Tsne python что это
Шаг 96.
Введение в машинное обучение с использованием Python. Методы машинного обучения без учителя . . Множественное обучение с помошью алгоритма t-SNE
На этом шаге мы рассмотрим назначение и использование этого алгоритма .
Хотя PCA часто выступает в качестве приоритетного метода, преобразующего данные таким образом, что можно визуализировать их с помощью диаграммы рассеяния, сам характер метода (вращение данных, а затем удаление направлений, объясняющих незначительную дисперсию данных) ограничивает его полезность, как мы уже убедились на примере диаграммы рассеяния для набора данных Labeled Faces in the Wild . Существует класс алгоритмов визуализации, называемых алгоритмами множественного обучения (manifold learning algorithms) , которые используют гораздо более сложные графические представления данных и позволяют получить визуализации лучшего качества. Особенно полезным является алгоритм t-SNE .
Алгоритмы множественного обучения в основном направлены на визуализацию и поэтому редко используются для получения более двух новых характеристик. Некоторые из них, в том числе t-SNE , создают новое представление обучающих данных, но при этом не осуществляют преобразования новых данных. Это означает, что данные алгоритмы нельзя применить к тестовому набору, они могут преобразовать лишь те данные, на которых они были обучены. Множественное обучение может использоваться для разведочного анализа данных, но редко используется в тех случаях, когда конечной целью является применение модели машинного обучения с учителем. Идея, лежащая в основе алгоритма t-SNE , заключается в том, чтобы найти двумерное представление данных, сохраняющее расстояния между точками наилучшим образом. t-SNE начинает свою работу со случайного двумерного представления каждой точки данных, а затем пытается сблизить точки, которые в пространстве исходных признаков находятся близко друг к другу, и отдаляет друг от друга точки, которые находятся далеко друг от друга. При этом t-SNE уделяет большее внимание сохранению расстояний между точками, близко расположенными друг к другу. Иными словами, он пытается сохранить информацию, указывающую на то, какие точки являются соседями друг другу.
Мы применим алгоритм множественного обучения t-SNE к набору данных рукописных цифр, который включен в scikit-learn .
Не следует путать с гораздо большим набором данных MNIST .
Каждая точка данных в этом наборе является изображением цифры в градациях серого. Рисунок 1 показывает примеры изображений для каждого класса:
[In 42]: from sklearn.datasets import load_digits digits = load_digits() fig, axes = plt.subplots(2, 5, figsize=(10, 5), subplot_kw='xticks':(), 'yticks': ()>) for ax, img in zip(axes.ravel(), digits.images): ax.imshow(img)
Рис.1. Примеры изображений из набора данных digits
Давайте используем PCA для визуализации данных, сведя их к двум измерениям. Мы построим график первых двух главных компонент и отметим цветом класс каждой точки (рисунок 2):
[In 43]: # строим модель PCA pca = PCA(n_components=2) pca.fit(digits.data) # преобразуем данные рукописных цифр к первым двум компонентам digits_pca = pca.transform(digits.data) colors = ["#476A2A", "#7851B8", "#BD3430", "#4A2D4E", "#875525", "#A83683", "#4E655E", "#853541", "#3A3120", "#535D8E"] plt.figure(figsize=(10, 10)) plt.xlim(digits_pca[:, 0].min(), digits_pca[:, 0].max()) plt.ylim(digits_pca[:, 1].min(), digits_pca[:, 1].max()) for i in range(len(digits.data)): # строим график, где цифры представлены символами вместо точек plt.text(digits_pca[i, 0], digits_pca[i, 1], str(digits.target[i]), color = colors[digits.target[i]], fontdict='weight': 'bold', 'size': 9>) plt.xlabel("Первая главная компонента") plt.ylabel("Вторая главная компонента")
Рис.2. Диаграмма рассеяния для набора данных digits , использующая первые две главные компоненты
Здесь мы вывели фактические классы цифр в виде символов, чтобы визуально показать расположение каждого класса. Цифры 0, 6 и 4 относительно хорошо разделены с помощью первых двух главных компонент, хотя по-прежнему перекрывают друг друга. Большинство остальных цифр значительно перекрывают друг друга.
