Как этим пользоваться, например в firefox и mpv?
Разработчики из компании NVIDIA представили открытую библиотеку libvdpau 1.5 с реализацией поддержкой API VDPAU (Video Decode and Presentation) для Unix-подобных систем. Библиотека VDPAU даёт возможность задействовать механизмы аппаратного ускорения для обработки видео в форматах h264, h265, VC1, VP9 и AV1, и вынести на сторону GPU такие задачи, как пост-обработка, слияние (compositing), отображение и декодирование видео. Изначально в библиотеке поддерживались только GPU от компании NVIDIA, но впоследствии появилась поддержка открытых драйверов для карт AMD. Код libvdpau распространяется под лицензией MIT.
serg002 ★★
09.04.22 20:05:40 MSK
- Ответить на это сообщение
- Ссылка

Для mpv надо добавить в ~/.mpv/config
hwdec=vdpauhwdec=vdpau-copy. Но, ИМХО, лучше добавить туда
hwdec=autoBityjPixel
( 09.04.22 22:43:14 MSK )
- Ответить на это сообщение
- Показать ответы
- Ссылка
Ответ на: комментарий от BityjPixel 09.04.22 22:43:14 MSK
serg002 ★★
( 09.04.22 22:50:22 MSK ) автор топика
- Ответить на это сообщение
- Показать ответы
- Ссылка
Ответ на: комментарий от serg002 09.04.22 22:50:22 MSK

в лисе пока жопа. Там промелькнул короткий момент пока VAAPI работало и опять все сдохло. AV1 прикручено через жопу (кастрированный кусок древнего ffmpeg 4.2 пропатченный и включенный в сорс лиса). VP8/VP9 работают через нативный ffmpeg но при условии отключения sandbox. ВРоде как все пилят — но 98,99 и скорее всего 100 лис работать не будет. МОжет быть в 101 или еще дальше.
Qui-Gon ★★★★
( 09.04.22 22:55:44 MSK )
- Ответить на это сообщение
- Ссылка
Ответ на: комментарий от serg002 09.04.22 22:50:22 MSK
firefox аппаратное ускорение вроде сам должен включать под вяленым, а под иксами у него с ним всё сложно. Но это не точно.
BityjPixel
( 09.04.22 22:57:32 MSK )
- Ответить на это сообщение
- Показать ответ
- Ссылка
Ответ на: комментарий от serg002 09.04.22 22:50:22 MSK

Отправиться в прошлое, разработать патчи, пропатчить, пользоваться. Сейчас Firefox двинулся немного в другую сторону, и с конкретно VDPAU ему уже не по пути. В принципе решаемо, но желающих нет.
i-rinat ★★★★★
( 09.04.22 23:02:22 MSK )
- Ответить на это сообщение
- Показать ответ
- Ссылка
Ответ на: комментарий от BityjPixel 09.04.22 22:57:32 MSK
Проблема не в иксах и не в вяленом, а в секьюрити. Новые драйвера хардверного ускорения требуют доступа к железу. А секьюрити с сэндбоксингом требуют все энкапсулировать и никакого доступа к железу не давать. Все работает на старых драйверах от интел — а вот со свежими драйверами все плохо. Решение предложенное Мартином — перетащить декодирование в отдельный RDD процесс. Но секьрасты и на этот процесс свой гондон нятянули — и соответственно все снова умерло.
Qui-Gon ★★★★
( 09.04.22 23:38:30 MSK )
- Ответить на это сообщение
- Ссылка
Ответ на: комментарий от i-rinat 09.04.22 23:02:22 MSK
Сейчас там по ходу началась некая движуха с переосмыслением декодирования — не только хардверного. В текущем коде адский ад с определением поддерживаемых кодеков — ffmpeg казалось бы универсальная штуковина но он хардкодом проброшен на VP8/VP9 а все остальное декодируется через всякую гадость. Вот за три дня борьбы вроде как удалось заставить свою сборку лиса декодировать AV1 через ffmpeg а не через уродливый падучий встроенный ffvpx. Но понятно такое не предложишь в основной код ибо я просто выгрыз все долбанные проверялки типа «а двайте временно отключим эту фичу потому что она мешает джону какашкину тестировать его хрень». ДЖон то видимо уже оттестировал свою хрень — судя по тому чо выгрызание этого куска кода никаких неприятных последствий не имеет — но вот убрать это походу забыли.
А новые наработки по более логичному определению имеющихся кодеков и выбору наиболее подхадящего без хардкодов в самой мозилле пока на стадии WIP. До такой степени WIP что даже патчи эти не накладываются.
Qui-Gon ★★★★
( 09.04.22 23:54:58 MSK )
- Ответить на это сообщение
- Показать ответ
- Ссылка
Ответ на: комментарий от Qui-Gon 09.04.22 23:54:58 MSK
через ffmpeg а не через уродливый падучий встроенный ffvpx
ffvpx это тот же ffmpeg, в котором оставили только VP8, VP9 и AV1. К тому же есть настройка «media.ffvpx.enabled» в about:config. Её выключение не помогало, что ли?
В любом случае, это решаемые проблемы. А вот упор на вырезание доступа к сокету иксов отовсюду, откуда только можно, ставит использование VDPAU под очень большой вопрос, потому что там для адекватного получения готовых кадров иксы таки нужны.
i-rinat ★★★★★
( 10.04.22 01:16:15 MSK )
Последнее исправление: i-rinat 10.04.22 01:21:47 MSK (всего исправлений: 1)
- Ответить на это сообщение
- Показать ответ
- Ссылка
high cpu usage by a firefox subprocess called RDD Process
Does anyone know how to fix this high cpu usage by a firefox subprocess called RDD Process . or as a temporary band-aid How can I disable «RDD Process» until it gets fixed on firefox ? as a loyal ff user since its «there be dragons» days I’d hate to stop using ff however new ff users will not put up with this ff bug here is top showing this
$ top top - 10:46:45 up 1:33, 1 user, load average: 1.52, 1.12, 0.75 Tasks: 451 total, 1 running, 449 sleeping, 0 stopped, 1 zombie %Cpu(s): 7.1 us, 10.2 sy, 0.0 ni, 82.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st MiB Mem : 63964.8 total, 48381.4 free, 10170.6 used, 5412.8 buff/cache MiB Swap: 67584.0 total, 67584.0 free, 0.0 used. 52009.7 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 9616 olaf 20 0 687632 124196 98824 S 167.6 0.2 8:06.11 RDD Process 11115 olaf 20 0 3478912 1.0g 142712 S 45.9 1.6 2:05.58 Isolated Web Co 9154 olaf 20 0 5345052 918880 434104 S 37.8 1.4 9:23.10 firefox-trunk 3318 olaf 20 0 7468292 375644 173560 S 8.1 0.6 4:51.18 gnome-shell 3828 root 20 0 394520 33684 27112 S 5.4 0.1 0:00.70 fwupd 19979 root 20 0 0 0 0 I 5.4 0.0 0:09.26 kworker/u32:0-i915 20667 root 20 0 0 0 0 I 5.4 0.0 0:06.43 kworker/u32:4-i915 65 root 20 0 0 0 0 S 2.7 0.0 0:00.78 ksoftirqd/8 3084 olaf 9 -11 2622692 31628 22540 S 2.7 0.0 0:25.00 pulseaudio 9014 olaf 20 0 751244 92592 66272 S 2.7 0.1 0:06.94 gnome-terminal- This just started other day . previously I have never seen RDD
firefox 118.0a1 (2023-08-19) (64-bit) uname -m && uname -r && cat /etc/*release x86_64 6.2.0-26-generic DISTRIB_ID=Ubuntu DISTRIB_RELEASE=22.04 DISTRIB_CODENAME=jammy DISTRIB_DESCRIPTION="Ubuntu 22.04.3 LTS" PRETTY_NAME="Ubuntu 22.04.3 LTS" NAME="Ubuntu" VERSION_ID="22.04" VERSION="22.04.3 LTS (Jammy Jellyfish)" VERSION_CODENAME=jammy and yes it did not help by resetting my local settings by issuing
rm -rf ~/.mozilla rm -rf ~/.cache/mozilla
this is on a beefy desktop and this RDD Process was consistently using high cpu forever . it was not a temp short lived cpu spike . however after repeatedly killing firefox and relaunching the RDD did reappear across several such cycles . as I write RDD Process is gone yet this entire sequence of events has repeated itself across past week or so coincidentally with above RDD issue, youtube now sometimes fails to play a video upon clicking the video yet same video plays OK on other browsers like Vivaldi Below answer does not solve this high cpu issue . How can I disable «RDD Process» until it gets fixed ? I do not want a cpu core pegged all day as I continuously use firefox even when only viewing very well behaved sites like SO . after killing ff all is OK until I try to watch a youtube video at which point cpu goes to 100% and stays pegged forever AND the youtube video fails to render UPDATE hamburger menu -> Troubleshoot Mode -> Restart . just to disable all addons afterwards the RDD issue goes away however I would never use ff without my addons so this is not a solution Major fault of this RDD bug is that cpu usage increases each time I click on a youtube video in a different tab even though none of these videos plays . the video just sits there not rendering any video after clicking on it AND this high cpu usage continues even after I click on a different tab say the tab for this SO question . see new tab under this condition :
top - 08:04:00 up 36 min, 1 user, load average: 2.40, 2.68, 1.68 Tasks: 420 total, 1 running, 413 sleeping, 0 stopped, 6 zombie %Cpu(s): 4.6 us, 9.5 sy, 0.0 ni, 85.8 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st MiB Mem : 63964.8 total, 49344.6 free, 6397.0 used, 8223.1 buff/cache MiB Swap: 67584.0 total, 67584.0 free, 0.0 used. 56082.6 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 85851 olaf 20 0 670148 122840 96472 S 162.5 0.2 4:09.69 RDD Process 26395 olaf 20 0 4256544 673516 298232 S 20.8 1.0 4:22.72 firefox-trunk 26727 olaf 20 0 2909912 374900 134212 S 14.6 0.6 1:37.87 Isolated Web Co 66057 olaf 20 0 3264688 688376 137424 S 13.2 1.1 1:41.47 Isolated Web Co 9 root 20 0 0 0 0 I 4.9 0.0 0:18.76 kworker/u32:0-i915 827 root 20 0 0 0 0 I 4.2 0.0 0:22.57 kworker/u32:11-i915 3350 olaf 20 0 7202140 354256 163644 S 2.1 0.5 1:06.91 gnome-shell 15 root 20 0 0 0 0 I 0.7 0.0 0:01.31 rcu_preempt 41 root 20 0 0 0 0 S 0.7 0.0 0:01.79 ksoftirqd/4 54 root 20 0 0 0 0 I 0.7 0.0 0:03.61 kworker/6:0-events Rdd process linux что это
Заказывай стафф с атрибутикой Mozilla и. пусть все вокруг завидуют тебе! Быть уникальным — быть с Mozilla!
