Звуки русского языка
Звук, как слово и предложение, является основной единицей языка. Однако звук не выражает какого-либо значения, но отражает звучание слова. Благодаря этому мы отличаем слова друг от друга. Слова различаются количеством звуков (порт — спорт, ворона — воронка) , набором звуков (лимон — лиман, кошка — мышка) , последовательностью звуков (нос — сон, куст — стук) вплоть до полного несовпадения звуков (лодка — катер, лес — парк) .
Звуки относятся к разделу фонетики. Изучение звуков включено в любую школьную программу по русскому языку. Ознакомление со звуками и их основными характеристиками происходит в младших классах. Более детальное изучение звуков со сложными примерами и нюансами проходит в средних и старших классах. На этой странице даются только основные знания по звукам русского языка в сжатом виде. Если вам нужно изучить устройство речевого аппарата, тональность звуков, артикуляцию, акустические составляющие и другие аспекты, выходящие за рамки современной школьной программы, обратитесь к специализированным пособиям и учебникам по фонетике.
Какие звуки бывают?
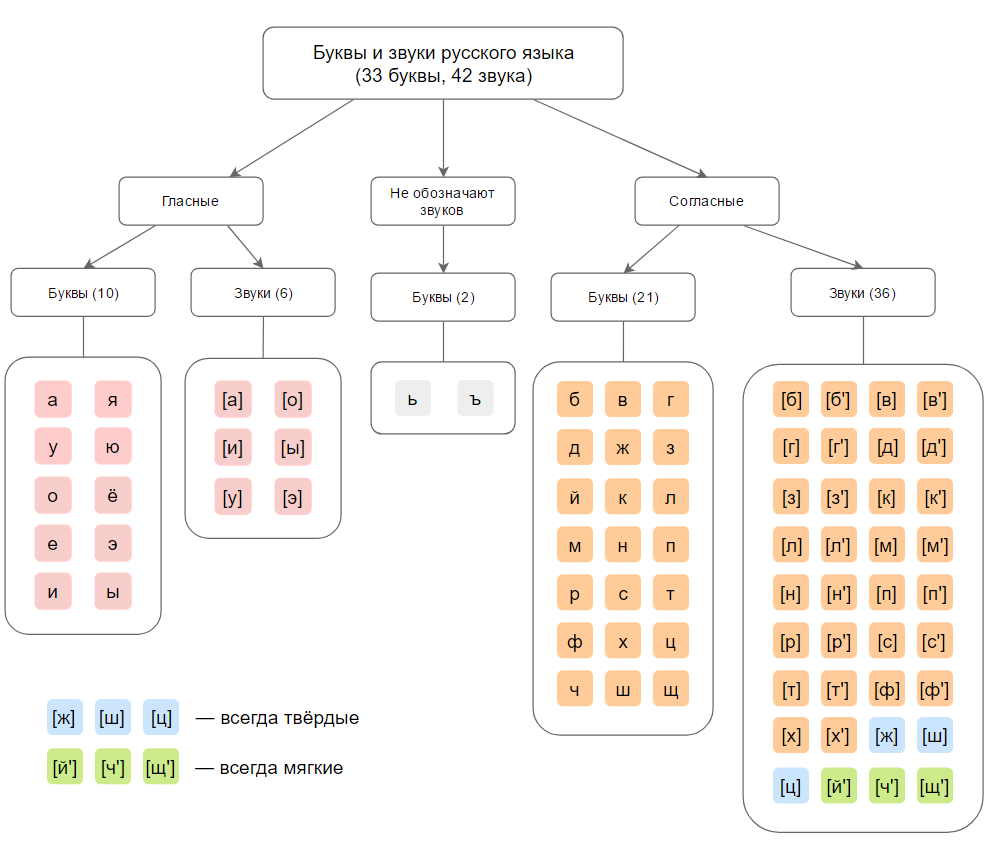
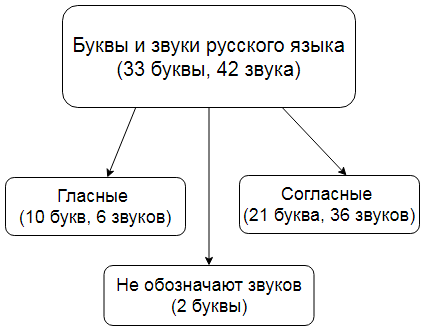
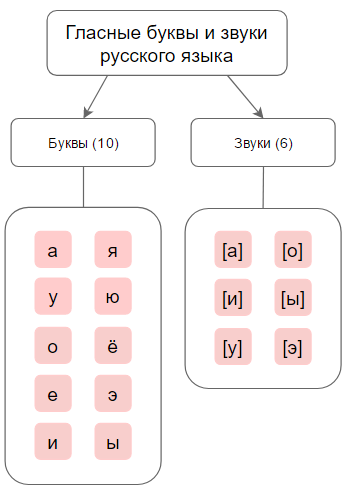
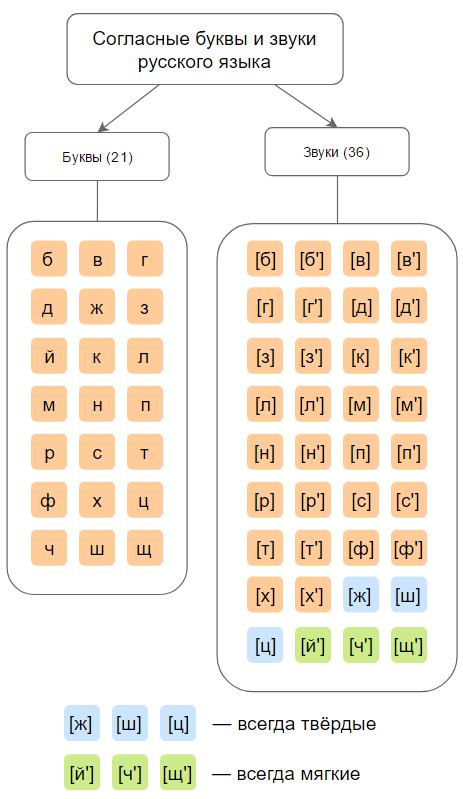
В русском языке звуки делятся на гласные и согласные. В русском языке 33 буквы и 42 звука: 6 гласных звуков, 36 согласных звуков, 2 буквы (ь, ъ) не обозначают звука. Несоответствие в количестве букв и звуков (не считая Ь и Ъ) вызвано тем, что на 10 гласных букв приходится 6 звуков, на 21 согласную букву — 36 звуков (если учитывать все комбинации согласных звуков глухие/звонкие, мягкие/твёрдые). На письме звук указывается в квадратных скобках.
