Извлечение данных с помощью объекта DataReader
Для извлечения данных с помощью объекта DataReader создайте экземпляр объекта Command, а затем создайте поставщика DataReader, вызвав метод Command.ExecuteReader для получения строк из источника данных. Объект DataReader предоставляет небуферизованный поток данных, позволяющий процедурам последовательно обрабатывать результаты из источника данных. Объект DataReader хорошо подходит для извлечения больших объемов данных, поскольку данные не кэшируются в памяти.
В следующем примере иллюстрируется использование объекта DataReader, где reader представляет допустимый DataReader, а command представляет допустимый объект Command.
reader = command.ExecuteReader(); reader = command.ExecuteReader() Используйте метод DataReader.Read для получения строки из результатов запроса. Доступ к отдельным столбцам возвращенной строки осуществляется по имени или порядковому номеру столбца через объект DataReader. Однако для максимальной производительности объект DataReader предоставляет ряд методов, позволяющих обращаться к значениям столбцов в их собственных типах данных (GetDateTime, GetDouble, GetGuid, GetInt32 и т. д.). Список типизированных методов доступа для dataReaders для конкретного поставщика данных см. в разделах OleDbDataReader и SqlDataReader. Использование типизированных методов доступа при известном базовом типе данных сокращает объем преобразований типов, необходимых при извлечении значения столбца.
В следующем примере просматриваются результаты, возвращенные объектом DataReader и возвращаются два столбца для каждой строки.
static void HasRows(SqlConnection connection) < using (connection) < SqlCommand command = new( "SELECT CategoryID, CategoryName FROM Categories;", connection); connection.Open(); SqlDataReader reader = command.ExecuteReader(); if (reader.HasRows) < while (reader.Read()) < Console.WriteLine("\t", reader.GetInt32(0), reader.GetString(1)); > > else < Console.WriteLine("No rows found."); >reader.Close(); > > Private Sub HasRows(ByVal connection As SqlConnection) Using connection Dim command As SqlCommand = New SqlCommand( _ "SELECT CategoryID, CategoryName FROM Categories;", _ connection) connection.Open() Dim reader As SqlDataReader = command.ExecuteReader() If reader.HasRows Then Do While reader.Read() Console.WriteLine(reader.GetInt32(0) _ & vbTab & reader.GetString(1)) Loop Else Console.WriteLine("No rows found.") End If reader.Close() End Using End Sub Закрытие DataReader
По окончании использования объекта DataReader всегда вызывайте метод Close.
Если метод Command содержит выходные параметры или возвращаемые значения, они будут недоступны до закрытия объекта DataReader.
Имейте в виду, что, пока объект DataReader открыт, соединение Connection используется исключительно этим объектом DataReader. Невозможно выполнять какие-либо команды для Connection, включая создание другого объекта DataReader, пока исходный объект DataReader не будет закрыт.
В методе Finalize вашего класса нельзя вызывать методы Close или Dispose объектов Connection, DataReader или любого другого управляемого объекта. В методе завершения следует только освобождать неуправляемые ресурсы, которыми ваш класс непосредственно владеет. Если класс не владеет какими-либо неуправляемыми ресурсами, не включайте в его определение метод Finalize. Дополнительные сведения см. в статье Сборка мусора.
Получение нескольких результирующих наборов с помощью NextResult
Если объект DataReader возвращает несколько результирующих наборов, используйте метод NextResult для просмотра наборов результатов по порядку. В следующем примере показан объект SqlDataReader, обрабатывающий результаты двух инструкций SELECT с помощью метода ExecuteReader.
static void RetrieveMultipleResults(SqlConnection connection) < using (connection) < SqlCommand command = new( "SELECT CategoryID, CategoryName FROM dbo.Categories;" + "SELECT EmployeeID, LastName FROM dbo.Employees", connection); connection.Open(); SqlDataReader reader = command.ExecuteReader(); while (reader.HasRows) < Console.WriteLine("\t\t", reader.GetName(0), reader.GetName(1)); while (reader.Read()) < Console.WriteLine("\t\t", reader.GetInt32(0), reader.GetString(1)); > reader.NextResult(); > > > Private Sub RetrieveMultipleResults(ByVal connection As SqlConnection) Using connection Dim command As SqlCommand = New SqlCommand( _ "SELECT CategoryID, CategoryName FROM Categories;" & _ "SELECT EmployeeID, LastName FROM Employees", connection) connection.Open() Dim reader As SqlDataReader = command.ExecuteReader() Do While reader.HasRows Console.WriteLine(vbTab & reader.GetName(0) _ & vbTab & reader.GetName(1)) Do While reader.Read() Console.WriteLine(vbTab & reader.GetInt32(0) _ & vbTab & reader.GetString(1)) Loop reader.NextResult() Loop End Using End Sub Получение сведений о схеме из DataReader
Когда открыт объект DataReader, с помощью метода GetSchemaTable можно получить данные схемы о текущем результирующем наборе. Метод GetSchemaTable возвращает объект DataTable, заполненный строками и столбцами, которые содержат данные схемы для текущего результирующего набора. Объект DataTable содержит одну строку для каждого столбца результирующего набора. Каждый столбец строки таблицы схемы соответствует свойству столбца, возвращенного в результирующем наборе, где ColumnName — это имя свойства, а значение столбца — это значение свойства. В следующем примере на консоль выводятся данные схемы для объекта DataReader.
static void GetSchemaInfo(SqlConnection connection) < using (connection) < SqlCommand command = new( "SELECT CategoryID, CategoryName FROM Categories;", connection); connection.Open(); SqlDataReader reader = command.ExecuteReader(); DataTable schemaTable = reader.GetSchemaTable(); foreach (DataRow row in schemaTable.Rows) < foreach (DataColumn column in schemaTable.Columns) < Console.WriteLine(string.Format("= ", column.ColumnName, row[column])); > > > > Private Sub GetSchemaInfo(ByVal connection As SqlConnection) Using connection Dim command As SqlCommand = New SqlCommand( _ "SELECT CategoryID, CategoryName FROM Categories;", _ connection) connection.Open() Dim reader As SqlDataReader = command.ExecuteReader() Dim schemaTable As DataTable = reader.GetSchemaTable() Dim row As DataRow Dim column As DataColumn For Each row In schemaTable.Rows For Each column In schemaTable.Columns Console.WriteLine(String.Format(" = ", _ column.ColumnName, row(column))) Next Console.WriteLine() Next reader.Close() End Using End Sub Работа с главами OLE DB
Иерархические наборы строк или главы (тип OLE DB DBTYPE_HCHAPTER, тип ADO adChapter) можно получить с помощью OleDbDataReader. Когда запрос, включающий главу, возвращается в виде DataReader, глава возвращается в виде столбца в этом DataReader и предоставляется в виде объекта DataReader .
