Как извлечь месяц из даты в Pandas (с примерами)
Вы можете использовать следующий базовый синтаксис для извлечения месяца из даты в pandas:
df['month'] = pd.datetimeIndex(df['date_column']). month В следующем примере показано, как использовать эту функцию на практике.
Пример: извлечь месяц из даты в Pandas
Предположим, у нас есть следующие Pandas DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame print(df) sales_date total_sales 0 2020-01-18 675 1 2020-02-20 500 2 2020-03-21 575 Мы можем использовать следующий синтаксис для создания нового столбца, содержащего месяц столбца «дата_продажи»:
#extract month as new column df['month'] = pd.datetimeIndex(df['sales_date']). month #view updated DataFrame print(df) sales_date total_sales month 0 2020-01-18 675 1 1 2020-02-20 500 2 2 2020-03-21 575 3 Мы также можем использовать следующий синтаксис для создания нового столбца, содержащего год столбца «дата_продажи»:
#extract year as new column df['year'] = pd.datetimeIndex(df['sales_date']). year #view updated DataFrame print(df) sales_date total_sales month year 0 2020-01-18 675 1 2020 1 2020-02-20 500 2 2020 2 2020-03-21 575 3 2020 Обратите внимание, что если в DataFrame есть какие-либо значения NaN, эта функция автоматически создаст значения NaN для соответствующих значений в новых столбцах месяца и года.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
Как извлечь название месяца и год из столбца даты в DataFrame
Я хочу извлечь название месяца и год простым способом в следующем формате:
45 Jan-2018 73 Feb-2018 74 Feb-2018 75 Feb-2018 76 Feb-2018 Я использовал df.Date.dt.to_period(«M») , который возвращает формат «2018-01» .
Поделиться Источник 15 июля 2019 в 05:27
2 ответа
Переведите дату из объекта в фактическое время и используйте dt для доступа к нужному вам.
import pandas as pd df = pd.DataFrame(<'Date':['2019-01-01','2019-02-08']>) df['Date'] = pd.to_datetime(df['Date']) # You can format your date as you wish df['Mon_Year'] = df['Date'].dt.strftime('%b-%Y') # the result is object/string unlike `.dt.to_period('M')` that retains datetime data type. print(df['Mon_Year']) Визуальный формат без влияния на типы данных
Мы также можем работать со стилем, чтобы получить визуальный цвет так, как мы хотим, не нарушая базовые типы
# note: returns a style object not df df.style.format()
Поделиться 15 июля 2019 в 05:41
Сначала преобразуйте столбец в тип данных даты и времени с помощью
sales_df['Date'] = pd.to_datetime(sales_df['Date']) затем вы можете сделать
sales_df['Month'] = sales_df['Date'].dt.month_name(locale='English') Как добавить и вычесть месяцы из даты в Pandas
Вы можете использовать следующие методы для добавления и вычитания месяцев из даты в pandas:
Способ 1: добавить месяцы к дате
from pandas. tseries.offsets import DateOffset df['date_column'] + DateOffset(months= 3 ) Метод 2: вычесть месяцы из даты
from pandas. tseries.offsets import DateOffset df['date_column'] - DateOffset(months= 3 ) В следующих примерах показано, как использовать каждый метод на практике со следующими пандами DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame print(df) date sales 0 2022-01-31 6 1 2022-02-28 8 2 2022-03-31 9 3 2022-04-30 5 4 2022-05-31 4 5 2022-06-30 8 6 2022-07-31 8 7 2022-08-31 3 8 2022-09-30 5 9 2022-10-31 9 Пример 1: добавить месяцы к дате в Pandas
В следующем коде показано, как создать новый столбец, добавляющий 3 месяца к значению в столбце даты :
from pandas. tseries.offsets import DateOffset #create new column that adds 3 months to date df['date_plus3'] = df.date + DateOffset(months= 3 ) #view updated DataFrame print(df) date sales date_plus3 0 2022-01-31 6 2022-04-30 1 2022-02-28 8 2022-05-28 2 2022-03-31 9 2022-06-30 3 2022-04-30 5 2022-07-30 4 2022-05-31 4 2022-08-31 5 2022-06-30 8 2022-09-30 6 2022-07-31 8 2022-10-31 7 2022-08-31 3 2022-11-30 8 2022-09-30 5 2022-12-30 9 2022-10-31 9 2023-01-31 Новый столбец date_plus3 представляет значения в столбце даты с добавлением трех месяцев к каждому значению.
