Sparse file
According to Wikipedia, in computer science, a sparse file is a type of computer file that attempts to use file system space more efficiently when blocks allocated to a file are mostly empty. This is achieved by writing brief information (metadata) representing the empty blocks to disk instead of the actual «empty» space which makes up the block, using less disk space. The full block size is written to disk as the actual size only when the block contains «real» (non-empty) data.
When reading sparse files, the file system transparently converts metadata representing empty blocks into «real» blocks filled with zero bytes at runtime. The application is unaware of this conversion.
Most modern file systems support sparse files, including most Unix variants and NTFS, but notably not Apple’s HFS+. Sparse files are commonly used for disk images (not to be confused with sparse images), database snapshots, log files and in scientific applications.
The advantage of sparse files is that storage is only allocated when actually needed: disk space is saved, and large files can be created even if there is insufficient free space on the file system.
Disadvantages are that sparse files may become fragmented; file system free space reports may be misleading; filling up file systems containing sparse files can have unexpected effects; and copying a sparse file with a program that does not explicitly support them may copy the entire file, including the empty blocks which are not on explicitly stored on the disk, which wastes the benefits of the sparse property of a file.
Creating sparse files
The truncate utility can create sparse files. This command creates a 512 MiB sparse file:
$ truncate -s 512M file.img
The dd utility can also be used, for example:
$ dd if=/dev/zero of=file.img bs=1 count=0 seek=512M
Sparse files have different apparent file sizes (the maximum size to which they may expand) and actual file sizes (how much space is allocated for data on disk). To check a file’s apparent size, just run:
$ du -h --apparent-size file.img
512M file.img
and, to check the actual size of a file on disk:
$ du -h file.img
0 file.img
As you can see, although the apparent size of the file is 512 MiB, its «actual» size is really zero—that’s because due to the nature and beauty of sparse files, it will «expand» arbitrarily to minimize the space required to store its contents.
Making existing files sparse
The fallocate utility can make existing files sparse on supported file systems:
$ fallocate -d copy.img $ du -h copy.img 0 copy.img
Making existing files non-sparse
The following command creates a non-sparse copy of a (sparse) file:
$ cp file.img copy.img --sparse=never $ du -h copy.img 512M copy.img
Creating a filesystem in a sparse file
This article or section needs language, wiki syntax or style improvements. See Help:Style for reference.
Reason: Sparse files do not have to contain a file system, the purpose should be explained. (Discuss in Talk:Sparse file)
Now that we have created a sparse file, it is time to format it with a filesystem; for example ReiserFS:
$ mkfs.reiserfs -f -q file.img
We can now check its size to see how a filesystem has affected it:
$ du -h --apparent-size file.img
512M file.img
$ du -h file.img
33M file.img
As you may have expected, formatting it with a filesystem has increased its actual size, but left its apparent size the same. Now we can create a directory which we will use to mount our file:
# mount --mkdir -o loop file.img mountpoint
Tada! We now have both a file and a folder into which we may store almost 512 MiB worth of information!
Mounting a file at boot
To mount a sparse image automatically at boot, add an entry to your fstab:
/path/to/file.img /path/to/mountpoint reiserfs loop,defaults 0 0
Note: Be sure to include the loop option, otherwise it will not mount.
Detecting sparse files
Since sparse files occupy less blocks than the apparent file size would require, they can be detected by comparing the two sizes. This is not a bulletproof method if the filesystem uses compression, extended attributes take up the difference in space, file is internally fragmented, has indirect blocks, and similar. Still, the standard way to check is:
$ ls -ls sparse-file.bin
If a file size is greater than the allocated size in the first column a file is sparse. The same can be achieved with du by comparing:
$ du sparse-file.bin $ du --apparent-size sparse-file.bin
A step further is to print sparsiness value with find:
$ find sparse-file.bin -printf '%S\t%p\n'
A sparse file has a sparsiness value of less than one whereas normal files have exactly one or just slightly above. The above command can be easily extended to list sparse files in a desired path:
$ find path/ -type f -printf '%S\t%p\n' | gawk '$1 < 1.0 ' | cut -f '2-'
Copying a sparse file
Copying with cp
Normally, cp is good at detecting whether a file is sparse, so it suffices to run:
$ cp file.img new_file.img
Then new_file.img will be sparse. However, cp does have a --sparse=when option. This is especially useful if a sparse file has somehow become non sparse (i.e. the empty blocks have been written out to disk in full). Disk space can be recovered by:
$ cp --sparse=always new_file.img recovered_file.img
Archiving with tar
This article or section needs language, wiki syntax or style improvements. See Help:Style for reference.