Все 42 звука русского языка:
[а], [о], [у], [э], [и], [ы], [б], [в], [г], [д], [з], [к], [л], [м], [н], [п], [р], [с], [т], [ф], [х], [б’], [в’], [г’], [д’], [з’], [к’], [л’], [м’], [н’], [п’], [р’], [с’], [т’], [ф’], [х’], [ж], [ш], [ц], [ч’], [щ’], [й’] .
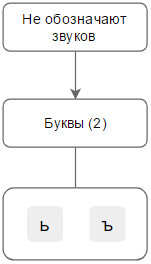
Не бывает звуков: [е], [ё], [ю], [я], [ь], [ъ], [ж’], [ш’], [ц’], [й], [ч], [щ].
Как произносятся звуки?
Звуки мы произносим при выдыхании (только в случае междометия «а-а-а», выражающем страх, звук произносится при вдыхании.). Разделение звуков на гласные и согласные связано с тем, как человек произносит их. Гласные звуки произносятся голосом за счет выдыхаемого воздуха, проходящего через напряженные голосовые связки и свободно выходящего через рот. Согласные звуки состоят из шума или сочетания голоса и шума за счет того, что выдыхаемый воздух встречает на своем пути преграду в виде смычки или зубов. Гласные звуки произносятся звонко, согласные звуки — приглушенно. Гласные звуки человек способен петь голосом (выдыхаемым воздухом), повышая или понижая тембр. Согласные звуки петь не получится, они произносятся одинаково приглушенно. Твёрдый и мягкий знаки не обозначают звуков. Их невозможно произнести как самостоятельный звук. При произнесении слова они оказывают влияние на стоящий перед ними согласный, делают мягким или твёрдым.