Пример 2: вычитание месяцев из даты в Pandas
В следующем коде показано, как создать новый столбец, который вычитает 3 месяца из значения в столбце даты :
from pandas. tseries.offsets import DateOffset #create new column that subtracts 3 months from date df['date_minus3'] = df.date + DateOffset(months= 3 ) #view updated DataFrame print(df) date sales date_minus3 0 2022-01-31 6 2021-10-31 1 2022-02-28 8 2021-11-28 2 2022-03-31 9 2021-12-31 3 2022-04-30 5 2022-01-30 4 2022-05-31 4 2022-02-28 5 2022-06-30 8 2022-03-30 6 2022-07-31 8 2022-04-30 7 2022-08-31 3 2022-05-31 8 2022-09-30 5 2022-06-30 9 2022-10-31 9 2022-07-31 Новый столбец date_minus3 представляет значения в столбце даты , из каждого значения вычитается три месяца.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
Работа с датой и временем в фрейме данных Pandas
Одной из распространенных задач, которые вам часто приходится выполнять с фреймами данных Pandas, является манипулирование датой и временем. В зависимости от того, как значения даты и времени изначально закодированы в наборе данных, вам часто приходится затрачивать значительные усилия на манипулирование ими, чтобы вы могли использовать их для целей анализа данных. В этой статье мы введем вас в тематику даты и время в библиотеке Pandas, также вы узнаете несколько распространенных методов работы с датой и временем в ваших фреймах данных Pandas.
CSV-файлы, которые будут использованы в этой статье, следующие:
- AAPL.csv — Исторический набор данных Apple (https://www.kaggle.com/datasets/prasoonkottarathil/apple-lifetime-stocks-dataset). Лицензия — CC0: Public Domain
- Flights.csv — Набор данных о задержках и отменах рейсов за 2015 год (https://www.kaggle.com/datasets/usdot/flight-delays). Лицензия — CC0: Public Domain
Преобразование столбца в тип данных datetime64
Давайте загрузим файл AAPL.csv в фрейм данных Pandas:
import pandas as pd df = pd.read_csv('AAPL.csv') df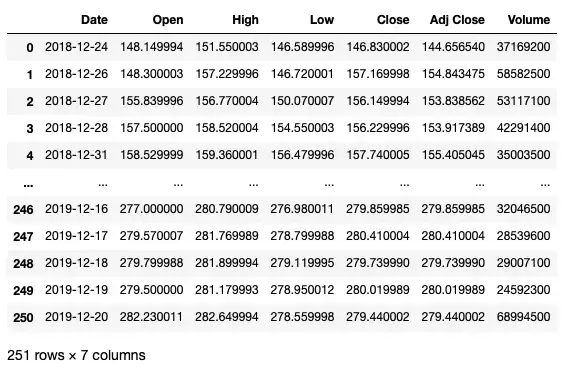
Вы можете проверить тип данных каждого столбца во DataFrame:
df.dtypesКак вы можете видеть из приведенных ниже выходных данных, столбец Date представлен в виде object :
Date object Open float64 High float64 Low float64 Close float64 Adj Close float64 Volume int64 dtype: objectВы можете преобразовать столбец Date в тип данных datetime64 с помощью функции datetime.strptime() :
from datetime import datetime df['Date'] = df['Date'].apply( lambda x: datetime.strptime(x,'%Y-%m-%d')) dfТеперь вы можете проверить тип данных для столбца Date :
df.dtypesИ столбец Date теперь имеет тип datetime64 :
Date datetime64[ns] Open float64 High float64 Low float64 Close float64 Adj Close float64 Volume int64 dtype: object[ns] в datetime64[ns] определяет точность объекта DateTime в наносекундах.
