Где хранятся временные таблицы sql server
В дополнение к табличным переменным можно определять временные таблицы. Такие таблицы могут быть полезны для хранения табличных данных внутри сложного комплексного скрипта.
Временные таблицы существуют на протяжении сессии базы данных. Если такая таблица создается в редакторе запросов (Query Editor) в SQL Server Management Studio, то таблица будет существовать пока открыт редактор запросов. Таким образом, к временной таблице можно обращаться из разных скриптов внутри редактора запросов.
После создания все временные таблицы сохраняются в таблице tempdb , которая имеется по умолчанию в MS SQL Server.
Если необходимо удалить таблицу до завершения сессии базы данных, то для этой таблицы следует выполнить команду DROP TABLE .
Название временной таблицы начинается со знака решетки #. Если используется один знак #, то создается локальная таблица, которая доступна в течение текущей сессии. Ели используются два знака ##, то создается глобальная временная таблица. В отличие от локальной глобальная временная таблица доступна всем открытым сессиям базы данных.
Например, создадим локальную временную таблицу:
CREATE TABLE #ProductSummary (ProdId INT IDENTITY, ProdName NVARCHAR(20), Price MONEY) INSERT INTO #ProductSummary VALUES ('Nokia 8', 18000), ('iPhone 8', 56000) SELECT * FROM #ProductSummary

И с этой таблицей можно работать в большей степени как и с обычной таблицей — получать данные, добавлять, изменять и удалять их. Только после закрытия редактора запросов эта таблица перестанет существовать.
Подобные таблицы удобны для каких-то временных промежуточных данных. Например, пусть у нас есть три таблицы:
CREATE TABLE Products ( Id INT IDENTITY PRIMARY KEY, ProductName NVARCHAR(30) NOT NULL, Manufacturer NVARCHAR(20) NOT NULL, ProductCount INT DEFAULT 0, Price MONEY NOT NULL ); CREATE TABLE Customers ( Id INT IDENTITY PRIMARY KEY, FirstName NVARCHAR(30) NOT NULL ); CREATE TABLE Orders ( Id INT IDENTITY PRIMARY KEY, ProductId INT NOT NULL REFERENCES Products(Id) ON DELETE CASCADE, CustomerId INT NOT NULL REFERENCES Customers(Id) ON DELETE CASCADE, CreatedAt DATE NOT NULL, ProductCount INT DEFAULT 1, Price MONEY NOT NULL );
Выведем во временную таблицу промежуточные данные из таблицы Orders:
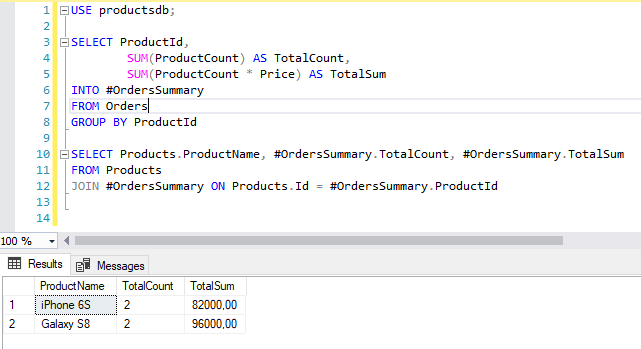
SELECT ProductId, SUM(ProductCount) AS TotalCount, SUM(ProductCount * Price) AS TotalSum INTO #OrdersSummary FROM Orders GROUP BY ProductId SELECT Products.ProductName, #OrdersSummary.TotalCount, #OrdersSummary.TotalSum FROM Products JOIN #OrdersSummary ON Products.Id = #OrdersSummary.ProductId
Здесь вначале извлекаются данные во временную таблицу #OrdersSummary. Причем так как данные в нее извлекаются с помощью выражения SELECT INTO, то предварительно таблицу не надо создавать. И эта таблица будет содержать id товара, общее количество проданного товара и на какую сумму был продан товар.
Затем эта таблица может использоваться в выражениях INNER JOIN.
