Удаление разрывов строк в Python
Если у вас возникла необходимость используя Python удалить разрывы строк из текста, то можно воспользоваться следующим методом текстовой переменной:
Метод replace заменяет в строке все вхождения подстроки old на подстроку new. Если методу replace задать еще один параметр count то заменены будут не все вхождения, а только первые count из них.
Существуют следующие типы разрывов строк:
Пример удаления разрывов строк в Python:
-
//Удаление всех трех типов разрывов строк
string = string.replace(«\r»,»»)
string = string.replace(«\n»,»»)
Как убрать символ новой строки (\n) при чтении строк из файла
При использовании file.readlines() получаем что-то вроде этого:
>>> file.readlines() ['12\n', '10\n', '9\n', '15\n', '10\n', '120'] Как убрать \n ?
Отслеживать
8,582 4 4 золотых знака 29 29 серебряных знаков 53 53 бронзовых знака
задан 30 ноя 2016 в 19:06
user216622 user216622
3 ответа 3
Сортировка: Сброс на вариант по умолчанию
>>> l = ['12\n', '10\n', '9\n', '15\n', '10\n', '120'] >>> l = [line.rstrip() for line in l] >>> l ['12', '10', '9', '15', '10', '120'] Отслеживать
ответ дан 30 ноя 2016 в 19:38
1,991 12 12 серебряных знаков 23 23 бронзовых знака
стоит заметить, что .rstrip() также удаляет любой пробел в конце строки, а не только символы новой строки как .rstrip(‘\n’) (это может и быть желаемым поведением).
Как удалить \n\r из документа?

С помощью Python закидываю данные в текстовый документ, предварительно отформатировав его.
Получается такой текст:
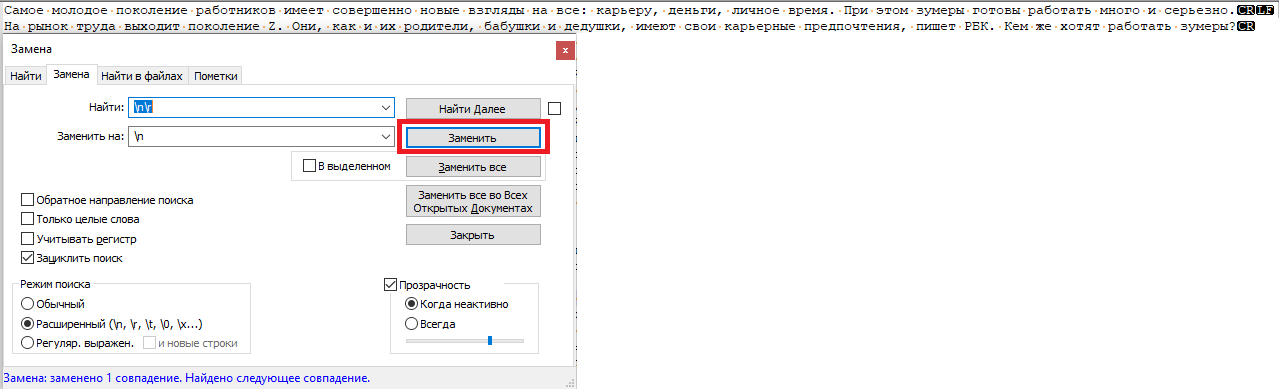
Хочу убрать \n\r оставив просто \n, заменяю таким образом, в Notepad++ все работает норм:
Но когда пытаюсь исправить текст в Python до записи в документ, ничего не происходит. Пробовал таких два варианта:
articleContent = articleContent.replace('\n\r', '\n') #или это articleContent = articleContent.replace('\n\r', '')
P.S. Может быть это как-то связано с самим Notepad? Т.к. при копирование этих строк в другое место, он делает некоторые изменения:
- Вопрос задан более трёх лет назад
- 816 просмотров
Python: удалить переносы строк и лишние пробелы из строки?
Всем привет. Подскажите плз, как решить задачу с минимальным изобретанием велосипедов. Нужно очистить строку от символов переноса (заменить на пробелы) и убрать лишние пробелы и пустые строки.
Сейчас это делается вот так:
‘ ‘.join(filter(None, map(unicode.strip, input_string.splitlines())))
Может есть более стандартный способ?
Попытки привлечь либу textwrap приводят только к раздутию кода… Может, я не умею ее готовить?
- Вопрос задан более трёх лет назад
- 95828 просмотров
Комментировать
Решения вопроса 1
Регуляркой:
import re
mystr = » balabla\n zzz »
re.sub(«^\s+|\n|\r|\s+$», », mystr)
В этом примере удаляем пробелы в начале и конце строки и символы переноса строки. Отредактируйте под свои нужды.
Ответ написан более трёх лет назад
Нравится 9 3 комментария
Fak3 @Fak3 Автор вопроса
Спасибо за наводку!
Задача решается так:
re.sub(«\s*\n\s*», ‘ ‘, s.strip())
re.sub(«\s+», » «, s)
все норм, только вот так:
import re
mystr = » balabla\n zzz »
mystr = re.sub(«^\s+|\n|\r|\s+$», », mystr)
PS Спасибо за способ, помогло
Ответы на вопрос 4
' '.join(s.split())не подойдёт?
Ответ написан более трёх лет назад
Нравится 5 1 комментарий
Правда при этом не только переносы и пробелы будут обработаны, но вообще все пробельные символы (табы например). Но в обычных юзкейсах это именно то что нужно.
php программист
Регулярка \s+ отличный способ =)
Ответ написан более трёх лет назад
Нравится 1 3 комментария
Fak3 @Fak3 Автор вопроса
Что-то мне фантазии не хватает, как это регуляркой решить. Поподробней можно?
Рустам Сафин @snegovikufa
Подозреваю через re.match (вроде?) создаешь список кандидатов на замену, а затем применяешь your_string.replace(what_from, what_to)
Fak3 @Fak3 Автор вопроса
А как регуляркой найти список кандидатов на замену?
__author__ = 'dikkini@gmail.com' from itertools import groupby def lines_filter(iterable): """ input: any iterable output: generator or list """ wait_chr = False is_begin = True #======================================================================================================== # You can delete "groupby" and the result will not change, but will increase the length of the input list. #======================================================================================================== for item, i in groupby(iterable): if item: is_begin = False if wait_chr: wait_chr = False yield '' yield item elif not is_begin and not wait_chr: wait_chr = True if __name__ == '__main__': list1 =['','','','i','hgf', '','','','9876','','','7','','9','','',''] # Input list print [i for i in lines_filter(list1)] # Output to the list Ответ написан более трёх лет назад
Комментировать
Нравится Комментировать
string.rstrip()
или
string = string.replace(«\n»,»»)
Ответ написан более трёх лет назад
Комментировать
Нравится Комментировать
Ваш ответ на вопрос
Войдите, чтобы написать ответ

- Python
- +1 ещё
Error Connecting: HTTPSConnectionPool(host=’url’, port=443) как решить?
- 1 подписчик
- 3 часа назад
- 10 просмотров