Введение в протокол IPv6 в сравнении с IPv4
В последнее время все чаще и чаще приходится сталкиваться с протоколом IPv6. Здесь я собрал основную информацию про IPv6, и постарался максимально кратко изложить ее с практической точки зрения. В этой статье описаны базовые термины IPv6.
Адресация в IPv6
2001:0db8:85a3:0000:0000:8a2e:0370:7334/64 Размер IPv6 адресов – 128 бит. То есть если указана маска /64, то это ровно половина от адреса. Есть правило по которому можно укоротить IPv6 адрес: если в адресе есть последовательные группы с нулями, то их можно заменить на :: . Старшие нули в группе можно не писать.
То есть адрес выше можно записать так:
2001:db8:85a3::8a2e:370:7334/64 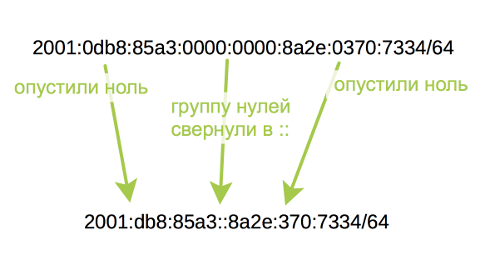
Как и в IPv4, в IPv6 есть anycast, multicast и unicast адреса. Broadcast-а больше нет, вместо него есть мультикаст группа “вообще все” ff02::1
В реальной жизни чаще всего приходится сталкиваться с anycast адресами, но и они бывают разных типов.
- Global anycast, например 2a03:b0c0:0:1010::424:8001/64 . Грубо говоря, это “белый” IP-адрес, он маршрутизируется в интернете, и выдается провайдером по DHCPv6 или RA (об этом ниже)
- Link local адреса из сети fe80::/10 . Пример такого адреса – fe80::601:4eff:fe9b:4e01/64 . Это подобие 169.254.0.0-ipv4 адресов, которы существуют для адресации внутри канала, когда нам никто не дал никакого глобального адреса. ОС сама выберет и присвоит интерфейсу такой адрес. В IPv6 на одном интерфейсе может висеть множество адресов, и это норма. Такие адреса обычно создаются на основе MAC-адреса интерфейса. В приведенном примере MAC-адрес машинки такой – 04:01:4e:9b:4e:01 . Видно что взяли MAC, посередине вставили ff:fe и получили link-local адрес.
- Unique local unicast адреса из сети fc00::/7 . Это адреса подобные 192.168.0.0/16, 10.0.0.0/8, 172.16.0.0/16. В жизни практически нигде не используются.
Получение IPv6 адресов
Получение IPv6 адресов немного отличается от IPv4, но в целом все осталось как прежде – запрос/ответ. В IPv6 расширили протокол ICMP, и теперь процедура получения адреса начинается с того, что клиент на multicast-адрес “все роутеры” со своего link-local адреса отправляет ICMPv6-пакет типа Router solicitation (RS), как бы говоря – “эй, есть тут кто? дайте адрес”. Если в сети есть роутер, он отвечает ICMPv6-пакетом типа Router advertisement (RA). В этом пакете содержится минимально необходимая информация, с помощью которой клиент сможет настроить свой интерфейс – префикс сети и DNS сервер.
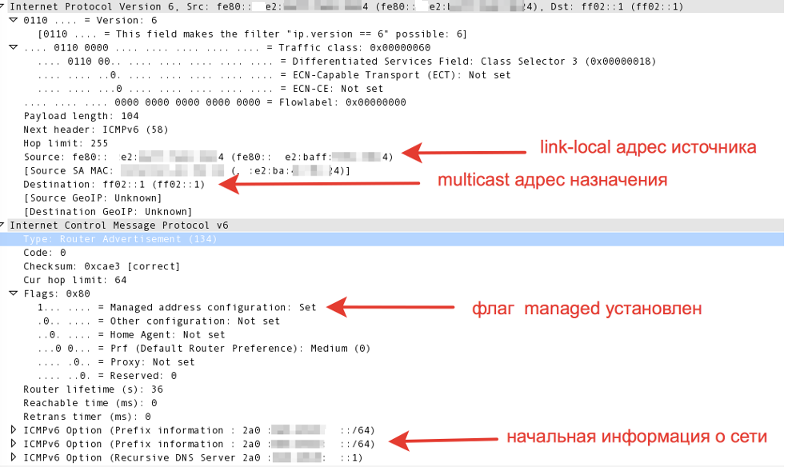
Пакет RA в wireshark:
И тут могут быть два варианта:
- Если в пакете RA есть флаг managed, то клиент сам назначает себе IP-адрес из той сети которая указана в RA. В этом случае клиент также будет использовать Duplicate Address Detection (DAD), чтобы удостовериться, что назначенный адрес ни с кем не пересекается.
- Если флага нет, то клиент должен пойти на DHCP-сервер, и арендовать себе адрес там. В этом случае процедура аналогична IPv4. DHCPv4-request=DHCPv6-solicit, DHCPv4-response=DHCPv6 advertise.
Существует еще вариант быстрого получения адреса, когда клиент в сеть посылает RS, а в ответ уже получает адрес от DHCP-сервера. Такой механизм называется Rapid Commit
После получения global unicast адреса сервер становится доступен по ipv6 из интернета. HTTP (и вообще любой другой протокол более высокго уровня) по IPv6, естественно, никак не отличается от IPv4, просто в пакетах в адресе отправителя/получателя указывается v6 адрес.
ARP в IPv6
В IPv4, чтобы узнать канальный адрес соседа, использовался протокол ARP, в IPv6 его нет, вместо него есть Neighbor Discovery Protocol (NDP). Когда мы хотим узнать MAC-адрес какого-то IP-адреса, то с нашего link-local адреса посылаем ICMPv6 пакет типа Neighbor Solicitation (NS) на специальную multicast-группу SNMA. Адрес этой группы связан с искомым IP-адресом. В итоге этот пакет получит только хост с искомым адресом. На NS искомый хост отвечает пакетом Neighbor Advertisement (NA) на наш link-local адрес – “это я, вот мой MAC”. Вот так это выглядит в wireshark:

Посмотреть список MAC-адресов в linux можно командой:
#ip -6 neigh show 2a03:b0c0:0:1010::1 dev eth0 lladdr 00:00:5e:00:02:96 router STALE fe80::1 dev eth0 lladdr 00:00:5e:00:02:96 router STALE Это аналог команды arp -n – он показывает кэш MAC-адресов в локальной сети. У них есть несколько состояний, вот граф возможных переходов с сайта technet:
Сбросить этот кэш можно так:
#ip neigh flush dev eth0 После этого все записи переходят в состояние FAILED, и через несколько секунд удаляются:
#ip -6 neigh show 2001:db8:0:2::1 dev eth0 router FAILED fe80::85d:8fff:fe1b:7590 dev eth0 router FAILED Как я писал в самом начале, здесь приведена лишь минимально необходимая для понимания работы IPv6 информация. Тема эта огромная, и полное описание займет не одну книгу.
Дополнительные материалы по теме IPv6:
- Курс лекций на youtube – https://www.youtube.com/playlist?list=PLVxaI3iD653BJ9vGb7U03au7JpR4wM-kY
- How to IPv6 works – https://technet.microsoft.com/en-us/library/cc781672(v=ws.10).aspx
IPv6, Mikrotik и Sarkor (инструкция)
Протокол IPv6 был создан более 25 лет назад. И несмотря на то, что на текущий момент он уже старше некоторых состоявшихся IT специалистов, для многих он является чем-то новым и неизведанным. Разговоры о переходе на IPv6 шли уже давно и подогревались паникой перед неизбежным концом далеко не бесконечных адресов v4. Но как бы не противилось человечество, научиться работать с этим, недружелюбным на первый взгляд протоколом, всё же, придётся.
Многие провайдеры до сих пор игнорируют необходимость внедрения нового протокола. Но это вовсе не помешало многим энтузиастам потренироваться на туннельных брокерах, некоторые из которых щедро раздают префиксы, вплоть до /48 совершенно бесплатно, практически любому желающему. Будучи одним из таких энтузиастов, я более-менее разобрался в базовых понятиях и принципах работы IPv6 и стал с нетерпеньем ждать, когда эти сети будут предоставляться нативно локальными провайдерами. И вот, в феврале 2022 года провайдер Sarkor Telecom первым в Узбекистане (по моей информации) анонсировал скорый запуск сетей IPv6 для обычных абонентов. С момента анонса прошло прилично времени, пока нововведение добралось до моего узла. Это и понятно, ведь внедрение ipv6 требует серьёзных изменений в работе сети и тесно связано с серьёзными последствиями, в случае плохо обдуманных решений.
Основные опасения тут связаны с тем, что в сети шестой версии абсолютно все устройства имеют собственный «белый» адрес, а значит, видимы из «мира». Людям, привыкшим к демилитаризованным зонам за NAT следует учесть это и очень серьёзно подойти к настройке фаерволлов. Если ранее в домашней сети можно было не беспокоиться о хранилище или камере со стандартным паролем (или вовсе без него) то теперь, получив глобальный адрес, такое устройство может легко стать жертвой злоумышленника. Правда, тут стоит оговориться, что «насканить» уязвимое устройство в сети v6 не так-то просто, поскольку даже в самом маленьком префиксе /64 (который дадут абоненту домой) чуть более 18 квинтиллионов адресов. Говоря проще – дохрена! Впрочем, есть ведь и шанс, что ваше устройство само обратится на вредоносный сервер, раскрыв свой адрес?
Что-ж, если вы дочитали (или пролистали) до этого абзаца – значит (по крайней мере, я на это надеюсь) вы в полной мере понимаете, что вы делаете и зачем вам это нужно.
Приступим, непосредственно, к настройке.
У меня установлена версия RouterOS 7.6 и в ней уже встроен IPv6. В случае с шестой веткой, возможно, вам потребуется включить одноимённый пакет поддержки протокола.
1) Включаем DHCPv6-client прямо на pppoe соединении.
Галочками отмечены опции для получения DNSv6 от провайдера, и ещё Rapid commit, которая позволяет быстрее «договориться» с DHCPv6 сервером, в случае, если на нём так-же включена такая опция.
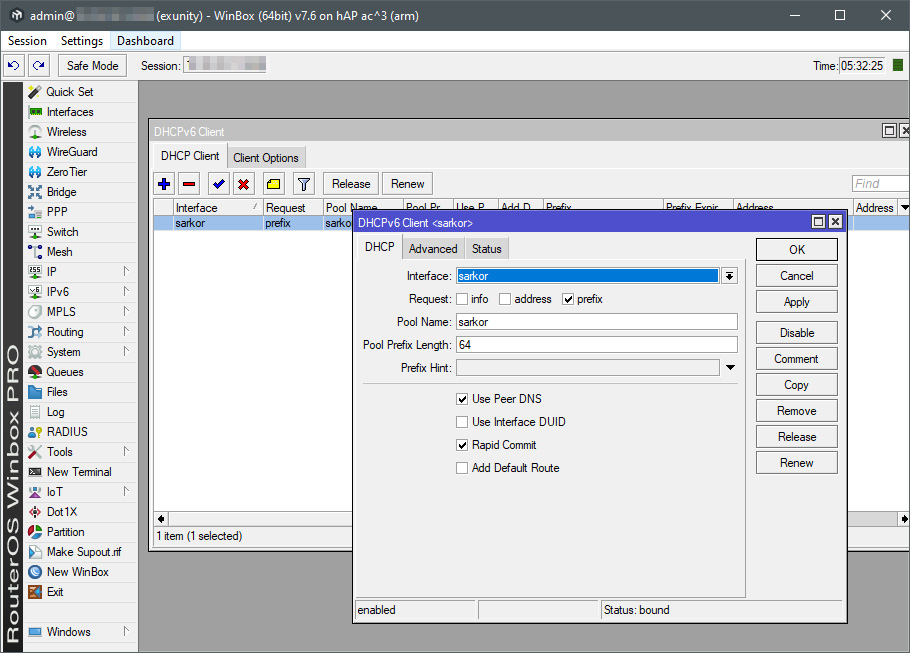
В интерфейсах выбираем ваше PPPoE соединение в сторону саркора. В качестве имени пула можно указать что фантазии угодно. Длинна префикса в моём случае /64 бита. Если вдруг вам посчастливится стать владельцем сети покрупнее – ставьте соответствующее число. Маршрут по умолчанию далее мы получим в любом случае, так что галочку тут можно не ставить.
