Как правильно задать обучающую выборку для нейронной сети?
К примеру, есть такой набор данных для supervised learning, задача классификации:
Входные данные — это 20 дискретных параметров в диапазоне от 1 до 200. Каждое значение — это некоторый класс. Номера классов никак не связаны, т.е. отношения больше\меньше между ними нет, так что номера по сути ничего не значат. Сами параметры равноправные, разницы между первым и вторым тоже нет.
Выходные данные — это номер одного из этих 20 параметров, которые надо выбрать.
Аналогия — есть несколько игральных карт различного достоинства, и надо выбрать одну из них.
Входные данные
1) Могут быть непосредственно 20 значений в диапазоне 1-200.
2) Или это может быть разбиение по количеству классов среди входных переменных — т.е. это будет 200 параметров в диапазоне 1-20. Большинство из них будут равны 0, некоторые — 1, с очень небольшой вероятностью — 2 и более. Но тогда связей в сети получается куда больше.
И по выходным данным —
1) Это может быть 200 значений, номер выбранного класса. Но такое представление допускает нейронной сети сделать выбор класса, который не представлен во входных значениях.
2) Номер выбранного параметра. Но тогда перестановка входных значений может легко привести к иному результату, наверное.
Как же правильно представить такие данные?
- Вопрос задан более трёх лет назад
- 2868 просмотров
Комментировать
Решения вопроса 1

B@rmaley.e>
Аналогично с выходом. Если предсказывать одно число, то это эквивалентно предположению, что предсказать 21 вместо 20 не так страшно, как выдать 1000. Опять же, для категориальных признаков это неправда.
Итого, если вход состоит из 20 категориальных признаков, то каждый признак нужно заменить на множество новых, получаемых one-hot-кодированием (так же известным как dummy variables): для каждого значения такого признака создаётся новый признак-индикатор, равный 1 только если соответствующий признак данного наблюдения равен соответствующему значению.
Ускорение обучения, начальные веса, стандартизация, подготовка выборки
На предыдущем занятии мы познакомились с алгоритмом обучения back propagation, но рассмотрели его лишь в целом, чтобы мы с вами понимали принцип его работы. Теперь, пришло время немного погрузиться в детали этого процесса и узнать:
- как оптимизировать алгоритм градиентного спуска для ускорения обучения;
- как инициализировать начальные значения весовых коэффициентов;
- как выполнять стандартизацию входных данных;
- как готовить обучающую выборку и как ее подавать на вход сети;
- какую функцию активации нейронов выбрать;
- когда останавливать процесс обучения;
- какие критерии качества обучения использовать.
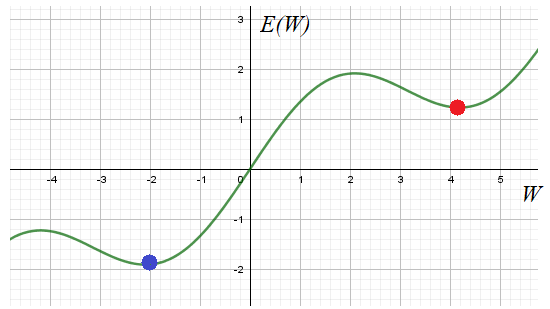
Без знания этих моментов, провести качественное обучение НС практически невозможно. Поэтому, для полноты картины, мне придется дать некоторый теоретический материал, чтобы вы могли ориентироваться в этих вопросах. Возможно, вам это покажется несколько скучным, но, знаете, яркие эффекты – это лишь вершина айсберга, в основании очень много подготовительного материала и кропотливой работы по проектированию и обучению сетей. Так что, если вы решили пойти по этому пути и начать работать в данной области, то без базовой математической подготовки, знания основных моментов и наработки опыта, тут никуда. Итак, начнем с основной «рабочей лошадки» — алгоритма обратного распространения, который базируется на алгоритме градиентного спуска. Но раз используется градиентный спуск, то мы сразу получаем все его проблемы реализации. Главная – это попадание в локальный минимум выбранного критерия качества E. Общего решения этой проблемы нет. Поэтому на практике запускают алгоритм обучения с разными начальными значениями весовых коэффициентов. Тем самым мы, как бы выбираем разные отправные точки на функции E в надежде, что одно из решений достигнет глобального минимума. Хотя, точно узнать: достигли мы дна или нет не представляется возможным. Поэтому процесс обучения останавливают, если достигается требуемое качество работы НС. Отсюда получаем рекомендацию обучения №1:
Запускать алгоритм для разных начальных значений весовых коэффициентов. И, затем, отобрать лучший вариант. Начальные значения генерируем случайным образом в окрестности нуля, кроме тех, что относятся к bias’ам.
