Python: потоки по-другому

Знаете, почему я решил написать эту статью? Я писал программу, где использовал потоки. Во время работы с ними в Python всё больше убеждаешь себя, что тут с ними всё плохо. Нет, не то, чтобы они плохо работали. Просто использовать их, мягко говоря, неудобно. Я решил написать простую, но более удобную библиотеку, и здесь поделюсь процессом.
P.S.: В конце оставлю ссылку на GitHub
Первые шаги
Первое, с чего я решил начать — это удобное создание потоков из функций. Для этого я написал простенький декоратор, выглядит он так:
# thr.py from threading import Thread as thrd __all__ = ['Thr'] # Класс для всего содержимого либы class Thr: # Собственно, декоратор def thread(fn): def thr(*args, **kwargs): thrd(target = fn, args = (*args,), kwargs=<**kwargs,>).start() pass return thr pass # конец файлаВот и всё. Теперь можно очень удобно создавать потоки:
from thr import Thr # пример использования @Thr.thread def func1(a, b, c): if a+b > c: if a+c > b: if b+c > a: print("треугольник существует") pass pass pass print("треугольник не существует") pass # возвращение значений пока не предусмотрено for a, b, c in zip(range(1, 10), range(6, 15), range(11, 20)): func1(a, b, c) passУдобнее чем было, так ведь? Но мне стало мало.
Среды для потоков
Мне стало не удобно обеспечивать верное взаимодействий потоков. Например, мне надо чтобы 2 цикла решали последовательности чисел для 3n+1. Тогда, мне приходилось мучить Python глобальными переменными. И я нашел выход!
P.S.: Возможно, это и есть ThreadPoolExecutor, которым я никогда не пользовался. Если это так, то, возможно, просто кому-то мой метод покажется удобнее.
Давайте объясню. Вы создаёте среду для потоков(можно несколько) и немного адаптируете потоковые функции под себя. код библиотеки:
# thr.py from curses.ascii import isalnum from threading import Thread as thrd from random import randrange from sys import exit as exitall __all__ = ['Thr'] # f-str не позволяет использовать "\" напрямую, # пришлось выкручиваться =) nl = "\n" bs = "\b" tb = "\t" rt = "\r" # просто полезная функция def strcleanup(s: str = ""): while s[0] == ' ': s = s[1:] while s[-1] == ' ': s = s[:-1] if not isalnum(s[0]): s = '_' + s s = s.replace(' ', '_') for i in range(len(s)): if not isalnum(s[i]): s = s.replace(s[i], '_') pass pass s += f"" return s # Класс для всего содержимого либы class Thr: # класс для сред потоков class Env(object): # поля # потоки thrs: list = None # возвращаемые значения rets: dict = None # название среды name: str = None # методы # инициализация def __init__(self, name): self.thrs = [] self.rets = <> self.__name__ = self.name = name # self.name на всякий случай. # __name__ - магическая переменная, вдруг поменяется. pass # в строку __str__ = lambda self:\ f"""ThreadSpace "": threads""" # тоже в строку, но скорее для дебага, чем для печати юзеру __repr__ = lambda self:\ f"""ThreadSpace "" threads: <(nl+" ").join(self.thrs)>total: """ def __add__(self, other): self.thrs = <**self.thrs, **other.thrs>pass # Декоратор/метод для добавления в список потоков. def append(self, fn): # функции нужен docstring self.thrs += [ID] self.rets[ID] = None # class Thrd(object): space = None fn = None thr = None runned = None ret = None def __init__(slf, ID, self, fn): slf.ID = ID slf.space = self slf.fn = fn slf.thr = None slf.runned = False slf.ret = False pass def run(slf, *args): if slf.runned: print(f"Exception: Thread \"\" of threadspace \"\" already started") exitall(1) pass slf.thr = thrd(target = slf.fn, args = (slf, slf.space, slf.ID, *args,)) slf.thr.start() slf.runned = True pass def join(slf): if not slf.runned: print(f"Exception: Thread \"\" of threadspace \"\" not started yet") exitall(1) pass slf.thr.join() slf.runned = False pass def get(slf): if not slf.ret: print(f"Exception: Thread \"\" of threadspace \"\" didn`t return anything yet") exitall(1) pass slf.runned = False return slf.space.rets[slf.ID] def getrun(slf, *args): slf.run(*args) slf.join() return slf.get() pass return Thrd(ID, self, fn) pass # Декоратор для "голого" потока def thread(fn): def thr(*args, **kwargs): thrd(target = fn, args = (*args,), kwargs=<**kwargs,>).start() pass return thr pass # конец файла Пример вывода об ошибке:
Traceback (most recent call last): File "test.py", line 37, in loop.run() File "thr.py", line 93, in run raise Exception(. ) Exception: Thread "3n_1_mainloop" of threadspace "3n+1" already startedКак быстро вырос объём кода по сравнению с предыдущим вариантом! Итак, пример использования:
from random import randint from thr import Thr Space = Thr.Env("3n+1") @Space.append def hdl(t, spc, ID, num): """3n+1_handle""" if num % 2 == 0: # значения возвращать так t.ret = True spc.rets[ID] = num/2 return # значения возвращать так t.ret = True spc.rets[ID] = 3*num+1 return @Space.append def loop(t, spc, ID, num): """3n+1_mainloop""" steps = 0 while num not in (4, 2, 1): num = hdl.getrun(num) steps += 1 pass # значения возвращать так t.ret = True spc.rets[ID] = steps return print() print(Space) print() print(repr(Space)) ticks = 0 num = randint(5, 100) loop.run(num) while not loop.ret: ticks += 1 pass print(f"loop reached 4 -> 2 -> 1 trap,\n" f"time has passed (loop ticks):\n" f", steps has passed: , start number: ")ThreadSpace "3n+1": 2 threads ThreadSpace "3n+1" threads: 3n_1_handle840 3n_1_mainloop515 total: 2 loop reached 4 -> 2 -> 1 trap, time has passed (loop ticks): 13606839, steps has passed: 33, start number: 78Итак, на этом и завершу эту статью. Спасибо за внимание!
