Урок 3. Корутины. Suspend функции
В этом уроке подробно разберем как создать suspend функции. Также рассмотрим, можно ли блокировать поток, как корутина может потеряться и зачем нужно слово suspend.
В прошлом уроке мы подробно рассмотрели взаимодействие Continuation и suspend функции со стороны Continuation. Теперь посмотрим на это взаимодействие со стороны suspend функций.
Как создать suspend функцию
Сейчас мы будем рассматривать, как создать suspend функцию из асинхронного кода. Если же у вас есть какой-то синхронный метод и его надо сделать suspend, то там просто используется билдер withContext. Об этом мы поговорим, когда начнем тему билдеров.
Давайте создадим suspend функцию download, которую мы использовали ранее в примерах.
suspend fun download(url: String): File
Ключевое слово здесь — suspend. Это даст Котлину понять, что это suspend функция и она будет приостанавливать корутину. В конце урока я дам более подробное объяснение, зачем нужно использовать слово suspend. Но перед этим нам нужно понять, как такая функция работает.
Предположим, у нас есть некий NetworkService, который асинхронно умеет загружать файлы. И мы хотим обернуть его в suspend функцию download:
suspend fun download(url: String): File < networkService.download(url, object: NetworkService.Callback < override fun onSuccess(result: File) < >>) >
В колбэк onSuccess придет загруженный файл.
Как вы помните из прошлого урока, suspend функция должна результаты своей работы передать в Continuation.invokeSuspend. Для этого используется метод Continuation.resume
suspend fun download(url: String): File < networkService.download(url, object: NetworkService.Callback < override fun onSuccess(result: File) < continuation.resume(result) >>) >
Метод resume содержит определенную логику, часть которой — это вызов метода invokeSuspend с передачей туда результата.
Осталось где-то взять continuation. Для этого мы используем функцию suspendCoroutine.
suspend fun download(url: String): File < return suspendCoroutine < continuation ->networkService.download(url, object: NetworkService.Callback < override fun onSuccess(result: File) < continuation.resume(result) >>) > >
Весь наш код уходит в блок suspendCoroutine. Этот блок дает нам доступ к continuation, в который мы передаем результат работы networkService.download.
Получается, что suspend функция выполнила асинхронную работу и результат передала в continuation.resume, а тот уже передаст его в continuation.invokeSuspend.
Возврат ошибки
Кроме успешного результата, continuation может принять данные об ошибке.
Пусть у NetworkService.Callback есть метод onFailure. Он будет вызван, если при загрузке произошла ошибка. В нем мы вызовем метод continuation.resumeWithException и передадим туда исключение.
suspend fun download(url: String): File < return suspendCoroutine < continuation ->networkService.download(url, object: NetworkService.Callback < override fun onSuccess(result: File) < continuation.resume(result) >override fun onFailure(error: Exception) < continuation.resumeWithException(error) >>) > >
В этом случае ошибка не пойдет в метод invokeSuspend, а будет обработана корутиной. Т.е. в этом случае continuation не продолжит свое выполнение и код, который в корутине находится после suspend функции не будет выполнен.
Простая suspend функция download готова. Ее можно вызывать в корутине, она не будет блокировать поток, но приостановит код.
Можно ли сразу вернуть результат
Я все время упоминаю, что suspend функция должна сначала выполнить свою работу, а потом вернуть результат. Но возможен и другой вариант в случае, если результат уже готов на момент вызова. В примере с функцией загрузки файла — это может быть использование кэша. suspend функция сначала проверяет кэш. Если файл уже есть в кэше, то функция сразу может вернуть его. Для этого ей надо просто сразу вызвать continuation.resume. А если файла в кэше нет, то действуем по старой схеме — стартуем асинхронную работу и по ее завершению вызываем continuation.resume.
Давайте посмотрим как в Kotlin добавить в suspend функцию такую возможность:
suspend fun download(url: String): File < return suspendCoroutine < continuation ->val file = getFileFromCache(url) if (file != null) < continuation.resume(file) >else < networkService.download(url, object : NetworkService.Callback < override fun onSuccess(result: File) < continuation.resume(result) >override fun onFailure(error: Exception) < continuation.resumeWithException(error) >>) > > >
Мы пытаемся получить файл из кэша. Если он там есть, то сразу передаем его в continuation, иначе запускаем асинхронную работу.
Блокирование потока
Когда мы создаем suspend функцию, мы должны позаботиться о том, чтобы она выполнялась асинхронно в другом потоке или вернула результат сразу. Если же мы напишем в suspend функции код, блокирующий поток, то слово suspend нам тут никак не поможет. Такая suspend функция просто заблокирует поток, в котором выполняется корутина.
Давайте рассмотрим пример некорректной suspend функции. Представим, что используемый в примере выше NetworkService теперь работает синхронно. Его метод download не уходит в фоновый поток и не просит колбэк, а загружает файл в текущем потоке и возвращает как результат вызова метода. Т.е. метод networkService.download блокирует поток, в котором он вызван. Если мы используем его напрямую в suspend функции, то получится неправильная suspend функция:
// wrong suspend function, don't do that! suspend fun download(url: String): File < return suspendCoroutine < continuation ->val file = networkService.download(url) continuation.resume(file) > >
Важно понимать, что ни метод suspendCoroutine, ни слово suspend в описании функции не cделают наш код асинхронным. Метод networkService.download будет выполнен в потоке корутины и заблокирует его. Поэтому от нас требуется обеспечить асинхронность кода в suspend функции, а в качестве колбэка использовать continuation.
О том, как в корутине выполнять синхронный код так, чтобы не блокировать поток корутины, мы поговорим позже, когда будем рассматривать билдеры.
