Пять способов улучшить читабельность кода
Для тех, кто ищет быстрые ответы, не желая читать весь текст, вот краткое содержание:
- Повторно используйте код, который повторяется более одного раза.
- Читабельность и простота поддержки важнее универсальности.
- Делайте модули, классы и компоненты как можно меньше.
- Используйте правила и стандарты для кода.
- Пишите код, как будто вы в команде, даже если работаете один.
Повторно используйте код, который повторяется более одного раза
Большинство разработчиков знакомы с принципом DRY (Don’t Repeat Yourself). Он позволяет избежать дублирования кода.
Зачем писать функцию снова и снова? Напишите ее один раз и используйте в нескольких местах. И, когда вам понадобится изменить этот кусок кода, сделать это придется только в одном месте, не занимаясь копипастой багфикса в кучу мест.
Но имейте в виду, что использование принципа DRY увеличивает сложность кода, потому что, в конце концов, количество повторно используемого кода будет расти.
А про важность написания тестов при повторном использовании частей кода вы узнаете, когда вы начнете изменять этот код.
Читабельность и простота поддержки важнее универсальности
Повторное использование, читабельность, и простота поддержки друзья и враги одновременно.
Когда вы начинаете придерживаться принципа DRY, сложность вашего кода начинает расти. Когда растет сложность — страдает читабельность.
Поэтому не начинайте написание кода с громоздких универсальных решений. Начинайте с простых! Не надо пытаться сделать идеально с первого раза.
Используя итеративный подход, вы сможете повторно использовать некоторые части своего кода, сохраняя при этом его читабельность и простоту поддержки.
Когда вы работаете в компании с несколькими командами разработчиков, в вашей команде скорее всего будут еще и внешние исполнители (фрилансеры или консультанты). Таким людям, как правило, приходится намного чаще переключаться с одного проекта на другой.
В этом случае, читабельность кода и простота его поддержки — ключ к успеху проекта. Громоздкий непонятный код, написанный человеком, который может покинуть команду в любой момент — не самое лучшее решение.
Правда иногда вам могут требоваться именно такие решения, но помните, что важно сделать их код как можно более читабельным и простым в поддержке.
Делайте модули, классы и компоненты как можно меньше
Разрабатывая новые функции для проекта, вы, скорее всего, стараетесь тщательно их продумать.
Помните, что лучшие решения — это те, которые можно разделить на небольшие модули, классы или компоненты. А знаете почему?
Маленькие куски кода проще тестировать и поддерживать.
Вспомните, что дома строятся путем перемещения более мелких компонентов в нужное место, и никто не пытается сначала построить дом, а потом переместить его туда, где он должен находиться. Хотя, конечно, бывают и исключения.
Большинство современных библиотек и фреймворков разбиты на маленькие строительных блоки, а не представлены в виде одного файла. JavaScript библиотеки и фреймворки такие, как Angular, React и Vue используют концепцию компонентов. Вряд ли они делают это случайно.
Используйте правила и стандарты для кода
Одна из составляющих написания читабельного и легко поддерживаемого кода — его архитектура. Другая — его стиль.
Я думаю, любому из вас хорошо известны эти бесконечные споры о том, что лучше использовать для выравнивания: табы или пробелы. Не хочу занимать ни чью сторону в этом споре, ведь на самом деле не важно, что использует ваша команда. Гораздо важнее, что это каждый член команды понимает и принимает эти правила.
И лучшим решением в данной ситуации будет автоматическое форматирования кода. Большинство IDE имеют для этого встроенные или устанавливаемые в виде плагинов инструменты.
Самый простой из таких инструментов, подходящий для большинства языков программирования и редакторов — editorconfig. Вы можете применять правила форматирования кода просто добавляя файл .editorconfig в свой проект.
В этот файл можно добавить различные настройки форматирования, как глобальные, так и специфичные для конкретного языка программирования. Например:
- Использование табов или пробелов для отступов
- Тип кавычек: двойные или одинарные
- Максимальную длину строки
- Набор символов
- и т.д.
Вот пример такого файла:
root = true [*] charset = utf-8 end_of_line = lf indent_size = 4 indent_style = tab insert_final_newline = false max_line_length = 120 tab_width = 4 [*.md] max_line_length = off trim_trailing_whitespace = false Подробнее про формат файла можно почитать на editorconfig.org
Кроме того, существуют более специализированные решения для конкретных языков программирования. Например, Prettier для JavaScript. Возможно, вы используете что-то другое. На самом деле не важно какие инструменты используются в вашей команде, самое главное — это использование единых правил и стандартов.
Пишите код, как будто вы в команде, даже если работаете один
Последний, но не менее важный пункт: пишите, как будто вы в команде!
Я могу представить, что людям, которые никогда не писали код в команде, очень трудно понять каково это.
Но если вы пишите проект в одиночку, есть большой соблазн начать писать код, который поймете только вы (например, использовать непонятные имена переменных или имена из 2–3 символов и т.д.).
Вместо этого попробуйте писать так, как будто вы в команде. Представьте, что ваш код настолько понятен, что кто-то другой сможет без труда в нем разобраться.
Вы можете легко проверить это, попросив друга или кого-нибудь из сообщества разработчиков проверить читабельность вашего кода. Обещаю, что вы получите такую обратную связь, о которой не могли и подумать.