Reason: Informal writing, see Help:Style#Language register. (Discuss in Talk:Sparse file)
One day, you may decide to back up your well-loved sparse file, and choose the tar utility for that very purpose; however, you soon realize you have a problem:
$ du -h file.img
33M file.img
$ tar -cf file.tar file.img
$ du -h file.tar
513M file.tar
Apparently, even though the current size of the sparse file is only 33 MB, archiving it with tar created an archive of the ENTIRE SIZE OF THE FILE! Luckily for you, though, tar has a `--sparse' (`-S') flag, that when used in conjunction with the `--create' (`-c') operation, tests all files for sparseness while archiving. If tar finds a file to be sparse, it uses a sparse representation of the file in the archive. This is useful when archiving files, such as dbm files, likely to contain many nulls, and dramatically decreases the amount of space needed to store such an archive.
$ tar -Scf file.tar file.img
$ du -h file.tar
12K file.tar
Resizing a sparse file
This article or section needs language, wiki syntax or style improvements. See Help:Style for reference.
Reason: Dependence on #Creating a filesystem in a sparse file is not apparent, not every sparse file contains a file system. Also too informal writing, see Help:Style#Language register. (Discuss in Talk:Sparse file)
Before we resize a sparse file, let us populate it with a couple small files for testing purposes:
$ for f in ; do touch folder/file$; done
$ ls folder/ file1 file2 file3 file4 file5
Now, let us add some content to one of the files:
$ echo "This is a test to see if it works. " >> folder/file1
$ cat folder/file1 This is a test to see if it works.
Growing a file
Should you ever need to grow a file, you may do the following:
# umount folder # dd if=/dev/zero of=file.img bs=1 count=0 seek=1G 0+0 records in 0+0 records out 0 bytes (0 B) copied, 2.2978e-05 s, 0.0 kB/s
This will increase its size to 1 Gb, and leave its information intact. Next, we need to increase the size of its filesystem:
# resize_reiserfs file.img resize_reiserfs 3.6.21 (2009 www.namesys.com) ReiserFS report: blocksize 4096 block count 262144 (131072) free blocks 253925 (122857) bitmap block count 8 (4) Syncing..done resize_reiserfs: Resizing finished successfully.
# mount -o loop file.img folder
Checking its size gives us:
# du -h --apparent-size file.img 1.0G file.img # du -h file.img 33M file.img
. and to check for consistency:
# df -h folder Filesystem Size Used Avail Use% Mounted on /tmp/file.img 1.0G 33M 992M 4% /tmp/folder
# ls folder file1 file2 file3 file4 file5 # cat folder/file1 This is a test to see if it works.
Tools
- sparse-fio — dd-like program to work with files that are sparsely filled with non-zero data
- sparseutils — utilities to work with sparsely-populated files, provides mksparse.py and sparsemap.py , can be installed with pip
Sources
- wikipedia:Sparse_file
- https://web.archive.org/web/20121026035748/http://www.apl.jhu.edu/Misc/Unix-info/tar/tar_85.html
Retrieved from "https://wiki.archlinux.org/index.php?title=Sparse_file&oldid=752459"
Внутреннее устройство разреженных файлов NTFS
Разреженные файлы в Windows это такие файлы, которые занимают меньше дискового пространства, чем их реальный размер. При этом не используется сжатие данных. Экономия места в разреженных файлах достигается за счёт компактного представления пустых областей файла, которые содержат одни лишь нули (символы 0x00). По-английски разреженные файлы называются sparse files.
Допустим, у нас есть большой файл, в основном состоящий из нулей, но всё же содержащий небольшие островки данных в разных местах. Как будет оптимизировано размещение на диске этого файла, если сделать его разреженным?