2) Если всё завязалось как надо, в нижнем правом углу окошка настройки DHCP клиента вы увидите надпись Status: bound а во вкладке status вы найдёте префикс, выданный провайдером.
Копируем этот префикс в буфер и переходим в IPv6 > Addresses
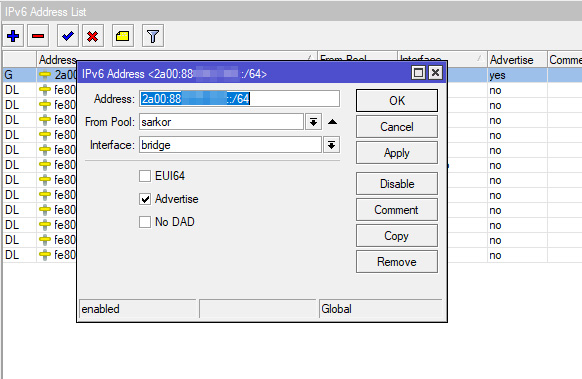
Добавляем новый адрес. В поле адреса вставляем из буфера ранее скопированный префикс. В поле From pool выбираем пул адресов. Если он у вас не появился, значит что-то пошло не так в предыдущих шагах.
В качестве интерфейса тут нужно выбрать тот интерфейс, через который ваш роутер будет раздавать адреса в локальную сеть. Этот способ заменят привычный нам DHCPv4. Тут вместо DHCP так называемый «Advertising» который в данном случае можно перевести как объявление адресов в сеть. Если хотим раздать адреса – отмечаем соответствующий чекбокс. Альтернативный путь – не раздавать адреса кому попало, а прописать их вручную только нужным устройствам. Имейте в виду, что на данный момент наш любимый tas-ix не особо в курсе, что такое ipv6 по этому, скорее всего, трафик в этом адресном пространстве побежит мимо всяких пиринговых стыков и локальных CDN. Подумайте хорошенько, нужно ли вам это. 🙂
3) Если не передумали, двигаем в IPv6 > Neghbor Discoveri и убеждаемся в том, что ND включен для интерфейса, в котором обитает наше сетевое окружение. По дефолту в этой настройке стоит разрешение на все интерфейсы, но я предпочёл ограничиться бриджем своей локалки, ибо интерфейсов у меня много, а раздавать туда адреса совершенно ни к чему.
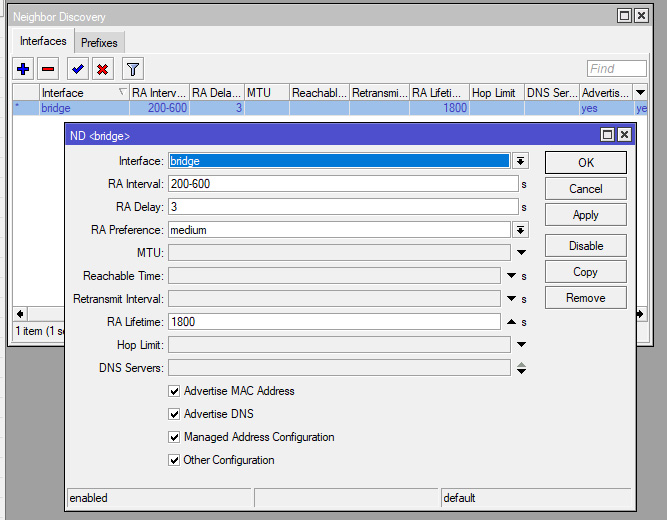
4) Так-же, на всякий пожарный, стоит заглянуть в ipv6 > settings и убедиться в том, что поддержка протокола не выключена, а транзит (forward) не запрещён.
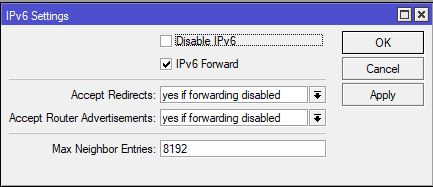
При необходимости, можно зайти в IP > DNS и добавить туда какие-либо дополнительные v6 адреса DNS серверов. В моём случае я уже получил их динамически по DHCPv6.
5) И вот наступает момент, когда, казалось бы, всё должно работать, но тут меня ждал подлый сюрприз. Половина сайтов не открывается, а SSH сессия по ipv6 тупо зависает, спустя несколько секунд после подключения. Я попробовал открыть ssh сессию прямо с микротика и как ни странно, она заработала нормально. Тогда мне пришло в голову проверить, какой размер пакета пролезает через сеть с роутера, а какой с клиента локалки. Пинги с разной длиной пакета сразу же указали на ключ к разгадке: если с роутера пакеты спокойно добегали в размере 1492 байта (MTU PPPoE соединения) то с клиентской машины максимальный размер оказался 1444 байта. Ну это уже ни в какие фреймы. 😉 Если честно, я пока так и не разобрался в причинах такого поведения, и решил проблему добавив в фаерволл правила для автоматической подстройки размера пакета.
И так, идём в IPv6 > Firewall > Mangle и жмём плюсик.
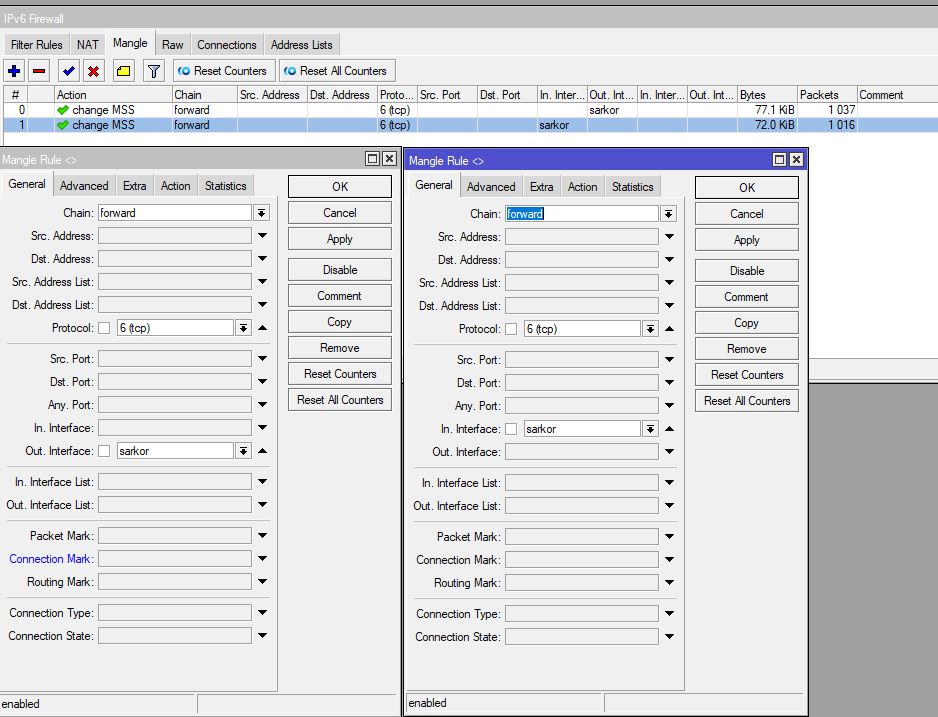
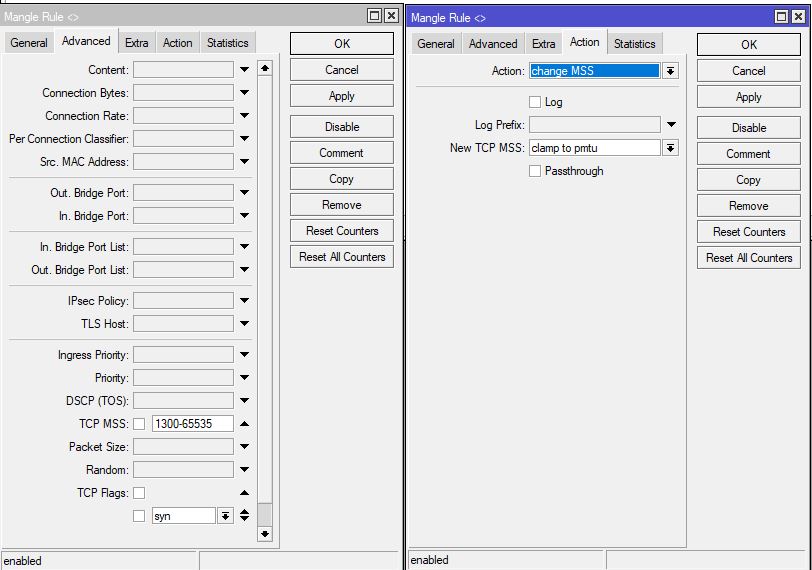
У двух правил разные только направления, всё остальное идентично друг другу.
Конечная остановка:
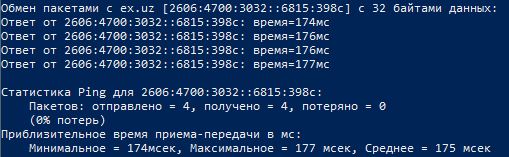
Если вы всё сделали верно – попингуйте мой сайт, и вы увидите длинный и некрасивый ipv6 адрес. 😉
!ВАЖНО!
Напоминаю ещё раз! Не забудьте про фаерволл. Вот базовые правила, которые закроют всю активность извне, разрешая при этом вашей локалке бегать в интернеты.
/ipv6 firewall filter
add action=accept chain=input comment=»Related, Established» connection-state=\
established,related,untracked
add action=accept chain=input comment=»accept from my net» in-interface=bridge
add action=accept chain=input comment=»accept ICMPv6″ protocol=icmpv6
add action=accept chain=forward comment=»Related, established» connection-state=\
established,related,untracked in-interface=sarkor
add action=drop chain=forward comment=»DROP fw to my net» connection-state=invalid,new in-interface=\
sarkor
add action=drop chain=input comment=»DROP all input» connection-state=invalid,new in-interface=sarkor \
protocol=tcp
Имя интерфейса заменить на имя вашего PPPoE соединения. Исключения добавлять по необходимости. Варить 20 минут, соли по вкусу. 😉
распределение адресов ipv6 в сети
Провайдер динамически выдает префикс ipv6 /64 (~18 квадриллионов адресов). Возник вопрос, как эти адреса распределять без SLAAC? т.е. надо как то передать динамически получаемый префикс на другие DHCP сервера и при этом как то поделить диапазоны ip между ними.
Как это делается?
torm7 ★
13.12.21 14:03:32 MSK

Провайдер динамически выдает префикс ipv6 /64
Это плохо — у меня также. По идее должен /48, с расчетом /64 на железку.
Turbid ★★★★★
( 13.12.21 14:24:03 MSK )
Но выше правильно написали, что провайдер должен был тебе /56 или /48 выделить т.к. slaac работает только с /64 префиксами.
Kolins ★★★
( 13.12.21 14:28:28 MSK )
Последнее исправление: Kolins 13.12.21 14:28:45 MSK (всего исправлений: 1)
Ответ на: комментарий от Turbid 13.12.21 14:24:03 MSK
Нафига столько адресов.
/96 должно хватать на всё с огромным запасом а вы /64 недоволны.
firkax ★★★★★
( 13.12.21 14:33:16 MSK )
Ответ на: комментарий от Kolins 13.12.21 14:28:28 MSK
Я так понимаю что это делегация сетей от /64 и больше. Меня же интересует дальнейшее дробление этой сети для распределения этих адресов.
torm7 ★
( 13.12.21 14:51:35 MSK ) автор топика
Ответ на: комментарий от torm7 13.12.21 14:51:35 MSK
Я так понимаю что это делегация сетей от /64 и больше.
нет. можно и /64 бить на более мелкие подсети. Конкретно у микротов в ipv6->pool указываешь исходный префикс и размер префиксов на которые ты будешь его бить.
