JSON
JSON (JavaScript Object Notation) это текстовый формат обмена данными, широко используемый в веб-приложениях. По сравнению с XML он является более лаконичным и занимает меньше места. Кроме этого все браузеры имеют встроенные средства для работы с JSON.
Необходимость работы с этим форматом на уровне платформы обусловлена не только тем, что это современный формат, который прикладные решения 1С:Предприятия сами по себе могут использовать для интеграции со сторонними приложениями. Другая причина заключается ещё и в том, что JSON активно используется в HTTP интерфейсах, для работы с которыми в 1С:Предприятии есть REST интерфейс приложения, автоматически генерируемый платформой, и HTTP-сервисы, которые можно создавать самостоятельно.
Существует несколько основных сценариев использования JSON.
- Интеграция с внешними системами через их HTTP интерфейсы: Google Calendar, Salesforce.com, REST интерфейс 1С:Предприятия, SharePoint и т. д.;
- Организация собственного HTTP интерфейса прикладного решения;
- Обмен файлами JSON с внешними системами. Формирование конфигурационных, настроечных файлов. Использование их в процедурах обмена данными, например, с интернет-магазинами;
- Использование файлов JSON для обмена данными между разными приложениями 1С:Предприятия.
В платформе реализовано несколько слоёв работы с JSON. Самые простые и гибкие — это низкоуровневые средства потоковой записи и чтения. Более высокоуровневые и не такие универсальные — средства сериализации в JSON примитивных типов и коллекций 1С:Предприятия. И, наконец, третий слой это средства, позволяющие сериализовать/десериализовать прикладные типы 1С:Предприятия: ссылки, объекты, наборы записей и вообще любые типы, для которых поддерживается XDTO сериализация.
Потоковое чтение и запись JSON
Объекты потоковой работы последовательно читают данные в формате JSON из файла или строки, или последовательно записывают их в файл или строку. Таким образом, чтение и запись данных происходят без формирования всего документа в памяти.
Потоковая запись JSON может выглядеть следующим образом. Записывается массив из четырёх элементов. Три из них примитивного типа, а четвёртый элемент — это объект с двумя свойствами:

Результат такой записи:
Сериализация примитивных типов и коллекций
Вторая группа средств работы с JSON хороша тем, что избавляет от рутинной работы по чтению/записи каждого отдельного значения или свойства. При чтении документы JSON отображаются в фиксированный набор типов платформы: Строка, Число, Булево, Неопределено, Массив, ФиксированныйМассив, Структура, ФиксированнаяСтруктура, Соответствие, Дата. Соответственно, в обратную сторону, композиция объектов этих типов позволяет сформировать в памяти и быстро записать в файл структуру JSON. Таким образом, чтение и запись небольшого объема JSON заранее известной структуры можно производить немногими строчками кода.
Основное назначение этих средств в обмене информацией с внешними системами, чтении конфигурационных файлов в формате JSON.
Пример сериализации (записи) в JSON может выглядеть так:

Сериализация прикладных типов 1С:Предприятия
Прежде всего, и в основном, XDTO сериализацию в JSON рекомендуется использовать при обмене данными между двумя прикладными решениями 1С:Предприятия. Также этот механизм можно использовать и для обмена с внешними системами, готовыми принимать типы данных 1С:Предприятия.
Простейший код, выполняющий сериализацию элемента справочника, может выглядеть так:
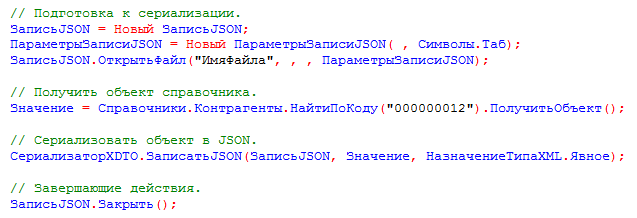
В результате будет получен файл JSON следующего содержания:
Функции преобразования и восстановления при сериализации
Не всегда сериализация может быть выполнена полностью автоматически. В жизни встречаются самые разные ситуации. Поэтому существует возможность использовать «самописную» функцию обработки значений при записи в JSON и при чтении из JSON.
При записи в JSON эта функция полезна потому, что позволяет самостоятельно преобразовать в JSON те типы, которые не подлежат автоматическому преобразованию. Или даже совсем отказаться от их сериализации.
При чтении из JSON функция восстановления может использоваться для того, чтобы преобразовать данные JSON в типы 1С, которые не могут являться результатом автоматического преобразования, или для того, чтобы самостоятельно (не автоматически) преобразовать даты JSON в даты 1С:Предприятия.
Во процессе десереализации прикладных типов 1С:Предприятия функция восстановления может потребоваться, например, для того, чтобы при переносе данных из одного прикладного решения в другое, заменить в них ссылки на связанные объекты. Так, чтобы после переноса эти данные ссылались уже на объекты новой базы. Или, например, для того, чтобы удалить из данных информацию, имеющую смысл только в исходной базе.
Использование JSON в HTTP интерфейсах приложений
Автоматически генерируемый REST интерфейс прикладных решений
При обращении к REST интерфейсу прикладного решения можно получать ответ в формате JSON. Есть возможность управлять объёмом передаваемой информации за счёт изменения детальности представления метаданных в выгрузке. Существуют три уровня: минимальный, средний и максимальный. Однако при этом нужно учитывать, что сокращение объёма передаваемой информации приводит к более интенсивным вычислениям на клиенте. И наоборот, когда вся информация включается в выгрузку, объём вычислений на клиенте будет минимальным.
HTTP-сервисы прикладного решения
HTTP-сервисы, реализованные в прикладном решении, также могут возвращать ответ в формате JSON. При этом, при формировании тела ответа, есть возможность указать, следует ли использовать BOM (Byte Order Mark, метка порядка байтов).
