Архивировать интернет-страницу
Обращаем ваше внимание, что не все страницы могут быть заархивированы, а добавленные в архив страницы могут быть в любое время удалены из него, например по требованию владельца сайта.
Вы можете подключить услугу гарантирующую сохранность архивной копии, если вы хотите исключить случайное или преднамеренное удаление заархивированной вами интернет-страницы из Интернет-Архива.
В случае направления владельцем сайта запроса на удаления архивной копии, она будет скрыта из публичной части архива, но в случае судебного спора или запроса компетентного органа, доступ к ней будет предоставлен.
- Заверить сайт
- Заверить видео
- Заверить переписку
- Заверить социальные сети
Архивирование файлов и их распаковка из архивов
Если Вы пользуетесь услугами хостинга, то для архивирования или распаковки файла сайта на хостинге из архива требуется перейти в файловый менеджер в панели управления.
Распаковка файлов из архивов
Чтобы извлечь файлы и папки из одного или нескольких архивов в текущую папку, выберите нужный архив в списке, нажмите кнопку «Архив», пункт «Извлечь».

и заполните форму:

- В каталог — укажите каталог, в который требуется распаковать выбранный архив (архивы)
- Создать каталог — если архив требуется распаковать в несуществующий каталог, в этом поле можно указать путь к каталогу. Введенный путь является относительным к пути, выбранному в дереве каталогов. К примеру, если архив требуется распаковать в каталог «/22/content», следует выбрать в дереве каталог «22» и ввести в поле «Создать каталог» значение «content».
- Перейти в выбранный каталог — если отмечено, выбранный каталог станет текущим после завершения операции.
Если нужно распаковать только некоторые файлы, войдите в архив как в простую папку, выберите нужные записи и воспользуйтесь функцией копирования и перемещения файлов и папок.
Архивирование файлов
Чтобы произвести архивирование файла, выберите его в списке, нажмите кнопку «Архив», пункт «Создать архив».

и заполните следующую форму:

- Тип — из списка выберите тип архива.
- Имя архива — укажите имя основного архива (расширение указывать не нужно).
- Удалить файлы — установите флаг, если хотите удалить выбранные файлы после того, как они будут помещены в архив.
В текущем каталоге будет создан архив, в который будут помещены все выбранные Вами файлы.






Все способы
© 2009–2024 «HANDYHOST.RU» 8-800-505-68-01


- Услуги
- Хостинг сайтов
- Домены
- Конструктор сайтов
- Linux VPS / Windows VPS
- Выделенные серверы
- SSL сертификаты
- Клиентам
- Контакты
- О компании
- Акции
- Оборудование
- Партнерская программа
- Поддержка
- Способы оплаты
- Регламент
- Документы
- Справка
Сохранить память: как веб-архивация спасает от забвения заблокированные медиа и «вымирающие» ссылки
Огромное пространство интернета хранит в себе петабайты информации, но при кажущейся надежности этого хранилища из него в любой момент может исчезнуть что угодно, не оставив и следа. Чтобы сохранить наиболее полную историю современности, придумали веб-архивацию, которая спасает научные статьи от «гниющих» ссылок, а в нынешних реалиях — еще и российские медиа от тотальной ликвидации. Разбираемся, как архивируют веб-сайты и где всё еще можно послушать старые передачи «Эха Москвы».
С конца февраля в России заблокировали уже более 50 сайтов средств массовой информации. На территории страны теперь недоступны без VPN «Радио Свобода»* и «Настоящее время»*, The Village и сайт журналиста и публициста Александра Невзорова, а также многие другие издания. Некоторые сайты, как «Эхо Москвы», были ликвидированы своими создателями, другие, как издание DOXA, кроме блокировки со стороны Роскомнадзора столкнулись с отключением от сервиса Tilda. Под блокировку попали и сайты общественных организаций и политиков, а также группы СМИ во «ВКонтакте» (и даже фан-группа Екатерины Шульман*).
Блокировку сайта в целом достаточно легко обойти за счет VPN-сервисов или браузерных расширений, но, если сайт был удален полностью, никакой VPN получить доступ к его содержимому уже не поможет.
Однако это совершенно не означает, что вся информация, хранившаяся на сайте, исчезла безвозвратно. Ее могли «спасти» специалисты в области веб-архивации.
Веб-архивация: в тени цифрового темного века
Международный консорциум по сохранению интернета определяет веб-архивацию как «процесс сбора фрагментов Всемирной паутины, сохранения их в архивном формате и последующего обслуживания архивов для всеобщего доступа и использования».
