Учебник. Обучение и развертывание модели классификации изображений с помощью примера Jupyter Notebook

ОБЛАСТЬ ПРИМЕНЕНИЯ:Пакет SDK для Python azureml версии 1
В этом руководстве необходимо обучить модель машинного обучения на удаленных вычислительных ресурсах. Вы будете использовать рабочий процесс обучения и развертывания для Машинного обучения Azure в Jupyter Notebook для Python. Затем можно использовать записную книжку как шаблон для обучения собственной модели машинного обучения со своими данными.
В руководстве показано, как обучить простую модель регрессии для функции логистики с помощью набора данных MNIST и Scikit-learn в Машинном обучении Azure. MNIST — это популярный набор данных, состоящий из 70 000 изображений в оттенках серого. Каждое изображение содержит рукописную цифру размером 28 x 28 пикселей, то есть числа от нуля до девяти. Целью является создание многоклассового классификатора для идентификации цифры, которую отображает данное изображение.
Узнайте, как выполнять следующие действия:
- Скачайте набор данных и просмотрите данные.
- Обучите модель классификации изображений и регистрируйте метрики с помощью MLflow.
- Разверните модель для вывода в режиме реального времени.
Предварительные требования
- Чтобы выполнить Краткое руководство. Начало работы со службой Машинного обучения Azure, необходимо:
- Создайте рабочую область.
- Создать облачный вычислительный экземпляр для использования в среде разработки.
Запуск записной книжки из рабочей области
Машинное обучение Azure включает в себя облачный сервер записной книжки в вашей рабочей области в качестве предварительно настроенного интерфейса, не требующего установки. Используйте собственную среду, если вы предпочитаете контролировать среду, пакеты и зависимости.
Клонирование папки записной книжки
Выполните следующие действия по настройке эксперимента и выполните шаги в Студии машинного обучения. Этот объединенный интерфейс включает в себя средства машинного обучения для выполнения сценариев обработки и анализа данных для специалистов по анализу с любым уровнем квалификации.

- Войдите в Студию машинного обучения Azure.
- Выберите свою подписку и рабочую область, которую создали.
- Выберите Записные книжки слева.
- В верхней части экрана перейдите на вкладку Примеры.
- Откройте папку SDK версии 1 .
- Нажмите кнопку . справа от папки Учебники, а затем выберите Клонировать.
- В списке папок отображается каждый пользователь, обращающийся к рабочей области. Выберите свою папку для клонирования папки Учебники.
Открытие клонированной записной книжки

- Откройте папку Учебники, которую вы клонировали в разделе Файлы пользователей.
- Выберите файл quickstart-azureml-in-10mins.ipynb в папке tutorials/compute-instance-quickstarts/quickstart-azureml-in-10mins.
Установка пакетов
После запуска вычислительного экземпляра и появления ядра добавьте новую ячейку кода для установки пакетов, необходимых для работы с этим руководством.
- Добавьте ячейку кода в верхней части записной книжки.
- В ячейку добавьте приведенную ниже команду, а затем выполните ячейку с помощью инструмента Выполнить или с помощью клавиш SHIFT+ВВОД.
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2Может появиться несколько предупреждений об установке. Эти сообщения можно спокойно проигнорировать.
Запустите записную книжку
Это руководство и дополняющий его файл utils.py также доступны на сайте GitHub, если вы хотите использовать их в собственной локальной среде. Если вы не используете вычислительный экземпляр, добавьте %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib в указанную выше установку.
Оставшаяся часть этой статьи содержит то же содержимое, что и записная книжка.
Перейдите в записную книжку Jupyter Notebook, если вы хотите выполнять код во время его просмотра. Чтобы выполнить одну ячейку кода в записной книжке, щелкните эту ячейку и нажмите клавиши SHIFT+ВВОД. Или запустите всю записную книжку, выбрав Запустить все в верхней части панели инструментов.
Импорт данных
Прежде чем начинать обучение модели, необходимо понимать, какие данные используются для ее обучения. Из этого раздела вы узнаете, как выполнять следующие действия.
- Скачивание набора данных MNIST
- Отображение некоторых примеров изображений
Вы будете использовать Открытые наборы данных Azure для получения необработанных файлов данных MNIST. Открытые наборы данных Azure — это проверенные общедоступные наборы данных, которые можно использовать для добавления функций конкретных сценариев в решения машинного обучения для создания более эффективных моделей. Каждый набор данных использует соответствующий класс (в данном случае — MNIST ) для получения данных различными способами.
import os from azureml.opendatasets import MNIST data_folder = os.path.join(os.getcwd(), "/tmp/qs_data") os.makedirs(data_folder, exist_ok=True) mnist_file_dataset = MNIST.get_file_dataset() mnist_file_dataset.download(data_folder, overwrite=True)Рассмотрим данные
Загрузите сжатые файлы в массивы numpy . Затем с помощью matplotlib постройте график 30 случайных изображений из набора данных с подписями над ними.
Учтите, что на этом шаге требуется функция load_data , которая содержится в файле utils.py . Этот файл находится в той же папке, что и эта записная книжка. Функция load_data выполняет анализ сжатых файлов, преобразовывая их в массивы numpy.
from utils import load_data import matplotlib.pyplot as plt import numpy as np import glob # note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster. X_train = ( load_data( glob.glob( os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True )[0], False, ) / 255.0 ) X_test = ( load_data( glob.glob( os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True )[0], False, ) / 255.0 ) y_train = load_data( glob.glob( os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True )[0], True, ).reshape(-1) y_test = load_data( glob.glob( os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True )[0], True, ).reshape(-1) # now let's show some randomly chosen images from the traininng set. count = 0 sample_size = 30 plt.figure(figsize=(16, 6)) for i in np.random.permutation(X_train.shape[0])[:sample_size]: count = count + 1 plt.subplot(1, sample_size, count) plt.axhline("") plt.axvline("") plt.text(x=10, y=-10, s=y_train[i], fontsize=18) plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys) plt.show()Приведенный выше код отображает произвольный набор изображений с их метками, как показано ниже:

