PostgreSQL – Выбор базы данных
В данном разделе мы обсудим различные методы доступа к базам данным. Предположим, что мы только что создали базу данных согласно инструкции, приведенной выше. Вы можете выбрать необходимую Вам базу данных из списка доступных баз данных следующими способами:
- Database SQL Prompt
- OS Command Prompt
Database SQL Prompt
Допустим, Вы уже запустили свой PostgreSQL и остановились на следующем SQL prompt:
postgres=#
Проверьте список баз данных при помощи \l, то есть команды backslash el:
postgres-# \l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+---------+-------+----------------------- postgres | postgres | UTF8 | C | C | template0 | postgres | UTF8 | C | C | =c/postgres + | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | C | C | =c/postgres + | | | | | postgres=CTc/postgres testdb | postgres | UTF8 | C | C | (4 rows) postgres-#
Теперь введите следующую команду для выбора нужной Вам базы данных; в данном случае мы выберем тестовую базу данных testdb.
postgres=# \c testdb; psql (9.2.4) Type "help" for help. You are now connected to database "testdb" as user "postgres". testdb=#
OS Command Prompt
Вы можете выбрать свою базу данных из самой командной строки во время входа в свою базу данных. Ниже приведен простой пример:
psql -h localhost -p 5432 -U postgress testdb Password for user postgress: **** psql (9.2.4) Type "help" for help. You are now connected to database "testdb" as user "postgres". testdb=#
Сейчас Вы находитесь в тестовой базе данных PostgreSQL testdb и можете выполнять команды внутри нее. Для того, чтобы выйти из базы, используйте команду \q.
Как выбрать базу данных postgresql
Создав базу данных, вы можете обратиться к ней:
Запустив терминальную программу Postgres Pro под названием psql , в которой можно интерактивно вводить, редактировать и выполнять команды SQL .
Используя существующие графические инструменты, например, pgAdmin или офисный пакет с поддержкой ODBC или JDBC , позволяющий создавать и управлять базой данных. Эти возможности здесь не рассматриваются.
Чтобы работать с примерами этого введения, начните с psql . Подключиться с его помощью к базе данных mydb можно, введя команду:
$psql mydb
Если имя базы данных не указать, она будет выбрана по имени пользователя. Об этом уже рассказывалось в предыдущем разделе, посвящённом команде createdb .
В psql вы увидите следующее сообщение:
psql (10.23.1) Type "help" for help. mydb=>
Последняя строка может выглядеть и так:
mydb=#
Что показывает, что вы являетесь суперпользователем, и так скорее всего будет, если вы устанавливали экземпляр Postgres Pro сами. В этом случае на вас не будут распространяться никакие ограничения доступа, но для целей данного введения это не важно.
Если вы столкнулись с проблемами при запуске psql , вернитесь к предыдущему разделу. Команды createdb и psql подключаются к серверу одинаково, так что если первая работает, должна работать и вторая.
Последняя строка в выводе psql — это приглашение, которое показывает, что psql ждёт ваших команд и вы можете вводить SQL -запросы в рабочей среде psql . Попробуйте эти команды:
mydb=>SELECT pgpro_version();version ------------------------------------------------------------------------------------------ PostgresPro 10.23.1 on x86_64-pc-linux-gnu, compiled by gcc (Debian 4.9.2-10) 4.9.2, 64-bit (1 row)mydb=>SELECT current_date;date ------------ 2016-01-07 (1 row)mydb=>SELECT 2 + 2;?column? ---------- 4 (1 row)
В программе psql есть множество внутренних команд, которые не являются SQL-операторами. Они начинаются с обратной косой черты, « \ » . Например, вы можете получить справку по различным SQL -командам Postgres Pro , введя:
mydb=>\h
Чтобы выйти из psql , введите:
mydb=>\q
и psql завершит свою работу, а вы вернётесь в командную оболочку операционной системы. (Чтобы узнать о внутренних командах, введите \? в приглашении командной строки psql .) Все возможности psql документированы в справке psql . В этом руководстве мы не будем использовать эти возможности явно, но вы можете изучить их и применять при удобном случае.
| Пред. | Наверх | След. |
| 1.3. Создание базы данных | Начало | Глава 2. Язык SQL |
Как выбрать базу данных postgresql
CREATE DATABASE — создать базу данных
Синтаксис
CREATE DATABASEимя[ [ WITH ] [ OWNER [=]имя_пользователя] [ TEMPLATE [=]шаблон] [ ENCODING [=]кодировка] [ LC_COLLATE [=]категория_сортировки] [ LC_CTYPE [=]категория_типов_символов] [ TABLESPACE [=]табл_пространство] [ ALLOW_CONNECTIONS [=]разр_подключения] [ CONNECTION LIMIT [=]предел_подключений] [ IS_TEMPLATE [=]это_шаблон] ]
Описание
Команда CREATE DATABASE создаёт базу данных PostgreSQL .
