Книга «40 алгоритмов, которые должен знать каждый программист на Python»

Привет, Хаброжители!
Понимание работы алгоритмов и умение применять их для решения прикладных задач – must-have для любого программиста или разработчика. Эта книга поможет вам не только развить навыки использования алгоритмов, но и разобраться в принципах их функционирования, в их логике и математике.
Вы начнете с введения в алгоритмы, от поиска и сортировки перейдете к линейному программированию, ранжированию страниц и графам и даже поработаете с алгоритмами машинного обучения. Теории не бывает без практики, поэтому вы займетесь прогнозами погоды, кластеризацией твитов, механизмами рекомендаций фильмов. И, наконец, освоите параллельную обработку, что даст вам возможность решать задачи, требующие большого объема вычислений.
Дойдя до конца, вы превратитесь в эксперта по решению реальных вычислительных задач с применением широкого спектра разнообразных алгоритмов.
Для кого эта книга
Эта книга для серьезного программиста! Она подойдет вам, если вы опытный программист и хотите получить более глубокое представление о математических основах алгоритмов. Если вы имеете ограниченные знания в области программирования или обработки данных и хотите узнать больше о том, как пользоваться проверенными в деле алгоритмами для совершенствования методов проектирования и написания кода, то эта книга также будет вам полезна. Опыт программирования на Python вам точно понадобится, а вот знания в области анализа и обработки данных полезны, но не обязательны.
Крупномасштабные алгоритмы
Крупномасштабные алгоритмы, или алгоритмы решения задач большой размерности (large-scale algorithms), предназначены для решения невероятно сложных задач. Они нуждаются в нескольких механизмах выполнения ввиду крупных объемов данных и серьезных требований к обработке. В этой главе мы рассмотрим типы алгоритмов, требующих параллельного выполнения, и обсудим распараллеливание. Далее мы познакомимся с архитектурой CUDA и выясним, как ускорять алгоритмы с помощью одного или нескольких графических процессоров (GPU). Мы научимся изменять алгоритм таким образом, чтобы эффективно использовать мощность GPU. Наконец, коснемся кластерных вычислений. Мы узнаем, как наборы данных RDD в Apache Spark используются для чрезвычайно быстрой параллельной реализации стандартных алгоритмов.
ВВЕДЕНИЕ В КРУПНОМАСШТАБНЫЕ АЛГОРИТМЫ
Людям нравится преодолевать трудности. На протяжении веков мы придумываем инновационные способы решения сложных проблем. От предсказания района нашествия саранчи и до вычисления наибольшего простого числа, методы поиска ответов на трудные вопросы продолжают развиваться. С появлением компьютеров мы получили новый мощный способ решения сложных задач.
Определение эффективного крупномасштабного алгоритма
- Он справляется с гигантским объемом данных и обширными требованиями к обработке, наилучшим образом используя доступные ресурсы.
- Он масштабируется. По мере усложнения проблемы алгоритм просто задействует больше ресурсов.
Терминология
Рассмотрим некоторые термины, используемые для количественной оценки качества крупномасштабных алгоритмов.
Задержка
Задержка (latency) — это общее время, необходимое для выполнения одного вычисления. Допустим, C1 — это одно вычисление, которое начинается в t1 и заканчивается в t2, тогда можно сказать следующее:
Latency = t2 – t1.Пропускная способность
В контексте параллельных вычислений пропускная способность (throughput) — это количество отдельных вычислений, которые могут выполняться одновременно. Например, если при t1 можно выполнить четыре одновременных вычисления, C1, C2, C3 и C4, то пропускная способность равна четырем.
Полоса бисекции сети
Полоса пропускания между двумя равными частями сети называется полосой бисекции сети (network bisection bandwidth). Это самый важный параметр, влияющий на эффективность распределенных вычислений. При недостаточной полосе бисекции скорость соединения будет медленной. Таким образом, будет потеряно преимущество, полученное благодаря наличию нескольких механизмов выполнения.
Эластичность
Способность инфраструктуры среагировать на внезапное увеличение требований к обработке и выделить большее количество ресурсов называется эластичностью.
Три гиганта облачных вычислений, Google, Amazon и Microsoft, способны обеспечить высокоэластичную инфраструктуру. Их общий пул ресурсов огромен, и существует очень мало компаний, способных добиться такой же эластичности.
Если инфраструктура эластична, она способна создать масштабируемое решение для задачи.