Обучайте модель и регистрируйте метрики с помощью MLflow
Модель будет обучена с помощью приведенного ниже кода. Обратите внимание, что для отслеживания метрик и регистрации артефактов модели используется автоматическое ведение журнала MLflow
Для классификации данных вы будете использовать классификатор LogisticRegression из платформы SciKit Learn.
Для обучения модели требуется около 2 минут.**
# create the model import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from azureml.core import Workspace # connect to your workspace ws = Workspace.from_config() # create experiment and start logging to a new run in the experiment experiment_name = "azure-ml-in10-mins-tutorial" # set up MLflow to track the metrics mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri()) mlflow.set_experiment(experiment_name) mlflow.autolog() # set up the Logistic regression model reg = 0.5 clf = LogisticRegression( C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42 ) # train the model with mlflow.start_run() as run: clf.fit(X_train, y_train)Просмотр эксперимента
В меню слева в Студии машинного обучения Azure выберите Задания, а затем выберите свое задание (azure-ml-in10-mins-tutorial). Задание представляет собой совокупность нескольких запусков указанного скрипта или фрагмента кода. Несколько заданий можно сгруппировать в один эксперимент.
Сведения о запуске хранятся в соответствующем задании. Если при отправке задания имя не существует, то при выборе запуска увидите различные вкладки, содержащие метрики, журналы, объяснения и т. д.
Управляйте версиями моделей с помощью реестра моделей
Используя регистрацию модели, вы можете сохранять и изменять модели в рабочей области. Зарегистрированные модели идентифицируются по имени и версии. При регистрации модели с уже существующим именем реестр увеличивает номер версии. Приведенный ниже код регистрирует и версионирует модель, которая была обучена ранее. После выполнения приведенной ниже ячейки кода вы сможете увидеть модель в реестре, выбрав Модели в меню слева в Студии машинного обучения Azure.
# register the model model_uri = "runs:/<>/model".format(run.info.run_id) model = mlflow.register_model(model_uri, "sklearn_mnist_model")Развертывание модели для вывода в режиме реального времени
В этом разделе вы узнаете, как развернуть модель, чтобы приложение могло использовать (выводить) модель через REST.
Создание конфигурации развертывания
Ячейка кода получает курируемую среду, в которой указаны все зависимости, необходимые для размещения модели (например, такие пакеты, как scikit-learn). Кроме того, вы создаете конфигурацию развертывания, в которой указывается объем вычислительных ресурсов, необходимых для размещения модели. В этом случае вычислительная среда будет иметь 1 ЦП и 1 ГБ памяти.
# create environment for the deploy from azureml.core.environment import Environment from azureml.core.conda_dependencies import CondaDependencies from azureml.core.webservice import AciWebservice # get a curated environment env = Environment.get( workspace=ws, name="AzureML-sklearn-0.24.1-ubuntu18.04-py37-cpu-inference", version=1 ) env.inferencing_stack_version='latest' # create deployment config i.e. compute resources aciconfig = AciWebservice.deploy_configuration( cpu_cores=1, memory_gb=1, tags=, description="Predict MNIST with sklearn", )Развертывание модели
Следующая ячейка кода развертывает модель в экземпляре контейнера Azure.
Развертывание занимает около 3 минут.**
%%time import uuid from azureml.core.model import InferenceConfig from azureml.core.environment import Environment from azureml.core.model import Model # get the registered model model = Model(ws, "sklearn_mnist_model") # create an inference config i.e. the scoring script and environment inference_config = InferenceConfig(entry_script="score.py", environment=env) # deploy the service service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4] service = Model.deploy( workspace=ws, name=service_name, models=[model], inference_config=inference_config, deployment_config=aciconfig, ) service.wait_for_deployment(show_output=True)Файл скрипта оценки, указанный в приведенном выше коде, можно найти в той же папке, что и эта записная книжка, и он имеет две функции.
- Функция init , которая выполняется один раз при запуске службы. В этой функции вы обычно получаете модель из реестра и устанавливаете глобальные переменные
- Функция run(data) , которая выполняется каждый раз при вызове службы. В этой функции обычно выполняется форматирование входных данных, выполнение прогноза и вывод прогнозируемого результата.
Просмотр конечной точки
После успешного развертывания модели вы можете просмотреть конечную точку, выбрав раздел Конечные точки в меню слева в Студии машинного обучения Azure. Вы увидите состояние конечной точки (работоспособное или неработоспособное), журналы и использование (как приложения могут использовать модель).
Тестирование службы модели
Вы можете протестировать модель, отправив необработанный HTTP-запрос для тестирования веб-службы.
# send raw HTTP request to test the web service. import requests # send a random row from the test set to score random_index = np.random.randint(0, len(X_test) - 1) input_data = '" headers = resp = requests.post(service.scoring_uri, input_data, headers=headers) print("POST to url", service.scoring_uri) print("label:", y_test[random_index]) print("prediction:", resp.text)Очистка ресурсов
Если вы не собираетесь продолжать использовать эту модель, удалите службу модели, используя:
# if you want to keep workspace and only delete endpoint (it will incur cost while running) service.delete()Если вы хотите дополнительно контролировать затраты, остановите вычислительный экземпляр, нажав кнопку «Остановить вычисления» рядом с раскрывающимся списком Вычисления. Затем запустите вычислительный экземпляр снова в следующий раз, когда он понадобится.
Удаление всех ресурсов
Выполните следующие действия, чтобы удалить рабочую область Машинного обучения Azure и все вычислительные ресурсы.
Созданные вами ресурсы могут использоваться в качестве необходимых компонентов при работе с другими руководствами по Машинному обучению Azure.
Если вы не планируете использовать созданные вами ресурсы, удалите их, чтобы с вас не взималась плата:

- На портале Azure выберите Группы ресурсов в левой части окна.
- Выберите созданную группу ресурсов из списка.
- Выберите Удалить группу ресурсов.
- Введите имя группы ресурсов. Теперь щелкните Удалить.
Дальнейшие действия
- Сведения обо всех вариантах развертывания Машинного обучения Azure.
- Узнайте, как выполнить проверку подлинности в развернутой модели.
- Асинхронное создание прогнозов на больших объемах данных.
- Мониторинг моделей машинного обучения в Azure с помощью Application Insights.
Запуск записных книжек Jupyter Notebook в рабочей области
В этой статье показано, как запускать записные книжки Jupyter в рабочей области Студия машинного обучения Azure. Существуют и другие способы запуска записной книжки: Jupyter, JupyterLab и Visual Studio Code. Vs Code Desktop можно настроить для доступа к вычислительному экземпляру. Или используйте VS Code для Интернета непосредственно из браузера и без каких-либо необходимых установок или зависимостей.
Мы рекомендуем попробовать VS Code для Интернета, чтобы воспользоваться преимуществами простой интеграции и расширенной среды разработки, которая предоставляется. VS Code для Интернета предоставляет множество функций VS Code Desktop, включая поиск и синтаксис при просмотре и редактировании. Дополнительные сведения об использовании VS Code Desktop и VS Code для Интернета см. в статье «Запуск Visual Studio Code» с Машинное обучение Azure (предварительная версия) и удаленное подключение к вычислительному экземпляру (предварительная версия) в VS Code.
Независимо от того, какое решение вы используете для запуска записной книжки, у вас будет доступ ко всем файлам из рабочей области. Сведения о создании файлов и управлении ими, включая записные книжки, см. в разделе Создание файлов и управление ими в рабочей области.
В этой статье показано, как запустить записную книжку непосредственно в студии.
Компоненты, которые помечены как «предварительная версия», предоставляются без соглашения об уровне обслуживания и не рекомендуются для использования в рабочей среде. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Необходимые компоненты
- Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись, прежде чем начинать работу.
- Рабочая область машинного обучения. См.раздел Создание ресурсов рабочей области.
- Удостоверение пользователя должно иметь доступ к учетной записи хранения по умолчанию вашей рабочей области. Возможность чтения, изменения и создания записных книжек зависит от уровня доступа к рабочей области. Например, участник может редактировать записную книжку, в то время как читатель может только просматривать ее.
Доступ к записным книжкам из рабочей области
Используйте раздел Записные книжки рабочей области для редактирования и запуска записных книжек Jupyter.
- Войдите в Студию машинного обучения Azure.
- Выберите рабочую область, если она еще не открыта
- Выберите Записные книжки слева.
Изменение записной книжки
Чтобы изменить записную книжку, откройте любую записную книжку, расположенную в разделе User Files (Файлы пользователя) рабочей области. Выберите ячейку, которую вы хотите изменить. Если у вас нет записных книжек в этом разделе, см. статью Создание файлов и управление ими в рабочей области.
Вы можете изменить записную книжку без подключения к вычислительному экземпляру. Если нужно выполнить ячейки в записной книжке, выберите или создайте вычислительный экземпляр. Если выбрать остановленный вычислительный экземпляр, он автоматически запустится при запуске первой ячейки.
Если выполняется вычислительная операция, можно также использовать функцию завершения кода на платформе IntelliSense в любой записной книжке Python.
Вы также можете запустить Jupyter или JupyterLab на панели инструментов записной книжки. Машинное обучение Azure не предоставляет обновления и не исправляет ошибки из Jupyter или JupyterLab, так как они находятся вне границы служба поддержки Майкрософт.
Режим фокусировки
Используйте режим фокусировки, чтобы развернуть текущее представление и сосредоточиться на активных вкладках. Режим фокусировки скрывает обозреватель файлов записных книжек.
- На панели инструментов окна терминала выберите режим фокусировки, чтобы включить режим фокусировки. В зависимости от ширины окна средство может находиться в меню . на панели инструментов.
- В режиме фокусировки вернитесь к стандартному представлению, выбрав Стандартное представление.
Завершение кода (IntelliSense)
IntelliSense — это вспомогательное средство для написания кода, включающее множество возможностей: «Список членов», «Сведения о параметрах», «Краткие сведения» и «Завершить слово». За несколько нажатий клавиш вы можете:
- узнать больше о коде, который вы используете;
- следить за параметрами, которые вы вводите;
- добавлять вызовы в свойства и методы.
Совместное использование записной книжки
Ваши записные книжки хранятся в учетной записи хранения рабочей области и могут использоваться совместно с другими пользователями в зависимости от уровня доступа к рабочей области. Они могут открывать и редактировать записную книжку, если у них есть соответствующий доступ. Например, участник может редактировать записную книжку, в то время как читатель может только просматривать ее.
Другие пользователи рабочей области могут найти записную книжку в разделе «Записные книжки«, «Файлы пользователей» Студия машинного обучения Azure. По умолчанию записные книжки находятся в папке с вашим именем пользователя, и другие пользователи могут получить к ним доступ.
Вы также можете скопировать URL-адрес из браузера при открытии записной книжки, а затем отправить его другим пользователям. Если у них есть соответствующий доступ к рабочей области, они могут открыть записную книжку.
Так как вы не делитесь вычислительными экземплярами, другие пользователи, запускающие записную книжку, будут использовать собственный вычислительный экземпляр.
Совместная работа с комментариями записной книжки (предварительная версия)
Используйте комментарий записной книжки для совместной работы с другими пользователями, имеющими доступ к этой записной книжке.
Переключить отображение области комментариев можно с помощью инструмента Notebook comments (Комментарии записной книжки) в верхней части записной книжки. Если экран недостаточно слишком широкий, откройте этот инструмент, выбрав … в конце набора инструментов.
Вне зависимости от того, отображается ли область комментариев, можно добавить комментарий в любую ячейку кода.
- Выделите фрагмент текста в ячейке кода. В ячейке кода можно комментировать только текст.
- Чтобы создать комментарий, используйте инструмент New comment thread (Создать цепочку комментариев).
- Если область комментариев была ранее скрыта, она откроется.
- Введите комментарий и опубликуйте его с помощью инструмента или нажав клавиши CTRL+ВВОД.
- После публикации комментария выберите . в правом верхнем углу:
- изменить комментарий;
- разрешить цепочку;
- удалить цепочку.
Текст, для которого был добавлен комментарий, будет отображаться в коде фиолетовым цветом. При выборе комментария в области комментариев записная книжка прокрутится до ячейки, содержащей выделенный текст.
Комментарии сохраняются в метаданных ячейки кода.
Очистка записной книжки (предварительная версия)
В ходе создания записной книжки обычно образуются ячейки, используемые для просмотра или отладки данных. Функция сбора поможет вам создать чистую записную книжку без этих лишних ячеек.
- Выполните все ячейки записной книжки.
- Выберите ячейку, содержащую код, который должна запускать новая записная книжка. Например, код, который отправляет эксперимент, или код, регистрирующий модель.
- Нажмите значок Сбор, отображаемый на панели инструментов ячейки.
- Введите имя новой, «собранной» записной книжки.
Новая записная книжка содержит только ячейки кода, при этом все ячейки должны получать те же результаты, что и выбранная ячейка для сбора.
Сохранение записной книжки и создание контрольных точек
Машинное обучение Azure создает файл контрольных точек при создании IPYNB-файла.
На панели инструментов записной книжки выберите меню, а затем Файл>Сохранить и создать контрольные точки, чтобы вручную сохранить записную книжку и добавить файл контрольных точек, связанный с записной книжкой.
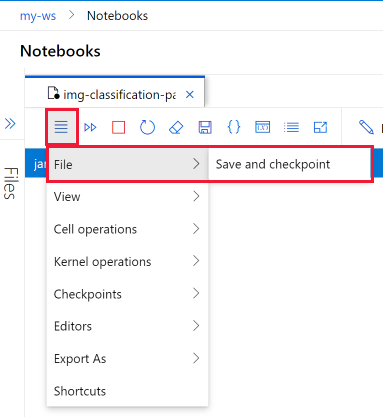
Записные книжки автоматически сохраняются каждые 30 секунд. Функция автосохранения обновляет только исходный IPYNB-файл, а не файл проверки.
Выберите Контрольные точки в меню записной книжки, чтобы создать именованную контрольную точку и вернуть записную книжку к сохраненной контрольной точке.
Экспорт записной книжки
На панели инструментов записной книжки выберите меню и нажмите Экспортировать как, чтобы экспортировать записную книжку как любой из поддерживаемых типов:
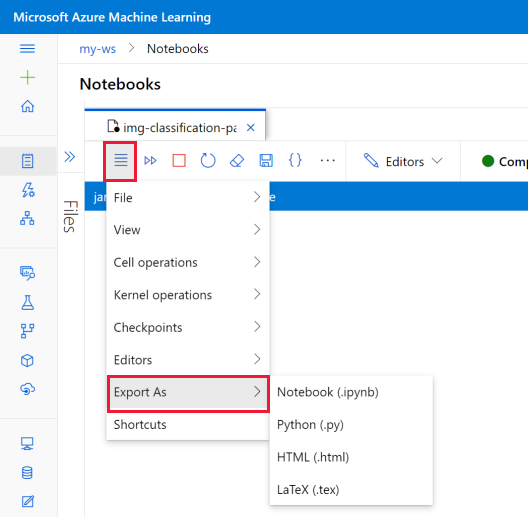
Экспортированный файл сохраняется на компьютере.
Запуск записной книжки или скрипта Python
Чтобы запустить записную книжку или скрипт Python, сначала подключитесь к выполняющемуся вычислительному экземпляру.
- Если у вас нет вычислительной операции, выполните следующие действия, чтобы создать ее:
- На панели инструментов записной книжки или скрипта справа от раскрывающегося списка «Вычислительная среда» нажмите + Создать вычислительную среду. В зависимости от размера экрана этот параметр может находиться в меню . .

- Присвойте имя вычислительной операции и выберите значение Virtual Machine Size (Размер виртуальной машины).
- Выберите Создать.
- Вычислительный экземпляр подключается к файлу автоматически. Теперь можно запускать ячейки записной книжки или скрипт Python, используя инструмент слева от вычислительного экземпляра.
- На панели инструментов записной книжки или скрипта справа от раскрывающегося списка «Вычислительная среда» нажмите + Создать вычислительную среду. В зависимости от размера экрана этот параметр может находиться в меню . .
- Если ваш вычислительный экземпляр остановлен, выберите Запустить вычислительную среду справа от раскрывающегося списка «Вычислительная среда». В зависимости от размера экрана этот параметр может находиться в меню . .

После подключения к вычислительному экземпляру используйте панель инструментов для запуска всех ячеек в записной книжке или control + ВВОД, чтобы запустить одну выбранную ячейку.
Только вы можете просматривать и использовать созданные вами вычислительные операции. Ваша папка User files (Файлы пользователя) хранится отдельно от виртуальной машины и является общей для всех вычислительных операций в рабочей области.
Изучение переменных в записной книжке
На панели инструментов записной книжки используйте Обозреватель переменных, чтобы отобразить имя, тип, длину и примеры значений для всех переменных, созданных в записной книжке.
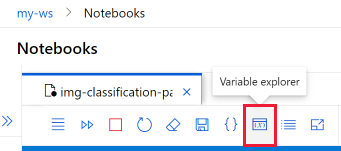
Выберите инструмент, чтобы открыть окно обозревателя переменных.