У вас может возникнуть вопрос: почему начальные значения весов нужно брать малыми? Смотрите, допустим, используется логистическая функция активации: 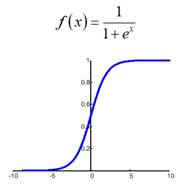 Если веса изначально буду значимыми, то часто суммарный сигнал на входе нейронов будет оказываться большим по модулю:
Если веса изначально буду значимыми, то часто суммарный сигнал на входе нейронов будет оказываться большим по модулю:  И мы попадаем на пологий участок функции активации. К чему это потом приводит? В процессе обучения градиент этого участка будет мал, а значит, веса будут медленно изменяться, что приведет к торможению обучения НС в целом. Чтобы этого избежать, мы, как раз и выбираем веса с малыми случайными значениями, и оказываемся на более выгодном крутом участке кривой. Bias же (смещения разделяющих гиперплоскостей) могут быть и с большими значениями, т.к. они отвечают именно за смещение разделяющей гиперплоскости и оно может быть значительным. Другая проблема градиентных алгоритмов – медленная сходимость на пологих участках функции:
И мы попадаем на пологий участок функции активации. К чему это потом приводит? В процессе обучения градиент этого участка будет мал, а значит, веса будут медленно изменяться, что приведет к торможению обучения НС в целом. Чтобы этого избежать, мы, как раз и выбираем веса с малыми случайными значениями, и оказываемся на более выгодном крутом участке кривой. Bias же (смещения разделяющих гиперплоскостей) могут быть и с большими значениями, т.к. они отвечают именно за смещение разделяющей гиперплоскости и оно может быть значительным. Другая проблема градиентных алгоритмов – медленная сходимость на пологих участках функции: 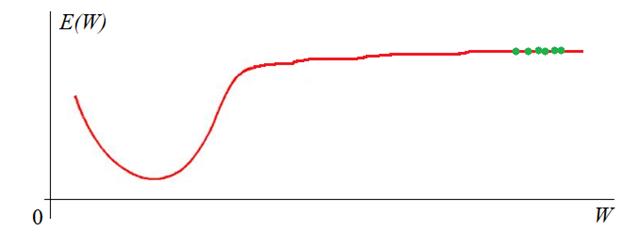 Для ее решения было предложено множество подходов. Среди них наиболее известные, следующие:
Для ее решения было предложено множество подходов. Среди них наиболее известные, следующие:
- оптимизация на основе моментов (momentum);
- ускоренные градиенты Нестерова (nesterov momentum);
- метод Adagrad;
- методы RMSProp и Adadelta;
- метод Adam и NAdam.
О первых двух я рассказывал на занятии по градиентному спуску: https://youtu.be/xDpe9KlYj9Q Почему так важно знать об этих методах оптимизации? Дело в том, что многие пакеты реализации и обучения НС, например, Keras или TFLearn позволяют использовать их для ускорения и улучшения обучения. Чаще всего применяется оптимизация по Нестерову и Adam’у. Позже, когда мы будем рассматривать один из этих пакетов, я покажу где и как настраиваются эти параметры. Итак, рекомендация обучения №2:
Запускаем алгоритм обучения с оптимизацией по Adam или Нестерову для ускорения обучения НС.
Входные значения
Предположим, что у нас имеется обучающая выборка с N наблюдениями:
| Номер | Входной вектор | Отклик |
| 1 | 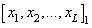 |
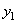 |
| 2 | 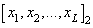 |
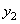 |
| … | … | … |
| N | 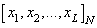 |
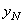 |
Стоит ли нам подавать значения 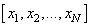 этой выборки так как они есть? Так делать не рекомендуется. В общем случае, среди этих величин могут оказаться большие значения и они нас сразу переместят в область насыщения функции активации, где производная практически равна нулю:
этой выборки так как они есть? Так делать не рекомендуется. В общем случае, среди этих величин могут оказаться большие значения и они нас сразу переместят в область насыщения функции активации, где производная практически равна нулю: 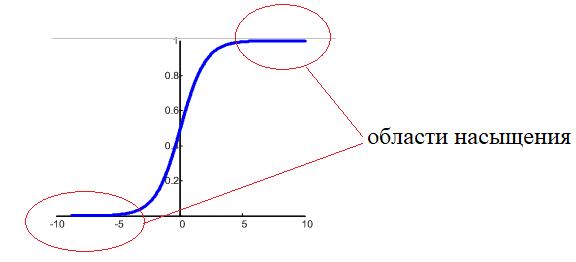 Поэтому на практике выполняют предварительную стандартизацию входных значений, например, по формуле:
Поэтому на практике выполняют предварительную стандартизацию входных значений, например, по формуле: 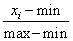 Здесь max, min – максимальное и минимальное значения входных данных по всему обучающему множеству. В результате, входные данные при обучении будут находиться в диапазоне от 0 до 1. И здесь начинающие нейронщики часто делают одну важную ошибку. После обучения НС в режиме ее эксплуатации забывают о нормализации данных на ее входах. Раз уж сеть обучена на нормированных значениях, то и потом, при ее непосредственной работе, данные также нужно нормировать. Об этом забывать не стоит. И, кроме того, нормировку следует делать через те же самые параметры min и max, которые были использованы в обучающей выборке! А не пересчитывать их заново! Рекомендация обучения №3:
Здесь max, min – максимальное и минимальное значения входных данных по всему обучающему множеству. В результате, входные данные при обучении будут находиться в диапазоне от 0 до 1. И здесь начинающие нейронщики часто делают одну важную ошибку. После обучения НС в режиме ее эксплуатации забывают о нормализации данных на ее входах. Раз уж сеть обучена на нормированных значениях, то и потом, при ее непосредственной работе, данные также нужно нормировать. Об этом забывать не стоит. И, кроме того, нормировку следует делать через те же самые параметры min и max, которые были использованы в обучающей выборке! А не пересчитывать их заново! Рекомендация обучения №3:
Выполнять нормировку входных значений и запоминать нормировочные параметры min, max из обучающей выборки.
