Организация хранения личных файлов локально и в облаках
Статья написана для тех, кто ищет наилучший способ организации хранения и управления своими файлами и хочет при этом пользоваться всеми преимуществами наиболее распространенных на сегодняшний день облачных хранилищ.
Найти
- Единую структуру папок для хранения и «обозрения» всех файлов.
- Способ реализации такой единой структуры с использованием преимуществ всех облачных хранилищ.
Дано
- Со временем мы накапливаем все больший объем информации (большая часть которого по-прежнему хранится в файлах). Эти файлы требуют организованного хранения и управления.
- Сейчас широко распространено не менее 5 основных облачных хранилищ (причем каждое обладает своими преимуществами):
— Google Drive — интеграция со всеми сервисами Google, распространено среди коллег (людей, с которыми часто приходится обмениваться информацией), удобный облачный офис;
— DropBox — распространено среди коллег;
— SkyDrive — распространено среди коллег, удобный облачный офис для работы с документами MS Office;
— Яндекс.Диск — (UPD) подарили навсегда 200 Гб за ошибку в одной из версий десктопного клиента, подарили 2 Гб на 2014 год;
— Облако.Mail.ru — подарили 1 Тб навсегда. - Файлы единой организованной структуры не могут быть размещены в одном облаке под двум причинам:
— бесплатные объемы недостаточны, и чем больше бесплатный объем тем беднее функционал и качество работы сервиса,
— предпочтения коллег также накладывают серьезные ограничения (по одному проекту могут быть одновременно файлы совместно редактируемые на Google Drive и SkyDrive, общие папки на DropBox). - Операционные системы
— десктоп: Windows 8.1,
— смартфон и планшет: Android 4.4. - Имею несколько мест работы, готовлюсь к поступлению в аспирантуру, файловый архив “коплю” уже около 15 лет, то есть информации, с которой приходится работать, достаточно много.
- Это вопрос, который так или иначе вынуждены решать для себя все, и все явно чувствуют несовершенство получаемых решений. В большой степени статья вдохновлена нижеследующими тщетными поисками:
— habrahabr.ru/post/68092
— habrahabr.ru/post/90326 - Сложность, трудоемкость, необходимость высокой квалификации не приветствуются.
Вариант решения
Файловая структура
Мне кажется, для организации хранения файлов уместна следующая классификация данных (файлов).
- Хранить вечно, доступ в будущем не предполагается. Эта категория данных, которую я называю “архивом”. Туда попадают документы “для истории”, которые в обозримом будущем нужны не будут, но когда-нибудь будут представлять “историческую ценность”.
- Хранить вечно, доступ в будущем очень вероятен. Это данные, относящиеся к категории постоянного (перманентного) хранения, доступ к таким данным периодически необходим. Это могут быть книги, музыка, дистрибутивы, сканы личных документов (паспорт, ИНН, прочее) и что угодно еще.
- Срок хранения не определен, доступ в будущем необходим. Это категория файлов проектов и “входящих” (в терминах GTD). Файлы разделены по папкам, каждая из которых соответствует одному проекту (в терминах GTD), и конечно отдельная папка для “входящих”.
Такое разделение данных позволяет четко понимать, что необходимо “старательно” бэкапить и что, в случае отсутствия потерь данных, будет доступно мне в любой момент в будущем.
Также важно, чтобы данное разделение данных было реализовано на одном уровне папок (без вложений), зачем это нужно — будет понятно из следующего раздела.
Структура каталогов, к которой я пришел, выглядит так (назовем ее базовой структурой каталогов):
\ |-archive (архив) |-permanent_books (доступ в будущем будет нужен) |-permanent_music |-permanent_pics |-permanent_scans |-permanent_soft |-permanent_video |-project_pr1 (файлы проекта) |-project_pr2 |-project_pr3 |-project_pr4 |-project_pr5 |-project_pr6 |-temp (“входящие”) Использование облачных хранилищ
Для унификации структуры хранения данных в каждом из облаков следует создать базовую структуру каталогов (если на данном облаке, например, файлы по проекту Х не хранятся, папку проекта можно не создавать, то же относится к архивам и данным постоянного хранения). После этого становится легко понятным — где именно в том или ином облаке сохранять данные, например, по тому или иному проекту.
Для удобства представления данных на компьютере базовую структуру каталогов (не обязательно полностью, по необходимости) предлагается реализовать на уровне библиотек Windows (про библиотеки можно почитать здесь: www.outsidethebox.ms/15096). Именно для этого базовая структура папок должна быть одноуровневой. Библиотеки отображают файлы, расположенные в нескольких папках на диске, и позволяют удобно управлять ими. Кроме того полезно создать библиотеку “Облака”, отображающую содержимое корневых папок всех используемых облачных хранилищ (в этой библиотеке будет несколько папок с одним именем — по одной из каждого облачного хранилища).