Сам консорциум появился лишь в начале двухтысячных, и его задачей стала разработка стандартов архивации сайтов. Как таковое веб-архивирование началось гораздо раньше.
Необходимость сохранения данных, размещенных в цифровой среде, возникла еще в начале 1990-х и была вызвана страхом ученых перед так называемым цифровым темным веком (digital dark age) — периодом, о котором может не остаться практически никаких свидетельств из-за того, что компьютеры банально не смогут прочесть данные, созданные в конце XX — начале XXI века. Так уже случилось с CD-дисками, ведь во многих современных компьютерах и ноутбуках нет дисковода.
То же самое относится и к данным, хранящимся в интернете. Например, в 2019 году одна из первых в мире социальных сетей MySpace из-за смены серверов потеряла все данные пользователей, загруженные с 2003 по 2015 год.
Веб-архивация была призвана устранить эти недоразумения. Возможно, многим знаком сервис Wayback Machine — иногда в «Википедии» некоторые ссылки в конце статьи помечены как «недоступные», а рядом с ними написано «архивировано» и есть другая ссылка, которая ведет на копию этой статьи. В копии тот же текст, те же иллюстрации, та же верстка, что и в оригинале, но только расположена она на сайте Wayback Machine.
Сервис запустили в 2001 году, и принадлежит он НКО Internet Archive («Архив интернета»). В прошлом году «Архиву» исполнилось 25 лет: в середине 1990-х его основал один из создателей предшественницы World Wibe Web — первой поисковой системы WAIS — Брюстер Кейл и его коллега Брюс Гиллиат.
Помимо «Архива» Кейл и Гиллиат создали коммерческую компанию Alexa Internet, которая тоже занималась каталогизацией веб-ресурсов, а за счет своей коммерческой составляющей могла обеспечивать Internet Archive финансово. Назвали Alexa Internet в честь Александрийской библиотеки. Кейл не раз проводил параллель между событиями разных эпох, связанными с утратой исторических памятников, и угрозой цифрового темного века в ближайшем будущем. Так, он писал:

Уже через год после создания «Архива» и «Алексы» появился специальный браузерный плагин, с помощью которого Alexa сама определяла, какие страницы наиболее ценны для архивации, исходя, например, из посещаемости сайта. В 2003 году к веб-архивации подключили поискового робота Heritrix, написанного на языке JavaScript. У него открытый код, и создатели загрузили его на GitHub.
Роботы, или, как их еще называют, веб-краулеры, работают по самому распространенному принципу веб-архивирования — харвестингу (от англ. harvesting — «сбор урожая»).
Краулеру сначала передают список URL-адресов, по которым находятся нужные для архивации сайты. Робот посылает HTTP-запрос на веб-сервер, а затем как бы «перехватывает» содержимое, передаваемое сервером. HTTP расшифровывается как HyperText Transfer Protocol (протокол передачи гипертекста) — это по своей сути стандартный запрос, который каждый день обрабатывает сервер исходя из того, что мы вбили в поисковую строку Google или «Яндекса».
Параллельно робот еще и создает новый список — он анализирует просмотренные страницы на предмет гиперссылок. По этим ссылкам лежат файлы или целые веб-страницы, которые тоже нужно будет заархивировать. После сбора данных (харвестинга) специальное ПО преобразовывает все файлы в формат ARC (ARChive) — сейчас его уже заменил WARC (Web ARChive).
Однако возможности краулера не безграничны: например, он не сможет заархивировать веб-сайт, если на нем установлено соответствующее ограничение. Это может случиться, если файл защищен паролем или если в файле robots.txt, который лежит в корне сайта и содержит определенные указания для роботов поисковых систем, прописано ограничение на архивацию данных. Кроме того, робот сталкивается с трудностями и при архивировании так называемых динамических веб-сайтов. Динамический сайт состоит из нескольких шаблонов и скриптов, которые хранятся на сервере в виде отдельных файлов или баз данных. Из-за того, что такой сайт не хранится в виде законченной страницы, краулеру тяжелее считывать данные.
Архивация бывает и «со стороны сервера». Харвестинг — это архивация «со стороны клиента»: робот отправляет запрос и получает ответ от сервера. При архивации «со стороны сервера» шаг с HTTP-запросом пропускают, но такой метод требует прямого доступа к серверу, а следовательно, прямого участия компании или организации, чей сайт будет заархивирован.
Почему ссылки вымирают?
Помимо Internet Archive долгое время был востребован сервис WebCite. Он был запущен в 2003 году и быстро завоевал популярность, потому что стал первым инструментом, который архивировал сайты по запросу пользователей.