Kolins ★★★
( 13.12.21 15:04:20 MSK )
Ответ на: комментарий от firkax 13.12.21 14:33:16 MSK

Хочешь поспорить со стандартом?
intelfx ★★★★★
( 13.12.21 15:40:18 MSK )
Ответ на: комментарий от Kolins 13.12.21 15:04:20 MSK
На это есть какая то инструкция? Что то беглый поиск ничего не дал.
torm7 ★
( 13.12.21 15:56:04 MSK ) автор топика
Ответ на: комментарий от torm7 13.12.21 15:56:04 MSK
Kolins ★★★
( 13.12.21 16:01:37 MSK )
Ответ на: комментарий от intelfx 13.12.21 15:40:18 MSK
Эм. Я бы ещё подумал если бы речь шла про действительно значимый и действительно стандарт. А тут сомнительные рекомендации по ведению бизнеса, впихнутые в технический документ, который и без этого был сомнительного качества. Нарезание сетей внутри автономной системы — это сфера исключительно коммерческих отношений между провайдером и его клиентами, а никак не стандарта.
Лично мне осознание того, что можно было сэкономить ненужные 8 байт заголовков из моих локальных адресов, коих мне выделили целых 128-48=80 бит=10 байт, оставив только 2 байта, которых заведомо на всё хватит, но нельзя из-за дури каких-то странных людей из 90-х, сочинивших этот «стандарт», вело бы только к негативу.
Впрочем, если ipv6 таки окажется массово принят, и всем действительно будут выдавать /48, то скорее всего эти лишние бесполезные 16 байт в ipv6 пакете (8 байт от адреса источника и 8 байт от адреса назначения) скорее всего научатся использовать под что-то более полезное (слать через них какие-нить другие метаданные, куки, мониторинг итд).
firkax ★★★★★
( 13.12.21 16:02:50 MSK )
Последнее исправление: firkax 13.12.21 16:11:25 MSK (всего исправлений: 2)
Ответ на: комментарий от firkax 13.12.21 16:02:50 MSK
А кто будет решать, что есть «действительно значимый и действительно стандарт»? Ты?
intelfx ★★★★★
( 13.12.21 16:45:32 MSK )
Ответ на: комментарий от intelfx 13.12.21 16:45:32 MSK
Не надо демагогии, все давно понимают что ipv6 это провал. То, что он вообще используется — происходит лишь потому, что конца ipv4-адресов действительно некоторые боятся, а альтернатив расширить адресное пространство нет.
А уж прописывать в стандарт, какими блоками провайдер должен раздавать адреса своим физлицам-клиентам — вообще дичь.
firkax ★★★★★
( 13.12.21 17:17:17 MSK )
Ответ на: комментарий от firkax 13.12.21 17:17:17 MSK
Вот именно — не надо демагогии.
intelfx ★★★★★
( 13.12.21 18:13:41 MSK )
Ответ на: комментарий от intelfx 13.12.21 18:13:41 MSK
Чем мне нравится лор — тяга людей к «поболтать под пивасик, желательно ни о чем» 🙂
ipv6 работает, работает замечательно, протокол заметно проще, чем ipv4 (одно отсутствие броадкаста чего стоит).
Что касается стандартов, то они определяют технологию, а не бизнес-процесс, и обычный DHCP вовсе не является обязательным для применения в провайдинге.
ipv6 предусматривает разные технологические варинаты раздачи, а провайдер сам вбирает из своих соображений — пользоваться ли ему преимуществом ipv6, или гонять его в режиме ipv4.
Oleg_Iu ★
( 13.12.21 20:03:54 MSK )
имхо
удаляй роутер подключай тупо свитч
всякие winxp подключай через роутер к свитчу
файсбук так и делает инфа100
nanosecond ★
( 13.12.21 22:28:16 MSK )
Последнее исправление: nanosecond 13.12.21 22:31:23 MSK (всего исправлений: 2)
Ответ на: комментарий от Turbid 13.12.21 14:24:03 MSK

/56 по полиси. /48 это уже чтобы роутиться можно было.
Dark_SavanT ★★★★★
( 13.12.21 22:43:50 MSK )
IPv6 — классовая система адресации. Существует несколько классов (которые политкорректно называются форматами) IPv6 адресов.
Нас в данном случае интересует unicast/anycast формат: 64 бита — префикс сети (номер сети в терминологии IPv4), 64 — бита идентификатор интерфейса (номер хоста в терминологии IPv4).
Предполагалось, что префикс сети будет состоять из 48 бит (глобального) префикса маршрутизации и 16-ти бит идентификатора подсети.
Прошу заметить, существует известная путаница между подсетями IPv4 и CIDR. Это — две разных спецификации: подсети были определены в рамках классовой маршрутизации IPv4, CIDR — как раз и есть бесклассовая маршрутизация. Отсюда, разница в нотациях (кстати, маску подсети можно/нужно было задавать а-ля 0.0.255.0).
Соответственно, предполагалось что глобальная маршрутизация IPv6 будет осуществляться максимум по 48 битам. Что существенно облегчало построение таблиц маршрутизации. Но реальность распорядилась иначе.
Никому даже и в голову не пришло бы использовать CIDR для IPv6 ввиду бессмысленности и ввиду того что CIDR проектировался как временный механизм (ага, как обычно, чо). Поэтому, подсети IPv6 следует понимать в оригинальной трактовке.
Оператор связи может выдавать /64 на абонента. Никаких проблем это не принесёт. Но, в этом случае абонент лишается возможности настраивать несколько глобально маршрутизируемых подсетей на своей территории. В современных реалиях это очень полезно.
Проблема IPv6 не в его форме адреса, а в том что IPv6 предлагает возврат к классической модели маршрутизации на уровне оператора связи. Ни один оператор связи никогда не применял классическую маршрутизацию в своих «хомячных» сетях доступа.
С внедрениями покрупнее, есть сомнения (и вполне обоснованные) в адекватности механизмов автоконфигурации IPv6.
anonymous
( 14.12.21 00:47:21 MSK )
Что то я не понимаю хода ваших мыслей. Вопрос был вполне конкретный, как в сети распределять ~18 квадриллионов адресов, которые выделили. Одна l2 сеть с одним DHCP, это как то ну совсем… Такое количество адресов как бы подразумевает деление сети на l3 уровне. При таком количестве узлов не принципиально что выделят /64, /56, /48, /96. Это всё очень много и всё равно надо как-то делить. Просто я этим никогда не занимался, за ненадобностью, а сейчас встал вопрос, т.к. виртуализация/контейнеризация/SDN стали доступны для простых смертных, а тут ещё и ipv6 завезли, так что стало возможно взаимодействовать со всем этим из вне…
torm7 ★
( 14.12.21 10:12:27 MSK ) автор топика
Ответ на: комментарий от torm7 14.12.21 10:12:27 MSK
Такое количество адресов как бы подразумевает деление сети на l3 уровне
По мнению авторов ipv6 не подразумевает. Типа держи /64 на хост и хоть на каждый процесс по ip генерируй.
Хочешь делить — да без проблем, можешь руками, можешь по dhcpv6-pd раздавать, но slaac в префиксах больше /64 работать не будет: настраивай статикой или запускай обычный dhcpv6 в каждом сегменте (хотя и там без ra не обойдешься т.к. def. route по dhcpv6 больше не раздается).
Kolins ★★★
( 14.12.21 10:45:12 MSK )
Ответ на: комментарий от anonymous 14.12.21 00:47:21 MSK
Но, в этом случае абонент лишается возможности настраивать несколько глобально маршрутизируемых подсетей на своей территории. В современных реалиях это очень полезно.
Это как это? Глобальная маршрутизация делается между провайдерами. Провайдер внутри себя (если большой) может делать ещё какую-то, но в целом не нагруженную таблицами. Ну а пользователь — тебе выдали аплинк, всё что снизу твоё, маршрутизируй сколько хочешь, в чём проблема? Глобально ты всё равно виден как 1 порт в свитче у провайдера.
firkax ★★★★★
( 14.12.21 10:54:29 MSK )
Ответ на: комментарий от torm7 14.12.21 10:12:27 MSK
сколь помню задумка множества адресов была для того чтобы твою локальную сеть осмотреть было трудно, коль она все равно голым задом в тырнет светит.
так что адреса выдавать рандомно.
pfg ★★★★★
( 14.12.21 11:05:45 MSK )
Ответ на: комментарий от Kolins 14.12.21 10:45:12 MSK
Меня SLAAC не интересует, это для «домохозяек», которым воткнул и работает. Мне нужно немного больше чем просто «работает».
За ссылки спасибо, я микротик вроде настроил, поделил /64 на /66 сегменты. Когда руки дойдут, попробую в виртуальную сеть передать этот кусок.
torm7 ★
( 14.12.21 11:30:51 MSK ) автор топика
Ответ на: комментарий от torm7 14.12.21 11:30:51 MSK
Меня SLAAC не интересует, это для «домохозяек», которым воткнул и работает.
Вопрос не в домохозяйках. SLAAC позволяет скрывать мониторинг клиента разными интернет-сервисами при помощи расширения безопасности. Это САМЫЙ важный «побочный» эффект протокола. А в целом, SLAAC сильно упрощает настройку стека ipv6.
Далее, в отличие от ipv4, в шестой версии у каждой ноды, подключенной к сети, по сути, своя роль. Условно можно выделить, как минимум, три вида нод — хост, роутер и сервер. И с ними можно (и нужно) работать по разному.
Хост — обычный ip-чайник/телевизор, которому нужен просто доступ к интернету. Тут slaac просто прописан по хрестоматии.
Роутер — тут понятно, что это нода, через которую осуществляется доступ к сетям. Тут, понятно, dhcpv6-pd, если это подчиненные сети. Ну и есть еще разные уловки, что бы реализовать настройку роутинга через тот же RA протокол. Но так делают очень редко.
Сервер — нода, к которой требуется аргументированный доступ из интернета. Например, сайт. Тут чаще всего используется статически настроенные ip, и не морочат себе голову.
У современных провайдеров в настройках/тарифах клиент сам выбирает уровень услуги — т.е. я, как клиент, заказываю делегирование /64 или /48 (или /56). Если мне оно надо. Но все это, как мы понимаем, квартирный интернет. Для профессиональной деятельности все делается немного не так.
Ну и последнее — как делить префикс… Как сказали выше — да как угодно. Как хочется, так и надо делить. И надо помнить, что префикс, это НЕ броадкаст. Если вы повесили префикс на интерфейс, то никто не запрещает вам кусок этого префикса (например /96 из /64) зароутить вообще в другую часть сети.
В общем, ipv6 — это еще то чудо. 🙂
Oleg_Iu ★
( 14.12.21 18:00:45 MSK )
Ответ на: комментарий от torm7 14.12.21 10:12:27 MSK
Для начала — выкинуть тупую пропаганду про «стотыщщпиццот сикстилионов» из головы.
Уникаст IPv6-адрес — пара 64-битных чисел: . Идентификатор, прошу заметить, а не «номер» или «адрес».
То что пространство идентификаторов интерфейса 64-бита, не значит что их должно быть/будет 2^64.
Избыточность пространства идентификаторов интерфейса позволяет решить задачу перенумерации хостов в случае смены провайдера: она не требуется. Большое количество подсетей позволяет без проблем настраивать адресное пространство на разных площадках, с возможностью маршрутизации между ними.
Ещё раз. В IPv6 — классовая маршрутизация. Поэтому, маршрутизация по префиксам > /64 невозможна, даже если в какой-то реализации она «работает».
Соответственно, распределить пространство идентификаторов интерфейсов можно единственным способом: выдавать из него 64-битные идентификаторы.
Делается это через механизм автоконфигурации.
- Хост рассчитывает 64-битный идентификатор интерфейса.
- Хост проверяет, что идентификатор не занят.
- Хост формирует локальный адерс: .
- Хост использует механизм ND (neighbor discovery) либо для дальнейшей поиска маршрутизатора и дальнейшей автоконфигурации, либо для поиска DHCPv6 сервера.
Поэтому, в простых ситуациях достаточно включить поддержку IPv6 в совместимом маршрутизаторе, а дальше «оно само».
anonymous
( 14.12.21 22:08:15 MSK )
Ответ на: комментарий от firkax 14.12.21 10:54:29 MSK
Это как это? Глобальная маршрутизация делается между провайдерами.
