Как правильно именовать schema database
«Всякое приказание должно быть отдано
в должное время, в должном месте,
и в выражениях, исключающих двоякое толкование»
(Из Устава Петровских времен)
Обсуждаемый вопрос заключается в следующем. Если мы начали разработку базы данных для некоторой задачи, определились с набором схем, таблиц, полей, внешних ключей, то как нам следует называть все эти объекты, и зачем вообще нужно говорить о какой-то особой системе наименований?
Проблема чем-то похожа на выбор имен для переменных при написании программного кода. Но разница в том, что в написании процедур мир давно уже пришел к идее локальных переменных, и их имена остаются на совести автора-программиста — согласуются только параметры вызова. А вот база данных — штука глобального характера. Имена таблиц и полей используются в процедурах обработки, в клиентских формах ввода, в отчетах. Стройная система имен позволит «протащить» логику организации данных сквозь весь проект, сделать все его части более читабельными, за что вы получите немало благодарностей как от коллег по команде, так и от себя лично, когда вернетесь к задаче эдак через полгодика. С другой стороны, полтысячи разношерстных огрызков вроде ‘trb_zrplt_mumu’, по десятку на одно и то же понятие, выведут из себя кого угодно.
- Единство именования программных единиц во всем проекте. Другими словами, если у нас есть, скажем «документ» (doc), или «номер документа» (docnum), то именно так должны называться таблица БД, ее соответствующее поле, соответствующие поля всевозможных VIEW, поля клиентских наборов данных, локальные переменные в процедурах обработки, классы, представляющие эту сущность на клиенте, поля (свойства) в этих классах, объекты во всех отчетах, и вообще все, что содержит в себе документ (номер). Другими словами, нельзя допускать размножения сущностей без необходимости. Нередко проектировщики свято соблюдают этот принцип Оккама при моделировании «внешних» данных, но напрочь игнорирую его во внутренней «кухне».
- Самодокументируемость структуры базы данных. Сформулировать это зыбкое понятие трудно, но без него работать еще труднее.
- Единообразие подачи информации пользователю. Если вернуться к тому же ‘номеру документа’, то с единством названия становится легче проследить и за единством подписей полей ввода, кнопок, шапок отчетов, содержащих этот реквизит, чтобы пользователь не терялся.
Выбор имени сущности
- Имя должно быть существительным (полным, сокращенным либо аббревиатурой) в единственном числе.
- Имя должно быть как можно короче. Оптимально — 2-4 буквы, максимум до 10.
- Имя должно быть уникальным в пределах базы данных.
- Имя должно быть мнемонически понятным проектантам без заглядывания в словарь (но словарь такой хорошо бы составить).
- Желательно, чтобы имена не начинались и не заканчивались на другие имена сущностей.
Нетрудно заметить, что все эти правила противоречат друг другу. И в инженерной практике это скорее правило, чем исключение. Чего стоит хотя бы идея плавающего танка. Так что придется выкручиваться.
Итак, почему как можно короче? Потому что на основании имени сущности мы будем «лепить» другие идентификаторы. Они будут встречаться целыми списками в секциях FROM, WHERE. И если названия таблицы и пяти соединенных справочников будут несокращенными словами в 16-20 символов, то это порадует лишь поклонников языка Шекспира, но успешно затуманит смысл простейших SQL-запросов.
Требование уникальности понятно само собой. Стоит лишь заметить, что здесь нужно максимально учесть перспективы роста БД. Возможно, стоит набросать список сущностей, которые могут войти в БД в следующих версиях системы, даже если эта работа отдаленного будущего.
Чтобы сделать имена понятными, нужно определиться — «salary» или «zarplata» ? То есть в качестве имен сущностей можно использовать английские слова и сокращения, либо русские (кстати, почему бы и не на других языках? Лишь бы. см. Правило 4 😉 Кстати, неплохо использовать комбинации из двух понятий. Например «группа пользователей» — «ugroup», «группа домов» — «hgroup».
Последнее, пятое правило говорит, что если у вас уже есть таблица ‘документ’ (doc), то для ‘докторов’ и ‘доктрин’ нужно выбрать что-то другое, а не ‘ doc tor’ и ‘ doc trine’. Океан тоже нехорошо называть ‘oc’ (иначе документ будет интуитивно восприниматься как нечто связанное с океаном — d oc ). Для решения такой проблемы можно изменить либо удлинить проблемный идентификатор, например ‘dcm’, ‘docum’,
Наименование таблиц
Многие проектировщики дают таблицам непосредственно имена сущностей (в единственном числе), например street, city. Другие же ратуют за то, что таблицы нужно называть множественным числом — streets, cities. И единого мнения быть не может. Дело в том, что если говорить об удобочитаемости SQL-запросов, вроде следующего:
SELECT * FROM cities, streets WHERE streets.cityid = cities.cityid AND streets.name LIKE "%тупик Третьего Интернационала%"
то нетрудно заметить, что секция FROM грамматически подразумевает множественное число — «ВЫБРАТЬ.. ИЗ городов, улиц «. В то же время секция WHERE «читается» с единственным числом — «ВЫБРАТЬ ту запись , ГДЕ название улицы ПОХОЖЕ . «, и это понятно — ведь условие под WHERE применяется к каждой записи набора по отдельности, то есть к каждой улице.
Если вспомнить, что мы хотим использовать имя сущности также в программах обработки данных, где объектом работы становится именно «единица» информации (например в названии класса для хранения одной улицы TStreet, а затем в названии переменой-объекта objStreet1), то разумнее остановиться на единственном числе как на стандарте. Но ведь в таблице все-таки живет множество сущностей! Как это выразить? Для таблиц примем следующее волюнтаристское решение:
Имя таблицы состоит из служебного префикса и имени сущности . Например.
| Префикс | Имя сущности | Имя таблицы | Название таблицы в целом (как множества сущностей) |
| C | STRTYPE (тип улицы) | C STRTYPE | Каталог типов улиц |
| S | STREET (улица) | S STREET | Справочник улиц |
| R | ABON (абонент) | R ABON | Реестр абонентов |
| J | CALCOP (выч. операция) | J CALCOP | Журнал вычислительных операций |
-
C — Catalog, список. Самая безобидная форма жизни информации. Представляет собой простейший справочник из десятка пунктов чего-то неизменного, или почти неизменного. Структурирует некую фундаментальную природу вещей. Например, перечисляет типы улиц — «улица», «переулок», «проезд», «тупик», «овраг». Через пару лет построят в деревне первый проспект — добавим «проспект».