Давайте применим t-SNE к этому же набору данных и сравним результаты. Поскольку t-SNE не поддерживает преобразование новых данных, в классе TSNE нет метода transform() . Вместо этого мы можем вызвать метод fit_transform() , который построит модель и немедленно вернет преобразованные данные (см. рисунок 3):
[In 44]: from sklearn.manifold import TSNE tsne = TSNE(random_state=42) # используем метод fit_transform вместо fit, т.к. класс TSNE не использует метод transform digits_tsne = tsne.fit_transform(digits.data)
[In 45]: plt.figure(figsize=(10, 10)) plt.xlim(digits_tsne[:, 0].min(), digits_tsne[:, 0].max() + 1) plt.ylim(digits_tsne[:, 1].min(), digits_tsne[:, 1].max() + 1) for i in range(len(digits.data)): # строим график, где цифры представлены символами вместо точек plt.text(digits_tsne[i, 0], digits_tsne[i, 1], str(digits.target[i]), color = colors[digits.target[i]], fontdict='weight': 'bold', 'size': 9>) plt.xlabel("t-SNE признак 0") plt.xlabel("t-SNE признак 1")
Рис.3. Диаграмма рассеяния для набора данных digits , которая использует первые две главные компоненты, найденные с помощью t-SNE
Результат, полученный с помощью t-SNE , весьма примечателен. Все классы довольно четко разделены. Единицы и девятки в некоторой степени распались, однако большинство классов образуют отдельные сплоченные группы. Имейте в виду, что этот метод не использует информацию о метках классов: он является полностью неконтролируемым. Тем не менее он может наити двумерное представление данных, которое четко разграничивает классы, используя лишь информацию о расстояниях между точками данных в исходном пространстве.
Алгоритм t-SNE имеет некоторые настраиваемые параметры, хотя, как правило, дает хорошее качество, когда используются настроики по умолчанию. Вы можете поэкспериментировать с параметрами perplexity и early_exaggeration , но эффекты от их применения обычно незначительны.
Архив блокнота со всеми вычислениями, выполненными на 82-96 шагах, можно взять здесь.
Со следующего шага мы начнем рассматривать кластеризацию .
t-SNE с нуля (ft. NumPy)
Эта статья предназначена для читателей, которые заинтересованы в понимании t-SNE посредством перевода математики из оригинальной статьи — Лоренса ван дер Маатена и Джеффри Хинтона — в реализацию кода на python.[1] Я нахожу, что такого рода упражнения достаточно проливают свет на внутреннюю работу статистических алгоритмов / моделей и действительно проверяют ваше базовое понимание относительно этих алгоритмов / моделей. Как минимум, успешная реализация всегда приносит большое удовлетворение!
Эта статья будет доступна лицам с любым уровнем взаимодействия с t-SNE. Однако, стоить заметить, что эта статья не будет каким-либо полноценным руководством:
- Строго концептуальное введение и исследование t-SNE, поскольку существует множество других замечательных ресурсов, которые делают это; тем не менее, я сделаю всё возможное, чтобы связать математические уравнения с их интуитивными / концептуальными аналогами на каждом этапе реализации.
- Всестороннее обсуждение применений и плюсов /минусов t-SNE, а также прямые сравнения t-SNE с другими методами уменьшения размерности. Я, однако, кратко коснусь этих тем на протяжении всей этой статьи, но ни в коем случае не буду подробно их освещать.
Без лишних слов давайте начнём с краткого введения в t-SNE.
Краткое введение в t-SNE
Стохастическое вложение соседей с t-распределением (t-SNE) — это инструмент уменьшения размерности, который в основном используется в наборах данных с пространством пространственных объектов большой размерности и позволяет визуализировать данные или спроецировать их в пространство меньшей размерности (обычно 2-D). Это особенно полезно для визуализации нелинейно разделяемых данных, в которых линейные методы, такие как анализ главных компонент (PCA), потерпели бы неудачу. Обобщение линейных структур уменьшения размерности (таких как PCA) на нелинейные подходы (такие как t-SNE) также известно как многообразное обучение. Эти методы могут быть чрезвычайно полезны для визуализации и понимания базовой структуры многомерного нелинейного набора данных, а также могут быть полезны для распутывания и группировки воедино наблюдений, которые похожи в многомерном пространстве. Для получения дополнительной информации о t-SNE и других разнообразных методах обучения документация scikit-learn является отличным ресурсом. Кроме того, чтобы прочитать о некоторых интересных областях применения t-SNE, на странице Википедии освещаются некоторые из этих областей со ссылками на работу.