Не паникуйте из-за негативного фидбека! Сфокусируйтесь на отзывах, которые сделают ваш код более читабельным.
Запомните, что грань между хорошо читаемым и плохо читаемым кодом очень тонка. И чаще всего субъективна.
Не расстраивайтесь, если кто-то скажет, что ваш код не читаем! Вместо этого поблагодарите человека за обратную связь.
Помогите сделать код читабельным
Подскажите как можно сделать данный код более читабельным. А то код новичка будто)). Если есть другой сайт для подобных вещей. То дайте плиз ссылку.
Отслеживать
81.1k 9 9 золотых знаков 78 78 серебряных знаков 135 135 бронзовых знаков
задан 13 мая 2016 в 13:02
3,471 15 15 серебряных знаков 49 49 бронзовых знаков
3 ответа 3
Сортировка: Сброс на вариант по умолчанию
switch(position) < case 1: Toast.makeText(Home.this, "Акции временно не работают", Toast.LENGTH_LONG).show(); break; case 2: if (strTotalPrice<500) Toast.makeText(Home.this, "Минимальная сумма заказа 500 руб.", Toast.LENGTH_SHORT).show(); else viewPager.setCurrentItem(position,false); break; default: viewPager.setCurrentItem(position,false); break; >drawerLayout.closeDrawers(); Отслеживать
ответ дан 13 мая 2016 в 13:07
69.8k 9 9 золотых знаков 66 66 серебряных знаков 124 124 бронзовых знака
Спасибо Юрий. Я код чуток изменил. Можете измененный код через свитч еще раз?
13 мая 2016 в 13:12
@xTIGRx, так просто же копирнуть и всё. А вообще менять ТЗ после его исполнения — плохо. Вы ж, вроде, фрилансер, а таким занимаетесь(
13 мая 2016 в 13:14
Все спасибо)). Копирнуть это дело школьников, а я хочу разобраться в этом. Благодаря вашему коду и чуток погулив в инете. Я понял как работает default. Спасибо большое))
13 мая 2016 в 13:15
Для начала, чтобы повысить читабельность кода, советую обратиться к документу
В конвенции есть правила которых стоит придерживаться при написании Java библиотек, правила стиля оформления кода, правила языка Java и т.д. Этих правил стоит придерживаться, чтобы ваш код был лаконичен, понятен и, самое главное, «привычен» всем программистам. Во многих компаниях есть свои соглашения по написанию кода, но это уже другая история.
Есть множество переводов Java Code Conventions на русский, но лучше, по возможности, все-таки прочитать в оригинале. Тем более сделать это надо всего лишь один раз.
Конкретно в вашем примере, следующие нарушения конвенции:
-
операторы необходимо отделять пробелами
if (position != 1 && position != 2) viewPager.setCurrentItem(position, false); if (strTotalPrice < 500) < Toast.makeText(Home.this, "Минимальная сумма заказа 500 руб.", Toast.LENGTH_SHORT).show(); >else
Я не обращаю внимания на структуру кода (ввести взаимоисключающие if. else, либо перейти на switch. case), я сделал пост о нарушении конвенции Java для написания кода, надеюсь это будет полезно
Читабельность кода

Несмотря на то, что читабельность кода очень важна, понятие это определено плохо — и часто в виде просто набора правил: использовать осмысленные имена переменных, большие функции разбивать на меньшие, применять стандартные шаблоны проектирования.
При этом наверняка всем приходилось иметь дело с кодом, который соответствует этим правилам, но почему-то представляет собой какую-то кашу.
Можно попытаться решить эту проблему, добавив новые правила: если имена переменных становятся очень длинными, нужно выполнить рефакторинг основной логики; если в одном классе накопилось множество вспомогательных методов, возможно, следует разделить его на два; нельзя применять шаблоны проектирования в неподходящем контексте.
Такие инструкции превращаются в лабиринт субъективных решений, и чтобы ориентироваться в нем, понадобится разработчик, который сможет делать правильный выбор — то есть, он уже должен уметь писать читабельный код.
Таким образом, набор инструкций — не выход. Поэтому нам придется сформировать более широкое представление о читабельности кода.
Для чего нужна читабельность
На практике под хорошей читабельностью обычно понимают, что код приятно читать. Однако на таком определении далеко не уедешь: во-первых, оно субъективно, во-вторых — привязывает нас к чтению обычного текста.
Нечитабельный код воспринимается как роман, который притворяется кодом: множество раскрывающих суть происходящего комментариев, простыни текста, которые нужно читать последовательно, умные формулировки, единственный смысл которых — быть «умными», боязнь повторного использования слов. Разработчик пытается сделать код читабельным, но нацеливается не на тот тип читателей.
Читабельность текста и читабельность кода — не одно и то же.
С помощью кода создаются интерфейсы. Но и сам код — это интерфейс.
Если код выглядит красиво, значит ли это, что он читабельный? Эстетичность — приятный побочный эффект читабельности, но как критерий не очень полезна. Возможно, в крайних случаях эстетика кода в проекте поможет удержать сотрудников — но с тем же успехом можно предложить хороший соцпакет. Кроме того, у каждого свое представление о том, что значит «красивый код». И со временем такое определение читабельности превращается в водоворот споров о табуляции, пробелах, скобках, «верблюжьей нотации» и т. п. Вряд ли кто-то потеряет сознание, увидев неправильные отступы, хотя это и привлекает внимание во время проверки кода.