Взаимодействие со сторонними HTTP сервисами
При взаимодействии со сторонними HTTP интерфейсами также существует возможность сформировать тело запроса в JSON, а затем установить его в HTTP запрос.
Авторы: Е.Ю. Хрусталева
ТОП-50 вопросов системному аналитику на собеседовании
Всем привет! Я проходил собеседования на системного аналитика в разных компаниях с декабря 2021 до сентября 2022 каждую неделю по одному разу и каждый раз записывал все вопросы. Компании были не только российские, но и расположенные в самых разных регионах Европы, Азии и запада. Я собрал ТОП-50 вопросов технического собеседования. Вероятность что вам на всех собеседованиях попадутся именно эти вопросы очень сильна и я уверен что подготовившись на эти вопросы вам точно дадут оффер большинство, если не все компании.
P.S — Вопросы телефонного и первых этапов собеседования тут не включены, только вопросы технического собеседования
Требования
- Какие виды требований вы знаете?
- Что входит в функциональные требования?
- Что входит в нефункциональные требования?
- ГОСТ 19 и 34 для чего нужны и в чем разница между ними?
- Критерии требований
- Use cases — это что и как пишутся?
- User stories — это что и как пишутся?
- Заинтересованные лица (стейкхолдеры) — кто это и как с ними взаимодействовать?
- Что содержится в вашей типовой постановке задач для разработчика
Процесс разработки
- Расскажите про процесс разработки, который был принят на вашем прошлом месте работы
- Чем Kanban отличается от Scrum?
- Где можно применять Scrum и где нельзя?
Интеграции и проектирование
- Что такое XSD?
- Чем SOAP отличается от REST?
- Что такое XML и что в нем содержится?
- Какие методы есть в REST
- Напишите пример rest-API для книжной библиотеки на JSON
- Что содержит URL в REST запросе?
- Что такое WSDL?
- Понимание работы основных протоколов и способов взаимодействия систем (REST, GRPC, брокеры сообщений);
- Чем POST отличается от GET?
- Что такое идемпотентность?
- Что такое брокеры сообщений?
- Проектировали взаимодействие информационных систем?
- Какие виды и способы интеграций вы знаете?
- Чем Kafka отличается от RabbitMQ?
- Чем отличается ошибка 200 от 201?
- Что такое корпоративная шина?
- К корпоративной шине подключены веб-сервисы. В одном веб-сервисе появились два новых обязательных поля. Что изменится в интеграции?
- Чем брокер сообщений отличается от корпоративной шины?
- Назовите все способы снизить нагрузку на веб-сервис.
- Приходилось ли вам проектировать API в нотации OpenAPI/Swagger?
- Что такое клиент-сервер и микросервисы?
- Какими UML диаграммами вы пользуетесь?
- Что такое диаграмма последовательности?
- Какие элементы BPMN вы знаете?
- Опишите работу банкомата в BPMN
- Что такое Хореография и Оркестрация?
SQL и Базы данных
- Как привести данные в форму: что такое нормализация и зачем она нужна?
- Писали ли вы SQL запросы и для чего?
- Можете ли писать сложные запросы?
- Зачем нужны индексы в таблицах БД?
- JOIN запросы, что это и какими бывают?
- Что такое первичный ключ и какими свойствами обладает?
- Поисковые пути в БД это?
Другие вопросы
- Как работает https?
- Что такое FTP?
- Что такое SFTP
- Чем отличаются синхронное и асинхронное взаимодействия?
- Чем авторизация отличается от аутентификации?
- Что такое СЭД и как они работают?
- Что такое синхронное и асинхронное шифрование?
- Какие уровни протоколов знаете?
- Какие UX принципы вы знаете?
Чаще всего требования к кандидатам следующие (помимо опыта работы в определенном домене):
- Основная деятельность: сбор, анализ и документирование требований к ПО на техническом языке. Сопутствующее общение с заказчиками и проектной командой, изучение предметной области, участие в проектировании решений, проверка реализованного функционала на соответствие требованиям, участие в показах.
- Требуемые hard skills: навыки разработки технической документации (BRD, SRS), опыт работы с различными СУБД, уверенные знания SQL, проектирование модели данных, знание нотаций UML, BPMN, знание различных методов интеграции систем, понимание принципов проектирования REST API, опыт работы с SOAP, понимание особенностей форматов обмена данными JSON/XML.
- Требуемые soft skills: коммуникабельность, способность находить общий язык и с разработкой, и с бизнесом, аналитическое мышление, умение работать в условиях недостатка информации, адаптивность к изменениям, проактивность и ответственность за конечный результат.
Что нужно знать системному аналитику уровня Middle и Senior: план развития Hard Skills
Решил составить для себя план развития (я в IT с 2007, как аналитик — с 2017). Что получилось: некий чек-лист с перечислением 13 блоков (от работы с требованиям до безопасности) с описанием, что обязательно и желательно знать/уметь.

С чего все началось. Я недавно менял работу, поэтому готовился к техническим собеседованиям. Для удобства составил шпаргалку частых вопросов по основным темам. Когда проходил собеседования и видел, чего я не знаю, то дописывал это в свою шпаргалку. А немного позже решил составить для себя что-то наподобие плана развития. При создании плана использовал личный опыт, опыт коллег, ряд статей, учебные планы нескольких школ, требования из вакансий.
В каждом блоке выделил обязательные знания/умения и дополнительные (в тексте это выделено как «Продвинутый уровень»).
- «Обязательно» — это то что системному аналитику точно нужно знать (с моей точки зрения).
- «Продвинутый уровень» — это дополнительные знания уровня Senior, либо это требуется из-за специфики проектов конкретного специалиста (например, мобильная разработка).
