Celery — распределенная очередь задач¶
Celery — это простая, гибкая и надежная распределенная система для обработки огромного количества сообщений, предоставляющая операторам инструменты, необходимые для обслуживания такой системы.
Это очередь задач, ориентированная на обработку в реальном времени, а также поддерживающая планирование задач.
Celery имеет большое и разнообразное сообщество пользователей и разработчиков, вам стоит присоединиться к нам на канале IRC или в рассылке .
Celery является открытым исходным кодом и лицензируется под BSD License.
Пожертвования¶
Этот проект зависит от ваших щедрых пожертвований.
Если вы используете Celery для создания коммерческого продукта, пожалуйста, рассмотрите возможность стать нашим backer или нашим sponsor, чтобы обеспечить будущее Celery.
Начало работы¶
- Если вы новичок в Celery, вы можете начать работу, следуя руководству Первые шаги с сельдереем .
- Вы также можете проверить FAQ .
Содержание¶
- Начало работы
- Знакомство с Celery
- Бэкенды и брокеры
- Первые шаги с сельдереем
- Следующие шаги
- Ресурсы
- Приложение
- Задачи
- Вызов задач
- Холст: Проектирование рабочих потоков
- Руководство для работников
- Демонизация
- Периодические задачи
- Задачи маршрутизации
- Руководство по мониторингу и управлению
- Безопасность
- Оптимизация
- Отладка
- Конкурентность (Параллелизм)
- Сигналы
- Тестирование с Celery
- Расширения и бутстепы
- Конфигурация и настройки по умолчанию
- Документирование задач с помощью Sphinx
- Django
- Общественные ресурсы
- Учебники
- Часто задаваемые вопросы
- Что нового в Celery 5.1 (Солнечная гармоника)
- Справочник по API
- Интерны
- История
- Глоссарий
Как настроить Celery в Django
В этом руководстве по использованию Celery совместно с Django я расскажу:
- Как настроить Celery с Django.
- Как протестировать Celery-задачу в Django-оболочке.
- Где контролировать работу Celery-приложения.
Вы можете использовать на исходный код проекта из этого репозитория.
Зачем приложению на Django нужен Celery
Celery нужен для запуска задач в отдельном рабочем процессе ( worker ), что позволяет немедленно отправить HTTP-ответ пользователю в веб-процессе (даже если задача в рабочем процессе все еще выполняется). Цикл обработки запроса не будет заблокирован, что повысит качество взаимодействия с пользователем.
Ниже приведены некоторые примеры использования Celery:- Вы создали приложение с функцией отправки комментариев, в которых пользователь может использовать символ @, чтобы упомянуть другого пользователя, после чего последний получит уведомление по электронной почте. Если пользователь упоминает 10 человек в своем комментарии, веб-процессу необходимо обработать и отправить 10 электронных писем. Иногда это занимает много времени (сеть, сервер и другие факторы). В данном случае Celery может организовать отправку писем в фоновом режиме, что в свою очередь позволит вернуть HTTP-ответ пользователю без ожидания.
- Нужно создать миниатюру загруженного пользователем изображения? Такую задачу стоит выполнить в рабочем процессе.
- Вам необходимо делать что-то периодически, например, генерировать ежедневный отчет, очищать данные истекшей сессии. Используйте Celery для отправки задач рабочему процессу в назначенное время.
Когда вы создаете веб-приложение, постарайтесь сделать время отклика не более, чем 500мс (используйте New Relic или Scout APM), если пользователь ожидает ответа слишком долго, выясните причину и попытайтесь устранить ее. В решении такой проблемы может помочь Celery.
Celery или RQ
RQ (Redis Queue) — еще одна библиотека Python, которая решает вышеуказанные проблемы.
Логика работы RQ схожа с Celery (используется шаблон проектирования производитель/потребитель). Далее я проведу поверхностное сравнение для лучшего понимания, какой из инструментов более подходит для задачи.- RQ (Redis Queue) проста в освоении, направлена на снижение барьера в использовании асинхронного рабочего процесса. В ней отсутствуют некоторые функции, и она работает только с Redis и Python.
- Celery предоставляет больше возможностей, поддерживает множество различных серверных конфигураций. Одним из минусов такой гибкости является более сложная документация, что довольно часто пугает новичков.
Я предпочитаю Celery, поскольку он замечательно подходит для решения многих проблем. Данная статья написана мной, чтобы помочь читателю (особенно новичку) быстро изучить Celery!
Брокер сообщений и бэкенд результатов
Брокер сообщений — это хранилище, которое играет роль транспорта между производителем и потребителем.
Из документации Celery рекомендуемым брокером является RabbitMQ, потому что он поддерживает AMQP (расширенный протокол очереди сообщений).Так как во многих случаях нам не нужно использовать AMQP, другой диспетчер очереди, такой как Redis, также подойдет.
Бэкенд результатов — это хранилище, которое содержит информацию о результатах выполнения Celery-задач и о возникших ошибках.
Здесь рекомендуется использовать Redis.
