unixforum.org
Получается, что по факту cout.precision(5); распространяется только на переменную d3, для переменной j задано 4 знака после запятой, да и то, непонятно каким образом. Подскажите, пожалуйста, в чём тут дело?
10% — это 0,1.
© Bizdelnick
Спасибо сказали:
NickLion Сообщения: 3408 Статус: аватар-невидимка ОС: openSUSE Tumbleweed x86_64
Re: C++: не разобрался с cout.precision
Сообщение NickLion » 08.06.2014 10:54
Для формата с плавающей запятой .precision(5) — задаёт не 5 знаков после точки, а 5 значащих знаков. Чтобы получить 5 после точки, надо переключить в режим с фиксированной точкой:
std::cout.precision(5); std::cout.setf(std::ios::fixed);
Спасибо сказали:
ArkanJR Сообщения: 1164 Статус: Профан
Re: C++: не разобрался с cout.precision
Сообщение ArkanJR » 08.06.2014 14:01
08.06.2014 10:54
Для формата с плавающей запятой .precision(5) — задаёт не 5 знаков после точки, а 5 значащих знаков. Чтобы получить 5 после точки, надо переключить в режим с фиксированной точкой:
std::cout.precision(5); std::cout.setf(std::ios::fixed);
Общие понятия
Здесь про TP, TN, FP, FN и понятия, через них выражающиеся, мы говорим в рамках одного класса бинарной классификации. То есть, в такой системе подразумевается, что реальное число объектов класса 0 (для бинарного случая 0/1) может выражаться как [math]\text[/math]
Confusion matrix (матрица ошибок / несоответствий / потерь, CM)
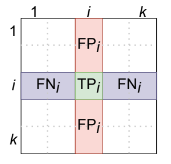
Вычисление TP, FP, FN по CM
— квадратная матрица размера k × k, где [math]\text_[/math] — число объектов класса [math]t[/math] , которые были квалифицированны как класс [math]c[/math] , а [math]k[/math] — число классов. Значения ячеек CM могут быть вычислены по формуле: [math]\text(y, \hat)_ = \displaystyle\sum_^[(y_i = t) ∧ (\hat = c)][/math] , где [math]y_i[/math] — реальный класс объекта, а [math]\hat[/math] — предсказанный.
Для бинарного случая:
| Принадлежит классу (P) | Не принадлежит классу (N) | |
|---|---|---|
| Предсказана принадлежность классу | TP | FP |
| Предсказано отсутствие принадлежности к классу | FN | TN |
Для многоклассовой классификации матрица несоответствий строится по тому же принципу:
| Предсказанный класс | Класс 1 (C₁) | Класс 2 (C₂) | Класс 3 (C₃) |
|---|---|---|---|
| 1 (P₁) | T₁ | F₁₂ | F₁₃ |
| 2 (P₂) | F₂₁ | T₂ | F₂₃ |
| 3 (P₃) | F₃₁ | F₃₂ | T₃ |
В этом случае TP, TN, FP и FN считаются относительно некоторого класса [math](i)[/math] следующим образом:
[math]\text_i = T_i[/math] [math]\text_i = \sum\limits_> \text_[/math] [math]\text_i = \sum\limits_> \text_[/math] [math]\text_i = \text_i — \text_i — \text_i[/math]
Простые оценки
- Accuracy — (точность) показывает долю правильных классификаций. Несмотря на очевидность и простоту, является одной из самых малоинформативных оценок классификаторов.
- Recall — (полнота, sensitivity, TPR (true positive rate)) показывает отношение верно классифицированных объектов класса к общему числу элементов этого класса.
- Precision — (точность, перевод совпадает с accuracy)показывает долю верно классифицированных объектов среди всех объектов, которые к этому классу отнес классификатор.
- Specificity — показывает отношение верных срабатываний классификатора к общему числу объектов за пределами класса. Иначе говоря, то, насколько часто классификатор правильно не относит объекты к классу.
- Fall-out — (FPR (false positive rate)) показывает долю неверных срабатываний классификатора к общему числу объектов за пределами класса. Иначе говоря то, насколько часто классификатор ошибается при отнесении того или иного объекта к классу.
Ввиду того, что такие оценки никак не учитывают изначальное распределение классов в выборке (что может существенно влиять на полученное значение), также существуют взвешенные варианты этих оценок (в терминах многоклассовой классификации):
Различные виды агрегации Precision и Recall
Примеры и картинки взяты из лекций курса «Введение в машинное обучение» [1] К.В. Воронцова
Арифметическое среднее:
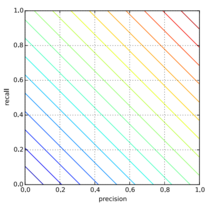
Линии уровня для среднего арифметического
- Если precision = 0.05, recall = 1, то A = 0.525
- Если precision = 0.525, recall = 0.525, то A = 0.525.
