Python – Дерево поиска
Бинарное дерево поиска (BST) – это дерево, в котором все узлы следуют указанным ниже свойствам. Левое поддерево узла имеет ключ, меньший или равный ключу его родительского узла. Правое поддерево узла имеет ключ больше, чем ключ его родительского узла. Таким образом, BST делит все свои поддеревья на два сегмента; левое поддерево и правое поддерево и может быть определено как –
left_subtree (keys) ≤ node (key) ≤ right_subtree (keys)
Поиск значения в B-дереве
Поиск значения в дереве включает сравнение входящего значения со значением, выходящим из узлов. Здесь также мы пересекаем узлы слева направо, а затем, наконец, с родителем. Если искомое значение не совпадает ни с одним из значений выходного значения, то мы возвращаем не найденное сообщение, иначе возвращается найденное сообщение.
class Node: def __init__(self, data): self.left = None self.right = None self.data = data # Insert method to create nodes def insert(self, data): if self.data: if data self.data: if self.left is None: self.left = Node(data) else: self.left.insert(data) elif data > self.data: if self.right is None: self.right = Node(data) else: self.right.insert(data) else: self.data = data # findval method to compare the value with nodes def findval(self, lkpval): if lkpval self.data: if self.left is None: return str(lkpval)+" Not Found" return self.left.findval(lkpval) elif lkpval > self.data: if self.right is None: return str(lkpval)+" Not Found" return self.right.findval(lkpval) else: print(str(self.data) + ' is found') # Print the tree def PrintTree(self): if self.left: self.left.PrintTree() print( self.data), if self.right: self.right.PrintTree() root = Node(12) root.insert(6) root.insert(14) root.insert(3) print(root.findval(7)) print(root.findval(14))
Когда приведенный выше код выполняется, он дает следующий результат –
Реализация дерева поиска¶
Двоичные деревья поиска полагаются то, что ключи меньше родительского находятся в левом поддереве, а больше — в правом. Мы будем называть это bst-свойством (от англ. binary search tree — прим. переводчика). В процессе реализации описанного выше интерфейса Map оно станет нашим верным проводником. Рисунок 1 иллюстрирует это свойство двоичных деревьев поиска, показывая ключи без ассоциированных с ними значений. Обратите внимание: им обладают и узлы-потомки, и узлы-предки. Все ключи в левых поддеревьях меньше ключа корня, а в правых — больше его.
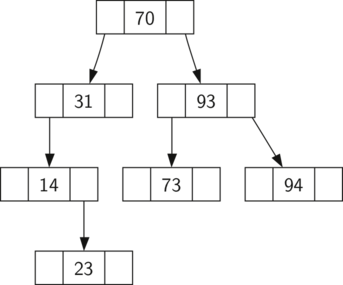
Рисунок 1: Простое двоичное дерево поиска
Теперь, когда вы знаете, что такое двоичное дерево поиска, можно рассмотреть процесс его создания. Дерево поиска на рисунке 1 содержит узлы, появившиеся после вставки следующих ключей в таком порядке: \(70,31,93,94,14,23,73\) . Так как 70 — первое вставляемое в дерево значение, то это корень. Число 31 меньше 70-и, поэтому оно уходит в левое поддерево. 93 наоборот больше — и вставляется в правое поддерево. Теперь у нас заполнены два уровня из трёх, так что следующий ключ должен стать потомком 31 или 93. 94 больше, чем 70 и 93, поэтому мы делаем его правым потомком 93. Аналогично, 14 меньше и 70, и 31, следовательно, оно уходит в левое поддерево 31. 23 меньше, чем 31, так что оно тоже должно быть в левом поддереве 31. Однако, это число больше 14, следовательно, становится его правым потомком.
Для реализации двоичного дерева поиска мы используем узлы и ссылки (аналогично связанному списоку и дереву выражения). Однако, поскольку нам надо быть готовыми использовать двоичное дерево поиска и когда оно пусто, мы создадим два класса. Первый назовём BinarySearchTree , а второй — TreeNode . BinarySearchTree будет иметь ссылку на объект TreeNode , который является корнем дерева. В большинстве случаев внешние методы, определённые во внешнем классе, просто проверяют дерево на пустоту. Если у него есть узлы, то запрос просто передаётся в приватный метод из BinarySearchTree , который принимает корень в качестве параметра. В случае, когда дерево пусто или мы хотим удалить ключ из корня, необходимо проделать специальные действия. Код для конструктора класса BinarySearchTree и нескольких других различных функций показан в листинге 1.
