3) R Типы данных и оператор
Переменные хранят значения и являются важным компонентом в программировании, особенно для исследователя данных. Переменная может хранить число, объект, статистический результат, вектор, набор данных, прогноз модели, в основном все, что выводит R. Мы можем использовать эту переменную позже, просто вызвав имя переменной.
Чтобы объявить переменную, нам нужно присвоить имя переменной. В имени не должно быть пробела. Мы можем использовать _, чтобы соединиться со словами.
Чтобы добавить значение в переменную, используйте
# First way to declare a variable: use the `В командной строке мы можем написать следующие коды, чтобы увидеть, что происходит:
Пример 1:
# Print variable x x## [1] 42Пример 2:
## [1] 10Пример 3:
# We call x and y and apply a subtraction x-y## [1] 32векторы
Вектор – это одномерный массив. Мы можем создать вектор со всеми базовыми типами данных, которые мы изучили ранее. Самый простой способ построить вектор в R, это использовать команду c.
Пример 1:
# Numerical vec_num## [1] 1 10 49Пример 2:
# Character vec_chr## [1] "a" "b" "c"Пример 3:
# Boolean vec_bool##[1] TRUE FALSE TRUEМы можем сделать арифметические вычисления на векторах.
Пример 4:
# Create the vectors vect_1[1] 3 7 11Пример 5:
В R возможно нарезать вектор. В некоторых случаях нас интересуют только первые пять строк вектора. Мы можем использовать команду [1: 5], чтобы извлечь значение от 1 до 5.
# Slice the first five rows of the vector slice_vector## [1] 1 2 3 4 5Пример 6:
Самый короткий способ создать диапазон значений – использовать: между двумя числами. Например, из приведенного выше примера мы можем написать c (1:10), чтобы создать вектор значений от одного до десяти.
# Faster way to create adjacent values c(1:10)## [1] 1 2 3 4 5 6 7 8 9 10Арифметические Операторы
Сначала мы увидим основные арифметические операции в R. Следующие операторы обозначают:
Пример 1:
# An addition 3 + 4Вы можете легко скопировать и вставить вышеуказанный код R в консоль Rstudio. Выход отображается после символа #. Например, мы напишем код print (‘Guru99’), в результате получим ## [1] Guru99.
## означает, что мы печатаем вывод, а число в квадратных скобках ([1]) – это номер дисплея
Предложения, начинающиеся с # аннотации . Мы можем использовать # внутри скрипта R, чтобы добавить любой комментарий, который мы хотим. R не будет читать это во время работы.
Пример 2:
# A multiplication 3*5## [1] 15Пример 3:
# A division (5+5)/2Пример 4:
# Exponentiation 2^5Пример 5:
## [1] 32# Modulo 28%%6Логические Операторы
С помощью логических операторов мы хотим возвращать значения внутри вектора на основе логических условий. Ниже приведен подробный список логических операторов, доступных в R
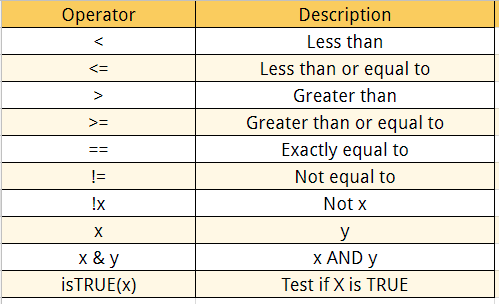
Логические операторы в R заключены в []. Мы можем добавить много условных выражений так, как нам нравится, но нам нужно включить их в скобки. Мы можем следовать этой структуре, чтобы создать условный оператор:
variable_name[(conditional_statement)]С переменным_имя, ссылающимся на переменную, мы хотим использовать для оператора. Мы создаем логическое утверждение, т.е. variable_name> 0. Наконец, мы используем квадратную скобку для завершения логического утверждения. Ниже приведен пример логического утверждения.
Пример 1:
# Create a vector from 1 to 10 logical_vector 5## [1]FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUEВ приведенном выше выводе R читает каждое значение и сравнивает его с оператором logic_vector> 5. Если значение строго больше пяти, то условие ИСТИНА, иначе ЛОЖЬ. R возвращает вектор ИСТИНА и ЛОЖЬ.
Пример 2:
В приведенном ниже примере мы хотим извлечь значения, которые соответствуют только условию «строго выше пяти». Для этого мы можем заключить условие в квадратную скобку, которой предшествует вектор, содержащий значения.
# Print value strictly above 5 logical_vector[(logical_vector>5)]## [1] 6 7 8 9 10Пример 3:
# Print 5 and 6 logical_vector 4) & (logical_vector<7)]Загружаем, устанавливаем…
Онлайн IDE для R — на тот случай, если у вас не установлен R:
- https://rstudio.cloud
- Создайте папку, где будут храниться ВСЕ материалы курса. Например: Мы будем ее называть рабочей директорией. В эту папку помещайте ВСЕ файлы с кодом (с расширением .R).
- Внутри папки linmodr создайте папку data , где будут храниться все файлы с данными для анализа.