- Первый классификатор — константный, не имеет смысла.
- Второй классификатор показывает неплохое качество.
Таким образом, взятие среднего арифметического не является показательным.
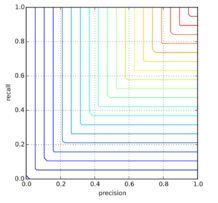
Линии уровня для минимума
- Если precision = 0.05, recall = 1, то M = 0.05
- Если precision = 0.525, recall = 0.525, то M = 0.525.
То есть, довольно неплохо отражает качество классификатора, не завышая его.
- Если precision = 0.2, recall = 1, то M = 0.2.
- Если precision = 0.2, recall = 0.3, то M = 0.2.
Но не отличает классификаторы с разными неминимальными показателями.
Гармоническое среднее, или F-мера:
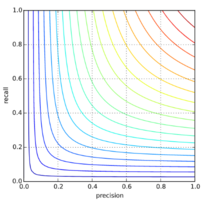
Линии уровня для F-меры
- Если precision = 0.05, recall = 1, то F = 0.1.
- Если precision = 0.525, recall = 0.525, то F = 0.525.
- Если precision = 0.2, recall = 1, то F = 0.33.
- Если precision = 0.2, recall = 0.3, то F = 0.24.
Является наиболее точным усреднением, учитывает оба показателя.
Геометрическое среднее, или Индекс Фоулкса–Мэллова (Fowlkes–Mallows index)
Менее строгая мера.
F-мера
Для общей оценки качества классификатора часто используют F₁-меру. Оригинально она вычисляется для позитивного класса случая бинарной классификации, обобщается с помощью приниципа «один против всех» (описан подробнее ниже, для многоклассовой классификации). F₁-мера — среднее гармоническое между precision и recall:
[math]\text_1 = \left ( \dfrac^ + \text^> \right )^ = 2 \cdot \dfrac \cdot \text>>[/math]
Среднее гармоническое взвешенное Fβ (F1-мера — частный случай Fβ-меры для β = 1). Fβ измеряет эффективность классификатора учитывая recall в β раз более важным чем precision:
[math]\text_β = (1 + β^2) \dfrac \cdot \text>>[/math]
F-мера для многоклассовой классификации. Три вида усреднения
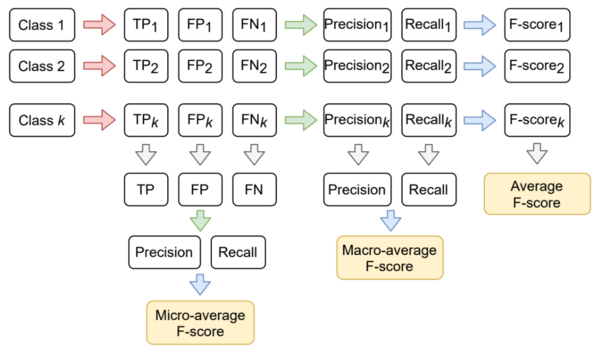
Принцип усреднения различных F-мер для нескольких классов
Вычисление TP, FP, FN для многоклассовой классификации
Для вычисления F-меры (и других) метрик в рамках многоклассовой классификации используется подход «один против всех»: каждый класс ровно один раз становится «положительным», а остальные — отрицательным (пример вычисления изображён на матрице).
Таким образом, в зависимости от этапа вычисления, на котором производится усреднение, можно вычислить micro-average, macro-average и average F-меры (логика вычисления изображена на схеме справа). Микро- и макро-:
[math]\text = 2 \cdot \dfrac \cdot \text>>[/math] ,
где для micro-average precision и recall вычислены из усреднённых TP, FP, FN;
для macro-average precision и recall вычислены из усреднённых precisioni, recalli;
[math]\text = \dfrac \displaystyle\sum_^ <\text_1score_i>[/math] ,
где [math]i[/math] — индекс класса, а [math]k[/math] — число классов.
ROC-кривая
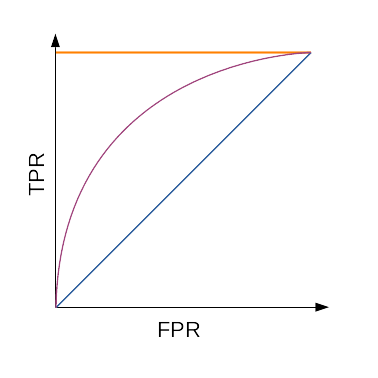
ROC-кривая; оранжевым показан идеальный алгоритм, фиолетовым — типичный, а синим — худший
Для наглядной оценки качества алгоритма применяется ROC-кривая. Кривая строится на плоскости, определённой TPR (по оси ординат) и FPR (по оси абсцисс).