Если код выдает меньше ошибок, можно ли считать его более читабельным? Чем меньше ошибок, тем лучше, но какой здесь механизм? Как сюда отнести расплывчатые приятные ощущения, которые испытываешь при виде читабельного кода? К тому же, сколько ни хмурь брови при чтении кода, ошибок это не добавит.
Если код легко править — он читабельный? А вот это, пожалуй, верное направление мысли. Меняются требования, добавляются функции, возникают ошибки — и в какой-то момент кому-то приходится править ваш код. А чтобы при этом не породить новые проблемы, разработчику нужно понимать, что конкретно он редактирует и как правки изменят поведение кода. Итак, мы нашли новое эвристическое правило: читабельный код должен легко редактироваться.
Какой код редактировать проще?
Сразу же хочется выпалить: «Код легче редактировать, когда имена переменных даются осмысленно», — но так мы просто переименуем «читабельность» в «удобство редактирования». Нам нужно более глубокое понимание, а не тот же набор правил в другом обличье.
Давайте начнем с того, что ненадолго забудем, что речь идет о коде. Программирование, которому несколько десятков лет, — лишь точка на шкале человеческой истории. Ограничившись этой «точкой», мы не сможем копнуть глубоко.
Поэтому посмотрим на читабельность через призму проектирования интерфейсов, с которыми мы сталкиваемся практически на каждому шагу — причем не только с цифровыми. Игрушка обладает функциональностью, которая заставляет ее кататься или пищать. У двери есть интерфейс, который позволяет открывать, закрывать и запирать ее. Данные в книге собраны в страницы, что обеспечивает более быстрый произвольный доступ, чем прокрутка. Изучая дизайн, об этих интерфейсах можно узнать намного больше — поинтересуйтесь у команды дизайнеров, если есть такая возможность. В общем же случае мы все отдаем предпочтение хорошим интерфейсам, даже если не всегда знаем, что делает их хорошими.
С помощью кода создаются интерфейсы. Но и сам код, в сочетании с IDE, — это интерфейс. Интерфейс, предназначенный для очень небольшой группы пользователей — наших коллег. Далее будем называть их «пользователями» — чтобы оставаться в пространстве проектирования пользовательского интерфейса.
Имея это в виду, рассмотрим такие примеры путей пользователя:
- Пользователь хочет добавить новую функцию. Для этого требуется найти нужное место и добавить функцию, не порождая новых ошибок.
- Пользователь хочет исправить ошибку. Ему потребуется найти источник проблемы и отредактировать код так, чтобы ошибка исчезла и при этом не появились новые ошибки.
- Пользователь хочет убедиться, что в пограничных случаях код ведет себя определенным образом. Ему нужно будет отыскать определенный кусок кода, затем проследить логику и смоделировать, что произойдет.
Можно уверенно предположить, что пользователь не сможет сразу открыть нужный участок кода. Это касается и собственных хобби-проектов: даже если функция написана вами, очень легко забыть, где она находится. Поэтому код должен быть таким, чтобы в нем было легко найти нужное.
Чтобы реализовать удобный поиск, понадобится некоторая поисковая оптимизация — здесь-то нам и приходят на выручку осмысленные имена переменных. Если пользователь не может найти функцию, перемещаясь по стеку вызовов из известной точки, он может запустить поиск по ключевым словам. Однако нельзя включать в имена слишком много ключевых слов. При поиске по коду ищется единственная точка входа, откуда можно продолжить работу дальше. Поэтому пользователю нужно помочь попасть в конкретное место, а если перестараться с ключевыми словами, будет слишком много бесполезных результатов поиска.
Если пользователь имеет возможность сразу убедиться, что на конкретном уровне логики всё верно, он может забыть предыдущие слои абстракции и освободить ум для последующих.
Искать можно и с помощью автодополнения: если есть общее представление о том, какую функцию нужно вызвать или какое перечисление использовать, можно начать набирать предполагаемое имя, а затем выбрать подходящий вариант из списка автодополнения. Если функция предназначена только для определенных случаев или в ее реализацию нужно внимательно вчитываться из-за особенностей использования, на это можно указать, дав название подлиннее: прокручивая список автодополнения, пользователь будет скорее избегать того, что выглядит сложно — если, конечно, он не уверен, что делает.
Поэтому короткие обычные имена с большей вероятностью будут восприниматься как варианты по умолчанию, подходящие для «случайных» пользователей. В функциях с такими именами не должно быть сюрпризов: нельзя вставлять сеттеры в функции, которые выглядят, как простые геттеры, — по той же причине, по которой кнопка «Просмотр» в интерфейсе не должна изменять пользовательские данные.