Файл делится на логические блоки размером 64 Кб. Анализируется каждый такой блок. Если любой байт в пределах блока имеет значение, отличное от 0x00, значит этот блок не пустой, он содержит данные. Блок, содержащий данные пишется на диск. Если же все байты в пределах блока имеют одинаковое значение 0x00, такой блок считается пустым. Содержимое такого блока вообще не сохраняется на диск.
При считывании файла драйверу NTFS известна общая длина файла и набор из нескольких блоков данных. Если происходит чтение из файла по смещению, которое расположено в пределах одного из имеющихся блоков данных, драйвер NTFS производит чтение с диска из соответствующего блока.
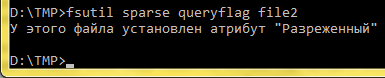
Проверка разреженности командой fsutil
Если происходит чтение из области, не совпадающей ни с одним из имеющихся блоков, драйвер NTFS отдаёт символы 0x00. Ведь известно, что раз подходящего блока данных нет, значит он не был записан на диск, следовательно он является пустым блоком, состоящим из одних лишь нулей.
Таким образом происходит экономия дискового пространства, ведь на диске оказываются записанными только те блоки, которые реально содержат данные. Всё остальное пустое пространство файла не хранится на диске, а генерируется драйвером на лету, если происходит чтение из этих областей.
При записи данных в пустую область разреженного файла у него появляется ещё один логический блок данных, который сохраняется на физический носитель. Возможно также увеличение длины существующего блока, если запись проведена в соседний логический блок.
Двоичное представление данных
С помощью программы NTFS Stream Explorer 1.07 я исследовал внутреннее устройство разреженных файлов. Вообще-то эта версия не показывает, как устроены такие файлы на диске, вместо этого она показывает их в виде формата Microsoft Backup (используемого в функциях BackupRead и BackupWrite). Это особый формат представления файлов, созданный Microsoft для целей архивации и резервного копирования. Устройство разреженных файлов в этом формате может не отображать реального положения вещей, но может показать некоторые принципы хранения таких файлов.
Создадим для экспериментов пустой файл размером 256 Кб, зададим ему атрибут «разреженный» и установим диапазон разреженности, равный его длине. Сделаем все эти операции с помощью системной консольной утилиты fsutil:
fsutil file createnew file 262144 fsutil sparse setflag file fsutil sparse setrange file 0 262144
Откроем файл в программе NTFS Stream Explorer, чтобы посмотреть его внутренее представление в виде потоков. В списке потоков отобразится один безымянный поток, имеющий тип «Блок разреженного файла», размером 8 байт.
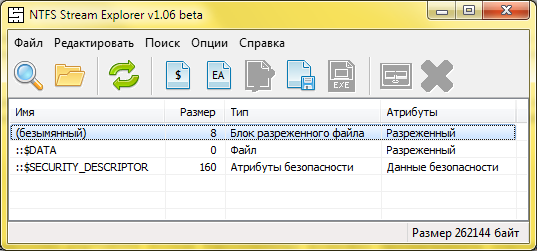
Блок пустого разреженного файла
Этот восьмибайтный поток хранит размер разреженного файла. Убедиться в этом можно, если экспортировать содержимое потока во внешний файл, а затем открыть его в 16-ричном редакторе. Также можно сдампить содержимое всех потоков файла сразу, используя программу NTFS BackupRead Dumper.
Сделаем дамп всех потоков и получим дамп размером всего лишь 48 байт:

Дамп пустого разреженного файла
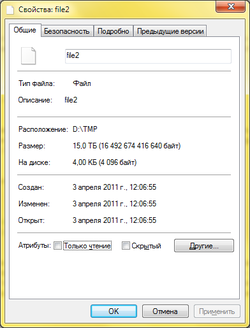
Разреженный файл размером 15 Тб
На картинке выделен sparse-поток. Его последние восемь байт содержат размер файла. Действительно, созданный файл имеет размер 256 Кб, в шестнадцатиричной системе счисления это 0x40000. Попробуем поменять это значение в hex-редакторе на какое-нибудь другое и восстановим файл из дампа с помощью NTFS BackupRead Dumper. Восстановленный файл назовём file2. Например, можно поменять значение 00004000 00000000 на 00000000 000F0000 . Проверим размер восстановленного файла в диалоге его свойств (на картинке справа).