ADO.NET DataSet также можно использовать для представления иерархических наборов строк с помощью связей «родители-потомки» между таблицами. Дополнительные сведения см. в разделах Наборы данных, DataTables и DataViews.
В следующем примере кода поставщик MSDataShape используется, чтобы сформировать столбец раздела заказов по каждому клиенту из списка клиентов.
Using connection As OleDbConnection = New OleDbConnection( "Provider=MSDataShape;Data Provider=SQLOLEDB;" & "Data Source=localhost;Integrated Security=SSPI;Initial Catalog=northwind") Using custCMD As OleDbCommand = New OleDbCommand( "SHAPE " & "APPEND ( AS CustomerOrders " & "RELATE CustomerID TO CustomerID)", connection) connection.Open() Using custReader As OleDbDataReader = custCMD.ExecuteReader() Do While custReader.Read() Console.WriteLine("Orders for " & custReader.GetString(1)) ' custReader.GetString(1) = CompanyName Using orderReader As OleDbDataReader = custReader.GetValue(2) ' custReader.GetValue(2) = Orders chapter as DataReader Do While orderReader.Read() Console.WriteLine(vbTab & orderReader.GetInt32(1)) ' orderReader.GetInt32(1) = OrderID Loop orderReader.Close() End Using Loop ' Make sure to always close readers and connections. custReader.Close() End Using End Using End Using using (OleDbConnection connection = new OleDbConnection( "Provider=MSDataShape;Data Provider=SQLOLEDB;" + "Data Source=localhost;Integrated Security=SSPI;Initial Catalog=northwind")) < using (OleDbCommand custCMD = new OleDbCommand( "SHAPE " + "APPEND ( AS CustomerOrders " + "RELATE CustomerID TO CustomerID)", connection)) < connection.Open(); using (OleDbDataReader custReader = custCMD.ExecuteReader()) < while (custReader.Read()) < Console.WriteLine("Orders for " + custReader.GetString(1)); // custReader.GetString(1) = CompanyName using (OleDbDataReader orderReader = (OleDbDataReader)custReader.GetValue(2)) < // custReader.GetValue(2) = Orders chapter as DataReader while (orderReader.Read()) Console.WriteLine("\t" + orderReader.GetInt32(1)); // orderReader.GetInt32(1) = OrderID orderReader.Close(); >> // Make sure to always close readers and connections. custReader.Close(); > > > Возврат результатов с помощью Oracle REF CURSOR
Поставщик данных .NET Framework для Oracle поддерживает использование параметров Oracle REF CURSOR для возвращения результата запроса. Параметр Oracle REF CURSOR возвращается в виде объекта OracleDataReader.
Объект, представляющий Oracle REF CURSOR, можно получить OracleDataReader с помощью ExecuteReader метода . Можно также указать объект , возвращающий OracleCommand один или несколько oracle REF CURSOR в качестве SelectCommand для объекта , используемого OracleDataAdapter для заполнения DataSet.
Чтобы получить доступ к REF CURSOR, возвращенному из источника данных Oracle, создайте OracleCommand для запроса и добавьте выходной параметр, который ссылается на REF CURSOR в Parameters коллекцию .OracleCommand Имя параметра должно соответствовать имени параметра REF CURSOR, используемого в запросе. Задайте для параметра OracleType.Cursorтип . Метод OracleCommand.ExecuteReader() объекта OracleCommand возвращает OracleDataReader для REF CURSOR.
Если возвращается OracleCommand несколько REF CURSORS, добавьте несколько выходных параметров. Вы можете получить доступ к различным REF CURSOR, вызвав OracleCommand.ExecuteReader() метод . Вызов возвращает ExecuteReader() объект , OracleDataReader ссылающийся на первый REF CURSOR. Затем можно вызвать OracleDataReader.NextResult() метод для доступа к последующим REF CURSOR. Хотя параметры в OracleCommand.Parameters коллекции соответствуют выходным параметрам REF CURSOR по имени, объект обращается к ним в том порядке, OracleDataReader в котором они были добавлены в коллекцию Parameters .
Например, рассмотрим следующий пакет и текст пакета Oracle.
CREATE OR REPLACE PACKAGE CURSPKG AS TYPE T_CURSOR IS REF CURSOR; PROCEDURE OPEN_TWO_CURSORS (EMPCURSOR OUT T_CURSOR, DEPTCURSOR OUT T_CURSOR); END CURSPKG; CREATE OR REPLACE PACKAGE BODY CURSPKG AS PROCEDURE OPEN_TWO_CURSORS (EMPCURSOR OUT T_CURSOR, DEPTCURSOR OUT T_CURSOR) IS BEGIN OPEN EMPCURSOR FOR SELECT * FROM DEMO.EMPLOYEE; OPEN DEPTCURSOR FOR SELECT * FROM DEMO.DEPARTMENT; END OPEN_TWO_CURSORS; END CURSPKG; Следующий код создает объект , OracleCommand который возвращает REF CURSORs из предыдущего пакета Oracle путем добавления двух параметров типа OracleType.Cursor в коллекцию OracleCommand.Parameters .
Dim cursCmd As OracleCommand = New OracleCommand("CURSPKG.OPEN_TWO_CURSORS", oraConn) cursCmd.Parameters.Add("EMPCURSOR", OracleType.Cursor).Direction = ParameterDirection.Output cursCmd.Parameters.Add("DEPTCURSOR", OracleType.Cursor).Direction = ParameterDirection.Output OracleCommand cursCmd = new OracleCommand("CURSPKG.OPEN_TWO_CURSORS", oraConn); cursCmd.Parameters.Add("EMPCURSOR", OracleType.Cursor).Direction = ParameterDirection.Output; cursCmd.Parameters.Add("DEPTCURSOR", OracleType.Cursor).Direction = ParameterDirection.Output; Следующий код возвращает результаты предыдущей команды с помощью Read() методов OracleDataReaderи NextResult() объекта . Параметры REF CURSOR возвращаются по порядку.