- “Общие элементы”. Все содержимое папок библиотеки выводится в единой таблице, без группировки по папке библиотеки (в нашем случае по облачному хранилищу).
- “Видео”. Содержимое библиотеки разбито по папкам библиотеки (облачным хранилищам), и представлено в виде крупных значков.
Теперь, работая с проектом, файлы по которому находятся в нескольких облачных хранилищах, достаточно войти в библиотеку проекта, и все файлы будут доступны для работы. Например, это может выглядеть так:
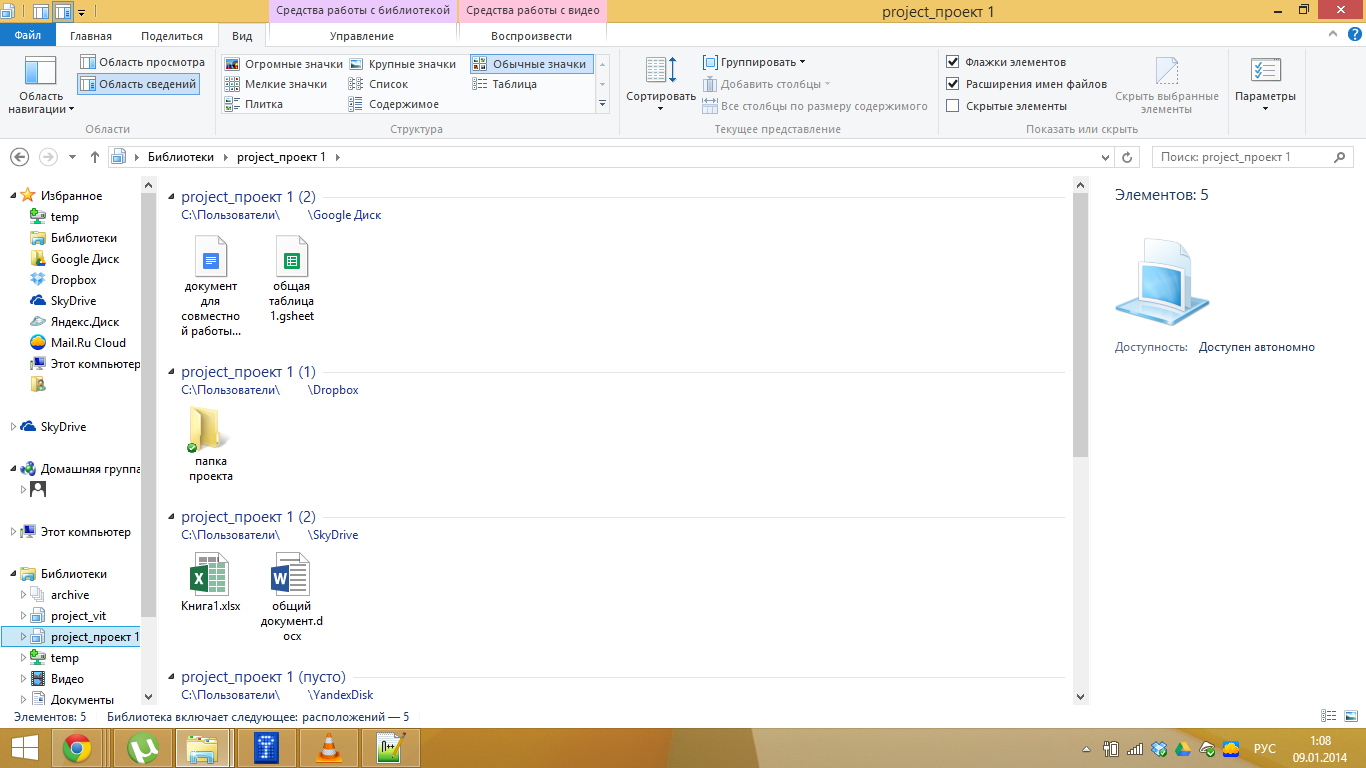
Библиотеки как инструмент крайне просты и удобны для централизованного управления облачными хранилищами и переброски файлов из одного облака в другое буквально в один клик.
Кстати, не все файлы нужно хранить на диске (объем доступного пространства в облачных хранилищах как правило больше объема физического диска). Например, папки “permanent_video” и “permanent_music” я вообще не синхронизирую с компьютером, а обмен с этими папками осуществляю через папку “temp” соответствующего облачного хранилища. Посмотрев какое-то видео, если я хочу сохранить его в облаке, я перемещаю его в папку “temp”, а затем через веб-интерфейс облака перемещаю файл в папку “permanent_video” — файл удаляется с диска компьютера, но сохраняется в облаке.
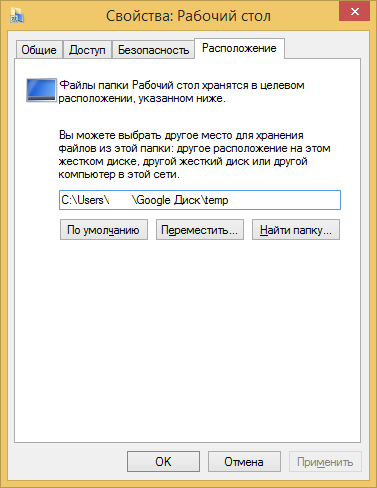
И еще одна небольшая “фишка”. Расположение папки “Рабочий стол” я перенастроил на папку “temp” в моем основном облаке (Google Drive), в эту же папку по умолчанию сохраняются все файлы, скачиваемые через браузер и торрент-клиент. Таким образом все новые файлы автоматически оказываются в одном единственном месте и сразу же попадают в облако.
Изложенное в статье, конечно же, не претендует ни на полноту, ни на абсолютную истинность, но, смею надеяться, может быть полезно читателям для организации собственной системы хранения файлов.
- хранение данных
- хранение файлов
- облачные хранилища
Хранилище файлов для вашей организации
Продолжая настраивать свой бизнес в Microsoft 365, важно понимать, где хранить файлы.
Один из лучших способов настроить хранилище файлов и общий доступ для вашей организации — использовать OneDrive для личных файлов, с которыми вы хотите управлять общим доступом, а SharePoint и Teams — для файлов, к которым должны иметь доступ все или большинство из них.