Можно ввести дополнительные соглашения, приятные для программистов. Например, что записи из таблиц типа ‘C’ не удаляются, а только иногда добавляются. Что в интерфейсе для работы с таким списком будет достаточно унифицированной формы с полным просмотром содержимого и простейшим поиском-фильтром, а для выбора значения — выпадающего списка (ComboBox).
Не будем также забывать, что в качестве имен сущностей мы разрешили себе использовать сокращения и аббревиатуры. А в этом случае добавление «s» или «es» вряд ли добавит ясности и читабельности.
Будем считать, что с правилом именования таблиц мы определились. Разумеется, из любого правила есть исключения. Скажем, как именовать таблицы, отражающие связи «много-ко-многим»?, например вхождение пользователей (сущность user ) в группы (сущность ugroup )? Предлагаю использовать специальный префикс «nn_» , и получится nn_user_ugroup . Возможны и другие исключения.
Наименование полей
Имена полей таблицы, как правило, составляются из имени сущности ( city ), смыслового суффикса ( id, name, area ), и необязательного дополнительного суффикса (применяется для полей внешних ключей в случае множественных ссылок, рассмотрим это ниже). Например
| scity — Справочник городов | |
| cityid | Ид (PK) |
| city name | Название |
| city area | Площадь (км2) |
| city populcnt | Население |
| cstrtype — Список типов улиц | |
| strtypeid | Ид (PK) |
| strtype name | Название |
| sstreet — Справочник улиц городов | ||
| 1 | streetid | Ид (PK) |
| 2 | cityid | Город.Ид (FK scity ) |
| 3 | strtypeid | Тип улицы.Ид (FK cstrtype) |
| 4 | street name | Название |
В зале слышны крики ревнителей минимализма и экономии символов. Мы видим, что в имени каждого поля таблицы участвует название сущности, то есть практически повторяется имя таблицы (без префикса). Оправдано ли это? Почему бы всегда не называть идентификаторы просто ID , названия — Name ? Ведь в SQL-запросах есть возможность полной нотации имен, с указанием таблицы: WHERE scity.name LIKE «%МОСКВА%» AND sstreet.name LIKE «%ЛЕНИНА%» ?
Первое, на чем споткнется такой подход — внешние ключи. Пусть в списке типов улиц cstrtype ключ мы назвали ID , и ключ улицы тоже назвали ID . Как прикажете назвать поле номер 3 в таблице улиц sstreet , которое ссылается на тип улицы cstrtype ? Ах, вот теперь вы хотите назвать его strtype_id ? Но тогда получается, что в БД есть поля, содержащие одну и ту же информацию, а названные по-разному. Кто здесь хотел не плодить сущности без необходимости? Для единообразия придется вернуться в cstrtype , и переименовать тамошний ключ ID тоже в strtype_id . К той же печке и пританцевали.
Ну хорошо, не унимаются минималисты. С ключами понятно. А названия, и прочие неключевые поля? Их-то можно назвать просто Name?
Хорошо. Назовем названия города, улицы и типа улицы просто Name, и составим запрос, выводящий «Улица Ленина, Москва».
SELECT cstrtype.name, sstreet.name, scity.name. Хм. FROM scity, cstrtype, sstreet WHERE . связи между таблицами и условия поиска.
Три поля с одинаковыми названиями в результате запроса. Какое безобразие! Интересно, что на большинстве SQL-серверов ошибки выдано не будет, и строки данных будут правильны. Но имена столбцов! Некоторые SQL-сервера молча переименуют поля, вроде name_1, name_2, или name_a, name_b (кстати, я не припомню, чтобы порядок такого переименовывания где-то документировался). Другие издевательски вернут набор данных с тремя одинаковыми полями — типа вам из погреба виднее, разбирайтесь. Редкий ClientDataSet не выдаст Access Violation от такого зрелища, не говоря уже о безнадежности задачи FieldByName().
В этом месте обычно вспоминают о возможности SELECT cstrtype.name AS strtypename , долго сопят, размышляя о бритве Оккама, а затем лезут в поля таблиц дописывать имя сущности. Опять пританцевали.
Ну хорошо, умоляют последние минималисты. Обозначать принадлежность поля таблице надо. Но зачем же полное имя сущности повторять? Можно ведь сократить — ‘STName’, ‘StrName’, ‘CName’.
Нет, господа минималисты! Ведь зачем мы добавляем имя сущности в имя поля? Обеспечить уникальность полей в результатах запросов! А уникальность эта в общем виде должна работать в масштабах базы данных. Вот завтра выйдете на международный рынок, появится у вас понятие стран (Country), и имя страны как сократите — опять «CName»? Поэтому ставим вопрос ребром. Если вы можете сократить имя сущности до удобочитаемой и в то же время уникальной величины — так это сокращение и используйте изначально как имя сущности. Нет — используйте полное. Но везде одно и то же.
С именем сущности в составе названия поля вроде бы разобрались. А что там за смысловой префикс, все эти -id, -name, -label, -area ?
- id — внутренний идентификатор, суррогатный ключ. Автоинкрементный. От пользователя скрывается. Никогда не модифицируется.
- code — пользовательский идентификатор, уникальный ключ. Например, табельный номер сотрудника. Как правило, неизменный; но при необходимости его можно менять (когда у отдела кадров сносит крышу), причем без каскадных обновлений БД.
- name — имя чего-либо (скорее идентификатор, или нечто каноническое)
- label — название (обычно человеческое удобное название)
- notes — поле типа TEXT, для примечаний
- num — номер чего-либо (может быть числовой либо текстовый, например Письмо N «1234/56-789«)
- . разумеется, список можно продолжать.
Ставить ли подчеркивание между сущностью и смысловым суффиксом, вроде street_name — дело вкуса. Это красиво выглядит в статье, но отвратительно в программном коде, потому что в точечной нотации objStreet.Street_Name подчеркивание выглядит как разделитель более высокого уровня, чем точка, и сбивает с толку. Кроме того, подчеркивания плохо видны на некоторых шрифтах и на бумажных распечатках. Поэтому подчеркивания я использую редко. В Pascal достаточно придерживаться общепринятой венгерской нотации — начинать каждое слово с заглавной буквы: StreetName, а в SQL чаще всего пишут ключевые слова большими буквами, идентификаторы — в венгерской нотации или просто маленькими буквами.