Страницы: 1
№1 10-02-2018 01:14:02

Aidrealgod Участник Группа: Members Зарегистрирован: 10-02-2018 Сообщений: 3 UA: 58.0
1 процесс в 5?
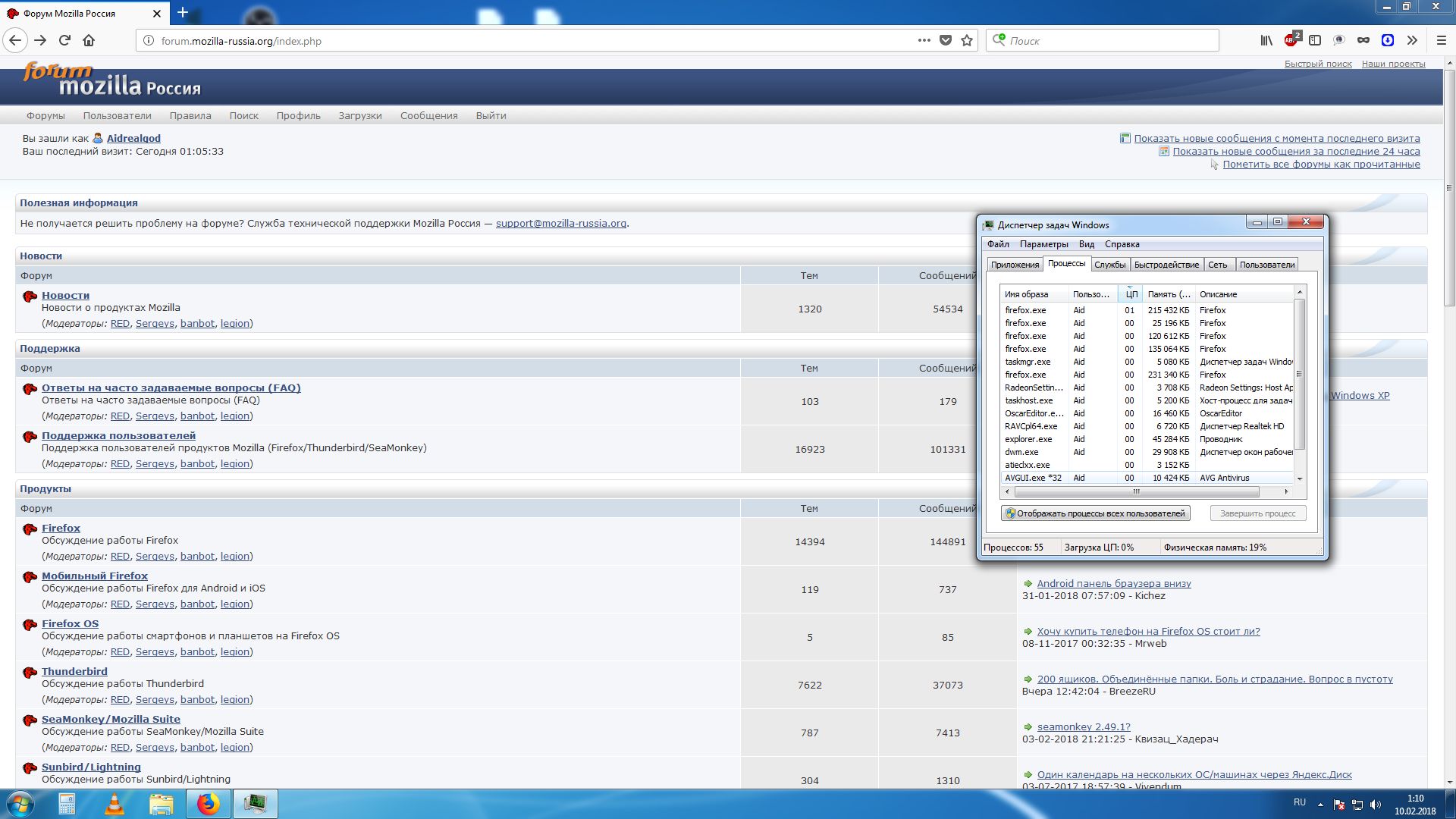
Зачем Браузеру столько процессов?
№2 10-02-2018 01:40:44
mokujin Участник Группа: Members Зарегистрирован: 17-02-2017 Сообщений: 494 UA: 45.0
Re: 1 процесс в 5?

из комы вышел, чтоле эт, тока начало .
. программисты словно войну какую-то ведут за свои обновления. Блин, почему сейчас повсюду мания ухудшать интерфейсы и делать их максимально неудобными?! Radiation
№3 10-02-2018 02:57:31
Coroner Участник Группа: Members Зарегистрирован: 29-10-2012 Сообщений: 3970 UA: 58.0
Re: 1 процесс в 5?

Хрому можно, а Firefox чем хуже?
№4 11-02-2018 23:48:00
Aidrealgod Участник Группа: Members Зарегистрирован: 10-02-2018 Сообщений: 3 UA: 58.0
Re: 1 процесс в 5?
Так я и интересуюсь, что это за зеркальные процессы =\
№5 12-02-2018 00:01:11
Coroner Участник Группа: Members Зарегистрирован: 29-10-2012 Сообщений: 3970 UA: 58.0
Re: 1 процесс в 5?
Aidrealgod пишет
Так я и интересуюсь, что это за зеркальные процессы
Один — на интерфейс браузера, второй — закладка открытая.
Третий — синхронизация. Четвёртый — проверка обновлений. Пятый — crashreporter. Шестой — updater.
Седьмой — скрытый майнинг
На деле чёрт его знает, кроме первого и второго. Какие-нибудь Service Workers или как они там называются. Или дополнения.
Дополнений даже если не устанавливали, то они всё равно есть : about:debugging#addons
У меня в однопроцессном Firefox и то их всегда два.
Можно поглядеть в about:memory или about:debugging#workers.
Отредактировано Coroner (12-02-2018 00:05:24)
№6 12-02-2018 06:32:43
VEG Участник Группа: Members Откуда: Minsk, Belarus Зарегистрирован: 05-03-2005 Сообщений: 581 UA: 52.0 Веб-сайт
Re: 1 процесс в 5?
Один — основной процесс, GUI браузера. Остальные 4 — занимаются рендерингом содержимого вкладок. В настройках браузера можно менять количество процессов, между которыми распределяется обработка вкладок. Больше процессов — лучше безопасность, стабильность и отзывчивость, но и больше расход оперативы. Меньше процессов — наоборот. В ближайших версиях в отдельный процесс будет вынесен композитинг — объединение картинок от разных процессов в одну. Делают для повышения стабильности, так как браузер часто падает из-за кривых видеодров. В случае если сборка итоговой картинки будет в отдельном процессе — падать будет только этот процесс и его будет легко перезапустить автоматически без краха всего браузера.
С наилучшими пожеланиями, Евгений
№7 12-02-2018 08:52:48

Журавлёва Участник Группа: Members Зарегистрирован: 10-07-2016 Сообщений: 129 UA: 64.0
Re: 1 процесс в 5?
так как браузер часто падает из-за кривых видеодров.
Вы можете назвать такой компьютер, чтобы производитель его выпускал с кривыми видеодровами?
Вам не кажется, что от кривых видеодров падает ОС, а не браузер?
Отредактировано Журавлёва (12-02-2018 08:53:09)
№8 12-02-2018 10:36:25
Coroner Участник Группа: Members Зарегистрирован: 29-10-2012 Сообщений: 3970 UA: 58.0
Re: 1 процесс в 5?
Журавлёва пишет
Вы можете назвать такой компьютер, чтобы производитель его выпускал с кривыми видеодровами?
Вам не кажется, что от кривых видеодров падает ОС, а не браузер?
У меня видеокарта, под которую дров для Win7 производитель уже не писал. Прикрутил неофициальные синей изолентой.
ОС не падает и работает стабильно уже лет 5. А браузер, случается, валится.
Я канеш понимаю, что я неудачник и нищеброд с кривыми руками, но при чём здесь производитель «выпускающий компьютеры», если у очень многих они не брендовые, а самые что ни на есть самопально собранные?
№9 12-02-2018 11:10:58
Журавлёва Участник Группа: Members Зарегистрирован: 10-07-2016 Сообщений: 129 UA: 64.0
Re: 1 процесс в 5?
Coroner пишет
ОС не падает и работает стабильно уже лет 5. А браузер, случается, валится.
Всё у вас правильно, так и должно быть, а неофициальные дрова это не значит кривые.
Вы, вообще, все видеодрова из ОС удалите, официальные неофициальные прямые и кривые, а браузер будет продолжать падать.
Что браузер может падать из-за видеодров это можно принять только как анекдот.
Отредактировано Журавлёва (12-02-2018 11:11:32)
№10 12-02-2018 11:17:59
Coroner Участник Группа: Members Зарегистрирован: 29-10-2012 Сообщений: 3970 UA: 58.0
Re: 1 процесс в 5?

На самом деле падает он редко, но понимаете, я свой браузер не только дома использую. И не помню, чтобы он падал на других машинах. И помню другую видюху, на этом же железе, с нормальными Win7 дровами, и ничего на падало. Пока она не сгорела
Но спорить не буду, не знаю я. Есть народные приметы и традиции:
1. «мазила» — тормозила. Но отключать свои 50 любимых аддонов не желаю.
2. «мазила» стал как хром, поэтому ухожу на хром. Вернусь через неделю.
3. При любой неисправности отключите аппаратное ускорение.
4. Если ничего не помогает — это драйвера виноваты.
Вот и грешу на дрова
№11 12-02-2018 15:39:12
VEG Участник Группа: Members Откуда: Minsk, Belarus Зарегистрирован: 05-03-2005 Сообщений: 581 UA: 52.0 Веб-сайт
Re: 1 процесс в 5?
Журавлёва пишет
Что браузер может падать из-за видеодров это можно принять только как анекдот.
Ну анекдотом это может показаться только человеку без соответствующей квалификации.
Отредактировано VEG (12-02-2018 17:41:22)
С наилучшими пожеланиями, Евгений
№12 12-02-2018 21:11:33
жрнжп Участник Группа: Members Зарегистрирован: 03-07-2011 Сообщений: 295 UA: 59.0
Re: 1 процесс в 5?