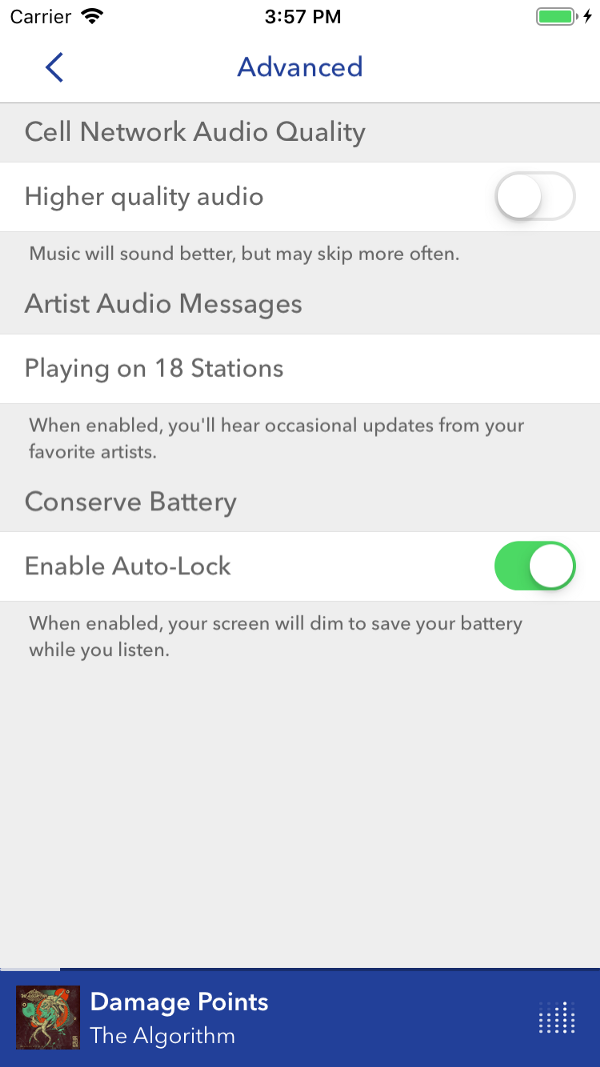
В обращенном к клиенту интерфейсе привычные функции, такие как пауза, обходятся практически без текста. По мере усложнения функциональности названия удлиняются, что заставляет пользователей притормозить и задуматься. Снимок экрана — Pandora
Пользователи хотят находить нужную информацию быстро. В большинстве случаев на компиляцию требуется значительное время, причем в запущенном приложении придется вручную проверить множество различных пограничных случаев. При возможности наши пользователи предпочтут прочитать код и понять, как он себя ведет, а не расставлять точки останова и запускать код.
Чтобы обойтись без запуска кода, должны выполняться два условия:
- Пользователь понимает, что код пытается сделать.
- Пользователь уверен, что код делает то, что заявляет.
Последовательное чтение файла или метода выполняется за линейное время. Но если пользователь может переходить вверх и вниз по стекам вызовов — это уже поиск по дереву, а если иерархия хорошо сбалансирована, это действие выполняется за логарифмическое время. В интерфейсах, безусловно, есть место и спискам, однако следует тщательно продумывать, должно ли быть в каком-то контексте больше двух-трех вызовов методов.
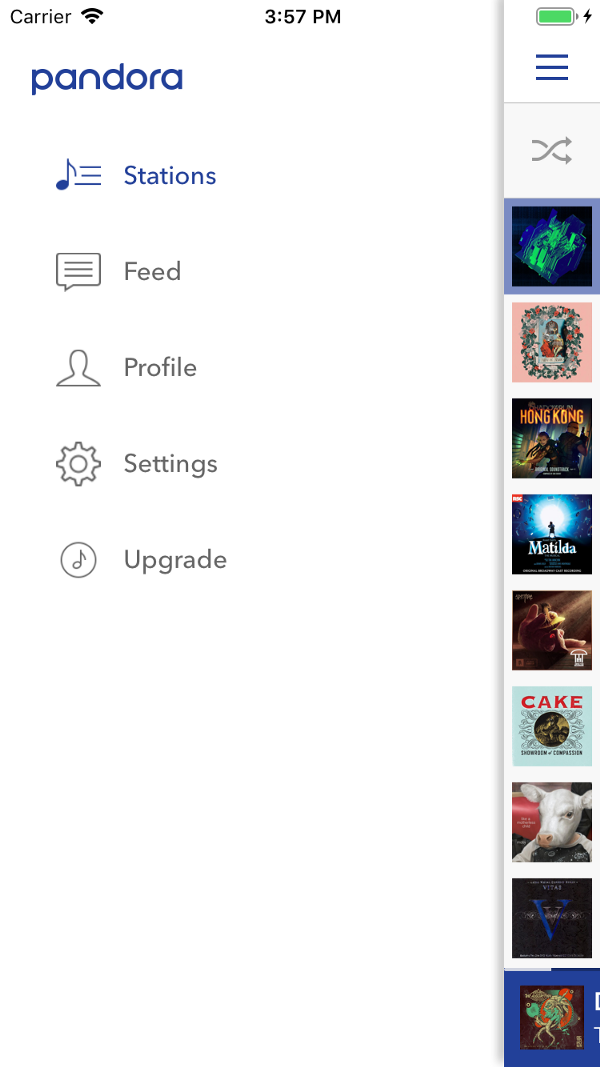

По коротким меню иерархическая навигация выполняется намного быстрее. В «длинном» меню справа — всего 11 строк. Как часто в коде методов мы укладываемся в это число? Снимок экрана — Pandora
Стратегии для второго условия у разных пользователей разные. В ситуациях с низким риском достаточным доказательством будут комментарии или имена методов. В более рискованных, сложных областях, а также когда код перегружен неактуальными комментариями, последние скорее всего будут игнорироваться. Иногда даже имена методов и переменных будут вызывать сомнение. В таких случаях пользователь должен прочитать намного больше кода и держать в голове более обширную модель логики. Здесь также поможет ограничение контекста небольшими областями, на которых легко удержать внимание. Если пользователь имеет возможность сразу убедиться, что на конкретном уровне логики всё верно, он может забыть предыдущие слои абстракции и освободить ум для последующих.