Как создавать и подавать обучающую выборку
Следующий важный вопрос: что из себя должна представлять обучающая выборка? Какие данные в нее следует поместить? Ответить можно так: чем больше разных наблюдений будет при обучении, тем выше качество работы сети. Здесь ключевое слово – разных, то есть, выборка должна охватывать самые разные «ситуации» в процессе обучения и эти «ситуации» должны появляться с равной частотой. Например, представьте, что вы учитесь водить машину, но ваш инструктор выбирает перекрестки только со светофором. Как думаете, сможете вы себя потом уверенно чувствовать на нерегулируемых перекрестках? Вряд ли. Я бы не смог. С нейросетью также: если в процессе эксплуатации будут попадаться входные данные, сильно отличающиеся от обучающей выборки, то высока вероятность возникновения ошибки. Или, другой пример. Ваш инструктор для «галочки» лишь показал как проезжать нерегулируемые перекрестки, но вы все равно, в основном проезжали по регулируемым со светофором. Здесь качество обучения также будет невысоким, т.к. навыка проезда обычных перекрестков будет недостаточно. Поэтому желательно, чтобы в обучающей выборке с равной частотой встречались самые разные данные, описывающие какие-то характерные, особенные, частные ситуации. Рекомендация обучения №4:
Помещать в обучающую выборку самые разнообразные данные примерно равного количества.
Хорошо, с этим разобрались, но какой объем обучающей выборки N следует брать? По идее, чем больше, тем лучше. Например, в литературе отмечают, что при классификации картинок (например, на мужчин и женщин, или кошек и собак и т.п.) необходимо по 5 000 000 наблюдений для каждого класса, тогда можно достичь хороших результатов различения. Если увеличить этот объем до 10 000 000, то есть шанс обучить нейросеть распознавать образы лучше человека. Вас, возможно, удивят такие большие цифры? Да, это так, данные для обучения – это как нефть «черное золото» для нашей экономики, они ценятся очень высоко, а их подготовка может потребовать немалых ресурсов и времени. Это еще одна причина, по которой нейронные сети лишь недавно завоевали свое место под солнцем: раньше практически невозможно было получить столько реальных данных. Теперь же, сеть Интернет, в частности, социальные сети, предоставляют весьма богатый материал. Итак, предположим, что мы создали обучающую выборку и собираемся приступить к обучению. Здесь возникает новый вопрос: как ее подавать на вход сети? В самом простом варианте, мы сначала перемешиваем наблюдения в выборке (чтобы они шли в случайном порядке), а затем поочередно подаем на вход. При этом для каждого наблюдения выполняем корректировку весовых коэффициентов. Именно так мы делали на предыдущем занятии. Но это не самый лучший вариант. Было замечено, что в процессе обучения часть наблюдений дают небольшой положительный прирост весовых коэффициентов, часть – небольшой отрицательный. В сумме они практически компенсируют друг друга и изменение весов практически не происходит. И лишь некоторая часть наблюдений из выборки приводит к их заметному изменению. Чтобы не «крутить» вхолостую весовые коэффициенты, коррекцию выполняют не сразу для каждого наблюдения, а после прогонки через сеть некоторого их количества. Такое множество получило название batch или, в последнее время чаще стали говорить mini—batch. А вся выборка получила название эпоха. Так вот, прогоняя mini-batch через сеть, суммируют локальные градиенты на каждом нейроне (я думаю вы помните, что это такое из предыдущего занятия), а затем, корректируют веса по результирующей их сумме. В процессе такого суммирования небольшие положительные и отрицательные значения будут скомпенсированы и останется полезное смещение, которое и приведет к изменению весов в пределах mini-batch. Такая идея позволила сократить время обучения в разы, что очень важно, так как для больших НС общее время обучения составляет иногда дни, недели и даже месяцы. Поэтому сокращение этого времени в несколько раз открывает новые горизонты применения НС. Когда целесообразно разбивать выборку на серию mini-batch? Считается, что для этого общее число выборки должно составлять от нескольких тысяч и более. Если наблюдений меньше, порядка тысячи, то ее можно воспринимать как один единственный mini-batch. Итак, мы получаем рекомендацию обучения №5:
Наблюдения на вход сети подавать случайным образом, корректировать веса после серии наблюдений, разбитых на mini-batch.
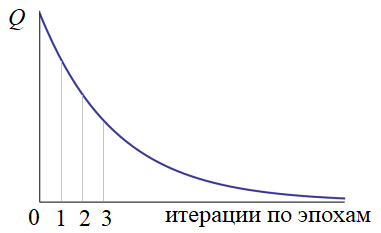
Значение критерия качества вычисляется только после прогонки всей эпохи. Если оно нас не устраивает (как правило, так и есть), то наблюдения снова тасуются случайным образом и обучение продолжается. В конце каждой эпохи снова и снова пересчитывается критерий качества. Получается такой график: Конечно, это идеализированный график. В реальности он, конечно, не такой гладкий и монотонный. Нередки случаи когда он может внезапно возрастать. Но об этом мы поговорим в другой раз. На следующем продолжим рассматривать эти, достаточно важные вопросы, без знания которых начинать работать с нейросетями не имеет особого смысла.
