Pg wal что это
Журнал предзаписи ( WAL ) — это стандартный метод обеспечения целостности данных. Детальное описание можно найти в большинстве книг (если не во всех) по обработке транзакций. Вкратце, основная идея WAL состоит в том, что изменения в файлах с данными (где находятся таблицы и индексы) должны записываться только после того, как эти изменения были занесены в журнал, т. е. после того как записи журнала, описывающие данные изменения, будут сохранены на постоянное устройство хранения. Если следовать этой процедуре, то записывать страницы данных на диск после подтверждения каждой транзакции нет необходимости, потому что мы знаем, что если случится сбой, то у нас будет возможность восстановить базу данных с помощью журнала: любые изменения, которые не были применены к страницам с данными, могут быть воссозданы из записей журнала. (Это называется восстановлением с воспроизведением, или REDO.)
Подсказка
Поскольку WAL восстанавливает содержимое файлов базы данных, журналируемая файловая система не является необходимой для надёжного хранения файлов с данными или файлов WAL. Фактически, журналирование может снизить производительность, особенно если журналирование заставляет сохранять данные файловой системы на диск. К счастью, такое сохранение при журналировании часто можно отключить с помощью параметров монтирования файловой системы, например, data=writeback для файловой системы ext3 в Linux. С другой стороны, с журналируемыми файловыми системами увеличивается скорость загрузки после сбоя.
Результатом использования WAL является значительное уменьшение количества запросов записи на диск, потому что для гарантии, что транзакция подтверждена, в записи на диск нуждается только файл журнала, а не каждый файл данных изменённый в результате транзакции. Файл журнала записывается последовательно и таким образом, затраты на синхронизацию журнала намного меньше, чем затраты на запись страниц с данными. Это особенно справедливо для серверов, которые обрабатывают много маленьких транзакций, изменяющих разные части хранилища данных. Таким образом, когда сервер обрабатывает множество мелких конкурентных транзакций, для подтверждения многих транзакций достаточно одного вызова fsync на файл журнала.
WAL также делает возможным поддержку онлайнового резервного копирования и восстановления на определённый момент времени, как описывается в Разделе 24.3. С помощью архивирования данных WAL поддерживается возврат к любому моменту времени, который доступен в данных WAL: мы просто устанавливаем предыдущую физическую резервную копию базы данных и воспроизводим журнал WAL до нужного момента времени. Более того, физическая резервная копия не должна быть мгновенным снимком состояния баз данных — если она была сделана некоторое время назад, воспроизведение журнала WAL за этот период исправит все внутренние несоответствия.
| Пред. | Наверх | След. |
| 29.1. Надёжность | Начало | 29.3. Асинхронное подтверждение транзакций |
Записки программиста
PostgreSQL хранит данные в страницах, а страницы кэшируются в разделяемых буферах. Казалось бы, в случае аварийной остановки грязные страницы не будут записаны на диск, и часть данных пропадет. Чтобы такого не происходило, СУБД пишет журнал предзаписи, он же Write Ahead Log, или WAL.
Теория
Идея заключается в следующем. Перед тем, как изменить что-либо на странице, СУБД делает соответствующую запись в WAL (он же XLOG, от Transaction Log). WAL хранится на диске. Запись содержит что-то уровня «открыть такую-то страницу и записать N таких-то байт по такому-то смещению». В случае аварийной остановки при следующем запуске СУБД откроет WAL и проиграет все записи из него. То есть, сделает все измения, которые могли потеряться.
Смещение записи относительно начала журнала называется Log Sequence Number, или LSN. Записи в среднем довольно короткие, десятки байт, и писать их по одной невыгодно. Поэтому в разделяемой памяти есть кольцевой буфер для WAL-записей . Размер буфера определяется параметром wal_buffers и по умолчанию составляет 1/32 от размера разделяемых буферов, но не менее 64 Кб и не более 16 Мб.
Как правило, страница не может быть вытеснена раньше WAL-записи о последних изменениях на этой странице. Это необходимо для корректного восстановления системы после сбоя. Ведь WAL-записи не могут применяться к страницам из будущего. По этой причине в PageHeaderData в поле pd_lsn хранится LSN. Исключением из правила являются нежурналируемые таблицы.
Во время восстановления WAL-запись должна быть пропущена, если на диске записана страница с большим LSN. Эта страница была вытеснена на диск после того, как была сделана текущая запись в WAL. Страница содержит более свежие данные. Далее в WAL для нее могут быть другие записи, с большим LSN.
Примечание: В PostgreSQL пользователю доступен тип pg_lsn, а также функции pg_current_wal_lsn(), pg_walfile_name(), pg_ls_waldir() и прочие. Подробности ищите в документации.
Запись в WAL происходит с fsync(). Кроме того, записи имеют контрольные суммы. При таком подходе данные не могут быть потеряны. Конечно, если только диск и/или сервер целиком не выйдут из строя. Но это при любом раскладе будет означать восстановление из резервной копии. Заметьте, что работа с WAL — это последовательная запись на диск, что является более дешевой операцией по сравнению со случайной записью в кучу.
По умолчанию в PostgreSQL транзакция считается завершенной успешно, когда все соответствующие ей WAL-записи были записаны на диск с fsync(). Установив synchronous_commit = off можно выжать больше производительности в обмен на потенциальную потерю нескольких последних транзакций в случае сбоя. Подробности описаны в документации.
Если СУБД будет работать долго, она напишет большой WAL, что приведет к медленному восстановлению в случае сбоя. Эта проблема решается при помощи контрольных точек, или checkpoints. Успешный checkpoint означает, что состояние всех страниц на такой-то момент времени (точнее, на такой-то LSN) было записано на диск. В случае восстановления после сбоя СУБД достаточно проиграть записи WAL только с последнего checkpoint’а.
Контрольную точку можно создать вручную, выполнив команду CHECKPOINT . Также чекпоинты периодически создает фоновый процесс под названием checkpointer. Его настройки подробно описаны в официальной документации.
Когда страница изменяется первый раз после контрольной точки, в WAL пишется полная копия страницы. Это необходимо по той причине, что запись грязной страницы в кучу может быть прервана. Страница окажется испорчена и мы не сможем докатить на нее изменения из WAL. Наличие копии страницы в WAL устраняет проблему. Это поведение можно изменить, указав в postgresql.conf параметр full_page_writes = off . Разумеется, настроенная таким образом система может терять данные.
В отличие от некоторых других СУБД, пишущих в WAL как undo, так и redo записи, PostgreSQL пишет только redo. То есть, какие действия нужно совершить, чтобы докатить изменения, но не откатить. Данное решение имеет свои сильные и слабые стороны.
К сильным сторонам относится уменьшение размера WAL, а также существенное упрощение алгоритма восстановления после сбоев (факт проигрывания undo записей при восстановлении нужно логировать, в отличие от redo). Как результат, упрощается тестирование этого алгоритма, в том числе при изменениях между версиями PostgreSQL, в случаях когда СУБД падает во время процесса восстановления, и так далее. Исполнение долгих транзакций не может быть прервано по причине удаления старых undo записей, как это бывает в других системах.