Чтобы создать базу данных, необходимо быть суперпользователем или иметь специальное право CREATEDB . См. CREATE USER .
По умолчанию новая база данных создаётся копированием стандартной системной базы данных template1 . Задать другой шаблон можно, добавив указание TEMPLATE имя . В частности, написав TEMPLATE template0 , можно создать девственно чистую базу данных, содержащую только стандартные объекты, предопределённые установленной версией PostgreSQL . Это бывает полезно, когда копировать в новую базу любые дополнительные объекты, добавленные локально в template1 , нежелательно.
Параметры
Имя создаваемой базы данных. имя_пользователя
Имя пользователя (роли), назначаемого владельцем новой базы данных, либо DEFAULT , чтобы владельцем стал пользователь по умолчанию (а именно, пользователь, выполняющий команду). Чтобы создать базу данных и сделать её владельцем другую роль, необходимо быть непосредственным или опосредованным членом этой роли, либо суперпользователем. шаблон
Имя шаблона, из которого будет создаваться новая база данных, либо DEFAULT , чтобы выбрать шаблон по умолчанию ( template1 ). кодировка
Кодировка символов в новой базе данных. Укажите строковую константу (например, ‘SQL_ASCII’ ) или целочисленный номер кодировки, либо DEFAULT , чтобы выбрать кодировку по умолчанию (а именно, кодировку шаблона). Наборы символов, которые поддерживает PostgreSQL , перечислены в Подразделе 23.3.1. Дополнительные ограничения описаны ниже. категория_сортировки
Порядок сортировки ( LC_COLLATE ), который будет использоваться в новой базе данных. Этот параметр определяет порядок сортировки строк, например, в запросах с ORDER BY, а также порядок индексов по текстовым столбцам. По умолчанию используется порядок сортировки, установленный в шаблоне. Дополнительные ограничения описаны ниже. категория_типов_символов
Классификация символов ( LC_CTYPE ), которая будет применяться в новой базе данных. Этот параметр определяет принадлежность символов категориям, например: строчные, заглавные, цифры и т. п. По умолчанию используется классификация символов, установленная в шаблоне. Дополнительные ограничения описаны ниже. табл_пространство
Имя табличного пространства, связываемого с новой базой данных, или DEFAULT для использования табличного пространства шаблона. Это табличное пространство будет использоваться по умолчанию для объектов, создаваемых в этой базе. За подробностями обратитесь к CREATE TABLESPACE . разр_подключения
Если false, никто не сможет подключаться к этой базе данных. По умолчанию имеет значение true, то есть подключения принимаются (если не ограничиваются другими механизмами, например, GRANT / REVOKE CONNECT ). предел_подключений
Максимальное количество одновременных подключений к этой базе данных. Значение -1 (по умолчанию) снимает ограничение. это_шаблон
Если true, базу данных сможет клонировать любой пользователь с правами CREATEDB ; в противном случае (по умолчанию), клонировать эту базу смогут только суперпользователи и её владелец.
Дополнительные параметры могут записываться в любом порядке, не обязательно так, как показано выше.
Замечания
CREATE DATABASE нельзя выполнять внутри блока транзакции.
Ошибки, содержащие сообщение « не удалось инициализировать каталог базы данных » , чаще всего связаны с нехваткой прав в каталоге данных, заполнением диска или другими проблемами в файловой системе.
Для удаления базы данных применяется DROP DATABASE .
Программа createdb представляет собой оболочку этой команды, созданную ради удобства.
Конфигурационные параметры уровня базы данных (устанавливаемые командой ALTER DATABASE ) и разрешения уровня базы (устанавливаемые командой GRANT ) из шаблона не копируются.
Хотя с помощью этой команды можно скопировать любую базу данных, а не только template1 , указав её имя в качестве имени шаблона, она не предназначена (пока) для использования в качестве универсального средства вроде « COPY DATABASE » . Принципиальным ограничением является невозможность копирования базы данных шаблона, если установлены другие подключения к ней. CREATE DATABASE выдаёт ошибку, если при запуске команды есть другие подключения к этой базе; в противном случае новые подключения к базе блокируются до завершения команды CREATE DATABASE . За дополнительными сведениями обратитесь к Разделу 22.3.
