skip connections и симметрия
Некоторое время назад в ходе определенных рассуждений, явно не связанных с архитектурами искусственных нейронных сетей, у меня возникла, скажем так, гипотеза, которая могла бы объяснить, почему в свое время skip connections смогли произвести своего рода революцию в развитии глубокого обучения и позволили строить действительно глубокие нейронные сети. С тех пор много воды утекло, но все современные SOTA архитектуры являются в той или иной степени продолжением развития ResNet архитектур. Чего там говорить, даже в трансформерах есть skip connections. К сожалению, времени и сил на полноценное исследование нет и вряд ли найдется, а между тем идея кажется как минимум интересной с академической точки зрения, так и могущей возыметь практический выхлоп, а потому я бы хотел поделиться ею, по крайней мере, с аудиторией хабра. Буду краток.
Для решения какой проблемы были введены skip connection в residual архитектурах?
Это один из вопросов, который можно услышать на собеседованиях на позицию ML-инженеров. По крайней мере, именно в такой формулировке мы в нашей компании задаем его соискателям на предварительном скрининг-собеседовании, и, согласно их отзывам, это один из весьма популярных и часто встречаемых вопросов. При этом абсолютное большинство соискателей отвечают на него… неправильно. Лишь немногим отличаясь, ответы в большинстве своем звучат примерно следующим образом: «для решения проблемы затухающего градиента». И это действительно неправильный ответ: заглянув в оригинальную статью, мы увидим, буквально на первой же странице во введении, следующие строки:
Driven by the significance of depth, a question arises: Is learning better networks as easy as stacking more layers? An obstacle to answering this question was the notorious problem of vanishing/exploding gradients [1, 9], which hamper convergence from the beginning. This problem, however, has been largely addressed by normalized initialization [23, 9, 37, 13] and intermediate normalization layers [16], which enable networks with tens of layers to start converging for stochastic gradient descent (SGD) with backpropagation [22].
Неказистый перевод
Из важности глубины возникает вопрос: так ли просто обучать более совершенные сети, как составлять большее количество слоев? Препятствием к ответу на этот вопрос стала пресловутая проблема исчезающих/взрывающихся градиентов [1, 9], которая препятствуют сходимости с самого начала. Эта проблема, однако, была в значительной степени решена с помощью нормализованной инициализации [23, 9, 37, 13] и промежуточных нормализационных слоев [16], которые позволяют сетям с десятками слоев начать сходиться в рамках стохастического градиентного спуска (SGD) с обратным распространением [22].
И ведь действительно, если вдуматься, наличие слоев нормализации должно позволять градиенту течь по сети без затухания. И хоть skip connections (a.k.a. shortcut connections) в принципе изначально были предложены еще до появления ResNet архитектуры, в том числе для решения проблемы затухающего градиента (что, возможно, и служит причиной столь широко распространенного заблуждения), в ResNet архитектурах они в действительности помогли решить другую проблему — проблему деградации точности (о чем в статье говориться буквально в следующем абзаце). Проблема деградации точности заключается в том, что при увеличении глубины сети точность сначала возрастает, потом, вопреки ожиданиям, выходит на плато, а после даже начинает снижаться вплоть до полной потери способности сети к обучению. Существует довольно популярное мнение (вероятно, среди тех, кто читал/помнит оригинальную статью и знает, что затухание градиента тут ни при чем), что: skip connection в residual архитектурах помогают модели выучить тождественное преобразование — таким образом, имея возможность пропускать сигнал без трансформаций, модель должна, по крайней мере, быть не хуже, чем ее менее глубокая версия, следовательно, деградировать точность не может. Подобное объяснение действительно имеет место быть, но оно носит, так сказать, симптоматический характер. А что, если копнуть глубже и попытаться разобраться, в чем вообще причина такого явления, как деградация точности глубокой нейронной сети при увеличении ее глубины? Разумеется, можно начать рассуждать про увеличение размерности параметрического пространства, про ухудшение сходимости, про застревание в локальных минимумах в процессе оптимизации и так далее, однако добавление skip connections не снижает размерность параметрического пространства. Стало быть, сама по себе высокая размерность не является причиной деградации точности. А что же тогда.
Симметрия в нейронных сетях
Причиной (многих) проблем глубокого обучения и подсказкой к поиску путей их решения может являться симметрия параметрического пространства. Именно параметрического, а не признакового, т.е. речь не идет о симметрии входных образов, как то симметрии отражения или поворотов, которыми могут обладать, например, некоторые классы изображений. Нет, речь в данном случае идет об инвариантности результата работы сети по отношению к некоторым операциям, действующим в пространстве параметров нейронной сети:
где — некоторое линейное преобразование в пространстве параметров .

Для простоты рассуждений возьмем полносвязную сеть с одним скрытым слоем (рис. 1). Рассмотрим, для начала, случай, когда все веса выходного линейного слоя фиксированы и равны , т.е. последний слой выполняет роль простого арифметического усреднения выходов нейронов скрытого слоя. Параметры же скрытого слоя удобно представить в виде прямоугольной матрицы размера , где — размерность входного слоя, — размерность скрытого слоя (для простоты, но не нарушая общности рассуждений, забудем про смещение, a.k.a. bias). Таким образом, результат работы сети можно представить в виде:
Что произойдет с результатом работы сети, если мы поменяем местами, скажем, первый и второй нейроны скрытого слоя? Очевидно, что при такой перестановке результат работы сети не изменится. При этом такая операция меняет местами первую и вторую строки матрицы весов скрытого слоя. Т.е. до и после перестановки мы имеем две, вообще говоря, разные матрицы весов, дающие один и тот же результат на выходе сети. Более того, переставить местами мы можем любые два нейрона (любые две строки матрицы ) — результат работы сети инвариантен к любым таким перестановкам, а всего вариантов перестановок Таким образом, как минимум наборов весов (точек в параметрическом пространстве) являются эквивалентными в смысле результата работы сети, независимо ни от входных данных, ни от функций активации и т.д. Это утверждение справедливо не только в рассмотренном нами случае, но и в общем случае, с той лишь разницей, что перестановка i-ого и j-ого нейронов l-го слоя представляет собой перестановку i-й и j-й строки матрицы вместе с перестановкой i-го и j-го столбцов матрицы -го слоя. Из этих рассуждений мы можем заключить, что один полносвязный слой задает в пространстве параметров степень симметрии, по крайней мере, не ниже, чем , а степень симметрии параметрического пространства всей сети равна произведению степеней симметрии каждого слоя, т.е. , поскольку перестановки нейронов в двух слоях выполняются независимо друг от друга. Таким образом, мы определили возможный вид преобразования из выражения 1 — перестановочная матрица. Сразу отмечу, что перестановка — не единственная возможная операция симметрии в пространстве параметров, и в зависимости от используемой нелинейности результат работы сети может оказаться инвариантен и к некоторым другим преобразованиям, специфичным для этой нелинейности (особенно широкий простор для симметрий, в т.ч. непрерывных, обеспечивает ReLU).
Проблемы сходимости, связанные с высокой степенью симметрии признакового пространства, могут возникать на гиперповерхностях симметрии — многообразиях в параметрическом пространстве, точки которых инвариантны к соответствующим операциям симметрии. Например, если две строки в матрице весов равны друг другу, то их перестановка местами не приводит к изменению не только результата, но и самого вектора параметров — такая точка в параметрическом пространстве лежит на одной из плоскостей симметрии. Для наглядности рассмотрим наиболее простой возможный пример (пусть и нарочито игрушечный):

Поскольку здесь всего два варьируемых параметра, мы можем изобразить ландшафт функции потерь на плоскости с использованием любого удобного представления, скажем, contour plot (рис. 3).