Из каких блоков состоит план
- Процесс разработки
- Работа с требованиями
- Моделирование систем
- Модели данных
- Пользовательский интерфейс (UI/UX)
- Интеграция систем
- Интеграция систем: архитектура REST
- Интеграция систем: протокол SOAP
- Интеграция систем: шина данных (ESB, MOM, MQ)
- Анализ данных
- Безопасность
- Тестирование
- Основы программирования
1. Процесс разработки
Обязательно
- Типы ПО и их особенности (системное/прикладное/инструментальное, индивидуальное/групповое, web/desktop/app).
- Жизненный цикл разработки программного обеспечения (Software development lifecycle — SDLC): сбор и анализ требований, проектирование, разработка, тестирование, внедрение, сопровождение.
- Основные модели управления разработкой ПО (водопадные, итерационные). Основные гибкие методологии (Agile, Scrum, Kanban).
- Основные участники команды разработки и сопровождения IT-проектов, их роли (разработчик, аналитик, тестировщик, product и project менеджер, сетевой инженер, DevOps). Разные виды аналитиков и чем они занимаются (системный, бизнес, продуктовый, веб, BI, аналитик данных).
- Виды документации и их назначение (BRD, FSD/SRS, руководства пользователя, инструкции, регламенты, база знаний и т.д.).
- Понятие «фреймворк».
- Суть концепция CI/CD.
- Общее представление о системе контроля версий.
- Выстраивать взаимодействие и совместную работу с заказчиками, командой, экспертами и другими участниками процесса создания, развития и сопровождения проектов.
- Планировать и выстраивать процесс работы; выделять, декомпозировать и приоритизировать задачи, управлять сроками и рисками.
- Создавать разные виды проектной документации.
Продвинутый уровень
- Прочие модели, методологии, подходы к управлению разработкой ПО (инкрементная, V-образная, Domain-driven design (DDD), Lean и т.д.).
- Планировать процесс разработки фич и проектов, декомпозировать сложные процессы и задачи, ставить задачи другим участникам проекта.
- Руководить реализацией отдельной фичи, руководить проектом, руководить другими сотрудниками. Планировать ресурсы. Управлять рисками.
2. Работа с требованиями
Обязательно
- Что такое требования к разработке ПО. Виды требований (бизнес/пользовательские/системные, функциональные/нефункциональные и т.д.).
- Источники требований, способы и инструменты сбора требований:
- интервью, опросы, анкетирование
- наблюдение за процессом
- анализ внутренних документов компании (бэклог, планы развития, обращения в тех.поддержку и т.п.)
- анализ требований законодательства и других внешних для компании документов
- анализ текущих решений (собственных и внешних), систем-аналогов, ранних версий, прототипов
- фокус-группы, мозговой штурм
- анализ предметной области
- сбор требований
- анализ, выстраивание приоритетов и устранение противоречий
- согласование
- моделирование системы, описание процессов
- ревью и итоговое согласование
- сопровождение и управление изменениями
- тестирование функционала, презентация результатов
- Выделять заказчиков, лиц принимающих решения, заинтересованных лиц проекта, экспертов, пользователей, специалистов создания, внедрения и сопровождения данного проекта.
- Выделять источники и собирать требования разными способами (особенно через интервью).
- Выявлять истинные причин появления проекта и требований:
- почему появилась задача: какую проблему решаем или что хотим улучшить
- зачем это реализовывать: ради какого измеряемого результата
- определение цены и ценности: какой результат получить реально в рамках данного проекта и имеющихся ресурсов, устроит ли он, стоит ли он потраченного времени и других ресурсов.
- определять границы проекта: что будет, а что не будет реализовано в текущем проекте, выделать MVP
Продвинутый уровень
- Расширенные знания стандартов описания требований: ГОСТ 19, ГОСТ 34, EARS (The Easy Approach to Requirements Syntax) и т.п.
- Выделять и описывать job story (Jobs-To-Be-Done).
- Строить Impact Map (структура «зачем, кто, как, что»).
3. Моделирование систем
Обязательно
- Основные виды архитектур, их описание, преимущества и недостатки, когда используются (локальная, монолитная, клиент/сервер/БД, SOA: сервис-ориентированная, MSA: микросервисная).
- Понятия «хореография» и «оркестрация».
- Понятия «фронтенд» и «бэкенд».
- Описание процессов с помощью блок-схем (Flowchart).
- Описание процессов в нотации BPMN
- Описание процессов и системы в нотации UML:
- Диаграмма вариантов использования — Use Case Diagram
- Диаграмма активностей — Activity Diagram
- Диаграмма состояний — State Machine Diagram
- Диаграмма последовательностей — Sequence Diagram
- Моделировать системы и описывать их с помощью разных нотаций (Flowchart, BPMN, UML) и разных способов (тексты, таблицы, схемы, диаграммы и т.п.).
- Описывать бизнес-процессы, поведение пользователей и отклик системы, системные функции (процессы, осуществляемые системой без участия пользователя).
Продвинутый уровень
- Более глубокие знания архитектур (многослойная, многоуровневая, MVC: Model-View-Controller, клиент-серверная, файл-серверная, облачная, событийно-ориентированная, микроядерная, модульный монолит, peer-to-peer и т.д.)
- Особенности реализации web, desktop и мобильных приложений. Кроссплатформенная разработка.
- Расширенные знания нотации BPMN и UML.
- Знание других нотаций, стандартов, фреймворков (IDEF0, IDEF3, EPC, DMN, VAD, SIPOC, BABOK и т.п.).
- Модель С4 архитектуры программного обеспечения.
- Описывать более сложные процессы в нотации BPMN.
- Описывать более сложные процессы в нотации UML, использовать прочие виды диаграмм (Deployment Diagram, Component Diagram и т.д.).
4. Модели данных
Обязательно
- Что такое концептуальная, логическая и физическая модели данных.
- Структурированные, неструктурированные и слабоструктурированные данные.
- Что такое и как между собой связаны: сущности (объекты), атрибуты, связи.
- Основные принципы ООП. Понятия «класс», «объект», «экземпляр».