Кодировка символов, указанная для новой базы данных, должна быть совместима с выбранными параметрами локали ( LC_COLLATE и LC_CTYPE ). Если выбрана локаль C (или равнозначная ей POSIX ), допускаются все кодировки, но для других локалей правильно будет работать только одна кодировка. (В Windows, однако, кодировку UTF-8 можно использовать с любой локалью.) CREATE DATABASE позволяет суперпользователям указать кодировку SQL_ASCII вне зависимости от локали, но этот вариант считается устаревшим и может привести к ошибочному поведению строковых функций, если в базе хранятся данные в кодировке, несовместимой с заданной локалью.
Параметры локали и кодировка должны соответствовать тем, что установлены в шаблоне, если только это не template0 . Это ограничение объясняется тем, что другие базы данных могут содержать данные в кодировке, отличной от заданной, или индексы, порядок сортировки которых определяются параметрами LC_COLLATE и LC_CTYPE . При копировании таких данных получится база, которая будет испорченной согласно новым параметрам локали. Однако template0 определённо не содержит какие-либо данные или индексы, зависящие от кодировки или локали.
Ограничение CONNECTION LIMIT действует только приблизительно; если одновременно запускаются два сеанса, тогда как в базе остаётся только одно « свободное место » , может так случиться, что будут отклонены оба подключения. Кроме того, это ограничение не распространяется на суперпользователей и фоновые рабочие процессы.
Примеры
Создание базы данных:
CREATE DATABASE lusiadas;
Создание базы данных sales , принадлежащей пользователю salesapp , с табличным пространством по умолчанию salesspace :
CREATE DATABASE sales OWNER salesapp TABLESPACE salesspace;
Создание базы данных music с кодировкой ISO-8859-1:
CREATE DATABASE music ENCODING 'LATIN1' TEMPLATE template0;
В этом примере предложение TEMPLATE template0 будет необходимым, только если кодировка template1 отличается от ISO-8859-1. Заметьте, что при смене кодировки может потребоваться также выбрать другие параметры LC_COLLATE и LC_CTYPE .
Совместимость
Оператор CREATE DATABASE отсутствует в стандарте SQL. Базы данных равнозначны каталогам, а их создание в стандарте определяется реализацией.
См. также
| Пред. | Наверх | След. |
| CREATE CONVERSION | Начало | CREATE DOMAIN |
Ключевые аспекты при выборе базы данных для вашего приложения

Положительный опыт пользователя вашего приложения напрямую зависит от выбранного вами способа управления данными. Если ваше приложение не способно быстро получать, обрабатывать и доставлять информацию, то совсем неважно, насколько удачен его интерфейс и чист его код. Более того, все рабочие данные должны быть защищены от попадания в руки злоумышленников. Чтобы достичь этого, нужно правильно подобрать систему управления базой данных.
База данных — это то место, где вы храните и систематизируете все данные, которые собирает ваше приложение, а система управления базой данных (СУБД) — это программное обеспечение для удобного управления базой данных.
На рынке представлено более 300 систем управления базами данных. Такой широкий выбор поистине ошеломляет. Но вам необязательно изучать их все самостоятельно. Мы сделали это за вас и теперь поделимся своими выводами. В этой статье мы даем ценные советы о том, как выбрать правильную базу данных для вашего приложения.
Базы данных SQL и NoSQL
Одна из главных проблем при выборе базы данных — это выбор между структурами данных SQL (реляционная модель) и NoSQL (нереляционная модель). Обе они обладают хорошей производительностью, но есть некоторые ключевые различия, о которых следует помнить.
Базы данных SQL
Реляционная база данных — это набор таблиц, между которыми установлены определенные взаимосвязи. Для обслуживания реляционной базы данных и создания запросов к ней система управления базой данных использует язык структурированных запросов (Structured Query Language, SQL) — обычное пользовательское приложение, предоставляющее простой интерфейс программирования для взаимодействия с базой данных.
Реляционные базы данных состоят из строк, называемых кортежами, и столбцов, называемых атрибутами. Кортежи в таблице используют одни и те же атрибуты.
Преимущества баз данных SQL
Реляционная база данных идеально подходит для хранения структурированных данных (почтовых кодов, номеров кредитных карточек, дат, идентификационных номеров). SQL — испытанная технология: она хорошо задокументирована, имеет прекрасную поддержку и отлично работает с большинством современных структур и библиотек. Наиболее яркими примерами баз данных SQL служат PostgreSQL и MySQL. Обе зарекомендовали себя как стабильные и безопасные.