Потерянная корутина
Что будет если в suspend функции не вызвать continuation.resume? Это очень важный момент! Если мы не вызовем ни один из методов continuation.resume*, то корутина просто не продолжит выполняться. Никогда. Потому что она ждет, что suspend функция продолжит ее через вызов Continuation. Поэтому тут будьте аккуратны, не теряйте вызов Continuation — передайте ему результат или ошибку, чтобы корутина могла продолжиться или завершиться.
Зачем нужно слово suspend?
Теперь мы знаем достаточно про suspend функции, чтобы поговорить о значении слова suspend. Само по себе это слово не добавляет к функции никакой магии. Оно не сделает так, чтобы синхронный код вдруг перестал блокировать поток. Оно вообще ничего не делает. Это просто маркер того, что данная функция умеет (и должна) работать с Continuation, чтобы приостановить выполнение корутины не блокируя поток.
Давайте взглянем на это с двух точек зрения: создание suspend функции и ее использование.
Создание
Чтобы suspend функция могла приостановить код не блокируя поток, ей нужен Continuation, выполнение которого она возобновит по завершению своей работы. Чтобы получить Continuation, используется функция suspendCoroutine. Возникает вопрос, почему любая другая функция без слова suspend не может этого сделать? Давайте допустим, что мы можем создать обычную (не suspend) функцию и вызвать в ней suspendCoroutine, который предоставит нам Continuation. Если мы вызовем такую функцию в корутине, то все отработает нормально, потому что у корутины есть Continuation. Его мы и получим. Но если мы вызовем ее вне корутины, то suspendCoroutine не сможет предоставить нам Continuation, потому что его просто нет.
Получается, что функция, в которой мы хотим получить доступ к Continuation, должна запускаться только в корутине. В обычном коде ее запускать нельзя. И вот именно для реализации этого ограничения и используется слово suspend. Мы не сможем запустить suspend функцию вне корутины, компилятор выдаст ошибку. Потому что компилятор знает, что suspend функции нужен будет Continuation, который есть только в корутине. Таким образом, когда мы создаем функцию и добавляем к ней слово suspend — мы можем быть уверены, что она будет запущена в корутине. А значит мы сможем добраться до Continuation.
Использование
Если мы в корутине собираемся использовать долго работающую функцию, которая помечена как suspend, то мы точно знаем, что эта функция приостановит код и не заблокирует при этом поток, в котором выполняется корутина. Если конечно, она написана корректно)
А обычная функция, которая не является suspend, не сможет такого сделать. Она либо заблокирует поток корутины, либо попросит дать ей колбэк.
Что происходит внутри suspendCoroutine?
Об этом я подробно расскажу в пятом уроке.
Присоединяйтесь к нам в Telegram:
— в канале StartAndroid публикуются ссылки на новые статьи с сайта startandroid.ru и интересные материалы с хабра, medium.com и т.п.
— в чатах решаем возникающие вопросы и проблемы по различным темам: Android, Compose, Kotlin, RxJava, Dagger, Тестирование, Performance
— ну и если просто хочется поговорить с коллегами по разработке, то есть чат Флудильня
Kotlin, как работает suspend под капотом
Как компилятор преобразует suspend код, чтобы корутины можно было приостанавливать и возобновлять?
Корутины в Kotlin представлены ключевым словом suspend. Интересно, что там происходит внутри? Как компилятор преобразует suspend блоки в код, поддерживающий приостановку и возобновление работы корутины?
Знание этого поможет понимать, почему suspend функция не возвращает управление, пока не завершится вся запущенная работа и как код может приостановить выполнение без блокировки потоков.
TL;DR; Компилятор Kotlin создает специальную машину состояний для каждой suspend функции, эта машина берет управление корутиной на себя!
Новенький в Android? Взгляни на эти полезные ресурсы по корутинам:
- Using coroutines in your Android app.
- Advanced Coroutines with Kotlin Flow and Live Data.
Для тех, кто предпочитает видео:
Корутины, краткое введение
Говоря по-простому, корутины это асинхронные операции в Android. Как описано в документации, мы можем использовать корутины для управления асинхронными задачами, которые иначе могут блокировать основной поток и приводить к зависанию UI приложения.
Также корутины удобно использовать для замены callback-кода на императивный код. Например, посмотрите на этот код с использованием колбеков:
// Simplified code that only considers the happy path fun loginUser(userId: String, password: String, userResult: Callback) < // Async callbacks userRemoteDataSource.logUserIn < user ->// Successful network request userLocalDataSource.logUserIn(user) < userDb ->// Result saved in DB userResult.success(userDb) > > >Заменяем эти колбеки на последовательные вызовы функций с использованием корутин:
suspend fun loginUser(userId: String, password: String): UserDb
Для функций, которые вызываются в корутинах, мы добавили ключевое слово suspend. Так компилятор знает, что эти функции для корутин. С точки зрения разработчика, рассматривайте suspend функцию как обычную, выполнение которой может быть приостановлено и возобновлено в определенный момент.
В отличие от колбеков, корутины предлагают простой способ переключения между потоками и обработки исключений.
Но что в действительности делает компилятор внутри, когда мы отмечаем функцию как suspend?
Suspend под капотом
Давайте вернемся к suspend функции loginUser , посмотрите, другие функции которые она вызывает являются также suspend функциями:
suspend fun loginUser(userId: String, password: String): UserDb < val user = userRemoteDataSource.logUserIn(userId, password) val userDb = userLocalDataSource.logUserIn(user) return userDb >// UserRemoteDataSource.kt suspend fun logUserIn(userId: String, password: String): User // UserLocalDataSource.kt suspend fun logUserIn(userId: String): UserDbКратко говоря, компилятор Kotlin берет suspend функции и преобразовывает их в оптимизированную версию колбеков с использованием конечной машины состояний (о которой мы поговорим позже).
Интерфейс Continuation
Suspend функции взаимодействуют друг с другом с помощью Continuation объектов. Continuation объект — это простой generic интерфейс с дополнительными данными. Позже мы увидим, что сгенерированная машина состояний для suspend функции будет реализовывать этот интерфейс.