Как настроить Celery
Celery не работает на Windows. Используйте Linux или терминал Ubuntu в Windows.
Далее я покажу вам, как импортировать Celery worker в ваш Django-проект.
Мы будем использовать Redis в качестве брокера сообщений и бэкенда результатов, что немного упрощает задачу. Но вы свободны в выборе любой другой комбинации, которая удовлетворяет требованиям вашего приложения.
Используйте Docker для подготовки среды разработки
Если вы работаете в Linux или Mac, у вас есть возможность использовать менеджер пакетов для настройки Redis (brew, apt-get install), однако я хотел бы порекомендовать вам попробовать применить Docker для установки сервера redis.
- Вы можете скачать Docker-клиент здесь.
- Затем попробуйте запустить службу Redis $ docker run -p 6379: 6379 —name some-redis -d redis
Команда выше запустит Redis на 127.0.0.1:6379.
- Если вы намерены использовать RabbitMQ в качестве брокера сообщений, вам нужно изменить только приведенную выше команду.
- Закончив работу с проектом, вы можете закрыть Docker-контейнер — окружение вашей рабочей машины по-прежнему будет чистым.
Теперь импортируем Celery в наш Django-проект.
Создание Django-проекта
Рекомендую создать отдельное виртуальное окружение и работать в нем.
$ pip install django==3.1 $ django-admin startproject celery_django $ python manage.py startapp pollsНиже представлена структура проекта.
├── celery_django │ ├── __init__.py │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── manage.py └── polls ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── tests.py └── views.pyФайл celery.py
Давайте приступим к установке и настройке Celery.
pip install celery==4.4.7 redis==3.5.3 flower==0.9.7Создайте файл celery_django/celery.py рядом с celery_django/wsgi.py.
""" Файл настроек Celery https://docs.celeryproject.org/en/stable/django/first-steps-with-django.html """ from __future__ import absolute_import import os from celery import Celery # этот код скопирован с manage.py # он установит модуль настроек по умолчанию Django для приложения 'celery'. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'celery_django.settings') # здесь вы меняете имя app = Celery("celery_django") # Для получения настроек Django, связываем префикс "CELERY" с настройкой celery app.config_from_object('django.conf:settings', namespace='CELERY') # загрузка tasks.py в приложение django app.autodiscover_tasks() @app.task def add(x, y): return x / yФайл __init__.py
Давайте продолжим изменять проект, в celery_django/__init__.py добавьте.
from __future__ import absolute_import, unicode_literals # Это позволит убедиться, что приложение всегда импортируется, когда запускается Django from .celery import app as celery_app __all__ = ('celery_app',)Дополнение settings.py
Поскольку Celery может читать конфигурацию из файла настроек Django, мы внесем в него следующие изменения.
CELERY_BROKER_URL = "redis://127.0.0.1:6379/0" CELERY_RESULT_BACKEND = "redis://127.0.0.1:6379/0"
Есть кое-что, о чем следует помнить.
При изучении документации Celery вы вероятно увидите, что broker_url — это ключ конфигурации, который вы должны установить для диспетчера сообщений, однако в приведенном выше celery.py:
- app.config_from_object('django.conf: settings', namespace = 'CELERY') сообщает Celery, чтобы он считывал значение из пространства имен CELERY , поэтому, если вы установите просто broker_url в своем файле настроек Django, этот параметр не будет работать. Правило применяется для всех ключей конфигурации в документации Celery.
- Некоторые конфигурационные ключи различаются между Celery 3 и Celery 4, так что, пожалуйста, загляните в документацию при настройке.
Отправка заданий Celery
После завершение работы с конфигурацией все готово к использованию Celery. Мы будем запускать некоторые команды в отдельном терминале, но я рекомендую вам взглянуть на Tmux, когда у вас будет время.
Сначала запустите Redis-клиент, потом celery worker в другом терминале, celery_django — это имя Celery-приложения, которое вы установили в celery_django/celery.py.
$ celery worker -A celery_django --loglevel=info -------------- celery@DESKTOP-111111 v4.4.7 (cliffs) --- ***** ----- -- ******* ---- Linux-4.4.0-19041-Microsoft-x86_64-with-glibc2.27 2021-03-15 15:03:44 - *** --- * --- - ** ---------- [config] - ** ---------- .> app: celery_django:0x7ff07f818ac0 - ** ---------- .> transport: redis://127.0.0.1:6379/0 - ** ---------- .> results: redis://127.0.0.1:6379/0 - *** --- * --- .> concurrency: 4 (prefork) -- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker) --- ***** ----- -------------- [queues] .> celery exchange=celery(direct) key=celery [tasks] . celery_django.celery.addДалее запустим приложение в новом терминале, которое поможет нам отслеживать Celery-задачу (я расскажу об этом чуть позже).
