WolframAlpha для всех
Для проверки статистических гипотез используются таблицы вероятностных распределений, которые не всегда под рукой. Кроме того, чаще всего нам доступны учебные таблицы, которые имеют ограниченный размер, и в них не всегда можно найти все необходимые данные. К примеру, при проверке гипотезы относительно статистического распределения выборки скорее всего Вам потребуется таблица распределения Хи-квадрат. Если же такой таблицы у вас нет, можете использовать калькулятор распределения хи-квадрат, который предоставляет система Вольфрам Альфа по запросу

Калькулятор распределения хи-квадрат не единственный калькулятор статистических распределений в Вольфрам Альфа.
В статьях про Дискретные вероятностные распределения и Непрерывные вероятностные распределения из раздела Теория вероятностей приведен список доступных в Вольфрам Альфа непрерывных и дискретных вероятностных распределений. Следуя этому списку, можно получить доступ к некоторым основным калькуляторам статистических распределений, просто прибавляя к названию распределения ключевой запрос probabilities for the .
Однако, в настоящее время для описанных в данных статьях вероятностных распределений, в Вольфрам Альфа доступны только восемь калькуляторов — 3 для непрерывных распределений и 5 — для дискретных.
Для непрерывных вероятностных распределений, кроме калькулятора распределения хи-квадрат доступны также:
probabilities for the normal distribution — калькулятор нормального распределения;
probabilities for the student’s t distribution — калькулятор t-распределения Стьюдента;
Коллекция калькуляторов дискретных вероятностных распределений в системе Вольфрам Альфа более богатая:
probabilities for the negative binomial distribution — отрицательное нормальное распределение;
probabilities for the geometric distribution — геометрическое распределение;
probabilities for the hypergeometric distribution — гипергеометрическое распределение;
probabilities for the poisson distribution — распределение Пуассона;
Как видите, в этом списке фигурируют далеко не все вероятностные распределения, доступные в Вольфрам Альфа. Это означает, что соответствующие алгоритмы расчета еще не доступны в системе. Однако система ВА постоянно развивается, и, вполне возможно, что уже в ближайшее время этот список пополнится.
Использование вычислительных возможностей R для проверки гипотезы о равенстве средних
Возникла недавно потребность решить вроде бы классическую задачу мат. статистики.
Проводится испытание определенного push воздействия на группу людей. Необходимо оценить наличие эффекта. Конечно, можно делать это с помощью вероятностного подхода.
Но рассуждать с бизнесом о нулевых гипотезах и значении p-value совершенно бесполезно и контрпродуктивно.
Как можно по состоянию на февраль 2019 года сделать это максимально просто и быстро имея под руками ноутбук «средней руки»? Заметка реферативная, формул нет.
Постановка задачи
Есть две статистически идентичные по измеряемому показателю группы пользователей (A и B). На группу B оказывается воздействие. Приводит ли это воздействие к изменению среднего значения измеряемому показателю?
Наиболее популярный вариант — посчитать статистические критерии и сделать вывод. Мне нравится пример «Классические методы статистики: критерий хи-квадрат». При этом совершенно неважно как это выполняется, с помощью спец. программ, Excel, R или еще чего-либо.
Однако, в достоверности получаемых выводов можно очень сильно сомневаться по следующим причинам:
- В действительности мат. статистику мало кто понимает от начала и до конца. Всегда надо держать в голове условия при которых можно применять те или иные методы.
- Как правило, использование инструментов и трактовка получаемых результатов идет по приципу однократного вычисления и принятия «светофорного» решения. Чем меньше вопросов, тем лучше для всех участников процесса.