oraConn.Open() Dim cursCmd As OracleCommand = New OracleCommand("CURSPKG.OPEN_TWO_CURSORS", oraConn) cursCmd.CommandType = CommandType.StoredProcedure cursCmd.Parameters.Add("EMPCURSOR", OracleType.Cursor).Direction = ParameterDirection.Output cursCmd.Parameters.Add("DEPTCURSOR", OracleType.Cursor).Direction = ParameterDirection.Output Dim reader As OracleDataReader = cursCmd.ExecuteReader() Console.WriteLine(vbCrLf & "Emp ID" & vbTab & "Name") Do While reader.Read() Console.WriteLine("" & vbTab & ", ", reader.GetOracleNumber(0), reader.GetString(1), reader.GetString(2)) Loop reader.NextResult() Console.WriteLine(vbCrLf & "Dept ID" & vbTab & "Name") Do While reader.Read() Console.WriteLine("" & vbTab & "", reader.GetOracleNumber(0), reader.GetString(1)) Loop ' Make sure to always close readers and connections. reader.Close() oraConn.Close() oraConn.Open(); OracleCommand cursCmd = new OracleCommand("CURSPKG.OPEN_TWO_CURSORS", oraConn); cursCmd.CommandType = CommandType.StoredProcedure; cursCmd.Parameters.Add("EMPCURSOR", OracleType.Cursor).Direction = ParameterDirection.Output; cursCmd.Parameters.Add("DEPTCURSOR", OracleType.Cursor).Direction = ParameterDirection.Output; OracleDataReader reader = cursCmd.ExecuteReader(); Console.WriteLine("\nEmp ID\tName"); while (reader.Read()) Console.WriteLine("\t, ", reader.GetOracleNumber(0), reader.GetString(1), reader.GetString(2)); reader.NextResult(); Console.WriteLine("\nDept ID\tName"); while (reader.Read()) Console.WriteLine("\t", reader.GetOracleNumber(0), reader.GetString(1)); // Make sure to always close readers and connections. reader.Close(); oraConn.Close(); В следующем примере используется предыдущая DataSet команда для заполнения с результатами пакета Oracle.
Dim ds As DataSet = New DataSet() Dim adapter As OracleDataAdapter = New OracleDataAdapter(cursCmd) adapter.TableMappings.Add("Table", "Employees") adapter.TableMappings.Add("Table1", "Departments") adapter.Fill(ds) DataSet ds = new DataSet(); OracleDataAdapter adapter = new OracleDataAdapter(cursCmd); adapter.TableMappings.Add("Table", "Employees"); adapter.TableMappings.Add("Table1", "Departments"); adapter.Fill(ds); Чтобы избежать исключения OverflowException, рекомендуется также обрабатывать любое преобразование типа Oracle NUMBER в допустимый тип платформа .NET Framework перед сохранением значения в DataRow. Событие можно использовать, FillError чтобы определить, произошло ли исключение OverflowException . Дополнительные сведения о событии см. в FillError разделе Обработка событий DataAdapter.
См. также
- Объекты DataAdapter и DataReader
- Команды и параметры
- Извлечение сведений о схеме базы данных
- Общие сведения об ADO.NET
2.2 Основы Git — Запись изменений в репозиторий
Итак, у вас имеется настоящий Git-репозиторий и рабочая копия файлов для некоторого проекта. Вам нужно делать некоторые изменения и фиксировать «снимки» состояния (snapshots) этих изменений в вашем репозитории каждый раз, когда проект достигает состояния, которое вам хотелось бы сохранить.
Запомните, каждый файл в вашем рабочем каталоге может находиться в одном из двух состояний: под версионным контролем (отслеживаемые) и нет (неотслеживаемые). Отслеживаемые файлы — это те файлы, которые были в последнем снимке состояния проекта; они могут быть неизменёнными, изменёнными или подготовленными к коммиту. Если кратко, то отслеживаемые файлы — это те файлы, о которых знает Git.
Неотслеживаемые файлы — это всё остальное, любые файлы в вашем рабочем каталоге, которые не входили в ваш последний снимок состояния и не подготовлены к коммиту. Когда вы впервые клонируете репозиторий, все файлы будут отслеживаемыми и неизменёнными, потому что Git только что их извлек и вы ничего пока не редактировали.
Как только вы отредактируете файлы, Git будет рассматривать их как изменённые, так как вы изменили их с момента последнего коммита. Вы индексируете эти изменения, затем фиксируете все проиндексированные изменения, а затем цикл повторяется.
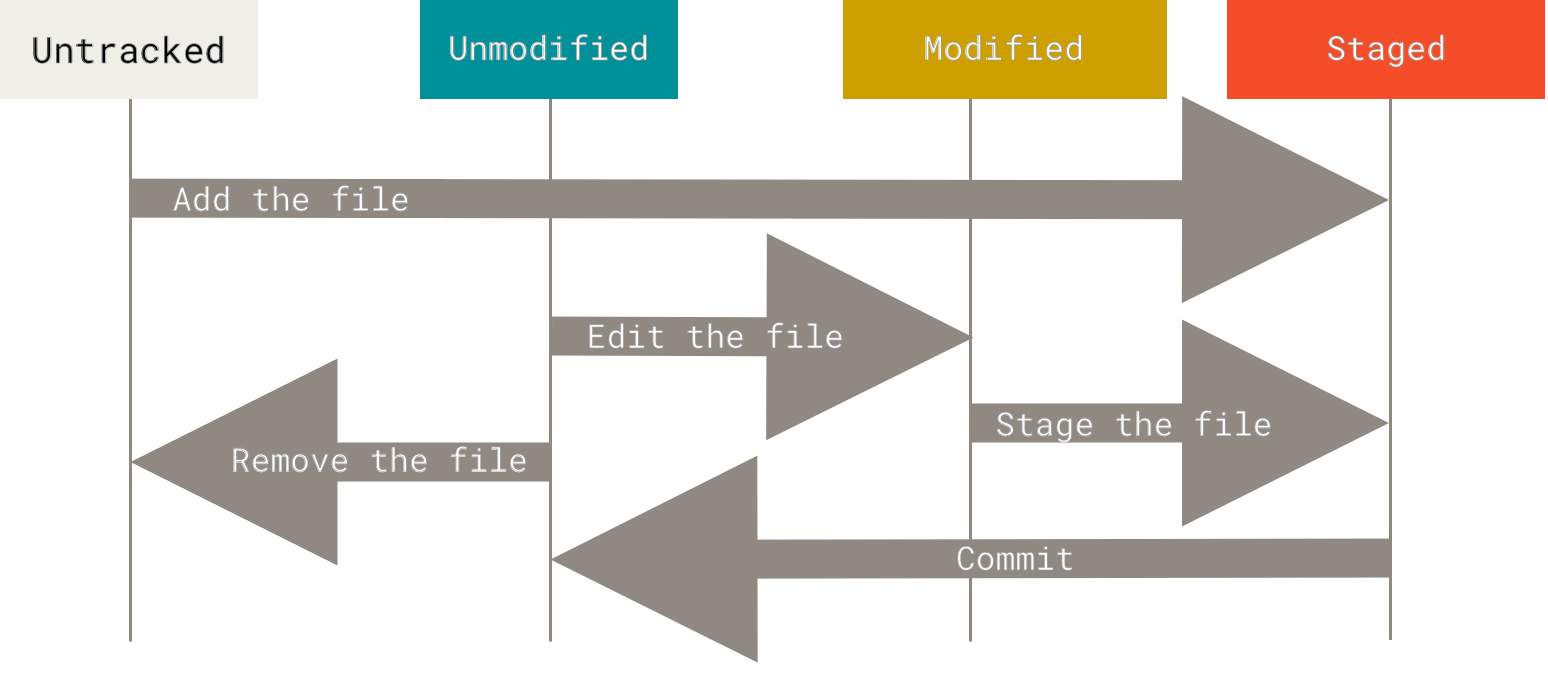
Рисунок 8. Жизненный цикл состояний файлов
Определение состояния файлов
Основной инструмент, используемый для определения, какие файлы в каком состоянии находятся — это команда git status . Если вы выполните эту команду сразу после клонирования, вы увидите что-то вроде этого:
$ git status On branch master Your branch is up-to-date with 'origin/master'. nothing to commit, working tree cleanЭто означает, что у вас чистый рабочий каталог, другими словами — в нём нет отслеживаемых изменённых файлов. Git также не обнаружил неотслеживаемых файлов, в противном случае они бы были перечислены здесь. Наконец, команда сообщает вам на какой ветке вы находитесь и сообщает вам, что она не расходится с веткой на сервере. Пока что это всегда ветка master , ветка по умолчанию; в этой главе это не важно. В главе Ветвление в Git будут рассмотрены ветки и ссылки более детально.
Примечание
В 2020 году GitHub изменил имя ветки по умолчанию с master на main , другие же git-хостинг платформы последовали этому примеру. Поэтому, вы можете обнаружить, что ветка по умолчанию для новых репозиториев — main , а не master . Более того, имя ветки по умолчанию можно изменить (как вы видели в Настройка ветки по умолчанию), поэтому вам может встретиться и другое имя. При этом Git продолжает использовать имя master , поэтому далее в книге мы используем именно его.
Предположим, вы добавили в свой проект новый файл, простой файл README . Если этого файла раньше не было, и вы выполните git status , вы увидите свой неотслеживаемый файл вот так:
$ echo 'My Project' > README $ git status On branch master Your branch is up-to-date with 'origin/master'. Untracked files: (use "git add . " to include in what will be committed) README nothing added to commit but untracked files present (use "git add" to track)Понять, что новый файл README неотслеживаемый можно по тому, что он находится в секции «Untracked files» в выводе команды status . Статус Untracked означает, что Git видит файл, которого не было в предыдущем снимке состояния (коммите); Git не станет добавлять его в ваши коммиты, пока вы его явно об этом не попросите. Это предохранит вас от случайного добавления в репозиторий сгенерированных бинарных файлов или каких-либо других, которые вы и не думали добавлять. Мы хотели добавить README, так давайте сделаем это.
Отслеживание новых файлов
Для того чтобы начать отслеживать (добавить под версионный контроль) новый файл, используется команда git add . Чтобы начать отслеживание файла README , вы можете выполнить следующее:
$ git add READMEЕсли вы снова выполните команду status , то увидите, что файл README теперь отслеживаемый и добавлен в индекс:
$ git status On branch master Your branch is up-to-date with 'origin/master'. Changes to be committed: (use "git restore --staged . " to unstage) new file: READMEВы можете видеть, что файл проиндексирован, так как он находится в секции «Changes to be committed». Если вы выполните коммит в этот момент, то версия файла, существовавшая на момент выполнения вами команды git add , будет добавлена в историю снимков состояния. Как вы помните, когда вы ранее выполнили git init , затем вы выполнили git add (файлы) — это было сделано для того, чтобы добавить файлы в вашем каталоге под версионный контроль. Команда git add принимает параметром путь к файлу или каталогу, если это каталог, команда рекурсивно добавляет все файлы из указанного каталога в индекс.
Индексация изменённых файлов
Давайте модифицируем файл, уже находящийся под версионным контролем. Если вы измените отслеживаемый файл CONTRIBUTING.md и после этого снова выполните команду git status , то результат будет примерно следующим:
$ git status On branch master Your branch is up-to-date with 'origin/master'. Changes to be committed: (use "git reset HEAD . " to unstage) new file: README Changes not staged for commit: (use "git add . " to update what will be committed) (use "git checkout -- . " to discard changes in working directory) modified: CONTRIBUTING.mdФайл CONTRIBUTING.md находится в секции «Changes not staged for commit» — это означает, что отслеживаемый файл был изменён в рабочем каталоге, но пока не проиндексирован. Чтобы проиндексировать его, необходимо выполнить команду git add . Это многофункциональная команда, она используется для добавления под версионный контроль новых файлов, для индексации изменений, а также для других целей, например для указания файлов с исправленным конфликтом слияния. Вам может быть понятнее, если вы будете думать об этом как «добавить этот контент в следующий коммит», а не как «добавить этот файл в проект». Выполним git add , чтобы проиндексировать CONTRIBUTING.md , а затем снова выполним git status :
$ git add CONTRIBUTING.md $ git status On branch master Your branch is up-to-date with 'origin/master'. Changes to be committed: (use "git reset HEAD . " to unstage) new file: README modified: CONTRIBUTING.mdТеперь оба файла проиндексированы и войдут в следующий коммит. В этот момент вы, предположим, вспомнили одно небольшое изменение, которое вы хотите сделать в CONTRIBUTING.md до коммита. Вы открываете файл, вносите и сохраняете необходимые изменения и вроде бы готовы к коммиту. Но давайте-ка ещё раз выполним git status :
$ vim CONTRIBUTING.md $ git status On branch master Your branch is up-to-date with 'origin/master'. Changes to be committed: (use "git reset HEAD . " to unstage) new file: README modified: CONTRIBUTING.md Changes not staged for commit: (use "git add . " to update what will be committed) (use "git checkout -- . " to discard changes in working directory) modified: CONTRIBUTING.mdЧто за чёрт? Теперь CONTRIBUTING.md отображается как проиндексированный и непроиндексированный одновременно. Как такое возможно? Такая ситуация наглядно демонстрирует, что Git индексирует файл в точности в том состоянии, в котором он находился, когда вы выполнили команду git add . Если вы выполните коммит сейчас, то файл CONTRIBUTING.md попадёт в коммит в том состоянии, в котором он находился, когда вы последний раз выполняли команду git add , а не в том, в котором он находится в вашем рабочем каталоге в момент выполнения git commit . Если вы изменили файл после выполнения git add , вам придётся снова выполнить git add , чтобы проиндексировать последнюю версию файла:
$ git add CONTRIBUTING.md $ git status On branch master Your branch is up-to-date with 'origin/master'. Changes to be committed: (use "git reset HEAD . " to unstage) new file: README modified: CONTRIBUTING.mdСокращённый вывод статуса
Вывод команды git status довольно всеобъемлющий и многословный. Git также имеет флаг вывода сокращённого статуса, так что вы можете увидеть изменения в более компактном виде. Если вы выполните git status -s или git status —short вы получите гораздо более упрощённый вывод:
$ git status -s M README MM Rakefile A lib/git.rb M lib/simplegit.rb ?? LICENSE.txtНовые неотслеживаемые файлы помечены ?? слева от них, файлы добавленные в отслеживаемые помечены A , отредактированные файлы помечены M и так далее. В выводе содержится два столбца — в левом указывается статус файла, а в правом модифицирован ли он после этого. К примеру в нашем выводе, файл README модифицирован в рабочем каталоге, но не проиндексирован, а файл lib/simplegit.rb модифицирован и проиндексирован. Файл Rakefile модифицирован, проиндексирован и ещё раз модифицирован, таким образом на данный момент у него есть те изменения, которые попадут в коммит, и те, которые не попадут.
