Создание клона IMDB с Java бэкендом на SparkJava и Neo4j
Мы решили создать курс для Java Backend и хотим обсудить некоторые аспекты и выбранные альтернативы, которые мы заметили при его создании.
Курс по разработке приложений шаг за шагом описывает внедрение конечных точек, начиная с тестовых наборов данных и заканчивая полноценным приложением, готовым к развертыванию.
Приложение представляет собой клон IMDB, основанный на наборе данных рекомендации MovieLens, дополненном данными о фильмах и ролях с themoviedb.org.
Внешний интерфейс написан на vue.js и выглядит довольно приятно.
Он вызывает несколько конечных точек REST API для вызова различных представлений и функций.

- регистрация и аутентификация пользователя и хранение его информации
- список жанров, фильмов, людей, отсортированных и отфильтрованных, и сопутствующая информация
- добавление фильмов в избранное и рейтинг, а также возврат этих списков и рекомендаций
Репозиторий содержит полный код приложения и может использоваться для сборки и запуска приложения.
У него есть ветки для каждого модуля курса, поэтому вы можете отслеживать прогресс/различия и переходить к завершенному решению, если что-то пойдет не так.
Инфраструктура курса использует Asciidoctor.js, поэтому мы можем использовать includes (используя тег region) непосредственно из нашего репозитория кода.
Таким образом, мы также получаем подсветку синтаксиса, предупреждающие маркеры и многие другие полезные вещи из коробки.
Во время интерактивного курса множество викторин проверяют понимание, позволяют запускать тесты или проверять базу данных на наличие успешных обновлений.
Курс также автоматически интегрируется с песочницей Neo4j, поэтому вы можете запускать тестовые запросы, а также приложение для своего персонального экземпляра, на котором размещен набор данных фильмов.

Настройка
Мы использовали традиционную настройку Java, установив Java 17 и Apache Maven через sdkman.
Поскольку в Java 17 появились строковые блоки и записи, мы захотели использовать эти возможности.
sdk install java 17-open sdk use java 17-open sdk install mavenВеб фреймворк — SparkJava
Возможно, вы не слышали о SparkJava, который существует уже довольно давно и представляет собой минималистичный веб фреймворк, эквивалентный Express/Sinatra для Java.
Поскольку появятся другие курсы со Spring (Data Neo4j), для этого курса мы хотели ограничиться чем-то простым. Quarkus также был вариантом, о котором мы думали, но затем выбрали SparkJava из-за его минимализма.
Также приложение курса JavaScript использовало Express.
Таким образом, перенос кода с JavaScript на Java был довольно простым, с помощью всего лишь нескольких замен у нас уже через несколько минут что-то заработало.
Минимальный пример hello world выглядит так:
import static spark.Spark.*; public class HelloWorld < public static void main(String[] args) < get("/hello", (req, res) -> "Hello World"); >>Все наше основное приложение, которое регистрирует маршруты, добавляет обработку ошибок, проверяет авторизацию, обслуживает форматирование публичных файлов в JSON (используя GSON) и запускает сервер, занимает не более 20 строк.
Документация для SparkJava очень короткая и в то же время исчерпывающая, все, что вам нужно, можно найти быстро.
package neoflix; import static spark.Spark.*; import java.util.*; import com.google.gson.Gson; import neoflix.routes.*; import org.neo4j.driver.*; public class NeoflixApp < public static void main(String[] args) throws Exception < AppUtils.loadProperties(); int port = AppUtils.getServerPort(); port(port); Driver driver = AppUtils.initDriver(); Gson gson = GsonUtils.gson(); staticFiles.location("/public"); String jwtSecret = AppUtils.getJwtSecret(); before((req, res) -> AppUtils.handleAuthAndSetUser(req, jwtSecret)); path("/api", () -> < path("/movies", new MovieRoutes(driver, gson)); path("/genres", new GenreRoutes(driver, gson)); path("/auth", new AuthRoutes(driver, gson, jwtSecret)); path("/account", new AccountRoutes(driver, gson)); path("/people", new PeopleRoutes(driver, gson)); >); exception(ValidationException.class, (exception, request, response) -> < response.status(422); var body = Map.of("message",exception.getMessage(), "details", exception.getDetails()); response.body(gson.toJson(body)); response.type("application/json"); >); System.out.printf("Server listening on http://localhost:%d/%n", port); > >Маршруты — AccountRoutes
Маршруты могут быть сгруппированы по корневому пути, а затем обработаны в простом DSL. Вот как получить список избранного в AccountRoutes
get("/favorites", (req, res) -> < var params = Params.parse(req, Params.MOVIE_SORT); String userId = AppUtils.getUserId(req); return favoriteService.all(userId, params); >, gson::toJson);Сначала мы анализируем некоторые параметры из URL-адреса запроса, затем извлекаем userId из атрибутов запроса и вызываем FavoriteService для запроса базы данных.
Fixtures
По мере прохождения курса постепенно добавляется реализация для использования базы данных.
Чтобы иметь возможность тестировать, запускать и взаимодействовать с приложением с самого начала, некоторые наборы данных статических фикстур используются для возврата ответов от служб.
Исходное Javascript приложение использовало файлы JS для хранения фикстур как JS объектов, но мы хотели более переносимый вариант.
Итак, мы преобразовали фикстуры в файлы JSON, а затем прочитали их в List структуры в сервисах, которые использовали фикстуры.
public static List loadFixtureList(final String name) < var fixture = new InputStreamReader(AppUtils.class.getResourceAsStream("/fixtures/" + name + ".json")); return GsonUtils.gson().fromJson(fixture,List.class); >Который затем можно использовать в сервисе с this.popular = AppUtils.loadFixtureList(«popular»); .
[< "actors": [ , , , ], "languages": ["English"], "plot": "Two imprisoned men bond over a number of years, finding solace and eventual redemption through acts of common decency.", "year": 1994, "genres": [,], "directors": [], "imdbRating": 9.3, "tmdbId": "0111161", "favorite": false, "title": "Shawshank Redemption, The", "poster": "https://image.tmdb.org/t/p/w440_and_h660_face/5KCVkau1HEl7ZzfPsKAPM0sMiKc.jpg" >]Чтобы сделать его не полностью статичным, мы использовали обработку Java Streams для реализации фильтрации, сортировки и разбиения на страницы данных фикстуры.
public static List process( List result, Params params) < return params == null ? result : result.stream() .sorted((m1, m2) ->(params.order() == Params.Order.ASC ? 1 : -1) * ((Comparable)m1.getOrDefault(params.sort().name(),"")).compareTo( m2.getOrDefault(params.sort().name(),"") )) .skip(params.skip()).limit(params.limit()) .toList(); >Который затем используется в сервисах, например:
public List all(Params params, String userId) < // TODO: Open an Session // TODO: Execute a query in a new Read Transaction // TODO: Get a list of Movies from the Result // TODO: Close the session return AppUtils.process(popular, params); >Драйвер Neo4j
Реализации реальной службы используют официальный драйвер Neo4j Java для запросов к базе данных.
Мы можем отправлять параметризованные запросы Cypher на сервер, использовать параметры и обрабатывать результаты в рамках функции повторяемой транзакции (транзакция чтения или записи).
Добавьте зависимость драйвера org.neo4j.driver:neo4j-java-driver в файл pom.xml.
Далее вы можете создать один экземпляр драйвера на весь срок службы вашего приложения и использовать сеансы драйвера по мере необходимости.
Сеансы не удерживают TCP-подключения, а используют их из пула по мере необходимости.
В рамках сеанса вы можете использовать транзакции чтения и записи для выполнения вашей единицы работы.
Мы прочитали учетные данные подключения из application.properties и для удобства установили в качестве системного свойства, и затем инициализировали драйвер.
static Driver initDriver()
Сервис FavoriteService
Затем драйвер передается каждой службе при построении и может использоваться оттуда для создания сеансов и взаимодействия с базой данных.
Здесь, в примере FavoriteService для перечисления избранного пользователя, вы можете увидеть, как мы используем блоки String для оператора Cypher и лямбда-выражения для обратного вызова readTransaction
public List all(String userId, Params params) < // Open a new session try (var session = this.driver.session()) < // Retrieve a list of movies favorited by the user var favorites = session.readTransaction(tx ->< String query = """ MATCH (u:User )-[r:HAS_FAVORITE]->(m:Movie) RETURN m < .*, favorite: true >AS movie ORDER BY m.title ASC SKIP $skip LIMIT $limit """; var res = tx.run(query, Values.parameters("userId", userId, "skip", params.skip(), "limit", params.limit())); return res.list(row -> row.get("movie").asMap()); >); return favorites; > >При добавлении любимого фильма мы используем транзакцию записи FavoriteService.add , чтобы создать связь FAVORITE между пользователем и фильмом.
public Map add(String userId, String movieId) < // Open a new Session try (var session = this.driver.session()) < // Create HAS_FAVORITE relationship within a Write Transaction var favorite = session.writeTransaction(tx -> < String statement = """ MATCH (u:User ) MATCH (m:Movie ) MERGE (u)-[r:HAS_FAVORITE]->(m) ON CREATE SET r.createdAt = datetime() RETURN m < .*, favorite: true >AS movie """; var res = tx.run(statement, Values.parameters("userId", userId, "movieId", movieId)); return res.single().get("movie").asMap(); >); return favorite; // Throw an error if the user or movie could not be found > catch (NoSuchRecordException e) < throw new ValidationException("Could not create favorite movie for user", Map.of("movie",movieId, "user",userId)); >>Метод result.single() завершится ошибкой, если нет ровно одного результата с NoSuchRecordException , поэтому нам не нужно проверять это в запросе.
Аутентификация
Наше приложение также обеспечивает управление пользователями для персонализации.
Вот почему мы должны:
- зарегистрировать пользователя
- аутентифицировать пользователя
- проверить токен авторизации и добавить информацию о пользователе в запрос
Для регистрации и аутентификации мы сохраняем пользователя непосредственно как узел в Neo4j и используем библиотеку bcrypt для хеширования и сравнения хешированных паролей с входными данными.
Вот пример из метода authenticate класса AuthService .
public Map authenticate(String email, String plainPassword) < // Open a new Session try (var session = this.driver.session()) < // Find the User node within a Read Transaction var user = session.readTransaction(tx -> < String statement = "MATCH (u:User ) RETURN u"; var res = tx.run(statement, Values.parameters("email", email)); return res.single().get("u").asMap(); >); // Check password if (!AuthUtils.verifyPassword(plainPassword, (String)user.get("password"))) < throw new ValidationException("Incorrect password", Map.of("password","Incorrect password")); >String sub = (String)user.get("userId"); // compute JWT token signature String token = AuthUtils.sign(sub, userToClaims(user), jwtSecret); return userWithToken(user, token); > catch(NoSuchRecordException e) < throw new ValidationException("Incorrect email", Map.of("email","Incorrect email")); >>Для передачи информации об аутентификации в виде токенов JWT в браузер и обратно мы используем библиотеку Java Auth0 для создания токена, а затем также проверяем его.
Это делается с помощью обработчика before в SparkJava, который при успешной проверке сохраняет атрибут sub , содержащий атрибут запроса userId . К которому затем могут получить доступ маршруты, например, для персонализации или рейтингов.
static void handleAuthAndSetUser(Request req, String jwtSecret) < String token = req.headers("Authorization"); String bearer = "Bearer "; if (token != null && !token.isBlank() && token.startsWith(bearer)) < token = token.substring(bearer.length()); String userId = AuthUtils.verify(token, jwtSecret); req.attribute("user", userId); >> // usage in NeoflixApp before((req, res) -> AppUtils.handleAuthAndSetUser(req, jwtSecret));Записи Java 17
Изначально мы планировали использовать записи Java 17 на протяжении всего курса, но потом столкнулись с двумя проблемами.
Во-первых, библиотека Google Gson еще не поддерживает (де-) сериализацию записей, поэтому вместо этого нам пришлось бы переключиться на Jackson (вероятно, следовало бы это сделать).
И результаты драйвера Java Neo4j не могли быть были просто конвертированы в экземпляр записи, как нам хотелось.
Поскольку мы не хотели добавлять много ненужных сложностей в образовательный код, особенно. если вы хотите сохранить однострочное лямбда замыкание для обратного вызова. Поэтому мы сохранили API toMap() , предлагаемый для результатов работы драйвера.
var movies = tx.run(query, params) .list(row -> row.get("movie") .computeOrDefault(v -> new Movie(v.get("title").asString(),v.get("tmbdId").asString()), v.get("published").asLocalDate())));var movies = tx.run(query, params).list(row -> row.get("movie").toMap());Тестирование
Мы использовали JUnit 5 для тестирования, что не составляло труда.
Поскольку мы хотели, чтобы один и тот же тест работал во всех ветвях репозитория, независимо от того, доступно соединение с базой данных или нет, мы использовали операторы Assume , чтобы пропустить несколько тестов и условие существования экземпляра драйвера для некоторого кода очистки в методы настройки @BeforeClass/Before .
В курсе для запуска тестов используется команда mvn test -Dtest=neoflix.TestName#testMethod , с помощью которой участник курса мог проверить свой прогресс и правильность выполнения.
Некоторые тесты также выводят результаты, которые пользователь должен заполнить в викторинах во время курса.
Вывод
Для реального приложения мы могли бы использовать одну из более крупных фреймворков приложений, так как нужно удовлетворить больше потребностей.
Кроме того, повторное использование простых запросов Cypher для операций, а также сопоставление и обработка ошибок должны были обрабатываться кодом инфраструктуры, который мы обычно рефакторим.
Но, в образовательных целях, мы оставили его в каждом сервисе.
Не стесняйтесь проверить курс Neo4j Java и приложение Neoflix
Если вам интересно переписать этот пример с любой другой веб фреймворк: Spring Boot, Quarkus, Micronaut, vert.x, Play и т. д., сообщите нам и поделитесь репозиторием, чтобы мы могли добавить его как ветку.
How do I export Cypher Favorites recorded in the browser
Cypher Favorites are common Cypher statements which one can save to the left panel of the Neo4j browser. A Favorite is created by entering the Cypher at the top prompt and then clicking the Favorite icon to the right as depicted:

After clicking on the Favorite Icon, the title of the Cypher statement (in this case ‘my favorite Cypher’) will be added to the left panel of the browser. For example:

These favorites are stored in local browser storage and as such are centric to the user/browser who has recorded those favorites. Additionally, if one clears their browser cache, recorded favorites will be removed.
To export favorites, use the Developer Console of Google Chrome and connect to the Neo4j browser URL.
- Launch Google Chrome and connect to the Neo4j browser on http://localhost:7474
- Access the Developer Console, https://developer.chrome.com/devtools/docs/console within Google Chrome
- Use the keyboard shortcut Command + Option + J (Mac) or Control + Shift + J (Windows/Linux).
var res = JSON.parse(localStorage.getItem('neo4j.documents')) for (x in res)

Is this page helpful?
NEO4J – графовые базы данных
В данной статье будет рассмотрена графовая система управления базами данных в Neo4j, а именно:
- Установим и настроим Neo4j;
- Создадим базы данных с использованием Python;
- Познакомимся с базовым синтаксисом языка Cypher для создания запросов;
- Рассмотрим пример использования данной СУБД.
Что такое Neo4j или немного теории
Neo4j — это графовая система управления базами данных с открытым исходным кодом, реализованная на Java. Она является ведущей графовой СУБД в мире. Аналогами Neo4j являются Oracle NoSQL Database, HypherGraphDB, GraphBase, InfiniteGraph и AllegroGraph.
Всем известно, что такое граф, и из чего он состоит. Так вот, графовые базы данных представляет собой набор объектов, где объекты связаны между собой, подобно как в графе вершины (узлы), связанные через ребра (отношения).

Почему графы и где они используются?
Графы – это удобная и наиболее понятная визуальная система описания данных. Обычно они используются в геоинформационных системах, логистике, социальных сетях и т.п.
На этом теории достаточно, переходим к практике
Итак, для того, чтобы работать с любой базой данных, необходимы данные, как бы тавтологично это не звучало. Для примера, будем использовать уже готовые таблицы (формат CSV) с данными, которые содержать информацию о работе интернет-магазина. Все необходимые данные находятся тут.

Ход работы:
- Скачиваем среду разработки Neo4j Desktop с официального сайта. Больше информации можно прочесть в гайде для разработчиков
- Создаем базу данных
Кликаем на «New» чтобы создать новый проект. После нажимаем на Add -> local DBMS и уже в самом конце называем её (больше информации тут). После всех проделанных действий нам необходимо запустить её и открыть Neo4j Browser (большая синяя кнопка с надписью «Open»).

3. Добавление администратора.
В Neo4j browser необходимо ввести команду server user add, для того, чтобы добавить пользователя и после заполнить все поля. В поле roles нужно выбрать admin.

4. Python + Neo4j. Подключение к СУБД.
Для того, чтобы подключится к базе данных, необходимо установить библиотеку neo4j.
pip install neo4jПосле импортируем GraphDatabase для подключения к СУБД.
from neo4j import GraphDatabase
Далее представлен код для подключения
class Neo4jConnection: def __init__(self, uri, user, password): self.driver = GraphDatabase.driver(uri, auth=(user, password)) def close(self): if self.driver is not None: self.driver.close() # Метод, который передает запрос в БД def query(self, query, db=None): assert self.driver is not None, "Driver not initialized!" session = None response = None try: session = self.driver.session(database=db) if db is not None else self.driver.session() response = list(session.run(query)) except Exception as e: print("Query failed:", e) finally: if session is not None: session.close() return responseЗапросы в Neo4j пишутся на языке Cypher. Он интуитивно понятный для освоения. Документацию по этому языку можно прочитать перейдя по ссылке.
Итак, подключаемся к СУБД. Создаем объект connection и передаем имя пользователя и пароль (который создавали при регистрации пользователя). Далее передаем запрос на создание самой базы данных «graphDb» — это название БД.
conn = Neo4jConnection(uri="bolt://localhost:7687", user="Mario", password="123123") conn.query("CREATE OR REPLACE DATABASE graphDb")Далее необходимо загрузить все данные из таблицы в БД (загружаем таблицу Product). Для этого пишем запрос:
query_string = ''' LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/bd/main/Product.csv' AS line FIELDTERMINATOR ',' MERGE (product:Product ) ON CREATE SET product.productName = line.ProductName, product.UnitPrice = toFloat(line.UnitPrice); ''' conn.query(query_string, db='graphDb')Как работает данный запрос? Он загружает CSV-файл из github, после построчно считывает данные, разделяя их по запятой (FIELDTERMINATOR ‘,’). Далее связываем узлы (объекты) и создаем свойства объекта
product.productName = line.ProductNameПосле запускаем код и переходим в Neo4j browser. В окне «Node Labels» кликаем по появившейся кнопке «Product».

Поздравляю! Вывели узлы Product. Если нажать на один узел, то в окне справа появятся все свойства (productName, productID, UnitPrice), которые мы прописывали в запросе.
Далее создаем запросы на загрузку остальных данных из других таблиц. Код можно посмотреть в GitHub. В итоге в левом окне должно быть 5 узлов:

Можно вывести все узлы в одно окно. Для этого необходимо прописать следующий запрос:
MATCH (n) RETURN n Пока наши узлы (объекты) не имеют отношений с другими узлами.
5. Запросы на создание отношений.
Допустим, нам нужно посмотреть какие заказы выполнили сотрудники. Для этого нужно связать узлы (объекты) Order и Employee. Создаем следующий запрос:
query_string =''' LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/bd/main/Order.csv' AS line MATCH (order:Order ) MATCH (employee:Employee ) CREATE (employee)-[:SOLD]->(order); ''' conn.query(query_string, db='graphDb')MATCH – это основной способ получения данных в текущем наборе привязок. С помощью CREATE создаем саму связь, синтаксис напоминает строение графа, в «[]» прописываем название связи. Более наглядно это можно продемонстрировать следующим образом:


Данный запрос создаст связь, которая отобразиться в левом окне. Эта связь показывает отношение между сотрудником и заказами, который выполнил сотрудник. Например, Aleekseev -> SOLD-> Grandma’s Bakery, означает, что сотрудник Алексеев продал что-то Grandma’s Bakery (это что-то мы узнаем чуть позже).
Чтобы узнать какие данные хранятся в узле, достаточно просто на него нажать и в правом окне появится информация об объекте. Важно отметить, что здесь появляется информация, а именно свойства, которые прописывали в запросе.

Теперь нам необходимо узнать, какой именно продукт приобрели в заказе. Для этого пишем следующий запрос:
query_string = ''' LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/bd/main/Order.csv' AS line MATCH (order:Order ) MATCH (product:Product ) MERGE (order)-[op:PURCHASED]->(product) ON CREATE SET op.quantity = toFloat(line.Quantity); ''' conn.query(query_string, db='graphDb')
И так, у нас есть связи сотрудника с заказом и с проданным в заказе продуктом. Теперь создадим связь между продуктом и поставщиком, а также свяжем его с категорией товара. Для этого выполните два запроса:
query_string = ''' LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/bd/main/Product.csv ' AS line MATCH (product:Product ) MATCH (supplier:Supplier ) MERGE (supplier)-[:SUPPLIES]->(product); ''' conn.query(query_string, db='graphDb'
query_string = ''' LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/bd/main/Product.csv' AS line MATCH (product:Product ) MATCH (category:Category ) MERGE (product)-[:IS_CATEGORY]->(category); ''' conn.query(query_string, db='graphDb')
Все узлы имеют отношения. Теперь можно увидеть, как каждый объект связан друг с другом. Для этого выведите все узлы.

Давайте проанализируем сотрудника Timofeeva. Из графа видно, какие именно товары она продала «Fresh product», и кто был поставщиком данных товаров.

Также помним, что это все-таки база данных, и здесь можно узнать имя, фамилию и должность сотрудника — кликнув по объекту.

6. Запросы для поиска конкретной информации.
До этого все запросы писались через Python, но их можно создавать в самой Neo4j browser (в строке сверху).