Многопоточность в Python. Библиотеки threading и multiprocessing.
Процесс — исполняемый экземпляр какой-либо программы. Каждый процесс состоит из следующих элементов:
- образ машинного кода;
- область памяти, в которую включается исполняемый код, данные процесса (входные и выходные данные), стек вызовов и куча (для хранения динамически создаваемых данных);
- дескрипторы операционной системы (например, файловые дескрипторы);
- состояние процесса.
В целях стабильности и безопасности, в современных операционных системы каждый процесс имеет прямой доступ только с своим собственным ресурсам. Доступ к ресурсам другого процесса возможен через межпроцессное взаимодействие (например, посредством файлов, при помощи именованных и неименованных каналов и другие).
Сам процесс может быть разделен на так называемые потоки. Поток (поток выполнения, thread) — наименьшая единица обработки, исполнение которой может быть назначено ядром операционной системы. В отличии от нескольких процессов, потоки существуют внутри одного процесса и имеют доступ к ресурсам этого процесса. Каждый поток обладет собственным набором регистров и собственным стеком вызова, но доступ к ним имеют и другие потоки.
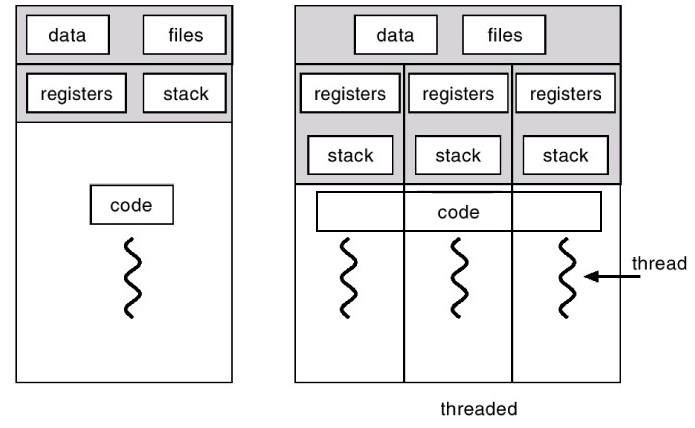
При работе с потоками стоит учесть несколько моментов:
- одно ядро процессора в один момент может исполнять только один поток;
- потоки одного процесса могут исполняться физически одновременно (на разных ядрах);
- бессмысленно порождать потоков больше, чем у вас есть ядер.
Потоки имеют несколько применений. Первое — ускорение работы программы. Ускорение достигается за счет параллельного выполнения независимых друг от друга вычислений. Например, при численном интегрировании область интегрирования может быть разбита на 3 участка. На каждый участок создается свой поток, в котором численно вычислется интеграл для конкретного участка. Второе — независимое исполнение операций. Отличие этого случая от первого хорошо видно на следующем примере. Пусть есть приложение с графическим интерфейсом, где весь код выполняется в одном потоке. При выполнении какой-нибудь долгой операции (например, копирование файла) интерфейс приложения просто перестанет отвечать до тех пор, пока долгий процесс не завершится. В таком случае в один поток помещается работа графического интерфейса, в другой — остальные вычисления. В таком случае интерфейс позволит проводить другие операции даже во время выполнения долгой операции в другом потоке (например, заполнение прогресс бара в процессе копирования файла).
threading
В Python работа с потоками осуществляется при помощи стандартной библиотеки threading. В библиотеке представлен класс Thread для создания потока выполнения. Задание исполняемого кода в отдельном потоке возможно двумя способами:
- передача исполняемого объекта (функции) в конструктор класса;
- переопределение функции run() в классе-наследнике.