Иногда в нескольких таблицах встречаются служебные поля, не связанные с какой-либо сущностью, а используемые программистом либо базой данных для служебных целей, например поля вроде Row_ID в Oracle. Здесь нужно следить, чтобы имена сущностей не пересекались с названиями таких полей, иначе служебные поля будут ошибочно «мысленно привязаны» к какой-то нашей таблице.
Множественные ссылки
Иногда в базах данных встречается ситуация, требующая дополнения описанных правил. Рассмотрим пример — точки и вектор, имеющий начало и конец:
| SPOINT — Справочник точек | |
| pointid | Ид |
| pointX | X |
| pointY | Y |
| pointName | Имя |
| pointColor | Цвет точки |
| SVECTOR — Справочник векторов | |
| vectorid | Ид |
| pointid_start | Начало (FK SPOINT ) |
| pointid_end | Конец (FK SPOINT ) |
| vectorColor | Цвет вектора |
В ситуации, когда из одной таблицы есть более одной ссылки на один и тот же справочник, приходится использовать дополнительный суффикс (_start, _end) в наименованиях полей-ссылок. Это тот редкий случай, когда я использую подчеркивание.
Кроме того, те же дополнительные суффиксы придется использовать и при переобозначении выходных полей запроса, если придется объединять оба экземпляра справочника. Например, выведем список векторов с указанием координат начала и конца:
SELECT vectorid, ps.pointX AS pointX_start, ps.pointY AS pointY_start, pe.pointX AS pointX_end, pe.pointY AS pointY_end FROM svector v, spoint ps, spoint pe WHERE v.pointid_start = ps.pointid AND v.pointid_end = pe.pointid
Другими словами, если справочник используется в двух вариантах (как _start и как _end), то мы должны быть готовы представить все его данные в этих двух вариантах одновременно добавлением соответствующих дополнительных суффиксов к именам полей, а для пользователя — добавлением слов «Начало», «Конец» к стандартным наименованиям шапок отчета.
Коварство ситуации заключается в том, что помимо очевидного случая (две ссылки из одной таблицы на другую), мы можем прийти к той же проблеме на внешне благополучной схеме БД, если, начав путешествие из какой-либо таблицы по стрелкам внешних ключей, имеем возможность попасть в какой-либо справочник более чем одним путем. Если в каком-либо запросе мы захотим объединения всех промежуточных таблиц, опять придется разруливать варианты справочника.
Небольшое замечание. Если в процессе проектирования наклевывается ситуация с множественными ссылками, особенно более чем в двух вариантах — проверьте, не лучше ли заменить эту схему таблицей один-то-многим. Например, если у города есть руководитель мэрии, и председатель обкома партии:
| SCITY — справочник городов | |
| cityid | |
| manid_mer | FK sman — люди |
| manid_partyboss | FK sman- люди |
| . | |
то это можно выразить иначе:
| SCITY- справочник городов | |
| cityid | |
| . | |
| SBOSS — справочник начальников (один город — много начальников) | |
| bossid | |
| cityid | FK scity |
| bstypeid | FK cbstype — виды начальников |
| manid | FK sman — люди |
и дополнительный справочник, отражающий, в сущности, понятия _mer и _partyboss первоначального варианта:
| CBSTYPE — виды начальников | |
| bstype id | |
| bstypename | Название (мэр, партийный лидер и т.д.) |
Когда же разумно применять такое преобразование? Например, трудно представить себе, что у вектора появится третья вершина, или что у бухгалтерской проводки появится что-то кроме дебета и кредита — следовательно, таблица 1-N не нужна. А вот новые начальники в городе могут появиться запросто — например, военный комендант, если произойдет военный переворот, и командир партизанского военного округа, возглавляющий ему сопротивление. Баррикады, стрельба, переделка структуры БД. А с 1-N таблицей нам и структуру базы данных менять не надо, только дополнить справочник CBSTYPE!
Другие объекты базы данных
- Первичные ключи называем так: PK_имя_таблицы.
- Уникальные: UN_имя_таблицы_имена_всех_полей (если хватит терпения и допустимой длины), или просто UN_имя_тфблицы_номер_ключа_по_порядку.
- Внешние ключи: FK_имя_таблицы_имя_поля_ссылки_имя_таблицы-справочника
Указанные правила выглядят более естественно при выполнении некоторых дополнительных условий, которые выходят за рамки проблемы наименования, но о которых стоит упомянуть. Как вы уже заметили, в рассмотренных примерах в каждой таблице есть первичный ключ, причем ключ суррогатный. В этом вопросе я являюсь поклонником мнения Анатолия Тенцера, высказанного в статье «Естественные ключи против искусственных ключей». Лучше всего, когда в первичном ключе всего одно поле. Разумные дополнения к этому правилу — это территориально распределенные базы данных, где в первичном ключе участвует еще одно поле — идентификатор узла БД, уже упоминавшиеся таблицы «много-ко-многим» (nn_), и различные реализации времязависимых таблиц с указанием сроков действия каждой записи — эти реквизиты тоже участвуют в PK.
Еще один вопрос, который напрашивается после «упорядочения» названий в БД — как автоматизировать использование этого богатства? У нас есть названия сущностей, в том числе с русской расшифровкой, названия и русская расшифровка названий полей — нельзя ли сохранить эту информацию в БД и использовать ее непосредственно в программе, ее диалогах, фильтрах, отчетах, независимо используемых компонентов и языков? К сожалению, не существует общепринятого способа сохранения таких метаданных для использования различными средами разработки. Все движения в этом направлении намертво завязаны на конкретные продукты (Репозиторий в Delphi, системный словарь в PowerBuilder, конфигуратор в 1C, метаданные в Visual FoxPro), и все они обладают определенными ограничениями и неудобствами. Так что здесь есть о чем помечтать.
Форум пользователей MySQL
This statement was added in MySQL 5.1.7 but was found to be dangerous and was removed in MySQL 5.1.23.
И как теперь базы переименовывать?
#2 16.03.2011 13:33:07
rgbeast Администратор Откуда: Москва Зарегистрирован: 21.01.2007 Сообщений: 3877
Re: как переименовать базу данных?
Остановить MySQL переименовать каталог, запустить MySQL. Лучше не переимновывать, а сохранить старое название и создать символическую ссылку.
#3 16.03.2011 19:29:47
LazY _cмельчак Зарегистрирован: 02.04.2007 Сообщений: 845
Re: как переименовать базу данных?
Понятно..
Я так и не понял, почему они эту возможность убрали. Что за идиотизм..
#4 17.03.2011 01:26:05
paulus Администратор Зарегистрирован: 22.01.2007 Сообщений: 6756
Re: как переименовать базу данных?