Создатель WebCite, Гюнтер Эйзенбах, в то время интересовался «вымиранием ссылок»: в журнале Science в 2003 году вышла статья под названием Going, Going, Gone: Lost Internet References. Наверное, она одна из первых четко обозначила проблему, которая возникла в области цитирования из-за «вымерших» или «сгнивших» ссылок. Такая ссылка ведет либо не на ту страницу, URL-адрес которой задавал пользователь, либо вовсе становится недоступной, из-за чего доступ к веб-странице теряется совсем.
Наиболее уязвимы научные работы: «вымершие» ссылки подрывают их доказательную базу. Так, уже в 2016 году 75% ссылок в исследовательских работах больше не указывали на первоисточник, процитированный автором.
То же самое с материалами на сайтах СМИ: чем старше статья, тем больше вероятность, что в ней встретятся битые или вообще «сгнившие» ссылки. Возможно, даже в этом материале уже через год вы найдете такую «вымершую» ссылку.
Обеспокоенный таким «вымиранием» ссылок, одновременно с WebCite Эйзенбах запустил консорциум, к которому могли присоединиться редакции и издательства научных журналов, чтобы архивировать те сайты и веб-страницы, на которые есть ссылки в научных публикациях.
Однако уже в начале 2010-х годов у сервиса появились финансовые проблемы, и с 2019-го WebCite не принимает запросы на архивирование веб-сайтов и доступен только для чтения.
Стратегии веб-архивации
По всему миру есть сотни инициатив, которые создают веб-архивы, занимаются оцифровкой и другими формами сохранения культуры. Они существуют в форме как государственных, так и общественных или частных проектов. Первые — это национальные библиотеки, как, например, Национальная библиотека Австралии и ее архив Pandora. С 1996 года в архив собирают сайты органов государственной власти, культурных учреждений, общественных движений и организаций.
Уже рассмотренный нами Internet Archive как бы симулирует поисковую систему, ориентируясь на цитируемость, — он охватывает практически все популярные страницы в интернете для того, чтобы их заархивировать. Это так называемая ненаправленная веб-архивация. Кроме Internet Archive таким же ненаправленным веб-архивом является, например, Common Crawl. Архивы национальных библиотек работают по другому принципу: это сфокусированные архивы, нацеленные на сохранение сайтов и документов по определенной тематике. Как правило, краулер в этих архивах обходит заданные сайты по несколько раз за определенный промежуток времени. Например, UK Government Web Archive — это веб-архив сайтов всех госслужб Великобритании. Выбранные сайты робот обходит несколько раз в сутки и сохраняет обновления в архив.
Другая стратегия веб-архивации — это тоже выборочное сохранение веб-сайтов и документов, но при этом сам процесс управляется человеком. Зачастую такие проекты по архивации фокусируются на сайтах, которые могут оказаться под угрозой исчезновения.
Так себя позиционирует команда Archive Team:
Файлы в формате WARC — архивы веб-сайтов — можно открыть с помощью программы ReplayWeb.page и посмотреть в офлайн-режиме. Остальные архивы — любым архиватором, который работает с форматами ZIP и GZ.
«Политики приходят и уходят, но знания должны сохраняться»
«Если к архивации относиться как к институциональной деятельности, то в России государство этим, к сожалению, не занимается, — говорит Иван Бегтин. — В мире обычно этим занимается государство: либо национальные библиотеки, либо национальные архивы — несколько сотен таких примеров есть в мире. В России, к сожалению, люди, стоящие у власти в области культуры, не мыслят категориями сохранения современности для будущего. В лучшем случае они мыслят сохранением прошлого. Но сохранением современности не мыслит никто. На государственном уровне такого не происходит».
Возможно, вполне логичен вопрос: зачем вообще заниматься веб-архивацией? В чем ценность веб-архивов для будущего? Здесь речь скорее идет о теоретической ценности: сохранение культурного и исторического наследия, информации о цивилизации. Ценность веб-архива для современности тоже сопряжена с культурной значимостью архивируемых документов, а главное — с возможностью их практического применения.
Практическая сторона веб-архивации, по словам Ивана Бегтина, заключается в том, что это «сохранение того, что может в любой момент исчезнуть, но имеет некоторую общественную, культурную значимость». Это СМИ с большой аудиторией, несколькими тысячами посетителей сайта в сутки, которые попали под давление Роскомнадзора. То же самое относится к НКО, особенно к тем, которые имеют статус иностранного агента, выданный Минюстом.
Собранные в ходе веб-архивации данные могут использоваться историками, исследователями в разных областях, журналистами.
