Как узнать сколько раз встречается слово в тексте
Argument ‘Topic id’ is null or empty
Сейчас на форуме
© Николай Павлов, Planetaexcel, 2006-2023
info@planetaexcel.ru
Использование любых материалов сайта допускается строго с указанием прямой ссылки на источник, упоминанием названия сайта, имени автора и неизменности исходного текста и иллюстраций.
| ООО «Планета Эксел» ИНН 7735603520 ОГРН 1147746834949 |
ИП Павлов Николай Владимирович ИНН 633015842586 ОГРНИП 310633031600071 |
Анализ сложности текста
Текстометр помогает определить уровень сложности и читабельности текста, посчитать количество слов и знаков, найти среднюю длину слова и предложения, ключевые слова текста, рассчитать коэффициент лексического разнообразия текста, получить список слов текста и рассчитать время его чтения.
Русский как иностранный
Русский как родной
Определить
Вставить демо текст
О проекте
Текстометр помогает бесплатно определить уровень сложности текста на русском языке, рассчитать индексы удобочитаемости, узнать уровень текста по шкале CEFR, рассчитать посчитать количество слов и знаков, найти ключевые слова текста, рассчитать коэффициент лексического разнообразия текста, получить список слов из текста и рассчитать время его чтения, а также определить статистику по вхождению слов в лексические минимумы.
Уровень CEFR и ТРКИ/TORFL
Определение уровня сложности текста по шкале CEFR от А1 до С2 происходит автоматически, с помощью регрессионной модели, обученной на корпусе из 800 текстов из пособий по РКИ. В разделе Публикации вы можете найти статьи с более подробной информацией о том, как работает автоматическое определение сложности текста в нашем сервисе [2], о корпусе текстов из пособий РКИ RuFoLa [3] и о том, как использовать Текстометр на уроке русского языка [1].
Уровень ACTFL
Уровень сложности текста по шкале ACTFL предлагается с помощью таблицы соответствий CEFR и ACTFL в разделе рецептивных навыков. Подробнее о соответствиях здесь.
Может ли она ошибаться? Эксперименты показывают, что модель склонна немного завышать уровень сложности текста, поскольку она производит расчеты исходя из данных лексических минимумов. Практика же показывает, что студенты обычно знают (или угадывают из контекста) больше слов, чем в минимумах. Особенно это касается интернационализмов и слов, которые похоже звучат на родном языке ученика. Это стоит учитывать при подготовке текстов для славяно- или англоговорящих учеников. Подробнее об эксперименте со сравнением работы программы, мнения экспертов-преподавателей и самих студентов можно почитать здесь [4].
Оценка уровня сложности текста для школьников
Уровни сложности текста для иностранцев хорошо стандартизированы и задокументированы. В текстах для носителей языка понятие сложности текста многограннее: текст бывает написан короткими словами и фразами, что позволяет стандартным формулам читабельности отнести его к простым, но «продраться» сквозь незнакомые слова или стилистические особенности затруднительно.
Поэтому проверка текст на читабельность носителями языка наша система оценивает по двум критериям: структурная сложность и лексическая. Структурная сложность учитывает классическую формулу читабельности Флеша, адаптированную для русского языка, а также наличие частей речи и оборотов, затрудняющих чтение (причастия, пассивные формы и др.) Лексическая сложность рассчитывается на основании вхождения слов текста в специализированные частотные списки. Усредненная оценка по этим двум векторам сложности позволяет оценить уровень текста по возрасту и классу. Об этой технологии можно подробнее прочитать здесь [5].
Длина текста в словах, в знаках и предложениях
Объем текста в словах, знаках и предложениях являются базовыми характеристиками текста, особенно полезными для расчета времени, которое потребуется на его освоение, или при подготовке проверочных материалов, где объем текста обычно строго определен государственным стандартом по РКИ. Например, рекомендуемая длина текста для чтения уровня A1 составляет 250–300 слов, А2 – 600–700 слов и т.д.