Как мы видим, функция потерь, имеющая два эквивалентных минимума, симметрична относительно прямой , или, правильнее в угоду общности будет сказать, относительно 1d-гиперплоскости, задаваемой вектором нормали (1, -1). Собственно, это и есть пример гиперповерхности симметрии, упомянутой ранее. Любая точка, принадлежащая этой прямой, является инвариантной относительно операции симметрии, благодаря которой функция потерь имеет два минимума. Так вот, важно здесь то, что на этой самой поверхности, в общем случае, вдоль ортогональных плоскости направлений функция потерь имеет локальный экстремум, который может быть как максимум, так и минимумом. Назовем такой минимум ложным, поскольку в общем случае он не является оптимальной точкой решения задачи оптимизации, а обусловлен свойствами параметрического пространства модели.
Картина усложняется, когда мы имеем множество пересекающихся гиперповерхностей в результате стекинга нескольких слоев — ландшафт функции потерь может усложняться чрезвычайно сильно — вероятность возникновения ложных минимумов повышается с увеличением степени симметрии параметрического пространства, которая, в свою очередь, растет катастрофически с увеличением глубины и ширины сети. Больше локальных минимумов — больше вероятность застрять в этих минимумах в процессе оптимизации. Собственно, основная гипотеза, выдвигаемая на основании всех этих рассуждений, состоит в том, что проблема деградации точности связана с ростом числа локальных минимумов при увеличении глубины сети, обусловленным ростом степени симметрии параметрического пространства.
И тут на помощь приходят skip connections
Так чем же тогда помогают skip connections? Тут все достаточно просто и Вы, возможно, уже догадались сами: skip connections существенно снижают симметрию параметрического пространства, уменьшая, тем самым, число локальных минимумов и облегчая сходимость. Если это утверждение не кажется столь очевидным, достаточно рассмотреть уже знакомый нам пример полносвязной сети, чтобы его понять. Добавим в сеть, изображенную на рисунке 1, skip connections между входом и выходом первого слоя (правда, для этого нам потребуется сделать размерность выхода равной размерности входа, но сути это не меняет).

Поскольку перестановка местами двух нейронов в слое не зависит от его входа, то в этот раз мы уже не можем переставлять местами нейроны в скрытом слое, не меняя выход сети, поскольку он зависит уже не только от весов скрытого слоя, но и входного значения, с которым суммируется активация. Т.е., добавив skip connection, причем, именно аддитивный (подойдет также, например, мультипликативный, но не конкатенативный), мы снизили степень перестановочной симметрии слоя с до 1! Таким образом, добавление skip connections по всей глубине сети позволяет значительно снизить степень симметрии параметрического пространства, а, значит, и число локальных минимумов функции потерь, делая ее ландшафт более «хорошим» для оптимизации.
После проведенных рассуждений не грех задаться вопросом: если skip connections действительно помогает решить проблему деградации точности за счет снижения симметрии параметрического пространства, то что еще может обладать подобным свойством? Рискну предположить, что к приемам, которые исторически помогли решить ту или иную проблему при дизайне новых нейросетевых архитектур, действительно можно отнести несколько, в частности: групповую (в пределе — поканальную) свертку (group and depth-wise convolutions), позиционное кодирование (positional encoding), dropout. Первые два приема, в ретроспективном рассмотрении, обладают тем свойством, что помогают в целом снизить степень симметрии параметрического пространства как и skip connections. Так, например, depth-wise convolution, используемая для факторизации операции свертки, с одной стороны, разумеется, позволяет снизить размерность параметрического пространства (что оказывается важным для инференса на устройствах), но также и снижает степень симметрии, поскольку каждый канал теперь обрабатывается своим фильтром, и, следовательно, результат работы сети уже не инвариантен к перестановкам ядер.
Что касается регуляризации dropout, то ее можно связать с симметрией следующим образом: отключение случайного подмножества нейронов на каждом шаге обучения локально (на данном шаге) нарушает симметрию признакового пространства, т.е. у оптимизатора появляется шанс пройти мимо ложного минимума, обеспеченного симметрией ландшафта функции потерь на гиперповерхностях симметрии или их пересечении.
Что-нибудь еще? Возможно… Предлагаю заинтересовавшимся подумать над этим вместе.
Послесловие
Получилось, на мой взгляд, достаточно кратко. Возможно, изложенная идея кому-то покажется простой, очевидной или незначительной, другого может натолкнет на какие-то интересные мысли. В любом случае, приглашаю к обсуждению.
Deep Learning — как это работает? Часть 4
Для задач обнаружения объектов выделяют два метода (источник и подробнее— тут):
- Двухэтапные методы (англ. two-stage methods), они же «методы, основанные на регионах» (англ. region-based methods) — подход, разделённый на два этапа. На первом этапе селективным поиском или с помощью специального слоя нейронной сети выделяются регионы интереса (англ. regions of interest, RoI) — области, с высокой вероятностью содержащие внутри себя объекты. На втором этапе выбранные регионы рассматриваются классификатором для определения принадлежности исходным классам и регрессором, уточняющим местоположение ограничивающих рамок.
- Одноэтапные методы (англ. one-stage methods) — подход, не использующий отдельный алгоритм для генерации регионов, вместо этого предсказывая координаты определённого количества ограничивающих рамок с различными характеристиками, такими, как результаты классификации и степень уверенности и в дальнейшем корректируя местоположение рамок.
Transfer learning
Transfer learning — это метод обучения нейронных сетей, при котором мы берем уже обученную на каких-то данных модель для дальнейшего дообучения для решения другой задачи. Например, у нас есть модель EfficientNet-B5, которая обучена на ImageNet-датасете (1000 классов). Теперь, в самом простом случае, мы изменяем ее последний classifier-слой (скажем, для классификации объектов 10-ти классов).
Взгляните на картинку ниже:
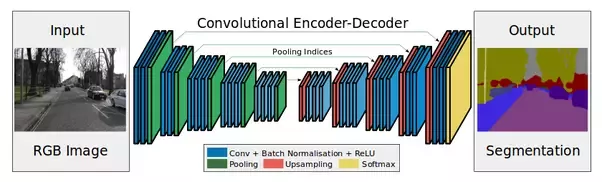
Encoder — это слои subsampling’а (свертки и пулинги).
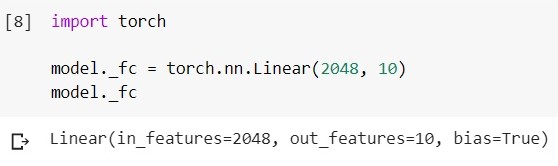
Замена последнего слоя в коде выглядит так (фреймворк — pytorch, среда — google colab):
Загружаем обученную модель EfficientNet-b5 и смотрим на ее classifier-слой:

Изменяем этот слой на другой:
Decoder нужен, в частности, в задаче сегментации (об этом далее).
Стратегии transfer learning
Стоит добавить, что по умолчанию все слои модели, которые мы хотим обучать дальше, обучаемы. Мы можем «заморозить» веса некоторых слоев.
Для заморозки всех слоев:

Чем меньше слоев мы обучаем — тем меньше нам нужно вычислительных ресурсов для обучения модели. Всегда ли эта техника оправданна?
