Что такое объектное хранилище S3
Рассказали, что такое объектное хранилище S3 и как с ним работать.

Объектное хранилище — это технология для удобного и надежного хранения большого объема данных.
Изначально технология была разработана компанией AWS в 2006 году, как API для простого доступа к объектам с помощью уникальных URL по HTTP или HTTPS. Сегодня объектное хранилище S3 — это одно из самых популярных решений в области облачного хранения данных для работы сервисов и их бэкапов. Технология позволяет не только хранить терабайты данных, но и масштабироваться на лету.
Арендовать S3 под датасеты для ML и аналитики можно в пару кликов. Если вам интересно узнать о технологии подробнее, погружайтесь в статью.
Как хранятся данные?
Количество генерируемых человечеством данных растет с каждым годом, что побуждает развивать технологии хранения. На текущий момент доступно множество решений для хранения информации любой сложности. Рассмотрим их в общих чертах.
Файловая система
Файловая система — самый простой и известный способ структурированного хранения данных. Файловые системы используются для хранения данных на персональных компьютерах, серверах и мобильных устройствах.
К обычным файловым системам имеют доступ все пользователи в пределах одного устройства. Для общего доступа используются особые расширения в виде сетевых файловых систем — например, Network File System (NFS).
Достоинства файловых систем очевидны:
— это привычный способ хранения, не требующий высокой квалификации для настройки.
Но недостатков существенно больше:
→ ограничение на размер файла,
→ ограничение на количество файлов в хранилище,
Файловая система — хорошее решение для начала, но с ростом объема данных этот способ вызывает все больше проблем.
Блочное хранилище
Блочное хранение — это способ хранения информации «кусочками», или блоками, на физических накопителях. Этот способ хранения используют специализированные программные продукты, чаще всего — базы данных и гипервизоры.
При использовании подхода данные хранятся в «сыром» виде. Отсутствие дополнительных абстракций вроде файловых систем значительно повышает производительность. Также отсутствие абстракций упрощает масштабирование хранилища: добавить пару новых дисков значительно легче.
Тем не менее, данный способ не лишен недостатков.
→ сложен в настройке,
→ требует узкой специализации,
→ необходимо следить за свободным местом и своевременно увеличивать объем хранилища.
Все это не позволяет использовать блочное хранилище для любых задач.
Объектное хранилище
Объектное хранилище — решение для надежного хранения данных большого объема. S3 предоставляет контейнеры — в некотором смысле бездонную бочку, в которую можно складывать файлы любых типов — объекты. Такой вид хранилища имеет множество достоинств:
→ практически неограниченный объем,
→ резервирование данных и географически распределенное хранение,
→ возможность добавить любые метаданные к файлу.
Но и тут есть ложка дегтя. Несмотря на широкое распространение, для работы с объектным хранилищем требуется специализированное ПО в правильной конфигурации. Также объектное хранилище S3 имеет ограниченную скорость в сравнении с блочным хранилищем. Размещать базу данных на объектном хранилище будет нецелесообразно.
Объектное хранилище имеет множество различных интерфейсов взаимодействия, о них мы поговорим позднее.
Что же такое объекты?
Какие данные позволяет хранить объектное хранилище S3 и из чего состоят объекты?
В качестве объекта могут выступать данные совершенно произвольного формата. Например, таблицы, отчеты, фото с видео и даже образы для операционных систем — выбор за пользователем.
Кроме самого содержимого, объекты содержат метаданные для сортировки (информация о формате, дате создания и другое), уникальный идентификатор. Последнее — это URL-адрес, по которому можно однозначно идентифицировать объект.
Особенности объектного хранилища S3
Объектное хранилище можно определить еще проще. Это HTTP-API, который позволяет загружать, получать и удалять данные по имени. То есть фактически KV-хранилище для больших кусков данных (BLOB).
Что важно отметить:
- Объектное хранилище гарантирует доступность и целостность данных.
- Пользователь может хранить условно бесконечное количество данных Можно хранить терабайты — а иногда и петабайты — данных.
- S3 имеет плоское пространство имен без вложенности на уровне идентификаторов. Объекты можно разделить по контейнерам, не более.
Эти особенности «диктуют» архитектуру и делают процесс использования более предсказуемым. Например, отсутствует необходимость хранить сложную структуру хранилища. Следовательно, алгоритмы доступа проще, а время доступа меньше и не сильно изменяется с ростом количества данных.
HTTP-API делает объектное хранилище более высокоуровневым в плане использования. Любой может реализовать свой простой протокол или обратиться к хранилищу вручную — через curl или telnet.
Классы объектных хранилищ и тарифы
Рассмотрим на примере решения Selectel. Облачные хранилища S3 можно разделить на холодные и стандартные.
- Холодный класс хранилища. Применяют для хранения редко используемых данных: резервных копий, архивов. Стоимость хранения ниже, но запросы и трафик дороже.
- Стандартный класс хранилища. Применяют для хранения и раздачи часто используемых данных. В стандартном хранилище стоимость трафика и запросов ниже, но хранение дороже, чем в холодном.
Важно. Объектное хранилище S3 по умолчанию позволяет создавать до 2 000 контейнеров, а данные хранить в трех экземплярах, независимо от класса хранения.
Почему бизнес выбирает облачное объектное хранилище?
Объектные хранилища набирают популярность не только среди компаний, но и обычных пользователей. Почему так? Разберем на примере.
Сценарии использования объектного хранилища
Хранение личных данных и бэкапы. Объектное хранилище не ограничено в объемах и распределено между множеством серверов, что позволяет хранить резервные копии любых размеров. Более того, резервная копия не обязательно должна быть архивом. Объектное хранилище S3 поддерживает версионирование, что позволяет загружать, например, файл с дипломом, а потом обращаться к более старой версии (то есть осуществить ее восстановление). При этом тарифицируется только занятое место.
Сеть доставки статического контента. Объектные хранилища позволяют получать файлы по протоколу HTTP. Это может быть полезно для создания, например, фотобанка. Логика сайта размещается на отдельном сервере, а контент — в объектном хранилище. В этом случае географическая распределенность серверов хранилища выступает в качестве сети доставки контента (CDN), ускоряя загрузку данных для пользователей по всему миру.
Статические сайты. Как отмечалось ранее, объектное хранилище S3 может размещать файлы любого типа и объема и отдавать их через HTTP. Это значит, что в объектном хранилище можно разместить файлы статического сайта-визитки, привязать к этим файлам пользовательский домен и получить простейший веб-хостинг.
Big Data. Обработка больших данных нередко производится кластером вычислительных машин, которые обмениваются данными. Для обмена данными можно использовать объектное хранилище: один узел кластера загружает данные в хранилище и передает идентификатор объекта следующему узлу.
Адаптивные к нагрузкам системы. Масштабирование ресурсов происходит автоматически. В случае резкого всплеска трафика — например, во время черной пятницы — ресурсы мгновенно пополнятся. Так можно одновременно обрабатывать большое число пользователей.
Безопасность, персональные данные и 152-ФЗ
Все выглядит хорошо, пока облачным хранилищем пользуется один человек. Но что делать бизнесу, у которого десятки или даже сотни сотрудников? К счастью, объектное хранилище предоставляет возможность разграничения прав. Для каждого контейнера можно задать список пользователей и их права доступа: чтение или чтение и запись.
Однако объектное хранилище находится под управлением провайдера инфраструктуры и обслуживается им, что приводит к вопросам о безопасности хранимых данных. Соответствие 152-ФЗ обозначает, что данные в хранилище надежно защищены от неавторизованного доступа на физическом уровне, а также обеспечивается безопасность сетевой инфраструктуры на уровне программного обеспечения.
Объектное хранилище Selectel соответствует 152-ФЗ для обработки персональных данных 3 и 4 уровня защищенности. Обратите внимание, что безопасность системы определяется безопасностью самого слабого звена. Если контейнер с важными данными имеет слабый пароль, то никакие другие усилия не помогут сохранить данные в безопасности.
Другие преимущества объектного хранилища S3
Кроме высокого уровня безопасности и защиты персональных данных, в объектном хранилище Selectel есть другие преимущества.
→ Гибкая оплата. Объектное хранилище оплачивается по модели pay-as-you-go — каждый час списывается сумма за ресурсы, потребленные за это время.
→ Простота использования. Пользователь может подключиться к объектному хранилищу любым удобным способом. Через S3 API, Swift API и Selectel Storage API, протоколы FTP/FTPS, SFTP и панель управления Selectel.
→ Встроенная IAM-система. Вы сами управляете доступом к данным: можете давать его одним, а ограничивать другим.
→ Настройки политик хранения данных. В объектном хранилище легко настраивать политики хранения: устанавливать ограничения на время хранения объектов, правила их удаления и восстановления.