Давайте начнём с разбиения названия стохастического вложение соседей с t-распределением на его компоненты. t-SNE — это расширение стохастического вложения соседей (SNE), представленное 6 годами ранее в этой статье Джеффри Хинтоном и Сэмом Роуэйсом. Итак, давайте начнём с этого. Стохастическая часть названия происходит от того факта, что целевая функция не является выпуклой и, следовательно, при разных инициализациях могут получаться разные результаты. Вложение соседей подчёркивает природу алгоритма — оптимальное отображение точек в исходном многомерном пространстве в соответствующее низкоразмерное пространство при наилучшем сохранении структуры точек ”окрестности». SNE состоит из следующих (упрощённых) шагов:
- Получение матрицы подобия между точками в исходном пространстве: Вычислите условные вероятности для каждой точки данных j относительно каждой точки данных i. Эти условные вероятности вычисляются в исходном многомерном пространстве с использованием гауссова уравнения с центром в точке i и принимают следующую интерпретацию: вероятность того, что i выберет j в качестве своего соседа в исходном пространстве. Это создаёт матрицу, которая представляет сходства между точками.
- Инициализация: Выберите случайные начальные точки в пространстве нижнего измерения (скажем, 2-D) для каждой точки данных в исходном пространстве и вычислите новые условные вероятности аналогично описанным выше в этом новом пространстве.
- Отображение: Итеративно улучшайте точки в пространстве меньшей размерности до тех пор, пока расхождения Кульбака-Лейблера между всеми условными вероятностями не будут сведены к минимуму. По сути, мы сводим к минимуму различия в вероятностях между матрицами подобия двух пространств, чтобы обеспечить наилучшее сохранение сходства при отображении исходного набора данных в низкоразмерный датасетах.
t-SNE улучшает SNE двумя основными способами:
- Это сводит к минимуму расхождения Кульбака-Лейблера между совместными вероятностями, а не условными. Авторы называют это “симметричным SNE”, поскольку их подход гарантирует, что совместные вероятности p_ij = p_ji. Это приводит к гораздо лучшему функционированию функции затрат, которую легче оптимизировать.
- Он вычисляет сходства между точками, используя распределение Стьюдента-t с одной степенью свободы (также распределение Коши), а не гауссово в низкоразмерном пространстве (шаг 2 выше). Здесь мы можем видеть, откуда берётся буква “t” в t-SNE. Это улучшение помогает устранить “проблему скученности”, выделенную авторами, и ещё больше улучшить задачу оптимизации. Эту “проблему скученности” можно представить следующим образом: представьте, что у нас есть 10-мерное пространство, объема пространства, доступного в 2-мерном пространстве, будет недостаточно для точного захвата этих умеренно непохожих точек по сравнению с объемом пространства для соседних точек относительно объема пространства, доступного в 10-мерном пространстве. Проще говоря, просто представьте, что вы берёте трёхмерное пространство и проецируете его в 2-D. В трёхмерном пространстве будет гораздо больше общего пространства для моделирования сходств относительно 2-D проекции. Распределение Стьюдента-t помогает облегчить эту проблему, поскольку имеет более тяжелые хвосты, чем нормальное распределение.
Я надеюсь, что когда мы реализуем это в коде, все части встанут на свои места. Основной вывод таков: t-SNE моделирует сходства между точками данных в многомерном пространстве, используя совместные вероятности точек данных, выбирающих других в качестве своих соседей, а затем пытается найти наилучшее отображение этих точек вниз в низкоразмерное пространство, наилучшим образом сохраняя исходные многомерные сходства.
Внедрение с Scratch
Давайте теперь перейдем к пониманию t-SNE посредством реализации оригинальной версии алгоритма, представленной в статье Лоуренса ван дер Маатена и Джеффри Хинтона. Сначала мы начнём с пошаговой реализации приведённого ниже алгоритма, который будет охватывать 95% основного алгоритма. Авторы отмечают два дополнительных улучшения: 1) Раннее преувеличение и 2) Адаптивная скорость обучения. Мы обсудим только добавление ранних преувеличений, поскольку это наиболее способствует интерпретации внутренней работы реальных алгоритмов, поскольку адаптивная скорость обучения направлена на повышение скорости сходимости.
t-SNE в машинном обучении
t-SNE – это очень мощный алгоритм машинного обучения, который можно использовать для визуализации многомерного набора данных также в двумерных фигурах. Аббревиатура означает t-распределенное стохастическое соседнее вложение. Если вы хотите узнать больше о t-SNE и о том, как визуализировать многомерный набор данных с помощью t-SNE, эта статья для вас. В этой статье я познакомлю вас с t-SNE в машинном обучении и его реализацией с использованием Python.