В итоге у вас должно получиться примерно это:
C:\linmodr\ C:\linmodr\data\Настройка RStudio
Все настройки RStudio находятся в меню Tools -> Global Options
- Восстановление рабочего пространства из прошлого сеанса — это лучше отменить, т.к. обычно переменные-призраки очень мешают. На вкладке General убираем галочку Restore .RData into workspace at startup , и меняем Save workspace to .RData on exit - Never
- Перенос длинных строк в окне кода — это удобно. На вкладке Code ставим галочку рядом с опцией Soft-wrap R source files
Комментарии
Комментарии в текстах программ обозначаются символом #
# это комментарии, они не будут выполнятьсяПолезные клавиатурные сокращения в RStudio
- Ctrl + Shift + C - закомментировать/раскомментировать выделенный фрагмент кода
- Ctrl + Enter - отправляет активную строку из текстового редактора в консоль, а если выделить несколько строк, то будет выполнен этот фрагмент кода.
- Tab или Ctrl + Space - нажмите после того как начали набирать название функции или переменной, и появится список автоподстановки. Это помогает печатать код быстро и с меньшим количеством ошибок.
Как получить помощь
- В RStudio можно поставить курсор на слово setwd и нажать F1
- Перед названием функции можно напечатать знак вопроса и выполнить эту строку ?setwd
- Можно воспользоваться функцией help()
help("setwd")R как калькулятор, математические операции
1024/2## [1] 512## [1] 1 2 3 4 5 6 7 8 9 10## [1] 136## [1] 16 sqrt(27)## [1] 5.196152Переменные
Переменные - это такие контейнеры, в которые можно положить разные данные и даже функции.
Имена переменных могут содержать латинские буквы обоих регистров, символы точки . и подчеркивания _ , а так же цифры. Имена переменных должны начинаться с латинских букв. Создавайте понятные и “говорящие” имена переменных.
var_1 1024 / 2 1238 * 3 -> var_2 var_2## [1] 3714Как выбрать название переменной?
- a - плохо, и даже b , с , или х . Но в некоторых случаях допустимо:)
- var1 - плохо, но уже лучше
- var_1 - плохо, но уже лучше
- shelllength - говорящее, но плохо читается
- shell_length , wing_colour или leg_num - хорошие говорящие и читабельные названия
Векторы - одномерные структуры данных
Данные в R можно хранить в виде разных объектов.
В результате выполнения следующих команд числа. Одно выражение - одно значение.
## [1] 23 sqrt(25)На самом деле, эти величины - просто векторы единичной длины
Векторы - один объект, внутри которого несколько значений.
Некоторые способы создания векторов:
- Оператор: используется для создания целочисленных векторов, где значения следуют одно за другим без пропусков
1:10 # от одного до 10## [1] 1 2 3 4 5 6 7 8 9 10 -5:3 # от -5 до 3## [1] -5 -4 -3 -2 -1 0 1 2 3- Функция seq() создает последовательности из чисел
seq(from = 1, to = 5, by = 0.5)## [1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0- Функция c() - от англ. concatenate. Следите, чтобы было английское си, а не русское эс:).
?c # посмотрите хелп к функцииФункция c принимает несколько (произвольное количество) аргументов, разделенных запятыми. Она собирает из них вектор.
c(2, 4, 6)## [1] 2 4 6 c(-9.3, 0, 2.17, 21.3)## [1] -9.30 0.00 2.17 21.30Векторы можно хранить в переменных для последующего использования
vect_num -11:12 # численный вектор от -11 до 12 сохранен в переменной vect_num vect_num_1 c(1.3, 1.7, 1.2, 0.9, 1.6, 1.4) # численный вектор, сохранен в переменной vect_num_1Адресация внутри векторов
При помощи оператора [] , можно обратится к некоторым элементам вектора. В квадратных скобках вам нужно указать один или несколько порядковых номеров элементов
vect_num[1] # первый элемент в векторе vect_num## [1] -11 vect_num[10] # 10-й элемент vect_num[22]## [1] 10Если вам нужно несколько элементов, то их нужно передать квадратным скобкам в виде вектора. Например, нам нужны элементы с 3 по 5. Вот вектор, который содержит значения 3, 4 и 5.
## [1] 3 4 5Если мы его напишем в квадратных скобках, то добудем элементы с такими порядковыми номерами
vect_num[3:5]## [1] -9 -8 -7Аналогично, если вам нужны элементы не подряд, то передайте вектор с номерами элементов, который вы создали при помощи функции c() c(2, 4, 6) # это вектор содержащий 2, 4 и 6, поэтому
vect_num[c(2, 4, 6)] # возвращает 2-й, 4-й и 6-й элементы## [1] -10 -8 -6 vect_num[c(1, 10, 20)] # возвращает 1-й, 10-й и 20-й элементы## [1] -11 -2 8Вектор - одномерный объект. У его элементов только один порядковый номер (индекс). Поэтому при обращении к элементам вектора нужно указывать только одно число или один вектор с адресами.
