Как правильно составить базу данных sqlite для словаря?
Например, нужна БД для 3 языков вида слово-значение , правильно ли будет создать 3 таблицы по 3 столбца в каждой?
Отслеживать
8,390 4 4 золотых знака 25 25 серебряных знаков 64 64 бронзовых знака
задан 25 дек 2017 в 22:32
Muscle Code Muscle Code
155 1 1 серебряный знак 9 9 бронзовых знаков
Почему не 1 таблица с 3 столбцами, хотя бы ?
25 дек 2017 в 22:39
В любом случае когда вы хотите создать более 1 таблицы с одинаковой структурой, есть повод задуматься, что тут что то не так, одна таблица и тип записи в ней (в вашем случае код или ID языка) более правильное решение с точки зрения реляционных баз
25 дек 2017 в 22:41
так я и спрашиваю правильно ли так, мои знания sql слабы поэтому хочу узнать в каком направлении двигаться
25 дек 2017 в 22:42
вот я и написал как примерно это выглядит. скорее всего одна таблица. (%95 что так), возможно еще вторая — справочник языков. большего по тому, что вы описали в вопросе сказать особо нечего. нет конкретики. А при разработке структуры БД важна каждая мелочь в природе данных и том, что с ними дальше предполагается делать
25 дек 2017 в 22:46
А что вы будете делать, когда у слова в данном языке несколько значений (как очень часто бывает) и надо дать переводы всех вариантов ? Тогда назревает 1я таблица: ID-слова, Язык, Слово, Описание. И вторая ID-слова1, ID-слова2. Т.е. таблица в которой ID слова «привет» и ID «hi», а так же (второй записью) ID «привет» и ID «hola»
25 дек 2017 в 22:59
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Думаю тут нужны минимум 2 таблицы:
Слова с описаниями:
create table words( ID integer primary key, lang char(3) NOT NULL, -- Код языка (или вместо него можно сделать ID языка) word varchar(100) not null, -- Слово desc text -- Описание ); Связи слов между собой:
create table word_link( word1 integer not null, word2 integer not null, primary key(word1, word2), FOREIGN KEY(word1) REFERENCES word(ID), FOREIGN KEY(word2) REFERENCES word(ID) ); Так же можно добавить справочник языков:
create table languages( lang char(3) primary key, -- Или числовой ID name varchar(100) not null -- Наименование (для вывода в приложении) ); Если такая таблица есть, то в words можно сделать FOREIGN KEY для поля LANG, что бы в него нельзя было добавить слова с несуществующими языками.
По поводу работы с таблицей word_link: Есть два варианта ее ведения, точнее поиска в ней. Есть скажем слово A в языке 1 и слова B и C в языке 2. Вопрос в том, что если мы говорим, что слова B и C являются переводами слова A, верно ли обратное утверждение, что слово A является переводом обоих слов B и C. Если да, и все переводы работают в обоих направлениях, то нам достаточно хранить только записи A-B и A-C (или наоборот C-A, B-A) и делать запрос вида:
select W2.* from words W1, word_link L, words W2 where W1.word='A' and ( (L.word1=W1.ID and L.word2=W2.ID) or (L.word2=W1.ID and L.word1=W2.ID) ) and W2.lang='ENG' -- Для поиска переводов на английский Т.е. искать как прямой вариант, так и обратный, потому что мы не знаем в каком виде сохранена связь.
Но возможен и другой вариант (лучше узнавать такие тонкости у лингвистов), что хоть слова B и C считаются переводом слова A, но обратное не верно и переводом слова B является A, а переводом слова C слово A не является (или не принято так переводить). В этом случае мы учитываем направление связей и храним записи A-B, B-A, A-C (но не C-A). Поиск упрощается, исчезает второе условие в OR. Но при этом мы обязаны создавать как прямые так и обратные связи, когда они нужны.
А еще можно хранить синонимы слов из одного языка в той же таблице word_link. Делаем обычную связь и при поиске если язык word1 совпадает с языком word2 мы понимаем, что это синоним, а не перевод.
Словарь модели данных
Систематизированный подход к управлению загрузками. Мы хотим рассказать, как упорядочить и автоматизировать наполнение хранилища информацией, и при этом не запутаться в потоках из различных источников.
Преамбула
В корпоративной базе данных любой компании рано или поздно наступает такой момент, когда она разрастается до размеров, что глаз архитектора перестает улавливать неопределенность (хаос) системы, и превращается в неуправляемую массу всевозможных загрузок из различных источников.