Формирование обучающей выборки при использовании искусственных нейронных сетей в задачах поиска ошибок баз данных Текст научной статьи по специальности «Компьютерные и информационные науки»
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Галушка Василий Викторович, Фатхи Владимир Ахатович
Описывается методика формирования обучающей выборки для обучения искусственных нейронных сетей при их использовании в задачах, связанных с поиском в таблицах баз данных строк, содержащих ошибки. Основной задачей при этом является обеспечение репрезентативности выборки. Выделены три составляющих репрезентативности — достаточность, разнообразие и равномерность. Предложены подходы к обеспечению каждого из указанных требований. Приводятся расчёты достаточного количества строк для обучения нейронных сетей различных типов, а также результаты экспериментов, подтверждающие корректность теоретических расчётов.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Галушка Василий Викторович, Фатхи Владимир Ахатович
Применение многослойных радиально-базисных нейронных сетей для верификации реляционных баз данных
Применение методов интеллектуального анализа данных для тестирования баз данных систем информационной безопасности
Применение методов интеллектуального анализа данных при разработке системы классификации компетентностей студентов для web-сайта университета
Нейросетевой подход к распознаванию образов
Методика обучения экспертной системы оценки стабильности работы сварщика
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
A train set forming for using artificial neural networks to database errors search
It describes a method of train set forming for using artificial neural networks to search inauthentic rows in databases tables. An existing methods of the reliability ensure involve the use of integrity constraints and provides a truthfulness, but there is still a possibility of entering of inauthentic data, appropriate to all constraints. A more accurate assessment of reliability is possible with the use of artificial neural networks that require a training set. The main requirement for the training set representation includes sufficiency, diversity and evenness. The approaches to each of these requirements are describes. Also calculations a sufficient number of rows for training neural networks of various types is given, as well as the results of experiments that confirm correctness of the theoretical calculations.
Текст научной работы на тему «Формирование обучающей выборки при использовании искусственных нейронных сетей в задачах поиска ошибок баз данных»
Формирование обучающей выборки при использовании искусственных нейронных сетей в задачах поиска ошибок баз данных
В.В. Галушка, В.А. Фатхи
Неотъемлемой частью современных информационных систем являются базы данных (БД), предназначенные для хранения и извлечения информации. Как правило, БД, находясь на нижнем уровне в структуре многоуровневой информационной системы, является источником данных для средств обработки информации и принятия решений. Соответственно среди требований к данным, хранимым в БД, на первый план выходят такие как полнота, актуальность и достоверность. Существующие подходы к обеспечению достоверности включают ограничения целостности, триггеры и использование хранимых процедур [1, 2]. Они предполагают проверку хранимых в ячейках значений на соответствие известным, заранее заданным пределам, однако даже значения в допустимых пределах могут не отражать реальные характеристики описываемого объекта или явления, приводя, таким образом, к ошибкам, выражающимся в недостоверности данных.
Более точную оценку достоверности данных, связанных с ошибками в таблицах БД можно проводить, используя методы интеллектуального анализа данных, основанных на применении искусственных нейронных сетей (ИНС) [3], ключевой особенностью которых является способность к обучению и обобщению. Особо важным этапом метода поиска ошибок в БД является этап формирования обучающей выборки (или эталонного фрагмента БД). При этом на первый план выходит необходимость обеспечения репрезентативности обучающей выборки.
Репрезентативность — соответствие характеристик выборки характеристикам популяции или генеральной совокупности в целом [4, 5]. Репрезентативность определяет, насколько возможно обобщать результаты
исследования с привлечением определённой выборки на всю генеральную совокупность, из которой она была собрана.
В контексте аналитических технологий под репрезентативностью исходных данных следует понимать наличие достаточного количества разнообразных обучающих примеров, отражающих правила и закономерности, которые должны быть обнаружены моделью в процессе обучения [6]. Она имеет три аспекта [4]:
— достаточность — число обучающих примеров должно быть достаточным для обучения. Для нейронной сети необходимо, чтобы число обучающих примеров было в несколько раз больше, чем число весов межнейронных связей, в противном случае модель может не приобрести способности к обобщению. Кроме этого, размер выборки должен быть достаточным для формирования обучающего и тестового множеств;
— разнообразие — большое число разнообразных комбинаций вход-выход в обучающих примерах. Способность ИНС к обобщению не будет достигнута, если число примеров достаточное, но все они одинаковые, т. е. представляющие лишь часть классов, характерных для исходного множества;
— равномерность представления классов — примеры различных классов должны быть представлены в обучающей выборке примерно в одинаковых пропорциях. Если один из классов будет преобладать, то это может привести к «перекосу» в процессе обучения модели, и данный класс будет определен моделью как наиболее вероятный для любых новых наблюдений [8].
Рассмотрим каждое из требований более подробно.