Навигация с помощью оглавления
На панели инструментов записной книжки используйте инструмент Оглавление, чтобы отобразить или скрыть оглавление. Запустите ячейку Markdown с заголовком, чтобы добавить ее в оглавление. Выберите запись в таблице, чтобы прокрутить эту ячейку в записной книжке.
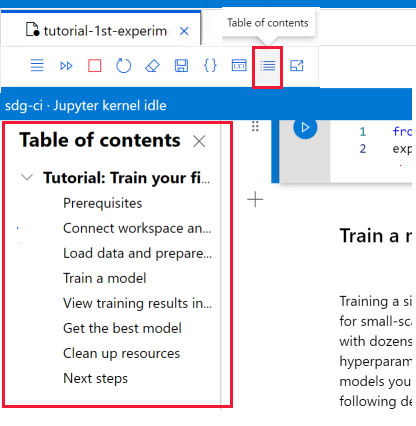
Изменение среды записной книжки
С помощью панели инструментов записной книжки можно изменить среду, в которой выполняется записная книжка.
Эти действия не изменят состояние записной книжки или значения каких-либо переменных в записной книжке:
Действие Результат Остановка ядра Все выполняемые ячейки останавливаются. При выполнении ячейки ядро автоматически перезапускается. Переход в другой раздел рабочей области Выполняемые ячейки останавливаются. Эти действия сбрасывают состояние записной книжки и все переменные в записной книжке.
Действие Результат Изменение ядра Записная книжка использует новое ядро. Переключение вычисления Записная книжка автоматически использует новое вычисление. Сброс вычисления Повторный запуск при попытке выполнить ячейку. Остановка вычисления Ячейки не выполняются. Открытие записной книжки в Jupyter или JupyterLab Записная книжка открывается на новой вкладке. Добавление новых ядер
Используйте терминал для создания и добавления новых ядер в вычислительный экземпляр. Записная книжка автоматически находит все ядра Jupyter, установленные на подключенном вычислительном экземпляре.
Используйте раскрывающееся меню ядра справа, чтобы перейти на любое из установленных ядер.
Управление пакетами
Так как вычислительный экземпляр имеет несколько ядер, убедитесь, что используются %pip или %conda волшебные функции, которые устанавливают пакеты в текущее работающее ядро. Не используйте !pip или !conda не относится ко всем пакетам (включая пакеты за пределами запущенного ядра).
Индикаторы состояния
Индикатор рядом с раскрывающимся списком Compute (Вычисление) отображает его состояние. Состояние также отображается в самом раскрывающемся списке.
Color Состояние вычисления Зеленый Вычисление выполняется Красный Сбой при вычислении Черный Вычисление остановлено Голубой Создание, запуск, перезапуск, настройка вычисления Серый Идет процесс удаления или остановки вычисления Индикатор рядом с раскрывающимся списком Kernel (Ядро) отображает его состояние.
Color Состояние ядра Зеленый Ядро подключено, неактивно или занято Серый Ядро не подключено Сведения о вычислениях
Сведения о вычислительных операциях см. на странице Compute (Вычисления) в Студии.
Полезные сочетания клавиш
Аналогично Jupyter Notebook, Студия машинного обучения Azure записные книжки имеют модальный пользовательский интерфейс. Клавиатура выполняет разные действия в зависимости от того, в каком режиме находится ячейка записной книжки. Студия машинного обучения Azure записные книжки поддерживают следующие два режима для заданной ячейки кода: режим команд и режим редактирования.
Сочетания клавиш для режима команд
Ячейка находится в командном режиме, если текстовый курсор не запрашивает ввод. Когда ячейка находится в режиме команд, вы можете редактировать записную книжку целиком, но не вводить ее в отдельные ячейки. Войдите в режим команд, нажав ESC или щелкнув за пределами области редактора ячейки с помощью мыши. Левая граница активной ячейки — синяя и сплошная, а кнопка Запуск — синяя.

Ярлык Description ВВОД Ввод режима редактирования SHIFT + ВВОД Запуск ячейки, выбор следующей CTRL/CMD+ВВОД Запустить ячейки ALT + ВВОД Запуск ячейки, вставка ячейки кода ниже CTRL/CMD + ALT + ВВОД Запуск ячейки, вставка ячейки Markdown ниже ALT + R Запустить все Y Преобразование ячейки в код M Преобразование ячейки в Markdown ВВЕРХ/K Выбор ячейки выше ВНИЗ/J Выбор ячейки ниже А Вставка ячейки кода выше Б Вставка ячейки кода ниже CTRL/CMD + SHIFT + A Вставка ячейки Markdown выше CTRL/CMD + SHIFT + B Вставка ячейки Markdown ниже X Вырезание выбранной ячейки C Копирование выбранной ячейки SHIFT + V Вставка выбранной ячейки выше V Вставка выбранной ячейки ниже D D Удаление выбранной ячейки O Переключить выходные данные SHIFT + O Переключение прокручивания выходных данных I I Прерывание ядра 0 0 Перезапуск ядра SHIFT + ПРОБЕЛ Прокрутка вверх Space Прокрутка вниз TAB Переход фокуса на следующий фокусируемый элемент (при отключенной ловушке фокуса) CTRL/CMD + S Сохранение записной книжки 1 Изменение на h1 2 Изменение на h2 3 Изменение на h3 4 Изменение на h4 5 Изменение на h5 6 Изменение на h6 Сочетания клавиш режима правки
Режим правки обозначается текстовым курсором для ввода текста в области редактора. Когда ячейка находится в режиме правки, можно ввести текст в ячейку. Введите режим редактирования, нажав Enter или выберите область редактора ячейки. Левая граница активной ячейки — зеленая и пунктирная, а кнопка Запуск — зеленая. Вы также видите курсор в ячейке в режиме редактирования.

С помощью приведенных ниже сочетаний клавиш вы можете легче перемещаться и выполнять код в записных книжках Машинного обучения Azure в режиме правки.
Ярлык Description ESCAPE Вход в режим команд CTRL/CMD + ПРОБЕЛ Активация IntelliSense SHIFT + ВВОД Запуск ячейки, выбор следующей CTRL/CMD+ВВОД Запустить ячейки ALT + ВВОД Запуск ячейки, вставка ячейки кода ниже CTRL/CMD + ALT + ВВОД Запуск ячейки, вставка ячейки Markdown ниже ALT + R Выполнение всех ячеек Up Перемещение курсора вверх или в предыдущую ячейку Down Перемещение курсора вниз или в следующую ячейку CTRL/CMD + S Сохранение записной книжки CTRL/CMD + стрелка вверх Переход к началу ячейки CTRL/CMD + стрелка вниз Передох к концу ячейки TAB Завершение кода или отступ (если включена ловушка фокуса) CTRL/CMD + M Включение или отключение ловушки фокуса CTRL/CMD + ] Отступ CTRL/CMD + [ Понижение уровня CTRL/CMD + A Выделить все CTRL/CMD + Z Отмена CTRL/CMD + SHIFT + Z Вернуть CTRL/CMD + Y Вернуть CTRL/CMD + HOME Переход к началу ячейки CTRL/CMD + END Передох к концу ячейки CTRL/CMD + стрелка влево Переход на одно слово влево CTRL/CMD + стрелка вправо Переход на одно слово вправо Control/Command + BACKSPACE Удаление слова перед CTRL/CMD + DELETE Удаление слова после CTRL/CMD + / Переключение комментария в ячейке Устранение неполадок
- Подключение к записной книжке. Если вы не можете подключиться к записной книжке, убедитесь, что связь с веб-сокетом не отключена. Для использования функциональности Jupyter экземпляра вычислительных ресурсов необходимо включить связь через веб-сокет. Убедитесь, что сеть разрешает подключения через веб-сокеты к *.instances.azureml.net и *.instances.azureml.ms.
- Частная конечная точка. При развертывании вычислительного экземпляра в рабочей области с частной конечной точкой доступ к нему можно получить только из виртуальной сети. Если вы используете пользовательский ФАЙЛ DNS или узлов, добавьте запись для < имени >экземпляра .< регион >.instances.azureml.ms с частным IP-адресом частной конечной точки рабочей области. Дополнительные сведения см. в статье о пользовательской DNS.
- Сбой ядра: если ядро разбилось и было перезапущено, можно выполнить следующую команду, чтобы просмотреть журнал Jupyter и узнать дополнительные сведения: sudo journalctl -u jupyter Если проблемы с ядром не исчезли, рекомендуется использовать вычислительный экземпляр с большим объемом памяти.
- Ядро не найдено или Операции ядра отключены. Такая ошибка может возникнуть при использовании ядра Python 3.8 по умолчанию в вычислительном экземпляре. Для ее исправления можно использовать один из следующих методов.
- Создание нового вычислительного экземпляра. Будет использован новый образ, в котором эта проблема была устранена.
- Используйте ядро Py 3.6 в существующем вычислительном экземпляре.
- В терминале в среде py38 по умолчанию запустите pip install ipykernel==6.6.0 ИЛИ pip install ipykernel==6.0.3
Следующие шаги
- Выполнение первого эксперимента
- Резервное копирование хранилища файлов с помощью моментальных снимков
- Работа в безопасных средах
Запускаем Jupyter на орбиту LXD
Приходилось ли вам экспериментировать с кодом или системными утилитами в Linux так, чтобы не трястись за базовую систему и не снести всё с потрохами в случае ошибки кода который должен запустится с root-привилегиями?
А как на счет того, что допустим, необходимо протестировать или запустить целый кластер разнообразных микросервисов на одной машине? Сотню или даже тысячу?
С виртуальными машинами управляемые гипервизором такие задачи решить может и получится, но какой ценой? Например, контейнер в LXD на базе дистрибутива Alpine Linux минимально потребляет всего 7.60MB ОЗУ, и где корневой раздел после запуска занимает 9.5MB ! Как тебе такое, Илон Маск? Рекомендую ознакомиться с базовыми возможностями LXD — системы контейнеров в Linux
После того, как в целом стало ясно, что такое контейнеры LXD, пойдем дальше и подумаем, а что, если бы была такая платформа-комбайн, где можно было бы безопасно запускать код для хоста, генерировать графики, динамически (интерактивно) связывать UI-виджеты с твоим кодом, дополнять код текстом с блекджеком. форматированием? Что-то типа интерактивного блога? Вауу… Хочу! Хочу! 🙂
Заглядывай под кат где мы запустим в контейнере JupyterLab — следующей генерации пользовательского интерфейса вместо устаревшего Jupyter Notebook, а также установим такие модули Python как NumPy, Pandas, Matplotlib, IPyWidgets которые позволят вытворять всё перечисленное выше и сохранять это всё в специальном файле — IPython-ноутбуке.
Навигация
- План взлёта на орбиту
- Установка и настройка базовой системы
- Установка базового софта и настройка системы
- Установка и настройка JupyterLab
- Разделяем данные с хостом
- Hello, World!
- Расширяем возможности Python
- Тестируем модули в JupyterLab
- Что ещё?
План взлёта на орбиту ^