- Типы баз данных (реляционные, объектно-реляционные, нереляционные — NoSQL, колоночные, текстовые). Когда какие используются. Популярные систем управления баз данных (СУБД) для каждого типа.
- Как организованы реляционные базы данных, правила проектирования:
- Основные принципы реляционных баз данных
- Типы данных
- Способы реализации связей
- Нормализация: что это, зачем нужна, 3 формы
- Первичный ключ, составной первичный ключ, внешний ключ, суррогатный ключ
- NULL и пустые значения
- Ограничения (NOT NULL, UNIQUE, PRIMARY KEY, FOREIGN KEY, CHECK, DEFAULT, INDEX, AUTO INCREMENT)
- Создавать ER-диаграммы.
- Проектировать простые базы данных.
Продвинутый уровень
- Более глубокие знания в проектировании реляционных БД
- Представление (виртуальная таблица). Виды представлений.
- Индексы
- Триггеры
- Транзакции. ACID-требования к транзакциям и CAP-теорема.
- Временные таблицы (таблицы для промежуточных данных)
- Хранимые процедуры
- Сериализация данных
- Что такое подмножества и какие бывают (DDL, DQL, DML, DCL, TCL).
- SQL-инъекции
- Чем отличаются и когда какую СУБД лучше выбрать (PostgreSQL, MySQL, Oracle, MS SQL, MongoDB, ClickHouse, DB2, Greenplum, SQLite, Elasticsearch, Cassandra и т.д.)
- Описывать классы в UML: Class Diagram.
- Проектировать более сложные реляционные базы данных.
- Проектировать нереляционные базы данных.
- Составлять логические модели по существующей базе данных.
- Осуществлять реинжиниринг модели данных.
5. Пользовательский интерфейс (UI/UX)
Обязательно
- Основы UI/UX, правила построения интерфейсов (принципы, этапы разработки, критерии качества).
- Типовые элементы (экранные формы, модальные окна, хлебные крошки, пагинация и т.д.).
- Понимание принципов адаптивной верстки.
- Понимание, что такое «клиентский путь».
- Создавать наброски и схемы графических интерфейсов системы.
- Взаимодействовать с UI/UX специалистами.
Продвинутый уровень
- Расширенные знания UI/UX. В том числе в разных направления (web, app и т.д.).
- Создавать макеты графического интерфейса системы (с помощью Figma или других специальных инструментов).
- Создавать интерактивные прототипы графических интерфейсов.
- Разрабатывать карты клиентского пути (CJM — Customer Journey Map).
6. Интеграция систем
Обязательно
- Виды интеграций информационных систем (API, шина данных — ESB/MOM/MQ, общая база данных, файловый обмен). Их описание, преимущества и недостатки разных способов, что когда используется.
- Pull-модель (первоначальный запрос производится клиентом) и push-модель (данные поступают от поставщика к пользователю на основе установленных контрактов).
- Синхронное, асинхронное и реактивное взаимодействие.
- Концепции stateful и stateless (с сохранением и без сохранения состояния на стороне сервера).
- Основы синтаксиса JSON и XML.
- Типы API (REST, SOAP, JSON:API, GraphQL, RPC, API нативных библиотек), их общее описание.
- Веб-сервисы. Webhook.
- Протокол HTTP
- структура запроса и ответа (стартовая строка, HTTP-заголовки, тело сообщения)
- основные методы в HTTP запросах, их назначение (GET, POST, PUT, DELETE, PATCH), концепция CRUD
- структура URL (протокол, хост, порт, путь до ресурса, запрос/параметры)
- коды состояния (1хх, 2хх, 3xx, 4xx, 5xx)
- как передать html документ, json-файл
- что такое HTTPS, отличие от HTTP
- Проектировать интеграционные взаимодействия:
- диаграммы потоков данных (DFD)
- диаграммы последовательности (Sequence Diagram)
- описание передаваемых и принимаемых данных
- обработка ошибок и нештатных ситуаций, журналирование
- ограничения на интеграцию
- требования к качеству интеграций
- описание преобразований данных
- регламент передачи данных
Продвинутый уровень
- Уровни сетевого взаимодействия: модель OSI, TCP/IP, UDP, FTP, SSH, SFTP, WebSocket и т.п.
- Какие есть сложности и проблемы при интеграции систем. Закон дырявых абстракций.
- Что такое идемпотентность. Какие HTTP методы являются идемпотентными, а какие нет, почему.
- Разрабатывать требования интеграции систем через GraphQL и JSON:API.
7. Интеграция систем: архитектура REST
Обязательно
- Принципы REST архитектуры.
- Отличие от SOAP.
- Особенности применения REST в HTML (нельзя отправлять PUT и DELETE запросы из HTML-формы).
- JSON Schema.
- Понимать документацию с описанными REST API (в том числе в Swagger).
- Проектировать и описывать интеграции REST API.
- Работать с Postman
Продвинутый уровень
- Отличие от JSON:API.
- Описывать интеграции REST API через OpenAPI и Swagger
- Работать с cURL.
8. Интеграция систем: протокол SOAP
Обязательно
- Основы протокола SOAP. Структура сообщения (XML файла). WSDL
- XSD схема (XML Schema).
- Понимать документацию с описанными SOAP API.
Продвинутый уровень
- Расширенные знания протокола SOAP (пространство имен, индикаторы элементов, XSLT, XPATH и т.д.).
- Проектировать и описывать интеграции SOAP API, XSD схемы.
- Работать с SOAP UI и Postman (для SOAP).
9. Интеграция систем: шина данных (ESB, MOM, MQ)
Обязательно
- Что из себя представляет ESB (Enterprise Service Bus — сервисная шина предприятия), MOM (Message-oriented Middleware — ПО, ориентированное на обмен сообщениями в распределенном окружении), MQ (Message Queue — очередь сообщений, брокер сообщений).
- Отличие ESB от MQ. Отличие ESB от ETL.
- Понятия «топик» (издатель-подписчик) и «очередь» (отправитель-получатель).