Транскрипция слова
Транскрипция слова — запись звуков в слове, то есть фактически запись того, как слово правильно произносится. Звуки заключаются в квадратные скобки. Сравните: а — буква, [а] — звук. Мягкость согласных обозначается апострофом: п — буква, [п] — твёрдый звук, [п’] — мягкий звук. Звонкие и глухие согласные на письме никак не обозначаются. Транскрипция слова записывается в квадратных скобках. Примеры: дверь → [дв’эр’], колючка → [кал’уч’ка]. Иногда в транскрипции указывают ударение — апострофом перед гласным ударным звуком.
Нет чёткого сопоставления букв и звуков. В русском языке много случаев подмены гласных звуков в зависимости от места ударения слова, подмены согласных или выпадения согласных звуков в определённых сочетаниях. При составлении транскрипции слова учитывают правила фонетики.
Цветовая схема
В фонетическом разборе слова иногда рисуют цветовые схемы: буквы разрисовывают разными цветами в зависимости от того, какой звук они означают. Цвета отражают фонетические характеристики звуков и помогают наглядно увидеть, как слово произносится и из каких звуков оно состоит.
Красным фоном помечаются все гласные буквы (ударные и безударные). Зелёно-красным помечаются йотированные гласные: зелёный цвет означает мягкий согласный звук [й‘], красный цвет означает следующий за ним гласный. Согласные буквы, имеющие твёрдые звуки, окрашиваются синим цветом. Согласные буквы, имеющие мягкие звуки, окрашиваются зелёным цветом. Мягкий и твёрдый знаки окрашивают серым цветом или не окрашивают вовсе.
| Гласные | а о у э и ы я ю е ё |
| Согласные | ц ш ж б в г д з к л м н п р с т ф х ч щ й |
| ь, ъ | ь ъ |
— гласная, — гласная йотированная, — согласная твёрдая, — согласная мягкая, — согласная мягкая или твёрдая, — не означает звука.
Примечание. Сине-зелёный цвет в схемах при фонетических разборах не используется, так как согласный звук не может быть одновременно мягким и твёрдым. Сине-зелёный цвет в таблице выше использован лишь для демонстрации того, что звук может быть либо мягким, либо твёрдым.
Слова с буквой ё обязательно пишите через ё. Фонетические разборы слов «все» и «всё» будут разными!
Разбор слов делается с помощью программы и не всегда может быть правильным. Представленный результат используйте исключительно для самопроверки.
2015—2024 [Ф] phoneticonline.ru — фонетический (звуко-буквенный) разбор слов
СКОЛЬКО СЛОВ В РУССКОМ ЯЗЫКЕ?
Кандидат филологических наук С. КАРПУХИН, (г. Самара).
Миниатюра из Радзивилловской летописи (ХIII век), на которой изображены создатели азбуки Кирилл и Мефодий.
«Букварь» Кариона Истомина. Гравюра на меди Л. Бунина (1694).
Первая светская гравюра появилась в «Азбуке» В. Ф. Бурцева (1637). Слева вверху надпись: «училище».
На вопрос, казалось бы, ответить очень просто. Достаточно обратиться к самому авторитетно му из современных словарей — Большому академическому словарю в 17-ти томах. БАС — так неофициально именуют это издание филологи; титульное же его название «Словарь современного русского литературного языка». Здесь нелишне вспомнить, что в 1970 году этот труд был отмечен Ленинской премией. К сожалению, с первого дня появления на свет он стал библиографической редкостью, и сегодня менее известен и доступен рядовому читателю, чем знаменитый, но несколько устаревший словарь Даля. Так вот, в Большом академическом словаре зафиксировано 131 257 слов.
Число, как видим, точное, но ответ на поставленный вопрос не то чтобы неточен или неполон — он условен и требует слишком многих оговорок, которые способны на порядок изменить это число. Так, указанное количество может «подрасти», если считать наречия на -о, -е, образован ные от качественных прилагательных, вроде откровенно (от откровенный ), безмолвно (от безмолвный), — они приводятся в словаре не самостоятельными единицами, а в статьях при исходных прилагательных.