Возьмём из головы пример. В наличии: домашняя беспроводная, домашняя проводная, домашняя беспроводная гостевая, DMZ для торрентокачалки.
Если бы провайдер не жлобился бы и выдавал несколько подсетей, задача сегментирования значительно бы упростилась: для каждой подсети отдельный механизм (авто)конфигурации, для каждой подсети свои правила доступа во внешние сети, для каждой подсети свои правила маршрутизации между подсетями. И всё это управлялось бы строго в одном месте.
anonymous
( 14.12.21 22:27:48 MSK )
Итого, пообщался со своим провайдером(«ЭР-ТЕЛЕКОМ»), они сказали что выделяют только префикс /64 и в обозримом будущем другой выделять не будут. На этом теоретические выкладки о SLAAC, автоконфигурации и как бы было хорошо если бы…, можно прекращать. Имею то что имею. Настроил как советовал Kolins
[rav@MikroTik] > /ipv6/dhcp-client/ print detail Flags: D - dynamic; X - disabled, I - invalid 0 interface=dom.ru status=bound duid="0x00030001cc2de078ef45" dhcp-server-v6=fe80::a67b:2cff:fe23:121f request=prefix add-default-route=yes default-route-distance=1 use-peer-dns=no dhcp-options="" pool-name="dhcp_v6_pool" pool-prefix-length=112 prefix-hint=::/0 dhcp-options="" prefix=xxxx:xxxx:xxxx:xxxx::/64, 23h39m37s [rav@MikroTik] > /ipv6/pool/print detail Flags: D - dynamic 0 D name="dhcp_v6_pool" prefix=xxxx:xxxx:xxxx:xxxx::/64 prefix-length=112 expires-after=23h54m5s [rav@MikroTik] > /ipv6/dhcp-server/print detail Flags: D - dynamic; X - disabled, I - invalid 0 name="v6_dhcp" interface=br1-lan address-pool=dhcp_v6_pool lease-time=3m rapid-commit=yes use-radius=no preference=255 dhcp-option="" route-distance=1 allow-dual-stack-queue=no duid="0x00030001cc2de078ef45" Вопрос, как настроить debian что бы этот префикс получить? Запись request_prefix 1 в /etc/network/interfaces ничего не дала.
torm7 ★
( 15.12.21 11:56:18 MSK ) автор топика
Ответ на: комментарий от torm7 15.12.21 11:56:18 MSK
Вопрос, как настроить debian что бы этот префикс получить? Запись request_prefix 1 в /etc/network/interfaces ничего не дала.
Если не ошибаюсь, то там может принимать pd wide-dhcpv6-client . В сети, если не ошибаюсь, полно описаний, как это сделать.
Oleg_Iu ★
( 15.12.21 13:21:26 MSK )
Ответ на: комментарий от torm7 15.12.21 11:56:18 MSK
Но там веселуха конечно, ты по dhcpv6-pd-client получаешь префикс и должен его скриптами передать в dhcpv6-server/radvd/dnsmasq для раздачи в подсеть. Автоматики в wide/kea/isc dhcp не было, но я этим проектом летом 2020 занимался (и у меня был не debian, а китайский sdk под MT7621), может кто и довел до ума.
Kolins ★★★
( 15.12.21 13:29:42 MSK )
Последнее исправление: Kolins 15.12.21 13:35:22 MSK (всего исправлений: 1)
Ответ на: комментарий от Kolins 15.12.21 13:29:42 MSK
Kolins от туда и брал. Правда глубоко погрузиться не удалось, времени не было. Oleg_Iu wide-dhcp не пробовал, с ним в wiki mikrotik передают префикс, если с ics не получится, то с ним попробую.
torm7 ★
( 15.12.21 14:04:20 MSK ) автор топика
Ответ на: комментарий от anonymous 14.12.21 22:27:48 MSK
Для этого достаточно одной сети из 256 адресов выше крыши. Надо только использовать адекватные инструменты без нелепых ограничений вида «без /48 не работаю». Это же твоя личная сеть, ты не ограничен в ней никакими стандартами, можешь даже свой кастомный dhcp написать, плюя на любые бумажки и решая свою личную задачу. Стандарт регламентирует только интерфейс аплинка.
firkax ★★★★★
( 15.12.21 14:46:47 MSK )
Ответ на: комментарий от firkax 15.12.21 14:46:47 MSK

Проблема только в том, что программы могут с тобой не согласиться. Например, я делал сеть с префиксом /107, но временные адреса в ней никто получить не мог (что в целом ни разу не удивительно, но было бы прикольно, если бы где-то это отработало)
Khnazile ★★★★★
( 15.12.21 15:10:09 MSK )
Ответ на: комментарий от Khnazile 15.12.21 15:10:09 MSK
Что значит «не мог»? Говорю же — ты можешь написать свой dhcp client, который будет получать какие угодно адреса по какому угодно протоколу. То, что какие-то программы не умеют получать адреса в /107 — это проблема этих программ, а не сетей /107.
Впрочем, повторюсь, ipv6 весь какое-то недоразумение, и вполне возможно младшие 64 бита адреса в итоге будут использовать для чего-то другого, а настоящий адрес останется 64-битным.
firkax ★★★★★
( 15.12.21 15:20:03 MSK )
Последнее исправление: firkax 15.12.21 15:20:18 MSK (всего исправлений: 1)
Ответ на: комментарий от firkax 15.12.21 15:20:03 MSK
А операционную систему мне тоже свою написать? Нафиг мне сеть, с которой не смогут работать реальные устройства из этого мира?
Khnazile ★★★★★
( 15.12.21 15:35:41 MSK )
Ответ на: комментарий от Khnazile 15.12.21 15:35:41 MSK
А операционную систему мне тоже свою написать?
Почему нет? Линус написал же и теперь она в каждом утюге. 🙂
anc ★★★★★
( 15.12.21 15:37:45 MSK )
По сабжу — твой провайдер гондон, а ты страдаешь фигней, пытаясь подстроится под него. Если очень надо много сетей, и больше вариантов нет — получи адресное пространство у какого-нибудь HE и делай NAT в адресное пространство сети /64 на роутере. Да это стремный костыль, но лучше костылять трансляцию, чем стремную адресацию внутри сети.
Khnazile ★★★★★
( 15.12.21 15:42:41 MSK )
Ответ на: комментарий от Khnazile 15.12.21 15:42:41 MSK
А может и не гондон, может ТС с чего-то решил что вся /64 его личная.
IPv6 в Cisco или будущее уже рядом

Протокол IPv6 является наследником повсеместно используемого сегодня протокола IP четвёртой версии, IPv4, и естественно, наследует большую часть логики работы этого протокола. Так, например, заголовки пакетов в IPv4 и IPv6 очень похожи, используется та же логика пересылки пакетов – маршрутизация на основе адреса получателя, контроль времени нахождения пакета в сети с помощью TTL и так далее. Однако, есть и существенные отличия: кроме изменения длины самого IP-адреса, произошёл отказ от использования широковещания в любой форме, включая направленное (Broadcast, Directed broadcast). Вместо него теперь используются групповые рассылки (multicast). Также исчез ARP-протокол, функции которого возложены на ICMP, что заставит отделы информационной безопасности внимательнее относиться к данному протоколу, так как простое его запрещение уже стало невозможным. Мы не станем описывать все изменения, произошедшие с протоколом, так как читатель сможет с лёгкостью найти их на большинстве IT-ресурсов. Вместо этого покажем практические примеры настройки устройств на базе Cisco IOS для работы с IPv6.
Многие начинающие сетевые специалисты задаются вопросом: «Нужно ли сейчас начинать изучать IPv6?» На наш взгляд, сегодня уже нельзя подходить к IPv6 как к отдельной главе или технологии, вместо этого все изучаемые техники и методики следует отрабатывать сразу на обеих версиях протокола IP. Так, например, при изучении работы протокола динамической маршрутизации EIGRP стоит проводить настройку тестовых сетей в лаборатории как для IPv4, так и для IPv6 одновременно. Перейдём от слов к делу!
Адресация в IPv6
Длина адреса протокола IPv6 составляет 128 бит, что в четыре раза больше той, которая была в IPv4. Количество адресов IPv6 огромно и составляет 2 128 ≈3,4•10 38 . Сам адрес протокола IPv6 можно разделить на две части: префикс и адрес хоста, который ещё называют идентификатором интерфейса. Такое деление очень похоже на то, что использовалось в IPv4 при бесклассовой маршрутизации.

Адреса в IPv6 записываются в шестнадцатеричной форме, каждая группа из четырёх цифр отделяется двоеточием. Например, 2001:1111:2222:3333:4444:5555:6666:7777. Маска указывается через слеш, то есть, например, /64. В адресе протокола IPv6 могут встречаться длинные последовательности нулей, поэтому предусмотрена сокращённая запись адреса. Во-первых, могут не записываться начальные нули каждой группы цифр, то есть вместо адреса 2001:0001:0002:0003:0004:0005:0006:7000 можно записать 2001:1:2:3:4:5:6:7000. Конечные нули при этом не удаляются. В случае, когда группа цифр в адресе (или несколько групп подряд) содержит только нули, она может быть заменена на двойное двоеточие. Например, вместо адреса 2001:1:0:0:0:0:0:1 может использоваться сокращённая запись вида 2001:1::1. Стоит отметить, что сократить адрес таким образом можно только один раз. Ниже приводятся правильные и неправильные формы записи IPv6 адресов.
Правильная запись.
Ошибочная форма.
Забавные сокращения.
::/0 – шлюз по умолчанию ::1 – loopback 2001:2345:6789::/64 – адрес какой-то сети
Однако не все адреса протокола IPv6 могут быть назначены узлам в глобальной сети. Существует несколько зарезервированных диапазонов и типов адресов. Адрес IPv6 может относиться к одному из трёх следующих типов.
Адреса Unicast очень похожи на аналогичные адреса протокола IPv4, они могут назначаться интерфейсам сетевых устройств, серверам и хостам конечных пользователей. Групповые или Multicast адреса предназначены для доставки пакетов сразу нескольким получателям, входящим в группу. При использовании Anycast адресов данные будут получены ближайшим узлом, которому назначен такой адрес. Стоит обратить особое внимание на то, что в списке поддерживаемых протоколом IPv6 адресов отсутствуют широковещательные адреса. Даже среди Unicast адресов существует более мелкое дробление на типы.
- Link local
- Global unicast
- Unique local
Адреса, относящиеся к группе Unique local, описаны в RFC 4193 и по своему назначению очень похожи на приватные адреса протокола IPv4, описанные в RFC 1918. Адреса группы Link local предназначены для передачи информации между устройствами, подключёнными к одной L2-сети. Большинство адресов из диапазона Global unicast могут быть назначены интерфейсам конкретных сетевых узлов. Список зарезервированных адресов представлен ниже.
| IPv6 адрес | Длина префикса | Описание | Заметки |
| :: | 128 | — | Аналог 0.0.0.0 в IPv4 |
| ::1 | 128 | Loopback | Аналог 127.0.0.1 в IPv4 |
| ::xx.xx.xx.xx | 96 | Встроенный IPv4 | IPv4 совместимый. Устарел, не используется |
| ::ffff:xx.xx.xx.xx | 96 | IPv4, отображённый на IPv6 | Для хостов, не поддерживающих IPv6 |
| 2001:db8:: | 32 | Документирование | Зарезервирован для примеров. RFC 3849 |
| fe80:: — febf:: | 10 | Link-Local | Аналог 169.254.0.0/16 в IPv4 |
| fec0:: — feff:: | 10 | Site-Local | Аналог сетей 10.0.0.0, 172.16.0.0, 192.168.0.0. RFC 3879. Устарел. |
| fc00:: | 7 | Unique Local Unicast | Пришёл на смену Site-Local. RFC 4193 |
| ffxx:: | 8 | Multicast | — |
Базовая настройка интерфейсов
Включение маршрутизации IPv6 производится с помощью команды ipv6 unicast-routing. В принципе, поддержка маршрутизатором протокола IPv6 будет производиться и без введения указанной команды, однако без неё устройство будет выполнять функции хоста для IPv6. Многие команды, к которым вы привыкли в IPv4, присутствуют также и в IPv6, однако для них вместо опции ip нужно будет указывать слово ipv6.