После того, как объект создан, поток запускается путем вызова метода start(). Рассмотрим простой пример:
import threading import sys def thread_job(number): print('Hello <>'.format(number)) sys.stdout.flush() def run_threads(count): threads = [ threading.Thread(target=thread_job, args=(i,)) for i in range(0, count) ] for thread in threads: thread.start() # каждый поток должен быть запущен for thread in threads: thread.join() # дожидаемся исполнения всех потоков run_threads(4) print(finish)
Конструктор класса Thread имеет следующие аргументы:
- group должно быть None; зарезервировано для будующих реализаций Python 3;
- target является исполняемым объектом (по умолчанию равен None, ничего не исполняется);
- name обозначет имя потока (по умолчанию имя генерируется автоматически);
- args — кортеж аргументов для исполняемого объекта;
- kwargs — словарь именованных аргументов для исполняемого объекта;
- daemon равное True обозначет служебный поток (служебные потоки завершаются принудительно при завершении процесса); по умолчанию False.
В Python выполнение программы заканчивается, когда все неслужебные потоки завершены. Модифицировав программу выше, мы все еще получим корректно работающий код:
import threading import sys import time def thread_job(number): time.sleep(2) # "усыпляем" поток на 2 сек print('Hello <>'.format(number)) sys.stdout.flush() def run_threads(count): threads = [ threading.Thread(target=thread_job, args=(i,)) for i in range(1, count) ] for thread in threads: thread.start() # каждый поток должен быть запущен run_threads(1) print(finish)
Как можно увидеть, программа завершается без ошибок (с кодом 0), но теперь строка «finish» печатается раньше строки «Hello 0», т.к. главный поток теперь не ждет завершения работы других потоков. Метод join() используется для блокирования исполнения родительского потока до тех пор, пока созданный поток не завершится. Это нужно в случаях, когда для работы потока-родителя необходим результат работы потока-потомка. Вспомним пример с численным интегрированием. Вычисление итогового значения интеграла выполняется в главном потоке, но это возможно только после завершения вычислений в побочных потоках. В таком случае главный поток нужно просто приостановить до тех пор, пока не завершатся все побочные потоки. Метод join() может принимать один аргумент — таймаут в секундах. Если таймаут задан, join() бликирует работу на указанное время. Если по истечении времени ожидаемый поток не будет завершен, join() все равно разблокирует работу потока, вызвашего его. Проверить, исполняется ли поток можно методом is_alive(). Подробнее ознакомиться с функционалом библиотеки можно в официальной документации по threading.
Упражнение №1
Запустите следующий код. В чем проблема данного кода? Всегда ли counter = 10 после исполнения кода программы?
import threading import sys def thread_job(): global counter old_counter = counter counter = old_counter + 1 print('<> '.format(counter), end='') sys.stdout.flush() counter = 0 threads = [threading.Thread(target=thread_job) for _ in range(10)] for thread in threads: thread.start() for thread in threads: thread.join() print(counter)
Демонстрация «проблемности» кода:
import threading import random import time import sys def thread_job(): global counter old_counter = counter time.sleep(random.randint(0, 1)) counter = old_counter + 1 print('<> '.format(counter), end='') sys.stdout.flush() counter = 0 threads = [threading.Thread(target=thread_job) for _ in range(10)] for thread in threads: thread.start() for thread in threads: thread.join() print(counter)
Почему так происходит? Есть несколько возможных решений этой проблемы.
import threading import random import time import sys def thread_job(): lock.acquire() # mutex global counter old_counter = counter time.sleep(random.randint(0, 1)) counter = old_counter + 1 print('<> '.format(counter), end='') sys.stdout.flush() lock.release() lock = threading.Lock() counter = 0 threads = [threading.Thread(target=thread_job) for _ in range(10)] for thread in threads: thread.start() for thread in threads: thread.join() print(counter)
import threading import random import time import sys def thread_job(): with lock: global counter old_counter = counter time.sleep(random.randint(0, 1)) counter = old_counter + 1 print('<> '.format(counter), end='') sys.stdout.flush() lock = threading.Lock() counter = 0 threads = [threading.Thread(target=thread_job) for _ in range(10)] for thread in threads: thread.start() for thread in threads: thread.join() print(counter)
Вариант с контекстным менеджером более предпочтителен. Вспомните работу с файлами при помощи with. По завершении with файл автоматически закрывался. В данном случае похожая ситуация. Для того, чтобы запретить нескольким потокам параллельно выполнять некоторые участки кода, мы используем Lock (в UNIX системах более известен как мьютекс (mutex)). Мьютекс может быть в двух состояниях: свободен и заблокирован. Если какой-либо поток пытается заблокировать уже заблокированный мьютекс, то поток блокируется до тех пор, пока мьютекс не освободится. Причем если несколько потоков претендует на блокирование мьютекса, то потоки просто выстраиваются в очередь. Главная проблема — не освобожденный мьютекс. Отсутствие строчки lock.release() может повесить остальные потоки в бесконечное ожидание. Контекстный менеджер позволит избежать этой проблемы. Как только он закончится, все захваченные им ресурсы будут освобождены, в том числе мьютекс.