«Другая форма применения относится к потреблению культуры и информации. Из российских — это, например, „Эхо Москвы“. Оно было закрыто своим учредителем одномоментно с ликвидацией всего контента, который существовал в открытом доступе, притом что у него была достаточно лояльная аудитория, огромное сообщество, которое крайне заинтересовано в том, чтобы иметь возможность прослушивать многие передачи ретроспективно. Это и авторы передач, и участники, и слушатели. Соответственно, для них веб- или цифровая архивация — возможность получить доступ к тому, что исчезло или может исчезнуть», — отмечает Иван Бегтин.
По его словам, кейс «Эха» был для их проекта очень показателен. Показателен в контексте того, как важно сообщество, которое сейчас формируется вокруг архива:
«Если бы мне в определенный момент 3 марта утром не написали: Иван, пожалуйста, возьмите на архивацию этот сайт срочно, — мы бы этого и не сделали. Не отследили бы. Обычно закрытие проекта длится около месяца-двух — то есть это медленная процедура. Когда предупредили о том, что сайт может исчезнуть за два дня, мы поставили его на консервацию и успели сохранить то, что успели. Это далеко не всё. А есть случаи, когда не успеваем: Znak.com закрылся одномоментно. Он недоступен ни в какой форме. Поэтому мы всячески формируем сообщество для того, чтобы нас заранее предупреждали о том, что может исчезнуть. Ну и, конечно, там формируется пул волонтеров, группы людей, которые сами что-то заархивировали и помогают нам сохранить и дополнить архивы».
«Даже если наши власти считают, что какие-то вещи не должны быть в открытом доступе, они всё равно должны быть заархивированы, они должны быть доступны для исследователей. И это я считаю некоторой безусловной ценностью. Политики приходят и уходят, политики меняются, но знания должны сохраняться», — добавляет Иван Бегтин.
Архивация по URL

Каждый год несколько процентов материалов, на которые я ссылаюсь, исчезают навсегда. Для человека, который старается не писать без пруфов, это неприемлемо, так что я разработал собственную стратегию борьбы с битыми ссылками. Если коротко — коллекция скриптов, демонов и архивных сервисов в интернете просто берёт и бэкапит всё подряд. URLы регулярно выгружаются из логов моего браузера и статей с моего сайта. Все страницы архивируются локально и на archive.org, так что при необходимости они будут вечно доступны из нескольких независимых источников.
linkchecker регулярно проходит по моему сайту в поисках битых ссылок; все обнаруженные потери могут быть либо заменены (если адрес поменялся, но страница всё ещё существует), либо восстановлены из архива. Кроме того, мои локальные архивы криптографически датируются через блокчейн биткойна на случай, если возникнут подозрения в фальсификации.
Вымирание ссылок
«Все составные вещи недолговечны. Стремитесь к собственному освобождению с особым усердием».
Последние слова Будды Шакьямуни
Величина вымирания вызывает возмущение. Вот взгляд Википедии:
В эксперименте 2003 года Фетерли (с соавторами) обнаружил, что примерно одна ссылка из 200 исчезает каждую неделю из интернета. МакКоун (с соавторами, 2005) обнаружил, что половина URL, указанных в статьях журнала D-Lib Magazine, не были доступны через 10 лет после публикации, а другие исследования показали даже худшее вымирание ссылок в научной литературе [5] [6]. Нельсон и Аллен [7] изучали вымирание ссылок в цифровых библиотеках и нашли, что около 3 % объектов были недоступны после одного года. В 2014 владелец сайта закладок Pinboard Мацей Цегловский сообщал, что «довольно стабильная доля» в 5 % ссылок вымирает за год [8]. Исследование ссылок из каталога Yahoo! показало период полураспада случайной страницы в 2016—2017 годах (вскоре после того, как Yahoo! перестала публиковать этот каталог) около двух лет [9].