Но это еще, так сказать, цветочки… Как указывает само название словаря, он включает только слова литературного, то есть нормированного , языка. Между тем общенародный русский язык богат огромным числом бытующих до сих пор в сельской местности и не учтенных полностью ни одним словарем диалектных слов, вроде вологодского нухрить в значении искать или существительного потка (птичка), бытующего в вятских селах, и т.д. Конечно, огромное богатство диалектной лексики (но опять-таки далеко не исчерпывающее!) отразил словарь Даля, составленный в позапрошлом веке. Всего в нем более 200 тысяч словарных единиц. Существуют и современные словари русских диалектов, выпущенные в той или иной области.
Однако если диалектизмы не свойственны литературному языку (за исключением художественной речи), то в нем весьма часто используются слова другого типа, которые вы тоже не найдете в общих толковых словарях, даже самых полных. Это термины, собственные имена, неологизмы и некоторые другие разряды слов. Возьмем обычную газетную фразу: «Создал этот уникальный учебник по компьютерной оптике коллектив сотрудников Института систем обработки изображений РАН во главе с известным ученым». Здесь все слова общепонятны и общеупотребительны. Однако в Большом академическом словаре отсутствует сокращение РАН (аббревиатуры лингвисты признают сегодня самостоятельными, отдельными от расшифровки словами, кстати, существуют специальные словари сокращенных слов), а также прилагательное компьютерный , которое, впрочем, как и исходное существительное компьютер , просто не могло попасть в словарь, созданный около полувека назад. Новые слова, появившиеся в русском языке за последние десятилетия, особенно связанные с бурными изменениями в общественной жизни 90-х годов, должно было отразить 2-е издание Большого академического словаря в 20-ти томах. Но… после 4-го тома, вышедшего в 1993 году, дело заглохло.
Особая область лексики — терминология — обозначение научных и технических понятий. Они известны и употребляются только среди специалистов той или иной научно-технической отрасли. Вряд ли кому-то знакомы, например, такие слова, как зигнелла — вид водоросли (бот.), изафет — вид словосочетаний в некоторых языках (лингв.) и т.п. Все термины, употребляемые в нашем языке, один человек знать не может в принципе — из-за их громадного количества. Каждая наука, техническая отрасль выработала свою терминологию, состоящую подчас из десятков тысяч единиц. Представьте, например, сколько их содержится в многотомной медицинской энциклопедии!
Собственные же имена существительные составляют такой лексический пласт общенародного языка (носящий специальное название — «ономастика»), который, видимо, не поддается даже приблизительной количественной оценке. В самом деле, сколько, скажем, в Российской Федерации городов и сел, рек и озер, местностей и гор? Общеизвестными, как и в любой другой стране, являются названия более или менее крупных географических объектов (Волга, Урал, Париж, Сена) — они образуют лишь малый процент всей топонимики. Львиную же долю составляют топонимы, употребляемые местными жителями на ограниченной территории, где нередко овраг или ручей, бугор или роща имеют собственное имя. Например, в Самарской области есть село Молгачи. Если жители употребляют в речи «был в Молгачах», «я из Молгачей» , значит, оно входит в русский язык, причем независимо от происхождения! А сколько космических объектов имеют собственные наименования — так называемые астронимы!
Есть и еще одно существенное замечание. В языкознании вообще нет точного и исчерпывающего определения, что такое слово. «Виновны» в этом не ученые-языковеды, а чрезвычайная сложность такого явления, как язык. Простой пример: идти и шедший — два слова или разновидности одного? Так же: дом и домишко? Вопрос не так-то легко разрешить. Ведь если считать отдельными словами все причастия (шедший), деепричастия, формы субъективной оценки (домишко) и другие образования и включить их в словарь, он может так разбухнуть, что один его экземпляр не поместится, пожалуй, в комнате средних размеров. Преувеличение? Тогда попробуйте сами прикинуть количество так называемых потенциальных слов, которые не являются устойчивыми единицами языка, а возникают в речи по потребности и в то же время внешне очень похожи на те, которыми мы обычно пользуемся. К ним, в частности, относятся сложные прилагательные с первым компонентом — числительным. Например: двухрублевый, двенадцатирублевый, однодневный, тридцатидневный, шестисотвосьмидесятипятикилометровый и т.д. Мой компьютер подчеркнул как несуществующие два последних слова(?!). Поэкспериментируем дальше: одноногий, двуногий, трехногий, четырехногий, пятиногий… Компьютер уверенно подчеркнул предпоследнее слово, а «поколебавшись», и последнее. Сколько же таких слов в принципе может встретиться в речи? И сколько их реально было употреблено за последние два века — приблизительно так оценивается возраст современного русского языка? Включать их все в словарь или нет? В Большом академическом словаре зафиксированы лишь некоторые из подобных образований.