→ Объектное хранилище обеспечивает отказоустойчивость — храним данные в трех экземплярах. Созданные копии размещаем на независимых друг от друга серверах в разных стойках.
Лимиты и квоты
Также одно из преимуществ, что лимиты контейнера клиент устанавливает самостоятельно. Можно установить ограничения на суммарный размер загружаемых файлов, их количество и время хранения в контейнере.
Всего одновременно можно совершать до 2000 запросов в секунду — по S3 API и Swift API — и создавать до 2000 контейнеров. Больше подробностей про лимиты и квоты читайте в нашей документации.
Как начать работу с объектным S3-совместимым хранилищем?
Объектное хранилище имеет множество интерфейсов для взаимодействия. Нередко говорят о S3-совместимом объектном хранилище. У этого хранилища есть собственный интерфейс доступа — S3 API. Любое хранилище, которое поддерживает обращения по S3 API, можно называть S3-совместимым.
Вернемся к интерфейсам взаимодействия с объектным хранилищем. Рассмотрим на примере объектного хранилища Selectel.
Доступ через веб-интерфейс

Панель управления позволяет выполнять простые операции над объектным хранилищем и контейнерами. Для начала хранения данных ваших приложений необходимо создать первый контейнер нажатием на кнопку Создать контейнер.
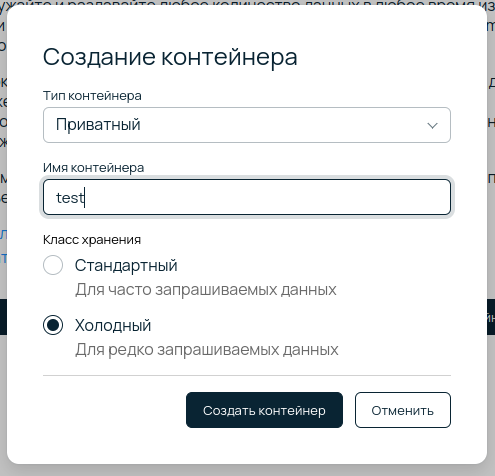
При создании контейнера необходимо задать его тип и имя. Тип контейнера определяет вид отображения и возможность доступа. Приватный контейнер предоставляет доступ только авторизованным пользователям. Обратите внимание, что тип контейнера можно редактировать после создания.
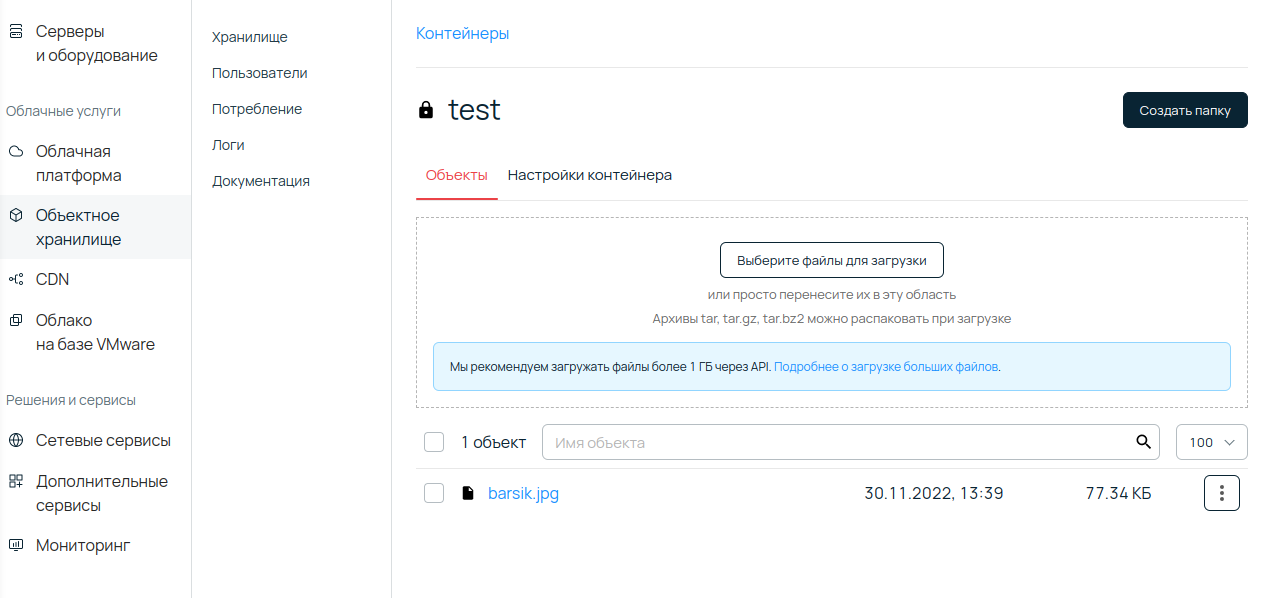
Загрузка файлов в объектное хранилище через веб-интерфейс интуитивна. Такой способ имеет существенное ограничение: размер загружаемых файлов не должен превышать 100 МБ.
Файлами могут выступать данные совершенно разных форматов: от txt до мультимедийного контента — аудио, видео, изображений. Можно загружать и архивные файлы форматов tar, tar.gz, tar.bz2 — они распакуются при загрузке. Если файлов слишком много, нужный можно найти через поиск.
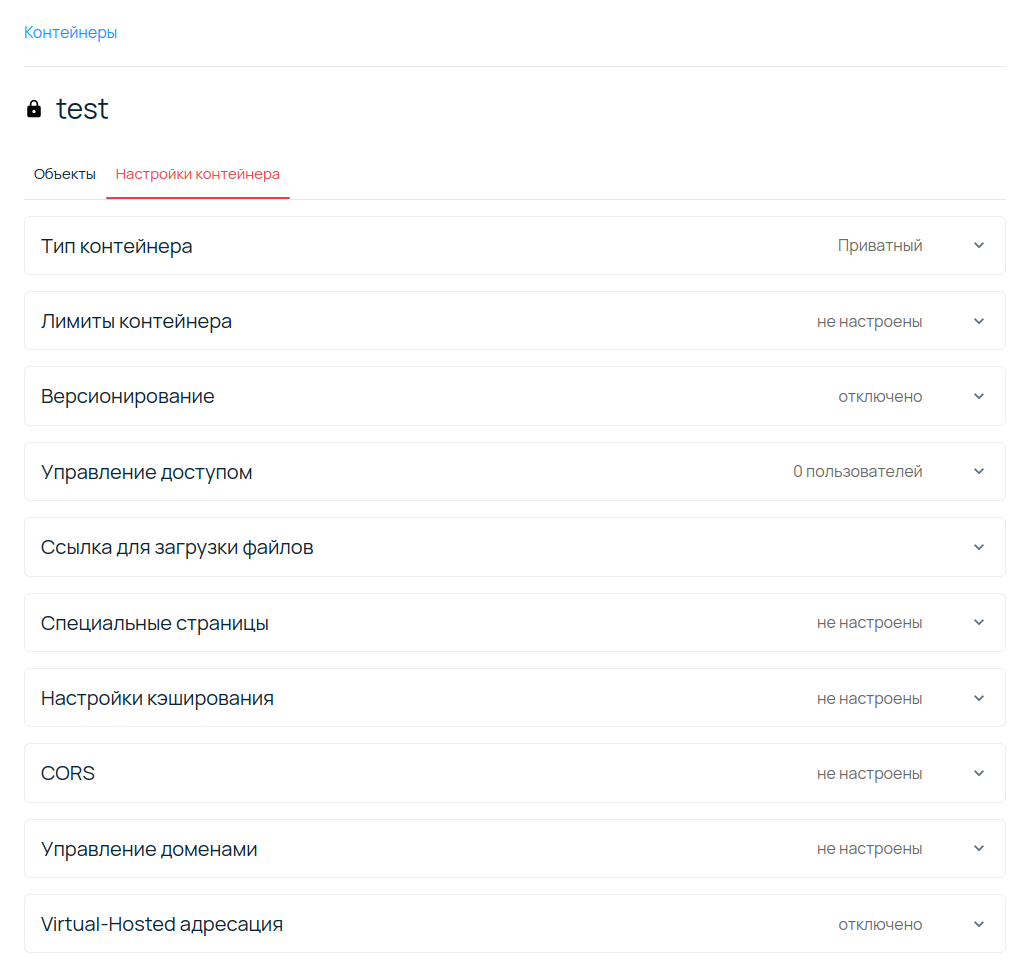
Однако веб-интерфейс удобно использовать для первоначальной конфигурации контейнера. На вкОднако веб-интерфейс удобно использовать для первоначальной конфигурации контейнера. На вкладке Настройки контейнера можно увидеть доступные настройки. Для доступа к контейнеру через другие интерфейсы рекомендуется создать отдельного пользователя.