Листинг 1
class BinarySearchTree: def __init__(self): self.root = None self.size = 0 def length(self): return self.size def __len__(self): return self.size def __iter__(self): return self.root.__iter__()
Класс TreeNode предоставляет множество вспомогательных функций, которые значительно облегчают работу BinarySearchTree . Конструктор TreeNode вместе с этими функциями показан в листинге 2. Из него видно, что большинство дополнительных функций помогают классифицировать узел в соответствии с его положением как потомка (левого или правого) и типом его детей.
Так же класс TreeNode явно отслеживает родителя, как атрибут каждого узла. Вы поймёте важность этого, когда мы будем обсуждать реализацию оператора del .
Другой любопытный аспект TreeNode в листинге 2 заключается в использовании опциональных параметров Python. Они позволяют нам упростить его создание в соответствии с различными обстоятельствами. Иногда мы захотим сконструировать новый объект TreeNode , имеющий и parent , и child . С уже существующими потомком и предком их можно просто передать, как параметры. В следующий раз мы создадим TreeNode с парой ключ-значение, не передавая при этом ни parent , ни child . В этом случае для параметров будут использоваться значения по умолчанию.
Листинг 2
class TreeNode: def __init__(self,key,val,left=None,right=None, parent=None): self.key = key self.payload = val self.leftChild = left self.rightChild = right self.parent = parent def hasLeftChild(self): return self.leftChild def hasRightChild(self): return self.rightChild def isLeftChild(self): return self.parent and self.parent.leftChild == self def isRightChild(self): return self.parent and self.parent.rightChild == self def isRoot(self): return not self.parent def isLeaf(self): return not (self.rightChild or self.leftChild) def hasAnyChildren(self): return self.rightChild or self.leftChild def hasBothChildren(self): return self.rightChild and self.leftChild def replaceNodeData(self,key,value,lc,rc): self.key = key self.payload = value self.leftChild = lc self.rightChild = rc if self.hasLeftChild(): self.leftChild.parent = self if self.hasRightChild(): self.rightChild.parent = self
Теперь, когда у нас есть обёртка BinarySearchTree и класс TreeNode , пришло время написать метод put , который позволит строить двоичные деревья поиска. Он будет принадлежать классу BinarySearchTree . Метод будет выполнять проверку на наличие корня дерева, а в случае отсутствия последнего создавать объект TreeNode и устанавливать его, как корневой узел. В противном случае put вызовет приватную рекурсивную вспомогательную функцию _put для поиска места в дереве по следующему алгоритму:
- Начиная от корня, проходим по двоичному дереву, сравнивая новый ключ с ключом текущего узла. Если первый меньше второго, то идём в левое поддерево. Наоборот — в правое.
- Когда не осталось левых или правых потомков для поиска — мы нашли позицию для установки нового узла.
- Чтобы добавить узел в дерево, создаём новый объект TreeNode и помещаем его на найденное за предыдущие шаги место.
Листинг 3 показывает код Python для вставки нового узла в дерево. Функция _put написана рекурсивно и следует описанным выше пунктам. Отметьте, что когда в дерево вставляется новый потомок, currentNode передаётся как родитель нового поддерева.
Одной из серьёзных проблем нашей реализации является то, что дубликаты ключей не обрабатываются правильным образом. У нас дубль создаст новый узел с точно таким же значением ключа и поместит его в правое поддерево узла с оригинальным ключом. В результате новый узел никогда не будет обнаружен в процессе поиска. Для управления вставкой дубликатов ключей есть способ лучше: сделать так, чтобы значение, ассоциированное с новым ключом, заменяло старое. Мы оставляем вам исправление этого недочёта в качестве упражнения.
Листинг 3
def put(self,key,val): if self.root: self._put(key,val,self.root) else: self.root = TreeNode(key,val) self.size = self.size + 1 def _put(self,key,val,currentNode): if key currentNode.key: if currentNode.hasLeftChild(): self._put(key,val,currentNode.leftChild) else: currentNode.leftChild = TreeNode(key,val,parent=currentNode) else: if currentNode.hasRightChild(): self._put(key,val,currentNode.rightChild) else: currentNode.rightChild = TreeNode(key,val,parent=currentNode)
Определив метод put , можно легко перегрузить оператор [] для присвоения с помощью вызова метода __setitem__ (см. листинг 4). Это позволит нам писать выражения вида myZipTree['Plymouth'] = 55446 , как для словарей Python.
Листинг 4
def __setitem__(self,k,v): self.put(k,v)
Рисунок 2 иллюстрирует процесс вставки нового узла в двоичное дерево поиска. Слегка затенённые узлы — это те, что были посещены в процессе вставки.