В таком режиме работы большее значение начинают иметь отдельные лексемы. Например, булевский флаг
element.visible = true/false
легко понять в отрыве от остального кода, однако для этого требуется объединить в уме две разных лексемы. Если же использовать
element.visibility = .visible/.hidden
то значение флага можно понять с ходу: в этом случае не нужно читать имя переменной, чтобы выяснить, что она имеет отношение к видимости.¹ Аналогичные подходы мы видели в проектировании ориентированных на клиента интерфейсов. За последние десятилетия кнопки подтверждения действий «ОК» и «Отмена» превратились в более описательные элементы интерфейса: «Сохранить» и «Отменить», «Отправить» и «Продолжить редактирование» и т. д., — чтобы понять, что будет выполнено, пользователю достаточно взглянуть на предложенные варианты, не считывая весь контекст полностью.
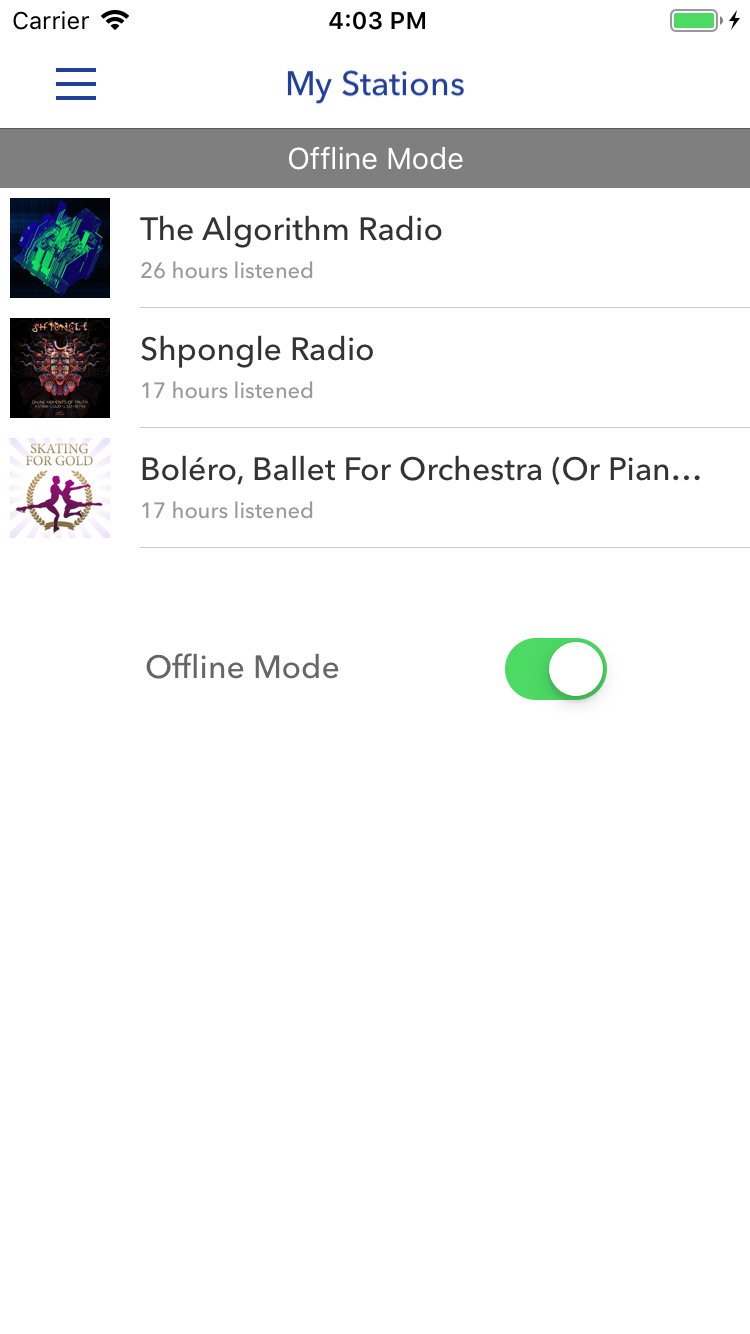
Строка «Offline Mode» в примере сверху указывает, что приложение работает в автономном режиме. Переключатель в примере ниже имеет тот же смысл, но чтобы понять его, нужно взглянуть на контекст. Снимок экрана — Pandora
Подтвердить ожидаемое поведение кода также помогают модульные тесты: они выступают как комментарии — которым, однако, можно доверять в большей степени, поскольку они лучше сохраняют актуальность. Правда, для них тоже нужно выполнять сборку. Но в случае хорошо налаженного CI-конвейера тесты запускаются регулярно, поэтому при внесении изменений в существующий код этот шаг можно пропустить.