Еще одно большое преимущество реляционных баз данных — их безопасность. Реляционные базы данных поддерживают разрешения на доступ, определяющие, кто может читать и редактировать данные. Администратор базы данных может предоставить конкретному пользователю права на доступ, выбор, вставку или удаление данных. Это защищает информацию от кражи третьими лицами.
Использование системы управления реляционными базами данных (РСУБД) защищает данные от потери и повреждения благодаря четырем свойствам ACID: атомарности, согласованности, изолированности и прочности. Чтобы лучше понять, что это значит, предположим, что две покупательницы одновременно пытаются купить красное платье одинакового размера. При соблюдении принципов ACID эти транзакции гарантированно друг друга не перекроют.

- Атомарность означает, что каждая транзакция (последовательность из одной или нескольких операций SQL) рассматривается как единое целое. Она может завершиться удачно или неудачно только целиком: если одна из операций завершается неудачно, вся транзакция завершается неудачно. Когда пользователь покупает товар, деньги снимаются с его счета и переводятся на счет продавца. Атомарность гарантирует, что, если транзакция для пополнения счета заканчивается неудачно, операция снятия средств не выполняется.
- Согласованность означает, что в базу данных можно записывать только достоверные данные, соответствующие всем правилам. Если вводимые данные недостоверны, база данных возвращается в состояние, предшествующее транзакции. Это гарантирует, что незаконные транзакции не смогут повредить базу данных.
- Изолированность означает, что незавершенные транзакции остаются изолированными. Это обеспечивает независимую и безопасную обработку всех транзакций.
- Прочность означает, что система сохраняет данные даже в случае неуспешной транзакции. Таким образом, данные не потеряются, даже если система выйдет из строя.
Соблюдение принципов ACID предпочтительно для приложений, обрабатывающих финансовые, медицинские и закрытые персональные данные, поскольку оно автоматически обеспечивает пользователям безопасность и конфиденциальность. Благодаря всем этим преимуществам реляционные базы данных идеально подходят для финансовых и медицинских проектов.
Недостатки реляционных баз данных
У реляционных баз данных есть и недостатки.
- Им не хватает гибкости. Реляционные базы данных не могут эффективно работать с полуструктурированными и неструктурированными данными, поэтому они не очень подходят для больших нагрузок и аналитики Интернета вещей.
- По мере усложнения структуры данных становится все труднее передавать информацию из одного программного решения, ориентированного на большие данные, в другое. В крупных организациях реляционные базы данных часто растут независимо в отдельных подразделениях.
- Реляционные базы данных работают только на одном сервере. Следовательно, чтобы ваша СУБД справлялась с еще большим объемом данных, вам придется потратиться на дорогостоящее физическое оборудование.
Эти недостатки вынудили разработчиков искать альтернативы реляционным базам данных. В результате появились базы данных NoSQL и NewSQL.
Базы данных NoSQL
Базы данных NoSQL, называемые также нереляционными или распределенными базами данных, служат альтернативой реляционным базам данных. Они предоставляют разработчикам большую степень гибкости и масштабируемости, поскольку в них можно хранить и обрабатывать неструктурированные данные (данные из социальных сетей, фотографии, MP3-файлы и т. д.).
Данные в нереляционных базах можно изменять динамически, не затрагивая существующие данные. Кроме того, базы данных NoSQL могут работать на нескольких серверах, поэтому масштабировать их дешевле и проще, чем базы данных SQL.
И поскольку базы данных NoSQL не зависят от одного-единственного сервера, они более отказоустойчивы. Это значит, что в случае отказа одного из компонентов база данных может продолжить работу.
Однако базы данных NoSQL еще не достигли такого уровня развития, как базы данных SQL, и среда NoSQL не так хорошо определена. К тому же базы данных NoSQL ради доступности и гибкости зачастую жертвуют соблюдением принципов ACID.
Базы данных NoSQL можно разделить на четыре типа.
Это база данных NoSQL простейшего типа, в которой могут храниться только пары «ключ-значение» и предлагаются базовые функции для получения значения, связанного с ключом. Хранилище типа «ключ-значение» — отличный вариант, если вы хотите быстро найти информацию с помощью ключа. Наиболее яркими примерами хранилищ такого типа являются базы данных Amazon DynamoDB и Redis.

Благодаря простой структуре базы данных DynamoDB и Redis чрезвычайно легко масштабируются. При отсутствии связей между значениями и обязательных схем построения количество значений ограничено только мощностью компьютера.