РАЗРАБОТКА ПАРАЛЛЕЛЬНЫХ АЛГОРИТМОВ
Важно отметить, что параллельные алгоритмы не являются панацеей. Даже лучшие параллельные архитектуры могут не обеспечить ожидаемой производительности. Рассмотрим закон, который широко применяется для разработки параллельных алгоритмов, — закон Амдала.
Закон Амдала
Джин Амдал был одним из первооткрывателей параллельной обработки в 1960-х годах. Он предложил закон, который актуален до сих пор. Закон Амдала может служить основой для понимания различных компромиссов, связанных с разработкой решений для параллельных вычислений.
Согласно закону Амдала, не все части вычислительного процесса могут выполняться параллельно. Всегда будет последовательная часть процесса, которая не может быть распараллелена.
- P1: просканировать файлы в каталоге, создать список имен файлов, соответствующих входному файлу, и передать список дальше.
- P2: прочитать файлы, создать пайплайн обработки данных, обработать файлы и обучить модель.
Анализ последовательного процесса
- P2 не может начать работу до завершения P1. Это представляется как P1 — >P2.
- Tseq(P) = Tseq(P1) + Tseq(P2).
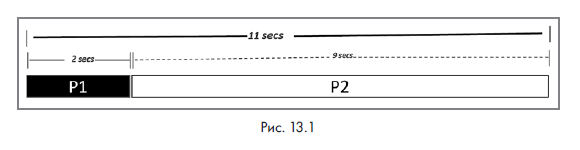
Важно отметить, что P1 является последовательным по своей природе. Этот процесс невозможно ускорить, сделав его параллельным. Вместе с тем P2 легко делится на подзадачи, которые могут выполняться одновременно. Их параллельный запуск ускоряет работу процесса.
Основным преимуществом облачных вычислений является наличие большого пула ресурсов, и многие из них используются параллельно. План применения этих ресурсов для конкретной задачи называется планом выполнения. Закон Амдала используется для тщательного выявления ограничений задачи и пула ресурсов.
Анализ параллельного выполнения
Если используется более одной ноды для ускорения P, это повлияет на P2 только с коэффициентом s > 1:

Ускорение процесса P можно легко рассчитать следующим образом:

Отношение распараллеливаемой части процесса к его общему количеству представлено b и рассчитывается так:
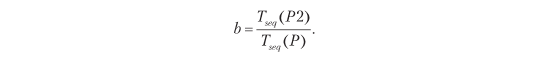
Например, в предыдущем сценарии b = 9/11 = 0.8182.
Упрощение этих уравнений даст нам закон Амдала:

- P — это общий процесс;
- b — отношение распараллеливаемой части P;
- s — ускорение, достигнутое в распараллеливаемой части P.
- P1 является последовательным и не может быть сокращен с помощью параллельных нод. Он по-прежнему длится 2 секунды.
- P2 теперь занимает 3 секунды вместо 9.
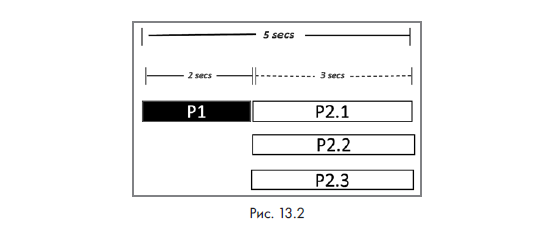
- np = количество процессоров = 3;
- b = параллельная часть = 9/11 = 81,82 %;
- s = ускорение = 3.
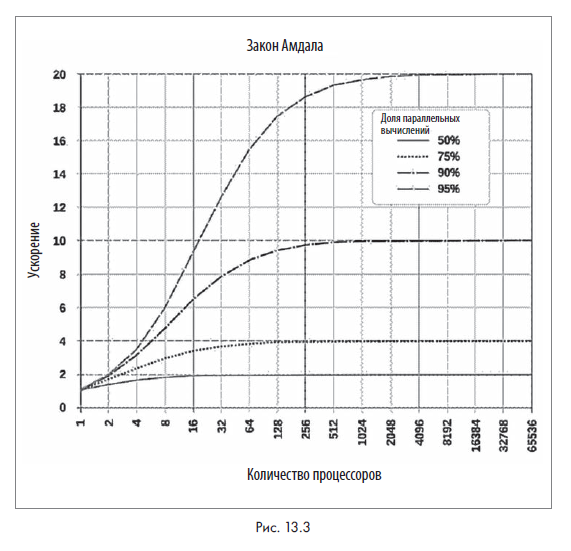
На этой диаграмме график строится между s и np для разных значений b.