В теории, безопасность следует из достаточного понимания: как только наш пользователь поймет поведение кода, он сможет безопасно вносить правки. На практике же приходится учитывать, что разработчики — обычные люди: наш мозг использует те же уловки и так же ленится. Поэтому чем меньше сил нужно потратить на понимание кода, тем безопаснее наши действия.
Читабельный код должен передавать бо́льшую часть проверок на ошибки компьютеру. Один из способов это осуществить — отладочные проверки «assert», однако и для них требуются сборка и запуск. Что еще хуже, если пользователь забыл о пограничных случаях, «assert» не поможет. Модульные тесты с проверкой часто забываемых пограничных случаев могут справляться лучше, но как только пользователь внес изменения, придется ждать прогона тестов.
Резюмируя: читабельный код должен быть удобен в использовании. И — как побочный эффект — он может выглядеть красиво.
Чтобы ускорить цикл разработки, мы используем функцию проверок на ошибки, встроенную в компилятор. Обычно для таких случаев полная сборка не требуется, а ошибки отображаются в реальном времени. Как использовать эту возможность в своих интересах? Вообще говоря, нужно найти ситуации, когда проверки компилятора становятся очень строгими. Например, большинство компиляторов не смотрят, насколько исчерпывающе описан оператор «if», но тщательно проверяют «switch» на пропущенные условия. Если пользователь пытается добавить или изменить условие, будет безопаснее, если все предыдущие аналогичные операторы были исчерпывающими. И в момент изменения условия «case» компилятор пометит все остальные условия, которые необходимо проверить.
Еще одна распространенная проблема читабельности — использование примитивов в условных выражениях. Особенно остро эта проблема проявляется, когда приложение анализирует JSON, ведь так и хочется понаставить операторов «if» вокруг строкового или целочисленного равенства. Это не только повышает вероятность опечаток, но и усложняет пользователям задачу определения возможных значений. При проверке пограничных случаев есть большая разница между тем, когда возможна любая строка, и когда — лишь два-три отдельных варианта. Даже если примитивы зафиксированы в константах, стоит один раз поспешить, стараясь закончить проект в срок, — и появится произвольное значение. Но если применять специально созданные объекты или перечисления, компилятор блокирует недопустимые аргументы и дает конкретный список допустимых.
Точно так же, если некоторые комбинации булевских флагов недопустимы, следует заменить их на одно перечисление. Возьмем, к примеру, композицию, которая может быть в следующих состояниях: буферизируется, загружена полностью и воспроизводится. Если представить состояния загрузки и воспроизведения как два булевских флага
(loaded, playing)
компилятор будет разрешать ввод недопустимых значений
(loaded: false, playing: true)
А если использовать перечисление
(.buffering/.loaded/.playing)
то недопустимое состояние указать будет невозможно. В ориентированном на клиента интерфейсе по умолчанию должен быть запрет недопустимых комбинаций настроек. Но когда мы пишем код внутри приложения, мы часто забываем обеспечить себе такую же защиту.
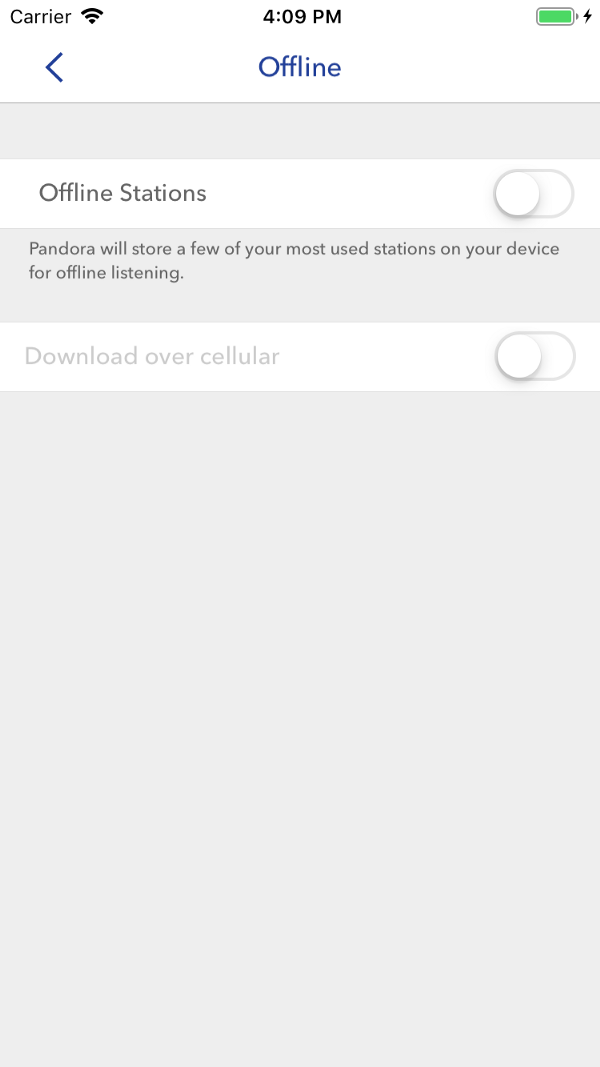
Недопустимые комбинации заранее отключены; пользователям не нужно задумываться, какие конфигурации несовместимы. Снимок экрана — Apple
Следуя по рассмотренным пользовательским путям, мы пришли к тем же правилам, что и в начале. Но теперь у нас есть принцип, по которому их можно формулировать самостоятельно и изменять в соответствии с ситуацией. Для этого мы спрашиваем себя:
- Будет ли пользователю легко искать нужный кусок кода? Не будут ли результаты поиска загромождены функциями, не связанными с запросом?