Каталоги переименовывать опасно. Например, с innodb_file_per_table это
гарантирует, что таблички не подцепятся. И именно поэтому rename database
выкинули — это опасная операция.
#5 17.03.2011 16:43:41
LazY _cмельчак Зарегистрирован: 02.04.2007 Сообщений: 845
Re: как переименовать базу данных?
Я бы понял, если бы они именно поэтому RENAME DATABASE исправили, а не выкинули
#6 17.03.2011 21:40:02
paulus Администратор Зарегистрирован: 22.01.2007 Сообщений: 6756
Re: как переименовать базу данных?
Ммм.. Миш, ну как тут объяснить. Пусть у тебя в руках есть циркулярная пила
большого диаметра. Она большая, тяжелая и крутится быстро. Аналогом RENAME
DATABASE в этом примере будет тяжелый маховик, который приделывается к
лезвию для того, чтобы снизить нагрузку на двигатель, когда ты вдруг начинаешь
пилить толстый бетонный столб. Но, если ты когда-нибудь держал маховик в ру-
ках, ты знаешь, что один неудачный поворот — и эта штука движется совсем не
туда, куда ты хочешь. А если это насажено на циркулярную пилу, оно тебе в
лучшем случае обрезает ноги, а в худшем — голову. И правильное решение тут
не доработать конструкцию маховика, а оторвать его совсем
#7 18.03.2011 13:38:10
LazY _cмельчак Зарегистрирован: 02.04.2007 Сообщений: 845
Re: как переименовать базу данных?
Зато бетонные столбы теперь не спилить, а только выкапывать
В общем, как я понял, порядок действий такой:
1) Каталог переименовать
2) UPDATE mysql.db SET Db = ‘newname’ WHERE Db = ‘oldname’;
Что еще? Ничего не забыл?
Да, это для муисамной базы. А как быть с InnoDB?
#8 18.03.2011 21:06:19
paulus Администратор Зарегистрирован: 22.01.2007 Сообщений: 6756
Re: как переименовать базу данных?
Брр, зачем же ты раскручиваешь циркулярку веревкой? Второй пункт — дикое
непотребное зло, срочно сотри его
mysqldump | mysql — единственный правильный способ переименовывать базы,
содержащие innodb. И mysqlhotcopy — если все таблички MyISAM.
#9 18.03.2011 22:55:43
LazY _cмельчак Зарегистрирован: 02.04.2007 Сообщений: 845
Re: как переименовать базу данных?
Э, погоди. Мы щас именно о переименовании говорим.
mysqldump | mysql — это копирование.
Копирование отличается от переименования тем, что:
1. Все выданные на старую базу права придется выдавать заново на новую
2. Если база больших размеров, то это займет дофига системных ресурсов вообще.
Так что, выходит, именно переименовать вообще никак нельзя?
Основы правил проектирования базы данных
Как это часто бывает, архитектору БД нужно разработать базу данных под конкретное решение.
Однажды в пятницу вечером, возвращаясь на электричке домой с работы, я подумал о том, как бы я создал сервис по найму сотрудников в разные компании. Ведь ни один из существующих сервисов не позволяет быстро понять насколько подходит тебе кандидат. Нет возможности создать сложные фильтры, включающие или исключающие совокупность определенных навыков, проектов или позиций. Максимум, что обычно предлагают сервисы — фильтры по компаниям и частично по навыкам.
В данной статье я позволю себе немного разбавить строгое изложение материала, смешав техническую информацию с не техническими примерами из жизни.
Для начала, разберем создание базы данных в MS SQL Server для сервиса поиска соискателей на работу.
Этот материал можно перенести и на другую СУБД такую как MySQL или PostgreSQL.
Основы правил проектирования
Для проектирования схемы базы данных, нужно вспомнить 7 формальных правил и саму концепцию нормализации и денормализации. Они и лежат в основе всех правил проектирования.
Опишем более детально 7 формальных правил:
-
отношение один к одному:
1.1) с обязательной связью:
примером может выступать гражданин и его паспорт: у любого гражданина должен быть паспорт; паспорт один для каждого гражданина
Реализовать данную связь можно двумя способами:
1.1.1) в одной сущности (таблице):

Рис.1. Сущность Citizen
Здесь таблица Citizen представляет собой сущность гражданина, а атрибут (поле) PassportData содержит все паспортные данные гражданина и не может быть пустым (NOT NULL).
1.1.2) в двух разных сущностях (таблицах):

Рис.2. Отношение сущностей Citizen и PassportData
Здесь таблица Citizen представляет собой сущность гражданина, а таблица PassportData — сущность паспортных данных гражданина (самого паспорта). Сущность гражданина содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) CitizenID, которое ссылается на первичный ключ CitizenID таблицы Citizen. Поле PassportID таблицы Citizen не может быть пустым (NOT NULL). Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.
1.2) с необязательной связью:
примером может выступать человек, имеющий или не имеющий паспорт конкретной страны. В первом случае он будет являться гражданином рассматриваемой страны, а во втором — нет.
Реализовать данную связь можно двумя способами:
1.2.1) в одной сущности (таблице):

Рис.3. Сущность Person
Таблица Person представляет собой сущность человека, а атрибут (поле) PassportData содержит все его паспортные данные и может быть пустым (NULL).
1.2.2) в двух сущностях (таблицах):
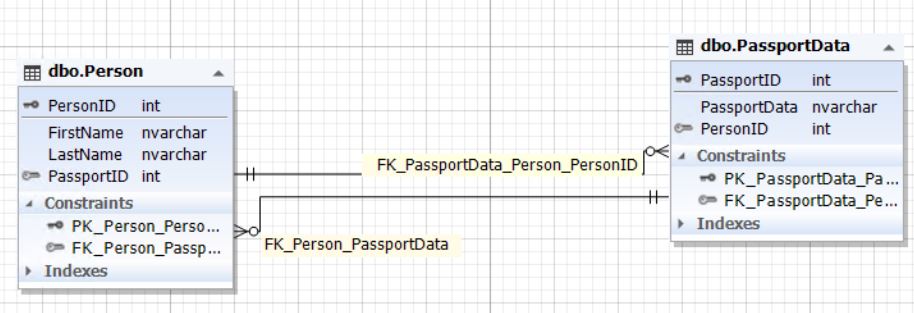
Рис.4. Отношение сущностей Person и PassportData
Таблица Person представляет собой сущность человека, а таблица PassportData — сущность паспортных данных человека (самого паспорта). Сущность человека содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) PersonID, которое ссылается на первичный ключ PersonID таблицы Person. Поле PassportID таблицы Person может быть пустым (NULL). Здесь также важно поддерживать целостность поля PersonID таблицы PassportData. Это нужно, чтобы обеспечить связь один к одному. Поле PassportID таблицы Person и поле PersonID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), показанная в пункте 1.2.1. Или же данные поля должны быть неопределенными, то есть, содержать NULL.