Гранулярность задачи
При распараллеливании алгоритма большая задача делится на несколько параллельных подзадач. Их оптимальное количество не всегда очевидно. Если подзадач слишком мало, параллельные вычисления не принесут особой пользы; слишком большое количество подзадач чересчур увеличит затраты ресурсов. Эта проблема называется гранулярностью задачи.
Балансировка нагрузки
В параллельных вычислениях за выбор ресурсов для выполнения задачи отвечает планировщик. Оптимальной балансировки нагрузки достичь сложно, а при ее отсутствии ресурсы используются не в полной мере.
Проблема расположения
При параллельной обработке не рекомендуется перемещать данные. По возможности их следует обрабатывать в той ноде, в которой они находятся. В противном случае качество распараллеливания снижается.
Запуск параллельной обработки на Python
Самый простой способ запустить параллельную обработку на Python — это клонировать текущий процесс, который запустит новый параллельный процесс, называемый дочерним.
Программисты Python (хотя они и не биологи) создали собственный процесс клонирования. Как и в случае с клонированной овцой, клонированный процесс является точной копией исходного процесса.
Об авторе
Имран Ахмад — сертифицированный инструктор Google с многолетним опытом. Преподает такие дисциплины, как программирование на языке Python, машинное обучение (МО), алгоритмы, большие данные (big data) и глубокое обучение. В своей диссертации он разработал новый алгоритм на основе линейного программирования под названием ASTRA. Этот алгоритм применяется для оптимального распределения ресурсов в облачных вычислениях. На протяжении последних четырех лет Имран работает над социально значимым проектом машинного обучения в аналитической лаборатории при Федеральном правительстве Канады. Проект связан с автоматизацией иммиграционных процессов. Имран разрабатывает алгоритмы оптимального использования GPU для обучения сложных моделей МО.
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — Алгоритмы
- Блог компании Издательский дом «Питер»
- Python
- Алгоритмы
- Профессиональная литература
Какие алгоритмы должен знать программист
Зачем изучать алгоритмы, если уже и так написано множество различных библиотек?
Изучение теории Алгоритмов даёт понимание техники проектирования алгоритмов, с помощью которой вы сможете решать любые алгоритмические задачи из реальных проектов.
Конечно, любую задачу можно решить «перебором» и каждый начинающий программист умеет запрограммировать такое решение «методом грубой силы». Однако, такое решение обычно не оптимально и работает очень долго.
Если же вы знаете суть динамического программирования и других методов оптимизаций, то сможете написать быстрый алгоритм для решения задачи, а ваш опыт и знания высоко и дорого будут цениться крупными IT-компаниями.
На этом вебинаре мы разберем, в какой мере программисту нужно знать теорию алгоритмов, рассмотрим все виды алгоритмов, которые нужно знать профессиональному программисту, а также рассмотрим основные методики проектирования алгоритмов на примере поэтапной оптимизации.
Целевая аудитория: Начинающие программисты.
Необходимые знания: Логика и математика в пределах школьной программы.
Покупай подписку с доступом ко всем курсам и сервисам
Библиотека современных IT знаний в удобном формате
Выбирай свой вариант подписки в зависимости от задач, стоящих перед тобой. Но если нужно пройти полное обучение с нуля до уровня специалиста, то лучше выбирать Базовый или Премиум. А для того чтобы изучить 2-3 новые технологии, или повторить знания, готовясь к собеседованию, подойдет Пакет Стартовый.
- Все видеокурсы на 3 месяца
- Тестирование по 10 курсам
- Проверка 5 домашних заданий
- Консультация с тренером 30 мин
- Все видеокурсы на 6 месяцев
- Тестирование по 16 курсам
- Проверка 10 домашних заданий
- Консультация с тренером 60 мин
- Все видеокурсы на 1 год
- Тестирование по 24 курсам
- Проверка 20 домашних заданий
- Консультация с тренером 120 мин
А нужно ли знать программисту алгоритмы?
Не встречали еще разработчика, который вместо стандартной в скриптовом языке функции деления строки по регулярке — пишет C-подобный код с конечным автоматом, который вводит неокрепшие умы в трепет?