Недостатком является тот факт, что в куче находятся и старые, и новые кортежи. Для удаления старых кортежей нужно периодически делать VACUUM. В СУБД с undo записями старые кортежи вытесняются из кучи в undo записи. VACUUM в таких СУБД не нужен.
Также, в отличие от других СУБД, PostgreSQL берет информацию об успешном checkpoint не из в WAL, а из отдельного файла pg_control. Файл содержит менее 512-и байт данных и имеет контрольную сумму. Это является слабым местом, поскольку запись в такой файл не обязана быть атомарной. Тем не менее, на практике все работает более-менее нормально. Отчасти, потому что грамотные DBA знают про такую особенность и кладут pg_control на журналируемую ФС, а простые DBA держат вообще все на ext4 с включенным журналированием.
Вместо использования отдельного файла более правильно было бы проигрывать WAL от конца к началу в поисках последнего checkpoint. На данный момент это не реализовано в PostgreSQL.
Если СУБД падает во время записи в WAL, то последняя запись может быть записана частично, и контрольная сумма для нее не сойдется. По этой причине некоторые СУБД игнорируют последнюю запись, если она повреждена. Однако повреждение WAL также может быть признаком деградации жесткого диска, или bit rot. Такие СУБД имеют больше шансов потерять данные незаметно для пользователя. Если PostgreSQL видит битую запись в WAL, он отказывается стартовать, и требует ручного вмешательства DBA. Заинтересованным читателям предлагается проверить это самостоятельно. Radare2 отлично подойдет для того, чтобы подправить пару байт в WAL.
Практика
Создадим новую базу данных с одной-единственной таблицей:
CREATE TABLE phonebook (
«name» VARCHAR ( 64 ) NOT NULL ,
«phone» INT NOT NULL ) ;
Таблица очень простая, без каких-либо индексов и без TOAST. В каталоге pg_wal при этом должен быть один файл размером 16 Мб:
$ ls -lah /home/eax/projects/pginstall/data-master/pg_wal
total 17M
drwx—— 3 eax eax 4.0K Jan 08 14:08 .
drwx—— 19 eax eax 4.0K Jan 08 14:08 ..
-rw——- 1 eax eax 16M Jan 08 14:10 000000010000000000000001
drwx—— 2 eax eax 4.0K Jan 08 14:08 archive_status
Также как и с кучей, это файл называется сегментом и разбит на страницы размером по 8 Кб. Размер сегмента может быть переопределен при помощи флага компиляции —wal-segsize , а размер страницы в WAL — при помощи —with-wal-blocksize . Номера сегментов строго возрастают. Никакого переиспользования (wraparound) номеров не предусмотрено, поскольку номеров много. Пройдет очень много времени прежде, чем они закончатся.
Для чтения сегментов предусмотрена утилита pg_waldump:
$ pg_waldump -p ~/projects/pginstall/data-master/pg_wal \
000000010000000000000001 | wc -l
pg_waldump: error: error in WAL record at 0/1B144C0: invalid record
length at 0/1B144F8: wanted 24, got 0
На сообщение об ошибке не обращайте внимания. Так утилита говорит о том, что нашла конец журнала.
Видим, что в журнале немало записей. Они там появились после инициализации базы данных. Также создание таблицы phonebook приводит к изменению таблиц каталога, что создает больше одной записи в журнале.
Допишем немного данных в таблицу:
INSERT INTO phonebook ( «name» , «phone» )
VALUES ( ‘Alice’ , 123 ) , ( ‘Bob’ , 456 ) , ( ‘Charlie’ , 789 ) ;
Повторив предыдущую команду с pg_waldump видим, что в журнале теперь 22007 записей. Воспользовавшись tail -n 5 , мы можем узнать, что конкретно записал наш INSERT:
rmgr: Heap len (rec/tot): 67/67, tx: 739, ⏎
lsn: 0/01B144F8, prev 0/01B144C0, desc: INSERT+INI ⏎
off 1 flags 0x08, blkref #0: rel 1663/16384/16389 blk 0
rmgr: Heap len (rec/tot): 63/63, tx: 739, ⏎
lsn: 0/01B14540, prev 0/01B144F8, desc: INSERT ⏎
off 2 flags 0x08, blkref #0: rel 1663/16384/16389 blk 0
rmgr: Heap len (rec/tot): 67/67, tx: 739, ⏎
lsn: 0/01B14580, prev 0/01B14540, desc: INSERT ⏎
off 3 flags 0x08, blkref #0: rel 1663/16384/16389 blk 0
rmgr: Transaction len (rec/tot): 46/46, tx: 739, ⏎
lsn: 0/01B145C8, prev 0/01B14580, desc: COMMIT ⏎
2023-01-08 14:14:27.585865 MSK
rmgr: Standby len (rec/tot): 50/50, tx: 0, ⏎
lsn: 0/01B145F8, prev 0/01B145C8, desc: RUNNING_XACTS ⏎
nextXid 740 latestCompletedXid 739 oldestRunningXid 740
Смысл полей rmgr, len и прочих станет понятен ниже, когда мы рассмотрим структуру XLogRecord.
Что же до файла pg_control, он имеет путь $PGDATA/global/pg_control. Для его чтения есть утилита pg_controldata. Убедиться, что файл содержит информацию о последнем checkpoint’е можно так:
pg_controldata ~ / projects / pginstall / data-master / > before.txt
psql -c ‘CHECKPOINT;’
pg_controldata ~ / projects / pginstall / data-master / > after.txt
diff before.txt after.txt
pg_controldata ~ / projects / pginstall / data-master / | \
grep ‘Latest checkpoint’
Страницы в WAL начинаются с заголовка XLogPageHeaderData размером 20 байт. Если проставлен флаг XLP_LONG_HEADER, заголовок имеет размер 36 байт и тип XLogLongPageHeaderData. XLogLongPageHeaderData включает в себя XLogPageHeaderData, а также избыточные данные для сверки с pg_control. К избыточным данным относятся 64-х битный идентификатор системы, а также размер сегментов и страниц WAL. Длинная версия заголовка пишется в первую страницу сегмента. Описание этих структур находится в файле xlog_internal.h.
Каждая запись в WAL начинается с заголовка фиксированного размера 24 байта:
typedef struct XLogRecord
{
uint32 xl_tot_len ; /* общая длина записи */
TransactionId xl_xid ; /* ID транзакции, создавшей запись */
XLogRecPtr xl_prev ; /* указатель на предыдущую запись */
uint8 xl_info ; /* флаги и 3 бита id операции */
RmgrId xl_rmid ; /* resource manager этой записи */
/* здесь 2 байта 0x00 для выравнивания */
pg_crc32c xl_crc ; /* контрольная сумма записи */
} XLogRecord ;
Следом идут данные, которые зависят от типа записи. Подробности ищите в файле xlogrecord.h.
За обработку записей конкретного типа отвечают так называемые resource managers. RmgrId кодируется одним байтом. На момент написания этих строк существует 22 разных resource managers, среди которых Heap, Btree, Generic, и другие. Каждый менеджер должен уметь проигрывать свои записи (ищите функции heap_redo, btree_redo, …), декодировать их в текстовое описание (heap_desc, btree_desc, …), и так далее. Подробности смотрите в rmgrlist.h.
Характерно, что для кучи существует два resource managers — Heap и Heap2. Так получилось по той причине, что трех бит (XLOG_HEAP_OPMASK) не хватило для кодирования всех требуемых операций. Поэтому resource manager для кучи распался на два, по 8 операций на каждый. Наверное, можно было бы изменить формат XLogRecord, но это наверняка сломает сторонние инструменты для резервного копирования и всякого такого.
Содержимое pg_control кодируется структурой ControlFileData. Ее описание находится в pg_control.h. В файлах pg_waldump.c и pg_controldata.c можно ознакомиться с исходниками одноименных утилит. Кроме того, есть расширение pg_walinspect. Оно аналогично pageinspect, только для WAL. Его исходники ищите в каталоге contrib/pg_walinspect.
Компонент, отвечающий за работу с WAL и pg_control, называется WAL manager. Его реализация находится в xlog.c, xlog.h и сопутствующих файлах. Наибольший интерес представляют функции XLogInsertRecord(), XLogFlush(), а также функция CreateCheckPoint(). Код инициализации находится в функциях XLOGShmemSize(), XLOGShmemInit() и StartupXLOG().
Как и buffer manager, WAL manager не является каким-то выделенным процессом. Однако есть выделенный процесс walwriter, занимающийся записью WAL. Он очень похож на ранее рассмотренный bgwriter, только вызывает в цикле XLogBackgroundFlush() из xlog.c. Полная реализация находится в walwriter.c.