Критика p-value
Материалов масса, ссылки на наиболее эффектные из найденных:
- Nature. Scientific method: Statistical errors. P values, the ‘gold standard’ of statistical validity, are not as reliable as many scientists assume., Regina Nuzzo. Nature 506, 150–152
- Nature Methods. The fickle P value generates irreproducible results, Lewis G Halsey, Douglas Curran-Everett, Sarah L Vowler & Gordon B Drummond. Nature Methods volume 12, pages 179–185 (2015)
- ELSEVIER. A Dirty Dozen: Twelve P-Value Misconceptions, Steven Goodman. Seminars in Hematology Volume 45, Issue 3, July 2008, Pages 135-140
Что можно сделать?
Сейчас у каждого есть компьютер под руками, поэтому метод Монте-Карло спасает ситуацию. От расчетов p-value переходим к расчету доверительных интервалов (confidence interval) для разницы среднего.
Книг и материалов множество, но в двух словах (resamapling & fitting) очень компактно изложено в докладе Jake Vanderplas — «Statistics for Hackers» — PyCon 2016. Сама презентация.
Одна из начальных работ по этой теме, включая предложения по графической визуализации, была написана хорошо известным в советское время популяризатором математики Мартином Гарднером: Confidence intervals rather than P values: estimation rather than hypothesis testing. M.J. Gardner and D.G. Altman, Br Med J (Clin Res Ed). 1986 Mar 15; 292(6522): 746–750.
Как использовать для этой задачи R?
Чтобы не делать все руками на нижнем уровне, посмотрим на текущее состояние экосистемы. Не так давно на R был переложен весьма удобный пакет dabestr : Data Analysis using Bootstrap-Coupled Estimation.
Принципы вычислений и анализа результатов, используемых в dabestr в формате шпаргалок описаны здесь:ESTIMATION STATISTICS BETA ANALYZE YOUR DATA WITH EFFECT SIZES.
Пример R Notebook для «пощупать»:
--- title: "A/B тестирование средствами bootstrap" output: html_notebook: self_contained: TRUE editor_options: chunk_output_type: inline ---library(tidyverse) library(magrittr) library(tictoc) library(glue) library(dabestr)Cимуляция
Создадим логнормальное распределение длительности операций.
my_rlnorm # N пользователей категории (A = Control) A_control % ; sd = "))> # N пользователей категории (B = Test) B_test % ; sd = "))> Собираем данные в виде, необходимом для анализа средствами dabestr , и проводим анализ.
df % gather(key = "group", value = "value") tic("bootstrapping") two_group_unpaired % dabest(group, value, # The idx below passes "Control" as the control group, # and "Test" as the test group. The mean difference # will be computed as mean(Test) - mean(Control). idx = c("Control", "Test"), paired = FALSE, reps = 5000 ) toc()Поглядим на результаты
two_group_unpaired plot(two_group_unpaired)Результат в виде CI
DABEST (Data Analysis with Bootstrap Estimation) v0.2.0 ======================================================= Unpaired mean difference of Test (n=1000) minus Control (n=1000) 223 [95CI 209; 236] 5000 bootstrap resamples. All confidence intervals are bias-corrected and accelerated.
и картинки
вполне понятен и удобен для разговора с бизнесом. Всех расчетов было на «выпить чашечку кофе».
Язык Wolfram Language ™
Точечный процесс Пуассона является обобщением одномерного процесса Пуассона и применяется для многомерных случаев. Однородный точечный процесс Пуассона в геометрической области может быть рассмотрен с помощью функции RandomPoint .
Создадим полигон для географического объекта, например, страны.
![]()
region = DiscretizeGraphics[CountryData[«Mexico», «Polygon»], ImageSize -> Medium]
Определим функцию, которая делает выборку точечного процесса Пуассона с тремя аргументами: регион, интенсивность и количество реализаций.