Вам повезло, если ваша система разрабатывалась с нуля (с первой таблицы) и велась одним архитектором, одной командой разработчиков и аналитиков. И к тому же этот архитектор грамотно вел модель хранилища данных. Но жизнь многогранна, в большинстве случаев DWH вырастает спонтанно, сначала было 30 таблиц, потом по мере необходимости добавили еще чуть-чуть, а потом «нам понравилось» и мы стали добавлять по каждому удобному случаю, и теперь у нас больше пяти тысяч, да еще появились слои, стейджинги и витрины. И все это «счастье» на нас свалилось в результате одного, но очень удобного процесса, представляющего собой жесткую причинно-следственную связь:
- бизнес говорит: «У нас есть потребность вот в таких-то данных. Нужен новый отчет»
- аналитик ищет
- разработчик реализует
- архитектор согласовывает и вносит в модель данных
Итак, кратенькое резюме:
- не существует DWH, которое родилось сразу и ранее не представляло собой обычную БД с набором таблиц;
- все, что существует сейчас, и представляет собой четко алгоритмизированную и документированную структуру, получено в результате «горького опыта» предыдущих наработок.
Так как источников информации может быть невообразимое количество, то и потоков загрузки и перегрузки разных объектов, минимум, столько же, а зачастую гораздо больше, так как каждый объект БД может проходить не одну трансформацию, прежде чем его данные могут быть использованы конечным пользователем для построения бизнес-отчетов. А ведь именно для него, для бизнеса, а не ради собственного удовольствия построена вся эта экосистема по «переливанию из сосуда в сосуд».
В качестве БД нашего хранилища используется Oracle. Когда-то, на стадии создания, центральное ядро нашей БД состояло из пары сотен таблиц. Мы и не думали о стейджингах и витринах. Но, как говорится, «все течет, все меняется», и теперь мы выросли! Бизнес диктует новые требования, и уже появилась интеграция с различными базами MS SQL, SyBASE, Vertica, Access. Откуда только не стекается к нам информация, даже появилась такая экзотика как XML и JSON-обмен со сторонними системами, и уж совсем анахронизм XLS-файл как источник информации.
Жизнь заставила нас пройти review и актуализировать модель данных, вести ее и поддерживать. Вот так выглядит одна из частей основного ядра:
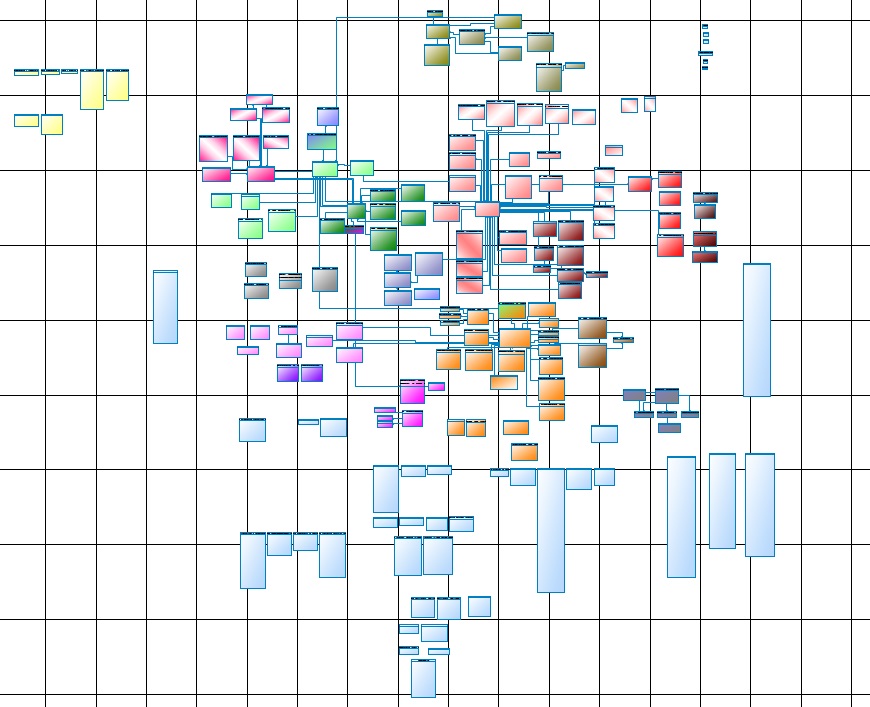
Рис. 1
Кому как, а по мне – это читаемо только на ватмане, причем A0 будет маловат, лучше 4A0, на экране это – ни глазу, ни воображению не поддается.