OneDrive — это платформа облачного хранилища, на которой можно хранить отдельные или личные файлы. OneDrive тесно интегрирован с такими приложениями, как Word, Excel и PowerPoint, что делает его удобным местом для безопасного хранения конфиденциальных документов и доступа к ним.
Используйте OneDrive, когда хотите создать документ, который будет только вашим, например при работе с конфиденциальными или конфиденциальными данными.
Чтобы приступить к работе с OneDrive, войдите в систему, чтобы скачать и установить классическое приложение OneDrive, а затем следуйте инструкциям и выберите папки, которые нужно синхронизировать с облаком.
- Чтобы создать файл в OneDrive, просто нажмите кнопку Создать и выберите нужный тип файла, например документ Word или электронную таблицу Excel.
- Чтобы управлять файлами в OneDrive, щелкните файл правой кнопкой мыши и выберите команду Переименовать , чтобы присвоить ему более описательное имя, или перетащите файлы в разные папки для лучшей организации.
- Чтобы поделиться файлами с OneDrive , нажмите кнопку Поделиться и введите адреса электронной почты пользователей, которым вы хотите предоставить общий доступ к файлу. Дополнительные сведения об управлении файлами в OneDrive.
SharePoint — это средство совместной работы, используемое для управления файлами и информацией в организации и совместного использования. SharePoint позволяет нескольким пользователям совместно работать в одном центральном расположении.
Используйте SharePoint, когда необходимо создать документ, который будет написан и управляться командой людей, или когда к нему необходимо предоставить общий доступ. Например, используйте его в качестве централизованного расположения для членов команды для просмотра временных шкал проекта, задач и вех. Это позволяет командам отслеживать ход выполнения, следить за расписанием и более эффективно сотрудничать.
- Чтобы создать файл в SharePoint, перейдите в библиотеку документов, в которой вы хотите создать файл, и нажмите кнопку Создать .
- Чтобы управлять файлами, проверка файл, чтобы внести в него изменения, а затем проверка файл обратно после завершения.
- Чтобы поделиться файлами, щелкните файл и выберите Поделиться. Вы также можете совместно работать в режиме реального времени, открыв файл в соответствующем приложении, например Word или Excel, и включив совместное редактирование. Чтобы просмотреть предыдущие версии файла, щелкните файл и выберите Журнал версий. Дополнительные сведения об управлении файлами в SharePoint.
Teams и SharePoint
При создании команды автоматически создается соответствующий сайт SharePoint, связанный с командой.
Вы можете использовать SharePoint для хранения файлов, связанных с работой вашей команды, и управления ими непосредственно в Teams. Вы также можете использовать разрешения SharePoint для управления тем, кто может просматривать, редактировать и удалять файлы, а также использовать управление версиями для отслеживания изменений в файлах с течением времени.
При создании канала в Teams создается новая папка на соответствующем сайте SharePoint. Это означает, что все файлы и беседы, связанные с этим каналом, будут храниться в этой папке, что упрощает организацию и управление работой.
Дальнейшие действия
Настроив способ хранения файлов для вашей организации, вы захотите начать совместное использование файлов и совместную работу с другими пользователями.
Домашнее сетевое хранилище — способы создания
Нехватка свободного места на компьютере или других устройствах всегда была актуальной проблемой. Собрать большое количество данных в виде изображений, музыки, видеозаписей, текстов и т.д. — не представляется сейчас чем-то сложным, ведь любой гаджет способен делать фото и видео, а любая мультимедийная информация легкодоступна в интернете.
Конечно, с хранением избыточной информации всегда неплохо справлялись съёмные накопители, особенно хороши на данный момент объёмные внешние винчестеры. Но все их вариации хороши только для хранения данных и их единовременного чтения на одном устройстве. Есть ли более передовые способы, позволяющие обращаться к накопителю любым устройствам одновременно? Да. Речь идёт о создании домашнего сетевого хранилища.
Что такое NAS

Сетевое хранилище NAS (Network Attached Storage) представляет собой подключенный к сети сервер с объёмным диском или дисковым массивом, предназначенный для хранения файлов. Данное оборудование не выполняет никаких вычислительных задач, однако может быть настроено на бесперебойную работу и вмещает в себя внушительный объём информации с доступом для любых устройств домашней сети (компьютеры, ноутбуки, телефоны, планшеты, умные телевизоры, IP-камеры и др.).
Подключается файловое сетевое хранилище по локальной сети, витой парой или через Wi-Fi. Отметим, что некоторые протоколы чувствительны к стабильности сети и беспроводное соединение для них фатально. Поэтому лучше осуществлять соединение с NAS только проводом, с пропускной способностью внутриквартирной сети не менее 1 Гбит/сек.
На какие характеристики ориентироваться при выборе сетевого хранилища
Выбирая NAS для дома обратите внимание на следующие параметры:
- Число дисков или слотов для них (может продаваться как с дисками, так и без). От количества накопителей зависит суммарный объём доступного пространства в файловом хранилище.
- Максимальный объём одного диска влияет на способность NAS конкретных моделей использовать накопители определённого объёма. Особое внимание нужно уделить вопросу поддержки винчестеров больше 2 Тб. Даже дорогие промышленные контролеры старых серий могут не поддерживать такие диски.
- Форм-фактор жёстких дисков. Может поддерживаться 3,5” и/или 2,5”. Данный параметр указывает на возможность установки в хранилище накопителей определённого физического размера. Советуем, заранее проверять высоту корзины для 2,5”.
- ОЗУ и частота процессора — показатели, влияющие на общую производительность, и для NAS относительно малозначимы. Обычно процессор оказывается сильно нагружен, только если NAS начинает выполнять что-то кроме хранения данных (создание/распаковка тяжелых архивов, работа VPN-клиентов и сервисов видеонабюдения). В противном случае, почти любой процессор и оперативная память вам подойдут.
- Функция HotSwap. Возможность заменить вышедший из строя HDD без выключения сервера. Однако учтите, что наличие корзины с внешним доступом к отсеку, не означает, наличие данной функции. Уточняйте возможность горячей замены жестких дисков в характеристиках. HotSwap значительно увеличивает стоимость серверов, зато вы можете поменять при необходимости диск, вообще ничего не выключая и не останавливая.
В зависимости от того сколько и какие устройства будут интегрироваться с локальным хранилищем, определите необходимое количество портов (Ethernet, USB, eSATA). Одного гигабитного порта обычно хватает даже большинству бизнес-клиентов. А портами USB перенебрегать не стоит — съёмные диски для холодных резервных копий, веб-камеры, да и просто 5 Вольт питания не помешают.
Поддержка различных сетевых протоколов и стандартов очень важна — именно она позволяет настраивать дополнительные функции и расширяет программные возможности. К примеру, UPnP (если он активирован на вашем роутере, конечно) сильно упростит работу встроенного torrent-клиента, а DLNA-сервер предназначен для передачи мультимедийных данных на телевизоры, смартфоны, планшеты и другие устройства с поддержкой DLNA.
Функции сетевых накопителей NAS на этом не заканчиваются. В зависимости от производителей и моделей возможна установка приложений (облачные сервисы, менеджеры закачки, torrent-трекеры и тд.), поддержка IP-видеонаблюдения, возможность создания RAID-массивов и многое другое.
Организация сетевого хранилища при помощи роутера
Более простой вариант удалённого сетевого хранилища — это подключение к роутеру через USB внешних HDD, SSD или объёмного флеш-накопителя. Подготовить к работе потребуется как роутер, так и подключаемый к нему диск.