vect_num[c(1, 2, 5)] # возвращает 1-й, 3-й и 5-й элементы## [1] -11 -10 -7Но R выдаст ошибку, если при обращении к вектору, вы не создавали вектор, а просто перечислили номера элементов через запятую.
vect_num[1, 3, 5] # ошибка vect_num[15, 9, 1] # ошибка vect_num[c(15, 9, 1)] # правильно## [1] 3 -3 -11При помощи функции c() можно объединять несколько векторов в один вектор
c(1, 1, 5:9)## [1] 1 1 5 6 7 8 9 c(vect_num, vect_num)## [1] -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 ## [20] 8 9 10 11 12 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 ## [39] 3 4 5 6 7 8 9 10 11 12 c(100, vect_num)## [1] 100 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 ## [20] 7 8 9 10 11 12Добываем 1, 3, 5 и с 22 по 24 элементы
vect_num[c(1, 3, 5, 22:24)]## [1] -11 -9 -7 10 11 12Типы данных в R
Числовые данные
Уже видели в прошлом разделе.
Текстовые данные
Каждый текстовый элемент (говорят “строка” - string или character) должен быть окружен кавычками - двойными или одинарными.
"это текст"## [1] "это текст" 'это тоже текст'## [1] "это тоже текст"Текстовые значения можно объединять в вектора.
Это текстовый вектор
rainbow c("red", "orange", "yellow", "green", "blue", "violet") rainbow # весь вектор## [1] "red" "orange" "yellow" "green" "blue" "violet"Добываем первый и последний элементы
В данном случае я точно знаю, что их 6, мне нужны 1 и 6.
rainbow[c(1, 6)]## [1] "red" "violet"Добываем элементы с 3 по 6
Если у вас вдруг слишком короткий вектор в этом задании, то можно склеить новый из двух
double_rainbow c(rainbow, rainbow) double_rainbow## [1] "red" "orange" "yellow" "green" "blue" "violet" "red" "orange" ## [9] "yellow" "green" "blue" "violet" rainbow[3:6] # элементы с 3 по 6## [1] "yellow" "green" "blue" "violet"Логические данные
TRUE # истина## [1] TRUE FALSE # ложь## [1] FALSEДля ленивых - можно сокращать первыми заглавными буквами. Но лучше так не делать, чтобы читать программы было легче.
c(T, T, T, T, F, F, T, T)## [1] TRUE TRUE TRUE TRUE FALSE FALSE TRUE TRUE c(TRUE, TRUE, TRUE, FALSE, FALSE, TRUE)## [1] TRUE TRUE TRUE FALSE FALSE TRUEЕще логический вектор
short_logical_vector c(FALSE, TRUE)Создаем длинный логический вектор.
Чтобы создавать длинные вектора из повторяющихся элементов, можно использовать функцию rep()
rep(x = 1, times = 3) # 1 повторяется 3 раза## [1] 1 1 1 rep(x = "red", times = 5) # "red" повторяется 5 раз## [1] "red" "red" "red" "red" "red" rep(x = TRUE, times = 2) # TRUE повторяется 2 раза## [1] TRUE TRUEВ R названия аргументов функций можно не указывать, если вы используете аргументы в том же порядке, что прописан в help к этой функции.
rep(TRUE, 5) # TRUE повторяется 5 раз, аргументы без названий## [1] TRUE TRUE TRUE TRUE TRUEСоздаем логический вектор, где TRUE повторяется 3 раза, FALSE 3 раза и TRUE 4 раза. Результат сохраняем в переменной vect_log
vect_log c(rep(TRUE, 3), rep(FALSE, 3), rep(TRUE, 4)) vect_log## [1] TRUE TRUE TRUE FALSE FALSE FALSE TRUE TRUE TRUE TRUEПрименение логических векторов для фильтрации данных
Логические векторы создаются при проверке выполнения каких либо условий, заданных при помощи логических операторов ( > , < , == , != , >= ,
Вспомните, у нас был вот такой текстовый вектор
double_rainbow## [1] "red" "orange" "yellow" "green" "blue" "violet" "red" "orange" ## [9] "yellow" "green" "blue" "violet"Задача 1. Допустим, мы хотим из этого вектора извлечь только желтый цвет.
Мы можем создать логический вектор, в котором TRUE будет только для 3-го и 9-го элементов
f_yellow double_rainbow == "yellow" f_yellow## [1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSEЭтот логический вектор-фильтр мы можем использовать для извлечения данных из double_rainbow
double_rainbow[f_yellow]## [1] "yellow" "yellow"Задача 2. Допустим, мы хотим извлечь из double_rainbow желтый и синий Желтый фильтр у нас уже есть, поэтому мы создадим фильтр для синего.
f_blue double_rainbow == "blue"Выражение “желтый или синий” можно записать при помощи логического “или” ( | )
f_yellow | f_blue## [1] FALSE FALSE TRUE FALSE TRUE FALSE FALSE FALSE TRUE FALSE TRUE FALSEЗадача решена, мы извлекли желтый и синий цвета.
double_rainbow[f_yellow | f_blue]## [1] "yellow" "blue" "yellow" "blue"То же самое можно было бы записать короче.