Игнорирование файлов
Зачастую, у вас имеется группа файлов, которые вы не только не хотите автоматически добавлять в репозиторий, но и видеть в списках неотслеживаемых. К таким файлам обычно относятся автоматически генерируемые файлы (различные логи, результаты сборки программ и т. п.). В таком случае, вы можете создать файл .gitignore . с перечислением шаблонов соответствующих таким файлам. Вот пример файла .gitignore :
$ cat .gitignore *.[oa] *~Первая строка предписывает Git игнорировать любые файлы заканчивающиеся на «.o» или «.a» — объектные и архивные файлы, которые могут появиться во время сборки кода. Вторая строка предписывает игнорировать все файлы заканчивающиеся на тильду ( ~ ), которая используется во многих текстовых редакторах, например Emacs, для обозначения временных файлов. Вы можете также включить каталоги log, tmp или pid; автоматически создаваемую документацию; и т. д. и т. п. Хорошая практика заключается в настройке файла .gitignore до того, как начать серьёзно работать, это защитит вас от случайного добавления в репозиторий файлов, которых вы там видеть не хотите.
К шаблонам в файле .gitignore применяются следующие правила:
- Пустые строки, а также строки, начинающиеся с # , игнорируются.
- Стандартные шаблоны являются глобальными и применяются рекурсивно для всего дерева каталогов.
- Чтобы избежать рекурсии используйте символ слеш (/) в начале шаблона.
- Чтобы исключить каталог добавьте слеш (/) в конец шаблона.
- Можно инвертировать шаблон, использовав восклицательный знак (!) в качестве первого символа.
Glob-шаблоны представляют собой упрощённые регулярные выражения, используемые командными интерпретаторами. Символ ( * ) соответствует 0 или более символам; последовательность [abc] — любому символу из указанных в скобках (в данном примере a, b или c); знак вопроса ( ? ) соответствует одному символу; и квадратные скобки, в которые заключены символы, разделённые дефисом ( [0-9] ), соответствуют любому символу из интервала (в данном случае от 0 до 9). Вы также можете использовать две звёздочки, чтобы указать на вложенные каталоги: a/**/z соответствует a/z , a/b/z , a/b/c/z , и так далее.
Вот ещё один пример файла .gitignore :
# Исключить все файлы с расширением .a *.a # Но отслеживать файл lib.a даже если он подпадает под исключение выше !lib.a # Исключить файл TODO в корневом каталоге, но не файл в subdir/TODO /TODO # Игнорировать все файлы в каталоге build/ build/ # Игнорировать файл doc/notes.txt, но не файл doc/server/arch.txt doc/*.txt # Игнорировать все .txt файлы в каталоге doc/ doc/**/*.txtGitHub поддерживает довольно полный список примеров .gitignore файлов для множества проектов и языков https://github.com/github/gitignore это может стать отправной точкой для .gitignore в вашем проекте.
Примечание
В простейшем случае репозиторий будет иметь один файл .gitignore в корневом каталоге, правила из которого будут рекурсивно применяться ко всем подкаталогам. Так же возможно использовать .gitignore файлы в подкаталогах. Правила из этих файлов будут применяться только к каталогам, в которых они находятся. Например, репозиторий исходного кода ядра Linux содержит 206 файлов .gitignore .
Детальное рассмотрение использования нескольких .gitignore файлов выходит за пределы этой книги; детали доступны в справке man gitignore .
Просмотр индексированных и неиндексированных изменений
Если результат работы команды git status недостаточно информативен для вас — вам хочется знать, что конкретно поменялось, а не только какие файлы были изменены — вы можете использовать команду git diff . Позже мы рассмотрим команду git diff подробнее; вы, скорее всего, будете использовать эту команду для получения ответов на два вопроса: что вы изменили, но ещё не проиндексировали, и что вы проиндексировали и собираетесь включить в коммит. Если git status отвечает на эти вопросы в самом общем виде, перечисляя имена файлов, git diff показывает вам непосредственно добавленные и удалённые строки — патч как он есть.
Допустим, вы снова изменили и проиндексировали файл README , а затем изменили файл CONTRIBUTING.md без индексирования. Если вы выполните команду git status , вы опять увидите что-то вроде:
$ git status On branch master Your branch is up-to-date with 'origin/master'. Changes to be committed: (use "git reset HEAD . " to unstage) modified: README Changes not staged for commit: (use "git add . " to update what will be committed) (use "git checkout -- . " to discard changes in working directory) modified: CONTRIBUTING.mdЧтобы увидеть, что же вы изменили, но пока не проиндексировали, наберите git diff без аргументов:
$ git diff diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md index 8ebb991..643e24f 100644 --- a/CONTRIBUTING.md +++ b/CONTRIBUTING.md @@ -65,7 +65,8 @@ branch directly, things can get messy. Please include a nice description of your changes when you submit your PR; if we have to read the whole diff to figure out why you're contributing in the first place, you're less likely to get feedback and have your change -merged in. +merged in. Also, split your changes into comprehensive chunks if you patch is +longer than a dozen lines. If you are starting to work on a particular area, feel free to submit a PR that highlights your work in progress (and note in the PR title that it'sЭта команда сравнивает содержимое вашего рабочего каталога с содержимым индекса. Результат показывает ещё не проиндексированные изменения.