Настройка роутера
В настройках маршрутизаторов можно включить следующие опции и компоненты:
- файловые системы (NTFS, FAT32, EXT2/3/4, HFS+);
- контроль и доступ к файлам и папкам (SMB/CIFS, AFP, Time Machine);
- DLNA-сервер;
- FTP-сервер;
- Torrent-клиент.
Поддержка перечисленных пакетов зависит от модели роутера и его прошивок. Очень большими возможностями обладают альтернативные прошивки, такие как OpenWRT, dd-wrt, Merlin-firmware. Создавая сетевое хранилище, важно учитывать, что само оборудование должно быть подходящим под те или иные настройки, от этого зависит возможность устройства тех или инфх функций. Например, у нас есть опыт поднятия на роутерах станций сетевой PXE-загрузки, серверов RADIUS, торрентокачалок и даже видеонаблюдения на одну-две камеры (хотя последние две задачи перекладывать на роутер мы не советуем).
Настройка внешнего диска
Подготовить съёмный накопитель также не сложно. Лучше всего подойдут внешние HDD или SSD. Всё что потребуется, это отформатировать устройство под файловую систему, которую принимает ваш маршрутизатор (в некоторых хороших моделях, к слову, это делается средствами самого роутера). ОС на вашем компьютере тоже может быть использована для подготовки носителя и предварительного размещения данных, если она умеет создавать нужные ФС.
Для архивного хранения или функций только на чтение, требования к ФС просты. Мы рекомендуем Ext3 / Ext4. FAT32 не читает файлы размером более 2 Гб — это проблемы с хранением фильмов и крупных образов, а NTFS не является родной системой для Linux, на которых, собственно, почти все роутеры и построены. Если же на носитель что-то пишется, лучше не ставить FAT / Ext2 — это старые нежурналируемые файловые системы, и после нештатного скачка питания или аварийного завершения работы есть повышенный шанс повреждения данных.
После настройки оборудования, остаётся только установить файловые менеджеры на устройства, которые должны получить доступ к хранилищу. Некоторые модели роутеров имеют свой удобный интерфейс, альтернативой служат сторонние программы-проводники и приложения для мобильных устройств.
Способов создать файловые хранилища, локальные или облачные, довольно много. Мы кратко рассмотрели несколько более подходящих для дома вариантов, но выходя за рамки статьи, наши специалисты знают о серверном хранении данных гораздо больше и готовы помочь вам в этом вопросе:
- практически, оказав услуги по настройке и обслуживанию серверного оборудования в Санкт-Петербурге, для организаций и частных лиц;
- теоретически, проконсультировав по теме в комментариях к нашему видеоролику.
Опыт построения и эксплуатации большого файлового хранилища

Рассказ о том, что каждый инженер должен сделать в своей жизни после того, как он родил ребенка, посадил дерево и построил дом – это сделать свое файловое хранилище.

Доклад мой называется «Опыт построения и эксплуатации большого файлового хранилища». Большое файловое хранилище мы строим и эксплуатируем последние три года. В тот момент, когда я подавал тезисы, доклад назывался «Ночью через лес. Опыт построения эксплуатации бла-бла-бла». Но программный комитет попросил меня быть серьезнее, тем не менее, на самом деле это доклад «Ночью через лес».
Этот образ придумал коллега Чистяков для конференции «Стачка», и там мы делали доклад «Ночью через лес» про докера, а я – про новые SQL-базы.
С тех пор, как я хожу на конференции, мне стало понятно, что слышать я хочу не истории успеха, а истории ужаса и кошмара, который нас всех ждет на пути к успеху. Потому что успех чужой мне ничего не даст. Конечно, если кто-то уже что-то сделал, само знание о том, что это возможно сделать, помогает мне двигаться, но в реальности я бы хотел знать, где там мины и ловушки.
Еще один кайфовый образ – книга «Пикник на обочине». Там есть научно-исследовательский институт, который исследует эту зону. У них есть летающие боты, у них есть автоматические маркеры, у них есть то и это, у них есть роботизированные системы, а есть сталкеры, которые бродят по этой зоне просто так, раскидывая гайки туда-сюда. Так вот, так уж получилось, что мы работаем в том сегменте, где востребованы сталкеры, а не научно-исследовательский институт. Мы работаем в том сегменте, где highload наиболее важен. Мы работаем в сегменте нищебродов. Highload – это, вообще-то, для нищебродов, потому что взрослые парни просто не допускают, чтобы нагрузка на сервера у них превышала 30%. Если вы решили, что ваш flow watermark 70%, во-первых, у вас начался highload, во-вторых, вы нищеброд.

Итак. Для начала, что такое файловое хранилище и зачем оно, вообще, может оказаться в нашей жизни?
Файл – это кусок информации (это его официальное определение), снабженный именем, по которому этот кусок информации можно извлечь. Но это же не единственный на свете кусок информации, который снабжен именем, почему же файл отличается от всех прочих? Потому что файл слишком большой, чтобы обращаться с ним как с одним куском. Смотрите: если вы хотите поддерживать, например, 100 тыс. одновременных соединений (это не так уж много) и отдаете вы файлы размером в 1 Мб. Это означает, что если вы хотите обращаться с файлом как с одним куском информации, вы вынуждены загрузить все 100 тыс. файлов по 1 Мб в память, это 100 Гб памяти. Невозможно. Соответственно, вам придется что-то сделать. Или ограничить количество одновременных соединений (для корпоративных применений это нормально), или обращаться с файлом так, как будто он состоит из кусочков информации, из отдельных мелких кусочков, из чанков. Слово чанк будет употребляться в докладе дальше.
Краеугольный камень здорового питания . Было зачеркнуто. Файл – это краеугольный камень сегодняшнего обмена информации, все об этом знают. Мы все, что можно, оформляем как файл просто по привычке. Потому что до недавнего времени у нас не было никаких средств хранить информацию иначе как файлах на диске. Об этом тоже будет позже – почему этот подход сегодня плохо срабатывает и лучше бы от него отказаться, но пока не удается.
Файловое хранилище – это место, где файлы хранятся. На самом деле, может быть, даже более важно, что файлы там хранятся – это то место, откуда к файлам предоставляется доступ, откуда они отдаются.

