codedokode / Особенности сравнения строк.md
Эта статья перенесена сюда: https://github.com/codedokode/pasta/blob/master/php/collation.md Ниже идет старая, неподдерживаемая версия статьи.
В программировании строки можно сравнивать. При этом обычно подразумевается алфавитное сравнение, то есть меньше то слово, которое идет раньше по алфавиту. Если начальные буквы совпадают, то меньше то слово, которое короче. Например, «аббат» < "аккорд", "кот" < "котёнок".
Если разобраться в теме сравнения строк на любых языках (а не только на русском), то все выглядит гораздо сложнее и появляется много особенностей, которые надо учитывать(по-английски эта тема называется «collation»). И проблема не в том, что там много букв из разных алфавитов, а в том что одни и те же буквы имеют разный порядок в разных языках. Например, буквы с точечками и черточками сравниваются по-разному: http://en.wikipedia.org/wiki/Alphabetical_order#Language-specific_conventions
В некоторых языках буквы вроде å идут после z , в некоторых между a и b . В некорых (английский) они имеют одинаковый вес с a . То есть сортировка зависит от языка.
В немецком, ß может быть равносильно ss , по крайней мере произносятся они одинаково.
В японском есть 2 алфавита (хирагана/катакана), обозначающих одни и те же слоги.
Лигатуры вроде Œ могут быть равносильны комбинации oe , а могут и не быть.
Также, одна буква (упомянутая выше å ) может храниться в строке как один символ либо как комбинация 2 символов: кружочек + a (чтобы избежать проблем из-за этого, строки перед сравнением можно нормализовать, приведя к единому виду).
Как ты, надеюсь догадался к этому моменту, сравнение строк очень нетривиальная вещь. Потому для этого есть специальные библиотеки, самая известная из них это открытая ICU (мануал на англ. http://userguide.icu-project.org/ ). В PHP ты можешь воспользоваться ее возможностями с помощью расширения Intl (которое умеет не только сравнение строк, но и многое другое, например писать числа прописью): http://php.net/manual/ru/book.intl.php . По моему, в Windows версии это расширение идет в комплекте с php и надо только включить его в php.ini. В линуксе оно ставится отдельно.
В этом расширении есть класс Collator для сравнения строк по правилам указанного языка: http://php.net/manual/ru/class.collator.php
Он умеет сравнивать строки и сортировать массивы, в том числе применяя нормализацию, по правилам в выбранной локали. Вот пример кода, сравнивающего 2 строки с учетом языка. В нем мы создаем объект Collator , передавая ему локаль (краткий код языка и территории — в нашем случае это ru_RU (русский язык в России). Территорию надо указывать, так как например американский ( en_US ) и британский ( en_GB ) английский немного различаются. Посмотреть возможные коды локалей можно тут: http://demo.icu-project.org/icu-bin/locexp . Прочитать подробно на англ. тут: http://userguide.icu-project.org/locale . Корневая локаль под названием root позволяет сравнивать строки по обобщенным правилам).
Дополнительные опции (например, считать ли символы хираганы/катаканы разными или учитывается ли регистр букв) задаются через атрибуты методом setAttribute . Возможные атрибуты указаны тут в виде констант: http://php.net/manual/ru/class.collator.php#intl.collator-constants
Одна из опций — уровень сравнения. На первом ( PRIMARY ) уровне игнорируются различия между буквами с акцентами вроде å и a , а по умолчанию выставлен третий уровень, который их проверяет.
$collatorRu = new Collator('ru_RU'); $result = $collatorRu->compare("Ель", "Ёлка"); var_dump($result); // 1, Ель > Ёлка $result2 = $collatorRu->compare("Е", "Ё"); var_dump($result2); // -1, Е < Ё// Немецкий $collatorDe = new Collator('de_DE'); // Игнорировать различия в написании букв и акценты $collatorDe->setAttribute(Collator::STRENGTH, Collator::PRIMARY); $result3 = $collatorDe->compare("ss", "ß"); var_dump($result3); // 0 - строки равны
Сам алгоритм сравнения подробно описан в UNICODE COLLATION ALGORITHM: http://www.unicode.org/reports/tr10/ (англ). Там в начале есть примеры всех этих сложностей со сравнением, интересно почитать.