- Какие брокеры сообщений чаще всего используются (RabbitMQ и Kafka).
- Понимать документацию с описанием интеграций через шину.
- Описать документацию при использовании интеграции через шину.
Продвинутый уровень
- Разница между RabbitMQ и Kafka. Когда что лучше выбрать.
- Как брокер сообщений (RabbitMQ и Kafka) гарантирует доставку сообщений.
10. Анализ данных
Обязательно
- Основы анализа данных.
- Знать что такое Big Data, BI, Data Science, ML.
- Анализировать данные, находить ответы на вопросы, формировать отчеты, уметь их презентовать.
- Работать с простыми SQL запросами
- CRUD-операции: SELECT, UPDATE, INSERT, DELETE
- Создание и удаление таблиц: CREATE, DROP, TRUNCATE
- Ограничение и сортировка: WHERE, LIMIT, DISTINCT, ORDER BY
- Дополнительные условия: = != <> >< AND, OR, BETWEEN, IN, IS NULL, IS NOT NULL, LIKE, NOT LIKE
- Арифметические операции: + — * / %
- Агрегирование данных: GROUP BY, AS, AVG, COUNT, MAX, MIN, SUM, HAVING
- Вложенные запросы (в части SELECT, FROM, WHERE)
- Объединение запросов: UNION, UNION ALL
- Объединение таблиц: JOIN (INNER, LEFT, RIGHT, FULL, CROSS)
- Комментарии
Продвинутый уровень
- Основы статистики.
- Основы продуктовой аналитики (продуктовые и маркетинговые метрики, CustDev, А/В тестирование, Unit-экономика и т.д.)
- Что такое OLTP (обработка транзакций в реальном времени), OLAP (интерактивный анализ данных — кубы), ETL (извлечение, преобразование, загрузка), ELT (извлечение, загрузка, преобразование), DWH (хранилище данных).
- Понимание принципов построения хранилищ данных.
- Основные системы аналитики данных.
- Проводить более сложный анализ данных, находить инсайты, аномалии. Формировать дашборды, визуализировать данные.
- Работать с более сложными SQL запросами
- Сложные составные запросы (в том числе с EXISTS, ANY, ALL, CASE, IF)
- Встроенные функции: ROUND, DATE, TIME, DATETIME, SUBSTR и т.д.
- Оконные функции (OVER)
11. Безопасность
Обязательно
- Что такое аутентификация, примеры способов аутентификации (пароль, ЭЦП, SMS, push уведомление, биометрия, многофакторная), что такое идентификация.
- Что такое авторизация, ролевая модель информационной системы.
- Что такое хеширование, как и где применяется (особенно для паролей).
- Что такое электронная подпись. Зачем и как используется.
Продвинутый уровень
- Что такое криптография, для чего используется. Симметричное и асимметричное шифрование. Открытый и закрытый ключи. TLS/SSL в HTTPS.
- Контрольная сумма: что это, как используется.
- Основные схемы и протоколы аутентификации (базовая аутентификация, аутентификация по cookies, аутентификация по предъявлению цифрового сертификата, аутентификация с помощью ключа API, OpenID/OAuth/JWT и т.д.)
- Что такое верификация и валидация.
- Принципы работы электронной подписи, виды (простая, неквалифицированная, квалифицированная), их отличия.
- Основные уязвимости веб сервисов и мобильных приложений.
12. Тестирование
Обязательно
- Процесс тестирования, тест кейсы и чек листы.
- Разрабатывать критерии и процесс проведения приемочного тестирования.
- Организовывать и проводить приемочное тестирование.
Продвинутый уровень
- Виды, подходы, инструменты тестирования.
- Написать тест кейсы и чек листы (все позитивные и основные негативные сценарии).
- Тестировать функционал (все позитивные и основные негативные сценарии).
13. Основы программирования
Обязательно
- Какие основные языки программирования существуют, где применяются.
- Основы программирования (переменные, операторы, ветвление, циклы, функции и т.п.).
- Основы языка разметки документов HTML.
- Написать простую программу на любом ООП языке программирования.
Продвинутый уровень
- Более глубокое знание хотя бы одного из популярных ООП языков.
- Понимание основ HTML/CSS/JavaScript.
- Понимание ООП в программировании.
- Написать более сложную программу на любом ООП языке программирования.
Итоги
Данный план больше напоминает меню в ресторане, где стоит выбирать что нужно, а не все позиции. Лично мне он в первую очередь помог структурировать имеющиеся опыт и знания, а также увидеть «белые пятна» и получить хотя бы общее представление по всем таким направлениям.
Какие знания и навыки нужны, и к какому уровню их отнести — это очень дискуссионный вопрос. Опять же, в каких-то блоках у меня знаний и опыта больше, а в каких-то меньше. Поэтому буду рад вашему мнению и вашим советам, особенно если что-то упустил (можно в комментариях, можно лично vk.com/chizhovav88).
Отдельная просьба — поделиться ссылками на митапы/форумы/каналы/соцсети, где происходит активное общение и публикуются полезные материалы по темам «аналитика», «управление IT-проектами», «запуск и развитие IT-проектов». Это тоже важная часть развития, которая у меня несколько просела.
- системный анализ
- обучение
- карьера в it
- Анализ и проектирование систем
- Учебный процесс в IT
- Карьера в IT-индустрии
JSON: что это за формат и как с ним работать
«ДжЕйсон» или «ДжейсОн»? JSON или JSON5? Отвечаем на эти и многие другие вопросы.

Иллюстрация: Оля Ежак для Skillbox Media

Рустам Сабиров
Востоковед, интересующийся IT. В прошлом редактор раздела «Системный блок» журнала «Fакел», автор журналов Computer Gaming World RE, Upgrade Special, руководитель веб-ресурсов компании 1С-Softclub.