Допустим, нужно найти конкретного поставщика (например, Peter ‘s Lands), и какие продукты он поставляет. Пишем запрос:
MATCH (s:Supplier)-[r1:SUPPLIES]->(p:Product) RETURN s, r1, p;
Необязательно всегда выводить нужную информацию в графах, можно и в таблице. Например, выведем информацию о том какие продукты продал сотрудник Nekrasov.
MATCH (p:Product)<-[:PURCHASED]-(:Order)<-[:SOLD]-(em:Employee) RETURN em.lastName + ' '+em.firstName as Full_name, p.productName as sold_products Результатом этого запроса будет:

Разница в том, какие данные возвращаем. Если это свойства объекта, то результатом выполнения запроса будет таблица.
Также мы можем выгрузить данные из БД. Для этого импортируем pandas.
query_string = ''' MATCH (em:Employee) RETURN em.firstName, em.lastName, em.post ''' dtf_data = DataFrame([dict(_) for _ in conn.query(query_string, db='graphDb')]) print(dtf_data)
Вы можете создавать любые запросы, и для этого в документации есть очень хорошая карта со всем синтаксисом Cypher Refcard.
После того, как рассмотрели базовые вопросы, касаемые Neo4j, нужно разобраться с вопросом, где же все-таки применяются графовые базы данных в реальных проектах? Один из таких примеров — это рекомендации по предложению продукта (товара). Мы же рассмотрим пример «Рекомендация статей для читателей» с использование Neo4j.
Пример «Рекомендация статей для читателей»
Суть нашей системы рекомендаций статей следующая: необходимо предлагать нашим читателям альтернативную статью. Например, если читатель проявляет интерес к определенной категории статей, можно создать рекомендацию, содержащую альтернативные статьи.
Чтобы показать, как это работает, давайте создадим модель данных:
Наша система рекомендаций будет содержать следующие объекты с атрибутами:
- articles – title,
- category_articles – title,
- reader – name, email, nickname,
- RecommendationArticleToReader – nickname
Отношения будут следующие:

На этом у нас закончилось моделирование сущностей.
Также стоит обратить внимание, что в Neo4j нет необходимости моделировать двунаправленные отношения, например, статья находится в категории, а категория имеет множество статей. Графические базы данных позволяют отслеживать ребра в обоих направлениях.
Кстати одним из преимуществ графических баз данных от реляционных в том, что мы можем добавлять, изменять и удалять сущности (узлы) и связи (ребра), не беспокоясь о внешних ключах.
2. Работа в Neo4J:
Заполняем нашу БД в соответствии с моделью, которую мы определили выше. Запросы будем писать в Neo4j Browser.
Загружаем данные в формате csv c github:
# LOAD CATEGORY query_string = ''' LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/ArticleBD/main/Category.csv' AS line FIELDTERMINATOR ',' MERGE (category:Category ) ON CREATE SET category.title = line.title; ''' conn.query(query_string, db='graphDb') # LOAD ARTICLES query_string = ''' LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/ArticleBD/main/Articles.csv' AS line FIELDTERMINATOR ',' MERGE (article:Article ) ''' conn.query(query_string, db='graphDb') # LOAD READER query_string = ''' LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/ArticleBD/main/Reader.csv' AS line FIELDTERMINATOR ',' MERGE (reader:Reader ) ON CREATE SET reader.nickname = line.nickname,reader.email = line.email; ''' conn.query(query_string, db='graphDb')Далее создаем отношения article-[:IS_IN]-> category и reader-[:READ]->article:
# LOAD CATEGORY_ARTICLES query_string =''' LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/ArticleBD/main/Category_articles.csv' AS line MATCH (category:Category ) MATCH (article:Article ) CREATE (article)-[:IS_IN]->(category); ''' conn.query(query_string, db='graphDb') # LOAD READ_ARTICLES query_string =''' LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/Mario-cartoon/ArticleBD/main/read_articles.csv' AS line MATCH (reader:Reader ) MATCH (article:Article ) CREATE (reader)-[:READ]->(article); ''' conn.query(query_string, db='graphDb')
3. Создадим рекомендации статей для читателей основываясь на прочитанных статьях. Для этого пишем запрос:
MATCH (reader:Reader) MATCH (unread_article:Article) WHERE NOT ((reader)-->(unread_article)) MATCH (article:Article) WHERE ((reader)-->(article)) MATCH (unread_article)-[:IS_IN]->()) WITH rec, unread_article, reader MERGE(rec)-[rel:USED_TO_PROMOTE ]->(unread_article) RETURN rec, unread_article, rel;В запросе отбираем прочитанные статьи от непрочитанных, создавая новую сущность RecommendationArticleToReader, которая содержит nickname читателей. После создаем новую связь: RECOMMEND_READING, где связываем не прочитанную статью, той же категории, что и статьи, которые уже прочитал читатель. В итоге получим следующий граф:

Обращаю внимание, что в связи: RECOMMEND_READING передается email читателя.
Итак, теперь выведем все связи и сущности, а также проанализируем получившийся граф, а именно, возьмем одного читателя и посмотрим все связи. Для примера возьмем Ivan Ivanov. Из графа видно, что он прочёл, и какие статьи ему предлагается прочитать.

Давайте напишем запрос чтобы вывести только рекомендации по читателю Ivan Ivanov:
MATCH (rec: RecommendationArticleToReader )-[:RECOMMEND_READING]->(article:Article) RETURN article,rec;
4. Также можно попробовать рекомендовать статьи, основываясь на прочтенных статьях других читателей, которые имеют хотя бы одну прочтённую статью с другим читателем. Для этого пишем запрос, который выведет всех читателей и прочтенные статьи:
MATCH (reader:Reader)-->(article:Article) RETURN reader, article;
Из графа видно, что у многих читателей есть общие прочитанные статьи, и мы можем рекомендовать им те статьи, которые прочёл читатель (с которым есть общая прочтённая статья), но не прочел другой. Для примера возьмем читателя Ivan Ivanov. Пишем запрос:
MATCH (reader_1:Reader)-->(article_1:Article)(article_2:Article) WHERE (article_2 <> article_1) RETURN reader_1, reader_2, article_2,article_1;С помощью этого запроса мы возвращаем статью, не прочитанную Ivan’ом, но прочитанную читателем, с которым у Ivan’a есть общая прочитанная статья. Т.е. в переменной article_2 хранится статья, не прочитанная Ivan’ом. Для примера возвратили все переменные чтобы увидеть связь между сущностями.