И так ужасно ли то, что ты не знаешь в тонкостях работу красно-черных деревьев или путаешь линейный дискриминантный анализ с вторым законом Ньютона?
О этом много говорят: на конференциях, на бигдатовских тусовках, на собеседованиях… Но на практике, при решении конкретных бизнес-задач в жесткие сроки, может оказаться — что твои академические знания как-то странным образом «не особо требуются» и горячий кэш мозга для эффективной работы содержит лишь названия библиотек в boost, java или консольных команд unix, пути к файлам логов и незарастаемую тропинку к бите в подсобке.

Да, я помню вычислительную машину Тьюринга, теорию регулярных выражений на основе конечных автоматов и не только, ragel — а на практике нужно знать, что есть grep, egrep, awk, немного perl и синтаксис регулярок на уровне популярных кейсов.
Да, очень прикольно удаляются узлы в RB-дереве, а очередь с приоритетами иногда даже может быть полезна… но я пишу старый добрый кулинарный SQL-запрос и использую индексы.
Конечно, понятно «в целом» для чего нужна операционная система — но в данный момент меня интересует ключ, выводящий подробности о принадлежности потоков в команде ps.
Полезно знать о поиске в глубину из теории графов и многочисленные NP-hard задачки и подвохи для неопытных, которыми можно пугать внуков — но гораздо чаще требуется понимать на пальцах рук и ног, как работает IP, из чего состоит пакет и почему тормозит этот скрипт, который написал коварно улыбающийся разработчик, попивающий горячий кофе.
Да, конечно, процессор выполняет жестко (не совсем, но нередко в CISC и RISC) запаянные в него команды и понимает небольшой, ограниченный, примитивный набор команд — но, коллеги, без strace часто не понятно, что дает дыхание жизни этому потребляющему 10ГБ ОЗУ крокодилу.
Оказывается, что практически все немногочисленные научные достижения в области вычислений за последние полвека, которые можно собрать в небольшую пригоршню — собраны, обсосаны и реализованы сотни раз и в базах данных, и в распределенных файловых системах и особенно модных сейчас NoSQL-решениях. И нередко возникает другая проблема — знать, что это уже давно сделано и готово и лежит там-то, а не изобретать велосипед и придумывать в рабочее время давно выстраданных кем-то в диссере алгоритм.
Складывается устойчивое впечатление, что на практике гораздо ценнее иметь не очень сложные, но требующие глубокого погружения обширные прикладные знания — тонкости C++, системные вызовы unix, структура пакета TCP, ключики команды ps, типы сборщиков мусора jvm — чем набивать голову обсосанной десятилетиями в научных кругах теорией алгоритмов и вычислений. Хотя конечно, расширение кругозора в свободное время — дело безусловно полезное.

Машинное обучение
С очередной, в который раз за последние десятилетия, модой на нейронки — deep learning и поиском «золота» в больших массивах данных, ну да, стало чуть повеселее. Начали вспоминать «подзабытую» банальную математическую статистику с логистическими регрессиями, бородатый столетний байесовский классификатор. Появились как грибы после дождя утилиты «анализа больших данных», которые ничего алгоритмически сложного внутри себя не представляют и пишутся средним разработчиков на пару отпусков: Spark, Hadoop/MR и т.п.
Анализ языков
В этой области на голом обратном индексе с примочками без машинного обучения, конечно, очень трудно. Но опять таки — это область достаточно узкая, и если ты не лингвист и знаешь русский язык на уровне школы — придется сильно попотеть годик-другой, пока не станешь разбираться в базовой терминологии.
Фанатизм в приобретении теоретических знаний может отобрать много времени и сил, а на практике знания могут не пригодиться и выветриться — т.к. почти все нужное человечеству уже написано/переписано по 100 раз в стандартных библиотеках, БД, файловых системах и прочей классике.
Приобретение практических навыков: детали языков программирования, особенности unix, настройки софта, среды разработки, SQL, модные NoSQL возможности (а это опять таки подзабытые старые добрые алгоритмы) и немодные, но не менее мощные SQL инструменты — гораздо более полезно.
Не нужно париться по поводу неглубоких знаний теории графов — возьмете готовое решение, если повезет столкнуться с этой задачкой.
Учимся коммуницироваться и работать в команде. Хорошее настроение — залог успеха проекта.