В одну строку — совершенно нечитабельно:
double_rainbow[double_rainbow == "yellow" | double_rainbow == "blue"]## [1] "yellow" "blue" "yellow" "blue"Фильтр отдельно — читается лучше:
f_colours double_rainbow == "yellow" | double_rainbow == "blue" double_rainbow[f_colours]## [1] "yellow" "blue" "yellow" "blue"У нас был числовой вектор
vect_num## [1] -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 ## [20] 8 9 10 11 12Задача 3. Давайте извлечем из числового вектора vect_num только значения больше 0
vect_num[vect_num > 0]## [1] 1 2 3 4 5 6 7 8 9 10 11 12Задача 4. Давайте извлечем из вектора vect_num все числа, которые либо меньше или равны -8, либо больше или равны 8
f_5_8 (vect_num -8) | (vect_num >= 8) vect_num[f_5_8]## [1] -11 -10 -9 -8 8 9 10 11 12Факторы
Факторы - это способ хранения дискретных (=категориальных данных). Например, если вы поймали 10 улиток и посмотрели их цвет. У большого количества улиток небольшое счетное количество возможных цветов.
snail_colours c("red", "green", "green", "green", "yellow", "yellow", "yellow", "yellow") snail_colours # это текстовый вектор.## [1] "red" "green" "green" "green" "yellow" "yellow" "yellow" "yellow"Но цвет “желтый” обозначает одно и то же для каждой из улиток. Поэтому в целях экономии места можно записать цвета этих улиток в виде вектора, в котором численным значениям будут сопоставлены “этикетки” (называются “уровни” - levels) - названия цветов. Мы можем создать “фактор” цвет улиток.
factor(snail_colours)## [1] red green green green yellow yellow yellow yellow ## Levels: green red yellowуровни этого фактора
- 1 - green,
- 2 - red,
- 3 - yellow
По умолчанию, R назначает порядок уровней по алфавиту. Можно изменить порядок (см. help("factor") ). Нам это пригодится позже
double_rainbow # текстовый вектор## [1] "red" "orange" "yellow" "green" "blue" "violet" "red" "orange" ## [9] "yellow" "green" "blue" "violet"Создаем фактор из текстового вектора и складываем его в переменную
f_double_rainbow factor(double_rainbow)Как узнать, что за данные хранятся в переменной?
Чтобы узнать, что за данные хранятся в переменной, используйте функцию class()
class(f_double_rainbow)## [1] "factor" class(vect_log)## [1] "logical" class(vect_num)## [1] "integer" class(rainbow)## [1] "character"Встроенные константы в R
Встроенные константы в R: NA, NULL, NAN, Inf
- NA - англ “not available”. Когда объект был, но его свойство не измерили или не записали.
- NULL - пусто - просто ничего нет
- NaN - “not a number”
- Inf - “infinity” - бесконечность
Вот текстовый вектор с пропущенным значением
rainbow_1 c("red", "orange", NA, "green", "blue", "violet")Кстати, если попросили добыть из вектора номер элемента, которого там точно нет, то R выдаст NA, потому, что такого элемента нет
rainbow_1[198]## [1] NAПоэкспериментируем с векторами. Проверим, как работают арифметические операции
vect_num + 2## [1] -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 vect_num * 2## [1] -22 -20 -18 -16 -14 -12 -10 -8 -6 -4 -2 0 2 4 6 8 10 12 14 ## [20] 16 18 20 22 24 vect_num * (-2)## [1] 22 20 18 16 14 12 10 8 6 4 2 0 -2 -4 -6 -8 -10 -12 -14 ## [20] -16 -18 -20 -22 -24 vect_num ^2## [1] 121 100 81 64 49 36 25 16 9 4 1 0 1 4 9 16 25 36 49 ## [20] 64 81 100 121 144Теперь посмотрим на встроенные константы в действии.
Создаем новый вектор для экспериментов
NAs_NANs c(1, 3, NA, 7, 0, 22:24)Вот так он выглядит
NAs_NANs## [1] 1 3 NA 7 0 22 23 24Что произойдет с NA?
NAs_NANs + 2 # останется NA## [1] 3 5 NA 9 2 24 25 26 NAs_NANs * 0 # останется NA## [1] 0 0 NA 0 0 0 0 0 NAs_NANs / 0 # останется NA## [1] Inf Inf NA Inf NaN Inf Inf InfНо в последнем случае вы увидите
- Inf при делении чисел на ноль
- NaN при делении нуля на ноль
NaN получится, если взять корень из отрицательного числа
sqrt(-1)## Warning in sqrt(-1): NaNs produced## [1] NaNФункции в R
Вы уже видели массу функций, их легко узнать по скобкам после ключевого слова. Познакомимся еще с несколькими и научимся писать пользовательские функции. Пользовательские функции позволяют автоматизировать повторяющиеся действия и делают код легко читаемым.