Но, чтобы вывести только нужные статьи, достаточно вернуть только переменную article_2.
В данной статье был рассмотрен базовый функционал Neo4j и примеры его использования. Это очень удобный и понятный инструмент графовых баз данных. Но использовать его стоит только для решения задач, которые решаются с использованием графов. Важно также отметить, что Neo4j это не фреймворк и сравнивать его с gephi или networkx нет смысла. Потому что Neo4j не просто визуализирует данные, но и содержит их, так как является базой данных.
- Python
- Программирование
- Визуализация данных
Neo4j Browser User Interface Guide
This page is no longer being maintained and its content may be out of date. For the latest guidance, please visit the Getting Started Manual .
This article demonstrates how to use the Neo4j Browser for querying, visualization, and data interaction.
Prerequisites
Please launch an AuraDB Instance or have Neo4j downloaded and installed. It also helps if you have read the section on graph databases.
Neo4j Browser is an interactive cypher command shell that allows you to interact with your graph and visualize the information in it. Neo4j Browser is bundled with Neo4j and is available in all editions and versions of Neo4j.
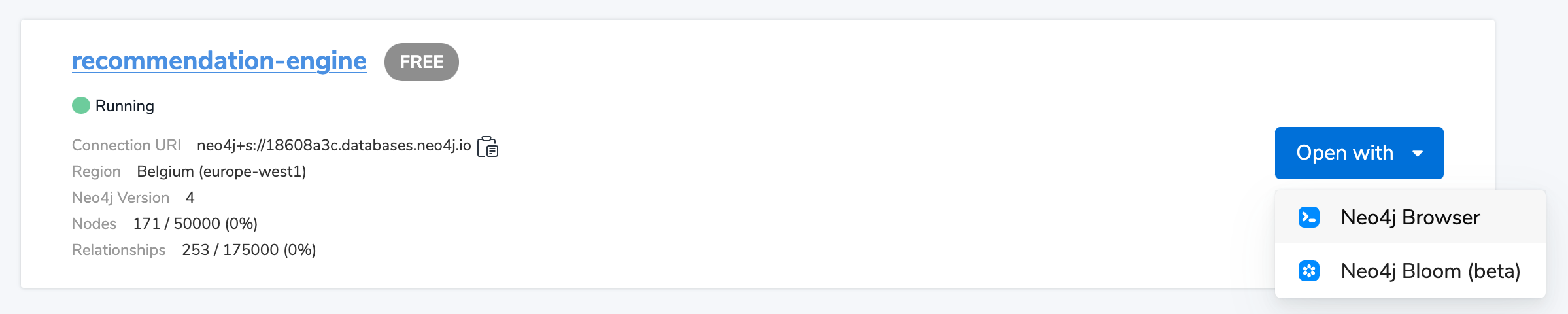
Launch Neo4j Browser
If you using AuraDB, go to the Aura Console, and find Neo4j Browser in the «Open» button.
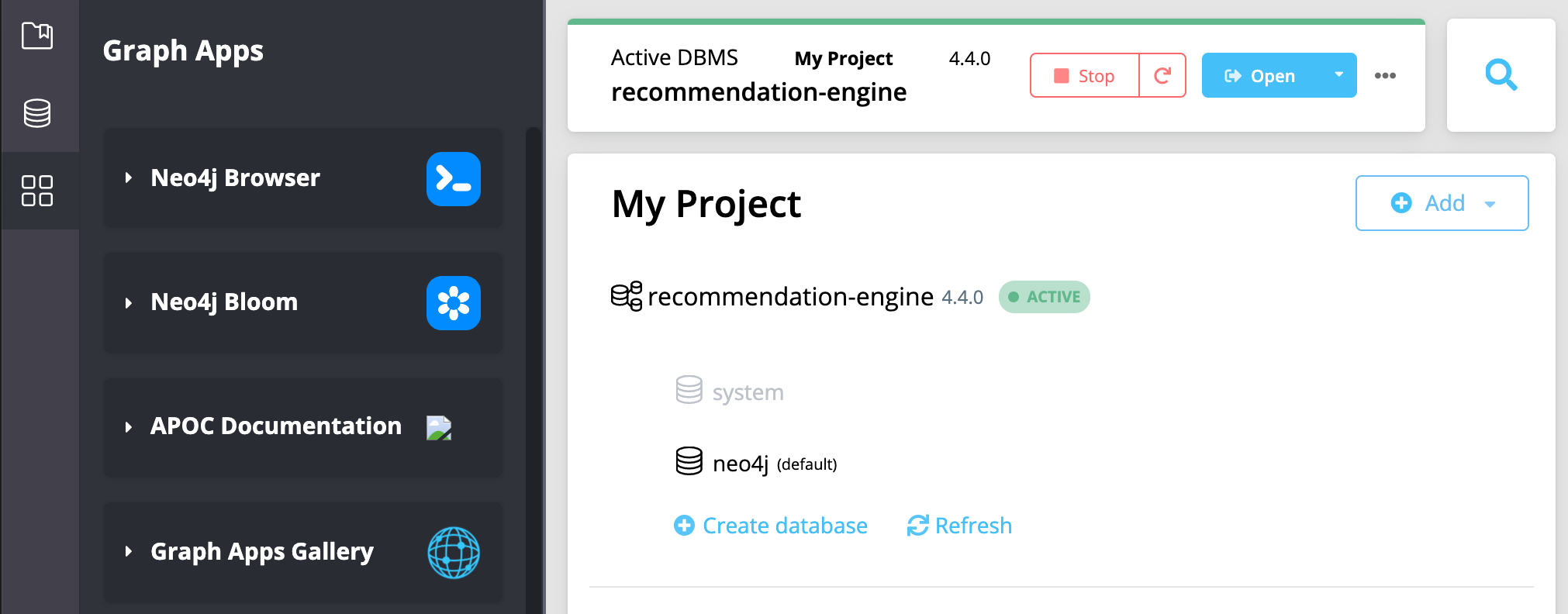
If you are using Neo4j Desktop, you can use the graph apps tab on the left hand side (which looks like four squares) to find Neo4j Browser, which will connect to any running database that you have.
If you are running Neo4j in another environment, Neo4j Browser is available via HTTP at http://localhost:7474 and HTTPS at https://localhost:7473 , substituting the right address for your environment.
Using Built-In Guides
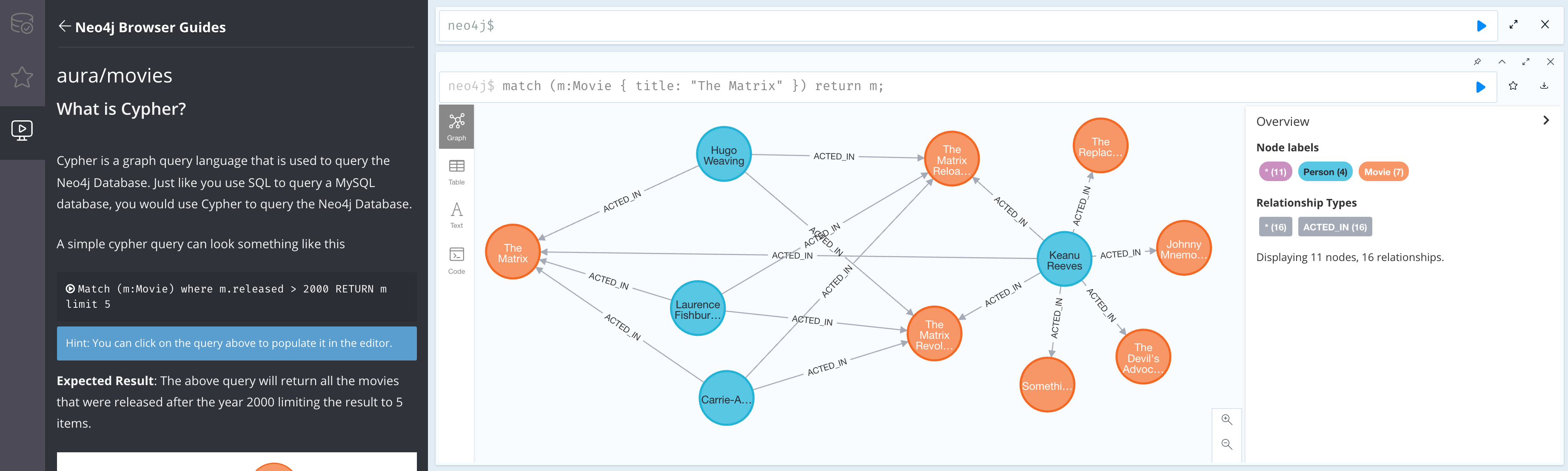
Neo4j Browser contains built-in guides which introduce different concepts. Now that we can access the graph, we can use these guides to start working with data using Cypher.
To use one of these guides, just type the command (such as :play intro ) into the command line on the right of Neo4j Browser and press Enter or click the play button ( ).
Title
Description
Command
A guided tour of Neo4j Browser
Graph database basics
Neo4j’s graph query language introduction
The Movie Graph
A mini graph model of connections between actors and movies
:play movie graph
The Northwind Database
A classic use case of RDBMS to graph with import instructions and queries
:play northwind graph
The full list of available browser guides can be found here. You can also create your own custom browser guides to share learning with colleagues, students, and others in the community.
If you’d like to pin guides to the top so they do not get pushed down as you run additional queries, just use the pushpin button ( ) in Neo4j Browser.
Graph Metadata
In the left menu, the top icon is the database section ( ), where you can find the currently used node labels, relationship types, and property keys. Clicking on any one of those options runs a quick query to show you a sample of the graph with those elements.
Change Graph Appearance
Any query you run in Neo4j Browser will populate your results below the command line. You can switch between visual graph, table format, and ascii-table results with the icons on the left side of the result frame. You can also adjust by moving the view or dragging nodes to re-arrange them. To see more of the graph, click any empty spot and drag it.
Nodes are assigned captions by the browser, which selects a property to use. These properties appear below the visualization when a node is selected. Larger property sets may be collapsed into a subset, but there is an option to expand them.
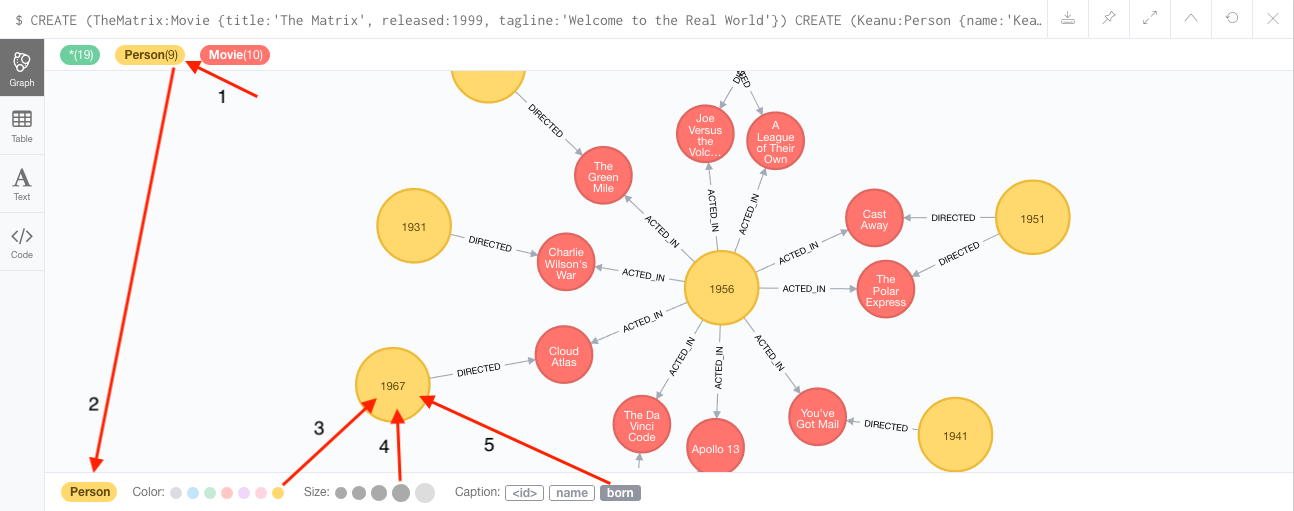
For example, if you click on one of the Movie nodes in the MovieGraph ( :play movie graph ), then you can see its properties below the graph visual. The same applies for Actor nodes or the ACTED_IN relationships. If you click on any label or relationship above the graph visualization, you can then choose its styling in the area below the graph. Colors, sizes, and captions are selectable from there.
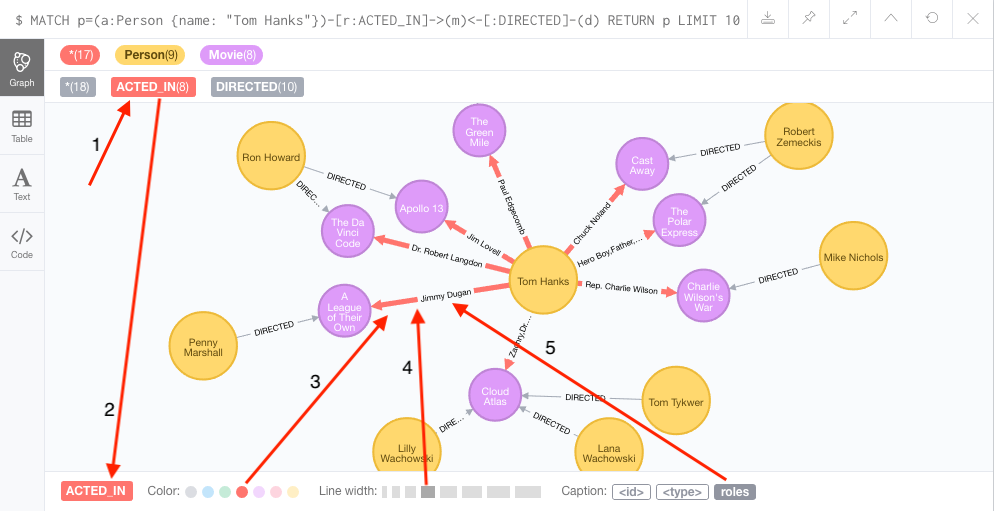
To see this for yourself, you can click on the Person label above the graph and change the color, size, and captions of all nodes labeled with Person . The first image below shows changes to nodes labeled Person . The second image shows changes to relationships labeled ACTED_IN .
Commands and Keyboard Shortcuts
Styling Popup & Reset
Ctrl + Enter or Cmd + Enter
Ctrl + Up or Cmd + Up
Enter Multiline Mode
Move Focus to Editor
Toggle Editor to Full Screen
Query and Command-Line Tips
Query Tips
You can remove all accumulated output frames with :clear . The ‘X’ button at the top right of each pane removes that frame and aborts a (long-)running statement. The maximum number of frames that are kept is configurable in the Browser Settings from the left-side menu.
If you want to review a past query, you can find the result pane and click the query above the graph visualisation to pull it back into the editor. The keyboard shortcuts listed above will help you work efficiently within the editor area.
You can also write and edit multi-line queries by switching to multi-line editing mode with Shift + Enter , then Enter will create newlines. You then need to run Ctrl + Enter or Cmd + Enter to run multi-line queries.
Command Tips
Ctrl + Up and Ctrl + Down (Mac users, use the Cmd key) allows you to navigate command history, and you can access all command history with :history . The command history is persisted across Browser restarts.
Output, Export, & Visualization Tips
You can switch between Graph , Table , Text , and Code views to see the results in various formats by clicking the icons on the left of each pane.
Don’t worry if you don’t see any output. You might just be in Graph mode, but had your query return tabular/scalar data. To see the results, just switch the mode to the Table view.
Query time is reported in the Table or Code views (don’t rely on that exact timing though), and it includes the latency and deserialization costs, not just the actual query execution time.
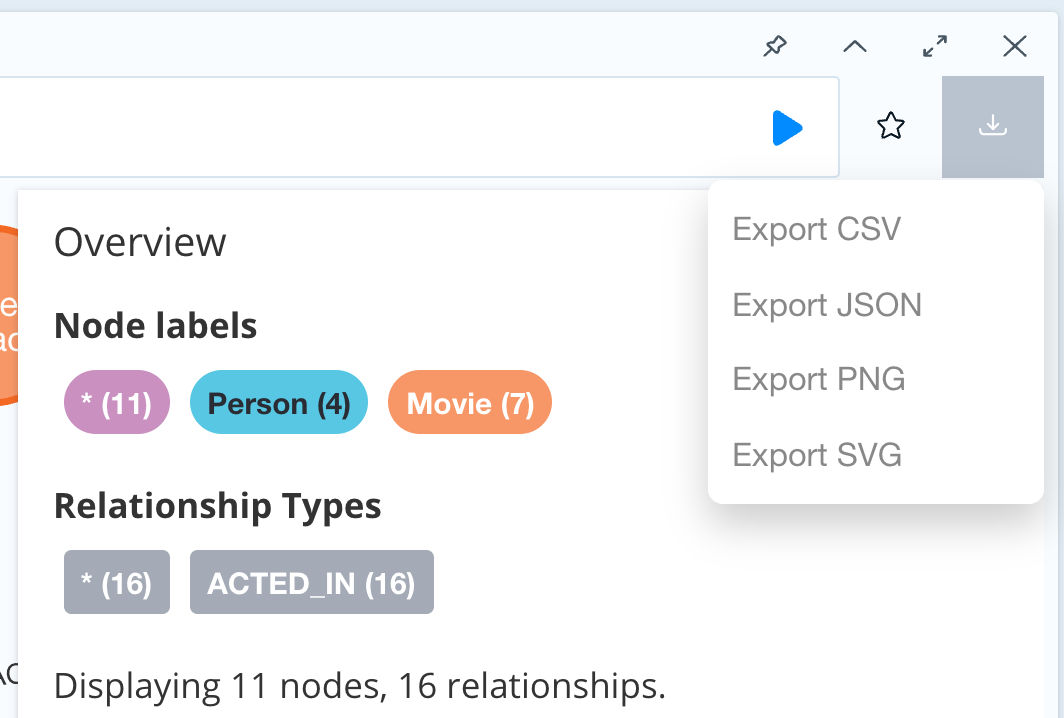
You can also export the results of queries as a CSV or JSON, and for the graph view, you may also export a PNG or SVG image, as shown below.
If you enter fullscreen mode of a graph visualization, you can zoom in and out. After a node is clicked, it gets a halo, where you can expand and remove nodes from the visualization. You can also turn previously dragged nodes loose again.
Setting Favorites
If you currently have an empty frame, you can display some nodes and relationships by using the Favorites ( ) in the left-side menu. Neo4j stores a few default favorites to get you started. Just click on the Basic Queries, then choose Get Some Data and run the query. This executes the statement MATCH (n) RETURN n limit 100 , which fetches some nodes.
You can save your own queries as favorites by «starring» them. Just populate the Browser command line with the query you want to favorite, then click the Favorites ( ) icon to the right of the command line. This will add the query to your Favorites list in the left-side menu. To run one of your Favorites, click on the left-side menu Favorites, choose the query, and run it.
To provide a title or helpful info, you can use a comment // comment above your query to provide a title. The Favorites menu uses your comment as the query name.
Creating folders can help organize your favorites, and you can rearrange them by dragging or delete them if they are no longer useful.
Advanced Styling
For more advanced styling, you can bring up the style-viewer with :style and copy/paste the graph-style-sheet (GRASS) that is returned. You can edit this stylesheet offline, save the file as a .grass file, and drag it back onto the drag-area of the viewer.
| You can reset to the default styles with :style reset . |
Within the GRASS file, you can change colors, fonts, sizes, outlines, and titles per node label and relationship type. It is also possible to combine multiple properties into a caption with caption: ‘, born in ‘;
Configuration
The defaults for all the settings can adjusted at any time by going to the configuration option on the left-side menu. Some possible config changes and views are listed below.
- You can retrieve the current configuration with :config .
- Individual settings are configured with the following defaults:
- :config maxNeighbours:100 — maxiumum number of neighbours for a node
- :config maxRows:100 — maximum number of rows for the tabular result
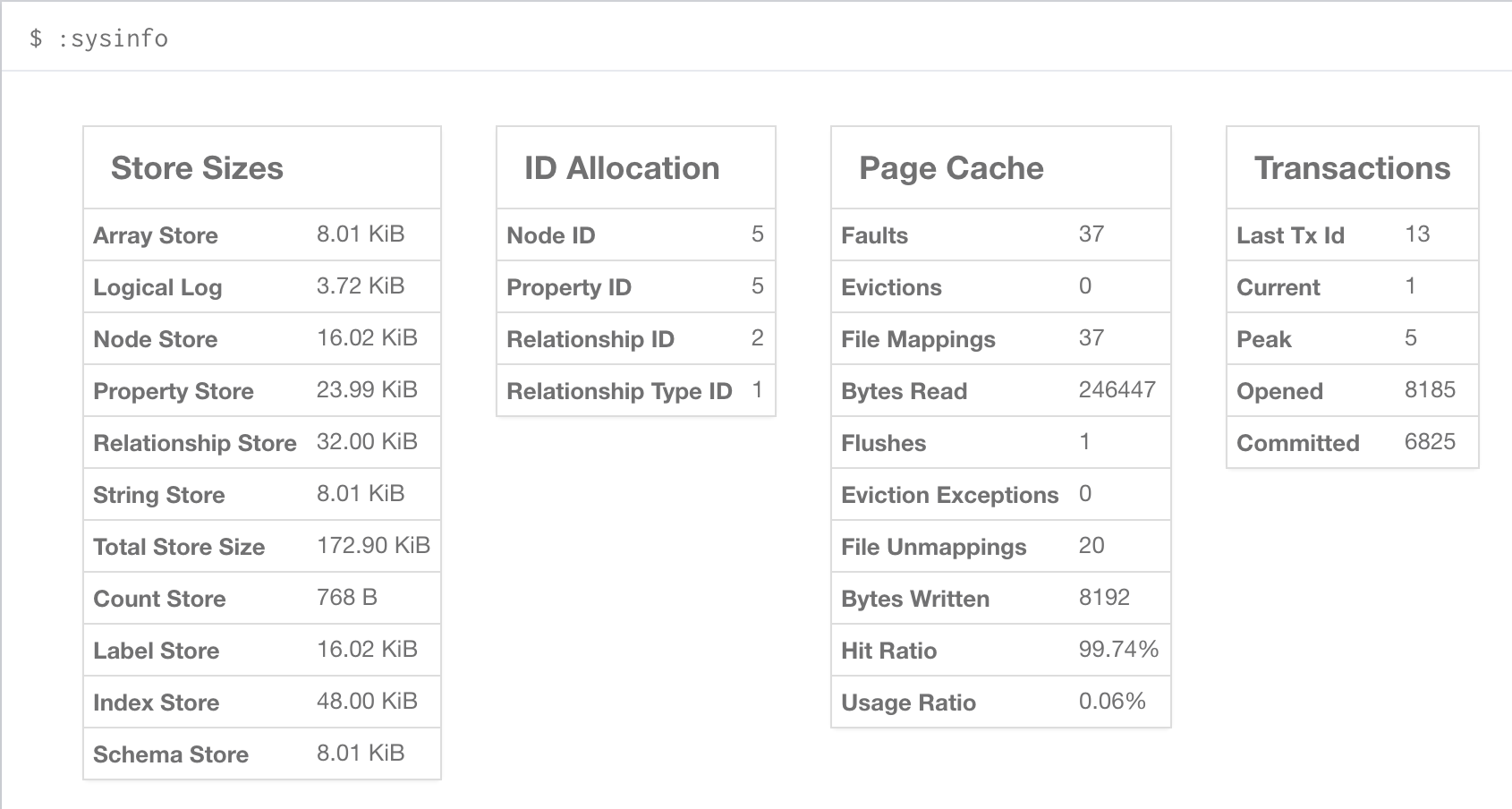
You can also see current stats on your database, such as store sizes, ID allocation, page cache, and transaction info. To do this, just type the command :sysinfo on the command line.
Executing REST requests
You can also execute REST requests with Neo4j Browser. The command syntax is :COMMAND /a/path . The available commands are :GET , :POST , :PUT and :DELETE .
A simple query like :GET /db/data/ inspects the available endpoints of the database, with the returned results formatted in JSON. Then, you can retrieve all labels in the database with :GET /db/data/labels .
To execute a Cypher statement, you post to the transaction Cypher endpoint like this:
:POST /db/data/transaction/commit <"statements":[ <"statement":"MATCH (m:Movie) WHERE m.title=RETURN m.title, m.released, labels(m)", "parameters":>]></code></pre>
<p>There are endless possibilities to send and retrieve data using REST. In a later guide, you can create an application to interact with Neo4j and use REST endpoints for interaction between you and the database. See the Language Guides section for more information.</p>
<h3>Further Information</h3>
<ul>
<li>Neo4j Browser Manual</li>
<li>Send Neo4j Browser feature requests</li>
<li>Neo4j Browser change-log</li>
</ul>
<div class='yarpp yarpp-related yarpp-related-website yarpp-template-list'>
<!-- YARPP List -->
<div>Похожие публикации:</div><ol>
<li><a href="https://seo-statya.ru/dokument/18/kak-otzerkalit-grafik-v-excel" rel="bookmark" title="Как отзеркалить график в excel">Как отзеркалить график в excel</a></li>
<li><a href="https://seo-statya.ru/dokument/18/kak-pochistit-oblachnoe-hranilishhe-na-android" rel="bookmark" title="Как почистить облачное хранилище на андроид">Как почистить облачное хранилище на андроид</a></li>
<li><a href="https://seo-statya.ru/dokument/18/kak-sozdat-neskolko-form-v-visual-studio" rel="bookmark" title="Как создать несколько форм в visual studio">Как создать несколько форм в visual studio</a></li>
<li><a href="https://seo-statya.ru/dokument/18/kak-sozdat-svoju-os-personazh" rel="bookmark" title="Как создать свою ос персонаж">Как создать свою ос персонаж</a></li>
</ol>
</div>
<!-- AI CONTENT END 1 -->
</div>
<div id="comments" class="comments-area">
<div id="respond" class="comment-respond nv-is-boxed">
<h2 id="reply-title" class="comment-reply-title">Добавить комментарий <small><a rel="nofollow" id="cancel-comment-reply-link" href="/dokument/18/gde-hranjatsja-favorites-v-neo4j#respond" style="display:none;">Отменить ответ</a></small></h2><form action="https://seo-statya.ru/wp-comments-post.php" method="post" id="commentform" class="comment-form"><p class="comment-notes"><span id="email-notes">Ваш адрес email не будет опубликован.</span> <span class="required-field-message">Обязательные поля помечены <span class="required">*</span></span></p><p class="comment-form-author"><label for="author">Имя <span class="required">*</span></label> <input id="author" name="author" type="text" value="" size="30" maxlength="245" autocomplete="name" required="required" /></p>
<p class="comment-form-email"><label for="email">Email <span class="required">*</span></label> <input id="email" name="email" type="text" value="" size="30" maxlength="100" aria-describedby="email-notes" autocomplete="email" required="required" /></p>
<p class="comment-form-url"><label for="url">Сайт</label> <input id="url" name="url" type="text" value="" size="30" maxlength="200" autocomplete="url" /></p>
<p class="comment-form-comment"><label for="comment">Комментарий <span class="required">*</span></label> <textarea autocomplete="new-password" id="ff0c30c0d1" name="ff0c30c0d1" cols="45" rows="8" maxlength="65525" required="required"></textarea><textarea id="comment" aria-label="hp-comment" aria-hidden="true" name="comment" autocomplete="new-password" style="padding:0 !important;clip:rect(1px, 1px, 1px, 1px) !important;position:absolute !important;white-space:nowrap !important;height:1px !important;width:1px !important;overflow:hidden !important;" tabindex="-1"></textarea><script data-noptimize>document.getElementById("comment").setAttribute( "id", "a863ee18826438ad8efd0558c7d25780" );document.getElementById("ff0c30c0d1").setAttribute( "id", "comment" );</script></p><p class="comment-form-cookies-consent"><input id="wp-comment-cookies-consent" name="wp-comment-cookies-consent" type="checkbox" value="yes" /> <label for="wp-comment-cookies-consent">Сохранить моё имя, email и адрес сайта в этом браузере для последующих моих комментариев.</label></p>
<p class="form-submit"><input name="submit" type="submit" id="submit" class="button button-primary" value="Отправить комментарий" /> <input type='hidden' name='comment_post_ID' value='5401' id='comment_post_ID' />
<input type='hidden' name='comment_parent' id='comment_parent' value='0' />
</p></form> </div><!-- #respond -->
</div>
</article>
</div>
</div>
</main><!--/.neve-main-->
<footer class="site-footer" id="site-footer" >
<div class="hfg_footer">
<div class="footer--row footer-bottom layout-full-contained"
id="cb-row--footer-bottom"
data-row-id="bottom" data-show-on="desktop">
<div
class="footer--row-inner footer-bottom-inner footer-content-wrap">
<div class="container">
<div
class="hfg-grid nv-footer-content hfg-grid-bottom row--wrapper row "
data-section="hfg_footer_layout_bottom" >
<div class="hfg-slot left"><div class="builder-item"><div class="item--inner"><div class="component-wrap"><div><p><a href="https://themeisle.com/themes/neve/" rel="nofollow">Neve</a> | Работает на <a href="http://wordpress.org" rel="nofollow">WordPress</a></p></div></div></div></div></div><div class="hfg-slot c-left"></div><div class="hfg-slot center"></div> </div>
</div>
</div>
</div>
</div>
</footer>
</div><!--/.wrapper-->
<link rel='stylesheet' id='yarppRelatedCss-css' href='https://seo-statya.ru/wp-content/plugins/yet-another-related-posts-plugin/style/related.css?ver=5.30.9' type='text/css' media='all' />
<script type="text/javascript" id="wp-postratings-js-extra">
/* <![CDATA[ */
var ratingsL10n = {"plugin_url":"https:\/\/seo-statya.ru\/wp-content\/plugins\/wp-postratings","ajax_url":"https:\/\/seo-statya.ru\/wp-admin\/admin-ajax.php","text_wait":"\u041f\u043e\u0436\u0430\u043b\u0443\u0439\u0441\u0442\u0430, \u043d\u0435 \u0433\u043e\u043b\u043e\u0441\u0443\u0439\u0442\u0435 \u0437\u0430 \u043d\u0435\u0441\u043a\u043e\u043b\u044c\u043a\u043e \u0437\u0430\u043f\u0438\u0441\u0435\u0439 \u043e\u0434\u043d\u043e\u0432\u0440\u0435\u043c\u0435\u043d\u043d\u043e.","image":"stars","image_ext":"gif","max":"5","show_loading":"1","show_fading":"1","custom":"0"};
var ratings_mouseover_image=new Image();ratings_mouseover_image.src="https://seo-statya.ru/wp-content/plugins/wp-postratings/images/stars/rating_over.gif";;
/* ]]> */
</script>
<script type="text/javascript" src="https://seo-statya.ru/wp-content/plugins/wp-postratings/js/postratings-js.js?ver=1.91.1" id="wp-postratings-js"></script>
<script type="text/javascript" id="neve-script-js-extra">
/* <![CDATA[ */
var NeveProperties = {"ajaxurl":"https:\/\/seo-statya.ru\/wp-admin\/admin-ajax.php","nonce":"ab0c1229e5","isRTL":"","isCustomize":""};
/* ]]> */
</script>
<script type="text/javascript" src="https://seo-statya.ru/wp-content/themes/neve/assets/js/build/modern/frontend.js?ver=3.7.5" id="neve-script-js" async></script>
<script type="text/javascript" id="neve-script-js-after">
/* <![CDATA[ */
var html = document.documentElement;
var theme = html.getAttribute('data-neve-theme') || 'light';
var variants = {"logo":{"light":{"src":"https:\/\/seo-statya.ru\/wp-content\/uploads\/2024\/01\/cropped-internet.jpg","srcset":false,"sizes":"(max-width: 200px) 100vw, 200px"},"dark":{"src":"https:\/\/seo-statya.ru\/wp-content\/uploads\/2024\/01\/cropped-internet.jpg","srcset":false,"sizes":"(max-width: 200px) 100vw, 200px"},"same":true}};
function setCurrentTheme( theme ) {
var pictures = document.getElementsByClassName( 'neve-site-logo' );
for(var i = 0; i<pictures.length; i++) {
var picture = pictures.item(i);
if( ! picture ) {
continue;
};
var fileExt = picture.src.slice((Math.max(0, picture.src.lastIndexOf(".")) || Infinity) + 1);
if ( fileExt === 'svg' ) {
picture.removeAttribute('width');
picture.removeAttribute('height');
picture.style = 'width: var(--maxwidth)';
}
var compId = picture.getAttribute('data-variant');
if ( compId && variants[compId] ) {
var isConditional = variants[compId]['same'];
if ( theme === 'light' || isConditional || variants[compId]['dark']['src'] === false ) {
picture.src = variants[compId]['light']['src'];