Если вы хотите посмотреть, что вы проиндексировали и что войдёт в следующий коммит, вы можете выполнить git diff —staged . Эта команда сравнивает ваши проиндексированные изменения с последним коммитом:
$ git diff --staged diff --git a/README b/README new file mode 100644 index 0000000..03902a1 --- /dev/null +++ b/README @@ -0,0 +1 @@ +My ProjectВажно отметить, что git diff сама по себе не показывает все изменения сделанные с последнего коммита — только те, что ещё не проиндексированы. Такое поведение может сбивать с толку, так как если вы проиндексируете все свои изменения, то git diff ничего не вернёт.
Другой пример: вы проиндексировали файл CONTRIBUTING.md и затем изменили его, вы можете использовать git diff для просмотра как проиндексированных изменений в этом файле, так и тех, что пока не проиндексированы. Если наше окружение выглядит вот так:
$ git add CONTRIBUTING.md $ echo '# test line' >> CONTRIBUTING.md $ git status On branch master Your branch is up-to-date with 'origin/master'. Changes to be committed: (use "git reset HEAD . " to unstage) modified: CONTRIBUTING.md Changes not staged for commit: (use "git add . " to update what will be committed) (use "git checkout -- . " to discard changes in working directory) modified: CONTRIBUTING.mdИспользуйте git diff для просмотра непроиндексированных изменений
$ git diff diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md index 643e24f..87f08c8 100644 --- a/CONTRIBUTING.md +++ b/CONTRIBUTING.md @@ -119,3 +119,4 @@ at the ## Starter Projects See our [projects list](https://github.com/libgit2/libgit2/blob/development/PROJECTS.md). +# test lineа так же git diff —cached для просмотра проиндексированных изменений ( —staged и —cached синонимы):
$ git diff --cached diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md index 8ebb991..643e24f 100644 --- a/CONTRIBUTING.md +++ b/CONTRIBUTING.md @@ -65,7 +65,8 @@ branch directly, things can get messy. Please include a nice description of your changes when you submit your PR; if we have to read the whole diff to figure out why you're contributing in the first place, you're less likely to get feedback and have your change -merged in. +merged in. Also, split your changes into comprehensive chunks if you patch is +longer than a dozen lines. If you are starting to work on a particular area, feel free to submit a PR that highlights your work in progress (and note in the PR title that it'sПримечание
Git Diff во внешних инструментах
Мы будем продолжать использовать команду git diff различными способами на протяжении всей книги. Существует ещё один способ просматривать эти изменения, если вы предпочитаете графический просмотр или внешнюю программу просмотра различий, вместо консоли. Выполнив команду git difftool вместо git diff , вы сможете просмотреть изменения в файле с помощью таких программ как emerge, vimdiff и других (включая коммерческие продукты). Выполните git difftool —tool-help чтобы увидеть какие из них уже установлены в вашей системе.
Коммит изменений
Теперь, когда ваш индекс находится в таком состоянии, как вам и хотелось, вы можете зафиксировать свои изменения. Запомните, всё, что до сих пор не проиндексировано — любые файлы, созданные или изменённые вами, и для которых вы не выполнили git add после редактирования — не войдут в этот коммит. Они останутся изменёнными файлами на вашем диске. В нашем случае, когда вы в последний раз выполняли git status , вы видели что всё проиндексировано, и вот, вы готовы к коммиту. Простейший способ зафиксировать изменения — это набрать git commit :
$ git commitЭта команда откроет выбранный вами текстовый редактор.
Примечание
Редактор устанавливается переменной окружения EDITOR — обычно это vim или emacs, хотя вы можете установить любой другой с помощью команды git config —global core.editor , как было показано в главе Введение).
В редакторе будет отображён следующий текст (это пример окна Vim):
# Please enter the commit message for your changes. Lines starting # with '#' will be ignored, and an empty message aborts the commit. # On branch master # Your branch is up-to-date with 'origin/master'. # # Changes to be committed: # new file: README # modified: CONTRIBUTING.md # ~ ~ ~ ".git/COMMIT_EDITMSG" 9L, 283CВы можете видеть, что комментарий по умолчанию для коммита содержит закомментированный результат работы команды git status и ещё одну пустую строку сверху. Вы можете удалить эти комментарии и набрать своё сообщение или же оставить их для напоминания о том, что вы фиксируете.
Примечание
Для ещё более подробного напоминания, что же именно вы поменяли, можете передать аргумент -v в команду git commit . Это приведёт к тому, что в комментарий будет также помещена дельта/diff изменений, таким образом вы сможете точно увидеть все изменения которые вы совершили.
Когда вы выходите из редактора, Git создаёт для вас коммит с этим сообщением, удаляя комментарии и вывод команды diff .
Есть и другой способ — вы можете набрать свой комментарий к коммиту в командной строке вместе с командой commit указав его после параметра -m , как в следующем примере:
$ git commit -m "Story 182: fix benchmarks for speed" [master 463dc4f] Story 182: fix benchmarks for speed 2 files changed, 2 insertions(+) create mode 100644 READMEИтак, вы создали свой первый коммит! Вы можете видеть, что коммит вывел вам немного информации о себе: на какую ветку вы выполнили коммит ( master ), какая контрольная сумма SHA-1 у этого коммита ( 463dc4f ), сколько файлов было изменено, а также статистику по добавленным/удалённым строкам в этом коммите.
Запомните, что коммит сохраняет снимок состояния вашего индекса. Всё, что вы не проиндексировали, так и висит в рабочем каталоге как изменённое; вы можете сделать ещё один коммит, чтобы добавить эти изменения в репозиторий. Каждый раз, когда вы делаете коммит, вы сохраняете снимок состояния вашего проекта, который позже вы можете восстановить или с которым можно сравнить текущее состояние.