- Сможет ли пользователь, найдя нужный код, быстро проверить правильность его поведения?
- Обеспечивает ли среда разработки безопасное редактирование и повторное использования кода?
Примечание
- Может показаться, что булевские переменные удобнее использовать повторно, однако такая возможность повторного использования подразумевает взаимозаменяемость. Возьмем, к примеру, флаги tappable и cached, которые представляют понятия, расположенные в совершенно разных плоскостях: возможность нажатия на элемент и состояние кэширования. Но если оба флага — булевские, их можно случайно поменять местами, получив в одной строке кода нетривиальное выражение, которое будет означать, что кэширование связано с возможностью нажатия на элемент. При использовании перечислений мы, чтобы сформировать подобные отношения, будем вынуждены создавать явную, проверяемую логику преобразования использованных нами «единиц измерения».
О переводчике
Перевод статьи выполнен в Alconost.
Alconost занимается локализацией игр, приложений и сайтов на 70 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем рекламные и обучающие видеоролики — для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store.
- Блог компании Alconost
- Программирование
- Совершенный код
- Разработка мобильных приложений
- Разработка игр
Как сделать код читабельным

Когда-нибудь мы все писали (а некоторые и пишут) плохой код, и, надеюсь, мы все работаем над улучшением наших навыков, а не просто чтением статей вроде этой.
Зачем нам писать хороший код, а не просто производительный код?
Хотя производительность вашего продукта или сайта важна, также важно и то, как выглядит ваш код. Причиной этого является то, что не только машина читает ваш код.
Во-первых, рано или поздно вам придется перечитывать собственный код, и когда это время наступит, только хорошо написанный код поможет вам понять, что вы написали, или выяснить, как это исправить.
Во-вторых, если вы работаете в команде или сотрудничаете с другими разработчиками, то все члены команды будут читать ваш код и пытаться интерпретировать его так, как они понимают. Чтобы сделать это проще для них, важно соблюдать некие правила при названии переменных и функций, ограничивать длину каждой строки и сохранять структуру вашего кода.
Наконец, давайте рассмотрим конкретный пример.
Часть 1: Как определить плохой код?
Самый простой способ определить плохой код, на мой взгляд, — попытаться прочитать код так, как если бы это было предложение или фраза.
Например, взглянем на этот код:
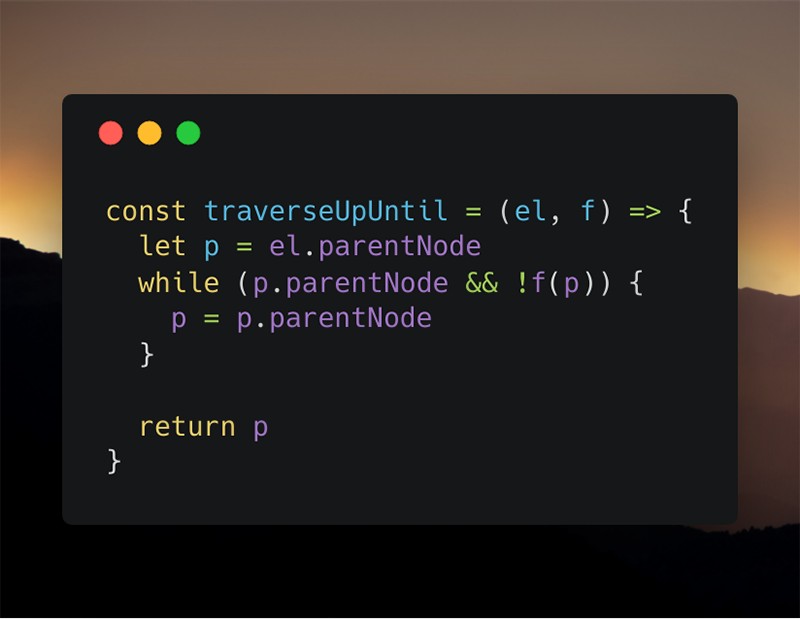
Скриншот плохой версии функции «traverseUpUntil»
Представленная выше функция принимает некий элемент и условную функцию и возвращает ближайший родительский узел, который удовлетворяет условной функции.
const traverseUpUntil = (el, f) => Исходя из того, что код должен читаться, как обычный текст, первая строка имеет три грубейших недостатка.
- Параметры функции не читаются, как слова.
- Допустим, el можно понять, поскольку такое имя обычно используется для обозначения элемента, но имя параметра f не объясняет ровным счётом ничего.