Что такое t-SNE?
Одна из проблем, с которой часто сталкиваются специалисты по анализу данных – понимание структуры очень сложного набора данных без ее визуализации. Здесь на помощь приходит алгоритм t-распределенного стохастического соседнего встраивания, он используется для визуализации многомерного набора данных с использованием двумерной фигуры. Вы также можете визуализировать многомерный набор данных, используя трехмерную фигуру, но самая важная особенность, которую он предоставляет, заключается в том, что его можно использовать для уменьшения размерности набора данных для сохранения внутренних связей.
Существует множество инструментов и библиотек визуализации, которые можно использовать для реализации t-SNE с использованием Python. В следующем разделе я расскажу вам о реализации t-SNE с использованием Python для визуализации многомерного набора данных на двухмерной фигуре с помощью plotly.
t-SNE с использованием Python
Теперь давайте посмотрим, как реализовать алгоритм t-распределенного стохастического соседнего вложения в машинном обучении с использованием языка программирования Python. Здесь я буду использовать классический набор данных радужной оболочки для этой задачи. Итак, вот как вы можете легко реализовать алгоритм t-SNE в машинном обучении с помощью Python:
from sklearn.manifold import TSNE import plotly.express as px df = px.data.iris() features = df.loc[:, :'petal_width'] tsne = TSNE(n_components=2, perplexity=20, random_state=1000) projections = tsne.fit_transform(features) fig = px.scatter( projections, x=0, y=1, color=df.species, labels= ) fig.show()

Реализация t-распределенного стохастического соседнего вложения в наборе данных Iris
На рисунке выше легко увидеть виды ирисов, сгруппированные в соответствии с их исходным распределением в наборе данных. Вот как вы можете использовать алгоритм t-распределенного стохастического соседнего встраивания в машинном обучении для визуализации многомерного набора данных за короткое время.
Резюме
Вот как можно реализовать алгоритм t-SNE в машинном обучении с помощью языка программирования Python. Это расшифровывается как t-Distributed Stochastic Neighbor Embedding (t-распределенное стохастическое соседнее встраивание) и используется для визуализации многомерного набора данных в двухмерной фигуре за очень короткий промежуток времени. Надеюсь, вам понравилась эта статья о t-SNE в машинном обучении и его реализации с использованием Python.
Снижаем размерность

Всем привет! Рассмотрю два популярных алгоритма уменьшения размерности, а именно T-distributed Stochastic Neighbor Embedding (t-SNE) и Uniform Manifold Approximation and Projection (UMAP). Их удобно использовать, когда необходимо визуализировать данные с большим количеством параметром (также будем называть это размерностью данных).
Оба алгоритма осуществляют преобразование данных большой размерности в меньшую. На выходе, обычно, получают два измерения, оси которых или расстояния между полученным объектами не поддаются прямой интерпретации, в отличии, например, от метода главных компонент (Principal component analysis, PCA).
Указанное выше не значит, что PCA лучше рассматриваемых нами алгоритмов. По своей сути они различны. PCA является линейным алгоритмом, присваивающим равные веса всем попарным расстояниям. Что касается t-SNE и UMAP, то они не линейны, и умеют определять приоритеты расстояний между соседями, что дает возможность выявить внутреннюю двумерность данных. При этом отличие t-SNE от UMAP заключается в том, что последний лучше сохраняет глобальную структуру при выводе итоговых результатов.
Сравним оба алгоритма на примере базы изображений COIL-20, созданной сотрудниками лаборатории CAVE Колумбийского университета, США. База содержит изображения 20 предметов по 76 штук изображений на каждый из 20 предметов Рис 1.