Брюс Шнайер вспоминает, что за девять лет у одного его друга сломалась половина ссылок на странице (и не то чтоб в 1998 году дела обстояли лучше), и что он сам порой выкладывал ссылку — а через пару дней она уже не работала. Виторио перебрал свои закладки из 1997 года в 2014-ом и обнаружил, что 91% не работает, а половины нет даже в Internet Archive. Эрни Смит взял книгу про интернет из 1994 года и нашёл в ней целую одну работающую ссылку. Internet Archive считает, что среднее время жизни страницы в интернете — 100 дней. Статья в Science утверждает, что учёные обычно не вставляют URLы в научные публикации, а когда вставляют — 13% не работает через два года. Французская компания Linterweb изучала внешние ссылки во франкоязычной Википедии и обнаружила, что в 2008 году 5% были мертвы. Англоязычная Википедия пережила вспышку битых ссылок в 2010-январе 2011, когда их число выросло от нескольких тысяч до ~110 000 из ~17.5 миллионов. На некогда легендарной Million Dollar Homepage, последняя ссылка на которой была поставлена в январе 2006 и стоила 38 тысяч долларов, к 2017 не меньше половины ссылок были мертвы или захвачены киберсквоттерами (с неё до сих пор идёт трафик, так что некоторые адреса могут иметь ценность). Сайт закладок Pinboard отмечал в августе 2014, что 17% 3-летних ссылок и 25% 5-летних не открываются. И так далее, и тому подобное, и прочее в том же духе.
Ссылки сыплются даже в более-менее стабильных, модерируемых и не разорившихся системах. Хотя Твиттер как таковой прекрасно себя чувствует, 11% твитов времён Арабской Весны не открывались уже через год. А иногда незаметно исчезают сразу огромные объёмы данных: например, администрация MySpace где-то потеряла всю музыку, загруженную с 2003 по 2015, и объявила, что они “перестроили MySpace с нуля и решили перенести часть пользовательского контента со старой версии”. Правда, часть загрузок 2008-2010 была восстановлена и выложена на IA “анонимным исследователем”.
Я хочу, чтобы мои данные хотя бы пережили меня; скажем, дожили до 2070. По состоянию на 10 марта 2011 года (прим. пер.: дата выхода первой версии этого текста. Последний апдейт датируется 5 января 2019), у меня на сайте примерно 6800 внешних ссылок, из них 2200 не на Википедию. Даже при минимальной оценке в 3% умирающих ссылок в год, до 2070 доживут немногие. Если шанс выживания данной конкретной ссылки в данный год 97%, то вероятность её не потерять до 2070 равна 0.97^(2070-2011)≈0.16. 95-процентный доверительный интервал для такого биномиального распределения подсказывает, что ~336-394 ссылки из 2200 будут работать в 2070 году. Если использовать верхнюю оценку смертности в 50% ссылок в год — то в 2070 году, скорее всего, не останется ни одной.
Истина где-то между этими двумя экстремумами, но безопаснее исходить из допущения, что все внешние ссылки (кроме разве что Википедии и Internet Archive, специально заботящихся о долгожительстве материалов) рано или поздно накроются. Во всяком случае, не стоит полагаться на то, что всё будет нормально. Если не позаботиться сейчас, то нормально точно не будет.
Если мы хотим заархивировать данную конкретную страницу — то всё просто. Нужно либо пойти на Internet Archive и нажать там соответствующую кнопку, либо распечатать страницу в PDF прямо из браузера. Для сохранения более сложных страниц есть специальные плагины, например ScrapBook. Но я захожу и ссылаюсь на огромное количество страниц, так что сохранять каждую из них вручную будет тяжеловато. Нужна система, которая бы автоматически обеспечивала корректные ссылки на все страницы, которые могут мне когда-нибудь понадобиться.
Поиск битых ссылок
Одну весну за другой
цветы излагают Закон,
не говоря ни единого слова,
но уяснив его суть
из срывающего их ветра
Сётэцу
Прежде всего, нужно как можно раньше находить свежеполоманные ссылки. Даже само по себе это позволит хотя бы подставлять материалы из архивов или кеша поисковых систем. У меня для этого используется linkchecker в задаче cron:
@monthly linkchecker --check-extern --timeout=35 --no-warnings --file-output=html \ --ignore-url=^mailto --ignore-url=^irc --ignore-url=http://.*\.onion \ --ignore-url=paypal.com --ignore-url=web.archive.org \ https://www.gwern.net В таком виде эта команда вернёт кучу ложноположительных сигналов. Несколько сотен якобы битых ссылок будут найдены на одной только Википедии, потому что я ссылаюсь на редиректы; кроме того, linkchecker читает robots.txt и не может проверить заблокированные в нём адреса. Это можно исправить, добавив в ~/.linkchecker/linkcheckerrc «ignorewarnings=http-moved-permanent,http-robots-denied» (полный список классов предупреждений есть в linkchecker -h ).
Чем раньше битая ссылка найдена, тем раньше можно что-то с ней сделать. Что именно?
Удалённое кеширование
Всё, что ты постишь в Интернете, будет существовать до тех пор, пока оно тебя позорит, и исчезнет, как только оно тебе понадобится.