отношение один ко многим:
2.1) с обязательной связью:
примером могут выступать родитель и его дети. У каждого родителя есть как минимум один ребенок.
Реализовать данную связь можно двумя способами:
2.1.1) в одной сущности (таблице):
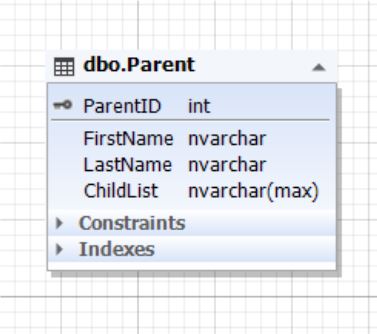
Рис.5. Сущность Parent
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле не может быть пустым (NOT NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
2.1.2) в двух сущностях (таблицах):
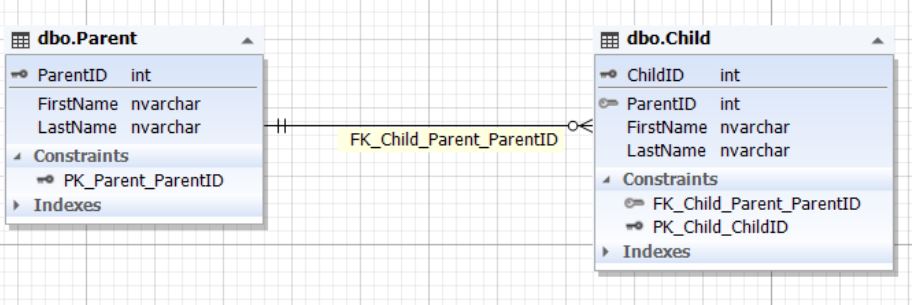
Рис.6. Отношение сущностей Parent и Child
Таблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child не может быть пустым (NOT NULL).
2.2) с необязательной связью:
примером может выступать человек, у которого могут быть дети или их может не быть.
Реализовать данную связь можно двумя способами:
2.2.1) в одной сущности (таблице):
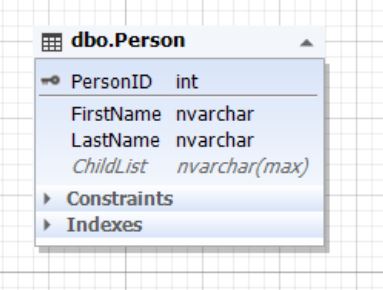
Рис.7. Сущность Person
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле может быть пустым (NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
2.2.2) в двух сущностях (таблицах):
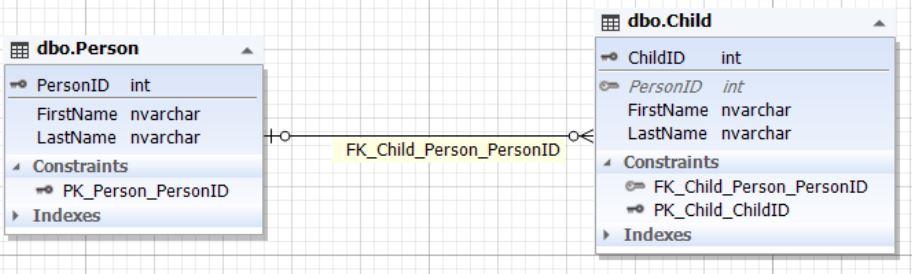
Рис.8. Отношение сущностей Person и Child
Таблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child может быть пустым (NULL).
2.2.3) в одной сущности со ссылкой на саму себя при условии, что у сущностей (таблиц) родителя и ребенка будут одинаковые наборы атрибутов (полей) без учета ссылки на родителя:

Рис.9. Сущность Person со связью на саму себя
Сущность (таблица) Person содержит атрибут (поле) ParentID, который ссылается на первичный ключ PersonID этой же таблицы Person и может содержать пустое значение (NULL).
Примером может выступить недвижимость: она может быть в собственности как одного человека, так и нескольких. С другой стороны, один человек может владеть несколькими домами или долями нескольких домов.
Реализовать данное отношение, с привлечением NoSQL, можно так же, как в описанных выше отношениях. Однако, в рамках реляционной модели обычно такое отношение реализуют через 3 сущности (таблицы):
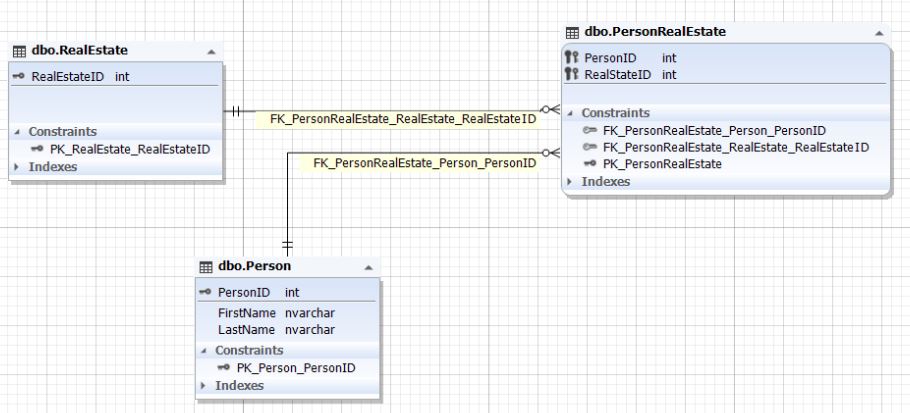
Рис.10. Отношение сущностей Person и RealEstate
Таблицы Person и RealEstate представляют соответственно сущности человека и недвижимости. Связываются данные сущности (таблицы) через сущность (таблицы) PersonRealEstate. Атрибуты (поля) PersonID и RealEstateID ссылаются на первичные ключи PersonID таблицы Person и RealEstateID таблицы RealEstate соответственно. Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.
А где же семь формальных правил?