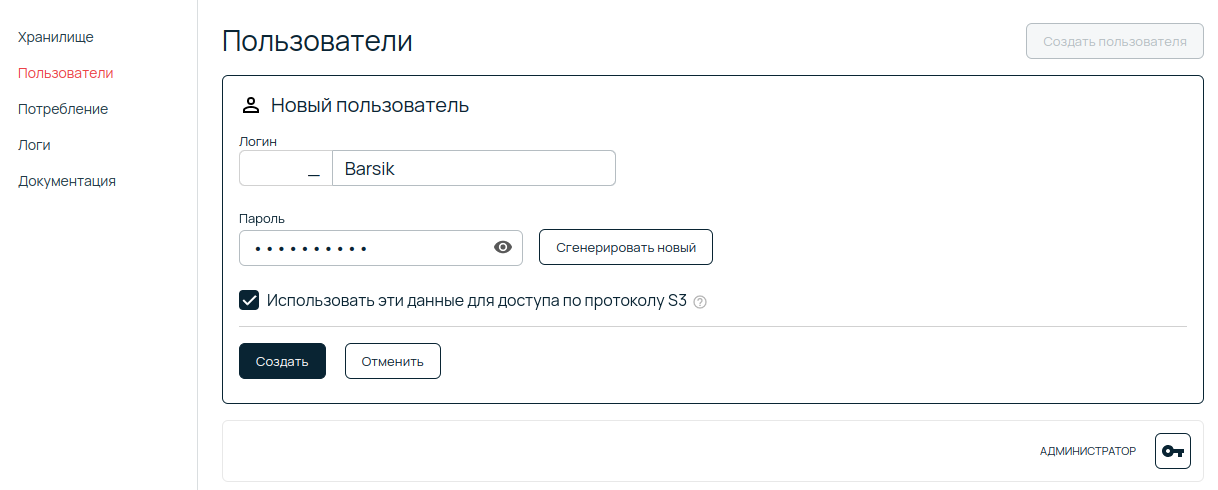
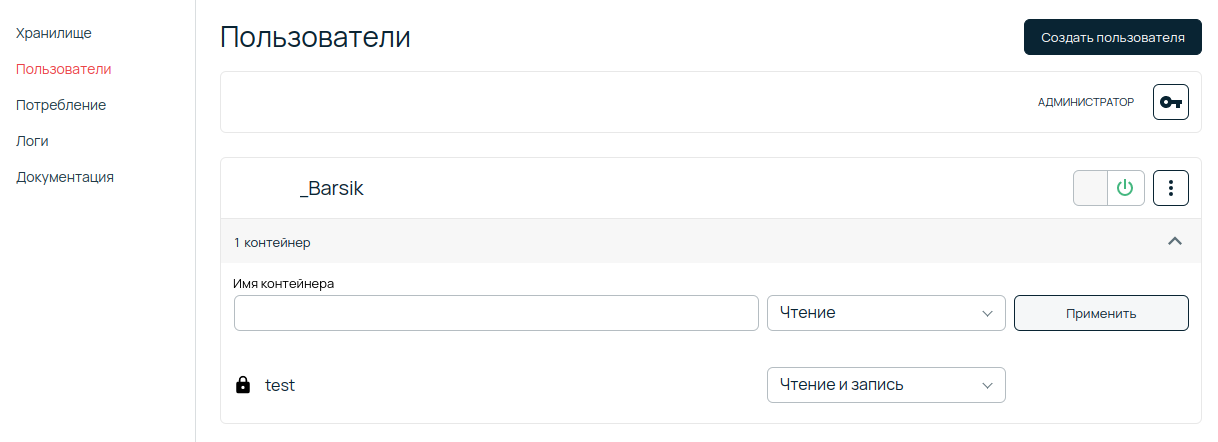
На странице Пользователи есть возможность создать пользователя и дать права на определенные контейнеры. По умолчанию созданный пользователь не имеет доступа по S3 API, однако это можно изменить, выставив соответствующий пункт в форме.
Дополнительные пользователи объектного хранилища всегда имеют префикс в виде номера аккаунта.
Доступ по FTP/FTPS/SFTP
К хранилищу можно получить доступ через FTP. Для этого используется домен ftp.selcdn.ru или sftp.selcdn.ru. Обратите внимание, что FTP — это прокси к существующим интерфейсам объектного хранилища — Swift API и S3 API. Более подробно — в базе знаний.
Доступ по S3 API: загружаем файлы через Rclone
Для взаимодействия с S3 API требуется дополнительное программное обеспечение — например, aws-cli, S3cmd или Rclone. Рассмотрим подключение к S3 API объектного хранилища через Rclone.
Сперва нужно создать конфигурацию для подключения.
$ rclone config 2022/11/30 13:24:58 NOTICE: Config file "/home/voldemar/.config/rclone/rclone.conf" not found - using defaults No remotes found - make a new one n) New remote s) Set configuration password q) Quit config n/s/q> n name> selectel Type of storage to configure. Enter a string value. Press Enter for the default (""). Choose a number from below, or type in your own value … 4 / Amazon S3 Compliant Storage Provider (AWS, Alibaba, Ceph, Digital Ocean, Dreamhost, IBM COS, Minio, etc) \ "s3" … Storage> 4 Выбираем n для создания новой конфигурации и задаем имя для подключения к удаленному хранилищу. Выбираем тип хранилища. В нашем случае это S3-совместимое, то есть пункт 4.
Choose your S3 provider. Enter a string value. Press Enter for the default (""). Choose a number from below, or type in your own value … 10 / Any other S3 compatible provider \ "Other" provider> 10 Get AWS credentials from runtime (environment variables or EC2/ECS meta data if no env vars). Only applies if access_key_id and secret_access_key is blank. Enter a boolean value (true or false). Press Enter for the default ("false"). Choose a number from below, or type in your own value 1 / Enter AWS credentials in the next step \ "false" 2 / Get AWS credentials from the environment (env vars or IAM) \ "true" env_auth> 1 Конфигуратор предложит выбрать один из известных ему провайдеров, но хранилища Selectel там нет. Поэтому выбираем пункт 10 — Other. Отмечаем, что задаем данные для доступа на следующем шагу (пункт 1).
AWS Access Key ID. Leave blank for anonymous access or runtime credentials. Enter a string value. Press Enter for the default (""). access_key_id> xxxxx_Barsik AWS Secret Access Key (password) Leave blank for anonymous access or runtime credentials. Enter a string value. Press Enter for the default (""). secret_access_key> Пароль Region to connect to. Leave blank if you are using an S3 clone and you don't have a region. Enter a string value. Press Enter for the default (""). Choose a number from below, or type in your own value 1 / Use this if unsure. Will use v4 signatures and an empty region. \ "" 2 / Use this only if v4 signatures don't work, eg pre Jewel/v10 CEPH. \ "other-v2-signature" region> ru-1 Endpoint for S3 API. Required when using an S3 clone. Enter a string value. Press Enter for the default (""). Choose a number from below, or type in your own value endpoint> https://s3.storage.selcloud.ru Заполняем данные для подключения.
- AWS Access Key ID — имя пользователя,
- AWS Secret Access Key — пароль/ключ,
- Region — ru-1,
- Endpoint — https://s3.storage.selcloud.ru.
После ввода данных для доступа Rclone задаст пару дополнительных вопросов, на которые можно не отвечать, то есть оставить пустую строку. Последним вопросом будет продвинутое редактирование конфигурации.
Edit advanced config? (y/n) y) Yes n) No y/n> n Remote config -------------------- [selectel] provider = Other env_auth = false access_key_id = xxxxx_Barsik secret_access_key = Пароль region = ru-1 endpoint = https://s3.storage.selcloud.ru -------------------- y) Yes this is OK e) Edit this remote d) Delete this remote y/e/d> Отказываемся от продвинутого редактирования файла конфигурации и сверяем данные. Если все в порядке, соглашаемся на создание.
Теперь с помощью Rclone можно загружать файлы. Например, загрузим файл barsik.jpg в контейнер с именем test, который был создан ранее.
$ rclone copy barsik.jpg selectel:testКоманда ничего не вывела, но код возврата 0. Заглянем в веб-интерфейс хранилища.