Теперь вспомним, что это только ядро (Core Data Layer), точнее его основная часть, полное ядро состоит из нескольких подсистем, которые не сильно уступают основной. Еще к этому добавляется Primary Data Layer и Data Mart Layer. Дальше – больше, первичный слой получает свою информацию из источников данных, а это, как уже говорилось выше, различные БД и файлы. С другой стороны, к слою витрин, потребителем стыкуются различные системы отчетности.
На первых порах, когда таблиц БД было немного и алгоритмы загрузки были реализованы на PL/SQL, особых сложностей в понимании обновления данных не вызывало. Но с ростом DWH, стратегически важным решением стало покупка Informatica PowerCenter. При всем удобстве этого инструмента, как в смысле надежности загрузки, так и визуализации разработки, этот инструмент имеет ряд недостатков. На рисунке ниже, представлена модель последовательности запуска загрузки DWH.
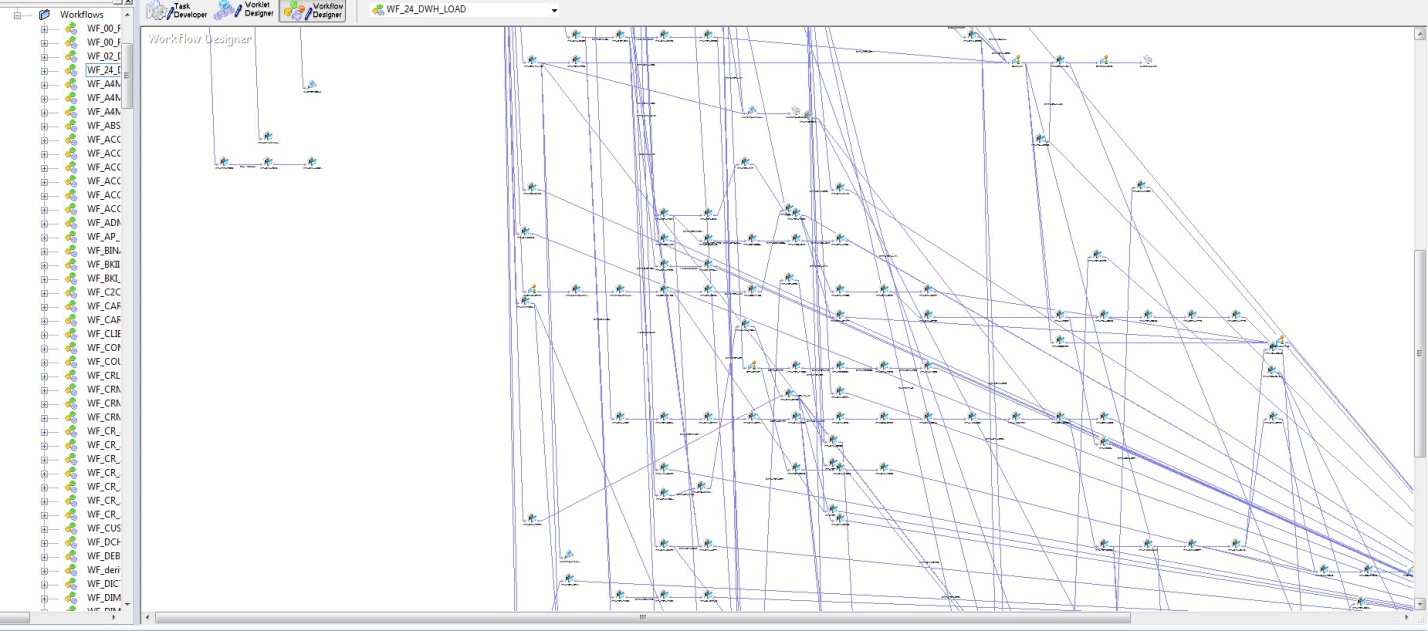
Рис. 2
Самый главный недостаток – это субъективность, точнее только архитектор может дать гарантию, что проводки не грузятся раньше счетов. К сожалению, с ростом DWH растет и энтропия информации. С учетом физической модели данных (рис. 1) и логикой загрузки этих данных (рис. 2) конструкция получается та еще.
Что делать и как этим рулить, спросите вы. Естественно: иметь гениального архитектора, который способен разобраться во всех связях этих хитросплетений. Который будет следить за всеми потоками, согласовывать новые потоки, и не допускать, чтобы таблица проводок грузилась раньше таблицы счетов. Конечно, все это вшивается в алгоритмы и регулируется в процесс отсечками загрузок, но изначально только архитектор может понять и задать загрузкам строгую последовательность, а при такой разветвленности вероятность ошибиться весьма высока.