ppp[region_, intensity_, n_] := Module[
Сформируем реализацию точечного процесса Пуассона в данном полигоне с интенсивностью 0,5 и визуализируем результат с помощью функции Graphics .
![]()
intensity = 0.5; sample = ppp[region, intensity, 1];
![]()
Show[region, Graphics[
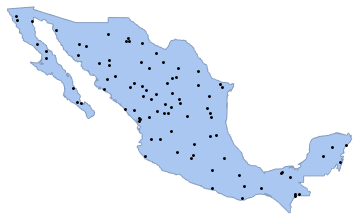
Сформируем 10^4 образцов на основе того же процесса. Общее количество точек в каждом образце/выборкe соответствует распределению Пуассона (см. PoissonDistribution ) со средним значением, равным произведению плотности и площади полигона.
![]()
samples = ppp[region, intensity, 10^4]; counts = Length /@ samples;

htd = PearsonChiSquareTest[counts, PoissonDistribution[intensity RegionMeasure[region]], «HypothesisTestData»];
htd[«TestDataTable»]

htd[«TestConclusion»]

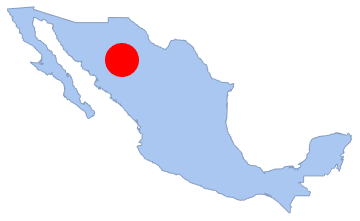
Выборка точек в любом субрегионе полигона также распределена по принципу Пуассона. На рисунке ниже это проиллюстрировано с помощью красного круга, лежащего внутри полигона; посчитаем количество точек в данном субрегионе:
![]()
disk1 = Disk[<-107, 28>, 1.5]; Show[region, Graphics[]]
![]()
memberfun1 = RegionMember[disk1]; counts1 = Table[Total[Boole[memberfun1[pts]]],
Выполним тест хи-квадрат Пирсона с помощью функции PearsonChiSquareTest с количеством посчитанных точек в распределении Пуассона.

htd = PearsonChiSquareTest[counts1, PoissonDistribution[intensity RegionMeasure[disk1]], «HypothesisTestData»];
Язык Wolfram Language ™
Распределение Уишарта — это распределение ковариационной матрицы с выборкой, полученной из независимых многомерных случайных векторов. Оно является обобщением (хи-квадрат) распределения в многочисленных измерениях. Распределение формируется естественным образом в многомерном статистическом анализе, таком как регрессия, ковариантность и др.
Сгенерируйте случайную положительную определённую матрицу для использования в качестве параметров для распределения Уишарта.
![]()
\[CapitalSigma] = DiagonalMatrix[RandomReal[10, 5]];
Матрицы из распределения Уишарта симметричны и положительно определены. »
![]()
dist = WishartMatrixDistribution[30, \[CapitalSigma]]; mat = RandomVariate[dist];
![]()
SymmetricMatrixQ[mat] && PositiveDefiniteMatrixQ[mat]

Обратное распределение Уишарта — это распределение обратных матриц из распределения Уишарта. »
![]()
invdist = InverseWishartMatrixDistribution[30, Inverse[\[CapitalSigma]]]; invmat = RandomVariate[invdist];
Матрицы из обратного распределения Уишарта симметричны и положительно определены.
![]()
SymmetricMatrixQ[invmat] && PositiveDefiniteMatrixQ[invmat]

Сравните распределение собственных значений для матриц из распределения и обратного распределения Уишарта.

eigs = Flatten[ RandomVariate[ MatrixPropertyDistribution[Eigenvalues[x], x \[Distributed] dist], 10^4]]; inveigs = Flatten[RandomVariate[ MatrixPropertyDistribution[Eigenvalues[x]^-1, x \[Distributed] invdist], 10^4]];
код на языке Wolfram Language целиком

SmoothHistogram[
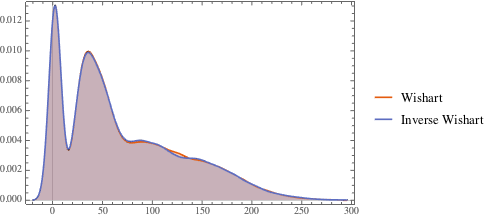
Для любого ненулевого вектора и матрицы Уишарта со шкалой матрицы , статистические имеют (хи-квадрат) распределение.

y = #/Sqrt[#.\[CapitalSigma].#] &[RandomReal[1, 5]]; data = RandomVariate[ MatrixPropertyDistribution[y.w.y, w \[Distributed] WishartMatrixDistribution[30, \[CapitalSigma]]], 10^4];
![]()
Show[Histogram[data, Automatic, PDF, PlotTheme -> «Detailed»], Plot[PDF[ChiSquareDistribution[30], x],