Исходя из свойств нейронных сетей, число нейронов входного слоя, при использовании таблицы (отношения) БД для обучения ИНС равно числу столбцов в таблице, выбранных для проведения проверки [6, 8]. Оно хранится в метаданных БД и может быть извлечено из служебных таблиц [7,
8]. Для многослойной сети число нейронов в скрытом слое должно превышать число нейронов во входном слое в 1,5 — 2 раза [9], таким образом, общее число нейронов во входном и скрытом слое составляет от 2,5п до 3п. Так как сеть полносвязная, т.е. каждый нейрон предыдущего слоя соединён со всеми нейронами следующего слоя, то число связей между 1-ым и 2-м слоями равно п*2*п = 2*п .
Общее же число связей для двухслойной сети:
Км = 2 х п2 + 2 х п х т = 2 х п х(п + т)
где п — число входных нейронов, т — число выходных нейронов.
Для сети Кохонена:
Однако число нейронов в выходном слое т является неизвестным, так как зависит от количества классов объектов [9, 10], информация о которых хранится в данной таблице. Таким образом, число связей между нейронами скрытого и выходного слоя равное 2п*т невозможно определить до окончания этапа кластеризации.
При п > 1 и т > 1 п х т < 2 х п + 2 х п х т
Это означает, что для обучения сети Кохонена требуется выборка значительно меньшая, чем для обучения многослойной сети, следовательно, на первом этапе анализа данных можно использовать обучающую выборку, содержащую количество элементов, значительно превышающее минимально необходимое.
Воспользуемся эмпирическим предположением, основанным на предыдущих практических результатах, и примем число классов т равным
Км = 2 х п2 + 20 х п
Выберем Км строк из таблицы в качестве обучающей выборки для обучения сети Кохонена, т.е. КК = Км, тогда
т х п = 2 х п + 20 х п,
То есть, сеть Кохонена обученная на Км примерах должна иметь возможность выделить до 2п+20 кластеров, что является достаточным для большинства задач и предметных областей.
Следующие два требования — разнообразие и равномерность возможно обеспечить случайным выбором строк из таблицы для обучающей выборки [11].
Однако метод случайного выбора не может гарантировать стопроцентное выполнение указанных условий. Присутствующий элемент случайности, особенно при достаточно большом количестве классов может вносить значительные погрешности, в том числе, приводящие к нерепрезентативности обучающей выборки. В некоторой степени устранить данный недостаток можно путём формирования 2-х обучающих выборок. В случае если в результате кластеризации двух выборок получено одинаковое число кластеров, можно говорить об их достаточной репрезентативности.
Рассмотрим результаты, полученные при использовании разработанного метода для поиска ошибок в тестовой БД, которая содержит 485 строк с информацией о деятельности некоторой транспортной компании, в 5 из которых намеренно внесены ошибки. Известно, что в таблице представлена информация о п = 3 кластерах различных объектов, тогда, в соответствии с формулой (1) т = 26 строк. Так как объем обучающей выборки должен превышать полученное значение в несколько (т.е. минимум в 2) раз и, так как в соответствии с разработанным методом [1], используются 2 выборки, то обще число строк равно 26 х 2 х 2 = 104.
Номера строк с ошибками заранее известны, необходимо переместить данные строки как можно ближе к началу таблицы, что позволит проверить их в первую очередь.
На графике (рис. 1) видно, что наилучший результат достигается при объёме обучающей выборки, составляющем 20% от всей таблицы, то есть 485 х 0.2 = 97 строк, что соответствует рассчитанному ранее объёму выборки.
Рис. 1 — Зависимость положения ошибочной строки от объема обучающей выборки
Для указанного объема обучающей выборки были проведены эксперименты по обучению ИНС и классификации строк тестовой таблицы. В результате каждой строке было поставлено в соответствие некоторое число
— уверенность ИНС в принадлежности строки к одному из классов данных, выделенных в обучающей выборке. Далее таблица была отсортирована по данному в порядке возрастания данного критерия. График распределения ошибочных строк в таблице на рис. 2. Из него видно, что все строки, содержащие ошибки находятся ближе к началу таблицы. Это означает, что проверка достоверности небольшой части отсортированных строк характеризует достоверность всей таблицы.
Рис. 2 — Распределение ошибочных строк
Таким образом, результаты экспериментов подтверждают теоретические расчёты достаточного объёма обучающей выборки, а также эффективность случайного выбора строк из таблицы БД, и позволяют сделать вывод о том, что в случае наличия в обучающей выборке достоверных данных, значение принадлежности строки к какому-либо классу является адекватным критерием её достоверности.
1. Карпова Т.С. Базы данных: модели, разработка, реализация [Текст]. — СПб.: Питер, 2001. — 304 с.; ил.
2. Nicolas J.-M. Logic for improving integrity checking in relational databases, Acta Informica, 18:3 (1982), p. 227 — 253.
3. Галушка В.В., Молчанов А.А., Фатхи А.А. Применение многослойных радиально-базисных нейронных сетей для верификации реляционных баз данных [Электронный ресурс] // «Инженерный вестник Дона», 2012, №1.
— Режим доступа: http://ivdon.ru/magazine/archive/n1y2012/686 (доступ свободный) — Загл. с экрана. — Яз. рус.