Вот почему хранилища типа «ключ-значение» используют поставщики услуг хостинга типа ScaleGrid, Compose и Redis Labs. Разработчики часто используют хранилища такого типа для кэширования данных. Эти хранилища также хорошо подходят для хранения комментариев в блогах, обзоров продукции, профилей пользователей и различных настроек.
Такие базы данных проще всего масштабировать по горизонтали, то есть добавлять новые сервера для хранения еще большего количества данных. Это менее затратно, чем масштабирование реляционных баз данных, но может привести к росту коммунальных платежей за охлаждение и электричество.
Однако простота хранилищ типа «ключ-значение» может быть и недостатком. С хранилищем такого типа трудно или даже невозможно выполнять большинство операций, доступных в базах данных другого типа. Хотя поиск по ключам действительно очень быстрый, поиск по значениям может занимать гораздо больше времени.
В большинстве случаев хранилища типа «ключ-значение» используются в сочетании с базой данных другого типа. В приложениях Healthfully и KPMG мы использовали хранилище Redis типа «ключ-значение» вместе с системой управления реляционными базами данных PostgreSQL.
В документно-ориентированных базах данных вся информация, относящаяся к определенному объекту, хранится в одном файле формата BSON, JSON или XML. Однотипные документы могут быть сгруппированы в так называемые коллекции или списки. Эти базы данных позволяют разработчикам не беспокоиться о типах данных и надежных связях.
Модель документно-ориентированной базы данных обычно представляет собой дерево или лес. В древовидной структуре у корневого узла имеется один или несколько узлов-листьев. Структура типа «лес» состоит из нескольких деревьев. Эти структуры данных помогают выполнять быстрый поиск в хранилищах документов. Это затрудняет управление сложными системами с многочисленными связями между элементами, однако позволяет разработчикам создавать коллекции документов по темам или типам.
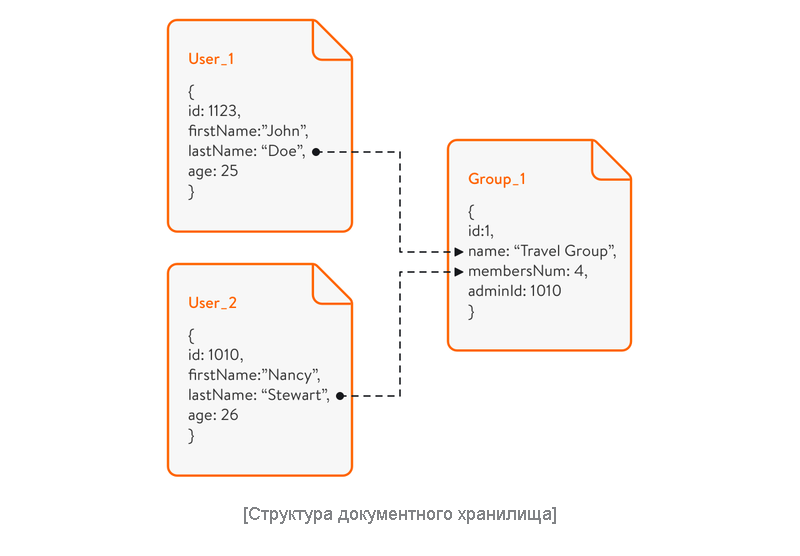
Например, если вы создаете приложение для потоковой передачи музыки, то можете использовать документно-ориентированную базу данных для создания коллекции песен Рианны, чтобы пользователям было легко найти ее треки.
Ради гибкости документно-ориентированные базы данных пренебрегают гарантиями, которые дает соблюдение принципов ACID. MongoDB и Couchbase — отличные примеры документно-ориентированных баз данных.
Благодаря своей структуре и гибкости документно-ориентированные базы данных обычно используются для управления контентом, быстрого создания прототипов и анализа данных.
Столбчатая база данных оптимизирована для быстрого поиска столбцов данных. В столбцово-ориентированных базах данных каждый столбец хранится в виде логического массива значений. Базы данных такого типа обеспечивают высокую масштабируемость и легко дублируются.

Столбцовое хранилище работает как со структурированными, так и с неструктурированными данными, максимально упрощая поиски в базе данных. Столбчатые базы данных очень быстро обрабатывают аналитические операции, но показывают плохие результаты при обработке транзакций. Apache Cassandra и Scylla входят в число самых популярных столбцовых хранилищ.