Все слова конкретного живого языка сосчитать нельзя уже потому, что он ни одного дня не остается неизменным. Выходят из употребления одни слова или отдельные их значения, появляются новые, и зафиксировать каждый такой факт, конечно, невозможно, поскольку процесс этот постепенный и, как правило, неуловимый.
Итак, если говорить о каком-то определенном, ограниченном «участке» языка, то более или менее точное количество слов известно: уже названо число наиболее употребительных в разных стилях и жанрах, — около 40 тысяч (по данным «Частотного словаря русского языка» под ред. Л. Н. Засориной. М., 1977). Можно назвать также, к примеру, количество наиболее употребительных сокращений — около 18 тысяч (см.: Алексеев Д. И. и др. «Словарь сокращений русского языка». М., 1983). На фоне данных о лексических богатствах всего национального языка представляет интерес объем личного словника, или, как говорят лингвисты, объем активного словаря, то есть количество слов, употребляемых одним человеком. Для образованного «простого смертного» он оценивается в среднем в 5-10 тысяч слов.
Но и здесь есть свои вершины. Так, в «Словаре языка Пушкина» в 4-х томах (М., 1956-1961) зафиксирован непревзойденный пока показатель — приблизительно 24 тысячи. Только «Словарь языка В. И. Ленина», который долго готовился к изданию Институтом русского языка и по известным причинам так и не вышел в свет, по некоторым данным, должен был включать около 30 тысяч слов. Но сегодня, при отсутствии самого словаря, трудно судить, чего в этом обещанном рекорде было больше — гениальности или идеологии.
Имеются статистические характеристики и по многим другим локальным проявлениям. Сосчитать же абсолютно все слова общенародного современного русского языка никто не может — ни ученые, ни самый мощный компьютер. Потому-то языковеды и пришли к выводу: язык в количественном отношении неисчислим.
средняя длина слов в разных языках
При анализе второй мировой войны американские военные историки обнаружили очень интересный факт. А именно, при внезапном столкновении с силами японцев американцы, как правило, гораздо быстрее принимали решения и, как следствие, побеждали даже превосходящие силы противника. Исследовав данную закономерность ученые пришли к выводу что средняя длина слова у американцев составляет 5,2 символа, тогда как у японцев 10,8, следовательно на отдачу приказов уходит на 56 % меньше времени, что в коротком бою играет немаловажную роль.
Ради «интереса» они проанализировали русскую речь и оказалось, что длина слова в русском языке составляет 7,2 символа на слово (в среднем), однако при критических ситуациях русско-язычный командный состав переходит на ненормативную лексику, и длина слова сокращается до (!) 3,2 символов в слове. Это связано с тем, что некоторые словосочетания и даже фразы заменяются ОДНИМ словом.
Для примера приводится фраза: «32-ой ё#ни по этому х@ю», что означает «32-ой приказываю немедленно уничтожить вражеский танк, ведущий огонь по нашим позициям».