4. Репрезентативность данных (Representativeness of data) // BaseGroup Labs
— Глоссарий [Электронный ресурс] URL:
5. Кобзарь Л.И. Прикладная математическая статистика. Для инженеров и научных работников [Текст]. — М.: Физматлит. — 2006 г. — 814 с.
6. Барсегян А.А., Куприянов М.С., Кузнецов М.С., Степаненко В.В., Холод И.И. Технологии анализа данных: Data Mining, Visual Mining, Text Mining, OLAP [Текст] — 2-е изд. перераб. и доп. — СПб.: БХВ-Петербург, 2007. — 384 с.: ил.
7. Сахил Малик Microsoft ADO.NET 2.0 для профессионалов = Pro ADO.NET 2.0. [Текст] — М.: «Вильямс», 2006. — с. 560.
8. Ian H. Witten, Eibe Frank and Mark A. Hall Data Mining: Practical Machine Learning Tools and Techniques. — 3rd Edition. — Morgan Kaufmann, 2011.
9. Саймон Хайкин Нейронные сети: полный курс = Neural Networks: A Comprehensive Foundation. [Текст] — 2-е. — М.: «Вильямс», 2006. — с. 1104.
10. С.П. Алёшин, Е.А. Бородина Нейросетевое распознавание классов в
режиме реального времени [Электронный ресурс] // «Инженерный вестник Дона», 2013, №1. — Режим доступа:
http://www.ivdon.ru/magazine/archive/n1y2013/1494 (доступ свободный) -Загл. с экрана. — Яз. рус.
11. Загоруйко Н. Г. Прикладные методы анализа данных и знаний. [Текст] — Новосибирск: ИМ СО РАН. — 1999. — 270 с.
Обучающие наборы данных для нейронных сетей: как обучить и проверить нейросеть на Python
Если вы хотите разработать нейронную сеть на Python, вы находитесь в правильном месте. Прежде чем углубиться в обсуждение о том, как использовать Excel для создания обучающих данных для вашей нейросети, для получения дополнительной информации посмотрите остальные статьи серии выше, в меню с содержанием.
Что такое обучающие данные?
В реальной жизни обучающие выборки состоят из данных измерений в сочетании с «решениями», которые помогут нейронной сети обобщить всю эту информацию в соответствующую связь вход-выход.
Например, предположим, что вы хотите, чтобы ваша нейронная сеть предсказывала вкусовые качества помидора на основе цвета, формы и плотности. Вы не представляете, как именно цвет, форма и плотность связаны с вкусностью, но вы можете измерить цвет, форму и плотность, и у вас есть вкусовые рецепторы. Таким образом, всё, что вам нужно сделать, это собрать тысячи и тысячи помидоров, записать их физические характеристики, попробовать каждый (лучшая часть), а затем поместить всю эту информацию в таблицу.
Каждая строка – это то, что я называю одной обучающей выборкой, и в ней четыре столбца: три из них (цвет, форма и плотность) являются столбцами входных данных, а четвертый – целевым выходным значением.
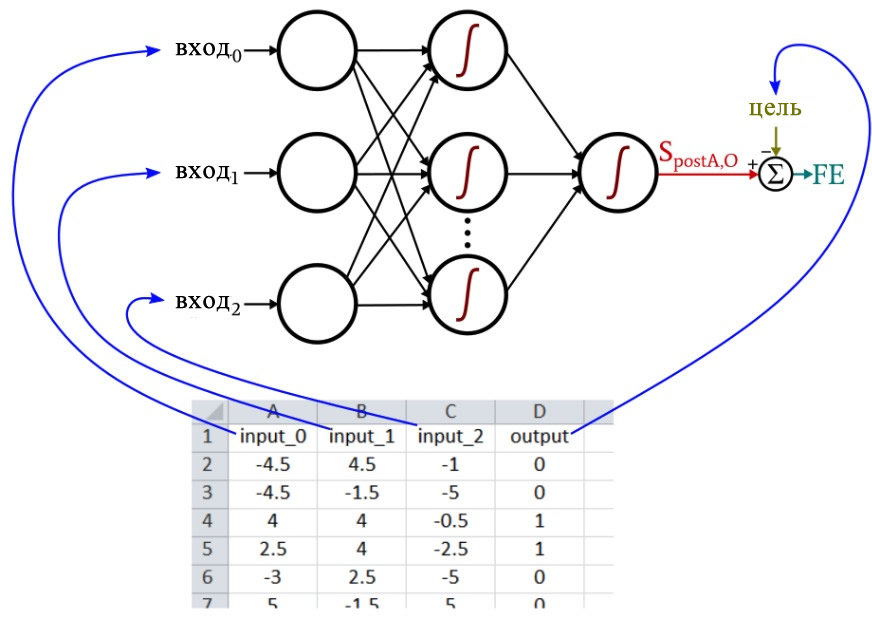
Во время обучения нейронная сеть найдет связь (если когерентная связь существует) между тремя входными значениями и выходным значением.