Сам интерфейс выглядит так:
interface Continuation < public val context: CoroutineContext public fun resumeWith(value: Result) >- context это экземпляр CoroutineContext , который будет использоваться при возобновлении.
- resumeWith возобновляет выполнение корутины с Result, он может либо содержать результат вычисления, либо исключение.
Компилятор заменяет ключевое слово suspend на дополнительный аргумент completion (тип Continuation ) в функции, аргуемнт используется для передачи результата suspend функции в вызывающую корутину:
fun loginUser(userId: String, password: String, completion: Continuation)
Для упрощения, наш пример возвращает Unit вместо объекта User .
Байткод suspend функций фактически возвращает Any? так как это объединение (union) типов T | COROUTINE_SUSPENDED . Что позволяет функции возвращать результат синхронно, когда это возможно.
Если suspend функция не вызывает другие suspend функции, компилятор добавляет аргумент Continuation, но не будет с ним ничего делать, байткод функции будет выглядеть как обычная функция.
Кроме того, интерфейс Continuation можно увидеть в:
- При конвертации колбек-API в корутины с использованием suspendCoroutine или suspendCancellableCoroutine (предпочтительнее использовать в большинстве случаев). Вы напрямую взаимодействуете с экземпляром Continuation , чтобы возобновить корутину, приостановленную после выполнения блока кода из аргументов suspend функции.
- Вы можете запустить корутину при помощи startCoroutine extension функции в suspend методе. Она принимает Continuation как аргумент, который будет вызван, когда новая корутина завершится либо с результатом, либо с исключением.
Используем Dispatchers
Вы можете переключаться между разными диспетчерами для запуска вычислений на разных потоках. Как Kotlin знает, где возобновить suspend вычисления?
Есть подтип Continuation , он называется DispatchedContinuation, где его метод resume делает вызов Dispatcher доступного в контексте корутины CoroutineContext . Все диспетчеры ( Dispatchers ) будут вызывать метод dispatch , кроме типа Dispatchers.Unconfined , он переопределяет метод isDispatchNeeded (он вызывается перед вызовом dispatch ), который возвращает false в этом случае.
Сгенрированная машина состояний
Уточнение: Приведенный код не полностью соответствует байткоду сгенерированному компилятором. Это будет код на Kotlin, достаточно точный, для понимания того, что в действительности происходит внутри. Это представление сгенерировано корутинами версии 1.3.3 и может поменяться в следующих версиях библиотеки.
Компилятор Kotlin определяет, когда функция может остановится внутри. Каждая точка останова представляется как отдельное состояние в конечной машине состояний. Такие состояния компилятор помечает метками:
fun loginUser(userId: String, password: String, completion: Continuation) < // Label 0 ->first execution val user = userRemoteDataSource.logUserIn(userId, password) // Label 1 -> resumes from userRemoteDataSource val userDb = userLocalDataSource.logUserIn(user) // Label 2 -> resumes from userLocalDataSource completion.resume(userDb) >Компилятор использует when для состояний:
fun loginUser(userId: String, password: String, completion: Continuation) < when(label) < 0 -> < // Label 0 ->first execution userRemoteDataSource.logUserIn(userId, password) > 1 -> < // Label 1 ->resumes from userRemoteDataSource userLocalDataSource.logUserIn(user) > 2 -> < // Label 2 ->resumes from userLocalDataSource completion.resume(userDb) > else -> throw IllegalStateException(/* . */) > >Этот код неполный, так как различные состояния не могут обмениваться информацией. Компилятор использует для обмена тот же самый объект Continuation . Вот почему родительски тип в Continuation это Any? вместо ожидаемого возвращаемого типа User .
При этом компилятор создает приватный класс, который:
- хранит нужные данные
- вызывает функцию loginUser рекурсивно для возобновления вычисления
Ниже представлен примерный вид такого сгенерированного класса:
Комментарии в коде были добавлены вручную для объяснения действий
fun loginUser(userId: String?, password: String?, completion: Continuation) < class LoginUserStateMachine( // completion parameter is the callback to the function // that called loginUser completion: Continuation): CoroutineImpl(completion) < // Local variables of the suspend function var user: User? = null var userDb: UserDb? = null // Common objects for all CoroutineImpls var result: Any? = null var label: Int = 0 // this function calls the loginUser again to trigger the // state machine (label will be already in the next state) and // result will be the result of the previous state's computation override fun invokeSuspend(result: Any?) < this.result = result loginUser(null, null, this) >> /* . */ >Поскольку invokeSuspend вызывает loginUser только с аргументом Continuation , остальные аргументы в функции loginUser будут нулевыми. На этом этапе компилятору нужно только добавить информацию как переходить из одного состояния в другое.
Компилятору нужно знать:
- Функция вызывается первый раз или
- Функция была возобновлена из предыдущего состояния Для этого проверяется тип аргумента Continuation в функции:
fun loginUser(userId: String?, password: String?, completion: Continuation) < /* . */ val continuation = completion as? LoginUserStateMachine ?: LoginUserStateMachine(completion) /* . */ >Если функция вызывается первый раз, то создается новый экземпляр LoginUserStateMachine и аргумент completion передается в этот экземпляр, чтобы возобновить вычисление. Иначе продолжится выполнение машины состояний.
Давайте взглянем на код, который генерирует компилятор для смены состояний и обмена информацией между ними:
fun loginUser(userId: String?, password: String?, completion: Continuation) < /* . */ val continuation = completion as? LoginUserStateMachine ?: LoginUserStateMachine(completion) when(continuation.label) < 0 -> < // Checks for failures throwOnFailure(continuation.result) // Next time this continuation is called, it should go to state 1 continuation.label = 1 // The continuation object is passed to logUserIn to resume // this state machine's execution when it finishes userRemoteDataSource.logUserIn(userId. password. continuation) >1 -> < // Checks for failures throwOnFailure(continuation.result) // Gets the result of the previous state continuation.user = continuation.result as User // Next time this continuation is called, it should go to state 2 continuation.label = 2 // The continuation object is passed to logUserIn to resume // this state machine's execution when it finishes userLocalDataSource.logUserIn(continuation.user, continuation) >/* . leaving out the last state on purpose */ > >Обратите внимание на различия между этим и предыдущим примером кода:
- Появилась переменная label из LoginUserStateMachine , которая передается в when .