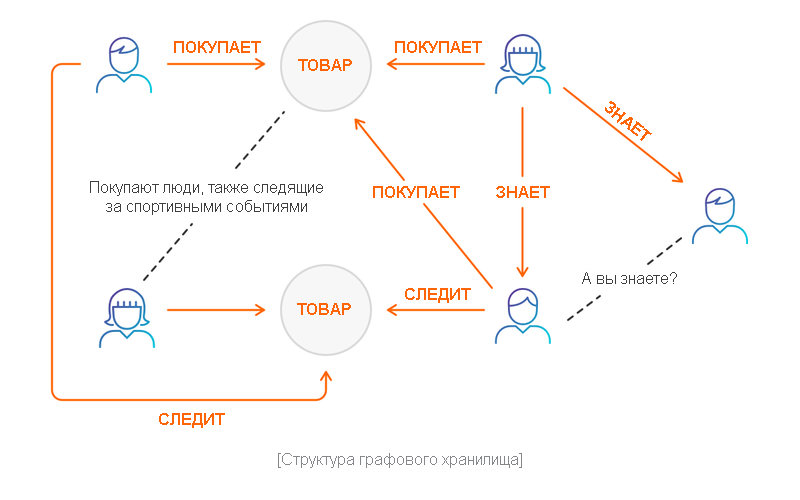
В графовом хранилище каждая структурная единица, называемая узлом, представляет собой изолированный документ с данными произвольной формы. Узлы соединены ребрами, которые определяют связи между ними.
Такой подход упрощает визуализацию данных и анализ графов. Графовые базы данных обычно используются для определения взаимосвязей между точками данных. Большинство графовых баз данных поддерживают такие функции, как поиск узла с наибольшим количеством связей и поиск всех связанных узлов.
Графовые базы данных оптимизированы для проектов с графовыми структурами данных, таких как социальные сети и семантическая паутина. Neo4J и Datastax Enterprise — лучшие образцы графовых баз данных.
NewSQL — объединение преимуществ баз данных SQL и NoSQL
Особого внимания заслуживает NewSQL — класс реляционных баз данных, сочетающий в себе возможности баз данных SQL и NoSQL.
Базы данных NewSQL предназначены для решения общих проблем баз данных SQL, связанных с традиционной обработкой онлайн-транзакций. NewSQL в наследство от NoSQL достались оптимизация обработки онлайн-транзакций, масштабируемость, гибкость и бессерверная архитектура. При этом структуры NewSQL, как и реляционные базы данных, поддерживают принципы ACID и согласованность. Они могут масштабироваться, зачастую по запросу, не влияя на логику приложения и не нарушая модель транзакций.
Класс NewSQL появился в 2011 году и пока не получил особой популярности. В нем реализована лишь часть богатого инструментария SQL. Гибкость и бессерверная архитектура в сочетании с высокой степенью безопасности и доступности без применения резервных систем — все это увеличивает шансы NewSQL на то, чтобы стать решением следующего поколения для облачных технологий.
Наиболее популярные базы данных NewSQL: ClustrixDB, CockroachDB, NuoDB, MemSQL и VoltDB.
Что нужно учитывать при выборе базы данных?
При выборе инструмента для управления базой данных следует обратить внимание на несколько моментов.
Базы данных SQL идеально подходят для хранения и обработки структурированных данных, а базы данных NoSQL — это наилучшее решение для работы с неструктурированными и полуструктурированными данными. Если вы будете управлять и структурированными, и неструктурированными данными, сделайте выбор в пользу объединения SQL и NoSQL.
По мере развития вашего веб-продукта должна расти и его база данных. На выбор базы данных может повлиять предпочитаемый вами тип масштабирования: горизонтальное или вертикальное. Нереляционные базы данных с их хранилищами типа «ключ-значение» оптимизированы для горизонтального масштабирования, а реляционные базы данных — для вертикального.
База данных должна быть хорошо защищена, поскольку в ней хранятся все данные пользователей. Реляционные базы данных, поддерживающие принципы ACID, более безопасны, чем нереляционные, которые делают упор на производительность и масштабируемость в ущерб согласованности и безопасности. Поэтому вам необходимо принять дополнительные меры для защиты своей базы данных NoSQL.
Важное замечание по выбору СУБД: убедитесь в том, что вашу систему управления базой данных можно интегрировать с другими инструментами и сервисами, входящими в ваш проект. Неспособность интегрироваться с другими решениями в большинстве случаев может привести к остановке проекта.
Например, ArangoDB показывает отличную производительность, но библиотеки для этой СУБД появились относительно недавно и пока не имеют поддержки. Использовать ArangoDB в сочетании с другими инструментами рискованно, поэтому сообщество не рекомендует применять ArangoDB для сложных проектов.
Популярные системы управления базами данных
Хотите знать, какие базы данных самые популярные в 2021 году? Взгляните на базы данных из следующего списка.