Упражнение №2
Иногда бывает нужно узнать доступность набора ip адресов. Неэффективный вариант представлен ниже.
Реализуйте то же самое, но используя threading.
import os, re received_packages = re.compile(r"(\d) received") status = ("no response", "alive but losses", "alive") for suffix in range(20, 30): ip = "192.168.178." + str(suffix) ping_out = os.popen("ping -q -c2 " + ip, "r") # получение вердикта print(". pinging ", ip) while True: line = ping_out.readline() if not line: break n_received = received_packages.findall(line) if n_received: print(ip + ": " + status[int(n_received[0])])
Global Interpreter Lock (GIL)
CPython — популярная реализация интерпретатора — имеет встроенный механизм, который обеспечивает выполнение ровно одного потока в любой момент времени. GIL облегчает реализацию интерпретатора, защищая объекты от одновременного доступа из нескольких потоков. По этой причине, создание несколько потоков не приведет к их одновременному исполнению на разных ядрах процессора.
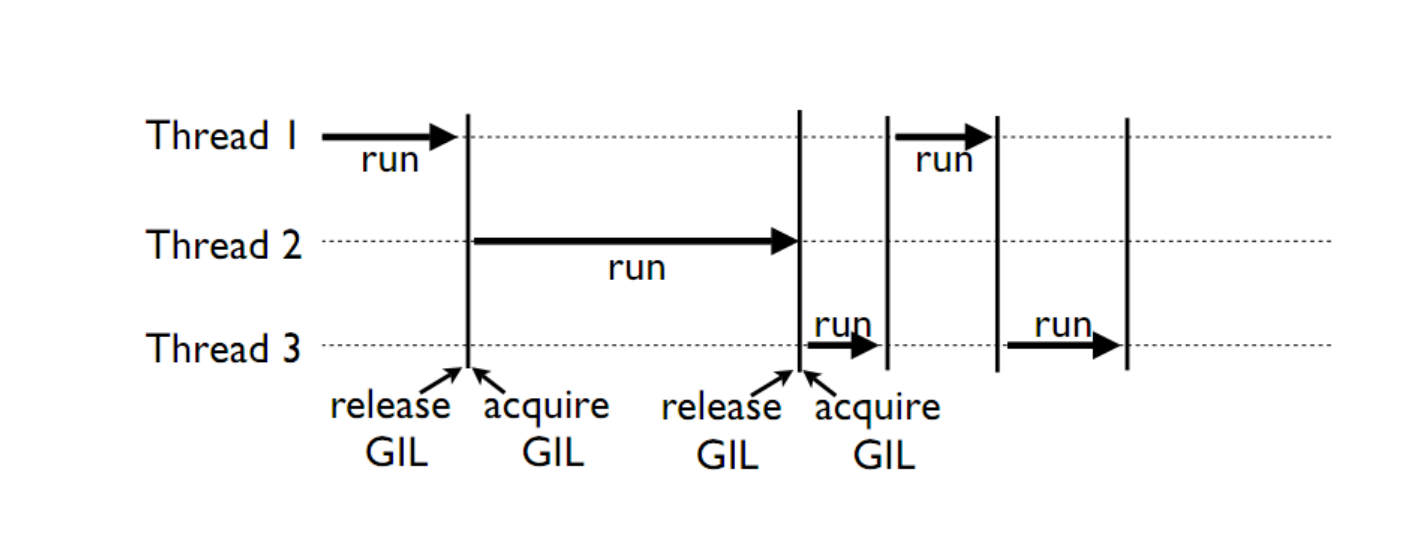
Однако, некоторые модули, как стандартные, так и сторонние, созданы для освобождения GIL при выполнении тяжелых вычислительных операций (например, сжатие или хеширование). К тому же, GIL всегда свободен при выполнении операций ввода-вывода.
Упражнение №3
Написать программу, которая будет находить сумму чисел массива с использованием N потоков. Запустить с разным параметром N. Убедиться, что несмотря на увеличение N, ускорения подсчета не происходит. Причина этому — GIL. В Python вычисления распараллеливать бессмысленно. Замерить время работы можно с помощью библиотеки time (ответ в секундах):
start = time.time() # код, время работы которого надо замерить print(time.time() - start)
Упражнение №4
Запустите на исполнение, замерив время работы. Перепишите с помощью потоков и опять замерьте время.
import urllib.request import time urls = [ 'https://www.yandex.ru', 'https://www.google.com', 'https://habrahabr.ru', 'https://www.python.org', 'https://isocpp.org', ] def read_url(url): with urllib.request.urlopen(url) as u: return u.read() start = time.time() for url in urls: read_url(url) print(time.time() - start)
Потоки очень уместны, если в коде есть блокирующие операции (ввод-вывод, сетевые взаимодействия). Также, удобно разбивать логические процессы по потокам (анимация, графический интерфейс, и тд).
multiprocessing
Библиотека multiprocessing позволяет организовать параллелизм вычислений за счет создания подпроцессов. Т.к. каждый процесс выполняется независимо от других, этот метод параллелизма позволяет избежать проблем с GIL. Предоставляемый библиотекой API схож с тем, что есть в threading, хотя есть уникальные вещи. Создание процесса происходит поутем создания объекта класса Process. Аргументы конструктора аналогичны тем, что есть в конструкторе Thread. В том числе аргумент daemon позволяет создавать служебные процессы. Служебные процессы завершаются вместе с родительским процессом и не могут порождать свои подпроцессы.