Как видно, восстановленный файл получился размером 15 терабайт, но на диске по-прежнему занимает всего лишь 4 Кб. Технология разреженных файлов позволяет создавать очень большие файлы. Размер файла даже может превышать размер жёсткого диска, на котором он расположен. Так, на моём жёстком диске, разумеется, нет свободного места для 15 терабайт.
Итак, видно, что пустой разреженный файл хранит на диске только собственный размер. Теперь нужно записать что-нибудь в разреженный файл, чтобы увидеть, как устроены потоки sparse-данных. Возьмём hex-редактор, и запишем что угодно по любому смещению нашего гигантского разреженного файла. Откроем file2 в NTFS Stream Explorer, чтобы посмотреть, какие потоки он содержит теперь. Видно, что потоков стало два.
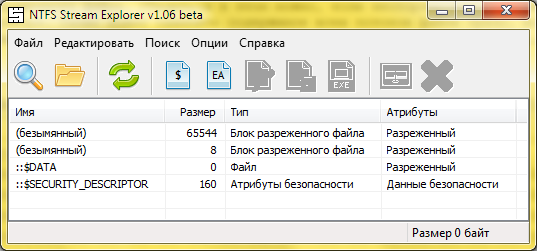
Блок разреженного файла с данными
Второй разреженный поток размером 65544 байт это поток данных разреженного файла. Его первые 8 байт занимает смещение, по которому начинается данный блок в файле. Остальные байты это байты данных. 65544 - 8 = 65536 , а значение 65536 это 64 Кб — минимальный размер логического блока внутри sparse-файла. Если произвести запись в соседний блок, то он увеличится уже до 128 Кб. Также файл может содержать несколько sparse-блоков с данными.
Получается, что внутри разреженного файла в отдельном потоке хранится размер файла, в других отдельных потоках хранятся блоки данных, при этом каждый такой блок содержит своё смещение в файле. Драйвер NTFS при чтении файла собирает из этих кусочков целый файл.
См. также
- Утилита sparser. Может устанавливать атрибут разреженности у заданного файла, проверять наличие этого атрибута, задавать диапазоны разреженности, а также самостоятельно искать в файле пустые области и помечать их разреженными.
- Баг в функции BackupSeek, связанный с неправильным пропуском разреженных блоков при получении списка потоков у файла. NTFS Stream Explorer умеет корректно отображать список потоков разреженных файлов, так как в программе был найден способ обхода данной ошибки.
- NTFS Stream Explorer — программа для отображения списка потоков NTFS и выполнения операций с ними. В статье упоминается версия 1.07. Начиная с версии 2.00, программа работает с разреженными файлами иным способом.
- NTFS BackupRead Dumper — программа для полного дампа потоков файла и восстановления файла из дампа.
По теме разреженных файлов также есть следующее:
- NTFS Stream Explorer 2.00 Программа поддерживает редактирование разреженности файлов.
- Баг в функции BackupSeek, связанный с обработкой потоков у разреженных файлов.
Автор: амдф
Дата: 03.04.2011
Разреженные файлы (sparse files)
Другой тип сжатия известен как разреженные файлы. Если у вас есть файлы, которые содержат множество нулей (попросту говоря в файле есть "пустые области"), то NTFS позволяет сохранять пространство диска, давая таким файлам определение sparse (разреженный). Так вот при сохранении таких файлов система просто не выделяет место для пустых областей файла - в результате чего и достигается уменьшение размера файла. При обращении системы к частям, отмеченным как пустые, NTFS просто возвращает нулевые значения. При просмотре свойств файла система сообщит о зарезервированном для него размере, хотя фактический объем может занимать в сотни тысяч раз меньший объем. Разреженные файлы применяются, в частности, в журнале NTFS ($LogFile).
Разреженные файлы (sparse files)
Разреженные файлы конвертируются с помощью следующей команды: fsutil sparse .
Многопоточные файлы
При необходимости в одном файле, записанном на диске NTFS, можно хранить несколько потоков информации. Это позволяет, в частности, снабжать файлы документов дополнительной информацией, хранить в одном файле несколько версий документов (например, на разных языках), хранить в отдельных потоках одного файла программный код и данные и т.п. При создании файла основные данные следует записать в неименованный поток. Затем необходимо создать внутри того же файла именованный поток, предназначенный для данных образа. Теперь один файл будет содержать два потока.