Aidrealgod
Сейчас процессы поделены следующим образом:
1) главный процесс (заведует записью на диск и пр.), имеет самые высокие привилегии;
2) процесс для расширений (webextensions);
можно отключить в about:config:
extensions.webextensions.remote false
3) процесс для работы с графикой;
можно отключить в about:config:
layers.gpu-process.enabled false
4) рендеринг содержимого вкладок;
можно отключить в about:config:
browser.tabs.remote.autostart false
или отрегулировать количество процессов данного вида
dom.ipc.processCount 1
5) media decoder process (RDD)
можно отключить в about:config:
media.rdd-process.enabled false
6) privileged content process (новая вкладка firefox)
можно отключить в about:config:
browser.tabs.remote.separatePrivilegedContentProcess true
или (лучше) выключить целиком (если используется расширение, заменяющее новую вкладку: Quick Dial, Speed Dial [FVD] и т. п.)
browser.newtabpage.enabled false
Отредактировано жрнжп (19-12-2018 15:22:21)
№13 12-02-2018 21:31:56
Журавлёва Участник Группа: Members Зарегистрирован: 10-07-2016 Сообщений: 129 UA: 64.0
Re: 1 процесс в 5?
Coroner пишет
И не помню, чтобы он падал на других машинах.
Давно не припомню падений, но, вроде, при падении, Мозилла пытается отсылать куда-то какие-то отчёты о падениях.
Вполне, как версия, чтобы увеличить количество таких отчётов, все эти падения могут быть специально запрограммированы, для сбора инфы.
На других ваших машинах функция отчётов запрещена и там падений нет.
А там, где разрешена, там специально и падает.
Для особо придирчивых, повторяю, всё это, всего-лишь, версия, предположение, подозрение.
Отредактировано Журавлёва (12-02-2018 21:33:04)
№14 12-02-2018 21:38:12
Coroner Участник Группа: Members Зарегистрирован: 29-10-2012 Сообщений: 3970 UA: 58.0
Re: 1 процесс в 5?
Журавлёва пишет
На других ваших машинах функция отчётов запрещена и там падений нет.
Дык профиль то один и тот же. Да и толку от таких отчётов? Поддержку XP убрали, очевидно же что на очереди Win7.
Ответ (если он был бы) заключал бы необходимость обновит версию ОС, бла-бла-бла.
Да и падения редки. Тяжёлые страницы не гружу, а видео. Видео привык смотреть на видеоплеере.
Обработка и анализ данных с использованием Scala и Spark в Azure
В этой статье приводятся сведения о том, как использовать Scala, чтобы выполнять контролируемые задачи машинного обучения, применяя масштабируемую библиотеку машинного обучения (MLlib) Spark и пакеты Spark ML в кластере Spark Azure HDInsight. Здесь подробно расписаны задачи, которые образуют процесс обработки и анализа данных: прием и исследование данных, визуализация, проектирование признаков, моделирование и использование моделей. В этой статье использованы такие модели, как логистическая и линейная регрессии, случайные леса и деревья с градиентным повышением (GBT), а также две распространенные контролируемые задачи машинного обучения:
- регрессия: прогнозирование суммы чаевых (в долларах) за поездку в такси;
- двоичная классификация: прогнозирование вероятности оплаты чаевых (1 или 0) за поездку в такси.
Моделирование предусматривает обучение и оценку на основе наборов тестовых данных и соответствующих метрик точности. В этой статье вы узнаете, как сохранять эти модели в хранилище BLOB-объектов Azure, а также оценивать и анализировать производительность прогнозирования. В этой статье также подробнее рассматриваются способы оптимизации моделей с помощью перекрестной проверки и перебора гиперпараметров. В качестве данных используется доступный на сайте GitHub пример с числом поездок и тарифами нью-йоркского такси за 2013 год.
Scala— это язык для виртуальных машин Java, который обеспечивает интеграцию объектно-ориентированного подхода и функциональных качеств языка. Это масштабируемый язык, который отлично подходит для распределенной обработки в облаке и работает в кластерах Spark в Azure.
Spark — это платформа параллельной обработки с открытым исходным кодом, которая поддерживает обработку в памяти, повышая производительность приложений для анализа больших данных. Подсистема обработки Spark призвана ускорить разработку, повысить удобство использования и реализовать сложную аналитику. Возможности распределенного вычисления в памяти Spark отлично подходят для итеративных алгоритмов в машинном обучении и графовых вычислениях. Пакет spark.ml включает в себя единый набор API высокого уровня, созданных поверх кадров данных, позволяющих создавать и настраивать действующие конвейеры машинного обучения. MLlib — это масштабируемая библиотека машинного обучения Spark, которая предоставляет возможности моделирования для этой распределенной среды.
HDInsight Spark представляет собой версию платформы Spark с открытым исходным кодом, размещенную в Azure. Он также поддерживает в кластере Spark записные книжки Jupyter на языке Scala и может выполнять интерактивные запросы Spark SQL для преобразования, фильтрации и визуализации данных из хранилища BLOB-объектов Azure. В этой статье фрагменты кода Scala, которые предоставляют решения и формируют соответствующие графики с целью визуализации данных, выполняются в записных книжках Jupyter, установленных в кластерах Spark. Этапы моделирования, описанные в этих разделах, содержат код, который демонстрирует способ обучения, анализа, сохранения и использования каждого типа модели.
Действия по настройке и код, указанные в этой статье, предназначены для HDInsight 3.4 Spark 1.6. Однако код в этой статье и в записных книжках Jupyter на языке Scala является универсальным и должен работать в любом кластере Spark. Действия по настройке кластера и управлению им могут немного отличаться от приведенных в этой статье, если вы не используете HDInsight Spark.
О том, как использовать Python вместо Scala для выполнения задач по полной обработке и анализу данных, см. в статье Общие сведения об обработке и анализе данных с помощью платформы Spark в Azure HDInsight.
Необходимые компоненты
- У вас должна быть подписка Azure. Если у вас ее нет, получите бесплатную пробную версию Azure.
- Для выполнения дальнейших действия требуется кластер Azure HDInsight 3.4 Spark 1.6. Создайте его, выполнив инструкции в статье Начало работы. Создание кластера Apache Spark в HDInsight на платформе Linux и выполнение интерактивных запросов с помощью SQL Spark. Укажите тип и версию кластера с помощью меню Выберите тип кластера .

Предупреждение
Счета за кластеры HDInsight выставляются пропорционально в минутах, независимо от их использования. Обязательно удалите кластер, когда завершите его использование. Дополнительные сведения см. в статье Удаление кластера HDInsight с помощью браузера, PowerShell или классического интерфейса Azure CLI.
Описание данных о поездках в такси Нью-Йорка и инструкции о том, как выполнить код из записной книжки Jupyter в кластере Spark, см. в соответствующих разделах статьи Общие сведения об обработке и анализе данных с помощью платформы Spark в Azure HDInsight.
Выполнение кода Scala из записной книжки Jupyter в кластере Spark
Записную книжку Jupyter можно запустить с портала Azure. На панели мониторинга найдите кластер Spark и щелкните его, чтобы войти на страницу управления кластером. Затем щелкните Панели мониторинга кластера и выберите элемент Записная книжка Jupyter, чтобы открыть записную книжку, связанную с кластером Spark.

Вы также можете получить доступ к записным книжкам Jupyter. https://.azurehdinsight.net/jupyter Замените именем кластера. Для доступа к записным книжкам Jupyter требуется пароль учетной записи администратора.

Выберите Scala , чтобы открыть каталог, содержащий несколько примеров предварительно упакованных записных книжек, в которых используется API PySpark. Записная книжка «Exploration Modeling and Scoring using Scala.ipynb» с примерами кода для этой группы разделов о Spark доступна на сайте GitHub.
Записную книжку можно отправить непосредственно из GitHub на сервер записных книжек Jupyter в кластере Spark. На домашней странице записной книжки Jupyter нажмите кнопку Отправить . В проводнике вставьте URL-адрес GitHub (необработанное содержимое) для записной книжки Scala и нажмите кнопку Открыть. Записная книжка Scala доступна по следующей URL-ссылке:
Настройка: предустановленные контексты Spark и Hive, а также магические команды и библиотеки Spark
Предустановленные контексты Spark и Hive
# SET THE START TIME import java.util.Calendar val beginningTime = Calendar.getInstance().getTime() Ядра Spark, входящие в состав записных книжек Jupyter, имеют предустановленные контексты. Перед началом работы с разрабатываемым приложением вам не нужно явно задавать контексты Spark или Hive. Предустановленные контексты:
- sc — для контекста Spark;
- sqlContext — для контекста Hive.
Волшебные команды Spark
Ядро Spark предусматривает несколько «магических команд». Это специальные команды, которые можно вызывать, используя %% . В следующих примерах кода используются две подобные команды.
- %%local указывает, что код в последующих строках будет выполнен локально. Это должен быть допустимый код Scala.
- %%sql -o выполняет запрос Hive к sqlContext . Если передан параметр -o , то результат запроса сохраняется в контексте %%local Scala в качестве кадра данных Spark.
Дополнительные сведения о ядрах для записных книжек Jupyter и предварительно заданных магических командах, вызываемых с помощью оператора %% (например, %%local ), см. в статье Ядра, доступные для использования записными книжками Jupyter с кластерами Apache Spark в HDInsight на платформе Linux.
Импорт библиотек
Импортируйте Spark, MLlib и другие необходимые библиотеки, используя следующий код:
# IMPORT SPARK AND JAVA LIBRARIES import org.apache.spark.sql.SQLContext import org.apache.spark.sql.functions._ import java.text.SimpleDateFormat import java.util.Calendar import sqlContext.implicits._ import org.apache.spark.sql.Row # IMPORT SPARK SQL FUNCTIONS import org.apache.spark.sql.types. import org.apache.spark.sql.functions.rand # IMPORT SPARK ML FUNCTIONS import org.apache.spark.ml.Pipeline import org.apache.spark.ml.feature. import org.apache.spark.ml.tuning. import org.apache.spark.ml.regression. import org.apache.spark.ml.classification. import org.apache.spark.ml.evaluation. # IMPORT SPARK MLLIB FUNCTIONS import org.apache.spark.mllib.linalg. import org.apache.spark.mllib.util.MLUtils import org.apache.spark.mllib.classification. import org.apache.spark.mllib.regression. import org.apache.spark.mllib.tree. import org.apache.spark.mllib.tree.configuration.BoostingStrategy import org.apache.spark.mllib.tree.model. import org.apache.spark.mllib.evaluation. # SPECIFY SQLCONTEXT val sqlContext = new SQLContext(sc) Прием данных
Чтобы начать анализ и обработку необходимых данных, требуется сначала принять эти данные. Данные принимаются из внешних источников или систем, в которых они находятся, в среду исследования и моделирования данных. В этой статье принимаемые данные являются объединенной 0,1-процентной выборкой файла данных поездок и тарифов такси (хранящегося в виде TSV-файла). В качестве среды исследования и моделирования данных используется среда Spark. Этот раздел содержит код, с помощью которого можно выполнить следующие задачи:
- Установка пути к каталогам для хранения данных и моделей.