Настройка адреса на интерфейсе возможна несколькими способами. При одном лишь включении поддержки IPv6 на интерфейсе автоматически назначается link-local адрес.
R1#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R1(config)#int gi0/0
R1(config-if)#ipv6 enable
R1(config-if)#^Z
R1#show ipv6 int bri
Ethernet0/0 [administratively down/down]
unassigned
GigabitEthernet0/0 [up/up]
FE80::C800:3FFF:FED0:A008
Вычисление части адреса link-local производится с помощью алгоритма EUI-64 на основе MAC-адреса интерфейса. Для этого в середину 48 байтного МАС-адреса автоматически дописывается два байта, которые в шестнадцатеричной записи имеют вид FFFE, а также производится инвертирование седьмого бита первого байта MAC-адреса. На рисунках ниже схематично показана работа обсуждаемого алгоритма.
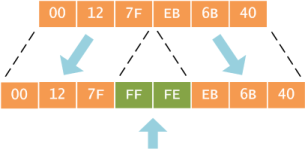
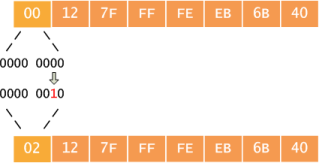
Сравните указанный выше link-local адрес с физическим адресом интерфейса Gi0/0 маршрутизатора (несущественная часть вывода команды sho int Gi0/0 удалена).
R1#show int gi0/0
GigabitEthernet0/0 is up, line protocol is up
Hardware is i82543 (Livengood), address is ca00.3fd0.a008 (bia ca00.3fd0.a008)
EUI-64 часть IPv6 адреса: C800:3FFF:FED0:A008.
Назначение адреса на интерфейс вручную производится с помощью команды ipv6 address, например, ipv6 address 2001:db8::1/64. Возможно лишь указывать адрес сегмента сети, оставшаяся часть будет назначаться автоматически с использованием преобразованного с помощью EUI-64 физического адреса интерфейса, для чего используйте команду с ключевым словом eui-64.
R2#conf t
R2(config)#int gi0/0
R2(config-if)#ipv ad 2001:db8::/64 eui-64
R2(config-if)#^Z
R2#show ipv6 int bri
Ethernet0/0 [administratively down/down]
unassigned
GigabitEthernet0/0 [up/up]
FE80::C801:42FF:FEA4:8
2001:DB8::C801:42FF:FEA4:8
Обмен сообщениями внутри одного L2-сегмента только с помощью адресов link-local возможен и в некоторых случаях используется, однако в большинстве ситуаций интерфейсу должен быть назначен обычный маршрутизируемый IPv6-адрес. Так, например, соседство по протоколам OSPF или EIGRP устанавливается с использованием link-local адресов. Автоматический поиск соседа и другие служебные протоколы также работают по link-local адресам.
R1#sho ipv6 int brief
Ethernet0/0 [administratively down/down]
unassigned
GigabitEthernet0/0 [up/up]
FE80::C800:42FF:FEA4:8
2001:DB8::1
R1#sho ipv ei ne
IPv6-EIGRP neighbors for process 1
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 Link-local address: Gi0/0 12 00:01:03 39 234 0 3
FE80::C801:42FF:FEA4:8
R1#ping FE80::C801:42FF:FEA4:8
Output Interface: GigabitEthernet0/0
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to FE80::C801:42FF:FEA4:8, timeout is 2 seconds:
Packet sent with a source address of FE80::C800:42FF:FEA4:8
.
Success rate is 100 percent (5/5), round-trip min/avg/max = 4/20/48 ms
Естественно, сохранилась и возможность автоматического назначения адреса в IPv6 с помощью протокола DHCP. Стоит, правда, отметить, что в IPv6 существует два различных типа DHCP: stateless и stateful, настройка которых производится с помощью команд ipv6 address autoconfig и ipv6 address dhcp соответственно.
Настройка «серверной» части практически не отличается от таковой для IPv4. Сначала требуется создать DHCP пул, после чего привязать его к интерфейсу. Привязка к интерфейсу осуществляется в явном виде с помощью интерфейсной команды ipv6 dhcp server name, где в качестве name выступает имя ранее созданного пула DHCP. Здесь же стоит отметить, что DHCPv6 не позволяет исключать определённые IPv6 адреса из диапазона так, как это делалось для IPv4 с помощью команды ip dhcp excluded-address, равно как и осуществлять ручную привязку адреса к клиенту.
ipv6 dhcp pool test
address prefix 2001:1::/64
dns-server 2001:1::1
domain-name foxnetwork.ru
interface GigabitEthernet1/0
no ip address
negotiation auto
ipv6 address 2001:1::1/64
ipv6 dhcp server test
ipv6 nd managed-config-flag
ipv6 nd other-config-flag
Команда ipv6 nd managed-config-flag указывает клиенту на необходимость использования DHCPv6 для получения адреса. Также можно уведомить клиента о необходимости получения дополнительных параметров (адрес DNS-сервера или имя домена) с помощью команды ipv6 nd other-config-flag.
Просмотреть информацию о настроенных пулах DHCPv6 можно с помощью команды show ipv6 dhcp pool.
R2#sho ipv dhcp pool
DHCPv6 pool: test
Address allocation prefix: 2001:1::/64 valid 172800 preferred 86400 (1 in use, 0 conflicts)
DNS server: 2001:1::1
Domain name: foxnetwork.ru
Active clients: 1
Список текущих клиентов отображается в выводе команды show ipv6 dhcp binding.
R2#show ipv6 dhcp binding
Client: FE80::C801:26FF:FEFC:1C
DUID: 00030001CA0126FC0008
Username : unassigned
IA NA: IA ID 0x00050001, T1 43200, T2 69120
Address: 2001:1::CDFD:B868:5AFF:F258
preferred lifetime 86400, valid lifetime 172800
expires at Mar 12 2015 08:56 AM (170469 seconds)
Сброс текущих привязок DHCPv6 производится с помощью команды clear ipv6 dhcp binding .
Вывод списка интерфейсов, на которых задействован протокол DHCPv6 производится с помощью команды show ipv6 dhcp interface.
R2#show ipv6 dhcp interface
GigabitEthernet1/0 is in server mode
Using pool: test
Preference value: 0
Hint from client: ignored
Rapid-Commit: disabled
Кроме stateful DHCPv6 оборудование Cisco поддерживает также версию DHCPv6 Lite, отличающуюся отсутствием команды address prefix внутри пула и интерфейсной опции managed-config-flag. В этом случае адрес интерфейса узла вычисляется на основе сообщения Router Advertisement.
ipv6 dhcp pool test
dns-server 2001:1::1
domain-name foxnetwork.ru
interface GigabitEthernet1/0
no ip address
negotiation auto
ipv6 address 2001:1::1/64
ipv6 dhcp server test
ipv6 nd other-config-flag
Также как и для IPv4 L3-коммутаторы и маршрутизаторы Cisco могут выполнять функции DHCP ретранслятора, для чего используется команда ipv6 dhcp relay destination ipv6-address, где ipv6-address – адрес сервера DHCPv6.
В DHCPv6 появилась очень интересная возможность – делегирование префиксов. Данная функция, на наш взгляд, будет наиболее востребована операторами связи, так как позволяет делегировать клиенту большой префикс для распределения внутри его корпоративной сети. Рассмотрим работу функции Prefix Delegation на примере. На схеме ниже маршрутизатор Delegating_router представляет оконечное оборудование оператора, CE_router – граничное оборудование клиента. Маршрутизаторы Client_net1 и Client_net2 эмулируют устройства, подключённые в разные IPv6-сети клиента. Стоит особо подчеркнуть, что Client_net1 и Client_net2 находятся в разных подсетях, между коммутатором SW1 и маршрутизатором CE_router поднят транк, в котором существуют две виртуальные сети №2 (для Client_net1) и №3 (для Client_net2). На маршрутизаторе CE_router для каждой виртуальной сети настраивается свой подынтерфейс.
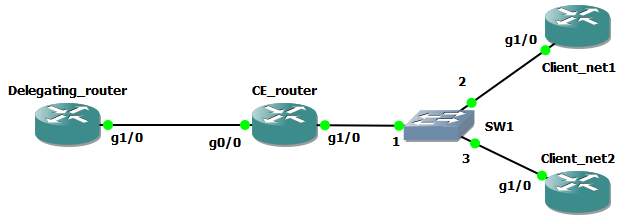
Первое, с чего следует начать настройку, — сконфигурировать адреса на канале между маршрутизаторами Delegating_router и CE_router.
Delegating_router(config)#int gi1/0
Delegating_router(config-if)#no sh
Delegating_router(config-if)#ipv6 address 2001:DB8:1::1/64
Delegating_router(config-if)#^Z
Delegating_router#
CE_router(config)#int gi0/0
CE_router(config-if)#no sh
CE_router(config-if)# ipv6 address 2001:DB8:1::2/64
CE_router(config-if)#^Z
CE_router#
На маршрутизаторе Delegating_router создадим локальный пул, из которого будет производиться раздача префиксов клиентам.
Delegating_router(config)#ipv6 local pool c_prefix 2001:DB8::/40 48
Пул c_prefix определён префиксом 2001:DB8::/40, из которого клиентам будут раздаваться меньшие префиксы с маской /48.
Вслед за локальным пулом необходимо создать пул DHCPv6, который привязать к интерфейсу Gi1/0.
Delegating_router(config)#ipv6 dhcp pool customers
Delegating_router(config-dhcpv6)# prefix-delegation pool c_prefix
Delegating_router(config-dhcpv6)#int gi1/0
Delegating_router(config-if)#ipv6 dhcp server customers
Настройка делегирующего маршрутизатора на этом завершается. На граничном маршрутизаторе клиента делегируемый префикс необходимо принять с помощью интерфейсной команды ipv6 dhcp client pd prefix, где prefix – имя принимаемого префикса, это имя будет использоваться в дальнейшем.
CE_router#sho run int gi0/0
Building configuration.
Current configuration : 170 bytes
interface GigabitEthernet0/0
no ip address
ipv6 address 2001:DB8:1::2/64
ipv6 dhcp client pd prefix
end
CE_router#sho ipv dhcp interface gi0/0
GigabitEthernet0/0 is in client mode
Prefix State is OPEN
Renew will be sent in 3d10h
Address State is IDLE
List of known servers:
Reachable via address: FE80::C801:2FF:FEC8:1C
DUID: 00030001CA0102C80008
Preference: 0
Configuration parameters:
IA PD: IA ID 0x00040001, T1 302400, T2 483840
Prefix: 2001:DB8::/48
preferred lifetime 604800, valid lifetime 2592000
expires at Apr 09 2015 10:39 AM (2587501 seconds)
Information refresh time: 0
Prefix name: prefix
Prefix Rapid-Commit: disabled
Address Rapid-Commit: disabled
Адреса клиентских подсетей будут назначаться из полученного префикса. Так как данному клиенту был выделен префикс 2001:DB8::/48, то адреса конечных сетей будут, например, такими 2001:DB8:0:1::/64 и 2001:DB8:0:2::/64. Произведём соответствующую настройку подынтерфейсов маршрутизатора CE_router. Как видно из приведённого ниже листинга, адреса не указываются в явном виде, вместо этого используется полученный ранее от провайдера префикс.
CE_router#sho run int gi1/0.2
Building configuration.
Current configuration : 97 bytes
interface GigabitEthernet1/0.2
encapsulation dot1Q 2
ipv6 address prefix ::1:0:0:0:1/64
end
CE_router#sho run int gi1/0.3
Building configuration.
Current configuration : 97 bytes
interface GigabitEthernet1/0.3
encapsulation dot1Q 3
ipv6 address prefix ::2:0:0:0:1/64
end
Единственное, что осталось сделать – получить адреса на клиентских узлах.
Client_net1#conf t
Enter configuration commands, one per line. End with CNTL/Z.