- п.1 (п.1.1 и п.1.2) — первое и второе формальные правила
- п.2 (п.2.1 и п.2.2) — третье и четвертое формальные правила
- п.3 (аналогично п.2) — пятое и шестое формальные правила
- п.4 — седьмое формальное правило
Говоря о нормализации, нужно понимать ее суть. Нормализация ведет к уменьшению повторяемости хранения информации, а следовательно и к уменьшению возможности появления аномалий в данных. Однако, нормализация при дроблении сущностей приводит к более сложным построениям запросов для манипуляций с данными (вставки, модификации, выборки и удаления).
Обратным процессом нормализации называется денормализация. Это упрощение построения запросов доступа к данным за счет укрупнения и вложенности сущностей (например, как было показано выше в пунктах 2.1.1 и 2.2.1 с помощью неполно-структурированных данных (NoSQL)).
Вот и вся суть правил проектирования баз данных.
А вы уверены, что поняли отношения в семи формальных правилах? Именно поняли, а не узнали? Ведь знать и понимать — две совершенно разных концепции.
Объясню более детально. Спросите себя, можете ли вы за пару часов набросать пусть и укрупненную по сущностям, но модель базы данных для любой предметной области и для любой информационной системы? (тонкости и детали можно достроить, поспрашивав аналитиков и представителей заказчиков). Если вопрос вас удивил, и вы думаете, что это невозможно, значит вы знаете семь формальных правил, но не понимаете их.
Почему-то многие источники игнорируют тот факт, что эти отношения были не придуманы, а выявлены. Они изначально существуют в реальном мире как между субъектами, так и между субъектами и объектами.
Также, эти отношения могут меняться, переходя из один к одному к одному ко многим, многие к одному или многие ко многим. Обязательность связи может меняться или остаться неизменной.
Позволю себе рассказать об одном случае, когда от знания семи формальных правил я пришел именно к пониманию этих отношений.
В свое время меня смущало то, что в ВУЗе я знал эти семь формальных правил, но на производственной практике (ВУЗ отправляет студентов в различные компании для приобретения профессионального опыта) очень долго строил модели баз для разных предметных областей. Я задумался и понял, что не понимаю этих отношений.
Мне помогло наблюдение за людьми, а суть отношений раскрылась в сновидении. Этот сон я перескажу в упрощенной форме: только то, что позволяет лучше понять именно эти семь формальных правил — без детализации всего остального.
Сон был про семью, в которой есть отец, мать и дети. Отец погибает в автомобильной катастрофе, а мать начинает пить, и детей в итоге забирают в детский дом. Эти дети надолго остаются без родителей. Затем у некоторых детей появляются попечители, их тоже несколько.
Вы проследили, какие отношения были между субъектами, и как менялись эти отношения?
Давайте присмотримся внимательнее.
- Когда семья была полной, с несколькими детьми, отношение между родителями и детьми имело вид многие ко многим.
- Когда остались мать и дети, отношение между родителем и детьми стало один ко многим с обязательной связью. Однако, в любой семье, где может и не быть детей, это отношение будет таким же, но уже с необязательной связью.
- А вот со стороны детей отношение к родителю было как многие к одному с обязательной связью пока родителя не лишили родительских прав.
- Когда дети оказались в детском доме — отношение изменилось на многие к одному с необязательной связью.
- Когда у детей появились попечители, связь между ними стала многие ко многим: у каждого попечителя могут быть другие подопечные дети, а у каждого ребенка могут быть другие попечители (родители).
Надеюсь, теперь вы значительно приблизились к пониманию этих семи формальных правил.
Стоит постоянно практиковаться: наблюдать за людьми и выявлять существующие отношения как между субъектами, так и между субъектами и объектами. Выше описывался гражданин и его паспорт как отношение один к одному с обязательной связью. В тоже время, пример человека и его паспорта — это отношение один к одному с необязательной связью.
Поняв семь формальных правил, вы сможете без труда спроектировать модель базы данных любой сложности для любой информационной системы.
Также вы увидите, что реализовать отношение можно разными способами, а сами отношения могут меняться. Модель (схема) базы данных — это «снимок» отношений между сущностями в определенный момент времени. Именно поэтому важно определить как сами сущности — образы объектов из реального мира или предметной области, так и их отношения между собой с учетом изменений в будущем.
Хорошо спроектированную модель базы данных с учетом изменения отношений в реальности или в предметной области не понадобится менять годами или даже десятилетия. Это особенно важно для хранилищ данных, где изменения влекут пересохранение больших объемов данных (от нескольких гигабайт до многих терабайт).
Важно запомнить, что таблицы в реляционной модели — это отношения сущностей, а строки (кортежи) — это экземпляры этих отношений. Но чтобы было проще, под таблицами часто понимаются сущности, а под строками таблицы — экземпляры сущностей. Их отношения выражаются через связи в форме внешних ключей.
Проектирование схемы базы данных для поиска соискателей на работу
После того, как мы описали основы правил проектирования БД в первой части, давайте создадим схему базы данных для поиска соискателей на работу.
Для начала, определим, что важно для сотрудников из компании, которые ищут кандидатов:
- Сотрудник (Employee)
- Компания (Company)
- Позиция (должность) (Position)
- Проект (Project)
- Навык (Skill)
- Компании и сотрудники относятся как многие ко многим, так как сотрудник мог работать в нескольких компаниях, а в компании работают многие люди.
- Аналогично относятся позиции и сотрудники: несколько сотрудников могут занимать одну позицию как в рамках как одной, так и нескольких компаний.
- С другой стороны, сотрудник мог работать на разных позициях как в рамках одной, так разных компаний. Таким образом, отношение между позициями и компаниями — многие ко многим.
- Аналогично и по проектам: проекты относятся ко всем выше рассмотренным сущностям как многие ко многим.
- Для простоты будем считать, что в проекте сотрудник использует один набор навыков.
- Тогда проекты и навык относятся как многие ко многим.