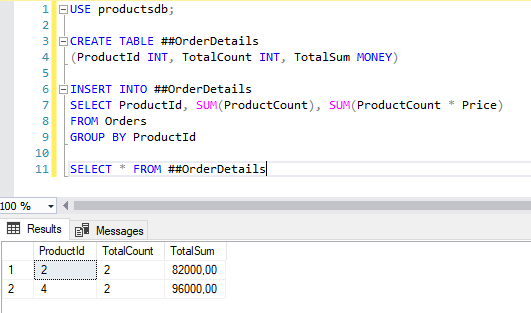
Подобным образом определяются глобальные временные таблицы, единственное, что их имя начинается с двух знаков ##:
CREATE TABLE ##OrderDetails (ProductId INT, TotalCount INT, TotalSum MONEY) INSERT INTO ##OrderDetails SELECT ProductId, SUM(ProductCount), SUM(ProductCount * Price) FROM Orders GROUP BY ProductId SELECT * FROM ##OrderDetails
Обобщенные табличные выражения
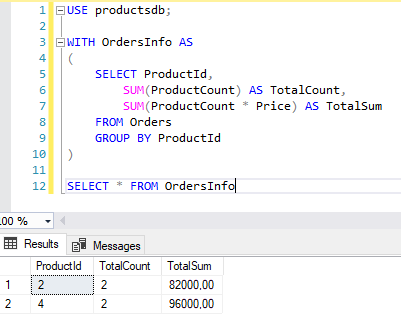
Кроме временных таблиц MS SQL Server позволяет создавать обобщенные табличные выражения (common table expression или CTE), которые являются производными от обычного запроса и в плане производительности являются более эффективным решением, чем временные. Обобщенное табличное выражение задается с помощью ключевого слова WITH :
WITH OrdersInfo AS ( SELECT ProductId, SUM(ProductCount) AS TotalCount, SUM(ProductCount * Price) AS TotalSum FROM Orders GROUP BY ProductId ) SELECT * FROM OrdersInfo -- здесь нормально SELECT * FROM OrdersInfo -- здесь ошибка SELECT * FROM OrdersInfo -- здесь ошибка
В отличие от временных таблиц табличные выполнения хранятся в оперативной памяти и существуют только во время первого выполнения запроса, который представляет это табличное выражение.
База данных tempdb в параллельном хранилище данных
tempdb — это системная база данных SQL Server PDW, в которой хранятся локальные временные таблицы для пользовательских баз данных. Временные таблицы часто используются для повышения производительности запросов. Например, можно использовать временную таблицу для модульизации скрипта и повторного использования вычисляемых данных.
Дополнительные сведения о системных базах данных см. в разделе «Системные базы данных».
Ключевые термины и понятия
локальная временная таблица
Локальная временная таблица использует префикс #перед именем таблицы и является временной таблицей, созданной локальным сеансом пользователя. Каждый сеанс может получить доступ только к данным в локальных временных таблицах для собственного сеанса.
Каждый сеанс может просматривать метаданные для локальных временных таблиц во всех сеансах. Например, все сеансы могут просматривать метаданные для всех локальных временных таблиц с запросом SELECT * FROM tempdb.sys.tables .
глобальная временная таблица
Глобальные временные таблицы, поддерживаемые в SQL Server с синтаксисом ##, не поддерживаются в этом выпуске SQL Server PDW.
pdwtempdb
pdwtempdb — это база данных, в которой хранятся локальные временные таблицы.
PDW не реализует временные таблицы с помощью базы данных tempdb SQL Server. Вместо этого PDW сохраняет их в базе данных с именем pdwtempdb. Эта база данных существует на каждом вычислительном узле и невидима для пользователя через интерфейсы PDW. В консоли Администратор на странице хранилища вы увидите эти учетные записи в системной базе данных PDW с именем tempdb-sql.
tempdb
tempdb — это база данных tempdb SQL Server. В нем используется минимальное ведение журнала. SQL Server использует tempdb на вычислительных узлах для хранения временных таблиц, необходимых в ходе выполнения операций SQL Server.
SQL Server PDW удаляет таблицы из tempdb , когда:
- Выполняется инструкция DROP TABLE.
- Сеанс отключен. Удаляются только временные таблицы для сеанса.
- (модуль) завершает работу.
- Узел управления имеет отработку отказа кластера.
Общие замечания
SQL Server PDW выполняет те же операции с временными таблицами и постоянными таблицами, если явно не указано в противном случае. Например, данные в локальных временных таблицах, как и постоянные таблицы, распределяются или реплика между вычислительными узлами.
