Выполнение проверки и перекрестной проверки
Прежде чем создавать окончательную поверхность, необходимо понять, насколько точно модель позволяет интерполировать значения в неизвестных точках. Перекрестная и обычная проверки помогают принять обоснованное решение относительно выбора модели, которая обеспечит лучшую интерполяцию. Вычисление статистики служит инструментом диагностики, который показывает, приемлемы ли модель и/или значения связанных с ней параметров.
Перекрестная и обычная проверки основаны на следующем принципе: удаление одного или нескольких местоположений данных и интерполяция связанных с ними значений с использованием данных в оставшихся местоположениях. Таким образом, можно сравнить интепролируемое значение с наблюдаемым и получить полезную информацию о качестве модели кригинга (например, о параметрах вариограммы и окрестности поиска).
Перекрестная проверка
Перекрестная проверка использует все данные для оценки моделей тренда и автокорреляции. В ходе этой проверки по очереди удаляются все местоположения данных и интерполируется связанное значение. Например, на приведенной ниже схеме показаны 10 точек данных. Перекрестная проверка пропускает точку (красную точку) и рассчитывает значение в этом местоположении, используя 9 остальных точек (синие точки). Затем выполняется сравнение интерполируемого и фактического значений в месте пропущенной точки. Эта процедура повторяется для второй точки и т. д. Перекрестная проверка сравнивает измеренные и интерполируемые значения для всех точек. В некотором смысле перекрестная проверка немного «обманывает», используя все данные для оценки моделей тренда и автокорреляции. По завершении перекрестной проверки некоторые местоположения данных, если они содержат существенные ошибки, могут быть исключены как аномальные, что потребует исправления моделей тренда и автокорреляции.

Перекрестная проверка выполняется автоматически, и ее результаты отображаются в последнем шаге Мастера геостатистики . Перекрестную проверку можно также выполнить вручную с помощью инструмента геообработки Перекрестная проверка .
Проверка
Проверка сначала удаляет часть данных (назовем ее тестовым набором данных). Затем на основе оставшихся данных (учебного набора данных) разрабатываются модели тренда и автокорреляции, которые будут использоваться для интерполяции. В Geostatistical Analyst для создания тестового и учебного наборов данных применяется инструмент Поднабор пространственных объектов . В остальном типы графиков и сводной статистики, которые используются для сравнения интерполируемых и истинных значений, одинаковы для обычной и перекрестной проверок. Обычная проверка создает модель только для поднабора данных, поэтому она не позволяет проверить напрямую окончательную модель, которая должна включать все доступные данные. Обычная проверка позволяет удостоверить правильность протокола решений, например, касающихся выбора модели вариограммы, размера лага и окрестности поиска. Если протокол решений работает для проверки, то это гарантирует, что он также будет работать для всего набора данных.
Проверку модели можно выполнить с помощью инструмента геообработки Слой GA в точки . Более подробно о проверке модели см. в разделе Использование проверки для оценки моделей.
Графики
Geostatistical Analyst предусматривает несколько диаграмм и сводок по сравнению измеренных значений с прогнозируемыми на последней странице Мастера геостатистики. Ниже приведена диаграмма рассеивания интерполируемых значений относительно истинных. Можно было бы ожидать, что точки должны рассеиваться относительно линии 1:1 (серая линия на приведенном ниже графике). Однако уклон обычно меньше 1 . Это особенность кригинга, который обычно при интерполяции занижает большие значения и завышает малые, как показано на следующем рисунке:

Подобранная линия, проходящая через область рассеивания точек, показана синим цветом, а уравнение приведено сразу под графиком. График ошибок аналогичен графику интерполяции, только измеренные значения вычитаются из прогнозируемых значений. Для графика нормированных ошибок разность измеренных и прогнозируемых значений делится на оценку стандартных ошибок кригинга. Все эти три графика показывают точность интерполяции кригинга. Если все данные были независимыми (нет автокорреляции), все интерполированные значения будут одинаковыми (каждое из них должно быть средним от измеренных данных), и потому синяя линяя будет горизонтальной. При наличии автокорреляции и хорошей модели кригинга синяя линия будет приближаться к серой линии 1:1. Уравнение регрессии под каждым из этих трех графиков вычисляется с использованием устойчивого к шумам уравнения регрессии. Эта процедура сначала помещает стандартную линию линейной регрессии на точечную диаграмму. Затем удаляются все точки, имеющие более двух стандартных отклонений выше или ниже линии регрессии, и вычисляется новое уравнение регрессии. Этот процесс гарантирует, что несколько выбросов не повлияют на целое уравнение регрессии.
Нормальный график КК показывает квантили разности между интерполируемыми и измеренными значениями, а также соответствующие квантили из стандартного нормального распределения. Если отклонения интерполируемых значений от истинных значений распределены по нормальному закону, точки должны располагаться примерно вдоль серой линии. Если ошибки распределены по нормальному закону, то можно уверенно использовать методы, основанные на этом законе (например, карты квантилей в простом кригинге).

Статистика ошибок интерполяции
Наконец, ниже приведены некоторые сводные статистические данные по ошибкам интерполяции кригинга. Используйте эти данные для диагностики. Этот диагностический расчет можно выполнить с помощью инструмента Перекрестная проверка или Мастера геостатистики .
- Желательно, чтобы интерполированные значения были несмещенными (центрированными относительно истинных значений). Если ошибки интерполяции несмещенные, то средняя ошибка интерполяции стремится к нулю. Однако это значение зависит от шкалы данных; для нормирования значений вычисляются нормированные ошибки кригинга, которые определяются как частное от деления ошибок интерполяции на стандартные ошибки интерполяции. Среднее этих ошибок также стремится к нулю.
- Желательно получить приемлемую оценку неопределенности, стандартные ошибки интерполяции. Каждый из методов кригинга дает оценку стандартных ошибок интерполяции. В дополнение к интерполяции, выполняется оценка отклонений интерполируемых значений от истинных (изменчивость). Важно получить правильную изменчивость. Например, в случае ординарного, простого, универсального и эмпирического байесова кригинга (предполагающего, что данные распределены по нормальному закону) карты квантилей и вероятности зависят от стандартных ошибок кригинга столь же существенно, как от самих интерполированных значений. Если средние стандартные ошибки близки к среднеквадратическим ошибкам интерполяции, оценка изменчивости интерполяции выполнена правильно. Если средние стандартные ошибки больше, чем среднеквадратические ошибки интерполяции, оценка изменчивости интерполяции выполнена с переоценкой. Если средние стандартные ошибки меньше, чем среднеквадратические ошибки интерполяции, оценка изменчивости интерполяции выполнена с недооценкой. Другой способ определить этот параметр – разделить каждую ошибку интерполяции на соответствующую оценку стандартной ошибки интерполяции. В среднем они должны быть равны друг другу, так что среднеквадратические ошибки интерполяции стремятся к 1, если стандартные ошибки интерполяции рассчитаны правильно. Если среднеквадратические нормированные ошибки интерполяции больше 1, оценка изменчивости интерполируемых значений занижена; если среднеквадратические нормированные ошибки интерполяции меньше 1, оценка изменчивости интерполируемых значений завышена.