В зависимости от количества данных, на которых мы хотим обучить сеть, и от данных, на которых была обучена сеть, есть 4 варианта развития событий для transfer learning’а (под «мало» и «много» можно принять условную величину 10k):
- У Вас мало данных, и они похожи на данные, на которых была обучена сеть до этого. Можно попробовать обучать только несколько последних слоев.
- У Вас мало данных, и они не похожи на данные, на которых была обучена сеть до этого. Самый печальный случай. Тут уже, скорее всего, придется просто подбирать модель под объем данных, т.к. даже обучение всех слоев может не помочь.
- У Вас много данных, и они похожи на данные, на которых была обучена сеть до этого. Можно попробовать не обучать всю сеть целиком, а обойтись лишь обучением нескольких последний слоев.
- У Вас много данных, и они не похожи на данные, на которых была обучена сеть до этого. Лучше обучать практически всю сеть.
Semantic segmentation
Семантическая сегментация — это когда мы на вход подаем изображение, а на выходе хотим получить что-то в духе:

Выражаясь более формально, мы хотим классифицировать каждый пиксель нашего входного изображения — понять, к какому классу он принадлежит.
Подходов и нюансов здесь очень много. Чего стоит только архитектура сети ResNeSt-269 🙂
Интуиция — на входе изображение (h, w, c), на выходе хотим получить маску (h, w) или (h, w, c), где c — количество классов (зависит от данных и модели). Давайте теперь после нашего encoder’а добавим decoder и обучим их.
Decoder будет состоять, в частности, из слоев upsampling’а (повышения размерности). Повышать размерность можно просто «вытягивая» по высоте и ширине наш feature map на том или ином шаге. При «вытягивании» можно использовать билинейную интерполяцию (в коде это будет просто один из параметров метода).
Архитектура сети deeplabv3+:
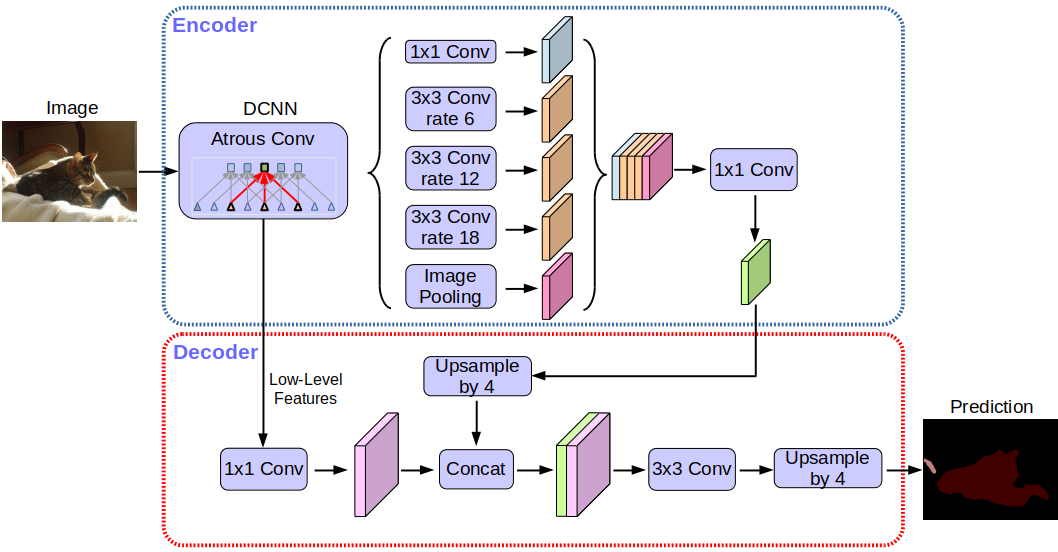
Если не углубляться в детали, то можно заметить, что сеть использует архитектуру encoder-decoder.
Более классический вариант, архитектура сети U-net:
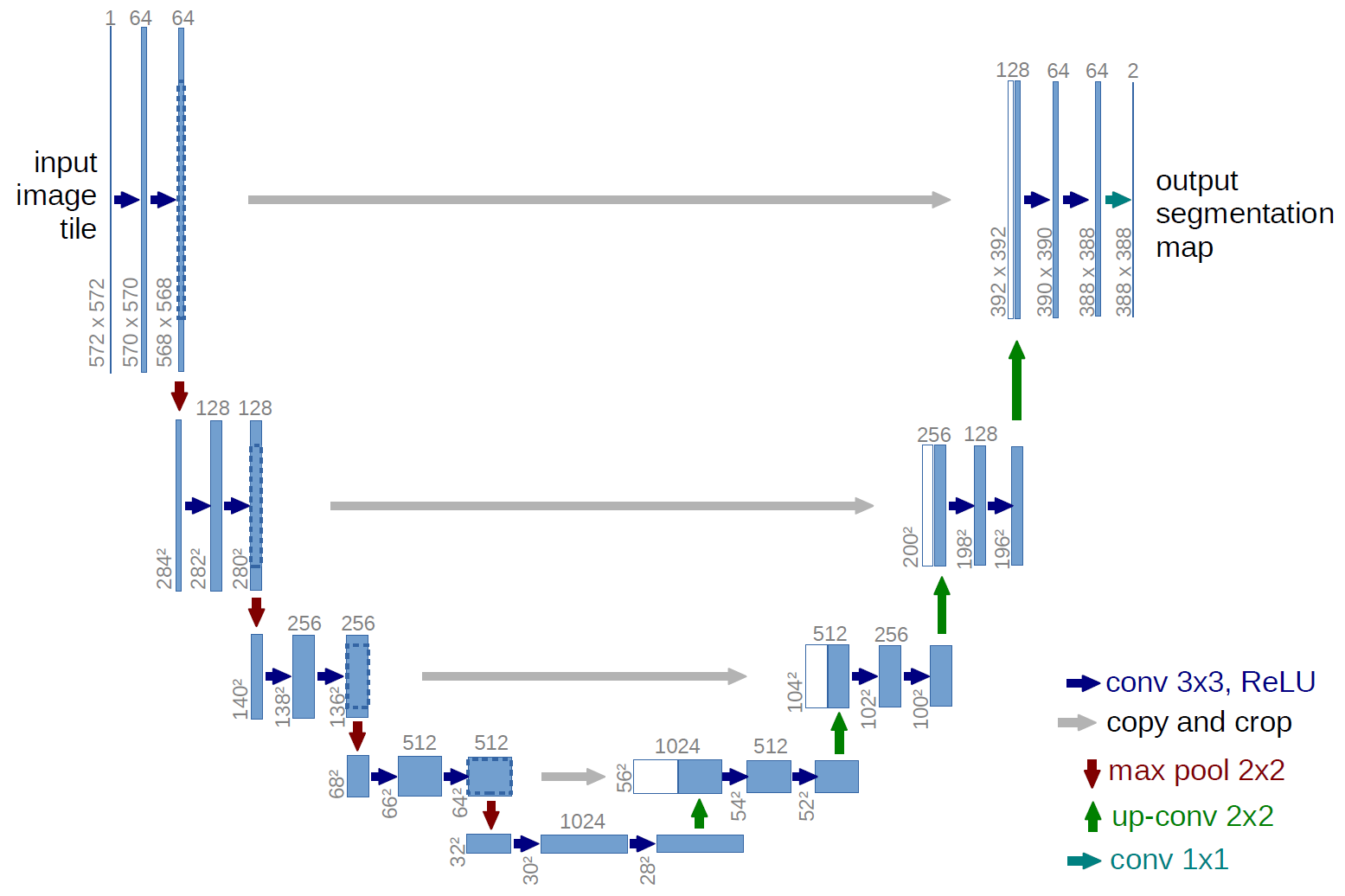
Что это за серые стрелочки? Это, так называемые, skip connections. Дело в том, что encoder «кодирует» наше входное изображение с потерями. Для того, чтобы минимизировать такие потери — как раз и используют skip connections.