Ограничения
Ограничения и ограничения базы данных tempdb SQL Server PDW. Невозможно :
- Создайте глобальную временную таблицу, начинающуюся с ##.
- Выполните резервное копирование или восстановление tempdb.
- Измените разрешения на tempdb с помощью инструкций GRANT, DENY или REVOKE .
- Выполните DBCC SHRINKLOG для tempdb tempdb.
- Выполнение операций DDL в tempdb. Существует несколько исключений для этого. Дополнительные сведения см. в следующем списке ограничений и ограничений для локальных временных таблиц.
Ограничения и ограничения для локальных временных таблиц. Невозможно :
- Переименование временной таблицы
- Создание секций, представлений или некластеризованных индексов во временной таблице. ALTER INDEX можно использовать для перестроения кластеризованного индекса для таблицы, созданной с помощью одной.
- Измените разрешения на временные таблицы с помощью инструкций GRANT, DENY или REVOKE.
- Запустите команды консоли базы данных во временных таблицах.
- Используйте одно и то же имя для двух или нескольких временных таблиц в одном пакете. Если в пакете используется несколько локальных временных таблиц, они должны иметь уникальные имена. Если несколько сеансов выполняют один пакет и создают одну и ту же локальную временную таблицу, SQL Server PDW внутренне добавляет числовой суффикс к имени локальной временной таблицы, чтобы сохранить уникальное имя для каждой локальной временной таблицы.
Вы можете создавать и обновлять статистику во временной таблице.ALTER INDEX можно использовать для перестроения кластеризованного индекса.
Разрешения
Любой пользователь может создавать временные объекты в базе данных tempdb. Если не предоставлены какие-либо дополнительные разрешения, то пользователи могут производить доступ только к тем объектам, которыми они владеют. Существует возможность отменить разрешение на соединение с базой данных tempdb, чтобы пользователь не мог ей пользоваться, но этого делать не рекомендуется, так как база данных tempdb необходима для работы некоторым подпрограммам.
Связанные задачи
| Задачи | Description |
|---|---|
| Создайте таблицу в tempdb. | Можно создать временную таблицу пользователя с помощью инструкций CREATE TABLE и CREATE TABLE AS SELECT. Дополнительные сведения см. в статье CREATE TABLE and CREATE TABLE AS SELECT. |
| Просмотрите список существующих таблиц в tempdb. | SELECT * FROM tempdb.sys.tables; |
| Просмотрите список существующих столбцов в tempdb. | SELECT * FROM tempdb.sys.columns; |
| Просмотрите список существующих объектов в tempdb. | SELECT * FROM tempdb.sys.objects; |
Связанный контент
Отличие способов хранения результирующих данных в T-SQL
Временные таблицы бывают двух видов. Таблицы переменные(@Table), временные таблицы(#table), ещё есть таблицы вида ##table, отличаются от #table областью видимости.
В связи с этим, можно дать краткое описание:
- Таблицы переменные — хранятся в оперативной памяти(если её хватает). Доступна в блоке кода, т.е. её можно переиспользовать в разных запросах. имеет локальную область видимости, так же как любая другая локальная переменная.
- Временные таблицы. Хранятся в tempdb, имеют более широкую область видимости, а именно по всему стеку вызовов. Т.е. если процедура А создала таблицу #A, потом вызвала процедуру B, которая создала таблицу #B — то и А имеет доступ к #B(после вызова В) и В имеет доступ к #A. Так же на временные таблицы можно создавать индексы, триггеры и прочее, в отличии от таблиц переменных. Таблицы ##Table имеют глобальную область видимости. Если кто-то создал таблицу ##Table — её видят все сессии, а существует она до тех пор, пока «жива» хоть одна сессия, которая обращалась к этой таблице.
- СТЕ. Тут область вилимости только внутри одного запроса! Т.е. переиспользовать результат нельзя. Более того, если вы обращаетесь к СТЕ несколько раз внутри одного апроса — она будет вычислена столько же раз! Есть недокументированные способы заставить оптимизатор запомнить СТЕ в оперативной памяти для повторного использования, но это совсем другая история:)
- Курсоры. В общем это немного из другой оперы. Курсоры позволяют построчно обрабатывать данные и предназначены не для хранения. Внутри курсора можно вызывать выполнение процедур, чего нельзя делать в запросе.