10 лет назад
6 лет назад
При подсчёте звуков, например, английскую лигатуру ch надо считать за один звук. И здесь проявляется ещё и то, что для родного то языка письменность отлажена на протяжении веков, а иностранная речь транслитируется чёрт знает как. Ну нет в русском трёх вариантов звука «э», но открытые и закрытые слоги и лигатура er уже предусмотрены, усложняя письмо, при этом статистическая частота звука отличается от английской. Русские мягкий и твёрдый знак тоже часто ли применяются? На сколько мне известно, их даже договариваются убирать в сторону перед тем, как сыграть в «эрудит». Кроме того, отдельное слово в большинстве случаев не несёт информации. Исключением являются во-первых полисинтетические языки. Во-вторых исключением может быть ответ в тех случаях, когда все остальные слова ответа кроме одного заключены в вопросе. В-третьих исключением является приказ о немедленном начале действия в тех случаях, когда смысл передан заранее (сначала распределены цели, а потом короткое «огонь»). В-четвёртых команды вроде «равняйсь», смысл которых также определён заранее, по сути являющиеся скорей кодами, чем словами. Поэтому считать надо среднее не в слове, а в предложении, или даже в группе предложений. И вот здесь английский проигрывает из-за огромного количества вспомогательных слов. В русском даже глагол «быть» (to be) применяется только когда действительно нужен для передачи смысла, в английском он встроен в структуру предложения и отличает, например, утвердительное предложение от вопросительного, для чего в русском языке достаточно интонации, а на письме — знака препинания в конце предложения. А ещё артикли. Например, «the» — это не «этот», а «конкретный». А какой именно? Тот? Или этот? А чёрт его знает, в слове «the» заложен лишь один бит, указывающий на то, что различие между тем и этим важно. А какой именно указывается отдельно. А зачем артикль? Русское «этот» соответствует не «the», а «this» и содержит больше информации, а слово «конкретный» (как раз соответствующее «the») вообще из числа редчайших. Даже русские клитики (вроде частицы «же») применяются лишь для большей выразительности. Да и без слова «например» в бою можно обойтись.
раскрыть ветку
10 лет назад
6 лет назад
Ну если годится «32-ой ё#ни по этому х@ю», то можно ограничиться простым «32-й огонь», просто «огонь», а то и вовсе заранее втолковать, что приказ в таких случаях не нужен, и молча смотреть, как подчинённые стреляют по танку. Даже простое указание пальцем содержит больше информации, так как конкретизирует цель, а мат — нет. По танку стрелять? Или по БТРу на сотню метров левее? А может 32-му по танку, а 27-му по БТРу? Без приказа, или с матом вместо приказа они могут оба влепить по танку, а БТР продолжит стрелять. Или оба по БТРу, а стрелять продолжит танк. А когда цель всего одна, можно заранее втолковать, что кто первый пришёл в движение из тех, кто в принципе может танк уничтожить, тот и стреляет, или же орать «32-й огонь». И не тратить время на мат.
6 лет назад
И приказы на передовой УСТНЫЕ, а значит считать надо звуки. Когда же приказы письменные, то выигрывает как раз японский с его двумя символами в любом слове. Только в других ситуациях.
Частота букв в русском языке
Написал забавный php-скрипт. Погонял через него все тексты на « Спектаторе» на предмет языка. Всего в текстах употребляется 39110 разных словоформ. Сколько именно разных слов — определить довольно сложно. Чтобы хоть как-то приблизиться к этой цифре, я брал только первые 5 букв слова и сравнивал их. Получилось 14373 таких комбинаций. С большой натяжкой это можно назвать словарным запасом « Спектатора».
Потом я взял слова и иследовал их на предмет частоты повторения букв. В идеале надо брать какой-нибудь словарь, для полноты картины. Прогонять тексты нельзя, нужно только уникальные слова. В тексте же одни слова повторяются чаще, чем другие. Итак, получились следующие результаты:
о — 9.28%
а — 8.66%
е — 8.10%
и — 7.45%
н — 6.35%
т — 6.30%
р — 5.53%
с — 5.45%
л — 4.32%
в — 4.19%
к — 3.47%
п — 3.35%
м — 3.29%
у — 2.90%
д — 2.56%
я — 2.22%
ы — 2.11%
ь — 1.90%
з — 1.81%
б — 1.51%
г — 1.41%
й — 1.31%
ч — 1.27%
ю — 1.03%
х — 0.92%
ж — 0.78%
ш — 0.77%
ц — 0.52%
щ — 0.49%
ф — 0.40%
э — 0.17%
ъ — 0.04%
Тем, кто поедет на « Поле чудес», советую заучить эту таблицу наизусть. И называть слова в таком порядке. Так, например, казалось бы, такая « привычная» буква « б» употребляется реже, чем « редкая» буква « ы». Помнить надо также и то, что в слове не одни гласные. И что если вы угадали одну гласную, то нужно начинать идти по согласным. И кроме того, слово угадывается именно по согласным. Сравните: « **а**и*е» и « ср*вн*т*». И в том и в другом случае — это слово « сравните».