Связанные разделы
Простое руководство по K-кратной перекрестной проверке
Чтобы оценить производительность некоторой модели в наборе данных, нам нужно измерить, насколько хорошо прогнозы, сделанные моделью, соответствуют наблюдаемым данным.
Наиболее распространенный способ измерить это — использовать среднеквадратичную ошибку (MSE), которая рассчитывается как:
MSE = (1/n)*Σ(y i – f(x i )) 2
- n: общее количество наблюдений
- y i : значение отклика i -го наблюдения
- f(x i ): прогнозируемое значение отклика i -го наблюдения.
Чем ближе прогнозы модели к наблюдениям, тем меньше будет MSE.
На практике мы используем следующий процесс для расчета MSE данной модели:
1. Разделите набор данных на обучающий набор и набор для тестирования.
2. Построить модель, используя только данные из обучающей выборки.
3. Используйте модель, чтобы делать прогнозы на тестовом наборе и измерять тестовую MSE.
Тестовая MSE дает нам представление о том, насколько хорошо модель будет работать с данными, которые она ранее не видела. Однако недостатком использования только одного тестового набора является то, что тестовая MSE может сильно различаться в зависимости от того, какие наблюдения использовались в обучающем и тестовом наборах.
Один из способов избежать этой проблемы — подобрать модель несколько раз, используя каждый раз другой набор для обучения и тестирования, а затем вычислить тестовую MSE как среднее значение всех тестовых MSE.
Этот общий метод известен как перекрестная проверка, а его конкретная форма известна как перекрестная проверка k-fold .
K-кратная перекрестная проверка
K-кратная перекрестная проверка использует следующий подход для оценки модели:
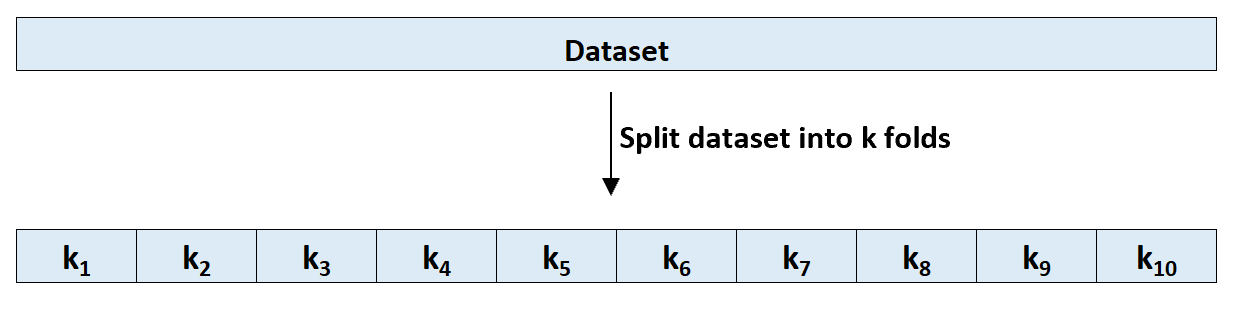
Шаг 1: Случайным образом разделите набор данных на k групп или «складок» примерно одинакового размера.
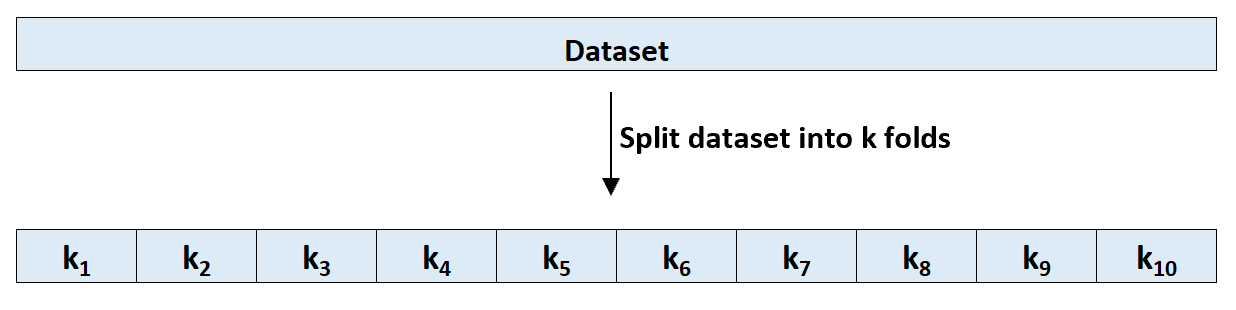
Шаг 2: Выберите один из сгибов в качестве опорного набора. Соедините модель с оставшимися k-1 складками. Рассчитайте тестовую MSE по наблюдениям в протянутой кратности.
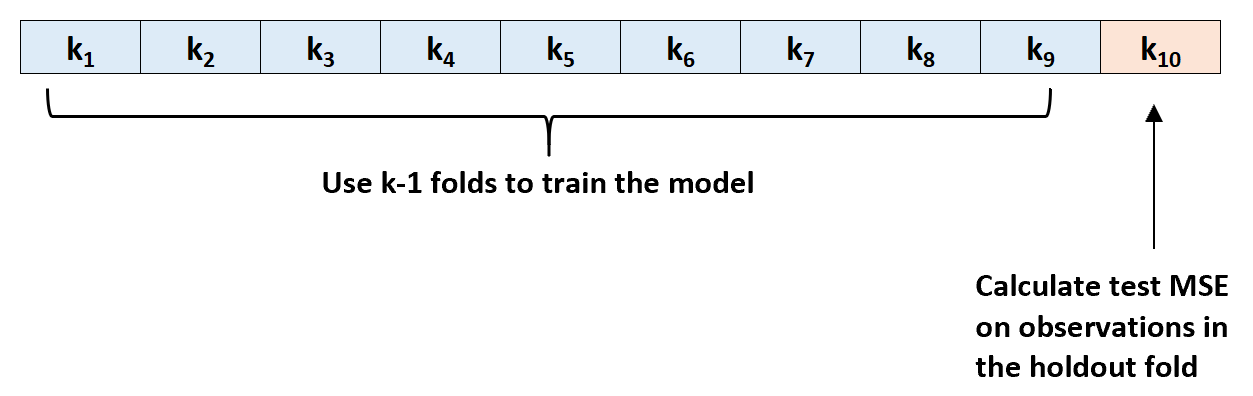
Шаг 3: Повторите этот процесс k раз, используя каждый раз другой набор в качестве набора удержания.