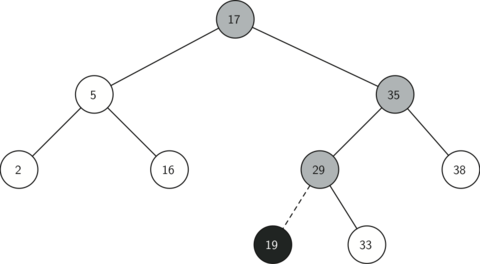
Рисунок 2: Вставка узла с ключом, равным 19.
Q-66: Какое из показанных деревьев будет правильным двоичным деревом поиска, ключи в которое вставлялись в следующем порядке: 5, 30, 2, 40, 25, 4?
Поскольку дерево уже сконструировано, то следующее задание — реализовать поиск значения по заданному ключу. Метод get проще put , потому что просто делает рекурсивный поиск, пока не дойдёт до листового узла или не найдёт искомое. Когда ключ найдётся, хранимое в узле значение будет возвращено.
Листинг 5 демонстрирует код для get , _get и __getitem__ . Поиск в методе _get``использует ту же логику для выбора правого или левого потомка, что и ``_put . Обратите внимание, _get возвращает в get объект TreeNode . Это позволяет использовать _get в качестве гибкого вспомогательного метода для других методов BinarySearchTree , которым, кроме полезной нагрузки, могут потребоваться и другие данные из TreeNode .
Реализовав метод __getitem__ , можно писать операторы Python, выглядящие так, будто мы имеем доступ к словарю, когда по факту используется двоичное дерево поиска. Например, z = myZipTree['Fargo'] . Как вы видите, всё, что делает __getitem__ , — это вызывает get .
Листинг 5
def get(self,key): if self.root: res = self._get(key,self.root) if res: return res.payload else: return None else: return None def _get(self,key,currentNode): if not currentNode: return None elif currentNode.key == key: return currentNode elif key currentNode.key: return self._get(key,currentNode.leftChild) else: return self._get(key,currentNode.rightChild) def __getitem__(self,key): return self.get(key)
С использованием get можно реализовать операцию in , написав метод __contains__ для BinarySearchTree . Он будет просто вызывать get и выдавать True , если get возвращает значение, или False в противном случае. Код для __contains__ показан в листинге 6.
Листинг 6
def __contains__(self,key): if self._get(key,self.root): return True else: return False
Напомним, что __contains__ перегружает оператор in и позволяет писать код наподобие
if 'Northfield' in myZipTree: print("oom ya ya")
В завершение обратим наше внимание на наиболее сложный метод для двоичного дерева поиска — удаление ключа (см. листинг 7). Первым заданием будет поиск в дереве удаляемого объекта. Если дерево имеет больше одного узла, то для этого используется метод _get . Если же оно состоит из единственного узла, то это подразумевает удаление корня. Однако, проверить корневой ключ на соответствие удаляемому объекту всё же необходимо. В обоих случаях, если ключ не найден, то оператор del выдаёт ошибку.
Листинг 7
def delete(self,key): if self.size > 1: nodeToRemove = self._get(key,self.root) if nodeToRemove: self.remove(nodeToRemove) self.size = self.size-1 else: raise KeyError('Error, key not in tree') elif self.size == 1 and self.root.key == key: self.root = None self.size = self.size - 1 else: raise KeyError('Error, key not in tree') def __delitem__(self,key): self.delete(key)
После того, как мы нашли ключ удаляемого значения, существует три варианта, каждый из которых следует рассмотреть по отдельности:
- Удаляемый узел не имеет потомков (см. рисунок 3).
- У удаляемого узла есть только один потомок (см. рисунок 4).
- У удаляемого узла есть оба потомка (см. рисунок 5).
В первом случае всё очевидно (см. листинг 8). Если текущий узел не имеет потомков, то всё, что от нас требуется, — это удалить его и ссылку на него у его родителя. Вот код для этого:
Листинг 8
if currentNode.isLeaf(): if currentNode == currentNode.parent.leftChild: currentNode.parent.leftChild = None else: currentNode.parent.rightChild = None
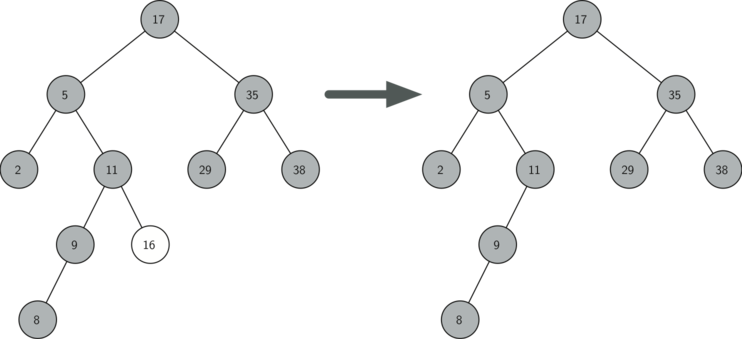
Рисунок 3: Удаление узла 16, не имеющего потомков
Второй случай ненамного сложнее (см. листинг 9). Если у узла всего один потомок, то мы просто поможем ему занять место родителя. Код для этого показан в следующем листинге. Из него вы можете видеть, что есть шесть случаев для рассмотрения. Поскольку они симметричны для обоих детей, мы обсудим только вариант, когда узел имеет левого потомка. Процесс поиска решения следующий:
- Если текущий узел — левый потомок, то нужно всего лишь обновить родительскую ссылку на него у предка, а затем обновить ссылку его потомка, чтобы она указывала на нового родителя.