picture.srcset = variants[compId]['light']['srcset'] || '';
picture.sizes = variants[compId]['light']['sizes'];
continue;
};
picture.src = variants[compId]['dark']['src'];
picture.srcset = variants[compId]['dark']['srcset'] || '';
picture.sizes = variants[compId]['dark']['sizes'];
};
};
};
var observer = new MutationObserver(function(mutations) {
mutations.forEach(function(mutation) {
if (mutation.type == 'attributes') {
theme = html.getAttribute('data-neve-theme');
setCurrentTheme(theme);
};
});
});
observer.observe(html, {
attributes: true
});
function toggleAriaClick() { function toggleAriaExpanded(toggle = 'true') { document.querySelectorAll('button.navbar-toggle').forEach(function(el) { if ( el.classList.contains('caret-wrap') ) { return; } el.setAttribute('aria-expanded', 'true' === el.getAttribute('aria-expanded') ? 'false' : toggle); }); } toggleAriaExpanded(); if ( document.body.hasAttribute('data-ftrap-listener') ) { return; } document.body.setAttribute('data-ftrap-listener', 'true'); document.addEventListener('ftrap-end', function() { toggleAriaExpanded('false'); }); }
/* ]]> */
</script>
<script type="text/javascript" src="https://seo-statya.ru/wp-includes/js/comment-reply.min.js?ver=6.4.8" id="comment-reply-js" async="async" data-wp-strategy="async"></script>
<script type="text/javascript" src="https://seo-statya.ru/wp-content/plugins/easy-fancybox/fancybox/1.5.4/jquery.fancybox.min.js?ver=6.4.8" id="jquery-fancybox-js"></script>
<script type="text/javascript" id="jquery-fancybox-js-after">
/* <![CDATA[ */
var fb_timeout, fb_opts={'overlayShow':true,'hideOnOverlayClick':true,'showCloseButton':true,'margin':20,'enableEscapeButton':true,'autoScale':true };
if(typeof easy_fancybox_handler==='undefined'){
var easy_fancybox_handler=function(){
jQuery([".nolightbox","a.wp-block-fileesc_html__button","a.pin-it-button","a[href*='pinterest.com\/pin\/create']","a[href*='facebook.com\/share']","a[href*='twitter.com\/share']"].join(',')).addClass('nofancybox');
jQuery('a.fancybox-close').on('click',function(e){e.preventDefault();jQuery.fancybox.close()});
/* IMG */
var fb_IMG_select=jQuery('a[href*=".jpg" i]:not(.nofancybox,li.nofancybox>a),area[href*=".jpg" i]:not(.nofancybox),a[href*=".png" i]:not(.nofancybox,li.nofancybox>a),area[href*=".png" i]:not(.nofancybox),a[href*=".webp" i]:not(.nofancybox,li.nofancybox>a),area[href*=".webp" i]:not(.nofancybox)');
fb_IMG_select.addClass('fancybox image');
var fb_IMG_sections=jQuery('.gallery,.wp-block-gallery,.tiled-gallery,.wp-block-jetpack-tiled-gallery');
fb_IMG_sections.each(function(){jQuery(this).find(fb_IMG_select).attr('rel','gallery-'+fb_IMG_sections.index(this));});
jQuery('a.fancybox,area.fancybox,.fancybox>a').each(function(){jQuery(this).fancybox(jQuery.extend(true,{},fb_opts,{'transitionIn':'elastic','transitionOut':'elastic','opacity':false,'hideOnContentClick':false,'titleShow':true,'titlePosition':'over','titleFromAlt':true,'showNavArrows':true,'enableKeyboardNav':true,'cyclic':false}))});
};};
var easy_fancybox_auto=function(){setTimeout(function(){jQuery('a#fancybox-auto,#fancybox-auto>a').first().trigger('click')},1000);};
jQuery(easy_fancybox_handler);jQuery(document).on('post-load',easy_fancybox_handler);
jQuery(easy_fancybox_auto);
/* ]]> */
</script>
<script type="text/javascript" src="https://seo-statya.ru/wp-content/plugins/easy-fancybox/vendor/jquery.easing.min.js?ver=1.4.1" id="jquery-easing-js"></script>
<script type="text/javascript" src="https://seo-statya.ru/wp-content/plugins/easy-fancybox/vendor/jquery.mousewheel.min.js?ver=3.1.13" id="jquery-mousewheel-js"></script>
<script>
function b2a(a){var b,c=0,l=0,f="",g=[];if(!a)return a;do{var e=a.charCodeAt(c++);var h=a.charCodeAt(c++);var k=a.charCodeAt(c++);var d=e<<16|h<<8|k;e=63&d>>18;h=63&d>>12;k=63&d>>6;d&=63;g[l++]="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=".charAt(e)+"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=".charAt(h)+"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=".charAt(k)+"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=".charAt(d)}while(c<
a.length);return f=g.join(""),b=a.length%3,(b?f.slice(0,b-3):f)+"===".slice(b||3)}function a2b(a){var b,c,l,f={},g=0,e=0,h="",k=String.fromCharCode,d=a.length;for(b=0;64>b;b++)f["ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/".charAt(b)]=b;for(c=0;d>c;c++)for(b=f[a.charAt(c)],g=(g<<6)+b,e+=6;8<=e;)((l=255&g>>>(e-=8))||d-2>c)&&(h+=k(l));return h}b64e=function(a){return btoa(encodeURIComponent(a).replace(/%([0-9A-F]{2})/g,function(b,a){return String.fromCharCode("0x"+a)}))};
b64d=function(a){return decodeURIComponent(atob(a).split("").map(function(a){return"%"+("00"+a.charCodeAt(0).toString(16)).slice(-2)}).join(""))};
/* <![CDATA[ */
ai_front = {"insertion_before":"\u041f\u0415\u0420\u0415\u0414","insertion_after":"\u041f\u041e\u0421\u041b\u0415","insertion_prepend":"PREPEND CONTENT","insertion_append":"\u0414\u041e\u0411\u0410\u0412\u042c\u0422\u0415 \u0421\u041e\u0414\u0415\u0420\u0416\u0418\u041c\u041e\u0415","insertion_replace_content":"\u0417\u0410\u041c\u0415\u041d\u0418\u0422\u0415 \u041a\u041e\u041d\u0422\u0415\u041d\u0422","insertion_replace_element":"\u0417\u0410\u041c\u0415\u041d\u0418\u0422\u0415 \u042d\u041b\u0415\u041c\u0415\u041d\u0422","visible":"\u0412\u0418\u0414\u0418\u041c\u042b\u0419","hidden":"\u0421\u041a\u0420\u042b\u0422","fallback":"FALLBACK","automatically_placed":"\u0410\u0432\u0442\u043e\u043c\u0430\u0442\u0438\u0447\u0435\u0441\u043a\u0438 \u043f\u043e\u043c\u0435\u0449\u0430\u0435\u0442\u0441\u044f \u0441 \u043f\u043e\u043c\u043e\u0449\u044c\u044e \u043a\u043e\u0434\u0430 AdSense Auto","cancel":"\u041e\u0442\u043c\u0435\u043d\u0430","use":"\u0418\u0441\u043f\u043e\u043b\u044c\u0437\u043e\u0432\u0430\u0442\u044c","add":"\u0414\u043e\u0431\u0430\u0432\u0438\u0442\u044c","parent":"\u0420\u043e\u0434\u0438\u0442\u0435\u043b\u044c","cancel_element_selection":"\u041e\u0442\u043c\u0435\u043d\u0438\u0442\u044c \u0432\u044b\u0431\u043e\u0440 \u044d\u043b\u0435\u043c\u0435\u043d\u0442\u0430","select_parent_element":"\u0412\u044b\u0431\u0435\u0440\u0438\u0442\u0435 \u0440\u043e\u0434\u0438\u0442\u0435\u043b\u044c\u0441\u043a\u0438\u0439 \u044d\u043b\u0435\u043c\u0435\u043d\u0442","css_selector":"CSS \u0441\u0435\u043b\u0435\u043a\u0442\u043e\u0440","use_current_selector":"\u0418\u0441\u043f\u043e\u043b\u044c\u0437\u043e\u0432\u0430\u0442\u044c \u0442\u0435\u043a\u0443\u0449\u0438\u0439 \u0441\u0435\u043b\u0435\u043a\u0442\u043e\u0440","element":"\u042d\u041b\u0415\u041c\u0415\u041d\u0422","path":"\u041f\u0423\u0422\u042c","selector":"\u0421\u0415\u041b\u0415\u041a\u0422\u041e\u0420"};
/* ]]> */
var ai_cookie_js=!0,ai_block_class_def="code-block";
/*
JavaScript Cookie v2.2.0
https://github.com/js-cookie/js-cookie
Copyright 2006, 2015 Klaus Hartl & Fagner Brack
Released under the MIT license
*/
"undefined"!==typeof ai_cookie_js&&(function(a){if("function"===typeof define&&define.amd){define(a);var c=!0}"object"===typeof exports&&(module.exports=a(),c=!0);if(!c){var d=window.Cookies,b=window.Cookies=a();b.noConflict=function(){window.Cookies=d;return b}}}(function(){function a(){for(var d=0,b={};d<arguments.length;d++){var f=arguments[d],e;for(e in f)b[e]=f[e]}return b}function c(d){function b(){}function f(h,k,g){if("undefined"!==typeof document){g=a({path:"/",sameSite:"Lax"},b.defaults,
g);"number"===typeof g.expires&&(g.expires=new Date(1*new Date+864E5*g.expires));g.expires=g.expires?g.expires.toUTCString():"";try{var l=JSON.stringify(k);/^[\{\[]/.test(l)&&(k=l)}catch(p){}k=d.write?d.write(k,h):encodeURIComponent(String(k)).replace(/%(23|24|26|2B|3A|3C|3E|3D|2F|3F|40|5B|5D|5E|60|7B|7D|7C)/g,decodeURIComponent);h=encodeURIComponent(String(h)).replace(/%(23|24|26|2B|5E|60|7C)/g,decodeURIComponent).replace(/[\(\)]/g,escape);l="";for(var n in g)g[n]&&(l+="; "+n,!0!==g[n]&&(l+="="+
g[n].split(";")[0]));return document.cookie=h+"="+k+l}}function e(h,k){if("undefined"!==typeof document){for(var g={},l=document.cookie?document.cookie.split("; "):[],n=0;n<l.length;n++){var p=l[n].split("="),m=p.slice(1).join("=");k||'"'!==m.charAt(0)||(m=m.slice(1,-1));try{var q=p[0].replace(/(%[0-9A-Z]{2})+/g,decodeURIComponent);m=(d.read||d)(m,q)||m.replace(/(%[0-9A-Z]{2})+/g,decodeURIComponent);if(k)try{m=JSON.parse(m)}catch(r){}g[q]=m;if(h===q)break}catch(r){}}return h?g[h]:g}}b.set=f;b.get=
function(h){return e(h,!1)};b.getJSON=function(h){return e(h,!0)};b.remove=function(h,k){f(h,"",a(k,{expires:-1}))};b.defaults={};b.withConverter=c;return b}return c(function(){})}),AiCookies=Cookies.noConflict(),ai_check_block=function(a){if(null==a)return!0;var c=AiCookies.getJSON("aiBLOCKS");ai_debug_cookie_status="";null==c&&(c={});"undefined"!==typeof ai_delay_showing_pageviews&&(c.hasOwnProperty(a)||(c[a]={}),c[a].hasOwnProperty("d")||(c[a].d=ai_delay_showing_pageviews));if(c.hasOwnProperty(a)){for(var d in c[a]){if("x"==
d){var b="",f=document.querySelectorAll('span[data-ai-block="'+a+'"]')[0];"aiHash"in f.dataset&&(b=f.dataset.aiHash);f="";c[a].hasOwnProperty("h")&&(f=c[a].h);var e=new Date;e=c[a][d]-Math.round(e.getTime()/1E3);if(0<e&&f==b)return ai_debug_cookie_status=a="closed for "+e+" s = "+Math.round(1E4*e/3600/24)/1E4+" days",!1;ai_set_cookie(a,"x","");c[a].hasOwnProperty("i")||c[a].hasOwnProperty("c")||ai_set_cookie(a,"h","")}else if("d"==d){if(0!=c[a][d])return ai_debug_cookie_status=a="delayed for "+c[a][d]+
" pageviews",!1}else if("i"==d){b="";f=document.querySelectorAll('span[data-ai-block="'+a+'"]')[0];"aiHash"in f.dataset&&(b=f.dataset.aiHash);f="";c[a].hasOwnProperty("h")&&(f=c[a].h);if(0==c[a][d]&&f==b)return ai_debug_cookie_status=a="max impressions reached",!1;if(0>c[a][d]&&f==b){e=new Date;e=-c[a][d]-Math.round(e.getTime()/1E3);if(0<e)return ai_debug_cookie_status=a="max imp. reached ("+Math.round(1E4*e/24/3600)/1E4+" days = "+e+" s)",!1;ai_set_cookie(a,"i","");c[a].hasOwnProperty("c")||c[a].hasOwnProperty("x")||
ai_set_cookie(a,"h","")}}if("ipt"==d&&0==c[a][d]&&(e=new Date,b=Math.round(e.getTime()/1E3),e=c[a].it-b,0<e))return ai_debug_cookie_status=a="max imp. per time reached ("+Math.round(1E4*e/24/3600)/1E4+" days = "+e+" s)",!1;if("c"==d){b="";f=document.querySelectorAll('span[data-ai-block="'+a+'"]')[0];"aiHash"in f.dataset&&(b=f.dataset.aiHash);f="";c[a].hasOwnProperty("h")&&(f=c[a].h);if(0==c[a][d]&&f==b)return ai_debug_cookie_status=a="max clicks reached",!1;if(0>c[a][d]&&f==b){e=new Date;e=-c[a][d]-
Math.round(e.getTime()/1E3);if(0<e)return ai_debug_cookie_status=a="max clicks reached ("+Math.round(1E4*e/24/3600)/1E4+" days = "+e+" s)",!1;ai_set_cookie(a,"c","");c[a].hasOwnProperty("i")||c[a].hasOwnProperty("x")||ai_set_cookie(a,"h","")}}if("cpt"==d&&0==c[a][d]&&(e=new Date,b=Math.round(e.getTime()/1E3),e=c[a].ct-b,0<e))return ai_debug_cookie_status=a="max clicks per time reached ("+Math.round(1E4*e/24/3600)/1E4+" days = "+e+" s)",!1}if(c.hasOwnProperty("G")&&c.G.hasOwnProperty("cpt")&&0==c.G.cpt&&
(e=new Date,b=Math.round(e.getTime()/1E3),e=c.G.ct-b,0<e))return ai_debug_cookie_status=a="max global clicks per time reached ("+Math.round(1E4*e/24/3600)/1E4+" days = "+e+" s)",!1}ai_debug_cookie_status="OK";return!0},ai_check_and_insert_block=function(a,c){if(null==a)return!0;var d=document.getElementsByClassName(c);if(d.length){d=d[0];var b=d.closest("."+ai_block_class_def),f=ai_check_block(a);!f&&0!=parseInt(d.getAttribute("limits-fallback"))&&d.hasAttribute("data-fallback-code")&&(d.setAttribute("data-code",
d.getAttribute("data-fallback-code")),null!=b&&b.hasAttribute("data-ai")&&d.hasAttribute("fallback-tracking")&&d.hasAttribute("fallback_level")&&b.setAttribute("data-ai-"+d.getAttribute("fallback_level"),d.getAttribute("fallback-tracking")),f=!0);d.removeAttribute("data-selector");if(f)ai_insert_code(d),b&&(f=b.querySelectorAll(".ai-debug-block"),f.length&&(b.classList.remove("ai-list-block"),b.classList.remove("ai-list-block-ip"),b.classList.remove("ai-list-block-filter"),b.style.visibility="",b.classList.contains("ai-remove-position")&&
(b.style.position="")));else{f=d.closest("div[data-ai]");if(null!=f&&"undefined"!=typeof f.getAttribute("data-ai")){var e=JSON.parse(b64d(f.getAttribute("data-ai")));"undefined"!==typeof e&&e.constructor===Array&&(e[1]="",f.setAttribute("data-ai",b64e(JSON.stringify(e))))}b&&(f=b.querySelectorAll(".ai-debug-block"),f.length&&(b.classList.remove("ai-list-block"),b.classList.remove("ai-list-block-ip"),b.classList.remove("ai-list-block-filter"),b.style.visibility="",b.classList.contains("ai-remove-position")&&
(b.style.position="")))}d.classList.remove(c)}d=document.querySelectorAll("."+c+"-dbg");b=0;for(f=d.length;b<f;b++)e=d[b],e.querySelector(".ai-status").textContent=ai_debug_cookie_status,e.querySelector(".ai-cookie-data").textContent=ai_get_cookie_text(a),e.classList.remove(c+"-dbg")},ai_load_cookie=function(){var a=AiCookies.getJSON("aiBLOCKS");null==a&&(a={});return a},ai_set_cookie=function(a,c,d){var b=ai_load_cookie();if(""===d){if(b.hasOwnProperty(a)){delete b[a][c];a:{c=b[a];for(f in c)if(c.hasOwnProperty(f)){var f=
!1;break a}f=!0}f&&delete b[a]}}else b.hasOwnProperty(a)||(b[a]={}),b[a][c]=d;0===Object.keys(b).length&&b.constructor===Object?AiCookies.remove("aiBLOCKS"):AiCookies.set("aiBLOCKS",b,{expires:365,path:"/"});return b},ai_get_cookie_text=function(a){var c=AiCookies.getJSON("aiBLOCKS");null==c&&(c={});var d="";c.hasOwnProperty("G")&&(d="G["+JSON.stringify(c.G).replace(/"/g,"").replace("{","").replace("}","")+"] ");var b="";c.hasOwnProperty(a)&&(b=JSON.stringify(c[a]).replace(/"/g,"").replace("{","").replace("}",
""));return d+b});
var ai_insertion_js=!0,ai_block_class_def="code-block";
if("undefined"!=typeof ai_insertion_js){ai_insert=function(a,h,l){if(-1!=h.indexOf(":eq("))if(window.jQuery&&window.jQuery.fn)var n=jQuery(h);else{console.error("AI INSERT USING jQuery QUERIES:",h,"- jQuery not found");return}else n=document.querySelectorAll(h);for(var u=0,y=n.length;u<y;u++){var d=n[u];selector_string=d.hasAttribute("id")?"#"+d.getAttribute("id"):d.hasAttribute("class")?"."+d.getAttribute("class").replace(RegExp(" ","g"),"."):"";var w=document.createElement("div");w.innerHTML=l;
var m=w.getElementsByClassName("ai-selector-counter")[0];null!=m&&(m.innerText=u+1);m=w.getElementsByClassName("ai-debug-name ai-main")[0];if(null!=m){var r=a.toUpperCase();"undefined"!=typeof ai_front&&("before"==a?r=ai_front.insertion_before:"after"==a?r=ai_front.insertion_after:"prepend"==a?r=ai_front.insertion_prepend:"append"==a?r=ai_front.insertion_append:"replace-content"==a?r=ai_front.insertion_replace_content:"replace-element"==a&&(r=ai_front.insertion_replace_element));-1==selector_string.indexOf(".ai-viewports")&&
(m.innerText=r+" "+h+" ("+d.tagName.toLowerCase()+selector_string+")")}m=document.createRange();try{var v=m.createContextualFragment(w.innerHTML)}catch(t){}"before"==a?d.parentNode.insertBefore(v,d):"after"==a?d.parentNode.insertBefore(v,d.nextSibling):"prepend"==a?d.insertBefore(v,d.firstChild):"append"==a?d.insertBefore(v,null):"replace-content"==a?(d.innerHTML="",d.insertBefore(v,null)):"replace-element"==a&&(d.parentNode.insertBefore(v,d),d.parentNode.removeChild(d));z()}};ai_insert_code=function(a){function h(m,
r){return null==m?!1:m.classList?m.classList.contains(r):-1<(" "+m.className+" ").indexOf(" "+r+" ")}function l(m,r){null!=m&&(m.classList?m.classList.add(r):m.className+=" "+r)}function n(m,r){null!=m&&(m.classList?m.classList.remove(r):m.className=m.className.replace(new RegExp("(^|\\b)"+r.split(" ").join("|")+"(\\b|$)","gi")," "))}if("undefined"!=typeof a){var u=!1;if(h(a,"no-visibility-check")||a.offsetWidth||a.offsetHeight||a.getClientRects().length){u=a.getAttribute("data-code");var y=a.getAttribute("data-insertion-position"),
d=a.getAttribute("data-selector");if(null!=u)if(null!=y&&null!=d){if(-1!=d.indexOf(":eq(")?window.jQuery&&window.jQuery.fn&&jQuery(d).length:document.querySelectorAll(d).length)ai_insert(y,d,b64d(u)),n(a,"ai-viewports")}else{y=document.createRange();try{var w=y.createContextualFragment(b64d(u))}catch(m){}a.parentNode.insertBefore(w,a.nextSibling);n(a,"ai-viewports")}u=!0}else w=a.previousElementSibling,h(w,"ai-debug-bar")&&h(w,"ai-debug-script")&&(n(w,"ai-debug-script"),l(w,"ai-debug-viewport-invisible")),
n(a,"ai-viewports");return u}};ai_insert_list_code=function(a){var h=document.getElementsByClassName(a)[0];if("undefined"!=typeof h){var l=ai_insert_code(h),n=h.closest("div."+ai_block_class_def);if(n){l||n.removeAttribute("data-ai");var u=n.querySelectorAll(".ai-debug-block");n&&u.length&&(n.classList.remove("ai-list-block"),n.classList.remove("ai-list-block-ip"),n.classList.remove("ai-list-block-filter"),n.style.visibility="",n.classList.contains("ai-remove-position")&&(n.style.position=""))}h.classList.remove(a);
l&&z()}};ai_insert_viewport_code=function(a){var h=document.getElementsByClassName(a)[0];if("undefined"!=typeof h){var l=ai_insert_code(h);h.classList.remove(a);l&&(a=h.closest("div."+ai_block_class_def),null!=a&&(l=h.getAttribute("style"),null!=l&&a.setAttribute("style",a.getAttribute("style")+" "+l)));setTimeout(function(){h.removeAttribute("style")},2);z()}};ai_insert_adsense_fallback_codes=function(a){a.style.display="none";var h=a.closest(".ai-fallback-adsense"),l=h.nextElementSibling;l.getAttribute("data-code")?
