Кодировка в Ubuntu
На данный момент в Ubuntu и поставляемых с ней приложениях полностью реализована поддержка и используется кодировка UTF-8. Сейчас стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO /IEC 10646 Annex D.
Специальные символы
Таблица символов
Таблицу символов можно найти среди предустановленных приложений Ubuntu.
Ручной способ ввода
Для ручного ввода символов Unicode, например, не представленных на клавиатуре, следует выполнить следующее:
Нажать и отпустить комбинацию клавиш Ctrl + Shift + U 1) — при этом действии в поле ввода символов появится маленькая латинская подчёркнутая буква u
Локализация и кодировка Linux
![]()
В этой статье мы рассмотрим переменные, которые отвечают за локализацию и кодировку операционной системы. Данная тема достаточно важна, т.к. некоторые прикладные сервисы требуют нестандартной кодировки или региональной локализации.
В Linux системах есть основная переменная $LANG – которая задает основной язык системы. Есть и другие переменные, но они берут изначально настройки с этой основной переменной $LANG . Можно настроить отдельные какие-то переменные, но можно все же давать значение основной переменной $LANG и она будет давать значение всем остальным.
Есть так же переменная LC_ALL – которая позволяет нам разом перезаписать все языковые настройки. Есть также утилита locale которая показывает кучу переменных, которые относятся к языковым настройкам.
$LANG= – данную переменную обычно используют для написания скриптов, чтобы те или иные настройки установить по умолчанию для выполнения скрипта. В большинстве случаев данная настройка включает английский язык по умолчанию.
Есть такая команда env , которая выводит заданные переменные в системе.

И тут в частности, есть переменная которая отвечает за языковые настройки. В нашем случае LANG=en_US.UTF-8 , т.к скриншот делался на операционной системе с английской локализацией по умолчанию. Мы видим en_US в кодировке UTF-8 . En_US – говорит о том, что у нас используется американский английский язык.
Посмотреть все переменные относящиеся к данной локализации мы можем с помощью утилиты locale .
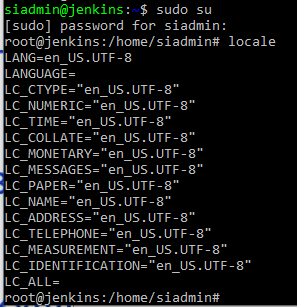
Как вы видите все остальные переменные на данной установленной операционной системе тоже американские. Почему это важно? Во-первых, это важно для логгирования. С такими настройками система будет писать файлы системных и других логов в американском формате yyyy-mm-dd (год-месяц-день: 2006-12-31), в русском формате же правильно будет dd-mm-yyyy . И при передаче логов из одной системы в другую возникнут ошибки. Другой пример — бывают нестандартные решения, допустим хранение базы данных 1С в postgre . Для того чтобы сервер приложений корректно работал с базой опять же необходима русская локализация. И таких примеров взаимодействия можно привести достаточно много.
Теперь, если у нас появилась необходимость поменять какую-нибудь, переменную, например, LC_TIME то делаем следующее:
LC_TIME=ru_RU.UTF-8 – задаем переменную.
export LC_TIME – загружаем переменную.
Мы можем сразу все настройки изменить — LC_ALL=ru_RU.UTF-8
Далее export LC_ALL .
Если мы ошибемся с вводом локали (языковой пакет настроек) или в системе не загружена такая локаль, то система нам выдаст ошибку:

Надо выполнить инсталляцию языкового пакета
sudo apt-get install language-pack-ru
Генерация файла с обновленной информацией о добавленных пакетах в систему: sudo locale-gen
И после этого опять попробовать сменить.
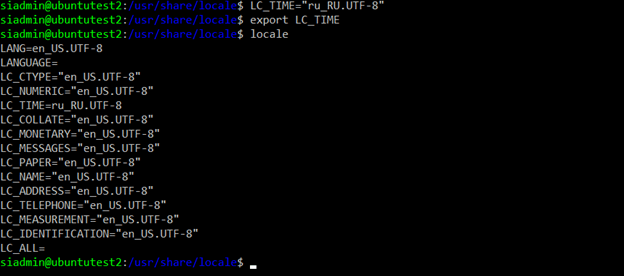
Для возврата в исходное состояние настроек мы можем выполнить команду unset LC_ALL . После выполнения данной команды все настройки языковые системы вернутся в исходное состояние.
Немного о кодировке. Кодировка — это представление символов в определенном виде. Самые распространенные кодировки, используемые в Linux:
- ASCII – 128 основных символов;
- ISO-8859 – большинство латинских символов;
- UTF-8 -символы Unicode.
Для конвертации используется утилита iconv , но есть более практический инструмент. Если нам необходимо конвертировать какой-то файл в другой, то проще всего использовать Notepad++. Открываем файл, в меню выбираем пункт кодировка. Программа покажет текущую и меняем на интересующую нас. Затем сохраняем.

В случае если у нас только консольное подключение, делаем это с помощью iconv . Общий вид команды:
iconv [опция] [-f кодировка 1] [-t кодировка 2] [исходный файл] [целевой файл]

Установка и настройка часовых зон.
Утилита tzselect позволяет осуществить поиск нужной временной зоны. Появляется мастер пошаговый, который позволяет сделать свой выбор и в конце дает инструкцию, как сделать, чтобы выбор сохранился.
Вторая утилита это date , которая выводит текущую дату и время, если запустить ее без параметров, а также позволяет установить их. Опции и форматы можно посмотреть при помощи команды man date
Для установки даты и времени необходимы права суперпользователя.
sudo date -s “yyyymmdd hh:mm” – обратите на формат вводимых данных.
Какую locale кодировку в linux лучше юзать с большими текстовыми файлами *.txt или *.lst?
Linux, Ubuntu в частности. Интересует вопрос, какую $ locale по умолчанию поставить и в какой кодировке лучше распознаются текстовые файлы, если например они с иероглифами (китайские, японские), кириллица, прочие языки (не инглишь).
Какую локаль выбрать, если основные массивы на английском, но так же чтобы распознавались с иероглифами и прочими разными языками?
en_US.UTF-8 UTF-8 ?
Или надо ASCII ? Другую?
Что выбрать из $ cat /etc/locale.gen ?
Посоветуйте плиз, чтобы не маяться потом с перекодировками.
Поставил русифицированную Ubuntu с LANG=ru_RU.UTF-8 , но что-то мне подсказывает, что это не лучший выбор.
Какое лучше расширение для создаваемых объемных текстовых файлов (или большим кол-вом размерами поменьше) выбрать?
*.txt или *.lst ? (При создании прогой crunch массива разницы не заметил, но специально время не замерял.)
С графическими оболочками текстовых прог не работаю, работа из терминала, сенкс.
Отслеживать
user262779
задан 25 дек 2017 в 11:35
617 6 6 серебряных знаков 18 18 бронзовых знаков
но что-то мне подсказывает, что это не лучший выбор — ваш внутренний голос промахнулся. но если вас не устраивает русифицированный интерфейс, в любой момент вы можете выбрать любой другой язык. это не повлияет ни на что кроме языка интерфейса. кодировку, главное, не меняйте, и будет вам счастье.
25 дек 2017 в 12:16
По поводу кодировок: кто юзает НЕ UTF-8 — должен страдать в адском пламени.
25 дек 2017 в 21:36
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Какую локаль выбрать, если основные массивы на английском, но так же чтобы распознавались с иероглифами и прочими разными языками?
в posix-совместимых операционных системах локаль состоит из трёх компонентов — языка интерфейса, региональных настроек и кодировки символов. язык интерфейса и региональные настройки можете выбирать по вкусу и настроению (для каждого отдельного процесса с помощью переменной окружения можно указать при его запуске какую-нибудь из поддерживаемых системой локалей, ведь локаль — это свойство процесса), разница будет только в сообщениях, формируемых процессом. а вот кодировку символов лучше оставить как есть — UTF-8 . это нынче «стандарт де-факто».
Какое лучше расширение для создаваемых объемных текстовых файлов (или большим кол-вом размерами поменьше) выбрать?
предполагаю, что под словом «расширение» вы подразумеваете не какую-то эзотречискую сущность (по аналогии с «расширением сознания»), а всего лишь суффикс в имени файла. так имя файла в posix-совместимых операционных системах не может оказать и не оказывает никакого влияния на программы, работающие с этим файлом. как хотите, так файл и называйте (в пределах возможностей файловой системы, в которой он хранится).
Qt 4, Qt 5 — Как узнать системную кодировку (UTF-8, KOI8-R, CP1251 . ) ?
Пишу кроссплатформенный проект. Мне нужно узнать системную кодировку. То есть:
— В Linux с UTF8 — знать, что кодировка «utf-8»;
— В Linux/BSD с KOI8-R — знать, что кодировка «koi8-r»;
— В Windows с CP1251 — знать, что кодировка «cp1251».
Вот как это узнать? Пытался через QLocale, но там нет методов получения кодировки, там можно только получить язык и языковые настройки.
А как узнать системную кодировку, причем сделать это кроссплатформенно?