- Если текущий узел — правый потомок, то мы обновляем родительскую ссылку его потомка, чтобы она указывала на предка текущего узла, а затем — ссылку на правого потомка у родителя текущего узла.
- Если текущий узел предка не имеет, то он должен быть корнем. В этом случае мы просто заменяем данные key , payload , leftChild и rightChild , вызвав для корня метод replaceNodeData .
Листинг 9
else: # this node has one child if currentNode.hasLeftChild(): if currentNode.isLeftChild(): currentNode.leftChild.parent = currentNode.parent currentNode.parent.leftChild = currentNode.leftChild elif currentNode.isRightChild(): currentNode.leftChild.parent = currentNode.parent currentNode.parent.rightChild = currentNode.leftChild else: currentNode.replaceNodeData(currentNode.leftChild.key, currentNode.leftChild.payload, currentNode.leftChild.leftChild, currentNode.leftChild.rightChild) else: if currentNode.isLeftChild(): currentNode.rightChild.parent = currentNode.parent currentNode.parent.leftChild = currentNode.rightChild elif currentNode.isRightChild(): currentNode.rightChild.parent = currentNode.parent currentNode.parent.rightChild = currentNode.rightChild else: currentNode.replaceNodeData(currentNode.rightChild.key, currentNode.rightChild.payload, currentNode.rightChild.leftChild, currentNode.rightChild.rightChild)
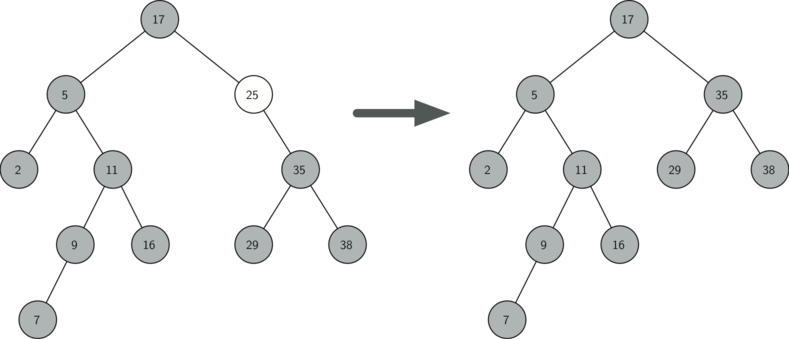
Рисунок 4: Удаление узла 25, имеющего единственного потомка.
Третий случай наиболее сложный для обработки (см. листинг 10). Если у узла есть оба потомка, то маловероятно, что можно просто поставить их на место родителя. Однако, мы можем пройти поиском по дереву и найти узел, способный заменить тот, который стоит в списке на выбывание. Нам нужно, чтобы этот узел сохранял принятые в двоичном дереве поиска отношения между существующими правым и левым поддеревьями, т.е. он будет иметь следующий по величине ключ. Мы назовём такой узел преемником и рассмотрим способ найти как можно быстрее. Преемник гарантированно имеет не более, чем одного потомка, так что мы знаем, как можно его удалить с использованием двух уже рассмотренных и написанных случаев. Как только преемник будет удалён, мы просто вставим его в дерево на место удаляемого узла.
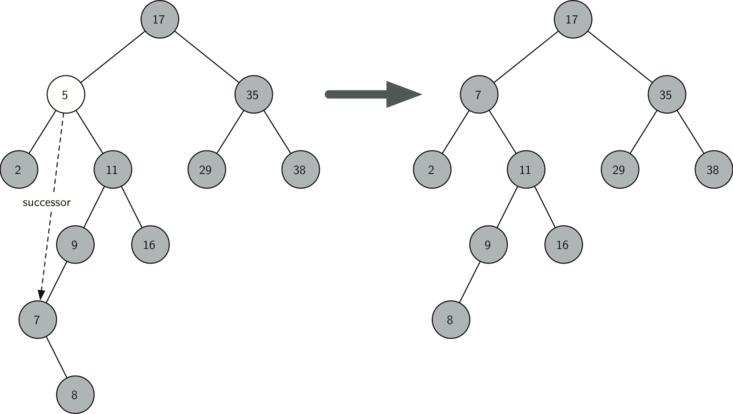
Рисунок 5: Удаление узла 5, имеющего двух потомков.