Не нужно страдать по поводу некомпетентности в области машинного обучения и больших данных. Это для ученых, математиков, аналитиков и научных работников — все равно ничего особо не поймете, если не решали задачи повышенной сложности со школы. Тут важнее понять бизнес-применение. И если окажется, что навороченая нейронка тянет на решение задачи распознавания образов и звуков и вашей онлайн-игре или веб-проекту ну никак не поможет — нечего тратить нервные клетки.
Читайте мануалы по unix и до конца. Их много, это надолго и серьезно. Когда программа будет стабильно и предсказуемо работать — нальете чаю, закажете книжку типа этой и насладитесь наукой.
Всем удачи, побольше практических кейсов и хорошего настроения!
- программирование
- алгоритмы
- большие данные
- Программирование
- Big Data
Какие алгоритмы должен знать уважающий себя программист?
В этом выпуске попросили наших экспертов перечислить алгоритмы, которые, по их мнению, должен знать каждый уважающий себя программист.
В этом выпуске попросили экспертов перечислить алгоритмы, которые должен знать каждый уважающий себя программист. Рекомендуем дочитать до конца, там есть развёрнутый ответ в виде эссе по алгоритмической подготовке.
Какие алгоритмы должен знать уважающий себя программист?
Павел Емельянов
главный архитектор Virtuozzo
Сейчас в … “ненаучном” программировании алгоритмы не так важны. Хорошая алгоритмическая подготовка и смекалка пригодится в специфических областях, например в Big Data или компьютерном моделировании физических, социологических и других процессов реального мира. Даже игровая индустрия уже пережила тот период, когда как воздух требовались новые классные алгоритмы, на “стандартных” в большинстве случаев вполне можно жить.
Так что если говорить “в среднем”, то программист должен уметь подобрать для решения своей задачи необходимые готовые компоненты, разобраться в предоставляемых ими интерфейсах и заставить их работать вместе.
Сергей Зефиров
программист с широким опытом работы, энтузиаст и евангелист языка Haskell
Он должен уметь выводить алгоритмы, а не знать их. Ровно как и математик должен уметь выводить доказательства.
На каких алгоритмах стоит потренироваться в выводе:
- сортировки — от пузырька, до параллельной кеш-независимой сортировки;
- динамическое программирование;
- алгоритмы сжатия данных — кодирование Хаффмана, арифметическое кодирование, сжатие подпоследовательностей;
- символические вычисления — как организовать;
- как сделать статическую структуру динамической — как сделать быструю (O(logN)) вставку в упорядоченный массив.
Материалы по перечисленным темам:
- Наша статья, посвященная пяти основным алгоритмам сортировки.
- Введение в динамическое программирование для начинающих.
- Книга, посвященная методам сжатия данных. Несколько тем, рассмотренных в книге: кодирование источников данных без памяти (канонический алгоритм Хаффмана, арифметическое сжатие, векторное квантование), словарные методы сжатия данных, методы контекстного моделирования и другие.
- Введение в структуры данных для новичков: динамический массив.
Роман Юферев
руководитель направления ИТ-менеджмента и мониторинга в компании VIAcode
Сортировка «пузырьком». Шутка. Алгоритмы — это то, что нам нужно для обработки данных, а сейчас весь мир сталкивается с совершенно новыми задачами при обработке данных и новыми возможностями, поэтому собрание сочинений Кнута на полке уже не является показателем вашей крутости. В то же время, это не значит, что преподаватели в вузе учат вас какой-то “фигне”. Повторюсь — изучением алгоритмов и работой над учебными задачами вы тренируете, «разминаете» свои мозги, готовите их к реальной работе, поэтому не брезгуйте материалом, который вам дают в вузе, но и не рассчитывайте особо на его практическое применение в реальной профессиональной жизни.
Где можно «потренировать» мозги:
- Codeforces.
- Сборник задач для практики от СppStudio.
- Задачи Типичного Программиста.
- Russian AI Cup.
Еще больше сайтов с задачками вы можете найти в нашей статье «28 сайтов, на которых можно порешать задачи по программированию».
Василий Кобзарь
преподаватель GeekBrains, специализируется на администрировании Linux
Уважающий себя программист должен понимать абсурдность данного вопроса.
Антон Пискунов
основатель и генеральный директор BeastGaming
Сортировку пузырьком. Если серьезно, то всё ищется в Гугле, а специфичные алгоритмы вы всё равно успеете забыть до того, как они вам понадобятся.