$ flower -A celery_django --port=5555 [I 210315 16:11:39 command:135] Visit me at http://localhost:5555 [I 210315 16:11:39 command:142] Broker: redis://127.0.0.1:6379/0 [I 210315 16:11:39 command:143] Registered tasks: ['celery.accumulate', 'celery.backend_cleanup', 'celery.chain', 'celery.chord', 'celery.chord_unlock', 'celery.chunks', 'celery.group', 'celery.map', 'celery.starmap', 'celery_django.celery.add'] [I 210315 16:11:39 mixins:229] Connected to redis://127.0.0.1:6379/0Затем откройте http://localhost:5555/. Вы должны увидеть информационную панель, на которой отображаются детали выполнения рабочего процесса Celery.
Теперь войдем в Django shell и попробуем отправить Celery несколько задач.
$ python manage.py migrate $ python manage.py shell . >>> from celery_django.celery import add >>> task = add.delay(1, 2)Рассмотрим некоторые моменты:
- Мы используем xxx.delay для отправки сообщения брокеру. Рабочий процесс получает эту задачу и выполняет ее.
- Когда вы нажимаете клавишу enter для ввода task = add.delay(1, 2) , кажется, что команда быстро завершает выполнение (отсутствие блокировки), но метод добавления все еще активен в рабочем процессе Celery.
- Если вы проверите вывод терминала, где был запущен Celery, то увидите что-то вроде этого:
[2021-03-15 15:04:32,859: INFO/MainProcess] Received task: celery_django.celery.add[e1964774-fd3b-4add-96ff-116e3578de de] [2021-03-15 15:04:32,882: INFO/ForkPoolWorker-1] Task celery_django.celery.add[e1964774-fd3b-4add-96ff-116e3578dede] s ucceeded in 0.013418699999988348s: 0.5Рабочий процесс получил задачу в 15:04:32, и она была успешно выполнена.
Думаю, теперь у вас уже есть базовое представление об использовании Celery. Попробуем ввести еще один блок кода.>>> print(task.state, task.result) SUCCESS 0.5Затем давайте попробуем вызвать ошибку в Celery worker и посмотрим, что произойдет.
>>> task = add.delay(1, 0) >>> type(task) celery.result.AsyncResult >>> task.state 'FAILURE' >>> task.result ZeroDivisionError('division by zero')Как видите, результатом вызова метода delay является экземпляр AsyncResult.
Мы можем использовать его следующим образом:- Проверить состояние задачи.
- Узнать возвращенное значение (результат) или сведения об исключении.
- Получить другие метаданные.
Мониторинг Celery с помощью Flower
Flower позволяет отобразить информацию о работу Celery более наглядно на веб-странице с дружественным интерфейсом. Это значительно упрощает понимание происходящего, поэтому я хочу обратить внимание на Flower, прежде чем углубиться в дальнейшее рассмотрение Celery.
URL-адрес панели управления: http://127.0.0.1:5555/. Откройте страницу задач — Tasks.
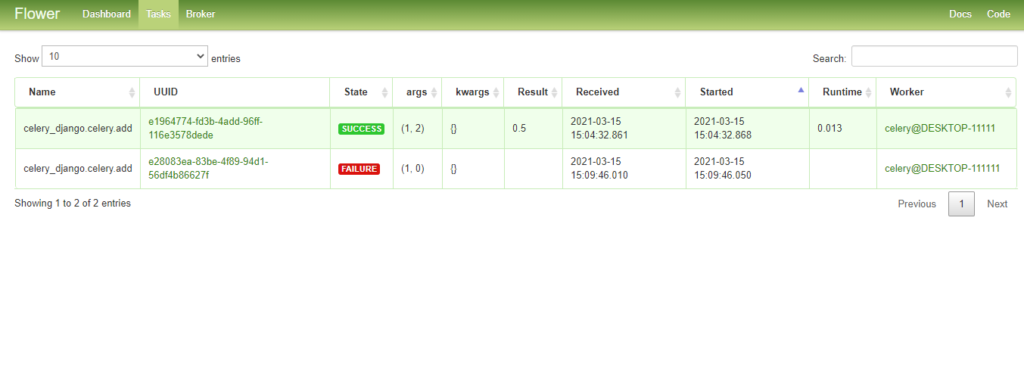
При изучении Celery довольно полезно использовать Flower для лучшего понимания деталей.
Когда вы развертываете свой проект на сервере, Flower не является обязательным компонентом. Я имею в виду, что вы можете напрямую использовать команды Celery, чтобы управлять приложением и проверять статус рабочего процесса.Заключение
В этой статье я рассказал об основных аспектах Celery. Надеюсь, что после прочтения вы стали лучше понимать процесс работы с ним. Исходный код проекта доступен по ссылке в начале статьи.
Celery: начинаем правильно

10 Фев. 2016 , Python, 171633 просмотров, Celery Best Practices: practical approach

В этой статье мне хотелось бы поделиться с читателями своим опытом работы с таким замечательным инструментом в Python как Celery. Celery это ничто иное как распределённая очередь заданий, реализованная на языке Python. На момент написания этой статьи, самой последней версией является 3.1.20. Неосведомлённый читатель может не знать для чего вообще нужна система очередей задач наподобие Celery, поэтому кратко поясню этот момент.