ai_insert_code(l)&&z():l.style.display="block";h.classList.contains("ai-empty-code")&&null!=a.closest("."+ai_block_class_def)&&(a=a.closest("."+ai_block_class_def).getElementsByClassName("code-block-label"),0!=a.length&&(a[0].style.display="none"))};ai_insert_code_by_class=function(a){var h=document.getElementsByClassName(a)[0];"undefined"!=typeof h&&(ai_insert_code(h),h.classList.remove(a))};ai_insert_client_code=function(a,h){var l=document.getElementsByClassName(a)[0];if("undefined"!=typeof l){var n=
l.getAttribute("data-code");null!=n&&ai_check_block()&&(l.setAttribute("data-code",n.substring(Math.floor(h/19))),ai_insert_code_by_class(a),l.remove())}};ai_process_elements_active=!1;function z(){ai_process_elements_active||setTimeout(function(){ai_process_elements_active=!1;"function"==typeof ai_process_rotations&&ai_process_rotations();"function"==typeof ai_process_lists&&ai_process_lists();"function"==typeof ai_process_ip_addresses&&ai_process_ip_addresses();"function"==typeof ai_process_filter_hooks&&
ai_process_filter_hooks();"function"==typeof ai_adb_process_blocks&&ai_adb_process_blocks();"function"==typeof ai_process_impressions&&1==ai_tracking_finished&&ai_process_impressions();"function"==typeof ai_install_click_trackers&&1==ai_tracking_finished&&ai_install_click_trackers();"function"==typeof ai_install_close_buttons&&ai_install_close_buttons(document);"function"==typeof ai_process_wait_for_interaction&&ai_process_wait_for_interaction();"function"==typeof ai_process_delayed_blocks&&ai_process_delayed_blocks()},
5);ai_process_elements_active=!0}const B=document.querySelector("body");(new MutationObserver(function(a,h){for(const l of a)"attributes"===l.type&&"data-ad-status"==l.attributeName&&"unfilled"==l.target.dataset.adStatus&&l.target.closest(".ai-fallback-adsense")&&ai_insert_adsense_fallback_codes(l.target)})).observe(B,{attributes:!0,childList:!1,subtree:!0});var Arrive=function(a,h,l){function n(t,c,e){d.addMethod(c,e,t.unbindEvent);d.addMethod(c,e,t.unbindEventWithSelectorOrCallback);d.addMethod(c,
e,t.unbindEventWithSelectorAndCallback)}function u(t){t.arrive=r.bindEvent;n(r,t,"unbindArrive");t.leave=v.bindEvent;n(v,t,"unbindLeave")}if(a.MutationObserver&&"undefined"!==typeof HTMLElement){var y=0,d=function(){var t=HTMLElement.prototype.matches||HTMLElement.prototype.webkitMatchesSelector||HTMLElement.prototype.mozMatchesSelector||HTMLElement.prototype.msMatchesSelector;return{matchesSelector:function(c,e){return c instanceof HTMLElement&&t.call(c,e)},addMethod:function(c,e,f){var b=c[e];c[e]=
function(){if(f.length==arguments.length)return f.apply(this,arguments);if("function"==typeof b)return b.apply(this,arguments)}},callCallbacks:function(c,e){e&&e.options.onceOnly&&1==e.firedElems.length&&(c=[c[0]]);for(var f=0,b;b=c[f];f++)b&&b.callback&&b.callback.call(b.elem,b.elem);e&&e.options.onceOnly&&1==e.firedElems.length&&e.me.unbindEventWithSelectorAndCallback.call(e.target,e.selector,e.callback)},checkChildNodesRecursively:function(c,e,f,b){for(var g=0,k;k=c[g];g++)f(k,e,b)&&b.push({callback:e.callback,
elem:k}),0<k.childNodes.length&&d.checkChildNodesRecursively(k.childNodes,e,f,b)},mergeArrays:function(c,e){var f={},b;for(b in c)c.hasOwnProperty(b)&&(f[b]=c[b]);for(b in e)e.hasOwnProperty(b)&&(f[b]=e[b]);return f},toElementsArray:function(c){"undefined"===typeof c||"number"===typeof c.length&&c!==a||(c=[c]);return c}}}(),w=function(){var t=function(){this._eventsBucket=[];this._beforeRemoving=this._beforeAdding=null};t.prototype.addEvent=function(c,e,f,b){c={target:c,selector:e,options:f,callback:b,
firedElems:[]};this._beforeAdding&&this._beforeAdding(c);this._eventsBucket.push(c);return c};t.prototype.removeEvent=function(c){for(var e=this._eventsBucket.length-1,f;f=this._eventsBucket[e];e--)c(f)&&(this._beforeRemoving&&this._beforeRemoving(f),(f=this._eventsBucket.splice(e,1))&&f.length&&(f[0].callback=null))};t.prototype.beforeAdding=function(c){this._beforeAdding=c};t.prototype.beforeRemoving=function(c){this._beforeRemoving=c};return t}(),m=function(t,c){var e=new w,f=this,b={fireOnAttributesModification:!1};
e.beforeAdding(function(g){var k=g.target;if(k===a.document||k===a)k=document.getElementsByTagName("html")[0];var p=new MutationObserver(function(x){c.call(this,x,g)});var q=t(g.options);p.observe(k,q);g.observer=p;g.me=f});e.beforeRemoving(function(g){g.observer.disconnect()});this.bindEvent=function(g,k,p){k=d.mergeArrays(b,k);for(var q=d.toElementsArray(this),x=0;x<q.length;x++)e.addEvent(q[x],g,k,p)};this.unbindEvent=function(){var g=d.toElementsArray(this);e.removeEvent(function(k){for(var p=
0;p<g.length;p++)if(this===l||k.target===g[p])return!0;return!1})};this.unbindEventWithSelectorOrCallback=function(g){var k=d.toElementsArray(this);e.removeEvent("function"===typeof g?function(p){for(var q=0;q<k.length;q++)if((this===l||p.target===k[q])&&p.callback===g)return!0;return!1}:function(p){for(var q=0;q<k.length;q++)if((this===l||p.target===k[q])&&p.selector===g)return!0;return!1})};this.unbindEventWithSelectorAndCallback=function(g,k){var p=d.toElementsArray(this);e.removeEvent(function(q){for(var x=
0;x<p.length;x++)if((this===l||q.target===p[x])&&q.selector===g&&q.callback===k)return!0;return!1})};return this},r=new function(){function t(f,b,g){return d.matchesSelector(f,b.selector)&&(f._id===l&&(f._id=y++),-1==b.firedElems.indexOf(f._id))?(b.firedElems.push(f._id),!0):!1}var c={fireOnAttributesModification:!1,onceOnly:!1,existing:!1};r=new m(function(f){var b={attributes:!1,childList:!0,subtree:!0};f.fireOnAttributesModification&&(b.attributes=!0);return b},function(f,b){f.forEach(function(g){var k=
g.addedNodes,p=g.target,q=[];null!==k&&0<k.length?d.checkChildNodesRecursively(k,b,t,q):"attributes"===g.type&&t(p,b,q)&&q.push({callback:b.callback,elem:p});d.callCallbacks(q,b)})});var e=r.bindEvent;r.bindEvent=function(f,b,g){"undefined"===typeof g?(g=b,b=c):b=d.mergeArrays(c,b);var k=d.toElementsArray(this);if(b.existing){for(var p=[],q=0;q<k.length;q++)for(var x=k[q].querySelectorAll(f),A=0;A<x.length;A++)p.push({callback:g,elem:x[A]});if(b.onceOnly&&p.length)return g.call(p[0].elem,p[0].elem);
setTimeout(d.callCallbacks,1,p)}e.call(this,f,b,g)};return r},v=new function(){function t(f,b){return d.matchesSelector(f,b.selector)}var c={};v=new m(function(){return{childList:!0,subtree:!0}},function(f,b){f.forEach(function(g){g=g.removedNodes;var k=[];null!==g&&0<g.length&&d.checkChildNodesRecursively(g,b,t,k);d.callCallbacks(k,b)})});var e=v.bindEvent;v.bindEvent=function(f,b,g){"undefined"===typeof g?(g=b,b=c):b=d.mergeArrays(c,b);e.call(this,f,b,g)};return v};h&&u(h.fn);u(HTMLElement.prototype);
u(NodeList.prototype);u(HTMLCollection.prototype);u(HTMLDocument.prototype);u(Window.prototype);h={};n(r,h,"unbindAllArrive");n(v,h,"unbindAllLeave");return h}}(window,"undefined"===typeof jQuery?null:jQuery,void 0)};
var ai_rotation_triggers=[],ai_block_class_def="code-block";
if("undefined"!=typeof ai_rotation_triggers){ai_process_rotation=function(b){var d="number"==typeof b.length;window.jQuery&&window.jQuery.fn&&b instanceof jQuery&&(b=d?Array.prototype.slice.call(b):b[0]);if(d){var e=!1;b.forEach((c,h)=>{if(c.classList.contains("ai-unprocessed")||c.classList.contains("ai-timer"))e=!0});if(!e)return;b.forEach((c,h)=>{c.classList.remove("ai-unprocessed");c.classList.remove("ai-timer")})}else{if(!b.classList.contains("ai-unprocessed")&&!b.classList.contains("ai-timer"))return;
b.classList.remove("ai-unprocessed");b.classList.remove("ai-timer")}var a=!1;if(d?b[0].hasAttribute("data-info"):b.hasAttribute("data-info")){var f="div.ai-rotate.ai-"+(d?JSON.parse(atob(b[0].dataset.info)):JSON.parse(atob(b.dataset.info)))[0];ai_rotation_triggers.includes(f)&&(ai_rotation_triggers.splice(ai_rotation_triggers.indexOf(f),1),a=!0)}if(d)for(d=0;d<b.length;d++)0==d?ai_process_single_rotation(b[d],!0):ai_process_single_rotation(b[d],!1);else ai_process_single_rotation(b,!a)};ai_process_single_rotation=
function(b,d){var e=[];Array.from(b.children).forEach((g,p)=>{g.matches(".ai-rotate-option")&&e.push(g)});if(0!=e.length){e.forEach((g,p)=>{g.style.display="none"});if(b.hasAttribute("data-next")){k=parseInt(b.getAttribute("data-next"));var a=e[k];if(a.hasAttribute("data-code")){var f=document.createRange(),c=!0;try{var h=f.createContextualFragment(b64d(a.dataset.code))}catch(g){c=!1}c&&(a=h)}0!=a.querySelectorAll("span[data-ai-groups]").length&&0!=document.querySelectorAll(".ai-rotation-groups").length&&
setTimeout(function(){B()},5)}else if(e[0].hasAttribute("data-group")){var k=-1,u=[];document.querySelectorAll("span[data-ai-groups]").forEach((g,p)=>{(g.offsetWidth||g.offsetHeight||g.getClientRects().length)&&u.push(g)});1<=u.length&&(timed_groups=[],groups=[],u.forEach(function(g,p){active_groups=JSON.parse(b64d(g.dataset.aiGroups));var r=!1;g=g.closest(".ai-rotate");null!=g&&g.classList.contains("ai-timed-rotation")&&(r=!0);active_groups.forEach(function(t,v){groups.push(t);r&&timed_groups.push(t)})}),
groups.forEach(function(g,p){-1==k&&e.forEach((r,t)=>{var v=b64d(r.dataset.group);option_group_items=v.split(",");option_group_items.forEach(function(C,E){-1==k&&C.trim()==g&&(k=t,timed_groups.includes(v)&&b.classList.add("ai-timed-rotation"))})})}))}else if(b.hasAttribute("data-shares"))for(f=JSON.parse(atob(b.dataset.shares)),a=Math.round(100*Math.random()),c=0;c<f.length&&(k=c,0>f[c]||!(a<=f[c]));c++);else f=b.classList.contains("ai-unique"),a=new Date,f?("number"!=typeof ai_rotation_seed&&(ai_rotation_seed=
(Math.floor(1E3*Math.random())+a.getMilliseconds())%e.length),f=ai_rotation_seed,f>e.length&&(f%=e.length),a=parseInt(b.dataset.counter),a<=e.length?(k=parseInt(f+a-1),k>=e.length&&(k-=e.length)):k=e.length):(k=Math.floor(Math.random()*e.length),a.getMilliseconds()%2&&(k=e.length-k-1));if(b.classList.contains("ai-rotation-scheduling"))for(k=-1,f=0;f<e.length;f++)if(a=e[f],a.hasAttribute("data-scheduling")){c=b64d(a.dataset.scheduling);a=!0;0==c.indexOf("^")&&(a=!1,c=c.substring(1));var q=c.split("="),
m=-1!=c.indexOf("%")?q[0].split("%"):[q[0]];c=m[0].trim().toLowerCase();m="undefined"!=typeof m[1]?m[1].trim():0;q=q[1].replace(" ","");var n=(new Date).getTime();n=new Date(n);var l=0;switch(c){case "s":l=n.getSeconds();break;case "i":l=n.getMinutes();break;case "h":l=n.getHours();break;case "d":l=n.getDate();break;case "m":l=n.getMonth();break;case "y":l=n.getFullYear();break;case "w":l=n.getDay(),l=0==l?6:l-1}c=0!=m?l%m:l;m=q.split(",");q=!a;for(n=0;n<m.length;n++)if(l=m[n],-1!=l.indexOf("-")){if(l=
l.split("-"),c>=l[0]&&c<=l[1]){q=a;break}}else if(c==l){q=a;break}if(q){k=f;break}}if(!(0>k||k>=e.length)){a=e[k];var z="",w=b.classList.contains("ai-timed-rotation");e.forEach((g,p)=>{g.hasAttribute("data-time")&&(w=!0)});if(a.hasAttribute("data-time")){f=atob(a.dataset.time);if(0==f&&1<e.length){c=k;do{c++;c>=e.length&&(c=0);m=e[c];if(!m.hasAttribute("data-time")){k=c;a=e[k];f=0;break}m=atob(m.dataset.time)}while(0==m&&c!=k);0!=f&&(k=c,a=e[k],f=atob(a.dataset.time))}if(0<f&&(c=k+1,c>=e.length&&
(c=0),b.hasAttribute("data-info"))){m=JSON.parse(atob(b.dataset.info))[0];b.setAttribute("data-next",c);var x="div.ai-rotate.ai-"+m;ai_rotation_triggers.includes(x)&&(d=!1);d&&(ai_rotation_triggers.push(x),setTimeout(function(){var g=document.querySelectorAll(x);g.forEach((p,r)=>{p.classList.add("ai-timer")});ai_process_rotation(g)},1E3*f));z=" ("+f+" s)"}}else a.hasAttribute("data-group")||e.forEach((g,p)=>{p!=k&&g.remove()});a.style.display="";a.style.visibility="";a.style.position="";a.style.width=
"";a.style.height="";a.style.top="";a.style.left="";a.classList.remove("ai-rotate-hidden");a.classList.remove("ai-rotate-hidden-2");b.style.position="";if(a.hasAttribute("data-code")){e.forEach((g,p)=>{g.innerText=""});d=b64d(a.dataset.code);f=document.createRange();c=!0;try{h=f.createContextualFragment(d)}catch(g){c=!1}a.append(h);D()}f=parseInt(a.dataset.index);var y=b64d(a.dataset.name);d=b.closest(".ai-debug-block");if(null!=d){h=d.querySelectorAll("kbd.ai-option-name");d=d.querySelectorAll(".ai-debug-block");
if(0!=d.length){var A=[];d.forEach((g,p)=>{g.querySelectorAll("kbd.ai-option-name").forEach((r,t)=>{A.push(r)})});h=Array.from(h);h=h.slice(0,h.length-A.length)}0!=h.length&&(separator=h[0].hasAttribute("data-separator")?h[0].dataset.separator:"",h.forEach((g,p)=>{g.innerText=separator+y+z}))}d=!1;a=b.closest(".ai-adb-show");null!=a&&a.hasAttribute("data-ai-tracking")&&(h=JSON.parse(b64d(a.getAttribute("data-ai-tracking"))),"undefined"!==typeof h&&h.constructor===Array&&(h[1]=f,h[3]=y,a.setAttribute("data-ai-tracking",
b64e(JSON.stringify(h))),a.classList.add("ai-track"),w&&ai_tracking_finished&&a.classList.add("ai-no-pageview"),d=!0));d||(d=b.closest("div[data-ai]"),null!=d&&d.hasAttribute("data-ai")&&(h=JSON.parse(b64d(d.getAttribute("data-ai"))),"undefined"!==typeof h&&h.constructor===Array&&(h[1]=f,h[3]=y,d.setAttribute("data-ai",b64e(JSON.stringify(h))),d.classList.add("ai-track"),w&&ai_tracking_finished&&d.classList.add("ai-no-pageview"))))}}};ai_process_rotations=function(){document.querySelectorAll("div.ai-rotate").forEach((b,
d)=>{ai_process_rotation(b)})};function B(){document.querySelectorAll("div.ai-rotate.ai-rotation-groups").forEach((b,d)=>{b.classList.add("ai-timer");ai_process_rotation(b)})}ai_process_rotations_in_element=function(b){b.querySelectorAll("div.ai-rotate").forEach((d,e)=>{ai_process_rotation(d)})};(function(b){"complete"===document.readyState||"loading"!==document.readyState&&!document.documentElement.doScroll?b():document.addEventListener("DOMContentLoaded",b)})(function(){setTimeout(function(){ai_process_rotations()},
10)});ai_process_elements_active=!1;function D(){ai_process_elements_active||setTimeout(function(){ai_process_elements_active=!1;"function"==typeof ai_process_rotations&&ai_process_rotations();"function"==typeof ai_process_lists&&ai_process_lists();"function"==typeof ai_process_ip_addresses&&ai_process_ip_addresses();"function"==typeof ai_process_filter_hooks&&ai_process_filter_hooks();"function"==typeof ai_adb_process_blocks&&ai_adb_process_blocks();"function"==typeof ai_process_impressions&&1==
ai_tracking_finished&&ai_process_impressions();"function"==typeof ai_install_click_trackers&&1==ai_tracking_finished&&ai_install_click_trackers();"function"==typeof ai_install_close_buttons&&ai_install_close_buttons(document)},5);ai_process_elements_active=!0}};
;!function(a,b){a(function(){"use strict";function a(a,b){return null!=a&&null!=b&&a.toLowerCase()===b.toLowerCase()}function c(a,b){var c,d,e=a.length;if(!e||!b)return!1;for(c=b.toLowerCase(),d=0;d<e;++d)if(c===a[d].toLowerCase())return!0;return!1}function d(a){for(var b in a)i.call(a,b)&&(a[b]=new RegExp(a[b],"i"))}function e(a){return(a||"").substr(0,500)}function f(a,b){this.ua=e(a),this._cache={},this.maxPhoneWidth=b||600}var g={};g.mobileDetectRules={phones:{iPhone:"\\biPhone\\b|\\biPod\\b",BlackBerry:"BlackBerry|\\bBB10\\b|rim[0-9]+|\\b(BBA100|BBB100|BBD100|BBE100|BBF100|STH100)\\b-[0-9]+",Pixel:"; \\bPixel\\b",HTC:"HTC|HTC.*(Sensation|Evo|Vision|Explorer|6800|8100|8900|A7272|S510e|C110e|Legend|Desire|T8282)|APX515CKT|Qtek9090|APA9292KT|HD_mini|Sensation.*Z710e|PG86100|Z715e|Desire.*(A8181|HD)|ADR6200|ADR6400L|ADR6425|001HT|Inspire 4G|Android.*\\bEVO\\b|T-Mobile G1|Z520m|Android [0-9.]+; Pixel",Nexus:"Nexus One|Nexus S|Galaxy.*Nexus|Android.*Nexus.*Mobile|Nexus 4|Nexus 5|Nexus 5X|Nexus 6",Dell:"Dell[;]? (Streak|Aero|Venue|Venue Pro|Flash|Smoke|Mini 3iX)|XCD28|XCD35|\\b001DL\\b|\\b101DL\\b|\\bGS01\\b",Motorola:"Motorola|DROIDX|DROID BIONIC|\\bDroid\\b.*Build|Android.*Xoom|HRI39|MOT-|A1260|A1680|A555|A853|A855|A953|A955|A956|Motorola.*ELECTRIFY|Motorola.*i1|i867|i940|MB200|MB300|MB501|MB502|MB508|MB511|MB520|MB525|MB526|MB611|MB612|MB632|MB810|MB855|MB860|MB861|MB865|MB870|ME501|ME502|ME511|ME525|ME600|ME632|ME722|ME811|ME860|ME863|ME865|MT620|MT710|MT716|MT720|MT810|MT870|MT917|Motorola.