В этой задаче мы можем применить transfer learning — например, можем взять сеть с уже обученным encoder’ом, дописать decoder и обучить его.
На каких данных и какие модели показывают себя лучше всего в этой задаче на данный момент — можно посмотреть тут.
Instance segmentation
Более сложный вариант задачи сегментации. Его суть в том, что мы хотим не только классифицировать каждый пиксель входного изображения, а еще и как-то выделять различные объекты одного класса:
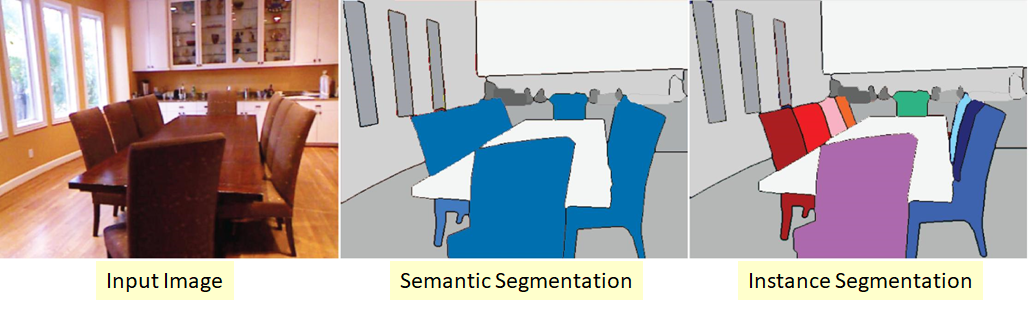
Бывает так, что классы «слипшиеся» или между ними нет видимой границы, но мы хотим разграничить объекты одного класса друг от друга.
Подходов здесь тоже несколько. Самый простой и интуитивный состоит в том, что мы обучаем две разные сети. Первую мы обучаем классифицировать пиксели для каких-то классов (semantic segmentation), а вторую — для классификации пикселей между объектами классов. Мы получаем две маски. Теперь мы можем вычесть из первой вторую и получить то, что хотели 🙂
На каких данных и какие модели показывают себя лучше всего в этой задаче на данный момент — можно посмотреть тут.
Object detection
Подаем на вход изображение, а на выходе хотим увидеть что-то в духе:

Самое интуитивное, что можно сделать — «бегать» по изображению различными прямоугольниками и, используя уже обученный классификатор, определять — есть ли на данном участке интересующий нас объект. Такая схема имеет место быть, но она, очевидно, не самая лучшая. У нас ведь есть сверточные слои, которые каким-то образом иначе интерпретируют feature map «до»(А) в feature map «после»(Б). При этом мы знаем размерности фильтров свертки => знаем какие пиксели из А в какие пиксели Б преобразовались.
Давайте взглянем на YOLO v3:
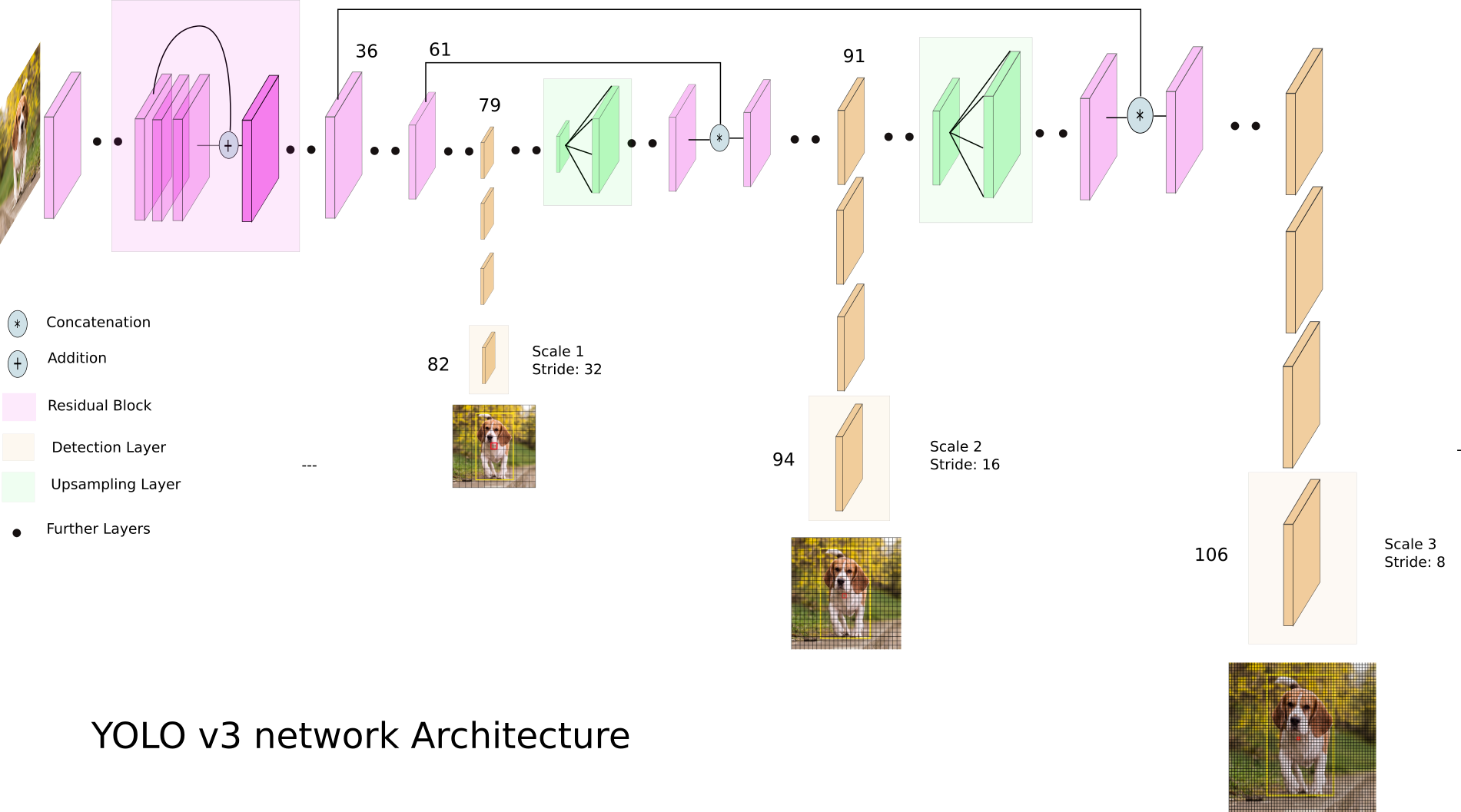
YOLO v3 использует разные размерности feature map’ов. Это делается, в частности, для того, чтобы корректно детектировать объекты разного размера.