Средняя длина слова и предложения
Подсчет средней длины слова и предложения служит для определения сложности текста или его отдельных фрагментов. Так, большое количество формул читабельности используют данные показатели в качестве основных (DuBay, 2004).
Коэффициент лексического разнообразия (lexical diversity)
Коэффициент лексического разнообразия рассчитывается как отношение количества уникальных слов текста к количеству всех слов текста и обозначается величиной от близкой к 0 до 1 (когда все слова в тексте уникальны и встретились только по одному разу). Эта мера полезна для оценки повторяемости, воспроизводимости лексики текста и также способна сигнализировать о его трудности. Например, коэффициент лексического разнообразия отрывка аутентичного публицистического текста в среднем составляет 0,8, а учебного текста уровня В1 – 0,5. Однако этот коэффициент стоит с осторожностью использовать на коротких учебных текстах: в одном абзаце, скорее всего, почти все знаменательные слова будут уникальны, тогда как в целом тексте более вероятно повторяются основные имена, локации, понятия и действия.
Поиск ключевых слов текста
Поиск ключевых слов текста вычисляется как отношение количества раз, которое слово встречается в анализируемом тексте к частоте слова по Национальному корпусу русского языка (мера TF/IDF с корректирующим коэффициентом). Наивысший рейтинг получают слова, которые часто встречаются в данном тексте, но редко – во всех других текстах корпуса, то есть максимально характерные именно для этого текста. Например, в тексте интервью с музыкантом слова музыка и рэп встречаются по три раза. Но при этом музыка встречается в Национальном корпусе 45 000 раз, а рэп – 270. С этой точки зрения, слово рэп является более характерным и необходимым для понимания данного текста. При этом появление слова в списке ключевых слов вовсе не означает, что оно должно остаться в тексте при адаптации: слово может быть заменено на синоним или снабжено толкованием. Его присутствие в списке говорит лишь о том, что оно играет важную роль для понимания данного текста и на него стоит обратить особое внимание при переработке текста.
Уровень сложности слов текста по шкале CEFR
Статистика по лексическим минимумам включает в себя информацию о том, сколько процентов текста покрывается лексическими минимумами того или иного уровня, а ниже указывается список слов, не вошедших в официальный лексический минимум стандартов ТРКИ данного уровня. Количество незнакомой лексики является важнейшим показателем языковой доступности текста: многочисленные исследования говорят о самой тесной связи знакомости лексики текста и успешности его понимания (Nation, 2006; Qian, 2002). Государственный стандарт по РКИ также содержит информацию о рекомендуемом количестве незнакомой лексики, который постепенно растет от 2–3% для уровня A1 до 10% для уровня C1.
Частотный анализ текста
Частотный анализ текста позволяет, во-первых, получить полный частотный список слов текста, а во-вторых, статистику по доле в тексте слов из списка 5 000 самых частотных слов русского языка. Для расчета статистики по частотности слов мы использовали Новый частотный словарь современного русского языка.
Расчетное время чтения текста
Расчет времени чтения текста опирается на информацию из государственного стандарта по РКИ и предлагает ориентировочное время чтения текста иностранным студентом в зависимости от задачи чтения – изучающего или просмотрового. Такая информация появляется в стандартах по РКИ начиная с уровня В1 и составляет для этого уровня 50 слов в минуту для изучающего чтения и 100 слов в минуту для просмотрового. Для уровней ниже В1 мы взяли на себя смелость продолжить эту шкалу расчетной скорости чтения исходя из педагогического опыта.

Виктория Максимова
преподаватель РКИ, основатель FB сообщества «Сторителлинг в РКИ»
Теперь, когда Текстометр появился, мне уже трудно представить, как бы я готовила тексты без него. Это незаменимый инструмент для моей работы: строгие объективные параметры оценки, простой и интуитивно понятный дизайн. Спасибо разработчикам проекта!

Анна Голубева
главный редактор издательства «Златоуст»
Сервис очень помогает в работе и при общении с авторами! Особенно полезен частотный список, объективирует, что целесообразно оставлять в тексте, а что адаптировать или тренировать. Спасибо коллегам из Института Пушкина!

Юлия Некрасова
преподаватель РКИ Университета Салерно
Очень ценная методическая находка! Огромный потенциал для подготовки заданий для уровней B1 — C1, диктантов, заданий для экзаменов и т.п. Прошу прощения за сленг, но огромный респект разработчикам!
Публикации
При ссылке на ресурс мы просим цитировать данную работу:
Ещё публикации о программе:
Контакты

Автор проекта — Антонина Лапошина
Если у вас возник вопрос, вы нашли ошибку или считаете, что не хватает какой-то функции, обязательно напишите мне с пометкой «Текстометр». Мы очень любим и ценим обратную связь!
Найти сколько раз слово встречается в тексте c++
Написал код на C++ для подсчета сколько раз слово встречается в тексте. Но программа считает все варианты, даже если это слово входит в состав другого слова. Пример: Текст: la lan hla la, jsla. Программа выведет 5, хотя само слово встречается только 2 раза. Как доработать код:
#include #include using namespace std; int main() < setlocale(LC_ALL, "Russian"); string text; string word; int count = 0; cout « "Введите текст: "; getline(cin, text); cout « "Введите слово для поиска: "; cin » word; for (int i = 0; i < text.length(); i++) text[i] = tolower(text[i]); // проверка преобразования в нижний регистр cout « text « endl; for (int i = 0; i < text.length(); i++)< if (text.substr(i, word.length()) == word)< count++; >> cout « "Cлово " « word « " встречается в тексте " « count « " раз." « endl; return 0; > Отслеживать
задан 9 мар 2023 в 18:33
27 4 4 бронзовых знака
Вам надо проверять, что символы перед и после найденной подстроки являются разделителями (т.е. пробелом, табуляцией, запятой, скобкой и т.п.)
9 мар 2023 в 18:53
@avp можно ли в c++ создать массив из этих символов и проверить, входят ли символы перед и после туда?
9 мар 2023 в 20:25
Конечно можно. Собственно, литерал #define SEPARATORS » \t.,() и т.д.» вполне годится. Проверять, например, можно — if (i == 0 || strchr(SEPARATORS, text[i — 1])) для начала слова. Только для поиска лучше использовать find, а не создавать substr-ом для каждого символа новую строку. И после найденного слова (даже если оно подстрока в др. слове) переходить к поиску лучше не со следующей позиции, а с позиции после слова (прибавлять к i размер искомого слова)
Подсчет количества вхождений значения
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Еще. Меньше
Предположим, что нужно определить, сколько раз встречается конкретный текст или число в диапазоне ячеек. Например:
- Если диапазон, например A2:D20, содержит числовые значения 5, 6, 7 и 6, то число 6 встречается два раза.
- Если столбец содержит поговорки «Климов», «Наворов», «Наворов» и «Наворов», то этот столбец встречается три раза.
Подсчитать количество вхождений значения можно несколькими способами.
Подсчет количества вхождений отдельного значения с помощью функции СЧЁТЕСЛИ
Используйте функцию СЧЁТЕСЛИ, чтобы узнать, сколько раз встречается определенное значение в диапазоне ячеек.
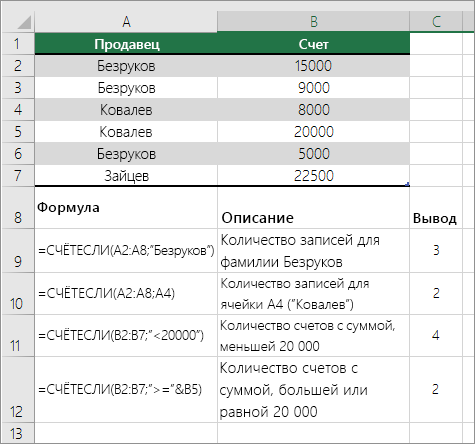
Дополнительные сведения см. в статье Функция СЧЁТЕСЛИ.
Подсчет количества вхождений на основе нескольких критериев с помощью функции СЧЁТЕСЛИМН
Функция СЧЁТЕСЛИМН аналогична функции СЧЁТЕСЛИ с одним важным исключением: СЧЁТЕСЛИМН позволяет применить критерии к ячейкам в нескольких диапазонах и подсчитывает число соответствий каждому критерию. С функцией СЧЁТЕСЛИМН можно использовать до 127 пар диапазонов и критериев.
Синтаксис функции СЧЁТЕСЛИМН имеет следующий вид:
СЧЁТЕСЛИМН(диапазон_условия1;условие1;[диапазон_условия2;условие2];…)
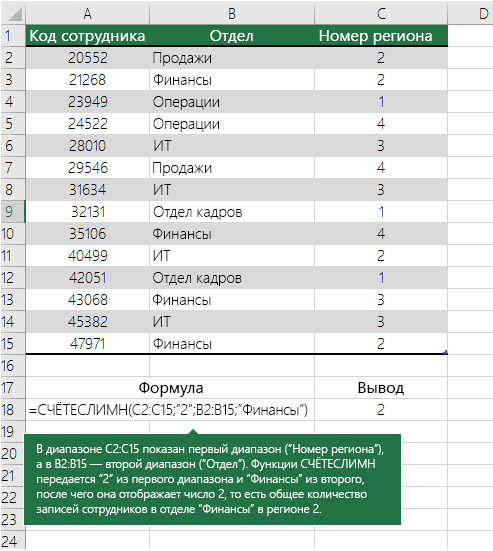
Дополнительные сведения об использовании этой функции для подсчета вхождений в нескольких диапазонах и с несколькими условиями см. в статье Функция СЧЁТЕСЛИМН.
Подсчет количества вхождений на основе условий с помощью функций СЧЁТ и ЕСЛИ
Предположим, вам нужно определить, сколько продавцов продало определенный товар в определенном регионе или сколько продаж было сделано конкретным продавцом. Функции ЕСЛИ и СЧЁТ можно использовать вместе. то есть сначала для проверки условия используется функция ЕСЛИ, а затем, только если функция ЕСЛИ имеет истинное положение, для подсчета ячеек используется функция СЧЁТ.
- Формулы в этом примере должны быть введены как формулы массива.
- Если у вас установлена текущая версия Microsoft 365, можно просто ввести формулу в верхней левой ячейке диапазона вывода и нажать клавишу ВВОД, чтобы подтвердить использование формулы динамического массива.
- Если вы открыли эту книгу в Excel для Windows или Excel 2016 для Mac и хотите изменить формулу или создать похожую, нажмите F2,а затем нажмите CTRL+SHIFT+ВВОД, чтобы формула возвращала нужные результаты. В более ранних версиях Excel для Mac используйте клавиши +SHIFT+ВВОД.
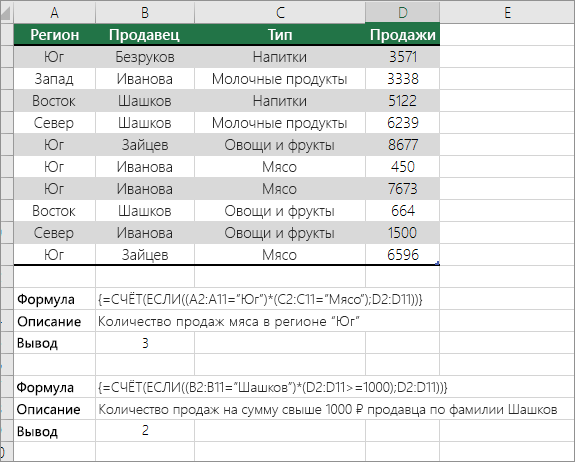
Дополнительные сведения об этих функциях см. в статьях Функция СЧЁТ и Функция ЕСЛИ.
Подсчет количества вхождений нескольких текстовых и числовых значений с помощью функций СУММ и ЕСЛИ
В следующих примерах функции ЕСЛИ и СУММ используются вместе. Функция ЕСЛИ сначала проверяет значения в определенных ячейках, а затем, если возвращается значение ИСТИНА, функция СУММ складывает значения, удовлетворяющие условию.
Примечания: Формулы, приведенные в этом примере, должны быть введены как формулы массива.
- Если у вас установлена текущая версия Microsoft 365, можно просто ввести формулу в верхней левой ячейке диапазона вывода и нажать клавишу ВВОД, чтобы подтвердить использование формулы динамического массива.
- Если вы открыли эту книгу в Excel для Windows или Excel 2016 для Mac и хотите изменить формулу или создать похожую, нажмите F2,а затем нажмите CTRL+SHIFT+ВВОД, чтобы формула возвращала нужные результаты. В более ранних версиях Excel для Mac используйте клавиши +SHIFT+ВВОД.
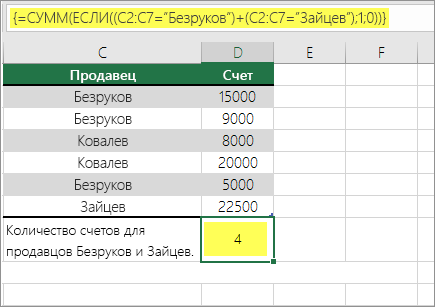
Функция выше означает, что если диапазон C2:C7 содержит значения Шашков и Туманов, то функция СУММ должна отобразить сумму записей, в которых выполняется условие. Формула найдет в данном диапазоне три записи для «Шашков» и одну для «Туманов» и отобразит 4.
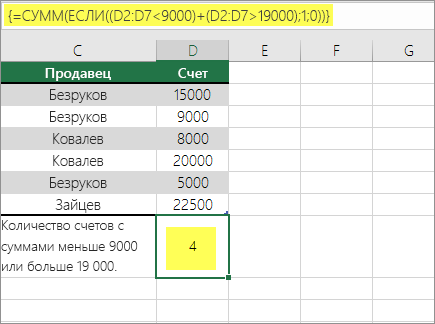
Функция выше означает, что если ячейка D2:D7 содержит значения меньше 9 000 ₽ или больше 19 000 ₽, то функция СУММ должна отобразить сумму всех записей, в которых выполняется условие. Формула найдет две записи D3 и D5 со значениями меньше 9 000 ₽, а затем D4 и D6 со значениями больше 19 000 ₽ и отобразит 4.
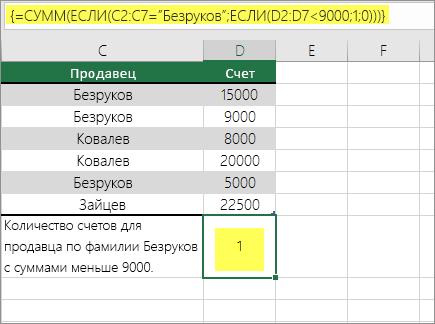
Функция выше сообщает, что если в функции D2:D7 есть счета для записи «Иванов» на сумму менее 9 000 рублей, то функция СУММ должна отобразить сумму записей, в которых условие должно быть выполнены. Формула найдет ячейку C6, которая соответствует условию, и отобразит 1.
Подсчет времени висячего значения с помощью с помощью pivotTable
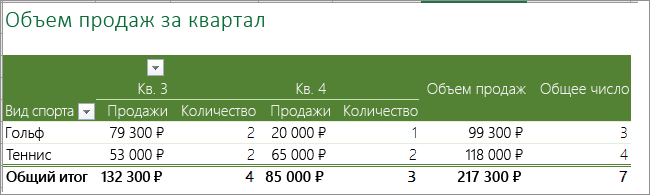
Вы можете использовать совокупные значения для отображения итогов и подсчета количества уникальных значений. Сводная таблица — это интерактивный способ быстрого суммирования больших объемов данных. Вы можете использовать ее для развертывания и свертывания уровней представления данных, чтобы получить точные сведения о результатах и детализировать итоговые данные по интересующим вопросам. Кроме того, можно перемещать строки в столбцы или столбцы в строки («сводить» их) для просмотра количества вхождений значения в сводной таблице. Рассмотрим пример электронной таблицы «Продажи», в которой можно подсчитать количество значений продаж для разделов «Гольф» и «Теннис» за конкретные кварталы.
- Введите данные в электронную таблицу Excel.
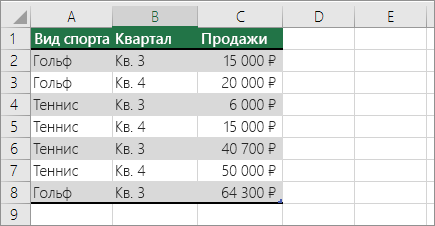
- Выделите диапазон A2:C8
- Выберите Вставка >Сводная таблица.
- В диалоговом окне «Создание сводной таблицы» установите переключатель Выбрать таблицу или диапазон, а затем — На новый лист и нажмите кнопку ОК. Пустая сводная таблица будет создана на новом листе.
- В области «Поля сводной таблицы» выполните одно из указанных ниже действий.
- Перетащите элемент Спорт в область Строки.
- Перетащите элемент Квартал в область Столбцы.
- Перетащите элемент Продажи в область Значения.
- Повторите третье действие. Имя поля Сумма_продаж_2 отобразится и в области «Сводная таблица», и в области «Значения». На этом этапе область «Поля сводной таблицы» будет выглядеть так:
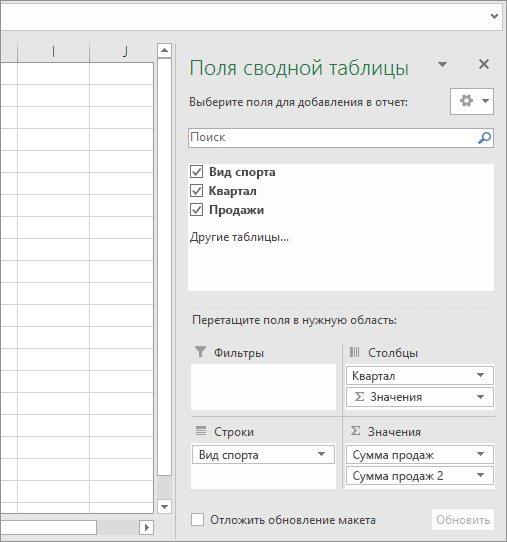
- В области Значения щелкните стрелку раскрывающегося списка рядом с полем Сумма_продаж_2 и выберите пункт Параметры поля значений.
- В диалоговом окне Параметры поля значений выполните указанные ниже действия.
- На вкладке Операция выберите пункт Количество.
- В поле Пользовательское имя измените имя на Количество.
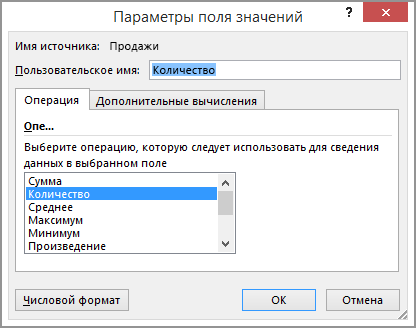
- Нажмите кнопку ОК.
Сводная таблица отобразит количество записей для разделов «Гольф» и «Теннис» за кварталы 3 и 4, а также показатели продаж.
Дополнительные сведения
Вы всегда можете задать вопрос эксперту в Excel Tech Community или получить поддержку в сообществах.