Для построении графика используется мягкая классификация: вместо того, чтобы чётко отнести объект к классу, классификатор возвращает вероятности принадлежности объекта к различным классам. Эта уверенность сравнивается с порогом (какой уверенности «достаточно», чтобы отнести объект к положительному классу). В зависимости от значения этого порога меняются значения TPR и FPR.
Алгоритм построения кривой:
- Запустить классификатор на тестовой выборке
- Отсортировать результаты по уверенности классификатора в принадлежности объекта к классу
- Пока не кончились элементы:
- Взять объект с максимальной уверенностью
- Сравнить метку с реальной
- Пересчитать TPR и FPR на взятых объектах
- Поставить точку, если обе характеристики не NaN / ±∞
Таким образом: число точек не превосходит число объектов идеальному алгоритму соответствует ROC-кривая, проходящая через точку [math](0;1)[/math] худшему алгоритму (например, монетке) соответствует прямая TPR = FPR.
Для численной оценки алгоритма по ROC-кривой используется значение площади под ней (AUC, area under curve). Идеальный алгоритм имеет AUC, равный 1, худший — 0,5.
С другой стороны, для построения ROC-кривой не обязательно пересчитывать TPR и FPR.
Существует альтернативный алгоритм построения ROC-кривой.
- сортируем объекты по уверенности классификатора в их принадлежности к положительному классу
- начинаем в точке (0, 0)
- последовательно продолжаем кривую вверх:
- для каждого «отрицательного» объекта вверх
- для каждого «положительного» — вправо.
Корректность алгоритма обосновывается тем, что с изменением предсказания для одного объекта в зависимости от его класса меняется либо TPR, либо FPR (значение второго параметра остаётся прежним). Ниже описана другая логика, подводящая к алгоритму выше.
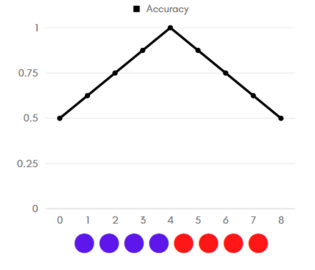
График Accuracy для идеальной классификации
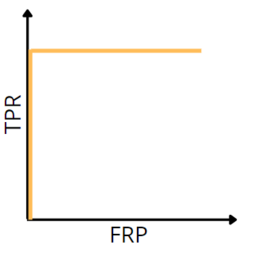
ROC-кривая для идеальной классификации
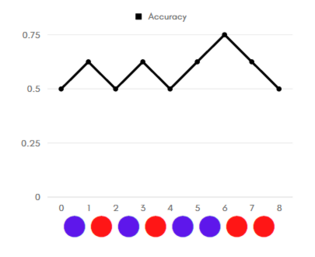
График Accuracy для неидеальной классификации
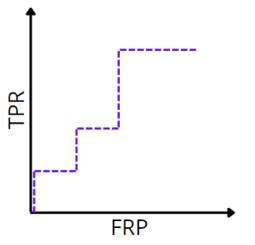
ROC-кривая для неидеальной классификации
Напомним, что мы работаем с мягкой классификацией.
Рассмотрим примеры (графики accuracy, цветом указан реальный класс объекта: красный — положительный, синий — отрицательный). Отсортируем наши объекты по возрастанию уверенности классификатора в принадлежности объекта к положительному классу. Допустим, что объекты находятся на равном (единичном) расстоянии друг от друга.
Начнём перебирать «границу раздела»: если граница в нуле — мы решаем относить все объекты к положительному классу, тогда accuracy = 1/2. Последовательно сдвигаем границу по единичке вправо:
- если реальный класс объекта, оказавшегося теперь по другую сторону границы — отрицательный, то accuracy увеличивается, так как мы «угадали» класс объекта, решив относить объекты левее границы к отрицательному классу;
- если же реальный класс объекта — положительный, accuracy уменьшается (по той же логике)
Таким образом, на графиках слева, видно, что:
- на графике идеальной классификации точность в 100% достигается, неидеальной — нет;
- площадь под графиком accuracy идеального классификатора больше, чем аналогичная площадь для неидеального.
Заметим, что, повернув график на 45 градусов, мы получим ROC-кривые для соответствующих классификаторов (графикам accuracy слева соответствуют ROC-кривые справа). Так объясняется альтернативный алгоритм построения ROC-кривой.