Заключение
Данная заметка не претендует на исчерпывающее описание всех тонкостей работы WAL в PostgreSQL. В лучшем случае, это лишь отправная точка.
Деталей действительно много — в одном только xlog.c почти 9000 строк кода. А ведь помимо него еще есть xloginsert.c, xlogrecovery.c и другие. Рассмотреть их все в рамках одного поста не представляется возможным, да и лишено особого смысла. Ведь со временем информация устареет.
В качестве дополнительных материалов можно рекомендовать:
- Главу 30 официальной документации PostgreSQL;
- Главу 9 книги «The Internals of PostgreSQL»;
- Главу 10 книги «PostgreSQL 15 изнутри»;
- Лекцию 20 из курса CMU Intro to Database Systems;
- Лекцию 10 из курса CMU Advanced Database Systems;
- Файл src/backend/access/transam/README;
Ну и, конечно же, читать код и комментарии к нему.
Вы можете прислать свой комментарий мне на почту, или воспользоваться комментариями в Telegram-группе.
Как настроить репликацию в PostgreSQL
Настраиваем репликацию данных в PostgreSQL на двух виртуальных серверах.
Эта инструкция — часть курса «PostgreSQL для новичков».
Смотреть весь курс
Введение
В статье мы расскажем, что такое репликация и где она применяется. Также на примере двух виртуальных серверов настроим репликацию данных в PostgreSQL и проверим, что она работает.
Что такое репликация
Репликация — это дублирование данных, когда данные с одного сервера полностью повторяются на других. Приложения пишут данные в одну базу данных PostgreSQL, а изменения автоматически синхронизируются на другие базы.
Репликация используется для достижения двух целей:
- Повышение отказоустойчивости. Если один из серверов выйдет из строя, то остальные продолжат работу.
- Повышение производительности. Распределение данных по серверам в разных частях страны или мира повышает скорость доступа к данным для местных пользователей.
Виды репликации в PostgreSQL
Существует несколько видов репликаций, у каждого из них свои особенности. Но прежде чем рассказывать о видах, нужно хотя бы поверхностно познакомиться с WAL — журналом предзаписи транзакций.
Когда PostgreSQL получает команду на изменение данных, она не сразу изменяет их на диске. Сначала она записывает изменения в WAL. Этот журнал нужен для того, чтобы в случае сбоя сервера можно было восстановить незафиксированные данные. Также WAL используется и для репликации данных.
Итак, в PostgreSQL есть несколько видов репликации:
Потоковая репликация (Streaming Replication). Это репликация, при которой от основного сервера PostgreSQL на реплики передается WAL. И каждая реплика затем по этому журналу изменяет свои данные. Для настройки такой репликации все серверы должны быть одной версии, работать на одной ОС и архитектуре. Потоковая репликация в Postgres бывает двух видов — асинхронная и синхронная.
- Асинхронная репликация. В этом случае PostgreSQL сначала применит изменения на основном узле и только потом отправит записи из WAL на реплики. Преимущество такого способа — быстрое подтверждение транзакции, т.к. не нужно ждать пока все реплики применят изменения. Недостаток в том, что при падении основного сервера часть данных на репликах может потеряться, так как изменения не успели продублироваться.
- Синхронная репликация. В этом случае изменения сначала записываются в WAL хотя бы одной реплики и только после этого фиксируются на основном сервере. Преимущество — более надежный способ, при котором сложнее потерять данные. Недостаток — операции выполняются медленнее, потому что прежде чем подтвердить транзакцию, нужно сначала продублировать ее на реплике.
Логическая репликация (Logical Replication). Логическая репликация оперирует записями в таблицах PostgreSQL. Этим она отличается от потоковой репликации, которая оперирует физическим уровнем данных: биты, байты, и адреса блоков на диске. Возможность настройки логической репликации появилась в PostgreSQL 10.
Этот вид репликации построен на механизме публикации/подписки: один сервер публикует изменения, другой подписывается на них. При этом подписываться можно не на все изменения, а выборочно. Например, на основном сервере 50 таблиц: 25 из них могут копироваться на одну реплику, а 25 — на другую.
Также есть несколько ограничений, главное из которых — нельзя реплицировать изменения структуры БД. То есть если на основном сервере добавится новая таблица или столбец — эти изменения не попадут в реплики автоматически, их нужно применять отдельно.
В отличие от потоковой репликации, логическая может работать между разными версиями PostgreSQL, ОС и архитектурами.
Облачные базы данных
Готовые к работе управляемые базы данных MySQL с встроенной репликацией.
Установить PostgreSQL
Перейдем к практике: настроим потоковую асинхронную репликацию в режиме Master-Replica: один сервер — основной, в него можно писать данные, другой — реплика, из него можно только читать.
На примере платформы Selectel создадим два отдельных сервера PostgreSQL, один из которых будет основным (Master), а второй — репликой (Replica).
В панели управления платформой заходим в раздел Облачная платформа — Серверы, нажимаем кнопку Создать сервер.
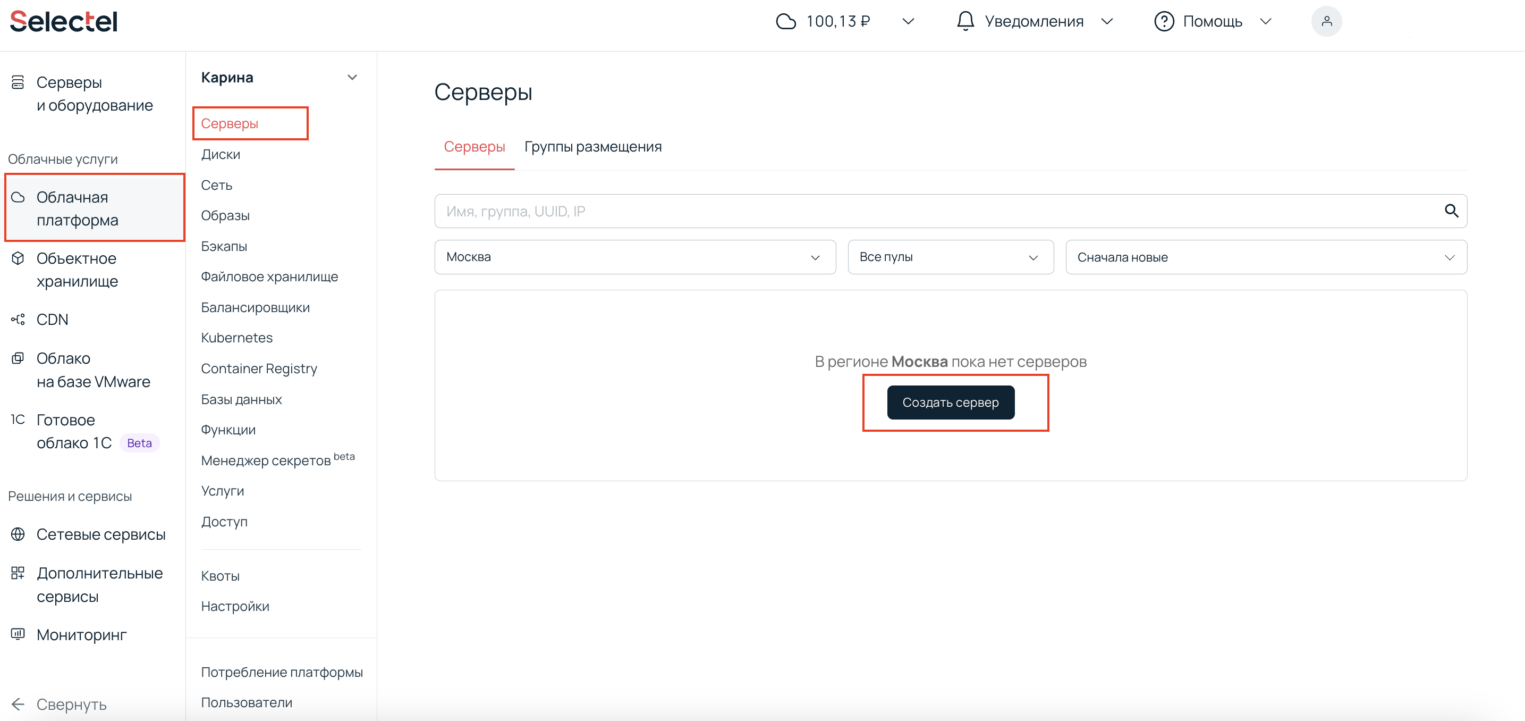
Укажем имя сервера — Master. Так нам будет проще ориентироваться в серверах. Выберем ОС — Ubuntu 22.04, конфигурацию — 2 vCPU, 8 ГБ оперативной памяти и 10 ГБ диска.
В разделе Сеть нужно выбрать подсеть с публичным адресом, чтобы к виртуальной машине можно было подключаться из интернета. В разделе Доступ нужно проверить, что вы либо записали пароль root-пользователя, либо указали правильный SSH-ключ для подключения к машине.
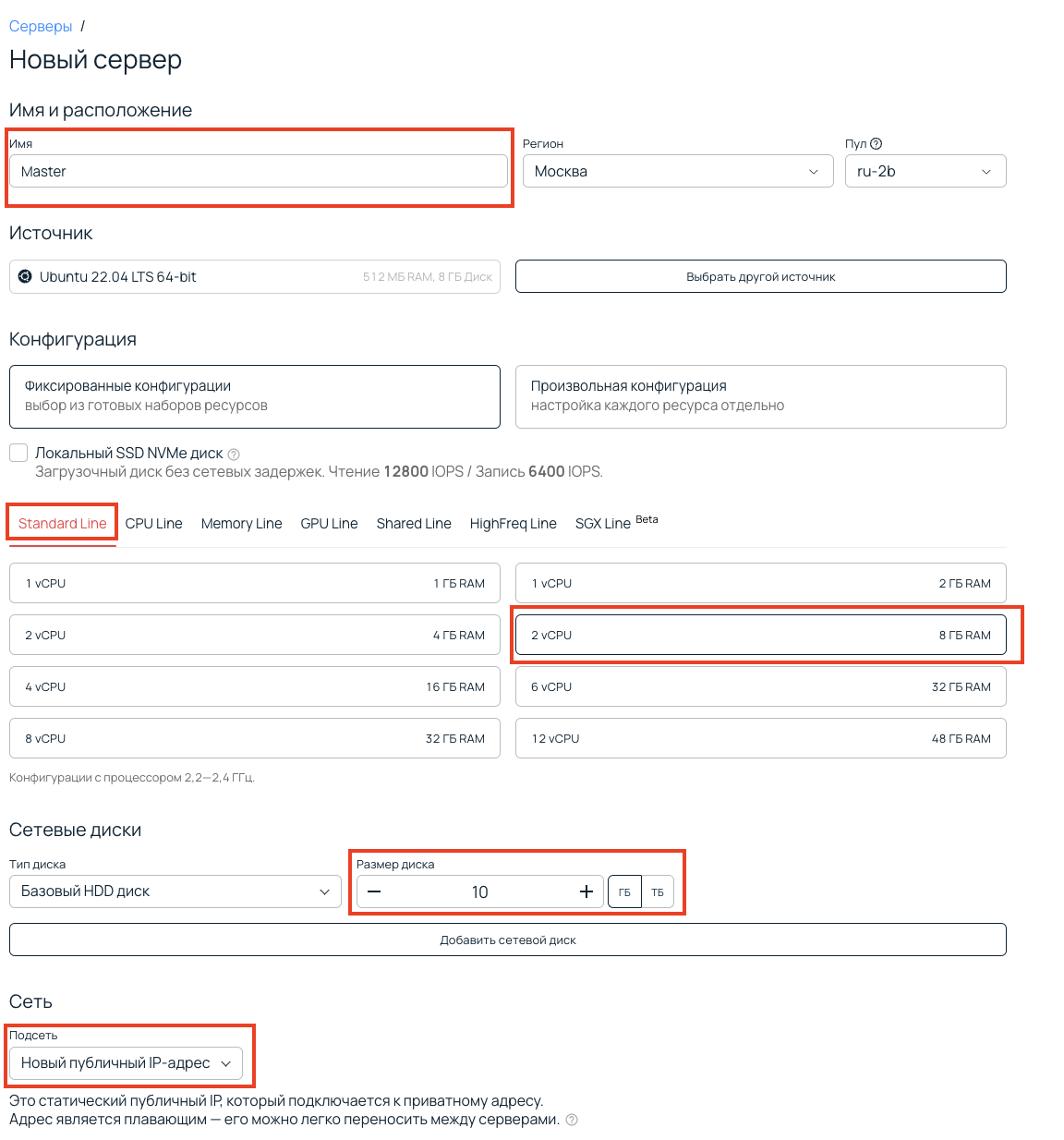
По такому же принципу создаем второй сервер, только укажем другое имя — Replica. Остальные параметры оставим такими же.
В итоге у нас получилось два сервера. Обратите внимание, что у них есть публичные и приватные IP-адреса.
Публичные адреса мы будем использовать для подключения к машинам, а приватные — для настройки репликации.
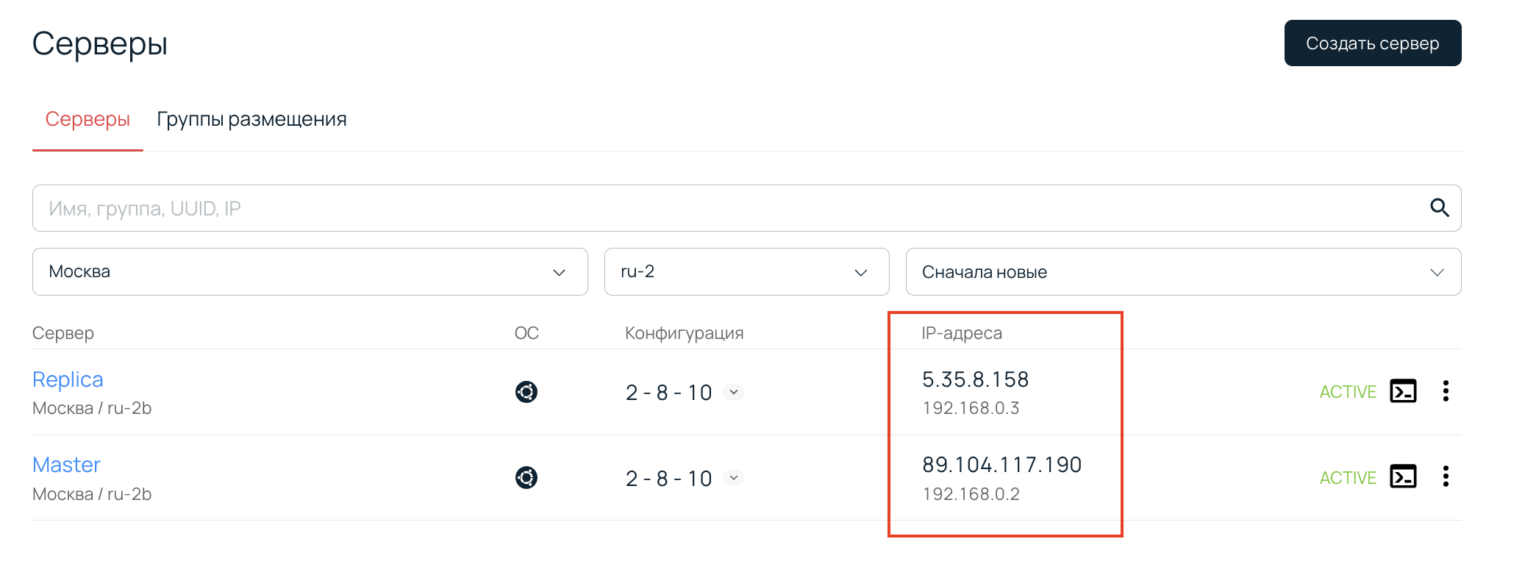
Теперь нужно подключиться к каждому серверу по SSH. Рекомендуем открыть 2 окна терминала и держать их открытыми, потому что мы будем часто переключаться между серверами.
Итак, подключаемся к серверам и устанавливаем PostgreSQL на каждом из них:
apt-get update apt-get install postgresql Все, сервера готовы к настройке репликации. Сейчас они ничем не отличаются друг от друга, кроме названия. Перейдем к настройке каждого из них.
Настроить Master-сервер
Репликацию будем выполнять под пользователем postgres, который автоматически создается после установки PostgreSQL. Установим ему пароль, он нам понадобится позже:
su - postgres psql -c "ALTER ROLE postgres PASSWORD 'ВАШ_ПАРОЛЬ'" exit Далее нужно разрешить этому пользователю подключаться из Replica-сервера в Master. Для этого мы отредактируем файл /etc/postgresql/12/main/pg_hba.conf.
Обратите внимание, что мы показываем настройку репликации на примере PostgreSQL 12, поэтому в пути к файлу есть номер — 12. Если у вас другая версия PostgreSQL, то вам нужно поменять путь к файлу.
Итак, откроем файл:
nano /etc/postgresql/12/main/pg_hba.conf Найдем в нем строчку «If you want to allow non-local connections, you need to add more» и впишем после нее такую строчку:
host replication postgres REPLICA_ВНУТРЕННИЙ_IP/32 md5Так мы разрешаем пользователю postgres подключаться к этому серверу из Replica.