Client_net1(config)#int gi1/0
Client_net1(config-if)#no sh
*Mar 10 11:38:07.959: %LINK-3-UPDOWN: Interface GigabitEthernet1/0, changed state to up
*Mar 10 11:38:08.959: %LINEPROTO-5-UPDOWN: Line protocol on Interface GigabitEthernet1/0, changed state to up
Client_net1(config-if)#ipv6 address autoconfig
Client_net1(config-if)#exi
Client_net1(config)#exi
Client_net1#sho ipv int bri
GigabitEthernet1/0 [up/up]
FE80::C803:1EFF:FE3C:1C
2001:DB8:0:1:C803:1EFF:FE3C:1C
Client_net1#
Ещё одной возможностью, связанной с использованием префиксов, является опция глобального определения префикса для маршрутизатора. Такая возможность позволяет упростить процедуру назначения адресов на интерфейсы маршрутизатора или L3-коммутатора. Допустим, что организации выделена сеть 2001:db8:1::/48. Это означает, что все адреса будут начинаться с «2001:db8:1». Начать нужно с определения префикса.
R1(config)#ipv6 general-prefix ?
WORD General prefix name
R1(config)#ipv6 general-prefix fox ?
6rd 6rd
6to4 6to4
X:X:X:X::X/ IPv6 prefix
R1(config)#ipv6 general-prefix fox 2001:DB8:1::/48
R1(config)#do sho ipv gene
IPv6 Prefix fox, acquired via Manual configuration
2001:DB8:1::/48 Valid lifetime infinite, preferred lifetime infinite
После того, как префикс сконфигурирован, можно переходить к его непосредственному назначению на интерфейс.
R1(config)#int gi0/0
R1(config-if)#ipv address ?
WORD General prefix name
X:X:X:X::X IPv6 link-local address
X:X:X:X::X/ IPv6 prefix
autoconfig Obtain address using autoconfiguration
dhcp Obtain a ipv6 address using dhcp
R1(config-if)#ipv address fox ?
X:X:X:X::X/ IPv6 prefix
R1(config-if)#ipv address fox 0:0:0:1::1/64
R1(config-if)#^Z
R1#sho ipv int bri
Ethernet0/0 [administratively down/down]
GigabitEthernet0/0 [up/up]
FE80::C801:3CFF:FED0:8
2001:DB8:1:1::1
R1#sho run int gi0/0
Building configuration.
Current configuration : 144 bytes
interface GigabitEthernet0/0
no ip address
duplex full
speed 1000
media-type gbic
negotiation auto
ipv6 address fox ::1:0:0:0:1/64
end
Стоит обратить особое внимание на синтаксис, который используется при назначении адреса на интерфейс. Левая часть адреса заполняется битами из основного префикса (количество бит соответствует длине основного префикса). Оставшаяся часть берётся из указанного в команде ipv6 address адреса. В принципе, левая часть указываемого на интерфейсе адреса может быть любой, в примере выше она заполнена нулями.
Использование основного префикса может быть совмещено с автоматическим назначением адреса на интерфейс с помощью SLAAC.
R1#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R1(config)#int e0/0
R1(config-if)#ipv add fox 0:0:0:2::/64 ?
anycast Configure as an anycast
cga Use CGA interface identifier
eui-64 Use eui-64 interface identifier
R1(config-if)#ipv add fox 0:0:0:2::/64 eui-64
R1(config-if)#^Z
R1#sho ipv int bri
Ethernet0/0 [administratively down/down]
FE80::C801:3CFF:FED0:6
2001:DB8:1:2:C801:3CFF:FED0:6
GigabitEthernet0/0 [up/up]
FE80::C801:3CFF:FED0:8
2001:DB8:1:1::1
С помощью команды sho ipv general-prefix можно просмотреть, на каких интерфейсах сконфигурированы адреса, использующие определённый основной префикс.
R1#sho ipv general-prefix
IPv6 Prefix fox, acquired via Manual configuration
2001:DB8:1::/48 Valid lifetime infinite, preferred lifetime infinite
GigabitEthernet0/0 (Address command)
Ethernet0/0 (Address command)
Справедливости ради, стоит отметить, что допускается определить несколько префиксов с одним именем. На интерфейсы будут назначены все сконфигурированные адреса.
R1#sho run | i general
ipv6 general-prefix fox 2001:DB8:1::/48
ipv6 general-prefix fox 2001:DB8:2::/48
R1#sho ipv gene
IPv6 Prefix fox, acquired via Manual configuration
2001:DB8:1::/48 Valid lifetime infinite, preferred lifetime infinite
2001:DB8:2::/48 Valid lifetime infinite, preferred lifetime infinite
GigabitEthernet0/0 (Address command)
Ethernet0/0 (Address command)
R1#sho ipv int bri
Ethernet0/0 [administratively down/down]
FE80::C801:3CFF:FED0:6
2001:DB8:1:2:C801:3CFF:FED0:6
2001:DB8:2:2:C801:3CFF:FED0:6
GigabitEthernet0/0 [up/up]
FE80::C801:3CFF:FED0:8
2001:DB8:1:1::1
2001:DB8:2:1::1
Как уже было отмечено ранее, в IPv6 протокол ARP более не используется. Определение соседей производится с помощью протокола NDP (Neighbor Discovery Protocol) путём обмена сообщениями ICMP, отправляя их на групповой адрес FF02::1.
R1#show ipv6 neighbors
IPv6 Address Age Link-layer Addr State Interface
FE80::C801:42FF:FEA4:8 25 ca01.42a4.0008 STALE Gi0/0
В операционных системах семейства Windows также присутствует возможность просмотра списка соседей (аналог команды arp –a), правда, теперь придётся использовать более длинный системный вызов.
C:\>netsh interface ipv6 show neighbors
Interface 1: Loopback Pseudo-Interface 1
Internet Address Physical Address Type
-------------------------------------------- ----------------- -----------
ff02::c Permanent
ff02::16 Permanent
ff02::1:2 Permanent
ff02::1:3 Permanent
ff02::1:ff1e:f939 Permanent
Interface 24: Подключение по локальной сети 4
Internet Address Physical Address Type
-------------------------------------------- ----------------- -----------
2001:db8:0: 5::1 00-11-5c-1b-3d-49 Reachable (Router)
fe80::ffff:ffff:fffe Unreachable Unreachable
fe80::211:5cff:fe1b:3d49 00-11-5c-1b-3d-49 Stale (Router)
fe80::218:f3ff:fe73:33d7 Unreachable Unreachable
fe80::a541:1a9:3b2d:7734 Unreachable Unreachable
ff02::1 33-33-00-00-00-01 Permanent
ff02::2 33-33-00-00-00-02 Permanent
ff02::c 33-33-00-00-00-0c Permanent
ff02::16 33-33-00-00-00-16 Permanent
ff02::1:2 33-33-00-01-00-02 Permanent
ff02::1:3 33-33-00-01-00-03 Permanent
ff02::1:ff00:0 33-33-ff-00-00-00 Permanent
ff02::1:ff00:1 33-33-ff-00-00-01 Permanent
Похожим образом осуществляется поиск маршрутизаторов в локальном сегменте, правда, в этом случае отправка пакетов производится на адрес FF02::2. Заинтересованный узел отправляет сообщение RS (Router Solicitation), на которое получает ответ RA (Router Advertisement) от маршрутизатора. Указанный ответ содержит параметры работы IP-протокола в данной сети. Описанный процесс представлен на рисунке ниже.
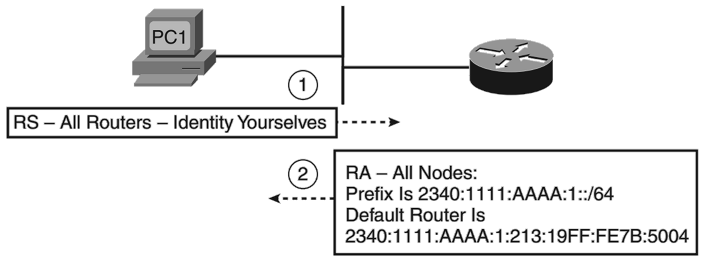
Обнаружение маршрутизатора, подключённого к сегменту локальной сети, используется для получения узлом адреса IPv6 с помощью процедуры stateless address autoconfiguration (SLAAC), которую ошибочно ещё называют Stateless DHCP.
Статические маршруты
Таблица маршрутизации протокола IPv6 по умолчанию содержит не только непосредственно подключённые сетки, но также и локальные адреса. Кроме того, в ней присутствует маршрут на групповые адреса.
R1#sho ipv6 routing
IPv6 Routing Table - Default - 3 entries
Codes: C - Connected, L - Local, S - Static, U - Per-user Static route
HA - Home Agent, MR - Mobile Router, R - RIP, I1 - ISIS L1
I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary, D - EIGRP
EX - EIGRP external
C 2001:DB8::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8::1/128 [0/0]
via GigabitEthernet0/0, receive
L FF00::/8 [0/0]
via Null0, receive
Привычным способом задаются статические маршруты в IPv6. Единственное, что хотелось бы отметить, что при использовании link-local адресов, кроме самого адреса следующего перехода, необходимо указать и интерфейс.
R1#conf t
R1(config)#ipv ro ::/0 gi0/0 FE80::C801:42FF:FEA4:8
R1(config)#^Z
R1#sho ipv6 routing
IPv6 Routing Table - Default - 4 entries
Codes: C - Connected, L - Local, S - Static, U - Per-user Static route
HA - Home Agent, MR - Mobile Router, R - RIP, I1 - ISIS L1
I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary, D - EIGRP
EX - EIGRP external
S ::/0 [1/0]
via FE80::C801:42FF:FEA4:8, GigabitEthernet0/0
C 2001:DB8::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8::1/128 [0/0]
via GigabitEthernet0/0, receive
L FF00::/8 [0/0]
via Null0, receive
Динамическая маршрутизация
Настройка динамической маршрутизации в IPv6 немногим сложнее. Во-первых, для добавления интерфейса в процесс маршрутизации команда network более не используется. Вместо этого на интерфейсе должна быть дана команда ipv6 eigrp 1 для включения EIGRP 1, либо ipv6 ospf 1 area 0 для добавления интерфейса в магистральную зону процесса OSPF 1. Процесс маршрутизации EIGRP для IPv6 по умолчанию выключен, поэтому его потребуется включить, но самой «приятной» особенностью является необходимость следить за назначением параметра router-id. При IPv4 маршрутизации данный параметр мог быть назначен вручную, либо выбран автоматически на основании IP-адресов, назначенных интерфейсам. Если на устройстве нет IPv4 адресов вовсе, то router-id для процессов динамической маршрутизации IPv6 может быть назначен только вручную.
Для элементарной сети, представленной на схеме ниже, проведём настройку EIGRP. Маршрутизатор R1 на интерфейсе Gi0/0 имеет адрес 2001:db8::1/64, R2 – 2001:db8::2/64.

Сначала настроим маршрутизатор R1.
R1#conf t
R1(config)#ipv6 router eigrp 1
R1(config-rtr)#no shut
R1(config-rtr)#eigrp router-id 1.1.1.1
R1(config-rtr)#int gi0/0
R1(config-if)#ipv6 eigrp 1
R1(config-if)#^Z
R1#sho ipv6 eigrp interfaces
EIGRP-IPv6 Interfaces for AS(1)
Xmit Queue PeerQ Mean Pacing Time Multicast Pending
Interface Peers Un/Reliable Un/Reliable SRTT Un/Reliable Flow Timer Routes
Gi0/0 0 0/0 0/0 0 0/0 0 0
R1#show ipv6 eigrp neighbors
EIGRP-IPv6 Neighbors for AS(1)
Введём аналогичные команды на R2, после это EIGRP-соседство устанавливается между двумя маршрутизаторами.
R1#
*Mar 21 12:01:13.763: %DUAL-5-NBRCHANGE: EIGRP-IPv6 1: Neighbor FE80::C80E:21FF:FEE4:8 (GigabitEthernet0/0) is up: new adjacency
R1#show ipv6 eigrp neighbors
EIGRP-IPv6 Neighbors for AS(1)
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 Link-local address: Gi0/0 11 00:00:15 40 240 0 2
FE80::C80E:21FF:FEE4:8
На каждом из маршрутизаторов создадим интерфейс Loopback1, который будет эмулировать подключённые сети. На R1 интерфейсу Loopback1 назначим IPv6 адрес 2001:db8:1::1/64, на R2 – 2001:db8:2::1/64. Передать информацию о новых сетях в протокол динамической маршрутизации можно двумя способами: включить новый интерфейс в соответствующий протокол, либо выполнить перераспределение маршрутов (redistribute). Единственное, о чём следует помнить во втором случае, — о необходимости указания метрик. Метрика может быть указана либо в явном виде для каждого перераспределения, либо при помощи команды default-metric. Данное действие полностью аналогично IPv4, поэтому подробно останавливаться не будем.