Игнорирование индексации
Несмотря на то, что индекс может быть удивительно полезным для создания коммитов именно такими, как вам и хотелось, он временами несколько сложнее, чем вам нужно в процессе работы. Если у вас есть желание пропустить этап индексирования, Git предоставляет простой способ. Добавление параметра -a в команду git commit заставляет Git автоматически индексировать каждый уже отслеживаемый на момент коммита файл, позволяя вам обойтись без git add :
$ git status On branch master Your branch is up-to-date with 'origin/master'. Changes not staged for commit: (use "git add . " to update what will be committed) (use "git checkout -- . " to discard changes in working directory) modified: CONTRIBUTING.md no changes added to commit (use "git add" and/or "git commit -a") $ git commit -a -m 'Add new benchmarks' [master 83e38c7] Add new benchmarks 1 file changed, 5 insertions(+), 0 deletions(-)Обратите внимание, что в данном случае перед коммитом вам не нужно выполнять git add для файла CONTRIBUTING.md , потому что флаг -a включает все файлы. Это удобно, но будьте осторожны: флаг -a может включить в коммит нежелательные изменения.
Удаление файлов
Для того чтобы удалить файл из Git, вам необходимо удалить его из отслеживаемых файлов (точнее, удалить его из вашего индекса) а затем выполнить коммит. Это позволяет сделать команда git rm , которая также удаляет файл из вашего рабочего каталога, так что в следующий раз вы не увидите его как «неотслеживаемый».
Если вы просто удалите файл из своего рабочего каталога, он будет показан в секции «Changes not staged for commit» (изменённые, но не проиндексированные) вывода команды git status :
$ rm PROJECTS.md $ git status On branch master Your branch is up-to-date with 'origin/master'. Changes not staged for commit: (use "git add/rm . " to update what will be committed) (use "git checkout -- . " to discard changes in working directory) deleted: PROJECTS.md no changes added to commit (use "git add" and/or "git commit -a")Затем, если вы выполните команду git rm , удаление файла попадёт в индекс:
$ git rm PROJECTS.md rm 'PROJECTS.md' $ git status On branch master Your branch is up-to-date with 'origin/master'. Changes to be committed: (use "git reset HEAD . " to unstage) deleted: PROJECTS.mdПосле следующего коммита файл исчезнет и больше не будет отслеживаться. Если вы изменили файл и уже проиндексировали его, вы должны использовать принудительное удаление с помощью параметра -f . Это сделано для повышения безопасности, чтобы предотвратить ошибочное удаление данных, которые ещё не были записаны в снимок состояния и которые нельзя восстановить из Git.
Другая полезная штука, которую вы можете захотеть сделать — это удалить файл из индекса, оставив его при этом в рабочем каталоге. Другими словами, вы можете захотеть оставить файл на жёстком диске, но перестать отслеживать изменения в нём. Это особенно полезно, если вы забыли добавить что-то в файл .gitignore и по ошибке проиндексировали, например, большой файл с логами, или кучу промежуточных файлов компиляции. Чтобы сделать это, используйте опцию —cached :
$ git rm --cached READMEВ команду git rm можно передавать файлы, каталоги или шаблоны. Это означает, что вы можете сделать что-то вроде:
$ git rm log/\*.logОбратите внимание на обратный слеш ( \ ) перед * . Он необходим из-за того, что Git использует свой собственный обработчик имён файлов вдобавок к обработчику вашего командного интерпретатора. Эта команда удаляет все файлы, имеющие расширение .log и находящиеся в каталоге log/ . Или же вы можете сделать вот так:
$ git rm \*~Эта команда удаляет все файлы, имена которых заканчиваются на ~ .
Перемещение файлов
В отличие от многих других систем контроля версий, Git не отслеживает перемещение файлов явно. Когда вы переименовываете файл в Git, в нём не сохраняется никаких метаданных, говорящих о том, что файл был переименован. Однако, Git довольно умён в плане обнаружения перемещений постфактум — мы рассмотрим обнаружение перемещения файлов чуть позже.
Таким образом, наличие в Git команды mv выглядит несколько странным. Если вам хочется переименовать файл в Git, вы можете сделать что-то вроде:
$ git mv file_from file_toи это отлично сработает. На самом деле, если вы выполните что-то вроде этого и посмотрите на статус, вы увидите, что Git считает, что произошло переименование файла:
$ git mv README.md README $ git status On branch master Your branch is up-to-date with 'origin/master'. Changes to be committed: (use "git reset HEAD . " to unstage) renamed: README.md -> READMEОднако, это эквивалентно выполнению следующих команд:
$ mv README.md README $ git rm README.md $ git add READMEGit неявно определяет, что произошло переименование, поэтому неважно, переименуете вы файл так или используя команду mv . Единственное отличие состоит лишь в том, что mv — одна команда вместо трёх — это функция для удобства. Важнее другое — вы можете использовать любой удобный способ для переименования файла, а затем воспользоваться командами add или rm перед коммитом.
Рекомендации по сочетаниям клавиш в Visual Studio
Перемещаться между компонентами Visual Studio можно более эффективно, если использовать описанные в этой статье сочетания клавиш. Сюда относятся сочетания клавиш на клавиатуре, кнопок и жестов мыши, а также текстовые команды, упрощающие выполнение задач.
Полный список сочетаний клавиш и памятка с возможностью печати см. в разделе «Сочетания клавиш» в Visual Studio.
Этот раздел относится к Visual Studio в Windows. Сведения о Visual Studio для Mac см. в Visual Studio для Mac сочетания клавиш по умолчанию.