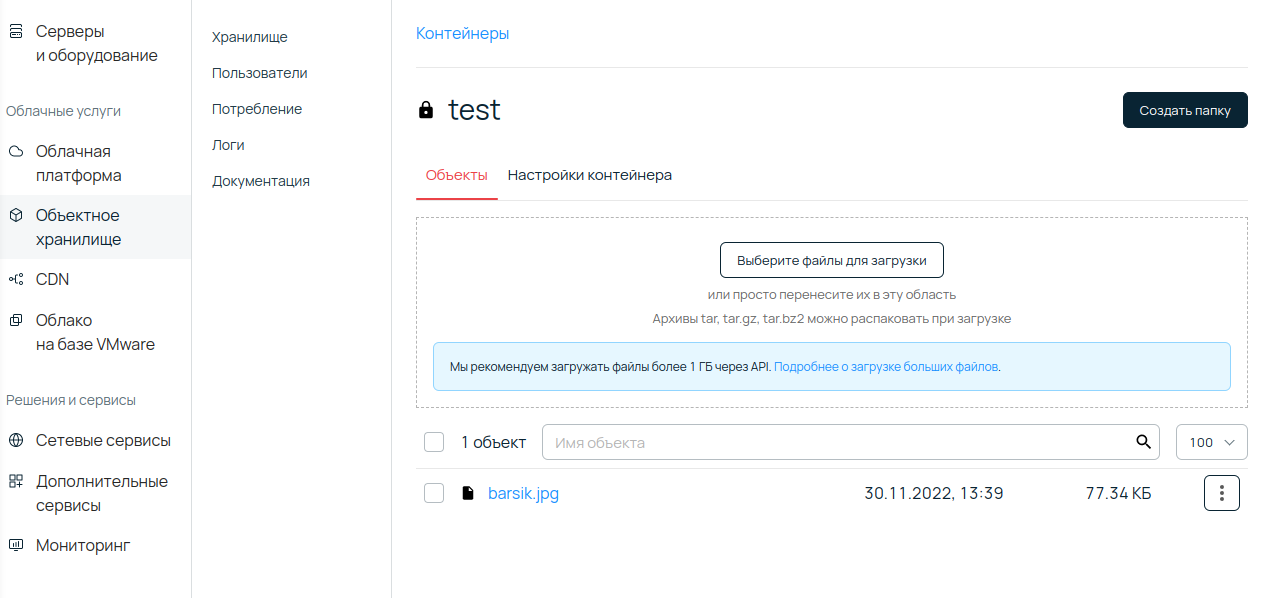
Файл barsik.jpg успешно загружен!
Начало работы с Amazon S3
Amazon Simple Storage Service (Amazon S3) – это сервис хранения объектов, предлагающий лучшие в отрасли показатели производительности, масштабируемости, доступности и безопасности данных. Amazon S3 можно использовать для хранения и доступа к любым объемам данных когда угодно и откуда угодно.
Чтобы в полной мере использовать возможности сервиса Amazon S3, вам необходимо понимать несколько простых концепций. В сервисе Amazon S3 данные хранятся в виде объектов в корзинах. Объект состоит из файла и (необязательно) любых метаданных, описывающих этот файл. Чтобы сохранить объект в сервисе Amazon S3, отправьте необходимый файл в корзину. При отправке файла можно задать разрешения для объекта и любые метаданные.
Корзины – это контейнеры для объектов. У вас может быть одна или несколько корзин. Вы можете управлять доступом к каждой корзине (то есть указывать, какие пользователи могут создавать и удалять объекты в ней, а также отображать список объектов), просматривать журналы доступа для корзин и объектов в них, а также выбрать географический регион, в котором сервис Amazon S3 будет хранить корзины и их содержимое.

Настройте аккаунт AWS и войдите в систему
Для использования Amazon S3 требуется аккаунт AWS Если аккаунта еще нет, вам будет предложено его создать при регистрации в Amazon S3. Никаких платежей за Amazon S3 не начисляется, пока вы не начнете использовать этот сервис.

Каждый объект Amazon S3 хранится в корзине. Прежде чем сохранять в Amazon S3 свои данные, необходимо создать корзину S3.

Начать разработку с AWS
После создания корзины можно добавлять в нее объекты. В качестве объекта можно использовать файл любого типа: текстовый файл, фото, видео и другие. Прочтите Руководство по началу работы, чтобы узнать подробности и начать разработку.
Большинство клиентов начинают разрабатывать новые приложения с помощью инструментов для разработчиков и SDK AWS. Альтернативным вариантом является веб-интерфейс Консоли управления AWS, который обеспечивает доступ ко всем ресурсам Amazon S3 и возможность управления ими.
Использование AWS SDK
Разработчики приложений могут воспользоваться множеством AWS SDK, позволяющих упростить использование сервиса Amazon S3. AWS SDK для Amazon S3 включают в себя библиотеки, образцы кода и документацию для следующих языков программирования и платформ.
![]()
AWS SDK для Java »
![]()
AWS SDK для .NET »
![]()
AWS SDK для Python »
![]()
AWS SDK для PHP »
![]()
AWS SDK для Node.js »
![]()
AWS SDK для Ruby »
Учебные курсы AWS: бесплатные онлайн-курсы по Amazon S3
AWS предлагает бесплатные онлайн-курсы по хранилищам, пройдя которые, вы научитесь проектировать высокодоступные решения хранилищ на базе сервиса Amazon S3 и управлять ими. Программа помогает перейти от основ к глубоким техническим знаниям. Вы расширите свой опыт работы с сервисом Amazon S3 и поможете своей организации быстрее перейти в облако.
Узнайте больше, изучив приведенные ниже варианты обучения. Посетите эту страницу, чтобы ознакомиться с планом обучения Object Strage и получить цифровой значок после успешного завершения курса и оценки.
Начать работу с S3
Узнать больше о S3, загрузке данных, деталях безопасности и ключевых возможностях.
Управление данными в S3
Обзор управления S3, принципы мониторинга работы и новинки в сфере хранения данных.
Классы хранилища S3
На этом курсе вы узнаете о классах хранилищ и научитесь выбирать правильное для вашего примера использования.
Оптимизация расходов с S3
Из этого курса вы узнаете о способах оптимизации своих затрат на Amazon S3.
Оптимизация производительности для S3
На этих занятиях вы узнаете, как добиться оптимальной производительности в работе S3.
Защита данных в S3
Узнайте рекомендации о безопасности в S3 и способы защиты доступа к данным.
Аудит доступа и безопасности S3
Узнайте возможности аудита действий и ресурсов S3 для лучшего обеспечения безопасности.
Непрерывность бизнеса и аварийное восстановление с помощью S3
Как использовать, защищать, мониторить и оптимизировать сервис Amazon S3, а также управлять им.
Пособия по началу работы и пошаговые руководства
Хранение и извлечение файлов
Хранение файлов в облаке с помощью Amazon S3
Пакетная отправка файлов в сервис S3
Простое создание собственных скриптов для резервного копирования файлов в облако
Amazon S3, Route 53, CloudFront
Размещение статического веб‑сайта
Размещение простого персонального сайта или веб‑сайта для бизнеса на AWS
Замена систем резервного копирования сервисом S3
Избавьтесь от локальных ленточных систем резервного копирования и начните использовать сервис S3 Glacier Deep Archive
Интеллектуальное многоуровневое хранение Amazon S3
Начало работы с интеллектуальным многоуровневым хранением Amazon S3
Начните хранить свои данные в классе хранения «Интеллектуальное многоуровневое хранение Amazon S3», чтобы получить автоматическую экономию затрат на хранение
Классы хранилищ Amazon S3 Glacier
Начало работы с классами хранилищ Amazon S3 Glacier
Храните свои архивные наборы данных в сервисах «Мгновенное извлечение данных Amazon S3 Glacier», «Гибкое извлечение данных Amazon S3 Glacier» и «Глубокий архив Amazon S3 Glacier»
Защита данных в Amazon S3
Защитите данные в Amazon S3 от случайного удаления или ошибок в приложении с помощью управления версиями, блокировки объектов и репликации S3
Репликация данных в S3
Реплицируйте данные в регионах AWS и между ними с помощью репликации S3
Проверка целостности данных в Amazon S3 с помощью дополнительных контрольных сумм
В Amazon S3 теперь доступно несколько вариантов контрольных сумм для ускорения проверки целостности данных. Дополнительные алгоритмы, которые поддерживает S3: SHA-1, SHA-256, CRC32 и CRC32-C. Проверяйте файлы на предмет изменений во время передачи данных, а также в процессе загрузки или отправки.
Amazon S3 Storage Lens
Начало работы с Amazon S3 Storage Lens
С помощью Объектива хранения данных Amazon S3 пользователь может получить наглядное представление об использовании объектного хранилища, тенденциях активности, а также практические рекомендации по повышению рентабельности и применению передовых методов защиты данных
Объект Lambda в Amazon S3
Начало работы с Объектом Lambda в Amazon S3
С помощью Объекта Lambda в Amazon S3 вы сможете добавлять собственный код в запросы S3 GET, HEAD и LIST, чтобы изменять данные, возвращаемые в приложение. Вы можете применить пользовательский код для изменения данных, возвращаемых запросами S3 GET, для конвертации форматов данных, динамического изменения размера изображений, удаления конфиденциальных данных и многого другого.