Вывод с маршрутизатора R1.
R1#show ipv6 route
IPv6 Routing Table - default - 6 entries
Codes: C - Connected, L - Local, S - Static, U - Per-user Static route
B - BGP, R - RIP, H - NHRP, I1 - ISIS L1
I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary, D - EIGRP
EX - EIGRP external, ND - ND Default, NDp - ND Prefix, DCE - Destination
NDr - Redirect, O - OSPF Intra, OI - OSPF Inter, OE1 - OSPF ext 1
OE2 - OSPF ext 2, ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2, l - LISP
C 2001:DB8::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8::1/128 [0/0]
via GigabitEthernet0/0, receive
C 2001:DB8:1::/64 [0/0]
via Loopback1, directly connected
L 2001:DB8:1::1/128 [0/0]
via Loopback1, receive
EX 2001:DB8:2::/64 [170/2560512]
via FE80::C80E:21FF:FEE4:8, GigabitEthernet0/0
L FF00::/8 [0/0]
via Null0, receive
R1#sho run int loo 1
Building configuration.
Current configuration : 87 bytes
interface Loopback1
no ip address
ipv6 address 2001:DB8:1::1/64
ipv6 eigrp 1
end
R1#sho run | sec router
ipv6 router eigrp 1
eigrp router-id 1.1.1.1
Вывод с маршрутизатора R2.
R2#show ipv6 route
IPv6 Routing Table - default - 6 entries
Codes: C - Connected, L - Local, S - Static, U - Per-user Static route
B - BGP, R - RIP, H - NHRP, I1 - ISIS L1
I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary, D - EIGRP
EX - EIGRP external, ND - ND Default, NDp - ND Prefix, DCE - Destination
NDr - Redirect, O - OSPF Intra, OI - OSPF Inter, OE1 - OSPF ext 1
OE2 - OSPF ext 2, ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2, l - LISP
C 2001:DB8::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8::2/128 [0/0]
via GigabitEthernet0/0, receive
D 2001:DB8:1::/64 [90/130816]
via FE80::C80D:1EFF:FE28:8, GigabitEthernet0/0
C 2001:DB8:2::/64 [0/0]
via Loopback1, directly connected
L 2001:DB8:2::1/128 [0/0]
via Loopback1, receive
L FF00::/8 [0/0]
via Null0, receive
R2#sho run int lo 1
Building configuration.
Current configuration : 73 bytes
interface Loopback1
no ip address
ipv6 address 2001:DB8:2::1/64
end
R2#sho run | sec router
ipv6 router eigrp 1
eigrp router-id 2.2.2.2
redistribute connected
default-metric 1000 1 100 100 1500
Если в сети используется протокол BGP, то для управления им придётся воспользоваться несколько иным подходом: в BGP не создаются различные процессы для IPv4 и IPv6. Вместо этого внутри одного «родительского» процесса деление на версии протокола IP производится с помощью команды address-family. Ниже приводится вывод с маршрутизатора R1. Настройка R2 выполнена аналогично.
R1#show run | sec router bgp
router bgp 65001
bgp router-id 1.1.1.1
bgp log-neighbor-changes
neighbor 2001:DB8::2 remote-as 65002
!
address-family ipv4
no neighbor 2001:DB8::2 activate
exit-address-family
!
address-family ipv6
network 2001:DB8:1::/64
neighbor 2001:DB8::2 activate
exit-address-family
R1#show bgp ipv6 summary
BGP router identifier 1.1.1.1, local AS number 65001
BGP table version is 3, main routing table version 3
2 network entries using 336 bytes of memory
2 path entries using 208 bytes of memory
2/2 BGP path/bestpath attribute entries using 272 bytes of memory
1 BGP AS-PATH entries using 24 bytes of memory
0 BGP route-map cache entries using 0 bytes of memory
0 BGP filter-list cache entries using 0 bytes of memory
BGP using 840 total bytes of memory
BGP activity 2/0 prefixes, 2/0 paths, scan interval 60 secs
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
2001:DB8::2 4 65002 12 12 3 0 0 00:07:24 1
% NOTE: This command is deprecated. Please use 'show bgp ipv6 unicast'
R1#show bgp ipv6 unicast summary
BGP router identifier 1.1.1.1, local AS number 65001
BGP table version is 3, main routing table version 3
2 network entries using 336 bytes of memory
2 path entries using 208 bytes of memory
2/2 BGP path/bestpath attribute entries using 272 bytes of memory
1 BGP AS-PATH entries using 24 bytes of memory
0 BGP route-map cache entries using 0 bytes of memory
0 BGP filter-list cache entries using 0 bytes of memory
BGP using 840 total bytes of memory
BGP activity 2/0 prefixes, 2/0 paths, scan interval 60 secs
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
2001:DB8::2 4 65002 12 12 3 0 0 00:07:34 1
R1#show bgp ipv6 unicast
BGP table version is 3, local router ID is 1.1.1.1
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 2001:DB8:1::/64 :: 0 32768 i
*> 2001:DB8:2::/64 2001:DB8::2 0 0 65002 i
На момент написания статьи (конец марта 2014 года) в глобальной таблице маршрутизации (BGP full view или BGP full table) насчитывалось примерно 500000 префиксов для IPv4 и около 17000 записей для IPv6.
Конфигурирование протокола OSPF для работы в сети IPv6 производится схожим образом. Протокол, который надо включать и настраивать, называется OSPFv3. Он полностью независим от IPv4. Третья версия протокола содержит ряд изменений и дополнений по сравнению с предыдущей реализацией OSPF.
interface GigabitEthernet0/0
no ip address
media-type gbic
speed 1000
duplex full
negotiation auto
ipv6 enable
ipv6 ospf 1 area 0
router ospfv3 1
router-id 1.1.1.1
address-family ipv6 unicast
redistribute connected
exit-address-family
Списки доступа
В списках доступа также есть небольшие изменения. Так, например, установка листа на интерфейс производится командой ipv6 traffic-filter, например, ipv6 traffic-filter TEST in.
R2#show run | section access
ipv6 access-list TEST
deny icmp any any echo-reply
deny icmp any any echo-request
permit ipv6 any any
R2#show ipv6 access-list
IPv6 access list test
deny icmp any any echo-reply sequence 10
deny icmp any any echo-request (5 matches) sequence 20
permit ipv6 any any (28 matches) sequence 30
interface GigabitEthernet0/0
no ip address
media-type gbic
speed 1000
duplex full
negotiation auto
ipv6 address 2001:DB8::2/64
ipv6 eigrp 1
ipv6 traffic-filter TEST in
После установки листа TEST на интерфейс Gi0/0 в приведённой выше схеме маршрутизатор R2 перестаёт отвечать на эхо-запросы по протоколу ICMP.
R1#ping 2001:db8::2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 2001:DB8::2, timeout is 2 seconds:
AAAAA
Success rate is 0 percent (0/5)
Туннелирование в среде IPv4 и IPv6
Не менее интересный вопрос связан с работой туннелей, поддерживающих IPv6. Самыми простыми туннелями в среде IPv4 были IPIP (IP-in-IP) и GRE. При использовании GRE с введением IPv6 для администратора практически ничего не меняется, однако поддержки IPv6 в IPIP нет. Вместо IPIP можно использовать IPv6IP. Приятной возможностью GRE является его универсальность, благодаря которой можно переносить протоколы IPv4 и IPv6 как поверх транспортной сети с IPv4, так и поверх сети IPv6. За выбор протокола транспортной сети отвечают ключевые слова ip или ipv6 после команды tunnel mode gre.
Вернёмся к нашей схеме и настроим между двумя маршрутизаторами туннель GRE так, чтобы поверх него работал протокол IPv4, а сам туннель существовал в сети IPv6. Листинг ниже представляет настройку туннельного интерфейса маршрутизатора R1. Устройство R2 конфигурируется аналогично.
R1#sho run int tunnel 1
Building configuration.
Current configuration : 180 bytes
interface Tunnel1
ip address 192.168.0.1 255.255.255.252
tunnel source GigabitEthernet0/0
tunnel mode gre ipv6
tunnel destination 2001:DB8::2
tunnel path-mtu-discovery
end
R1#ping 192.168.0.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.0.2, timeout is 2 seconds:
.
Success rate is 100 percent (5/5), round-trip min/avg/max = 48/87/120 ms
На сегодняшний день, скорее всего, администратор столкнётся с противоположной ситуацией: потребуется передавать IPv6 трафик поверх сети IPv4. Конфигурация в этом случае симметрична: настройки IPv4 и IPv6 меняются местами. Пожалуй, стоит ещё отметить, что на данный момент в туннелях GRE поверх IPv6 отсутствует поддержка keepalive сообщений.
Кроме перечисленных туннелей существует ещё несколько распространённых типов: 6to4, 6in4, 6rd, Teredo, ISATAP, однако их рассмотрение выходит далеко за рамки данного материала. Сосуществование сетей IPv4 и IPv6 может происходить по одному из трёх сценариев: использование разнообразных туннелей, о которых упоминалось выше, в режиме dual stack, при котором всеми устройствами одновременно поддерживаются обе версии протокола IP, либо при помощи трансляций, например, NAT-PT.
Виртуальные процессы маршрутизации (VRF)
Ещё одна тема, которой хотелось бы коснуться в рамках беглого рассмотрения IPv6 – VRF. Конфигурирование VRF в многопротокольной среде производится немного иначе – без указания ключевого ip в начале. Здесь также используется подход с конструкцией address-family, который мы видели при настройке BGP. При создании VRF используется ключевое слово definition.
R1#conf t
R1(config)#vrf definition test
R1(config-vrf)#rd 1:1
VPN Routing/Forwarding instance configuration commands:
address-family Enter Address Family command mode
default Set a command to its defaults
description VRF specific description
exit Exit from VRF configuration mode
no Negate a command or set its defaults
rd Specify Route Distinguisher
route-target Specify Target VPN Extended Communities
vnet Virtual NETworking configuration
vpn Configure VPN ID as specified in rfc2685
R1(config-vrf)#address-family ?
ipv4 Address family
ipv6 Address family
R1(config-vrf)#address-family ipv6
R1(config-vrf-af)#?
IP VPN Routing/Forwarding instance configuration commands:
default Set a command to its defaults
exit-address-family Exit from vrf address-family configuration submode
export VRF export
import VRF import
inter-as-hybrid Inter AS hybrid mode
maximum Set a limit
mdt Backbone Multicast Distribution Tree
no Negate a command or set its defaults
protection Configure local repair
route-target Specify Target VPN Extended Communities
snmp Modify snmp parameters
R1(config-vrf-af)#^Z
R1#conf t
R1(config-if)#int loo 2
R1(config-if)#vrf forwarding test
R1(config-if)#^Z
R1#sho vrf
Name Default RD Protocols Interfaces
test 1:1 ipv6 Lo2
Добавление протокола маршрутизации в VRF производится также с использованием опции address-family. Добавить в VRF можно не только поименованные процессы, но и пронумерованные.