JSON (JavaScript Object Notation) — стандартный текстовый формат для хранения и передачи структурированных данных. Он основан на синтаксисе объекта в JavaScript, но не привязан к нему. Работу с ним поддерживают многие современные языки программирования: Python, Java и другие.
До создания формата JSON запросы к серверу требовали постоянного обновления страницы в браузере. Это замедляло работу сайтов. AJAX-запросы , работающие с JSON-форматом, выполняются в фоновом режиме и не требуют обновления страницы. Благодаря этому скорость работы с веб-ресурсами значительно выросла, а JSON стал стандартом передачи данных в интернете.
Сегодня мы узнаем про JSON:
- как появился формат;
- его преимущества над другими форматами;
- базовую структуру и синтаксис;
- объекты и массивы;
- что такое JSON5 и чем он отличается от JSON4;
- что такое JSON Schema;
- как работать с JSON;
Как появился JSON
Создателем JSON считается Дуглас Крокфорд, известный американский программист и один из разработчиков JavaScript. Он автор популярного статического анализатора кода JSLint и книг JavaScript: The Good Parts и How JavaScript Works.

«Я открыл JSON. Я не утверждаю, что изобрёл его, поскольку он уже существовал в природе. Я просто нашёл его, дал ему название и рассказал, в чём его польза. Я знаю, что есть и другие люди, которые открыли его, по крайней мере, за год до меня. Самый первый известный мне случай связан с Netscape — кто-то в компании использовал литералы массивов JavaScript для передачи данных ещё в 1996 году, то есть как минимум за пять лет до того, как я наткнулся на эту идею».
Дуглас Крокфорд,
The JSON SagaВ начале 2001 года Дуглас Крокфорд и Чип Морнингстар основали компанию State Software. Работая над проектами, они столкнулись с проблемой — передача данных между сервером и браузером требовала постоянного обновления страницы. Это замедляло работу.
Для решения проблемы тогда использовали разные подходы, например специальные плагины для браузеров на основе Flash или Java-апплетов . Но работа с ними была сложной и сопровождалась частыми ошибками.
Тогда Крокфорд вспомнил идею, которую впервые услышал у кого-то из компании Netscape, и внедрил объект JavaScript внутрь HTML-кода, который передавал сообщение на страницу. Первый вариант выглядел так:
html> head> script> document.domain = "fudco"; parent.session.receive( < to: "session," do: "test," text: "Hello world" > ) script> head> html>
Этот код должен был отправить сообщение от дочернего окна к родительскому окну с использованием объекта parent. Но он не сработал, поскольку слово do было зарезервировано в JavaScript. Чтобы обойти эту проблему, Крокфорд использовал кавычки, заключив в них все слова внутри объекта:
html> head> script> document.domain = 'fudco'; parent.session.receive( < "to": "session", "do": "test", "text": "Hello world" > ) script> head> html>
Так появился новый формат, который сначала хотели назвать JSML (JavaScript Markup Language), но победило название JSON (JavaScript Object Notation).
В 2001 году Крокфорд создал веб-страницу с описанием этого формата, чтобы все разработчики могли его использовать в своей работе.
«Разрабатывая JSON, я стремился к минимализму. Моя идея заключалась в том, что чем меньше вопросов нам придётся согласовывать, тем выше вероятность, что нам будет просто взаимодействовать друг с другом. Я хотел, чтобы стандарт JSON умещался на обратной стороне визитной карточки».
Дуглас Крокфорд,
HackernoonСтандарт JSON на обратной стороне визитной карточки
Фото: Eric Miraglia / FlickrJSON отличался от своих конкурентов — XML , CSV и YAML — простотой синтаксиса и небольшим размером файлов, что было удобно при работе с вебом. Благодаря этому он быстро набирал популярность.
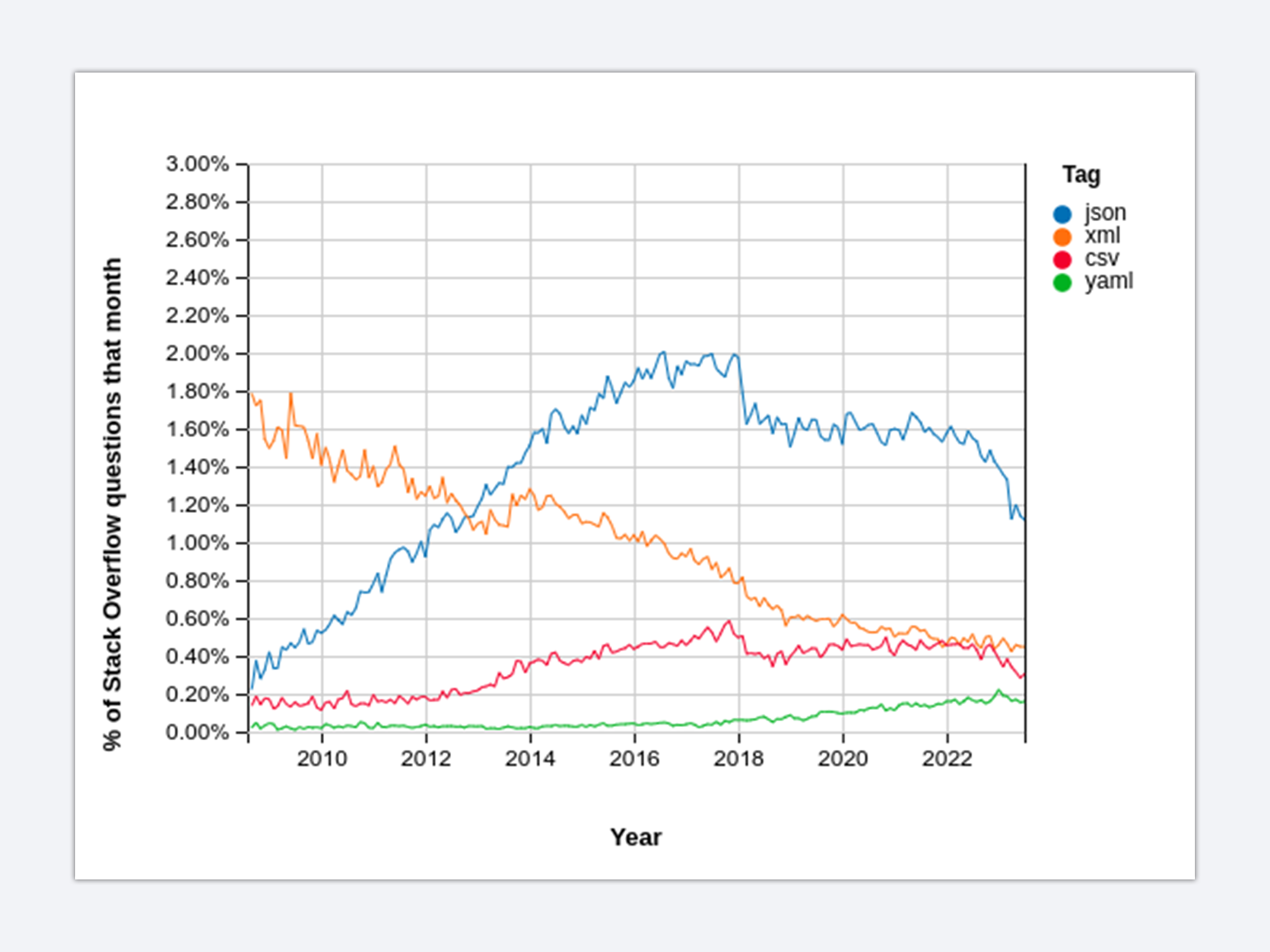
В 2014 году орган по стандартизации ECMA принял JSON и официально специфицировал его. Сегодня этот формат является основным для передачи данных при взаимодействии веб-сервера и браузера.