Что такое Celery и зачем оно нам?
Часто ли вам приходилось сталкиваться с типовыми задачами в веб-приложениях вроде отправки электронного письма посетителю или обработки загруженных данных. Чаще всего такого рода манипуляции не требуют участия конечного пользователя вашего проекта, то есть их можно выполнять в фоновом режиме. Те из нас, кто реализует выполнение этих задач в одном из процессов веб-сервера, "тормозят" тем самым его работу, увеличивая время отклика и ухудшают user experience.
В данной заметке я опущу вводную информацию по установке и настройке Celery в вашем проекте. Кстати, Celery из коробки умеет работать с Django. Ранее был отдельный python пакет, соединяющий Django и Celery,именовался он django-celery. Сейчас он заброшен, так как последнее обновление было более года назад. Стоит отметить, что django-celery не работает Django 1.9 из-за изменений в работе cache backend. Исправленную версию можно посмотреть в моём форке. Одной из удобных фич django-celery является интеграция с Django Admin по части управления periodic tasks.
Советы по работе с Celery
Не используйте базу данных в качестве broker/backend
Брокер отвечает за передачу сообщений (задач) между так называемыми исполнителями (workers). Проблема использования базы данных заключается в её ограничениях - она просто не предназначена для этого. Дело в том, что с ростом количества исполнителей, нагрузка на базу будет только возрастать, а учитывая тот факт, что каждый worker имеет ещё ряд потоков, ситуация может стать катастрофической даже при малых нагрузках. Всё это приведёт к бутылочному горлышку в виде затыка на I/O, потере задач, а возможно и неоднократному их исполнению (два воркера могут получить одну и ту же задачу на исполнение). Отличным production-ready решением является использование RabbitMQ или Redis для этой роли.
Бэкэнд в случае с Celery выступает в качестве хранилища результатов выполнения задач (task). Одной из причин создания django-celery как раз являлась возможность подключения БД для сохранения результатов. Признаюсь, что в самом начале работы с Celery я неоднократно в проектах использовал этот подход. Пожалуйста, не повторяйте мою ошибку. С ростом нагрузки на приложение проблемы будут расти словно грибы после дождя (более того, "из коробки" celery не чистит базу от "устаревших" результатов) . Правда тут есть нюансы касательно вашего приложения. Об этом читайте ниже. Production-ready решением для роли backend неплохо зарекомендовал себя демон memcached. Пользуемся более 2-х лет, проблем ни разу не было.
Разделяйте задачи по очередям
Это очень важный момент. По мере развития вашего приложения, в проекте будут появляться критичные для выполнения задачи: проверка статуса платежа, формирование отчёта, отправка электронных писем и так далее. Терять их недопустимо. Если все задачи складировать в одну очередь, то в один прекрасный момент она может забиться, поставив под угрозу выполнение критически важного кода. Мой подход: разделяйте очереди по приоритетам.
Несомненно очередей может быть больше, тут всё на усмотрение разработчика и архитектуры его приложения.
В базовых настройках Celery это выглядит следующим образом:
CELERY_QUEUES = ( Queue('high', Exchange('high'), routing_key='high'), Queue('normal', Exchange('normal'), routing_key='normal'), Queue('low', Exchange('low'), routing_key='low'), ) CELERY_DEFAULT_QUEUE = 'normal' CELERY_DEFAULT_EXCHANGE = 'normal' CELERY_DEFAULT_ROUTING_KEY = 'normal' CELERY_ROUTES = < # -- HIGH PRIORITY QUEUE -- # 'myapp.tasks.check_payment_status': , # -- LOW PRIORITY QUEUE -- # 'myapp.tasks.close_session': , >В данном конкретном примере объявлена очередь по-умолчанию под названием normal. То есть задачи явно не указанные в списке будут автоматически распределены в эту очередь. В high попадает задача под названием check_payment_status, а в low задача close_session.
Запускать исполнителей Celery для этих очередей необходимо следующим образом:
celery worker -E -l INFO -n worker.high -Q high celery worker -E -l INFO -n worker.normal -Q normal celery worker -E -l INFO -n worker.low -Q lowЗдесь мы явно задаём имена исполнителей и названия очередей в которых необходимо мониторить задачи на исполнение.
ВАЖНО! Если вы явно указали для задачи очередь в которую ей нужно будет падать, и при этом запустили одного из исполнителей Celery без явного указания очереди, например вот так:
celery worker -E -l INFO -n worker.whateverТо при наступлении ситуации, когда все исполнители очереди high будут заняты, Celery автоматически перенаправит новую задачу исполнителям без конкретной очереди. Поэтому при использовании раздельных очередей задач, не запускайте исполнителей без указания для них явного наименования очереди.