Далее происходит конкатенация всех трех scale’ов:
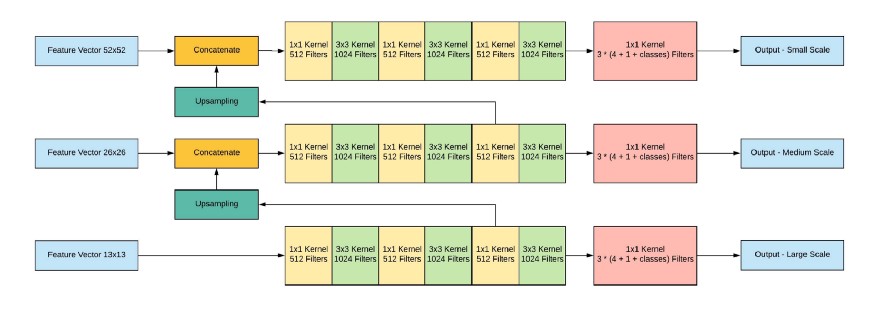
Выход сети, при входном изображении 416х416, 13х13х(B * (5 + С)), где С — количество классов, B — количество боксов для каждого региона (у YOLO v3 их 3). 5 — это такие параметры, как: Px, Py — координаты центра объекта, Ph, Pw — высота и ширина объекта, Pobj — вероятность того, что объект находится в этом регионе.
Давайте посмотрим на картинку, так будет чуть более понятно:

YOLO отсеивает данные предсказания изначально по objectness score по какому-то значению (обычно 0.5-0.6), а затем по non-maximum suppression.
На каких данных и какие модели показывают себя лучше всего в этой задаче на данный момент — можно посмотреть тут.
Заключение
Различных моделей и подходов к задачам сегментации и локализации объектов в наши дни очень много. Существуют определенные идеи, поняв которые, станет легче разбирать тот зоопарк моделей и подходов. Эти идеи я попытался выразить в данной статье.
В следующих статьях поговорим про style transfer и GAN’ы.
- машинное обучение
- глубокое обучение
- искусственный интеллект
- Машинное обучение
- Искусственный интеллект
Трансформер
Трансформер (англ. transformer) — архитектура глубоких нейронных сетей, основанная на механизме внимания без использования рекуррентных нейронных сетей (сокр. RNN). Самое большое преимущество трансформеров по сравнению с RNN заключается в их высокой эффективности в условиях параллелизации. Впервые модель трансформера была предложена в статье Attention is All You Need [1] от разработчиков Google в 2017 году.
Архитектура трансформера
![]()
Архитектура трансформера [2]
Устройство трансформера состоит из кодирующего и декодирующего компонентов. На вход принимается некая последовательность, создается ее векторное представление (англ. embedding), прибавляется вектор позиционного кодирования, после чего набор элементов без учета порядка в последовательности поступает в кодирующий компонент (параллельная обработка), а затем декодирующий компонент получает на вход часть этой последовательности и выход кодирующего. В результате получается новая выходная последовательность.
Внутри кодирующего и декодирующего компонента нет рекуррентности. Кодирующий компонент состоит из кодировщиков, которые повторяются несколько раз, аналогично устроен декодирующий компонент. Трансформер — это поставленные друг за другом модели внимания, которые позволяют исходную последовательность векторов перевести в новую последовательность векторов, которые кодируют информацию о контексте каждого элемента. Трансформер-кодировщик переводит исходные векторы в скрытые, которые правильно сохраняют в себе информацию о контексте каждого элемента. Далее трансформер-декодировщик декодирует результат кодировщика в новую последовательность, которая состоит из эмбедингов элементов выходного языка. После по эмбедингам генерируются сами итоговые элементы с помощью вероятностной языковой модели.
Ниже рассмотрим архитектуру кодировщика и декодировщика подробнее.
Архитектура трансформера-кодировщика
![]()
Архитектура трансформера-кодировщика [3]
Рассмотрим последовательно шаг за шагом этапы работы кодировщика:
1. На вход поступает последовательность элементов [math]w_i[/math] , по ней создается последовательность эмбедингов, где каждый [math]x_i[/math] это векторное представление элемента [math]w_i[/math] .
2. Добавляются позиционные векторы [math]p_i[/math] : [math]h_i = x_i + p_i[/math] , [math]H = (h_1. h_n)[/math] . Это необходимо для того, чтобы отобразить информацию о позиции элемента в исходной последовательности. Основное свойство позиционного кодирования — чем дальше два вектора будут стоять друг от друга в последовательности, тем больше между ними будет расстояние. Более подробное устройство позиционного кодирования будет рассмотрено ниже.
3. Полученный вектор [math]h_i[/math] подается на вход в блок многомерного самовнимания (англ. multi-headed self-attention). [math]h^j_i = \mathrm(Q^j h_i, K^j H, V^j H)[/math] , где обучаемые матрицы: [math]Q[/math] для запроса, [math]K[/math] для ключа, [math]V[/math] для значения. Подробное объяснения работы механизма self-attention будет разобрано ниже.
4. Затем необходима конкатенация, чтобы вернуться в исходную размерность: [math] h’_i = M H_j (h^j_i) = [h^1_i. h^J_i] [/math]
5. Добавим сквозные связи (англ. skip connection) — по факту просто добавление из входного вектора к выходному ( [math]h’_i + h_i[/math] ). После делаем нормализацию слоя (англ. layer normalization): [math]h»_i = \mathrm(h’_i + h_i; \mu_1, \sigma_1)[/math] . У нее два обучаемых параметра, для каждой размерности вектора вычисляется среднее и дисперсия.
6. Теперь добавим преобразование, которое будет обучаемым — полносвязную двухслойную нейронную сеть: [math] h»’_i = W_2 \mathrm (W_1 h»_i + b_1) + b_2 [/math]
7. Повторим пункт 5 еще раз: добавим сквозную связь и нормализацию слоя: [math]z_i = \mathrm(h»’_i + h»_i; \mu_2, \sigma_2)[/math]
После, в кодирующем компоненте пункты кодировщика 3—7 повторяются еще несколько раз, преобразовывая друг за другом из контекста контекст. Тем самым мы обогащаем модель и увеличиваем в ней количество параметров.
Позиционное кодирование
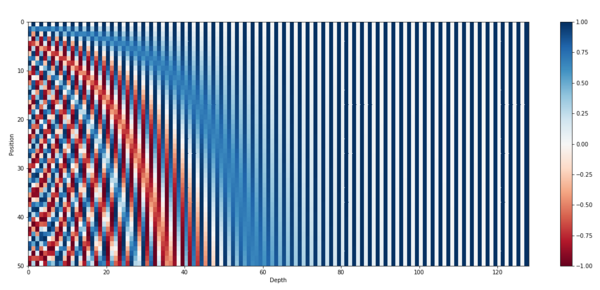
Визуализация работы позиционного кодирования [4]
Так как в архитектуре трансформер обработка последовательности заменяется на обработку множества мы теряем информацию о порядке элементов последовательности. Чтобы отобразить информацию о позиции элемента в исходной последовательности мы используем позиционное кодирование.
Позиционное кодирование (англ. positional encoding) — позволяет модели получить информацию о порядке элементов в последовательности путем прибавления специальных меток к вектору входных элементов. Позиции элементов [math]i[/math] кодируются векторами [math]p_i[/math] , [math]i = 1, 2, . n[/math] , так, что чем больше [math]|i — j|[/math] , тем больше [math]||p_i — p_j||[/math] , и [math]n[/math] не ограничено. Пример такого кодирования:
[math] p_ <(i, s)>= \begin \sin \left(i \cdot 10000^>>\right) & \quad \text s=2k\\ \cos \left(i \cdot 10000^>>\right) & \quad \text s=2k+1 \end [/math]
Self-attention
Self-Attention — разновидность механизма внимания, задачей которой является выявление закономерности между входными данными.