- Каждый раз при обработке нового состояния проверяется есть ли ошибка.
- Перед вызовом следующей suspend функции ( logUserIn ), LoginUserStateMachine обновляет переменную label .
- Когда внутри машины состояний вызывается другая suspend функция, экземпляр Continuation (с типом LoginUserStateMachine ) передается как аргумент. Вложенная suspend функция также была преобразована компилятором со своей машиной состояний. Когда эта внутренняя машина состояний завершит свою работу, она возобновит выполнение “родительской” машины состояний.
Последнее состояние должно возобновить выполнение completion через вызов continuation.cont.resume (очевидно что входной аргумент completion , сохраняется в переменной continuation.cont экземпляра LoginUserStateMachine ):
fun loginUser(userId: String?, password: String?, completion: Continuation) < /* . */ val continuation = completion as? LoginUserStateMachine ?: LoginUserStateMachine(completion) when(continuation.label) < /* . */ 2 -> < // Checks for failures throwOnFailure(continuation.result) // Gets the result of the previous state continuation.userDb = continuation.result as UserDb // Resumes the execution of the function that called this one continuation.cont.resume(continuation.userDb) >else -> throw IllegalStateException(/* . */) > > Компилятор Kotlin делает много работы “под капотом”. Из suspend функции:
suspend fun loginUser(userId: String, password: String): User
Генерируется большой кусок кода:
fun loginUser(userId: String?, password: String?, completion: Continuation) < class LoginUserStateMachine( // completion parameter is the callback to the function that called loginUser completion: Continuation): CoroutineImpl(completion) < // objects to store across the suspend function var user: User? = null var userDb: UserDb? = null // Common objects for all CoroutineImpl var result: Any? = null var label: Int = 0 // this function calls the loginUser again to trigger the // state machine (label will be already in the next state) and // result will be the result of the previous state's computation override fun invokeSuspend(result: Any?) < this.result = result loginUser(null, null, this) >> val continuation = completion as? LoginUserStateMachine ?: LoginUserStateMachine(completion) when(continuation.label) < 0 -> < // Checks for failures throwOnFailure(continuation.result) // Next time this continuation is called, it should go to state 1 continuation.label = 1 // The continuation object is passed to logUserIn to resume // this state machine's execution when it finishes userRemoteDataSource.logUserIn(userId. password. continuation) >1 -> < // Checks for failures throwOnFailure(continuation.result) // Gets the result of the previous state continuation.user = continuation.result as User // Next time this continuation is called, it should go to state 2 continuation.label = 2 // The continuation object is passed to logUserIn to resume // this state machine's execution when it finishes userLocalDataSource.logUserIn(continuation.user, continuation) >2 -> < // Checks for failures throwOnFailure(continuation.result) // Gets the result of the previous state continuation.userDb = continuation.result as UserDb // Resumes the execution of the function that called this one continuation.cont.resume(continuation.userDb) >else -> throw IllegalStateException(/* . */) > >Компилятор Kotlin преобразовывает каждую suspend функцию в машину состояний, с использованием обратных вызовов.
Зная как компилятор работает “под капотом”, вы лучше понимаете:
- почему suspend функция не вернет результат пока не завершится вся работа, которая она начала;
- каким образом код приостанавливается не блокируя потоки (вся информация, о том что нужно выполнить при возобновлении работы, хранится в объекте Continuation ).
Учим домашний сервер Linux засыпать при простое и просыпаться по запросу
Всё началось с, казалось бы, обыденного изменения в моём домашнем сервере для хостинга бэкапов Time Machine: я хотел, чтобы он уходил в сон, когда находился в состоянии простоя, и пробуждался при необходимости. Уход в сон при простое — кажется, в Windows эта функция встроена с Windows 98? Насколько сложно будет это настроить на современной версии Ubuntu?
Честно говоря, мне требовалось нечто большее, чем засыпание при простое, мне нужно было ещё и пробуждение по запросу; оказалось, вот это второе требование реализовать довольно сложно. Я много раз заходил в тупик, но продолжал искать решение, которое «просто работает» без необходимости ручного включения сервера для каждого бэкапа. Вы можете прочитать статью целиком, чтобы узнать о моём пути, или просто прочитать готовые инструкции.
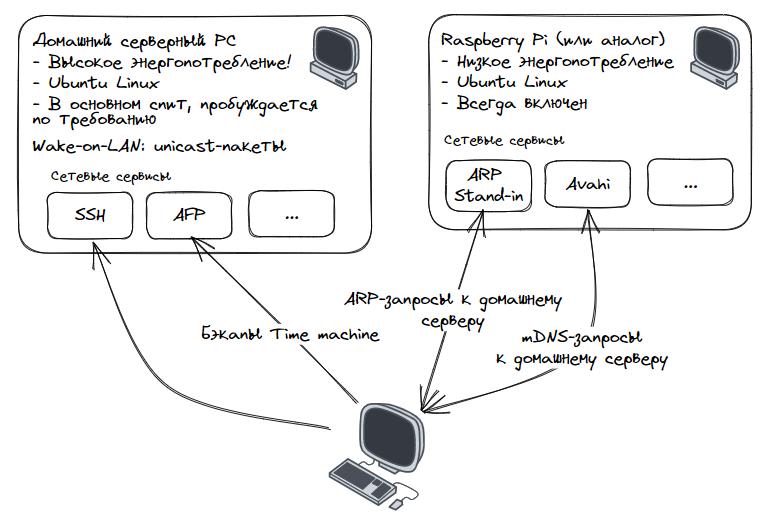
Результат:
- Сервер автоматически сохраняет состояние в ОЗУ при простое
- Сервер автоматически пробуждается при необходимости всем остальным в сети, включая SSH, бэкапы Time Machine и так далее.