# If you want to allow non-local connections, you need to add more # “host” records. In that case you will also need to make PostgreSQL # listen on a non-local interface via the listen_address # configuration parameter, or via the -i or -h command line switches. host replication postgres 192.168.0.3/32 md5 Обратите внимание, что мы используем приватные адреса, потому что виртуальные машины находятся в одной сети. При этом нам не нужно открывать порты, настраивать Firewall и так далее. Если ваши машины будут находиться в разных сетях или вы хотите, чтобы они общались друг с другом по публичным адресам — скорее всего вам придется настроить Firewall.
Далее нужно указать настройки репликации. Открываем конфигурационный файл PostgreSQL:
nano /etc/postgresql/12/main/postgresql.conf Находим в нем эти параметры, раскомментируем их и подставляем указанные значения.
listen_addresses = 'localhost, MASTER_ВНУТРЕННИЙ_IP' wal_level = hot_standby archive_mode = on archive_command = 'cd .' max_wal_senders = 8 hot_standby = on Все, Master настроен. Чтобы применить настройки, перезапускаем сервер:
service postgresql restart Настроить Replica-сервер
Переключаемся в окно терминала Replica-сервера. Перед началом настройки нужно остановить PostgreSQL-сервер:
service postgresql stop Аналогично Master-серверу отредактируем файл pg_hba.conf. В то же самое место вставим ту же самую строчку, но только теперь укажем IP-адрес мастера.
nano /etc/postgresql/12/main/pg_hba.conf Добавляем в него строчку:
host replication postgres MASTER_ВНУТРЕННИЙ_IP/32 md5 Затем правим файл postgresql.conf. Настройки те же самые, как и у Master, только нужно поменять IP-адрес. Открываем файл на редактирование:
nano /etc/postgresql/12/main/postgresql.conf Находим в нем эти параметры, раскомментируем их и подставляем указанные значения:
listen_addresses = 'localhost, REPLICA_ВНУТРЕННИЙ_IP' wal_level = hot_standby archive_mode = on archive_command = 'cd .' max_wal_senders = 8 hot_standby = on Сейчас настройки обоих серверов одинаковые, отличаются только IP-адреса. Это потому, что при необходимости реплики могут становиться мастером, а вся разница будет в наличии одного лишь файла. О нем расскажем далее.
Прежде чем Replica-сервер сможет начать реплицировать данные, нужно создать новую БД, идентичную Master-серверу. Для этого воспользуемся утилитой pg_basebackup. Она создаст бэкап с Master-сервера и скачает его на Replica-сервер. Эту операцию нужно выполнять от имени пользователя postgres, поэтому логинимся от него:
su - postgres Далее переходим в каталог с базой данных:
cd /var/lib/postgresql/12/ Удалим каталог с дефолтной БД и снова его создадим, но уже пустой:
rm -rf main; mkdir main; chmod go-rwx main Теперь выгрузим БД с мастера. Для выполнения этой команды нужно будет ввести пароль от пользователя postgres, который мы задавали в самом начале настройки Master-сервера.
pg_basebackup -P -R -X stream -c fast -h MASTER_ВНУТРЕННИЙ_IP -U postgres -D ./main В этой команде есть важный параметр -R. Он означает, что PostgreSQL-сервер также создаст пустой файл standby.signal. Несмотря на то, что файл пустой, само наличие этого файла означает, что этот сервер — реплика.
Файл standby.signal появился только в PostgreSQL версии 12. Раньше вместо него создавался файл recovery.conf, в котором хранились настройки для подключения к Master-серверу. Имейте это ввиду, если вы используете более ранние версии PostgreSQL.
Возвращаемся в root-пользователя и запускаем PostgreSQL-сервер:
exit service postgresql start Проверить репликацию
Теперь нужно протестировать репликацию и убедиться, что мы все правильно настроили. На Master-сервере создадим таблицу и вставим в нее одну строчку:
su - postgres psql -c "CREATE TABLE test_table (id INT, name TEXT);" psql -c "INSERT INTO test_table (id, name) VALUES (1, 'test');" Переключимся в терминал Replica-сервера и проверим, что таблица с данными появилась:
su - postgres psql -c "SELECT * FROM test_table;" id | name ----+------ 1 | test (1 row)
Еще одна проверка — попробуем создать новую таблицу на сервере Replica. Если мы все сделали правильно, то сервер не должен позволить нам этого сделать, потому что он настроен только на репликацию с основной БД.
На Replica-сервере выполняем команду:
psql -c "CREATE TABLE test_table2 (id INT, name TEXT);" ERROR: cannot execute CREATE TABLE in a read-only transaction Значит репликация настроена правильно.
Теперь покажем, как можно из Replica-сервера сделать Master. Сымитируем ситуацию, что основной сервер вышел из строя. Для этого в консоли управления платформой Selectel просто выключим сервер Master.
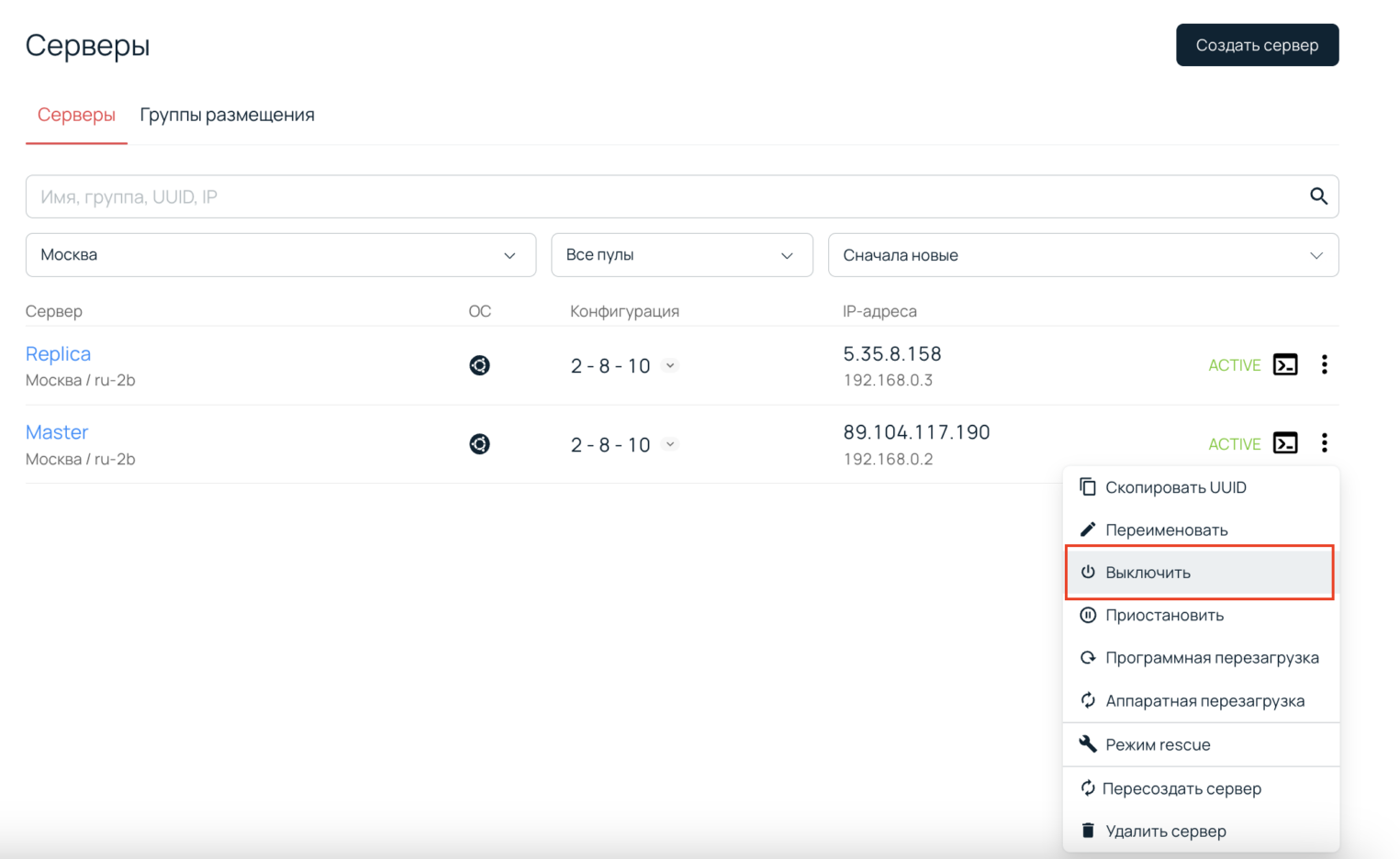
Чтобы перевести Replica-сервер в режим записи, выполните команду:
/usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main Проверяем, снова пробуем создать новую таблицу:
psql -c "CREATE TABLE test_table2 (id INT, name TEXT);" На этот раз таблица создастся. Значит, мы перевели сервер из режима чтения в режим записи.
Но нужно понимать, что запросы от приложений не начнут автоматически направляться на этот сервер. Если сервисы и приложения подключались к «старому» Master-серверу напрямую, они так и будут пытаться подключаться к нему.
Обычно в такой ситуации используется балансировщик нагрузки. Он сам следит за состоянием серверов и распределяет нагрузку между всеми рабочими инстансами. При этом приложения отправляют запросы не напрямую в СУБД, а в балансировщик нагрузки.
Заключение
В статье мы показали, как настроить репликацию в PostgreSQL и проверить ее. Это не сложно, но требует некоторой подготовки. Есть и другой способ — использовать managed-решения.
На нашей платформе есть управляемая PostgreSQL, которая создается в несколько кликов мыши. Вам не придется настраивать и сопровождать СУБД, а репликация и балансировщик нагрузки есть «из коробки». Если Master-сервер выйдет из строя, платформа автоматически переключит одну из реплик в режим записи и перенаправить на нее все запросы.
Установка и использование PostgreSQL в Ubuntu 22.04
Резервное копирование и восстановление PostgreSQL: pg_dump, pg_restore, wal-g
Зарегистрируйтесь в панели управления
И уже через пару минут сможете арендовать сервер, развернуть базы данных или обеспечить быструю доставку контента.
Читайте также:
Инструкция
Как создать 100 серверов в облаке за минуту? Работа с OpenStack клиентом
Инструкция
Как создать веб-приложение на базе Telegram Mini Apps
Инструкция
Что делает команда chmod и как ее использовать в Linux
Welcome to Write-Ahead Log (PostgreSQL’s Write-Ahead Log)
Хейки Олави Линнакангас (Heikki Olavi Linnakangas): Здравствуйте! Меня зовут Хейки Линнакангас. Я работаю с PostgreSQL уже несколько лет. Мы занимаемся проблемами совместимости разных вещей с Oracle. Сегодня мы поговорим о PostgreSQL WAL – журнале регистрации записи с упреждением.
PostgreSQL – очень традиционная SQL-СУБД. Ее разработали в университете Беркли в 1995 году. Она очень быстро была лицензирована, сейчас ее широко распространяют. Лицензию вы можете получить легко.
Она очень гибкая, конечно. Вы можете написать все: все типы, все функции можно ввести туда.
PostgreSQL – достаточно стабильная традиционная база данных SQL. Я хочу рассказать о регистрации записей с упреждением в PostgreSQL.
По сути, все базы данных используются для транзакций и для совместимости. Это очень важно. Это центральное звено нашей технологии базы данных: используется система файлов в журнале обновлений.
В чем идея? Вы производите обновление в базе данных. Прежде всего, вы вводите запись обновления, модифицируете эту страницу. Вы делаете запись на диск, прежде чем обратиться к базе данных.