Поиск строк на основе определенных дат
Преобразование столбца Date в тип данных datetime64 позволяет легко выполнять операции, связанные с датой, например, находить все строки за декабрь 2018 года:
df[(df['Date'].dt.month == 12) & (df['Date'].dt.year == 2018)]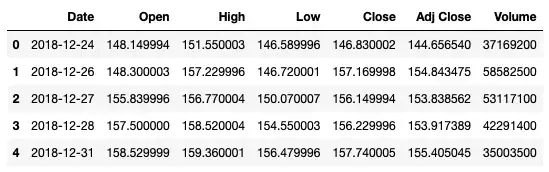
Поиск строк на основе дня недели
Вы также можете использовать атрибут dayofweek , чтобы найти определенный день недели (например, понедельник, вторник и так далее). Например, следующий оператор находит все строки, даты которых приходятся на понедельник:
# 0 is Monday, 1 is Tue, etc df[df['Date'].dt.dayofweek == 0].sample(5)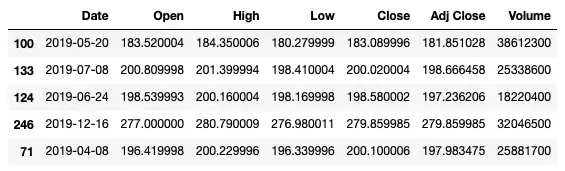
Сортировка по дням недели
Другой распространенный сценарий, с которым вы столкнетесь при работе с датами, — это сортировка данных по дням недели (например, с понедельника по воскресенье или с воскресенья по субботу).
Вот техника, которую вы можете использовать. Сначала извлеките день недели из столбца Date (объект datetime64[ns] ), используя функцию strftime() :
df['Day'] = df['Date'].apply( lambda x: x.strftime('%a')) dfИзвлеченный день недели сохраняется в новом столбце с именем Day :
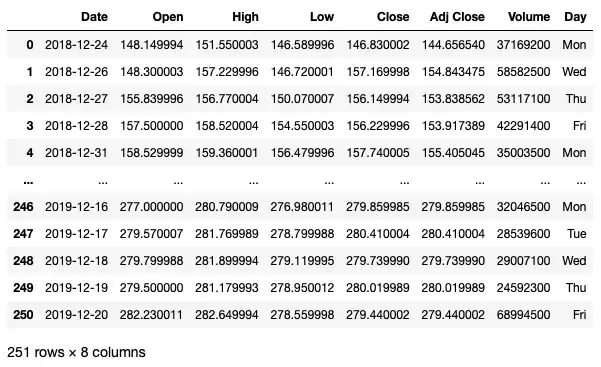
Затем вы определяете порядок дат, которые вы хотите заказать:
#---define your category order--- cats = ['Mon','Tue','Wed','Thu','Fri'] # omit Sat and SunВ приведенном выше примере опустим субботу и воскресенье, поскольку нет данных о запасах за эти два дня (выходные).
