Метод intersection
Метод intersection осуществляет пересечение нескольких множеств, в результате чего возвращает новое множество с общими для указанных множеств элементами. В параметре метода передаем множество, для которого хотим узнать общие элементы.
Синтаксис
множество.intersection(множество, с которым хотим найти общие элементы)
Пример
Давайте применим метод intersection , чтобы получить общие элементы для двух множеств:
st1 = <'a', 'b', 'c'>st2 = res = st1.intersection(st2) print(res)
Результат выполнения кода:
Пример
У метода intersection также есть короткая форма:
st1 = <'a', 'b', 'c'>st2 = res = st1 & st2 print(res)
Результат выполнения кода:
Смотрите также
- метод union ,
который объединяет множества - метод difference ,
который возвращает различия между множествами
Пересечение множества в Python
Пересечение (A∩B) двух множеств A и B в Python – это набор, содержащий все элементы, общие для обоих множеств.
Мы также можем выполнить пересечение нескольких множеств. На следующем изображении показан пример пересечения двух и трех множеств.

В Python мы можем использовать функцию set class crossction(), чтобы получить пересечение двух множеств.
Давайте посмотрим на пример.
set1 = set('abcde') set2 = set('ae') print(set1) print(set2) # two sets intersection print(set1.intersection(set2))

Функция crossction() также принимает несколько заданных аргументов. Давайте посмотрим на еще один пример пересечения нескольких множеств.
set1 = set('abcde') set2 = set('ae') set3 = print(set1.intersection(set2, set3))

Как установить пересечение без аргументов?
Мы также можем вызывать функцию crossction() без аргументов. В этом случае копия набора будет возвращена.
Посмотрим, относится ли возвращенная копия к тому же набору или к другому.
set1 = set('ab') set4 = set1.intersection() print(set4) # check if shallow copy or deep copy set1.add('0') set1.remove('a') print(set1) print(set4)
Пересечение нескольких множеств в одну строчку
![]()
Сегодня на паре по программированию для журналистики данных мы столкнулись с такой задачей: есть список множеств, нужно найти пересечение их всех. Как это проще всего сделать в Python? Оказывается, у этой задачи есть решение в одну строчку.
Собственно, дело было так. Мы смотрели на данные по госзакупкам через API сайта clearspending.ru. Там у каждого контракта куча разных атрибутов. Как видно из следующих примеров, наборы атрибутов (в данном случае, ключей в словаре) у разных контрактов различаются. Мы хотели найти такие атрибуты, которые есть у всех контрактов.
import requests # пример из документации # https://github.com/idalab/clearspending-examples/wiki/Описание-API-Контракты entrypoint = "http://openapi.clearspending.ru/restapi/v3/contracts/search/" r = requests.get(entrypoint, 'customerregion': '05', 'sort':'-price'>) response = r.json() contracts = response['contracts']['data']
contracts[0].keys()
dict_keys(['finances', 'documentBase', 'versionNumber', 'mongo_id', 'suppliers', 'placingWayCode', 'contractUrl', 'foundation', 'products', 'scan', 'fileVersion', 'contractProcedure', 'economic_sectors', 'signDate', 'fz', 'currentContractStage', 'printFormUrl', 'price', 'protocolDate', 'number', 'regNum', 'currentContractStage_raw', 'loadId', 'attachments', 'customer', 'placing', 'regionCode', 'id', 'currency', 'singleCustomerReason', 'execution', 'publishDate', 'schemaVersion'])
contracts[1].keys()
dict_keys(['signDate', 'versionNumber', 'mongo_id', 'finances', 'contractUrl', 'foundation', 'misuses', 'regionCode', 'fileVersion', 'documentBase', 'fz', 'currentContractStage', 'price', 'placing', 'number', 'products', 'publishDate', 'customer', 'regNum', 'suppliers', 'id', 'currency', 'execution', 'loadId'])
По такому поводу я рассказал про множества в Python (давно откладывал это — к слову не приходилось) и написал такой код.
fields = set(contracts[0]) # сделали множество из списка ключей первого контракта # здесь словарь contracts[0] рассматривается как iterable # а в этом случае он итерирует свои ключи # поэтому .keys() дописывать не нужно for contract in contracts[1:]: fields.intersection_update(contract) # пересечь множество fields с множеством, полученным из списка ключей # очередного контракта и результат записать в fields # иными словами, выкинуть из fields те элементы, которых нет в # списке ключей очередного контракта fields
Он мне перестал нравиться ещё до того, как я закончил его писать. Ну, право дело, ведь когда нам нужно сложить числа в списке, мы не пишем цикл — мы просто вызываем функцию sum() . Должно, наверное, и для множеств быть что-то похожее? На паре тратить время на поиски не хотелось, но, придя домой, я всё же решил найти ответ на этот вопрос. Оказывается, есть очень просто решение!
fields = set.intersection(*[set(contract) for contract in contracts]) fields
Дело в том, что set.intersection() принимает на вход любое количество аргументов! С помощью спискового включения мы делаем список множеств, составленных из ключей каждого контракта, затем звёздочкой «распаковываем» этот список в набор аргументов set.intersection() — вжух — и всё готово!