Код, обрабатывающий третий случай, показан в следующем листинге. Обратите внимание на использование вспомогательных методов findSuccessor и findMin для поиска преемника. Чтобы его удалить, мы применяем метод spliceOut . Причина, по которой это делается, состоит в том, что он идёт точно в тот узел, который мы хотим соединить, и осуществляет правильную замену. Можно было бы рекурсивно вызвать delete , но это означает пустую трату времени на повторный поиск ключевого узла.
Листинг 10
elif currentNode.hasBothChildren(): #interior succ = currentNode.findSuccessor() succ.spliceOut() currentNode.key = succ.key currentNode.payload = succ.payload
Код для поиска преемника показан ниже (см. листинг 11) и, как вы можете видеть, это метод класса«TreeNode«. Здесь используются те же свойства двоичных деревьев поиска, что и при распечатке узлов от меньшего к большему при симметричном обходе. Вот три случая, которые следует рассмотреть при поиске преемника:
- Если у узла есть правый потомок, то преемник — наименьший ключ в правом поддереве.
- Если у узла нет правого потомка и сам он — левый потомок родителя, то преемником будет родитель.
- Если узел — правый потомок своего родителя и сам правого потомка не имеет, то его преемником будет преемник родителя (исключая сам этот узел).
Первое условие — единственное имеющее для нас значение при удалении узла из двоичного дерева поиска. Однако, метод findSuccessor имеет ещё одно применение, которое будет исследовано в упражнениях в конце этой главы.
Метод findMin вызывается для поиска минимального ключа в дереве. Вам следует самостоятельно убедиться, что минимальный ключ в любом двоичном дереве поиска — самый левый из потомков. Поэтому метод findMin всего лишь следует по ссылкам leftChild до тех пор, пока не достигнет узла, не имеющего левых потомков.
Листинг 11
def findSuccessor(self): succ = None if self.hasRightChild(): succ = self.rightChild.findMin() else: if self.parent: if self.isLeftChild(): succ = self.parent else: self.parent.rightChild = None succ = self.parent.findSuccessor() self.parent.rightChild = self return succ def findMin(self): current = self while current.hasLeftChild(): current = current.leftChild return current def spliceOut(self): if self.isLeaf(): if self.isLeftChild(): self.parent.leftChild = None else: self.parent.rightChild = None elif self.hasAnyChildren(): if self.hasLeftChild(): if self.isLeftChild(): self.parent.leftChild = self.leftChild else: self.parent.rightChild = self.leftChild self.leftChild.parent = self.parent else: if self.isLeftChild(): self.parent.leftChild = self.rightChild else: self.parent.rightChild = self.rightChild self.rightChild.parent = self.parent
Нам осталось рассмотреть последний метод интерфейса для двоичного дерева поиска. Предположим, вы просто хотите перебрать все ключи в дереве по порядку. Это определённо то, что мы делаем со словарями, так почему бы не сделать это и с деревом? Вы уже знаете, как обходить двоичное дерево по порядку с использованием алгоритма обхода inorder . Однако, написание итератора поребует немного больше работы, поскольку он должен возвращать только один узел за каждый свой вызов.
Для создания итератора Python предоставляет очень мощную функцию под названием yield . Она аналогична return , возвращающему значение вызывающему коду. Однако, yield так же делает дополнительный шаг, замораживая состояние функции, чтобы когда она будет вызвана в следующий раз, вычисления продолжились с оставленного места. Функция, создающая объект, который может быть итерирован, называется генератором функций.
Код для итератора inorder двоичного дерева показан в следующем листинге. Посмотрите на него внимательнее: на первый взгляд может показаться, будто он не рекурсивный. Однако, вспомните, что __iter__ перегружает опреацию for x in для итерирования. Так что на самом деле рекурсия здесь есть. Поскольку код рекурсивен для объектов TreeNode , метод __iter__ определён в классе TreeNode .
def __iter__(self): if self: if self.hasLeftChild(): for elem in self.leftChiLd: yield elem yield self.key if self.hasRightChild(): for elem in self.rightChild: yield elem
Сейчас вам можете захотеться целиком загрузить файл, содержащий полную версию классов BinarySearchTree и TreeNode .