Оценка обучающих данных
Имейте в виду, что всё должно обрабатываться в числовом виде. Вы не можете в качестве входного параметра вашей нейронной сети использовать строку «сливовидная форма», а «аппетитный» не будет работать в качестве выходного значения. Вы должны количественно оценить ваши измерения и ваши классификации.
Для формы вы можете присвоить каждому помидору значение от –1 до +1, где –1 представляет собой идеальную сферу, а +1 означает крайне вытянутую форму. Что касается вкусовых качеств, вы можете оценивать каждый помидор по пятибалльной шкале от «несъедобного» до «восхитительного», а затем использовать унитарный код для сопоставления этих оценок с выходным вектором из пяти элементов.
Следующая диаграмма показывает, как этот тип кодирования используется для классификации выходных значений нейронной сети.
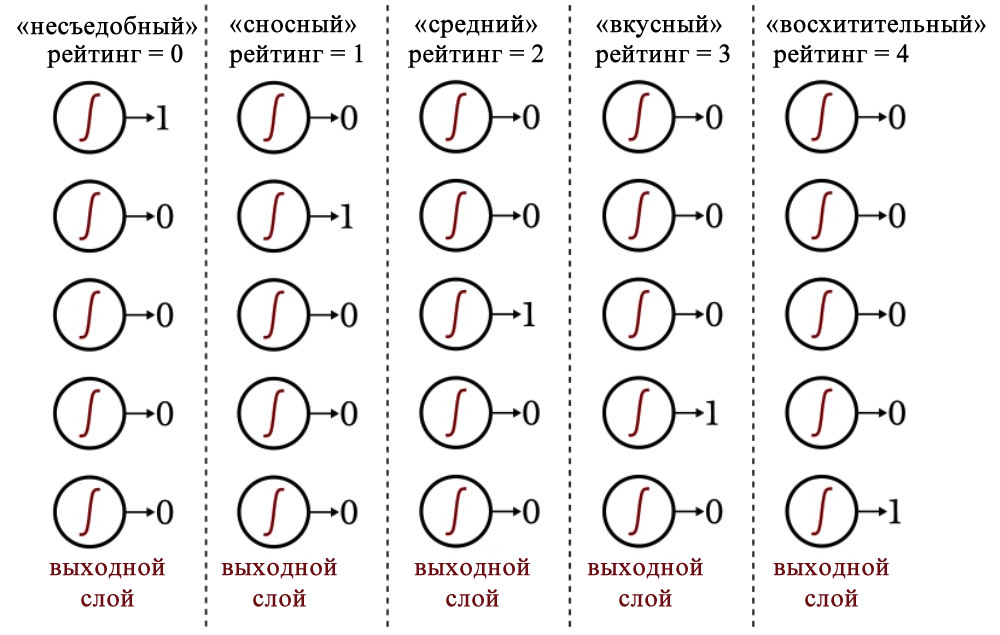
Выходная схема, использующая унитарный код, позволяет нам определить недвоичные классификации таким образом, чтобы это было совместимо с логистической сигмоидной функцией активации. Выходные данные логистической функции являются, по сути, двоичными, поскольку область перехода на графике является узкой по сравнению с бесконечным диапазоном входных значений, для которых выходное значение очень близко к минимальному или максимальному значению:
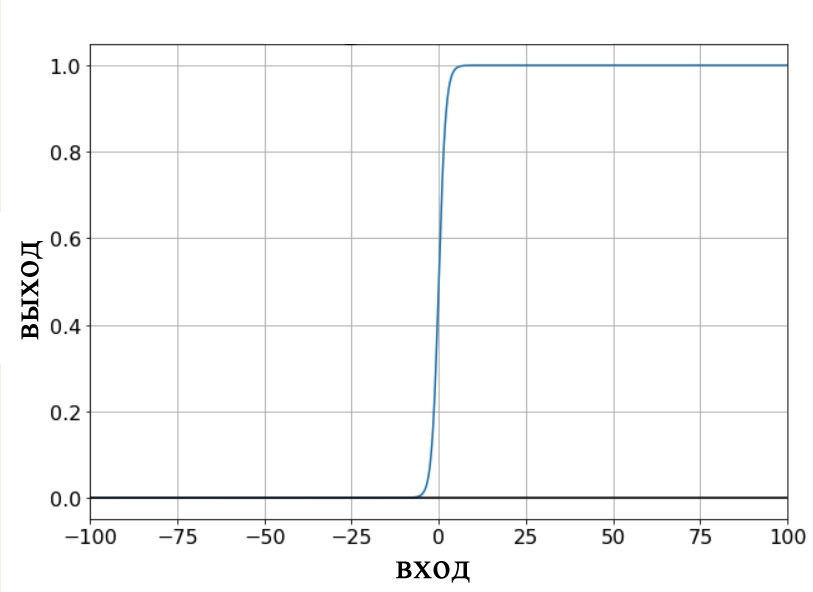
Таким образом, мы не хотим создавать эту нейросеть с одним выходным узлом, а затем предоставлять обучающие выборки, которые имеют выходные значения 0, 1, 2, 3 или 4 (или, если вы хотите оставаться в диапазоне от 0 до 1, это будут 0, 0,2, 0,4, 0,6 или 0,8), поскольку логистическая функция активации выходного узла будет устойчиво придерживаться минимального и максимального выходных значений.