- Считывание входного набора данных (TSV-файл).
- Определение схемы для данных и очистка данных.
- Создание очищенного кадра данных и его кэширование в памяти.
- Регистрация данных в виде временной таблицы в SQLContext.
- Выполнение запроса к таблице и импорт результатов в кадр данных.
Настройка путей каталога к местам хранения в хранилище BLOB-объектов Azure
Spark может выполнять чтение и запись данных в хранилище BLOB-объектов Azure. Существующие данные можно обрабатывать с помощью Spark, а затем сохранять полученные данные в хранилище BLOB-объектов.
Чтобы сохранить модели или файлы в хранилище BLOB-объектов, необходимо правильно указать путь. Укажите контейнер по умолчанию, присоединенный к кластеру Spark, с помощью пути, который начинается с wasb:/// . Другие расположения указываются с помощью wasb:// .
В следующем примере кода указывается расположение входных данных для чтения и путь к хранилищу BLOB-объектов, присоединенному к кластеру Spark, в котором будет сохранена модель.
# SET PATHS TO DATA AND MODEL FILE LOCATIONS # INGEST DATA AND SPECIFY HEADERS FOR COLUMNS val taxi_train_file = sc.textFile("wasb://mllibwalkthroughs@cdspsparksamples.blob.core.windows.net/Data/NYCTaxi/JoinedTaxiTripFare.Point1Pct.Train.tsv") val header = taxi_train_file.first; # SET THE MODEL STORAGE DIRECTORY PATH # NOTE THAT THE FINAL BACKSLASH IN THE PATH IS REQUIRED. val modelDir = "wasb:///user/remoteuser/NYCTaxi/Models/"; Импорт данных, создание RDD и определение кадра данных согласно схеме
# RECORD THE START TIME val starttime = Calendar.getInstance().getTime() # DEFINE THE SCHEMA BASED ON THE HEADER OF THE FILE val sqlContext = new SQLContext(sc) val taxi_schema = StructType( Array( StructField("medallion", StringType, true), StructField("hack_license", StringType, true), StructField("vendor_id", StringType, true), StructField("rate_code", DoubleType, true), StructField("store_and_fwd_flag", StringType, true), StructField("pickup_datetime", StringType, true), StructField("dropoff_datetime", StringType, true), StructField("pickup_hour", DoubleType, true), StructField("pickup_week", DoubleType, true), StructField("weekday", DoubleType, true), StructField("passenger_count", DoubleType, true), StructField("trip_time_in_secs", DoubleType, true), StructField("trip_distance", DoubleType, true), StructField("pickup_longitude", DoubleType, true), StructField("pickup_latitude", DoubleType, true), StructField("dropoff_longitude", DoubleType, true), StructField("dropoff_latitude", DoubleType, true), StructField("direct_distance", StringType, true), StructField("payment_type", StringType, true), StructField("fare_amount", DoubleType, true), StructField("surcharge", DoubleType, true), StructField("mta_tax", DoubleType, true), StructField("tip_amount", DoubleType, true), StructField("tolls_amount", DoubleType, true), StructField("total_amount", DoubleType, true), StructField("tipped", DoubleType, true), StructField("tip_class", DoubleType, true) ) ) # CAST VARIABLES ACCORDING TO THE SCHEMA val taxi_temp = (taxi_train_file.map(_.split("\t")) .filter((r) => r(0) != "medallion") .map(p => Row(p(0), p(1), p(2), p(3).toDouble, p(4), p(5), p(6), p(7).toDouble, p(8).toDouble, p(9).toDouble, p(10).toDouble, p(11).toDouble, p(12).toDouble, p(13).toDouble, p(14).toDouble, p(15).toDouble, p(16).toDouble, p(17), p(18), p(19).toDouble, p(20).toDouble, p(21).toDouble, p(22).toDouble, p(23).toDouble, p(24).toDouble, p(25).toDouble, p(26).toDouble))) # CREATE AN INITIAL DATA FRAME AND DROP COLUMNS, AND THEN CREATE A CLEANED DATA FRAME BY FILTERING FOR UNWANTED VALUES OR OUTLIERS val taxi_train_df = sqlContext.createDataFrame(taxi_temp, taxi_schema) val taxi_df_train_cleaned = (taxi_train_df.drop(taxi_train_df.col("medallion")) .drop(taxi_train_df.col("hack_license")).drop(taxi_train_df.col("store_and_fwd_flag")) .drop(taxi_train_df.col("pickup_datetime")).drop(taxi_train_df.col("dropoff_datetime")) .drop(taxi_train_df.col("pickup_longitude")).drop(taxi_train_df.col("pickup_latitude")) .drop(taxi_train_df.col("dropoff_longitude")).drop(taxi_train_df.col("dropoff_latitude")) .drop(taxi_train_df.col("surcharge")).drop(taxi_train_df.col("mta_tax")) .drop(taxi_train_df.col("direct_distance")).drop(taxi_train_df.col("tolls_amount")) .drop(taxi_train_df.col("total_amount")).drop(taxi_train_df.col("tip_class")) .filter("passenger_count > 0 and passenger_count < 8 AND payment_type in ('CSH', 'CRD') AND tip_amount >= 0 AND tip_amount < 30 AND fare_amount >= 1 AND fare_amount < 150 AND trip_distance >0 AND trip_distance < 100 AND trip_time_in_secs >30 AND trip_time_in_secs < 7200")); # CACHE AND MATERIALIZE THE CLEANED DATA FRAME IN MEMORY taxi_df_train_cleaned.cache() taxi_df_train_cleaned.count() # REGISTER THE DATA FRAME AS A TEMPORARY TABLE IN SQLCONTEXT taxi_df_train_cleaned.registerTempTable("taxi_train") # GET THE TIME TO RUN THE CELL val endtime = Calendar.getInstance().getTime() val elapsedtime = ((endtime.getTime() - starttime.getTime())/1000).toString; println("Time taken to run the above cell: " + elapsedtime + " seconds."); Выходные данные:
Время, затраченное на выполнение кода, — 8 секунд.
Выполнение запроса к таблице и импорт результатов в кадр данных
Теперь запросите данные о поездках, пассажирах и чаевых из таблицы, отфильтруйте поврежденные и несвойственные данные, а затем выведите несколько строк.
# QUERY THE DATA val sqlStatement = """ SELECT fare_amount, passenger_count, tip_amount, tipped FROM taxi_train WHERE passenger_count > 0 AND passenger_count < 7 AND fare_amount >0 AND fare_amount < 200 AND payment_type in ('CSH', 'CRD') AND tip_amount >0 AND tip_amount < 25 """ val sqlResultsDF = sqlContext.sql(sqlStatement) # SHOW ONLY THE TOP THREE ROWS sqlResultsDF.show(3) Выходные данные:
| fare_amount | passenger_count | tip_amount | tipped |
|---|---|---|---|
| 13,5 долл. США | 1.0 | 2,9 | 1.0 |
| 16,0 | 2.0 | 3,4 | 1.0 |
| 10,5 | 2.0 | 1.0 | 1.0 |
Исследование и визуализация данных
После помещения данных в Spark необходимо исследовать и визуализировать их, чтобы получить более глубокое представление. В этом разделе вы изучите данные такси, используя запросы SQL. Затем вы импортируете результаты в кадр данных, чтобы графически показать целевые переменные и потенциальные признаки, а также проверить их визуально с помощью функции автоматической визуализации Jupyter.
Использование волшебных команд local и SQL для графического представления данных
По умолчанию выходные данные фрагмента кода, выполняемого из записной книжки Jupyter, доступны в контексте сеанса, сохраненного на рабочих узлах. Если для каждого вычисления нужно сохранить данные о поездке на рабочих узлах и все данные, необходимые для вычислений, доступны локально на узле сервера Jupyter (который является головным), то можно использовать магическую команду %%local , чтобы выполнить фрагмент кода на сервере Jupyter.
- Волшебная команда SQL ( %%sql ). Ядро HDInsight Spark позволяет легко выполнять встроенные запросы HiveQL к SQLContext. Аргумент ( -o VARIABLE_NAME ) сохраняет выходные данные запроса SQL в формате кадра данных Pandas на сервере Jupyter. Этот параметр означает, что выходные данные будут доступны в локальном режиме.
- %%local Волшебная команда. Магическая команда %%local локально выполняет код на сервере Jupyter, который представляет собой головной узел кластера HDInsight. Как правило, команда %%local используется в комбинации с магической командой %%sql с параметром -o . Параметр -o сохраняет выходные данные запроса SQL локально, после чего магическая команда %%local активирует следующий набор фрагментов кода, который выполняется локально с выходными данными запросов SQL, сохраненными на локальном компьютере.
Выполнение запроса на данные с использованием SQL
Этот запрос извлекает данные о поездках в такси на основе сведений суммы к оплате, количества пассажиров и суммы чаевых.
# RUN THE SQL QUERY %%sql -q -o sqlResults SELECT fare_amount, passenger_count, tip_amount, tipped FROM taxi_train WHERE passenger_count > 0 AND passenger_count < 7 AND fare_amount >0 AND fare_amount < 200 AND payment_type in ('CSH', 'CRD') AND tip_amount >0 AND tip_amount < 25 В приведенном ниже коде магическая команда %%local создает локальный кадр данных, sqlResults. Его можно использовать для построения графического представления с применением matplotlib.
В этой статье магическая команда local используется несколько раз. Если используется большой набор данных, сделайте выборку, чтобы создать кадр данных, который можно сохранить в локальной памяти.
Графическое представление данных
Данные можно графически показать с помощью кода Python, когда таблица данных уже находится в локальном контексте в формате кадра данных Pandas.