с сайта Ycombinator
Можно попросить кого-нибудь другого хранить кэши всех нужных нам страниц. Как раз на такой случай есть несколько веб-архивов:
- The Internet Archive
- WebCite
- Perma.cc (сильно ограничен)
- WikiWix (но у него есть конкретная функция — бэкапить исходящие ссылки Википедии — так что весь остальной интернет его интересует довольно мало).
- Archive.is
- Pinboard предоставляет архивацию за 25$ в год
- Hiyo.jp и Megalodon.jp (но они на японском) Прим.пер.: по состоянию на март 2021 первая ссылка не открывается. Что забавно, локальный архив Гверна честно отдаёт мне сохранённую главную страницу сервиса, но воспользоваться ей уже вряд ли получится.
Кстати, хранить в этих архивах собственный сайт — тоже неплохая идея:
- Бэкапы — это хорошо, но локальный бэкап тоже может случайно погибнуть (это я из собственного опыта говорю), так что неплохо бы иметь удалённые копии.
- Уменьшается пресловутый “автобусный фактор”: если завтра я попаду под автобус, то кто и как получит доступ к моим бэкапам? У кого будет время и желание в них потом разбираться? А про IA люди в целом понимают, что там и как, к тому же для работы с ним созданы специальные инструменты.
- Фокус на бэкапе самого сайта отвлекает внимание от необходимости бэкапить то, на что ты ссылаешься. Многие страницы мало чего стоят, если ссылки в них перестали открываться, а скрипты / демоны для архивации можно настроить так, чтобы они автоматически подтягивали всё необходимое.
В конце концов я написал archiver, простенький демон, который мониторит текстовый файл с URL’ами. Исходники можно скачать через
git clone https://github.com/gwern/archiver-bot.gitArchiver состоит из библиотеки, которая по сути является просто обёрткой вокруг соответствующих HTTP-запросов, и исполняемого файла, который берёт список адресов, сообщает Internet Archive, что их не мешало бы сохранить, потом удаляет соответствующую строку из файла и продолжает в том же духе, пока файл не опустеет.
Вызов выглядит так:
archiver ~/.urls.txt gwern@gwern.netОн у меня когда-то крашился по непонятным причинам, так что я завернул команду в while true:
while true; do archiver ~/.urls.txt gwern@gwern.net; doneПотом я завернул его ещё и в сессию GNU screen:
screen -d -m -S "archiver" sh -c 'while true; do archiver ~/.urls.txt gwern@gwern.net; done'Ну и запускаем не руками, а через cron, так что в итоге получается:
@reboot sleep 4m && screen -d -m -S "archiver" sh -c 'while true; do archiver ~/.urls.txt gwern2@gwern.net "cd ~/www && nice -n 20 ionice -c3 wget --unlink --limit-rate=20k --page-requisites --timestamping -e robots=off --reject .iso,.exe,.gz,.xz,.rar,.7z,.tar,.bin,.zip,.jar,.flv,.mp4,.avi,.webm --user-agent='Firefox/4.9'" 500; done'Локальное кэширование
Удалённые архивы — это хорошо, но у них есть один фатальный недостаток: архивные сервисы не поспевают за ростом интернета и большей части материалов там может не быть. Ainsworth et al. 2012 показали, что менее 35% веб-страниц заархивированы хоть где-нибудь, и подавляющее большинство из них сохранены только в одном архиве. К тому же и сами архивы в принципе могут умереть вместе со всем их содержимым. Так что локальное кэширование тоже должно быть.
Самый фундаментальный подход — взять кэширующее прокси, которое будет сохранять буквально весь ваш веб-трафик. Например, Live Archiving Proxy (LAP) или WarcProxy будет писать WARC-файлы для каждой посещённой через HTTP веб-страницы. Zachary Vance пишет, что можно настроить локальный HTTPS-сертификат и добраться до содержимого HTTPS-страниц за счёт MitM-атаки на собственный трафик.
Но это довольно тяжеловесное и прожорливое решение, так что хочется чего-то более аккуратного. Например, выгружать из браузера список посещённых страниц и пытаться их заархивировать.
Раньше я использовал скрипт с потрясающе оригинальным названием local-archiver:
local-archiver.sh
#!/bin/sh set -euo pipefail cp `find ~/.mozilla/ -name "places.sqlite"` ~/ sqlite3 places.sqlite "SELECT url FROM moz_places, moz_historyvisits \ WHERE moz_places.id = moz_historyvisits.place_id \ and visit_date > strftime('%s','now','-1.5 month')*1000000 ORDER by \ visit_date;" | filter-urls >> ~/.tmp rm ~/places.sqlite split -l500 ~/.tmp ~/.tmp-urls rm ~/.tmp cd ~/www/ for file in ~/.tmp-urls*; do (wget --unlink --continue --page-requisites --timestamping --input-file $file && rm $file &); done find ~/www -size +4M -delete Код не самый красивый, но вроде всё понятно.