Теория
Теперь я постараюсь изложить основные мысли словаря модели данных, а так же какие задачи он решает.
Так как данные в хранилище находятся в таблицах, а источниками данных являются частично таблицы, а частично представления, последние сами представляют собой таблицы. То отсюда вытекает простая идея – создать структуру зависимостей TABLE–TABLE. Форма 3NF как нельзя лучше для этого подходит.
Во-первых, наполнение данными сущности DWH, называем их (target), в самом общем случае можно представить в виде select из разных таблиц. Будут ли это таблицы Oracle, SyBase, MSSQL, xls-файлы или еще что-нибудь, не так уж и важно, все это, называем их источники (source). То есть у нас есть source, который перетекает в target.
Во-вторых, у каждой сущности DWH есть зависимости между собой references.
В-третьих, есть хронология старта загрузок различных сущностей DWH.
Осталось дело за малым, реализовать – как? Казалось бы, очень просто, с основания вашего DWH, архитектор при появлении очередной таблицы сущности (target) должен посмотреть и занести в словарь сущность приемник и все сущности, которые служат источниками. Далее, во второй таблице словаря задать связки между этими сущностями источниками в select, а также все подчиненные таблицы который связаны references. Далее можно загрузку этой сущности встроить в цепочку загрузок хранилища. Всего две таблицы – и возможность учета в алгоритме последовательности наполнения хранилища данными решена.
Словарь модели данных позволит решить следующие задачи:
- Просмотр зависимостей. Можно смотреть какие данные, откуда тянутся. Это удобно для аналитиков, которые вечно мучаются вопросами: «где, что лежит и откуда все берется». Представить это в приложении в виде дерева, причем как от source к target, так и наоборот: от target к source.
- Разрыв петель. При встраивании очередной загрузки в уже работающий общий поток, не имея словаря модели данных вполне можно ошибиться и назначить время старта загрузки очередного target впереди одного из его source. При этом возникает петля. Словарь модели данных легко позволит избежать этого.
- Можно написать алгоритм наполнения хранилища с учетом словаря модели. В этом случае вообще пропадает необходимость встраивать куда-либо очередную загрузку, достаточно ее отразить в словаре и алгоритм сам определит ему место. Останется нажать на вожделенную кнопку «Сделать ВСЕ». Загрузчик лавинообразно будет запускать загрузки всех сущностей хранилища – от простых (независимых) к сложным (зависимым).
Реализация
В теории всегда все просто и красиво, на практике дела обстоят несколько иначе. То что написано в предыдущем разделе, есть идеальная ситуация, когда DWH развивалось с нуля, когда при ней неотлучно находился архитектор. Если вам не повезло, все это вы «благополучно» миновали, архитектора нет, а есть гигантский набор таблиц, то все равно, выход есть.
Теперь, собственно, расскажу, как мы сумели наверстать упущенное и сделать review и rebuild достаточно дешево. Наше DWH начало развиваться с решения руководства о ого (DWH) назревшей необходимости. В качестве инструмента сначала использовался PL/SQL. Немного позже переключились на Informatica. Естественно, в приоритете были сроки создания. Модель данных в PowerDesigner появилась спустя некоторое время, к тому моменту, когда четко сформировалась уверенность, что уже никто четко не представляет себе полной и ясной картины DWH. С моделью на стене мы прожили еще какое-то время, когда стало ясно, что мы не справляемся с управлением всей этой системы, стали искать решение, которое вкратце постараюсь здесь описать.
Сам словарь модели данных прост как палка. Но заполнить его – это проблема. N-месяцев кропотливого, а самое главное, внимательного учета трех вышеизложенных частей:
- из каких источников (source) состоит каждая сущность хранилища (target);
- какие взаимоотношения между объектами хранилища (references);
- хронология старта загрузок и наполнения хранилища.
Что же из всего этого получилось?
- Во-первых, мы распутали все петли, которые сумели накрутить в процессе эволюции нашего DWH.
- Во-вторых, получили замечательное дерево для аналитиков:

Рис. 3
В-третьих, наш суперзагрузчик, представленный на рис. 2 превратился в элегантный (простите, коллеги, но размытость картинки – намеренная, так как это рабочие данные):
Рис. 4
Возможно, у вас найдется еще масса способов применения словаря модели данных.
Как правильно составить бд для словаря?
Словарь для андроид приложения на sqlite.
