Получение данных веб-страницы путем предоставления примеров
Получение данных с веб-страницы позволяет пользователям легко извлекать данные из веб-страниц. Однако часто данные на веб-страницах не находятся в простых таблицах, которые легко извлекать. Получение данных из таких страниц может быть сложным, даже если данные структурированы и согласованы.
Есть решение. С помощью функции «Получить данные из Интернета» можно по сути отображать данные Power Query, которые необходимо извлечь, предоставив один или несколько примеров в диалоговом окне соединителя. Power Query собирает другие данные на странице, которая соответствует вашим примерам. С помощью этого решения можно извлечь все виды данных из веб-страниц, включая данные, найденные в таблицах и других не табличных данных.
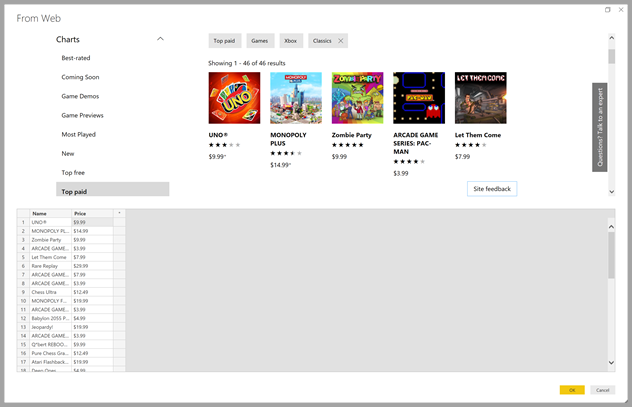
Цены, перечисленные в изображениях, являются только для целей.
Использование получения данных из Интернета по примеру
Выберите веб-параметр в выборе соединителя, а затем выберите Подключение, чтобы продолжить.
В интернете введите URL-адрес веб-страницы, из которой вы хотите извлечь данные. В этой статье мы будем использовать веб-страницу Microsoft Store и покажем, как работает этот соединитель.
Если вы хотите продолжить, можно использовать URL-адрес Microsoft Store, который мы используем в этой статье:
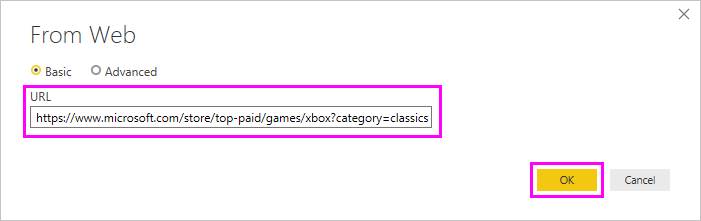
При нажатии кнопки «ОК» вы перейдете в диалоговое окно «Навигатор» , где отображаются все автоматически заданные таблицы на веб-странице. В приведенном ниже примере таблицы не найдены. Выберите » Добавить таблицу», используя примеры .
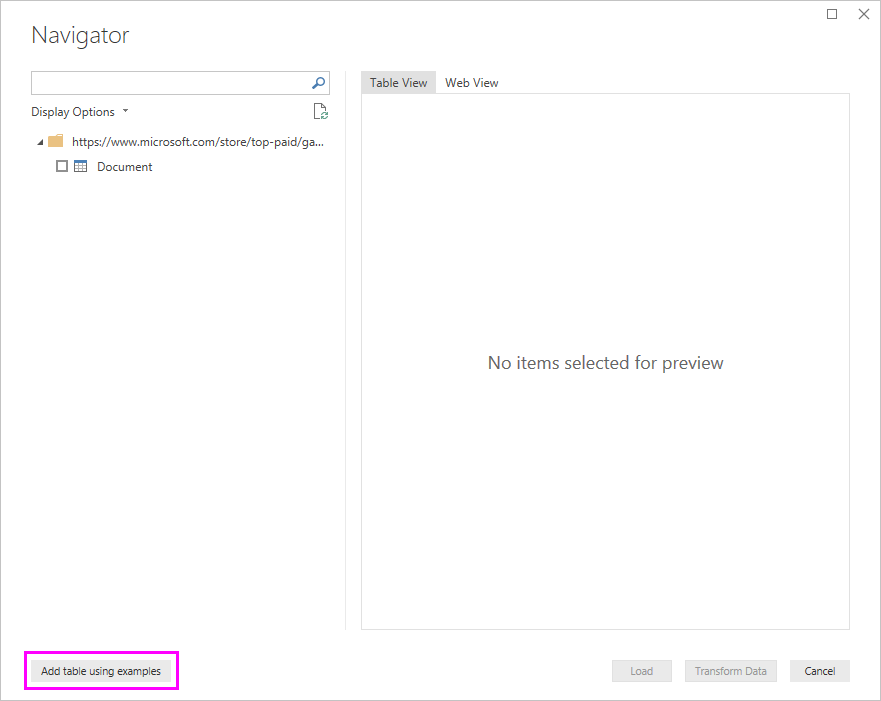
Добавление таблицы с помощью примеров представляет интерактивное окно, в котором можно просмотреть содержимое веб-страницы. Введите примеры значений данных, которые требуется извлечь.