# RUN THE CODE LOCALLY ON THE JUPYTER SERVER %%local # USE THE JUPYTER AUTO-PLOTTING FEATURE TO CREATE INTERACTIVE FIGURES. # CLICK THE TYPE OF PLOT TO GENERATE (LINE, AREA, BAR, ETC.) sqlResults Ядро Spark автоматически визуализирует выходные данные запросов SQL (HiveQL) после выполнения кода. Вы можете выбрать тип визуализации среди нескольких типов:
- Таблицу
- Круговая
- Линия
- Область
- Линейчатая диаграмма
Ниже приведен код для графического представления данных:
# RUN THE CODE LOCALLY ON THE JUPYTER SERVER AND IMPORT LIBRARIES %%local import matplotlib.pyplot as plt %matplotlib inline # PLOT TIP BY PAYMENT TYPE AND PASSENGER COUNT ax1 = sqlResults[['tip_amount']].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show() # PLOT TIP BY PASSENGER COUNT ax2 = sqlResults.boxplot(column=['tip_amount'], by=['passenger_count']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') plt.suptitle('') plt.show() # PLOT TIP AMOUNT BY FARE AMOUNT; SCALE POINTS BY PASSENGER COUNT ax = sqlResults.plot(kind='scatter', x= 'fare_amount', y = 'tip_amount', c='blue', alpha = 0.10, s=5*(sqlResults.passenger_count)) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.show() Выходные данные:



Создание и преобразование признаков, а также последующая подготовка данных для ввода в функции моделирования
Для использования функций древовидного моделирования из Spark ML и MLlib необходимо подготовить целевые объекты и признаки, применяя различные методы, такие как группирование, индексирование, прямое кодирование и векторизация. В этом разделе рассматриваются следующие процедуры:
- Создание нового признака путем группирования часов в периоды трафика.
- Применение индексирования и прямого кодирования к категориальным признакам.
- Выборка и разбиение набора данных на обучающую и проверочную части.
- Указание переменной обучения и признаков, а затем создание индексированных или прямо закодированных обучающих и проверочных устойчивых распределенных наборов данных (RDD) или входящих кадров данных с помеченной вершиной.
- Автоматическая категоризация и векторизация целевых объектов и признаков для использования в качестве входных данных моделей машинного обучения.
создание нового признака путем группирования часов в периоды трафика;
В следующем коде показано, как создать признак путем группирования часов в периоды трафика и как кэшировать итоговый кадр данных в памяти. Если RDD и кадры данных используются постоянно, то на их кэширование необходимо меньше времени. Ниже описан процесс кэширования RDD и кадров данных, выполняемый в несколько этапов.
# CREATE FOUR BUCKETS FOR TRAFFIC TIMES val sqlStatement = """ SELECT *, CASE WHEN (pickup_hour = 20) THEN "Night" WHEN (pickup_hour >= 7 AND pickup_hour = 11 AND pickup_hour = 16 AND pickup_hour Индексирование и прямое кодирование категориальных признаков
Перед использованием в функциях моделирования и прогнозирования MLlib категориальные входные данные сначала необходимо проиндексировать или закодировать. В этом разделе показано, как индексировать и кодировать категориальные признаки в качестве ввода для функций моделирования.
В зависимости от модели этот процесс происходит по-разному. Например, для моделей логистической и линейной регрессии требуется прямое кодирование. Скажем, признак с тремя категориями можно представить в виде трех столбцов признаков. Каждый столбец будет содержать 0 или 1 в зависимости от категории наблюдения. Для прямого кодирования можно использовать функцию OneHotEncoder в MLlib. Этот кодировщик сопоставляет столбец с индексами меток со столбцом двоичных векторов, имеющих максимум одно отдельное значение. Благодаря этой кодировке алгоритмы, для которых необходимы признаки с числовыми значениями (например, логистическая регрессия), можно применять к категориальным признакам.
Здесь вы преобразуете только четыре переменных, чтобы показать примеры, которые представляют собой строки символов. Вы также можете индексировать другие переменные, такие как день недели, представленные числовыми значениями, в качестве категориальных переменных.
Для индексирования используйте функцию StringIndexer() , а для прямого кодирования — OneHotEncoder() из MLlib. Ниже приведен пример кода, с помощью которого можно проиндексировать и закодировать категориальные признаки.
# CREATE INDEXES AND ONE-HOT ENCODED VECTORS FOR SEVERAL CATEGORICAL FEATURES # RECORD THE START TIME val starttime = Calendar.getInstance().getTime() # INDEX AND ENCODE VENDOR_ID val stringIndexer = new StringIndexer().setInputCol("vendor_id").setOutputCol("vendorIndex").fit(taxi_df_train_with_newFeatures) val indexed = stringIndexer.transform(taxi_df_train_with_newFeatures) val encoder = new OneHotEncoder().setInputCol("vendorIndex").setOutputCol("vendorVec") val encoded1 = encoder.transform(indexed) # INDEX AND ENCODE RATE_CODE val stringIndexer = new StringIndexer().setInputCol("rate_code").setOutputCol("rateIndex").fit(encoded1) val indexed = stringIndexer.transform(encoded1) val encoder = new OneHotEncoder().setInputCol("rateIndex").setOutputCol("rateVec") val encoded2 = encoder.transform(indexed) # INDEX AND ENCODE PAYMENT_TYPE val stringIndexer = new StringIndexer().setInputCol("payment_type").setOutputCol("paymentIndex").fit(encoded2) val indexed = stringIndexer.transform(encoded2) val encoder = new OneHotEncoder().setInputCol("paymentIndex").setOutputCol("paymentVec") val encoded3 = encoder.transform(indexed) # INDEX AND TRAFFIC TIME BINS val stringIndexer = new StringIndexer().setInputCol("TrafficTimeBins").setOutputCol("TrafficTimeBinsIndex").fit(encoded3) val indexed = stringIndexer.transform(encoded3) val encoder = new OneHotEncoder().setInputCol("TrafficTimeBinsIndex").setOutputCol("TrafficTimeBinsVec") val encodedFinal = encoder.transform(indexed) # GET THE TIME TO RUN THE CELL val endtime = Calendar.getInstance().getTime() val elapsedtime = ((endtime.getTime() - starttime.getTime())/1000).toString; println("Time taken to run the above cell: " + elapsedtime + " seconds."); Выходные данные:
Время, затраченное на выполнение кода, — 4 секунды.
Выборка и разбиение набора данных на обучающую и проверочную части
С помощью кода в этом разделе создается случайная выборка данных (в примере используется 25 %). Несмотря на то, что из-за небольшого размера используемого набора данных выполнять выборку необязательно, данная статья покажет, как ее делать. Это поможет вам в случае возникновения проблем. Если выборки большие, этот процесс может значительно сэкономить время обучения моделей. Затем мы разобьем выборку данных на наборы для обучения (в примере используется 75 %) и тестирования (25 % соответственно), которые будут использоваться для классификации и регрессии.
Добавьте случайное число (от 0 до 1) в каждую строку (в столбце rand), которую можно использовать для выбора сверток перекрестной проверки во время обучения.
# RECORD THE START TIME val starttime = Calendar.getInstance().getTime() # SPECIFY SAMPLING AND SPLITTING FRACTIONS val samplingFraction = 0.25; val trainingFraction = 0.75; val testingFraction = (1-trainingFraction); val seed = 1234; val encodedFinalSampledTmp = encodedFinal.sample(withReplacement = false, fraction = samplingFraction, seed = seed) val sampledDFcount = encodedFinalSampledTmp.count().toInt val generateRandomDouble = udf(() => < scala.util.Random.nextDouble >) # ADD A RANDOM NUMBER FOR CROSS-VALIDATION val encodedFinalSampled = encodedFinalSampledTmp.withColumn("rand", generateRandomDouble()); # SPLIT THE SAMPLED DATA FRAME INTO TRAIN AND TEST, WITH A RANDOM COLUMN ADDED FOR DOING CROSS-VALIDATION (SHOWN LATER) # INCLUDE A RANDOM COLUMN FOR CREATING CROSS-VALIDATION FOLDS val splits = encodedFinalSampled.randomSplit(Array(trainingFraction, testingFraction), seed = seed) val trainData = splits(0) val testData = splits(1) # GET THE TIME TO RUN THE CELL val endtime = Calendar.getInstance().getTime() val elapsedtime = ((endtime.getTime() - starttime.getTime())/1000).toString; println("Time taken to run the above cell: " + elapsedtime + " seconds."); Выходные данные:
Время, затраченное на выполнение кода, — 2 секунды.
Указание переменной обучения и признаков, а также последующее создание индексированных или прямо закодированных обучающих и проверочных RDD или входящих кадров данных с помеченной вершиной
В этом разделе содержится код, с помощью которого можно индексировать категориальные текстовые данные в тип данных с помеченной вершиной, а затем закодировать их. После этого данные можно использовать для обучения и проверки модели логистической регрессии MLlib и других моделей классификации. Объекты с помеченной вершиной отформатированы в RDD, которые можно использовать в качестве входных данных для большинства алгоритмов машинного обучения в MLlib. Объект с помеченной вершиной — это разреженный или плотный локальный вектор, связанный с меткой или ответом.
В этом коде вы указываете целевую (зависимую) переменную и признаки, которые будут использоваться для обучения моделей. Затем вы создаете индексированные или прямо закодированные обучающие и проверочные RDD или входящие кадры данных с помеченной вершиной.
# RECORD THE START TIME val starttime = Calendar.getInstance().getTime() # MAP NAMES OF FEATURES AND TARGETS FOR CLASSIFICATION AND REGRESSION PROBLEMS val featuresIndOneHot = List("paymentVec", "vendorVec", "rateVec", "TrafficTimeBinsVec", "pickup_hour", "weekday", "passenger_count", "trip_time_in_secs", "trip_distance", "fare_amount").map(encodedFinalSampled.columns.indexOf(_)) val featuresIndIndex = List("paymentIndex", "vendorIndex", "rateIndex", "TrafficTimeBinsIndex", "pickup_hour", "weekday", "passenger_count", "trip_time_in_secs", "trip_distance", "fare_amount").map(encodedFinalSampled.columns.indexOf(_)) # SPECIFY THE TARGET FOR CLASSIFICATION ('tipped') AND REGRESSION ('tip_amount') PROBLEMS val targetIndBinary = List("tipped").map(encodedFinalSampled.columns.indexOf(_)) val targetIndRegression = List("tip_amount").map(encodedFinalSampled.columns.indexOf(_)) # CREATE INDEXED LABELED POINT RDD OBJECTS val indexedTRAINbinary = trainData.rdd.map(r => LabeledPoint(r.getDouble(targetIndBinary(0).toInt), Vectors.dense(featuresIndIndex.map(r.getDouble(_)).toArray))) val indexedTESTbinary = testData.rdd.map(r => LabeledPoint(r.getDouble(targetIndBinary(0).toInt), Vectors.dense(featuresIndIndex.map(r.getDouble(_)).toArray))) val indexedTRAINreg = trainData.rdd.map(r => LabeledPoint(r.getDouble(targetIndRegression(0).toInt), Vectors.dense(featuresIndIndex.map(r.getDouble(_)).toArray))) val indexedTESTreg = testData.rdd.map(r => LabeledPoint(r.getDouble(targetIndRegression(0).toInt), Vectors.dense(featuresIndIndex.map(r.getDouble(_)).toArray))) # CREATE INDEXED DATA FRAMES THAT YOU CAN USE TO TRAIN BY USING SPARK ML FUNCTIONS val indexedTRAINbinaryDF = indexedTRAINbinary.toDF() val indexedTESTbinaryDF = indexedTESTbinary.toDF() val indexedTRAINregDF = indexedTRAINreg.toDF() val indexedTESTregDF = indexedTESTreg.toDF() # CREATE ONE-HOT ENCODED (VECTORIZED) DATA FRAMES THAT YOU CAN USE TO TRAIN BY USING SPARK ML FUNCTIONS val assemblerOneHot = new VectorAssembler().setInputCols(Array("paymentVec", "vendorVec", "rateVec", "TrafficTimeBinsVec", "pickup_hour", "weekday", "passenger_count", "trip_time_in_secs", "trip_distance", "fare_amount")).setOutputCol("features") val OneHotTRAIN = assemblerOneHot.transform(trainData) val OneHotTEST = assemblerOneHot.transform(testData) # GET THE TIME TO RUN THE CELL val endtime = Calendar.getInstance().getTime() val elapsedtime = ((endtime.getTime() - starttime.getTime())/1000).toString; println("Time taken to run the above cell: " + elapsedtime + " seconds."); Выходные данные:
Время, затраченное на выполнение кода, — 4 секунды.