Накидаем краткий план действий, чтобы нам было проще реализовать схему выше:
- Установим и запустим контейнер на базе дистрибутива Alpine Linux. Мы будем использовать этот дистрибутив так как он направлен на минималистичность и установим в него только самый необходимый софт, ничего лишнего.
- Добавим дополнительный виртуальный диск в контейнере которому зададим имя — hostfs и смонтируем к корневой ФС. Этот диск даст возможность использовать файлы на хосте из заданного каталога внутри контейнера. Тем самым данные будут у нас независимы от контейнера. В случае удаления контейнера, данные останутся на хосте. Также, эта схема полезна для разделения одних данных между многими контейнерами не используя штатные сетевые механизмы дистрибутива контейнера.
- Установим Bash, sudo, необходимые библиотеки, добавим и настроим системного пользователя
- Установим Python, модули и скомпилируем для них бинарные зависимости
- Установим и запустим JupyterLab, настроим внешний вид, установим расширения для него.
В этой статье мы с вами начнём с запуска контейнера, не будем рассматривать установку и настройку LXD, всё это вы можете найти в другой статье — Базовые возможности LXD — системы контейнеров в Linux.
Установка и настройка базовой системы ^
Создаём контейнер командой в которой указываем образ — alpine3 , идентификатор для контейнера — jupyterlab и при необходимости профили конфигурации:
lxc init alpine3 jupyterlab --profile=default --profile=hddrootЗдесь я использую профиль конфигурации hddroot который указывает создать контейнер с root-разделом в Storage Pool расположенным на физическом HDD диске:
lxc profile show hddroot config: <> description: "" devices: root: path: / pool: hddpool type: disk name: hddroot used_by: []lxc storage show hddpool config: size: 10GB source: /dev/loop1 volatile.initial_source: /dev/loop1 description: "" name: hddpool driver: btrfs used_by: - /1.0/images/ebd565585223487526ddb3607f5156e875c15a89e21b61ef004132196da6a0a3 - /1.0/profiles/hddroot status: Created locations: - noneЭто даёт мне возможность экспериментировать с контейнерами на HDD диске экономя ресурсы SSD диска который также имеется в моей системе 🙂 для которого у меня создан отдельный профиль конфигурации ssdroot .
После создания контейнера он находится в состоянии STOPPED , поэтому нам надо запустить в нём init-систему:
lxc start jupyterlabВыведем список контейнеров в LXD используя ключ -c который указывает какие columns вывести на экран:
lxc list -c ns4b +------------+---------+-------------------+--------------+ | NAME | STATE | IPV4 | STORAGE POOL | +------------+---------+-------------------+--------------+ | jupyterlab | RUNNING | 10.0.5.198 (eth0) | hddpool | +------------+---------+-------------------+--------------+При создании контейнера IP адрес выбрался случайным образом, так как мы использовали профиль конфигурации default который был ранее сконфигурирован в статье Базовые возможности LXD — системы контейнеров в Linux.
Мы поменяем этот IP адрес на более запоминающийся, создав сетевой интерфейс на уровне контейнера, а не на уровне профиля конфигурации как это сейчас в текущей конфигурации. Это не обязательно делать, вы можете пропустить это.
Создаём сетевой интерфейс eth0 который линкуем с коммутатором (сетевым мостом) lxdbr0 в котором мы включили NAT по прошлой статье и контейнеру сейчас будет доступ в Интернет, а также интерфейсу назначаем статический IP адрес — 10.0.5.5 :
lxc config device add jupyterlab eth0 nic name=eth0 nictype=bridged parent=lxdbr0 ipv4.address=10.0.5.5После добавления устройства, контейнер необходимо перезагрузить:
lxc restart jupyterlabПроверяем статус контейнера:
lxc list -c ns4b +------------+---------+------------------+--------------+ | NAME | STATE | IPV4 | STORAGE POOL | +------------+---------+------------------+--------------+ | jupyterlab | RUNNING | 10.0.5.5 (eth0) | hddpool | +------------+---------+------------------+--------------+Установка базового софта и настройка системы ^
Для администрирования нашего контейнера необходимо установить следующий софт:
Package Description bash The GNU Bourne Again shell bash-completion Programmable completion for the bash shell sudo Give certain users the ability to run some commands as root shadow Password and account management tool suite with support for shadow files and PAM tzdata Sources for time zone and daylight saving time data nano Pico editor clone with enhancements Дополнительно, вы можете установить поддержку в системе man-pages установив следующие пакеты — man man-pages mdocml-apropos less
lxc exec jupyterlab -- apk add bash bash-completion sudo shadow tzdata nanoРазберём команды и ключи который мы использовали:
- lxc — Вызов клиента LXD
- exec — Метод клиента LXD, который запускает команду в контейнере
- jupyterlab — Идентификатор контейнера
- — — Специальный ключ, который указывает не интерпретировать дальше ключи как ключи для lxc и передать всю оставшуюся строку как есть в контейнер
- apk — Пакетный менеджер дистрибутива Alpine Linux
- add — Метод пакетного менеджера который инсталлирует указанные после команды пакеты
Далее, установим в системе тайм-зону Europe/Moscow :
lxc exec jupyterlab -- cp /usr/share/zoneinfo/Europe/Moscow /etc/localtimeПосле установки тайм-зоны, пакет tzdata в системе больше не нужен, он будет занимать место, поэтому, удалим его:
lxc exec jupyterlab -- apk del tzdatalxc exec jupyterlab -- date Wed Apr 15 10:49:56 MSK 2020Чтобы не тратить много времени на настройку Bash для новых пользователей в контейнере, следующими действиями мы скопируем в него такие файлы как .bash_profile , .bashrc , .dir_colors из директории /etc/skel вашей системы, это приукрасит Bash в контейнере, в интерактивном режиме. У меня, установка этих файлов из дистрибутива Manjaro Linux не вызывает критических проблем в контейнере, но у вас может быть иначе, и вам нужно самостоятельно разобраться с этим в случае ошибки в контейнере.
Копируем skel-файлы в контейнер. Ключ —create-dirs создаст необходимые директории, если они не существуют:
lxc file push /etc/skel/.bash_profile jupyterlab/etc/skel/.bash_profile --create-dirs lxc file push /etc/skel/.bashrc jupyterlab/etc/skel/.bashrc lxc file push /etc/skel/.dir_colors jupyterlab/etc/skel/.dir_colorsДля уже существующего root пользователя скопируем в домашнюю директорию только что установленные в контейнере skel-файлы:
lxc exec jupyterlab -- cp /etc/skel/.bash_profile /root/.bash_profile lxc exec jupyterlab -- cp /etc/skel/.bashrc /root/.bashrc lxc exec jupyterlab -- cp /etc/skel/.dir_colors /root/.dir_colorsВ Alpine Linux для пользователей устанавливается системная оболочка /bin/sh , мы заменим её у root пользователя на Bash:
lxc exec jupyterlab -- usermod --shell=/bin/bash rootКомандой ниже мы сгенерируем случайный пароль для пользователя root который вы увидите на экране консоли после её выполнения. Запомните и запишите его куда-нибудь или забудьте, скорее всего он вам не пригодится больше 🙂
lxc exec jupyterlab -- /bin/bash -c "PASSWD=\$(head /dev/urandom | tr -dc A-Za-z0-9 | head -c 12); echo \"root:\$PASSWD\" | chpasswd && echo \"New Password: \$PASSWD\"" New Password: sFiXEvBswuWAДобавим нового системного пользователя — jupyter для которого позже настроим JupyterLab
lxc exec jupyterlab -- useradd --create-home --shell=/bin/bash jupyterСгенерируем и установим ему пароль:
lxc exec jupyterlab -- /bin/bash -c "PASSWD=\$(head /dev/urandom | tr -dc A-Za-z0-9 | head -c 12); echo \"jupyter:\$PASSWD\" | chpasswd && echo \"New Password: \$PASSWD\"" New Password: ZIcbzWrF8tkiДалее выполним две команды, первая создаст системную группу sudo , а вторая добавит в неё пользователя jupyter :
lxc exec jupyterlab -- groupadd --system sudo lxc exec jupyterlab -- groupmems --group sudo --add jupyterПросмотрим, в какие группы входит пользователь jupyter :
lxc exec jupyterlab -- id -Gn jupyter jupyter sudoВсё — ок, двигаемся дальше.
Разрешим всем пользователям которые входят в группу sudo использовать команду sudo . Для этого выполните следующий скрипт, где sed снимет комментарий со строчки параметра в конфигурационном файле /etc/sudoers :
lxc exec jupyterlab -- /bin/bash -c "sed --in-place -e '/^#[ \t]*%sudo[ \t]*ALL=(ALL)[ \t]*ALL$/ s/^[# ]*//' /etc/sudoers"Установка и настройка JupyterLab ^
JupyterLab — это Python приложение, поэтому мы должны прежде установить этот интерпретатор. Также, JupyterLab мы будем устанавливать с помощью питоновского пакетного менеджера pip , а не системного, потому что в системном репозитории он может быть устаревшим, и поэтому, мы должны вручную разрешить зависимости для него установив следующие пакеты — python3 python3-dev gcc libc-dev zeromq-dev :
lxc exec jupyterlab -- apk add python3 python3-dev gcc libc-dev zeromq-devОбновим python-модули и пакетный менеджер pip до актуальной версии:
lxc exec jupyterlab -- python3 -m pip install --upgrade pip setuptools wheelУстанавливаем JupyterLab через пакетный менеджер pip :
lxc exec jupyterlab -- python3 -m pip install jupyterlabТак как расширения в JupyterLab являются экспериментальными и официально они не поставляются вместе с пакетом jupyterlab, поэтому, мы должны установить и настроить это вручную.
Установим NodeJS и менеджер пакетов для него — NPM, так как JupyterLab использует их для своих расширений:
lxc exec jupyterlab -- apk add nodejs npmЧтобы расширения для JupyterLab которые мы установим работали, их нужно устанавливать в пользовательскую директорию так как приложение будет запускаться от пользователя jupyter . Проблема в том, что нет параметра в команде запуска которой можно передать каталог, приложение воспринимает только переменную окружения и поэтому мы её должны определить. Для этого, мы пропишем команду экспорта переменной JUPYTERLAB_DIR в окружении пользователя jupyter , в файл .bashrc , который выполняется каждый раз при входе пользователя в систему:
lxc exec jupyterlab -- su -l jupyter -c "echo -e \"\nexport JUPYTERLAB_DIR=\$HOME/.local/share/jupyter/lab\" >> .bashrc"Следующей командой установим специальное расширение — менеджер расширений в JupyterLab:
lxc exec jupyterlab -- su -l jupyter -c "export JUPYTERLAB_DIR=\$HOME/.local/share/jupyter/lab; jupyter labextension install --no-build @jupyter-widgets/jupyterlab-manager"Сейчас уже всё готово для первого запуска JupyterLab, но мы можем еще установить несколько полезных расширений:
- toc — Table of Contents, генерирует список заголовков в статье/ноутбуке
- jupyterlab-horizon-theme — Тема оформления UI
- jupyterlab_neon_theme — Тема оформления UI
- jupyterlab-ubu-theme — Ещё одна тема оформления от автора этой статьи 🙂 Но в этом случае, будет показана установка из репозитория GitHub
Итак, выполните последовательно следующие команды, чтобы установить эти расширения:
lxc exec jupyterlab -- su -l jupyter -c "export JUPYTERLAB_DIR=\$HOME/.local/share/jupyter/lab; jupyter labextension install --no-build @jupyterlab/toc @mohirio/jupyterlab-horizon-theme @yeebc/jupyterlab_neon_theme"lxc exec jupyterlab -- su -l jupyter -c "wget -c https://github.com/microcoder/jupyterlab-ubu-theme/archive/master.zip"lxc exec jupyterlab -- su -l jupyter -c "unzip -q master.zip && rm master.zip"lxc exec jupyterlab -- su -l jupyter -c "export JUPYTERLAB_DIR=\$HOME/.local/share/jupyter/lab; jupyter labextension install --no-build jupyterlab-ubu-theme-master"lxc exec jupyterlab -- su -l jupyter -c "rm -r jupyterlab-ubu-theme-master"После установки расширений мы должны их скомпилировать, так как ранее, при установке указывали ключ —no-build для экономии времени. Сейчас мы значительно ускоримся если выполним компиляцию сразу для всех расширений:
lxc exec jupyterlab -- su -l jupyter -c "export JUPYTERLAB_DIR=\$HOME/.local/share/jupyter/lab; jupyter lab build"Почистим кеши установок:
lxc exec jupyterlab -- su -l jupyter -c "jupyter lab clean && jlpm cache clean && npm cache clean --force"Далее выполните следующие две команды для первого запуска JupyterLab. Можно было бы его запустить одной командой, но в этом случае, команда запуска JupyterLab будет запоминаться bash’ем в контейнере, а не на хосте, где и так команд хватает для записи их в историю 🙂
Логинимся в контейнере как пользователь jupyter :
lxc exec jupyterlab -- su -l jupyterДалее запустите JupyterLab с ключами и параметрами как указано:
[jupyter@jupyterlab ~]$ jupyter lab --ip=0.0.0.0 --no-browserПерейдите в web-браузере по адресу http://10.0.5.5:8888 и на открывшейся странице введите token доступа который вы увидите в консоли. Скопируйте его и вставьте на странице, затем нажмите Login. После входа, перейдите слева в меню расширений, как показано на рисунке ниже, где вам предложат при активации менеджера расширений принять на себя риски по безопасности устанавливая расширения от третьих лиц за которые команда JupyterLab development ответственности не несёт:

Однако, мы как раз для этого изолируем целиком JupyterLab и помещаем его в контейнер, чтобы сторонние расширения требующие и использующие NodeJS не смогли как минимум похитить данные на диске кроме тех, которые мы откроем внутри контейнера. Добраться к вашим приватным документам на хосте в /home процессам из контейнера вряд ли получится, а если и получится, то на это нужно иметь привилегии на файлы в хостовой системе, так как мы запускаем контейнер в непривилегированном режиме. Исходя из этой информации вы можете оценить риск включения расширений в JupyterLab.
Созданные IPython-ноутбуки (страницы в JupyterLab) сейчас будут создаваться в домашней директории пользователя — /home/jupyter , но в наших планах разделить данные (расшарить) между хостом и контейнером, поэтому, вернитесь в консоль и остановите JupyterLab выполнив hotkey — CTRL+C и ответив y на запрос. Затем разорвите интерактивную сессию пользователя jupyter выполнив хоткей CTRL+D .
Разделяем данные с хостом ^
Чтобы разделить данные с хостом, нужно создать в контейнере такое устройство, которое это позволяет делать и для этого выполните следующую команду где мы указываем следующие ключи:
- lxc config device add — Команда добавляет конфигурацию устройства
- jupyter — Идентификатор контейнера в который добавляется конфигурация
- hostfs — Идентификатор устройства. Вы можете задать любое имя.
- disk — Указывается тип устройства
- path — Указывается путь в контейнере к которому LXD смонтирует это устройство
- source — Указывается источник, путь к каталогу на хосте который вы желаете разделить с контейнером. Укажите путь согласно вашим предпочтениям
lxc config device add jupyterlab hostfs disk path=/mnt/hostfs source=/home/dv/projects/ipython-notebooksДля каталога /home/dv/projects/ipython-notebooks должно быть установлено разрешение контейнерному пользователю который сейчас имеет UID равный SubUID + UID , смотрите главу Безопасность. Привилегии контейнеров в статье Базовые возможности LXD — системы контейнеров в Linux.
Устанавливаем разрешение на хосте, где владельцем будет контейнерный пользователь jupyter , а переменная $USER укажет вашего хостового пользователя в качестве группы:
sudo chown 1001000:$USER /home/dv/projects/ipython-notebooksHello, World! ^
Если у вас еще открыта консольная сессия в контейнере с JupyterLab, то перезапустите её с новым ключом —notebook-dir задав значение /mnt/hostfs в качестве пути до корня ноутбуков в контейнере для устройства которое мы создали в предыдущем шаге:
jupyter lab --ip=0.0.0.0 --no-browser --notebook-dir=/mnt/hostfsЗатем перейдите на страницу http://10.0.5.5:8888 и создайте первый ваш ноутбук нажав кнопку на странице как указано на картинке ниже:
Затем в поле на странице введите код на языке Python который выведет классический Hello World! . По окончании ввода нажмите CTRL+ENTER или кнопку «play» на панели инструментов сверху чтобы JupyterLab выполнил это:

На этом почти всё готово к использованию, но будет неинтересно, если мы не установим дополнительные Python-модули (полноценные приложения) которые позволяют значительно расширить стандартные возможности Python в JupyterLab, поэтому, двигаемся дальше 🙂
P.S. Интересно то, что старая реализация Jupyter под кодовым именем Jupyter Notebook никуда не делась и она существует параллельно с JupyterLab. Для перехода к старой версии перейдите по ссылке добавив в адресе суффикс /tree , а переход к новой версии осуществляется с суффиксом /lab , но его не обязательно указывать:
- Jupyter Notebook — http://10.0.5.5:8888/tree
- Jupyter Lab — http://10.0.5.5:8888/lab
Расширяем возможности Python ^
В этом разделе мы установим такие мощные модули языка Python как NumPy, Pandas, Matplotlib, IPyWidgets результаты работы которых интегрируются в ноутбуки JupyterLab.
Прежде чем установить перечисленные модули Python через пакетный менеджер pip мы должны вначале разрешить системные зависимости в Alpine Linux:
- g++ — Нужен для компиляции модулей, так как некоторые из них реализованы на языке C++ и подключаются к Python в рантайме как бинарные модули
- freetype-dev — зависимость для Python модуля Matplotlib
lxc exec jupyterlab -- apk add g++ freetype-devЕсть одна проблема, в текущем состоянии дистрибутива Alpine Linux скомпилировать новую версию NumPy не получится, вылетит ошибка компиляции которую мне не удалось разрешить:
ERROR: Could not build wheels for numpy which use PEP 517 and cannot be installed directly
Поэтому, этот модуль мы установим как системный пакет который распространяет уже скомпилированную версию, но немного старее, чем доступна сейчас на сайте:
lxc exec jupyterlab -- apk add py3-numpy py3-numpy-devДалее устанавливаем Python-модули через пакетный менеджер pip . Наберитесь терпения, так как некоторые модули будут компилироваться и это займет несколько минут. На моей машине компиляция заняла ~15 минут:
lxc exec jupyterlab -- python3 -m pip install pandas matplotlib ipywidgetsЧистим кеши установок:
lxc exec jupyterlab -- rm -rf /home/*/.cache/pip/* lxc exec jupyterlab -- rm -rf /root/.cache/pip/*Тестируем модули в JupyterLab ^
Если у вас запущен JupyterLab, перезапустите его, чтобы новые установленные модули активировались. Для этого в консольной сессии нажмите CTRL+C там где он у вас запущен и введите y на запрос остановки, а затем запустите заново JupyterLab нажав стрелочку на клавиатуре «вверх», чтобы не вводить команду заново и потом Enter чтобы запустить:
jupyter lab --ip=0.0.0.0 --no-browser --notebook-dir=/mnt/hostfsПерейдите на страницу http://10.0.5.5:8888/lab или обновите в браузере страницу, а затем введите следующий код в новой ячейке ноутбука:
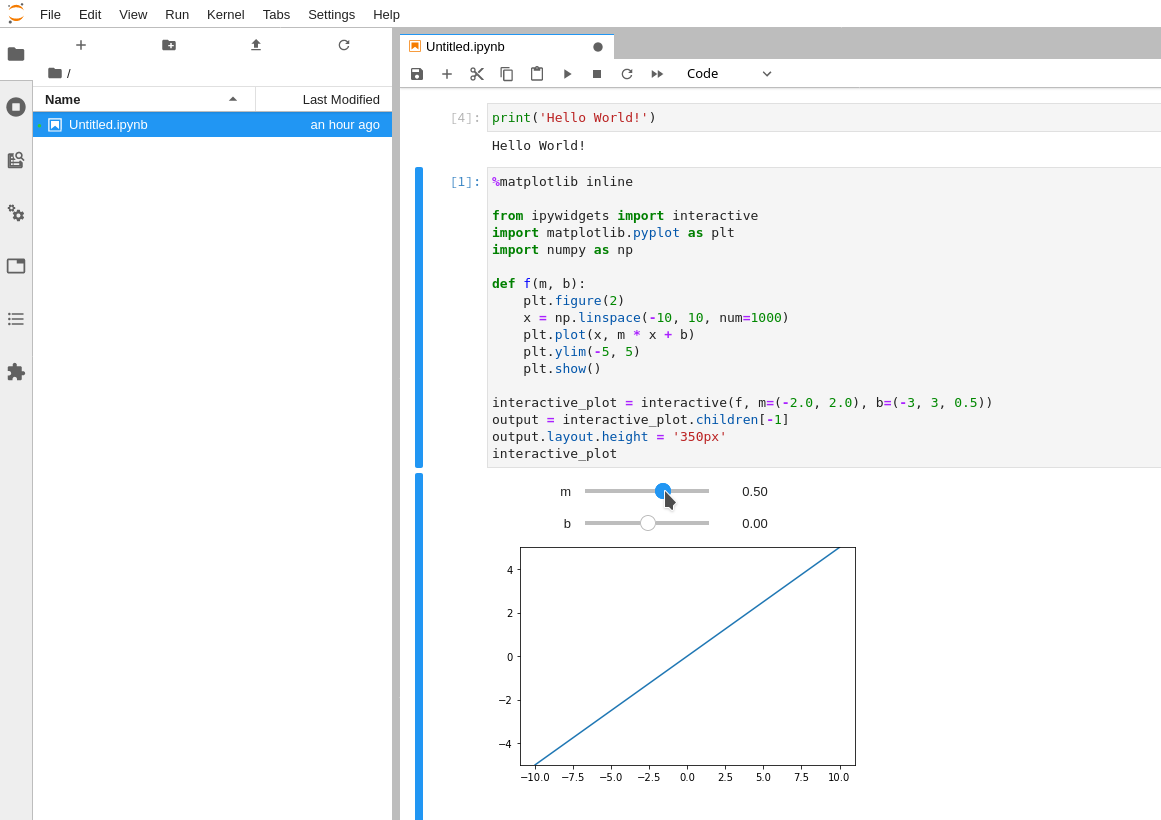
%matplotlib inline from ipywidgets import interactive import matplotlib.pyplot as plt import numpy as np def f(m, b): plt.figure(2) x = np.linspace(-10, 10, num=1000) plt.plot(x, m * x + b) plt.ylim(-5, 5) plt.show() interactive_plot = interactive(f, m=(-2.0, 2.0), b=(-3, 3, 0.5)) output = interactive_plot.children[-1] output.layout.height = '350px' interactive_plotУ вас должен получиться результат как на картинке ниже, где IPyWidgets генерирует UI-элемент на странице который интерактивно взаимодействует с исходным кодом, а также Matplotlib выводит результат кода в виде картинки как график функции:
Многие примеры IPyWidgets вы можете найти в туториалах здесь
Что ещё? ^
Вы молодцы, если остались и дошли до самого конца статьи. Я специально не стал выкладывать готовый скрипт в конце статьи который бы установил JupyterLab в «один клик», чтобы поощрить тружеников 🙂 Но вы можете это сделать самостоятельно, так как уже знаете как, собрав команды в единый Bash скрипт 🙂
Также, вы можете:
- Задать сетевое имя для контейнера вместо IP адреса прописав его в простом /etc/hosts и в браузере набирать адрес http://jupyter.local:8888
- Поиграться с ограничением ресурсов для контейнера, для этого прочтите главу в базовых возможностях LXD или получите больше информации на сайте разработчика LXD.
- Поменять тему оформления:
И много чего ещё вы можете! На этом всё. Желаю вам успехов!
UPDATE: 15.04.2020 18:30 — Исправил ошибки в главе «Hello, World!»
UPDATE: 16.04.2020 10:00 — Скорректировал и добавил текст в описании активации менеджера расширений JupyterLab
UPDATE: 16.04.2020 10:40 — Исправил найденные ошибки в тексте и немного изменил к лучшему главу «Установка базового софта и настройка системы»Python. Урок 6. Работа с IPython и Jupyter Notebook