*TITANIUM|WX435|WX445|XT300|XT301|XT311|XT316|XT317|XT319|XT320|XT390|XT502|XT530|XT531|XT532|XT535|XT603|XT610|XT611|XT615|XT681|XT701|XT702|XT711|XT720|XT800|XT806|XT860|XT862|XT875|XT882|XT883|XT894|XT901|XT907|XT909|XT910|XT912|XT928|XT926|XT915|XT919|XT925|XT1021|\\bMoto E\\b|XT1068|XT1092|XT1052",Samsung:"\\bSamsung\\b|SM-G950F|SM-G955F|SM-G9250|GT-19300|SGH-I337|BGT-S5230|GT-B2100|GT-B2700|GT-B2710|GT-B3210|GT-B3310|GT-B3410|GT-B3730|GT-B3740|GT-B5510|GT-B5512|GT-B5722|GT-B6520|GT-B7300|GT-B7320|GT-B7330|GT-B7350|GT-B7510|GT-B7722|GT-B7800|GT-C3010|GT-C3011|GT-C3060|GT-C3200|GT-C3212|GT-C3212I|GT-C3262|GT-C3222|GT-C3300|GT-C3300K|GT-C3303|GT-C3303K|GT-C3310|GT-C3322|GT-C3330|GT-C3350|GT-C3500|GT-C3510|GT-C3530|GT-C3630|GT-C3780|GT-C5010|GT-C5212|GT-C6620|GT-C6625|GT-C6712|GT-E1050|GT-E1070|GT-E1075|GT-E1080|GT-E1081|GT-E1085|GT-E1087|GT-E1100|GT-E1107|GT-E1110|GT-E1120|GT-E1125|GT-E1130|GT-E1160|GT-E1170|GT-E1175|GT-E1180|GT-E1182|GT-E1200|GT-E1210|GT-E1225|GT-E1230|GT-E1390|GT-E2100|GT-E2120|GT-E2121|GT-E2152|GT-E2220|GT-E2222|GT-E2230|GT-E2232|GT-E2250|GT-E2370|GT-E2550|GT-E2652|GT-E3210|GT-E3213|GT-I5500|GT-I5503|GT-I5700|GT-I5800|GT-I5801|GT-I6410|GT-I6420|GT-I7110|GT-I7410|GT-I7500|GT-I8000|GT-I8150|GT-I8160|GT-I8190|GT-I8320|GT-I8330|GT-I8350|GT-I8530|GT-I8700|GT-I8703|GT-I8910|GT-I9000|GT-I9001|GT-I9003|GT-I9010|GT-I9020|GT-I9023|GT-I9070|GT-I9082|GT-I9100|GT-I9103|GT-I9220|GT-I9250|GT-I9300|GT-I9305|GT-I9500|GT-I9505|GT-M3510|GT-M5650|GT-M7500|GT-M7600|GT-M7603|GT-M8800|GT-M8910|GT-N7000|GT-S3110|GT-S3310|GT-S3350|GT-S3353|GT-S3370|GT-S3650|GT-S3653|GT-S3770|GT-S3850|GT-S5210|GT-S5220|GT-S5229|GT-S5230|GT-S5233|GT-S5250|GT-S5253|GT-S5260|GT-S5263|GT-S5270|GT-S5300|GT-S5330|GT-S5350|GT-S5360|GT-S5363|GT-S5369|GT-S5380|GT-S5380D|GT-S5560|GT-S5570|GT-S5600|GT-S5603|GT-S5610|GT-S5620|GT-S5660|GT-S5670|GT-S5690|GT-S5750|GT-S5780|GT-S5830|GT-S5839|GT-S6102|GT-S6500|GT-S7070|GT-S7200|GT-S7220|GT-S7230|GT-S7233|GT-S7250|GT-S7500|GT-S7530|GT-S7550|GT-S7562|GT-S7710|GT-S8000|GT-S8003|GT-S8500|GT-S8530|GT-S8600|SCH-A310|SCH-A530|SCH-A570|SCH-A610|SCH-A630|SCH-A650|SCH-A790|SCH-A795|SCH-A850|SCH-A870|SCH-A890|SCH-A930|SCH-A950|SCH-A970|SCH-A990|SCH-I100|SCH-I110|SCH-I400|SCH-I405|SCH-I500|SCH-I510|SCH-I515|SCH-I600|SCH-I730|SCH-I760|SCH-I770|SCH-I830|SCH-I910|SCH-I920|SCH-I959|SCH-LC11|SCH-N150|SCH-N300|SCH-R100|SCH-R300|SCH-R351|SCH-R400|SCH-R410|SCH-T300|SCH-U310|SCH-U320|SCH-U350|SCH-U360|SCH-U365|SCH-U370|SCH-U380|SCH-U410|SCH-U430|SCH-U450|SCH-U460|SCH-U470|SCH-U490|SCH-U540|SCH-U550|SCH-U620|SCH-U640|SCH-U650|SCH-U660|SCH-U700|SCH-U740|SCH-U750|SCH-U810|SCH-U820|SCH-U900|SCH-U940|SCH-U960|SCS-26UC|SGH-A107|SGH-A117|SGH-A127|SGH-A137|SGH-A157|SGH-A167|SGH-A177|SGH-A187|SGH-A197|SGH-A227|SGH-A237|SGH-A257|SGH-A437|SGH-A517|SGH-A597|SGH-A637|SGH-A657|SGH-A667|SGH-A687|SGH-A697|SGH-A707|SGH-A717|SGH-A727|SGH-A737|SGH-A747|SGH-A767|SGH-A777|SGH-A797|SGH-A817|SGH-A827|SGH-A837|SGH-A847|SGH-A867|SGH-A877|SGH-A887|SGH-A897|SGH-A927|SGH-B100|SGH-B130|SGH-B200|SGH-B220|SGH-C100|SGH-C110|SGH-C120|SGH-C130|SGH-C140|SGH-C160|SGH-C170|SGH-C180|SGH-C200|SGH-C207|SGH-C210|SGH-C225|SGH-C230|SGH-C417|SGH-C450|SGH-D307|SGH-D347|SGH-D357|SGH-D407|SGH-D415|SGH-D780|SGH-D807|SGH-D980|SGH-E105|SGH-E200|SGH-E315|SGH-E316|SGH-E317|SGH-E335|SGH-E590|SGH-E635|SGH-E715|SGH-E890|SGH-F300|SGH-F480|SGH-I200|SGH-I300|SGH-I320|SGH-I550|SGH-I577|SGH-I600|SGH-I607|SGH-I617|SGH-I627|SGH-I637|SGH-I677|SGH-I700|SGH-I717|SGH-I727|SGH-i747M|SGH-I777|SGH-I780|SGH-I827|SGH-I847|SGH-I857|SGH-I896|SGH-I897|SGH-I900|SGH-I907|SGH-I917|SGH-I927|SGH-I937|SGH-I997|SGH-J150|SGH-J200|SGH-L170|SGH-L700|SGH-M110|SGH-M150|SGH-M200|SGH-N105|SGH-N500|SGH-N600|SGH-N620|SGH-N625|SGH-N700|SGH-N710|SGH-P107|SGH-P207|SGH-P300|SGH-P310|SGH-P520|SGH-P735|SGH-P777|SGH-Q105|SGH-R210|SGH-R220|SGH-R225|SGH-S105|SGH-S307|SGH-T109|SGH-T119|SGH-T139|SGH-T209|SGH-T219|SGH-T229|SGH-T239|SGH-T249|SGH-T259|SGH-T309|SGH-T319|SGH-T329|SGH-T339|SGH-T349|SGH-T359|SGH-T369|SGH-T379|SGH-T409|SGH-T429|SGH-T439|SGH-T459|SGH-T469|SGH-T479|SGH-T499|SGH-T509|SGH-T519|SGH-T539|SGH-T559|SGH-T589|SGH-T609|SGH-T619|SGH-T629|SGH-T639|SGH-T659|SGH-T669|SGH-T679|SGH-T709|SGH-T719|SGH-T729|SGH-T739|SGH-T746|SGH-T749|SGH-T759|SGH-T769|SGH-T809|SGH-T819|SGH-T839|SGH-T919|SGH-T929|SGH-T939|SGH-T959|SGH-T989|SGH-U100|SGH-U200|SGH-U800|SGH-V205|SGH-V206|SGH-X100|SGH-X105|SGH-X120|SGH-X140|SGH-X426|SGH-X427|SGH-X475|SGH-X495|SGH-X497|SGH-X507|SGH-X600|SGH-X610|SGH-X620|SGH-X630|SGH-X700|SGH-X820|SGH-X890|SGH-Z130|SGH-Z150|SGH-Z170|SGH-ZX10|SGH-ZX20|SHW-M110|SPH-A120|SPH-A400|SPH-A420|SPH-A460|SPH-A500|SPH-A560|SPH-A600|SPH-A620|SPH-A660|SPH-A700|SPH-A740|SPH-A760|SPH-A790|SPH-A800|SPH-A820|SPH-A840|SPH-A880|SPH-A900|SPH-A940|SPH-A960|SPH-D600|SPH-D700|SPH-D710|SPH-D720|SPH-I300|SPH-I325|SPH-I330|SPH-I350|SPH-I500|SPH-I600|SPH-I700|SPH-L700|SPH-M100|SPH-M220|SPH-M240|SPH-M300|SPH-M305|SPH-M320|SPH-M330|SPH-M350|SPH-M360|SPH-M370|SPH-M380|SPH-M510|SPH-M540|SPH-M550|SPH-M560|SPH-M570|SPH-M580|SPH-M610|SPH-M620|SPH-M630|SPH-M800|SPH-M810|SPH-M850|SPH-M900|SPH-M910|SPH-M920|SPH-M930|SPH-N100|SPH-N200|SPH-N240|SPH-N300|SPH-N400|SPH-Z400|SWC-E100|SCH-i909|GT-N7100|GT-N7105|SCH-I535|SM-N900A|SGH-I317|SGH-T999L|GT-S5360B|GT-I8262|GT-S6802|GT-S6312|GT-S6310|GT-S5312|GT-S5310|GT-I9105|GT-I8510|GT-S6790N|SM-G7105|SM-N9005|GT-S5301|GT-I9295|GT-I9195|SM-C101|GT-S7392|GT-S7560|GT-B7610|GT-I5510|GT-S7582|GT-S7530E|GT-I8750|SM-G9006V|SM-G9008V|SM-G9009D|SM-G900A|SM-G900D|SM-G900F|SM-G900H|SM-G900I|SM-G900J|SM-G900K|SM-G900L|SM-G900M|SM-G900P|SM-G900R4|SM-G900S|SM-G900T|SM-G900V|SM-G900W8|SHV-E160K|SCH-P709|SCH-P729|SM-T2558|GT-I9205|SM-G9350|SM-J120F|SM-G920F|SM-G920V|SM-G930F|SM-N910C|SM-A310F|GT-I9190|SM-J500FN|SM-G903F|SM-J330F|SM-G610F|SM-G981B|SM-G892A|SM-A530F",LG:"\\bLG\\b;|LG[- ]?(C800|C900|E400|E610|E900|E-900|F160|F180K|F180L|F180S|730|855|L160|LS740|LS840|LS970|LU6200|MS690|MS695|MS770|MS840|MS870|MS910|P500|P700|P705|VM696|AS680|AS695|AX840|C729|E970|GS505|272|C395|E739BK|E960|L55C|L75C|LS696|LS860|P769BK|P350|P500|P509|P870|UN272|US730|VS840|VS950|LN272|LN510|LS670|LS855|LW690|MN270|MN510|P509|P769|P930|UN200|UN270|UN510|UN610|US670|US740|US760|UX265|UX840|VN271|VN530|VS660|VS700|VS740|VS750|VS910|VS920|VS930|VX9200|VX11000|AX840A|LW770|P506|P925|P999|E612|D955|D802|MS323|M257)|LM-G710",Sony:"SonyST|SonyLT|SonyEricsson|SonyEricssonLT15iv|LT18i|E10i|LT28h|LT26w|SonyEricssonMT27i|C5303|C6902|C6903|C6906|C6943|D2533|SOV34|601SO|F8332",Asus:"Asus.*Galaxy|PadFone.*Mobile",Xiaomi:"^(?!.*\\bx11\\b).*xiaomi.*$|POCOPHONE F1|MI 8|Redmi Note 9S|Redmi Note 5A Prime|N2G47H|M2001J2G|M2001J2I|M1805E10A|M2004J11G|M1902F1G|M2002J9G|M2004J19G|M2003J6A1G",NokiaLumia:"Lumia [0-9]{3,4}",Micromax:"Micromax.*\\b(A210|A92|A88|A72|A111|A110Q|A115|A116|A110|A90S|A26|A51|A35|A54|A25|A27|A89|A68|A65|A57|A90)\\b",Palm:"PalmSource|Palm",Vertu:"Vertu|Vertu.*Ltd|Vertu.*Ascent|Vertu.*Ayxta|Vertu.*Constellation(F|Quest)?|Vertu.*Monika|Vertu.*Signature",Pantech:"PANTECH|IM-A850S|IM-A840S|IM-A830L|IM-A830K|IM-A830S|IM-A820L|IM-A810K|IM-A810S|IM-A800S|IM-T100K|IM-A725L|IM-A780L|IM-A775C|IM-A770K|IM-A760S|IM-A750K|IM-A740S|IM-A730S|IM-A720L|IM-A710K|IM-A690L|IM-A690S|IM-A650S|IM-A630K|IM-A600S|VEGA PTL21|PT003|P8010|ADR910L|P6030|P6020|P9070|P4100|P9060|P5000|CDM8992|TXT8045|ADR8995|IS11PT|P2030|P6010|P8000|PT002|IS06|CDM8999|P9050|PT001|TXT8040|P2020|P9020|P2000|P7040|P7000|C790",Fly:"IQ230|IQ444|IQ450|IQ440|IQ442|IQ441|IQ245|IQ256|IQ236|IQ255|IQ235|IQ245|IQ275|IQ240|IQ285|IQ280|IQ270|IQ260|IQ250",Wiko:"KITE 4G|HIGHWAY|GETAWAY|STAIRWAY|DARKSIDE|DARKFULL|DARKNIGHT|DARKMOON|SLIDE|WAX 4G|RAINBOW|BLOOM|SUNSET|GOA(?!nna)|LENNY|BARRY|IGGY|OZZY|CINK FIVE|CINK PEAX|CINK PEAX 2|CINK SLIM|CINK SLIM 2|CINK +|CINK KING|CINK PEAX|CINK SLIM|SUBLIM",iMobile:"i-mobile (IQ|i-STYLE|idea|ZAA|Hitz)",SimValley:"\\b(SP-80|XT-930|SX-340|XT-930|SX-310|SP-360|SP60|SPT-800|SP-120|SPT-800|SP-140|SPX-5|SPX-8|SP-100|SPX-8|SPX-12)\\b",Wolfgang:"AT-B24D|AT-AS50HD|AT-AS40W|AT-AS55HD|AT-AS45q2|AT-B26D|AT-AS50Q",Alcatel:"Alcatel",Nintendo:"Nintendo (3DS|Switch)",Amoi:"Amoi",INQ:"INQ",OnePlus:"ONEPLUS",GenericPhone:"Tapatalk|PDA;|SAGEM|\\bmmp\\b|pocket|\\bpsp\\b|symbian|Smartphone|smartfon|treo|up.browser|up.link|vodafone|\\bwap\\b|nokia|Series40|Series60|S60|SonyEricsson|N900|MAUI.*WAP.*Browser"},tablets:{iPad:"iPad|iPad.*Mobile",NexusTablet:"Android.*Nexus[\\s]+(7|9|10)",GoogleTablet:"Android.*Pixel C",SamsungTablet:"SAMSUNG.*Tablet|Galaxy.*Tab|SC-01C|GT-P1000|GT-P1003|GT-P1010|GT-P3105|GT-P6210|GT-P6800|GT-P6810|GT-P7100|GT-P7300|GT-P7310|GT-P7500|GT-P7510|SCH-I800|SCH-I815|SCH-I905|SGH-I957|SGH-I987|SGH-T849|SGH-T859|SGH-T869|SPH-P100|GT-P3100|GT-P3108|GT-P3110|GT-P5100|GT-P5110|GT-P6200|GT-P7320|GT-P7511|GT-N8000|GT-P8510|SGH-I497|SPH-P500|SGH-T779|SCH-I705|SCH-I915|GT-N8013|GT-P3113|GT-P5113|GT-P8110|GT-N8010|GT-N8005|GT-N8020|GT-P1013|GT-P6201|GT-P7501|GT-N5100|GT-N5105|GT-N5110|SHV-E140K|SHV-E140L|SHV-E140S|SHV-E150S|SHV-E230K|SHV-E230L|SHV-E230S|SHW-M180K|SHW-M180L|SHW-M180S|SHW-M180W|SHW-M300W|SHW-M305W|SHW-M380K|SHW-M380S|SHW-M380W|SHW-M430W|SHW-M480K|SHW-M480S|SHW-M480W|SHW-M485W|SHW-M486W|SHW-M500W|GT-I9228|SCH-P739|SCH-I925|GT-I9200|GT-P5200|GT-P5210|GT-P5210X|SM-T311|SM-T310|SM-T310X|SM-T210|SM-T210R|SM-T211|SM-P600|SM-P601|SM-P605|SM-P900|SM-P901|SM-T217|SM-T217A|SM-T217S|SM-P6000|SM-T3100|SGH-I467|XE500|SM-T110|GT-P5220|GT-I9200X|GT-N5110X|GT-N5120|SM-P905|SM-T111|SM-T2105|SM-T315|SM-T320|SM-T320X|SM-T321|SM-T520|SM-T525|SM-T530NU|SM-T230NU|SM-T330NU|SM-T900|XE500T1C|SM-P605V|SM-P905V|SM-T337V|SM-T537V|SM-T707V|SM-T807V|SM-P600X|SM-P900X|SM-T210X|SM-T230|SM-T230X|SM-T325|GT-P7503|SM-T531|SM-T330|SM-T530|SM-T705|SM-T705C|SM-T535|SM-T331|SM-T800|SM-T700|SM-T537|SM-T807|SM-P907A|SM-T337A|SM-T537A|SM-T707A|SM-T807A|SM-T237|SM-T807P|SM-P607T|SM-T217T|SM-T337T|SM-T807T|SM-T116NQ|SM-T116BU|SM-P550|SM-T350|SM-T550|SM-T9000|SM-P9000|SM-T705Y|SM-T805|GT-P3113|SM-T710|SM-T810|SM-T815|SM-T360|SM-T533|SM-T113|SM-T335|SM-T715|SM-T560|SM-T670|SM-T677|SM-T377|SM-T567|SM-T357T|SM-T555|SM-T561|SM-T713|SM-T719|SM-T813|SM-T819|SM-T580|SM-T355Y?|SM-T280|SM-T817A|SM-T820|SM-W700|SM-P580|SM-T587|SM-P350|SM-P555M|SM-P355M|SM-T113NU|SM-T815Y|SM-T585|SM-T285|SM-T825|SM-W708|SM-T835|SM-T830|SM-T837V|SM-T720|SM-T510|SM-T387V|SM-P610|SM-T290|SM-T515|SM-T590|SM-T595|SM-T725|SM-T817P|SM-P585N0|SM-T395|SM-T295|SM-T865|SM-P610N|SM-P615|SM-T970|SM-T380|SM-T5950|SM-T905|SM-T231|SM-T500|SM-T860",Kindle:"Kindle|Silk.*Accelerated|Android.*\\b(KFOT|KFTT|KFJWI|KFJWA|KFOTE|KFSOWI|KFTHWI|KFTHWA|KFAPWI|KFAPWA|WFJWAE|KFSAWA|KFSAWI|KFASWI|KFARWI|KFFOWI|KFGIWI|KFMEWI)\\b|Android.*Silk/[0-9.]+ like Chrome/[0-9.]+ (?!Mobile)",SurfaceTablet:"Windows NT [0-9.]+; ARM;.*(Tablet|ARMBJS)",HPTablet:"HP Slate (7|8|10)|HP ElitePad 900|hp-tablet|EliteBook.*Touch|HP 8|Slate 21|HP SlateBook 10",AsusTablet:"^.*PadFone((?!Mobile).)*$|Transformer|TF101|TF101G|TF300T|TF300TG|TF300TL|TF700T|TF700KL|TF701T|TF810C|ME171|ME301T|ME302C|ME371MG|ME370T|ME372MG|ME172V|ME173X|ME400C|Slider SL101|\\bK00F\\b|\\bK00C\\b|\\bK00E\\b|\\bK00L\\b|TX201LA|ME176C|ME102A|\\bM80TA\\b|ME372CL|ME560CG|ME372CG|ME302KL| K010 | K011 | K017 | K01E |ME572C|ME103K|ME170C|ME171C|\\bME70C\\b|ME581C|ME581CL|ME8510C|ME181C|P01Y|PO1MA|P01Z|\\bP027\\b|\\bP024\\b|\\bP00C\\b",BlackBerryTablet:"PlayBook|RIM Tablet",HTCtablet:"HTC_Flyer_P512|HTC Flyer|HTC Jetstream|HTC-P715a|HTC EVO View 4G|PG41200|PG09410",MotorolaTablet:"xoom|sholest|MZ615|MZ605|MZ505|MZ601|MZ602|MZ603|MZ604|MZ606|MZ607|MZ608|MZ609|MZ615|MZ616|MZ617",NookTablet:"Android.*Nook|NookColor|nook browser|BNRV200|BNRV200A|BNTV250|BNTV250A|BNTV400|BNTV600|LogicPD Zoom2",AcerTablet:"Android.*; \\b(A100|A101|A110|A200|A210|A211|A500|A501|A510|A511|A700|A701|W500|W500P|W501|W501P|W510|W511|W700|G100|G100W|B1-A71|B1-710|B1-711|A1-810|A1-811|A1-830)\\b|W3-810|\\bA3-A10\\b|\\bA3-A11\\b|\\bA3-A20\\b|\\bA3-A30|A3-A40",ToshibaTablet:"Android.*(AT100|AT105|AT200|AT205|AT270|AT275|AT300|AT305|AT1S5|AT500|AT570|AT700|AT830)|TOSHIBA.*FOLIO",LGTablet:"\\bL-06C|LG-V909|LG-V900|LG-V700|LG-V510|LG-V500|LG-V410|LG-V400|LG-VK810\\b",FujitsuTablet:"Android.*\\b(F-01D|F-02F|F-05E|F-10D|M532|Q572)\\b",PrestigioTablet:"PMP3170B|PMP3270B|PMP3470B|PMP7170B|PMP3370B|PMP3570C|PMP5870C|PMP3670B|PMP5570C|PMP5770D|PMP3970B|PMP3870C|PMP5580C|PMP5880D|PMP5780D|PMP5588C|PMP7280C|PMP7280C3G|PMP7280|PMP7880D|PMP5597D|PMP5597|PMP7100D|PER3464|PER3274|PER3574|PER3884|PER5274|PER5474|PMP5097CPRO|PMP5097|PMP7380D|PMP5297C|PMP5297C_QUAD|PMP812E|PMP812E3G|PMP812F|PMP810E|PMP880TD|PMT3017|PMT3037|PMT3047|PMT3057|PMT7008|PMT5887|PMT5001|PMT5002",LenovoTablet:"Lenovo TAB|Idea(Tab|Pad)( A1|A10| K1|)|ThinkPad([ ]+)?Tablet|YT3-850M|YT3-X90L|YT3-X90F|YT3-X90X|Lenovo.*(S2109|S2110|S5000|S6000|K3011|A3000|A3500|A1000|A2107|A2109|A1107|A5500|A7600|B6000|B8000|B8080)(-|)(FL|F|HV|H|)|TB-X103F|TB-X304X|TB-X304F|TB-X304L|TB-X505F|TB-X505L|TB-X505X|TB-X605F|TB-X605L|TB-8703F|TB-8703X|TB-8703N|TB-8704N|TB-8704F|TB-8704X|TB-8704V|TB-7304F|TB-7304I|TB-7304X|Tab2A7-10F|Tab2A7-20F|TB2-X30L|YT3-X50L|YT3-X50F|YT3-X50M|YT-X705F|YT-X703F|YT-X703L|YT-X705L|YT-X705X|TB2-X30F|TB2-X30L|TB2-X30M|A2107A-F|A2107A-H|TB3-730F|TB3-730M|TB3-730X|TB-7504F|TB-7504X|TB-X704F|TB-X104F|TB3-X70F|TB-X705F|TB-8504F|TB3-X70L|TB3-710F|TB-X704L",DellTablet:"Venue 11|Venue 8|Venue 7|Dell Streak 10|Dell Streak 7",YarvikTablet:"Android.*\\b(TAB210|TAB211|TAB224|TAB250|TAB260|TAB264|TAB310|TAB360|TAB364|TAB410|TAB411|TAB420|TAB424|TAB450|TAB460|TAB461|TAB464|TAB465|TAB467|TAB468|TAB07-100|TAB07-101|TAB07-150|TAB07-151|TAB07-152|TAB07-200|TAB07-201-3G|TAB07-210|TAB07-211|TAB07-212|TAB07-214|TAB07-220|TAB07-400|TAB07-485|TAB08-150|TAB08-200|TAB08-201-3G|TAB08-201-30|TAB09-100|TAB09-211|TAB09-410|TAB10-150|TAB10-201|TAB10-211|TAB10-400|TAB10-410|TAB13-201|TAB274EUK|TAB275EUK|TAB374EUK|TAB462EUK|TAB474EUK|TAB9-200)\\b",MedionTablet:"Android.*\\bOYO\\b|LIFE.*(P9212|P9514|P9516|S9512)|LIFETAB",ArnovaTablet:"97G4|AN10G2|AN7bG3|AN7fG3|AN8G3|AN8cG3|AN7G3|AN9G3|AN7dG3|AN7dG3ST|AN7dG3ChildPad|AN10bG3|AN10bG3DT|AN9G2",IntensoTablet:"INM8002KP|INM1010FP|INM805ND|Intenso Tab|TAB1004",IRUTablet:"M702pro",MegafonTablet:"MegaFon V9|\\bZTE V9\\b|Android.*\\bMT7A\\b",EbodaTablet:"E-Boda (Supreme|Impresspeed|Izzycomm|Essential)",AllViewTablet:"Allview.*(Viva|Alldro|City|Speed|All TV|Frenzy|Quasar|Shine|TX1|AX1|AX2)",ArchosTablet:"\\b(101G9|80G9|A101IT)\\b|Qilive 97R|Archos5|\\bARCHOS (70|79|80|90|97|101|FAMILYPAD|)(b|c|)(G10| Cobalt| TITANIUM(HD|)| Xenon| Neon|XSK| 2| XS 2| PLATINUM| CARBON|GAMEPAD)\\b",AinolTablet:"NOVO7|NOVO8|NOVO10|Novo7Aurora|Novo7Basic|NOVO7PALADIN|novo9-Spark",NokiaLumiaTablet:"Lumia 2520",SonyTablet:"Sony.*Tablet|Xperia Tablet|Sony Tablet S|SO-03E|SGPT12|SGPT13|SGPT114|SGPT121|SGPT122|SGPT123|SGPT111|SGPT112|SGPT113|SGPT131|SGPT132|SGPT133|SGPT211|SGPT212|SGPT213|SGP311|SGP312|SGP321|EBRD1101|EBRD1102|EBRD1201|SGP351|SGP341|SGP511|SGP512|SGP521|SGP541|SGP551|SGP621|SGP641|SGP612|SOT31|SGP771|SGP611|SGP612|SGP712",PhilipsTablet:"\\b(PI2010|PI3000|PI3100|PI3105|PI3110|PI3205|PI3210|PI3900|PI4010|PI7000|PI7100)\\b",CubeTablet:"Android.*(K8GT|U9GT|U10GT|U16GT|U17GT|U18GT|U19GT|U20GT|U23GT|U30GT)|CUBE U8GT",CobyTablet:"MID1042|MID1045|MID1125|MID1126|MID7012|MID7014|MID7015|MID7034|MID7035|MID7036|MID7042|MID7048|MID7127|MID8042|MID8048|MID8127|MID9042|MID9740|MID9742|MID7022|MID7010",MIDTablet:"M9701|M9000|M9100|M806|M1052|M806|T703|MID701|MID713|MID710|MID727|MID760|MID830|MID728|MID933|MID125|MID810|MID732|MID120|MID930|MID800|MID731|MID900|MID100|MID820|MID735|MID980|MID130|MID833|MID737|MID960|MID135|MID860|MID736|MID140|MID930|MID835|MID733|MID4X10",MSITablet:"MSI \\b(Primo 73K|Primo 73L|Primo 81L|Primo 77|Primo 93|Primo 75|Primo 76|Primo 73|Primo 81|Primo 91|Primo 90|Enjoy 71|Enjoy 7|Enjoy 10)\\b",SMiTTablet:"Android.*(\\bMID\\b|MID-560|MTV-T1200|MTV-PND531|MTV-P1101|MTV-PND530)",RockChipTablet:"Android.*(RK2818|RK2808A|RK2918|RK3066)|RK2738|RK2808A",FlyTablet:"IQ310|Fly Vision",bqTablet:"Android.*(bq)?.*\\b(Elcano|Curie|Edison|Maxwell|Kepler|Pascal|Tesla|Hypatia|Platon|Newton|Livingstone|Cervantes|Avant|Aquaris ([E|M]10|M8))\\b|Maxwell.*Lite|Maxwell.*Plus",HuaweiTablet:"MediaPad|MediaPad 7 Youth|IDEOS S7|S7-201c|S7-202u|S7-101|S7-103|S7-104|S7-105|S7-106|S7-201|S7-Slim|M2-A01L|BAH-L09|BAH-W09|AGS-L09|CMR-AL19",NecTablet:"\\bN-06D|\\bN-08D",PantechTablet:"Pantech.*P4100",BronchoTablet:"Broncho.*(N701|N708|N802|a710)",VersusTablet:"TOUCHPAD.*[78910]|\\bTOUCHTAB\\b",ZyncTablet:"z1000|Z99 2G|z930|z990|z909|Z919|z900",PositivoTablet:"TB07STA|TB10STA|TB07FTA|TB10FTA",NabiTablet:"Android.*\\bNabi",KoboTablet:"Kobo Touch|\\bK080\\b|\\bVox\\b Build|\\bArc\\b Build",DanewTablet:"DSlide.*\\b(700|701R|702|703R|704|802|970|971|972|973|974|1010|1012)\\b",TexetTablet:"NaviPad|TB-772A|TM-7045|TM-7055|TM-9750|TM-7016|TM-7024|TM-7026|TM-7041|TM-7043|TM-7047|TM-8041|TM-9741|TM-9747|TM-9748|TM-9751|TM-7022|TM-7021|TM-7020|TM-7011|TM-7010|TM-7023|TM-7025|TM-7037W|TM-7038W|TM-7027W|TM-9720|TM-9725|TM-9737W|TM-1020|TM-9738W|TM-9740|TM-9743W|TB-807A|TB-771A|TB-727A|TB-725A|TB-719A|TB-823A|TB-805A|TB-723A|TB-715A|TB-707A|TB-705A|TB-709A|TB-711A|TB-890HD|TB-880HD|TB-790HD|TB-780HD|TB-770HD|TB-721HD|TB-710HD|TB-434HD|TB-860HD|TB-840HD|TB-760HD|TB-750HD|TB-740HD|TB-730HD|TB-722HD|TB-720HD|TB-700HD|TB-500HD|TB-470HD|TB-431HD|TB-430HD|TB-506|TB-504|TB-446|TB-436|TB-416|TB-146SE|TB-126SE",PlaystationTablet:"Playstation.*(Portable|Vita)",TrekstorTablet:"ST10416-1|VT10416-1|ST70408-1|ST702xx-1|ST702xx-2|ST80208|ST97216|ST70104-2|VT10416-2|ST10216-2A|SurfTab",PyleAudioTablet:"\\b(PTBL10CEU|PTBL10C|PTBL72BC|PTBL72BCEU|PTBL7CEU|PTBL7C|PTBL92BC|PTBL92BCEU|PTBL9CEU|PTBL9CUK|PTBL9C)\\b",AdvanTablet:"Android.* \\b(E3A|T3X|T5C|T5B|T3E|T3C|T3B|T1J|T1F|T2A|T1H|T1i|E1C|T1-E|T5-A|T4|E1-B|T2Ci|T1-B|T1-D|O1-A|E1-A|T1-A|T3A|T4i)\\b ",DanyTechTablet:"Genius Tab G3|Genius Tab S2|Genius Tab Q3|Genius Tab G4|Genius Tab Q4|Genius Tab G-II|Genius TAB GII|Genius TAB GIII|Genius Tab S1",GalapadTablet:"Android [0-9.]+; [a-z-]+; \\bG1\\b",MicromaxTablet:"Funbook|Micromax.*\\b(P250|P560|P360|P362|P600|P300|P350|P500|P275)\\b",KarbonnTablet:"Android.