Добавлю ещё своё субъективное мнение когда что нужно использовать.
- Таблицы переменные. Когда нужно использовать небольшое количество данных. Например промежуточный результат сложного запроса записать в таблицу переменную, разбив тем самым сложный запрос на два простых.
- Временные таблицы. Когда информации довольно много и/или её нужно передать в другое место выполнения. Эти таблицы ничем не отличаются от обычных таблиц, кроме того, что не нужно беспокоиться о их очищении и удалении.
- СТЕ — когда нельзя использовать временные таблицы(т.е. такие места, которые обязывают нас использовать только один SQL запрос), Например, внутри тела табличной функции.
- Курсоры — когда нельзя обойтись другими способами. Например, когда для каждой строки временного результата нужно запустить выполнение хранимой процедуры. В MS SQL курсоры обычно работают медленнее запросов. Так что елси есть возможность — лучше их избегать.
Улучшение производительности временной таблицы и табличной переменной с помощью оптимизации памяти
Если вы используете временные таблицы, табличные переменные или возвращающие табличные значения параметры, рекомендуем преобразовать их в оптимизированные для памяти таблицы и табличные переменные с целью повышения производительности. Изменения, которые необходимо внести в код, обычно минимальны.
В этой статье рассматриваются следующие вопросы:
- сценарии, в которых выгоднее преобразование в хранящиеся в памяти объекты;
- технические инструкции по реализации преобразования в хранящиеся в памяти объекты;
- предварительные требования для преобразования в хранящиеся в памяти объекты;
- образец кода, демонстрирующий преимущества оптимизации для памяти в плане производительности.
А. Основные сведения о табличных переменных, оптимизированных для памяти
Оптимизированная для памяти табличная переменная позволяет повысить эффективность благодаря использованию тех же алгоритмов и структур данных, которые применяются в оптимизированных для памяти таблицах. Эффективность максимальна в случае, если доступ к табличной переменной осуществляется из модуля, скомпилированного в собственном коде.
Оптимизированная для памяти табличная переменная:
- хранится только в памяти и не имеет компонента на диске;
- не требует операций ввода-вывода;
- не требуется использования базы данных tempdb и не создает соответствующих конфликтов;
- может передаваться в хранимую процедуру как возвращающий табличное значение параметр;
- должна иметь по крайней мере один индекс (некластеризованный или хэш-индекс):
- для хэш-индекса число контейнеров в идеале должно в 1–2 раза превышать предполагаемое число уникальных ключей индекса, но допускается и более значительное превышение (до 10 раз). Дополнительные сведения см. в разделе Индексы для оптимизированных для памяти таблиц.
Типы объектов
Выполняющаяся в памяти OLTP предоставляет следующие объекты, которые можно использовать для оптимизированных для памяти временных таблиц и табличных переменных:
- Оптимизированные для памяти таблицы
- Durability = SCHEMA_ONLY
- Должен быть объявлен двумя шагами (а не встроенными):
- CREATE TYPE my_type AS TABLE . ; , а затем
- DECLARE @mytablevariable my_type; .
B. Сценарий. Замена глобальной базы данных tempdb ##table
Замена глобальной временной таблицы на оптимизированную для памяти таблицы SCHEMA_ONLY достаточно проста. Наиболее существенное изменение состоит в том, что таблица создается во время развертывания, а не во время выполнения. Создание оптимизированных для памяти таблиц занимает больше времени, чем у традиционных, из-за оптимизации во время компиляции. Создание и удаление оптимизированных для памяти таблиц в рамках сетевой рабочей нагрузки повлияет на производительность рабочей нагрузки, а также производительность повторного входа во вторую группу доступности AlwaysOn и восстановление базы данных.
Предположим, что у вас есть приведенная ниже глобальная временная таблица.
CREATE TABLE ##tempGlobalB ( Column1 INT NOT NULL , Column2 NVARCHAR(4000) );Рассмотрите возможность замены глобальной временной таблицы на приведенную ниже таблицу, оптимизированную для памяти, с параметром DURABILITY = SCHEMA_ONLY.
CREATE TABLE dbo.soGlobalB ( Column1 INT NOT NULL INDEX ix1 NONCLUSTERED, Column2 NVARCHAR(4000) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY);Б.1. Этапы
Чтобы преобразовать глобальную временную таблицу в таблицу с параметром SCHEMA_ONLY, выполните указанные ниже действия.