Начало работы с точками доступа Amazon S3 для нескольких регионов
Начните использовать точки доступа Amazon S3 для нескольких регионов и средства управления отказоустойчивостью
Репликация существующих объектов в корзинах Amazon S3 с помощью пакетной репликации Amazon S3
Реплицируйте объекты, уже существующие в корзинах S3, в одном или разных регионах AWS с помощью пакетной репликации Amazon S3
Amazon S3, Amazon CloudFront
Настройка распространения контента Amazon CloudFront для Amazon S3
Amazon CloudFront эффективно работает с Amazon S3, ускоряя доставку веб-контента и снижая нагрузку на серверы источников. Ускорьте загрузку динамического контента с помощью CloudFront и S3.
Перемещение данных в сервис Amazon S3
AWS предлагает целый набор сервисов передачи данных, и вы можете выбрать подходящее решение для любого проекта по миграции данных. Важным фактором при миграции данных является уровень подключения. У AWS есть предложения, которые обеспечивают потребности клиентов в гибридном облачном хранилище, а также в перемещении данных как по сети, так и без использования таковой.
Гибридное облачное хранилище
AWS Storage Gateway – это сервис гибридного облачного хранилища, который позволяет без особых усилий подключать локальные приложения к хранилищам AWS. Благодаря Storage Gateway клиенты могут переносить резервные копии в облако, пользоваться локальными файловыми хранилищами при поддержке облачного хранилища и обеспечивать низкий уровень задержки при доступе локальных приложений к данным в AWS. С помощью сервиса AWS Direct Connect можно создать частное подключение между AWS и локальным ЦОД, офисом или колокационной средой, что во многих случаях позволяет снизить затраты на использование сети, повысить пропускную способность системы и обеспечить более стабильную работу сети по сравнению с подключением через Интернет.
Передача данных без использования сети
Группа сервисов AWS Snow состоит из AWS Snowcone, AWS Snowball и AWS Snowmobile. AWS Snowcone и AWS Snowball – это небольшие прочные и защищенные портативные накопители и периферийные вычислительные устройства, позволяющие собирать и обрабатывать данные, а также выполнять их миграцию. Эти устройства специально разработаны для использования в периферийных местоположениях, в которых либо нет сети, либо ее пропускная способность ограничена. Таким образом вы можете использовать накопители и возможности вычислений в труднодоступных средах. AWS Snowmobile – это сервис для передачи данных, объем которых измеряется эксабайтами. Он позволяет без труда перемещать большие массивы данных, например библиотеки видео или репозитории образов, и даже выполнять миграцию всего ЦОД.
Передача данных по сети
Сервис AWS DataSync позволяет просто и эффективно передавать сотни терабайтов и миллионы файлов в сервис Amazon S3 на скоростях, до 10 раз больших, чем скорости, обеспечиваемые средствами с открытым исходным кодом. Сервис DataSync автоматически выполняет многие ручные задачи или устраняет необходимость их выполнения. Перечень таких задач включает написание скриптов заданий копирования, составление расписаний и отслеживание передачи данных, проверку данных и оптимизацию использования сети. Используя Snowcone в сочетании с AWS DataSync можно переносить данные по сети даже из периферийных местоположений.
AWS Transfer Family без лишних усилий обеспечивает эффективную полностью управляемую передачу файлов в сервис Amazon S3 с использованием протоколов SFTP, FTPS и FTP.
Сервис Amazon S3 Transfer Acceleration позволяет быстро передавать файлы на большие расстояния между клиентом и корзиной Amazon S3. Сервисы Amazon Kinesis и AWS IoT Core упрощают и обеспечивают безопасность записи потоковых данных с устройств Интернета вещей (IoT) и их загрузки в сервис Amazon S3.
Возможности Amazon S3
Amazon S3 предлагает различные инструменты, которые позволяют организовать и контролировать для поддержки определенных сценариев использования, сокращения расходов, обеспечения безопасности и соблюдения законодательных требований. Данные хранятся как объекты в ресурсах, которые называют корзинами, при этом размер одного объекта может составлять до 5 ТБ. Хранилище S3 позволяет добавлять теги метаданных в объекты, перемещать и сохранять данные в классах хранилища S3, настраивать и применять элементы управления доступом к данным, защищать данные от несанкционированного использования, применять аналитику больших данных, выполнять мониторинг данных на уровне объекта и корзины, а также просматривать статистику использования хранилищ и тенденции активности в своей организации. Доступ к объектам можно получить через точки доступа S3 или непосредственно с помощью имени узла контейнера.
Управление хранилищем и его мониторинг
Плоская неиерархическая структура Amazon S3 и различные возможности управления помогают клиентам любого уровня и из любых отраслей организовать данные выгодным для бизнеса и сотрудников образом. Все объекты хранятся в корзинах S3, и их можно организовать с помощью общих имен, которые называют префиксами. Кроме того, в каждый объект можно добавить до 10 пар «ключ-значение», которые называют тегами объектов S3. Эти пары можно создавать, обновлять и удалять в любое время в течение жизненного цикла объекта. Для отслеживания объектов и связанных с ними тегов, корзин и префиксов, можно использовать отчет S3 Inventory, в котором указываются объекты, хранимые в корзине S3 или имеющие определенный префикс, а также соответствующие метаданные и статус шифрования. Сервис S3 Inventory можно настроить для ежедневного или еженедельного создания отчетов.
Управление хранилищем
С помощью имен корзин, префиксов, тегов объектов S3 и сервиса S3 Inventory можно классифицировать данные, создавать отчеты и настраивать другие возможности S3. Сервис Пакетные операции S3 упрощает эти задачи, независимо от количества объектов, и позволяет управлять данными в Amazon S3 в любом масштабе. Используя Пакетные операции S3, вы можете копировать объекты между корзинами, заменять наборы тегов объектов, изменять элементы управления доступом и восстанавливать архивные объекты из хранилищ классов сервисов Гибкое извлечение данных S3 Glacier и Глубокий архив S3 Glacier с помощью одного запроса к API S3 или нескольких шагов в консоли S3. С помощью сервиса Пакетные операции S3 также можно применять функции AWS Lambda к объектам для запуска настраиваемой бизнес-логики, например для обработки данных или перекодировки файлов изображений. Для начала работы создайте список целевых объектов, используя отчет S3 Inventory, или укажите собственный список, а затем выберите требуемую операцию в меню. После выполнения запроса пакетных операций S3 вы получите оповещение и отчет обо всех изменениях. Подробные сведения о сервисе Пакетные операции S3 см. в обучающем видео.
Amazon S3 также поддерживает возможности для контроля версий данных и предотвращения случайного удаления, а также для репликации данных в пределах одного региона AWS или в другой регион AWS. С помощью управления версиями в S3 можно сохранять, извлекать и восстанавливать все версии объекта, хранящегося в Amazon S3, что позволяет восстанавливать систему после непреднамеренных действий пользователей и сбоев приложений. Для предотвращения случайного удаления включите удаление с использованием многофакторной аутентификации (MFA) для корзины S3. При попытке удалить объект из корзины с включенным удалением с использованием MFA потребуются два этапа аутентификации: данные для доступа к аккаунту AWS и последовательность из действительного серийного номера, пробела и шестизначного кода с экрана принятого устройства аутентификации, такого как аппаратный ключ или ключ безопасности U2F.
С помощью репликации в S3 можно реплицировать объекты (и связанные метаданные и теги объектов) в одну или несколько целевых корзин в пределах одного региона назначения AWS или в другой регион назначения AWS для снижения задержек, обеспечения соответствия требованиям, безопасности, аварийного восстановления и ряда других стандартных примеров использования. Межрегиональную репликацию в S3 (CRR) можно настроить для репликации объектов из исходной корзины S3 в одну или несколько целевых корзин в другом регионе AWS. Репликация в рамках региона (SRR) в S3 позволяет реплицировать объекты между корзинами в пределах одного региона AWS. Репликация в режиме реального времени, такая как CRR и SRR, автоматически реплицирует вновь загруженные объекты по мере их записи в корзину, в то время как пакетная репликация S3 позволяет работать с уже существующими объектами. Пакетную репликацию S3 можно использовать для заполнения новой корзины существующими объектами, повторной попытки неудавшейся ранее репликации объектов, переноса данных между аккаунтами или добавления новых хранилищ в озеро данных. Возможность контроля времени репликации в Amazon S3 (S3 RTC) закреплена в Соглашении об уровне обслуживания (SLA) и обеспечивает прозрачность данных при репликации и соответствие требованиям к репликации данных.