Вам понадобится:
- Постоянно включённое устройство с Linux в той же сети, что и ваш сервер, например, Raspberry Pi
- Устройство сетевого интерфейса для сервера, поддерживающее wake-on-LAN при помощи unicast-пакетов
На сервере:
- Включить wake-on-LAN при помощи unicast-пакетов (не только при помощи magic-пакетов), сделать его постоянным
sudo ethtool -s eno1 wol ug sudo tee /etc/networkd-dispatcher/configuring.d/wol - Настроить cron job для засыпания при простое (замените /home/ubuntu на нужное вам местоположение скрипта)
tee /home/ubuntu/auto-sleep.sh - Отключить IPv6: при таком способе применяется ARP, который IPv6 не использует
sudo nano /etc/default/grub # Найдите GRUB_CMDLINE_LINUX="" # Измените на GRUB_CMDLINE_LINUX="ipv6.disable=1" sudo update-grub sudo reboot- Необязательно: сконфигурировать сетевые сервисы (например, Netatalk) так, чтобы они отключались перед сном, чтобы избежать нежелательных пробуждений при сетевой активности
sudo tee /etc/systemd/system/netatalk-sleep.service В постоянно включённом устройстве:
- Установить ARP Stand-in: сверхпростой скрипт на Ruby, выполняемый как системный сервис и отвечающий на ARP-запросы от лица другой машины. Сконфигурировать его так, чтобы он отвечал от лица спящего сервера.
- Необязательно: сконфигурировать Avahi так, чтобы он объявлял о сетевых сервисах от лица сервера, когда тот спит.
sudo apt install avahi-daemon sudo tee /etc/systemd/system/avahi-publish.service Тонкости
- Сетевое устройство сервера должно поддерживать wake-on-LAN от unicast-пакетов
- Чтобы предотвратить нежелательные пробуждения, нужно сделать так, чтобы никакое устройство в сети не отправляло серверу посторонних пакетов
Как я этого добился
Сначала я расскажу о своём оборудовании, потому что моё решение частично зависит от него:
- HP ProDesk 600 G3 SFF
- CPU: Intel Core i5-7500
- Сетевой адаптер: Intel I219-LM
Засыпание при простое
Я начал решение задачи с засыпания при простое, которое сводилось к двум вопросам:
- Как определить, находится ли сервер в простое или он занят в конкретный момент времени
- Как автоматически выполнить сохранение состояния в ОЗУ после простоя в течение определённого времени
Определение состояния простоя/загруженности
Я задался вопросом, какие действия сервера можно считать загруженностью, и пришёл к двум пунктам:
- Подключенные SSH-сессии
- Выполняемые бэкапы Time Machine
- Подсчёт залогиненных пользователей при помощи who
- Подсчёт количества подключений к порту AFP (548) при помощи lsof (я использую AFP для сетевого ресурса Time Machine)
Автоматическое сохранение состояния в ОЗУ
Чтобы не усложнять, я решил использовать cron job, запускающий bash-скрипт — см. показанную выше готовую версию. Пока он работает хорошо; если мне придётся учитывать другие метрики для выявления состояния простоя, то я подумаю над применением более функционального инструмента наподобие circadian .
Пробуждение по запросу
Разобравшись с засыпанием при простое, я начал выяснять, как будить сервер по запросу.
Можно ли настроить машину так, чтобы она автоматически просыпалась при получении сетевого запроса? Я знал, что Wake-on-LAN поддерживает пробуждение компьютера при помощи специально созданного «магического пакета», и создать такую систему очень легко. Вопрос заключался в том, может ли то же самое делать обычный, «немагический» пакет.
Пробуждение по PHY?
После онлайн-поисков я нашёл обсуждение на superuser, которое выглядело многообещающе. Там приводилась ссылка на man-страницу ethtool — Linux-утилиты, используемой для конфигурирования сетевого оборудования. На странице приведены все опции конфигурации wake-on-LAN ethtool:
wol p|u|m|b|a|g|s|f|d. Sets Wake-on-LAN options. Not all devices support this. The argument to this option is a string of characters specifying which options to enable. p Wake on PHY activity u Wake on unicast messages m Wake on multicast messages b Wake on broadcast messages a Wake on ARP g Wake on MagicPacket™ s Enable SecureOn™ password for MagicPacket™ f Wake on filter(s) d Disable (wake on nothing). This option clears all previous options.В частности, в обсуждении упоминалась опция Wake on PHY activity , которая для моей ситуации казалась идеальной. Вроде бы любой пакет, отправленный на MAC-адрес сетевого интерфейса, должен был его пробуждать. Я включил флаг при помощи ethtool , вручную перевёл машину в режим сна, а затем попытался снова залогиниться при помощи SSH и отправлять пинги. Увы, несмотря на множество попыток, машина продолжала спать. Неудача.