Многопоточные файлы
Проведем следующий эксперимент. На машине Windows 2003 откроем окно командной строки. Перейдем в раздел NTFS (например, в папку, содержащую системные шрифты) и введем следующую команду (не делайте лишних пробелов!): С:\WINDOWS\Fonts> dir > New_Stream.TXT:New_Stream В результате выполнения этой команды система создаст файл New_Stream.TXT. Он будет содержать два потока: неименованный, в котором находится 0 байт, и именованный (с именем New_Stream), где будет находиться результат выполнения команды dir. Доступ к именованному потоку можно получить, обратившись к нему по имени через двоеточие после имени файла. Для вывода содержимого именованного потока воспользуемся:
C:\WINDOWS\Fonts> more < New_Stream.TXT:New_Stream
Каталоги NTFS
Каталог на NTFS представляет собой специфический файл, хранящий ссылки на другие файлы и каталоги, создавая иерархическое строение данных на диске. Файл каталога поделен на блоки, каждый из которых содержит имя файла, базовые атрибуты и ссылку на элемент MFT, который уже предоставляет полную информацию об элементе каталога. Внутренняя структура каталога представляет собой бинарное B+ дерево (форма двоичного дерева, в каждом узле которого хранится несколько элементов), элементы которого сортируются по имени. Для поиска файла с данным именем в линейном каталоге, таком, например, как у FAT-а, системе приходится просматривать все элементы каталога, пока она не найдет нужный. Бинарное же дерево располагает имена файлов таким образом, чтобы поиск файла осуществлялся более быстрым способом - с помощью получения двухзначных ответов на вопросы о положении файла. Вывод - для поиска одного файла среди 1000, например, FAT придется осуществить в среднем 500 сравнений (наиболее вероятно, что файл будет найден на середине поиска), а системе на основе дерева - всего около Log 2 (N), т.е 10-ти (2^10 = 1024).
Разреженные файлы
Файл, в котором большая часть данных равна нулям, содержит разреженный набор данных. Такие файлы обычно очень большие, например, файл, содержащий данные изображения для обработки, или матрица в высокоскоростной базе данных. Проблема с файлами, содержащими разреженные наборы данных, заключается в том, что большая часть файла не содержит полезных данных, и из-за этого они являются неэффективным использованием дискового пространства.
Сжатие файлов в файловой системе NTFS является частичным решением проблемы. Все данные в файле, которые не записаны явным образом, равны нулю. Сжатие файлов сжимает эти диапазоны нулей. Однако недостаток сжатия файлов заключается в том, что время доступа может увеличиться из-за сжатия и распаковки данных.
Поддержка разреженных файлов реализована в файловой системе NTFS в качестве еще одного способа повышения эффективности использования дискового пространства. Если функция разреженного файла включена, система не выделяет место на жестком диске для файла, за исключением регионов, где он содержит ненулевое значение. При попытке операции записи, когда большой объем данных в буфере равен нулям, нули не записываются в файл. Вместо этого файловая система создает внутренний список, содержащий расположения нулей в файле, и этот список обращается во время всех операций чтения. При выполнении операции чтения в областях файла, где были обнаружены нули, файловая система возвращает соответствующее количество нулей в буфере, выделенном для операции чтения. Таким образом, обслуживание разреженного файла прозрачно для всех процессов, обращаюющихся к нему, и более эффективно, чем сжатие для конкретного сценария.
Значение данных разреженного файла по умолчанию равно нулю; однако для него можно задать другие значения.
Дополнительные сведения о разреженных файлах см. в следующих разделах.
В этом разделе
| Раздел | Описание |
|---|---|
| Операции с разреженным файлом | Определите, поддерживает ли файловая система разреженные файлы, вызвав функцию GetVolumeInformation. |
| Получение размера разреженного файла | Получите выделенный размер или общий размер файла с помощью функции GetCompressedFileSize или GetFileSize . |
| Разреженные файлы и дисковые квоты | Разреженный файл влияет на квоты пользователей по номинальному размеру файла, а не фактическому выделенному объему дискового пространства. |