Чтобы получить доступ к реплицированным наборам данных в корзинах S3 в регионах AWS, используйте точки доступа S3 для нескольких регионов Amazon, чтобы создать единый глобальный адрес, который ваши приложения и клиенты будут использовать, где бы они не были. Глобальный адрес позволяет создавать приложения для нескольких регионов с такой же простой архитектурой, как для одного региона, а затем запускать их в любой точке мира. Точки доступа Amazon S3 для нескольких регионов могут повысить производительность до 60 % при доступе к наборам данных, которые реплицируются в нескольких регионах AWS. Точки доступа S3 для нескольких регионов, основанные на Международном ускорителе AWS, учитывают такие факторы, как перегрузка сети и местоположение запрашивающего приложения, чтобы динамически направлять ваши запросы по сети AWS к копии ваших данных с наименьшей задержкой. С помощю Средства управления отказоустойчивостью точек доступа S3 для нескольких регионов вы можете обрабатывать отказ между реплицированными наборами данных в регионах AWS, что дает возможность за считанные минуты переносить трафик запросов данных S3 в альтернативный регион AWS.
Вы также можете применить политики «однократная запись, многократное чтение» (WORM) с помощью S3 Object Lock . Возможность управления S3 блокирует удаление версий объектов в течение периода хранения, установленного клиентом. Эта возможность позволяет применять политики хранения в качестве дополнительного уровня защиты данных либо для выполнения нормативных требований. Рабочие нагрузки можно переносить из существующих систем WORM в Amazon S3, а S3 Object Lock можно настроить на уровне объектов или корзин для предотвращения удаления версий объектов до заданной даты, которую вы можете определить самостоятельно или в соответствии с нормативными требованиями. Объекты с блокировкой S3 Object Lock сохраняют защиту WORM даже после перемещения в другие классы хранилища с политикой жизненного цикла S3. Для отслеживания объектов с блокировкой S3 Object Lock можно использовать отчет S3 Inventory, содержащий сведения о статусе WORM объектов. S3 Object Lock можно настроить в одном из двух режимов. При использовании в режиме Governance аккаунты AWS с определенными разрешениями IAM могут снимать защиту S3 Object Lock с объектов. Если вам требуется большая надежность по неизменности для выполнения законодательных требований, можно использовать режим Compliance. В режиме Compliance защиту не может снять ни один пользователь, в том числе аккаунт root.
Мониторинг хранилища
В дополнение к этим возможностям управления, функции S3 и другие сервисы AWS можно использовать для мониторинга и контроля ресурсов S3. С помощью тегов корзин S3 можно распределять расходы в рамках нескольких подразделений бизнеса (например, центры затрат, имена приложения или владельцы), а затем использовать отчеты о распределении расходов AWS, чтобы просматривать сведения об использовании и расходах, сгруппированные по тегам корзины. Можно также использовать Amazon CloudWatch, чтобы отслеживать работоспособность ресурсов AWS и настраивать предупреждения об оплате при достижении предела предполагаемых расходов, заданного пользователем. Используйте AWS CloudTrail для отслеживания действий с корзинами и объектами и создания отчетов о них, а также для настройки оповещений о событиях S3, чтобы запускать рабочие процессы и предупреждения или вызывать функцию AWS Lambda при внесении определенных изменений в ресурсы S3. Оповещения о событиях S3 автоматически перекодируют мультимедийные файлы после завершения загрузки в Amazon S3, обрабатывают файлы данных по мере их поступления и синхронизируют объекты с другими хранилищами данных. Кроме того, можно проверить целостность данных, переданных или полученных из Amazon S3, и получить доступ к информации о контрольных суммах с помощью API S3 GetObjectAttributes или отчета S3 Inventory. Выбирайте один из четырех поддерживаемых алгоритмов контрольных сумм (SHA-1, SHA-256, CRC32 или CRC32C) для проверки целостности данных в загружаемых и скачиваемых запросах, в зависимости от потребностей приложения.
В дополнение к этим возможностям управления, можно использовать функции S3 и другие сервисы AWS для мониторинга и контроля использования ресурсов S3. К корзинам S3 можно применять теги, распределяя расходы в рамках нескольких подразделений бизнеса (таких как центры затрат, имена приложения или владельцы), и затем использовать отчеты о распределении расходов AWS для просмотра сведений об использовании и расходах, сгруппированные по тегам корзины. Можно также использовать Amazon CloudWatch для отслеживания работоспособности ресурсов AWS и настройки предупреждений об оплате, которые отправляются, если предполагаемые расходы достигают предела, заданного пользователем. Другой сервис мониторинга AWS, AWS CloudTrail, отслеживает действия на уровне объекта и корзины, а также предоставляет соответствующие отчеты. Оповещения о событиях S3 можно настроить для инициации рабочих процессов, предупреждений и вызова AWS Lambda при внесении определенных изменений в ресурсы S3. Оповещения о событиях S3 можно использовать для автоматической перекодировки мультимедийных файлов после завершения загрузки в Amazon S3, обработки файлов данных по мере их поступления или синхронизация объектов с другими хранилищами данных.
Статистика и аналитика хранения данных
S3 Storage Lens
С помощью функции S3 Storage Lens пользователь может получить наглядное представление об использовании объектного хранилища, тенденциях активности в масштабах организации, а также практические рекомендации по повышению рентабельности и применению передовых методов защиты данных. S3 Storage Lens – это первый инструмент для аналитической обработки данных облачного хранилища, с помощью которого можно получить единое представление об использовании и активности объектного хранилища в сотнях или даже тысячах учетных записей организации, а также детальные данные для составления аналитических оценок на уровне учетной записи, сегмента или даже префикса. В основу функции S3 положено более 14 лет опыта помощи клиентам в оптимизации хранения данных. Благодаря этому она выполняет анализ количественных показателей в масштабах всей организации и предоставляет ситуативные рекомендации относительно снижения затрат на хранение и применения передовых методов защиты данных. Чтобы узнать подробнее, перейдите на страницу со статистикой и аналитикой хранения данных.
S3 Storage Class Analysis
Amazon S3 Storage Class Analysis анализирует шаблоны доступа к хранилищам, благодаря чему вы сможете решить, когда переносить определенные данные в хранилище более подходящего класса. Возможность Amazon S3 позволяет изучить шаблоны доступа к данным и определить, когда нужно перевести хранилища, которые используются менее часто, в класс хранилища с меньшей стоимостью. Результат можно использовать для улучшения политик жизненного цикла S3. Аналитику классов хранилищ можно настроить таким образом, чтобы осуществлялся анализ всех объектов в корзине. Также можно настроить фильтры, благодаря которым объекты для анализа будут группироваться по общему префиксу, тэгу объекта или по обоим параметрам сразу. Подробные сведения см. на странице со статистикой и аналитикой хранения данных.
Классы хранилищ
Amazon S3 позволяет хранить данные в хранилищах S3 различных классов, которые подходят для различных стандартных примеров использования и шаблонов доступа: S3 Intelligent-Tiering, S3 Standard, S3 Standard-Infrequent Access (S3 Standard-IA), S3 One Zone-Infrequent Access (S3 One Zone-IA), S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval, S3 Glacier Deep Archive и S3 Outposts.
Каждый класс хранилища S3 поддерживает определенный уровень доступа к данным по соответствующей цене или выбор географического местоположения.
Для данных с изменчивыми, неизвестными и непрогнозируемыми шаблонами доступа, как, например, для озер данных, аналитики или новых приложений, лучше использовать уровень S3 Intelligent-Tiering, на котором стоимость хранения оптимизируется автоматически. S3 Intelligent-Tiering автоматически перемещает данные между тремя уровнями доступа с низкой задержкой, оптимизированные для частого, нечастого и редкого доступа. Когда со временем небольшие наборы объектов отправляются в архив, можно активировать уровень архивного доступа, созданный для асинхронного доступа.
В разрезе прогнозируемых шаблонов доступа применима описанная далее схема. Критические важные производственные данные можно хранить в S3 Standard для частого доступа. Нечасто используемые данные можно отправить в S3 Standard – IA или S3 One Zone – IA для сокращения расходов. Архивировать данные по минимальной стоимости можно в архивных классах хранилища – S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval и S3 Glacier Deep Archive. Можно использовать анализ классов хранилищ S3 для мониторинга шаблонов доступа к объектам, чтобы выявить данные, которые следует перенести в менее затратные классы хранилища. Затем эти сведения можно использовать для настройки политики жизненного цикла S3, которая регулирует перенос данных. Политики жизненного цикла S3 также можно применять для принудительного истечения срока действия объектов после окончания их жизненного цикла.