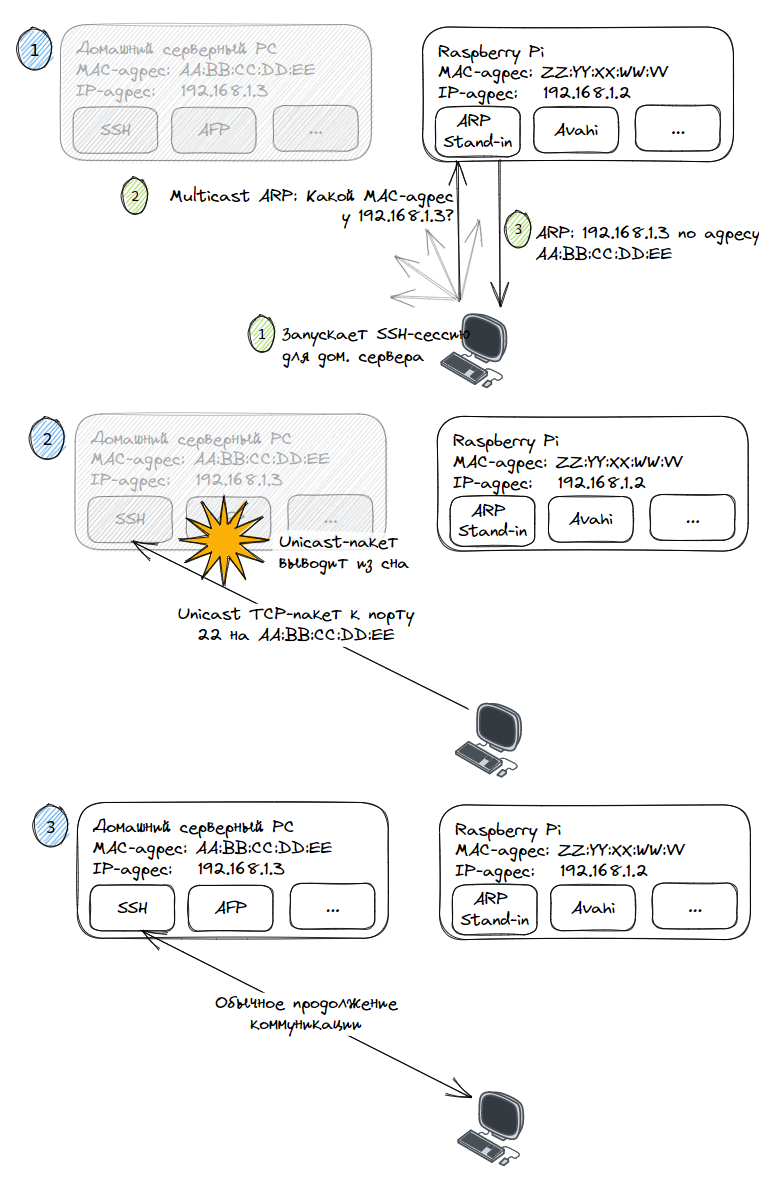
Прорыв: пробуждение по unicast
Ни одна из других опций wake-on-LAN ethtool не показалась мне подходящей, однако после поисков я нашёл другой вариант для проверки — Wake on unicast messages . Я включил флаг при помощи ethtool , вручную перевёл машину в сон, а затем попытался залогиниться при помощи SSH. Бинго! На этот раз машина проснулась. Я понял, что задача решена.
Впрочем, не стоит торопиться, оставалось ещё две проблемы:
- Иногда сервер пробуждался без заметной мне сетевой активности
- Спустя какое-то время после перехода сервера в сон его оказывалось невозможно разбудить при помощи какой бы то ни было сетевой активности, за исключением магического пакета
ARP
То есть после того, как срок действия кэшированной записи ARP на других машинах сети истекал, они больше не могли резолвить IP-адрес сервера в его MAC-адрес. Иными словами, при попытках пинга моего сервера 192.168.1.2 не удавалось даже передать пакет на сервер, потому что MAC-адрес был неизвестен. Без отправки пакета сервер никак нельзя было заставить пробудиться.
Статический ARP?
Моей первой реакцией было следующее: будем вручную создавать записи кэша ARP на каждом сетевом клиенте. Это возможно в macOS при помощи следующей команды:
sudo arp -s [IP address] [MAC address]Но это не соответствует моим требованиям, мне нужно было, чтобы всё «просто работало»: не хотелось создавать статические записи кэша ARP на каждой машине, которая будет получать доступ к серверу. Так что придётся искать другие варианты.
Перенос протокола ARP?
После дальнейших поисков я обнаружил нечто интересное: эту проблему в мире Windows уже очень давно решили.
Это называется ARP protocol offload (перенос протокола ARP):
- Сетевое оборудование способно отвечать на ARP-запросы независимо от CPU
- Перед уходом в сон ОС конфигурирует сетевое оборудование так, чтобы оно отвечало на ARP-запросы
- Во сне сетевое оборудование самостоятельно отвечает на ARP-запросы, не пробуждая остальную часть машины для использования CPU
Единственная проблема заключалась в том, что поддержка Linux отсутствовала. Я поискал в самых дальних уголках Интернета, и наконец наткнулся на исходный код драйвера для Linux, только для того, чтобы выяснить, что перенос ARP не поддерживается драйвером для Linux. Я попытался пропатчить драйвер, чтобы добавить в него поддержку переноса ARP… но потом напомнил себе, что патчинг кода драйвера для Linux — это гораздо больше, чем я надеялся достичь в таком хобби-проекте. (Хотя, возможно, когда-нибудь. )
Другие решения при помощи магических пакетов
Ещё немного поискав, я нашёл другие умные и сложные решения с задействованием магических пакетов. Основная идея заключалась в автоматизации отправки магических пакетов. Одно решение (wake-on-arp) слушает ARP-запросы к указанному хосту, чтобы запустить отправку на этот хост магического пакета. В другом решении реализован веб-интерфейс и интеграция с Home Assistant для отправки магического пакета из веб-браузера смартфона. Всё это впечатляет, но мне требовалось что-то более простое и не требующее ручного пробуждения сервера.
Я рассмотрел ещё несколько вариантов, но отказался от них, потому что они показались слишком сложными и нестабильными:
- Создание скрипта для отправки магического пакета, а затем мгновенный запуск бэкапа Time Machine при помощи tmutil . Скрипт нужно будет устанавливать вручную, после чего запланировать его периодический запуск на каждом Mac.
- Применение HAProxy для проксирования всего релевантного сетевого трафика через Raspberry Pi и использование хука для отправки магического пакета на сервер в случае активности.