Мы знаем, что регистрация записи с упреждением также известна, как журнал транзакций или журнал обновлений. Практически в каждой СУБД есть такой журнал. Он иногда называется «журнал обновлений» или «журнал транзакций». Если вы сделаете выбор инструмента, то также увидите, что там имеется журнал записей.

Как это работает? Когда вы говорите о концепции, вы говорите о последовательности. Для каждого изменения делается одна записть. Вы пишете что-то, обновляете – вы говорите, что именно вы собираетесь сделать: обновить запись либо вычеркнуть, уничтожить. Тогда вы задаете эту функцию в записи: что вы хотите сделать, какова ваша цель.

В PostgreSQL эта функция была введена в версии 7.1. Она была написана Вадимом Макеевым в 2001 году. Он из России, это очень активный разработчик PostgreSQL. Он учитывал все функции, как и журнал транзакций. Он описал очень много индексов, в том числе для загрузки.
В PostgreSQL, что интересно, у вас есть только журнал обновлений. Это означает, что если вы что-то уничтожаете, вы находитесь в этом статусе до крэша. Например, если вы делаете какие-то изменения, что-то вносите в базу данных и хотите осуществить возврат, «откат» – вы создаете запись по возвращению. Это великолепное свойство для записи обновлений.
Несколько лет назад я использовал Microsoft SQL. Я делал огромную транзакцию, которая проходила полтора часа. Было очень много разных маленьких отчетов. Что-то там было не так с транзакцией. В течение всей этой длинной транзакции приходилось часто вызывать обратные функции, делать откат. Все это требовало большого времени.
Теперь у нас в PostgreSQL нет этой проблемы, она была решена благодаря функции «root back». Если вы применяете ее в PostgreSQL, реакция происходит мгновенно, и функция становится видимой. Можно «уничтожить мусор», то есть то, что вам не нужно и от чего можно избавиться.
Что еще используется? Нет ограничений для транзакций. Нет ограничений по размеру транзакции – не имеет значения, насколько она большая. Мы можем также выполнять операции проверки. На определенных этапах мы можем проверять, каким образом происходит транзакция, открылась ли она, и до сих пор ли она проходит. Возможно, вы не хотите этого делать… Но постоянно открытая транзакция – это не очень хорошая идея. Это несет угрозу другим данным в базе.