В этом примере вы извлеките имя и цену для каждой игры на странице. Это можно сделать, указав несколько примеров на странице для каждого столбца. При вводе примеров Power Query извлекает данные, соответствующие шаблону примеров записей с помощью алгоритмов интеллектуального извлечения данных.
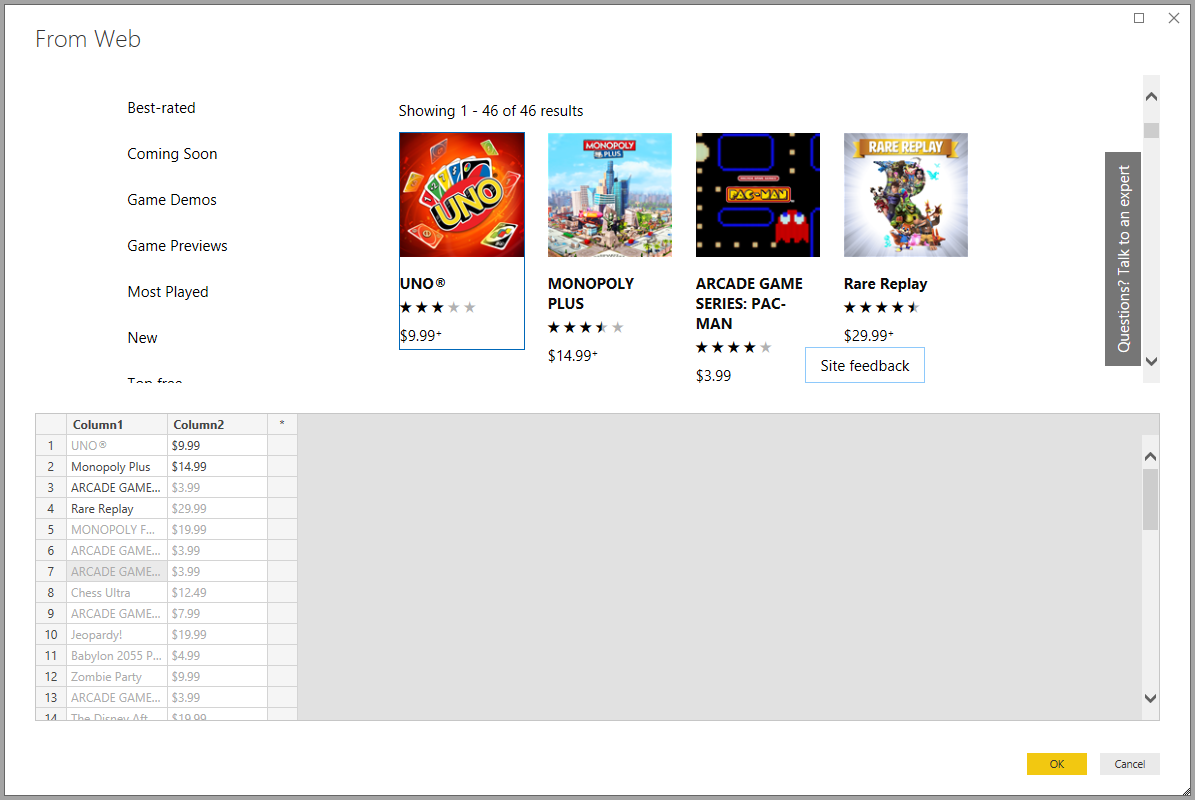
Предложения по значению включают только значения меньше или равно 128 символам длины.
Когда вы довольны данными, извлеченными на веб-странице, нажмите кнопку «ОК«, чтобы перейти к Редактор Power Query. Затем можно применить дополнительные преобразования или сформировать данные, например объединение этих данных с другими источниками данных.
См. также
- Добавление столбца из примеров
- Фигура и объединение данных
- Получение данных
- Устранение неполадок соединителя Power Query Web
Импорт данных из Интернета
Начните работу с Power Query и переведите свои навыки преобразования данных на следующий уровень. Сначала импортируем некоторые данные.
Примечание: Хотя видео в этом обучении основаны на Excel для Microsoft 365, мы добавили инструкции в качестве меток видео, если вы используете Excel 2016.