Xintrea ★★★★★
02.01.14 15:15:28 MSK

Через переменные окружения?
ziemin ★★
( 02.01.14 15:17:17 MSK )
Ответ на: комментарий от ziemin 02.01.14 15:17:17 MSK
Ну и в какой переменной окружения в винде указывается кодировка?
Да, и еще я забыл еще про Андроид.
Xintrea ★★★★★
( 02.01.14 15:20:49 MSK ) автор топика
А какую задачу ты решаешь? Зачем вообще знать кодировку?
Reset ★★★★★
( 02.01.14 15:26:27 MSK )

Насколько мне известно, кросс-платформенное решение отсутствует. Пиши свои методы для определения кодировки в каждой из нужных тебе ОС.
EXL ★★★★★
( 02.01.14 15:26:38 MSK )

А может всё сделать в UTF-8 и пусть пользователи сами сношаются.
А вообще советовал бы тебе создать модуль с функцией определения кодировки и в каждой ОС использовать свой.
rezedent12 ☆☆☆
( 02.01.14 15:41:12 MSK )

а зачем? если надо только перегонять строки, то:
wota ★★
( 02.01.14 15:46:03 MSK )

В Linux с UTF8 — знать, что кодировка «utf-8»;
читай man 7 locale
помни, что в общем случае, у каждого юзера своя локаль. Мало того, юзер может запускать твою программу например в украинской локали, хотя у него русская. При этом твоя программа должна работать «по-украински».
В других системах — я не в курсе.
emulek ★
( 02.01.14 15:49:43 MSK )
Qt по-умолчанию для всех операций использует системную кодировку, если иная не задана через setCodec.
Y ★★
( 02.01.14 15:51:35 MSK )

QTextCodec * localCodec = QTextCodec::codecForLocale(); QByteArray name = localCodec->name();E ★★★
( 02.01.14 15:53:03 MSK )
Ответ на: комментарий от E 02.01.14 15:53:03 MSK
Если не ошибаюсь, оно вернет «System».
EXL ★★★★★
( 02.01.14 16:04:58 MSK )
Ответ на: комментарий от EXL 02.01.14 16:04:58 MSK
Тогда только locale().name или boost.
E ★★★
( 02.01.14 16:07:30 MSK )

Мне нужно узнать системную кодировку.
ИМХО вопрос в данной постановке имеет смысл только для Windows.
asaw ★★★★★
( 02.01.14 16:31:29 MSK )

Одно дело узнать имя системной кодировки, другое дело — получить возможность перекодировать (из неё в какую-либо известную кодировку и обратно).
nl_langinfo(CODESET) для Linux (SUSv2, POSIX) и GetCPInfoEx(CP_ACP. ) для Windows (Win2k+) позволяют узнать «имя» (или номер кодовой страницы). Упомянутый выше QTextCodec::codecForLocale позволяет в эту кодировку перекодировать (с сохранением кросс-платформенности).
Лучше включать в такие вопросы пояснение, зачем это вам нужно (не обязательно в деталях, просто добавить чуточку контекста задачи). К примеру, на Windows «системная кодировка» может вообще быть не нужна, за исключением случая, когда юзер подсовывает вам текстовый файл и явно просит, чтобы его раскодировали в ANSI code page.
LeninGad ★
( 02.01.14 17:57:27 MSK )
Ответ на: комментарий от Y 02.01.14 15:51:35 MSK