- Выгружаем адреса из SQL-файла Firefox и скармливаем их wget. Это не самый подходящий инструмент для скачивания сайтов: он не может запускать JS/Flash, скачивать потоковое видео и прочая и прочая. Весь джаваскрипт будет просто скачан в виде файла, который, скорее всего, перестанет исполняться через пару лет, а динамически подгружаемый контент не сохранится. С другой стороны, это не такая уж большая проблема, потому что на практике мне нужен в основном как раз статический контент (а JS по большей части обеспечивает только ненужные свистелки), а видео можно бэкапить руками через youtube-dl . Если страница приватная и без логина не открывается — то можно вытащить куки из Firefox специальным аддоном, скормить их wget через ключ —load-cookies и всё будет хорошо. Так что в целом wget мне хватает.
- Скрипт дробит список URL на множество файлов и параллельно запускает бэкапы на каждом из них, потому что wget не умеет одновременно качать с нескольких доменов и может подвиснуть.
- filter-urls — это ещё один скрипт, удаляющий адреса, которые не надо бэкапить. По сути это просто гора костылей:
#!/bin/sh set -euo pipefail cat /dev/stdin | sed -e "s/#.*//" | sed -e "s/&sid=.*$//" | sed -e "s/\/$//" | grep -v -e 4chan -e reddit
Так что я сел писать archiver, который бы постоянно крутился в фоне и собирал адреса, бэкапил бы в Internet Archive и вёл себя более разумно с большими медиафайлами.
Я добавил туда ещё пару фич: во-первых, он принимает в качестве третьего аргумента произвольную sh-команду, которой будет отдана ссылка. Это полезно, если вам хочется что-нибудь делать со всеми сохранёнными страницами (например, вести логи).
Во-вторых, все страницы криптографически датируются и помечаются, так что если возникнут подозрения в том, что я сфальсифицировал что-то в своём архиве — можно будет подтвердить, что он не поменялся с момента создания. Система подробно расписана в приложении, но смысл в том, что специальный сервис посылает копеечную транзакцию на адрес Bitcoin, производный от хэша документа, и при необходимости всегда можно найти в блокчейне доказательство, что в такую-то дату действительно существовала страница с таким-то хэшом.
Расход ресурсов
Кажется, что такой локальный бэкап будет пожирать огромные ресурсы, но на самом деле за год набирается 30-50 Гб. Меньше, если настроить игнорирование страниц более жёстко, больше, если сохранять сайты целиком (а не только посещённые страницы). В долгосрочной перспективе всё это вполне жизнеспособно: с 2003 по 2011 средняя страница увеличилась в 7 раз (что неприятно), но цена хранения за тот же период упала в целых 128 раз. По состоянию на 2011 год, за 80 долларов можно купить минимум пару терабайт, так что гигабайт места на жёстком диске стоит около 4 центов. Получается, что весь бэкап стоит один-два доллара в год. На самом деле больше, потому что всё это надо хранить в нескольких копиях, но всё равно копейки. К тому же нам тут повезло: большая часть документов изначально цифровая и может быть автоматически перенесена с диска на диск или конвертирована в другой формат. Обратная совместимость в браузерах неплохо работает даже с документами из начала девяностых, и даже если что-то не откроется сразу, об этой проблеме можно будет думать, когда и если она действительно возникнет. Разумеется, если нужные данные зашиты в анимацию Adobe Flash или динамически подтягиваются из облака — то они пропали, но это всё ещё куда меньшая боль, чем если бы мы пытались сохранять программы и библиотеки (что потребовало бы полного стека двоично совместимых виртуалок или интерпретаторов).
Размер можно и уменьшить: tar-архив, пожатый 7-zip на максимальных настройках, примерно впятеро меньше исходника. Ещё процентов 10 можно убрать, найдя идентичные файлы через fdupes и подменив их на хардлинки (на веб-страницах полно абсолютно идентичного джаваскрипта). Хорошая фильтрация тоже не помешает. Например, за период с 2014-02-25 по 2017-04-22, я посетил 2,370,111 URL (в среднем 2055 в день); после фильтрации осталось 171,446 URL’ов, из которых всего 39,523 уникальных (34 в день, 12,520 в год).
По состоянию на 2017-04-22 архивы за 6 лет весят всего 55 Гб за счёт компрессии, агрессивной фильтрации, удаления больших доменов, которые и так бэкапит Internet Archive, и прочих ручных оптимизаций.