OracleDB
OracleDB — РСУБД, созданная в 1977 году и по сей день остающаяся самым известным и надежным решением. Она занимает первое место в рейтинге DB-Engines. Рассмотрим подробнее причины популярности OracleDB.
- Ее поддерживает компания Oracle, поэтому она надежна. Разработчики отмечают, что OracleDB редко выходит из строя и получает регулярные обновления.
- Она хорошо масштабируется и способна обрабатывать очень большие объемы данных. В настоящее время Oracle переносит все свои продукты и сервисы в облако, что обеспечивает большую гибкость.
- Она безопасна за счет строгого следования всем современным стандартам безопасности (включая совместимость с PCI) и предлагает надежное шифрование конфиденциальных данных.
- Она эффективно управляет памятью и легко справляется со сложными операциями. Кроме того, она эффективно взаимодействует с различными сторонними инструментами.
- Она превосходит другие решения с точки зрения скорости доступа к данным по сети.
У OracleDB имеются и недостатки.
- OracleDB — самая популярная СУБД, но и одна из самых дорогих. Одна лицензия на процессор для стандартной версии будет стоить 17 500 долл. США.
- Документация Oracle слишком сложна, и хороших руководств не хватает. Служба поддержки очень полезна, однако некоторые разработчики жалуются на слишком долгое ожидание ответа.
Все это делает OracleDB идеальным решением для крупных предприятий, которым требуется хранить большой объем данных. Малым и средним предприятиям лучше поискать менее затратные альтернативы.
MySQL
MySQL — одна из самых популярных систем управления реляционными базами данных, которая была создана в 1995 году и сейчас находится под управлением Oracle. У этой системы баз данных с открытым исходным кодом имеются огромная пользовательская база и отличная поддержка, и она хорошо работает с большинством структур и библиотек. Предоставляется бесплатно, но предлагаются дополнительные функции по фиксированной цене.
Разработчики могут установить и использовать MySQL, не тратя много времени на настройку. Большинство задач можно выполнить из командной строки. Это хорошо структурированная база данных с регулярными обновлениями.
MySQL превосходно работает со структурированными данными на базовом уровне. Но если в будущем вы планируете масштабировать свой продукт, вам может потребоваться дополнительная поддержка, которая стоит немалых денег. Кроме того, создание инкрементных резервных копий или изменение архитектуры данных в MySQL занимает много времени в отличие от конкурентов, которые могут делать это автоматически.
Uber, Facebook, Tesla, YouTube, Netflix, Spotify, Airbnb и многие другие компании используют в своих сервисах MySQL. Мы тоже используем эту СУБД в наших проектах.
PostgreSQL
Это объектно-реляционная база данных, то есть она похожа на реляционные базы данных, но все данные в ней представлены в виде объектов, а не столбцов и строк.
PostgreSQL — идеальное решение для больших систем, поскольку она масштабируемая и предназначена для обработки терабайтов данных. Иерархия ролей для реализации прав пользователей обеспечивает дополнительную защиту.
В отличие от MySQL, база данных PostgreSQL полностью бесплатна. Ее открытый исходный код означает, что всю документацию и поддержку предоставляют добровольцы-энтузиасты. Это также означает, что в случае возникновения проблем с PostgreSQL вам нужно будет искать специалиста, который сможет их решить.
Мы перенесли приложение World Cleanup (приложение для управления мероприятием World Cleanup Day) из CouchDB в PostgreSQL. Переход на PostgreSQL позволяет нам не только одновременно выполнять операции ввода и вывода, но и легко справляться с большими нагрузками.
MongoDB
MongoDB — наиболее популярная база данных NoSQL, которую мы используем в наших проектах. В MongoDB все данные хранятся в документах формата BSON (Binary JSON). Благодаря этому данные можно легко передавать между веб-приложениями и серверами в человекочитаемом формате.
В MongoDB есть встроенная репликация, что обеспечивает хорошую масштабируемость и доступность. Благодаря автоматическому разделению данных вы легко можете распределять данные по серверам, связанным с вашим приложением. В общем, MongoDB — отличное решение для работы с объемными наборами неструктурированных данных. Ее можно использовать в большинстве систем обработки больших данных — и не только как оперативное хранилище данных в реальном времени, но и в автономном режиме.
Однако у этой платформы баз данных есть и некоторые недостатки. В ней хранятся имена ключей для каждой пары значений, что увеличивает объем используемой памяти. Кроме того, в ней нет ограничений по внешнему ключу, что могло бы гарантировать согласованность, а глубина вложенности ограничена сотней уровней.