Логгируйте ошибки
Логгирование ошибок и своевременный их анализ это основа надёжных приложений. Очень важно иметь полную картину происходящего внутри вашего кода. По-умолчанию Celery все ошибки пишет в stderr, а прочая информация, связанная с исполнением попадает в stdout. Контролировать вывод ошибок можно через стандартный python logging, достаточно повесить свой handler на logger под названием "celery". Практика развёртывания боевых приложений, использующих Celery, показывает, что в качестве процесс-менеджера используют supervisord. В его настройках можно задавать путь до файла в который он будет складировать всю информацию, генерируемую демоном. Но вручную анализировать текстовые логи на предмет ошибок неудобно и неэффективно. Лично я использую для этих целей Sentry. Вот как выглядит у меня logging config:
CELERYD_HIJACK_ROOT_LOGGER = False LOGGING = < 'handlers': < 'celery_sentry_handler': < 'level': 'ERROR', 'class': 'core.log.handlers.CelerySentryHandler' >>, 'loggers': < 'celery': < 'handlers': ['celery_sentry_handler'], 'level': 'ERROR', 'propagate': False, >, > >Важной опцией здесь является наличие CELERYD_HIJACK_ROOT_LOGGER = False. По-умолчанию значение этой переменной является True, что позволяет celery "перекрывать" все ранее объявленные кастомные обработчики logging.
При указанном выше подходе нет необходимости дополнительно в коде задач (task) логгировать ошибки/исключения отдельно. О том что такое Sentry, для чего оно используется и как его настроить я напишу отдельную статью немного позже.
Пишите задачи маленькими
При написании задач старайтесь придерживаться принципа минимализма кода. То есть не нужно в самом celery task описывать бизнес логику задачи. Например, если вам необходимо генерировать и отправлять отчёт, то не нужно в самом task писать код генерации и отправки. Разбейте его на 3 части:
- Код генерации отчёта
- Код отправки письма
- Задача (task) по выполнению этих действий
from .utils import generate_report, send_email @app.task(bind=True) def send_report(): filename = generate_report() send_email(subject, message, attachments=[filename])Это, во-первых, позволит легче читать код (есть явное разделение на подзадачи). Во-вторых, тестировать такой код намного легче (привет модульным тестам!). В-третьих, отлавливать ошибки также будет намного легче и прозрачнее.
"Гасите" задачи вовремя
Явно указывайте лимит на выполнение задачи. Это можно сделать несколькими способами:
- Через декоратор @app.task, передавая soft_time_limit, time_limit.
- Глобально задать таймлимит при запуске исполнителя (worker), передав ему соответствующие аргументы (их можно найти в документации к Celery). В этом случае для всех задач, попадающих в заданную очередь будет один и тот же таймлимит.
Указание таймлимита очень важно, так как в некоторых случаях его отсутствие попросту приведёт к "зависанию" исполнителя при выполнении неоднозначных задач (требующих длительного времени, коннект к внешнему сервису и так далее).
Не храните результаты исполнения без необходимости
В большинстве случаев результат выполнения вашей задачи вам не нужен (например, если происходит отправка письма). В такой ситуации вам нет необходимости хранить что-то. Если ваши задачи полностью попадают в эту категорию, то в настройках Celery можно задать глобальный параметр CELERY_IGNORE_RESULT = True, который будет игнорировать результат исполнения всех ваших task-функций.
Используйте Flower для мониторинга исполнения задач
Всегда используйте Flower при работе с Celery. Всегда! Данный инструмент это небольшое веб приложение, написанное с использованием микрофреймворка Flask, а также Tornado для поддержки веб-сокетов. Flower позволяет вам всегда быть в курсе того как исполняются ваши задачи. Немного скриншотов:

Не поленитесь и потратьте время на его изучение. Оно окупится многократно!
Не передавайте ORM объекты в качестве аргументов
Я пару раз попадался на этом хитром трюке, который потрепал мне изрядно нервы. Рассмотрим вот такой код:
from .models import Profile @app.task(bind=True): def send_notification(profile): send_email(profile.user.email, subject, message_body) profile.notified = True profile.save() def notify_user(): profile = Profile.objects.get(id=1) check_smthng() send_notification.delay(profile) profile.activated = True profile.save()Не самый лучший пример для демонстрации побочного эффекта при передаче ORM объекта, но всё же. В данной ситуации код, описанный в send_notification, сохранит объект, изменив лишь notified = True, но activated останется по-прежнему равен False. Лучшим решением будет передача идентификатора объекта в базе данных, а в самой task функции необходимо непосредственно обращаться к объекту через его id.
BROKER_TRANSPORT_OPTIONS и visibility_timeout
При использовании Celery нередко приходиться прибегать к помощи отложенных задач, используя apply_async и передавая аргументы eta или countdown. Но делать это нужно осторожно, так как даже здесь нас поджидают "подводные камни". О чём речь? Очень часто у разработчиков, начинающих использовать очередь задач вроде Celery, происходят аномалии вроде выполнения одного и того же таска несколькими воркерами одновременно. Согласитесь, нежелательный сценарий. Так может происходить по причине того, что время, через которое должна выполниться задача, превышает visibility_timeout. По умолчанию для Redis этот параметр равен 1 часу. То есть если вы укажете выполнение задачи через 2 часа, то демон celery подождёт 1 час, поймёт, что никто из доступных воркеров не откликнулся и насильно назначит всем воркерам её выполнение при наступлении дедлайна (eta/countdown). Поэтому не забывайте про этот параметр, если вы собираетесь использовать механизмы eta/countdown/retry, задайте visibility_timeout равным самому длительному eta/countdown в вашем проекте. Подробнее можно почитать тут.