- Название функции можно прочитать так так: «переходить до тех пор, пока el не пройдет f», которое, вероятно, лучше читать как «переходить до тех пор, пока f не пройдет для el». Конечно, лучший способ сделать это — позволить функции вызываться как el.traverseUpUntil(f) , но это другая проблема.
let p = el.parentNodeЭто вторая строка. Снова проблема с именами, на этот раз с переменной. Если бы кто-то посмотрел на код, то, скорее всего, понял бы, что такое p . Это parentNode параметра el . Однако, что происходит, когда мы смотрим на p , используемое где-либо еще, у нас больше нет контекста, который объясняет, что это такое.
while (p.parentNode && !f(p)) В следующей строке основная проблема, с которой мы сталкиваемся — это непонимание того, что означает или делает !f(p) , потому что «f» может означать всё, что угодно. Предполагается, что человек, читающий код, должен понимать, что !f(p) — это проверка текущего узла на удовлетворение определённому условию. Если она проходит, то цикл прерывается.
p = p.parentNodeЗдесь всё понятно.
return pНе совсем очевидно, что возвращается из-за неправильного имени переменной.
Часть 2: Давайте отрефакторим
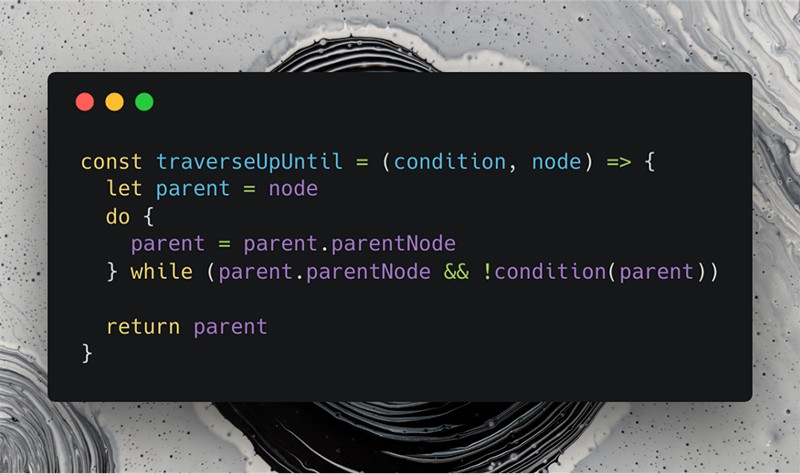
Скриншот хорошей версии функции «traverseUpUntil»
Сначала мы изменяем имена параметров и их порядок: (el, f) => в (condition, node) => .
Возможно, вам интересно, почему вместо «element (рус. элемент) я использовал «node» (рус. узел). Я использовал его по следующим причинам:
- Мы пишем код в терминах узлов, например .parentNode , поэтому почему бы не сделать его консистентным.
- «Node» короче, чем «element», и при этом смысл не теряется.
Затем мы переходим к именам переменных:
let parent = nodeОчень важно полностью раскрыть значение вашей переменной в её имени, поэтому «p» теперь «parent» (рус. родитель). Возможно, вы также заметили, что теперь мы не начинаем с получения родительского узла node.parentNode , вместо этого получаем только узел.
do < parent = parent.parentNode >while (parent.parentNode && !condition(parent))Вместо обычного цикла while я выбрал цикл do . while . Это означает, что нам нужно каждый раз перед проверкой условия получать родительский узел, а не наоборот. Использование цикла do . while также способствует тому, чтобы читать код, как обычный текст.
Давайте попробуем прочитать: «Присвоить родительский узел родителя родителю, пока у родителя есть родительский узел, а функция условия не возвращает true». Уже гораздо понятнее.
return parentЧасто разработчики предпочитают использовать какую-то общую переменную ret (или returnValue ), но это довольно плохая практика. Если вы правильно назовёте свои возвращаемые переменные, становится очевидным то, что возвращается. Однако иногда функции могут быть длинными и сложными, что приводит к большой путанице. В этом случае я бы предложил разделить вашу функцию на несколько функций, и если она всё ещё слишком сложна, то, возможно, добавление комментариев может помочь.
Часть 3: Упрощение кода
Теперь, когда вы сделали код читабельным, пришло время убрать ненужный код. Я уверен, что некоторые из вас уже заметили, что нам вообще не нужна переменная parent .
const traverseUpUntil = (condition, node) => < do < node = node.parentNode >while (node.parentNode && !condition(node)) return node >Я просто убрал первую строку и заменил «parent» на «node». Таким образом, я пропустил ненужный шаг создания «parent» и перешёл прямо в цикл.
Но что насчёт имени переменной?
Хотя «node» не лучшее описание для этой переменной, оно удовлетворительное. Но давайте не будем останавливаться на этом, давайте переименуем её. Как насчёт «currentNode»?
const traverseUpUntil = (condition, currentNode) => < do < currentNode = currentNode.parentNode >while (currentNode.parentNode && !condition(currentNode)) return currentNode >Так-то лучше! Теперь, когда мы читаем метод, мы знаем, что currentNode всегда представляет собой узел, в котором мы сейчас находимся, вместо того, чтобы быть «каким-то» узлом.
- читабельность
- совершенный код
- перевод с английского
- программирование
- разработка
- devcolibri
- никто не читает теги
- Программирование
- Совершенный код