R1#sho run | sec router
router eigrp test
address-family ipv6 unicast vrf test autonomous-system 1
topology base
exit-af-topology
eigrp router-id 1.1.1.1
exit-address-family
R1#sho run int gi0/0
interface GigabitEthernet0/0
vrf forwarding test
no ip address
media-type gbic
speed 1000
duplex full
negotiation auto
ipv6 address 2001:DB8::1/64
end
R1#sho ipv route vrf test
IPv6 Routing Table - test - 4 entries
Codes: C - Connected, L - Local, S - Static, U - Per-user Static route
B - BGP, R - RIP, H - NHRP, I1 - ISIS L1
I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary, D - EIGRP
EX - EIGRP external, ND - ND Default, NDp - ND Prefix, DCE - Destination
NDr - Redirect, O - OSPF Intra, OI - OSPF Inter, OE1 - OSPF ext 1
OE2 - OSPF ext 2, ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2, l - LISP
C 2001:DB8::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8::1/128 [0/0]
via GigabitEthernet0/0, receive
D 2001:DB8:2::/64 [90/2570240]
via FE80::C80E:21FF:FEE4:8, GigabitEthernet0/0
L FF00::/8 [0/0]
via Null0, receive
R1#sho eigrp address-family ipv6 vrf test neighbors
EIGRP-IPv6 VR(test) Address-Family Neighbors for AS(1)
VRF()
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 Link-local address: Gi0/0 10 00:01:53 56 336 0 3
FE80::C80E:21FF:FEE4:8
Фрагментация
В литературе можно нередко встретить упоминания о том, что в IPv6 фрагментация невозможна. Действительно, если внимательно посмотреть на заголовок пакетов IPv6, можно обнаружить, что в нём нет полей, отвечающих за процедуру фрагментации. На рисунке ниже представлено сравнение заголовков пакетов IPv4 и IPv6. Тёмно-серым отмечены изменившиеся поля.
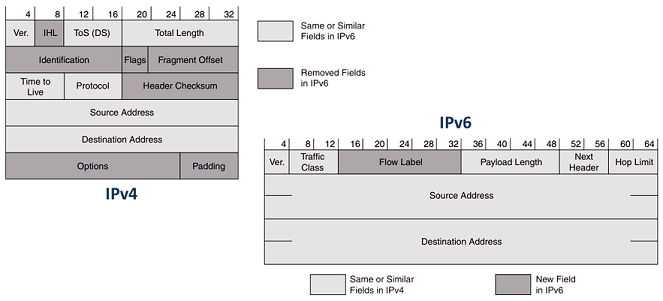
Как видно из представленного выше сравнения, поля Identification, Flags и Fragment Offset были удалены.
Проведём небольшой эксперимент, для чего соберём схему, представленную ниже.

Маршрутизаторы используют следующие адреса на своих интерфейсах со стандартной маской /64.
| Маршрутизатор и интерфейс | Адрес |
| R1 Gi0/0 | 2001:db8:12::1 |
| R2 Gi0/0 | 2001:db8:12::2 |
| R2 Gi1/0 | 2001:db8:23::2 |
| R3 Gi1/0 | 2001:db8:23::3 |
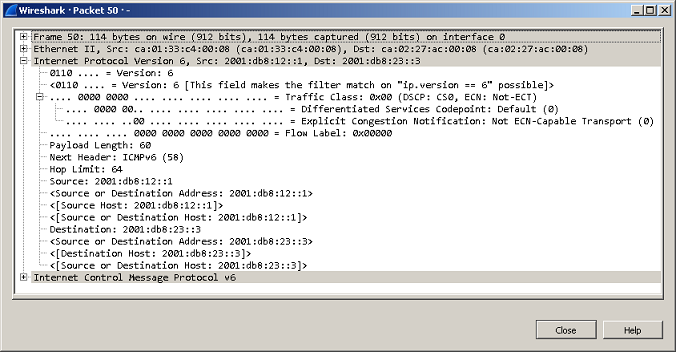
Сначала удостоверимся, что в IPv6 заголовке на самом деле отсутствуют указанные выше поля, для чего с помощью ICMP протокола убедимся в наличии связности между маршрутизаторами R1 и R3 и изучим содержимое одного из перехваченных на линке R1-R2 пакетов.
R1#ping 2001:db8:23::3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 2001:DB8:23::3, timeout is 2 seconds:
.
Success rate is 100 percent (5/5), round-trip min/avg/max = 8/14/16 ms
Выясним теперь значение MTU для интерфейса Gi0/0 маршрутизатора R1.
R1#sho ipv int gi0/0
GigabitEthernet0/0 is up, line protocol is up
IPv6 is enabled, link-local address is FE80::C801:33FF:FEC4:8
No Virtual link-local address(es):
Global unicast address(es):
2001:DB8:12::1, subnet is 2001:DB8:12::/64
Joined group address(es):
FF02::1
FF02::2
FF02::1:FF00:1
FF02::1:FFC4:8
MTU is 1500 bytes
ICMP error messages limited to one every 100 milliseconds
ICMP redirects are enabled
ICMP unreachables are sent
ND DAD is enabled, number of DAD attempts: 1
ND reachable time is 30000 milliseconds (using 30000)
ND advertised reachable time is 0 (unspecified)
ND advertised retransmit interval is 0 (unspecified)
ND router advertisements are sent every 200 seconds
ND router advertisements live for 1800 seconds
ND advertised default router preference is Medium
Hosts use stateless autoconfig for addresses.
Так как значение MTU для протокола IPv6 равно 1500 байт, то мы не сможем передать ICMP сообщения большего размера. Для того, чтобы это проверить, отправим с помощью команды ping несколько сообщений echo request размером 2000 байт.
R1#ping 2001:db8:23::3 si
R1#ping 2001:db8:23::3 size 2000
Type escape sequence to abort.
Sending 5, 2000-byte ICMP Echos to 2001:DB8:23::3, timeout is 2 seconds:
.
Success rate is 100 percent (5/5), round-trip min/avg/max = 32/32/36 ms
Удивительно, не так ли?! Заглянем в дамп и выясним, что же происходит в сети на самом деле.
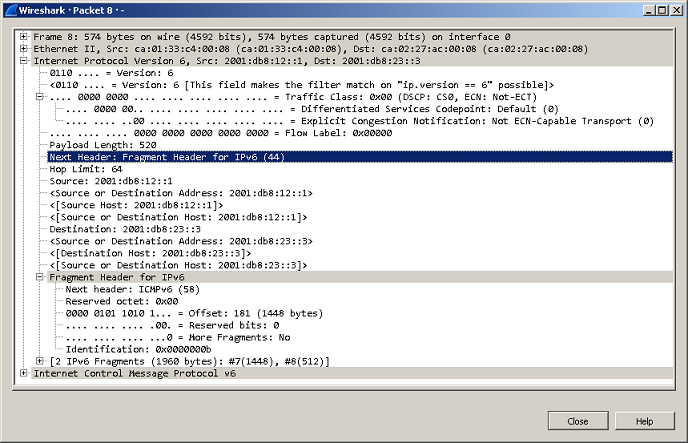
В представленном выше пакете IPv6 появился дополнительный заголовок Fragment Header for IPv6, которого не было ранее. Этот дополнительный заголовок и содержит такие важные для процесса фрагментации поля как: Offset, More Fragments и Identification. Таким образом, фрагментация в IPv6 всё-таки возможна и выполняется она отправителем с использованием вспомогательного заголовка Fragment Header for IPv6.
Стоит заметить, что в IPv6 заголовок пакета имеет строго фиксированную длину в 40 байт, а все вспомогательные опции вынесены в последующие заголовки. Данный подход носит название IPv6 header chain. Обратите внимание на значения поля Next Header в заголовке пакета IPv6 и последующем заголовке Fragment Header for IPv6.
Продолжим наши эксперименты и вручную уменьшим значение MTU для маршрутизатора R2 на линке R2-R3.
R2#conf t
Enter configuration commands, one per line. End with CNTL/Z.
R2(config)#int gi1/0
R2(config-if)#ipv mtu ?
MTU (bytes)
R2(config-if)#ipv mtu 1300
R2(config-if)#do sho ipv int gi1/0 | i MTU
MTU is 1300 bytes
Теперь вновь сгенерируем на маршрутизаторе R1 несколько больших пакетов.
R1#ping 2001:db8:23::3 size 2000
Type escape sequence to abort.
Sending 5, 2000-byte ICMP Echos to 2001:DB8:23::3, timeout is 2 seconds:
B.
Success rate is 80 percent (4/5), round-trip min/avg/max = 28/33/36 ms
Первый пакет был потерян, зато все остальные оказались успешно доставленными. Заглянем теперь в дамп трафика. Итак, маршрутизатор R1 сразу же выполняет фрагментацию и отправляет два пакета с размерами 1496 и 560 байт (на картинке ниже поле Length отображает длину кадра Ethernet, заголовок которого составляет 14 байт).
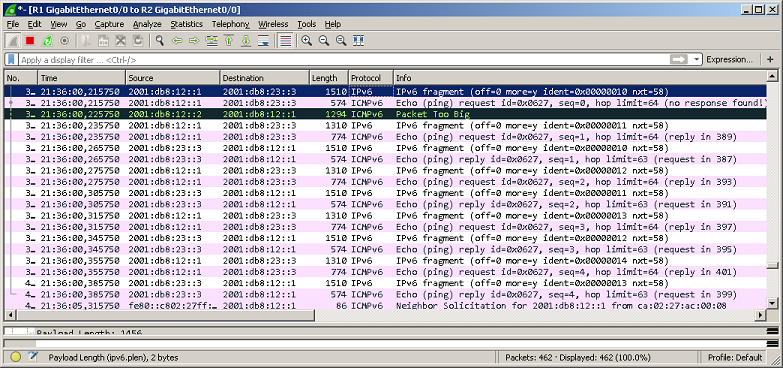
Однако первый пакет не может быть передан через линк R2-R3, о чём маршрутизатор R2 генерирует ICMP сообщение Packet Too Big (Type=2, Code=0). Маршрутизатор R1 реагирует на полученное ICMP-сообщение и начинает отправку данных, используя более мелкие пакеты: 1296 и 760 байт.
Да, протокол IPv4 ведёт себя совершенно иначе: маршрутизатор по пути следования трафика будет просто фрагментировать проходящие IP-пакеты без установленного бита DF, если их размер превышает значение MTU для исходящего интерфейса; и отбрасывать IP-пакеты с установленным битом DF в том же случае. Конечно, промежуточный маршрутизатор будет генерировать ICMP сообщение (Type=2, Code=4) Destination Unreachable (Fragmentation Needed), но отправляющая сторона никак не сможет на них отреагировать из-за выставленного бита DF.
В заключение хотели бы обратить внимание читателя на размеры IPv6 пакетов, которые получались при фрагментации для передачи через канал с IPv6 MTU равным 1300 байт. Пакеты имели размеры 1296 и 760 байт. Но почему именно 1296, а не 1300 байт? Ответ кроется в деталях реализации процедуры фрагментации, а именно в размере поля Offset заголовка Fragment Header for IPv6. Дело в том, что поле Offset имеет длину равную 13 бит и указывает на количество блоков по 8 байт, на которое смещён данный фрагмент. Таким образом, смещение фрагмента должно быть кратным 8 байтам. Аналогичная ситуация наблюдается и в протоколе IPv4, где поле Fragment Offset имеет абсолютно такую же длину.
Заключение
Завершая этот вводный кусочек, хочется отметить следующее.
- Администраторам стало сложнее запоминать адресацию своих сетей.
- Требуется освоиться с длиннющей записью сетей/хостов в IPv6.
- Нужно привыкнуть и освоить автоматический поиск и исследование соседей (маршрутизаторов и конечных станций), смириться с отсутствием широковещания.
- Наличие канальной информации об узле сразу в IP-адресе. Протокол ARP (или аналоги) в большинстве случаев более не требуется – вполне достаточно использования EUI-64 для определения хоста.
- Не так страшен черт, как его малюют: IP и есть IP – идеологически все очень близко, замена транспорта не существенно влияет на идеологию современных сетей передачи данных.
- Использование в IPv6 трансляции сетевых адресов NAT/PAT, довольно ресурсоёмкой операции, в большинстве ситуаций более не требуется.
- В сети могут существовать несколько хостов с абсолютно идентичными валидными маршрутизируемыми IPv6 адресами. Это так называемый anycast. Также стоит привыкнуть к наличию на разных интерфейсах маршрутизаторов адресов из одной и той же подсети не маршрутизируемых link-local адресов.
- Можно постепенно мигрировать от IPv4 к IPv6, либо поддерживать оба протокола в течение времени, необходимого на глобальный переход к IPv6.
- Компания Cisco и другие производители сетевого оборудования уже давно готовы к переходу на IPv6. Дело за администраторами.
You have no rights to post comments