IPython представляет собой мощный инструмент для работы с языком Python. Базовые компоненты IPython – это интерактивная оболочка для с широким набором возможностей и ядро для Jupyter. Jupyter notebook является графической веб-оболочкой для IPython, которая расширяет идею консольного подхода к интерактивным вычислениям.
Основные отличительные особенности данной платформы – это комплексная интроспекция объектов, сохранение истории ввода на протяжении всех сеансов, кэширование выходных результатов, расширяемая система “магических” команд, логирование сессии, дополнительный командный синтаксис, подсветка кода, доступ к системной оболочке, стыковка с pdb отладчиком и Python профайлером.
IPython позволяет подключаться множеству клиентов к одному вычислительному ядру и, благодаря своей архитектуре, может работать в параллельном кластере.
В Jupyter notebook вы можете разрабатывать, документировать и выполнять приложения на языке Python, он состоит из двух компонентов: веб-приложение, запускаемое в браузере, и ноутбуки – файлы, в которых можно работать с исходным кодом программы, запускать его, вводить и выводить данные и т.п.
Веб приложение позволяет:
- редактировать Python код в браузере, с подсветкой синтаксиса, автоотступами и автодополнением;
- запускать код в браузере;
- отображать результаты вычислений с медиа представлением (схемы, графики);
- работать с языком разметки Markdown и LaTeX.
Ноутбуки – это файлы, в которых сохраняются исходный код, входные и выходные данные, полученные в рамках сессии. Фактически, он является записью вашей работы, но при этом позволяет заново выполнить код, присутствующий на нем. Ноутбуки можно экспортировать в форматы PDF, HTML.
Установка и запуск
Jupyter Notebook входит в состав Anaconda. Описание процесса установки можно найти в первом уроке. Для запуска Jupyter Notebook перейдите в папку Scripts (она находится внутри каталога, в котором установлена Anaconda) и в командной строке наберите:
> ipython notebookВ результате будет запущена оболочка в браузере.

Примеры работы
Будем следовать правилу: лучше один раз увидеть… Рассмотрим несколько примеров, выполнив которые, вы сразу поймете принцип работы с Jupyter notebook.
Запустите Jupyter notebook и создайте папку для наших примеров, для этого нажмите на New в правой части экрана и выберите в выпадающем списке Folder.

По умолчанию папке присваивается имя “Untitled folder”, переименуем ее в “notebooks”: поставьте галочку напротив имени папки и нажмите на кнопку “Rename”.

Зайдите в эту папку и создайте в ней ноутбук, воспользовавшись той же кнопкой New, только на этот раз нужно выбрать “Python [Root]”.

В результате будет создан ноутбук.

.
Код на языке Python или текст в нотации Markdown нужно вводить в ячейки:

Если это код Python, то на панели инструментов нужно выставить свойство “Code”.

Если это Markdown текст – выставить “Markdown”.

Для начал решим простую арифметическую задачу: выставите свойство “Code”, введите в ячейке “2 + 3” без кавычек и нажмите Ctrl+Enter или Shift+Enter, в первом случае введенный вами код будет выполнен интерпретатором Python, во втором – будет выполнен код и создана новая ячейка, которая расположится уровнем ниже так, как показано на рисунке.

Если у вас получилось это сделать, выполните еще несколько примеров.

Основные элементы интерфейса Jupyter notebook
У каждого ноутбука есть имя, оно отображается в верхней части экрана. Для изменения имени нажмите на его текущее имя и введите новое.

Из элементов интерфейса можно выделить, панель меню:


и рабочее поле с ячейками:

Ноутбук может находиться в одном из двух режимов – это режим правки (Edit mode) и командный режим (Command mode). Текущий режим отображается на панели меню в правой части, в режиме правки появляется изображение карандаша, отсутствие этой иконки значит, что ноутбук находится в командном режиме.

Для открытия справки по сочетаниям клавиш нажмите “Help->Keyboard Shortcuts”

В самой правой части панели меню находится индикатор загруженности ядра Python. Если ядро находится в режиме ожидания, то индикатор представляет собой окружность.

Если оно выполняет какую-то задачу, то изображение измениться на закрашенный круг.
Запуск и прерывание выполнения кода
Если ваша программа зависла, то можно прервать ее выполнение выбрав на панели меню пункт Kernel -> Interrupt.
Для добавления новой ячейки используйте Insert->Insert Cell Above и Insert->Insert Cell Below.
Для запуска ячейки используете команды из меню Cell, либо следующие сочетания клавиш:
Ctrl+Enter – выполнить содержимое ячейки.
Shift+Enter – выполнить содержимое ячейки и перейти на ячейку ниже.
Alt+Enter – выполнить содержимое ячейки и вставить новую ячейку ниже.
Как сделать ноутбук доступным для других людей?
Существует несколько способов поделиться своим ноутбуком с другими людьми, причем так, чтобы им было удобно с ним работать:
- передать непосредственно файл ноутбука, имеющий расширение “.ipynb”, при этом открыть его можно только с помощью Jupyter Notebook;
- сконвертировать ноутбук в html;
- использовать https://gist.github.com/ ;
- использовать http://nbviewer.jupyter.org/.
Вывод изображений в ноутбуке
Печать изображений может пригодиться в том случае, если вы используете библиотеку matplotlib для построения графиков. По умолчанию, графики не выводятся в рабочее поле ноутбука. Для того, чтобы графики отображались, необходимо ввести и выполнить следующую команду:
%matplotlib inline
Пример вывода графика представлен на рисунке ниже.

Магия
Важной частью функционала Jupyter Notebook является поддержка магии. Под магией в IPython понимаются дополнительные команды, выполняемые в рамках оболочки, которые облегчают процесс разработки и расширяют ваши возможности. Список доступных магических команд можно получить с помощью команды
%lsmagic

Для работы с переменными окружения используется команда %env.

Запуск Python кода из “.py” файлов, а также из других ноутбуков – файлов с расширением “.ipynb”, осуществляется с помощью команды %run.

Для измерения времени работы кода используйте %%time и %timeit.
%%time позволяет получить информацию о времени работы кода в рамках одной ячейки.

%timeit запускает переданный ей код 100000 раз (по умолчанию) и выводит информацию среднем значении трех наиболее быстрых прогонах.

Информацию по остальным магическим командам можете найти здесь:
Интересные примеры ноутбуков, в которых довольно полно раскрыты возможности Jupyter Notebook можно найти в ресурсах, перечисленных ниже.
P.S.
Если вам интересна тема анализа данных, то мы рекомендуем ознакомиться с библиотекой Pandas. На нашем сайте вы можете найти вводные уроки по этой теме. Все уроки по библиотеке Pandas собраны в книге “Pandas. Работа с данными”.
Раздел: Python Уроки по Python Метки: Python, Уроки Python
Python. Урок 6. Работа с IPython и Jupyter Notebook : 4 комментария
- Уведомление: Adopting IPython & Jupyter For Selenium Testing: Plan, Write, Validate Tests in Python | Shakuro
- Михаил Филиппов 17.01.2021 ” это интерактивная оболочка для с широким набором возможностей ”
после ДЛЯ пропало слово
- Ксения 30.10.2023 Сначала прописать activate baze, затем jupyter notebook. Также можно вызвать Anaconda Navigator и из него Jupiter Notebook