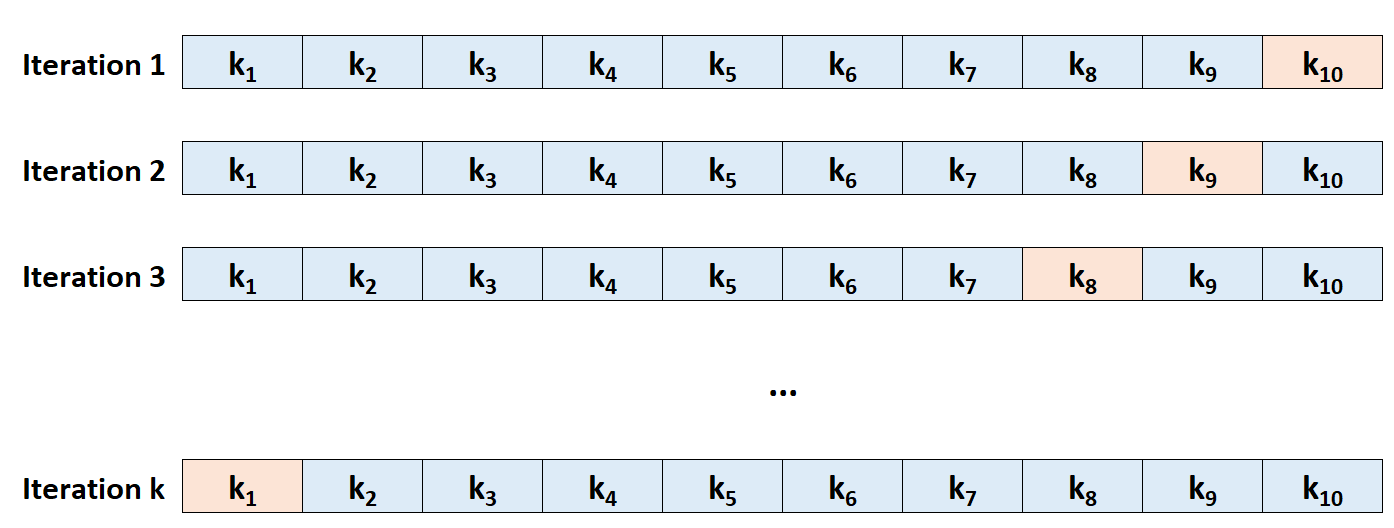
Шаг 4: Рассчитайте общую тестовую MSE как среднее значение k тестовых MSE.
СКО теста = (1/k)*ΣСКО i
- k: количество складок
- MSE i : проверка MSE на i -й итерации.
Как выбрать К
В общем, чем больше кратностей мы используем в k-кратной перекрестной проверке, тем меньше систематическая ошибка теста MSE, но выше дисперсия. И наоборот, чем меньше фолдов мы используем, тем выше смещение, но ниже дисперсия. Это классический пример компромисса смещения и дисперсии в машинном обучении.
На практике мы обычно используем от 5 до 10 кратностей. Как отмечено во Введении в статистическое обучение , было показано, что это количество кратностей обеспечивает оптимальный баланс между смещением и дисперсией и, таким образом, обеспечивает надежные оценки тестовой MSE:
Подводя итог, можно сказать, что существует компромисс между смещением и дисперсией, связанный с выбором k в k-кратной перекрестной проверке.
Как правило, с учетом этих соображений выполняется k-кратная перекрестная проверка с использованием k = 5 или k = 10, поскольку эмпирически было показано, что эти значения дают оценки частоты ошибок теста, которые не страдают ни чрезмерно высоким смещением, ни очень высокой дисперсией.
-Страница 184, Введение в статистическое обучение
Преимущества перекрестной проверки K-Fold
Когда мы разделяем набор данных только на один обучающий набор и один тестовый набор, тестовая MSE, рассчитанная для наблюдений в тестовом наборе, может сильно различаться в зависимости от того, какие наблюдения использовались в обучающем и тестовом наборах.
Используя k-кратную перекрестную проверку, мы можем рассчитать тестовую MSE, используя несколько различных вариантов обучающих и тестовых наборов. Это повышает вероятность того, что мы получим объективную оценку тестовой MSE.
K-кратная перекрестная проверка также предлагает вычислительное преимущество по сравнению с перекрестной проверкой с исключением одного (LOOCV) , потому что она должна соответствовать модели только k раз, а не n раз.
Для моделей, подгонка которых занимает много времени, перекрестная проверка в k-кратном порядке может вычислить тестовую MSE намного быстрее, чем LOOCV, и во многих случаях тестовая MSE, рассчитанная каждым подходом, будет очень похожей, если вы используете достаточное количество кратностей.
Расширения перекрестной проверки K-Fold
Существует несколько расширений k-кратной перекрестной проверки, в том числе:
Повторная перекрестная проверка K-кратности: здесь перекрестная проверка k-кратности просто повторяется n раз. Каждый раз наборы для обучения и тестирования перемешиваются, поэтому это еще больше снижает погрешность в оценке тестовой MSE, хотя это занимает больше времени, чем обычная перекрестная проверка в k-кратном порядке.
Перекрестная проверка с исключением одного: это особый случай перекрестной проверки k-кратности, в которой k = n.Подробнее об этом методе можно прочитать здесь .
Стратифицированная перекрестная проверка K-кратности: это версия перекрестной проверки k-кратности, в которой набор данных перестраивается таким образом, что каждая кратность представляет собой целое. Как отмечает Кохави , этот метод, как правило, предлагает лучший компромисс между смещением и дисперсией по сравнению с обычной перекрестной проверкой в k-кратном порядке.
Вложенная перекрестная проверка: здесь выполняется k-кратная перекрестная проверка в каждой кратной перекрестной проверке. Это часто используется для настройки гиперпараметров во время оценки модели.
Понимание критериев обучения и разделения в машинном обучении
В области машинного обучения разделение поезд-тест — простой, но эффективный метод. По сути, это влечет за собой разделение вашего набора данных на два отдельных набора: один для обучения вашей модели, а другой для оценки ее правильности. С помощью этого метода можно оценить эффективность прогнозов вашей модели в свете свежих данных. Вы можете оценить, насколько эффективно модель обобщает и, следовательно, насколько хорошо она будет работать в реальном мире, предоставив ей совершенно новый набор данных, на котором она не обучалась. Разделение поезд-тест по существу действует как «проверка реальности» возможностей вашей модели, предоставляя вам лучшее понимание ее преимуществ и недостатков. Это позволяет вам корректировать и улучшать свою модель для лучшего достижения ваших целей, что в конечном итоге позволит получать более точные и заслуживающие доверия прогнозы. В этом посте мы рассмотрим критерии поезда и разделения, включая их значение и практическое применение.