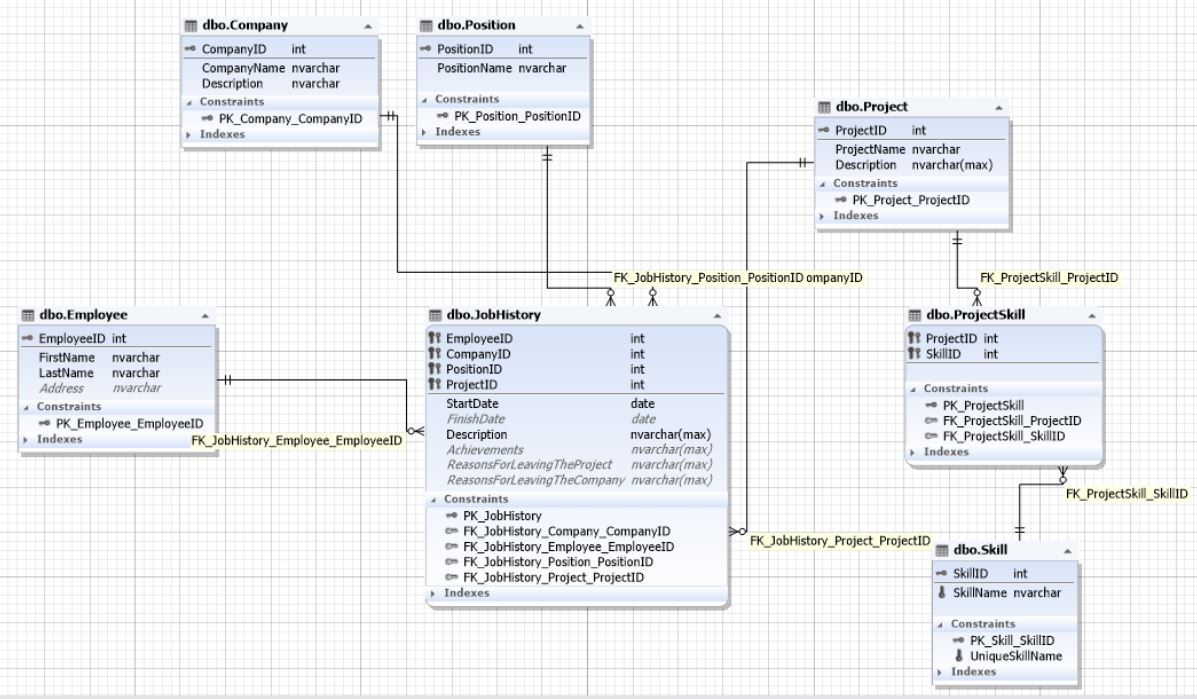
Рис.11. Схема базы данных для поиска соискателей на работу
Здесь таблица JobHistory выступает как сущность истории работы каждого соискателя. То есть, это резюме, которое педставляет отношения многие ко многим между сущностями сотрудник, компания, позиция и проект.
Проекты и навыки относятся друг другу как многие ко многим и потому связываются между собой через сущность (таблицу) ProjectSkill.
Когда вы понимаете отношения между субъектами и между субъектами и объектами — уже упомянутые семь формальных правил — эту или схожую схему можно реализовать «на коленке»: на листке бумаги, мене чем за час. И это еще с учетом усталости после плодотворного рабочего дня.
Здесь можно было упростить схему добавления данных, если «навыки» вложить в сущность «проекты» через неполно структурированные данные (NoSQL) в виде XML, JSON или просто перечислять названия навыков через точку с запятой. Но это бы усложнило выборку с группировкой по навыкам и фильтрацию по отдельным навыкам.
Подобная модель лежит в основе базы данных проекта Geecko.
Как видите, ничего сложного в проектировании информационных систем в части проектирования базы данных нет. Это всего лишь отражение объектов и субъектов из реальности, перенесенное в «сущности» схемы базы данных. Отношения между этими сущностями фиксируются на определенный момент времени, с учетом будущих изменений.
Что именно мы возьмем из реальности и вложим в сущность схемы, и какие отношения построим в модели, будет зависеть от того, что мы хотим от информационной системы в общем, здесь и в будущем. Иными словами — какие данные мы хотим получить в текущий момент времени и через определенное время в будущем.
Немного лирики
После того, как вы внедрите модель в работу, остановитесь на миг и подумайте: только что был создан новый маленький мир. В нем есть свои сущности из реального мира и свои отношения. Да, это цифровой мир, но он теперь будет развиваться своей дорогой. Он будет общаться (интегрироваться) с другими системами (мирами), тоже созданными по своим правилам. Данные будут течь в этих системах, как кровь в живом организме.
А перед сном подумайте о том, что семь формальных правил были всегда, и что они окружают нас всюду. Не больше и не меньше, всегда семь. Все отношения реальной жизни можно разложить на эти семь формальных правил. А когда вы думаете или видите сны, как там сущности относятся друг к другу — не по тем же семи формальным правилам?
Вообще, я уверен, что эти отношения (семь формальных правил) выявил очень хороший психотерапевт, возможно — женщина. Это было очень давно, задолго до появления самого понятия информационных технологий. И самое интересное, что эти отношения живут вне базы данных и ИТ — последние лишь используют их для моделирования информационных систем.
Но мы немного отошли от темы. Я лишь призываю в момент создания новой системы подойти к этому процессу с душой. И тогда поверьте, случится момент творения. Спроектированная таким образом система будет живее всех живых в цифровом мире.
Послесловие
Диаграммы для примеров были реализованы с помощью инструмента Database Diagram Tool for SQL Server. Однако, подобный функционал есть и в DBeaver.
Источники
- SQL Database Design Basics with Example
- Geecko
- Microsoft SQL documentation
- SSMS
- Database Diagram Tool for SQL Server
RENAME (Transact-SQL)
Переименовывает созданную пользователем таблицу в Azure Synapse Analytics. Переименовывает созданную пользователем таблицу, столбец в созданной пользователем таблице или базе данных в Система платформы аналитики (PDW).
Сведения в этой статье относятся только к Azure Synapse Analytics и Analytics Platform System (PDW):
- Чтобы переименовать базу данных в SQL Server, используйте хранимую процедуру sp_renamedb.
- Чтобы переименовать базу данных в службе базы данных SQL Azure, используйте инструкцию ALTER DATABASE (база данных SQL Azure).
- Поддерживается переименование изолированных выделенных пулов SQL (прежнее название — хранилище данных SQL). Переименование выделенного пула SQL в рабочих областях Azure Synapse Analytics в настоящее время не поддерживается.
- Этот синтаксис не поддерживается бессерверным пулом SQL в Azure Synapse Analytics.