Простой пример работы с библиотекой:
from multiprocessing import Process def f(name): print('hello', name) if __name__ == '__main__': p = Process(target=f, args=('bob',)) p.start() p.join()
Чтобы убедить, что каждый процесс имеет свой ID, запустите пример:
from multiprocessing import Process import os def info(title): print(title) print('module name:', __name__) print('parent process:', os.getppid()) print('process id:', os.getpid()) def f(name): info('function f') print('hello', name) if __name__ == '__main__': info('main line') p = Process(target=f, args=('bob',)) p.start() p.join()
Старайтесь не забывать про конструкцию __name__ == ‘__main__’ . Это надо для того, чтобы ваш модуль можно было безопасно подключать в другие модули и при этом не создавались новые процессы без вашего ведома.
Упражнение №5
Запустите код. Попробуйте объяснить, почему LIST — пуст.
import multiprocessing def worker(): LIST.append('item') LIST = [] if __name__ == "__main__": processes = [ multiprocessing.Process(target=worker) for _ in range(5) ] for p in processes: p.start() for p in processes: p.join() print(LIST)
Общение между процессами
multiprocessing предоставляет два вида межпроцессного обмена данными: очереди и каналы данных (pipe).
Очереди (класс Queue) аналогичны структуре данных «очередь», рассмотренной вами в курсе алгоритмов.
from multiprocessing import Process, Queue def f(q): q.put([42, None, 'hello']) if __name__ == '__main__': q = Queue() p = Process(target=f, args=(q,)) p.start() print(q.get()) # выводит "[42, None, 'hello']" p.join()
Класс Pipe отвечает за канал обмена данными (по умолчанию, двунаправленный), представленный двумя концами, объектами класса Connection. С одним концом канала работает родительский процесс, а с другим концом — подпроцесс.
from multiprocessing import Process, Pipe def f(conn): conn.send([42, None, 'hello']) conn.close() if __name__ == '__main__': parent_conn, child_conn = Pipe() p = Process(target=f, args=(child_conn,)) p.start() print(parent_conn.recv()) # выводит "[42, None, 'hello']" p.join()
Еще один вид обмена данными может быть достигнут путем записи/чтения обычных файлов. Чтобы исключить одновременную работу двух процессов с одним файлом, в библиотеке есть классы аналогичные threading.
from multiprocessing import Process, Lock def f(l, i): l.acquire() try: print('hello world', i) finally: l.release() if __name__ == '__main__': lock = Lock() for num in range(10): Process(target=f, args=(lock, num)).start()
Подробнее ознакомиться с функционалом библиотеки можно в официальной документации по multiprocessing.
Класс Pool в multiprocessing
Класс Pool — удобный механизм распараллеливания выполнения функций, распределения входных данных по процессам и т.д.
Наиболее интересные функции: Pool.apply, Pool.map, Pool.apply_async, Pool.map_async.
apply, map работают аналогично питоновским built-in apply, map.
Как работает Pool можно понять на примере:
from multiprocessing import Pool def cube(x): return x**3 if __name__ == "__main__": pool = Pool(processes=4) # создаем пул из 4 процессов # в apply можно передать несколько аргументов results = [pool.apply(cube, args=(x,)) for x in range(1,7)] # раскидываем числа от 1 до 7 по 4 процессам print(results) pool = Pool(processes=4) # то же самое, но с map. разбивает итерируемый объект (range(1,7)) на chunks и раскидывает аргументы по процессам results = pool.map(cube, range(1,7)) print(results)
map, apply — блокирующие вызовы. Главная программа будет заблокирована, пока процесс не выполнит работу.
map_async, apply_async — неблокирующие. При их вызове, они сразу возвращают управление в главную программу (возвращают ApplyResult как результат). Метод get() объекта ApplyResult блокирует основной поток, пока функция не будет выполнена.
pool = mp.Pool(processes=4) results = [pool.apply_async(cube, args=(x,)) for x in range(1,7)] output = [p.get() for p in results] print(output)
Упражение №6*
Для этого упражнения скачайте архив viterbi_mp.zip с кодом и необходимыми данными.