Здесь есть пример. Он сделан для очень простого отчета, для ведения журнала транзакции. Прежде сего, вы вводите Heap, который сам по себе записывается в таблице. Затем у вас есть индекс в дереве Btree. Если у вас система с двумя индексами, это проявляется здесь.
Дальше идет маршрут изменения. По сути, это автоматически происходит. Вы просто записываете эти данные. Вы можете видеть, каким образом индекс разбивается по страницам. Вот таким образом это происходит.
Наконец, есть последняя запись по совершению транзакции с указанием времени. Затем идет то, что уже сделано. Есть сброс – те запросы данных, где идет контроль кэша.
У вас также есть период задержки, но он небольшой. Нужно все-таки еще работать над решением проблемы с задержкой.
Что вам нужно? Только одно: сбрасывать эти данные на диски. Это не страница базы данных, которая имеет отношение к журналу транзакций. Это все очень быстро происходит, это очень хорошо реализовано в PostgreSQL.
В журнале обновления есть два момента относительно работы с данными. Вы вписываете индексы и вносите те же изменения в журнал обновления, журнал транзакций. Это гораздо быстрее делать последовательно.
Также здесь есть обновления в системе файлов, которые делятся на два сегмента. 60 мегабайт внутри, вы видите директории. Когда вы работаете, вы видите, что появляется все больше файлов.