Если ваши требования к размещению не могут быть удовлетворены существующим регионом AWS, можно использовать класс хранилища S3 Outposts для локального хранения своих данных типа S3 с помощью S3 on Outposts.
Управление доступом и безопасность
Управление доступом
Для защиты данных в Amazon S3 по умолчанию пользователям предоставляется доступ только к созданным ими ресурсам S3. Вы можете предоставить доступ другим пользователям с помощью одной из следующих возможностей управления доступом или их сочетания: Управление идентификацией и доступом AWS (IAM) для создания пользователей и управления их доступом, списки контроля доступа (ACL) для предоставления доступа к отдельным объектам авторизованным пользователям, политики корзины для настройки разрешений для всех объектов в одной корзине S3, точки доступа S3 для упрощения управления доступом к наборам общих данных путем создания точек доступа с именами и разрешениями для каждого приложения или набора приложений и аутентификация строки запроса для предоставления ограниченного во времени доступа другим пользователям с помощью временных URL-адресов. Amazon S3 также поддерживает журналы аудита, которые содержат запросы к ресурсам S3 для обеспечения полной визуализации действий пользователей и данных, которые они запрашивают.
Безопасность
Amazon S3 предоставляет гибкие возможности обеспечения безопасности для предотвращения доступа неавторизованных пользователей к данным. С помощью адреса VPC можно подключаться к ресурсам S3 из виртуального частного облака Amazon (Amazon VPC) и из помещения. Amazon S3 шифрует все новые данные, загруженные в любую корзину (по состоянию на 5 января 2023 года). Amazon S3 поддерживает шифрование на стороне сервера (с тремя ключевыми вариантами управления) и на стороне клиента для передачи данных. Используйте S3 Inventory для проверки статуса шифрования объектов S3 (подробнее о S3 Inventory см. в разделе об управлении хранилищем).
S3 Block Public Access – это набор механизмов контроля безопасности, который позволяет запретить публичный доступ к корзинам и объектам S3. Достаточно нескольких нажатий клавиш в Консоли управления Amazon S3, чтобы применить параметры S3 Block Public Access ко всем корзинам аккаунта AWS или только к некоторым корзинам S3. После того как параметры применены к аккаунту AWS, любые существующие или новые корзины и объекты, связанные с этим аккаунтом, будут наследовать параметры, запрещающие публичный доступ. Параметры Amazon S3 Block Public Access переопределяют другие разрешения S3. Благодаря этому администратору аккаунта легко обеспечить применение политики «Запрет публичного доступа» независимо от способа добавления объекта или создания корзины или существующих разрешений доступа. Механизмы контроля S3 Block Public Access поддерживают аудит, что предоставляет дополнительный уровень контроля, и используют проверки разрешений корзины AWS Trusted Advisor, журналы AWS CloudTrail и предупреждения Amazon CloudWatch. Необходимо включить параметр блокирования публичного доступа для всех аккаунтов и корзин, которые не должны быть общедоступными.
S3 Object Ownership – это возможность, которая отключает списки контроля доступа (ACL) и назначает владельца корзины владельцем всех объектов в ней, что позволяет упростить управление доступом к данным, сохраненным в S3. Когда вы настраиваете в S3 Object Ownership параметр Bucket owner enforced (Принудительное назначение владельца корзины), для этой корзины и размещенных в ней объектов более не применяются разрешения списков контроля доступа. Любой контроль доступа после этого определяется политиками на основе ресурсов, пользовательскими политиками или их сочетанием. Перед тем как отключать списки контроля доступа, ознакомьтесь с соответствующими списками для корзины и объекта. Чтобы определить запросы Amazon S3, требующие для авторизации списки контроля доступа, используйте поле aclRequired в или .
Используя точки доступа S3 для сервиса Виртуальное частное облако (VPC), можно легко защитить брандмауэром данные S3 в своей частной сети. Кроме того, с помощью политик управления сервисами AWS можно требовать, чтобы для всех новых точек доступа S3 в организации действовало ограничение, разрешающее доступ только из VPC.
IAM Access Analyzer для S3 – это возможность, которая упрощает управление разрешениями по мере назначения, проверки и уточнения политик для точек доступа и корзин S3. Access Analyzer для S3 выполняет мониторинг существующих политик доступа к корзинам и предоставляет к ресурсам S3 исключительно требуемый доступ. Access Analyzer для S3 оценивает политики доступа к корзинам, что позволяет быстро отключить нежелательный доступ к любой корзине. При проверке результатов, указывающих на возможный общий доступ к корзине, можно заблокировать публичный доступ к корзине одним нажатием в консоли S3. В целях аудита результаты работы сервиса Access Analyzer для S3 можно загрузить в виде CSV‑отчета. Кроме того, по мере авторизации политик S3 на консоли S3 отображаются предупреждения, ошибки и предложения в разрезе безопасности от IAM Access Analyzer. Консоль автоматически проводит более 100 проверок политик для подтверждения ваших политик. Эти проверки экономят ваше время, а также предоставляют возможность исправить ошибки и применить рекомендации в отношении безопасности.
С помощью IAM легче анализировать доступ и уменьшить число разрешений для предоставления минимума полномочий путем проставления метки времени с информацией о том, когда пользователь или роль в последний раз использовали S3 и выполняли связанные с этим действия. Используйте информацию о последнем доступе, чтобы анализировать доступ к S3, идентифицировать неиспользованные разрешения и уверенно удалять их. Подробные сведения см. в разделе Refining Permissions Using Last Accessed Data.
Сервис Amazon Macie можно использовать для обнаружения и защиты конфиденциальных данных, которые хранятся в Amazon S3. Macie автоматически собирает полный реестр S3 и непрерывно оценивает каждую корзину, чтобы предупреждать о наличии любых общедоступных или незашифрованных корзин, а также корзин, совместно используемых с аккаунтами AWS за пределами организации или реплицируемых в такие аккаунты. Затем сервис Macie применяет методы машинного обучения и сопоставления с шаблонами к выбранным корзинам, чтобы распознавать конфиденциальные данные, например персональную информацию, и отправлять уведомления о них. По мере генерирования отчетов о безопасности рассылаются события сервиса Amazon CloudWatch Events, что облегчает интеграцию с существующими системами управления рабочими процессами, а также позволяет запустить автоматическое устранение неполадок с помощью сервисов типа AWS Step Functions и выполнять такие действия, как закрытие общедоступной корзины или добавление тегов ресурсов.
AWS PrivateLink для S3 обеспечивает частное подключение между Amazon S3 и локальной средой. Вы можете предоставить интерфейсные адреса VPC для S3 в VPC для подключения локальных приложений непосредственно к S3 по AWS Direct Connect или AWS VPN. Запросы к конечным точкам интерфейса VPC для S3 автоматически перенаправляются в S3 по сети Amazon. Вы можете создать группы безопасности и настроить политики конечных точек VPC для конечных точек интерфейса VPC, чтобы пользоваться дополнительными возможностями управления доступом.
Обработка данных
S3 Object Lambda
С помощью функции S3 Object Lambda вы сможете добавлять собственный код в запросы S3 GET, HEAD и LIST, чтобы изменять и обрабатывать данные, возвращаемые в приложение. Вы можете применить пользовательский код для изменения данных, возвращаемых стандартными запросами S3 GET, для фильтрации строк, динамического изменения размера изображений, удаления конфиденциальных данных и многого другого. Вы также можете использовать S3 Object Lambda для изменения результатов запросов S3 LIST, чтобы создать пользовательское представления объектов в корзине и запросы S3 HEAD с целью изменения метаданных объекта, таких как его имя и размер. Выполнение кодов на базе функций AWS Lambda осуществляется в инфраструктуре, полностью управляемой AWS, что устраняет необходимость в создании и хранении производных копий данных или запуске дорогостоящих прокси, при этом не нужно вносить какие-либо изменения в приложения.
В S3 Object Lambda автоматическая обработка выходных данных стандартного запроса S3 GET, HEAD или LIST осуществляется с помощью функций AWS Lambda. AWS Lambda – это бессерверный вычислительный сервис, выполняющий заданный пользователем код без необходимости управления базовыми вычислительными ресурсами. Чтобы начать настройку функции Lambda и прикрепить ее к точке доступа S3 Object Lambda, достаточно нескольких щелчков мышью в консоли управления AWS. С этого момента S3 будет автоматически вызывать функцию Lambda для обработки любых данных, полученных через точку доступа S3 Object Lambda, а приложение будет получать преобразованный результат. Вы сможете создавать и выполнять собственные пользовательские функции Lambda, адаптируя процесс преобразования данных S3 Object Lambda к требованиям конкретного примера использования.