- Откройте Excel и на начальном экране выберите Создать.
В поле Поиск шаблонов в Интернете найдите Power Query. - Откройте учебник по Power Query и нажмите кнопку Создать.
- На листе Импорт данных из Интернета скопируйте URL-адрес, который является страницей Википедии для турнирной таблицы Чемпионата мира ПО ФИФА.
- Выберите Data >Get & Transform > From Web (Получить> преобразования & из Интернета).
- Нажмите клавиши CTRL+V, чтобы вставить URL-адрес в текстовое поле, а затем нажмите кнопку ОК.
- В области Навигатор в разделе Параметры отображения выберите таблицу Результаты .
Совет: Чтобы получить обновления для этих данных Кубка мира, выберите таблицу, а затем нажмите кнопку Обновить запрос.
Парсинг сайта с помощью Excel
На первый взгляд Excel и парсинг понятия несовместимые. Как с помощью табличного редактора можно получать информацию из сети? И ведь многие недооценивают Excel, а это вполне посильная задача для него. При этом все делается стандартными методами без необходимости дополнительно что-то устанавливать/настраивать.
Разберем на конкретном примере по получению информации с сайта Минюста, а именно, нам необходим перечень действующих адвокатов Российской Федерации. Кнопки «выгрузить списочно всех адвокатов» — конечно же, нет. На официальном сайте http://lawyers.minjust.ru/ выводится по 20 адвокатов на 1 странице, всего 74 754 страниц, итого на выходе мы должны получить чуть меньше 150 тыс. адвокатов.
Для начала открываем VBA и создаем объект InternetExplorer, посредством которого будем получать данные.
Затем надо определить, как будем переходить между страницами на сайте – для этого просматриваем элемент перехода на следующую страницу. Ссылка между станицами отличается значением в конце и соответствует номеру страницы – 1.
Имея информацию о ссылке страницы — осуществляем их перебор, загружаем в InternetExplorer и забираем все данные со страницы.
В коде страницы представлена структура таблицы со всеми столбцами, которые нам необходимы: реестровый номер, ФИО адвоката, субъект РФ, номер удостоверения, текущий статус.
Для получения этой информации с помощью ключевых слов осуществляем поиск по тегам и забираем требуемые данные.
В итоге получаем список всех адвокатов в таблицу Excel для дальнейшей обработки.
Как правильно парсить данные из Excel файла?
Здравствуйте!
Заранее извиняюсь за не совсем ясное, как по мне, объяснение своей проблемы.
В вузе работаю над проектом, суть которого заключается в парсинге данных из Excel с последующем сохранением в PostgreSQL.
Мне дали таблицу, попросили написать для неё программу. Я написал, данные успешно парсились. Но затем мне скинули ещё с десяток таблиц, и вот тут начались проблемы. Таблицы несколько отличаются в том плане, что данные, которые в первой таблице находятся на n-ой строчке и j-ом столбце (1 скриншот), в других таблицах могут находиться в иных местах (2 скриншот).
Скриншоты

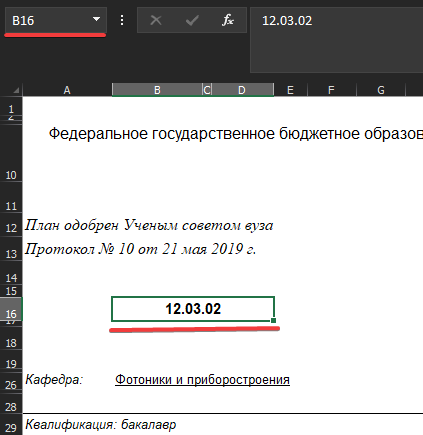
И таких не совпадающих по координатам ячеек в таблицах достаточно много.
А я написал программу, которая начинает парсить данные с конкретного столбца и конкретной строчки конкретной таблицы, ибо предполагал, что таблицы по структуре будут одинаковы.
Вопрос: как грамотно написать парсер таким образом, чтобы он не был привязан к определенным строчкам и столбцам при поиске конкретных данных и, соответственно, не ломался, если нужные данные в таблице находятся, условно говоря, в ячейке C16, а не B16, как предполагалось. Как можно учесть все эти несоответствия?
Спрашиваю не потому, что сам не хочу напрягаться, а потому, что меня самого интересует, как можно написать такую «адаптивную» программу без костылей с кучей if-else и циклов for, и возможно ли такое в принципе.
Не знаю, нужна эта информация или нет, но:
1) Использую язык Java и библиотеку apache.poi.
2) Сам проект на GitHub
- Вопрос задан более трёх лет назад
- 2580 просмотров