Затем создайте новый категориальный тип данных, используя класс CategoricalDtype , передав порядок дней, который вы определили ранее:
from pandas.api.types import CategoricalDtype cat_type = CategoricalDtype(categories=cats, ordered=True)Наконец, преобразуйте столбец Day в новый категориальный тип, который вы только что создали:
#---cast the Day column as categorical--- df['Day'] = df['Day'].astype(cat_type) df.dtypesТеперь вы можете видеть, что Day относится к типу данных category :
Date object Open float64 High float64 Low float64 Close float64 Adj Close float64 Volume int64 Day category dtype: objectЕсли вы хотите распечатать все данные о запасах, отсортированные по дням недели, теперь вы можете использовать функцию groupby() :
for _, gp in df.groupby('Day'): display(gp.sample(3))Обратите внимание, что группы отсортированы по дням, сначала понедельник, затем вторник и т.д.:
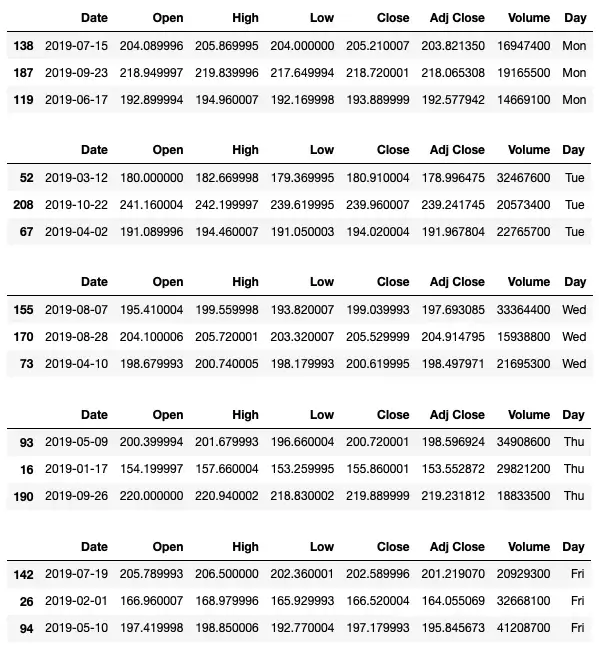
Если вы хотите, чтобы сначала отображались Tues, затем Wed и так далее, измените порядок в переменной cats :
cats = ['Tue','Wed','Thu','Fri','Mon'] # omit Sat and Sun cat_type = CategoricalDtype(categories=cats, ordered=True) #---cast the Day column as categorical--- df['Day'] = df['Day'].astype(cat_type) for _, gp in df.groupby('Day'): display(gp.sample(3))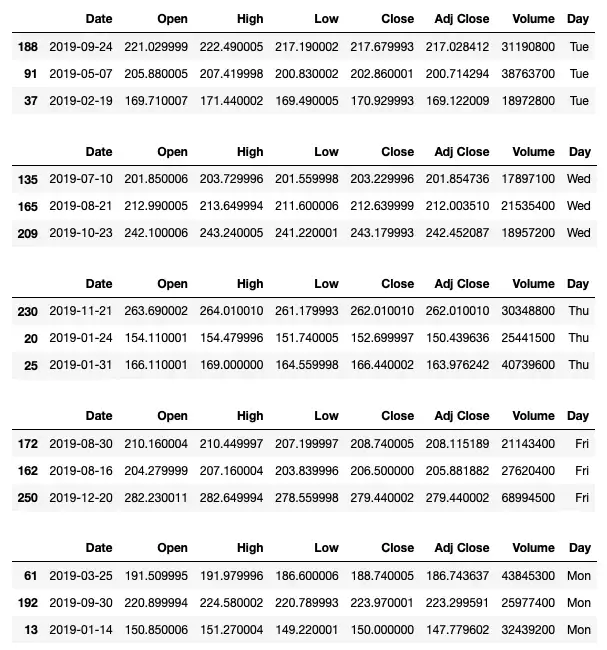
Преобразование столбцов даты и времени во время загрузки
В предыдущем разделе вы преобразовали столбец Date в тип данных datetime64 после того, как весь CSV-файл был загружен в DataFrame. Другим способом сделать то же самое было бы выполнить преобразование во время загрузки CSV с использованием параметра parse_dates :
df = pd.read_csv("AAPL.csv", parse_dates=['Date'])Параметр parse_dates указывает столбец (столбцы) для анализа как объект datetime64 .
Обратите внимание, что если параметру parse_dates присвоено значение True , Pandas попытается проанализировать индекс как объект datetime64
Анализ нескольких столбцов в качестве даты
Иногда даты в наборе данных хранятся отдельно в разных столбцах, например, один столбец для года, один столбец для месяцев и т.д. Хотя у сохранения данных таким образом есть свои плюсы и минусы, иногда бывает проще, если все разные столбцы можно объединить в один. Хороший пример такого представления находится в файле flights.csv.