Есть пограничный момент, где можно проверить, какие файлы идут. Названия файлов очень интересны: они идут последовательно. Но иногда происходят перебои – это очень забавно выглядит. Прежде всего, идут цифры – цифра 1. Если вы делаете это в течение какого-то времени, вы видите в основном последовательную организацию записей.

Также стоит упомнуть про инструменты, которые были разработаны недавно. Те примеры, которые я вам здесь представил, касаются функций отработки и настройки. Вы можете отразить эту опцию (WAL_DEBUG compile option), чтобы отработать версию конфигурации. Это очень хорошая разработка – видно, каким образом работает вся система. Вы можете загрузить все файлы и посмотреть, каким образом они работают. Достаточно продуктивно, по-моему.

Очень важная часть работы журнала транзакций – сброс файла на диск до того, как будут произведены какие-то изменения для страниц данных. Вы можете отслеживать Btree-страницу, смотрет, что и как в действительности происходит.
Мы видим, что произошли изменения, до того, как запись транзакции была сделана. Их нужно отразить в журнале транзакций. В случае сбоя WAL «переигрывается», чтобы воспроизвести несохраненные изменения.
Например, мы можем использовать право копирования FCK. Если у вас произошел сбой, вы можете увидеть все ошибки и исправить их. Но журнал транзакций здесь играет основную роль. Здесь есть специальные индексы и механизм индексирования, который позволяет видеть все, что происходит.
«Начинка» здесь совершенно другая, в отличие от права копирования, которое всем известно. Это очень простой способ сделать индексы и реализовать эти функции.

В случае сбоя, вы начнете восстанавливаться с последней контрольной точки. Вы увидите много изменений. Вы можете иметь сотни разных файлов с нарушенной структурой.
Вы можете отсечь их. Для этого у нас существуют контрольные точки. Они позволяют нам отсекать все сбои, все файлы, которые были повреждены.
Когда вы проводите контрольный замер, в буфере обмена происходит запись. Вам не нужно беспокоиться, потому что контрольные точки создаются автоматически. Есть также команды, которые можно использовать для выставления контрольных точек вручную, если почему-то не сработает автоматическая функция.

Иметь журнал транзакций нужно для того, чтобы избежать последствий сбоя или максимально обезопасить свою платформу. Это очень важно: вы сохраняете тот же порядок. В PostgreSQL это происходит очень стабильно. В случае сбоя используется механизм защиты от сбоев.
Однако было бы очень плохо, если бы имелся некий индекс, указывающий на отчет, который не существует. Транзакции выполняются последовательно, чтобы избежать всех этих проблем. Если и происходят какие-то изменения, они вносятся в таблицу. Это также решает проблему с разбиением страницы индекса.
Таким образом, мы можем использовать бустерный порядок, чтобы использовать нечто вроде инструкции, и реорганизовать файлы в нужном порядке. Это самое лучшее, что здесь можно сделать.

Итак, резюме всего вышесказанного.
Мы можем подвести итог тому, о чем говорили в этой части презентации. Регистрация записей в журнале WAL очень пригождается в том случае, если происходит какой-то сбой, если что-то случается с базой данных. Все это находится под контролем.
Индекс может указывать на то, чего не существует. Этого можно избежать. Если индекс имеющейся страницы 50/50, транзакция сможет этого избежать.

В рамках журнала транзакций вы можете использовать и другие функции. Что они позволяют сделать? Это резервное копирование онлайн. Для нас неприемлемо блокировать, «закрывать» какие-то данные. Транзакция будет продолжаться, и мы совершим необходимое «оперативное вмешательство».
Вы видите все возможности, все черты, которые важны. Транзакция проходит благодаря журналу обновлений транзакций.

Еще вы можете использовать продвинутые возможности архивизации, создания архивов. До этого я говорил: когда вы делаете проверку и отсекаете все поврежденное, чтобы сохранять соответствие с проходящей операцией, стоит применить архивы.

PostgreSQL очень гибко действует по отношению к архивам. Есть команда conf file и команда архива, которая задается для каждого файла WAL. Будет вызываться команда, которая будет выполнять «cp %p», либо она может задавать характеристики, которые здесь представлены.
Когда вы запускаете сервер, то можете копировать файлы WAL в архив. Это нужно выполнить самим – задачу отсечения сбоев.
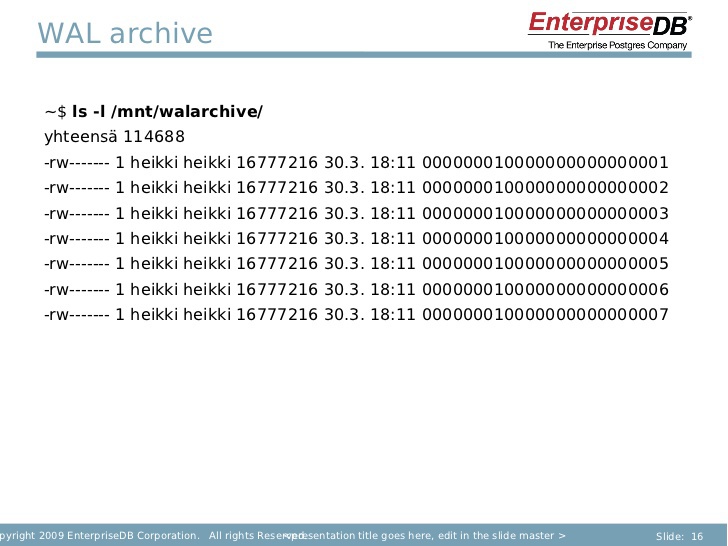
Это вы можете делать сами. Как вы видите, это можно реализовать очень быстро.

В отношении резервирования это обычно перекрывается базой данных. В это время вы можете задействовать резервирование и использовать для копирования снимок состояния. Если вы сможете это сделать, это очень вам поможет. Но обычно снимок делается в файловой системе, что очень сложно. WAL-архив позволяет делать это, необходимая функция осуществляется.

Как это работает? Вы начинаете создание резервной копии базы данных с команды SELECT pg_start_backup(). После того, как вы это сделали, определяете ту команду, которая вам нужна. Вы выполняете rsync/tar/что угодно. Когда вы это сделаете, то используете команду стоп, чтобы выполнить резервирование.
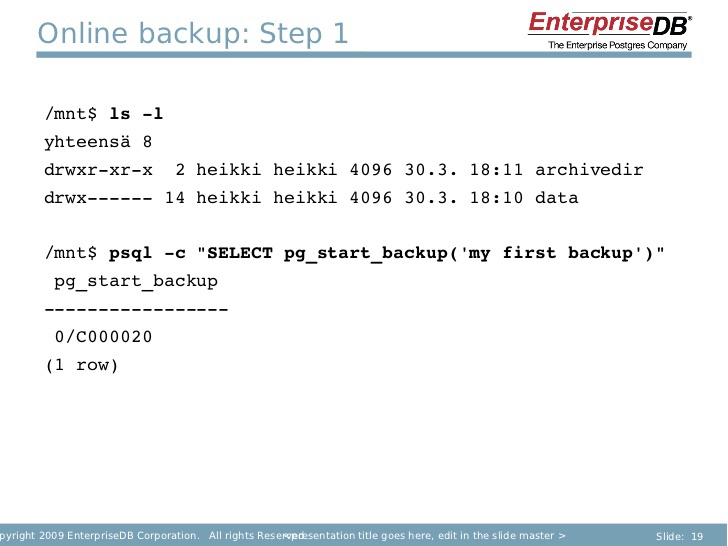
Первый шаг, действительно, позволяет создать резервную копию. Затем вы используете эту команду, чтобы копировать данные из директории.