Обход двоичного дерева на Python
Да, двоичные деревья — не самая любимая тема программистов. Это одна из тех старых концепций, о целесообразности изучения которых постоянно ведутся споры. В работе вам довольно редко придется реализовывать двоичные деревья и обходить их, так зачем же уделять им так много внимания на технических собеседованиях?
Сегодня мы не будем переворачивать двоичное дерево (ффухх!), но рассмотрим пару методов его обхода. К концу статьи вы поймете, что двоичные деревья не так страшны, как кажется.
Что такое двоичное дерево?
Недавно мы разбирали реализацию связных списков на Python. Каждый такой список состоит из некоторого количества узлов, указывающих на другие узлы. А если бы узел мог указывать не на один другой узел, а на большее их число? Вот это и есть деревья. В них каждый родительский узел может иметь несколько узлов-потомков. Если у каждого узла максимум два узла-потомка (левый и правый), такое дерево называется двоичным (бинарным).
В приведенном выше примере «корень» дерева, т. е. самый верхний узел, имеет значение 1. Его потомки — 2 и 3. Узлы 3, 4 и 5 называют «листьями»: у них нет узлов-потомков.
Строим двоичное дерево на Python
Как построить дерево на Python? Реализация будет похожей на наш класс Node в реализации связного списка. В этом случае мы назовем класс TreeNode .
class TreeNode: pass
Определим метод __init__() . Как всегда, он принимает self . Также мы передаем в него значение, которое будет храниться в узле.
class TreeNode: def __init__(self, value):
Установим значение узла, а затем определим левый и правый указатель (для начала поставим им значение None ).
class TreeNode: def __init__(self, value): self.value = value self.left = None self.right = None
И… все! Что, думали, что деревья куда сложнее? Если речь идет о двоичном дереве, единственное, что его отличает от связного списка, это то, что вместо next у нас тут есть left и right .
Давайте построим дерево, которое изображено на схеме в начале статьи. Верхний узел имеет значение 1. Далее мы устанавливаем левые и правые узлы, пока не получим желаемое дерево.
tree = TreeNode(1) tree.left = TreeNode(2) tree.right = TreeNode(3) tree.left.left = TreeNode(4) tree.left.right = TreeNode(5)
Обход двоичного дерева
Итак, вы построили дерево и теперь вам, вероятно, любопытно, как же его увидеть. Нет никакой команды, которая позволила бы вывести на экран дерево целиком, тем не менее мы можем обойти его, посетив каждый узел. Но в каком порядке выводить узлы?
Самые простые в реализации обходы дерева — прямой (Pre-Order), обратный (Post-Order) и центрированный (In-Order). Вы также можете услышать такие термины, как поиск в ширину и поиск в глубину, но их реализация сложнее, ее мы рассмотрим как-нибудь потом.
Итак, что из себя представляют три варианта обхода, указанные выше? Давайте еще раз посмотрим на наше дерево.
При прямом обходе мы посещаем родительские узлы до посещения узлов-потомков. В случае с нашим деревом мы будем обходить узлы в таком порядке: 1, 2, 4, 5, 3.
Обратный обход двоичного дерева — это когда вы сначала посещаете узлы-потомки, а затем — их родительские узлы. В нашем случае порядок посещения узлов при обратном обходе будет таким: 4, 5, 2, 3, 1.
При центрированном обходе мы посещаем все узлы слева направо. Центрированный обход нашего дерева — это посещение узлов 4, 2, 5, 1, 3.
Давайте напишем методы обхода для нашего двоичного дерева.
Pre-Order
Начнем с определения метода pre_order() . Наш метод принимает один аргумент — корневой узел (расположенный выше всех).
def pre_order(node): pass
Дальше нам нужно проверить, существует ли этот узел. Вы можете возразить, что лучше бы проверить существование потомков этого узла перед их посещением. Но для этого нам пришлось бы написать два if-предложения, а так мы обойдемся одним.
def pre_order(node): if node: pass
Написать обход просто. Прямой обход — это посещение родительского узла, а затем каждого из его потомков. Мы «посетим» родительский узел, выведя его на экран, а затем «обойдем» детей, вызывая этот метод рекурсивно для каждого узла-потомка.
# Выводит родителя до всех его потомков def pre_order(node): if node: print(node.value) pre_order(node.left) pre_order(node.right)
Просто, правда? Можем протестировать этот код, совершив обход построенного ранее дерева.
pre_order(tree)
1 2 4 5 3
Post-Order
Переходим к обратному обходу. Возможно, вы думаете, что для этого нужно написать еще один метод, но на самом деле нам нужно изменить всего одну строчку в предыдущем.
Вместо «посещения» родительского узла и последующего «обхода» детей, мы сначала «обойдем» детей, а затем «посетим» родительский узел. То есть, мы просто передвинем print на последнюю строку! Не забудьте поменять имя метода на post_order() во всех вызовах.