NAs_NANs## [1] 1 3 NA 7 0 22 23 24Длину вектора можно вычислить при помощи функции length()
length(NAs_NANs)Сумму элементов вектора при помощи функции sum()
sum(NAs_NANs)## [1] NAУпс! Почему-то получилось NA
Чтобы узнать, почему и как это исправить - посмотрите в help("sum") . Выяснится, что у функции sum() есть аргумент na.rm , который по умолчанию принимает значение FALSE , то есть NA не учитываются при подсчете суммы.
Если мы передадим функции sum аргумент na.rm = TRUE , то получится правильная сумма
sum(NAs_NANs, na.rm = TRUE)## [1] 80Та же история с функцией mean
mean(NAs_NANs, na.rm = TRUE)## [1] 11.42857Попробуем написать пользовательскую функцию mmean() , которая будет по умолчанию считать среднее значение элементов в векторе с учетом пропущенных значений ( NA )
mmean function(x) mean(x, na.rm = TRUE) >В этом коде: - mmean - переменная, название функции. В эту переменную мы складываем функцию, которую создает функция function() - function() - функция, которая делает функции. В скобках перечисляются аргументы (названия переменных, которые мы передаем в функцию, чтобы она что-то сделала с ними) - < >- в фигурных скобках тело функции - последовательность действий, которую нужно сделать с аргументами
У больших функций бывает еще инструкция return() , которая сообщает, что именно должна возвращать наша функция. Вот как выглядела бы наша функция с этой инструкцией
mmean function(x) res mean(x, na.rm = TRUE) return(res) >Проверим нашу функцию при помощи встроенной функции
mean(vect_num, na.rm = TRUE)## [1] 0.5 mmean(vect_num)## [1] 0.5Объекты и типы данных R: таблицы данных

Таблица данных (data frame) представляет собой объект R, по структуре напоминающий лист электронной таблицы Microsoft Excel. Каждый столбец таблицы является вектором, содержащим данные определенного типа. При этом действует правило, согласно которому все столбцы должны иметь одинаковую длину (собственно, с "точки зрения" R таблица данных является частным случаем списка, в котором все компоненты-векторы имеют одинаковый размер). Часто на практике некоторые значения в таблице отсутствуют, что может быть обусловлено множеством причин: на момент измерения прибор вышел из строя, по невнимательности персонала измерение не было занесено в протокол исследования, испытуемый отказался отвечать на определенный вопрос(ы) в анкете, была утеряна проба, и т.п. Ячейки с такими отсутствующими значениями (missing values) в таблицах данных R не могут быть просто пустыми – иначе столбцы таблицы окажутся разной длины. Для обозначения отсутствующих наблюдений в языке R имеется специальное значение – NA (not available – не доступно).
Таблицы данных – это основной класс объектов R, используемых для хранения данных. Обычно такие таблицы подготавливаются при помощи сторонних приложений (особенно популярна и удобна программа Microsoft Excel) и затем загружаются в среду R. Подробнее об импортировании данных в R рассказано здесь. Тем не менее, небольшую таблицу можно собрать из нескольких векторов средствами самой системы R. Для этого используют функцию data.frame() .
Предположим, у нас есть наблюдения по общей численности мужского ( Male ) и женского ( Female ) населения в трех городах City1 , City2 , и City3 . Представим эти данные в виде одной таблицы с именем CITY . Для начала создадим текстовые векторы с названиями городов ( сity ) и пола ( sex ), а также вектор со значениями численности представителей каждого пола ( number ):
city c("City1", "City1", "City2", "City2", "City3", "City3") sex c("Male", "Female", "Male", "Female", "Male", "Female") number c(12450, 10345, 5670, 5800, 25129, 26000)
Теперь объединим эти три вектора в одну таблицу данных и посмотрим, что получилось:
CITY data.frame(City = city, Sex = sex, Number = number)
CITY City Sex Number 1 City1 Male 12450 2 City1 Female 10345 3 City2 Male 5670 4 City2 Female 5800 5 City3 Male 25129 6 City3 Female 26000
Обратите внимание на синтаксис функции data.frame() : ее аргументы перечисляются в формате " заголовок столбца = добавляемый вектор ". В качестве заголовков столбцов могут выступать любые пользовательские имена, удовлетворяющие требованиям R (см. об этом подробнее в следующем сообщении).