Что такое сплит поезд-тест?
Разделение поезд-тест в машинном обучении предполагает разделение вашего набора данных на два отдельных набора: один для обучения вашей модели, а другой — для оценки ее производительности. Цель этого разделения — оценить точность вашей модели на гипотетических данных, что важно для обеспечения эффективного обобщения и получения точных прогнозов на практике. Ваша модель может быть протестирована путем сравнения прогнозов, которые она делает с использованием набора для тестирования, с фактическими значениями в наборе данных после того, как она была обучена с использованием обучающего набора для изменения ее весов и смещений. Чтобы убедиться, что данные верны во всем наборе данных и что модель не переопределяет обучающий набор, разделение часто выполняется случайным образом. Используя этот метод, вы можете гарантировать, что ваша модель будет максимально точной и сможет точно прогнозировать будущие данные.
Почему важно разделить поезд-тест?
Эффективность модели машинного обучения на невидимых данных должна оцениваться с помощью науки о данных. Это связано с тем, что модель может невероятно хорошо работать с набором данных, на котором она обучалась, но плохо работать с совершенно новыми, непроверенными данными. Другими словами, модель, которая была адаптирована к обучающим данным, может давать неправильные прогнозы при применении к новым данным. Когда модель становится слишком сложной, происходит переобучение, и модель начинает запоминать данные обучения, а не изучать основные закономерности. В результате получается модель, которая слишком настроена для обучающего набора данных и плохо работает на тестовом наборе. Чтобы избежать переобучения и гарантировать точность и надежность модели при использовании в практических приложениях, важно оценить ее эффективность на ненаблюдаемых данных.
Понимание критериев разделения поезд-тест
Случайное разделение
Разделение данных чаще всего осуществляется посредством случайного разделения. Данные случайным образом делятся на две группы: обычно 70 % для обучения и 30 % для тестирования. Если в данных нет врожденных шаблонов или структур, которые вы хотите сохранить в тестовом наборе, этот метод весьма полезен. Преимущество случайного разделения заключается в том, что обучающий и тестовый наборы репрезентативны для всего набора данных, что снижает вероятность переобучения.

Стратифицированный раскол
При стратифицированном разбиении распределение определенной переменной как в обучающем, так и в тестовом наборах сохраняется за счет разделения данных на подмножества на основе этой переменной. При работе с несбалансированными наборами данных, то есть когда для каждого класса имеется неодинаковое количество примеров, этот критерий очень полезен. Стратифицированное разделение может помочь повысить точность модели, гарантируя, что обучающий и тестовый наборы содержат одинаковое количество случаев для каждого класса.

Разделение по времени
Данные разделяются на подгруппы в зависимости от времени с разделением по времени. При работе с данными временных рядов, где важна последовательность событий, этот метод часто используется. При разбиении по времени тестовый набор обычно содержит все события, произошедшие после определенного момента времени, тогда как обучающий набор часто содержит все случаи, произошедшие до этого момента. При прогнозировании временных рядов важно, чтобы модель была обучена на исторических данных и оценена на перспективных данных.

K-кратная перекрестная проверка
K-кратная перекрестная проверка включает в себя разделение данных на K подмножества или складки, используя каждую складку в качестве тестового набора, а оставшиеся складки K-1 в качестве обучающего набора. Каждая складка служит тестовым набором один раз в течение K-времени этой процедуры. При работе с небольшими наборами данных, где может быть недостаточно информации для разделения на обучающие и тестовые наборы, очень полезна K-кратная перекрестная проверка.

Заключение
Разделение обучения и тестирования в машинном обучении — это важный этап, позволяющий убедиться, что ваша модель может эффективно обобщать и делать точные прогнозы на совершенно новых, непроверенных данных. Данные можно разделить на два подмножества, чтобы вашу модель можно было обучать на одном наборе и оценивать на другом, создавая прогнозы, которые в конечном итоге будут более точными. Однако невозможно переоценить важность выбора подходящего критерия разделения данных. Некоторые критерии могут оказаться более подходящими, чем другие, в зависимости от типа данных и проблемы, которую вы пытаетесь решить. Можно повысить точность модели, избежать переобучения и гарантировать устойчивость модели к совершенно новым, непроверенным данным. В заключение отметим, что преимущества использования различных критериев в различных обстоятельствах могут, наконец, обеспечить более точные и надежные модели машинного обучения.