Допустим нужно создать словарь для 3 языков, это значит надо создать 3 таблицы с 3 столбцами в каждой таблице? Или же есть более правильные варианты?
- Вопрос задан более трёх лет назад
- 675 просмотров
Комментировать
Решения вопроса 0
Ответы на вопрос 3

В простом случае таблица translations с такими полями:
src | dest | lang_id
Ответ написан более трёх лет назад
Нравится 1 3 комментария
Beginner @otetsgoogla Автор вопроса
Если создается таблица на 2 языка то получается ищешь слово привет на английском выходит hi, а если таблицы с английскими словами идет отдельно то как дать понять бд откуда достать нужное слово?
Так не подходит?
select dest from translations where lang_id=1 /*English */ and src='привет'Что такое «словарь данных» и почему он нужен специалистам по B2B-коммуникациям?
Мир маркетинговых коммуникаций сегодня построен на полученных данных пользователей. Бренды тратят огромные бюджеты на анализ данных, чтобы сделать маркетинговые кампании более эффективными. Однако, многие бренды испытывают трудности уже в начале пути – у них возникают проблемы на организационном уровне изучения данных, полученных по всем каналам коммуникации. Поэтому при изучении данных стоит всегда задавать важный вопрос «А с чего начать?». Ответ простой – начните со «словаря данных».
Кристина Мацак
Менеджер по коммуникациям Fresh Russian Communications
«Словарь данных» (англ. — data dictionary) – это централизованное хранилище метаданных. Оно представляет собой базу данных, созданную для хранения метаданных, т.е. информации о структурах, которые содержат фактические данные. В ближайшем будущем, в эпоху пост-cookie, словари данных станут чрезвычайно важными инструментами для работы с таргетингом и своими аудиториями.
У компаний существует множество источников получения данных, от интернет-данных и данных, полученных по программе лояльности, до данных, которые предоставляет сервис поддержки клиента. С такими широкими возможностями в индустрии и развитыми бизнес-моделями, полученные данные могут отличаться друг от друга. Скорее всего, компании даже могут потребоваться разные «словари данных» для разных источников данных или систем, но все же есть несколько общих сведений, которые могут быть включены в один формат «словаря данных».
Такие сведения могут включать:
- Названия данных, содержащиеся во всех базах данных организации
- Где хранятся эти данные
- Как используются эти данные
- Классификация типов данных, включая целочисленные, вещественные и символьные данные
- Описание того, что означает каждое поле базы данных
- Источник полученных данных для каждого поля базы данных
- Классификация, какие отделы и какие сотрудники могут получать доступ к этим данным
Почему «словарь данных» столь важен для эффективной работы?
«Словарь данных» может позволить всей команде получить общие представления о данных компании, а это в свою очередь поможет лучше узнать аудиторию и в будущем выстраивать с ней коммуникацию. В большей степени в создании «словаря данных» заинтересованы маркетологи, поскольку эти знания помогут разработать более стабильную долгосрочную коммуникационную стратегию. К тому же, «словарь данных» может выявить новые виды данных, о которых отдел маркетинга ранее даже не знал. Словарь также может показать, что некоторые вещи, которые организация считала основой своей стратегии обработки данных, не совсем соответствуют действительности и нуждаются в чистке и реорганизации для более эффективного использования.
С чего начать создание / апдейт «словаря данных»?
Цель каждой компании состоит в том, чтобы объединить разрозненные наборы данных, и сделать их полезными и точными, а также получить новую информацию, которая поможет отделу маркетинга и сейлзам. Чтобы создать «словарь данных», стоит начать с ответов на следующие вопросы:
- Кто должен участвовать в процессе создания словаря?
- Кто в настоящее время имеет доступ к данным?
- Как регулярно обновляется доступ к данным и как долго он сохраняется?
- Какие вопросы конфиденциальности или безопасности относятся к данным компании и использованию этих данных?
Прежде чем вы задумаетесь о том, как дальше развиваться на рынке и как таргетинг рекламы будет изменен в будущем, вам нужно знать все о данных, которыми вы уже располагаете. «Словарь данных» в данном случае будет всегда актуальным инструментом, который позволит идти в ногу с изменениями и гарантирует бесценное преимущество перед непредсказуемыми изменениями.
Подготовлено по материалам: TheDrum.com
Подписывайтесь на наш Telegram-канал и будьте в курсе самых актуальных новостей В2В-коммуникаций!
Чтобы получать нашу e-mail-рассылку «Дайджест #PRinB2B», отправьте заявку на почту: b2b-journal@frc-pr.com.