Как и в случае со списками, извлечь отдельные компоненты таблиц для выполнения необходимых вычислений можно с использованием знака $ , двойных квадратных скобок [[]] , либо непосредственно по имени столбца:
CITY$Sex [1] Male Female Male Female Male Female Levels: Female Male CITY$Number [1] 12450 10345 5670 5800 25129 26000 # Идентичные результаты можно получить при помощи следующих команд: CITY[[2]] [1] Male Female Male Female Male Female Levels: Female Male CITY[[3]] [1] 12450 10345 5670 5800 25129 26000 CITY["Sex"] [1] Male Female Male Female Male Female Levels: Female Male CITY["Number"] [1] 12450 10345 5670 5800 25129 26000
После имени или индексного номера столбца можно указывать индексные номера отдельных ячеек таблицы, что позволяет извлекать содержимое этих ячеек:
# Извлекаем 4-й элемент из столбца Number: CITY$Number[4] [1] 5800 # Извлекаем элементы 1-3 из столбца Number: CITY$Number[1:3] [1] 12450 10345 5670 # Извлекаем все значения численности населения, превышающие 10000 CITY$Number[CITY$Number > 10000] [1] 12450 10345 25129 26000 # Извлекаем все значения численности мужского населения: CITY$Number[CITY$Sex == "Male"] [1] 12450 5670 25129 # Повторяем те же команды, но с использованием [[]]: CITY[[3]][4] [1] 5800 CITY[[3]][1:3] [1] 12450 10345 5670 CITY[[3]][CITY$Number >10000] [1] 12450 10345 25129 26000 CITY[[3]][CITY$Sex == "Male"] [1] 12450 5670 25129
При работе с большими таблицами данных бывает сложно визуально исследовать всё их содержимое перед началом анализа. Однако визуального просмотра содержимого таблиц и не требуется - полную сводную информацию о них (равно как и о других объектах R) можно лекго получить при помощи команды str() (structure - структура):
str(CITY) 'data.frame': 6 obs. of 3 variables: $ City : Factor w/ 3 levels "City1","City2",. 1 1 2 2 3 3 $ Sex : Factor w/ 2 levels "Female","Male": 2 1 2 1 2 1 $ Number: num 12450 10345 5670 5800 25129 .
Как следует из представленного отчета, объект CITY является таблицей данных, в состав которой входят три перменные с шестью наблюдениями каждая. Две из этих перменных - City и Sex - программа автоматически распознала как факторы с тремя и двумя уровнями соответственно. Переменная Number является количественной. Для удобства выводятся также несколько первых значений каждой переменной.
Часто возникает необходимость выяснить лишь имена переменных, входящих в таблицу данных. Это можно сделать при помощи команды names() :
names(CITY) [1] "City" "Sex" "Number"
Имеется также возможноть быстро просмотреть несколько первых или несколько последних значений каждой переменной, входящей в состав таблицы данных. Для этого используются функции head() и tail() соответственно:
head(CITY, n = 3) City Sex Number 1 City1 Male 12450 2 City1 Female 10345 3 City2 Male 5670
tail(CITY, n = 2) City Sex Number 5 City3 Male 25129 6 City3 Female 26000
При необходимости внесения исправлений в таблицу можно воспользоваться встроенным в R редактором данных. Внешне этот редактор напоминает обычный лист Excel, однако имеет весьма ограниченные функциональные возможности. Все, что он позволяет делать – это добавлять новые или исправлять уже введенные значения переменных, изменять заголовки столбцов, а также добавлять новые строки и столбцы. Работая в стандартной версии R, редактор данных можно запустить из меню File -> Data editor либо выполнив команду fix() (fix – исправлять, чинить) из командной строки консоли R (например, fix(CITY) ). После внесения исправлений редактор просто закрывают – все изменения будут сохранены автоматически:
Обратите внимание, что в программе RStudio функция fix() в настоящее время не поддерживается.
Редактирование таблиц данных в R
В прошлый раз мы говорили о том, как загрузить данные в среду R. Следующим важным этапом является их подготовка к визуализации и статистическому анализу. Для этого нам, как правило, необходимо внести некоторые изменения в таблицу, например: удалить столбец или строку, переименовать колонку, произвести сортировку или фильтрацию данных. Многие из этих операций можно сделать в Excel. Однако, зачастую возникают ситуации, когда необходимо изменить структуру или содержание таблицы прямо в ходе анализа. И вот тут у начинающих пользователей R могут возникнуть проблемы. В этой статье мы научимся их решать.
Структура таблицы и изменение типов данных
Лучший способ для закрепления новых знаний - это практика. Поэтому мы продолжим работать с таблицей физических данных студентов одного из военных вузов "voenvuz". Итак, загрузим знакомую уже нам таблицу в Rgui (таблицу можно скачать здесь).
Функции head и str
Для того, чтобы посмотреть правильно ли загрузились данные, введем команду head(voenvuz) , которая покажет первые 6 строчек нашей таблицы. Если все загрузилось нормально, то переходим к команде str(voenvuz) , которая выведет в консоль структуру таблицы.

Итак, в поле "data.frame" мы видим, что наша таблица состоит из 20 строк и 6 столбцов. Под ним располагается список названий столбцов, тип данных и первые шесть элементов каждого столбца. Обратите внимание, что колонки "Name" и "Rhesus.factor" сейчас хранят в себе категориальный тип данных (Factor), а остальные - целочисленный. Компьютер вычислил это автоматически, но в нашем случае - вычислил неверно. Прежде чем мы исправим типы этих данных, немного теоретической информации.
О типах данных
Почему важно правильно распознать тип данных в столбцах таблицы? Потому что при проведении статистических тестов, информация о типе данных учитывается и влияет на результат.