UPD: С недавних пор у блога появился свой Telegram канал, где я стараюсь делиться со своими подписчиками интересными находками из сети на тему разработки программного обеспечения и смежных с этой областью материалов.
Long-running tasks
Старайтесь не использовать Celery для выполнения долгих задач. На этот аргумент есть ряд причин:
- Процессы, живущие долго, потребляют память, но не освобождают её. Даже с учётом работы сборщика мусора. Такой механизм необходим, чтобы избежать фрагментации оперативной памяти.
- Celery заточен на выполнение большого количества задач, требующих мало времени на их исполнение. Когда задачи тяжелые и выполняются долго, образуются очереди.
Если нет возможности использовать что-то другое, то при работе с long-running tasks в Celery знайте следующее:
По-умолчанию 1 воркер процесс будет забирать из очереди 4 задачи за раз. Это особенно актуально знать, если Celery масштабируется на кластере через центрального брокера. То есть, если у вас 3 отдельные машины и на каждой крутится по 10 воркеров на очередь, то каждая машина будет забирать по 40 задач. Отсюда очевидно возникает проблема равномерного распределения задач по кластеру. Такое поведение оправдано в некоторых случаях, т.к. оно уменьшает количество обращений к брокеру, увеличивая производительность при выполнении небольших тасков. Чтобы изменить это, переопределите параметр CELERYD_PREFETCH_MULTIPLIER. Например:
CELERYD_PREFETCH_MULTIPLIER = 1Долгоживущие процессы имеют тенденцию к пожиранию памяти, но вот назад её зачастую не возвращают, поэтому в контексте использования Celery с ними иногда имеет смысл перезагружать воркеры после выполнения заданного количества тасков. За это отвечает параметр CELERYD_MAX_TASKS_PER_CHILD
CELERYD_MAX_TASKS_PER_CHILD= 1Настройка выше будет перезагружать воркер-процесс после выполнения 1 таска.
Полезные ссылки
- Документация Celery
- Celery: Distributed Task Queue
- Flower: Celery task monitoring
- Пакет django-celery
- Python RQ: очередь задач на базе Redis
Первые шаги с сельдереем¶
Celery - это очередь задач с батарейками в комплекте. Она проста в использовании, поэтому вы можете начать работу без изучения всей сложности проблемы, которую она решает. Он разработан на основе лучших практик, чтобы ваш продукт мог масштабироваться и интегрироваться с другими языками, и поставляется с инструментами и поддержкой, необходимыми для запуска такой системы в производство.
В этом руководстве вы узнаете абсолютные основы использования Celery.
- Выбор и установка транспорта сообщений (брокера).
- Установка Celery и создание вашей первой задачи.
- Запуск рабочего и вызов задач.
- Отслеживание задач по мере их перехода через различные состояния и проверка возвращаемых значений.
Поначалу сельдерей может показаться пугающим, но не волнуйтесь - это руководство поможет вам быстро начать работу. Он намеренно упрощен, чтобы не запутать вас в расширенных возможностях. После того, как вы закончите это руководство, вам стоит просмотреть остальную документацию. Например, учебник Следующие шаги продемонстрирует возможности Celery.
Выбор брокера¶
Celery требует решения для отправки и получения сообщений; обычно это происходит в виде отдельной службы, называемой message broker.
На выбор предлагается несколько вариантов, в том числе:
RabbitMQ¶
RabbitMQ обладает полным набором функций, стабильностью, долговечностью и простотой установки. Это отличный выбор для производственной среды. Подробная информация об использовании RabbitMQ с Celery:
Если вы используете Ubuntu или Debian, установите RabbitMQ, выполнив эту команду:
$ sudo apt-get install rabbitmq-serverИли, если вы хотите запустить его на Docker, выполните следующее:
$ docker run -d -p 5672:5672 rabbitmq
Когда команда завершится, брокер уже будет работать в фоновом режиме, готовый перемещать сообщения для вас: Starting rabbitmq-server: SUCCESS .
Не волнуйтесь, если вы не используете Ubuntu или Debian, вы можете перейти на этот сайт, чтобы найти такие же простые инструкции по установке для других платформ, включая Microsoft Windows:
Redis¶
Redis также обладает полным набором функций, но более подвержен потере данных в случае резкого завершения работы или сбоев питания. Подробная информация об использовании Redis:
Если вы хотите запустить его на Docker, выполните следующее:
$ docker run -d -p 6379:6379 redis
Другие брокеры¶
Помимо вышеперечисленных, существуют и другие экспериментальные реализации транспорта, включая Amazon SQS .
Полный список см. в Обзор брокера .