Источники URL
Список страниц, которые надо сохранить, заполняется из нескольких источников. Во-первых, есть скрипт под названием firefox-urls:
firefox-urls.sh
#!/bin/sh set -euo pipefail cp --force `find ~/.mozilla/firefox/ -name "places.sqlite"|sort|head -1` ~/ sqlite3 -batch places.sqlite "SELECT url FROM moz_places, moz_historyvisits \ WHERE moz_places.id = moz_historyvisits.place_id and \ visit_date > strftime('%s','now','-1 day')*1000000 ORDER by \ visit_date;" | filter-urls rm ~/places.sqlite (filter-urls тот же самый, что и в local-archiver. Если я не хочу сохранять страницу локально, то я и в удалённый архив её не стану отправлять. Более того, у WebCite есть ограничение на число запросов, так что archiver еле справляется с нагрузкой и не надо грузить его ещё и пустой болтовнёй на форчане).
Этот скрипт запускается раз в час по крону:
@hourly firefox-urls >> ~/.urls.txtПосещённые с последнего запуска адреса оказываются в файле и archiver их увидит при следующем запуске, так что всё, что я читаю, сохраняется навечно. Если у вас Chromium, то существуют аналогичные скрипты от Zachary Vance для извлечения истории и закладок.
Второй и, пожалуй, более полезный источник — парсер Markdown. Все ссылки аналогичным образом выдираются из моих документов (link-extractor.hs), отправляются в файл списка, и рано или поздно они отправляются в архивы.
Наконец, иногда я скачиваю полный дамп всего сайта. В принципе я мог бы прокликать все страницы вручную и положиться на мои скрипты, но это не очень удобно. linkchecker по определению проверяет ссылки, так что неудивительно, что он может вернуть список всех URL на сайте и даже построить карту. Правда, среди многочисленных форматов, которые он умеет возвращать, нет простого списка адресов по одному на строчку, так что выхлоп нужно дорабатывать напильником (обратите внимание, что сильно перелинкованные сайты типа википедии лучше так не обходить):
linkchecker --check-extern -odot --complete -v --ignore-url=^mailto --no-warnings http://www.longbets.org | fgrep http | fgrep -v -e "label=" -e "->" -e '" [' -e '" ]' -e "/ " | sed -e "s/href=\"//" -e "s/\",//" -e "s/ //" | filter-urls | sort --unique >> ~/.urls.txtЧто я в итоге делаю с битыми ссылками
Благодаря связке linkchecker и archiver, на Gwern.net почти нет битых ссылок. Когда они обнаруживаются, у меня уже подготовлено множество запасных вариантов:
- Найти работающую версию страницы
- Подставить копию из Internet Archive
- Подставить копию из WebCite
- Подставить копию из WikiWix
- Использовать локальный дамп.
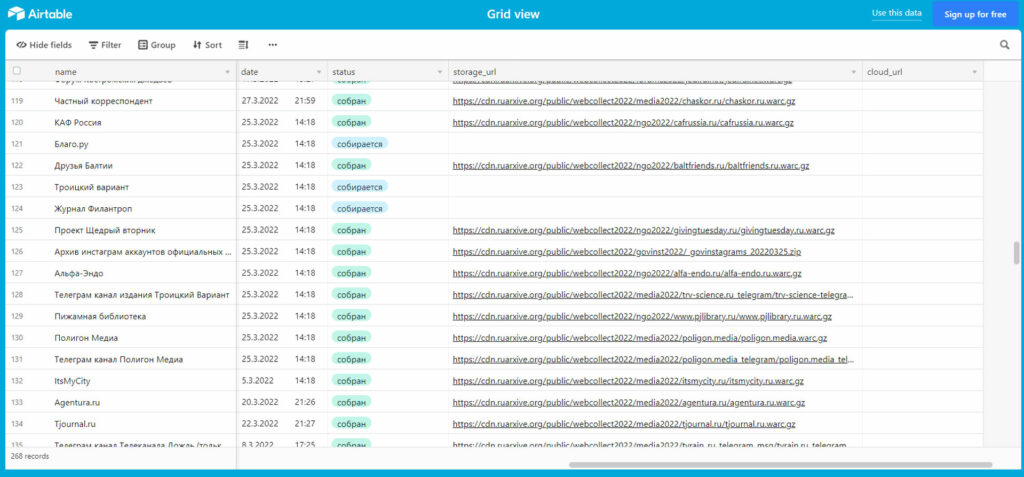
- архив интернета
- архивирование данных
- бэкапы