Все права защищены. © Linux-Console.net • 2019-2024
Прогнозирование осложнений язвенной болезни с помощью метода перекрёстной проверки Текст научной статьи по специальности «Клиническая медицина»
МЕТОД ПЕРЕКРЁСТНОЙ ПРОВЕРКИ / ДРЕВО РЕШЕНИЙ / ЯЗВЕННАЯ БОЛЕЗНЬ ЖЕЛУДКА И ДВЕНАДЦАТИПЕРСТНОЙ КИШКИ / КРОВОТЕЧЕНИЕ / ПЕРФОРАЦИЯ / ПРЕДСКАЗАНИЕ ОСЛОЖНЕНИЙ ЯЗВЕННОЙ БОЛЕЗНИ / CROSS-VALIDATION / DECISION TREE / DIAGNOSTICS / PEPTIC ULCER DISEASE / DUODENAL ULCER HEMORRHAGE / ULCER PERFORATION / PEPTIC ULCERS COMPLICATIONS PREDICTION
Аннотация научной статьи по клинической медицине, автор научной работы — Гололобов Григорий Юрьевич, Стамов Александр Александрович, Мехдиев Эмиль Джамаладдинович
В статье обсуждаются результаты предпринятого авторами исследования возможности применения метода перекрёстной проверки для оценки эффективности аналитической модели прогнозирования осложнений язвенной болезни. Полученные данные свидетельствуют о высокой точности метода перекрёстной проверки . Применение данного метода в целях диагностики в практике медицины позволяет отслеживать малейшие нюансы в изменении состояния больного, существенно оптимизирует работу врача, а также снижает риски осложнений от множества других заболеваний.Peptic ulcer disease (PUD) is easily cured, but it can often lead to complications demanding serious operations, even at young age. The last decades is characterized by a sharp decrease in the frequency of planned operations for PUD (more than 2 times), but the number of emergency operations for complications (perforations and bleeding) increased 2 and 3 times, respectively. In other words, the success of conservative therapy in general did not affect the frequency of these complications and the issues of surgical treatment of peptic ulcer, especially given the increased number of its complicated forms, will be relevant for a long time. Therefore, early diagnosis and prediction of the possible complications result in successful treatment of the disease. Mathematical methods are obligatory for developments in this direction. Well-studied ones, such as regression analysis, have reached their theoretical limit of accuracy and applicability. In this regard, new methods of mathematical data analysis for the diagnosis of diseases and their complications come to the forefront. So, the subject of our study is the cross-validation method as one of the most promising logical-mathematical approaches for medical practice. In the basis for our model development, we put data on 171 test subjects, 130 of whom suffered from PUD, 35 had a different pathology and 6 were healthy in the period 2014-2016. We modeled the database for each patient. This database included 227 variables, as follows: passport information, clinical diagnosis, combined pathology, complaints, treatment in the past, complications, radiology, ultrasound findings, information on surgical intervention. During cross-validation , we used the Decision Tree algorithm, as well as statistical analysis and the Monte Carlo method. The reliability of clinical diagnosis prediction was 89.47% while such indicator for mortality predicting was 98.83%. Such PUD complications as perforation and bleeding are predicted particularly well: the results were 94.15% and 87.92%, respectively. In the course of our approach, overall prediction accuracy was 92.59%. Based on these data, we conclude that cross-validation is a highly accurate method, and its application as modern diagnostic model in personalized medicine will make it possible both to mention even small changes in patient’s condition and as reduce complications hazard in many diseases.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по клинической медицине , автор научной работы — Гололобов Григорий Юрьевич, Стамов Александр Александрович, Мехдиев Эмиль Джамаладдинович
Корреляции кристаллографии и морфологического исследования биоптатов желудочной слизи
На пути к новой парадигме в медицине
Влияние хронического воспаления нёбных миндалин и тонзиллэктомии на акустические параметры голоса
Бактериологическое исследование микрофлоры отделяемого носоглотки у учащихся 11-летнего возраста
Pathogenesis of complications of Oocytes Donation (od)
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Текст научной работы на тему «Прогнозирование осложнений язвенной болезни с помощью метода перекрёстной проверки»
Электронное научное издание Альманах Пространство и Время Т. 15. Вып. 1 • 2017
STUDIA STUDIOSORUM: УСПЕХИ МОЛОДЫХ ИССЛЕДОВАТЕЛЕЙ
Тематический выпуск в рамках года подготовки и проведения XIX Всемирного фестиваля молодежи и студентов в России
Electronic Scientific Edition Almanac Space and Time volume 15, issue 1
STUDIA STUDIOSORUM: Achievements of Young Researchers
Thematic Issue in the run-up to the year of preparation and holding the 19th World Festival of Youth and Students in Russia Elektronische wissenschaftliche Auflage Almanach ‘Raum und Zeit Band 15, Ausgb. 1.
STUDIA STUDIOSORUM: Fortschritte der Nachwuchsforscher
Thematische Ausgabe im Rahmen des Jahres der Vorbereitung und Durchführung des XIX. Weltfestivals der Jugend und Studenten in Russland
Успехи в науках о человеке
Achievements in Human Sciences / Fortschritte in der H umanw issenschaften
Гололобов Г.Ю.*, Стамов А.А.**, Мехдиев Э.Д.
Прогнозирование осложнений язвенной болезни с помощью метода перекрёстной проверки
*Гололобов Григорий Юрьевич, студент 4 курса Дирекции образовательных программ «Медицина будущего» Первого Московского государственного медицинского университета им. И.М. Сеченова
ORCID ID https://orcid.org/0000-0002-7374-9800
E-mail: grigoriy-yu-gololobov@j-spacetime.com; grriffan@gmail.com
**Стамов Александр Александрович, студент 5 курса лечебного факультета Первого Московского государственного медицинского университета им. И.М. Сеченова
ORCID ID https://orcid.org/0000-0001-5642-7255
E-mail: alexander-a-stamov@j-spacetime.com; faust2539@gmail.com
***Мехдиев Эмиль Джамаладдинович, студент 4 курса Дирекции образовательных программ «Медицина будущего» Первого Московского государственного медицинского университета им. И.М. Сеченова
ORCID ID https://orcid.org/0000-0001-9773-1341
E-mail: emil-d-mekhdiev@j-spacetime.com; emilenus@yandex.ru
В статье обсуждаются результаты предпринятого авторами исследования возможности применения метода перекрёстной проверки для оценки эффективности аналитической модели прогнозирования осложнений язвенной болезни. Полученные данные свидетельствуют о высокой точности метода перекрёстной проверки. Применение данного метода в целях диагностики в практике медицины позволяет отслеживать малейшие нюансы в изменении состояния больного, существенно оптимизирует работу врача, а также снижает риски осложнений от множества других заболеваний.
Ключевые слова: метод перекрёстной проверки; древо решений; язвенная болезнь желудка и двенадцатиперстной кишки; кровотечение; перфорация; предсказание осложнений язвенной болезни.
Язвенная болезнь (ЯБ) желудка и двенадцатиперстной кишки остается одной из важнейших проблем современной хирургической гастроэнтерологии. На XXII Российской гастроэнтерологической неделе в 2016 г. отмечалось, что гастро-дуоденальные язвы являются одними из самых распространённых заболеваний органонов пищеварения. По диспансер-
Electronic Scientific Edition Almanac Space and Time volume 15, issue 1 ‘STUPIA STUPIOSORUM: Achievements of Young Researchers’
Achievements in Human Sciences
Elektronische wissenschaftliche Auflage Almanach ‘Raum und Zeit Bd. 15, Ausgb. 1. ‘STUPIA STUPIOSORUM: Fortschritte der Nachwuchsforscher’
Fortschritte in der Humanwissenschaften
Гололобов Г.Ю., Стамов А.А., Мехдиев Э.Д. Прогнозирование осложнений язвенной болезни
с помощью метода перекрёстной проверки
ным данным, на учёте состоит более 3 млн. больных. Также отмечено, что от осложнений умирает около 6 тысяч человек в год [Якубчик 2011]. Последнее десятилетие характеризуется резким снижением частоты плановых операций по поводу гастродуоденальных язв (более чем в 2 раза), но количество экстренных операций, выполняемых по поводу осложнений — перфораций и кровотечений, — увеличилось в 2 и 3 раза соответственно [Галимов и др. 2002; Нуртдинов 2005]. Иными словами, успехи консервативной терапии в целом не повлияли на частоту этих осложнений и вопросы хирургического лечения язвенной болезни, особенно с учетом возросшего количества её осложненных форм, будут актуальны ещё долгое время [Афендулов, Журавлев 2008].
Всё это свидетельствует о необходимости проведения ранней и современной диагностики, которые помогут вовремя заподозрить данное заболевание на догоспитальном этапе. В настоящие время «золотым стандартом» диагностики является эндоскопическое исследование (фиброгастродуоденоскопия) и R-логическое исследование [Афендулов, Журавлев 2008; Нуртдинов 2005].
Хорошо изученные на сегодняшний день математические методы, такие как регрессионный анализ, дошли до своего теоретического предела точности и применимости. В связи с этим на первый план выходят новые методы математического анализа данных для диагностики заболеваний и их осложнений [Гололобов и др. 2016, Назаренко и др. 2010, Хаса-нов и др. 2016; Akhmetshin et al. 2012]. Большой популярностью пользуется метод искусственных нейронных сетей, который уже зарекомендовал себя в медицинской практике.
С точки зрения последней, особый интерес, на наш взгляд, вызывает как один из наиболее перспективных метод перекрёстной проверки (cross-validation), который и будет рассмотрен в данной работе.
Перекрёстная проверка (сross-validation) представляет собой статистический метод оценки и сравнения алгоритмов обучения путем деления данных на два сегмента: один используется для узнавания или обучения модели, а другой используется для проверки модели. В типичной модели перекрёстной проверки циклы тренировки и проверки должны перепроверяться в последовательных циклах таким образом, чтобы каждый пункт сверялся повторно. Основой формы перекрестной проверки является К-кратная перепроверка (K-fold cross-validation) [Refaeilzadeh et al. 2009].
С учётом изложенного целью данной работы явилось использование метода перекрёстной проверки в прогнозировании осложнений язвенной болезни.
Материалы и методы
В основу модели положены данные 171 человека, 130 из которых имеют язвенную болезнь, 35 имеют иную патологию и 6 являются здоровыми в период 2014—2016 гг.
Смоделированная база данных на каждого пациента включала себя в 227 переменных, содержащих паспортную информацию, клинический диагноз, сочетанную патологию, жалобы, лечение в прошлом, осложнения, рентгенологическое заключение, УЗИ заключение, информацию по оперативному вмешательству.
В рамках работы использовалось программное обеспечение, способное построить необходимую нам модель. Метод перекрёстной проверки осуществлялся с применением алгоритм «древо решений» (Decision Tree).
В K-кратной перекрёстной проверке данные сначала в равной степени распределяются на K-сегменты (подвыбор-ки). Затем полученные подвыборки используются следующим образом: один сегмент сохраняется в качестве проверочных данных для тестирования модели, а остальные K-1 сегменты используются в качестве обучающих данных.
Таким образом, каждая подвыборка K-1 раз участвует в обучающей выборке и ровно один раз служит тестовой выборкой. Именно в этом заключается преимущество K-кратной перекрёстной проверки перед некоторыми другими её типами, например, перекрёстной проверкой на основе метода Монте-Карло, когда весь массив данных разбивается случайным образом на данные для проверки и для обучения, что в итоге со случайной долей вероятности гарантирует повторное участие одних и тех же подвыборок как в проверке, так и в обучении, а также абсолютное неучастие в вычислениях некоторых отдельно взятых подвыборок. Обычно в K-кратной перекрёстной проверке все данные стратифицируются до начала K-итераций, что подразумевает под собой перегруппировку и присвоение числовых значений для гарантии существования единственно возможного логического толкования теории. Например, если поставлена задача бинарной классификации объектов, где каждый класс содержит 50% данных, лучше всего ранжировать данные таким образом, чтобы на каждом этапе каждый класс включал в себя около половины примеров.
В результате получается оценка эффективности выбранной модели с наиболее равномерным использованием имеющихся данных [Refaeilzadeh et al. 2009].
Electronic Scientific Edition Almanac Space and Time volume 15, issue 1 ‘STUDIA STUDIOSORUM: Achievements of Young Researchers’
Achievements in Human Sciences
Elektronische wissenschaftliche Auflage Almanach ‘Raum und Zeit Bd. 15., Ausgb. 1. ‘STUDIA STUDIOSORUM: Fortschritte der Nachwuchsforscher’
Fortschritte in der Humanwissenschaften
Гололобов Г.Ю., Стамов А.А., Мехдиев Э.Д. Прогнозирование осложнений язвенной болезни
с помощью метода перекрёстной проверки
Для построения модели переменные анализировались на полноту, характер распределения и корреляцию между собой. Поскольку данная модель необходима для ранней диагностики заболевания без лабораторно-инструментальных методов, были использованы 38 переменных, большая часть которых является жалобами пациента.
Для метода перекрёстной проверки (cross-validation) использовался алгоритм «древо решений» (Decision Tree). Были смоделированы древа решений, использовавшие 34 входных параметра, для предсказания контрольного заключения (Х35—Х38, для каждого создавалось своё древо). Тестировался диагноз язвенной болезни, летальный исход, осложнения, требующие незамедлительного хирургического вмешательства — перфорация и кровотечение.
Входные данные включали:
X2 — возраст, локализация болей
X3 — эпигастральная область,
X4 — правое подреберье,
X5 — левое подреберье,
X8 — по всему животу,
X9 — другое место,
X10 — иррадиация в плечо,
XII — иррадиация в спину, X12 — интенсивность,
X13 — до приёма пищи (голодные боли), Х13 — после приёма пищи Х14 — сразу,
Х15 — через полтора-два часа, Х16 — ночные,
Х17 — изжога, отрыжка Х18 — воздухом, Х19 — съеденной пищей,
Х20 — боль усиливалась, прекращалась
Х21 — в горизонтальном положении, Х22 — при наклонах,
Х23 — тошнота, Х24 — рвота, Х25 — запоры, Х26 — жидкий стул, Х27 — метеоризм, Х28 — курение,
Х29 — систолическое давление, Х30 — диастолическое давление, Х31 — пульс.
Также учитывалось лечение
Х32 — амбулаторно или
Х33 — стационарно в прошлом,
Х34 — язвенный анамнез при поступлении.
Х35 — летальный исход, Х36 — язвенная болезнь, Х37 — кровотечение, Х38 — перфорация.
Контрольные древа решений представлены на рис. 1—3.