*\\b(A39|A37|A34|ST8|ST10|ST7|Smart Tab3|Smart Tab2)\\b",AllFineTablet:"Fine7 Genius|Fine7 Shine|Fine7 Air|Fine8 Style|Fine9 More|Fine10 Joy|Fine11 Wide",PROSCANTablet:"\\b(PEM63|PLT1023G|PLT1041|PLT1044|PLT1044G|PLT1091|PLT4311|PLT4311PL|PLT4315|PLT7030|PLT7033|PLT7033D|PLT7035|PLT7035D|PLT7044K|PLT7045K|PLT7045KB|PLT7071KG|PLT7072|PLT7223G|PLT7225G|PLT7777G|PLT7810K|PLT7849G|PLT7851G|PLT7852G|PLT8015|PLT8031|PLT8034|PLT8036|PLT8080K|PLT8082|PLT8088|PLT8223G|PLT8234G|PLT8235G|PLT8816K|PLT9011|PLT9045K|PLT9233G|PLT9735|PLT9760G|PLT9770G)\\b",YONESTablet:"BQ1078|BC1003|BC1077|RK9702|BC9730|BC9001|IT9001|BC7008|BC7010|BC708|BC728|BC7012|BC7030|BC7027|BC7026",ChangJiaTablet:"TPC7102|TPC7103|TPC7105|TPC7106|TPC7107|TPC7201|TPC7203|TPC7205|TPC7210|TPC7708|TPC7709|TPC7712|TPC7110|TPC8101|TPC8103|TPC8105|TPC8106|TPC8203|TPC8205|TPC8503|TPC9106|TPC9701|TPC97101|TPC97103|TPC97105|TPC97106|TPC97111|TPC97113|TPC97203|TPC97603|TPC97809|TPC97205|TPC10101|TPC10103|TPC10106|TPC10111|TPC10203|TPC10205|TPC10503",GUTablet:"TX-A1301|TX-M9002|Q702|kf026",PointOfViewTablet:"TAB-P506|TAB-navi-7-3G-M|TAB-P517|TAB-P-527|TAB-P701|TAB-P703|TAB-P721|TAB-P731N|TAB-P741|TAB-P825|TAB-P905|TAB-P925|TAB-PR945|TAB-PL1015|TAB-P1025|TAB-PI1045|TAB-P1325|TAB-PROTAB[0-9]+|TAB-PROTAB25|TAB-PROTAB26|TAB-PROTAB27|TAB-PROTAB26XL|TAB-PROTAB2-IPS9|TAB-PROTAB30-IPS9|TAB-PROTAB25XXL|TAB-PROTAB26-IPS10|TAB-PROTAB30-IPS10",OvermaxTablet:"OV-(SteelCore|NewBase|Basecore|Baseone|Exellen|Quattor|EduTab|Solution|ACTION|BasicTab|TeddyTab|MagicTab|Stream|TB-08|TB-09)|Qualcore 1027",HCLTablet:"HCL.*Tablet|Connect-3G-2.0|Connect-2G-2.0|ME Tablet U1|ME Tablet U2|ME Tablet G1|ME Tablet X1|ME Tablet Y2|ME Tablet Sync",DPSTablet:"DPS Dream 9|DPS Dual 7",VistureTablet:"V97 HD|i75 3G|Visture V4( HD)?|Visture V5( HD)?|Visture V10",CrestaTablet:"CTP(-)?810|CTP(-)?818|CTP(-)?828|CTP(-)?838|CTP(-)?888|CTP(-)?978|CTP(-)?980|CTP(-)?987|CTP(-)?988|CTP(-)?989",MediatekTablet:"\\bMT8125|MT8389|MT8135|MT8377\\b",ConcordeTablet:"Concorde([ ]+)?Tab|ConCorde ReadMan",GoCleverTablet:"GOCLEVER TAB|A7GOCLEVER|M1042|M7841|M742|R1042BK|R1041|TAB A975|TAB A7842|TAB A741|TAB A741L|TAB M723G|TAB M721|TAB A1021|TAB I921|TAB R721|TAB I720|TAB T76|TAB R70|TAB R76.2|TAB R106|TAB R83.2|TAB M813G|TAB I721|GCTA722|TAB I70|TAB I71|TAB S73|TAB R73|TAB R74|TAB R93|TAB R75|TAB R76.1|TAB A73|TAB A93|TAB A93.2|TAB T72|TAB R83|TAB R974|TAB R973|TAB A101|TAB A103|TAB A104|TAB A104.2|R105BK|M713G|A972BK|TAB A971|TAB R974.2|TAB R104|TAB R83.3|TAB A1042",ModecomTablet:"FreeTAB 9000|FreeTAB 7.4|FreeTAB 7004|FreeTAB 7800|FreeTAB 2096|FreeTAB 7.5|FreeTAB 1014|FreeTAB 1001 |FreeTAB 8001|FreeTAB 9706|FreeTAB 9702|FreeTAB 7003|FreeTAB 7002|FreeTAB 1002|FreeTAB 7801|FreeTAB 1331|FreeTAB 1004|FreeTAB 8002|FreeTAB 8014|FreeTAB 9704|FreeTAB 1003",VoninoTablet:"\\b(Argus[ _]?S|Diamond[ _]?79HD|Emerald[ _]?78E|Luna[ _]?70C|Onyx[ _]?S|Onyx[ _]?Z|Orin[ _]?HD|Orin[ _]?S|Otis[ _]?S|SpeedStar[ _]?S|Magnet[ _]?M9|Primus[ _]?94[ _]?3G|Primus[ _]?94HD|Primus[ _]?QS|Android.*\\bQ8\\b|Sirius[ _]?EVO[ _]?QS|Sirius[ _]?QS|Spirit[ _]?S)\\b",ECSTablet:"V07OT2|TM105A|S10OT1|TR10CS1",StorexTablet:"eZee[_']?(Tab|Go)[0-9]+|TabLC7|Looney Tunes Tab",VodafoneTablet:"SmartTab([ ]+)?[0-9]+|SmartTabII10|SmartTabII7|VF-1497|VFD 1400",EssentielBTablet:"Smart[ ']?TAB[ ]+?[0-9]+|Family[ ']?TAB2",RossMoorTablet:"RM-790|RM-997|RMD-878G|RMD-974R|RMT-705A|RMT-701|RME-601|RMT-501|RMT-711",iMobileTablet:"i-mobile i-note",TolinoTablet:"tolino tab [0-9.]+|tolino shine",AudioSonicTablet:"\\bC-22Q|T7-QC|T-17B|T-17P\\b",AMPETablet:"Android.* A78 ",SkkTablet:"Android.* (SKYPAD|PHOENIX|CYCLOPS)",TecnoTablet:"TECNO P9|TECNO DP8D",JXDTablet:"Android.* \\b(F3000|A3300|JXD5000|JXD3000|JXD2000|JXD300B|JXD300|S5800|S7800|S602b|S5110b|S7300|S5300|S602|S603|S5100|S5110|S601|S7100a|P3000F|P3000s|P101|P200s|P1000m|P200m|P9100|P1000s|S6600b|S908|P1000|P300|S18|S6600|S9100)\\b",iJoyTablet:"Tablet (Spirit 7|Essentia|Galatea|Fusion|Onix 7|Landa|Titan|Scooby|Deox|Stella|Themis|Argon|Unique 7|Sygnus|Hexen|Finity 7|Cream|Cream X2|Jade|Neon 7|Neron 7|Kandy|Scape|Saphyr 7|Rebel|Biox|Rebel|Rebel 8GB|Myst|Draco 7|Myst|Tab7-004|Myst|Tadeo Jones|Tablet Boing|Arrow|Draco Dual Cam|Aurix|Mint|Amity|Revolution|Finity 9|Neon 9|T9w|Amity 4GB Dual Cam|Stone 4GB|Stone 8GB|Andromeda|Silken|X2|Andromeda II|Halley|Flame|Saphyr 9,7|Touch 8|Planet|Triton|Unique 10|Hexen 10|Memphis 4GB|Memphis 8GB|Onix 10)",FX2Tablet:"FX2 PAD7|FX2 PAD10",XoroTablet:"KidsPAD 701|PAD[ ]?712|PAD[ ]?714|PAD[ ]?716|PAD[ ]?717|PAD[ ]?718|PAD[ ]?720|PAD[ ]?721|PAD[ ]?722|PAD[ ]?790|PAD[ ]?792|PAD[ ]?900|PAD[ ]?9715D|PAD[ ]?9716DR|PAD[ ]?9718DR|PAD[ ]?9719QR|PAD[ ]?9720QR|TelePAD1030|Telepad1032|TelePAD730|TelePAD731|TelePAD732|TelePAD735Q|TelePAD830|TelePAD9730|TelePAD795|MegaPAD 1331|MegaPAD 1851|MegaPAD 2151",ViewsonicTablet:"ViewPad 10pi|ViewPad 10e|ViewPad 10s|ViewPad E72|ViewPad7|ViewPad E100|ViewPad 7e|ViewSonic VB733|VB100a",VerizonTablet:"QTAQZ3|QTAIR7|QTAQTZ3|QTASUN1|QTASUN2|QTAXIA1",OdysTablet:"LOOX|XENO10|ODYS[ -](Space|EVO|Xpress|NOON)|\\bXELIO\\b|Xelio10Pro|XELIO7PHONETAB|XELIO10EXTREME|XELIOPT2|NEO_QUAD10",CaptivaTablet:"CAPTIVA PAD",IconbitTablet:"NetTAB|NT-3702|NT-3702S|NT-3702S|NT-3603P|NT-3603P|NT-0704S|NT-0704S|NT-3805C|NT-3805C|NT-0806C|NT-0806C|NT-0909T|NT-0909T|NT-0907S|NT-0907S|NT-0902S|NT-0902S",TeclastTablet:"T98 4G|\\bP80\\b|\\bX90HD\\b|X98 Air|X98 Air 3G|\\bX89\\b|P80 3G|\\bX80h\\b|P98 Air|\\bX89HD\\b|P98 3G|\\bP90HD\\b|P89 3G|X98 3G|\\bP70h\\b|P79HD 3G|G18d 3G|\\bP79HD\\b|\\bP89s\\b|\\bA88\\b|\\bP10HD\\b|\\bP19HD\\b|G18 3G|\\bP78HD\\b|\\bA78\\b|\\bP75\\b|G17s 3G|G17h 3G|\\bP85t\\b|\\bP90\\b|\\bP11\\b|\\bP98t\\b|\\bP98HD\\b|\\bG18d\\b|\\bP85s\\b|\\bP11HD\\b|\\bP88s\\b|\\bA80HD\\b|\\bA80se\\b|\\bA10h\\b|\\bP89\\b|\\bP78s\\b|\\bG18\\b|\\bP85\\b|\\bA70h\\b|\\bA70\\b|\\bG17\\b|\\bP18\\b|\\bA80s\\b|\\bA11s\\b|\\bP88HD\\b|\\bA80h\\b|\\bP76s\\b|\\bP76h\\b|\\bP98\\b|\\bA10HD\\b|\\bP78\\b|\\bP88\\b|\\bA11\\b|\\bA10t\\b|\\bP76a\\b|\\bP76t\\b|\\bP76e\\b|\\bP85HD\\b|\\bP85a\\b|\\bP86\\b|\\bP75HD\\b|\\bP76v\\b|\\bA12\\b|\\bP75a\\b|\\bA15\\b|\\bP76Ti\\b|\\bP81HD\\b|\\bA10\\b|\\bT760VE\\b|\\bT720HD\\b|\\bP76\\b|\\bP73\\b|\\bP71\\b|\\bP72\\b|\\bT720SE\\b|\\bC520Ti\\b|\\bT760\\b|\\bT720VE\\b|T720-3GE|T720-WiFi",OndaTablet:"\\b(V975i|Vi30|VX530|V701|Vi60|V701s|Vi50|V801s|V719|Vx610w|VX610W|V819i|Vi10|VX580W|Vi10|V711s|V813|V811|V820w|V820|Vi20|V711|VI30W|V712|V891w|V972|V819w|V820w|Vi60|V820w|V711|V813s|V801|V819|V975s|V801|V819|V819|V818|V811|V712|V975m|V101w|V961w|V812|V818|V971|V971s|V919|V989|V116w|V102w|V973|Vi40)\\b[\\s]+|V10 \\b4G\\b",JaytechTablet:"TPC-PA762",BlaupunktTablet:"Endeavour 800NG|Endeavour 1010",DigmaTablet:"\\b(iDx10|iDx9|iDx8|iDx7|iDxD7|iDxD8|iDsQ8|iDsQ7|iDsQ8|iDsD10|iDnD7|3TS804H|iDsQ11|iDj7|iDs10)\\b",EvolioTablet:"ARIA_Mini_wifi|Aria[ _]Mini|Evolio X10|Evolio X7|Evolio X8|\\bEvotab\\b|\\bNeura\\b",LavaTablet:"QPAD E704|\\bIvoryS\\b|E-TAB IVORY|\\bE-TAB\\b",AocTablet:"MW0811|MW0812|MW0922|MTK8382|MW1031|MW0831|MW0821|MW0931|MW0712",MpmanTablet:"MP11 OCTA|MP10 OCTA|MPQC1114|MPQC1004|MPQC994|MPQC974|MPQC973|MPQC804|MPQC784|MPQC780|\\bMPG7\\b|MPDCG75|MPDCG71|MPDC1006|MP101DC|MPDC9000|MPDC905|MPDC706HD|MPDC706|MPDC705|MPDC110|MPDC100|MPDC99|MPDC97|MPDC88|MPDC8|MPDC77|MP709|MID701|MID711|MID170|MPDC703|MPQC1010",CelkonTablet:"CT695|CT888|CT[\\s]?910|CT7 Tab|CT9 Tab|CT3 Tab|CT2 Tab|CT1 Tab|C820|C720|\\bCT-1\\b",WolderTablet:"miTab \\b(DIAMOND|SPACE|BROOKLYN|NEO|FLY|MANHATTAN|FUNK|EVOLUTION|SKY|GOCAR|IRON|GENIUS|POP|MINT|EPSILON|BROADWAY|JUMP|HOP|LEGEND|NEW AGE|LINE|ADVANCE|FEEL|FOLLOW|LIKE|LINK|LIVE|THINK|FREEDOM|CHICAGO|CLEVELAND|BALTIMORE-GH|IOWA|BOSTON|SEATTLE|PHOENIX|DALLAS|IN 101|MasterChef)\\b",MediacomTablet:"M-MPI10C3G|M-SP10EG|M-SP10EGP|M-SP10HXAH|M-SP7HXAH|M-SP10HXBH|M-SP8HXAH|M-SP8MXA",MiTablet:"\\bMI PAD\\b|\\bHM NOTE 1W\\b",NibiruTablet:"Nibiru M1|Nibiru Jupiter One",NexoTablet:"NEXO NOVA|NEXO 10|NEXO AVIO|NEXO FREE|NEXO GO|NEXO EVO|NEXO 3G|NEXO SMART|NEXO KIDDO|NEXO MOBI",LeaderTablet:"TBLT10Q|TBLT10I|TBL-10WDKB|TBL-10WDKBO2013|TBL-W230V2|TBL-W450|TBL-W500|SV572|TBLT7I|TBA-AC7-8G|TBLT79|TBL-8W16|TBL-10W32|TBL-10WKB|TBL-W100",UbislateTablet:"UbiSlate[\\s]?7C",PocketBookTablet:"Pocketbook",KocasoTablet:"\\b(TB-1207)\\b",HisenseTablet:"\\b(F5281|E2371)\\b",Hudl:"Hudl HT7S3|Hudl 2",TelstraTablet:"T-Hub2",GenericTablet:"Android.*\\b97D\\b|Tablet(?!.*PC)|BNTV250A|MID-WCDMA|LogicPD Zoom2|\\bA7EB\\b|CatNova8|A1_07|CT704|CT1002|\\bM721\\b|rk30sdk|\\bEVOTAB\\b|M758A|ET904|ALUMIUM10|Smartfren Tab|Endeavour 1010|Tablet-PC-4|Tagi Tab|\\bM6pro\\b|CT1020W|arc 10HD|\\bTP750\\b|\\bQTAQZ3\\b|WVT101|TM1088|KT107"},oss:{AndroidOS:"Android",BlackBerryOS:"blackberry|\\bBB10\\b|rim tablet os",PalmOS:"PalmOS|avantgo|blazer|elaine|hiptop|palm|plucker|xiino",SymbianOS:"Symbian|SymbOS|Series60|Series40|SYB-[0-9]+|\\bS60\\b",WindowsMobileOS:"Windows CE.*(PPC|Smartphone|Mobile|[0-9]{3}x[0-9]{3})|Windows Mobile|Windows Phone [0-9.]+|WCE;",WindowsPhoneOS:"Windows Phone 10.0|Windows Phone 8.1|Windows Phone 8.0|Windows Phone OS|XBLWP7|ZuneWP7|Windows NT 6.[23]; ARM;",iOS:"\\biPhone.*Mobile|\\biPod|\\biPad|AppleCoreMedia",iPadOS:"CPU OS 13",SailfishOS:"Sailfish",MeeGoOS:"MeeGo",MaemoOS:"Maemo",JavaOS:"J2ME/|\\bMIDP\\b|\\bCLDC\\b",webOS:"webOS|hpwOS",badaOS:"\\bBada\\b",BREWOS:"BREW"},uas:{Chrome:"\\bCrMo\\b|CriOS|Android.*Chrome/[.0-9]* (Mobile)?",Dolfin:"\\bDolfin\\b",Opera:"Opera.*Mini|Opera.*Mobi|Android.*Opera|Mobile.*OPR/[0-9.]+$|Coast/[0-9.]+",Skyfire:"Skyfire",Edge:"\\bEdgiOS\\b|Mobile Safari/[.0-9]* Edge",IE:"IEMobile|MSIEMobile",Firefox:"fennec|firefox.*maemo|(Mobile|Tablet).*Firefox|Firefox.*Mobile|FxiOS",Bolt:"bolt",TeaShark:"teashark",Blazer:"Blazer",Safari:"Version((?!\\bEdgiOS\\b).)*Mobile.*Safari|Safari.*Mobile|MobileSafari",WeChat:"\\bMicroMessenger\\b",UCBrowser:"UC.*Browser|UCWEB",baiduboxapp:"baiduboxapp",baidubrowser:"baidubrowser",DiigoBrowser:"DiigoBrowser",Mercury:"\\bMercury\\b",ObigoBrowser:"Obigo",NetFront:"NF-Browser",GenericBrowser:"NokiaBrowser|OviBrowser|OneBrowser|TwonkyBeamBrowser|SEMC.*Browser|FlyFlow|Minimo|NetFront|Novarra-Vision|MQQBrowser|MicroMessenger",PaleMoon:"Android.*PaleMoon|Mobile.*PaleMoon"},props:{Mobile:"Mobile/[VER]",Build:"Build/[VER]",Version:"Version/[VER]",VendorID:"VendorID/[VER]",iPad:"iPad.*CPU[a-z ]+[VER]",iPhone:"iPhone.*CPU[a-z ]+[VER]",iPod:"iPod.*CPU[a-z ]+[VER]",Kindle:"Kindle/[VER]",Chrome:["Chrome/[VER]","CriOS/[VER]","CrMo/[VER]"],Coast:["Coast/[VER]"],Dolfin:"Dolfin/[VER]",Firefox:["Firefox/[VER]","FxiOS/[VER]"],Fennec:"Fennec/[VER]",Edge:"Edge/[VER]",IE:["IEMobile/[VER];","IEMobile [VER]","MSIE [VER];","Trident/[0-9.]+;.*rv:[VER]"],NetFront:"NetFront/[VER]",NokiaBrowser:"NokiaBrowser/[VER]",Opera:[" OPR/[VER]","Opera Mini/[VER]","Version/[VER]"],"Opera Mini":"Opera Mini/[VER]","Opera Mobi":"Version/[VER]",UCBrowser:["UCWEB[VER]","UC.*Browser/[VER]"],MQQBrowser:"MQQBrowser/[VER]",MicroMessenger:"MicroMessenger/[VER]",baiduboxapp:"baiduboxapp/[VER]",baidubrowser:"baidubrowser/[VER]",SamsungBrowser:"SamsungBrowser/[VER]",Iron:"Iron/[VER]",Safari:["Version/[VER]","Safari/[VER]"],Skyfire:"Skyfire/[VER]",Tizen:"Tizen/[VER]",Webkit:"webkit[ /][VER]",PaleMoon:"PaleMoon/[VER]",SailfishBrowser:"SailfishBrowser/[VER]",Gecko:"Gecko/[VER]",Trident:"Trident/[VER]",Presto:"Presto/[VER]",Goanna:"Goanna/[VER]",iOS:" \\bi?OS\\b [VER][ ;]{1}",Android:"Android [VER]",Sailfish:"Sailfish [VER]",BlackBerry:["BlackBerry[\\w]+/[VER]","BlackBerry.*Version/[VER]","Version/[VER]"],BREW:"BREW [VER]",Java:"Java/[VER]","Windows Phone OS":["Windows Phone OS [VER]","Windows Phone [VER]"],"Windows Phone":"Windows Phone [VER]","Windows CE":"Windows CE/[VER]","Windows NT":"Windows NT [VER]",Symbian:["SymbianOS/[VER]","Symbian/[VER]"],webOS:["webOS/[VER]","hpwOS/[VER];"]},utils:{Bot:"Googlebot|facebookexternalhit|Google-AMPHTML|s~amp-validator|AdsBot-Google|Google Keyword Suggestion|Facebot|YandexBot|YandexMobileBot|bingbot|ia_archiver|AhrefsBot|Ezooms|GSLFbot|WBSearchBot|Twitterbot|TweetmemeBot|Twikle|PaperLiBot|Wotbox|UnwindFetchor|Exabot|MJ12bot|YandexImages|TurnitinBot|Pingdom|contentkingapp|AspiegelBot",MobileBot:"Googlebot-Mobile|AdsBot-Google-Mobile|YahooSeeker/M1A1-R2D2",DesktopMode:"WPDesktop",TV:"SonyDTV|HbbTV",WebKit:"(webkit)[ /]([\\w.]+)",Console:"\\b(Nintendo|Nintendo WiiU|Nintendo 3DS|Nintendo Switch|PLAYSTATION|Xbox)\\b",Watch:"SM-V700"}},g.detectMobileBrowsers={fullPattern:/(android|bb\d+|meego).+mobile|avantgo|bada\/|blackberry|blazer|compal|elaine|fennec|hiptop|iemobile|ip(hone|od)|iris|kindle|lge |maemo|midp|mmp|mobile.+firefox|netfront|opera m(ob|in)i|palm( os)?|phone|p(ixi|re)\/|plucker|pocket|psp|series(4|6)0|symbian|treo|up\.(browser|link)|vodafone|wap|windows ce|xda|xiino/i,
shortPattern:/1207|6310|6590|3gso|4thp|50[1-6]i|770s|802s|a wa|abac|ac(er|oo|s\-)|ai(ko|rn)|al(av|ca|co)|amoi|an(ex|ny|yw)|aptu|ar(ch|go)|as(te|us)|attw|au(di|\-m|r |s )|avan|be(ck|ll|nq)|bi(lb|rd)|bl(ac|az)|br(e|v)w|bumb|bw\-(n|u)|c55\/|capi|ccwa|cdm\-|cell|chtm|cldc|cmd\-|co(mp|nd)|craw|da(it|ll|ng)|dbte|dc\-s|devi|dica|dmob|do(c|p)o|ds(12|\-d)|el(49|ai)|em(l2|ul)|er(ic|k0)|esl8|ez([4-7]0|os|wa|ze)|fetc|fly(\-|_)|g1 u|g560|gene|gf\-5|g\-mo|go(\.w|od)|gr(ad|un)|haie|hcit|hd\-(m|p|t)|hei\-|hi(pt|ta)|hp( i|ip)|hs\-c|ht(c(\-| |_|a|g|p|s|t)|tp)|hu(aw|tc)|i\-(20|go|ma)|i230|iac( |\-|\/)|ibro|idea|ig01|ikom|im1k|inno|ipaq|iris|ja(t|v)a|jbro|jemu|jigs|kddi|keji|kgt( |\/)|klon|kpt |kwc\-|kyo(c|k)|le(no|xi)|lg( g|\/(k|l|u)|50|54|\-[a-w])|libw|lynx|m1\-w|m3ga|m50\/|ma(te|ui|xo)|mc(01|21|ca)|m\-cr|me(rc|ri)|mi(o8|oa|ts)|mmef|mo(01|02|bi|de|do|t(\-| |o|v)|zz)|mt(50|p1|v )|mwbp|mywa|n10[0-2]|n20[2-3]|n30(0|2)|n50(0|2|5)|n7(0(0|1)|10)|ne((c|m)\-|on|tf|wf|wg|wt)|nok(6|i)|nzph|o2im|op(ti|wv)|oran|owg1|p800|pan(a|d|t)|pdxg|pg(13|\-([1-8]|c))|phil|pire|pl(ay|uc)|pn\-2|po(ck|rt|se)|prox|psio|pt\-g|qa\-a|qc(07|12|21|32|60|\-[2-7]|i\-)|qtek|r380|r600|raks|rim9|ro(ve|zo)|s55\/|sa(ge|ma|mm|ms|ny|va)|sc(01|h\-|oo|p\-)|sdk\/|se(c(\-|0|1)|47|mc|nd|ri)|sgh\-|shar|sie(\-|m)|sk\-0|sl(45|id)|sm(al|ar|b3|it|t5)|so(ft|ny)|sp(01|h\-|v\-|v )|sy(01|mb)|t2(18|50)|t6(00|10|18)|ta(gt|lk)|tcl\-|tdg\-|tel(i|m)|tim\-|t\-mo|to(pl|sh)|ts(70|m\-|m3|m5)|tx\-9|up(\.b|g1|si)|utst|v400|v750|veri|vi(rg|te)|vk(40|5[0-3]|\-v)|vm40|voda|vulc|vx(52|53|60|61|70|80|81|83|85|98)|w3c(\-| )|webc|whit|wi(g |nc|nw)|wmlb|wonu|x700|yas\-|your|zeto|zte\-/i,tabletPattern:/android|ipad|playbook|silk/i};var h,i=Object.prototype.hasOwnProperty;return g.FALLBACK_PHONE="UnknownPhone",g.FALLBACK_TABLET="UnknownTablet",g.FALLBACK_MOBILE="UnknownMobile",h="isArray"in Array?Array.isArray:function(a){return"[object Array]"===Object.prototype.toString.call(a)},function(){var a,b,c,e,f,j,k=g.mobileDetectRules;for(a in k.props)if(i.call(k.props,a)){for(b=k.props[a],h(b)||(b=[b]),f=b.length,e=0;e<f;++e)c=b[e],j=c.indexOf("[VER]"),j>=0&&(c=c.substring(0,j)+"([\\w._\\+]+)"+c.substring(j+5)),b[e]=new RegExp(c,"i");k.props[a]=b}d(k.oss),d(k.phones),d(k.tablets),d(k.uas),d(k.utils),k.oss0={WindowsPhoneOS:k.oss.WindowsPhoneOS,WindowsMobileOS:k.oss.WindowsMobileOS}}(),g.findMatch=function(a,b){for(var c in a)if(i.call(a,c)&&a[c].test(b))return c;return null},g.findMatches=function(a,b){var c=[];for(var d in a)i.call(a,d)&&a[d].test(b)&&c.push(d);return c},g.getVersionStr=function(a,b){var c,d,e,f,h=g.mobileDetectRules.props;if(i.call(h,a))for(c=h[a],e=c.length,d=0;d<e;++d)if(f=c[d].exec(b),null!==f)return f[1];return null},g.getVersion=function(a,b){var c=g.getVersionStr(a,b);return c?g.prepareVersionNo(c):NaN},g.prepareVersionNo=function(a){var b;return b=a.split(/[a-z._ \/\-]/i),1===b.length&&(a=b[0]),b.length>1&&(a=b[0]+".",b.shift(),a+=b.join("")),Number(a)},g.isMobileFallback=function(a){return g.detectMobileBrowsers.fullPattern.test(a)||g.detectMobileBrowsers.shortPattern.test(a.substr(0,4))},g.isTabletFallback=function(a){return g.detectMobileBrowsers.tabletPattern.test(a)},g.prepareDetectionCache=function(a,c,d){if(a.mobile===b){var e,h,i;return(h=g.findMatch(g.mobileDetectRules.tablets,c))?(a.mobile=a.tablet=h,void(a.phone=null)):(e=g.findMatch(g.mobileDetectRules.phones,c))?(a.mobile=a.phone=e,void(a.tablet=null)):void(g.isMobileFallback(c)?(i=f.isPhoneSized(d),i===b?(a.mobile=g.FALLBACK_MOBILE,a.tablet=a.phone=null):i?(a.mobile=a.phone=g.FALLBACK_PHONE,a.tablet=null):(a.mobile=a.tablet=g.FALLBACK_TABLET,a.phone=null)):g.isTabletFallback(c)?(a.mobile=a.tablet=g.FALLBACK_TABLET,a.phone=null):a.mobile=a.tablet=a.phone=null)}},g.mobileGrade=function(a){var b=null!==a.mobile();return a.os("iOS")&&a.version("iPad")>=4.3||a.os("iOS")&&a.version("iPhone")>=3.1||a.os("iOS")&&a.version("iPod")>=3.1||a.version("Android")>2.1&&a.is("Webkit")||a.version("Windows Phone OS")>=7||a.is("BlackBerry")&&a.version("BlackBerry")>=6||a.match("Playbook.*Tablet")||a.version("webOS")>=1.4&&a.match("Palm|Pre|Pixi")||a.match("hp.*TouchPad")||a.is("Firefox")&&a.version("Firefox")>=12||a.is("Chrome")&&a.is("AndroidOS")&&a.version("Android")>=4||a.is("Skyfire")&&a.version("Skyfire")>=4.1&&a.is("AndroidOS")&&a.version("Android")>=2.3||a.is("Opera")&&a.version("Opera Mobi")>11&&a.is("AndroidOS")||a.is("MeeGoOS")||a.is("Tizen")||a.is("Dolfin")&&a.version("Bada")>=2||(a.is("UC Browser")||a.is("Dolfin"))&&a.version("Android")>=2.3||a.match("Kindle Fire")||a.is("Kindle")&&a.version("Kindle")>=3||a.is("AndroidOS")&&a.is("NookTablet")||a.version("Chrome")>=11&&!b||a.version("Safari")>=5&&!b||a.version("Firefox")>=4&&!b||a.version("MSIE")>=7&&!b||a.version("Opera")>=10&&!b?"A":a.os("iOS")&&a.version("iPad")<4.3||a.os("iOS")&&a.version("iPhone")<3.1||a.os("iOS")&&a.version("iPod")<3.1||a.is("Blackberry")&&a.version("BlackBerry")>=5&&a.version("BlackBerry")<6||a.version("Opera Mini")>=5&&a.version("Opera Mini")<=6.5&&(a.version("Android")>=2.3||a.is("iOS"))||a.match("NokiaN8|NokiaC7|N97.*Series60|Symbian/3")||a.version("Opera Mobi")>=11&&a.is("SymbianOS")?"B":(a.version("BlackBerry")<5||a.match("MSIEMobile|Windows CE.*Mobile")||a.version("Windows Mobile")<=5.2,"C")},g.detectOS=function(a){return g.findMatch(g.mobileDetectRules.oss0,a)||g.findMatch(g.mobileDetectRules.oss,a)},g.getDeviceSmallerSide=function(){return window.screen.width<window.screen.height?window.screen.width:window.screen.height},f.prototype={constructor:f,mobile:function(){return g.prepareDetectionCache(this._cache,this.ua,this.maxPhoneWidth),this._cache.mobile},phone:function(){return g.prepareDetectionCache(this._cache,this.ua,this.maxPhoneWidth),this._cache.phone},tablet:function(){return g.prepareDetectionCache(this._cache,this.ua,this.maxPhoneWidth),this._cache.tablet},userAgent:function(){return this._cache.userAgent===b&&(this._cache.userAgent=g.findMatch(g.mobileDetectRules.uas,this.ua)),this._cache.userAgent},userAgents:function(){return this._cache.userAgents===b&&(this._cache.userAgents=g.findMatches(g.mobileDetectRules.uas,this.ua)),this._cache.userAgents},os:function(){return this._cache.os===b&&(this._cache.os=g.detectOS(this.ua)),this._cache.os},version:function(a){return g.getVersion(a,this.ua)},versionStr:function(a){return g.getVersionStr(a,this.ua)},is:function(b){return c(this.userAgents(),b)||a(b,this.os())||a(b,this.phone())||a(b,this.tablet())||c(g.findMatches(g.mobileDetectRules.utils,this.ua),b)},match:function(a){return a instanceof RegExp||(a=new RegExp(a,"i")),a.test(this.ua)},isPhoneSized:function(a){return f.isPhoneSized(a||this.maxPhoneWidth)},mobileGrade:function(){return this._cache.grade===b&&(this._cache.grade=g.mobileGrade(this)),this._cache.grade}},"undefined"!=typeof window&&window.screen?f.isPhoneSized=function(a){return a<0?b:g.getDeviceSmallerSide()<=a}:f.isPhoneSized=function(){},f._impl=g,f.version="1.4.5 2021-03-13",f})}(function(a){if("undefined"!=typeof module&&module.exports)return function(a){module.exports=a()};if("function"==typeof define&&define.amd)return define;if("undefined"!=typeof window)return function(a){window.MobileDetect=a()};throw new Error("unknown environment")}());var ai_lists=!0,ai_block_class_def="code-block";