Будем для каждого элемента [math]x_i[/math] получать обучаемым преобразованием три вектора:
- Запрос (query) [math]q_i = Q x_i[/math]
- Ключ (key) [math]k_i = K x_i[/math]
- Значение (value) [math]v_i = V x_i[/math]
Векторы [math]q_i[/math] и [math]k_i[/math] будем использовать, чтобы посчитать важность элемента [math]x_j[/math] для элемента [math]x_i[/math] . Чтобы понять, насколько для пересчета вектора элемента [math]x_i[/math] важен элемент [math]x_j[/math] мы берем [math]k_j[/math] (вектор ключа элемента [math]x_j[/math] ) и умножаем на [math]q_i[/math] (вектор запроса элемента [math]x_i[/math] ). Так мы скалярно перемножаем вектор запроса на все векторы ключей, тем самым понимаем, насколько каждый входной элемент нам нужен, чтобы пересчитать вектор элемента [math]x_i[/math] .
Далее считаем важность элемента [math]x_j[/math] для кодирования элемента [math]x_i[/math] : [math]w_=\frac< \exp \left(\frac<\langle q_i, k_j \rangle>> \right) >< \sum_^n \exp \left(\frac<\langle q_i, k_p \rangle>> \right) >[/math] , где [math]d[/math] — размерность векторов [math]q_i[/math] и [math]k_j[/math] , а [math]n[/math] — число элементов во входной последовательности.
Таким образом, новое представление элемента [math]x_i[/math] считаем как взвешенную сумму векторов значения: [math]z_i = \mathrm(Q x_i, K X, V X) = \sum_^n w_
v_p[/math] , где [math]X = (x_1, x_2, . x_n)[/math] — входные векторы. По факту self-attention — это soft-arg-max с температурой [math]\sqrt[/math] . Мы перемешиваем все входные векторы, чтобы получить новые векторы всех элементов, где каждый элемент зависит от всех входных элементов.
Multi-headed self-attention
Multi-headed self-attention — улучшенная модификация self-attention.
Слой внимания снабжается множеством «подпространств представлений» (англ. representation subspaces). Теперь у нас есть не один, а множество наборов матриц запроса/ключа/значения. Каждый из этих наборов создается случайным образом. Далее после обучения каждый набор используется для отображения входящих векторов в разных подпространствах представлений. Также появляется способность модели фокусироваться на разных аспектах входной информации.
То есть параллельно независимо несколько раз делаем attention. Потом результат каждого attention по элементам конкатенируем, затем сжимаем получившуюся матрицу и получаем для каждого элемента свой вектор той же размерности.
[math]с^j = \mathrm(Q^j q, K^j X, V^j X)[/math] , где [math]j = 1. J[/math] , [math]J[/math] — число разных моделей внимания, [math]X = (x_1, x_2, . x_n)[/math] — входные векторы, а [math]W[/math] — обучаемые матрицы.
Архитектура трансформера-декодировщика
![]()
Архитектура трансформера-декодировщика [5]
На вход декодировщику подается выход кодировщика. Главное отличие архитектуры декодировщика заключается в том, что дополнительно имеется attention к вектору, который получен из последнего блока кодирующего компонента. Компонент декодировщика тоже многослойный и каждому блоку компонента на вход подается вектор именно с последнего блока кодирующего компонента. Разберем по порядку этапы работы декодировщика:
1. Для того, чтобы распараллелить декодировщик и уйти от рекуррентности, но тем не менее генерировать элементы друг за другом, используется прием маскирования данных из будущего. Идея в том, что мы запрещаем себе подглядывать в те элементы, которые еще не сгенерированы с учетом порядка. Когда генерируем элемент под номером [math]t[/math] , имеем право смотреть только первые [math]t-1[/math] элементов: [math]h_t = y_ + p_t[/math] ; [math]H_t=(h_1, . h_t)[/math]
2. Далее идет этап многомерного самовнимания: линейная нормализация и multi-headed self-attention. Особенность в том, что в attention ключи и значения применяются не ко всем векторам, а только к тем, значения которых уже синтезировали ( [math]H_t[/math] ): [math] h’_t = \mathrm \circ M H_j \circ \mathrm(Q^j h_t, K^j H_t, V^j H_t) [/math] , где [math]\circ[/math] — композиция.
3. На следующем этапе мы делаем многомерное внимание на кодировку [math]Z[/math] , результат работы компонента кодировщика: [math] h»_t = \mathrm \circ M H_j \circ \mathrm(Q^j h_t, K^j Z, V^j Z) [/math]
4. Линейная полносвязная сеть (по аналогии с кодировщиком): [math] y_t = \mathrm \circ FNN(h»_t) [/math]
5. В самом конце мы хотим получить вероятностную порождающую модель для элементов. Результат (индекс слова с наибольшей вероятностью): [math]\mathrm(W_y y_t + b_y) [/math] , где [math] W_y [/math] , [math] b_y [/math] — обучаемые параметры линейного преобразования. Для каждой позиции [math]t[/math] выходной последовательности мы строим вероятностную модель языка, то есть все элементы из выходного словаря получают значение вероятности. Эти значения как раз получаются из векторов [math]y_t[/math] из предыдущего пункта, которые мы берем с последнего блока трансформера-декодировщика.
Последний этап выполняется только после того, когда повторились пункты 1—4 для всех декодировщиков. На выходе получаем вероятности классов, по факту для каждой позиции решаем задачу многоклассовой классификации, для того, чтобы понять какие элементы лучше поставить на каждые позиции.
Источники информации
- ↑https://arxiv.org/abs/1706.03762
- ↑https://jalammar.github.io/illustrated-transformer/
- ↑https://arxiv.org/abs/1706.03762
- ↑https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
- ↑https://arxiv.org/abs/1706.03762
skip connections и симметрия
Некоторое время назад в ходе определенных рассуждений, явно не связанных с архитектурами искусственных нейронных сетей, у меня возникла, скажем так, гипотеза, которая могла бы объяснить, почему в свое время skip connections смогли произвести своего рода революцию в развитии глубокого обучения и позволили строить действительно глубокие нейронные сети. С тех пор много воды утекло, но все современные SOTA архитектуры являются в той или иной степени продолжением развития ResNet архитектур. Чего там говорить, даже в трансформерах есть skip connections. К сожалению, времени и сил на полноценное исследование нет и вряд ли найдется, а между тем идея кажется как минимум интересной с академической точки зрения, так и могущей возыметь практический выхлоп, а потому я бы хотел поделиться ею, по крайней мере, с аудиторией хабра. Буду краток.
Для решения какой проблемы были введены skip connection в residual архитектурах?
Это один из вопросов, который можно услышать на собеседованиях на позицию ML-инженеров. По крайней мере, именно в такой формулировке мы в нашей компании задаем его соискателям на предварительном скрининг-собеседовании, и, согласно их отзывам, это один из весьма популярных и часто встречаемых вопросов. При этом абсолютное большинство соискателей отвечают на него… неправильно. Лишь немногим отличаясь, ответы в большинстве своем звучат примерно следующим образом: «для решения проблемы затухающего градиента». И это действительно неправильный ответ: заглянув в оригинальную статью, мы увидим, буквально на первой же странице во введении, следующие строки:
Driven by the significance of depth, a question arises: Is learning better networks as easy as stacking more layers? An obstacle to answering this question was the notorious problem of vanishing/exploding gradients [1, 9], which hamper convergence from the beginning. This problem, however, has been largely addressed by normalized initialization [23, 9, 37, 13] and intermediate normalization layers [16], which enable networks with tens of layers to start converging for stochastic gradient descent (SGD) with backpropagation [22].