Electronic Scientific Edition Almanac Space and Time volume 15, issue 1
‘STUDIA STUDIOSORUM: Achievements of Young Researchers’
Achievements in Human Sciences
Elektronische wissenschaftliche Auflage Almanach ‘Raum und Zeit Bd. 15, Ausgb. 1. ‘STUDIA STUDIOSORUM: Fortschritte der Nachwuchsforscher’
Fortschritte in der Humanwissenschaften
Гололобов Г.Ю., Стамов А.А., Мехдиев Э.Д. Прогнозирование осложнений язвенной болезни
с помощью метода перекрёстной проверки
Рис. 1. Древо «Язвенная болезнь»
Рис. 2. Древо «Кровотечение»
Рис. 3. Древо «Перфорация»
Для метода перекрёстной проверки (cross-validation) были использованы те же параметры, что и для нейронной сети. Однако разделение данных на «train» и «test» происходит соответственно с методом, от большего «train» и к меньшему «test», к большему «test» и меньшему «train».
Electronic Scientific Edition Almanac Space and Time volume 15, issue 1 ‘STUDIA STUDIOSORUM: Achievements of Young Researchers’
Achievements in Human Sciences
Elektronische wissenschaftliche Auflage Almanach ‘Raum und Zeit Bd. 15, Ausgb. 1. ‘STUDIA STUDIOSORUM: Fortschritte der Nachwuchsforscher’
Fortschritte in der Humanwissenschaften
Гололобов Г.Ю., Стамов А.А., Мехдиев Э.Д. Прогнозирование осложнений язвенной болезни
с помощью метода перекрёстной проверки
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Результаты использования алгоритма «древо решений» (Decision Tree) представлены в табл. 1.
Результаты применения алгоритма «древо решений»
Параметры Точность, % Верно Ошибок
Клинический диагноз 89,47 153 18
Летальный исход 98,83 169 2
Перфорация 94,15 161 10
Кровотечение 87,92 150 21
Общая точность, % 92,59
Предсказание клинического диагноза составило 89,47%, что является хорошим результатом. Предсказание смертности 98,83%. Особенно хорошо прогнозируются осложнения — перфорация и кровотечение, 94,15% и 87,92% соответственно. Общая точность при этом составила 92,59%.
Точность прогнозирования данных параметров варьирует на адекватном уровне. Большой процент предсказания летального исхода объясняется малым количеством летальных исходов в тестируемой выборке.
При сравнении с методом искусственных нейронных сетей, данный метод показывает более высокую точность, что связанно с функциональной особенностью обоих методов. Однако нельзя сказать, что метод перекрёстной проверки (cross-validation) превосходит метод искусственных нейронных сетей, поскольку не известно, как повлияет на общую точность вычислений добавление новых параметров в качественном и количественном их соотношении. Это даёт нам полное право полагать, что новые математические модели предсказания отлично работают в диагностической сфере.
Таким образом, высокая точность предсказания осложнений позволяет судить о полезности данного метода в медицине. Появляется возможность тестировать курируемых пациентов на данной базе данных, прослеживать возможные осложнения и подбирать лучшую тактику лечения язвенной болезни. Персонализированный подход с внедрением новейших моделей позволит отслеживать незначительные нюансы и сильно оптимизировать работу врача, что позволит снизить риски осложнений множества заболеваний.
1. Афендулов С.А., Журавлев Г.Ю. Хирургическое лечение больных язвенной болезнью М.: ГЭОТАР-
Медиа. 2008. 344 с.
2. Галимов О.В., Шамсутдинов А.Р., Нуртдинов М.А., Дмитриев Д.М., Галимова Е.С., Нигматуллин Р.Т.,
Шумкин А.М., Муслимов С.А., Зарипов Ш.А. Способ лечения гастродуоденальных язв, осложненных рубцово-язвенным стенозом верхних отделов желудочно-кишечного тракта. Патент РФ на изобретение RUS 2189822. 2000. 10 апр. [Электронный ресурс] // FreePatent. 2002. 27 сент. Режим доступа: http://www.freepatent.ru/patents/2189822.
3. Гололобов Г.Ю., Тайсин Р.Р., Козлова О.О., Мехдиев Э.Д., Хабибуллин И.Р. Внедрение нейронных сетей
в диагностику язвенной болезни // Сборник материалов LVI научной конференции студентов и молодых учёных Западно-Казахстанского государственного медицинского университета имени Марата Оспанова с международным участием, посвященной 25-летию Независимости Республики Казахстан. Актобе, 2016. С. 62 — 63.
4. Назаренко Г.И., Осипов Г.С., Назаренко А.Г., Молодченков А.И. Интеллектуальные системы в клиниче-
ской медицине. Синтез плана лечения на основе прецедентов // Информационные технологии и вычислительные системы. 2010. № 1. С. 24 — 35.
Electronic Scientific Edition Almanac Space and Time volume 15, issue 1 ‘STUPIA STUPIOSORUM: Achievements of Young Researchers’
Achievements in Human Sciences
Elektronische wissenschaftliche Auflage Almanach ‘Raum und Zeit Bd. 15., Ausgb. 1. ‘STUPIA STUPIOSORUM: Fortschritte der Nachwuchsforscher’
Fortschritte in der Humanwissenschaften
Гололобов Г.Ю., Стамов А.А., Мехдиев Э.Д. Прогнозирование осложнений язвенной болезни
с помощью метода перекрёстной проверки
5. Нуртдинов М.А. Оптимизация комплексного лечения язвенной болезни желудка и двенадцатиперст-
ной кишки в хирургической клинике: Дисс. . д. мед. н. Уфа, 2005. 225 с.
6. Хасанов А.Г., Нуртдинов М.А. Гололобов Г.Ю. О прогнозировании осложнений язвенной болезни на
основе нейронных сетей // Анналы хирургии. 2016. Т. 21. № 4. С. 231 —234.
7. Якубчик Т.Н. Клиническая гастроэнтерология. Гродно: Гродненский Государственный Медицинский
Университет, 2011. 308 с.
8. Akhmetshin R.M., Giniyatullin V.M., Kirlan S.A. «Identification of Structures of Organic Substances by Means of
Complex-valued Perceptron.» Optical Memory & Neural Networks (Information Optics) 21.1 (2012): 11 — 16.
9. Refaeilzadeh P., Tang L., Liu H. «Cross Validation.» Encyclopedia of Database Systems. Eds. M. Tamer A-Zsu, and
Ling Liu. New York: Springer, 2009, pp. 532 — 538.
Цитирование по ГОСТ Р 7.0.11—2011:
Гололобов, Г. Ю., Стамов, А. А., Мехдиев, Э. Д. Прогнозирование осложнений язвенной болезни с помощью метода перекрёстной проверки [Электронный ресурс] / Г.Ю. Гололобов, А.А. Стамов, Э.Д. Мехдиев // Электронное научное издание Альманах Пространство и Время. — 2017. — Т. 15. — Вып. 1: Studia studiosorum: успехи молодых исследователей. — Стационарный сетевой адрес: 2227-9490e-aprovr_e-ast15-1.2017.23.