Без него (расширения Intl), например в выражении if ($x > $y) , php сравнивает строки побайтово, по кодам символов. То есть у кого код больше тот и ниже в списке. Вот получающийся порядок символов, например, для кириллицы: http://unicode-table.com/ru/#cyrillic
Видно что буква Ё там идет раньше чему буква А (а маленькая ё наоборот ниже чем я).
Кстати вопрос про сравнение строк хорошо задавать на собеседовании, мне кажется, чтобы посмотреть ход мыслей кандидата
Сравнение строки по алфавиту

Здравствуйте, подскажите пожалуйста как сравнить строку по алфавиту? То есть мне нужно что бы каждая буква проверялась на указаный алфавит.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
#include #include #include using namespace std; int main(){ char string[255]; char HEX[22] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 'a', 'b', 'c', 'd', 'e', 'f', 'A', 'B', 'C', 'D', 'E', 'F' }; int DEC[10] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }; int OCT[8] = { 0, 1, 2, 3, 4, 5, 6, 7 }; int BIN[2] = { 0, 1 }; int stringLength; cout "Input your string: "; cin >> string; stringLength = strlen(string); for (int i = 0; i stringLength; i++){ if (strcmp(string, HEX) == 0){ //strchr cout "number"; } else { cout "not a number"; } } _getch(); }
Сравнение строк по алфавиту
У меня есть список структуры, в которой есть поле string, я хочу два элемента структуры сравнить согласно алфавиту(для сортировки), а если быть точнее, то первым должно быть слово, первая буква которого в алфавите находится раньше, если же они одинаковые, то сравниваем по второй букве и так далее. Подскажите какой функцией я могу воспользоваться.
Отслеживать
задан 1 апр 2021 в 18:55
33 5 5 бронзовых знаков
где ваш пример реализации?
1 апр 2021 в 18:56
Просто сравнить две строки через < ?
1 апр 2021 в 19:03
1 апр 2021 в 20:23
Уточните, это C или C++ ? Ответы будут очень разные.
3 апр 2021 в 8:25
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Вопрос, на самом деле, совсем не простой. Если Ваши строки содержат только 7-битные символы ASCII, то проще всего воспользоваться стандарной функцией strcmp().
Однако, если в эти строки входят какие-то другие символы, то для сравнения необходимо знать способ кодирования этих «других» симвлов. И здесь всё плохо. Способов кодирования много, таблиц кодировок ещё больше и проблема перестаёт иметь однозначное решение.
Теоретически, по стандарту POSIX, если Вы правильно указали locale, то функция strcmp() должна работать правильно. Однако это остаётся на совести разработчика ОС.
Согласно POSIX, сведения из локали используют функци strcoll(), strxfrm() и некоторые другие.
Функция strcoll() сравнивает строки s1 и s2. Она возвращает целое число, которое может быть меньше, равно или больше ноля, если выяснится, что s1 меньше, равна или больше s2 соответственно. Сравнение производится на основе правил текущей локали, указанной в категории
LC_COLLATE (см. setlocale(3)).
Ситуация несколько упрощается, если используется кодировка UTF-8. Её не нужно подстраивать под конкретную локаль, она универсальная.
Ну, если Вы пишите для Linux, то можете использовать эту библиотеку для работы с UTF-8:
Как сравнить строки в Python? Операторы сравнения строк
Строка в Python представляет собой набор символов, находящихся в кавычках. При этом сравнение строк отличается от сравнения чисел и имеет свои особенности. В этой статье мы кратко и простым языком расскажем о сравнении строк в Python и посмотрим, какие операторы для этого есть, и как эти операторы используются.