В языке R можно выделить 5 основных типов данных, хранящихся в столбцах таблицы:
- числовой (numeric);
- целочисленный (integer);
- текстовый (character);
- категориальный (Factor);
- логический (logical).
Есть также комплексный (complex) и сырой (raw) типы данных, но они редко встречаются, и поэтому я о них здесь писать не буду. Пропущенные данные обозначаются как "NA" (от англ. not available - недоступно), и тогда R игнорирует их.
Изменим типы данных на практике
Посмотрим еще раз на таблицу. Логично предположить, что столбец "Name" с именами студентов не содержит никаких категорий, поэтому, преобразуем эту колонку в обычный текстовый тип данных:
voenvuz$NameИдем дальше, столбец "Age" был правильно идентифицирован как целочисленный. А вот столбцы "Height" и "Weight" являются скорее числовыми, т.к. могут содержать промежуточные значения, например 182.5. Переделаем их из типа Integer в тип Numeric:
voenvuz$Height
voenvuz$WeightПоследнее, что нам нужно - это изменить тип данных в столбце "Blood.group". Каждый из студентов так или иначе имеет одну из 4 групп крови, соответственно, этот столбец содержит четыре категории: "1", "2", "3", "4". Другими словами, в нем должен находиться категориальный тип данных:
voenvuz$Blood.groupВ итоге, повторив команду str(voenvuz) , мы должны получить вот такую картинку.
Редактирование элементов таблицы
Иногда возникают ситуации, когда необходимо вставить в таблицу столбец или строку, изменить значение элемента или название колонки. Наша таблица - не исключение и нуждается в доработке.
Добавление строк
Добавим в таблицу данные о двух новых студентах: Иване и Олеге. Для этого необходимо создать новую структуру - список (list) , В список мы по порядку вносим параметры, совпадающие со структурой таблицы (напомню, что в кавычках мы пишем нечисловые типы данных):
Ivan
OlegПосле, при помощи функции rbind (от англ. row bind, что дословно означает "связать строчки") мы объединим эти два списка с нашей таблицей:
voenvuzДобавление столбцов
Теперь у нас в таблице два Ивана и два Олега. В данном случае хорошо было бы прописать для каждого студента свой идентификационный номер (ID), чтобы не запутаться, кто есть кто. Для этого создадим структуру, которая называется вектор (последовательность элементов одного типа). В него мы запишем последовательность от 1 до 22, так, чтобы у каждого из наших 22 студентов был свой уникальный ID:
Теперь объединим наш вектор с таблицей, воспользовавшись функцией cbind (от англ. column bind):
voenvuzНе забудьте поменять тип данных нового столбца на символьный:
voenvuz$IDВ качестве еще одного примера добавления новых столбцов с данными в таблицу, рассчитаем индекс массы тела (BMI) для каждого студента. Для этого, мы воспользуемся новым способом: напишем математическую формулу индекса на языке R и присвоим ей новое имя столбца "BMI" внутри нашей таблицы:
voenvuz$BMIПроверьте, что получилось, используя уже знакомые нам функции head и str
Удаление строк и столбцов
Существует относительно "универсальная формула" для удаления элементов таблицы: new.data
Для того, чтобы корректно ее использовать необходимо запомнить несколько правил:
- После имени таблицы пространство внутри квадратных скобок следует разделить на две части запятой.
- Все, что находится до запятой, относится к строчкам, все что после - к столбцам.
- Поставьте минус перед номером столбца или номером строки, которую собираетесь удалить.
- Если таких элементов несколько, используйте функцию c(. ) : внутри скобок перечисление элементов через запятую.
В нашем случае, удалять из таблицы ничего не надо, но я покажу пару примеров, назвав "укороченные" таблицы именами "trash1", "trash2", "trash3", "trash4":
trash1 # удалим раннее созданный столбец "ID"
trash2 # удалим строку под номером 2 (данные Петра)
trash3 # удалим первые десять строк
trash4 # то же самое, только код корочеИзменение имен столбцов и данных в ячейках:
Переименуем колонку "Rhesus.factor" на укороченное "Rhesus". Для этого нужно вызвать функцию names , написать в параметрах функции имя таблицы и номер столбца, и присвоить ему новое имя :
names(voenvuz)[6]Изменение данные в ячейках таблицы не представляет особой сложности. В квадратных скобках прописываем координаты нужной ячейки (до запятой - строка, после запятой - столбец) и присваиваем новое значение:
voenvuz[1, "Name"]
После всех наших манипуляций мы должны получить вот такую таблицу данных:
Фильтрация и сортировка данных
В качестве примера, исключим из таблицы данных студентов, чей возраст больше 23 лет. Существует множество способов решения подобного рода задач, включая циклы if-else, for или while (о них будет написана отдельная статья). Однако в нашем случае хватит простого фильтра, основанного на логическом операторе " < wp-block-preformatted">voenvuz.final
Того же результата мы добьемся, если будем использовать логические операторы ">" (больше) и "!" (исключить):
voenvuz.final 23, ]Итак, мы получили финальную версию таблицы "voenvuz.final ". Осталось лишь упорядочить столбцы:
voenvuz.finalИ произвести сортировку данных по имени студентов, используя функцию order :
voenvuz.final
После завершения редактирования таблицы, обновим имена строк, т.к. сейчас они не соответствуют действительности, и выведем таблицу на экран, введя имя таблицы в консоль:
rownames(voenvuz.final) = c(1:length(voenvuz.final$ID))
voenvuz.finalЗаключение
Описанные выше способы редактирования данных в таблице не уникальны, существует множество других методов и команд, позволяющих получить желаемый результат. Я рассказал лишь о наиболее простых и часто используемых. Для более детального ознакомления с этой темой я хотел бы порекомендовать два источника на английском языке:
- сайт http://stackoverflow.com/ (уже подробно разобраны тысячи вопросов по этой теме)
- книгу-справочник "R book" by Michael J. Crawley (легко найти бесплатную PDF версию в интернете).
