеты передающиеся выше CIR, но до PIR,
- violate — пакеты передающиеся выше PIR.
| Категория | Требования | Токены, которые забраны из bucket |
|---|---|---|
| Conform | Если Xp | Xp токенов из Bc bucket и Xp токенов из Be bucket |
| Exceed | Если Xp > Xbc и Xp | Xp токенов из Be bucket |
| Violate | Если Xp > Xbc и Xp > Xbe | не забираются |
[править] Настройка CB policing
police cir 8000 bc 1000 be 500 conform-action transmit exceed-action transmit violate-action drop
Если не указаны значения Bc или Be, то используются значения по умолчанию, которые зависят от типа policing.
| Тип policing | Как определить тип по команде police | Значения по умолчанию |
|---|---|---|
| Single rate, two color | не настроено violate-action | Bc = CIR/32, Be = 0 |
| Single rate, three color | настроено violate-action | Bc = CIR/32, Be = Bc |
| Dual rate, three color | настроено PIR | Bc = CIR/32, Be = PIR/32 |
[править] Multi-action policing
Multi-action policing — маркировка нескольких полей в одном пакете с помощью CB policing.
[править] Commited access rate (CAR)
CAR это single-rate, two-color policing.
CAR оптимизирован для высокоскоростных соединений.
CAR применяется для входных и выходных интерфейсов (включая подинтерфейсы в том числе Frame Relay и ATM)
может так же использоваться для предотвращения DOS атак.
dyn5(config-if)# rate-limit [access-group [rate-limit] acl-index] bps burst-normal burst-max conform-action action exceed-action action
- access-group — аксесс лист классификации
- bps — скорость бит/с (commited access rate)
- burst-normal — размер всплеска рекомендовано считать по формуле ([4]):
- burst-normal = bps * (1 byte)/(8 bits) * 1.5 seconds
- burst-max — максимальный размер всплеска
- burst-max=burst-normal*2
- conform-action action — действие при соответствии ограничения
- exceed-action action — действие при превышении ограничения
- Возможные варианты действий:
- drop – уничтожить
- transmit — передать
- set-dscp-transmit – пометить пакет
interface Tunnel122 ip address 10.84.239.230 255.255.255.252 ip mtu 1420 rate-limit input access-group 199 8000 1600 2000 conform-action transmit exceed-action drop . end
Просмотр трафика, который попадает под CAR:
sm-sht-c2811#sh int tu 122 rate-limit Tunnel122 crypto tunnel sm Input matches: access-group 199 params: 8000 bps, 1600 limit, 2000 extended limit conformed 23741 packets, 1994692 bytes; action: transmit exceeded 3210 packets, 184395 bytes; action: drop last packet: 1149595396ms ago, current burst: 0 bytes last cleared 14w0d ago, conformed 0 bps, exceeded 0 bps
На интерфейс можно описывать любое число правил, ограничивающих трафик на данном интерфейсе
Следующий пример ограничивает ICMP трафик до 500 kb/s, а так же UDP трафик до уровня 2 Мб/s на одном из интерфейсов! sm-c3660(config-if)#rate-limit input access-group 100 500000 62500 62500 conform-action transmit exceed-action drop sm-c3660(config-if)#rate-limit input access-group 101 2010000 250000 250000 conform-action transmit exceed-action drop ! sm-c3660(config)#access-list 100 permit icmp any any sm-c3660(config)#access-list 101 permit udp any any
[править] rate-limit ACL
dyn1(config)# access-list rate-limit ? Precedence ACL index MAC address ACL index mpls exp ACL index
dyn1(config)# access-list rate-limit 1 mask
Порядок вычисления параметра mask:
- Определить какие значения IPP нужны.
- Каждому значению IP precedence соответствует бит в выделенном байте:
- 00000001 — 0
- 00001000 — 3
- 00100001 — 5
- Сложить получившиеся 8мибитные числа. Например, если необходимо совпадение значений 0, 3 и 5, то итоговое значение будет 00101001.
- Перевести полученное значение в соответствующее шестнадцатеричное число. Для приведенного примера это будет число 0x29.
- Настроить соответствующий ACL. Для указанного примера: access-list rate-limit 1 mask 29.
[править] QoS Policy Propagation через BGP (QPPB)
[править] Дополнительная информация
- Class-Based Shaping Configuration
- Shaping vs. Policing At A Glance
- Comparing Traffic Policing and Traffic Shaping for Bandwidth Limiting (англ.)
- QoS для DMVPN
- Understanding How Routing Updates and Layer 2 Control Packets Are Queued on an Interface with a QoS Service Policy (pak_priority) (англ.)
- Bridging the gap between 3550 and 3560 QoS: Part I (англ.)
- Bridging the gap between 3550 and 3560 QoS: Part II (англ.)
- Traffic Classification in the 3550/3560 Switches (англ.)
- Comparing Traffic Policing Features in the 3550 and 3560 switches (англ.)
- Quick Notes on the 3560 Egress Queuing (англ.)
Cisco Systems, Inc. Устройства Cisco 871 • Cisco Router • Cisco Switch • Сisco Сatalyst • Cisco IPS • Cisco ASA • PIX • Dynamips Безопасность
(коммутаторы и
маршрутизаторы)Cisco Security • Port security • DHCP snooping • Dynamic ARP Protection • IP Source Guard • Аутентификация при доступе к сети • 802.1X в Cisco • Zone-Based Policy Firewall • Cisco NAT • NAT в Cisco • Cisco SSH Cisco ASA Cisco ASA/NAT • Cisco ASA/Troubleshooting • Cisco ASA/IPS • Cisco ASA failover • Cisco ASA/Transparent firewall • Cisco ASA/Site-to-Site_VPN • Cisco ASA/Easy_VPN • Cisco ASA/WebVPN • Объединение OSPF-сетей туннелем между двумя системами ASA (без GRE) • Центр сертификатов на Cisco ASA VPN IPsec в Cisco • Cisco IOS Site-to-Site VPN • DMVPN • Cisco Easy VPN • Cisco Web VPN • Cisco ipsec preshared Канальный уровень CDP • VLAN в Cisco • ISL • VTP • STP в Cisco • Cisco Express Forwarding • Агрегирование каналов • Зеркалирование трафика • QinQ • Frame Relay Сетевой уровень Маршрутизация в Cisco • RIP • EIGRP • IS-IS • OSPF • BGP • PIM • Multicast • GLBP • VRRP • HSRP • DHCP • IPv6 • IPv6 vs IPv4 • Резервирование Интернет-каналов без использования BGP • Использование BGP для резервирования Интернет-каналов Разное Режим ROMMON в Cisco • Опция 82 DHCP • 802.1X и RADIUS • SNMP в Cisco • QoS в Cisco • EEM • Troubleshooting • Автоматизация работы устройств Cisco • Cisco NTP • Cisco IP SLA • Cisco Enhanced Object Tracking
- Возможные варианты действий: