Форматирование Python-кода
Python, точнее его самый известный представитель CPython, не очень предназначен для каких-либо быстрых расчетов. Иначе говоря, производительность у него не такая уж хорошая. А вот скорость разработки и читаемости отличная.
О читаемости и пойдет речь, а точнее как ее увеличить.
Проблемы форматирования
Идеального форматирования кода не существует. Для каждого языка стоит подстраиваться под общепринятые правила оформления кода. Да что говорить, если среди новичков С++ еще до сих пор войны по поводу ставить скобки на следующей строке или нет.
Для python’а основными проблемами форматирования является «C стиль». Не редко в рассматриваемый язык приходят из С-подобных языков, а для них свойственно писать с символами «)(;».
Символы не единственная проблема, есть еще и проблема избыточности написания конструкций. Питон, в отличие от Java, менее многословен и чтобы к этому привыкнуть у новичков уходит большое количество времени.
Это две основные проблемы, которые встречаются чаще всего.
Стандарты и рекомендации к оформлению
Если для повышения скорости исполнения кода можно использовать разные подходы, хотя эти подходы очень индивидуальны, то для форматирования текста существует прям slyle guide — это pep8. Далее его буду называть «стандарт».
Почитать про стандарт можно здесь, на русском языке можно здесь
Pep8 весьма обширный и позволяет программисту писать РЕАЛЬНО читаемый код.
- максимальную длину строк кода и документации
- кодировки файлов с исходным кодом
- рекомендации как правильно оформлять комментарии
- соглашения именования функций/классов, аргументов
- и многое другое
Автоматизируем форматирование
Если посмотреть сколько всяких правил в pep8, то можно сесть за рефакторинг надолго. Вот только это лениво, да и при написании нового кода сиравно будут какие-то ошибки правил. Для этого рассмотрим как же себе можно упростить жизнь.
pep8
Дабы иметь представление сколько ошибок оформления в коде, стоит использовать утилиту pep8.
У нее достаточный список параметров, который позволяет рекурсивно просмотреть все файлы в папках на предмет соответствия стандарту pep8.
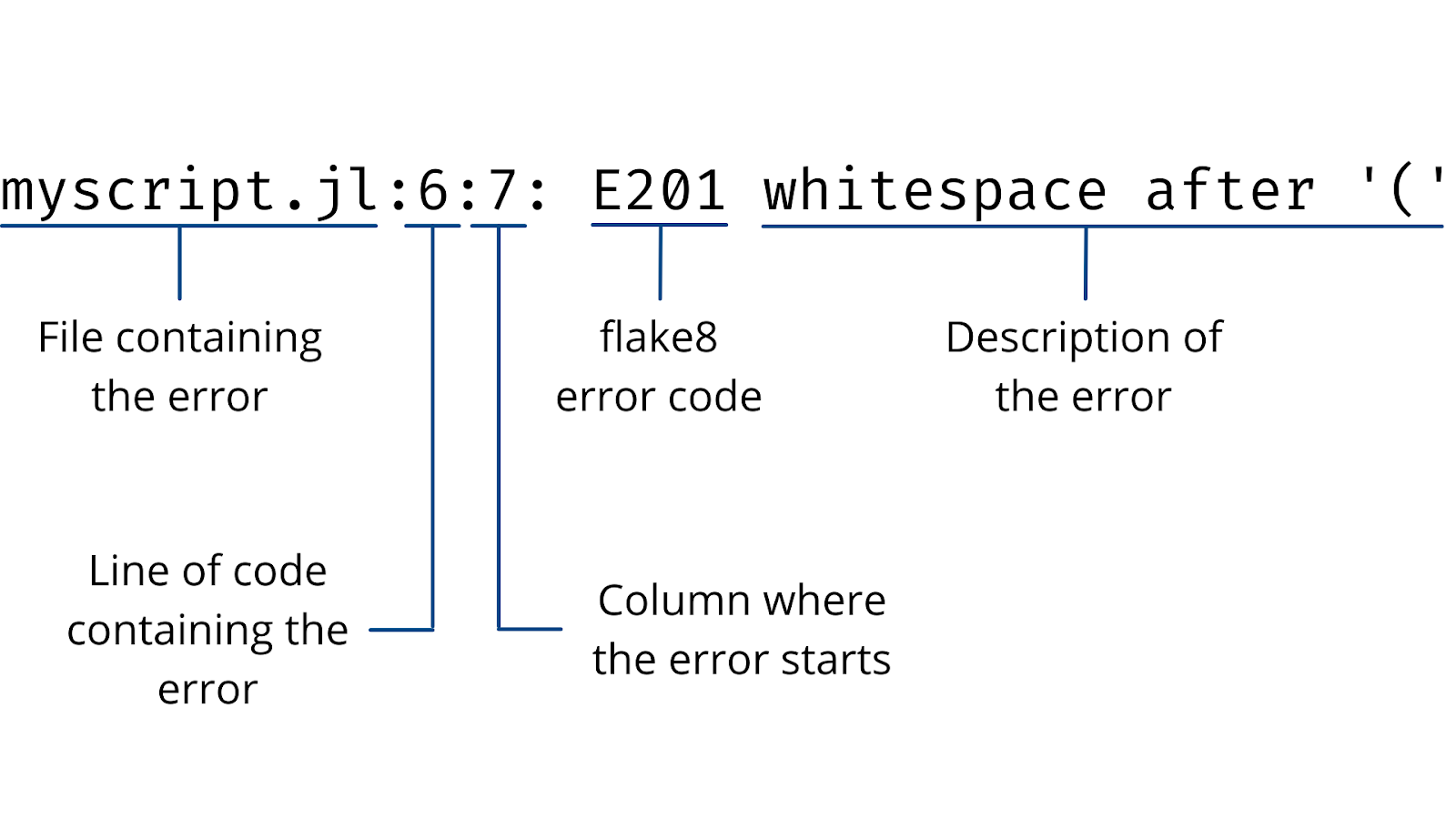
Вывод утилиты примерно такой:
$ pep8 --first optparse.py optparse.py:69:11: E401 multiple imports on one line optparse.py:77:1: E302 expected 2 blank lines, found 1 optparse.py:88:5: E301 expected 1 blank line, found 0 optparse.py:222:34: W602 deprecated form of raising exception optparse.py:347:31: E211 whitespace before '(' optparse.py:357:17: E201 whitespace after 'По нему можно однозначно понять: где ошибка и что случилось.
autopep8
Ошибки стандарта часто повторяются от файла в файлу. И возникает сильное желание исправление автоматизировать. В этом случае на арену выходит autopep8.
Как и pep8, он умеет самостоятельно определять ошибки, а также исправлять их. Список исправляемых ошибок форматирования можно найти здесь
Само использование autopep8 крайне простое и может выглядеть так:
$ autopep8 ./ --recursive --in-place -aПосле выполнения данной команды, утилита рекурсивно пойдет по подпапкам и начнет в самих же файлах исправлять ошибки.
autoflake
Можно пойти дальше и в качестве оружия взять autoflake. Эта утилита помогает удалить не используемые импорты и переменные.
Используется примерно так:
$ autoflake --in-place --remove-all-unused-imports --remove-unused-variables -r ./Тем самым будут рекурсивно почищены файлы в директории.
unify
Крайний, заключительный момент в редактировании кода — это строки. Кто-то любит их писать в одиночных апострофах, кто-то в двойных. Вот только и для этого существует рекомендации, а также и утилита, которая позволяет автоматически приводить в соответствие — unify
Использование:
$ unify --in-place -r ./src/Как и везде, утилита выполнит свое грязное дело рекурсивно для файлов в папке.
docformatter
Все время говорим о самом коде, а о комментариях еще ни разу не шло речи. Настало время — docformatter. Эта утилита помогает привести ваши docstring по соглашению PEP 257. Соглашение предписывает как следует оформлять документацию.
Использование утилиты ничуть не сложнее предыдущих:
$ docformatter --in-place example.pyА все вместе можно?
Выше описаны утилиты, их запуск можно добавить какой-нибудь bash скрипт под магическим названием clean.bash и запускать. А можно пойти и по другому пути и использовать wrapper над этими утилитами — pyformat
Выводы
Python-код легко читается, однако, есть способы сделать лапшу и из читаемого кода.
В данной статье были озвучены некоторые проблемы оформления кода, а также способы поиска этих проблем. Были рассмотрены несколько утилит, которые позволяют в автоматическом режиме убрать некоторые изъяны оформления кода.
Стоит озвучить вслух следующую рекомендацию при написании кода, которая универсальна для любого языка: более важным правилом оформлением, чем подобные pep8-документы — это постоянство стиля. Выбрали в каком стиле будете писать программу, в этом же и пишите весь код.
Если читателям будет интересно, то в следующей статье я опишу как в автоматическом режиме искать ошибки в коде.
- python
- оформление кода
- идеальный код
- форматирование кода
- Python
- Программирование
Как писать питонический код: три рекомендации и три книги

Новички в Python часто спрашивают, как писать питонический код. Проблема — расплывчатое определение слова "питонический". Подробным материалом, в котором вы найдёте ответы на вопрос выше и три полезные книги, делимся к старту курса по Fullstack-разработке на Python.
Что значит «питонический»?
Python более 30 лет. За это время накоплен огромный опыт его применения в самых разных задачах. Этот опыт обобщался, и возникали лучшие практики, которые обычно называют «питоническим» кодом.
Философия Python раскрывается в The Zen of Python Тима Питерса, доступной в любом Python по команде import this в REPL:
>>> import this The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!Начинающих в Python больше всего раздражает красота Zen of Python. В Zen передаётся дух того, что значит «питонический» — и без явных советов. Вот первый принцип дзена Python: «Красивое лучше, чем уродливое». Согласен на 100%! Но как сделать красивым мой некрасивый код? Что это вообще такое — «красивый код»?
Сколь бы ни раздражала эта неоднозначность, именно она делает Zen of Python таким же актуальным, как и в 1999 году, когда Тим Питерс написал этот набор руководящих принципов. Они помогают понять, как отличать питонический и непитонический код, и дают ментальную основу принятия собственных решений.
Каким же будет определение слова «питонический»? Лучшее найденное мной определение взято из ответа на вопрос «Что означает «питонический» В этом ответе питонический код описывается так:
Код, где правилен не только синтаксис, но соблюдаются соглашения сообщества Python, а язык используется так, как он должен использоваться.
Из этого делаем два ключевых вывода:
- Слово «питонический» связано скорее со стилем, чем с синтаксисом. Хотя идиомы Python часто имеют последствия за рамками чисто стилистического выбора, в том числе повышение производительности кода.
- То, что считается «питоническим», определяется сообществом Python.
Итак, у нас сложилось хотя бы какое-то представление о том, что имеют в виду программисты на Python, называя код «питоническим». Рассмотрим три конкретных и доступных способа написания более питонического кода.
1. Подружитесь с PEP8
PEP8 — это официальное руководство по стилю кода Python. PEP расшифровывается как Python Enhancement Proposal («Предложение по улучшению Python»). Это документы, предлагающие новые особенности языка. Они образуют официальную документацию особенности языка, принятие или отклонение которой обсуждается в сообществе Python. Следование PEP8 не сделает код абсолютно «питоническим», но способствует узнаваемости кода для многих Python-разработчиков.
В PEP8 решаются вопросы, связанные с символами пробелов. Например, использование четырёх пробелов для отступа вместо символа табуляции или максимальной длиной строки: согласно PEP8, это 79 символов, хотя данная рекомендация, вероятно, самая игнорируемая.
Первое, что стоит усвоить из PEP8 новичкам, — это рекомендации и соглашения по именованию. Например, следует писать имена функций и переменных в нижнем регистре и с подчёркиваниями между словами lowercase_with_underscores:
# Correct seconds_per_hour = 3600 # Incorrect secondsperhour = 3600 secondsPerHour = 3600Имена классов следует писать с прописными первыми буквами слов и без пробелов, вот так: CapitalizedWords:
# Correct class SomeThing: pass # Incorrect class something: pass class some_thing: passКонстанты записывайте в верхнем регистре и с подчёркиваниями между словами: UPPER_CASE_WITH_UNDERSCORES:
# Correct PLANCK_CONSTANT = 6.62607015e-34 # Incorrect planck_constant = 6.6260715e-34 planckConstant = 6.6260715e-34В PEP8 изложены рекомендации по пробелам: как использовать их с операторами, аргументами и именами параметров функций и для разбиения длинных строк. Хотя эти рекомендации можно освоить, годами практикуясь в чтении и написании совместимого с PEP8 кода, многое всё равно пришлось бы запоминать.
Запоминать все соглашения PEP8 не нужно: найти и устранить проблемы PEP8 в коде могут помочь такие инструменты, как flake8. Установите flake8 с помощью pip:
# Linux/macOS $ python3 -m pip install flake8 # Windows $ python -m pip install flake8flake8 можно использовать как приложение командной строки для просмотра файла Python на предмет нарушений стиля. Допустим, есть файл myscript.py с таким кодом:
def add( x, y ): return x+y num1=1 num2=2 print( add(num1,num2) )При запуске на этом коде flake8 сообщает, как и где именно нарушается стиль:
$ flake8 myscript.py myscript.py:1:9: E201 whitespace after '(' myscript.py:1:11: E231 missing whitespace after ',' myscript.py:1:13: E202 whitespace before ')' myscript.py:4:1: E305 expected 2 blank lines after class or function definition, found 1 myscript.py:4:5: E225 missing whitespace around operator myscript.py:5:5: E225 missing whitespace around operator myscript.py:6:7: E201 whitespace after '(' myscript.py:6:16: E231 missing whitespace after ',' myscript.py:6:22: E202 whitespace before ')'В каждой выводимой строке flake8 сообщается, в каком файле и в какой строке проблема, в каком столбце строки начинается ошибка, номер ошибки и её описание. Используйте эти обозначения, flake8 можно настроить на игнорирование конкретных ошибок:
Для проверки качества кода с помощью flake8 вы даже можете настроить редакторы, например VS Code. Пока вы пишете код, он постоянно проверяется на нарушения PEP8. Когда обнаруживается проблема, во flake8 под частью кода с ошибкой появляется красная волнистая линия, найденные ошибки можно увидеть во вкладке встроенного терминала Problems:

flake8 — отличный инструмент для поиска связанных с нарушением PEP8 ошибок, но исправлять их придётся вручную. А значит, будет много работы. К счастью, весь процесс автоматизируемый. Автоматически форматировать код согласно PEP можно с помощью инструмента под названием Black.
Конечно, рекомендации PEP8 оставляют много возможностей для выбора стиля, и в black многие решения принимаются за вас. Вы можете соглашаться с ними или нет. Конфигурация black минимальна.
Установите black c помощью pip:
# Linux/macOS $ python3 -m pip install black # Windows $ python -m pip install blackПосле установки командой black --check можно посмотреть, будут ли black изменять файл:
$ black --check myscript.py would reformat myscript.py Oh no! �� �� �� 1 file would be reformatted.Чтобы увидеть разницу после изменений, используйте флаг --diff:
$ black --diff myscript.py --- myscript.py 2022-03-15 21:27:20.674809 +0000 +++ myscript.py 2022-03-15 21:28:27.357107 +0000 @@ -1,6 +1,7 @@ -def add( x, y ): - return x+y +def add(x, y): + return x + y -num1=1 -num2=2 -print( add(num1,num2) ) + +num1 = 1 +num2 = 2 +print(add(num1, num2)) would reformat myscript.py All done! ✨ �� ✨ 1 file would be reformatted.Чтобы автоматически отформатировать файл, передайте его имя команде black:
$ black myscript.py reformatted myscript.py All done! ✨ �� ✨ 1 file reformatted. # Show the formatted file $ cat myscript.py def add(x, y): return x + y num1 = 1 num2 = 2 print(add(num1, num2))Чтобы проверить совместимость с PEP8, снова запустите flake8 и посмотрите на вывод:
# No output from flake8 so everything is good! $ flake8 myscript.pyПри работе с black следует иметь в виду, что максимальная длина строки по умолчанию в нём — это 88 символов. Это противоречит рекомендации PEP8 о 79 символах, поэтому при использовании black в отчёте flake8 вы увидете ошибки о длине строки.
Многие разработчики Python используют 88 знаков вместо 79, а некоторые — строки ещё длиннее. Можно настроить black на 79 символов, или flake8 — на строки большей длины.
Важно помнить, что PEP8 — это лишь набор рекомендаций, хотя многие программисты на Python относятся к ним серьёзно. PEP8 не применяется в обязательном порядке. Если в нём есть что-то, с чем вы категорически не согласны, вы вправе это игнорировать! Если же вы хотите строго придерживаться PEP8, инструменты типа flake8 и black сильно облегчат вам жизнь.
2. Избегайте циклов в стиле C
В таких языках, как C или C++, отслеживание индексной переменной при переборе массива — обычное дело. Поэтому программисты, которые перешли на Python из C или C++, при выводе элементов списка нередко пишут:
>>> names = ["JL", "Raffi", "Agnes", "Rios", "Elnor"] >>> # Using a `while` loop >>> i = 0 >>> while i < len(names): . print(names[i]) . i += 1 JL Raffi Agnes Rios Elnor >>> # Using a `for` loop >>> for i in range(len(names)): . print(names[i]) JL Raffi Agnes Rios ElnorВместо итерации можно перебрать все элементы списка сразу:
>>> for name in names: . print(name) JL Raffi Agnes Rios ElnorЭтим вторая рекомендация не ограничивается: она намного глубже простого перебора элементов списка. Такие идиомы Python, как списковые включения, встроенные функции (min(), max() и sum()) и методы объектов, может помочь вывести ваш код на новый уровень.
Отдавайте предпочтение списковым включениям, а не простым циклам for
Обработка элементов массива и сохранение результатов в новом — типичная задача программирования. Допустим, нужно преобразовать список чисел в список их квадратов. Избегая циклов в стиле C, можно написать:
>>> nums = [1, 2, 3, 4, 5] >>> squares = [] >>> for num in nums: . squares.append(num ** 2) . >>> squares [1, 4, 9, 16, 25]Но более питонически применить списковое включение:
>>> squares = [num ** 2 for num in nums] # >> squares [1, 4, 9, 16, 25]Списковые включения понять сразу может быть трудно, но они покажутся знакомыми тем, кто помнит математическую форму записи множества.
Вот так я обычно пишу списковые включения:
- Начинаю с создания литерала пустого списка:
[]. - Первым в списковое включение помещаю то, что обычно идёт в метод .append()при создании списка с помощью цикла for:
[num ** 2]. - И, наконец, помещаю в конец списка заголовок цикла for:
[num ** 2 for num in nums].
Списковое включение — важное понятие, которое нужно освоить для написания идиоматичного кода Python, но ими не стоит злоупотреблять. Это не единственный вид списковых включений в Python. Далее поговорим о выражениях-генераторах и словарных включениях, вы увидите пример, когда спискового включения имеет смысл избегать.
Используйте встроенные функции, такие как min(), max() и sum()
Ещё одна типичная задача программирования — это поиск минимального или максимального значения в массиве чисел. Найти наименьшее число в списке можно с помощью for:
>>> nums = [10, 21, 7, -2, -5, 13] >>> min_value = nums[0] >>> for num in nums[1:]: . if num < min_value: . min_value = num . >>> min_value -5Но более «питонически» применять встроенную функцию min():
>>> min(nums) -5То же касается нахождения наибольшего значения в списке: вместо цикла применяется встроенная функция max():
>>> max(nums) 21Чтобы найти сумму чисел списка, написать цикл for можно, но более питонически воспользоваться sum():
>>> # Not Pythonic: Use a `for` loop >>> sum_of_nums = 0 >>> for num in nums: . sum_of_nums += num . >>> sum_of_nums 44 >>> # Pythonic: Use `sum()` >>> sum(nums) 44Также sum() полезна при подсчёте количества элементов списка, для которых выполняется некое условие. Например, вот цикл for для подсчёта числа начинающихся с буквы A строк списка:
>>> capitals = ["Atlanta", "Houston", "Denver", "Augusta"] >>> count_a_capitals = 0 >>> for capital in capitals: . if capital.startswith("A"): . count_a_capitals += 1 . >>> count_a_capitals 2Функция sum() со списковым включением сокращает цикл for до одной строки:
>>> sum([capital.startswith("A") for capital in capitals]) 2Красота! Но ещё более питонической эту строку сделает замена спискового включения на выражение-генератор. Убираем скобки списка:
>>> sum(capital.startswith("A") for capital in capitals) 2Как именно работает код? И списковое включение, и выражение-генератор возвращают итерируемый объект со значением True, если строка в списке capitals начинается с буквы A, и False — если это не так:
>>> [capital.startswith("A") for capital in capitals] [True, False, False, True]В Python True и False — это завуалированные целые числа. True равно 1, а False — 0:
>>> isinstance(True, int) True >>> True == 1 True >>> isinstance(False, int) True >>> False == 0 TrueКогда в sum() передаётся списковое включение или выражение-генератор, значения True и False считаются 1 и 0 соответственно. Всего два значения True и два False, поэтому сумма равна 2.
Использование sum() для подсчёта числа удовлетворяющих какому-то условию элементов списка подчёркивает важность понятия «питонический». Я нахожу такое применение sum() очень питонически. Ведь с sum() используется несколько особенностей этого языка и создаётся, на мой взгляд, лаконичный и удобный для восприятия код. Но, возможно, не каждый разработчик на Python со мной согласится.
Можно было бы возразить, что в этом примере нарушается один из принципов Zen of Python: «Явное лучше неявного». Ведь не очевидно, что True и False — целые числа и что sum() вообще должна работать со списком значений True и False. Чтобы освоить это применение sum(), нужно глубоко понимать встроенные типы Python.
Узнать больше о True и False как целых числах, а также о других неожиданных фактах о числах в Python можно из статьи 3 Things You Might Not Know About Numbers in Python («3 факта о числах в Python, которых вы могли не знать»).
Жёстких правил, когда называть и не называть код питоническим, нет. Всегда есть некая серая зона. Имея дело с примером кода, который может находиться в этой серой зоне, руководствуйтесь здравым смыслом. Для удобства восприятия всегда применяйте err и не бойтесь обращаться за помощью.
3. Используйте правильную структуру данных
Большая роль при написании чистого, питонического кода для конкретной задачи отводится выбору подходящей структуры данных. Python называют языком «с батарейками в комплекте». Некоторые батарейки из комплекта Python — это эффективные, готовые к применению структуры данных.
Используйте словари для быстрого поиска
Вот CSV-файл clients.csv с данными по клиентам:
first_name,last_name,email,phone Manuel,Wilson,mwilson@example.net,757-942-0588 Stephanie,Gonzales,sellis@example.com,385-474-4769 Cory,Ali,coryali17@example.net,810-361-3885 Adam,Soto,adams23@example.com,724-603-5463Нужно написать программу, где в качестве входных данных принимается адрес электронной почты, а выводится номер телефона клиента с этой почтой, если такой клиент существует. Как бы вы это сделали?
Используя объект DictReader из модуля csv, можно прочитать каждую строку файла как словарь:
>>> import csv >>> with open("clients.csv", "r") as csvfile: . clients = list(csv.DictReader(csvfile)) . >>> clients [, , , ]clients — это список словарей. Поэтому, чтобы найти клиента по адресу почты, например sellis@example.com, нужно перебрать список и сравнить почту каждого клиента с целевой почтой, пока не будет найден нужный клиент:
>>> target = "sellis@example.com" >>> phone = None >>> for client in clients: . if client["email"] == target: . phone = client["phone"] . break . >>> print(phone) 385-474-4769Но есть проблема: перебор списка клиентов неэффективен. Если в файле много клиентов, на поиск клиента с совпадающим адресом почты у программы может уйти много времени. А сколько теряется времени, если такие проверки проводятся часто!
Более питонически сопоставить клиентов с их почтами, а не хранить клиентов в списке. Для этого отлично подойдёт словарное включение:
>>> with open("clients.csv", "r") as csvfile: . # Use a `dict` comprehension instead of a `list` . clients = . >>> clients
Словарные включения очень похожи на списковые включения:
- Я начинаю с создания пустого словаря:
<>. - Затем помещаю туда разделённую двоеточием пару «ключ — значение»:
. - И пишу выражение с for, которое перебирает все строки в CSV:
.
Вот это словарное включение, преобразованное в цикл for:
>>> clients = <> >>> with open("clients.csv", "r") as csvfile: . for row in csv.DictReader(csvfile): . clients[row["email"]] = row["phone"]С этим словарём clients вы можете найти телефон клиента по его почте без циклов:
>>> target = "sellis@example.com" >>> clients[target] 385-474-4769Этот код не только короче, но и намного эффективнее перебора списка циклом. Но есть проблема: если в clients нет клиента с искомой почтой, поднимается ошибка KeyError:
>>> clients["tsanchez@example.com"] Traceback (most recent call last): File "", line 1, in KeyError: 'tsanchez@example.com'Поэтому, если клиент не найден, можно перехватить KeyError и вывести значение по умолчанию:
>>> target = "tsanchez@example.com" >>> try: . phone = clients[target] . except KeyError: . phone = None . >>> print(phone) NoneНо более питонически применять метод словаря .get(). Если пара с ключом существует, этот метод возвращает значение пары, иначе возвращается None:
>>> clients.get("sellis@example.com") '385-474-4769'Сравним решения выше:
import csv target = "sellis@example.com" phone = None # Un-Pythonic: loop over a list with open("clients.csv", "r") as csvfile: clients = list(csv.DictReader(csvfile)) for client in clients: if client["email"] == target: phone = client["phone"] break print(phone) # Pythonic: lookup in a dictionary with open("clients.csv", "r") as csvfile: clients = phone = clients.get(target) print(phone)Питонический код короче, эффективнее и не менее удобен для восприятия.
Используйте операции над множествами
Множества — это настолько недооценённая структура данных Python, что даже разработчики среднего уровня склонны их игнорировать, упуская возможности. Пожалуй, самое известное применение множеств в Python — это удаление повторяющихся в списке значений:
>>> nums = [1, 3, 2, 3, 1, 2, 3, 1, 2] >>> unique_nums = list(set(nums)) >>> unique_nums [1, 2, 3]Но множества этим не ограничиваются. Я часто применяю их для эффективной фильтрации значений итерируемого объекта. Работа множеств лучше всего видна, когда нужны уникальные значения.
Вот придуманный, но реалистичный пример. У владельца магазина есть CSV-файл клиентов с адресами их почты. Снова возьмём файл clients.csv. Есть также CSV-файл заказов за последний месяц orders.csv, тоже с адресами почты:
date,email,items_ordered 2022/03/01,adams23@example.net,2 2022/03/04,sellis@example.com,3 2022/03/07,adams23@example.net,1Владельцу магазина нужно отправить купон на скидку каждому клиенту, который в прошлом месяце ничего не заказывал. Для этого он может считать адреса почты из файлов clients.csv и orders.csv и отфильтровать их списковым включением:
>>> import csv >>> # Create a list of all client emails >>> with open("clients.csv", "r") as clients_csv: . client_emails = [row["email"] for row in csv.DictReader(clients_csv)] . >>> # Create a list of emails from orders >>> with open("orders.csv") as orders_csv: . order_emails = [row["email"] for row in csv.DictReader(orders_csv)] . >>> # Use a list comprehension to filter the clients emails >>> coupon_emails = [email for email in clients_emails if email not in order_emails] >>> coupon_emails ["mwilson@example.net", "coryali17@example.net"]Код нормальный и выглядит вполне питонически. Но что, если каждый месяц клиентов и заказов будут миллионы? Тогда при фильтрации почты и определении, каким клиентам отправлять купоны, потребуется перебор всего списка client_emails. А если в файлах client.csv и orders.csv есть повторяющиеся строки? Бывает и такое.
Более питонически считать адреса почты клиентов и заказов в множествах и отфильтровать множества почтовых адресов клиентов оператором разности множеств:
>>> import csv >>> # Create a set of all client emails using a set comprehension >>> with open("clients.csv", "r") as clients_csv: . client_emails = . >>> # Create a set of emails frp, orders using a set comprehension >>> with open("orders.csv", "r") as orders_csv: . order_emails = . >>> # Filter the client emails using set difference >>> coupon_emails = client_emails - order_emails >>> coupon_emails
Этот подход намного эффективнее предыдущего: адреса клиентов перебираются только один раз, а не два. Вот ещё одно преимущество: все повторы почтовых адресов из обоих CSV-файлов удаляются естественным образом.
Три книги, чтобы писать более питонический код
За один день писать чистый питонический код не научиться. Нужно изучить много примеров кода, пробовать писать собственный код и консультироваться с другими разработчиками Python. Чтобы облегчить вам задачу, я составил список из трёх книг, очень полезных для понимания питонического кода. Все они написаны для программистов уровня выше среднего или среднего.
Если вы новичок в Python (и тем более в программировании в целом), загляните в мою книгу Python Basics: A Practical Introduction to Python 3 («Основы Python: Практическое введение в Python 3»).
Python Tricks Дэна Бейдера
Короткая и приятная книга Дэна Бейдера Python Tricks: A Buffet of Awesome Python Features («Приёмы Python: набор потрясающих функций Python») — отличная отправная точка для начинающих и программистов, желающих больше узнать о том, как писать питонический код.
С Python Tricks вы изучите шаблоны написания чистого идиоматичного кода Python, лучшие практики для написания функций, эффективное применение функционала объектно-ориентированного программирования Python и многое другое.
Effective Python Бретта Слаткина
Effective Python («Эффективный Python») Бретта Слаткина — это первая книга, которую я прочитал после изучения синтаксиса Python. Она открыла мне глаза на возможности питонического кода.
В Effective Python содержится 90 способов улучшения кода Python. Одна только первая глава Python Thinking («Мыслить на Python») — это кладезь хитростей и приёмов, которые будут полезными даже для новичков, хотя остальная часть книги может быть для них трудной.
Fluent Python Лучано Рамальо
Если бы у меня была только одна книга о Python, это была бы книга Лучано Рамальо Fluent Python («Python. К вершинам мастерства»). Рамальо недавно обновил свою книгу до современного Python. Сейчас можно оформить предзаказ. Настоятельно рекомендую сделать это: первое издание устарело.
Полная практических примеров, чётко изложенная книга Fluent Python — отличное руководство для всех, кто хочет научиться писать питонический код. Но имейте в виду, что Fluent Python не предназначена для новичков. В предисловии к книге написано:
«Если вы только изучаете Python, эта книга будет трудной для вас».
У вас может сложиться впечатление, что в каждом скрипте на Python должны использоваться специальные методы и приёмы метапрограммирования. Преждевременная абстракция так же плоха, как и преждевременная оптимизация.
Опытные программисты на Python извлекут из этой книги большую пользу.
А мы поможем вам прокачать скиллы или с самого начала освоить профессию в IT, актуальную в любое время:
- Профессия Fullstack-разработчик на Python
- Профессия Data Scientist

Краткий каталог курсов и профессий
Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
- Профессия iOS-разработчик
- Профессия Android-разработчик
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
- Курс «Алгоритмы и структуры данных»
- Профессия C++ разработчик
- Профессия Этичный хакер
А также
Python-сообщество
![]()
- Начало
- » Центр помощи
- » Задача: Логи-2
#1 Окт. 4, 2014 18:57:31
nokados От: Ростов Зарегистрирован: 2013-10-15 Сообщения: 52 Репутация: 0 Профиль Отправить e-mail
Задача: Логи-2
Ограничение времени 1 секунда
Ограничение памяти 64Mb
Ввод стандартный ввод или input.txt
Вывод стандартный вывод или output.txt
Вася хочет проанализировать логи некоторой поисковой системы, в которых записан сам запрос, дата, регион пользователя и частота запроса. Вася хочет найти самые популярные запросы за каждую дату. Логи он уже достал, и теперь просит вас написать код для их анализа.