Рассмотрим следующую задачу. Положение мобильного робота на двумерной карте может быть представлено тремя числами: x, y и направлением θ. Точное положение робота нам не известно. В связи с этим мы строим N гипотез о его пложении, сумма их вероятностей равна 1. В процессе движения робота некоторые гипотезы исчезали, а некоторые порождали новые. Однако в каждый момент времени количество гипотез — константа. Известно, какая гипотеза из какой была порождена.
Представленный (и слегка упрощенный) выше метод оценки положения робота множеством гипотез называется фильтром частиц, а сами гипотезы называются частицами. Фильтр частиц используется для оценки положения робота в процессе его движения. Вспомним, что в процессе работы некоторые частицы погибают, а некоторые порождают другие. Переходы между частицами образуют граф перехода. Используя этот граф, можно оценить траекторию робота с некоторой точностью.
Задача: необходимо восстановить траекторию движения робота. Есть несколько способов приближенно решить данную задачу. Один из способов — восстановить наиболее вероятную траекторию. Для этого воспользуемся алгоритмом Витерби, одним из алгоритмов динамического программирования.
Пусть у нас было T моментов времени. На каждом моменте времени t мы для каждой частицы, существующей в момент времени t, выбираем наиболее вероятный переход из какой-нибудь частицы с момента времени t-1. Тогда ответом будет — argmax по вероятности среди всех частиц в последний момент времени. Однако, сам алгоритм довольно медленный. Его асимптотика O(T * N^2) .
В архиве вам предоставлен код в файле generate_viterbi_trajectory.py . Однако, он написан без распараллеливания. Ваша задача — распараллелить код, используя multiprocessing. Файл graph.ldj представляет собой текстовый файл, где каждая строка в формате JSON. Каждая строка представляет собой один момент времени. В этом задании вам предлагаются первые 10 моментов времени движения робота. В каждый момент времени количество частиц N = 2000 . Файл localization_config.json — файл конфигурации, содержащий параметры с которыми происходила генерация графа. Файл true_trajectory.json содержит массив троек чисел (x, y, θ), построенный нераспараллеленым алгоритмом. Вам надо будет сравнить полученную вами траекторию с данной при помощи скрипта correspond_trajectories.py . Для тех, кто хочет попробовать свой код на больших данных, используйте файл full_graph.ldj , который содержит порядка 1700 строк. Архив с файлом.
Не забудьте замерить время работы. Примерное время работы на моем компьютере для 10 строк в 1 процесс — 300 сек.
Сайт построен с использованием Pelican. За основу оформления взята тема от Smashing Magazine. Исходные тексты программ, приведённые на этом сайте, распространяются под лицензией GPLv3, все остальные материалы сайта распространяются под лицензией CC-BY.
Python. Урок 22. Потоки и процессы в Python. Часть 1. Управление потоками


Этот урок открывает цикл статей, посвященных параллельному программированию в Python. В рамках данного урока будут рассмотрены вопросы терминологии, относящиеся к параллельному программированию, GIL, создание и управление потоками в Python.
- Синхронность и асинхронность. Параллелизм в конкурентность
- Несколько слов о GIL
- Потоки в Python
- Создание и ожидание завершения работы потоков. Класс Thread
- Создание классов наследников от Thread
- Принудительное завершение работы потока
- Потоки-демоны
Синхронность и асинхронность. Параллелизм и конкурентность
Для начала разберемся с терминологией, которую мы будем использовать в рамках данного цикла статей, посвященного параллельному программированию на Python .
Синхронное выполнение программы подразумевает последовательное выполнение операций. Асинхронное – предполагает возможность независимого выполнения задач.
Приведем пример из математики, представьте, что у нас есть функция:
Для того, чтобы определить, чему равно значение функции при x=4, нам необходимо вначале вычислить выражение (x+1) и только потом, полученное значение возвести в квадрат:
Это пример синхронного порядка вычисления: операции были выполнены последовательно и, в данном случае, по-другому быть не могло.
Теперь посмотрите на такую функцию:
Для вычисления значения функции в точке x=4 мы также можем придерживаться синхронного порядка: вначале выполнить операцию возведения в квадрат, потом вычислим произведение и просуммируем полученные результаты:
Если внимательно посмотреть на эту функцию, то можно заметить, что для того, чтобы вычислить x^2 не нужно знать значение произведения 2*x и наоборот. Операции вычисления квадратного корня и произведения можно выполнять независимо друг от друга.
… значения 4^2 и 2*4 вычисляются независимо разными вычислителями…
Более житейский пример будет выглядеть так: синхронность — это когда вы сначала сварили картошку, а потом помыли кастрюлю, и помыть ее раньше того, как в ней приготовили вы не можете. Асинхронность — это когда вы варите картошку и одновременно прибираетесь на кухне – эти задачи можно выполнять параллельно.
Теперь несколько слов о конкурентности и параллелизме . Конкурентность предполагает выполнение нескольких задач одним исполнителем. Из примера с готовкой: один человек варит картошку и прибирается, при этом, в процессе, он может переключаться: немного прибрался, пошел помешал-посмотрел на картошку, и делает он это до тех пор, пока все не будет готово.