Автоматическая категоризация и векторизация целевых объектов и признаков для использования в качестве входных данных моделей машинного обучения
С помощью Spark ML категоризируйте целевой объект и признаки, которые нужно использовать в функциях древовидного моделирования. Код выполняет две задачи:
- Создает двоичный целевой объект для классификации, присваивая значение 0 или 1 каждой точке данных со значением от 0 до 1, используя пороговое значение 0,5.
- Автоматически категоризирует признаки. Если количество уникальных числовых значений для любого из признаков меньше 32, то этот признак категоризирован.
Ниже приведен код для этих двух задач.
# CATEGORIZE FEATURES AND BINARIZE THE TARGET FOR THE BINARY CLASSIFICATION PROBLEM # TRAIN DATA val indexer = new VectorIndexer().setInputCol("features").setOutputCol("featuresCat").setMaxCategories(32) val indexerModel = indexer.fit(indexedTRAINbinaryDF) val indexedTrainwithCatFeat = indexerModel.transform(indexedTRAINbinaryDF) val binarizer: Binarizer = new Binarizer().setInputCol("label").setOutputCol("labelBin").setThreshold(0.5) val indexedTRAINwithCatFeatBinTarget = binarizer.transform(indexedTrainwithCatFeat) # TEST DATA val indexerModel = indexer.fit(indexedTESTbinaryDF) val indexedTrainwithCatFeat = indexerModel.transform(indexedTESTbinaryDF) val binarizer: Binarizer = new Binarizer().setInputCol("label").setOutputCol("labelBin").setThreshold(0.5) val indexedTESTwithCatFeatBinTarget = binarizer.transform(indexedTrainwithCatFeat) # CATEGORIZE FEATURES FOR THE REGRESSION PROBLEM # CREATE PROPERLY INDEXED AND CATEGORIZED DATA FRAMES FOR TREE-BASED MODELS # TRAIN DATA val indexer = new VectorIndexer().setInputCol("features").setOutputCol("featuresCat").setMaxCategories(32) val indexerModel = indexer.fit(indexedTRAINregDF) val indexedTRAINwithCatFeat = indexerModel.transform(indexedTRAINregDF) # TEST DATA val indexerModel = indexer.fit(indexedTESTbinaryDF) val indexedTESTwithCatFeat = indexerModel.transform(indexedTESTregDF) Модель двоичной классификации: прогнозирование вероятности выплаты чаевых за поездку
В этом разделе создаются модели двоичной классификации трех типов, чтобы составить прогноз того, будут ли выплачены чаевые за поездку:
- модель логистической регрессии, используя функцию Spark ML LogisticRegression() ;
- модель классификации случайного леса, используя функцию Spark ML RandomForestClassifier() ;
- модель классификации по методу деревьев с градиентным повышением, используя функцию MLlib GradientBoostedTrees() .
Создание модели машинного обучения с помощью R
Теперь создайте модель логистической регрессии, используя функцию Spark ML LogisticRegression() . Создание кода сборки модели предполагает такую последовательность шагов:
- Обучение модели с использованием данных с одним набором параметров.
- Оценка модели на основе набора тестовых данных с метриками.
- Сохранение модели в хранилище BLOB-объектов для последующего использования.
- Оценка модели на основе тестовых данных.
- Графическое представление результатов в виде кривых ROC (рабочих характеристик приемника).
Ниже приведен код для выполнения этих процедур.
# CREATE A LOGISTIC REGRESSION MODEL val lr = new LogisticRegression().setLabelCol("tipped").setFeaturesCol("features").setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8) val lrModel = lr.fit(OneHotTRAIN) # PREDICT ON THE TEST DATA SET val predictions = lrModel.transform(OneHotTEST) # SELECT `BinaryClassificationEvaluator()` TO COMPUTE THE TEST ERROR val evaluator = new BinaryClassificationEvaluator().setLabelCol("tipped").setRawPredictionCol("probability").setMetricName("areaUnderROC") val ROC = evaluator.evaluate(predictions) println("ROC on test data = " + ROC) # SAVE THE MODEL val datestamp = Calendar.getInstance().getTime().toString.replaceAll(" ", ".").replaceAll(":", "_"); val modelName = "LogisticRegression__" val filename = modelDir.concat(modelName).concat(datestamp) lrModel.save(filename); Загрузите, оцените и сохраните результаты.
# RECORD THE START TIME val starttime = Calendar.getInstance().getTime() # LOAD THE SAVED MODEL AND SCORE THE TEST DATA SET val savedModel = org.apache.spark.ml.classification.LogisticRegressionModel.load(filename) println(s"Coefficients: $ Intercept: $") # SCORE THE MODEL ON THE TEST DATA val predictions = savedModel.transform(OneHotTEST).select("tipped","probability","rawPrediction") predictions.registerTempTable("testResults") # SELECT `BinaryClassificationEvaluator()` TO COMPUTE THE TEST ERROR val evaluator = new BinaryClassificationEvaluator().setLabelCol("tipped").setRawPredictionCol("probability").setMetricName("areaUnderROC") val ROC = evaluator.evaluate(predictions) # GET THE TIME TO RUN THE CELL val endtime = Calendar.getInstance().getTime() val elapsedtime = ((endtime.getTime() - starttime.getTime())/1000).toString; println("Time taken to run the above cell: " + elapsedtime + " seconds."); # PRINT THE ROC RESULTS println("ROC on test data = " + ROC) Выходные данные:
ROC для тестовых данных — 0,9827381497557599.
Примените код Python к кадрам данных Pandas, чтобы построить кривую ROC.
# QUERY THE RESULTS %%sql -q -o sqlResults SELECT tipped, probability from testResults # RUN THE CODE LOCALLY ON THE JUPYTER SERVER AND IMPORT LIBRARIES %%local %matplotlib inline from sklearn.metrics import roc_curve,auc sqlResults['probFloat'] = sqlResults.apply(lambda row: row['probability'].values()[0][1], axis=1) predictions_pddf = sqlResults[["tipped","probFloat"]] # PREDICT THE ROC CURVE # predictions_pddf = sqlResults.rename(columns=) prob = predictions_pddf["probFloat"] fpr, tpr, thresholds = roc_curve(predictions_pddf['tipped'], prob, pos_label=1); roc_auc = auc(fpr, tpr) # PLOT THE ROC CURVE plt.figure(figsize=(5,5)) plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc) plt.plot([0, 1], [0, 1], 'k--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('ROC Curve') plt.legend(loc="lower right") plt.show() Выходные данные:

Создание модели классификации случайного леса
Затем создайте модель классификации случайного леса, используя функцию Spark ML RandomForestClassifier() , и оцените модель на основе тестовых данных.
# RECORD THE START TIME val starttime = Calendar.getInstance().getTime() # CREATE THE RANDOM FOREST CLASSIFIER MODEL val rf = new RandomForestClassifier().setLabelCol("labelBin").setFeaturesCol("featuresCat").setNumTrees(10).setSeed(1234) # FIT THE MODEL val rfModel = rf.fit(indexedTRAINwithCatFeatBinTarget) val predictions = rfModel.transform(indexedTESTwithCatFeatBinTarget) # EVALUATE THE MODEL val evaluator = new MulticlassClassificationEvaluator().setLabelCol("label").setPredictionCol("prediction").setMetricName("f1") val Test_f1Score = evaluator.evaluate(predictions) println("F1 score on test data: " + Test_f1Score); # GET THE TIME TO RUN THE CELL val endtime = Calendar.getInstance().getTime() val elapsedtime = ((endtime.getTime() - starttime.getTime())/1000).toString; println("Time taken to run the above cell: " + elapsedtime + " seconds."); # CALCULATE BINARY CLASSIFICATION EVALUATION METRICS val evaluator = new BinaryClassificationEvaluator().setLabelCol("label").setRawPredictionCol("probability").setMetricName("areaUnderROC") val ROC = evaluator.evaluate(predictions) println("ROC on test data = " + ROC) Выходные данные:
ROC для тестовых данных — 0,9847103571552683.
Создание модели классификации по методу деревьев с градиентным повышением
Теперь создайте модель классификации по методу деревьев с градиентным повышением (GBT), используя функцию MLlib GradientBoostedTrees() , и оцените модель на основе тестовых данных.