Что такое файловое хранилище, мы поняли. Что такое большое файловое хранилище? Эксплуатируя большое файловое хранилище, я обнаружил, что это не характеристика самого хранилища. Например, у Васи Пупкина есть архив подросткового кино на 5 ПБ. Это большое файловое хранилище? Нет, потому что оно никому не нужно, потому что Вася Пупкин не может смотреть все 5 ПБ одновременно. Он смотрит один маленький фильм. Там есть еще несколько характеристик у этого пупкинского хранилища, например, если он его потеряет, он расплачется и скачает все заново из Интернета.
Много файлов. Можно предположить, что если много байт – это не большое, тогда много файлов – это большое? Нет. Есть хранилища, в которых очень много записей. У нас есть базы, в которых миллиард строк и, тем не менее, они не являются большими. Почему? Потому что если у вас есть миллиард строк в базе, у вас есть удобные и надежные средства управления этими строками. Для файлов такого средства нет. Все наши активно используемые сегодня файловые системы – иерархические. Это значит, что для того, чтобы выяснить, что происходит у нас на файловой системе, нам надо пройтись по ней, все имеющиеся каталоги открыть, их почитать. Иногда у нас нет, даже обычно у нас нет индексов на каталоге, поэтому мы вынуждены прочитать его от начала до конца, найти нужный файл – все это себе прекрасно представляют.
Так вот, большое – это описание ситуации, в которой вы оказались со своим файловым хранилищем, а не самого хранилища. Очень часто, и это мой любимый фокус, можно превратить большое файловое хранилище в нормальное, просто перенеся его на SSD. Там значительно больше IOPS’ов и стандартные средства управления информацией, которые используются на файловых системах, начинают работать достаточно быстро, чтобы управление таким файловым хранилищем не представляло собой проблему.

Парадокс файлового хранилища. С точки зрения бизнеса эти файловые хранилища не зачем не нужны. Когда у вас есть довольно большой проект, который принимает от пользователей файлы, отдает пользователям файлы, показывает пользователям рекламу – все, в общем, понятно. А почему примерно половина бюджета проекта составляют какие-то железки невнятные, на которых лежат какие-то невнятные байты? Бизнес, в принципе, понимает, зачем это, но на самом деле файловые хранилища не нужны. В бизнес-требованиях никогда не будет написано «хранить файлы». В бизнес-требованиях будет написано «отдавать файлы». Существует ТЗ, в котором будет написано «хранить файлы» – это ТЗ на систему резервного копирования. Но это тоже вранье. Когда мы хотим систему резервного копирования, мы не хотим систему резервного копирования, мы хотим систему аварийного восстановления. Т.е. мы опять хотим файлы читать, а не хранить.
К сожалению, создатели файловых хранилищ этого не понимают. Может быть, только создатели S3 додумались до этой простой вещи. Всех остальных интересует, чтобы файлы были сложены, чтобы они ни в коем случае не разрушились, и если опасность разрушения возникает, то надо прекратить всякую деятельность, ни в коем случае не отдавать файл, который может быть побит, и ни в коем случае не загружать новые файлы, если у нас есть опасность разрушения имеющейся информации.
Это традиционный подход, но, тем не менее, к тому, чем мы занимаемся, он отношения не имеет. Файловое хранилище – вещь необходимая, никак без нее не обойдешься, она и нужна, и нет. А без нее никак, потому что файлики должны где-то быть, чтобы ты мог их отдавать.

Основной источник опыта общения с файловыми хранилищами в моей жизни – это проект Setup.Ru. Setup.Ru – это массовый хостинг с некоторыми фишечками, там сайты генерятся по шаблону. Есть шаблон, пользователь его заполняет, нажимает «сгенерировать», генерируется от 20 до 200 файлов, они все складываются в хранилище. Пользователи загружают картинки, разнообразные другие бинарные файлы. В общем, это неограниченный источник этого всего. На данный момент в хранилище Setup лежат 450 млн. файлов, поделенных на 1,5 млн. сайтов. Это довольно много. Как мы дошли до жизни такой – это основное содержание моего доклада. Как мы двигались к тому, что у нас там есть сейчас. 20 млн. файлов в сутки – это объем обновления Setup сегодня в пике. Само по себе, 20 млн. – это уже много. В первый раз мы столкнулись с проблемами, когда у нас было 6,5 млн. файлов, но тем не менее.

В 2012 году файловое хранилище Setup было организовано очень просто. Генераторы контента публиковали на два сервера с целью обеспечения отказоустойчивости. Синхронизация – если у нас один из этих серверов умирал, мы брали другой такой же, копировали rsync’ом с одного на другой всю эту массу файлов, и все у нас было хорошо. Для горячего контента у нас использовался SSD, тогда еще Hetzner. Это все в Hetzner, извините. Это к вопросу о том, что мы именно сталкеры. Т.е. Hetzner – это такое смешное место, такая зона, мы оттуда выносим время от времени ведьмин студень, продаем его на черном рыке и с этого живем.
В чем мы увидели проблему, когда с этой схемой познакомились в 2012 году? В тот момент, когда у нас один из дублирующих серверов помер, мы некоторое время подряд живем без файловера, соответственно, пока идет rsync, мы вынуждены молиться и трястись от страха. Со статистикой по файловой системе тоже проблемы. Если по SSD все еще это удавалось собирать, по 60 Гб (64 Гб тогда были SSD в Hetzner и никаких других), то по HDD мы очень быстро к весне 2012-го поняли, что мы не знаем, что у нас лежит на дисках, и никогда не узнаем. Правда тогда мы еще не думали, что это станет проблемой.

Летом 2012 года у нас сдох очередной сервер. Мы привычным движением заказали новый, запустили rsync, и он никогда не закончился. Вернее, никогда не закончился скрипт, который запускал rsync в цикле, пока не обнаруживал, что все файлы скопированы. Оказалось, что файлов уже достаточно много, что обход дерева занимает шесть часов, что копируются файлы плюс к этим шести часам, еще 12. И за 18 часов контент успевает измениться настолько, что реплика наша неактуальна. «Ночью через лес», т.е. никто не ожидал, что эта палка угодит нам в глаз. Так вот. Сейчас-то это очевидно, а тогда мы были очень удивлены, типа: как же так?
Тогда же ваш покорный слуга придумал сложить файлы в базу. Почему он это придумал, откуда вообще взялась эта идиотская идея? Потому что все-таки мы собрали какую-то статистику. 95% файлов были меньше 64 Кб. 64 Кб – это даже при 100 тыс. одновременных соединений – вполне подъемный размер, чтобы обращаться с этим как с одним куском. Остальные файлы были спрятаны в базу, большие файлы были спрятаны в BLOB’ы. Позже я буду говорить о том, что это самая главная ошибка этого решения. Буду говорить, почему.
Это все было сделано в в Postgres’e. Мы тогда верили в мастер-мастер репликацию, а в Postgres нет никакой мастер-мастер репликации (и нигде нет, на самом деле, ни в одной СУБД нет мастер-мастер репликации), поэтому мы написали свою, которая учитывала особенности нашего контента и обновления этого контента, и могла функционировать нормально.
И весной 2013 года мы, наконец, столкнулись с проблемами того, что мы понаписали.