Управление окнами
| Задача | Ярлык |
|---|---|
| Развернуть плавающее окно | Дважды щелкнуть заголовок окна |
| Развернуть или свернуть окна | WIN+Стрелка вверх / Win+Стрелка вниз |
| Закрепить плавающее окно | CTRL+Дважды щелкнуть заголовок окна |
| Переместить или закрепить плавающие окна | WIN+Стрелка влево / WIN+Стрелка вправо |
| Закрыть активный документ | CTRL+F4 |
| Показать список открытых файлов | SHIFT+ALT+Стрелка вниз |
| Показать все плавающие окна | CTRL+SHIFT+M |
| Показать список переходов | WIN+ALT+N |
| Запустить новый экземпляр | WIN+SHIFT+N |
| Переключиться между окнами | WIN+N |
Search
| Задача | Ярлык |
|---|---|
| Искать в обозревателе решений | CTRL+; |
| Поместить фокус в поле поиска в любом окне инструментов (за исключением редактора) | ALT+`, когда окно инструментов в фокусе |
| Поиск по Visual Studio | CTRL+Q |
| Фильтр в области результатов поиска | @opt — параметры @cmd — команды @mru — последнее используемое @doc — открытие документов |
| Искать в «Инструменты» > «Параметры» | CTRL+E |
Поиск в редакторе
| Задача | Ярлык |
|---|---|
| Быстрый поиск | CTRL+F |
| Быстрый поиск — следующий результат | Введите |
| Быстрый поиск — предыдущий результат | Shift+Ввод |
| Быстрый поиск — развернуть раскрывающийся список | ALT+Стрелка вниз |
| Закрыть поиск | Esc |
| Быстрая замена | CTRL+H |
| Быстрая замена — заменить следующий | ALT+R |
| Быстрая замена — заменить все | ALT+A |
| Поиск в файлах | CTRL+SHIFT+F |
| Замена в файлах | CTRL+SHIFT+H |
Редактор кода
| Задача | Ярлык |
|---|---|
| Перейти ко всем | CTRL+T |
| Перейти к последним файлам | CTRL+T, R |
| Несколько точек вставки | CTRL+ALT+нажатие |
| Добавление совпадений выбранного фрагмента в нескольких местах | Shift+Alt+Ins |
| Форматировать документ | CTRL+K, D |
| Режим предложений IntelliSense | CTRL+ALT+ПРОБЕЛ (переключатель) |
| Принудительно показывать IntelliSense | CTRL+J |
| Быстрые действия | CTRL+. |
| Выбор фрагментов кода | CTRL+K,X или ?,TAB (Visual Basic) |
| Окружить | CTRL+K,S |
| Показать краткие сведения | CTRL+K,I |
| Функция «Перейти к» | CTRL+, |
| Перейти по выделенным ссылкам | CTRL+SHIFT+Стрелка вверх (предыдущая) CTRL+SHIFT+Стрелка вниз (следующая) |
| Масштабирование в редакторе | Ctrl+Shift+> (увеличение) Ctrl+Shift+ (уменьшение) |
| Выбор блоков | Удерживая ALT, перетащите указатель мыши SHIFT+ALT+Клавиши со стрелками |
| Переход на строку вверх или вниз | ALT+Стрелка вверх / Alt+Стрелка вниз |
| Дублировать строку | CTRL+E,V |
| Развернуть выделение | SHIFT+ALT+= |
| Свернуть выделение | SHIFT+ALT+— |
| Перейти к определению | F12 |
| Показать определение | ALT+F12 |
| Переход к стеку определений | CTRL+SHIFT+8 (назад) CTRL+SHIFT+7 (вперед) |
| Закрыть окно «Показать определение» | Esc |
| Повысить уровень окна «Показать определение» до обычной вкладки документа | CTRL+ALT+HOME |
| Перемещение между несколькими окнами «Показать определение» | CTRL+ALT+— и CTRL+ALT+= |
| Перемещение между несколькими результатами «Показать» | F8 и SHIFT+F8 |
| Переключение между окном редактора кода и окном «Показать определение» | SHIFT+ESC |
| Переход к внешнему блоку | CTRL+ALT+Стрелка вверх |
| Переход к следующей или предыдущей проблеме | ALT+PGUP / ALT+PGDN |
| Контекстное меню навигации | Alt+` |
Панели инструментов
| Задача | Ярлык |
|---|---|
| Добавление кнопок | Нажать кнопку переполнения панели инструментов |
| Поле со списком поиска на панели инструментов «Стандартная» | CTRL+D |
| Режим команд для поля поиска | Введите >. |
| Создать новый псевдоним | В окне «Команда» введите псевдоним нового псевдонима<>>. |
Отладка
| Задача | Ярлык |
|---|---|
| Запуск отладки | F5 |
| Остановить отладку | SHIFT+F5 |
| Перезапуск отладки | CTRL+SHIFT+F5 |
| Шаг с обходом | F10 |
| Шаг с заходом | F11 |
| Шаг с выходом | Shift+F11 |
| Выполнить до текущей позиции | CTRL+F10 |
| Установка следующей инструкции | CTRL+SHIFT+F10 |
| Задать и переключить состояние точки останова | F9 |
| Отключить точку останова | Ctrl+F9 |
| окно интерпретации | CTRL+ALT+I |
| Режим команд окна интерпретации | Введите >. |
| Очистить буфер окна интерпретации | Введите cls |
| Печать значения в окне интерпретации | Введите ?имя_переменной |
См. также
- Специальные возможности. Советы и рекомендации
- Возможности для повышения продуктивности в Visual Studio
- Сочетания клавиш в Visual Studio
- Сочетания клавиш по умолчанию в Visual Studio для Mac
Ввод-вывод, оператор присваивания, арифметические операции
Данный курс будет посвящен изучению программирования с использованием языка Python. Это — современный язык программирования, работающий на всех распространных операционных системах.
В настоящее время существует две версии языка Python: более старая, но пока ещё более распространненая версия 2 и современная версия 3. Они не вполне совместимы друг с другом: программа, написанная для одной версии языка может оказаться невыполнимой для другой версии. Но в основном обе версии очень похожи.
Мы будем использовать версию 3 данного языка, некоторые из используемых примеров не будут работать с версией 2. Последняя версия языка, доступная в сентябре 2010 года — 3.1.2, именно её необходимо установить дома, скачав данную версию с сайта www.python.org.
Запустить интерпретатор python можно из командной строки:
$ python3
Будьте внимательны — команда python запустит интерпретатор версии 2, с которым мы работать не будем. В системе Windows можно использовать пункт меню “Python (command line)”
Вы увидите примерно следующее приглашение командной строки:
Python 3.1.2 (r312:79147, Jun 12 2010, 15:29:06)
[GCC 4.4.3 20100316 (ALT Linux 4.4.3-alt2)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>
Смело вводите команды и наслаждайтесь результатом. А что можно вводить? Несколько примеров:
>>> 2 + 2
4
>>> 2 ** 100
1267650600228229401496703205376
>>> 'Hello' + 'World'
'HelloWorld'
>>> 'ABC' * 100
'ABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABC
ABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABC
ABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABC
ABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABC
ABCABCABCABCABCABCABCABCABCABCABCABCABCABCABCABC'
Первая команда вычисляет сумму двух чисел, вторая команда вычисляет 2 в степени 100, третья команда выполняет операцию конкатенации для строк, а четвертая команда печатает строку ‘ABC’, повторенную 100 раз.
Хотите закончить работу с питоном? Введите команду exit() (именно так, со скобочками, так как это — функция), или нажмите Ctrl+D.