Если у Вас возникли вопросы или проблемы с редактированием таблиц данных, Вы всегда можете оставить комментарий под этой статьей, и он не останется без внимания. А в качестве продолжения, читайте следующую статью, посвященную сохранению данных в среде R.
Комментарии: 41
Февраль 21, 2021 в 13:52 ВладимирЗдравствуйте! Хотел отфильтровать записи в своем файле ничего не получилось. Тогда взял Ваш пример и попытался отфильтровать записи прямо по Вашему примеру, но получил тоже самое. Вот R-файл
voenvuz=read.csv(«D:/progaR/voenvuz_clean.csv»,sep=»;»)
voenvuz.fin=voenvuz[voenvuz$age=23]
Это текст на консоли(фрагмент) voenvuz voenvuz=read.csv(«D:/progaR/voenvuz_clean.csv»,sep=»;»)
> voenvuz.fin=voenvuz[voenvuz$age voenvuz
Name Age Height Weight Blood.group Rhesus.factor
1 Ivan 23 178 80 2 +
2 Peter 18 169 62 1 —
3 Oleg 22 185 77 2 +
4 Sergey 19 182 73 2 —
5 Dmitriy 25 190 93 3 +
6 Vladimir 20 166 65 1 +
7 Alexey 19 185 90 1 +
8 Alexandr 21 182 89 2 +
9 Boris 18 172 59 4 +
10 Igor 23 175 75 3 +
11 Artem 18 176 69 2 +
12 Andrey 20 184 81 3 —
ENVIRONMENT
voenvuz 20 obs of 6 variables
voenvuz.fin 0 obs of 6 variables
voenvuz.fin1 20 obs of 0 variables
с уважением ВладимирАпрель 20, 2020 в 16:49 Олег
kod col.x col.y delta
1 00046949 1,000 1,000 2
2 00047069 3,000 3,000 2
3 00047070 19,000 19,000 2
4 00047071 49,000 49,000 2
5 00047072 21,000 21,000 2
356 CB128164 2,000 2
252 CB164884 1,000 2
Всем привет! Только начал изучать R и столкнулся с некой проблемой: Есть такая волшебная таблица. И задача, вывести в последний столбец разницу 2 и 3 го, и с учетом того что данные в последних строках NA, соответственно вывести в последний столбец NA2 или NA3, в зависимости от того где стоит NA. Проблема в том, что стандартные функции(о которых я еще мало знаю) удаляют строки с NA, а мне важно их сохранить и обработать.
Если у кого то будут мысли по теме, буду рад помощи. Да и еще, у меня типы данных факторы в первых трех столбцах, а последний число.Апрель 21, 2020 в 11:47 Samoedd (Автор записи)
https://samoedd.comПривет, Олег! А где у тебя NA?
Столбец со значениями 1,2,3,4,5,356,252 — это что?
delta — это столбец со значениями 2?Апрель 10, 2020 в 18:46 Данила
Здравствуйте! Подскажите, пожалуйста, что я делаю не так.
У меня есть данные, записанные в одну строку «tree» в таком виде: ((ETH1567:0.07723012967,((ETH1478:0.03477412382,ETH1481:0.03998172409)100:0.01982264043,(LAV2470:0.04453502013,LAV2519:0.04666678739) и т.д. без пробелов. Мне нужно извлечь блоки содержащие буквы и последующие цифры до знака двоеточия, т.е.: ETH1567 ETH1478 ETH1481 LAV2470 LAV2519 Я подобрал регулярку для этого: ([A-z][0-9]*) Но мой код: treenames named character(0) Перерыд весь stackoverflow и иже с ним, но ответа не нашел.
Буду благодарен за подсказку.Апрель 11, 2020 в 20:07 Samoedd (Автор записи)
https://samoedd.comЗдравствуйте, Данила! Вот одно из возможных решений Вашей задачи: tree
tree1
tree2
tree3
tree4
tree4 # Your result! P.S. я мало анализирую текстовые данные, поэтому это решение вероятно не самое элегантное, но должно работать.