Файлов стало к тому времени 25 млн. Оказалось, что при таком объеме обновлений, который к тому времени происходил в системе, транзакции занимают существенное время. Поэтому некоторые транзакции, которые были короче, успевали закончиться раньше, чем начавшиеся раньше, но более длинные. В результате – автоинкрементный счетчик, на который мы ориентировались в нашей мастер-мастер репликации, оказался с дырочками. Т.е. некоторые файлы никогда наша мастер-мастер репликация не видела. Это был большой сюрприз для меня лично. Я пил три дня.
Потом, наконец, придумал, что надо всякий раз, когда мы запускаем мастер-мастер репликацию, от последнего этого счетчика отнять. Сначала приходилось отнимать 1000, потом 2000, потом и 10000. Когда я вписал в это поле 25 тыс., я понял, что надо что-то делать, но к тому моменту я не знал, что делать. Мы наткнулись опять на ту же самую проблему – контент менялся быстрее, чем мы его синхронизировали.
Оказалось, что эта наша мастер-мастер репликация работает довольно медленно, и работает медленно, на самом деле, не она, работает медленно вставка в Postgres, особенно медленно работает вставка в BLOB’ы. Поэтому в какой-то момент, ночью, когда количество публикаций уменьшалось радикально, база сходилась. Но днем она все время была немножко неконсистентная, чуть-чуть. Наши пользователи заметили это следующим образом: они загружают картинку, они хотят ее тут же увидеть, а ее нет, потому что загрузили они ее на один сервер, а запрашивают они ее через round-robin с другого. Ну, пришлось учить наши сервера, заменять бизнес-логику, пришлось доставать картинку с того же сервера, на который мы ее загрузили. Это аукнулось нам потом проблемами со сдохшим сервером – когда сервер сдох, надо лезть туда, где этот router и менять ему параметры routing’а.

Осенью 2013 года файлов стало 50 млн. И тут мы наткнулись на то, что наша база, в общем-то, не тянет, потому что там довольно сложный был join для того, чтобы отдать пользователю именно последнюю версию того файла, которую он загрузил. И у нас перестало хватать наших восьми ядер. Что с этим делать, мы не знали, но коллега Чистяков нашел решение – коллега Чистяков на триггерах сделал нам materialized view, т.е. по запросу файлик из вьюхи, в которой был долгий join, переезжал в отдельную таблицу, откуда в дальнейшем запрашивался. Понятно, как это было устроено, и это все тоже стало работать прекрасно. Репликация мастер-мастер к тому времени уже работала очень плохо, но этот костылик мы подкостылили, и все, вроде бы, было хорошо. До весны 2014 года.

120 млн. файлов. Контент перестал помещаться на одну машину в Hetzner. Взять машины, в которых было бы больше, чем четыре по три т-винта нам не удалось. Поэтому было придумано следующее. Мелкие файлы остались в Postgres, крупные файлы переехали на leofs. Тут же выяснилось, что leofs – довольно медленное хранилище. Мы тогда же попробовали разные другие кластерные хранилища, они все довольно медленные. Но еще оказалось, что ни одно из них не транзакционное. Сюрприз, правда?
Транзакционная файловая система нужна для того, чтобы изменить весь сайт целиком. Если пользователь опубликовал новый сайт, он не хочет, чтобы он в течение получаса по файлику менялся. Пусть даже сайт будет публиковаться полчаса, пользователь хочет, чтобы новый сайт был опубликован весь целиком.
Ни одно из тестированных нами хранилищ эту функциональность нам не дало. Мы могли бы ее реализовать на POSIX-совместимых кластерных файловых хранилищах с помощью симлинков, как это делается на стандартной файловой системе, но, оказалось, что ни одно из них не обеспечивает нам достаточного количества IOPS’ов, чтобы отдавать наши 500 запросов в секунду. Поэтому мелкие файлы остались в Postgres, а вместо больших файлов и BLOB’ ов, оказались ссылки на leofs хранилища. И все опять стало хорошо. Сейчас это понятно, что это мы еще один костылик подпихнули под нашу систему, но, тем не менее, все стало хорошо на некоторое время.

2015 год, начало. На leofs кончилось место. Там уже было 400 млн. файлов – видимо, пользователи наши все время наращивают обороты. У нас на leofs кончилось место, мы решили, что надо добавить парочку нод, мы их добавили. Некоторое время подряд ребалансинг шел, потом он как бы закончился, и оказалось, что мастер-нода теперь не знает, где у нее какие файлы лежат.
Хорошо, мы отключили эти две новые ноды. Оказалось, что теперь она совсем ничего не знает. Мы подключили эти две новые ноды обратно, и оказалось, что теперь ребалансинг не идет вообще. Вот так вот.
Технический руководитель команды setup нанял переводчика с японского, и мы позвонили в Токио. В 8 утра. Поговорить с компанией Rakuten. Компания Rakuten поговорила с нами час, и простите меня, я буду ее ругать, потому что так со мной еще не обращались в моей жизни, а я 20 лет в бизнесе… Компания Rakuten поговорила с нами час, выслушала внимательно наши проблемы, почитала наши баг-репорты в их трекере, после чего сказала: «Знаете, у нас закончилось время, спасибо, извините». И тут мы поняли, что к нам пришел пушной зверь, потому что у нас 400 млн. файлов, у нас (с учетом replication factor 3) контента 20 Тб с лишним. На самом деле это не совсем так, но реального контента там 8 Тб. Ну, вот что делать?
Поначалу мы паниковали, пробовали расставлять по коду leofs метрики, пробовали понять, что происходит, коллега Чистяков не спал ночами. Мы пытались выяснить, не хочет ли кто-нибудь из питерских Erlang’истов потрогать это палочкой. Питерские Erlang’исты оказались разумными людьми, они не стали трогать это палочкой.
Тут возникла идея, что хорошо, ладно, пусть, но есть же взрослые парни, у взрослых парней бывает СХД. Мы берем СХД, и на эту СХД кладем все наши файлы и ведем себя как взрослые парни. Мы согласовали бюджет. Мы пошли в Hetzner. Нам не дали СХД. Более того, когда мы придумали, что мы возьмем девяти-дисковую машину, поднимем на ней iSCSI на FreeBSD, iSCSI по внутренней Гбитной сети, пробросим это все в наши отдающие сервера, поднимем там старое хранилище на Postgres в том виде, в каком оно было. И даже посчитали, вроде как, в 128 Гб оперативки мы еще полгода влезали. Оказалось, что эти девяти-дисковые машины невозможно подключить к нашему кластеру по внутренней сети, потому что они стоят совсем в других стойках. «Ночью через лес» – никто не ожидал, что эта яма попадется нам под ноги. И никто не ожидал, что мы все-таки в зоне. Что это очередная давилка. Короче, по общей сети Hetzner идея с квази-СХД по iSCSI не проканала. Там слишком большая была latency, у нас разваливался кластерная файловая система.