Формат ввода
Первая строка входного файла содержит одно число N от 0 до 1000. Затем идет не более 10000 строк с информацией о запросах в формате “дата\tзапрос\tрегион\tколичество”, причем для каждого региона каждый запрос встречается не более одного раза за день. Количество — натуральное число от 1 до 109. День, запрос и регион — строки длины не более 100, не содержащие символов табуляции.
Формат вывода
Для каждой даты рассмотрите N самых популярных запросов за эту дату. При равенстве частот запросов сравнивайте запросы лексикографически, и берите первые. Выведите получившиеся результаты в формате “дата\tзапрос”, отсортировав их лексикографически по дате, затем по популярности, и наконец лексикографически по запросу.
Пример
Ввод
2
01.01.2014 We love python HSE 1
01.01.2014 We love PEP8 too HSE 1
01.01.2014 E225 missing whitespace around operator Moscow 2
01.01.2014 E201 whitespace after '01.01.2014 E231 missing whitespace after ':' Moscow 5
02.01.2014 E225 missing whitespace around operator Moscow 3
02.01.2014 E225 missing whitespace around operat32[code python][/code]or Saint Petersburg 1312
02.01.2014 E501 line too long (80 > 79 characters) Moscow 4
02.01.2014 E203 whitespace before ':' Moscow 5
03.01.2014 E231 missing whitespace after ': Moscow 19
03.01.2014 E225 missing whitespace around operator New-York 12
04.01.2014 We will solve this problem HSE 1
Вывод
01.01.2014 E201 whitespace after '01.01.2014 E231 missing whitespace after ':'
02.01.2014 E225 missing whitespace around operator
02.01.2014 E203 whitespace before ':'
03.01.2014 E231 missing whitespace after ':
03.01.2014 E225 missing whitespace around operator
04.01.2014 We will solve this problem
Мое решение 1
import sys N = int(input()) requests = <> for line in sys.stdin: date, query, region, number = line.split('\t') number = int(number) if date in requests: if query in requests[date]: requests[date][query] += number else: requests[date][query] = number else: requests[date] = query: number> dates = list(requests.keys()) dates.sort() for date in dates: queries = requests[date] res_q = [] for i in range(N): max_val = 0 max_key = -1 for query in queries: if queries[query] > max_val: max_val = queries[query] max_key = query elif queries[query] == max_val: if query max_key: max_key == query if max_key != -1: print(date, max_key, sep='\t') queries.pop(max_key)
Решение в лоб. Работает, но из-за своей неэфективности превышает лимит по времени на одном из тестов.
Мое решение 2
import sys N = int(input()) requests = <> resinput = '' for line in sys.stdin: resinput += line date, query, region, number = line.split('\t') number = int(number) if date in requests: if query in requests[date]: requests[date][query] += number else: requests[date][query] = number else: requests[date] = query: number> dates = list(requests.keys()) dates.sort() for date in dates: queries = requests[date] res_q = [] l = 0 for query in queries: num = queries[query] if l == 0: res_q.append('num': num, 'query': query>) l = 1 else: i = 0 j = l-1 m = (i+j)//2 while i j: if num > res_q[m]['num']: j = m-1 elif num res_q[m]['num']: i = m+1 else: if query res_q[m]['query']: j = m-1 else: i = m+1 m = (i+j)//2 res_q.insert(i, 'num': num, 'query': query>) l += 1 if l > N: res_q = res_q[:N] l = N for res in res_q: print(date, res['query'], sep='\t')
Заменил полный перебор массива на бинарный поиск места, куда вставляется очередной запрос, в сортированном массиве (res_q). Но теперь ошибка в тесте раньше того, на котором был Time Limit в прошлом примере.
Отредактировано nokados (Окт. 4, 2014 18:58:28)
Whitespace after '(' (E201)
Open parentheses should not have any space before or after them.
Anti-pattern
# The space after open is unnecessary with open( 'file.dat') as f: contents = f.read() Best practice
with open('file.dat') as f: contents = f.read() Additional links
Flake8 Rules
- View on GitHub
- grantmcconnaughey
- @gmcconnaughey
Descriptions and examples for each of the rules in Flake8 (pyflakes, pycodestyle, and mccabe).
From the creator of Postpone for Reddit.