Для того, чтобы иметь возможность применить рассматриваемые алгоритмы необходимо изображения предобработать, например, привести их в пиксельные значения. Используем для этого код ниже.
data = [] path = 'datasets/coil-20-proc/' for file in os.listdir(path): im = Image.open('datasets/coil-20-proc/'+file) pixels = list(im.getdata()) cl = int(file.split('__')[0][3:]) data.append([cl] + pixels) df = pd.DataFrame(data) df.columns = ['label'] + ['a<>'.format(i) for i in range(df.shape[1]-1)]Мы получили матрицу с параметрами рассматриваемых изображений и теперь можем применять t-SNE и UMAP.
tsne = TSNE() embedding_tsne = tsne.fit_transform(df.drop('label', axis = 1)) umap = UMAP() embedding_umap = umap.fit_transform(df.drop('label', axis = 1))
Заметно, что UMAP уплотнил данные и развел большинство из них сильнее, чем t-SNE (рис 2). При этом UMAP затратил на работу 29 секунд, а t-SNE около 103 секунд. С этой точки зрения UMAP выглядит предпочтительнее. Однако, существует мнение, что такое сравнение не корректно, из-за стохастического характера t-SNE. Для нивелирования данного момента необходимо сделать t-SNE детерминированным, инициализировав через PCA. Давайте попробуем это сделать, применив PCA также к UMAP.

Хотя данные изображения визуально выглядят приятнее, но получились они менее плотные (рис.3). Попытки поработать с параметрами алгоритмов t-SNE и UMAP в контексте инициализации через PCA существенного изменения изображений выше не дали. Таким образом можно сделать вывод, что для нашего случая применение PCA не оправдано. А значит вывод о предпочтительности UMAP, остается прежним.
Давайте рассмотрим основные параметры алгоритма UMAP:
A) n_components – это размерность итоговых данных. Для двухмерного представления необходимо установить значение 2, для трехмерного, соответственно, 3.
B) n-neighbours – определяет работу алгоритма с глобальной структурой данных. Значение по умолчанию установлено 15. Чем большая величина задается, тем большее количество соседних значений рассматривает UMAP, то есть смещает свое внимание с локальной структуры данных в пользу глобальной.
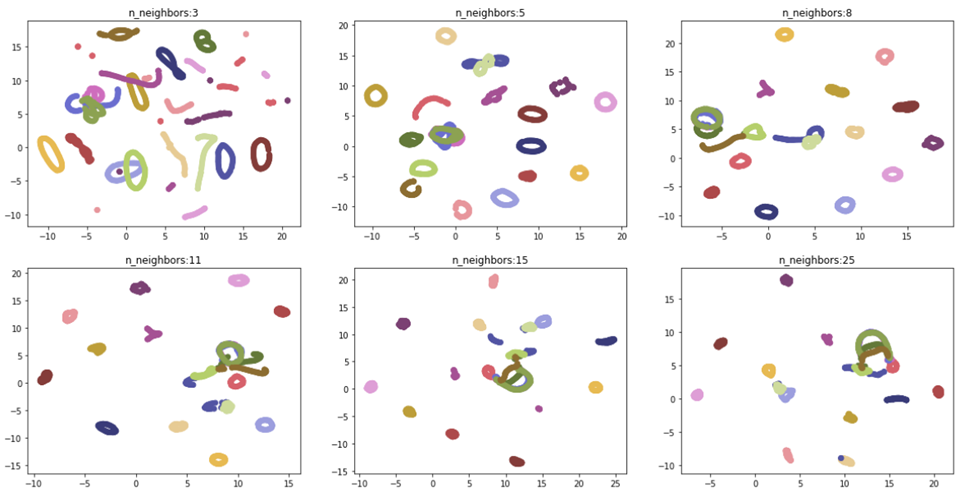
На рисунке 4 видно, что данные лучше всего разделились при значениях n_neighbors равным пяти и восьми. Это обусловлено небольшим размером рассматриваемого нами датасета.
C) min_dist – параметр задает минимальное расстояние для точек в итоговом представлении меньшей размерности. По умолчанию величина 0.1.

При устремлении параметра к нулю алгоритм начинает искать различия внутри полученных кластеров. При увеличении – внутренние различия стираются и структура данных представляется в виде единого целого (рис.5).
D) spread – задает максимальное расстояние между точками в группе. По умолчанию значение равно 1. В сочетании с min_dist определяет на сколько сгруппированы и разгруппированы точки.

В сочетании с min_dist, позволяет более тонко балансировать между отражением внутренней структуры и глобальной картины. (рис.6)
В завершении хотелось бы добавить, что UMAP успешно справляется не только с картинками, но и векторизованными текстами, социологическими опросами и т.п., позволяя сразу сформировать общее представление о данных, не вчитываясь в них. Данный инструмент значительно превосходит конкурентов по скорости и лучше отражает внутреннюю структуру данных.
- Python
- Программирование
- Визуализация данных