2015 года, весна. 450 млн. файлов. На leofs место закончилось совсем, т.е. вообще. Rakuten даже не стал с нами разговаривать. Спасибо им. Но ужас, самое страшное с нами случилось весной 2015 года. Все было хорошо еще вчера, а сегодня disc saturation в сервере Postgres поднялся до 70% и уже не опустился вниз. Через недельку он поднялся до 80%, и сейчас, до переключения на наш последний вариант, он все время держался от 95 до 99%. Это означает, что, во-первых, диски скоро умрут, во-вторых, все очень плохо в смысле скорости отдачи и скорости публикации. И тут мы поняли, что надо уже сделать шаг вперед. Что ситуация такая, что нас с этого проекта выгонят все равно, после этого проект закроют, потому что эти 450 млн. файлов – это и есть весь проект. В общем, мы поняли, что надо идти ва-банк.
Про решения, которые мы разработали весной 2015 года и внедрили, которые сейчас функционируют, я расскажу чуть позже. А пока – чему мы научились за то время, пока все это эксплуатировали?

Во-первых, отказоустойчивость. Отказоустойчивость – это не хранить файлы. Никому не нужно знать, что у тебя надежно спрятаны 450 млн. пользовательских файлов, если пользователи не справляются получить к ним доступ.
Файловый кэш. Я к нему относился слегка с презрением, пока не обнаружил, что если у тебя действительно высокая нагрузка, ты никуда не денешься, ты должен hot set спрятать в память. Там hot set не такой уж и большой. На самом деле, hot set составляет около 70 тыс. сайтов, и около 10 млн. файлов. Т.е. если бы в Hetzner можно было взять за дешево машину с 1 Тб оперативной памяти, мы бы все это спрятали в память, и у нас опять бы не было проблем, если бы мы были взрослые мальчики, а не сталкеры с помойки.
Распределенные системы хранения. Если у вас есть деньги на большую СХД, которая сама по себе имеет синхронизацию с другой такой СХД… Когда я последний раз проверял, шасси стоило около 50 тыс. евро. И диски туда какие попало не вставишь. Может быть, сейчас это стало дороже, а, может быть, подешевело, на этом рынке много игроков – IBM, Hewlett-Packard, EMC… Тем не менее, мы пробовали несколько дешевых решений – CEF, leofs и еще парочку каких-то, названий которых я не запомнил.
Если ваше хранилище заявлено как eventual consistency – это значит, что вы попали в проблемы. В какие проблемы вы попали с eventual consistency, я рассказывал только что. А в какие проблемы мы попадаем со strong consistency? Мы туда запихиваем файл, он почему-то не запихивается и обламывается. Пользователь повторяет попытку, публикация ложится в очередь. Через некоторое время очередь разрастается, еще через некоторое время оказывается, что ваше файловое хранилище легло под той нагрузкой, которую создают пользователи, которые все время как обезьянки тычут в кнопку. В корпоративной среде можно было бы объяснить, что так делать нельзя, но они заплатили деньги, они хотят тыкать в кнопку.
Отдельной проблемой оказался ребалансинг. Первое, что люди научаются делать с системой CEF – они научаются прикручивать ему ребалансинг, чтобы в тот момент, когда он нужен, он не съедал 100% пропускной способности диска и внутренней сети.
А еще оно тормозит. Все распределенные системы хранения, которые мы попробовали, страшно тормозят. В смысле – на них IOPS’ов меньше 100. Если это POSIX-система – это, вообще, приговор. Если это объектное хранилище, то это может быть хорошо. У нас к leofs был пристроен Varnish, чтобы самый популярный контент все-таки отдавать из кэша, а не запрашивать каждый раз оттуда.

Чему еще мы научились? Тому, что мелкие файлы – это не файлы. Мелкие файлы – это записи в базе данных. Все, что можно забрать из хранилища одним куском и одним куском отдать пользователю – это все не файл, это все очень удобный контент, с которым можно обращаться.
PostgreSQL BLOB. Никогда его не используйте. Можно, конечно, было прочесть об этом в документации, но я почему-то не прочел. PostgreSQL BLOB не попадает в стандартную репликацию PostgreSQL. Ни в такую, ни в сякую. Реально это таблица Postgres, внутренняя, в которой поделенный на кусочки лежит этот самый файл, но эта таблица не попадает в репликацию никогда. Может, они исправят эту проблему, но это то, на что мы наткнулись, когда у нас уже лежали 4 Тб данных в этом самом Postgres, и что-либо делать было поздно.
Материализация view – это оказалось серебряной пулей. Если у вас начинает подтормаживать на join’ах, на CPU база, то материализация view может вам помочь. Это очень легко – 3-4 триггера, и все у вас хорошо. Главное – не забывать проверять, что данные изменились, и соответственно, данные в материализованной view’хе надо бы инвалидировать.
Самописная репликация. Я ей очень гордился, пока не обнаружил, как она работает. Не надо, не пишите самописную репликацию. Мне говорили об этом, начиная с 2012 года. В 2012 осенью на HighLoad++ я все это рассказывал с большой гордостью, про то, как прекрасно у нас работает файловое хранилище на Postgres. И мне сразу сказали, что будет плохо. Я знал, что будет плохо, я не знал, что так скоро.
Когда мы начинали со всем этим возиться, мы знали, что взрослые мальчики вроде ВКонтакте никогда не удаляют файлы. Они только помечают их как удаленные. Мы подумали, что нам даже помечать их как удаленные не надо, у нас все будет хорошо и так. Пока к нам не пришел Роскомнадзор и не попросил удалить вот это, это и это. Мы удалили сайт, удаление сайта мы предусмотрели. Но оказалось, что в поисковиках прячутся прямые ссылки на контрафактные картинки, поэтому дальше начался реальный кошмар.
И опять привет компании Rakuten – Java лучше, чем Erlang. Не в смысле, что сама Java лучше, чем Erlang. А в смысле, что Java-программисты недостаточно сообразительны. Java-программисты полезли бы в эту клоаку и починили бы нам, может быть, leofs.