И еще одно соображение. Как вы учили английский? Помните? Э пен, э пенсил, э тэйбл. Что вижу — о том и пою. А смысл. Как часто вы в нормальной жизни говорите слово « карандаш»? Если задача — научить говорить как можно быстрее и эффективнее, то и учить надо соответствующе. Проводим анализ языка, выделяем самые употребимые слова. И учить начинаем именно с них. Чтобы более-менее говорить на английском языке, достаточно всего полторы тысячи слов.
Еще одно баловство: составлять слова из букв случайным образом, но учитывая частоту появления, чтобы было похоже на нормальные слова. В первой же десятке « случайных» четырехбуквенных слов выскочило « осел». В следующей полсотне — слова « мчим» и « нато». Но, увы, очень много неблагозвучных комбинаций, таких, как « блтт» или « нрро».
Поэтому — следующий шаг. Я разбил все слова на двухбуквенные сочетания и начал случайным образом (но с учетом частоты повторения) комбинировать их. Стали в больших количествах получатся слова, похожие на « нормальные». Например: « коивдиот», « воабма», « апый», « депоид», « дебяко», « орфа», « поеснавы», « озза», « ченя», « риторя», « урдеед», « утоичи», « стых», « сапоть», « гравда», « абабап», « обарто», « еелует», « лярезы», « мыни», « бромомер» и даже « тодебыст».
Куда применить. есть варианты. Например, написать генератор красивых фирменных игривых имен. Для йогуртов. Типа, « мемолисо» или « уторорерто». Или — генератор футуристических стихов « Бурлюк-php»: « опелдиий миатон, линоаз окмиая. деесопен одесон».
И есть еще один вариант. Надо попробовать.
Некоторые статистические данные об использовании русских слов:
После заметки мне пришло вот такое письмо:
Здравствуйте, Дмитрий !
Проанализировав статью « Язык до Киева доведет» и ту ее часть, где Вы описываете свою программу, возникла идея.
Вами написанный скрипт кажется мне предназначенным абсолютно не для « Поля чудес» в большей мере, а для другого.
Первое самое разумное применение результатов работы Вашего скрипта — определение порядка букв при программировании кнопок для мобильных устройств. Да, да — именно в мобильниках и нужно все это.
Я распределил это по волнам (см. рисунок)
Далее распределение по кнопкам:
1. Все буквы из первой волны уходят на 4 кнопки в первый ряд
2. Все буквы из второй волны тоже на остальные 4 кнопки в тот же первый ряд
3. Все буквы из третьей волны туда же на оставшиеся две кнопки
4. 4,5 и 6 волны уходят во второй ряд
5. 7,8,9 волны уходят на третий ряд, причем 9-я волна уходит вся полностью (не смотря на кажущееся большое количество букв) в третий ряд 9-й кнопки, что-бы 10 кнопку оставить под всякие там знаки препинания (точка, запятая и прочее).
Я думаю все понятно и так, без детальных обьяснений. Но все же не могли бы Вы обработать Вашим скриптом (включая знаки припинания) тексты следующего содержания:
1. Л. Н. Толстой. « Анна Каренина» (лучше конечно « Войну и мир», но я не нашел на www.lib.ru) -http://www.lib.ru/LITRA/TOLSTOJ/anna_kar.txt
2. Ф. М. Достоевский. « Игрок» — www.lib.ru/LITRA/DOSTOEWSKIJ/igrok.txt
3. Леонид Филатов. « Про Федота Стрельца» — www.lib.ru/ANEKDOTY/fedot.txt
4. Вильям Шекспир. Сонеты (перевод С. Я. Маршака) www.lib.ru/SHAKESPEARE/sonets.txt
5. Б. И А.Стругацкие. Пикник на обочине. www.lib.ru/STRUGACKIE/picnic.txt
А потом выложить статистику? Мне показалось? что тексты максимально отражают нашу современную речь, а ведь мы как говорим, так и пишем sms.