Прорыв: ARP Stand-in
То, что я пытался реализовать, не сильно отличалось от сопоставления статического IP, которое стандартно конфигурируется на домашних роутерах, только оно выполнялось для DHCP, а не для ARP. Может ли мой роутер делать то же самое для ARP?
Подробнее изучив протокол ARP, я выяснил, что для резолвинга ARP даже не требуется, чтобы на запросы отвечал конкретный полномочный хост — на ARP-запросы может отвечать любое другое сетевое устройство. Иными словами, резолвить ARP-запросы необязательно должен мой сервер, это может быть кто угодно. То есть можно просто настроить любое устройство отвечать от лица спящего сервера?
Вот, что я пытался сделать:
Я подумал, что это можно реализовать как сетевую конфигурацию Linux, но самое близкое, что мне удалось обнаружить — это Proxy ARP, выполнявшую другую цель. Поэтому я опустился на один уровень ниже, к сетевому программированию.
Как же нам подойти к решению задачи прослушивания пакетов ARP-запросов? Очевидно, это можно сделать при помощи сырого сокета, но я также знал, что tcpdump и Wireshark могут использовать фильтры для перехвата пакетов только заданного типа. Поэтому я решил изучить libpcap — библиотеку, лежащую в основе обоих этих инструментов. Я узнал, что использование libpcap имеет явное преимущество перед сырым сокетом: libpcap реализует очень эффективную фильтрацию непосредственно в ядре, а сырой сокет потребовал бы ручной фильтрации пакетов в пользовательском пространстве, что менее эффективно.
Чтобы не усложнять, я решил написать решение на Ruby, что привело меня к pcaprub — Ruby-обвязке для libpcap . Далее мне достаточно было разобраться, какой фильтр использовать с libpcap . После исследований, проб и ошибок я получил следующий фильтр:
arp and arp[6:2] == 1 and arp[24:4] == [IP address converted to hex]Например, при использовании целевого IP -адреса 192.168.1.2 :
arp and arp[6:2] == 1 and arp[24:4] == 0xc0a80102Давайте разберём эту строку при помощи определения структуры ARP-пакета для байтовых смещений и длин:
- arp — ARP-пакеты
- arp[6:2] == 1 — пакеты ARP-запросов. [6:2] означает «2 байта, найденные по байтовому смещению 6».
- arp[24:4] == [IP address converted to hex] — ARP-пакеты с «указанным целевым адресом». [24:4] означает «4 байта, найденные по байтовому смещению 24».
- Запускает себя, получает такие опции конфигурации:
- IP-адрес и MAC-адрес машины, которую он подменяет («цели»)
- Сетевой интерфейс, с которым нужно работать
Для установки демона или для изучения исходного кода перейдите по следующей ссылке: репозиторий arp_standin в GitHub.
ARP используется в IPv4, а в IPv6 его заменил Neighbor Discovery Protocol (NDP). Пока у меня нет никакой потребности в IPv6, поэтому я полностью отключил IPv6 на сервере при помощи описанных ниже действий. В будущем можно будет добавить в сервис ARP-Standin поддержку Neighbor Discovery.
Запустив на Raspberry Pi новый сервис, я воспользовался Wireshark, чтобы убедиться, что отправляемые на сервер ARP-запросы вызывали ответы от ARP Stand-in. Всё сработало, система выглядела многообещающе.
Соединяем всё вместе
Две основные части были реализованы:
- сервер уходил в сон в состоянии простоя
- сервер мог просыпаться от unicast-пакетов
- другие машины могли резолвить MAC-адрес сервера при помощи ARP ещё долго после того, как он ушёл в сон
Нежелательные пробуждения
Первым делом я проверил системные логи Linux, но они оказались не особо полезными, потому что в них не указывалось, какой именно пакет приводит к пробуждению. Wireshark/tcpdump здесь тоже не помогли, потому что они не запускались, когда компьютер спал. Тогда я подумал использовать зеркалирование: перехватывать пакеты с промежуточного устройства между сервером и остальной сетью. После краткой безуспешной попытки настроить дополнительный роутер для запуска OpenWRT поиск самого дешёвого сетевого коммутатора с зеркалированием портов привёл меня к TP-Link TL-SG105E ценой примерно $30.

TL-SG105E: простой недорогой коммутатор с поддержкой зеркалирования портов
Подключив коммутатор и настроив зеркалирование, я начал перехватывать пакеты с помощью Wireshark, и виновники сразу были выявлены:
- Мой Mac, сконфигурированный для использования сервера как хоста бэкапов Time Machine при помощи AFP, отправлял серверу AFP-пакеты после того, как он уходил в сон
- Netgear R7000, работающий в качестве точки беспроводного доступа, самовольно отправлял серверу частые NBTSTAT -запросы NetBIOS
Устраняем AFP-пакеты
У меня была догадка о том, почему Mac отправлял эти пакеты:
- Mac монтировал общий ресурс AFP, чтобы выполнить бэкап Time Machine
- Бэкап Time Machine завершался, однако ресурс оставался примонтированным
- Mac периодически проверял состояние ресурса, как это обычно делается для примонтированного сетевого ресурса
К счастью, у systemd есть поддержка такой возможности, и я относительно просто определил отдельный сервис systemd для подключения к событиями сна/пробуждения (конфигурация показана выше). Перехват Wireshark подтвердил, что всё сработало.
Устранение пакетов NetBIOS
Это оказалось более сложной задачей, поскольку пакеты поступали по собственной инициативе, они казались случайными и не связанными с действиями, выполняемыми сервером. Я подумал, что они могут быть связаны с запущенными на сервере сервисами Samba, но пакеты продолжали поступать, даже когда я полностью удалил Samba с сервера.