Пожалуй, по сравнению с моим исходным подходом есть только один недостаток: по памяти это решение более требовательное, потому что сначала создаётся список, потом он передаётся функции. Причём из-за необходимости распаковывать элементы здесь бессмысленно заменять список на генератор — всё равно память придётся тратить. Впрочем, с практической точки зрения это скорее всего не принципиально.
UPD. После подсказки @rusorrow о том, что .keys() не нужен при создании множества, я подумал, что можно было бы сделать ещё короче: с помощью map — мне кажется, что так даже лучше — это, пожалуй, тот случай, когда map упрощает код по сравнению со списочными включениями.
set.intersection(*map(set, contracts))
Пересечение списков, совпадающие элементы двух списков
В данной задаче речь идет о поиске элементов, которые присутствуют в обоих списках. При этом пересечение списков и поиск совпадающих (перекрывающихся) элементов двух списков будем считать несколько разными задачами.
Если даны два списка, в каждом из которых каждый элемент уникален, то задача решается просто, так как в результирующем списке не может быть повторяющихся значений. Например, даны списки:
[5, 4, 2, ‘r’, ‘ee’] и [4, ‘ww’, ‘ee’, 3]
Областью их пересечения будет список [4, ‘ee’] .
Если же исходные списки выглядят так:
[5, 4, 2, ‘r’, 4, ‘ee’, 4] и [4, ‘we’, ‘ee’, 3, 4] ,
то списком их совпадающих элементов будет [4, ‘ee’, 4] , в котором есть повторения значений, потому что в каждом из исходных списков определенное значение встречается не единожды.
Начнем с простого — поиска области пересечения. Cначала решим задачу «классическим» алгоритмом, не используя продвинутые возможностями языка Python: будем брать каждый элементы первого списка и последовательно сравнивать его со всеми значениями второго.
a = [5, [1, 2], 2, 'r', 4, 'ee'] b = [4, 'we', 'ee', 3, [1, 2]] c = [] for i in a: for j in b: if i == j: c.append(i) break print(c)
Результат выполнения программы:
[[1, 2], 4, 'ee']
Берется каждый элемент первого списка (внешний цикл for ) и последовательно сравнивается с каждым элементом второго списка (вложенный цикл for ). В случае совпадения значений элемент добавляется в третий список c . Команда break служит для выхода из внутреннего цикла, так как в случае совпадения дальнейший поиск при данном значении i бессмыслен.
Алгоритм можно упростить, заменив вложенный цикл на проверку вхождения элемента из списка a в список b с помощью оператора in :
a = [5, [1, 2], 2, 'r', 4, 'ee'] b = [4, 'we', 'ee', 3, [1, 2]] c = [] for i in a: if i in b: c.append(i) print(c)
Здесь выражение i in b при if по смыслу не такое как выражение i in a при for . В случае цикла оно означет извлечение очередного элемента из списка a для работы с ним в новой итерации цикла. Тогда как в случае if мы имеем дело с логическим выражением, в котором утверждается, что элемент i есть в списке b . Если это так, и логическое выражение возвращает истину, то выполняется вложенная в if инструкция, то есть элемент i добавляется в список c .
Принципиально другой способ решения задачи – это использование множеств. Подходит только для списков, которые не содержат вложенных списков и других изменяемых объектов, так как встроенная в Python функция set() в таких случаях выдает ошибку.
a = [5, 2, 'r', 4, 'ee'] b = [4, 1, 'we', 'ee', 'r'] c = list(set(a) & set(b)) print(c)
['ee', 4, 'r']
Выражение list(set(a) & set(b)) выполняется следующим образом.
- Сначала из списка a получают множество с помощью команды set(a) .
- Аналогично получают множество из b .
- С помощью операции пересечения множеств, которая обозначается знаком амперсанда & , получают третье множество, которое представляет собой область пересечения двух исходных множеств.
- Полученное таким образом третье множество преобразуют обратно в список с помощью встроенной в Python функции list() .
Множества не могут содержать одинаковых элементов. Поэтому, если в исходных списках были повторяющиеся значения, то уже на этапе преобразования этих списков во множества повторения удаляются, а результат пересечения множеств не будет отличаться от того, как если бы в исходных списках повторений не было.