Синтаксис
-- Syntax for Azure Synapse Analytics -- Rename a table. RENAME OBJECT [::] [ [ database_name . [schema_name ] ] . ] | [schema_name . ] ] table_name TO new_table_name [;] -- Syntax for Analytics Platform System (PDW) -- Rename a table RENAME OBJECT [::] [ [ database_name . [ schema_name ] . ] | [ schema_name . ] ] table_name TO new_table_name [;] -- Rename a database RENAME DATABASE [::] database_name TO new_database_name [;] -- Rename a column RENAME OBJECT [::] [ [ database_name . [schema_name ] ] . ] | [schema_name . ] ] table_name COLUMN column_name TO new_column_name [;] Аргументы
RENAME OBJECT [::] [ [database_name . [ schema_name ] . ] | [ schema_name . ] ] table_name TO new_table_name
Область применения: Azure Synapse Analytics, Analytics Platform System (PDW)
Изменение имени определяемой пользователем таблицы. Указание таблицы для переименования с именем, состоящим из одной, двух или трех частей. Указание имени_новой_таблицы, состоящего из одной части.
RENAME DATABASE [::] [ database_name TO new_database_name
Область применения: Analytics Platform System (PDW)
Измените имя пользовательской базы данных с имени_базы_данных на новое_имя_базы_данных. Недопустимо переименование базы данных в следующие зарезервированные имена Analytics Platform System (PDW):
- master
- model
- msdb
- tempdb
- pdwtempdb1
- pdwtempdb2
- DWConfiguration
- DWDiagnostics
- DWQueue
RENAME OBJECT [::] [ [database_name . [ schema_name ] . ] | [ schema_name . ] ]table_name COLUMN column_name TO new_column_name
Область применения: Analytics Platform System (PDW)
Изменение имени столбца в таблице.
Разрешения
Для выполнения этой команды требуется следующее разрешение:
Ограничения
Невозможно переименовать внешние таблицы, индексы и представления
Вы не можете переименовать внешние таблицы, индексы и представления. Вместо переименования можно удалить внешнюю таблицу, индекс или представление и затем создать этот объект повторно с новым именем.
Невозможно переименовать используемую таблицу
Вы не можете переименовать таблицу или базу данных во время использования. Для переименования таблицы требуется монопольная блокировка таблицы. Если таблица используется, может потребоваться завершить сеансы, которые используют таблицу. Для завершения сеанса можно использовать команду KILL. Используйте инструкцию KILL осторожно, так как при завершении сеанса для всей незафиксированной работы будет выполнен откат. Сеансы в Azure Synapse Analytics имеют префикс «SID». Префикс «SID» и номер сеанса необходимо указать при вызове команды KILL. В этом примере мы получаем список активных или неактивных сеансов и затем завершаем сеанс «SID1234».
Ограничения переименования столбцов
Вы не можете переименовать столбец, используемый для распределения таблицы. Кроме того, невозможно переименовывать столбцы во внешней или временной таблице.
Представления не обновляются
При переименовании базы данных все представления, в которых используется предыдущее имя базы данных, станут недействительными. Это поведение относится к представлениям как внутри, так и вне базы данных. Например, при переименовании базы данных Sales представления, содержащие SELECT * FROM Sales.dbo.table1 , станут недействительными. Чтобы устранить эту проблему, старайтесь не использовать имена из трех частей в представлениях или обновите представления так, чтобы в них использовалось новое имя базы данных.
При переименовании таблицы обновления имени таблицы в представлениях не происходит. Все представления внутри или вне базы данных, которые ссылаются на предыдущее имя таблицы, станут недействительными. Чтобы устранить эту проблему, обновите представления так, чтобы в них использовалось новое имя базы данных.
При переименовании столбца обновление представлений для их ссылки на это новое имя столбца не выполняется. Представления продолжат отображать старое имя столбца до выполнения инструкции ALTER VIEW. В некоторых случаях представления могут стать недействительными, в результате чего потребуется удалить их и создать заново.
Блокировка
Для переименования таблицы необходима совмещаемая блокировка для объекта базы данных, совмещаемая блокировка для объекта СХЕМЫ и монопольная блокировка таблицы.
Примеры
A. Переименование базы данных
Область применения: только Analytics Platform System (PDW)
В этом примере мы переименовываем пользовательскую базу данных AdWorks в AdWorks2.
-- Rename the user defined database AdWorks RENAME DATABASE AdWorks to AdWorks2; При переименовании таблицы все объекты и свойства, связанные с этой таблицей, обновляются, так чтобы в них использовалось новое имя таблицы. Например, обновляются определения таблиц, индексы, ограничения и разрешения. Представления не обновляются.
Б. Переименование таблицы
Область применения: Azure Synapse Analytics, Analytics Platform System (PDW)
В этом примере мы переименовываем таблицу Customer в Customer1.
-- Rename the customer table RENAME OBJECT Customer TO Customer1; RENAME OBJECT mydb.dbo.Customer TO Customer1; При переименовании таблицы все объекты и свойства, связанные с этой таблицей, обновляются, так чтобы в них использовалось новое имя таблицы. Например, обновляются определения таблиц, индексы, ограничения и разрешения. Представления не обновляются.
В. Перемещение таблицы в другую схему
Область применения: Azure Synapse Analytics, Analytics Platform System (PDW)
Если вы хотите переместить объект в другую схему, используйте инструкцию ALTER SCHEMA. Например, следующая инструкция перемещает элемент таблицы из схемы product в схему dbo.
ALTER SCHEMA dbo TRANSFER OBJECT::product.item; Г. Завершение сеансов перед переименованием таблицы
Область применения: Azure Synapse Analytics, Analytics Platform System (PDW)
Переименовать таблицу, которая сейчас используется, невозможно. Для переименования таблицы требуется монопольная блокировка таблицы. Если таблица используется, может потребоваться завершить сеансы, которые используют таблицу. Для завершения сеанса можно использовать команду KILL. Используйте инструкцию KILL осторожно, так как при завершении сеанса для всей незафиксированной работы будет выполнен откат. Сеансы в Azure Synapse Analytics имеют префикс «SID». Префикс SID и номер сеанса потребуется указать при вызове команды KILL. В этом примере мы получаем список активных или неактивных сеансов и затем завершаем сеанс «SID1234».
-- View a list of the current sessions SELECT session_id, login_name, status FROM sys.dm_pdw_exec_sessions WHERE status='Active' OR status='Idle'; -- Terminate a session using the session_id. KILL 'SID1234'; Д. Переименование столбца
Область применения: Analytics Platform System (PDW)
В этом примере столбец FName таблицы Customer переименовывается в FirstName.
-- Rename the Fname column of the customer table RENAME OBJECT::Customer COLUMN FName TO FirstName; RENAME OBJECT mydb.dbo.Customer COLUMN FName TO FirstName; Дальнейшие действия
- sp_renamedb
- CREATE DATABASE (база данных SQL Azure)