Но почему вообще сетевой роутер отправляет NetBIOS-запросы? Оказалось, что у роутеров Netgear есть функция ReadySHARE для отображения USB-устройств по сети при помощи протокола SMB. Предположительно, внутри прошивки роутера находится Samba, которая использует NetBIOS-запросы для создания и поддержания собственного представления хостов NetBIOS в сети. Решение просто — достаточно отключить ReadySHARE, ведь так? Увы, в стандартной прошивке Netgear сделать это невозможно.
Это заставило меня прошить роутер опенсорсной FreshTomato. Я рад, что сделал это, потому что эта прошивка гораздо лучше стандартной, и она мгновенно прекратила отправку нежелательных пакетов NetBIOS.
Time Machine не запускает пробуждение
Я уже был близок к решению своей задачи: сервер не пробуждался и я мог стабильно будить его, логинясь по SSH, даже спустя долгое время после ухода в сон.
Это было замечательно, но одна функция не работала: когда я запускал бэкап на Mac, то Time Machine бесконечно показывала состояние загрузки сообщением Connecting to backup disk. и в конце концов сдавалась. Причина была в том, что серверу не удавалось разбудить отправляемыми Mac пакетами или Mac вообще не отправлял пакеты?
На этот вопрос ответил перехват Wireshark со включенным зеркалированием: Mac не отправлял пакетов серверу, даже спустя долгое время после сообщения Connecting to backup disk. . Я начал изучать логи Time Machine в macOS при помощи следующей команды:
log show --style syslog --predicate 'senderImagePath contains[cd] "TimeMachine"' --infoБлагодаря нескольким записям всё стало понятно:
(TimeMachine) [com.apple.TimeMachine:Mounting] Attempting to mount 'afp://backup_mbp@homeserver._afpovertcp._tcp.local./tm_mbp' . (TimeMachine) [com.apple.TimeMachine:General] Failed to resolve CFNetServiceRef with name = homeserver type = _afpovertcp._tcp. domain = local.Для резолвинга IP-адреса сервера бэкапов по его имени хоста Mac использовал mDNS (он же Bonjour, Zeroconf). Сервер находился во сне, а потому не отвечал на запросы, поэтому Mac не удавалось резолвить IP-адрес. Это объясняло, почему Mac не отправлял пакеты серверу, не пробуждая его.
mDNS stand-in
У меня уже был сервис ARP stand-in, теперь мне нужно было, чтобы Raspberry Pi ещё и отвечала на mDNS-запросы к серверу, пока он спит. Я знал, что одной из основных реализаций mDNS для Linux был Avahi. Сначала я попробовал использовать эти инструкции при помощи файлов .service для настройки Raspberry Pi так, чтобы она отвечала на mDNS-запросы от лица сервера. Для проверки результата я использовал на Mac следующую команду:
dns-sd -L homeserver _afpovertcp._tcp localПо какой-то причине этот подход просто не работал; Avahi не отвечал от лица сервера. Потом я поэкспериментировал с avahi-publish (man-страница), и, к моему приятному удивлению, это сразу сработало. Я использовал следующую команду:
avahi-publish -s homeserver _afpovertcp._tcp 548 -H homeserver.localДалее мне достаточно было лишь создать определение сервиса systemd , который будет автоматически запускать команду avahi-publish при включении (конфигурация показана выше).
Завершение
После устранения всех неполадок система уже более месяца работает без проблем. Надеюсь, вам понравилась статья, а моё решение подойдёт для вас.
Suspend-функция
Давайте поговорим об одном из компонентов составляющих понятия Корутины Suspend-функции. Помните мы говорили о том что Корутины не блокируют поток, а приостанавливают работу кода. Ну так вот, такое свойство обеспечивает Suspend-функция. То есть, код который вписан в тело Suspend-функции при запуске не заблокирует поток, но этот код приостановит свою работу. Это означает что мы можем даже запустить Корутину в Main-потоке. Давайте приведем пример:
val url = "http://myurl.com/file.pdf" // long synchronous function getFile(url) println("File is downloaded")Простой пример, в котором пытаемся загрузить файл по определенному URL. Здесь функция getFile() синхронная, то есть блокирует поток. Но чтобы запускать функцию из основного потока нам нужно будет сделать ее асинхронной и прокинуть в нее лямбду-коллбек с функцией println(), который будет выполнен после загрузки файла:
getFile(url)
Из выше сказанного следует что, при запуске массивного кода(с тяжелыми вычислениями) в основном потоке нам придется либо блокировать основной поток либо писать колбэк(и плодить колбэкхэлл)
Но благодаря Корутинам и саспенд-функции у нас возможность написать код в которой тяжелая функция не блокирует поток но и код который стоит после этой функции выполнялся после завершения тяжелой функции без коллбэков. Давайте посмотрим как это сделать в переписанном примере:
CoroutineScope(Job()).launch < val url = "http://myurl.com/file.pdf" // long synchronous function suspendedGetFile(url) println("File is downloaded") >Тут launch — это Builders, который создает Корутину. В ее теле появилась Suspend-функция suspendedGetFile(url). Помните? Builder, Suspend-функция все это части Корутины. Эту конструкцию мы можем назвать Корутиной. Ну так вот, эта Корутина не блокирует поток и ее можно запустить в основном потоке. Suspend-функция suspendedGetFile() запустит загрузку файла в рабочем потоке, а функция println() отработает после завершения функции suspendedGetFile().
+ Suspend-функция возвращает свой ответ асинхронно поэтому ее нельзя вызвать из обычной функции
+ Suspend-функция может выполнять код в разных потоках. Нужно помнить про возможный рассинхрон, так как нет гарантии что исполнение и возврат ответа будет на одном потокеПусть это и выглядит как фантастика, но помните что Котлин-код далее будет трансформирован в Java-классы. И в процессе этих преобразований наша Корутина будет трансформирована и будет использован механизм Continuation. Все наши компоненты Корутины «под капотом» реализуют колбэк, который выполнит println() после загрузки suspendedGetFile().