# Выводит потомков, а затем родителя def post_order(node): if node: post_order(node.left) post_order(node.right) print(node.value)
В выводе мы получим:
4 5 2 3 1
Каждый узел-потомок посещен до посещения его родителя.
In-Order
Наконец, напишем метод центрированного обхода. Как нам обойти левый узел, затем родительский, а затем правый? Опять же, нужно переместить предложение print!
# выводит левого потомка, затем родителя, затем правого потомка def in_order(node): if node: in_order(node.left) print(node.value) in_order(node.right)
4 2 5 1 3
Вот и все, мы рассмотрели три простейших способа совершить обход двоичного дерева.
Python алгоритмы
Блог про алгоритмы и все что с ними связано. Основной инструмент реализации — Python.
Дай 10 !)
суббота, 30 июля 2011 г.
Бинарные деревья

Бинарное дерево представляет собой структуру, в которой каждый узел (или вершина) имеет не более двух узлов-потомков и в точности одного родителя. Самый верхний узел дерева является единственным узлом без родителей; он называется корневым узлом. Бинарное дерево
с N узлами имеет не меньше [log2N + 1] уровней (при максимально плотной упаковке узлов).
Если уровни дерева занумеровать, считая что корень лежит на уровне 1, то на уровне с номером К лежит 2 К-1 узел. У полного бинарного дерева с j уровнями (занумерованными от 1 до j) все листья лежат на уровне с номером j, и у каждого узла на уровнях с первого по j — 1
в точности два непосредственных потомка. В полном бинарном дереве с j уровнями 2 j — 1 узел.
*-Нравится статья? Кликни по рекламе! 🙂
Бинарные деревья поиска обычно применяются для реализации множеств и ассоциативных массивов. И применяются для быстрого поиска информации. Например в статье Двоичный (бинарный) поиск элемента в массиве мы искали во встроенной в Python структуре данных, типа list, а могли реализовать бинарное дерево. Двоичные деревья, как и связные списки, являются рекурсивными структурами.
Различные реализации одного и того же бинарного дерева

- полное(расширенное) бинарное дерево — каждый узел, за исключением листьев, имеет по 2 дочерних узла;
- идеальное бинарное дерево — это полное бинарное дерево, в котором все листья находятся на одной высоте;
- сбалансированное бинарное дерево — это бинарное дерево, в котором высота 2-х поддеревьев для каждого узла отличается не более чем на 1. Глубина такого дерева вычисляется как двоичный логарифм log(n), где n — общее число узлов;
- вырожденное дерево — дерево, в котором каждый узел имеет всего один дочерний узел, фактически это связный список;
- бинарное поисковое дерево (BST) — бинарное дерево, в котором для каждого узла выполняется условие: все узлы в левом поддереве меньше, и все узлы в правом поддереве больше данного узла.
S = N +1
Если путь от корневого узла до листа обозначить как внешний путь, а путь от корневого узла до НЕлиста обозначить как внутренний путь, тогда сумма всех внешних путей для дерева, изображенного на рисунке, примере полного дерева, ниже:
E=3+3+2+3+4+4+3+3=25,
а сумма внутренних путей будет равна:
I=2+1+0+2+3+1+2=11.
и тогда будет справедлива формула:
E=I+2n, где n - число узлов.

- сконструировать бинарное дерево таким образом, чтобы сумма путей была минимальной, так как это сокращает время вычислений для различных алгоритмов.
- сконструировать полное расширенное бинарное дерево таким образом, чтобы сумма произведений путей от корневого узла до листьев на значение листового узла была минимальной.
2 3 5 7 11 13 17 19 23 29 31 37 41 5 5 7 11 13 17 19 23 29 31 37 41 10 7 11 13 17 19 23 29 31 37 41 17 24 17 19 23 29 31 37 41 24 34 19 23 29 31 37 41 24 34 42 29 31 37 41 42 53 65 37 41 42 53 65 78 95 65 78 95 143 238
Бинарное дерево, построенное по алгоритму Хаффмана

Более полную статью, по кодам Хаффмана читай в моей более ранней статье.
Реализация:
До этого, в своих статьях я показывал силу функционального программирования Python.
Теперь, пришло время, показать ООП в действии, создав новую структуру данных Tree, состоящую из других структур, типа Node.