- Однократно создайте таблицу dbo.soGlobalB так же, как любую традиционную таблицу на диске.
- Из Transact-SQL удалите создание таблицы ##tempGlobalB . Важно создавать оптимизированную для памяти таблицу во время развертывания, а не во время выполнения, чтобы избежать дополнительных временных затрат при компиляции, связанных с созданием таблицы.
- В T-SQL замените все упоминание ##tempGlobalB на dbo.soGlobalB.
C. Сценарий. Замена #table tempdb сеанса
Для подготовки к замене временной таблицы сеансов требуется больше кода T-SQL, чем в предыдущем сценарии с глобальной временной таблицей. К счастью, больший объем кода T-SQL не означает, что для преобразования потребуется больше усилий.
Как и в случае с глобальной временной таблицей, самым значительным изменением является создание таблицы во время развертывания, а не выполнения, позволяющее избежать дополнительной нагрузки при компиляции.
Предположим, что у вас есть приведенная ниже временная таблица сеансов.
CREATE TABLE #tempSessionC ( Column1 INT NOT NULL , Column2 NVARCHAR(4000) );Сначала создайте приведенную ниже функцию, возвращающую табличное значение, для фильтрации по @@spid. Эту функцию смогут использовать все таблицы SCHEMA_ONLY, преобразованные из временных таблиц сеансов.
CREATE FUNCTION dbo.fn_SpidFilter(@SpidFilter smallint) RETURNS TABLE WITH SCHEMABINDING , NATIVE_COMPILATION AS RETURN SELECT 1 AS fn_SpidFilter WHERE @SpidFilter = @@spid;Затем создайте таблицу SCHEMA_ONLY, а также политику безопасности для нее.
Обратите внимание на то, что каждая оптимизированная для памяти таблица должна содержать как минимум один индекс.
- Для таблицы dbo.soSessionC, возможно, лучше подойдет хэш-индекс, если вычислить соответствующее значение BUCKET_COUNT. Но для простоты в этом примере мы используем некластеризованный индекс.
CREATE TABLE dbo.soSessionC ( Column1 INT NOT NULL, Column2 NVARCHAR(4000) NULL, SpidFilter SMALLINT NOT NULL DEFAULT (@@spid), INDEX ix_SpidFiler NONCLUSTERED (SpidFilter), --INDEX ix_SpidFilter HASH -- (SpidFilter) WITH (BUCKET_COUNT = 64), CONSTRAINT CHK_soSessionC_SpidFilter CHECK ( SpidFilter = @@spid ), ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY); go CREATE SECURITY POLICY dbo.soSessionC_SpidFilter_Policy ADD FILTER PREDICATE dbo.fn_SpidFilter(SpidFilter) ON dbo.soSessionC WITH (STATE = ON); goНаконец, в общем коде T-SQL сделайте следующее:
- Измените все ссылки на временную таблицу в инструкциях Transact-SQL на новую таблицу, оптимизированную для памяти:
- Старый: #tempSessionC
- Новое имя: dbo.soSessionC
- Замените инструкции CREATE TABLE #tempSessionC в своем коде на DELETE FROM dbo.soSessionC , чтобы сеанс не обращался к содержимому таблицы, добавленному в предыдущем сеансе с тем же идентификатором session_id. Важно создавать оптимизированную для памяти таблицу во время развертывания, а не во время выполнения, чтобы избежать дополнительных временных затрат при компиляции, связанных с созданием таблицы.
- Удалите из кода инструкции DROP TABLE #tempSessionC . Если есть опасения относительно размера используемой памяти, вы можете добавить инструкцию DELETE FROM dbo.soSessionC .
D. Сценарий: табличная переменная может иметь параметр MEMORY_OPTIMIZED=ON
Традиционная табличная переменная представляет таблицу в базе данных tempdb. Чтобы значительно повысить производительность, можно оптимизировать табличную переменную для памяти.
Ниже приведен код T-SQL для традиционной табличной переменной. Ее область действия завершается, когда заканчивается пакет или сеанс.
DECLARE @tvTableD TABLE ( Column1 INT NOT NULL , Column2 CHAR(10) );Г.1. Преобразование встроенной переменной в явную
Предыдущий синтаксис создает так называемую встроеннуютабличную переменную. Встроенный синтаксис не поддерживает оптимизацию для памяти. Поэтому давайте преобразуем встроенный синтаксис в явный для TYPE.