PREDICTION OF PEPTIC ULCER DISEASE COMPLICATIONS BASED ON CROSS-VALIDATION METHOD
Grigorii Yu. Gololobov, 4th year student at the Directorate of Educational Programs of the International School «Medicine of the Future», I.M. Sechenov First Moscow State Medical University
ORCID ID https://orcid.org/0000-0002-7374-9800
E-mail: grigorii-yu-gololobov@j-spacetime.com; grriffan@gmail.com
Alexander A. Stamov, 5th year student at the Department of General Medicine, I.M. Sechenov First Moscow State Medical University
ORCID ID https://orcid.org/0000-0001-5642-7255
E-mail: alexander-a-stamov@j-spacetime.com; faust2539@gmail.com
Emil D. Mekhdiev, 4th year student at the Directorate of Educational Programs of the International School «Medicine of the Future», I.M. Sechenov First Moscow State Medical University
ORCID ID https://orcid.org/0000-0001-9773-1341
E-mail: emil-d-mekhdiev@j-spacetime.com; emilenus@yandex.ru
Peptic ulcer disease (PUD) is easily cured, but it can often lead to complications demanding serious operations, even at young age. The last decades is characterized by a sharp decrease in the frequency of planned operations for PUD (more than 2 times), but the number of emergency operations for complications (perforations and bleeding) increased 2 and 3 times, respectively. In other words, the success of conservative therapy in general did not affect the frequency of these complications and the issues of surgical treatment of peptic ulcer, especially given the increased number of its complicated forms, will be relevant for a long time. Therefore, early diagnosis and prediction of the possible complications result in successful treatment of the disease. Mathematical methods are obligatory for developments in this direction. Well-studied ones, such as regression analysis, have reached their theoretical limit of accuracy and applicability. In this regard, new methods of mathematical data analysis for the diagnosis of diseases and their complications come to the forefront.
Electronic Scientific Edition Almanac Space and Time volume 15, issue 1 ‘STUDIA STUDIOSORUM: Achievements of Young Researchers’
Achievements in Human Sciences
Elektronische wissenschaftliche Auflage Almanach ‘Raum und Zeit Bd. 15, Ausgb. 1. ‘STUDIA STUDIOSORUM: Fortschritte der Nachwuchsforscher’
Fortschritte in der Humanwissenschaften
Гололобов Г.Ю., Стамов А.А., Мехдиев Э.Д. Прогнозирование осложнений язвенной болезни
с помощью метода перекрёстной проверки
So, the subject of our study is the cross-validation method as one of the most promising logical-mathematical approaches for medical practice.
In the basis for our model development, we put data on 171 test subjects, 130 of whom suffered from PUD, 35 had a different pathology and 6 were healthy in the period 2014—2016. We modeled the database for each patient. This database included 227 variables, as follows: passport information, clinical diagnosis, combined pathology, complaints, treatment in the past, complications, radiology, ultrasound findings, information on surgical intervention. During cross-validation, we used the Decision Tree algorithm, as well as statistical analysis and the Monte Carlo method.
The reliability of clinical diagnosis prediction was 89.47% while such indicator for mortality predicting was 98.83%. Such PUD complications as perforation and bleeding are predicted particularly well: the results were 94.15% and 87.92%, respectively. In the course of our approach, overall prediction accuracy was 92.59%.
Based on these data, we conclude that cross-validation is a highly accurate method, and its application as modern diagnostic model in personalized medicine will make it possible both to mention even small changes in patient’s condition and as reduce complications hazard in many diseases.
Keywords: cross-validation; decision tree; diagnostics; peptic ulcer disease; duodenal ulcer hemorrhage; ulcer perforation; peptic ulcers complications prediction.
1. Afendulov S.A., Zhuravlev G.Yu. Surgical Treatment of Patients with Peptic Ulcer Disease. Moscow: GEOTAR-
Media Publisher, 2008. 344 p. (In Russian).
2. Akhmetshin R.M., Giniyatullin V.M., Kirlan S.A. «Identification of Structures of Organic Substances by Means of
Complex-valued Perceptron.» Optical Memory & Neural Networks (Information Optics) 21.1 (2012): 11 — 16.
3. Galimov O.V., Shamsutdinov A.R., Nurtdinov M.A., Dmitriev D.M., Galimova E.S., Nigmatullin R.T., Shumkin
A.M., Muslimov S.A., Zaripov Sh.A. «Gastroduodenal Ulcers Treatment Method Complicated by Scar-Ulcerative Stenosis of Upper Gastrointestinal Tract. Russian Federation Patent, invention RUS 2189822, 10 Apr. 2000.» FreePatent. Rospatent, 27 Sep. 2002. Web. . (In Russian).
4. Gololobov G.Yu., Taysin R.R., Kozlova O.O., Mekhdiev E.D., Khabibullin I.R. «The Introduction of Neural
Networks in Ulcer Disease Diagnosis.» Proceedings of 56th Scientific Conference of Students and Young Scientists of Marat Ospanov West Kazakhstan State Medical University with International Participation Devoted to the 25th Anniversary of Independence of the Republic of Kazakhstan. Aktobe, 2016, pp. 62 — 63. (In Russian).
5. Khasanov A.G., Nurtdinov M.A., Gololobov G.Yu. «Prediction of Predict Ulcer Disease Complications of, based
on artificial neural networks.» Surgery Annals 21.4 (2016): 231—234 (In Russian).
6. Nazarenko G.I., Osipov G.S., Nazarenko A.G., Molodchenkov A.I. «Intelligent Systems in Clinical Medicine.
Case-based Treatment Plan Synthesis.» Information Technologies and Computer Systems 1 (2010): 24 — 35. (In Russian).
7. Nurtdinov M.A. Optimization of Gastric and Duodenal Ulcer Combination Treatment in Surgical Clinic. Doctoral
diss. Ufa, 2005. 225 p. (In Russian).
8. Refaeilzadeh P., Tang L., Liu H. «Cross Validation.» Encyclopedia of Database Systems. Eds M. Tamer A-Zsu, and
Ling Liu. New York: Springer, 2009, pp. 532 — 538.
9. Yakubchik T.N. Clinical Gastroenterology. Grodno: Grodno State Medical University Publisher, 2011. 308 p. (In
Gololobov, G. Yu., A. A. Stamov, and E. D. Mekhdiev. «Prediction of Peptic Ulcer Disease Complications Based on Cross-validation Method.» Electronic Scientific Edition Almanac Space and Time 15.1 (Studia Studiosorum: Achievements of Young Researchers) (2017). Web. . (In Russian).