Как вы видите, здесь 40 мегабайт – это не такая уж большая база данных. В базе могут быть терабайты данных – она может достигать очень больших размеров. Можно в течение целого дня вести эту транзакцию, независимо от размеров. Но в этом случае все происходит очень медленно.
Специально так сделано, чтобы функция не задействовала всю систему. Тогда ее выполнение не приведет к сбою всей системы. Я говорю о том, что вы выполняете в рамках резервного копирования.

Система сообщает вам, что все сегменты заархивированы.

После того, как вы это сделали, остется последнее действие: нужно скопировать все файлы из архива WAL в резервную копию. Можно поместить их в тот же файл или в другой файл. Эти два файла вместе обеспечат вам достаточно надежное резервирование.

Еще одна интересная функция – восстановление на определенный момент времени. Кто из вас это делал в «живой» базе данных? Были же ситуации, когда стиралась таблица или информация из таблицы, а потом вы забывали все восстановить? В случае такого сбоя очень помогает функция восстановления базы на определенный момент времени.

Если у вас реализовано собственное онлайн-резервирование и есть возможности WAL, можно восстановить данные на любой момент времени, который нужен. Если в течение недели вы ведете WAL-архив, на любой момент из этого периода можно будет «заказать» такое восстановление. Можно выбрать момент прямо перед тем, как вы случайно все стерли из таблицы.
Если вы хотите восстановить базу данных, то обращаетесь к резервному файлу, резервному архиву. Вы видите, какие записи надо сделать. Вы формируете команду recovery.conf формируете. Далее вы видите, какие команды надо написать.
По умолчанию восстановление будет идти до конца записи журнала WAL. Если вы хотите, чтобы процесс остановился раньше (в какой-то момент времени), вы должны указать это как цель восстановления. Это очень удобный инструмент.

Еще одна продвинутая функция – репликация. PostgreSQL может производить репликацию, когда у вас есть архив WAL и используются резервные серверы. Можно передавать WAL, по мере его генерирования, на резервный сервер, и будет производиться репликация. Либо можно осуществлять прямую потоковую передачу с сервера по TCP в ходе этого процесса. Резервный сервер может использоваться только для запросов на чтение.
Когда у вас есть ведущий (англ. master) и ведомый (англ. slave) серверы, можно всю копию базы данных ведущего сервера перенести как резервную на ведомый сервер или вызвать уже имеющуюся копию с ведомого сервера. Репликация – очень удобный инструмент. Можно пользоваться им в файловой системе. Можно иметь сколько угодно ведомых серверов, использовать ту или иную систему – вы можете хранить файлы, как вам удобно.

Есть ли какие-то вопросы относительно транзакций с журнальными записями или вообще системы WAL?
Вопросы и ответы
Реплика из зала: По какой причине вы ждали так долго и добавили репликацию только в версии 9.1? У вас уже два года назад была эта технология. Почему вы медлили с релизом? В самой первой версии у вас были такие инструменты.
Хейки Линнакангас: В самом начале Write-Ahead Log (WAL) это существовало только как задумка. Сейчас это более продвинутая функция. Формат WAL позволяет проводить онлайн-репликацию записей в журнале, но все-таки здесь есть сложности с выполнением этого на ведомых серверах.
Мы работали над этим. Это уже шаг вперед по сравнению с простым журналом транзакций. Это продвинутая функция. Репликация присутствует начиная с версий 8.1, 8.2. Но это новый вариант репликации. Я думаю, ответ на ваш вопрос заключается в том, что отдельно это не казалось достаточно значимым, а сейчас мы это сделали.
Реплика из зала: Я не понял, WAL хранит снимки данных или утверждения о манипулировании данными?
Хейки Линнакангас: Снимки в онлайн-резервировании – вы это имеете ввиду?
Реплика из зала: Нет. Я говорю о хранении в WAL-журналах. Что хранится: заявления о модификации (команды о модификации) страниц или снимки?
Хейки Линнакангас: Мы физически модифицируем журнал, а не внесенные записи или утверждения. Давайте посмотрим: здесь у нас запись, но мы ее саму не меняем. Мы выполняем какие-то действия с журналом.
Реплика из зала: Данные вы не изменяете – это модификация низкого уровня. Вы используете резервирование WAL, но в вашем примере это очень специфично. Где вы будете хранить данные, которые были утеряны или сброшены? Вы показывали пример со стертыми записями и говорили о возможностях резервирования WAL. Когда какие-то данные стираются в таблице, где они хранятся, если они не хранятся в WAL?
Хейки Линнакангас: Что мы делаем, если стираем, например, какие-то строки и потом хотим их вернуть – такой у вас вопрос? Когда мы стираем что-то, мы отмечаем, что данные стерты. Сами данные физически сохраняются. Есть только запись о транзакции «убрать данные».
Реплика из зала: Если создается вакуум, и он начинает работать, данные уже восстановить нельзя.
Хейки Линнакангас: Да, после формирования вакуума. Но когда вы стираете данные, они сначала просто делаются невидимыми. Они еще хранятся, их можно восстановить.
Здесь архитектура, которая отличается от ряда других баз данных. Нам необходимо будет лишь отметить стертые строки. Например, пометить, что нужен возврат к старой версии. Либо отметить новую версию как новую, старую как старую – тогда обе они будут сохранены в системе хранения. Но вы должны будете потом определиться, что вам нужно.
Реплика из зала: Все-таки меня вот что интересует: если вакуум начинает функционировать в таблице, вы уже не можете восстановить данные, используя резервирование WAL. Можно или нет восстановить эти данные?
Хейки Линнакангас: Вы спрашиваете, можно ли восстановить данные, когда вакуум уже запущен или после того, как он сработал?
Реплика из зала: Да. Вы говорили, что можно использовать резервирование WAL, и можно произвести восстановление данных на какой-то момент времени.
Хейки Линнакангас: Идея восстановления данных на какой-то момент времени заключается в том, что вы начинаете с полного резервирования. Сначала вы проводите полное резервирование, а потом уже воспроизводите журнал заново до того момента времени, который определили. У вас должны иметься все сохраненные данные. Если вы что-то переписали или что-то удалили, и там уже сработал вакуум, конечно, это восстановить нельзя.
Реплика из зала: Большое спасибо за вашу презентацию. Я не слишком хорошо знаком с PostgreSQL. Это распределенная система? Можно ли в ней масштабировать горизонтально?
Хейки Линнакангас: Это не распределенная система. Можно сделать репликацию по схеме «ведущий-ведомый», и есть целый ряд проектов, которые проводят такие репликации поверх PostgreSQL, но сама эта система не распределенная.
Реплика из зала: Как физически хранится информация?
Хейки Линнакангас: В виде файлов, файловой системы.
Реплика из зала: По узлам. Один узел на один экземпляр PostgreSQL. Да?
Хейки Линнакангас: Это зависит от того, зачем вы делаете репликацию. Если репликация основана на одном типе журнальных записей, опирающихся на ведомые серверы, тогда информация с них и будет воспроизводиться. Есть триггерные системы, которые реплицируют транзакции на разные узлы.
Реплика из зала: Как производительность в таких продуктах зависит от интенсивности нагрузки? Есть ли технология резервирования некоторых баз данных, а не всех?
Хейки Линнакангас: Нет. Здесь либо все, либо ничего. Можно делать частичное резервирование в триггерных программах. Но здесь вы должны всю базу данных резервировать, а потом можно будет с этим работать.
Реплика из зала: А какова производительность в варианте «ведущий-ведомый» при применении этой технологии? Например, насколько медленно будет проходить транзакция, и какая нагрузка будет применяться?
Хейки Линнакангас: Здесь нет прямой зависимости. Многое зависит от «железа». Это однопотоковый процесс. Если вы применяете проект «ведущий-ведомый», и если на уровне ведущего сервера у вас большое количество обновлений, может создаться очередь при передаче на ведомый. Но других ограничений нет.
Реплика из зала: Проекты на ближайшее будущее. Есть ли разработки по новым системам визуализации?
Хейки Линнакангас: Пока не знаю. Может быть, кто-то этим заинтересуется. Если здесь есть студенты, сейчас «Google» и другие компании заинтересованы в привлечении к разработкам инициативной молодежи.
Если вопросов больше нет, спасибо.