Область действия. Определение TYPE, созданное первым пакетом, отделенным командой GO, сохраняется даже после завершения работы и перезапуска сервера. Но после первого разделителя GO объявленная таблица @tvTableC сохраняется только до тех пор, пока не будет достигнут следующий разделитель GO и пакет не завершится.
CREATE TYPE dbo.typeTableD AS TABLE ( Column1 INT NOT NULL , Column2 CHAR(10) ); go SET NoCount ON; DECLARE @tvTableD dbo.typeTableD ; INSERT INTO @tvTableD (Column1) values (1), (2) ; SELECT * from @tvTableD; goГ.2. Преобразование явной таблицы на диске в оптимизированную для памяти таблицу
Оптимизированная для памяти табличная переменная не хранится в базе данных tempdb. Оптимизация для памяти приводит к повышению скорости работы до 10 раз и более.
Преобразование таблиц в оптимизированные для памяти производится в один шаг. Оптимизируйте явное создание TYPE следующим образом. При этом добавляются:
- Индекс. Еще раз напомним, что каждая оптимизированная для памяти таблица должна содержать как минимум один индекс.
- MEMORY_OPTIMIZED = ON.
CREATE TYPE dbo.typeTableD AS TABLE ( Column1 INT NOT NULL INDEX ix1, Column2 CHAR(10) ) WITH (MEMORY_OPTIMIZED = ON);Д. Файловая группа, необходимая для SQL Server
Для использования оптимизированных для памяти функций в Microsoft SQL Server база данных должна иметь файловую группу, объявленную с параметром MEMORY_OPTIMIZED_DATA.
- База данных SQL Azure не требует создания такой файловой группы.
Предварительное требование. Приведенный ниже код Transact-SQL для файловой группы необходим для развернутых образцов кода T-SQL в дальнейших подразделах этого раздела.
- Необходимо использовать SSMS.exe или другое средство, позволяющее отправлять код T-SQL.
- Вставьте образец кода T-SQL для файловой группы в среду SSMS.
- Отредактируйте код T-SQL, изменив имена и пути к каталогам по своему желанию.
- Все каталоги в значении FILENAME уже должны существовать, за исключением последнего каталога, который не должен существовать.
- Выполните отредактированный код T-SQL.
- Запускать файловую группу T-SQL несколько раз не нужно, даже если вы повторно настраиваете и перезапускаете скрипт T-SQL для сравнения скорости в следующем подразделе.
ALTER DATABASE InMemTest2 ADD FILEGROUP FgMemOptim3 CONTAINS MEMORY_OPTIMIZED_DATA; go ALTER DATABASE InMemTest2 ADD FILE ( NAME = N'FileMemOptim3a', FILENAME = N'C:\DATA\FileMemOptim3a' -- C:\DATA\ preexisted. ) TO FILEGROUP FgMemOptim3; goСледующий скрипт создает файловую группу и настраивает рекомендованные параметры базы данных: enable-in-memory-oltp.sql
Дополнительные сведения о ALTER DATABASE . ADD для FILE и FILEGROUP см. в следующих разделах:
- Параметры инструкции ALTER DATABASE для файлов и файловых групп (Transact-SQL)
- Оптимизированная для памяти файловая группа
F. Небольшой тест для проверки повышения быстродействия
В этом разделе приводится код Transact-SQL, с помощью которого можно протестировать и оценить прирост скорости выполнения операций INSERT-DELETE при использовании табличной переменной, оптимизированной для памяти. Код состоит из двух половин, которые почти одинаковы за тем исключением, что в первой половине используется таблица оптимизированного для памяти типа.
Сравнительный тест длится примерно 7 секунд. Запуск примера:
- Предварительное требование. Вы уже должны были выполнить код T-SQL для файловой группы из предыдущего подраздела.
- Выполните приведенный ниже скрипт T-SQL INSERT-DELETE.
- Обратите внимание на инструкцию GO 5001, которая повторно отправляет код T-SQL 5001 раз. Вы можете изменить это число и перезапустить тест.
В базе данных SQL скрипт следует запускать из виртуальной машины, находящейся в вашем регионе.