Заранее большое спасибо.
Итак, анализировать частоту повторения букв можно двумя способами. Способ 1. Взять текст, найти в нем уникальные (не повторяющиеся) словоформы и анализировать их. Способ хорош для построения статистики по словам русского языка, а не по текстам. Способ 2. Не искать в тексте уникальные слова, а сразу перейти к подсчету частоты повторения букв. Получаем частоту букв в русском тексте, а не в русских словах. Для создания клавиатур и прочего нужно использовать именно этот способ: на клавиатуре набираются именно тексты.
Клавиатуры должны учитывать не только частоту букв, но и самые упортебимые слова (словоформы). Не так уж и трудно догадаться, какие именно слова самые употребимые: это, во-первых, служебные части речи, ибо роль у них такая — служить всегда и везде, и местоимения, роль у которых не менее важная: заменять в речи любую вещь/человека (это, он, она). Ну и основные глаголы (быть, сказать). По результатам анализа перечисленных выше текстов я получил такие самые « популярные» слова: « и, не, в, что, он, я, на, с, она, как, но, его, это, к, а, все, ее, было, так, же, то, сказал, за, ты, о, у, ему, мне, только, по, меня, бы, да, вы, от, был, когда, из, для, еще, теперь, они, сказала, уже, него, нет, была, ей, быть, ну, ни, если, очень, ничего, вот, себя, чтобы, себе, этого, может, того, до, мы, их, ли, были, есть, чем, или, ней» и так далее.
Возвращаясь к клавиатурам — очевидно, что в клавиатуре буквосочетания « не», « что», « он», « на» идругие должны находится как можно ближе друг к другу, или если не вплотную, то каким-то наиболее оптимальным образом. Нужно провести исследования, каким именно образом пальцы движутся по клавиатуре, найти самые « удобные» позиции и поместить в них самые употребляемые буквы, не забывая, однако, про буквосочетания.
Проблема, как всегда, одна: даже если и получиться создать Уникальную Клавиатуру, куда деть миллионы людей, которые уже привыкли к qwerty/йцукен?
Насчет же мобильных устройств. Наверное, it makes sense. По крайней мере, буквы « о», « а», « е» и « и» должны точно находиться на одной клавише. Знаки препинания в порядке частоты употребления : , . — ? ! » ; : ) (
Запятая употребляется в 2 раза чаще, чем точка. А точка на стандартной русской клавиатуре расположена удобней.
Статистика по приведенным выше текстам:
По уникальным словам:
о — 9.36%
а — 8.40%
е — 8.08%
и — 6.91%
н — 6.12%
с — 5.67%
т — 5.49%
р — 5.30%
л — 5.00%
в — 4.67%
п — 3.38%
у — 3.17%
к — 3.14%
м — 2.97%
д — 2.72%
я — 2.50%
ь — 2.08%
ы — 2.06%
з — 1.85%
б — 1.61%
г — 1.47%
ш — 1.32%
ч — 1.22%
й — 1.21%
ж — 1.01%
ю — 0.99%
х — 0.97%
щ — 0.48%
ц — 0.37%
ф — 0.20%
э — 0.06%
ъ — 0.05%
По текстам в целом:
о — 11.35%
е — 8.93%
а — 8.23%
н — 6.71%
и — 6.48%
т — 6.17%
с — 5.22%
л — 4.95%
в — 4.47%
р — 4.17%
к — 3.35%
д — 2.97%
м — 2.93%
у — 2.86%
п — 2.39%
я — 2.17%
ь — 2.09%
ы — 1.90%
г — 1.811%
б — 1.77%
ч — 1.67%
з — 1.65%
ж — 1.14%
й — 1.09%
ш — 0.89%
х — 0.79%
ю — 0.66%
э — 0.33%
ц — 0.29%
щ — 0.29%
ф — 0.10%
ъ — 0.02%