Precision-Recall кривая
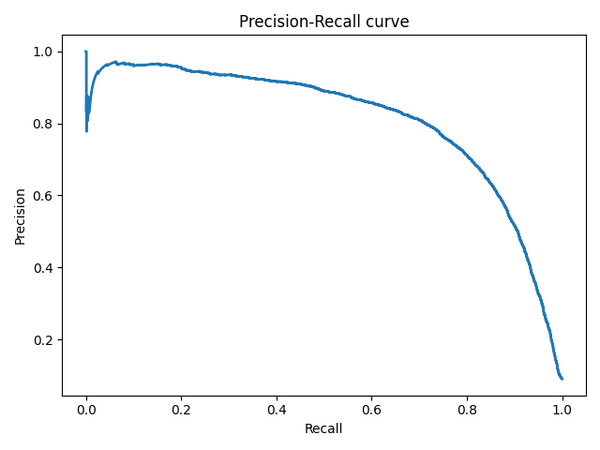
Обоснование: Чувствительность к соотношению классов.
Рассмотрим задачу выделения математических статей из множества научных статей. Допустим, что всего имеется 1.000.100 статей, из которых лишь 100 относятся к математике. Если нам удастся построить алгоритм [math]a(x)[/math] , идеально решающий задачу, то его TPR будет равен единице, а FPR — нулю. Рассмотрим теперь «плохой» алгоритм, дающий положительный ответ на 95 математических и 50.000 нематематических статьях. Такой алгоритм совершенно бесполезен, но при этом имеет TPR = 0.95 и FPR = 0.05, что крайне близко к показателям идеального алгоритма. Таким образом, если положительный класс существенно меньше по размеру, то AUC-ROC может давать неадекватную оценку качества работы алгоритма, поскольку измеряет долю неверно принятых объектов относительно общего числа отрицательных. Так, алгоритм [math]b(x)[/math] , помещающий 100 релевантных документов на позиции с 50.001-й по 50.101-ю, будет иметь AUC-ROC 0.95.
Precison-recall (PR) кривая.
Избавиться от указанной проблемы с несбалансированными классами можно, перейдя от ROC-кривой к PR-кривой. Она определяется аналогично ROC-кривой, только по осям откладываются не FPR и TPR, а полнота (по оси абсцисс) и точность (по оси ординат). Критерием качества семейства алгоритмов выступает площадь под PR-кривой (англ. Area Under the Curve — AUC-PR)
Источники
- Coursera: https://www.coursera.org/learn/vvedenie-mashinnoe-obuchenie
- Оценка качества в задачах классификации и регрессии
- Лекции А. Забашта
- Лекции Е. А. Соколова
- Оценка классификатора (точность, полнота, F-мера)
Типы данных
Вывод действительных чисел на C++ Перед выводом действительных чисел (float, double, long double) следует указать выходному потоку точность вывода. Например:
float x; x = 123.456789; cout.setf(ios::fixed); // вывод в фиксированном формате cout.precision(6); // вывод до 6 знака после точки, включительно cout
Вы используете гостевой доступ (Вход)
Эта страница: General type: incourse. Context Страница: Вывод действительных чисел на C++ (context id 276028). Page type mod-page-view.
Почему может уменьшиться точность чисел с плавающей запятой
Десятичные значения с плавающей запятой, как правило, не имеют точного двоичного представления. Это побочный эффект того, как данные с плавающей запятой представляются в ЦП. По этой причине может происходить некоторая потеря точности, а некоторые операции с плавающей запятой могут давать непредвиденный результат.
Причины такого поведения могут быть следующими.
- Двоичное представление десятичного числа может быть неточным.
- Несоответствие типов используемых чисел (например, float и double).
Для решения этой проблемы большинство программистов либо гарантируют, что значение больше или меньше необходимого, либо используют библиотеку двоично-десятичного кода (BCD), которая будет обеспечивать точность.
Двоичное представление значений с плавающей запятой влияет на точность и правильность вычислений с плавающей запятой. В Microsoft Visual C++ используется формат IEEE с плавающей запятой.
Пример
// Floating-point_number_precision.c // Compile options needed: none. Value of c is printed with a decimal // point precision of 10 and 6 (printf rounded value by default) to // show the difference #include #define EPSILON 0.0001 // Define your own tolerance #define FLOAT_EQ(x,v) (((v - EPSILON) < x) && (x <( v + EPSILON))) int main() < float a, b, c; a = 1.345f; b = 1.123f; c = a + b; // if (FLOAT_EQ(c, 2.468)) // Remove comment for correct result if (c == 2.468) // Comment this line for correct result printf_s("They are equal.\n"); else printf_s("They are not equal! The value of c is %13.10f " "or %f",c,c); >They are not equal! The value of c is 2.4679999352 or 2.468000Комментарии
Для EPSILON можно использовать константу FLT_EPSILON, которая определена для float как 1,192092896e-07F, или DBL_EPSILON, которая определена для double как 2,2204460492503131e-016. Для этих констант необходимо включить файл float.h. Эти константы определены как наименьшее положительное число x, при котором x + 1,0 не равно 1,0. Так как это очень маленькое число, для вычислений с очень большими числами следует использовать пользовательскую погрешность.