Давайте загрузим файл flights.csv и рассмотрим пять выборочных строк в первых пяти столбцах:
df = pd.read_csv("flights.csv") # display sample 5 rows and first 5 columns df.sample(5).iloc[. 5]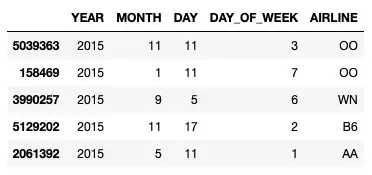
Объединение столбцов во время загрузки
В файле flights.csv дата каждого рейса представлена с использованием трех разных столбцов — YEAR, MONTH и DAY. Для выполнения анализа данных было бы проще, если бы вы могли объединить три столбца в один столбец даты, используя параметр parse_dates :
df = pd.read_csv("flights.csv", parse_dates=[[0,1,2]]) df.sample(5).iloc[. 5]В приведенном выше фрагменте кода мы использовали индекс столбца, чтобы указать столбцы для объединения в один столбец. Можно также указать название столбцов:
df = pd.read_csv("flights.csv", parse_dates=[['YEAR','MONTH','DAY']])В результате первые три столбца удаляются и заменяются новым столбцом, имя которого является объединением имен трех столбцов:
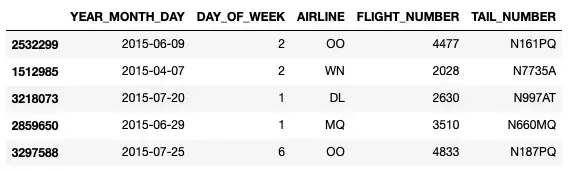
Обратите внимание, что ранее в статье был установлен параметр parse_dates с помощью списка — parse_dates=[‘Date’] . Установка его в список приведет к тому, что отдельные столбцы будут загружены как объекты datetime . Если вы установите для него значение list of list, например parse_dates=[[‘YEAR’,’MONTH’,’DAY’]] , то эти столбцы будут объединены в один объект datetime .
Предполагая, что у вас есть CSV, который выглядит следующим образом:
DATE,YEAR,MONTH,DAY 2015-09-13,2015,9,13 2015-09-14,2015,9,14Вы можете преобразовать столбец DATE в объект datetime и в то же время объединить столбцы YEAR , MONTH и DAY в единый объект datetime , используя следующие значения для параметра parse_dates :
df = pd.read_csv("test.csv", parse_dates=['DATE',['YEAR','MONTH','DAY']])Результат выглядит следующим образом:
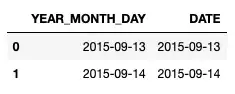
Распечатка dtypes из df подтверждает типы данных для обоих столбцов:
YEAR_MONTH_DAY datetime64[ns] DATE datetime64[ns] dtype: objectОбъединение столбцов после загрузки фрейма данных
Вы также можете объединить столбцы фрейма данных после его загрузки с помощью функции to_datetime() :
df = pd.read_csv("flights.csv") df['DATETIME'] = pd.to_datetime(df[['YEAR', 'MONTH', 'DAY']]) df.sample(5).iloc[:,-3:]Следующий вывод показывает последние три столбца фрейма данных, причем последний столбец является результатом объединения трех столбцов — YEAR , MONTH и DAY :
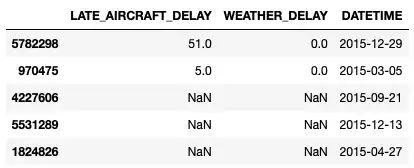
Форматирование Time
Помимо сохранения запланированной даты вылета в трех отдельных столбцах, вы также заметите, что существует столбец с именем SCHEDULED_DEPARTURE :
df[['SCHEDULED_DEPARTURE']]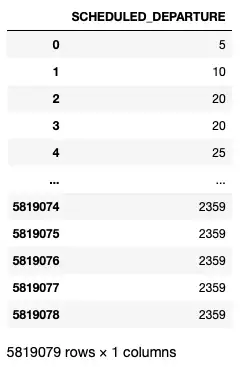
Этот столбец представляет собой целочисленный столбец, в котором хранятся такие числа, как 5,10, вплоть до 2359. То, что представляет каждое значение, на самом деле является временем отправления в формате HHMM. Таким образом, 5 на самом деле представляет 00:05, в то время как 2359 на самом деле представляет 23:59. Если бы вы собирались выполнить аналитику по этому столбцу, вам определенно нужно было бы обработать этот столбец дальше.