В этом разделе ответим и на главный вопрос разработчиков — как произносить JSON? Есть два варианта — с ударением на «е» и на «о». Лучше всего на это ответит один из разработчиков формата — Чип Морнингстар:
«Многие люди говорят „ДжейсОн“, что меня всегда радует. Всякий раз, когда я нахожусь на встрече и кто-то говорит „ДжейсОн“, я отвечаю „ДжЕйсон“. Они спрашивают: „Откуда ты знаешь?“ А я им отвечаю: „Ну, потому что это я придумал“.
Преимущества JSON
JSON не единственный формат передачи данных. Некоторые разработчики используют XML или YAML. Но в сравнении с ними у JSON есть ряд преимуществ:
Простой и легко читаемый синтаксис, который понятен и компьютеру, и человеку. Необязательно даже разбираться в JavaScript, чтобы научиться записывать и читать данные. Скоро вы это увидите сами.
Лёгкость и компактность. JSON-файлы весят меньше, чем файлы других форматов, и загружаются быстрее. Согласно некоторым исследованиям, современные браузеры обрабатывают JSON в десятки раз быстрее XML.
Отсутствие зависимости от конкретного языка программирования. Для работы с JSON можно использовать почти любой популярный язык программирования, например Python или Java.
Универсальность в типах данных. JSON можно использовать для хранения массивов, упорядоченных списков и коллекций пар «ключ — значение». Но и это не всё. Формат подходит для представления сложных структур данных, включая деревья и иерархические структуры.
Широкая поддержка в браузерах. Все современные браузеры поддерживают работу с JSON.
Самостоятельное документирование. В JSON можно включить метаданные, которые описывают представленные данные, упрощая работу с ними.
Структура и синтаксис JSON
Синтаксис JSON повторяет синтаксис обычного объекта в JavaScript: данные записываются в виде пар «ключ — значение» и разделяются запятыми. Важно запомнить, что после последней пары запятая не ставится — это распространённая ошибка, которую можно долго искать.
Ключи — строковые переменные, а значения могут быть строками, числами, булевыми значениями, объектами, массивами или null. Функции и даты в обычном JSON не поддерживаются.
Вот как выглядит простой JSON-файл:
//ключ // значение < "name": "John Smith", "age": 37 >
Несмотря на изначальную привязку формата к JavaScript, спецификация JSON допускает вещи, которые недопустимы в JavaScript-коде. Например, в JSON символы разделения строк и абзацев можно указывать без экранирования.
Для работы с датами в JSON необходимо переводить их в строковый формат в соответствии со стандартом ISO 8601 :
2023-08-24T20:45:03.408Z
С детальным описанием требований к синтаксису JSON можно познакомиться на сайте Datatracker. Для проверки правильности синтаксиса или его форматирования в соответствии с правилами существует множество онлайн-валидаторов, например JSON Validator.
Объекты и массивы JSON
Для хранения данных в JSON используются две структуры — объекты и массивы.
Объекты — неупорядоченная коллекция. Для них не принципиально в каком порядке следуют пары «ключ — значение». То есть их можно менять местами. Но будьте осторожны! Когда разработчик перемещает пару «ключ — значение» с любого места на последнюю, часто забывает удалить запятую, что приводит к ошибке.
Объект JSON очень похож на объект в JavaScript, но ключ всегда должен быть в кавычках. Например:
< "name": "Иван", "age": 34, "married": true >
Массивы — упорядоченный список значений. Выглядят они так:
[ "яблоко", "персик", "банан", "киви" ]
В отличие от объекта, порядок элементов в массиве важен. Тут нет ключей, поэтому обращаться к значениям мы можем только по индексу элемента. Важно помнить, что у первого элемента индекс 0.
Объекты и массивы могут быть вложены друг в друга, а количество уровней вложенности не ограничено.
Что такое JSON5
JSON5 — это расширение стандарта JSON, повышающее читаемость и удобство написания JSON-данных. Кроме этого, он добавляет новые возможности, например использование комментариев, которых нет в самом стандарте.