Чему мы не научились? Мы не смогли научиться большой отказоустойчивой СХД. У заказчика просто нет такого бюджета, и мы его понимаем. А даже, если заказчик нашел бюджет, ему пришлось бы найти бюджет на переезд из Hetzner, потому что в Hetzner ничего такого не дают.
Распределенные POSIX-совместимые файловые системы. Вообще, POSIX-совместимая файловая система – это система, которая обеспечивает случайный доступ. Фактически она этим отличается от объектного хранилища, случайный доступ на запись по файлу. Это не зачем не нужно под наши задачи. Поэтому она не нужна. Но ее никто и не использует, она в бетах.

Теперь про то, как мы решили проблему и, будем надеяться, решили ее на ближайший год как минимум, а может быть и на два. А потом, конечно, все начнется по-новой.
- Мы взяли кластерную NoSQL СУБД. Мы взяли Aerospike, но можно взять любую. Мы взяли Aerospike потому что у него прекрасные показатели по latency. Он
прошлой осенью сделался бесплатным, поэтому мы им воспользовались. - Мы сами рубим файлики на чанки и каждый чанк мы храним отдельно, отдельной строкой в базе данных и отдельно его извлекаем, когда он нам нужен.
- Мы написали версионирование. Ту самую транзакционность. Фактически это модернизация идеи симлинков. Т.е. у нас есть некая transaction id, к которой
относятся все файлы под ней загруженные, а потом в таблице с сайтами меняется ссылка на транзакцию. - Самописный dedup. Если уж мы сами режем на чанки, то мы можем посчитать для каждого чанка SHA1, мы можем этот SHA1 хранить в базе, как ключ доступа к этому
чанку. В общем, dedup уменьшил нам это. Расскажу подробнее. У нас был dedup, он был на файловом уровне, мы считали сумму для файла и дублировавшиеся файлы
хранились в базе только один раз. Использование почанкового dedup уменьшило нам объем базы с восьми Тб до шести. Это чистый объем данных, без репликации. - Самописные транзакции. Тут понятно, что в распределенных базах данных нет транзакций. Нам пришлось написать свои, которые чисто под ту задачу, которую мы
решаем. - И понятно, LZ4-сжатие мы туда прикрутили.

Серверов в этом кластере восемь, и это связанно с тем, что у нас на меньшее количество серверов не помещается контент. У нас replication factor 3, у нас там диски, два по три. Мы очень смелые ребята, поэтому они стоят у нас в RAID 0. Соответственно, мы имеем восемь серверов по 3 Т. На данный момент каждый сервер заполнен уже на 66%, соответственно, мы собираемся взять еще два и подключить в тот же самый кластер и дождаться окончания ребалансинга.
1,5 К запросов в секунду – это то, на чем я тестировал. Уперся я при этом не в кластер из восьми машин, понятно дело, а в производительность одного тестового сервера. Ну, я решил, что 1,5 К – это в 2,5 раза больше, чем у нас сейчас есть, поэтому я на этом месте продолжать тестирование не стал.

Но все-таки, «Ночью через лес». Мы очень гладко с этой нашей NoSQL базой переводили пользователей, и все было очень хорошо, пока не оказалось, что мы залили по 2 Тбайта на каждый сервер. Фантастика – вот кластер еще 5 минут назад работал, а вот он уже не работает. Вот он отдает 500-ые ошибки, вот он отдает 404-ые ошибки, вот он отдает 403-ие ошибки. Не работает публикация. В логах очень странные сообщения: «Я не смогла найти такой-то сектор».
Спасибо поддержке Aerospike, я не спал всего одну ночь. На утро они мне ответили, оказалось, что нельзя сконфигурировать один файл хранилища низкоуровнего в Aerospike больше, чем 2 Т. Можно при этом их сконфигурировать несколько, сейчас сконфигурирован на три файла по 1 Т. Но первый наш кластер Aerospike был сконфигурирован на каждой ноде один файл на 3 Т. Как только мы добрались до двух Т, оно немедленно все прекратило функционировать. И причем, очень неприятным образом – мы потеряли некоторое количество загруженного пользователями контента, которого на старом сторадже уже не было, а на новом он уже обломался.
Это то самое «Ночью через лес» – ты упал в овраг и лежишь в грязи, ты не видишь небо, ты не понимаешь, куда вылезти, адские твари уже воют. А рестарт одной ноды занимает три часа, потому что она строит в памяти индекс, она вынуждена считать с диска все данные. 100 Мб в секунду – это простой SATA диск. И полный ребалансинг. Мы проверили это, мы вырубили одну ноду, стерли с нее данные, включили ее обратно, одна нода полная, восстановление кластера при замене одной ноды занимает 60 часов. Это означает, что никакого replication factor меньше трех мы себе позволить не можем.
Этот доклад — расшифровка одного из лучших выступлений на профессиональной конференции по эксплуатации и devops RootConf. Мы уже готовим конференцию 2017 года, хотя что значит готовим? Открыли регистрацию на билеты и доклады. Сейчас все силы брошены на HighLoad++, она съедает все наши силы и сон 🙁
В этом году много интересного по теме хранилищ данных, вот самые спорные и зубодробительные доклады:
- Велосипед уже изобретен. Что умеют промышленные СХД? / Антон Жбанков;
- Archival Disc на смену Blu-ray: построение архивного хранилища на оптических технологиях / Александр Васильев, Герман Гаврилов;
- Архитектура хранения и отдачи фотографий в Badoo / Артем Денисов.
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
- даниил подольский
- файловые хранилища
- схд