Неказистый перевод
Из важности глубины возникает вопрос: так ли просто обучать более совершенные сети, как составлять большее количество слоев? Препятствием к ответу на этот вопрос стала пресловутая проблема исчезающих/взрывающихся градиентов [1, 9], которая препятствуют сходимости с самого начала. Эта проблема, однако, была в значительной степени решена с помощью нормализованной инициализации [23, 9, 37, 13] и промежуточных нормализационных слоев [16], которые позволяют сетям с десятками слоев начать сходиться в рамках стохастического градиентного спуска (SGD) с обратным распространением [22].
И ведь действительно, если вдуматься, наличие слоев нормализации должно позволять градиенту течь по сети без затухания. И хоть skip connections (a.k.a. shortcut connections) в принципе изначально были предложены еще до появления ResNet архитектуры, в том числе для решения проблемы затухающего градиента (что, возможно, и служит причиной столь широко распространенного заблуждения), в ResNet архитектурах они в действительности помогли решить другую проблему — проблему деградации точности (о чем в статье говориться буквально в следующем абзаце). Проблема деградации точности заключается в том, что при увеличении глубины сети точность сначала возрастает, потом, вопреки ожиданиям, выходит на плато, а после даже начинает снижаться вплоть до полной потери способности сети к обучению. Существует довольно популярное мнение (вероятно, среди тех, кто читал/помнит оригинальную статью и знает, что затухание градиента тут ни при чем), что: skip connection в residual архитектурах помогают модели выучить тождественное преобразование — таким образом, имея возможность пропускать сигнал без трансформаций, модель должна, по крайней мере, быть не хуже, чем ее менее глубокая версия, следовательно, деградировать точность не может. Подобное объяснение действительно имеет место быть, но оно носит, так сказать, симптоматический характер. А что, если копнуть глубже и попытаться разобраться, в чем вообще причина такого явления, как деградация точности глубокой нейронной сети при увеличении ее глубины? Разумеется, можно начать рассуждать про увеличение размерности параметрического пространства, про ухудшение сходимости, про застревание в локальных минимумах в процессе оптимизации и так далее, однако добавление skip connections не снижает размерность параметрического пространства. Стало быть, сама по себе высокая размерность не является причиной деградации точности. А что же тогда.
Симметрия в нейронных сетях
Причиной (многих) проблем глубокого обучения и подсказкой к поиску путей их решения может являться симметрия параметрического пространства. Именно параметрического, а не признакового, т.е. речь не идет о симметрии входных образов, как то симметрии отражения или поворотов, которыми могут обладать, например, некоторые классы изображений. Нет, речь в данном случае идет об инвариантности результата работы сети по отношению к некоторым операциям, действующим в пространстве параметров нейронной сети:
где — некоторое линейное преобразование в пространстве параметров .
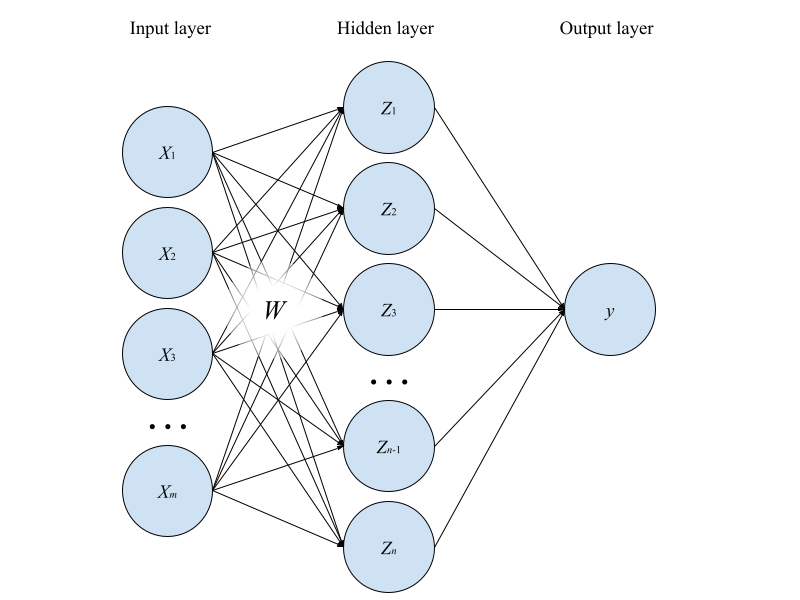
Для простоты рассуждений возьмем полносвязную сеть с одним скрытым слоем (рис. 1). Рассмотрим, для начала, случай, когда все веса выходного линейного слоя фиксированы и равны , т.е. последний слой выполняет роль простого арифметического усреднения выходов нейронов скрытого слоя. Параметры же скрытого слоя удобно представить в виде прямоугольной матрицы размера , где — размерность входного слоя, — размерность скрытого слоя (для простоты, но не нарушая общности рассуждений, забудем про смещение, a.k.a. bias). Таким образом, результат работы сети можно представить в виде:
Что произойдет с результатом работы сети, если мы поменяем местами, скажем, первый и второй нейроны скрытого слоя? Очевидно, что при такой перестановке результат работы сети не изменится. При этом такая операция меняет местами первую и вторую строки матрицы весов скрытого слоя. Т.е. до и после перестановки мы имеем две, вообще говоря, разные матрицы весов, дающие один и тот же результат на выходе сети. Более того, переставить местами мы можем любые два нейрона (любые две строки матрицы ) — результат работы сети инвариантен к любым таким перестановкам, а всего вариантов перестановок Таким образом, как минимум наборов весов (точек в параметрическом пространстве) являются эквивалентными в смысле результата работы сети, независимо ни от входных данных, ни от функций активации и т.д. Это утверждение справедливо не только в рассмотренном нами случае, но и в общем случае, с той лишь разницей, что перестановка i-ого и j-ого нейронов l-го слоя представляет собой перестановку i-й и j-й строки матрицы вместе с перестановкой i-го и j-го столбцов матрицы -го слоя. Из этих рассуждений мы можем заключить, что один полносвязный слой задает в пространстве параметров степень симметрии, по крайней мере, не ниже, чем , а степень симметрии параметрического пространства всей сети равна произведению степеней симметрии каждого слоя, т.е. , поскольку перестановки нейронов в двух слоях выполняются независимо друг от друга. Таким образом, мы определили возможный вид преобразования из выражения 1 — перестановочная матрица. Сразу отмечу, что перестановка — не единственная возможная операция симметрии в пространстве параметров, и в зависимости от используемой нелинейности результат работы сети может оказаться инвариантен и к некоторым другим преобразованиям, специфичным для этой нелинейности (особенно широкий простор для симметрий, в т.ч. непрерывных, обеспечивает ReLU).