Мы тут объединим четыре столбца в столбец datetime :
Объединить первые три несложно, как мы видели в предыдущем разделе. Четвертый столбец нуждается в некоторой обработке:
- Вам нужно отформатировать время отправления в виде строки, а затем извлечь первые 2 цифры для представления часа (HH).
- Затем извлеките последние две цифры, представляющие минуты (MM)
Вышеуказанные действия могут быть реализованы следующим образом:
import datetime # function to convert HHMM to datetime.time def format_time(time): # format the time as string time = "".format(int(time)) # extract hh and mm and then convert to time hhmm = datetime.time(int(time[0:2]), int(time[2:4])) return hhmm df['SCHEDULED_DEPARTURE'] = \ df['SCHEDULED_DEPARTURE'].apply(format_time) df[['SCHEDULED_DEPARTURE']]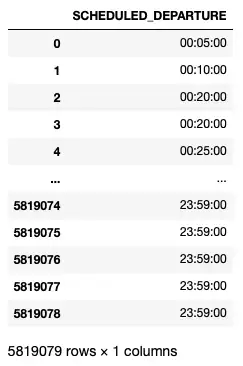
Объединение столбцов даты и времени
Теперь, когда в нашем фрейме данных есть два столбца типа данных datetime — DATETIME и SCHEDULED_DEPARTURE , теперь мы можем объединить их в один столбец. Следующий фрагмент кода использует функцию apply() вместе с функцией datetime.combine() для объединения двух указанных столбцов:
from datetime import datetime df['SCHEDULED_DEPARTURE'] = \ df.apply( lambda r: datetime.combine(r['DATETIME'], r['SCHEDULED_DEPARTURE']), axis=1) df.sample(5)[['SCHEDULED_DEPARTURE']]Столбец SCHEDULED_DEPARTURE теперь содержит как дату, так и время отправления:
И теперь вы можете легко найти все рейсы, вылетающие в определенное время:
df[(df['SCHEDULED_DEPARTURE'].dt.month == 12) & (df['SCHEDULED_DEPARTURE'].dt.year == 2015) & (df['SCHEDULED_DEPARTURE'].dt.hour >= 22) & (df['SCHEDULED_DEPARTURE'].dt.minute > 30)]\ [['FLIGHT_NUMBER','SCHEDULED_DEPARTURE']]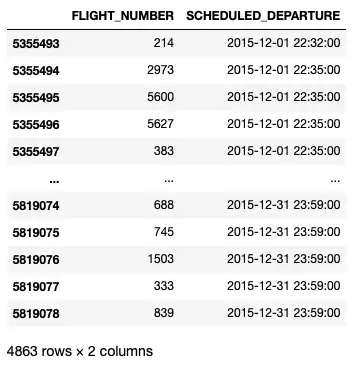
Заключение
Надеемся, что эта статья будет полезна для вас, когда дело дойдет до обработки даты и времени в ваших фреймах данных Pandas. В частности, мы рассмотрели:
- Как преобразовать столбец в тип данных datetime64 после загрузки фрейма данных
- Как загрузить столбец в качестве объекта datetime64 во время загрузки
- Как найти день недели для определенной даты
- Как отсортировать фрейм данных по дню недели
- Как объединить разные столбцы в качестве объекта datetime64 во время загрузки
- Как объединить разные столбцы в объект datetime64 после загрузки фрейма данных
- Как преобразовать строки в формат времени
- Как объединить столбцы даты и времени