Основные операторы сравнения в Python
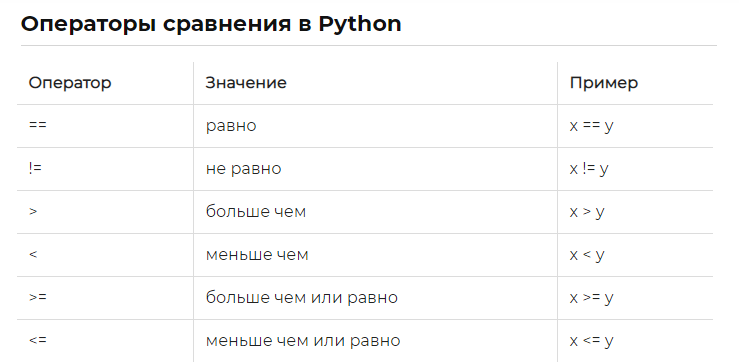
Итак, в языке программирования Python для сравнения строк используют следующие операторы:
- оператор < , «меньше»;
- оператор
- оператор == , «равно»;
- оператор != , «не равно»;
- оператор > , «больше»;
- оператор >= , «больше или равно».
Использование оператора «больше/меньше»
Ниже вы увидите простейший пример сравнения строк в Python с помощью соответствующих операторов: > и < . Давайте сравним строки со словами banana и apple:
print("apple" > "banana") False print("apple" < "banana") TrueТак как буква «a» находится перед «b», слово apple будет находиться перед словом banana, что логично (то есть banana больше, чем apple). Однако всё сложнее, чем может показаться на первый взгляд. Давайте для наглядности сравним, равны ли слова Apple и apple:
print("apple" == "Apple") False print("apple" > "Apple") TrueМы увидим отсутствие равенства, а всё потому, что в Python одинаковые буквы, имеющие разный регистр, считаются разными символами, и компьютер их различает по присвоенным им уникальным значениям.
Что касается нашей ситуации, то здесь латинская «А» имеет значение 65, в то время как значение строчной «а» равно 97.
Кстати, если хотите узнать уникальное значение какого-нибудь символа, используйте функцию ord:
print(ord("A")) 65При сравнении символов или строк, Python конвертирует символы в их соответствующие порядковые значения, после чего сравнивает слева направо.
Существует функция chr, преобразовывающая порядковое значение в символ. Пример:
print(chr(1040)) АНапример, кириллическая А соответствует значению 1040. Есть свои значения у цифр, а также вспомогательных знаков, включая «?», «=», пробел.
В принципе, вы всегда можете выполнить сравнение строк в Python, предварительно конвертировав строки в один формат, к примеру, в нижний регистр (используем метод lower ):
str1 = "apple" str2 = "Apple" str2.lower() print(str1 == str1) TrueПрименение оператора «равенство»
Мы можем проверить, равны ли строки, посредством оператора == :
print("строка1" == "строка2") FalseЕстественно, строки не являются равными, т. к. выполняется точное сравнение в Python. Неравными будут и те строки, которые содержат одинаковые, но переставленные местами символы. В последнем случае есть выход: превратить нашу строку в список, отсортировать, сравнить и вывести содержимое:
strA = "abcde" strB = "abdec" print(sorted(list(strA)) == sorted(list(strB))) print(sorted(list(strA))) print(sorted(list(strB))) True ['a', 'b', 'c', 'd', 'e'] ['a', 'b', 'c', 'd', 'e']Использование оператора «не равно»
Оператор != выполняет проверку неравенства:
print("abc" != "zxc") TrueРазумеется, результат True, ведь abc не равно zxc.
Применение операторов «больше или равно/меньше или равно»
print("abc"В нашем случае «abc» меньше.
Аналогично работает и оператор >= :
print("abc" >= "abc") TrueВ этой ситуации очевидно, что строки равны.