Сразу скажу, что код взят с сайта IBM с минимальными изменениями и дополнениями. С моей точки зрения данный класс является недееспособным с точки зрения добавления элементов,по причине того, что мы сами должны строить дерево, помня структуру у себя в голове, а ведь мы можем и ошибиться. И позже я напишу так, как мне кажется верным, где добавление элемента является рекурсивным проходом по дереву и поиску подходящего места. А пока, разберем, что есть:
class node: def __init__(self, data = None, left = None, right = None): self.data = data self.left = left self.right = right def __str__(self): return 'Node ['+str(self.data)+']' #/* класс, описывающий само дерево */ class Tree: def __init__(self): self.root = None #корень дерева # /* функция для добавления узла в дерево */ def newNode(self, data): return node(data,None,None)
Дальше, все функции расширяют класс Tree.
Высота бинарного дерева
Для определения высоты дерева потребуется пройти от корня сначала по левому поддереву, потом по правому, сравнить две этих высоты и выбрать максимальное значение. И не забыть к получившемуся значению прибавить единицу (корневой элемент). Мы реализуем её в привычном уже нам рекурсивном виде.
# /* функция для вычисления высоты дерева */ def height(self,node): if node==None: return 0 else: lheight = self.height(node.left) rheight = self.height(node.right) if lheight > rheight: return(lheight+1) else: return(rheight+1)
«Зеркальное» отражение бинарного дерева
Когда два дерева являются зеркальным отражением друг друга, то говорится, что они симметричны. Для получения «зеркальной» копии дерева сначала выполняется проверка на наличие у корня дерева дочерних узлов, и если эти узлы есть, то они меняются местами. Потом эти же действия рекурсивно повторяются для левого и правого дочерних узлов. Если существует только один дочерний узел, тогда можно переходить на один уровень ниже по дереву и продолжать.
# /* функция для зеркального отражения дерева */ def mirrorTree(self, node): if node.left and node.right: node.left,node.right=node.right,node.left self.mirrorTree(node.right) self.mirrorTree(node.left) else: if node.left==None and node.right: return self.mirrorTree(node.right) if node.right==None and node.left: return self.mirrorTree(node.left)
Проверка наличия узла в бинарном дереве
Нужно только учесть, что данная функция не работает для зеркального отображения дерева!
# /* функция для проверки наличия узла */ def lookup(self, node, target): if node == None:return 0 else: if target == node.data: return 1 else: if target < node.data: return self.lookup(node.left, target) else: return self.lookup(node.right, target)
Ширина бинарного дерева
Под шириной дерева понимается максимальное количество узлов, которые расположены на одной высоте. Чтобы определить ширину дерева, достаточно просто добавить счетчик в уже рассмотренный алгоритм для определения высоты дерева.
# /* функция для вычисления ширины дерева */ def getMaxWidth(self,root): maxWdth = 0 i = 1 width = 0 ; h = self.height(root) while( i < h): width = self.getWidth(root, i) if(width >maxWdth): maxWdth = width; i +=1 return maxWdth; def getWidth(self, root, level): if root == None: return 0 if level == 1: return 1 elif level > 1: return self.getWidth(root.left, level-1) + self.getWidth(root.right, level-1)
Распечатка дерева:
# /* функция для распечатки элементов на определенном уровне дерева */ def printGivenLevel(self, root, level): if root == None: return if level == 1: print ("%d " % root.data) elif level > 1: self.printGivenLevel(root.left, level-1); self.printGivenLevel(root.right, level-1); # /* функция для распечатки дерева */ def printLevelOrder(self, root): h = self.height(self.root) i=1 while(i<=h): self.printGivenLevel(self.root, i) i +=1
Сравнение бинарных деревьев
Вынесите её за пределы класса только)
def sameTree(a, b): if a==None and b==None: return 1 elif a and b: return( a.data == b.data and sameTree(a.left, b.left) and sameTree(a.right, b.right) ) return 0
Количество узлов в бинарном дереве
Вычислить количество узлов в бинарном дереве также можно с помощью рекурсии.
Хотя с точки зрения производительности и принципов ООП, правильнее встроить счетчик в сам объект.
def size(node): if node==None:return 0; return(size(node.left) + 1 + size(node.right));
Немножко о производительности
Я протестировал наш класс на поиск. К сожалению, данная его реализация проиграла бинарному поиску по списку, описанному ранее. Я тестировал, запуская в 100000 цикле поиска элемента со значением 5 и результат нашего класса
400003 function calls (100003 primitive calls) in 3.481 seconds
против
200003 function calls in 1.791 seconds
Я считаю, что причина в рекурсивном исполнении данного метода + реализации на Python, а не Си)
- Дж. Макконнелл - Основы современных алгоритмов.
- Структуры данных: бинарные деревья. Часть 1
- Работа со структурами данных в языках Си и Python: Часть 6. Двоичные деревья
- Может быть полезным Обходы бинарных деревьев