if("undefined"!=typeof ai_lists){function X(b,e){for(var p=[];b=b.previousElementSibling;)("undefined"==typeof e||b.matches(e))&&p.push(b);return p}function fa(b,e){for(var p=[];b=b.nextElementSibling;)("undefined"==typeof e||b.matches(e))&&p.push(b);return p}var host_regexp=RegExp(":\\/\\/(.[^/:]+)","i");function ha(b){b=b.match(host_regexp);return null!=b&&1<b.length&&"string"===typeof b[1]&&0<b[1].length?b[1].toLowerCase():null}function Q(b){return b.includes(":")?(b=b.split(":"),1E3*(3600*parseInt(b[0])+
60*parseInt(b[1])+parseInt(b[2]))):null}function Y(b){try{var e=Date.parse(b);isNaN(e)&&(e=null)}catch(p){e=null}if(null==e&&b.includes(" ")){b=b.split(" ");try{e=Date.parse(b[0]),e+=Q(b[1]),isNaN(e)&&(e=null)}catch(p){e=null}}return e}function Z(){null==document.querySelector("#ai-iab-tcf-bar")&&null==document.querySelector(".ai-list-manual")||"function"!=typeof __tcfapi||"function"!=typeof ai_load_blocks||"undefined"!=typeof ai_iab_tcf_callback_installed||(__tcfapi("addEventListener",2,function(b,
e){e&&"useractioncomplete"===b.eventStatus&&(ai_tcData=b,ai_load_blocks(),b=document.querySelector("#ai-iab-tcf-status"),null!=b&&(b.textContent="IAB TCF 2.0 DATA LOADED"),b=document.querySelector("#ai-iab-tcf-bar"),null!=b&&(b.classList.remove("status-error"),b.classList.add("status-ok")))}),ai_iab_tcf_callback_installed=!0)}ai_process_lists=function(b){function e(a,d,k){if(0==a.length){if("!@!"==k)return!0;d!=k&&("true"==k.toLowerCase()?k=!0:"false"==k.toLowerCase()&&(k=!1));return d==k}if("object"!=
typeof d&&"array"!=typeof d)return!1;var l=a[0];a=a.slice(1);if("*"==l)for(let [,n]of Object.entries(d)){if(e(a,n,k))return!0}else if(l in d)return e(a,d[l],k);return!1}function p(a,d,k){if("object"!=typeof a||-1==d.indexOf("["))return!1;d=d.replace(/]| /gi,"").split("[");return e(d,a,k)}function z(){if("function"==typeof __tcfapi){var a=document.querySelector("#ai-iab-tcf-status"),d=document.querySelector("#ai-iab-tcf-bar");null!=a&&(a.textContent="IAB TCF 2.0 DETECTED");__tcfapi("getTCData",2,function(k,
l){l?(null!=d&&d.classList.add("status-ok"),"tcloaded"==k.eventStatus||"useractioncomplete"==k.eventStatus)?(ai_tcData=k,k.gdprApplies?null!=a&&(a.textContent="IAB TCF 2.0 DATA LOADED"):null!=a&&(a.textContent="IAB TCF 2.0 GDPR DOES NOT APPLY"),null!=d&&(d.classList.remove("status-error"),d.classList.add("status-ok")),setTimeout(function(){ai_process_lists()},10)):"cmpuishown"==k.eventStatus&&(ai_cmpuishown=!0,null!=a&&(a.textContent="IAB TCF 2.0 CMP UI SHOWN"),null!=d&&(d.classList.remove("status-error"),
d.classList.add("status-ok"))):(null!=a&&(a.textContent="IAB TCF 2.0 __tcfapi getTCData failed"),null!=d&&(d.classList.remove("status-ok"),d.classList.add("status-error")))})}}function C(a){"function"==typeof __tcfapi?(ai_tcfapi_found=!0,"undefined"==typeof ai_iab_tcf_callback_installed&&Z(),"undefined"==typeof ai_tcData_requested&&(ai_tcData_requested=!0,z(),cookies_need_tcData=!0)):a&&("undefined"==typeof ai_tcfapi_found&&(ai_tcfapi_found=!1,setTimeout(function(){ai_process_lists()},10)),a=document.querySelector("#ai-iab-tcf-status"),
null!=a&&(a.textContent="IAB TCF 2.0 MISSING: __tcfapi function not found"),a=document.querySelector("#ai-iab-tcf-bar"),null!=a&&(a.classList.remove("status-ok"),a.classList.add("status-error")))}if(null==b)b=document.querySelectorAll("div.ai-list-data, meta.ai-list-data");else{window.jQuery&&window.jQuery.fn&&b instanceof jQuery&&(b=Array.prototype.slice.call(b));var x=[];b.forEach((a,d)=>{a.matches(".ai-list-data")?x.push(a):(a=a.querySelectorAll(".ai-list-data"),a.length&&a.forEach((k,l)=>{x.push(k)}))});
b=x}if(b.length){b.forEach((a,d)=>{a.classList.remove("ai-list-data")});var L=ia(window.location.search);if(null!=L.referrer)var A=L.referrer;else A=document.referrer,""!=A&&(A=ha(A));var R=window.navigator.userAgent,S=R.toLowerCase(),aa=navigator.language,M=aa.toLowerCase();if("undefined"!==typeof MobileDetect)var ba=new MobileDetect(R);b.forEach((a,d)=>{var k=document.cookie.split(";");k.forEach(function(f,h){k[h]=f.trim()});d=a.closest("div."+ai_block_class_def);var l=!0;if(a.hasAttribute("referer-list")){var n=
a.getAttribute("referer-list");n=b64d(n).split(",");var v=a.getAttribute("referer-list-type"),E=!1;n.every((f,h)=>{f=f.trim();if(""==f)return!0;if("*"==f.charAt(0))if("*"==f.charAt(f.length-1)){if(f=f.substr(1,f.length-2),-1!=A.indexOf(f))return E=!0,!1}else{if(f=f.substr(1),A.substr(-f.length)==f)return E=!0,!1}else if("*"==f.charAt(f.length-1)){if(f=f.substr(0,f.length-1),0==A.indexOf(f))return E=!0,!1}else if("#"==f){if(""==A)return E=!0,!1}else if(f==A)return E=!0,!1;return!0});var r=E;switch(v){case "B":r&&
(l=!1);break;case "W":r||(l=!1)}}if(l&&a.hasAttribute("client-list")&&"undefined"!==typeof ba)switch(n=a.getAttribute("client-list"),n=b64d(n).split(","),v=a.getAttribute("client-list-type"),r=!1,n.every((f,h)=>{if(""==f.trim())return!0;f.split("&&").every((c,t)=>{t=!0;var w=!1;for(c=c.trim();"!!"==c.substring(0,2);)t=!t,c=c.substring(2);"language:"==c.substring(0,9)&&(w=!0,c=c.substring(9).toLowerCase());var q=!1;w?"*"==c.charAt(0)?"*"==c.charAt(c.length-1)?(c=c.substr(1,c.length-2).toLowerCase(),
-1!=M.indexOf(c)&&(q=!0)):(c=c.substr(1).toLowerCase(),M.substr(-c.length)==c&&(q=!0)):"*"==c.charAt(c.length-1)?(c=c.substr(0,c.length-1).toLowerCase(),0==M.indexOf(c)&&(q=!0)):c==M&&(q=!0):"*"==c.charAt(0)?"*"==c.charAt(c.length-1)?(c=c.substr(1,c.length-2).toLowerCase(),-1!=S.indexOf(c)&&(q=!0)):(c=c.substr(1).toLowerCase(),S.substr(-c.length)==c&&(q=!0)):"*"==c.charAt(c.length-1)?(c=c.substr(0,c.length-1).toLowerCase(),0==S.indexOf(c)&&(q=!0)):ba.is(c)&&(q=!0);return(r=q?t:!t)?!0:!1});return r?
!1:!0}),v){case "B":r&&(l=!1);break;case "W":r||(l=!1)}var N=n=!1;for(v=1;2>=v;v++)if(l){switch(v){case 1:var g=a.getAttribute("cookie-list");break;case 2:g=a.getAttribute("parameter-list")}if(null!=g){g=b64d(g);switch(v){case 1:var y=a.getAttribute("cookie-list-type");break;case 2:y=a.getAttribute("parameter-list-type")}g=g.replace("tcf-gdpr","tcf-v2[gdprApplies]=true");g=g.replace("tcf-no-gdpr","tcf-v2[gdprApplies]=false");g=g.replace("tcf-google","tcf-v2[vendor][consents][755]=true && tcf-v2[purpose][consents][1]=true");
g=g.replace("tcf-no-google","!!tcf-v2[vendor][consents][755]");g=g.replace("tcf-media.net","tcf-v2[vendor][consents][142]=true && tcf-v2[purpose][consents][1]=true");g=g.replace("tcf-no-media.net","!!tcf-v2[vendor][consents][142]");g=g.replace("tcf-amazon","tcf-v2[vendor][consents][793]=true && tcf-v2[purpose][consents][1]=true");g=g.replace("tcf-no-amazon","!!tcf-v2[vendor][consents][793]");g=g.replace("tcf-ezoic","tcf-v2[vendor][consents][347]=true && tcf-v2[purpose][consents][1]=true");g=g.replace("tcf-no-ezoic",
"!!tcf-v2[vendor][consents][347]");var F=g.split(","),ca=[];k.forEach(function(f){f=f.split("=");try{var h=JSON.parse(decodeURIComponent(f[1]))}catch(c){h=decodeURIComponent(f[1])}ca[f[0]]=h});r=!1;var I=a;F.every((f,h)=>{f.split("&&").every((c,t)=>{t=!0;for(c=c.trim();"!!"==c.substring(0,2);)t=!t,c=c.substring(2);var w=c,q="!@!",T="tcf-v2"==w&&"!@!"==q,B=-1!=c.indexOf("["),J=0==c.indexOf("tcf-v2")||0==c.indexOf("euconsent-v2");J=J&&(B||T);-1!=c.indexOf("=")&&(q=c.split("="),w=q[0],q=q[1],B=-1!=w.indexOf("["),
J=(J=0==w.indexOf("tcf-v2")||0==w.indexOf("euconsent-v2"))&&(B||T));if(J)document.querySelector("#ai-iab-tcf-status"),B=document.querySelector("#ai-iab-tcf-bar"),null!=B&&(B.style.display="block"),T&&"boolean"==typeof ai_tcfapi_found?r=ai_tcfapi_found?t:!t:"object"==typeof ai_tcData?(null!=B&&B.classList.add("status-ok"),w=w.replace(/]| /gi,"").split("["),w.shift(),r=(w=e(w,ai_tcData,q))?t:!t):"undefined"==typeof ai_tcfapi_found&&(I.classList.add("ai-list-data"),N=!0,"function"==typeof __tcfapi?C(!1):
"undefined"==typeof ai_tcData_retrying&&(ai_tcData_retrying=!0,setTimeout(function(){"function"==typeof __tcfapi?C(!1):setTimeout(function(){"function"==typeof __tcfapi?C(!1):setTimeout(function(){C(!0)},3E3)},1E3)},600)));else if(B)r=(w=p(ca,w,q))?t:!t;else{var U=!1;"!@!"==q?k.every(function(ja){return ja.split("=")[0]==c?(U=!0,!1):!0}):U=-1!=k.indexOf(c);r=U?t:!t}return r?!0:!1});return r?!1:!0});r&&(N=!1,I.classList.remove("ai-list-data"));switch(y){case "B":r&&(l=!1);break;case "W":r||(l=!1)}}}a.classList.contains("ai-list-manual")&&
(l?(I.classList.remove("ai-list-data"),I.classList.remove("ai-list-manual")):(n=!0,I.classList.add("ai-list-data")));(l||!n&&!N)&&a.hasAttribute("data-debug-info")&&(g=document.querySelector("."+a.dataset.debugInfo),null!=g&&(g=g.parentElement,null!=g&&g.classList.contains("ai-debug-info")&&g.remove()));y=X(a,".ai-debug-bar.ai-debug-lists");var ka=""==A?"#":A;0!=y.length&&y.forEach((f,h)=>{h=f.querySelector(".ai-debug-name.ai-list-info");null!=h&&(h.textContent=ka,h.title=R+"\n"+aa);h=f.querySelector(".ai-debug-name.ai-list-status");
null!=h&&(h.textContent=l?ai_front.visible:ai_front.hidden)});g=!1;if(l&&a.hasAttribute("scheduling-start")&&a.hasAttribute("scheduling-end")&&a.hasAttribute("scheduling-days")){var u=a.getAttribute("scheduling-start");v=a.getAttribute("scheduling-end");y=a.getAttribute("scheduling-days");g=!0;u=b64d(u);F=b64d(v);var V=parseInt(a.getAttribute("scheduling-fallback")),O=parseInt(a.getAttribute("gmt"));if(u.includes("-")||F.includes("-"))P=Y(u)+O,K=Y(F)+O;else var P=Q(u),K=Q(F);P??=0;K??=0;var W=b64d(y).split(",");
y=a.getAttribute("scheduling-type");var D=(new Date).getTime()+O;v=new Date(D);var G=v.getDay();0==G?G=6:G--;u.includes("-")||F.includes("-")||(u=(new Date(v.getFullYear(),v.getMonth(),v.getDate())).getTime()+O,D-=u,0>D&&(D+=864E5));scheduling_start_date_ok=D>=P;scheduling_end_date_ok=0==K||D<K;u=scheduling_start_date_ok&&scheduling_end_date_ok&&W.includes(G.toString());switch(y){case "B":u=!u}u||(l=!1);var la=v.toISOString().split(".")[0].replace("T"," ");y=X(a,".ai-debug-bar.ai-debug-scheduling");
0!=y.length&&y.forEach((f,h)=>{h=f.querySelector(".ai-debug-name.ai-scheduling-info");null!=h&&(h.textContent=la+" "+G+" current_time: "+Math.floor(D.toString()/1E3)+" start_date:"+Math.floor(P/1E3).toString()+"=>"+scheduling_start_date_ok.toString()+" end_date:"+Math.floor(K/1E3).toString()+"=>"+scheduling_end_date_ok.toString()+" days:"+W.toString()+"=>"+W.includes(G.toString()).toString());h=f.querySelector(".ai-debug-name.ai-scheduling-status");null!=h&&(h.textContent=l?ai_front.visible:ai_front.hidden);
l||0==V||(f.classList.remove("ai-debug-scheduling"),f.classList.add("ai-debug-fallback"),h=f.querySelector(".ai-debug-name.ai-scheduling-status"),null!=h&&(h.textContent=ai_front.fallback+" = "+V))})}if(n||!l&&N)return!0;a.style.visibility="";a.style.position="";a.style.width="";a.style.height="";a.style.zIndex="";if(l){if(null!=d&&(d.style.visibility="",d.classList.contains("ai-remove-position")&&(d.style.position="")),a.hasAttribute("data-code")){n=b64d(a.dataset.code);u=document.createRange();
g=!0;try{H=u.createContextualFragment(n)}catch(f){g=!1}g&&(null!=a.closest("head")?(a.parentNode.insertBefore(H,a.nextSibling),a.remove()):a.append(H));da(a)}}else if(g&&!u&&0!=V){null!=d&&(d.style.visibility="",d.classList.contains("ai-remove-position")&&d.css({position:""}));n=fa(a,".ai-fallback");0!=n.length&&n.forEach((f,h)=>{f.classList.remove("ai-fallback")});if(a.hasAttribute("data-fallback-code")){n=b64d(a.dataset.fallbackCode);u=document.createRange();g=!0;try{var H=u.createContextualFragment(n)}catch(f){g=
!1}g&&a.append(H);da(a)}else a.style.display="none",null!=d&&null==d.querySelector(".ai-debug-block")&&d.hasAttribute("style")&&-1==d.getAttribute("style").indexOf("height:")&&(d.style.display="none");null!=d&&d.hasAttribute("data-ai")&&(d.getAttribute("data-ai"),a.hasAttribute("fallback-tracking")&&(H=a.getAttribute("fallback-tracking"),d.setAttribute("data-ai-"+a.getAttribute("fallback_level"),H)))}else a.style.display="none",null!=d&&(d.removeAttribute("data-ai"),d.classList.remove("ai-track"),
null!=d.querySelector(".ai-debug-block")?(d.style.visibility="",d.classList.remove("ai-close"),d.classList.contains("ai-remove-position")&&(d.style.position="")):d.hasAttribute("style")&&-1==d.getAttribute("style").indexOf("height:")&&(d.style.display="none"));a.setAttribute("data-code","");a.setAttribute("data-fallback-code","");null!=d&&d.classList.remove("ai-list-block")})}};function ea(b){b=`; ${document.cookie}`.split(`; ${b}=`);if(2===b.length)return b.pop().split(";").shift()}function ma(b,
e,p){ea(b)&&(document.cookie=b+"="+(e?";path="+e:"")+(p?";domain="+p:"")+";expires=Thu, 01 Jan 1970 00:00:01 GMT")}function m(b){ea(b)&&(ma(b,"/",window.location.hostname),document.cookie=b+"=; Path=/; Expires=Thu, 01 Jan 1970 00:00:01 GMT;")}(function(b){"complete"===document.readyState||"loading"!==document.readyState&&!document.documentElement.doScroll?b():document.addEventListener("DOMContentLoaded",b)})(function(){setTimeout(function(){ai_process_lists();setTimeout(function(){Z();if("function"==
typeof ai_load_blocks){document.addEventListener("cmplzEnableScripts",e);document.addEventListener("cmplz_event_marketing",e);function e(p){"cmplzEnableScripts"!=p.type&&"all"!==p.consentLevel||ai_load_blocks()}}},50);var b=document.querySelector(".ai-debug-page-type");null!=b&&b.addEventListener("dblclick",e=>{e=document.querySelector("#ai-iab-tcf-status");null!=e&&(e.textContent="CONSENT COOKIES");e=document.querySelector("#ai-iab-tcf-bar");null!=e&&(e.style.display="block")});b=document.querySelector("#ai-iab-tcf-bar");
null!=b&&b.addEventListener("click",e=>{m("euconsent-v2");m("__lxG__consent__v2");m("__lxG__consent__v2_daisybit");m("__lxG__consent__v2_gdaisybit");m("CookieLawInfoConsent");m("cookielawinfo-checkbox-advertisement");m("cookielawinfo-checkbox-analytics");m("cookielawinfo-checkbox-necessary");m("complianz_policy_id");m("complianz_consent_status");m("cmplz_marketing");m("cmplz_consent_status");m("cmplz_preferences");m("cmplz_statistics-anonymous");m("cmplz_choice");m("cmplz_banner-status");m("cmplz_functional");
m("cmplz_policy_id");m("cmplz_statistics");m("moove_gdpr_popup");m("real_cookie_banner-blog:1-tcf");m("real_cookie_banner-blog:1");e=document.querySelector("#ai-iab-tcf-status");null!=e&&(e.textContent="CONSENT COOKIES DELETED")})},5)});function da(b){setTimeout(function(){"function"==typeof ai_process_rotations_in_element&&ai_process_rotations_in_element(b);"function"==typeof ai_process_lists&&ai_process_lists();"function"==typeof ai_process_ip_addresses&&ai_process_ip_addresses();"function"==typeof ai_process_filter_hooks&&
ai_process_filter_hooks();"function"==typeof ai_adb_process_blocks&&ai_adb_process_blocks(b);"function"==typeof ai_process_impressions&&1==ai_tracking_finished&&ai_process_impressions();"function"==typeof ai_install_click_trackers&&1==ai_tracking_finished&&ai_install_click_trackers();"function"==typeof ai_install_close_buttons&&ai_install_close_buttons(document)},5)}function ia(b){var e=b?b.split("?")[1]:window.location.search.slice(1);b={};if(e){e=e.split("#")[0];e=e.split("&");for(var p=0;p<e.length;p++){var z=
e[p].split("="),C=void 0,x=z[0].replace(/\[\d*\]/,function(L){C=L.slice(1,-1);return""});z="undefined"===typeof z[1]?"":z[1];x=x.toLowerCase();z=z.toLowerCase();b[x]?("string"===typeof b[x]&&(b[x]=[b[x]]),"undefined"===typeof C?b[x].push(z):b[x][C]=z):b[x]=z}}return b}};
ai_js_code = true;
</script>
</body>
</html>
<!-- Dynamic page generated in 0.381 seconds. -->
<!-- Cached page generated by WP-Super-Cache on 2026-07-16 17:07:43 -->
<!-- super cache -->