Запросы к данным без извлечения
Amazon S3 предоставляет встроенную возможность и дополнительные сервисы, которые запрашивают данные без необходимости в копировании и загрузке на отдельную аналитическую платформу или в хранилище данных. Это значит, что аналитику больших данных можно проводить непосредственно на данных, которые хранятся в Amazon S3. S3 Select – это возможность S3, предназначенная для повышения производительности запросов на 400 % и сокращения расходов на запросы на 80 %. Она позволяет извлекать подмножество данных объекта (с помощью простых выражений SQL) вместо всего объекта, размер которого может составлять до 5 ТБ.
Amazon S3 также совместим с аналитическими сервисами AWS Amazon Athena и Amazon Redshift Spectrum. Amazon Athena запрашивает данные из Amazon S3 без извлечения и загрузки в отдельный сервис или платформу. Он использует стандартные выражения SQL для анализа данных, предоставления результатов за считаные секунды, а также часто применяется для специализированного обнаружения данных. Amazon Redshift Spectrum также выполняет SQL-запросы напрямую к данным в Amazon S3 и больше подходит для сложных запросов и крупных наборов данных (размером до нескольких экзабайт). Так как Amazon Athena и Amazon Redshift используют общие форматы и каталог данных, их можно использовать для одинаковых наборов данных в Amazon S3.
Передача данных
AWS предлагает целый набор сервисов передачи данных, и вы можете выбрать нужное решение для любого проекта по миграции данных. При миграции данных уровень подключения – очень важный фактор, и у AWS есть предложения, которые могут удовлетворить ваши потребности в гибридном облачном хранилище, а также в переносе данных по сети и в автономном режиме.
AWS Storage Gateway – это сервис гибридного облачного хранилища, который позволяет без особых усилий подключать ваши локальные приложения к хранилищу AWS Storage. Клиенты используют сервис Storage Gateway, чтобы без особого труда заменять ленточные библиотеки облачным хранилищем, создавать файловые ресурсы на основе облачного хранилища или кеши с малыми задержками для доступа локальных приложений к данным в AWS.
Сервис AWS DataSync позволяет просто и эффективно передавать сотни терабайтов и миллионы файлов в сервис Amazon S3 на порядок быстрее, чем средства с открытым исходным кодом. Сервис DataSync автоматически выполняет многие ручные задачи или устраняет необходимость их выполнения. Перечень таких задач включает написание скриптов заданий копирования, составление расписаний и отслеживание передачи данных, проверку данных и оптимизацию использования сети. Кроме того, вы можете использовать AWS DataSync для копирования объектов из корзины S3 on Outposts в корзину, расположенную в регионе AWS, или наоборот. AWS Transfer Family обеспечивает полностью управляемую передачу файлов в сервис Amazon S3 с использованием протоколов SFTP, FTPS и FTP. Сервис Amazon S3 Transfer Acceleration позволяет быстро передавать файлы на большие расстояния между клиентом и корзиной Amazon S3.
Сервис AWS Snow Family специально разработан для использования в периферийных расположениях, в которых либо нет сети, либо ее пропускная способность ограничена. Он позволяет использовать накопители и возможности вычислений в неблагоприятных средах. В сервисе AWS Snowball используются физически защищенные портативные накопители и периферийные вычислительные устройства, позволяющие собирать и обрабатывать данные, а также выполнять их миграцию. Клиенты могут отправлять физические устройства Snowball в AWS для миграции данных без использования сети. AWS Snowmobile – это сервис для передачи данных, объем которых измеряется эксабайтами. Он позволяет без труда перемещать большие массивы данных, например видеобиблиотеки и репозитории образов, или выполнять миграцию всего ЦОД.
Вместе со сторонними поставщиками из сети AWS Partner Network (APN) клиенты также могут развертывать гибридные архитектуры хранилищ, интегрировать Amazon S3 в существующие приложения и рабочие процессы и переносить данные из облака AWS и в него.
Производительность
В Amazon S3 предоставляется лучшая в отрасли производительность для хранения объектов в облаке. Amazon S3 поддерживает параллельные запросы, благодаря чему производительность S3 можно масштабировать с помощью коэффициента вычислительного кластера, не внося изменения в приложение. Производительность масштабируется для каждого префикса, благодаря чему для достижения необходимой пропускной способности можно параллельно использовать необходимое количество префиксов. Количество префиксов не ограничено. В Amazon S3 можно осуществлять не менее 3500 запросов в секунду на добавление данных и 5500 запросов в секунду на их извлечение. Каждый префикс S3 может обеспечивать такие значения, благодаря чему значительно повысить производительность довольно просто.
Для достижения такой скорости обработки запросов в S3 не нужно настраивать генерацию случайных префиксов объектов. Это означает, что можно использовать логический или последовательный шаблон присвоения имен объектам S3 без отрицательного влияния на производительность. Чтобы получить актуальную информацию об оптимизации производительности в Amazon S3, см. Рекомендации по повышению производительности в Amazon S3 и Шаблоны производительности в Amazon S3.
Согласованность
Amazon S3 автоматически тщательно проверяет согласованность операций чтения после записи во всех приложениях. Этот процесс не влияет на производительность или доступность и региональную изолированность приложений, а также абсолютно бесплатный. Благодаря обеспечению согласованности S3 упрощает миграцию локальных аналитических процессов, устраняя необходимость вносить изменения в приложения и снижая затраты из-за отсутствия потребности в дополнительной инфраструктуре для тщательной проверки согласованности.
Все запросы к хранилищу S3 тщательно согласовываются. После успешной записи нового объекта или повторной записи существующего все последующие запросы на чтение незамедлительно получают последнюю версию объекта. S3 также тщательно проверяет согласованность операций получения списка, благодаря чему сразу после записи вы сможете создать список объектов в корзине со всеми внесенными изменениями.
Объектное хранилище для извлечения любых объемов данных из любого места
Масштабируйте ресурсы хранилища, чтобы соответствовать меняющимся потребностям с надежностью данных 99,999999999 % (11 9 секунд).
Храните данные в разных классах хранилища Amazon S3, чтобы сократить затраты за счет отсутствия авансовых вложений или периодического обновления оборудования.
Защитите данные благодаря самым широким возможностям по обеспечению безопасности, соблюдению законодательных требований и аудиту.
С легкостью управляйте данными в любом масштабе с помощью надежных средств контроля доступа, гибких инструментов репликации и
видимости целой организации.
Как это работает
Amazon Simple Storage Service (Amazon S3) – это сервис хранения объектов, предлагающий лучшие в отрасли показатели производительности, масштабируемости, доступности и безопасности данных. Клиенты любой величины и из любой промышленной отрасли могут хранить и защищать необходимый объем данных для практически любого примера использования. Например, для озер данных, облачных приложений и мобильных приложений. Выгодные классы хранилища и простые в использовании инструменты администрирования позволяют оптимизировать затраты, организовать данные и точно настроить ограничения доступа в соответствии с потребностями бизнеса или законодательными требованиями.

Увеличить и прочитать описание изображения.

На схеме показано, как перемещать данные в Amazon S3, управлять сохраненными данными в Amazon S3 и анализировать данные с помощью других служб. Три раздела отображаются слева направо.
Первый раздел содержит иллюстрацию базы данных, сервера и документа. Первый раздел называется «Перемещение данных». Текст первого раздела: «Перемещайте данные на Amazon S3, где бы они ни находились – в облаке или в приложениях, а также локальные данные». Значки рядом показывают различные типы данных: данные аналитики, файлы журналов, данные приложений, видео и изображения, а также данные резервного копирования и архивации.
Второй раздел содержит иллюстрацию пустой корзины. Второй раздел называется Amazon S3. Текст второго раздела: «Объектное хранилище, рассчитанное на хранение и извлечение любых объемов данных из любой точки сети».
Второй раздел содержит больше текста под заголовком «Хранение данных». Текст гласит: «Создайте корзину, укажите регион, элементы контроля доступом и параметры управления. Загружайте любой объем данных». На иллюстрации рядом изображена корзина, в которой находятся квадрат, круг и треугольник.
Во втором разделе также есть значки, отображающие возможности Amazon S3. Среди них: контроль доступа к данным, оптимизация расходов с помощью классов хранилищ, репликация данных в любой регион, доступ из локальной сети или VPC, защита данных, а также прозрачность хранения данных.
Третий раздел называется «Анализ данных». Текст третьего раздела: «Используйте AWS и сторонние сервисы для анализа данных, чтобы получить полезную аналитическую информацию». Значки рядом показывают способы анализа данных: искусственный интеллект (ИИ), расширенная аналитика и машинное обучение (ML).