Параллельность предполагает параллельное выполнение задач разными исполнителями: один человек занимается готовкой, другой приборкой. В примере с математикой операции 4^2 и 2*4 могут выполнять два разных процессора.
Несколько слов о GIL
Для того, чтобы двигаться дальше необходимо сказать несколько слов о GIL . GIL — это аббревиатура от Global Interpreter Lock – глобальная блокировка интерпретатора. Он является элементом эталонной реализации языка Python , которая носит название CPython . Суть GIL заключается в том, что выполнять байт код может только один поток. Это нужно для того, чтобы упростить работу с памятью (на уровне интерпретатора) и сделать комфортной разработку модулей на языке C . Это приводит к некоторым особенностям, о которых необходимо помнить. Условно, все задачи можно разделить на две большие группы: в первую входят те, что преимущественно используют процессор для своего выполнения, например, математические, их ещё называют CPU-bound , во вторую – задачи работающие с вводом выводом (диск, сеть и т.п.), такие задачи называют IO-bound . Если вы запустили в одном интерпретаторе несколько потоков, которые в основном используют процессор, то скорее всего получите общее замедление работы, а не прирост производительности. Пока выполняется одна задача, остальные простаивают (из-за GIL), переключение происходит через определенные промежутки времени. Таким образом, в каждый конкретный момент времени, будет выполняться только один поток, несмотря на то, что у вас может быть многоядерный процессор (или многопроцессорный сервер), плюс ко всему, будет тратиться время на переключение между задачами. Если код в потоках в основном выполняет операции ввода-вывода, то в этом случае ситуация будет в вашу пользу. В CPython все стандартные библиотечные функций, которые выполняют блокирующий ввод-вывод, освобождают GIL , это дает возможность поработать другим потокам, пока ожидается ответ от ОС.
Потоки в Python
Потоки позволяют запустить выполнение нескольких задач в конкурентном режиме в рамках одного процесса интерпретатора. При этом, нужно помнить о GIL . Все потоки будут выполняться на одном CPU , даже если задачи могут выполняться параллельно. Поэтому есть такое правило, если ваши задачи в основном потребляют ресурсы процессора, то используйте процессы, если ввод-вывод, то потоки и другие инструменты асинхронного программирования, которые в Python обладают довольно мощным функционалом.
Создание и ожидание завершения работы потоков. Класс Thread
За создание, управление и мониторинг потоков отвечает класс Thread из модуля threading . Поток можно создать на базе функции, либо реализовать свой класс – наследник Thread и переопределить в нем метод run() . Для начала рассмотрим вариант создания потока на базе функции:
from threading import Thread from time import sleep def func(): for i in range(5): print(f"from child thread: ") sleep(0.5) th = Thread(target=func) th.start() for i in range(5): print(f"from main thread: ") sleep(1)
В приведенном выше примере мы импортировали нужные модули. После этого объявили функцию func() , которая выводит пять раз сообщение с числовым маркером с задержкой в 500 мс. Далее создали объект класса Thread , в нем, через параметр target, указали, какую функцию запускать как поток и запустили его. В главном потоке добавили код вывода сообщений с интервалом в 1000 мс.
В результате запуска этого кода получим следующее:
from child thread: 0 from main thread: 0 from child thread: 1 from main thread: 1 from child thread: 2 from child thread: 3 from main thread: 2 from child thread: 4 from main thread: 3 from main thread: 4
Как вы можете видеть, код из главного и дочернего потоков выполняются псевдопараллельно (во всяком случае создается такое ощущение), т.к. задержка в дочернем потоке меньше, то сообщение из него появляются чаще.
Если необходимо дождаться завершения работы потока(ов) перед тем как начать выполнять какую-то другую работу, то воспользуйтесь методом join() :
th1 = Thread(target=func) th2 = Thread(target=func) th1.start() th2.start() th1.join() th2.join() print("--> stop")
У join() есть параметр timeout , через который задается время ожидания завершения работы потоков.
Для того, чтобы определить выполняет ли поток какую-то работу или завершился используется метод is_alive() .
th = Thread(target=func) print(f"thread status: ") th.start() print(f"thread status: ") sleep(5) print(f"thread status: ")
В результате получим следующее:
thread status: False from child thread: 0 thread status: True from child thread: 1 from child thread: 2 from child thread: 3 from child thread: 4 thread status: False
Для задания потоку имени воспользуйтесь свойством name .