Главные отличия JSON5, полезные в работе:
Допустимы комментарии:
Необязательно использовать кавычки для ключей, но только в том случае, если ключ состоит из букв, цифр или знаков подчёркивания и не является зарезервированным словом:
< key: "value", // Ключ без кавычек >Есть специальный формат для дат и времени:
Поддерживает многострочный текст, что позволяет записывать строки без неудобного экранирования:
Допускает запись чисел с подчёркиваниями для улучшения читаемости:
< largeNumber: 1_000_000, // Число с подчёркиваниями для улучшения читаемости >Поддерживает шестнадцатеричную и восьмеричную системы счисления:
0xCAFE_BABE // Шестнадцатеричное число >
Но важно помнить, что JSON5 поддерживается не всеми парсерами, приложениями и библиотеками, что пока ограничивает его использование.
Что такое JSON Schema
Для описания и проверки данных в формате JSON есть специальный язык JSON Schema. Допустим, у нас есть обычный JSON-файл:
< "name": "John Doe", "age": 30, "address": < "city": "New York", "zip": "10001" > >
Разработчик не знает, какие из этих полей являются обязательными, к какому типу данных могут принадлежать значения и так далее. JSON Schema позволяет добавить необходимые метаданные, или «правила» для этой информации, и описать, какие поля должны быть заполнены и что они могут содержать.
JSON Schema используется для валидации данных при обмене информацией между разными системами или при работе с данными, получаемыми от пользователей. Если новые данные не соответствуют заданной схеме, то разработчик быстро узнает об ошибке и сможет внимательно изучить информацию, исправив её или запросив обновление.
Благодаря этому код становится надёжным, предсказуемым и устойчивым к ошибкам, позволяя явно определять требования к представлению данных. Вот как будет выглядеть вышеупомянутый файл, описанный с помощью JSON Schema:
< "$schema": "http://json-schema.org/draft-07/schema#", "type": "object", "properties": < "name": < "type": "string" >, "age": < "type": "number" >, "address": < "type": "object", "properties": < "city": < "type": "string" >, "zip": < "type": "string" > >, "required": ["city", "zip"] > >, "required": ["name", "age", "address"] >
Разберём код построчно:
- в первой строке указана ссылка на версию спецификации JSON Schema;
- данные должны быть объектом типа «object»;
- объект должен содержать три обязательных поля: «name», «age» и «address»;
- у каждого поля свой тип данных: «string» для имени, «number» для возраста и «object» для адреса;
- поле «address» должно быть объектом и содержать два обязательных подполя: «city» и «zip», которые относятся к строкам.
Как работать с JSON
Умение работать с JSON-файлами — один из базовых навыков для разработчиков, поскольку именно этот формат является стандартом для обмена данными в веб- и мобильных приложениях.
Как правило, работа с JSON сводится к двум действиям: сериализации и десериализации. Поговорим о них подробнее.
Сериализация — это преобразование данных из внутреннего формата, например из JavaScript-объекта, в формат JSON, который может быть отправлен на сервер. В большинстве языков программирования для этого есть встроенные функции или библиотеки. Например, в JavaScript преобразование объекта person в JSON-файл выглядит так:
const person = < name: 'John Doe', age: 30, address: < city: 'New York', zip: '10001' > >; const jsonString = JSON.stringify(person); // Метод JSON.stringify преобразует объект person в JSON-формат console.log(jsonString); // Выводит данные в консоль
Десериализация, наоборот, преобразует данные из формата JSON обратно во внутренний формат, с которым программист может работать в своём коде:
const jsonString = '>'; const person = JSON.parse(jsonString); // Преобразуем JSON в объект person console.log(person); // Выводит данные в консоль
Что запомнить
Вспомним всё, что мы узнали про JSON:
- JSON — стандартный текстовый формат для хранения структурированных данных и обмена ими. Чаще всего используется в вебе.
- Данные в JSON представлены в виде пар «ключ — значение».
- Для хранения данных в JSON используются две структуры — объекты и массивы. Объекты — неупорядоченные коллекция, массивы — упорядоченная.
- JSON5 расширяет возможности формата, но пока не поддерживается браузерами.
- JSON Schema используется для определения требований к данным: разработчик может указать обязательные поля и их допустимые форматы.
- Для работы с JSON используется два основных подхода: сериализация, позволяющая преобразовать JavaScript-код или код другого языка программирования в JSON-формат, и десериализация, работающая наоборот: из JSON формата данные переводятся в обычный код.
Больше интересного про код — в нашем телеграм-канале. Подписывайтесь!
Читайте также:
- Как конвертировать HTML-документ в JSON: пишем рабочую программу на JavaScript
- Что такое API и как он работает
- Как изменились зарплаты PHP-программистов в России в 2023 году: исследование Skillbox Media
AJAX (Asynchronous JavaScript and XML) — запросы, которые выполняются сервером и браузером асинхронно.
Небольшая программа, чаще всего написанная на языке программирования Java в форме байт-кода.
Extensible Markup Language, язык для создания и обработки документов как программами, так и человеком, с акцентом на использование в интернете.
Comma-separated values (значения, разделённые запятыми) — текстовый формат, предназначенный для хранения табличных данных.
Акроним от названия YAML Ain’t Markup Language, «YAML — не язык разметки». YAML — язык сериализации данных, то есть их перевода в битовую последовательность.
ISO 8601 — международный стандарт, который описывает форматы дат и времени и даёт рекомендации для его использования в международном контексте.
Курс
Fullstack-разработчик создаёт сайты: и ту часть, которая видна пользователю (frontend), и ту, что остаётся «под капотом» (backend).
На курсе вы с нуля научитесь создавать сайты «под ключ» на языках PHP, Python или JavaScript. Сможете начать карьеру fullstack-специалиста в IT-студии или на фрилансе. Выйдете на новый уровень в веб-разработке.
Узнать про курс

Профессии с трудоустройством