Установка сельдерея¶
Celery находится в индексе пакетов Python (PyPI), поэтому его можно установить с помощью стандартных инструментов Python, таких как pip или easy_install :
$ pip install celeryПриложение¶
Первое, что вам нужно, это экземпляр Celery. Мы называем его приложение Celery или просто app для краткости. Поскольку этот экземпляр используется как точка входа для всего, что вы хотите делать в Celery, например, создавать задачи и управлять рабочими, другие модули должны иметь возможность импортировать его.
В этом учебнике мы держим все в одном модуле, но для больших проектов вы захотите создать dedicated module .
Давайте создадим файл tasks.py :
from celery import Celery app = Celery('tasks', broker='pyamqp://guest@localhost//') @app.task def add(x, y): return x + y
Первым аргументом Celery является имя текущего модуля. Это необходимо только для того, чтобы имена могли быть автоматически сгенерированы, когда задачи определены в модуле __main__ .
Второй аргумент - это аргумент ключевого слова broker, указывающий URL брокера сообщений, который вы хотите использовать. Здесь используется RabbitMQ (также вариант по умолчанию).
Смотрите Выбор брокера выше для большего выбора - для RabbitMQ вы можете использовать amqp://localhost , или для Redis вы можете использовать redis://localhost .
Вы определили единственную задачу с именем add , возвращающую сумму двух чисел.
Запуск рабочего сервера Celery¶
Теперь вы можете запустить рабочий, выполнив нашу программу с аргументом worker :
$ celery -A tasks worker --loglevel=INFO
См. раздел Устранение неполадок , если рабочий не запускается.
На производстве вы захотите запустить рабочий в фоновом режиме в качестве демона. Для этого вам нужно использовать инструменты, предоставляемые вашей платформой, или что-то вроде supervisord (см. Демонизация для получения дополнительной информации).
Для получения полного списка доступных опций командной строки выполните следующие действия:
$ celery worker --helpИмеется также несколько других команд, а также доступна справка:
$ celery --helpВызов задания¶
Для вызова нашей задачи можно использовать метод delay() .
Это удобное сокращение метода apply_async() , которое дает больший контроль над выполнением задачи (см. >>):
>>> from tasks import add >>> add.delay(4, 4)
Теперь задание обработано рабочим, который вы запустили ранее. Вы можете убедиться в этом, посмотрев на консольный вывод рабочего.
Вызов задачи возвращает экземпляр AsyncResult . Его можно использовать для проверки состояния задачи, ожидания завершения задачи или получения ее возвращаемого значения (или, если задача не выполнилась, для получения исключения и трассировки).
Результаты не включены по умолчанию. Чтобы выполнять удаленные вызовы процедур или отслеживать результаты выполнения задач в базе данных, вам необходимо настроить Celery на использование бэкенда результатов. Это описано в следующем разделе.
Поддержание результатов¶
Если вы хотите отслеживать состояния задач, Celery необходимо где-то хранить или отправлять эти состояния. Есть несколько встроенных бэкендов результатов на выбор: SQLAlchemy/Django ORM, MongoDB, Memcached, Redis, RPC (RabbitMQ/AMQP), и – или вы можете определить свой собственный.
В данном примере мы используем бэкенд результатов rpc , который отправляет состояния обратно в виде переходных сообщений. Бэкенд задается через аргумент backend в Celery , (или через параметр result_backend , если вы решили использовать модуль конфигурации):
app = Celery('tasks', backend='rpc://', broker='pyamqp://')
Или если вы хотите использовать Redis в качестве бэкенда результатов, но при этом использовать RabbitMQ в качестве брокера сообщений (популярная комбинация):
app = Celery('tasks', backend='redis://localhost', broker='pyamqp://')
Более подробную информацию о бэкендах результатов можно найти в разделе Бэкенды результатов .
Теперь, когда бэкенд результатов настроен, давайте снова вызовем задачу. На этот раз вы будете удерживать экземпляр AsyncResult , возвращаемый при вызове задачи:
>>> result = add.delay(4, 4)
Метод ready() возвращает, закончила ли задача обработку или нет:
>>> result.ready() False
Вы можете дождаться завершения результата, но это редко используется, поскольку превращает асинхронный вызов в синхронный:
>>> result.get(timeout=1) 8
В случае, если задача вызвала исключение, get() вызовет исключение повторно, но вы можете отменить это, указав аргумент propagate :
>>> result.get(propagate=False)
Если задача вызвала исключение, вы также можете получить доступ к исходной трассировке:
>>> result.traceback
Бэкенды используют ресурсы для хранения и передачи результатов. Чтобы гарантировать освобождение ресурсов, вы должны в конечном итоге вызвать get() или forget() на КАЖДОМ экземпляре AsyncResult , возвращенном после вызова задачи.
Полное описание объекта результата см. в celery.result .
Конфигурация¶
Сельдерей, как бытовой прибор, не требует особой настройки для работы. У него есть вход и выход. Вход должен быть подключен к брокеру, а выход может быть опционально подключен к бэкенду результатов. Однако, если вы внимательно посмотрите на заднюю часть, там есть крышка, на которой находится множество ползунков, циферблатов и кнопок: это и есть конфигурация.