Создание классов наследников от Thread
Ещё одни способ создавать и управлять потоками – это реализовать класс наследник от Thread и переопределить у него метод run() .
class CustomThread(Thread): def __init__(self, limit): Thread.__init__(self) self._limit = limit def run(self): for i in range(self._limit): print(f"from CustomThread: ") sleep(0.5) cth = CustomThread(3) cth.start()
В терминале получим следующее:
from CustomThread: 0 from CustomThread: 1 from CustomThread: 2
Принудительное завершение работы потока
В Python у объектов класса Thread нет методов для принудительного завершения работы потока. Один из вариантов решения этой задачи – это создать специальный флаг, через который потоку будет передаваться сигнал остановки. Доступ к такому флагу должен управляться объектом синхронизации.
from threading import Thread, Lock from time import sleep lock = Lock() stop_thread = False def infinit_worker(): print("Start infinit_worker()") while True: print("--> thread work") lock.acquire() if stop_thread is True: break lock.release() sleep(0.1) print("Stop infinit_worker()") # Create and start thread th = Thread(target=infinit_worker) th.start() sleep(2) # Stop thread lock.acquire() stop_thread = True lock.release()
Если мы запустим эту программу, то в консоли увидим следующее:
Start infinit_worker() --> thread work --> thread work --> thread work --> thread work --> thread work Stop infinit_worker()
Разберемся с этим кодом более подробно. В строке 4 мы создаем объект класса Lock , он используется для синхронизации доступа к ресурсам из нескольких потоков, про них мы более подробно расскажем в следующей статье. В нашем случае, ресурс — это переменная stop_thread , объявленная в строке 6, которая используется как сигнал для остановки потока. После этого, в строке 8, объявляется функция infinit_worker() , ее мы запустим как поток. В ней выполняется бесконечный цикл, каждый проход которого отмечается выводом в терминал сообщения “ –> thread work ” и проверкой состояния переменной stop_thread . В главном потоке программы создается и запускается дочерний поток (строки 24, 25), выполняется функция задержки и принудительно завершается поток путем установки переменной stop_thread значения True .
Потоки-демоны
Есть такая разновидность потоков, которые называются демоны (терминология взята из мира Unix -подобных систем). Python-приложение не будет закрыто до тех пор, пока в нем работает хотя бы один недемонический поток.
def func(): for i in range(5): print(f"from child thread: ") sleep(0.5) th = Thread(target=func) th.start() print("App stop")
from child thread: 0 App stop from child thread: 1 from child thread: 2 from child thread: 3 from child thread: 4
Как вы можете видеть, приложение продолжает работать, даже после того, как главный поток завершился (сообщение: “App stop”).
Для того, чтобы потоки не мешали остановке приложения (т.е. чтобы они останавливались вместе с завершением работы программы) необходимо при создании объекта Thread аргументу daemon присвоить значение True , либо после создания потока, перед его запуском присвоить свойству deamon значение True . Изменим процесс создания потока в приведенной выше программе:
th = Thread(target=func, daemon=True)
Запустим ее, получим следующий результат:
from child thread: 0 App stop
Поток остановился вместе с остановкой приложения.
P.S.
Вводные уроки по “Линейной алгебре на Python” вы можете найти соответствующей странице нашего сайта . Все уроки по этой теме собраны в книге “Линейная алгебра на Python”.
Если вам интересна тема анализа данных, то мы рекомендуем ознакомиться с библиотекой Pandas. Для начала вы можете познакомиться с вводными уроками. Все уроки по библиотеке Pandas собраны в книге “Pandas. Работа с данными”.
Python. Урок 22. Потоки и процессы в Python. Часть 1. Управление потоками : 2 комментария
- Константин 19.08.2020 Замечательные уроки, коротко и понятно излагаете важные вещи!
Жду следующие статьи, продолжайте в том же духе!
Использование потоков в Python
Во время выполнения программы могут возникать задачи, требующие параллельного выполнения. Например, если программа должна обрабатывать большой объем данных, она может быть разделена на несколько потоков, каждый из которых будет обрабатывать часть данных. Это позволит ускорить выполнение программы и сделать ее более эффективной.
В Python для создания потоков используется модуль threading. Рассмотрим простой пример, в котором создаются два потока, каждый из которых выполняет свою функцию.
import threading import time def function1(): for i in range(5): print('Function 1:', i) time.sleep(1) def function2(): for i in range(5): print('Function 2:', i) time.sleep(1) thread1 = threading.Thread(target=function1) thread2 = threading.Thread(target=function2) thread1.start() thread2.start() thread1.join() thread2.join()
В этом примере функция threading.Thread используется для создания потока. Аргумент target определяет функцию, которую будет выполнять поток. Метод start запускает поток, а метод join гарантирует, что поток будет выполнен до конца, прежде чем программа продолжит выполнение следующего кода.
Обратите внимание, что порядок выполнения потоков не гарантирован. В зависимости от того, как операционная система управляет потоками, функция function1 может быть выполнена до, после или одновременно с функцией function2 .
Работа с потоками требует внимательности, так как одновременное использование одних и тех же данных несколькими потоками может привести к ошибкам. Для управления доступом к данным можно использовать блокировки из модуля threading.
Так, с помощью потоков можно ускорить выполнение программы, разделив ее на несколько независимых частей.