Джозеф Браун
профессор Университета Иннополис
В любом случае, каждая программа оперирует входящими и исходящими данными. И они редко бывают чистыми на входе: необходимо удалить промежутки, или найти недостающие значения, или исправить некорректные. Поэтому необходимо обрабатывать данные и сортировать их, чтобы затем использовать более продвинутые алгоритмы.
Я не могу сказать, какие из алгоритмов более важные. Думаю, предпочтительнее знать несколько алгоритмов из каждого класса. Сортировка пузырьком хорошо работает, когда, к примеру, у вас есть 4 элемента в массиве, которые нужно отсортировать для генетического алгоритма. Но следует помнить, что использование быстрой сортировки не всегда лучший выбор.
Андрей Ситник
веб-разработчик в Evil Martians
Алгоритмы не важны. Вы можете найти их в Гугле за несколько минут. Уважающий себя программист должен уметь правильно ставить сроки, понимать задачи клиентов, мудро выбирать между краткосрочными и долгосрочными целями, всегда изучать что-то новое и не бояться сложных задач. Важны умения и личные качества — чистая теория перестала быть важной после создания Гугла.
Александр Чистяков
главный инженер в Git in Sky
Алгоритмы сортировки и поиска, очевидно. Наша жизнь — это сортировка и поиск.
Александр Рожнов
Team Lead в компании Undev
- Сортировка пузырьком;
- разворачивание однонаправленного списка;
- алгоритмы работы с бинарными деревьями;
- алгоритмы работы с хеш-таблицами;
- поиск описания работы интересующего алгоритма за o(n) в Интернете.
Материалы для изучения упомянутых Александром тем:
- Алгоритмы поиска пути в графе.
- Алгоритм двоичного (бинарного) дерева поиска.
- Введение в Хеш-таблицы.
- 8 сервисов для визуализации алгоритмов.
- Введение в анализ сложности алгоритмов.
Всеволод Шмыров
разработчик в команде API Яндекс.Карт
Павел Егоров
заместитель руководителя управления разработки СКБ Контур
Что такое хорошая алгоритмическая подготовка?
Да, хорошая алгоритмическая подготовка важна для программиста. И нет, хорошая — это вовсе не заучивание алгоритмов из списка “Самых Важных Алгоритмов, Которые Должен Знать Каждый”. На мой взгляд хорошая алгоритмическая подготовка должна стремиться дать программисту следующие три умения.
Во-первых, это умение решать непонятные задачи. В нечетких формулировках жизненных задач видеть возможные строгие трактовки. По строгим трактовкам накидывать варианты решения. Всесторонне анализировать разные варианты и выбирать самый подходящий.
Очевидно, для этого недостаточно просто знать алгоритмы. Нужно уметь “видеть их”, распознавать возможности их применения.
Во-вторых, алгоритмическая подготовка должна прививать привычку анализировать эффективность каждого вашего решения. Не пропускать в критических местах квадратичные или экспоненциальные алгоритмы, и не закладывать в архитектуру программы идеи, которые потом невозможно будет реализовать достаточно эффективно.
В-третьих, алгоритмическая подготовка должна помогать умело пользоваться готовыми инструментами. Базы данных — это сплошные структуры данных и алгоритмы. Причем на концептуальном уровне довольно простые и понятные — деревья поиска, хэштаблицы, SS-Table, …
Например, зная, что индекс в БД — это просто дерево поиска, несложно понять, какие запросы могут быть выполнены быстро, а какие обречены на full-scan.
Зная, как на каких алгоритмах работает полнотекстовый поиск в Lucene, можно предсказать, какие запросы к Elastic будут давать релевантные ответы, а какие — нет, и даже как это можно доработать.
Как стать топ-100 на Kaggle и топовым Data Scientist, за которым охотятся работодатели
Если подводить итог:
- Кроме самих алгоритмов — учитесь их распознавать в задачах реального мира.
- Прививайте себе привычку анализировать эффективность кода, который вы пишите.
- Изучайте алгоритмы под капотом у инструментов, которыми вы пользуетесь — это пригодится при их эксплуатации.
Несколько статей, которые помогут вам получить хорошую алгоритмическую подготовку:
- Алгоритмы интеллектуального анализа данных.
- Материалы по продвинутым алгоритмам и структурам данных.
- Курс по алгоритмам от Стэнфордского университета.
- Основы компьютерных наук от университета Райса.