Мы используем MongoDB в сочетании с Redis в Boothapp — платформе социальной электронной коммерции для ближневосточного рынка.
Redis
Redis — это хранилище типа «ключ-значение» с открытым исходным кодом, которое часто используется в качестве кэша для работы с другим решением для хранения данных. Основная причина, по которой разработчики выбирают Redis, — скорость, значительно превосходящая другие системы управления базами данных. И еще ее легко устанавливать, настраивать и использовать.
Но в Redis отсутствует встроенное шифрование и хранятся данные только пяти типов: списки, наборы, отсортированные наборы, хэши и строки. Redis в первую очередь предназначена для хранения наборов данных без сложной структуры. Поэтому этот инструмент обычно используется в сочетании с системой баз данных другого типа и иногда для микросервисов. Так как Redis — отличное решение для кэширования, мы используем его в этом качестве в большинстве своих проектов, включая приложения KPMG, Half Cost Hotels, Mikitsune и Healthfully.
Elasticsearch
Elasticsearch — это документно-ориентированная база данных с открытым исходным кодом, в которой хранятся и индексируются данные любого типа (текстовые, числовые или геопространственные) в формате JSON. Тем самым она обеспечивает быстрый поиск и получение данных. Elasticsearch создана на основе Lucene — Java-библиотеки с открытым исходным кодом, реализующей функции хранения и поиска данных.
Одна из основных причин популярности Elasticsearch — это масштабируемость. Она легко масштабируется по горизонтали, позволяя добавлять дополнительные ресурсы.
Начиная с версии Elasticsearch 6.7, пользователи могут управлять жизненным циклом данных. Данные можно отнести к категории «горячих», «теплых» или «холодных» в зависимости от количества запросов к ним и хранить в «горячих», «теплых» или «холодных» узлах соответственно. Это позволяет быстрее получать самые актуальные (то есть самые горячие) данные, поскольку в качестве горячих узлов используются твердотельные накопители — устройства хранения более нового и более быстрого типа. Теплым и холодным узлам вполне подходят традиционные жесткие диски, которые работают медленнее.
Netflix, Stack Overflow, LinkedIn и Medium используют базу данных Elasticsearch.

Объединение и совмещение баз данных
В одном проекте можно использовать несколько баз данных. Однако объединение двух баз данных — не всегда хорошая идея. Перед принятием такого решения разработчикам следует тщательно проанализировать потребности проекта и определить комплекс технологий.
Redis часто используется в сочетании с другими базами данных. Мы использовали Redis вместе с PostgreSQL для Healthfully — медицинской платформы для связи пациентов и медицинских работников. Мы выбрали систему Redis для хранения кэша и маркеров (токенов), поскольку она работает быстрее, чем большинство современных баз данных. По той же причине мы использовали Redis вместе с PostgreSQL при разработке приложения для KPMG. Мы часто используем эту пару в наших проектах, поскольку можем легко и быстро делать ссылки из Redis на PostgreSQL.
Сочетание MongoDB и PostgreSQL — не лучшая идея, потому что эти базы данных равны с точки зрения использования ресурсов и хранения данных. Например, предположим, что у вас есть социальная сеть типа Instagram и вам требуется хранить информацию о сообщениях, лайках, подписчиках и профилях пользователей. Данные о лайках и сообщениях хранятся в MongoDB, а данные о профилях пользователей и подписчиках — в PostgreSQL. Сперва вам нужно взять данные о профилях из PostgreSQL, а затем данные о сообщениях из MongoDB, что затратно по времени и неэффективно.
Как видите, выбор БД для вашего проекта зависит от множества факторов, включая типы данных, которые планируется собирать и обрабатывать, интеграцию с другими инструментами и подход к масштабированию, которого вы придерживаетесь. Это не просто вопрос выбора между SQL и NoSQL, как многие думают.
И даже несмотря на то, что надлежащее управление данными не является первым пунктом, который вы оцениваете при оптимизации взаимодействия с пользователем, его определенно не следует сбрасывать со счетов. Мы можем помочь вам в поиске наилучшего из возможных решений для базы данных вашего мобильного или веб-приложения. Напишите нам, если хотите, чтобы мы помогли вам выбрать правильную базу данных для вашего приложения.
Перевод статьи подготовлен в преддверии старта курса «Базы данных».
Напоминаем о том, что завтра пройдет второй день онлайн-интенсива «Бэкапы и репликация PostgreSQL. Практика применения». Цели занятия: настроить бэкапы; восстановить информацию после сбоя.