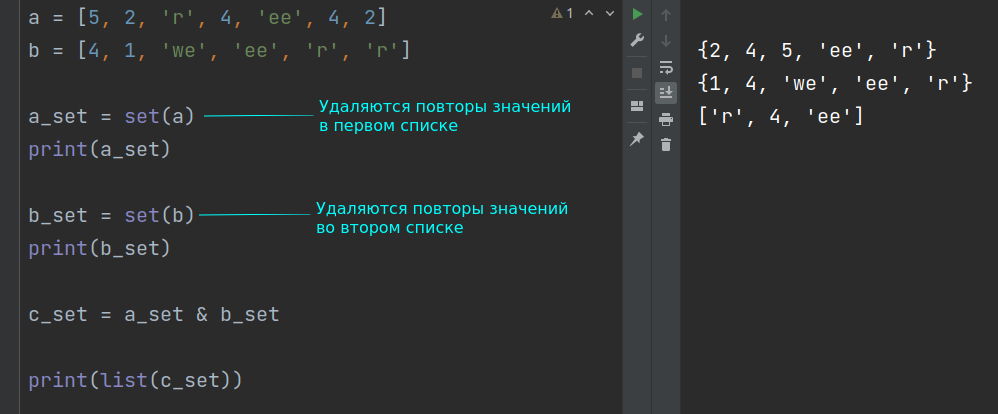
Однако если мы вернемся к решению задачи без использования множеств и добавим в первый список повтор значения, то получим некорректный результат:
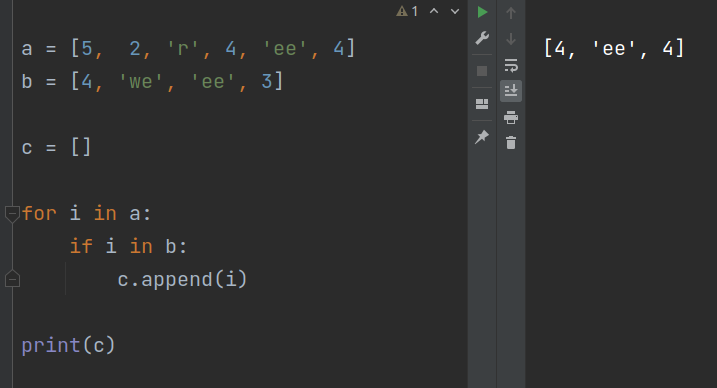
В список пересечения попадают оба равных друг другу значения из первого списка. Это происходит потому, что когда цикл извлекает, в данном случае, вторую 4-ку из первого списка, выражение i in b также возвращает истину, как и при проверке первой 4-ки. Следовательно, выражение c.append(i) выполняется и для второй четверки.
Чтобы решить эту проблему, добавим дополнительное условие в заголовок инструкии if . Очередной значение i из списка a должно не только присутствовать в b , но его еще не должно быть в c . То есть это должно быть первое добавление такого значения в c :
a = [5, 2, 'r', 4, 'ee', 4] b = [4, 'we', 'ee', 3] c = [] for i in a: if i in b and i not in c: c.append(i) print(c)
[4, 'ee']
Теперь усложним задачу. Пусть если в обоих списках есть по несколько одинаковых значений, они должны попадать в список совпадающих элементов в том количестве, в котором встречаются в списке, где их меньше. Или если в исходных списках их равное количетво, то такое же количество должно быть в третьем. Например, если в первом списке у нас три 4-ки, а во втором две, то в третьем списке должно быть две 4-ки. Если в обоих исходных по две 4-ки, то в третьем также будет две.
Алгоритмом решения такой задачи может быть следующий:
- В цикле будем перебирать элементы первого списка.
- Если на текущей итерации цикла взятого из первого списка значения нет в третьем списке, то только в этом случае следует выполнять все нижеследующие действия. В ином случае такое значение уже обрабатывалось ранее, и его повторная обработка приведет к добавлению лишних элементов в результирующий список.
- С помощью спискового метода count() посчитаем количество таких значений в первом и втором списке. Выберем минимальное из них.
- Добавим в третий список количество элементов с текущим значением, равное ранее определенному минимуму.
a = [5, 2, 4, 'r', 4, 'ee', 1, 1, 4] b = [4, 1, 'we', 'ee', 'r', 4, 1, 1] c = [] for item in a: if item not in c: a_item = a.count(item) b_item = b.count(item) min_count = min(a_item, b_item) # c += [item] * min_count for i in range(min_count): c.append(item) print(c)
[4, 4, 'r', 'ee', 1, 1]
Если значение встречается в одном списке, но не в другом, то метод count() другого вернет 0. Соответственно, функция min() вернет 0, а цикл с условием i in range(0) не выполнится ни разу. Поэтому, если значение встречается в одном списке, но его нет в другом, оно не добавляется в третий.
При добавлении значений в третий список вместо цикла for можно использовать объединение списков с помощью операции + и операцию повторения элементов с помощью * . В коде выше данный способ показан в комментарии.
X Скрыть Наверх
Решение задач на Python