Нейронная сеть просто не понимает, насколько нелепым было бы сделать вывод, что все помидоры либо несъедобны, либо восхитительны.
Создание набора обучающих данных
Нейронная сеть на Python, о которой мы говорили в части 12, импортирует обучающие выборки из файла Excel. Обучающие данные, которые я буду использовать для этого примера, организованы следующим образом:
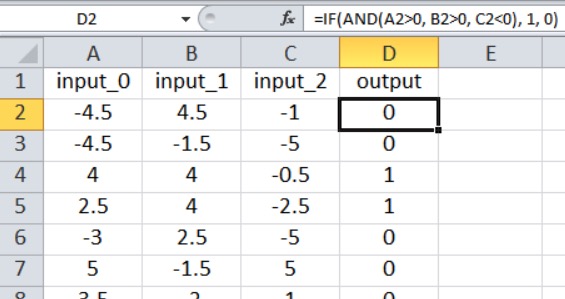
Наш текущий код для перцептрона ограничен одним выходным узлом, поэтому всё, что мы можем сделать, – это выполнить классификацию типа «истина/ложь». Входные значения – это случайные числа от –5 до +5, сгенерированные по формуле Excel:
=RANDBETWEEN(-10, 10)/2Как показано на скриншоте, результат рассчитывается следующим образом:
=IF(AND(A2>0, B2>0, C2<0), 1, 0)Таким образом, выходное значение равно true , только если input_0 больше нуля, input_1 больше нуля, а input_2 меньше нуля. В противном случае выходное значение равно false .
Это математическая связь вход-выход, которую перцептрон должен извлечь из обучающих данных. Вы можете создать столько выборок, сколько захотите. Для такой простой задачи, как эта, вы можете достичь очень высокой точности классификации с 5000 выборками и одной эпохой.
Обучение нейросети
Вам нужно установить входную размерность на три ( I_dim = 3, если вы используете мои имена переменных). Я настроил нейросеть так, чтобы в ней было четыре скрытых узла ( H_dim = 4), и выбрал скорость обучения 0,1 ( LR = 0,1).
Найдите инструкцию training_data = pandas.read_excel(. ) и введите название своей таблицы (если у вас нет доступа к Excel, библиотека Pandas также может читать файлы ODS). Затем просто нажмите кнопку «Run». Обучение с 5000 выборками занимает всего несколько секунд на моем ноутбуке.
Если вы используете полную программу « MLP_v1.py », которую я включил в часть 12, валидация(смотрите следующий раздел) начинается сразу после завершения обучения, поэтому перед тем, как приступить к обучению нейросети, вам необходимо подготовить данные валидации.
Валидация нейросети
Чтобы проверить эффективность нейросети, я создаю вторую электронную таблицу и генерирую входные и выходные значения, используя точно такие же формулы, а затем импортирую эти проверочные данные так же, как импортировал обучающие данные:
training_data = pandas.read_excel('MLP_Tdata.xlsx') target_output = training_data.output training_data = training_data.drop(['output'], axis=1) training_data = np.asarray(training_data) training_count = len(training_data[:,0]) validation_data = pandas.read_excel('MLP_Vdata.xlsx') validation_output = validation_data.output validation_data = validation_data.drop(['output'], axis=1) validation_data = np.asarray(validation_data) validation_count = len(validation_data[:,0])В следующем фрагменте кода показано, как выполнить базовую валидацию:
##################### # проверка ##################### correct_classification_count = 0 for sample in range(validation_count): for node in range(H_dim): preActivation_H[node] = np.dot(validation_data[sample,:], weights_ItoH[:, node]) postActivation_H[node] = logistic(preActivation_H[node]) preActivation_O = np.dot(postActivation_H, weights_HtoO) postActivation_O = logistic(preActivation_O) if postActivation_O > 0.5: output = 1 else: output = 0 if output == validation_output[sample]: correct_classification_count += 1 print('Percentage of correct classifications:') print(correct_classification_count*100/validation_count)Я использую стандартную процедуру прямого распространения для вычисления сигнала постактивации выходного узла, а затем использую оператор if / else для применения порогового значения, который преобразует значение постактивации в классификационное значение true / false .
Точность классификации вычисляется путем сравнения значения классификации с целевым значением для текущей выборки валидации, подсчета количества правильных классификаций и деления на количество выборок валидации.
Помните, что если вы закомментировали инструкцию np.random.seed(1) , при каждом запуске программы веса будут инициализироваться различными случайными значениями, и, следовательно, точность классификации будет меняться от одного запуска к следующему. Я выполнил 15 отдельных запусков с параметрами, указанными выше, 5000 обучающих выборок и 1000 проверочных выборок.
Самая низкая точность классификации составила 88,5%, самая высокая – 98,1%, а средняя – 94,4%.
Заключение
Мы рассмотрели важную теоретическую информацию, относящуюся к обучающим данным нейронной сети, и провели первый эксперимент по обучению и валидации нашего многослойного перцептрона на языке Python. Я надеюсь, вам интересна эта серия статей о нейронных сетях – мы добились большого прогресса со времени первой статьи, и есть еще много, что нам нужно обсудить!