Не знаю как 5-й qt, а вот 4-й на убунте (с русской локализацией) что-то не правильно себя вел с кириллицей, приходилось принудительно указывать utf8
RiseOfDeath ★★★★
( 03.01.14 12:08:47 MSK )
Последнее исправление: RiseOfDeath 03.01.14 12:09:17 MSK (всего исправлений: 1)
Ответ на: комментарий от LeninGad 02.01.14 17:57:27 MSK
Есть программа на Qt.
1. Мне нужно корректно работать с именами файлов в любой ОС, даже если имя и путь к файлу содержат национальные символы.
Ограничиваюсь только UTF8 (с ней то проблем нет) и однобайтовыми кодировками.
То есть, например, если имя пользователя под виндой задано по-русски, то чтобы достучаться до пользовательского каталога, и создать там конфиг-файл, надо корректно работать с CP866. Это необходимо, потому что путь к конфиг-файлу будет содержать русские символы (имя пользователя) в кодировке CP866.
Поэтому мне и нужно узнавать системную кодировку. Или, правильнее будет кодировку файловой системы?
2. У меня есть окно, которое выводит сообщения стандартного потока запущенной в отдельном процессе программы. Эдакий примитивный эмулятор терминала, который только показывает стандартный вывод. Он выводит данные в кодировке UTF8.
Нужно, чтобы национальные символы выводились правильно. То есть, перед тем как вывести символы в терминал, их нужно преобразовать из системной кодировки в UTF8.
Xintrea ★★★★★
( 03.01.14 15:10:15 MSK ) автор топика
Последнее исправление: Xintrea 03.01.14 15:11:39 MSK (всего исправлений: 1)
Ответ на: комментарий от Xintrea 03.01.14 15:10:15 MSK
То есть, например, если имя пользователя под виндой задано по-русски, то чтобы достучаться до пользовательского каталога, и создать там конфиг-файл, надо корректно работать с CP866.
То есть, перед тем как вывести символы в терминал, их нужно преобразовать из системной кодировки в UTF8.
wota ★★
( 03.01.14 15:17:08 MSK )
Последнее исправление: wota 03.01.14 15:21:31 MSK (всего исправлений: 1)
Ответ на: комментарий от RiseOfDeath 03.01.14 12:08:47 MSK
Это для строк в исходниках, наверное.
А я о кодировке, используемой при чтении/записи файлов.
Y ★★
( 03.01.14 17:44:44 MSK )
Ответ на: комментарий от Y 03.01.14 17:44:44 MSK
Возможно. Я сталкивался с таким только на виджетах. (причем в дизайнере и в исходнике все норм было, а при запуске программы все было печально).
RiseOfDeath ★★★★
( 03.01.14 18:39:33 MSK )
Последнее исправление: RiseOfDeath 03.01.14 18:40:14 MSK (всего исправлений: 2)
Ответ на: комментарий от RiseOfDeath 03.01.14 18:39:33 MSK
Это объясняется тем, чточто программа, написанная на Qt (Qt Creator) в системе, где UTF-8 — основная кодировка при чтении файлов (исходников и форм) использует UTF-8, а компилятор интерпретирует строки в исходнике по-умолчанию как ASCII/Latin1. Тут необходимо указать (в Qt4 с помощью setCodecForCStrings (и, если вы используете tr, с setCodecForTr)), в какой кодировке они присутствуют в исходинке. [snob_mode]Но хорошим тоном будет не использовать не-ASCII символы в исходном коде и пользоваться файлами перевода, благо Qt предоставляет удобные средства для работы с ними.[/snobe_mode]