Конфигурация по умолчанию должна быть достаточно хорошей для большинства случаев использования, но есть много опций, которые можно настроить, чтобы Celery работал именно так, как нужно. Чтение о доступных опциях - хорошая идея, чтобы ознакомиться с тем, что можно настроить. Вы можете прочитать об опциях в справке Конфигурация и настройки по умолчанию .
Конфигурация может быть задана непосредственно в приложении или с помощью специального модуля конфигурации. В качестве примера вы можете настроить сериализатор по умолчанию, используемый для сериализации полезной нагрузки задачи, изменив параметр task_serializer :
app.conf.task_serializer = 'json'
Если вы настраиваете много параметров одновременно, вы можете использовать update :
app.conf.update( task_serializer='json', accept_content=['json'], # Ignore other content result_serializer='json', timezone='Europe/Oslo', enable_utc=True, )
Для крупных проектов рекомендуется использовать специальный модуль конфигурации. Не рекомендуется жестко кодировать периодические интервалы между заданиями и варианты маршрутизации заданий. Гораздо лучше хранить их в централизованном месте. Это особенно актуально для библиотек, поскольку позволяет пользователям контролировать поведение своих задач. Централизованная конфигурация также позволит вашему системному администратору вносить простые изменения в случае неполадок в системе.
Вы можете указать своему экземпляру Celery использовать модуль конфигурации, вызвав метод app.config_from_object() :
app.config_from_object('celeryconfig')
Этот модуль часто называют « celeryconfig », но вы можете использовать любое имя модуля.
В приведенном выше случае модуль с именем celeryconfig.py должен быть доступен для загрузки из текущего каталога или по пути Python. Это может выглядеть примерно так:
broker_url = 'pyamqp://' result_backend = 'rpc://' task_serializer = 'json' result_serializer = 'json' accept_content = ['json'] timezone = 'Europe/Oslo' enable_utc = True
Чтобы убедиться, что ваш файл конфигурации работает правильно и не содержит синтаксических ошибок, вы можете попробовать импортировать его:
$ python -m celeryconfigПолный перечень опций конфигурации приведен в разделе Конфигурация и настройки по умолчанию .
Чтобы продемонстрировать возможности конфигурационных файлов, вот как можно направить непослушную задачу в специальную очередь:
task_routes = 'tasks.add': 'low-priority', >
Или вместо маршрутизации вы можете ограничить задание по скорости, так что только 10 заданий этого типа могут быть обработаны в минуту (10/m):
task_annotations = 'tasks.add': 'rate_limit': '10/m'> >
Если вы используете RabbitMQ или Redis в качестве брокера, вы также можете направить рабочих на установку нового предела скорости для задачи во время выполнения:
$ celery -A tasks control rate_limit tasks.add 10/m worker@example.com: OK new rate limit set successfully
Смотрите Задачи маршрутизации , чтобы узнать больше о маршрутизации заданий, и настройку task_annotations , чтобы узнать больше об аннотациях, или Руководство по мониторингу и управлению , чтобы узнать больше о командах удаленного управления и о том, как следить за тем, что делают ваши работники.
Куда двигаться дальше¶
Если вы хотите узнать больше, вам следует перейти к учебнику Next Steps , а после него вы можете прочитать >>.
Устранение неполадок¶
В разделе Часто задаваемые вопросы также есть раздел по устранению неисправностей.
Рабочий не запускается: Ошибка разрешения¶
- Если вы используете Debian, Ubuntu или другие дистрибутивы на базе Debian:
Debian недавно переименовал специальный файл /dev/shm в /run/shm . Простым обходным решением является создание символической ссылки:
# ln -s /run/shm /dev/shmЕсли вы предоставляете любой из аргументов --pidfile , --logfile или --statedb , то вы должны убедиться, что они указывают на файл или каталог, который доступен для записи и чтения пользователю, запускающему рабочий.
Бэкенд результатов не работает или задачи всегда находятся в состоянии PENDING ¶
По умолчанию все задачи имеют значение PENDING , поэтому состояние лучше было бы назвать «неизвестно». Celery не обновляет состояние, когда задача отправляется, и предполагается, что любая задача без истории находится в ожидании (в конце концов, вы знаете id задачи).
-
Убедитесь, что в задании не включена функция ignore_result .
Включение этой опции заставит работника пропустить обновление состояний.
Легко случайно запустить несколько рабочих, поэтому убедитесь, что предыдущий рабочий был правильно выключен перед запуском нового. Возможно, запущен старый рабочий, который не настроен на бэкенд ожидаемых результатов, и перехватывает задания. Аргумент --pidfile может быть установлен на абсолютный путь, чтобы этого не произошло.
Если по какой-то причине клиент настроен на использование бэкенда, отличного от рабочего, вы не сможете получить результат. Убедитесь, что бэкенд настроен правильно:
>>> result = task.delay() >>> print(result.backend)