# TRAIN A GBT CLASSIFICATION MODEL BY USING MLLIB AND A LABELED POINT # RECORD THE START TIME val starttime = Calendar.getInstance().getTime() # DEFINE THE GBT CLASSIFICATION MODEL val boostingStrategy = BoostingStrategy.defaultParams("Classification") boostingStrategy.numIterations = 20 boostingStrategy.treeStrategy.numClasses = 2 boostingStrategy.treeStrategy.maxDepth = 5 boostingStrategy.treeStrategy.categoricalFeaturesInfo = Map[Int, Int]((0,2),(1,2),(2,6),(3,4)) # TRAIN THE MODEL val gbtModel = GradientBoostedTrees.train(indexedTRAINbinary, boostingStrategy) # SAVE THE MODEL IN BLOB STORAGE val datestamp = Calendar.getInstance().getTime().toString.replaceAll(" ", ".").replaceAll(":", "_"); val modelName = "GBT_Classification__" val filename = modelDir.concat(modelName).concat(datestamp) gbtModel.save(sc, filename); # EVALUATE THE MODEL ON TEST INSTANCES AND THE COMPUTE TEST ERROR val labelAndPreds = indexedTESTbinary.map < point =>val prediction = gbtModel.predict(point.features) (point.label, prediction) > val testErr = labelAndPreds.filter(r => r._1 != r._2).count.toDouble / indexedTRAINbinary.count() //println("Learned classification GBT model:\n" + gbtModel.toDebugString) println("Test Error = " + testErr) # USE BINARY AND MULTICLASS METRICS TO EVALUATE THE MODEL ON THE TEST DATA val metrics = new MulticlassMetrics(labelAndPreds) println(s"Precision: $") println(s"Recall: $") println(s"F1 Score: $") val metrics = new BinaryClassificationMetrics(labelAndPreds) println(s"Area under PR curve: $") println(s"Area under ROC curve: $") # GET THE TIME TO RUN THE CELL val endtime = Calendar.getInstance().getTime() val elapsedtime = ((endtime.getTime() - starttime.getTime())/1000).toString; println("Time taken to run the above cell: " + elapsedtime + " seconds."); # PRINT THE ROC METRIC println(s"Area under ROC curve: $") Выходные данные:
площадь под ROC — 0,9846895479241554.
Модель регрессии: прогнозирование суммы чаевых
В этом разделе создаются модели регрессии двух типов, чтобы спрогнозировать сумму чаевых:
- модель регуляризованной линейной регрессии, используя функцию Spark ML LinearRegression() ; модель сохраняется и оценивается на основе тестовых данных;
- модель регрессии по методу деревьев с градиентным повышением, используя функцию Spark ML GBTRegressor() .
Создание регуляризованной линейной регрессии
# RECORD THE START TIME val starttime = Calendar.getInstance().getTime() # CREATE A REGULARIZED LINEAR REGRESSION MODEL BY USING THE SPARK ML FUNCTION AND DATA FRAMES val lr = new LinearRegression().setLabelCol("tip_amount").setFeaturesCol("features").setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8) # FIT THE MODEL BY USING DATA FRAMES val lrModel = lr.fit(OneHotTRAIN) println(s"Coefficients: $ Intercept: $") # SUMMARIZE THE MODEL OVER THE TRAINING SET AND PRINT METRICS val trainingSummary = lrModel.summary println(s"numIterations: $") println(s"objectiveHistory: $") trainingSummary.residuals.show() println(s"RMSE: $") println(s"r2: $") # SAVE THE MODEL IN AZURE BLOB STORAGE val datestamp = Calendar.getInstance().getTime().toString.replaceAll(" ", ".").replaceAll(":", "_"); val modelName = "LinearRegression__" val filename = modelDir.concat(modelName).concat(datestamp) lrModel.save(filename); # PRINT THE COEFFICIENTS println(s"Coefficients: $ Intercept: $") # SCORE THE MODEL ON TEST DATA val predictions = lrModel.transform(OneHotTEST) # EVALUATE THE MODEL ON TEST DATA val evaluator = new RegressionEvaluator().setLabelCol("tip_amount").setPredictionCol("prediction").setMetricName("r2") val r2 = evaluator.evaluate(predictions) println("R-sqr on test data = " + r2) # GET THE TIME TO RUN THE CELL val endtime = Calendar.getInstance().getTime() val elapsedtime = ((endtime.getTime() - starttime.getTime())/1000).toString; println("Time taken to run the above cell: " + elapsedtime + " seconds."); Выходные данные:
Время, затраченное на выполнение кода, — 13 секунд.
# LOAD A SAVED LINEAR REGRESSION MODEL FROM BLOB STORAGE AND SCORE A TEST DATA SET # RECORD THE START TIME val starttime = Calendar.getInstance().getTime() # LOAD A SAVED LINEAR REGRESSION MODEL FROM AZURE BLOB STORAGE val savedModel = org.apache.spark.ml.regression.LinearRegressionModel.load(filename) println(s"Coefficients: $ Intercept: $") # SCORE THE MODEL ON TEST DATA val predictions = savedModel.transform(OneHotTEST).select("tip_amount","prediction") predictions.registerTempTable("testResults") # EVALUATE THE MODEL ON TEST DATA val evaluator = new RegressionEvaluator().setLabelCol("tip_amount").setPredictionCol("prediction").setMetricName("r2") val r2 = evaluator.evaluate(predictions) println("R-sqr on test data = " + r2) # GET THE TIME TO RUN THE CELL val endtime = Calendar.getInstance().getTime() val elapsedtime = ((endtime.getTime() - starttime.getTime())/1000).toString; println("Time taken to run the above cell: " + elapsedtime + " seconds."); # PRINT THE RESULTS println("R-sqr on test data = " + r2) Выходные данные:
R-sqr для тестовых данных — 0,5960320470835743.
Теперь запросите результаты теста в формате кадра данных и визуализируйте их с помощью AutoVizWidget и matplotlib.
# RUN A SQL QUERY %%sql -q -o sqlResults select * from testResults # RUN THE CODE LOCALLY ON THE JUPYTER SERVER %%local # USE THE JUPYTER AUTO-PLOTTING FEATURE TO CREATE INTERACTIVE FIGURES # CLICK THE TYPE OF PLOT TO GENERATE (LINE, AREA, BAR, AND SO ON) sqlResults Этот код создает локальный кадр данных из выходных данных запроса и формирует графическое представление данных. Магическая команда %%local создает локальный кадр данных sqlResults , который можно использовать для формирования графического представления данных с помощью matplotlib.
В этой статье данная магическая команда Spark используется несколько раз. Если объем данных большой, сделайте выборку, чтобы создать кадр данных, который можно разместить в локальной памяти.
Создайте график с помощью "matplotlib" Python.
# RUN THE CODE LOCALLY ON THE JUPYTER SERVER AND IMPORT LIBRARIES %%local sqlResults %matplotlib inline import numpy as np # PLOT THE RESULTS ax = sqlResults.plot(kind='scatter', figsize = (6,6), x='tip_amount', y='prediction', color='blue', alpha = 0.25, label='Actual vs. predicted'); fit = np.polyfit(sqlResults['tip_amount'], sqlResults['prediction'], deg=1) ax.set_title('Actual vs. Predicted Tip Amounts ($)') ax.set_xlabel("Actual") ax.set_ylabel("Predicted") #ax.plot(sqlResults['tip_amount'], fit[0] * sqlResults['prediction'] + fit[1], color='magenta') plt.axis([-1, 15, -1, 8]) plt.show(ax) Выходные данные:

Создание модели регрессии GBT
Создайте модель регрессии по методу деревьев с градиентным повышением (GBT), используя функцию Spark ML GBTRegressor() , и оцените модель на основе тестовых данных.
Деревья с градиентным бустингом (GBTS) — это совокупности деревьев принятия решений. GBTS предусматривает итеративное обучение деревьев принятия решений, что позволяет свести потери к минимуму. Деревья с градиентным бустингом можно использовать для моделей регрессии и классификации. С их помощью можно обрабатывать категориальные признаки, а также определять нелинейные зависимости и взаимодействия признаков. Этот метод не требует масштабирования признаков. Кроме того, их можно использовать для создания модели мультиклассовой классификации.
# RECORD THE START TIME val starttime = Calendar.getInstance().getTime() # TRAIN A GBT REGRESSION MODEL val gbt = new GBTRegressor().setLabelCol("label").setFeaturesCol("featuresCat").setMaxIter(10) val gbtModel = gbt.fit(indexedTRAINwithCatFeat) # MAKE PREDICTIONS val predictions = gbtModel.transform(indexedTESTwithCatFeat) # COMPUTE TEST SET R2 val evaluator = new RegressionEvaluator().setLabelCol("label").setPredictionCol("prediction").setMetricName("r2") val Test_R2 = evaluator.evaluate(predictions) # GET THE TIME TO RUN THE CELL val endtime = Calendar.getInstance().getTime() val elapsedtime = ((endtime.getTime() - starttime.getTime())/1000).toString; println("Time taken to run the above cell: " + elapsedtime + " seconds."); # PRINT THE RESULTS println("Test R-sqr is: " + Test_R2); Выходные данные:
Test R-sqr — 0,7655383534596654.
Служебные программы расширенного моделирования для оптимизации
В этом разделе используются служебные программы машинного обучения, которые часто применяют для оптимизации моделей. В частности, есть три разных способа оптимизации моделей машинного обучения с использованием перебора параметров и перекрестной проверки.
- Разбиение данных на наборы данных для обучения и для проверки, оптимизация модели с использованием перебора гиперпараметров набора данных для обучения и оценки проверочного набора (линейная регрессия).
- Оптимизация модели с помощью перекрестной проверки и перебора гиперпараметров с использованием функции Spark ML "CrossValidator" (двоичная классификация).
- Оптимизация модели с помощью настраиваемого кода перекрестной проверки и перебора параметров, чтобы она использовала любые функции машинного обучения и наборы параметров (линейная регрессия).
Перекрестная проверка — это метод, который позволяет оценить, насколько хорошо модель, обученная на известном наборе данных, будет обобщаться для прогнозирования признаков наборов данных, на которых она не прошла обучение. Суть этого метода в том, что модель обучается на наборе известных данных, а затем точность ее прогнозов тестируется на независимом наборе данных. Это распространенная реализация, разделяющая набор данных на k-свертки и затем обучающая модель путем циклического перебора по всем сверткам, кроме одной.
Оптимизация гиперпараметров — это задача выбора набора гиперпараметров для алгоритма обучения, обычно с целью оптимизации меры производительности алгоритма на независимом наборе данных. Гиперпараметр — это значение, которое должно быть указано за пределами процедуры обучения модели. Предположения относительно значений гиперпараметров могут повлиять на гибкость и точность моделей. Деревья принятия решений содержат гиперпараметры, такие как требуемая глубина и число листьев на дереве. Для метода опорных векторов (SVM) необходимо задать условие штрафа за неправильную классификацию.
Распространенный способ выполнения оптимизации гиперпараметров — использовать поиск в сетке. Его также называют перебором параметров. Поиск в сетке заключается в выполнении тщательного поиска по значениям указанного подмножества пространства гиперпараметров для алгоритма обучения. Перекрестная проверка может предоставить метрику производительности, чтобы отсортировать оптимальные результаты, выданные алгоритмом поиска в сетке. Использование перекрестной проверки с перебором гиперпараметров помогает ограничить такие проблемы, как лжевзаимосвязи модели с обучающими данными. При этом модель сохраняет возможность применения к общему набору данных, из которого извлекаются данные для обучения.