Проблемы сходимости, связанные с высокой степенью симметрии признакового пространства, могут возникать на гиперповерхностях симметрии — многообразиях в параметрическом пространстве, точки которых инвариантны к соответствующим операциям симметрии. Например, если две строки в матрице весов равны друг другу, то их перестановка местами не приводит к изменению не только результата, но и самого вектора параметров — такая точка в параметрическом пространстве лежит на одной из плоскостей симметрии. Для наглядности рассмотрим наиболее простой возможный пример (пусть и нарочито игрушечный):
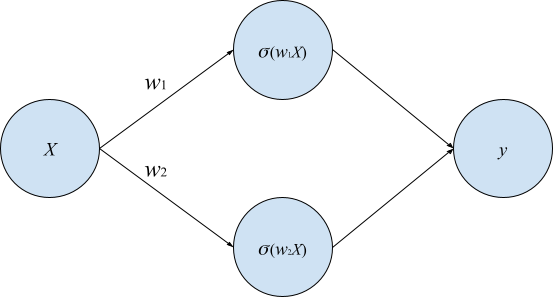
Поскольку здесь всего два варьируемых параметра, мы можем изобразить ландшафт функции потерь на плоскости с использованием любого удобного представления, скажем, contour plot (рис. 3).
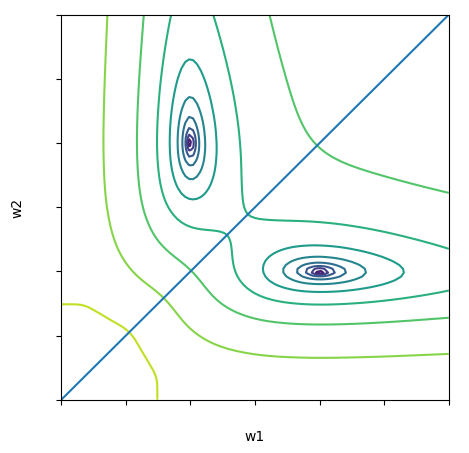
Как мы видим, функция потерь, имеющая два эквивалентных минимума, симметрична относительно прямой , или, правильнее в угоду общности будет сказать, относительно 1d-гиперплоскости, задаваемой вектором нормали (1, -1). Собственно, это и есть пример гиперповерхности симметрии, упомянутой ранее. Любая точка, принадлежащая этой прямой, является инвариантной относительно операции симметрии, благодаря которой функция потерь имеет два минимума. Так вот, важно здесь то, что на этой самой поверхности, в общем случае, вдоль ортогональных плоскости направлений функция потерь имеет локальный экстремум, который может быть как максимум, так и минимумом. Назовем такой минимум ложным, поскольку в общем случае он не является оптимальной точкой решения задачи оптимизации, а обусловлен свойствами параметрического пространства модели.
Картина усложняется, когда мы имеем множество пересекающихся гиперповерхностей в результате стекинга нескольких слоев — ландшафт функции потерь может усложняться чрезвычайно сильно — вероятность возникновения ложных минимумов повышается с увеличением степени симметрии параметрического пространства, которая, в свою очередь, растет катастрофически с увеличением глубины и ширины сети. Больше локальных минимумов — больше вероятность застрять в этих минимумах в процессе оптимизации. Собственно, основная гипотеза, выдвигаемая на основании всех этих рассуждений, состоит в том, что проблема деградации точности связана с ростом числа локальных минимумов при увеличении глубины сети, обусловленным ростом степени симметрии параметрического пространства.
И тут на помощь приходят skip connections
Так чем же тогда помогают skip connections? Тут все достаточно просто и Вы, возможно, уже догадались сами: skip connections существенно снижают симметрию параметрического пространства, уменьшая, тем самым, число локальных минимумов и облегчая сходимость. Если это утверждение не кажется столь очевидным, достаточно рассмотреть уже знакомый нам пример полносвязной сети, чтобы его понять. Добавим в сеть, изображенную на рисунке 1, skip connections между входом и выходом первого слоя (правда, для этого нам потребуется сделать размерность выхода равной размерности входа, но сути это не меняет).
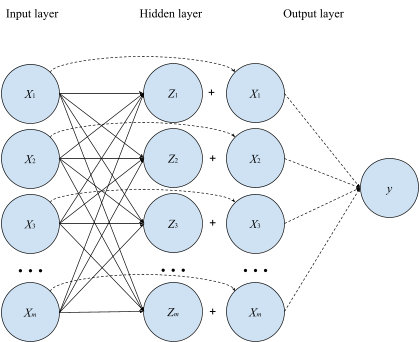
Поскольку перестановка местами двух нейронов в слое не зависит от его входа, то в этот раз мы уже не можем переставлять местами нейроны в скрытом слое, не меняя выход сети, поскольку он зависит уже не только от весов скрытого слоя, но и входного значения, с которым суммируется активация. Т.е., добавив skip connection, причем, именно аддитивный (подойдет также, например, мультипликативный, но не конкатенативный), мы снизили степень перестановочной симметрии слоя с до 1! Таким образом, добавление skip connections по всей глубине сети позволяет значительно снизить степень симметрии параметрического пространства, а, значит, и число локальных минимумов функции потерь, делая ее ландшафт более «хорошим» для оптимизации.
Как верно заметил @maty, в том случае, когда все веса последнего слоя одинаковы, перестановка местами нейронов в скрытом слое даже при наличии skip connections не приведет к изменению результата сети:
Однако в общем случае это не так, т.е. пространство параметров симметрией относительно перестановки нейронов в слое со skip connections не обладает ( и — веса последнего слоя):
После проведенных рассуждений не грех задаться вопросом: если skip connections действительно помогает решить проблему деградации точности за счет снижения симметрии параметрического пространства, то что еще может обладать подобным свойством? Рискну предположить, что к приемам, которые исторически помогли решить ту или иную проблему при дизайне новых нейросетевых архитектур, действительно можно отнести несколько, в частности: групповую (в пределе — поканальную) свертку (group and depth-wise convolutions), позиционное кодирование (positional encoding), dropout. Первые два приема, в ретроспективном рассмотрении, обладают тем свойством, что помогают в целом снизить степень симметрии параметрического пространства как и skip connections. Так, например, depth-wise convolution, используемая для факторизации операции свертки, с одной стороны, разумеется, позволяет снизить размерность параметрического пространства (что оказывается важным для инференса на устройствах), но также и снижает степень симметрии, поскольку каждый канал теперь обрабатывается своим фильтром, и, следовательно, результат работы сети уже не инвариантен к перестановкам ядер.
Замечено читателем кулуарно.
Как правило, depth-wise convolution используется в связке с 1×1 convolution. В этом случае, замена классической свертки на факторизованную при одинаковой глубине карты признаков на выходе не приводит к снижению симметрии признакового пространства (за счет 1×1 convolution, но не depth-wise convolution).
Однако в тех случаях, когда используются групповые свертки вместо классических, снижение симметрии действительно имеет место быть. Так например, степень перестановочной симметрии операции свертки с n=64 фильтрами равна 64!, а в групповой свертке с числом групп m=4 и числом фильтров в группе n=16 степень симметрии равна 4*16!, что много меньше, чем 64!
Что касается регуляризации dropout, то ее можно связать с симметрией следующим образом: отключение случайного подмножества нейронов на каждом шаге обучения локально (на данном шаге) нарушает симметрию признакового пространства, т.е. у оптимизатора появляется шанс пройти мимо ложного минимума, обеспеченного симметрией ландшафта функции потерь на гиперповерхностях симметрии или их пересечении.
Что-нибудь еще? Возможно… Предлагаю заинтересовавшимся подумать над этим вместе.
Послесловие
Получилось, на мой взгляд, достаточно кратко. Возможно, изложенная идея кому-то покажется простой, очевидной или незначительной, другого может натолкнет на какие-то интересные мысли. В любом случае, приглашаю к обсуждению.
- machine leraning
- neural networks
- convergence
- optimization
- hypothesis