PRINT ' '; PRINT '---- Next, memory-optimized, faster. ----'; DROP TYPE IF EXISTS dbo.typeTableC_mem; GO CREATE TYPE dbo.typeTableC_mem -- !! Memory-optimized. AS TABLE ( Column1 INT NOT NULL INDEX ix1, Column2 CHAR(10) ) WITH (MEMORY_OPTIMIZED = ON); GO DECLARE @dateString_Begin NVARCHAR(64) = CONVERT(NVARCHAR(64), GETUTCDATE(), 121); PRINT CONCAT ( @dateString_Begin, ' = Begin time, _mem.' ); GO SET NOCOUNT ON; DECLARE @tvTableC dbo.typeTableC_mem;-- !! INSERT INTO @tvTableC (Column1) VALUES (1), (2); INSERT INTO @tvTableC (Column1) VALUES (3), (4); DELETE @tvTableC;GO 5001 DECLARE @dateString_End NVARCHAR(64) = CONVERT(NVARCHAR(64), GETUTCDATE(), 121); PRINT CONCAT ( @dateString_End, ' = End time, _mem.' ); GO DROP TYPE IF EXISTS dbo.typeTableC_mem; GO ---- End memory-optimized. ------------------------------------------------- ---- Start traditional on-disk. PRINT ' '; PRINT '---- Next, tempdb based, slower. ----'; DROP TYPE IF EXISTS dbo.typeTableC_tempdb; GO CREATE TYPE dbo.typeTableC_tempdb -- !! Traditional tempdb. AS TABLE ( Column1 INT NOT NULL, Column2 CHAR(10) ); GO DECLARE @dateString_Begin NVARCHAR(64) = CONVERT(NVARCHAR(64), GETUTCDATE(), 121); PRINT CONCAT ( @dateString_Begin, ' = Begin time, _tempdb.' ); GO SET NOCOUNT ON; DECLARE @tvTableC dbo.typeTableC_tempdb;-- !! INSERT INTO @tvTableC (Column1) VALUES (1), (2); INSERT INTO @tvTableC (Column1) VALUES (3), (4); DELETE @tvTableC;GO 5001 DECLARE @dateString_End NVARCHAR(64) = CONVERT(NVARCHAR(64), GETUTCDATE(), 121); PRINT CONCAT ( @dateString_End, ' = End time, _tempdb.' ); GO DROP TYPE IF EXISTS dbo.typeTableC_tempdb; GO PRINT '---- Tests done. ----'; GO---- Next, memory-optimized, faster. ---- 2016-04-20 00:26:58.033 = Begin time, _mem. Beginning execution loop Batch execution completed 5001 times. 2016-04-20 00:26:58.733 = End time, _mem. ---- Next, tempdb based, slower. ---- 2016-04-20 00:26:58.750 = Begin time, _tempdb. Beginning execution loop Batch execution completed 5001 times. 2016-04-20 00:27:05.440 = End time, _tempdb. ---- Tests done. ----G. Прогнозирование потребления активной памяти
Чтобы узнать, как прогнозировать потребность оптимизированных для памяти таблиц в активной памяти, обратитесь к следующим ресурсам:
- Оценка требований к объему памяти для таблиц, оптимизированных для памяти
- Размер строк и таблицы для таблиц, оптимизированных для памяти: пример вычисления
В случае с большими табличными переменными некластеризованные индексы потребляют больше памяти, чем в случае с таблицами, оптимизированными для памяти. Чем больше число строк и ключ индекса, тем сильнее эта разница.
Если в каждой операции доступа к оптимизированной для памяти табличной переменной используется только одно точное значение ключа, хэш-индекс может быть предпочтительнее некластеризованного индекса. Однако, если вы не можете оценить подходящее значение BUCKET_COUNT, можно использовать и некластеризованный индекс.
H. См. также
- Таблицы, оптимизированные для памяти.
- Определение устойчивости для оптимизированных для памяти объектов.
- Накопительное обновление, позволяющее исключить вероятность возникновения неправильных ошибок нехватки памяти, объявленное в блоге в сентябре 2017 г.
- В статье Версии сборки SQL Server 2016 приводятся подробные сведения о выпусках, пакетах обновления и накопительных обновлениях.
- Эти случайные неправильные ошибки не возникали в выпуске Enterprise для SQL Server.