Оптимизация модели линейной регрессии с помощью перебора гиперпараметров
Теперь разбейте данные на наборы данных для обучения и для проверки, используйте перебор гиперпараметров набора данных для обучения, чтобы оптимизировать модель, и оцените проверочный набор (линейная регрессия).
# RECORD THE START TIME val starttime = Calendar.getInstance().getTime() # RENAME `tip_amount` AS A LABEL val OneHotTRAINLabeled = OneHotTRAIN.select("tip_amount","features").withColumnRenamed(existingName="tip_amount",newName="label") val OneHotTESTLabeled = OneHotTEST.select("tip_amount","features").withColumnRenamed(existingName="tip_amount",newName="label") OneHotTRAINLabeled.cache() OneHotTESTLabeled.cache() # DEFINE THE ESTIMATOR FUNCTION: `THE LinearRegression()` FUNCTION val lr = new LinearRegression().setLabelCol("label").setFeaturesCol("features").setMaxIter(10) # DEFINE THE PARAMETER GRID val paramGrid = new ParamGridBuilder().addGrid(lr.regParam, Array(0.1, 0.01, 0.001)).addGrid(lr.fitIntercept).addGrid(lr.elasticNetParam, Array(0.1, 0.5, 0.9)).build() # DEFINE THE PIPELINE WITH A TRAIN/TEST VALIDATION SPLIT (75% IN THE TRAINING SET), AND THEN THE SPECIFY ESTIMATOR, EVALUATOR, AND PARAMETER GRID val trainPct = 0.75 val trainValidationSplit = new TrainValidationSplit().setEstimator(lr).setEvaluator(new RegressionEvaluator).setEstimatorParamMaps(paramGrid).setTrainRatio(trainPct) # RUN THE TRAIN VALIDATION SPLIT AND CHOOSE THE BEST SET OF PARAMETERS val model = trainValidationSplit.fit(OneHotTRAINLabeled) # MAKE PREDICTIONS ON THE TEST DATA BY USING THE MODEL WITH THE COMBINATION OF PARAMETERS THAT PERFORMS THE BEST val testResults = model.transform(OneHotTESTLabeled).select("label", "prediction") # COMPUTE TEST SET R2 val evaluator = new RegressionEvaluator().setLabelCol("label").setPredictionCol("prediction").setMetricName("r2") val Test_R2 = evaluator.evaluate(testResults) # GET THE TIME TO RUN THE CELL val endtime = Calendar.getInstance().getTime() val elapsedtime = ((endtime.getTime() - starttime.getTime())/1000).toString; println("Time taken to run the above cell: " + elapsedtime + " seconds."); println("Test R-sqr is: " + Test_R2); Выходные данные:
Test R-sqr — 0,6226484708501209
Оптимизация модели двоичной классификации с помощью перекрестной проверки и перебора гиперпараметров
В этом разделе показано, как оптимизировать модель двоичной классификации с помощью перекрестной проверки и перебора гиперпараметров. Для этого используется функция Spark ML CrossValidator .
# RECORD THE START TIME val starttime = Calendar.getInstance().getTime() # CREATE DATA FRAMES WITH PROPERLY LABELED COLUMNS TO USE WITH THE TRAIN AND TEST SPLIT val indexedTRAINwithCatFeatBinTargetRF = indexedTRAINwithCatFeatBinTarget.select("labelBin","featuresCat").withColumnRenamed(existingName="labelBin",newName="label").withColumnRenamed(existingName="featuresCat",newName="features") val indexedTESTwithCatFeatBinTargetRF = indexedTESTwithCatFeatBinTarget.select("labelBin","featuresCat").withColumnRenamed(existingName="labelBin",newName="label").withColumnRenamed(existingName="featuresCat",newName="features") indexedTRAINwithCatFeatBinTargetRF.cache() indexedTESTwithCatFeatBinTargetRF.cache() # DEFINE THE ESTIMATOR FUNCTION val rf = new RandomForestClassifier().setLabelCol("label").setFeaturesCol("features").setImpurity("gini").setSeed(1234).setFeatureSubsetStrategy("auto").setMaxBins(32) # DEFINE THE PARAMETER GRID val paramGrid = new ParamGridBuilder().addGrid(rf.maxDepth, Array(4,8)).addGrid(rf.numTrees, Array(5,10)).addGrid(rf.minInstancesPerNode, Array(100,300)).build() # SPECIFY THE NUMBER OF FOLDS val numFolds = 3 # DEFINE THE TRAIN/TEST VALIDATION SPLIT (75% IN THE TRAINING SET) val CrossValidator = new CrossValidator().setEstimator(rf).setEvaluator(new BinaryClassificationEvaluator).setEstimatorParamMaps(paramGrid).setNumFolds(numFolds) # RUN THE TRAIN VALIDATION SPLIT AND CHOOSE THE BEST SET OF PARAMETERS val model = CrossValidator.fit(indexedTRAINwithCatFeatBinTargetRF) # MAKE PREDICTIONS ON THE TEST DATA BY USING THE MODEL WITH THE COMBINATION OF PARAMETERS THAT PERFORMS THE BEST val testResults = model.transform(indexedTESTwithCatFeatBinTargetRF).select("label", "prediction") # COMPUTE THE TEST F1 SCORE val evaluator = new MulticlassClassificationEvaluator().setLabelCol("label").setPredictionCol("prediction").setMetricName("f1") val Test_f1Score = evaluator.evaluate(testResults) # GET THE TIME TO RUN THE CELL val endtime = Calendar.getInstance().getTime() val elapsedtime = ((endtime.getTime() - starttime.getTime())/1000).toString; println("Time taken to run the above cell: " + elapsedtime + " seconds."); Выходные данные:
Время, затраченное на выполнение кода, — 33 секунды.
Оптимизация модели линейной регрессии с помощью пользовательского кода перекрестной проверки и перебора параметров
Теперь оптимизируйте модель с помощью пользовательского кода и определите оптимальные параметры модели, используя критерий высокой точности. Затем создайте окончательную модель, оцените ее на основе тестовых данных и сохраните в хранилище BLOB-объектов. Наконец, загрузите модель, оцените тестовые данные и точность.
# RECORD THE START TIME val starttime = Calendar.getInstance().getTime() # DEFINE THE PARAMETER GRID AND THE NUMBER OF FOLDS val paramGrid = new ParamGridBuilder().addGrid(rf.maxDepth, Array(5,10)).addGrid(rf.numTrees, Array(10,25,50)).build() val nFolds = 3 val numModels = paramGrid.size val numParamsinGrid = 2 # SPECIFY THE NUMBER OF CATEGORIES FOR CATEGORICAL VARIABLES val categoricalFeaturesInfo = Map[Int, Int]((0,2),(1,2),(2,6),(3,4)) var maxDepth = -1 var numTrees = -1 var param = "" var paramval = -1 var validateLB = -1.0 var validateUB = -1.0 val h = 1.0 / nFolds; val RMSE = Array.fill(numModels)(0.0) # CREATE K-FOLDS val splits = MLUtils.kFold(indexedTRAINbinary, numFolds = nFolds, seed=1234) # LOOP THROUGH K-FOLDS AND THE PARAMETER GRID TO GET AND IDENTIFY THE BEST PARAMETER SET BY LEVEL OF ACCURACY for (i = validateLB && $"rand" < validateUB) val trainCV = trainData.filter($"rand" < validateLB || $"rand" >= validateUB) val validationLabPt = validationCV.rdd.map(r => LabeledPoint(r.getDouble(targetIndRegression(0).toInt), Vectors.dense(featuresIndIndex.map(r.getDouble(_)).toArray))); val trainCVLabPt = trainCV.rdd.map(r => LabeledPoint(r.getDouble(targetIndRegression(0).toInt), Vectors.dense(featuresIndIndex.map(r.getDouble(_)).toArray))); validationLabPt.cache() trainCVLabPt.cache() for (nParamSets if (param == "numTrees") > val rfModel = RandomForest.trainRegressor(trainCVLabPt, categoricalFeaturesInfo=categoricalFeaturesInfo, numTrees=numTrees, maxDepth=maxDepth, featureSubsetStrategy="auto",impurity="variance", maxBins=32) val labelAndPreds = validationLabPt.map < point =>val prediction = rfModel.predict(point.features) ( prediction, point.label ) > val validMetrics = new RegressionMetrics(labelAndPreds) val rmse = validMetrics.rootMeanSquaredError RMSE(nParamSets) += rmse > validationLabPt.unpersist(); trainCVLabPt.unpersist(); > val minRMSEindex = RMSE.indexOf(RMSE.min) # GET THE BEST PARAMETERS FROM A CROSS-VALIDATION AND PARAMETER SWEEP var best_maxDepth = -1 var best_numTrees = -1 for (nParams if (param == "numTrees") > # CREATE THE BEST MODEL WITH THE BEST PARAMETERS AND A FULL TRAINING DATA SET val best_rfModel = RandomForest.trainRegressor(indexedTRAINreg, categoricalFeaturesInfo=categoricalFeaturesInfo, numTrees=best_numTrees, maxDepth=best_maxDepth, featureSubsetStrategy="auto",impurity="variance", maxBins=32) # SAVE THE BEST RANDOM FOREST MODEL IN BLOB STORAGE val datestamp = Calendar.getInstance().getTime().toString.replaceAll(" ", ".").replaceAll(":", "_"); val modelName = "BestCV_RF_Regression__" val filename = modelDir.concat(modelName).concat(datestamp) best_rfModel.save(sc, filename); # PREDICT ON THE TRAINING SET WITH THE BEST MODEL AND THEN EVALUATE val labelAndPreds = indexedTESTreg.map < point =>val prediction = best_rfModel.predict(point.features) ( prediction, point.label ) > val test_rmse = new RegressionMetrics(labelAndPreds).rootMeanSquaredError val test_rsqr = new RegressionMetrics(labelAndPreds).r2 # GET THE TIME TO RUN THE CELL val endtime = Calendar.getInstance().getTime() val elapsedtime = ((endtime.getTime() - starttime.getTime())/1000).toString; println("Time taken to run the above cell: " + elapsedtime + " seconds."); # LOAD THE MODEL val savedRFModel = RandomForestModel.load(sc, filename) val labelAndPreds = indexedTESTreg.map < point =>val prediction = savedRFModel.predict(point.features) ( prediction, point.label ) > # TEST THE MODEL val test_rmse = new RegressionMetrics(labelAndPreds).rootMeanSquaredError val test_rsqr = new RegressionMetrics(labelAndPreds).r2 Выходные данные:
Время, затраченное на выполнение кода, — 61 секунда.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участник.
- Марк Табладильо | Старший архитектор облачных решений
Чтобы просмотреть недоступные профили LinkedIn, войдите в LinkedIn.